t分布与t检验

t分布
从数理统计的理论上讲,并且上节的实例也已说明,在总体均数为μ,总体标准差为σ的正态总体中随机抽取n相等的许多样本,分别算出样本均数,这些样本均数呈正态分布。而当样本含量n不太小时,即使总体不呈正态分布,样本均数的分布也接近正态。在下式中,
由于μ与(样本均数的标准差)都是常量,又
X呈正态分布,所以u
也呈正态分布。但实际上总体标准差往往是不知道的,上式分母中的σ要由S替代,成为
,那么由于样本标
准差有抽样波动,SX也有抽样波动,于是,在用S代替σ
后上式等号右边的变量便不呈正态分布而呈t分布,其定义公式是
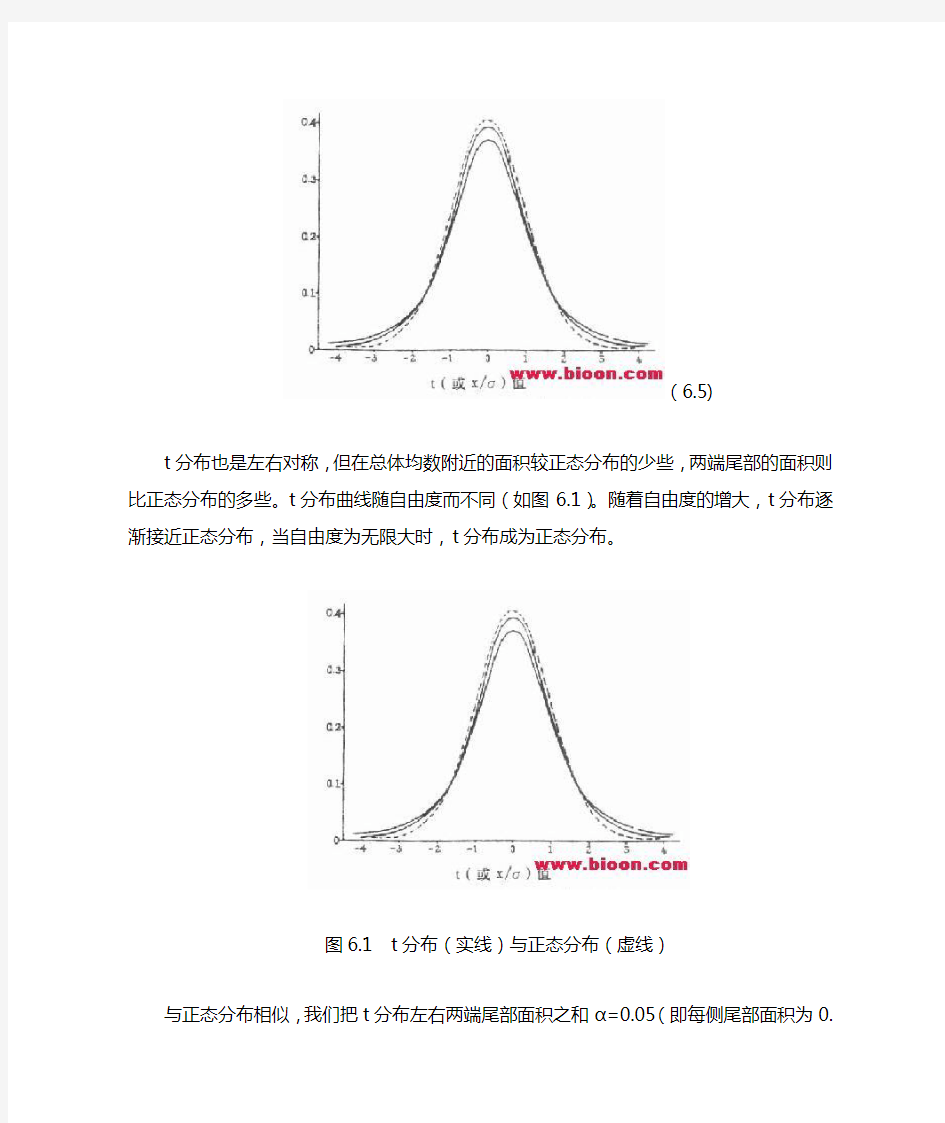
(6.5)
t分布也是左右对称,但在总体均数附近的面积较正态分布的少些,两端尾部的面积则比正态分布的多些。t分布曲线随自由度而不同(如图6.1)。随着自由度的增大,t分布逐渐接近正态分布,当自由度为无限大时,t分布成为正态分布。
图6.1t分布(实线)与正态分布(虚线)
与正态分布相似,我们把t分布左右两端尾部面积之和α=0.05(即每侧尾部面积为0.025)相应的t值称为5%界,符号为t0.05,,,这里ν是自由度。把左右两端尾部面积之和α为0.01相应的t值称为1%界,符号为t0.01,,。t的5%界与1%界可查附表3,t值表。例如当自由度为10-1=9时,t0.05,9=2.262,t0.01,9=3.250。
可信区间的估计
一、参数估计的意义
一组调查或实验数据,如果是计量资料可求得平均数,标准差等统计指标,如果是计数资料则求百分率藉以概括说明这群观察数据的特征,故称特征值。由于样本特征值是通过统计求得的,所以又称为统计量以区别于总体特征值。总体特征值一般称为参数(总体量)。我们进行科研所要探索的是总体特征值即总体参数,而我们得到的却是样本统计量,用样本统计量估计或推论总体参数的过程叫参数估计。
本章第一节例6.1通过检查110个健康成人的尿紫质算得阳性率为10%,这是样本率,可用它来估计总体率,说明健康成人的尿紫质阳性率水平,这样的估计叫“点估计”。但由于存在抽样误差,不同样本(如再检查110人)可能得到不同的估计值。因此我们常用“区间估计”总体率(或总体均数)大概在那一个范围内,这个范围就叫可信区间。区间小的一端叫下限,大的一端叫上限。常用的有95%可信区间与99%可信区间。根据同一资料所作95%可信区间比99%可信区间窄些(上、下限较靠近),但估计错误的概率后者为1%,前者为5%,进行总体参数的区间估计时可根据研究目的与标准误的大小选用95%、或99%。
二、总体均数的估计
http://127.0.0.1:11643/library/stats/html/Distributions.html
本文来自: 人大经济论坛R语言论坛版,详细出处参考:https://www.360docs.net/doc/0219204641.html,/forum.php?mod=viewt hread&tid=3615789&page=1
为了说明常用的总体均数之区间估计法,我们不妨回顾一下上节所叙的t分布。
由求t的基本公式
我们看到X与μ的距离等于t(SX),又根据X集中分布在μ周围的特点,若取t的5%
界即t0.05,,(或1%界)乘以SX作为X与μ的距离范围,就可用式(6.6)或式(6.7)求
出区间来估计总体均数μ所在范围,估错的概率仅有5%或1%,因此称95%或99%可信区间。下面用实例说明其求法。
95%可信区间X-t0.05,νSX<μ
99%可信区间X-t0.05,νSX<μ
例6.2上面抽样实验中第1号样本的均数为488.6,标准差为61.65,例数10,自由度ν=10-1=9,试求95%与99%可信区间。
