《环境监测技术》考试题及答案A

《环境监测技术》试卷A参考答案和评分标准
一、简答题(每题5分,共80分)
说明:仅为参考答案,不要求学生回答非常全面。主要观点符合当前环境监测领域的通用说法,并且阐述中没有明显违背基本原则的内容,可给4-5分;基本内容偏少,或者有少量内容错误,可给2-3分;没有回答,或者有明显错误,可给0-1分。
1.空气污染指数(API)
空气污染指数(API)是将常规监测的几种空气污染物浓度简化成为单一的概念性指数值形式,并分级表征空气污染程度和空气质量状况,适合于表示城市的短期空气质量状况和变化趋势;是根据空气环境质量标准和各项污染物的生态环境效应及其对人体健康的影响来确定污染指数的分级数值及相应的污染物浓度限值。指数越大,级别越高,说明污染越严重。
2.优先控制污染物
潜在危险性大(难降解、生物累积性、毒性大和属三致物质);在环境中出现频率高,高残留;检测方法成熟的化学物质制订优先监测目标,实施优先和重点监测。
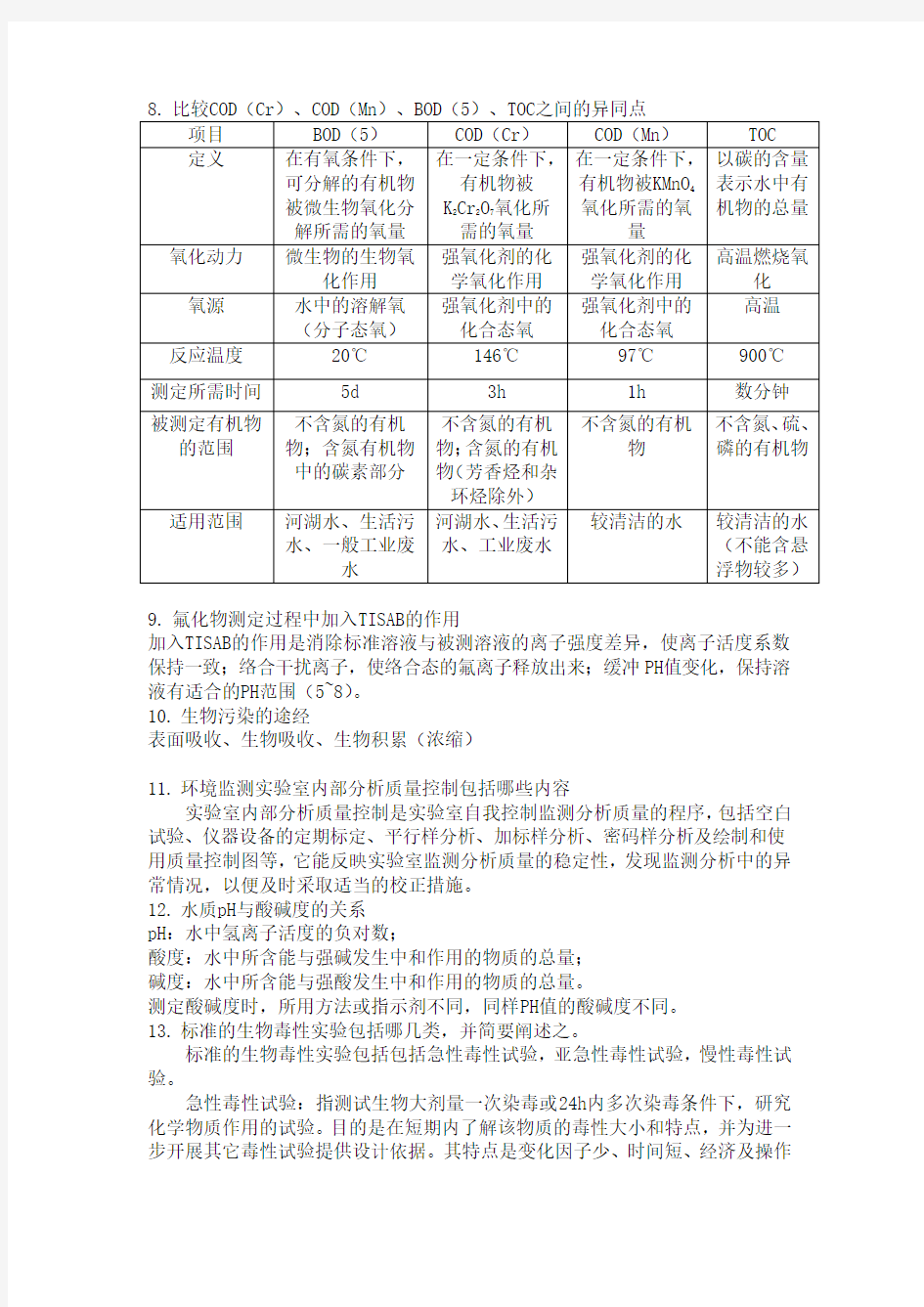
3.环境监测的目的、特点、一般过程
目的:为保护环境和保障人群健康,运用化学、生物学、物理学和公共卫生学等方法间断或连续地测定环境中污染物的浓度,观察、分析其变化和对环境影响的过程。
特点:①高灵敏度、高准确度、高分辨率;②自动化、标准化、计算机化;
③多学科性、边缘性、综合性、社会性等。
一般过程:现场调查资料收集→确定监测项目→确定监测点布置及采样时间和方式→选择和确定环境样品的保存方法→环境样品的分析测试→数据处理→环境监测报告
4.危险废物及常规监测方法
危险废物是指列入《国家危险废物名录》或根据国家规定的危险废物鉴别标准和鉴别方法认定的具有危险特性的废物;一般也称有害固体废物。危险废物在环境中任意排放或处置不当,除造成燃烧、起火、爆炸及直接污染水体、大气以外,还影响土壤和地下水的质量,造成长期且难以恢复的严重后果。
常规监测方法:易燃性实验方法;化学反应性试验方法;腐蚀性试验;急性毒性的初筛试验;浸出毒性试验。
5.放射性样品预处理方法
衰变法、共沉淀法、灰化法、电化学法、离子交换法、溶剂萃取法
6.静态配气法
静态配气法是把一定量的气态或蒸汽态的原料气加入已知容积的容器中,再充入稀释气体,混匀制得。
7.生物监测在环境监测领域中的地位和作用
生物监测是利用生物个体、种群和群落对环境污染所发出的各种信息,作为判断环境污染状况的一种手段。它具有累积效应和综合反应的特点。现代生物技术的快速发展,使捕捉生物信息的能力大大增强,正在给传统的生物监测技术注入新的活力和监测手段上的变革,对于了解污染的性质、分析污染的程度、追踪污染发生的历史、预测污染的影响及发展趋势等方面都具有十分重要的意义。
9.氟化物测定过程中加入TISAB的作用
加入TISAB的作用是消除标准溶液与被测溶液的离子强度差异,使离子活度系数保持一致;络合干扰离子,使络合态的氟离子释放出来;缓冲PH值变化,保持溶液有适合的PH范围(5~8)。
10.生物污染的途经
表面吸收、生物吸收、生物积累(浓缩)
11.环境监测实验室内部分析质量控制包括哪些内容
实验室内部分析质量控制是实验室自我控制监测分析质量的程序,包括空白试验、仪器设备的定期标定、平行样分析、加标样分析、密码样分析及绘制和使用质量控制图等,它能反映实验室监测分析质量的稳定性,发现监测分析中的异常情况,以便及时采取适当的校正措施。
12.水质pH与酸碱度的关系
pH:水中氢离子活度的负对数;
酸度:水中所含能与强碱发生中和作用的物质的总量;
碱度:水中所含能与强酸发生中和作用的物质的总量。
测定酸碱度时,所用方法或指示剂不同,同样PH值的酸碱度不同。
13.标准的生物毒性实验包括哪几类,并简要阐述之。
标准的生物毒性实验包括包括急性毒性试验,亚急性毒性试验,慢性毒性试验。
急性毒性试验:指测试生物大剂量一次染毒或24h内多次染毒条件下,研究化学物质作用的试验。目的是在短期内了解该物质的毒性大小和特点,并为进一步开展其它毒性试验提供设计依据。其特点是变化因子少、时间短、经济及操作
简便。
亚急性毒性试验:指测试生物在短期时间内多次重复染毒条件下,研究化学物质毒性作用的试验。目的是在急性试验的基础上,在短期时间内了解受试物对机体的毒性作用,探讨敏感观测指标和剂量效应的关系,为慢性毒性试验设计提供依据。
慢性毒性试验:指测试生物在较长时间内,以小剂量反复染毒后所引起损害作用的试验。目的是评价化学物在长期小剂量作用条件下对机体产生的损害及特点,确定其慢性作用阈剂量和最大无作用剂量,为制定环境中有害物质最高容许浓度提供实验依据。
14.光度分析法中规定测定上、下限的原因
提高检测的灵敏度,避免检测量超过上、下限,导致检测不准。
15.可吸入颗粒物PM10,细颗粒物PM2.5,总悬浮颗粒物TSP
可吸入颗粒物PM10:空气动力学当量质量中位径等于10μm的悬浮颗粒物;
细颗粒物PM2.5:也称为可入肺颗粒物,是指在PM10中空气动力学直径小于等于2.5μm的悬浮颗粒物,是大气溶胶的一部分;
总悬浮颗粒物TSP:指悬浮在空气中,空气动力学当量直径小于等于100μm的颗粒物。分为一次颗粒物和二次颗粒物。一次颗粒物是由天然污染源和人为污染源释放到大气中直接造成污染的物质。二次颗粒物是通过某些大气化学过程所产生的微粒。
