数据库查询方法

数据查询(检索)
一、简单查询(单张表)
字段筛选输出全部列select *
select select 列名…
记录筛选比较运算符>< = != !> !<>= <= <>
Where逻辑运算符and or
范围运算符Between小值and 大值
列表运算符In(值1,值2,….)
模糊匹配运算符Like ‘通配表达式’
空值运算符is null
关键字辅助distinctselect distinct 列名…
Topselect top n 列名…
二、高级查询(多张表)
一、简单查询
1、基本语法格式
结合实现的查询功能
1)输出表的全部列(全部行、列)
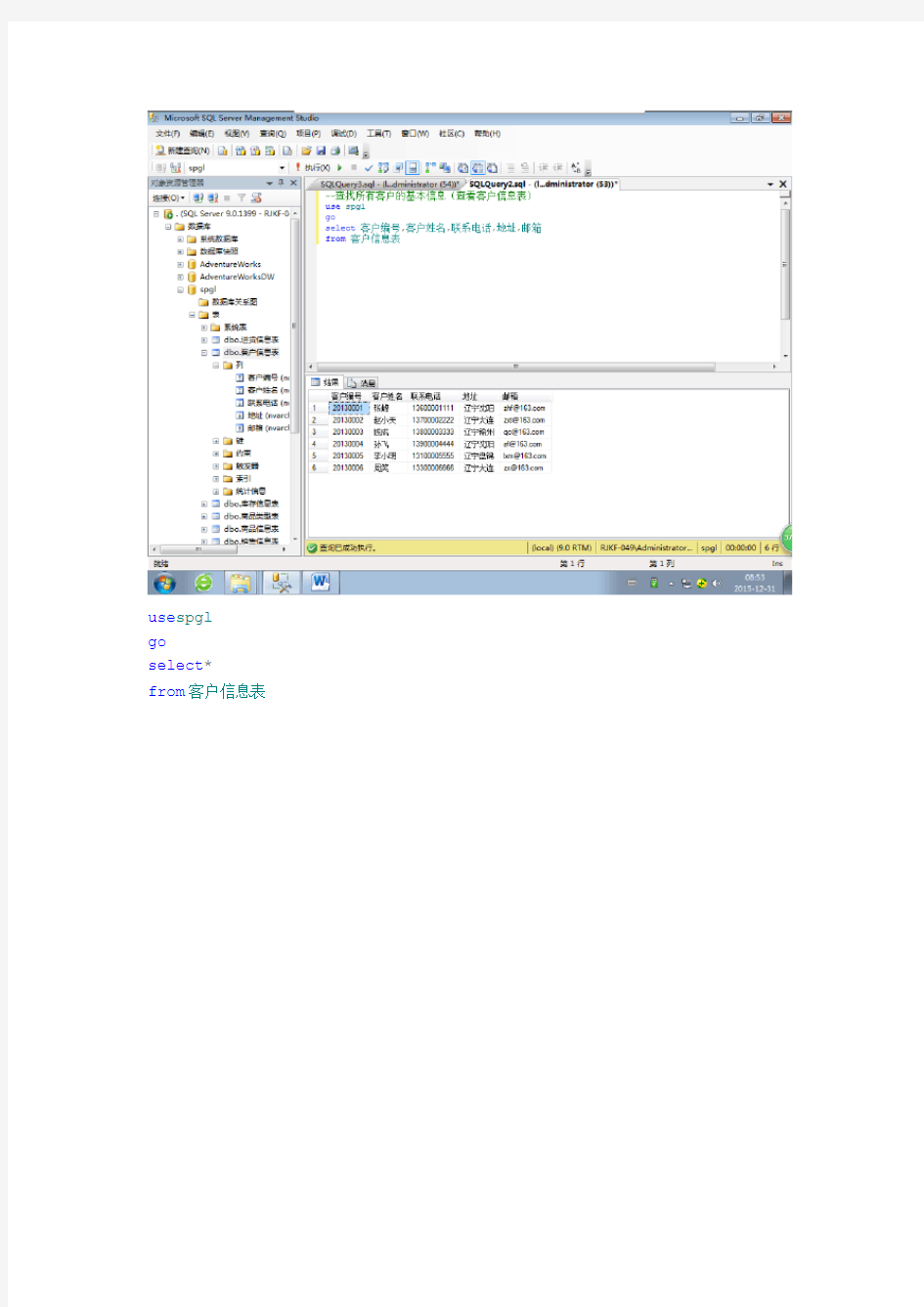
查找所有客户的基本信息(查看客户信息表)use spgl
go
select客户编号,客户姓名,联系电话,地址,邮箱
from客户信息表
use spgl
go
select*
from客户信息表
2)输出表的部分列
查找所有客户的姓名(查看客户信息表的姓名列)select客户姓名
from客户信息表
查找所有商品的编号(查看商品信息表的商品编
号列)
select商品编号
from商品信息表
3)输出表中满足条件的记录
--查找所有单位是“个”的商品的编号(查看商品信息表的商品编号列)select商品编号
from商品信息表
where商品单位='个'
查找11110001商品的销售信息(查看销售信息表
的商品编号为指定值的这些行,相当于进行条件
筛选)
select*
from销售信息表
where商品编号=11110001
--查找11110001和11110003商品的销售信息
select*
from销售信息表
where商品编号=11110001 or商品编号=11110003
--查找11110001商品的销售信息,要求只显示数量大于的信息select*
from销售信息表
where商品编号=11110001 and销售数量>100
查找11110001商品的销售给哪些客户select客户编号
from销售信息表
where商品编号=11110001
上述查询中涉及到:表,表中字段,查询条件
格式:select *︱列名称1,列名称2….