1.求标准误
95%可信区间488.6-2.262(19.50)<μ<488.6+2.262(19.50),即有95%的把握估计μ是在444.49~532.71区间内
99%可信区间488.6-3.250(19.50)<μ<488.6+3.250(19.50),可有99%的把握估计μ是在425.22~551.98区间内
这里两个可信区间都包含μ=500在内,所以这次估计是估计对了。
抽样实验共抽了100个样本,除1号样本外其余99个样本均数也对μ作了区间估计,这些95%可信区间列在表6.4中。我们看到,只有5个95%可信区间(右上角标有星号)不包含总体均数μ=500在内,它们是:
样本号X 95%可信区间 6 546.7 515.78~577.62 7 524.5 500.45~548.55 28 476.1 454.91~497.29 72 4 65.3 447.02~483.58 75 526.6 503.10~550.10
平时我们并不重复抽取许多样本来一次次估计总体均数而仅是一次,至于算出的均数会类似一百个样本均数中的那一个就很难说了。如果不遇到类似上列那些均数过大或过小的样本,求出可信区间后总体均数真是在该区间内,那么便是一次成功的估计:但是极少数情况下我们也会遇到极端的样本,以至总体均数并不在我们提出的区间内。不过,我们具体所作的这次估计到底属于前种情况还是后一种,这是无法知道的,因为我们不知道μ是多少(若已知μ便不必估计它了)。然而象后种情况那样作出错估的概率终究很小,只5%或1%,所以用这样的方法估计总体均数还是可行的。
三、总体率的估计
上面已经提到,计数资料可以计算相对数(率)。我们若由样本统计量P估计总体参数π,同样要考虑率的抽样误差,据数理统计研究结果,样本率的分布也近似正态分布,尤其当π比较靠近50%且样本较大时。于是对样本,百分率的可信区间可利用正态分布规律估计,公式是:
95%可信区间P-1.96Sp<π< p>
99%可信区间P-2.58Sp<π< p>
(按正态分布,双侧尾部面积α=0.05时的u值为1.96,α=0.01时的u值为2.58,故用这两式求可信区间时不必查表找临界u值,记住这两数即可。)
例6.3某医院收治200例急性菌痢患者,其中粪便细菌培养阳性者共80例,试估计菌痢细菌培养的总体阳性率95%与99%可信区间。
1.求阳性率P=80/200×100%=40%(或0.40)
2.
3.求可信区间
95%可信区间40%-1.96(3.46%)<π<40%+1.96(3.46%),即估计π在33.22%~46.78%之间
99%可信区间40%-2.58(3.46%)<π<40%+2.58(3.46%),即估计π在31.07%~48.93%之间
如果是小样本的百分率,求可信区间可通过查表获得,附表4是n为10、15、20、30时查95%与99%可信区间的一个简表。此外,统计学专著中还有更详细的表可查
t检验与u检验
抽样研究包含参数估计与通过假设检验作统计推断这样一些重要内容。前者在第六章最后一节中已经涉及,后者如X2检验,我们亦已有过接触。本章将介绍两均数相比时的假设检验。
第一节t检验
一、样本均数与总体均数的比较
为了判断观察到的一组计量数据是否与其总体均数接近,两者的相差系同一总体中样本与总体之间的误差,相差不大;还是已超出抽样误差的一般允许范围而存在显著差别?应进行假设检验,下面通过实例介绍t检验的方法步骤。
例7.1根据大量调查得知,健康成年男子脉搏均数为72次/分,某医生在某山区随机抽查健康成年男子25人,其脉搏均数为74.2次/分,标准差为6.5次/分。根据这个资料能否认为某山区健康成年男子的脉搏数与一般健康成年男子的不同?