16.总挥发性有机物TVOC,及通用测定方法举例
总挥发性有机物TVOC:指可以在空气中挥发的有机化合物,按其化学结构可以分为八类,造成室内空气污染的有害气体氨、苯及甲苯、二甲苯等都属于TVOC 范畴。
选择合适的吸附剂(Tenax GC或Tenax TA),用吸附管采集一定体积的空气样品,空气流中的挥发性有机化合物保留在吸附管中。采样后,将吸附管加热,解吸挥发性有机化合物,待测样品随惰性载气进入毛细管气相色谱仪,用保留时间定性,峰高或峰面积定量。
本法适用于室内、环境和工作场所空气,也适用于评价小型或大型测试舱内材料的释放。
二、论述题(二选一,共20分)
1. 环保局要对某河流水受污染状况进行监测,请你制定水污染监测方案。(假设此河流在检测境内全长15km,主河流宽150m、深20m;支流宽30m、深8m。河流上游为居民生活取水点,下游为工业区从左到有依次为酒厂、食品加工厂、印染厂)
只要在(1)基础资料收集(2)监测断面和采样点设置(3)采样和监测(4)监测数据处理(5)监测报告编制等几个主要方面有合理并且较为丰富的阐述,即可得到14-20分;如果有显著的内容缺失,或者有明显错误的,可给7-13分;其它情况,可给0-6分。
2.现有一工业废水,内含微量汞、铜、铅和痕量酚,设计一个预处理方案,实现四种化合物的分别测定,同时给出检测所用的方法或仪器,并简要说明方法或仪器依据的基本原理。
1.样品的分离与富集:采用液-液萃取的方式进行分离与富集。
取一定量(5~10 ml)的工业废水,将PH调节为1,用少量(约3ml)二苯硫腙-CCl
4,
萃取,可将Hg萃取出来,萃取液为A;再将PH调节为6.5~10,用少量二苯硫腙-CCl
4,萃取,可将Pb和Cu萃取出来,萃取液为B;
2.消解:
将萃取液A用硝酸-高锰酸钾(体积比为2:4)进行消解,消化1h后完成,再稀释定容至25 ml,溶液为D;
将萃取液B用盐酸-硝酸-高氯酸(体积比为2:5:2)进行消解,消化1h后完成,再稀释定容至25 ml,溶液为F;
3.检测:
采用冷原子吸收分光光度法测定Hg.原理:汞蒸汽对253.7nm的紫外光有强烈的吸收作用。当试样经适当的前处理,将样品中各种形态的汞变为可测态的汞离子后,用氯化亚锡将汞离子还原成元素汞,再用干燥清洁的空气或氯气将汞吹出,并送入吸收池。在吸收池中,汞蒸汽吸收汞空心阴极灯发出的特征谱线,而使谱线强度减弱,减弱程度(吸光度)与基态原子数即原子总数的关系符合比耳定律:
A=lgI
0/I=KLN=K/C(I
—入射特征谱线强度;I—透射强度;K—吸光系数;L—吸
收池长度;N—原子总数;K/--常数;C—溶液中汞的浓度)。由此定量测定汞;
采用火焰原子吸收分光光度法定量测定铜和铅。原理:当试样进入火焰原子化炉时,当火焰的绝对温度低于3000K时,即可认为原子蒸汽中基态原子的数目实际上接近于原子总数,在固定的实验条件下,基态原子蒸汽对共振线的吸收符合比耳定律。由此定量测定铜和铅。
采用高效液相色谱法直接测定废水中的酚。原理:仪器由输液系统、进样系统、分离系统(色谱柱)、检测器、记录系统和辅助系统组成。样品由进样器注入系统,流动相由泵抽入流经色谱柱,使样品在色谱柱上被分离,依次进入检测器,由记录仪器将检测器的信号记录下来。由此定量测定酚。
说明:可有多种分析监测方案,只要给出合理的预处理手段,并且采用了正确的监测方案,并且有较详细的阐述,可给14-20分;如果有明显不合理的技术手段,或者缺少其中一到两种目标物的分析,可给7-13分;其它情况,可给0-6分。
最新随机过程考试试题及答案详解1
随机过程考试试题及答案详解 1、(15分)设随机过程C t R t X +?=)(,),0(∞∈t ,C 为常数,R 服从]1,0[区间上的均 匀分布。 (1)求)(t X 的一维概率密度和一维分布函数; (2)求)(t X 的均值函数、相关函数和协方差函数。 【理论基础】 (1)? ∞ -= x dt t f x F )()(,则)(t f 为密度函数; (2))(t X 为),(b a 上的均匀分布,概率密度函数?? ???<<-=其他,0,1 )(b x a a b x f ,分布函数 ?? ??? >≤≤--<=b x b x a a b a x a x x F ,1,,0)(,2)(b a x E += ,12)()(2a b x D -=; (3)参数为λ的指数分布,概率密度函数???<≥=-0,00 ,)(x x e x f x λλ,分布函数 ?? ?<≥-=-0 ,00,1)(x x e x F x λ,λ1)(=x E ,21 )(λ=x D ; (4)2 )(,)(σμ==x D x E 的正态分布,概率密度函数∞<<-∞= -- x e x f x ,21 )(2 22)(σμπ σ, 分布函数∞<<-∞= ? ∞ --- x dt e x F x t ,21)(2 22)(σμπ σ,若1,0==σμ时,其为标准正态分布。 【解答】本题可参加课本习题2.1及2.2题。 (1)因R 为]1,0[上的均匀分布,C 为常数,故)(t X 亦为均匀分布。由R 的取值范围可知, )(t X 为],[t C C +上的均匀分布,因此其一维概率密度?? ???+≤≤=其他,0,1 )(t C x C t x f ,一维分布 函数?? ??? +>+≤≤-<=t C x t C X C t C x C x x F ,1,,0)(;
