多元线性回归SPSS实验报告
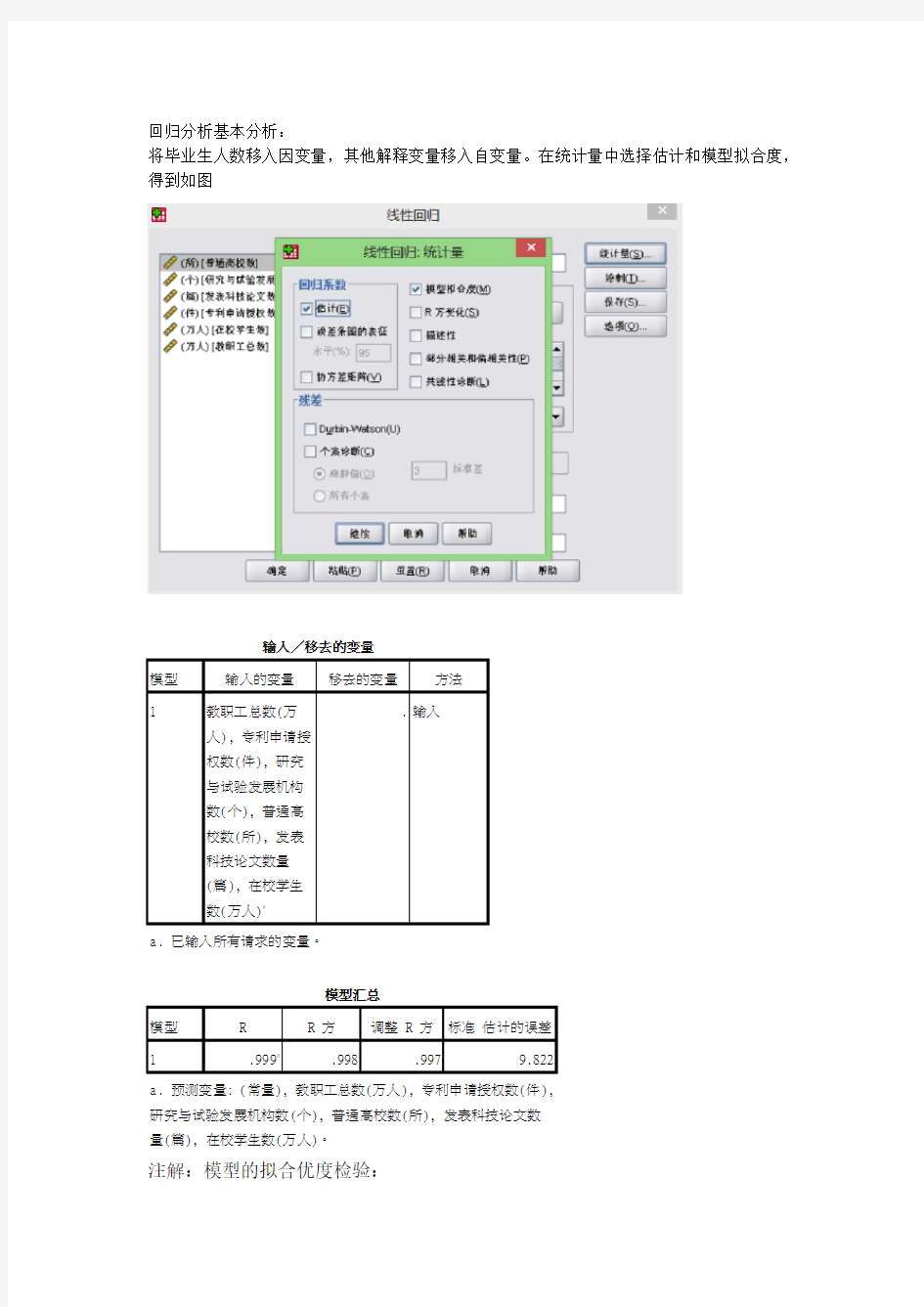

回归分析基本分析:
将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图
注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。
第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。
第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。
第五列:回归方程的估计标准误差=9.822
回归方程的显著性检验-回归分析的方差分析表
F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。
注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。
第四列:标准化偏回归系数。
第五列:偏回归系数T检验的t统计量。
第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。
于是,多元线性回归方程为:
y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6
回归分析的进一步分析:
1.多重共线性检验
从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
注解:第二列:特征根
第三列:条件指数
从条件指数看,第3、4、5、6、7个条件指数都大于10,说明变量之间存在多重共线性。
第4-10列:各特征根解释各解释变量的方差比。
从方差比看,第5个特征根解释投入普通高校人数96%;发表科技论文数49%;可以认为:这些变量存在多重共线性。需要建立回归方程。
2.重建回归方程
注解:引入/剔除变量表
分别剔除在校学生数(万人),普通高校数(所),研究与试验发展机构数(个),专利申请授权数(件)四个变量
注解:利用向后筛选策略建立回归模型,经过四步完成回归方程的建立,最终模型为第五个模型,依次剔除的变量是在校学生数(万人),普通高校数(所),研究与试验发展机构数(个),专利申请授权数(件)
模型五的负相关系数R=0.999。
判别系数R2=0.998.