From 表名称
Where 条件表达式
注意:列名称必须是from子句指定表中的列
Select进行的纵向的选择(只决定输出哪些列),当输出的列是表中全部列且列顺序一致时,可用“*”
Where进行的横向的选择(决定输出哪些行)
2、关键字
1)Distinct
格式:
Select distinct 列名称
From 表名
--有哪些客户订过货
--分析:当客户编号出现在销售信息表中就表明该客户订过货
--1、明确从哪张表查询;、明确输出哪些列;、明确是否进行行筛选
--由于客户可以多次订货,所以不需要显示多次可以使用distinct
use spgl
go
selectdistinct客户编号
from销售信息表
--有哪些客户订过货,以及他们分别订了哪些商品
use spgl
go
selectdistinct客户编号,商品编号
from销售信息表
注意:该关键字只针对输出结果的整行,不是某个字段。
2)Top
格式:
Select top n 列名称
From 表名
--查看数据库中进货信息储存了哪些内容
--分析: 只是要看看有哪些列,所以只需要显示几行就够
selecttop 10 percent*
from进货信息表
3、where子句
1)范围运算符
Where 列名称[not] Between初始值and 终止值--查看销售金额在100-300的商品编号select商品编号
from销售信息表
where销售金额between 100 and 300
where销售金额>=100 and销售金额<=300
2)in
where 列名称in(值1,值2……)
--查看和两种货品的销售情况
select*
from销售信息表
where商品编号in(11110001,22220001)
where商品编号=11110001 or商品编号=22220001
3)like
Where 列名称like ‘字符通配格式’
--查找商品类型是S开头的商品类型信息select*
from商品类型表
where商品类型编号like'S_____'
4)IS NULL
Where 列名称is null
--检查客户中邮箱还未填写的客户有哪些,联系他select客户姓名,联系电话
from客户信息表
where邮箱isnull
数据库数据处理
实验三数据处理 【实验目的】 1.学会处理表数据、查看表记录 2.学会使用SQL语句处理表数据 【实验内容】 1.使用SQL语句给课程表、成绩添加数据--INSERT语句 2.使用SQL语句给学生表、成绩表更新数据--UPDATE语句 3.使用SQL语句为学生表删除记录--DELETE语句 【实验准备】 1.复习与本次实验内容相关知识 2.对本次实验中要求自己完成的部分做好准备 【实验步骤】 特别说明:本实验中使用的数据仅为实验而已,无任何其他作用。 1.给班级表添加记录 o用自己的帐号、密码,注册并连接到SQL Server服务器。 o展开连接的服务器-->展开"数据库"-->展开你的数据库(你的学号)-->单击"表"。 o在右边的窗格内,右击班级表(U_CLASSES),在弹出的快捷菜单中,将鼠标移到"打开表(O)"上,再移到"返回所有行(A)"上单击.参见下图。 o o接着按下图输入数据,注意,ID列不用输入(为什么?)。 o
o输入完成后,若要对数据行(如:删除行)进行操作,可在某行上右击鼠标,在弹出菜单中选择要执行的命令。关闭该查询窗口。 2.修改表记录数据 o若要修改数据,可用上述方法打开数据表,直接修改即可。 3.用界面方式给学生表(U_STUDENTS)添加数据 o参照前面方法给用界面方式给学生表输入如下记录。在输入过程中,注意观察如果输入相同学号有什么现象(什么原因?),如果班级编号不输入,又会怎 样(为什么?)。 o 4.用SQL命令给课程表(U_COURSES)、成绩表(U_SCORES)添加数据、修改数据 o先运用界面方式给课程表(U_COURSES)增加一列CREDIT,数据类型为tinyint o启动数据库引擎查询(如下图所示),进入到查询编辑窗口。 o o输入(为减少输入工作量,可将下面的语句复制)如下语句并执行之,为课程表(U_COURSES)插入插入5条记录。 o INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('计算机文化基础',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('C语言程序设 计',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('数据结构',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('数据库原理与 应用',4) INSERT INTO [U_COURSES] (COURSE,CREDIT) VALUES ('SQL Server',3) o输入"SELECT * FROM U_COURSES"查看课程表记录。
数据库应用基础教程答案
数据库应用基础教程答案 【篇一:access数据库应用基础教程(第三版)习题及答 案】 txt>程(第三版)习题集答案 第1章数据库系统概述 1. 什么是数据库?什么是数据库系统?答:数据库(database) 是存放数据的仓库,严格的讲,数据库是长期存储在计算机内,有组 织的,可共享的大量数据集合。 数据库系统(database systems),是由数据库及其管理软件组成的系统。它是为适应数据处理的需要而发展起来的一种较为理想的 数据处理的核心机构。它是一个实际可运行的存储、维护和应用系 统提供数据的软件系统,是存储介质、处理对象和管理系统的集合体。 2. 什么是数据库管理系统?它有哪些主要功能? 答:数据库管理系统(database management system)是一种操纵 和管理数据 库的大型软件,用于建立、使用和维护数据库,简称dbms。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。 数据库管理系统的主要功能有:数据定义、数据操作、数据库的运 行管理、数据组织、数据库的保护、数据库的维护和通信。 3. 说出几种常用的数据模型。 答:层次模型、网状模型、关系模型。 4. 什么是关系模型? 答:关系模型是用二维表的形式表示实体和实体间联系的数据模型。 5. 简述数据库设计的步骤。 答:需求分析、概念结构设计、逻辑结构设计、物理结构设计、数 据库的建立和测试、数据库运行和维护。 第2章 sql 语言简介 1. 什么是sql语言?sql语言具有哪些特点和功能? 答:sql是一种数据库查询和程序设计语言,用于存取数据以及查询更新和管理关系 数据库系统。 sql的特点和功能有:查询,操作,定义和控制四个方面,sql语言 具有高度的非过程化,语言简洁,语义明显,语法结构简单,直观