数据挖掘考试题目聚类
数据挖掘考试题目——聚类 一、填空题 1、密度的基于中心的方法使得我们可以将点分类为:__________、________ 、_________。 2、DBSCAN算法在最坏的情况下,时间复杂度是__________、空间复杂度是__________。 3、DBSCAN算法的优点是_______、__________________________。 4、DBSCAN算法的缺点是处理_________________、_____________的数据效果不好。 5、DBSCAN算法的参数有:___________、____________。 6、簇的有效性的非监督度量常常可以分为两类:__________、__________,它常采用的指标为__________。 7、簇的有效性的监督度量通常称为___________,它度量簇标号与外部提供的标号的匹配程度主要借助____________。 8、在相似度矩阵评价的聚类中,如果有明显分离的簇,则相似度矩阵应当粗略地是__________。 9、DBSCAN算法的参数确定的基本方法是观察____________________的特性。 10、不引用附加的信息,评估聚类分析结果对数据拟合情况属于__________技术。 答案: 1、核心点边界点噪声点 2、O(n2) O(n) 3、耐噪声能够处理任意大小和形状的簇 4、高维数据变密度的 5、EPS MinPts 6、簇的凝聚性簇的分离性均方差(SSE) 7、外部指标监督指标的熵 8、块对角的 9、点到它的第K个最近邻的距离(K-距离) 10、非监督 二、选择题 1、DBSCAN算法的过程是(B)。 ①删除噪声点。 ②每组连通的核心点形成一个簇。 ③将所有点标记为核心点、边界点和噪声点。 ④将每个边界点指派到一个与之关联的核心点的簇中。 ⑤为距离在Eps之内的所有核心点之间赋予一条边。 A:①②④⑤③ B:③①⑤②④ C:③①②④⑤ D:①④⑤②③ 2、如果有m个点,DBSCAN在最坏的情况下的时间复杂度度为(C)。 A O(m) B O(mlogm) C O(m2) D O(logm) 3、在基本DBSCAN的参数选择方法中,点到它的K个最近邻的距离中的K选作为哪一个参数(B)。 A Eps B MinPts C 质心 D 边界
《数据挖掘》试题与标准答案
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2.时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
中国科学大学随机过程(孙应飞)复习题及答案
(1) 设}0),({≥t t X 是一个实的零均值二阶矩过程,其相关函数为 t s s t B t X s X E ≤-=),()}()({,且是一个周期为T 的函数,即0),()(≥=+τττB T B ,求方差函数)]()([T t X t X D +-。 解:由定义,有: )(2)0()0()}()({2)0()0()]} ()()][()({[2)] ([)]([)]()([=-+=+-+=+-+--++=+-T B B B T t X t X E B B T t EX T t X t EX t X E T t X D t X D T t X t X D (2) 试证明:如果}0),({≥t t X 是一独立增量过程,且0)0(=X ,那么它必是一个马 尔可夫过程。 证明:我们要证明: n t t t <<<≤? 210,有 } )()({})(,,)(,)()({11112211----=≤=====≤n n n n n n n x t X x t X P x t X x t X x t X x t X P 形式上我们有: } )()(,,)(,)({} )()(,,)(,)(,)({} )(,,)(,)({} )(,,)(,)(,)({})(,,)(,)()({1122221111222211112211112211112211--------------========≤= ======≤=====≤n n n n n n n n n n n n n n n n n n n n x t X x t X x t X x t X P x t X x t X x t X x t X x t X P x t X x t X x t X P x t X x t X x t X x t X P x t X x t X x t X x t X P 因此,我们只要能证明在已知11)(--=n n x t X 条件下,)(n t X 与2 ,,2,1,)(-=n j t X j 相互独立即可。 由独立增量过程的定义可知,当2,,2,1,1-=<<<-n j t t t a n n j 时,增量 )0()(X t X j -与)()(1--n n t X t X 相互独立,由于在条件11)(--=n n x t X 和0)0(=X 下,即 有)(j t X 与1)(--n n x t X 相互独立。由此可知,在11)(--=n n x t X 条件下,)(n t X 与 2,,2,1,)(-=n j t X j 相互独立,结果成立。 (3) 设随机过程}0,{≥t W t 为零初值(00=W )的、有平稳增量和独立增量的过程, 且对每个0>t ,),(~2t N W t σμ,问过程}0,{≥t W t 是否为正态过程,为什么? 解:任取n t t t <<<≤? 210,则有: n k W W W k i t t t i i k ,,2,1][1 1 =-=∑=-