调整判别系数R2=0.997,若将作用不显著的变量引入方程,则该系数会减少。
估计的标准误差=9.774。
模型二中偏F检验的概率P值=0.749,对于显著性水平0.05,接受原假设(剔除变量的偏回归系数与0无显著性差异),认为:剔除的变量在校大学生人数的偏回归系数与0无显著性差异。该变量对被解释变量的线性解释没有显著性贡献,不应保留在回归方程中。
模型三中偏F检验的概率P值=0.526,对于显著性水平0.05,接受原假设(剔除变量的偏回归系数与0无显著性差异),认为:剔除的变量普通高校数的偏回归系数与0无显著性差异。该变量对被解释变量的线性解释没有显著性贡献,不应保留在回归方程中。
模型四中偏F检验的概率P值=0.135,对于显著性水平0.05,接受原假设(剔除变量的偏回归系数与0无显著性差异),认为:剔除的变量研究与试验发展机构数(个)的偏回归系数与0无显著性差异。该变量对被解释变量的线性解释没有显著性贡献,不应保留在回归方程中。
模型五中偏F检验的概率P值=0.304,对于显著性水平0.05,接受原假设(剔除变量的偏回归系数与0无显著性差异),认为:剔除的变量专利申请授权数(件)的偏回归系数与0无显著性差异。该变量对被解释变量的线性解释没有显著性贡献,不应保留在回归方程中。
最终保留的回归方程的变量有:教职工总数和发表论文数
回归方程的DW检验值=1.971,表现残差序列存在正相关。说明该回归方程没有充分说明被解释变量的变化规律,可能方程中遗漏了一些重要的解释变量
【实验报告】SPSS相关分析实验报告
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。
多元线性回归SPSS实验报告
回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
SPSS多元线性回归分析实例操作步骤
SPSS统计分析 多元线性回归分析方法操作与分析 实验目得: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率与房屋空置率作为变量,来研究上海房价得变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)与房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19、0 操作过程: 第一步:导入Excel数据文件 1.open datadocument——open data——open; 2、Opening excel data source——OK、
第二步: 1、在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise、 进入如下界面: 2、点击右侧Statistics,勾选RegressionCoefficients(回归系数)选项组中得Estimates;勾选Residuals(残差)选项组中得Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearitydiagnotics;点击Continue、
3、点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中得Standardized Resi dual Plots(标准化残差图)中得Histogram、Normal probability plot;点击Continue、 4、点击右侧Save,勾选Predicted Vaniues(预测值)与Residu als(残差)选项组中得Unstandardized;点击Continue、
SPSS实验报告_线性回归_曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
SPSS相关分析报告实验报告材料
本科教学实验报告 (实验)课程名称:数据分析技术系列实验
实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。
1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1. 分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze \ Descriptive Statistics \ Crosstabs Step2.将性别(Gender)和收入(Current Salary)分别移入Rows列表框和Columns 列表框。
Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。
多元回归分析SPSS1
多元线性回归分析预测法 多元线性回归分析预测法(Multi factor line regression method,多元线性回归分析法) [编辑] 多元线性回归分析预测法概述 在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。这时采用一元回归分析预测法进行预测是难以奏效的,需要采用多元回归分析预测法。 多元回归分析预测法,是指通过对两上或两个以上的自变量与一个因变量的相关分析,建立预测模型进行预测的方法。当自变量与因变量之间存在线性关系时,称为多元线性回归分析。 [编辑] 多元线性回归的计算模型[1] 一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。