数据库查询实验
实验二:数据库的简单查询和连接查询 实验目的: 掌握简单表的数据查询、数据排序和数据联结查询的操作方法。 实验内容: 简单查询操作和连接查询操作。 实验步骤: 一. 单表查询: 1. 查询全体学生的学号和姓名: select sno, sname from student 2. 查询全体学生的所有信息: select * from student 或者 select sno, sname, ssex,sage, sdept from student 3. 查询全体学生的姓名, 出生年份,和所在系, 并用小写字母表示所有系名: VFP中: select sname, '出生年份为: ', year(date() - sage, lower(sdept) from student SQLServer中: select sname, '出生年份为: ', year(getdate()) - sage, lower(sdept) from student 4. 查询选修了课程的学生的学号: select distinct sno from sc 比较: select sno from sc 5. 查询年龄在20岁以下的学生的姓名及其年龄: select sname, sage from student where sage<20 6. 查询考试成绩有不及格的学生的学号: select distinct sno from sc where grade<60 比较: select sno from sc where grade<60 7. 查询年龄在20-30岁直接的学生的姓名, 姓名, 所在系: select sname, ssex, sdept from student where sage between 20 and 30 8. 查询 IS,CS,MA系的所有学生的姓名和性别: select sname, ssex from student where sdept in ('IS', 'MA','CS') 9. 查找所有姓’李’的学生的姓名, 学号和性别: select sname, sno, ssex from student where sname like '李%'
数据库查询方法
数据查询(检索) 一、简单查询(单张表) 字段筛选输出全部列select * select 输出部分列select 列名… 记录筛选比较运算符> < = != !> !< >= <= <> Where 逻辑运算符and or 范围运算符Between小值and 大值 列表运算符In(值1,值2,….) 模糊匹配运算符Like ‘通配表达式’ 空值运算符is null 关键字辅助distinct select distinct 列名… Top select top n 列名… 二、高级查询(多张表) 一、简单查询 1、基本语法格式 结合实现的查询功能 1)输出表的全部列(全部行、列) 查找所有客户的基本信息(查看客户信息表) use spgl go select客户编号,客户姓名,联系电话,地址,邮箱 from客户信息表
use spgl go select* from客户信息表
2)输出表的部分列 查找所有客户的姓名(查看客户信息表的姓名列) select客户姓名 from客户信息表 查找所有商品的编号(查看商品信息表的商品编 号列) select商品编号 from商品信息表
3)输出表中满足条件的记录 --查找所有单位是“个”的商品的编号(查看商品信息表的商品编号列)select商品编号 from商品信息表 where商品单位='个'
查找11110001商品的销售信息(查看销售信息表 的商品编号为指定值的这些行,相当于进行条件 筛选) select* from销售信息表 where商品编号=11110001
--查找11110001和11110003商品的销售信息select* from销售信息表 where商品编号=11110001 or商品编号=11110003
sql数据库一些查找删除方法
查找数据库中重复数据T-SQL ========第一篇========= 在一张表中某个字段下面有重复记录,有很多方法,但是有一个方法,是比较高效的,如下语句: select data_guid from adam_entity_datas a where a.rowid > (select min (b.rowid) from adam_entity_datas b where b.data_guid = a.data_guid) 如果表中有大量数据,但是重复数据比较少,那么可以用下面的语句提高效率select data_guid from adam_entity_datas where data_guid in (select da ta_guid from adam_entity_datas group by data_guid having count(*) > 1) 此方法查询出所有重复记录了,也就是说,只要是重复的就选出来,下面的语句也许更高效 select data_guid from adam_entity_datas where rowid in (select rid fr om (select rowid rid,row_number()over(partition by data_guid order by rowid) m from adam_entity_datas) where m <> 1) 目前只知道这三种比较有效的方法。 第一种方法比较好理解,但是最慢,第二种方法最快,但是选出来的记录是所有重复的记录,而不是一个重复记录的列表,第三种方法,我认为最好。 ========第二篇========= select usercode,count(*) from ptype group by usercode h aving count(*) >1 ========第三篇========= 找出重复记录的ID: select ID from ( select ID ,count(*) as Cnt from 要消除重复的表 group by ID ) T1