数据挖掘考试题库【最新】
一、填空题 1.Web挖掘可分为、和3大类。 2.数据仓库需要统一数据源,包括统一、统一、统一和统一数据特征 4个方面。 3.数据分割通常按时间、、、以及组合方法进行。 4.噪声数据处理的方法主要有、和。 5.数值归约的常用方法有、、、和对数模型等。 6.评价关联规则的2个主要指标是和。 7.多维数据集通常采用或雪花型架构,以表为中心,连接多个表。 8.决策树是用作为结点,用作为分支的树结构。 9.关联可分为简单关联、和。 10.B P神经网络的作用函数通常为区间的。 11.数据挖掘的过程主要包括确定业务对象、、、及知识同化等几个步 骤。 12.数据挖掘技术主要涉及、和3个技术领域。 13.数据挖掘的主要功能包括、、、、趋势分析、孤立点分析和偏 差分析7个方面。 14.人工神经网络具有和等特点,其结构模型包括、和自组织网络 3种。 15.数据仓库数据的4个基本特征是、、非易失、随时间变化。 16.数据仓库的数据通常划分为、、和等几个级别。 17.数据预处理的主要内容(方法)包括、、和数据归约等。 18.平滑分箱数据的方法主要有、和。 19.数据挖掘发现知识的类型主要有广义知识、、、和偏差型知识五种。 20.O LAP的数据组织方式主要有和两种。 21.常见的OLAP多维数据分析包括、、和旋转等操作。 22.传统的决策支持系统是以和驱动,而新决策支持系统则是以、建 立在和技术之上。 23.O LAP的数据组织方式主要有和2种。 24.S QL Server2000的OLAP组件叫,OLAP操作窗口叫。 25.B P神经网络由、以及一或多个结点组成。 26.遗传算法包括、、3个基本算子。 27.聚类分析的数据通常可分为区间标度变量、、、、序数型以及混合 类型等。 28.聚类分析中最常用的距离计算公式有、、等。 29.基于划分的聚类算法有和。
期末随机过程试题及标准答案
《随机过程期末考试卷》 1.设随机变量X 服从参数为λ的泊松分布,则X 的特征函数为 。 2.设随机过程X(t)=Acos( t+),- 1.设随机变量X 服从参数为λ的泊松分布,则X 的特征函数为 。 2.设随机过程X(t)=Acos( t+),- 数据挖掘考试题 LG GROUP system office room 【LGA16H-LGYY-LGUA8Q8-LGA162】 数据挖掘考试题 一.选择题 1. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离( ) A.分类 B.聚类 C.关联分析 D.主成分分析 2. ( )将两个簇的邻近度定义为不同簇的所有点对邻近度的平均值,它是一种凝聚层次聚类技术。 (单链) (全链) C.组平均方法 3.数据挖掘的经典案例“啤酒与尿布试验”最主要是应用了( )数据挖掘方法。 A 分类 B 预测 C关联规则分析 D聚类 4.关于K均值和DBSCAN的比较,以下说法不正确的是( ) 均值丢弃被它识别为噪声的对象,而DBSCAN一般聚类所有对象。 均值使用簇的基于原型的概念,DBSCAN使用基于密度的概念。 均值很难处理非球形的簇和不同大小的簇,DBSCAN可以处理不同大小和不同形状的簇 均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇 5.下列关于Ward’s Method说法错误的是:( ) A.对噪声点和离群点敏感度比较小 B.擅长处理球状的簇 C.对于Ward方法,两个簇的邻近度定义为两个簇合并时导致的平方误差 D.当两个点之间的邻近度取它们之间距离的平方时,Ward方法与组平均非常相似 6.下列关于层次聚类存在的问题说法正确的是:( ) A.具有全局优化目标函数 B.Group Average擅长处理球状的簇 C.可以处理不同大小簇的能力 D.Max对噪声点和离群点很敏感 7.下列关于凝聚层次聚类的说法中,说法错误的事:( ) A.一旦两个簇合并,该操作就不能撤销 B.算法的终止条件是仅剩下一个簇 C.空间复杂度为()2m O D.具有全局优化目标函数 8.规则{牛奶,尿布}→{啤酒}的支持度和置信度分别为:( ) 9.下列( )是属于分裂层次聚类的方法。 Average 10.对下图数据进行凝聚聚类操作,簇间相似度使用MAX计算,第二步是哪两个簇合并:( ) A.在{3}和{l,2}合并 B.{3}和{4,5}合并 C.{2,3}和{4,5}合并 D. {2,3}和{4,5}形成簇和{3}合并 二.