设y为因变量,为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为: 其中,b 0为常数项,为回归系数,b1为固定时,x1每增加一 个单位对y的效应,即x 1对y的偏回归系数;同理b2为固定时,x2每增加一 个单位对y的效应,即,x 2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为: 其中,b 0为常数项,为回归系数,b1为固定时,x2每增加 一个单位对y的效应,即x 2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为: y = b 0 + b1x1 + b2x2 + e 建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是: (1)自变量对因变量必须有显著的影响,并呈密切的线性相关; (2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的; (3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度; (4)自变量应具有完整的统计数据,其预测值容易确定。 多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和()为最小的前提下,用最小二乘法求解参数。以二线性回归模型为例,求解回归参数的标准方程组为 解此方程可求得b 0,b1,b2的数值。亦可用下列矩阵法求得 即 [编辑] 多元线性回归模型的检验[1] 多元性回归模型与一元线性回归模型一样,在得到参数的最小二乘法的估计值之后,也需要进行必要的检验与评价,以决定模型是否可以应用。
SPSS多元线性回归分析实例操作步骤
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK.
第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.
spss多元回归分析报告案例
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
SPSS 10.0高级教程十二:多元线性回归与曲线拟合
SPSS 10.0高级教程十二:多元线性回归与曲线拟合 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。 §10.1Linear过程 10.1.1 简单操作入门 调用此过程可完成二元或多元的线性回归分析。在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。 例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响? 显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。 回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。 这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。 10.1.1.1 界面详解 在菜单中选择Regression==>liner,系统弹出线性回归对话框如下:
除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。 【Dependent框】 用于选入回归分析的应变量。 【Block按钮组】 由Previous和Next两个按钮组成,用于将下面Independent框中选入的自变量分组。由于多元回归分析中自变量的选入方式有前进、后退、逐步等方法,如果对不同的自变量选入的方法不同,则用该按钮组将自变量分组选入即可。下面的例子会讲解其用法。 【Independent框】 用于选入回归分析的自变量。
spss软件分析异常值检验实验报告
实验五:残差分析 【实验目的】 (1)通过残差检验,掌握残差分析的方法 (2)异常值检验 【仪器设备】 计算机、spss软件、何晓群《实用回归分析》表和表的数据 【实验内容、步骤和结果】 对何晓群《实用回归分析》表的数据进行残差分析 原始数据如表1,其中y表示货运总量(亿吨)x1表示工业总产值(亿元)x2表示农业总产值(亿元)x3表示居民非商业支出(亿元) 表1. 对表1数据用spss软件进行分析得以下各表
由上表可知复相关系数R=,决定系数R方=,由决定系数看出回归方程的显著性不高,接下来看方差分析表3 由表3知F值为较小,说明x1、x2、x3整体上对y的影响不太显著。 表4系数 模型非标准化系数标准系数 t Sig. B标准误差试用版 1(常量).096 x1.385.100 x2.535.049 x3.277.284
表4系数 模型 非标准化系数 标准系数 t Sig. B 标准 误差 试用版 1 (常量) .096 x1 .385 .100 x2 .535 .049 x3 .277 .284 回归方程为 123348.280 3.7547.10112.447y x x x =-+++
图1.学生化残差
差 残差: 对数据用spss进行分析得 表6异常值的诊断分析
数据不存在异常值.绝对值最大的删除学生化残差为SDR=,因而根据学生化删除残差诊断认为第6个数据为异常值.其中中心化杠杆值,cook距离为位于第一大.因此第6个数据为异常值. 对何晓群《实用回归分析》表的数据进行残差分析 原始数据为 : 表个啤酒品牌的广告费用和销售量
回归分析实验报告
实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日
一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1)
图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏
5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。
spss相关分析实验报告
实验五相关分析实验报关费 一、实验目的: 学习利用spss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表1如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析和肯德尔等级相关 分析。 2.在控制物理成绩不变的条件下,做数学成绩与英语成绩的相关分析(这 种情况下的相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中的相关分析。 三、实验步骤: 1.选择分析→相关→双变量,弹出窗口,在对话框的变量列表中选变量 “数学成绩”、“物理成绩”,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)和肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差和均值。单击确定,得出输出结果,对结果 进行分析解释。 2.选择分析→相关→偏相关,弹出窗口,在对话框的变量列表选变量“数 学成绩”、“英语成绩”,在控制列表选择要控制的变量“物理成绩” 以在控制物理成绩的影响下对变量数学成绩与英语成绩进行偏相关分 析;在“显著性检验”框中选双侧检验,单击确定,得出输出结果, 对结果进行分析解释。 3.选择分析→描述统计→交叉表,弹出窗口,对交叉表的行和列进行选 择,行选择为数学成绩,列选择为物理成绩。然后对统计量进行设置, 选择相关性,点击继续→确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
表1
五、实验结果及其分析:
分析一:由实验结果可观察出,数学成绩与物理成绩的积差相关系数r=,肯德尔等级相关系数r=可知该班物理成绩和数学成绩之间存在显著相关。
spss多元线性回归研究分析
spss多元线性回归分析
作者: 日期:
SPSS多元线性回归分析试验 在科学研究中,我们会发现某些指标通常受到多个因素的影响,如血压值除了受年龄影响之外,还受到性别、体重、饮食习惯、吸烟情况等因素的影响,用方程定量描述一个因变量y与多个自变量x1、x2、x3 之间的线性依存关系,称为多元线性回归。 有学者认为血清中低密度脂蛋白增高是引起动脉硬化的一个重要原因。现测量30名怀疑患有动脉硬化的就诊患者的载脂蛋白A、载脂蛋白B、载脂蛋白E、载脂蛋白C、低密度脂蛋白中的胆固醇含量。资料如下表所示。求低密度脂蛋白中的胆固醇含量对载脂蛋白A、载脂蛋白E、载脂蛋白E、载脂蛋白C的线性回归方程。 表1 30名就诊患者资料表
spss数据处理步骤: (1)打开spss输入数据后,点击“分析”—“回归”—“线性”。然后将“低密度脂蛋白”选入因变量框,将“载脂蛋白A” “载脂蛋白E” “载脂蛋白E” “载脂蛋白C”依次选入自变量框。方法选为“逐步”。 (2)单击“统计量”选项,原有选项基础上选择“R方变化”。在残差中选“Durbin-Watson”,单击“继续”。
i [粘贴(E)] i ss (印11取消i L 帮助 (3)单击“绘制”,将“DEPENDNT ”选入“X2”中,将“*SRESID ”选入“Y 中,在标准残差图选项中选择“直方图”和“正态概率图”。单击“继续”。 S3 闵蠢墨fD): 制IK DEPEHDNT T ZPRED *ZF?ESID PRESID ?ADdPRED 怡尺匚SID 怡口穆 ESILJ 呵直方便(比 “正态槪率副曰 继续 将(3),, 取卷 帮肋 銭性回归 册回归:圏 踰点1的1 厂产空所有制分團(巳 (4)单击“选项”,在原有选项的基础上单击“继续”,最后单击“确定”,就完 成了。
SPSS多元回归分析报告实例
多元回归分析 在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型: 其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。 多元回归在病虫预报中的应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。 预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。 表2-1 x1 x2 x3 x4 y 年蛾量级别卵量级别降水量级别雨日级别幼虫密 度 级别 1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3
spss相关分析实验报告
实验五相关分析实验报关费 一、实验目得: 学习利用s pss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表 1 如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析与肯德尔等级相关分 析. 2.在控制物理成绩不变得条件下,做数学成绩与英语成绩得相关分析(这 种情况下得相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中得相关分析。 三、实验步骤: 1.选择分析—相关—双变量,弹出窗口,在对话框得变量列表中选变量 “数学成绩"、“物理成绩” ,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)与肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差与均值.单击确定,得出输出结果,对结果进 行分析解释。 2.选择分析一相关一偏相关,弹出窗口,在对话框得变量列表选变量数学 成绩”、“英语成绩”,在控制列表选择要控制得变量“物理成绩”以 在控制物理成绩得影响下对变量数学成绩与英语成绩进行偏相关分析; 在“显著性检验”框中选双侧检验,单击确定,得出输出结果,对结果 进行分析解释. 3.选择分析一描述统计-交叉表,弹出窗口,对交叉表得行与列进行选 择,行选择为数学成绩,列选择为物理成绩.然后对统计量进行设置, 选择相关性,点击继续-确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