数据库操作及查询
第三章数据库操作及查询§1刨建数据库表 一、表的分类:库表、自由表。 二、数据库表与自由表的区别 库表:各个表之间有关联 特点:A:长表名和长字段名。 B:每个字可以有提示和注释。 C:可以定义缺省值。 D:字段级的规则和记录级的规则。 自由表: foxbase 表,独立 三、表结构的定义 操作方法:A:表设计器 B:命令create < 表名> 四、表记录的输入 1、追加方式 2、定义结构时同时输入
五、表记录添加 1)、键盘输入 2)、从已有文件中追加 A、INSERT –SQL 命令 命令格式: INSERT INTO 表名[(字段名1[,字段名2,…])] V ALUES(表达式1[,表达式2,…]) 功能:在表尾追加一个新记录,并直接输入记录数据。 说明:表不必事先打开,字段与表达式的类型必须相同。 例如:INSERT INTO TEACHER(BH,XM,XB,JBGZ)V ALUES (“02005”,“张华”,“女”,2021) B、APPEND 命令 格式:APPEND [BLANK] 功能:向表中追加记录 说明:使用BLANK子句能在表尾追加一条空记录。若不选取则进入全屏幕编缉方式。 C、APEND FROM 命令
格式:APPEND FROM <文件名> FIELDS <字段名表> [FOR< 条件>][[TYPE ] DELIMITED[WITH <定界符>/WITH BLANK/WITH TAB]/SDF/XLS]] 功能:在当前的表尾部追加一批记录,这些记录来自于指定的文件。 说明:1、源文件的类型可以为表、系统数据格式文件、定界格文本文件、Excel文件。 2、执行该文件时源表不用打开。 例如:先将表数据导入到EXCEL表中,然后再追加到空表中。 appe from tyty type xls 六、表的打开和关闭 1、表的打开 A: 命令 use
数据库查询操作详解
一、数据查询-----单表查询 (1)查询语句格式 Select [all|distinct] <目标列表达式> [,<目标列表达式>]…… From <表名或视图> [,<表名或视图>]…… [where <条件表达式>] [group by <列名1> [having <条件表达式>]] [order by <列名2> [asc|desc]] ; 注:[all|distinct]中all为缺省值,取消结果中的重复列则用distinct; [asc|desc]中asc为缺省值,表示按照升序排列。对于空值,若按照升序排,则含空值的元组显示在最后面;若按降序排,则空值的元组最先显示。 (2)查询指定列 a)查询部门表dept中所有部门的详细信息,并且列名用汉字表示。 select DNO,DNAME,ADDR from dept; b)查询部门表dept中人力资源部的部门编号。 select DNO from dept where DNAME='人力资源部'; <目标列表达式>中各个列的先后顺序可以与表中的顺序不一致. (3)查询全部列 查询全体学生的详细记录 Select * From Student ; (4)将查询结果的列名用别名显示 查询部门表dept中所有部门的详细信息,并且列名用汉字表示。 select DNO部门编号,DNAME部门名称,ADDR部门地址 from dept; (5)在查询的结果中插入新的一列用来显示指定的内容 Select Sname NAME ,’Year of Birth:’BIRTH ,Sbirth BIRTHDAY ,Sdept DEPARTMENT From Stuent ; 则显示的结果中,每个元组的第二列均为”Year of Birth:”,此列在原数据库中是不存在的. (6)查询经过计算的值 Select 子句的<目标列表达式> 不仅可以是表中的属性列,也可以是表达式。 例:查询全体学生的姓名及其出生年月 Select Sname ,2004 – Sage /*当时年份减去年龄为出生年月
易语言数据库教程之ACCESS数据库全操作
易语言数据库教程之ACCESS数据库 前面我们已经对比分析过易语言所支持的几种常见数据库,在这几种数据库中,我们先来学习一个ACCESS数据库,当然,MSSQL数据库是完全一样的。 数据库的学习可以说非常的简单,也可以说很不简单,这要看你的出发点来定,当然,前面所学习的易语言基础同样很重要! 和前面所有的教程一样,所讲的内容部分来源我的课堂教学,面对的是高中学生,有些地方的讲解会非常的详细,而有些地方又会相对简单的一笔带过,如果有什么地方你理解起来有困难的话,请与我联系,呵呵! 本教程并不是要把易语言中对ACCESS数据库的所有操作和应用都讲一遍,都讲清楚,那是不可能的,这一点倒是有点遗憾,但我会尽我所能把一些必需的内容讲清楚! 一、准备工作 1、ACCESS的安装参见Microsoft Office2003安装图解教程 2、ACCESS数据库中数据表的建立 3、易语言ACCESS数据库控件介绍 二、数据库操作 1、易语言ACCESS数据库的连接及打开 2、易语言ACCESS数据库的读操作 3、易语言ACCESS数据库的读操作问题解决 4、易语言ACCESS数据库的高级打开操作 5、易语言ACCESS数据库的写操作 6、易语言ACCESS数据库记录的简单修改 7、易语言ACCESS数据库记录的高级修改 三、数据库与高级表格
1、易语言ACCESS数据库与高级表格一 ACCESS数据库中数据表的建立 在ACCESS中建立一个数据库及在数据库中建立数据库其实是非常简单的。 1、新建数据库,这就不用多说了,在“文件”菜单下第一个就是“新建”,它的快捷键是“Ctrl+N”,和大多数软件完全一样。 2、新建的数据库第一步操作就是要保存,这也不用多说了,相信大家都会的。 3、新建数据表,新建的数据库如下图,是一个表都没有,新建一个数据表的方法有很多,这里我们选择“使用设计器创建表”,如下图所示。 3、这里我们以建立一个学生成绩表为例进行操作,随便写了一些字段在里面,注意一下字段的类型,有些是“自动编号”,有些是“文本”,有些是“数字”,根据需要来,最后别忘记给“id”这个字段设置为“主键”。