填空题: 1.属性包括的四种类型:、、、。 2.是两个簇的邻近度定义为不同簇的所有点对邻近度的平均值。 3. 基本凝聚层次聚类算法空间复杂度,时间复杂度,如果某个簇到其他所有簇的距离存放在一个有序表或堆中,层次聚类所需要的时间复杂度将为。 4. 聚类中,定义簇间的相似度的方法有(写出四 个):、、、。 5. 层次聚类技术是第二类重要的聚类方法。两种层次聚类的基本方 法:、。 6. 组平均是一种界于和之间的折中方法。 一.填空题(每空2分,共20分) 1.设随机变量X 服从参数为λ的泊松分布,则X 的特征函数为it (e -1) e λ。 2.设随机过程X(t)=Acos( t+),- 数据挖掘考试题目——关联分析 一、10个选择 1.以下属于关联分析的是() A.CPU性能预测B.购物篮分析 C.自动判断鸢尾花类别D.股票趋势建模 2.维克托?迈尔-舍恩伯格在《大数据时代:生活、工作与思维的大变革》一书中,持续强调了一个观点:大数据时代的到来,使我们无法人为地去发现数据中的奥妙,与此同时,我们更应该注重数据中的相关关系,而不是因果关系。其中,数据之间的相关关系可以通过以下哪个算法直接挖掘() A.K-means B.Bayes Network C.C4.5 D.Apriori 3.置信度(confidence)是衡量兴趣度度量()的指标。 A.简洁性B.确定性 C.实用性D.新颖性 4.Apriori算法的加速过程依赖于以下哪个策略() A.抽样B.剪枝 C.缓冲D.并行 5.以下哪个会降低Apriori算法的挖掘效率() A.支持度阈值增大B.项数减少 C.事务数减少D.减小硬盘读写速率 6.Apriori算法使用到以下哪些东东() A.格结构、有向无环图B.二叉树、哈希树 C.格结构、哈希树D.多叉树、有向无环图 7.非频繁模式() A.其置信度小于阈值B.令人不感兴趣 C.包含负模式和负相关模式D.对异常数据项敏感 8.对频繁项集、频繁闭项集、极大频繁项集的关系描述正确的是()[注:分别以1、2、3代表之] A.3可以还原出无损的1 B.2可以还原出无损的1 C.3与2是完全等价的D.2与1是完全等价的 9.Hash tree在Apriori算法中所起的作用是() A.存储数据B.查找 C.加速查找D.剪枝 10.以下不属于数据挖掘软件的是() A.SPSS Modeler B.Weka C.Apache Spark D.Knime 二、10个填空 1.关联分析中表示关联关系的方法主要有:和。 2.关联规则的评价度量主要有:和。 3.关联规则挖掘的算法主要有:和。 4.购物篮分析中,数据是以的形式呈现。 5.一个项集满足最小支持度,我们称之为。 6.一个关联规则同时满足最小支持度和最小置信度,我们称之为。 单选题 1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3. 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 4. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6. 使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务?(A) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 11.下面哪种不属于数据预处理的方法?(D) A变量代换B离散化 C 聚集 D 估计遗漏值 12. 假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内?(B) A 第一个 B 第二个 C 第三个 D 第四个 13.上题中,等宽划分时(宽度为50),15又在哪个箱子里?(A) A 第一个 B 第二个 C 第三个 D 第四个 16. 只有非零值才重要的二元属性被称作:( C ) A 计数属性 B 离散属性C非对称的二元属性 D 对称属性 17. 以下哪种方法不属于特征选择的标准方法:(D) A嵌入 B 过滤 C 包装 D 抽样 18.下面不属于创建新属性的相关方法的是:(B) A特征提取B特征修改C映射数据到新的空间D特征构造 22. 假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A 0.821 B 1.224 C 1.458 D 0.716 23.假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,30,33,33,35,35,36,40,45,46,52,70, 问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。第二个箱子值为:(A) A 18.3 B 22.6 C 26.8 D 27.9 28. 数据仓库是随着时间变化的,下面的描述不正确的是(C) A. 数据仓库随时间的变化不断增加新的数据内容; B. 捕捉到的新数据会覆盖原来的快照; C. 数据仓库随事件变化不断删去旧的数据内容; D. 