囲戏变量相关0 变旻(Y): 歹物理戍悄 相关浆勤 0 Pearson 叼兰endsll 的tau-b(K) J Spearman 叼标记SL苦性徇关(E) I ?―I粘址妃)][賞Jt? ][ ■備~ [ 鹽 ,丘示渎际說曹性水半(D 确定 ]|殆贴(E) H St賣(B)][ 取禱选顶(2)… 农孝号 /其 语威纽 显著性检验 双侧檢勉I) 单侧檢验(D 选他…]
SPSS多元线性回归分析教程.doc
线性回归分析的SPSS操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1.数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑窗口显示数据输入格式如下图7-8(文件7-6-1.sav): 图7-8:回归分析数据输入 2.用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1)操作 ①单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
图7-9 线性回归分析主对话框 ②请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。 图7-10:线性回归分析的Statistics选项图7-11:线性回归分析的Options选项 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。 ③用户在进行回归分析时,还可以选择是否输出方程常数。单击Options…按钮,打开它的对话框,可以看到中间有一项Include constant in equation可选项。选中该项可输出对常数的检验。在Options对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程的准则,这里我们采用系统的默认设置,如图7-11所示。设置完成后点击Continue返回主对话框。 ④在主对话框点击OK得到程序运行结果。
SPSS对主成分回归实验报告
《多元统计分析分析》实验报告 2012 年月日学院经贸学院姓名学号 实验 实验成绩名称 一、实验目的 (一)利用SPSS对主成分回归进行计算机实现. (二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释. 二、实验内容 以教材例题为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用 三、实验步骤(以文字列出软件操作过程并附上操作截图) 1、数据文件的输入或建立:(文件名以学号或姓名命名) 将表数据输入spss:点击“文件”下“新建”——“数据”见图1: 图1 点击左下角“变量视图”首先定义变量名称及类型:见图2: 图2: 然后点击“数据视图”进行数据输入(图3): 图3
完成数据输入 2、具体操作分析过程: (1)首先做因变量Y与自变量X1-X3的普通线性回归: 在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4): 图4 将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5): 然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9) 其他选项按软件默认。最后点击“确定”,运行线性回归,输出相关结果(见表1-3)
SPSS多元线性回归分析教程
线性回归分析的SPSS操作 本节容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含 有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前, 我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点 图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑 窗口显示数据输入格式如下图7-8 (文件7-6-1.sav): 图7-8 :回归分析数据输入 2?用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1) 操作 ①单击主菜单An alyze / Regression / Li near ,?进入设置对话框如图7-9所示。从左边变量表 列中把因变量y选入到因变量(Depe ndent)框中,把自变量x选入到自变量 (I ndepe ndent)框中。在方法即Method —项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方 程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