在医学领域中有一些公认的生理常数如本例提到的健康成人平均脉搏次数72次/分,一般可看作为总体均数μ。已知在总体均数μ和总体标准差σ已知的情况下可以予测样本均数分布情况,现缺总体标准差,则需用样本标准差来估计它,那么样本均数围绕总体均数散布的情况服从t分布(尤其当样本含量n较小时,)。t分布的基本公式即6.5。
从式中可知,t是样本均数与总体均数之差(以标准误为单位),t的绝对值越大也即X距μ越远。在t分布中距μ越远的样本均数分布得越少(所占百分比小,P值小),后面附表3右上角的示意图中展示了这种关系,如欲知各自由度下t值与其相应的P值可查附表3。
下面回答本例提出的问题而进行假设检验。按一般步骤:
(1)提出检验假设H0与备择假设H1。本例H0为某山区成年男子的脉搏均数与一般成年男子的相等,μ=μ0=72次/分;H1为两者不相等μ≠μ0,即μ大于或小于μ0(这是双侧检验,如果事先已肯定山区人的脉搏不可能低于一般人,只检验它是否高于一般人,则应用单侧检验,H1必为μ>μ)。
(2)定显著性水准α,并查出临界t值。α是:若检验假设为真但被错误地拒绝的概率。现令α=0.05,本例自由度ν=n-1=25-1=24、查附表3得t0.05,24=2.064。若从观察资料中求出的∣t∣值小于此数,我们就接受H0;若等于或大于此值则在α=0.05水准处拒绝H0而接受H1。
(3)求样本均数X、标准差S及标准误Sχ并进而算出检验统计量t。现已知X=74.2次/分,S=6.5次/分,只要求出Sχ及t值即可。
(4)下结论:因∣t∣t0.05,24=2.064,所以检验假设H0得以接受,从而认为就本资料看,尚不能得出山区健康成年人的脉搏数不同于一般人而具有显著差别的结论。
二、成对资料样本均数的比较
上面介绍了已知总体均数时的显著性检验方法,但有时我们并不知道总体均数,且医学数据资料中更为常见的是成对资料,若一批某病病人治疗前有某项测定记录,治疗后再次测定以观察疗效,这样,观察n例就有n对数据,这即是成对资料(也可对动物做成病理模型进行治疗实验以收集类似的成对资料);如果有两种处理要比较,将每一份标本分成两份各接受一种处理,这样观察到的一批数据也是成对资料,医学科研中有时无法对同一批对象进行前后或对应观察,而只得将病人(或实验动物)配成对子,尽量使同对中的两者在性别、年龄或其它可能会影响处理效果的各种条件方面极为相似,然后分别给以一种不同的处理后观察反应,这样获得的许多对不可拆散的数据同样是成对资料。由于成对资料可控制个体差异使之较小,故检验效率是较高的。
关于成对资料,每对数据始终相联这是它的特点,我们可以先初步观察每对数据的差别情况,进一步算出平均相差作为样本均数,再与假设的总体均数比较看相差是否显著,下面举实例说明检验过程。
表7.1豚鼠注入上腺素前后每分钟灌流滴数
豚鼠号每分钟灌流滴数用药前用药后增加数d 1 30 46 16 2 38 50 12 3 48 52 4 4 48 52 4 5 60 5 8 -2 6 46 64 18 7 26 56 30 8 58 54 -4 9 46 54 8 10 48 58 10 11 44 36 -8 12 46 54 8 总计——96
例7.2为了验证肾上腺素有无降低呼吸道阻力的作用,以豚鼠12只,进行支气管灌流实验,在注入定量肾上腺素前后,测定每分钟灌流滴数,结果见表7.1,问用药后灌流速度有无显著增加?
(1)假设用药前后灌流滴数相同,则相差的总体均数μ为0;即H0:μ=μ0;H1:μ≠μ0。
(2)令显著性水准α=0.05,由本例ν=12-1=11查得临界值t0.05,11=2.201。
(3)求样本统计量平均相差数d、差数的标准差S d、标准误Sd及检验统计量t值。
(4)下结论。今∣t∣t0.05,11,p <0.05,故认为检验假设μ=μ0难以接受,在α=0.05水准外拒绝H O而接受H1,相差显著,注入肾上腺素后每分钟灌流滴数比注射前要多。
例7.3从以往资料发现,慢性支气管炎病人血中胆碱酯酶活性常常偏高。某校药理教研室将同性别同年龄的病人与健康人配成8对,测量该值加以比较,资料如下。问可否通过这一资料得出较为明确的结论?
表7.2慢性气管炎病人与健康人血液胆碱酯酶活性测定(μM/ml)
对子序号病人组,X1健康人组,X2差数
D=X1-X21 3.28 2.36 0.92 2 2.60 2.40 0.20 3 3.32 2.40 0.92 4 2.72 2.52 0.20 5 2.3 8 3.04 -0.66 6 3.64 2.64 1.00 7 2.98 2.56 0.42 8 4.40 2.40 2.00
(1)检验假设H0:μ=μ0;H1:μ>μ0
(2)令α=0.05,得t0.05,7=1.895(单侧)
(3)用差数求统计量
(4)结论∣t∣=2.264>t0.05,7=1.895,P<0.05,在α=0.05水准处拒绝H0,接受备择假设,认为慢性气管炎病人血中胆碱酯酶高于正常人。
上例用了单侧检验是因为事先并不认为该类病人血中胆碱酯含量会出现低于健康人的情况。
三、两组资料样本均数的比较
在日常工作中,我们经常要比较某两组计量资料的均数间有无显著差别,如研究不同疗法的降压效果或两种不同制剂对杀灭鼠体内钩虫的效果(条数)等。这时假若事先难以找到年龄、性别等条件完全一样的人(或动物)作配对比较,那么不能求每对的差数只能先算出各组的均数,然后进行比较。两组例数可以相等也可稍有出入。检验的方法同样是先假定两组相应的总体均数相等,看两组均数实际相差与此假设是否靠近,近则把相差看成抽样误差表现,远到一定界限则认为由抽样误差造成这样大的相差的可能性实在太小,拒绝假设而接受H1,作出两总体不相等的结论。
例7.4为观察中成药青黛明矾片对急性黄疸肝炎的退黄效果,以单用输液保肝的病人作为对照进行了观察,两组患者均为成人,黄疸指数在30-50之间,各人退黄天数如下,试比较用药组(1组)与对照组(2组)退黄天数有无显著差别。
表7.3急性黄疸性肝炎病人的退黄天数
中药组,X15 10 14 21 17 ∑X1=67 对照组,X218 21 30 23 22 22 ∑X2=136
(1)检验假设设该药对缩短退黄天数无效,两组的总体均数相等,即H0=μ1=μ2;H1:μ1≠μ2。
(2)求自由度ν
ν=n1+n2-2
=5+6-2=9 (7.1)
定α=0.05,ν=9时的t值为t0.05,9=2.262
(3)计算各组均数,合并方差S2c及两均数相差的标准误Sχ1-χ2,然后求t值。
合并方差:(7.2)
代入得
两均数相差的标准误:
(7.3)
代入得
求t:
(7.4)
(4)下结论因│t┃>t0.05,9,P<0.02,所以我们在α=0.05水准处拒绝H0而接受H1,两者平均退黄天数和有显著差别,服青黛明矾片药的病人退黄天数较短。如果检验假设属实,这样的结论也还可能下错,但概率在2%以下。
上例为两组资料均数间的比较,与前面成对资料的t检验有些区别。前者每对中两数据不能分离,后者任一组中的各数据可以在组内前后互换位置;前者只有一个样本平均差数d对应于一个假设的总体平均差数μ0,后者,认为X1为第一个总体的随机样本均数,X2则来自μ2,所以后者要计算两组合并的方差S2 c(方差是标准差的平方)。再者,与前者相比标准误、自由度的计算方法也不相同。
例7.5某人测定半岁至1岁小儿、7至8岁儿童各9人的免疫球蛋白IgG(国际单位/ml),算得平均数与标准差前者(第1组)为55.1±11.5,后者(第2组)为95.5 ±17.8,试检验这两种不同年龄的人免疫球蛋白IgG有无显著差别。
(1)检验假设H0:μ1=μ2;H1:μ1≠μ2。
(2)令α=0.01,查自由度ν=9+9-2=16时的临界值,得t0.01,16=2.921
(3)求统计量已知X1=55.1,X2=95.5,至于求t值时作为分母的标准误,在暂缺原始数据时由已知的两个标准差先推算出合并方差S c2进而求出Sχ1-χ2即可,方法如下;
①一般方法;根据标准差算式
则
于是
由式(7.2)
由式(7.3)
②在两组例数相等时也可直接用S1、S2代入下式求Sχ1-χ2,结果一样。
现已有了均数及标准误可由X1、X2、Sχ1-χ2求出t值。