数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合. 29. 关于基本数据的元数据是指: (D) A. 基本元数据与数据源,数据仓库,数据集市和应用程序等结构相关的信息; B. 基本元数据包括与企业相关的管理方面的数据和信息; C. 基本元数据包括日志文件和简历执行处理的时序调度信息; D. 基本元数据包括关于装载和更新处理,分析处理以及管理方面的信息. 北京邮电大学2012——2013学年第1学期 《概率论与随机过程》期末考试试题答案 考试注意事项:学生必须将答题内容(包括填空题)做在试题答题纸上,做在试卷纸上一律无效。在答题纸上写上你的班号和选课单上的学号,班内序号! 一. 单项选择题和填空题:(每空3分,共30分) 1.设A 是定义在非空集合Ω上的集代数,则下面正确的是 .A (A )若A B ∈∈A,A ,则A B -∈A ; (B )若A A B ∈?A,,则B ∈A ; (C )若12n A n =∈?A,,,,则 1 n n A ∞=∈A ; (D )若12n A n =∈?A,,,,且123A A A ??? ,则 1 n n A ∞ =∈A . 2. 设(),ΩF 为一可测空间,P 为定义在其上的有限可加测度,则下面正确的是 .c (A )若A B ∈∈F,F ,则()()()P A B P A P B -=-; (B )若12n A n =∈?F,,,,,且123A A A ??? ,则1 li ( )()m n n n n P A A P ∞→∞ ==; (C )若A B C ∈∈∈F,F,F,,则()()()()P A B C P A P AB P A BC =++; (D )若12n A n =∈?F,,,,,且,i j A i j A =??=/,1 1 ( )()n n n n P P A A ∞ ∞===∑. 3.设f 为从概率空间(),P ΩF,到Borel 可测空间(),R B 上的实可测函数,表达式为100 0()k A k f kI ω==∑,其中1000 ,, i j n n i j A A A ==??=Ω/=,则fdP Ω=? ; 一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2. 时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。 北京工业大学2009-20010学年第一学期期末 数理统计与随机过程(研) 课程试卷 学号 姓名 成绩 注意:试卷共七道大题,请写明详细解题过程。 考试方式:半开卷,考试时只允许看教材《概率论与数理统计》 浙江大学 盛 骤等编第三版(或第二版)高等教育出版社。可以看笔记、作业,但不允许看其它任何打印或复印的资料。考试时允许使用计算器。考试时间120分钟。考试日期:2009年12月31日 一、随机抽取某班28名学生的英语考试成绩,算得平均分数为80=x 分,样本标准差8=s 分,若全年级的英语成绩服从正态分布,且平均成绩为85分,问:能否认为该班的英语成绩与全年级学生的英语平均成绩有显著差异(取显著性水平050.=α)? 解:这是单个正态总体 ),(~2σμN X ,方差2σ未知时关于均值μ的假设检验问题,用T 检验法. 解 85:0=μH ,85:1≠μH 选统计量 n s x T /0 μ-= 已知80=x ,8=s ,n =28,850=μ, 计算得n s x T /0μ-= 31 .328/885 80=-= 查t 分布表,05.0=α,自由度27,临界值052.2)27(025.0=t . 由于052.2>T 2622.2>,故拒绝 0H ,即在显著水平05.0=α下不能认为 该班的英语成绩为85分. 050.= 解:由极大似然估计得.2?==x λ 在X 服从泊松分布的假设下,X 的所有可能的取值对应分成两两不相交的子集A 0, A 1,…, A 8。 则}{k X P =有估计 =i p ?ΛΛ,7,0, !2}{?2 ===-k k e k X P k =0?p 一、名词解释 1.数据仓库:是一种新的数据处理体系结构,是面向主题的、集成的、不可更新 的(稳定性)、随时间不断变化(不同时间)的数据集合,为企业决策支持系统提供所需的集成信息。 2.孤立点:指数据库中包含的一些与数据的一般行为或模型不一致的异常数据。 3.OLAP:OLAP是在OLTP的基础上发展起来的,以数据仓库为基础的数据分析处 理,是共享多维信息的快速分析,是被专门设计用于支持复杂的分析操作,侧重对分析人员和高层管理人员的决策支持。 4.粒度:指数据仓库的数据单位中保存数据细化或综合程度的级别。粒度影响存 放在数据仓库中的数据量的大小,同时影响数据仓库所能回答查询问题的细节程度。 5.数据规范化:指将数据按比例缩放(如更换大单位),使之落入一个特定的区域 (如0-1)以提高数据挖掘效率的方法。规范化的常用方法有:最大-最小规范化、零-均值规范化、小数定标规范化。 6.关联知识:是反映一个事件和其他事件之间依赖或相互关联的知识。如果两项 或多项属性之间存在关联,那么其中一项的属性值就可以依据其他属性值进行预测。 7.