SQL数据库快捷键大全
快捷键·F5 这个恐怕是最常用的快捷键了,用来代替那个“!执行”按钮,写完SQL语句后手不用离开键盘。虽然没什么技术含量,但不会用的人八成是菜鸟。 快捷键·CTRL+C/V 复制/粘贴。COPY流程序员神器,安全环保无污染。不多说,只会右键的同学直接定性为菜鸟。MS所有文本编辑器通用。 快捷键·↑↓←→ 上下左右。功能全人类都知道。另外据验证,在SSMS启动时快速输入↑↑↓↓←→←→BABA没有加30条命效果。MS所有文本编辑器通用。 快捷键·SHIFT+↑↓←→ 移动的同时选中移动范围内的代码,配合F5和其它命令用。MS所有文本编辑器通用。 快捷键·CTRL+↑↓ 不移动光标,上下滑动查询窗口。效果等同按竖行滑动条拖。全键盘流同学和装B流同学可用。 快捷键·CTRL+←→ 行内跳词移动光标。自己写个SELECT * FROM TB再试试这个就知道了。MS所有文本编辑器通用。 快捷键·CTRL+A 全选所有文本。用来清空编辑界面,或复制本界面全部语句时常用。MS所有文本编辑器通用。 快捷键·HOME/END 光标移动至本行首/尾。使用以下连招可选中本行文字:HOME -- SHIFT+END 或END -- SHIFT+HOME。MS所有文本编辑器通用。 快捷键·CTRL+HOME/END 光标移动至全文首/尾。按住CTRL加上面那个连招能选中所有文字,效果同CTRL+A。另外在浏览超长SQL时,用滚轮会慢,用CTRL+END看最后一行的内容比较快。MS所有文本编辑器通用。 快捷键·TAB 不选中文本或选中部分文本时是添加一个制表符,选中整行或多行代码时按下是全部增加缩进。 快捷键·SHIFT+TAB 不选中整行时无效果,选中整行或多行代码时是全部减少缩进。和上面那个功能一起练熟多用能让代码更有层次感。
组态王历史数据查询例程
组态王历史数据查询例程 配置参考文档 北京亚控科技发展有限公司 技术部
目录 一、功能概述 (3) 一、功能概述 (3) 二、工程实例 (3) 三、操作步骤: (3) 1、定义设备: (3) 2、定义变量: (3) 3.制作画面: (4) 3.1) 创建报表: (4) 3.2) 命令语言: (5) 4.进入运行系统: (10) 四、注意事项 (14) 图表 图一报表 (4) 图二报表设计 (5) 图三历史数据报表 (5) 图四快捷菜单 (6) 图五按钮属性 (6) 图六按钮属性 (6) 图七动画连接 (7) 图八选择函数 (8) 图九命令语言 (8) 图十打印报表 (9) 图十一历史数据查询画面 (10) 图十二报表属性 (11) 图十三时间属性 (11) 图十四变量属性 (12) 图十五变量顺序设置 (12) 图十六历史数据查询 (13) 图十七报表打印 (14)
一、功能概述 常规需求:很多工业现场会存储数据并对存储的历史数据进行查询、打印输出。 历史数据查询一般为起始时间、结束时间、间隔时间都不固定,最终用户根据实际需要进行查询。 组态王中的实现方法: 利用组态王内置报表以及报表的函数来实现对历史数据的查询。 组态王内置报表的操作类似excel,操作简单、方便,并且组态王提供了大量的报表函数来实现各种复杂功能。 二、工程实例 我们举一个例子来说明日报表的实现方法。在此例程中我们定义五个变量,分别为“压力”、“温度”、“密度”、“电流”、“电压”,运行系统运行后记录历史数据,查询日报表数据时自动从历史数据中查询整点数据生成报表,并可以保存、打印报表。下面就以此为例来演示完成这一要求的具体步骤。 三、操作步骤: 1、定义设备: 根据工程中实际使用得设备进行定义,本例程使用亚控的仿真PLC设备,使用“PLC-亚控-仿真PLC-串口”驱动,定义设备名称为”PLC” 。 2、定义变量: 在组态王中定义三个变量:压力(IO实数类型)、温度(IO实数类型)、密度(IO实数类型)。压力变量:最小值0,最大值100,最小原始值0,最大原始值100,连接设备PLC,寄存器INCREA100,数据类型short,读写属性为只读,采集频率1000。记录和安全区选择“数据变化记录”,变化灵敏度选择“0”。 温度变量:最小值0,最大值50,最小原始值0,最大原始值100,连接设备PLC,寄存器DECREA100,数据类型short,读写属性为只读,采集频率1000。记录和安全区选择“数据变化记录”,变化灵敏度选择“0”。 密度变量:最小值0,最大值1,最小原始值0,最大原始值100,连接设备PLC,寄存器INCREA100,数据类型short,读写属性为只读,采集频率1000。记录和安全区选择“数据变
ACCESS数据库操作必须更新查询的解决办法
ACCESS数据库操作必须更新查询的解决办法 1、在通常情况下,Web应用程序只读属性并不影响Web系统运行。在需要写入、更新数据库时,Web程序操作数据库因权限不够会提示"操作必须使用一个可更新的查询。"这种情况可能会在NTFS分区环境下出现,FTA32一般分区不会出现。将Web应用程序放在FTA32分区下运行时,不会出现因权限等问题而导致系统不能正常运行的情况,但是其安全性不如NTFS好。因此,一般网站软件可在FTA32下测试运行,单位正式网站软件建议放置在NTFS 下运行。 2、现以XP环境下,NTFS格式为例。进入网站根目录,工具—>文件夹选项—>查看,将“使用简单文件共享”前的勾选去掉。 3、网站根目录赋予Everyone完全控制、读写权限。 下面以一个例子更详细的介绍解决此类问题的方法和过程 出错举例: Microsoft JET Database Engine (0x80004005)操作必须使用一个可更新的查询。/LeadBBS/inc/Board_Popfun.asp, 第569 行需要权限:服务器管理员,否则联系服务器管理员进行示例操作系统:Windows 2000 Server1.找到你存放网站的文件夹,比如你的网站存放在D:\WEB\https://www.360docs.net/doc/fb449492.html,右键点击文件夹,选择属性 2.出来新窗口,选择安全,点击按钮添加(D)
3.在出来的窗口中,找到IUSER_开头的名称,并双击,点击确定. 4.确定后的结果是这个窗口,在安全的名称列表中多了刚才选择的用户点击下面的按钮高级(V)...
5.在弹出的新小窗口中,继续点击查看/编辑(V)按钮 6.出来新窗口..