(4)结论│t│>=5.719>t0.01,16=2.921,P<0.001,在α=0.01水准处拒绝H0,接受H1,两年龄组的人免疫球蛋白IgG的均数相差显著,7-8岁组的高于小几组。
关于检验水准α定在0.05还是0.01或其它处,要看检验者事先对结论的可靠性要求之高低而定。本例定α=0.01,要求是较高的,最后查出P值小于0.001就更说明X1-X2=-40.4随机来自μ1-μ2=0的假设总体的可能性是很小的。
t分布与t检验
本讲自测(占一定期末成绩)1 【单选题】 关于t分布,以下说法不正确的是 ?A、 t分布是一种连续性分布 ?B、 是以0为中心的对称分布 ?C、 t分布就是样本均数的分布 ?D、 当自由度为无穷大时,t分布就是标准正态分布 ?E、 t分布的曲线形状固定 正确答案:E 我的答案:E得分:3.3分 2 【单选题】 α=0.05, t>t0.05,ν,统计上可认为() ?A、
两总体均数差别无统计学意义 ?B、 两样本均数差别无统计学意义 ?C、 两总体均数差别有统计学意义 ?D、 两样本均数差别有统计学意义 ?E、 以上均不对 正确答案:C 我的答案:A得分:0.0分 3 【单选题】 12名妇女分别用两种测量肺活量的仪器测最大呼气率(l/min),比较两种方法检测结果有无差别,可进行: ?A、 卡方检验 ?B、 两独立样本t检验 ?C、 配对卡方检验
?D、 配对样本t检验 正确答案:D 我的答案:D得分:3.3分 4 【单选题】 两样本均数比较,经t 检验,差别有统计学意义时,P 越小,说明:?A、 两样本均数差别越大 ?B、 两总体均数差别越大 ?C、 越有理由认为两总体均数不同 ?D、 越有理由认为两样本均数不同 ?E、 样本均数与总体均数不同 正确答案:C 我的答案:C得分:3.3分 5 【单选题】
关于学生t分布,下面哪种说法不正确()。 ?A、 要求随机样本 ?B、 适用于任何形式的总体分布 ?C、 可用于小样本 ?D、 可用样本标准差S代替总体标准差 正确答案:B 我的答案:B得分:3.3分 6 【单选题】 在由两样本均数的差别推断两总体均数的差别的t检验中,检验假设的无效假设是: ( ) ?A、 两样本均数差别无统计意义 ?B、 两总体均数差别无统计意义 ?C、 两样本均数相等
t分布与t检验
t分布 从数理统计的理论上讲,并且上节的实例也已说明,在总体均数为μ,总体标准差为σ的正态总体中随机抽取n相等的许多样本,分别算出样本均数,这些样本均数呈正态分布。而当样本含量n不太小时,即使总体不呈正态分布,样本均数的分布也接近正态。在下式中, 由于μ与(样本均数的标准差)都是常量,又 X呈正态分布,所以u 也呈正态分布。但实际上总体标准差往往是不知道的,上式分母中的σ要由S替代,成为 ,那么由于样本标 准差有抽样波动,SX也有抽样波动,于是,在用S代替σ 后上式等号右边的变量便不呈正态分布而呈t分布,其定义公式是 (6.5)
t分布也是左右对称,但在总体均数附近的面积较正态分布的少些,两端尾部的面积则比正态分布的多些。t分布曲线随自由度而不同(如图6.1)。随着自由度的增大,t分布逐渐接近正态分布,当自由度为无限大时,t分布成为正态分布。 图6.1t分布(实线)与正态分布(虚线) 与正态分布相似,我们把t分布左右两端尾部面积之和α=0.05(即每侧尾部面积为0.025)相应的t值称为5%界,符号为t0.05,,,这里ν是自由度。把左右两端尾部面积之和α为0.01相应的t值称为1%界,符号为t0.01,,。t的5%界与1%界可查附表3,t值表。例如当自由度为10-1=9时,t0.05,9=2.262,t0.01,9=3.250。 可信区间的估计 一、参数估计的意义 一组调查或实验数据,如果是计量资料可求得平均数,标准差等统计指标,如果是计数资料则求百分率藉以概括说明这群观察数据的特征,故称特征值。由于样本特征值是通过统计求得的,所以又称为统计量以区别于总体特征值。总体特征值一般称为参数(总体量)。我们进行科研所要探索的是总体特征值即总体参数,而我们得到的却是样本统计量,用样本统计量估计或推论总体参数的过程叫参数估计。
(完整版)t分布的概念及表和查表方法.doc
t分布介绍 在概率论和统计学中,学生 t - 分布(t -distribution ),可简称为 t 分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t 分布曲线形态与 n(确切地说与自由度 df )大小有关。与标准正态分布曲线相比,自由度df 越小, t 分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度 df 愈大, t 分布曲线愈接近正态分布曲线,当自由度 df= ∞时, t 分布曲线为标准正态分布曲线。 中文名t 分布应用在对呈正态分布的总体 外文名t -distribution 别称学生 t 分布 学科概率论和统计学相关术语t 检验 目录 1历史 2定义 3扩展 4特征 5置信区间 6计算 历史 在概率论和统计学中,学生 t -分布( Student's t-distribution )经常应用在对呈正态分布的总体的均值进行估计。它是对两个样本均值差异进行显著性测试的学生t 测定的基础。 t 检定改进了Z 检定(en:Z-test ),不论样本数量大或小皆可应用。在样本数量大(超过 120 等)时,可以应用Z 检定,但 Z 检定用在小的样本会产生很大的误差,因此样本很小的情况下得改用学生t 检定。在数据有三组以上时,因为误差无法压低,此时可以用变异数分析代替学生t 检定。 当母群体的标准差是未知的但却又需要估计时,我们可以运用学生t-分布。 学生 t-分布可简称为t 分布。其推导由威廉·戈塞于 1908 年首先发表,当时他还在都柏林的健力士酿酒厂工作。因为不能以他本人的名义发表,所以论文使用了学生(Student )这一笔名。之后t 检验以及相关理论经由罗纳德·费雪的工作发扬光大,而正是他将此分布称为学生分布。 定义
统计临界值表
目录 附表一:随机数表 _________________________________________________________________________ 2附表二:标准正态分布表 ___________________________________________________________________ 3附表三:t分布临界值表____________________________________________________________________ 4 附表四: 2 分布临界值表 __________________________________________________________________ 5 附表五:F分布临界值表(α=0.05)________________________________________________________ 7附表六:单样本K-S检验统计量表___________________________________________________________ 9附表七:符号检验界域表 __________________________________________________________________ 10附表八:游程检验临界值表 _________________________________________________________________ 11附表九:相关系数临界值表 ________________________________________________________________ 12附表十:Spearman等级相关系数临界值表 ___________________________________________________ 13附表十一:Kendall等级相关系数临界值表 ___________________________________________________ 14附表十二:控制图系数表 __________________________________________________________________ 15
统计学附录F分布,t分布临界值表全.docx