数据挖掘:从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐 含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。 8.OLTP:OLTP为联机事务处理的缩写,OLAP是联机分析处理的缩写。前者是以数 据库为基础的,面对的是操作人员和低层管理人员,对基本数据进行查询和增、删、改等处理。 9.ROLAP:是基于关系数据库存储方式的,在这种结构中,多维数据被映像成二维 关系表,通常采用星型或雪花型架构,由一个事实表和多个维度表构成。10.MOLAP:是基于类似于“超立方”块的OLAP存储结构,由许多经压缩的、类似 于多维数组的对象构成,并带有高度压缩的索引及指针结构,通过直接偏移计算进行存取。 11.数据归约:缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能 够得到和原始数据相同的分析结果。 12.广义知识:通过对大量数据的归纳、概括和抽象,提炼出带有普遍性的、概括 性的描述统计的知识。 13.预测型知识:是根据时间序列型数据,由历史的和当前的数据去推测未来的数 据,也可以认为是以时间为关键属性的关联知识。 14.偏差型知识:是对差异和极端特例的描述,用于揭示事物偏离常规的异常现象, 如标准类外的特例,数据聚类外的离群值等。 武汉大学计算机学院 20XX级研究生“数据仓库和数据挖掘”课程期末考试试题 要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。每张答题纸都要写上姓名和学号。 一、单项选择题(每小题2分,共20分) 1. 下面列出的条目中,()不是数据仓库的基本特征。B A.数据仓库是面向主题的 B.数据仓库是面向事务的 C.数据仓库的数据是相对稳定的 D.数据仓库的数据是反映历史变化的 2. 数据仓库是随着时间变化的,下面的描述不正确的是()。 A.数据仓库随时间的变化不断增加新的数据内容 B.捕捉到的新数据会覆盖原来的快照 C.数据仓库随事件变化不断删去旧的数据内容C D.数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合 3. 以下关于数据仓库设计的说法中()是错误的。A A.数据仓库项目的需求很难把握,所以不可能从用户的需求出发来进行数据仓库的设计,只能从数据出发进行设计 B.在进行数据仓库主题数据模型设计时,应该按面向部门业务应用的方式来设计数据模型 C.在进行数据仓库主题数据模型设计时要强调数据的集成性 D.在进行数据仓库概念模型设计时,需要设计实体关系图,给出数据表的划分,并给出每个属性的定义域 4. 以下关于OLAP的描述中()是错误的。A A.一个多维数组可以表示为(维1,维2,…,维n) B.维的一个取值称为该维的一个维成员 C.OLAP是联机分析处理 D.OLAP是数据仓库进行分析决策的基础 5. 多维数据模型中,下列()模式不属于多维模式。D A.星型模式 B.雪花模式 C.星座模式 D.网型模式 6. 通常频繁项集、频繁闭项集和最大频繁项集之间的关系是()。C A.频繁项集?频繁闭项集?最大频繁项集 B.频繁项集?最大频繁项集?频繁闭项集 C.最大频繁项集?频繁闭项集?频繁项集 D.频繁闭项集?频繁项集?最大频繁项集 2014-2015-1《数据仓库与数据挖掘》 期末考试题型 一、单项选择题(每小题2分,共20分) 二、填空题(每空1分,共20分) 三、简答题(每题6分,共30分) 四、析题与计算题(共30分) 请同学们在考试时不要将复习资料带入考场!!! 单选题 1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 2. 以下两种描述分别对应哪两种对分类算法的评价标准?(A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision, Recall B. Recall, Precision A. Precision, ROC D. Recall, ROC 3. 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 4. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 5. 什么是KDD?(A) A. 数据挖掘与知识发现 B. 领域知识发现 C. 文档知识发现 D. 动态知识发现 6. 使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务?(A) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7. 为数据的总体分布建模;把多维空间划分成组等问题属于数据挖掘的哪一类任务?(B) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 8. 建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 9. 