MYSQL数据库基本操作详细教程
MYSQL数据库 学习目标: ●掌握MYSQL基本知识 ●学习数据库管理和操作 ●掌握数据库设计方法 ●熟练运用SQL编程语言 基本概念 MYSQL数据库是关系型数据库。 关系型:使用一个关系,来表示实体信息和实体之间的联系。关系:就是二维表,有行有列的表格。 这两张表通过班级名称关联起来。 关系型数据库:就是由二维表及其之间的联系组成的数据组织。 同一个表中数据结构完全一致。 数据是由记录组成 记录是由字段组成。 SQL:结构化查询语言 专门用于处理关系型数据库编程语言。 PHP也是编程语言 变量,流程控制,函数
数据库服务器的结构 DBS = DBMS + DB 数据库系统= 数据库管理系统+ 数据库(数据) 命令行客户端
数据在服务器上是如何存储的? 操作服务器 通过服务管理来操作服务器 开始->运行-> 3306是MYSQL服务程序的默认端口号 可以用netstat –an命令查看服务是否启动
命令行命令控制服务器的启动和关闭 Net start mysql Net stop mysql 错误原因:没有权限 解决办法:用管理员方式启动命令行窗口 C/S, client / server客户端/服务器方式访问数据库命令行客户端工具
流程: 1.连接和认证,提供4个参数,分别是主机地址,端口号,用户名,密码 2.向MYSQL数据库服务器发送SQL 3.MYSQL服务器接收并执行SQL,并且把结果返回给客户端 4.客户端对结果进行显示 5.断开服务器连接。Exit, quit, \q 2,3,4这几步可以循环执行 知识: 非关系型数据库,NOSQL,not only sql 不仅仅是SQL 代表:redis, mongodb 数据存储有点象数组,key/value SQL语言 存储数据: 首先建立数据库 之后建立数据表(字段定义) 操作数据 数据有哪些操作 CURD CREATE UPDATE READ DELETE(DROP)
数据库查询题目
现有3张数据表如下: 项目表:记录项目基本信息。 房间表:记录房间基本信息,一个项目有多个房间,一个房间只属于一个项目。收款表:一个房间会有多笔款项类型、款项名称不一样的收款,一笔收款信息只属于一个房间。 表关系图如下: 项目表:s_project
房间表:s_room 根据提供的信息,完成如下题目(每题10分): 1)写出项目表的创建语句(不考虑外键约束) 2)以标准总价升序s_room Total、签署日期降序Qsdate显示房间表中的记录 3)用一个SQL统计每一个项目款项类型为非贷款类房款的收款金额合计 (s_getin.itemtype=’非贷款类房款’)、款项类型为贷款类房款((s_getin.itemtype=’贷款类房款’))的收款金额合计 个房间的收款合计(s_getin之和),显示公司名称、父级项目名称、项目名称、房间代码、房号、建筑面积、标准单价、标准总价、签署日期、成交单价、成交总价、销售状态,收款金额合计 说明:项目开盘当日:项目表(s_project)开盘日期 成交的房间:房间表(s_room)销售状态为签约
5)查询所有销售状态为‘签约’的房间收款金额合计不等于成交总价的记录, 并计算出差额(s_getin.amout之和<>s_room.cjtotal) 6)更新所有已经收取银行按揭金额房间(存在s_getin.itemname=‘银行按揭’ 的房间)的按揭放款日期(s_room.ajfkdate)为该房间银行按揭收款的收款日期(s_getin.getdate) 7)基于项目、房间、收款表,创建一张视图,包含字段有,公司名称、父级项 目名称、项目代码、项目名称、开盘日期、房间代码、房号、建筑面积、标准单价、标准总价、成交单价、签署日期、成交总价、收款金额合计。 8)查询各项目的房间的成交总价(s_room.cjtotal)在该项目降序排序为第6到 第10的房间的项目名称、房间代码、累计收款金额 (s_getin.amount之和) 9)基于收款表创建insert触发器,在收取银行按揭款(款项名称为‘银行按揭’) 后,根据收款日期自动更新房间表按揭放款日期 10)创建一个表函数 fn_test(y int,m int) 参数定义:y 为年份,m 为月份 返回值定义:return {项目名称 varchar(100),上旬销售套数 int,中旬销 要求输入年份和月份,输出每个项目该月份在上旬、中旬、下旬分别销售的套数。 时间维度定义:每月1日-10日为上旬,11日-20日为中旬,21日到月末为下旬。select*from s_room --第二题 select*from dbo.s_room orderby total asc,qsdate desc --第三题 select p.projname as项目名称, sum(case g.itemtype when'贷款类房款'then g.amount else 0 end)as贷款类房款, sum(case g.itemtype when'非贷款类房款'then g.amount else 0 end)as非贷款类
Android 中数据库查询方法 query
Android 中数据库查询方法query() 中的select Android 中涉及数据库查询的地方一般都会有一个query() 方法,而这些query 中有大都(全部?)会有一个参数selectionArgs,比如下面这个 android.database.sqlite.SQLiteDatabase.query(): view plaincopy to clipboardprint? public Cursor query (String table, String[] columns, String selection, String[] selectionArgs, String groupBy, String having, String orderBy) public Cursor query (String table, String[] columns, String selection, String[] selectionArgs, String groupBy, String having, String orderBy) selection 参数很好理解,就是SQL 语句中WHERE 后面的部分,即过滤条件,比如可以为id=3 AND name='Kevin Yuan' 表示只返回满足id 为 3 且name 为"Kevin Yuan" 的记录。 再实际项目中像上面那样简单的“静态”的selection 并不多见,更多的情况下要在运行时动态生成这个字符串,比如 view plaincopy to clipboardprint? public doQuery(long id, final String name) { mDb.query("some_table", // table name null, // columns "id=" + id + " AND name='" + name + "'", // selection //...... 更多参数省略 ); } public doQuery(long id, final String name) { mDb.query("some_table", // table name null, // columns "id=" + id + " AND name='" + name + "'", // selection //...... 更多参数省略 ); }