统计学附录F—分布临界值表 ——α( 0.005 ―0.10 ) α=0.005 Fα k112345681224∞k2 116211200002161522500230562343723925244262494025465 2198.5199.0199.2199.2199.3199.3199.4199.4199.5199.5 355.5549.8047.4746.1945.3944.8444.1343.3942.6241.83 431.3326.2824.2623.1522.4621.9721.3520.7020.0319.32 522.7818.3116.5315.5614.9414.5113.9613.3812.7812.14 618.6314.4512.9212.0311.4611.0710.5710.039.478.88 716.2412.4010.8810.059.529.168.688.187.657.08 814.6911.049.608.818.307.957.507.01 6.50 5.95 913.6110.118.727.967.477.13 6.69 6.23 5.73 5.19 1012.839.438.087.34 6.87 6.54 6.12 5.66 5.17 4.64 1112.238.917.60 6.88 6.42 6.10 5.68 5.24 4.76 4.23 1211.758.517.23 6.52 6.07 5.76 5.35 4.91 4.43 3.90 1311.378.19 6.93 6.23 5.79 5.48 5.08 4.64 4.17 3.65 1411.067.92 6.68 6.00 5.56 5.26 4.86 4.43 3.96 3.44 1510.807.70 6.48 5.80 5.37 5.07 4.67 4.25 3.79 3.26 1610.587.51 6.30 5.64 5.21 4.91 4.52 4.10 3.64 3.11 1710.387.35 6.16 5.50 5.07 4.78 4.39 3.97 3.51 2.98 1810.227.21 6.03 5.37 4.96 4.66 4.28 3.86 3.40 2.87 1910.077.09 5.92 5.27 4.85 4.56 4.18 3.76 3.31 2.78 209.94 6.99 5.82 5.17 4.76 4.47 4.09 3.68 3.22 2.69
t检验
(二)t 检验 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t 检验分为单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ σ-= 。 如果样本是属于大样本(n >30)也可写成: X t μ σ-= 。 在这里,t 为样本平均数与总体平均数的离差统计量; X 为样本平均数; μ为总体平均数; X σ为样本标准差; n 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步 建立原假设0H ∶μ=73 第二步 计算t 值 79.273 1.63X t μ σ--= = = 第三步 判断 因为,以0.05为显著性水平,119df n =-=,查t 值表,临界值 0.05(19) 2.093t =,而样本离差的t =1.63小与临界值2.093。所以,接受原假设,即进步不显著。 2.双总体t 检验
双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过0r =。 相关样本的t 检验公式为: t = 在这里,1X ,2X 分别为两样本平均数; 1 2X σ,22 X σ分别为两样本方差; γ为相关样本的相关系数。 例:在小学三年级学生中随机抽取10名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为79.5和72分,标准差分别为9.124,9.940。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步 建立原假设0H ∶1μ=2μ 第二步 计算t 值 t = =3.459。 第三步 判断 根据自由度19df n =-=,查t 值表0.05(9) 2.262t =,0.01(9) 3.250t =。由于实际计算出来的t =3.495>3.250=0.01(9)t ,则0.01P <,故拒绝原假设。 结论为:两次测验成绩有及其显著地差异。 由以上可以看出,对平均数差异显著性检验比较复杂,究竟使用Z 检验还是使用t 检验必须根据具体情况而定,为了便于掌握各种情况下的Z 检验或t 检验,我们用以下一览表图示加以说明。
T检验临界值表
自由度自由度(df )0.100.05 0.01 (df )0.100.05 0.01 n -m -1n -m -11 6.31412.70663.657301 1.650 1.968 2.5922 2.920 4.3039.925302 1.650 1.968 2.5923 2.353 3.182 5.841303 1.650 1.968 2.5924 2.132 2.776 4.604304 1.650 1.968 2.5925 2.015 2.571 4.032305 1.650 1.968 2.5926 1.943 2.447 3.707306 1.650 1.968 2.5927 1.895 2.365 3.499307 1.650 1.968 2.5928 1.860 2.306 3.355308 1.650 1.968 2.5929 1.833 2.262 3.250309 1.650 1.968 2.59210 1.812 2.228 3.169310 1.650 1.968 2.59211 1.796 2.201 3.106311 1.650 1.968 2.59212 1.782 2.179 3.055312 1.650 1.968 2.59213 1.771 2.160 3.012313 1.650 1.968 2.59214 1.761 2.145 2.977314 1.650 1.968 2.59215 1.753 2.131 2.947315 1.650 1.968 2.59216 1.746 2.120 2.921316 1.650 1.967 2.59117 1.740 2.110 2.898317 1.650 1.967 2.59118 1.734 2.101 2.878318 1.650 1.967 2.59119 1.729 2.093 2.861319 1.650 1.967 2.59120 1.725 2.086 2.845320 1.650 1.967 2.59121 1.721 2.080 2.831321 1.650 1.967 2.59122 1.717 2.074 2.819322 1.650 1.967 2.59123 1.714 2.069 2.807323 1.650 1.967 2.59124 1.711 2.064 2.797324 1.650 1.967 2.59125 1.708 2.060 2.787325 1.650 1.967 2.59126 1.706 2.056 2.779326 1.650 1.967 2.59127 1.703 2.052 2.771327 1.650 1.967 2.59128 1.701 2.048 2.763328 1.650 1.967 2.59129 1.699 2.045 2.756329 1.649 1.967 2.59130 1.697 2.042 2.750330 1.649 1.967 2.59131 1.696 2.040 2.744331 1.649 1.967 2.59132 1.694 2.037 2.738332 1.649 1.967 2.59133 1.692 2.035 2.733333 1.649 1.967 2.59134 1.691 2.032 2.728334 1.649 1.967 2.59135 1.690 2.030 2.724335 1.649 1.967 2.59136 1.688 2.028 2.719336 1.649 1.967 2.59137 1.687 2.026 2.715337 1.649 1.967 2.59038 1.686 2.024 2.712338 1.649 1.967 2.59039 1.685 2.023 2.708339 1.649 1.967 2.59040 1.684 2.021 2.704340 1.649 1.967 2.59041 1.683 2.020 2.701341 1.649 1.967 2.59042 1.682 2.018 2.698342 1.649 1.967 2.59043 1.681 2.017 2.695343 1.649 1.967 2.59044 1.680 2.015 2.692 344 1.649 1.967 2.590 显著性水平(a )显著性水平(a )T 检验临界值表