用户有一种感兴趣的模式并且希望在数据集中找到相似的模式,属于数据挖掘哪一类任务?(A) 2.设{X (t ),t ≥0}是独立增量过程, 且X (0)=0, 证明{X (t ),t ≥0}是一个马尔科夫过程。 证明:当12n 0t t t t <<< <<时, 1122n n P(X(t)x X(t )=x ,X(t )=x ,X(t )=x )≤= n n 1122n n P(X(t)-X(t )x-x X(t )-X(0)=x ,X(t )-X(0)=x , X(t )-X(0)=x )≤= n n P(X(t)-X(t )x-x )≤,又因为n n P(X(t)x X(t )=x )=≤n n n n P(X(t)-X(t )x-x X(t )=x )≤= n n P(X(t)-X(t )x-x )≤,故1122n n P(X(t)x X(t )=x ,X(t )=x , X(t )=x )≤=n n P(X(t)x X(t )=x )≤ 3.设{}n X ,n 0≥为马尔科夫链,状态空间为I ,则对任意整数n 0,1 《随机过程期末考试卷》 1 ?设随机变量X服从参数为■的泊松分布,则X的特征函数为 ___________ 。 2?设随机过程X(t)二Acos(「t+「),-::vt<::其中「为正常数,A和门是相互独立的随机变量,且A和“服从在区间10,1 1上的均匀分布,则X(t)的数学期望为。 3?强度为入的泊松过程的点间间距是相互独立的随机变量,且服从均值为_ 的同一指数分布。 4?设「W n ,n 一1是与泊松过程:X(t),t - 0?对应的一个等待时间序列,则W n服从分布。5?袋中放有一个白球,两个红球,每隔单位时间从袋中任取一球,取后放回, r 对每一个确定的t对应随机变量x(t)=」3’如果t时取得红球,则这个随机过 e t, 如果t时取得白球 程的状态空间__________ 。 6 ?设马氏链的一步转移概率矩阵P=(p j),n步转移矩阵P(n)=8(;)),二者之间的关系为。 7?设汉.,n -0?为马氏链,状态空间I,初始概率P i二P(X。二i),绝对概率 P j(n)二P^X n二j?,n步转移概率p j n),三者之间的关系为_____________ 。 8 .设{X(t),t 一0}是泊松过程,且对于任意t2t^ 0则 P{X ⑸= 6|X (3) = 4} = _______ t 9?更新方程K t二H t ? .°K t-s dF s解的一般形式为__________________ 。10?记二-EX n,对一切a 一0,当t—一:时,M t+a -M t > ____________ 3.设]X n,n — 0?为马尔科夫链,状态空间为I,则对任意整数n—0,仁I 武汉大学计算机学院 2014级研究生“数据仓库和数据挖掘”课程期末考试试题 要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。每张答题纸都要写上姓名和学号。 一、单项选择题(每小题2分,共20分) 1. 下面列出的条目中,()不是数据仓库的基本特征。B A.数据仓库是面向主题的 B.数据仓库是面向事务的 C.数据仓库的数据是相对稳定的 D.数据仓库的数据是反映历史变化的 2. 数据仓库是随着时间变化的,下面的描述不正确的是()。 A.数据仓库随时间的变化不断增加新的数据内容 B.捕捉到的新数据会覆盖原来的快照 C.数据仓库随事件变化不断删去旧的数据内容C D.数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合 3. 以下关于数据仓库设计的说法中()是错误的。A A.数据仓库项目的需求很难把握,所以不可能从用户的需求出发来进行数据仓库的设计,只能从数据出发进行设计 B.在进行数据仓库主题数据模型设计时,应该按面向部门业务应用的方式来设计数据模型 C.在进行数据仓库主题数据模型设计时要强调数据的集成性 D.在进行数据仓库概念模型设计时,需要设计实体关系图,给出数据表的划分,并给出每个属性的定义域 4. 以下关于OLAP的描述中()是错误的。A A.一个多维数组可以表示为(维1,维2,…,维n) B.维的一个取值称为该维的一个维成员 C.OLAP是联机分析处理 D.OLAP是数据仓库进行分析决策的基础 5. 多维数据模型中,下列()模式不属于多维模式。D A.星型模式 B.雪花模式 C.星座模式 D.网型模式 6. 通常频繁项集、频繁闭项集和最大频繁项集之间的关系是()。C A.频繁项集?频繁闭项集?最大频繁项集 B.频繁项集?最大频繁项集?频繁闭项集 C.最大频繁项集?频繁闭项集?频繁项集 D.频繁闭项集?频繁项集?最大频繁项集随机过程试题带答案
数据挖掘考试题
随机过程试题及答案
最新数据挖掘考试题目——关联分析资料
数据挖掘试题
(完整版)北邮研究生概率论与随机过程2012-2013试题及答案
《数据挖掘》试题与答案
学期数理统计与随机过程(研)试题(答案)
数据挖掘考试题库讲解
数据仓库与数据挖掘试题
《数据仓库与数据挖掘》复习题
随机过程复习试题及答案
2017 2018期末随机过程试题及答案
武汉大学计算机专业数据仓库及数据挖掘期末考试题