常用数据库的树形查询
常用数据库的树形查询 在ORACLE、MSSQL、MYSQL中树结构表递归查询的实现方法 表recursion数据如下: id name parentid 1 食品分类 -1 2 肉类 1 3 蔬菜类 1 4 产品分类 -1 5 保健品 4 6 医药 4 7 建筑 4 一ORACLE中实现方法: Oracle中直接支持,使用语句select * from tablename start with connect by prior id(子层的列)=parentid(属于顶层的列) 语句说明: start with 指定层次开始的条件,即满足这个条件的行即可以作为层次树的最顶层 connect by prior指层之间的关联条件,即什么样的行是上层行的子行(自连接条件) 实例: select * from recursionstart with connect by prior>查询结果: id name parentid 1 食品分类 -1 2 肉类 1 3 蔬菜类 1 二MSSQL中的实现方法 在MSSQL中需要使用临时表和循环多次查询的方式实现. 创建函数: create function GetRecursion(@id int) returns @t table( idint, namevarchar(50), parentidint ) as begin insert @tselect * from recursion where> while @@rowcount>0 insert @t select a.* from recursion as a inner join @t as b on a.parentid=b.id and a.id not in(select id from @t) return end 使用方法:
数据库基础教程课后习题答案顾韵华
习题1 1、简述数据库系统的特点。 答:数据库系统的特点有: 1)数据结构化 在数据库系统中,采用统一的数据模型,将整个组织的数据组织为一个整体;数据不再仅面向特定应用,而是面向全组织的;不仅数据内部是结构化的,而且整体是结构化的,能较好地反映现实世界中各实体间的联系。这种整体结构化有利于实现数据共享,保证数据和应用程序之间的独立性。 2)数据共享性高、冗余度低、易于扩充 数据库中的数据能够被多个用户、多个应用程序共享。数据库中相同的数据不会多次重复出现,数据冗余度降低,并可避免由于数据冗余度大而带来的数据冲突问题。同时,当应用需求发生改变或增加时,只需重新选择不同的子集,或增加数据即可满足。 3)数据独立性高 数据独立性是由DBMS 的二级映像功能来保证的。数据独立于应用程序,降低了应用程序的维护成本。 4)数据统一管理与控制 数据库中的数据由数据库管理系统(DBMS )统一管理与控制,应用程序对数据的访问均经由DBMS 。DBMS 提供四个方面的数据控制功能:并发访问控制、数据完整性、数据安全性保护、数据库恢复。 2、什么是数据库系统? 答:在计算机系统上引入数据库技术就构成一个数据库系统(DataBase System ,DBS )。数据库系统是指带有数据库并利用数据库技术进行数据管理的计算机系统。DBS 有两个基本要素:一是DBS 首先是一个计算机系统;二是该系统的目标是存储数据并支持用户查询和更新所需要的数据。 3、简述数据库系统的组成。 答:数据库系统一般由数据库、数据库管理系统(及其开发工具)、数据库管理员(DataBase Administrator ,DBA )和用户组成。 4、试述数据库系统的三级模式结构。这种结构的优点是什么? 答:数据库系统的三级模式结构是指数据库系统是由外模式、模式和内模式三级构成,同时包含了二级映像,即外模式/模式映像、模式/内模式映像,如下图所示。 数据库应用1…… 外模式A 外模式B 模式 应用2应用3应用4应用5…… 模式 外模式/模式映像 模式/内模式映像 数据库系统的这种结构具有以下优点: (1)保证数据独立性。将外模式与模式分开,保证了数据的逻辑独立性;将内模式与模式分开,保证了数据的物理独立性。 (2)有利于数据共享,减少了数据冗余。 (3)有利于数据的安全性。不同的用户在各自的外模式下根据要求操作数据,只能对
SQLServer数据查询的优化方法
SQLServer数据查询的优化方法聂文燕 摘要:SQLServer是一种功能强大的数据库管理系统,许多数据库应用系统都是以它作为后台数据库。本文在分析影响SQLSERVER数据查询效率的因素的基础上,提出了几种优化数据查询的方法。 关键词:SQLServer,数据,查询,优化 一、引言 SQLServer是是由微软公司开发的基于Windows操作系统的关系型数据库管理系统,它是一个全面的、集成的、端到端的数据解决方案,为企业中的用户提供了一个安全、可靠和高效的平台用于企业数据管理和商业智能应用。目前,许多中小型企业的数据库应用系统都是用SQLServer作为后台数据库管理系统设计开发的。设计一个应用系统并不难,但是要想使系统达到最优化的性能并不是一件容易的事。根据多年的实践,由于初期的数据库中表的记录数比较少,性能不会有太大问题,但数据积累到一定程度,达到数百万甚至上千万条,全面扫描一次往往需要数十分钟,甚至数小时。20%的代码用去了80%的时间,这是程序设计中的一个著名定律,在数据库应用程序中也同样如此。如果用比全表扫描更好的查询策略,往往可以使查询时间降为几分钟。而且我们知道,目前数据库系统应用中,查询操作占了绝大多数,查询优化成为数据库性能优化最为重要的手段之一。 二、影响查询效率的因素 SQLServer处理查询计划的过程是这样的:在做完查询语句的词法、语法检查之后,将语句提交给SQLServer的查询优化器,查询优化器通过检查索引的存在性、有效性和基于列的统计数据来决定如何处理扫描、检索和连接,并生成若干执行计划,然后通过分析执行开销来评估每个执行计划,从中选出开销最小的执行计划,由预编译模块对语句进行处理并生成查询规划,然后在合适的时间提交给系统处理执行,最后将执行结果返回给用户。所以,SQLServer中影响查询效率的因素主要有以下几种:1.没有索引或者没有用到索引。索引是数据库中重要的数据结构,使用索引的目的是避免全表扫描,减少磁盘I/O,以加快查询速度。 2.没有创建计算列导致查询不优化。 3.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)。 4.返回了不必要的行和列。 5.查询语句不好,没有优化。其中包括:查询条件中操作符使用是否得当;查询条件中的数据类型是否兼容;对多个表查询时,数据表的次序是否合理;多个选择条件查询时,选择条件的次序是否合理;是否合理安排联接选择运算等。 三、SQLServer数据查询优化方法 3.1建立合适的索引索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。当根据索引码的值搜索数据时,索引提供了对数据的快速访问。事实上,没有索引,数据库也能根据SELECT语句成功地检索到结果,但随着表变得越来越大,使用“适当”的索引的效果就越来越明显。索引的使用要恰到好处,其使用原则有: (1)对于基本表,不宜建立过多的索引; (2)对于那些查询频度高,实时性要求高的数据一定要建立索引,而对于其他的数据不考虑建立索引; (3)在经常进行连接,但是没有指定为外键的列上建立索引; (4)在频繁进行排序或分组(即进行groupby或orderby操作)的列上建立索引;