t分布的概念及表和查表方法
t分布介绍 在概率论和统计学中,学生t-分布(t-distribution),可简称为t分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。 目录 1历史 2定义 3扩展 4特征 5置信区间 6计算 历史 在概率论和统计学中,学生t-分布(Student's t-distribution)经常应用在对呈正态分布的总体的均值进行估计。它是对两个样本均值差异进行显著性测试的学生t测定的基础
。t检定改进了Z检定(en:Z-test),不论样本数量大或小皆可应用。在样本数量大(超过120等)时,可以应用Z检定,但Z检定用在小的样本会产生很大的误差,因此样本很小的情况下得改用学生t 检定。在数据有三组以上时,因为误差无法压低,此时可以用变异数分析代替学生t检定。 当母群体的标准差是未知的但却又需要估计时,我们可以运用学生t-分布。 学生t-分布可简称为t分布。其推导由威廉·戈塞于1908年首先发表,当时他还在都柏林的健力士酿酒厂工作。因为不能以他本人的名义发表,所以论文使用了学生(Student)这一笔名。之后t检验以及相关理论经由罗纳德·费雪的工作发扬光大,而正是他将此分布称为学生分布。 定义 由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t 值的分布称为t分布。 假设X服从标准正态分布N(0,1),Y服从分布,那么的分布称为自由度为n 的t分布,记为。 分布密度函数, 其中,Gam(x)为伽马函数。
统计分布临界值表
附录 附表一:随机数表 _________________________________________________________________________ 2附表二:标准正态分布表 ___________________________________________________________________ 3附表三:t分布临界值表____________________________________________________________________ 4 附表四: 2 分布临界值表 __________________________________________________________________ 5 附表五:F分布临界值表(α=0.05)________________________________________________________ 7附表六:单样本K-S检验统计量表___________________________________________________________ 9附表七:符号检验界域表 __________________________________________________________________ 10附表八:游程检验临界值表 _________________________________________________________________ 11附表九:相关系数临界值表 ________________________________________________________________ 12附表十:Spearman等级相关系数临界值表 ___________________________________________________ 13附表十一:Kendall等级相关系数临界值表 ___________________________________________________ 14附表十二:控制图系数表 __________________________________________________________________ 15
t分布的概念及表和查表方法
t分布的概念及表和查 表方法 本页仅作为文档封面,使用时可以删除 This document is for reference only-rar21year.March
t分布介绍 在概率论和统计学中,学生t-分布(t-distribution),可简称为t分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。 目录 1历史 2定义 3扩展 4特征 5置信区间 6计算 历史 在概率论和统计学中,学生t-分布(Student's t-distribution)经常应用在对呈正态分布的总体的均值进行估计。它是对两个样本均值差异进行显著性测试的学生t测定的基础。t检定改进了Z检定(en:Z-test),不论样本数量大或小皆可应用。在样本数量大(超过120等)时,可以应用Z检定,但Z检定用在小的样本会产生很大的误差,因此样本很小的情况下得改用学生t检定。在数据有三组以上时,因为误差无法压低,此时可以用变异数分析代替学生t检定。 当母群体的标准差是未知的但却又需要估计时,我们可以运用学生t-分布。 学生t-分布可简称为t分布。其推导由威廉·戈塞于1908年首先发表,当时他还在都柏林的健力士酿酒厂工作。因为不能以他本人的名义发表,所以论文使用了学生(Student)这一笔名。之后t检验以及相关理论经由罗纳德·费雪的工作发扬光大,而正是他将此分布称为学生分布。
统计分布临界值表
附表一:随机数表_____________________________________________________________________________ 2附表二:标准正态分布表______________________________________________________________________ 3附表三:t分布临界值表________________________________________________________________________ 4 2 附表四:分布临界值表_____________________________________________________________________ 5附表五:F分布临界值表(a =0.05)7附表六:单样本K-S检验统计量表_______________________________________________________________ 9附表七:符号检验界域表______________________________________________________________________ 10附表八:游程检验临界值表___________________________________________________________________ 11附表九:相关系数临界值表____________________________________________________________________ 12附表十:Spearman等级相关系数临界值表 _____________________________________________________ 13附表十一:Kendall等级相关系数临界值表_______________________________________________________ 14附表十二:控制图系数表_____________________________________________________________________ 15