② 请单击Statistics 按钮,可以选择需要输出的一些统计量。 女口 Regression Coefficients (回 归 系数)中的Estimates ,可以输出回归系数及相关统计量,包括回归系数 B 、标准误、标准化回归 系数BETA 、T 值及显著性水平等。 Model fit 项可输出相关系数 R ,测定系数R 2,调整系数、 成后点击Continue 返回主对话框。 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反 回归分析的假定,为此需进行多项残差分析。由于此部分容较复杂而且理论性较强,所以不在此 详细介绍,读者如有兴趣,可参阅有关资料。 ③ 用户在进行回归分析时,还可以选 择是否输出方程常数。单击 Options ??按钮,打开它的 对话框,可以看到中间有一项 Include constant in equation 可选项。选中该项可输出对常数的检验。 在Options 对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程 的准则,这里我们采用系统的默认设置,如图 7-11所示。设置完成后点击 Continue 返回主对话 框。 估计标准误及方差分析表。 上述两项为默认选项, 请注意保持选中。 设置如图7-10所示。设置完 图7-9线性回归分析主对话框 图7-10: 线性回归分析的 Statistics 选项 图7-11 :线性回归分析的 Options 选项
SPSS实验报告材料91487
CENTRAL SOUTH UNIVERSITY SPSS实验报告 学生王强 学号4303110516 指导教师邵留国 学院商学院 专业工商1101
实验一、数据集 实验目的:掌握基本的统计学理论,学会使用SPSS录入数据,建立SPSS数据集。 实验容: 1.3:三十名儿童身高、体重样本数据如下表所示。建立SPSS数据集。 三十名儿童身高、体重样本数据
13 14 15 男 男 男 14 14 14 168.0 164.5 153.0 50.0 44.0 58.0 28 29 30 女 女 女 15 15 15 158.0 158.6 169.0 44.3 42.8 51.1 实验步骤: 步骤一:启动SPSS。 步骤二:选择文件,新建,数据,如图。 步骤三:切换到变量视图,定义变量。其中,性别变量需要设置值标签。如图所 示。 步骤四:切换到数据视图,按照次序依次输入数据。 步骤五:保存数据。
实验结果:
实验二:统计量描述 实验目的: (1)结合图表描述掌握各种描述性统计量的构造原理及其应用。 (2)熟练掌握运用SPSS进行统计描述的基本技能。 实验容:大学生在校期间的各门课程考试成绩,尽管在学生与学生之间、院系之间、男女生之间以及不同的课程之间,都存在着各种各样的差异,但整体上的分布状况还是有规律可循的。今有两个学院共1040名男女生的统计学和经济学期末考试成绩数据,储存在SPSS数据文件中,文件名:lytjcj.sav。试运用图表描述与统计量描述的方法,对此数据展开尽可能全面和深入的描述与分析。 实验步骤: 步骤一:打开SPSS数据,文件名:lytjcj.sav。如图。
完整word版,SPSS聚类分析实验报告
SPSS聚类分析实验报告 一.实验目的: 1、理解聚类分析的相关理论与应用 2、熟悉运用聚类分析对经济、社会问题进行分析、 3、熟练SPSS软件相关操作 4、熟悉实验报告的书写 二.实验要求: 1、生成新变量总消费支出=各变量之和 2、对变量食品支出和居住支出进行配对样本T检验,并说明检验结果 3、对各省的总消费支出做出条形图(用EXCEL做图也行) 4、利用K-Mean法把31省分成3类 5、对聚类分析结果进行解释说明 6、完成实验报告 三.实验方法与步骤 准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS数据文件中。 分析:由于本实验中要对31个个案进行分类,数量比较大,用系统聚类法当然也可以得出结果,但是相比之下在数据量较大时,K均值聚类法更快速高效,而且准确性更高。 四、实验结果与数据处理: 1.用系统聚类法对所有个案进行聚类:
生成新变量总消费支出=各变量之和如图所示: 2. 对变量食品支出和居住支出进行配对样本T检验,如图所示:
得出结论: 3. 对各省的总消费支出做出条形图,如图所示: 4.对聚类分析结果进行解释说明: K均值分析将这样的城市分为三类: 第一类北京、上海、广东 第二类除第一类第三类以外的 第三类天津、福建、内蒙古、辽宁、山东 第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。第二类城市位于中西部地区,经济落后,人民消费水平低。第三类城市位于中东部地区,经济发展较好。
迭代历史记录a 迭代 聚类中心内的更改 1 2 3 1 1250.592 1698.865 1216.114 2 416.864 70.786 173.731 3 138.955 2.949 24.819 4 46.318 .123 3.546 5 849.114 319.179 1362.411 6 805.004 15.199 606.915 7 161.001 .724 75.864 8 32.200 .034 9.483 9 6.440 .002 1.185 10 1.288 7.815E-5 .148 初始聚类中心 聚类 1 2 3 食品支出 7776.98 3052.57 5790.72 衣着支出 1794.06 1205.89 1281.25 居住支出 2166.22 1245.00 1606.27 家庭设备及服务支出 1800.19 612.59 972.24 医疗保健支出 1005.54 774.89 617.36 交通和通信支出 4076.46 1340.90 2196.88 文化与娱乐服务支出 3363.25 1229.68 1786.00 其它商品和服务支出 1217.70 331.14 499.30 总消费支出 23200.40 9792.66 14750.02