hibernate查询数据库的三种方式
Hibernate查询数据库的三种方式 一、Hibernate的HQL与SQL查询 1.Hql(Hibernate Query Language )是面向对象的查询查询方式,HQL查询提供了更加丰富的和灵活的查询特性,因此Hibernate将HQL查询方式立为官方推荐的标准查询方式,提供了类似标准SQL语句的查询方式,同时也提供了面向对象的封装。HQL查询语句from关键字后面跟的类名+类对象, where 后用对象的属性做条件; 示例代码:(User是映射数据库的一个类) public boolean checkUser(UserForm userForm) { // TODO Auto-generated method stub //String HQLString = "from User u where https://www.360docs.net/doc/fb449492.html,ername='"+userForm.getUsername()+"'"; String HQLString = "from User u where https://www.360docs.net/doc/fb449492.html,ername=:uname"; Session session = HibernateSessionFactory.currentSession(); // 获取事务 session.beginTransaction(); Query query = session.createQuery(HQLString); query.setParameter("uname", userForm.getUsername());//绑定参数 Object list = query.list().get(0);//list获取数据集,get获取数据集的某条记录 // 提交事务 session.getTransaction().commit(); // 关闭Session HibernateSessionFactory.closeSession(); User user=(User)list; if(user.getPassword().equals(userForm.getPassword())){ return true; } else{ return false; } } 2.sql 是面向数据库表查询,from 后面跟的是表名,where 后用表中字段做条件; 示例代码:([xxdb].[dbo].[student]就是要查询的数据库表) public boolean checkUser(UserForm userForm) { // TODO Auto-generated method stub //String SQLString="select * from [xxdb].[dbo].[student] u where https://www.360docs.net/doc/fb449492.html,erName='"+userForm.getUsername()+"'"; String SQLString=”select * from [xxdb].[dbo].[student] u where https://www.360docs.net/doc/fb449492.html,erName=:uname”; Session session = HibernateSessionFactory.currentSession(); session.beginTransaction(); //Query query = session.createSQLQuery(SQLString).addEntity(User.class);//实体查询 Query query = session.createSQLQuery(SQLString).
数据库实用教程答案(第三版)董健全 清华大学出版社
数据库实用教程答案(第三版).doc 第1、2章 1.1 名词解释: ◆ DB:数据库(Database),DB是统一管理的相关数据的集合。DB能为各种用户共享,具有最小冗余度,数据间联系密切,而又有较高的数据独立性。 ◆ DBMS:数据库管理系统(Database Management System),DBMS是位于用户与操作系统之间的一层数据管理软件,为用户或应用程序提供访问DB的方法,包括DB的建立、查询、更新及各种数据控制。DBMS总是基于某种数据模型,可以分为层次型、网状型、关系型、面向对象型DBMS。 ◆ DBS:数据库系统(Database System),DBS是实现有组织地、动态地存储大量关联数据,方便多用户访问的计算机软件、硬件和数据资源组成的系统,即采用了数据库技术的计算机系统。 ◆ 1:1联系:如果实体集E1中的每个实体最多只能和实体集E2中的一个实体有联系,反之亦然,好么实体集E1对E2的联系称为“一对一联系”,记为“1:1”。 ◆ 1:N联系:如果实体集E1中每个实体与实体集E2中任意个(零个或多个)实体有联系,而E2中每个实体至多和E1中的一个实体有联系,那么E1对E2的联系是“一对多联系”,记为“1:N”。 ◆ M:N联系:如果实体集E1中每个实体与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么E1对E2的联系是“多对多联系”,记为“M:N”。 ◆ 数据模型:表示实体类型及实体类型间联系的模型称为“数据模型”。它可分为两种类型:概念数据模型和结构数据模型。 ◆ 概念数据模型:它是独门于计算机系统的模型,完全不涉及信息在系统中的表示,只是用来描述某个特定组织所关心的信息结构。 ◆ 结构数据模型:它是直接面向数据库的逻辑结构,是现实世界的第二层抽象。这类模型涉及到计算机系统和数据库管理系统,所以称为“结构数据模型”。结构数据模型应包含:数据结构、数据操作、数据完整性约束三部分。它主要有:层次、网状、关系三种模型。 ◆ 层次模型:用树型结构表示实体间联系的数据模型 ◆ 网状模型:用有向图结构表示实体类型及实体间联系的数据模型。 ◆ 关系模型:是由若干个关系模式组成的集合,其主要特征是用二维表格结构表达实体集,用外鍵表示实体间联系。