t分布临界值表(3)
t分布临界值表 Y 单侧tf-0.10 0.05 0.025 0.01 0.005 ^*020 0.10 0.W 0.Q2 0.01 ¥?1 3.078 6314 12.706 3⑷I 63437 2l.就6 2.920 ~ ^.SOJ 6.W5 9.925 3 1.63S2333 lltt 4J4I 5.S41 4g 2.13: 5.776 1747 4.604 5 L47 6 2.01$ 2.571 3.3?<032 ?1,440]w 2.447 1143 3.707 1 1.41$I,*452,365 2.99S 3咖 8 1397】.M0 2JQ6 2.S96 2.35$ 9 IJ83 1.833 2.2*2 XR3I 5J50 10 1.372 1812 2.228 2764 3 I&9 11 1.363 1,7% 2 2Q1 2.718 3.106 12 L556 1179 2.6S1 3,055 13 1.350 1.77t2J602650 3012 14 l.MS 1.761 2.145 2.624 2.^77 15 1341 k753 2431 2 602 2弼7 16 1.337 1.746 2.120 25*3 2.921 17 133) 1.740 2.1)0 2.567zm IK L3J0L7J4 2401 2^52 2.87S \9|.52? 1.729 2,093 2.539 2.861 2D 1325 J.725 2.OS6 2.S28 2.S45 21 1323 \31\ 2.080 2.51S 2妙 22132! \m 2.074 2.508 1819 2313191JI4 2.069 2.500 2 807 24⑶g L7LL 2064 2.4922,797 25 1316 IM 2.060 2.4H5 2.787 26IJ15 1.7师 2.056 2櫛 2.779 27IJH l.?032,052 2.475 2.77) 2?1313 L701 2.048 2.467 2.763 291311 i.699 2(M5 2.462 2.?56 301310 i 69? 2,042 2.457 2.750 401J03 I£S4 2.021 2.423 2.704 50 1.299 1.676 2.009 2 403 2.678 60 1.2^ 1.671 2.000 2J90 2.660 70 1.294 1.W7 1.9W 伽 2.64& 80 1.202 1.990 2.374 2.639 901291h662 1.487 2368 "32 100 1290 1.660 i.QM 2364 2.626 125I.2S8 1 657 I.W 235? 2.616 ISO 1 2M7 1 655k?76 2351 2.609 200 I.2B6 1653 L972 2.345 2.601 8I.2K:I.M5I960 1326 2.576
t分布的概念表和查表方法
t分布介绍 在和中,学生t-分布(t-distribution),可简称为t分布,用于根据小样本来估计呈且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。 目录 1 2 3 4 5 6 历史 在和统计学中,学生t-分布(Student's t-distribution)经常应用在对呈的总体的进行估计。它是对两个差异进行测试的学生t测定的基础。t检定改进了Z检定(en:Z-test),不论样本数量大或小皆可应用。在样本数量大(超过120等)时,可以应用Z检定,但Z检定用在小的样本会产生很大的误差,因此样
本很小的情况下得改用学生t检定。在数据有三组以上时,因为误差无法压低,此时可以用代替学生t检定。 当母群体的是未知的但却又需要估计时,我们可以运用学生t-分布。 学生t-分布可简称为t分布。其推导由于1908年首先发表,当时他还在都柏林的健力士酿酒厂工作。因为不能以他本人的名义发表,所以论文使用了学生(Student)这一笔名。之后t检验以及相关理论经由的工作发扬光大,而正是他将此分布称为学生分布。 定义 由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t 值的分布称为t分布。 假设X服从标准正态分布N(0,1),Y服从分布,那么的分布称为自由度为n 的t分布,记为。 分布密度函数, 其中,Gam(x)为伽马函数。 扩展
T分布临界值表 (2)
T分布表 Df 自由度 P 概率0.1 0.05 0.025 0.01 0.005 0.001 0.0005 单尾0.2 0.1 0.05 0.02 0.01 0.002 0.001 双尾 1 3.078 6.314 12.706 31.821 63.657 318.309 636.619 2 1.886 2.920 4.30 3 6.965 9.925 22.327 31.599 3 1.638 2.353 3.182 4.541 5.841 10.215 12.924 4 1.533 2.132 2.776 3.747 4.604 7.173 8.610 5 1.47 6 2.015 2.571 3.365 4.032 5.893 6.869 6 1.440 1.943 2.44 7 3.143 3.707 5.20 8 5.959 7 1.415 1.895 2.365 2.998 3.499 4.785 5.408 8 1.397 1.860 2.306 2.896 3.355 4.501 5.041 9 1.383 1.833 2.262 2.821 3.250 4.297 4.781 10 1.372 1.812 2.228 2.764 3.169 4.144 4.587 11 1.363 1.796 2.201 2.718 3.106 4.025 4.437 12 1.356 1.782 2.179 2.681 3.055 3.930 4.318 13 1.350 1.771 2.160 2.650 3.012 3.852 4.221 14 1.345 1.761 2.145 2.624 2.977 3.787 4.140 15 1.341 1.753 2.131 2.602 2.947 3.733 4.073 16 1.337 1.746 2.120 2.583 2.921 3.686 4.015 17 1.333 1.740 2.110 2.567 2.898 3.646 3.965 18 1.330 1.734 2.101 2.552 2.878 3.610 3.922 19 1.328 1.729 2.093 2.539 2.861 3.579 3.883 20 1.325 1.725 2.086 2.528 2.845 3.552 3.850 21 1.323 1.721 2.080 2.518 2.831 3.527 3.819 22 1.321 1.717 2.074 2.508 2.819 3.505 3.792 23 1.319 1.714 2.069 2.500 2.807 3.485 3.768 24 1.318 1.711 2.064 2.492 2.797 3.467 3.745 25 1.316 1.708 2.060 2.485 2.787 3.450 3.725 26 1.315 1.706 2.056 2.479 2.779 3.435 3.707 27 1.314 1.703 2.052 2.473 2.771 3.421 3.690 28 1.313 1.701 2.048 2.467 2.763 3.408 3.674 29 1.311 1.699 2.045 2.462 2.756 3.396 3.659 30 1.310 1.697 2.042 2.457 2.750 3.385 3.646 31 1.309 1.696 2.040 2.453 2.744 3.375 3.633 32 1.309 1.694 2.037 2.449 2.738 3.365 3.622 33 1.308 1.692 2.035 2.445 2.733 3.356 3.611
t分布的概念及表和查表方法
在概率论和统计学中,学生t-分布(t-distributen ),可简称为t分布,用于根据 小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t分布曲线形态与n (确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大, t分布曲线愈接近正态分布曲线,当自由度df= %时,t分布曲线为标准正态分布曲线。 目录 1历史 2定义 3扩展 4特征 5置信区间 6计算 历史 在概率论和统计学中,学生t -分布(Student's t-distribution )经常应用在对呈正态分布的总体 的均值进行估计。它是对两个样本均值差异进行显著性测试的学生t测定的基础。t检定改进了Z检定(en:Z-test ),不论样本数量大或小皆可应用。在样本数量大(超过120等)时,可以应用Z检定,但
Z检定用在小的样本会产生很大的误差,因此样本很小的情况下得改用学生t检定。在数据有三组以上时,
t-分布。 当母群体的标准差是未知的但却又需要估计时,我们可以运用学生 学生t-分布可简称为t分布。其推导由威廉?戈塞于1908年首先发表,当时他还在都柏林的健力士酿酒厂工作。因为不能以他本人的名义发表,所以论文使用了学生( Student )这一笔名。之后t检验以 及相关理论经由罗纳德?费雪的工作发扬光大,而正是他将此分布称为学生分布。 定义 由于在实际工作中,往往(7是未知的,常用S作为(T的估计值,为了与U变换区别,称为t变换, 统计量t值的分布称为t分布。 假设X服从标准正态分布N(0,1 ), Y服从分布,那么的分布称为自由度为n的t分布,记为。 分布密度函数, 其中,Gam(x)为伽马函数。 扩展 正态分布(normal distribution )是数理统计中的一种重要的理论分布,是许多统计方法的理论基 础。正态分布有两个参数,卩和7,决定了正态分布的位置和形态。为了应用方便,常将一般的正态变 量X通过u变换[(X-卩)/ 7 ]转化成标准正态变量u,以使原来各种形态的正态分布都转换为卩=0,7 =1 的标准正态分布(standard normal distribution ),亦称u分布。 根据中心极限定理,通过上述的抽样模拟试验表明,在正态分布总体中以固定n,抽取若干个样本时,样本均数的分布仍服从正态分布,即N(「)。所以,对样本均数的分布进行u变换,也可变换为标 准正态分布N (0,1)。 特征 1.以0为中心,左右对称的单峰分布; 2.t分布是一簇曲线,其形态变化与n(确切地说与自由度df )大小有关。自由度df越小,t分布曲线越低平;自由度df越大,t分布曲线越接近标准正态分布(u分布)曲线,如图:
t-分布临界值表
t -分布临界值表 ()(){}1P t n t n αα?=> n α=0.25 0.10 0.05 0.025 0.01 0.005 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 1.0000 0.8165 0.7649 0.7407 0.7267 0.7176 0.7111 0.7064 0.7027 0.6998 0.6974 0.6955 0.6938 0.6924 0.6912 0.6901 0.6892 0.6884 0.6876 0.6870 0.6864 0.6858 0.6853 0.6848 0.6844 0.6840 0.6837 0.6834 0.6830 0.6828 3.0777 1.8856 1.6377 1.5332 1.4759 1.4398 1.4149 1.3968 1.3830 1.3722 1.3634 1.3562 1.3502 1.3450 1.3406 1.3368 1.3334 1.3304 1.3277 1.3253 1.3232 1.3212 1.3195 1.3178 1.3163 1.3150 1.3137 1.3125 1.3114 1.3104 6.3138 2.9200 2.3534 2.1318 2.0150 1.9432 1.8946 1.8595 1.8331 1.8125 1.7959 1.7823 1.7709 1.7613 1.7531 1.7459 1.7396 1.7341 1.7291 1.7247 1.7207 1.7171 1.7139 1.7109 1.7081 1.7056 1.7033 1.7011 1.6991 1.6973 12.7062 4.3207 3.1824 2.7764 2.5706 2.4469 2.3646 2.3060 2.2622 2.2281 2.2010 2.1788 2.1604 2.1448 2.1315 2.1199 2.1098 2.1009 2.0930 2.0860 2.0796 2.0739 2.0687 2.0639 2.0595 2.0555 2.0518 2.0484 2.0452 2.0423 31.8207 6.9646 4.5407 3.7469 3.3649 3.1427 2.9980 2.8965 2.8214 2.7638 2.7181 2.6810 2.6503 2.6245 2.6025 2.5835 2.5669 2.5524 2.5395 2.5280 2.5177 2.5083 2.4999 2.4922 2.4851 2.4786 2.4727 2.4671 2.4620 2.4573 63.6574 9.9248 5.8409 4.6041 4.0322 3.7074 3.4995 3.3554 3.2498 3.1693 3.1058 3.0545 3.0123 2.9768 2.9467 2.9028 2.8982 2.8784 2.8609 2.8453 2.8314 2.8188 2.8073 2.7969 2.7874 2.7787 2.7707 2.7633 2.7564 2.7500
T分布临界值表
T分布表 Df 自由度P 概率0.1 0.05 0.025 0.01 0.005 0.001 0.0005 单尾0.2 0.1 0.05 0.02 0.01 0.002 0.001 双尾 1 3.078 6.314 12.706 31.821 63.657 318.309 636.619 2 1.886 2.920 4.30 3 6.965 9.925 22.327 31.599 3 1.638 2.353 3.182 4.541 5.841 10.215 12.924 4 1.533 2.132 2.776 3.747 4.604 7.173 8.610 5 1.47 6 2.015 2.571 3.365 4.032 5.893 6.869 6 1.440 1.943 2.44 7 3.143 3.707 5.20 8 5.959 7 1.415 1.895 2.365 2.998 3.499 4.785 5.408 8 1.397 1.860 2.306 2.896 3.355 4.501 5.041 9 1.383 1.833 2.262 2.821 3.250 4.297 4.781 10 1.372 1.812 2.228 2.764 3.169 4.144 4.587 11 1.363 1.796 2.201 2.718 3.106 4.025 4.437 12 1.356 1.782 2.179 2.681 3.055 3.930 4.318 13 1.350 1.771 2.160 2.650 3.012 3.852 4.221 14 1.345 1.761 2.145 2.624 2.977 3.787 4.140 15 1.341 1.753 2.131 2.602 2.947 3.733 4.073 16 1.337 1.746 2.120 2.583 2.921 3.686 4.015