编译原理第4章作业答案

编译原理第4章作业
答案
本页仅作为文档封面,使用时可以删除
This document is for reference only-rar21year.March
第四章
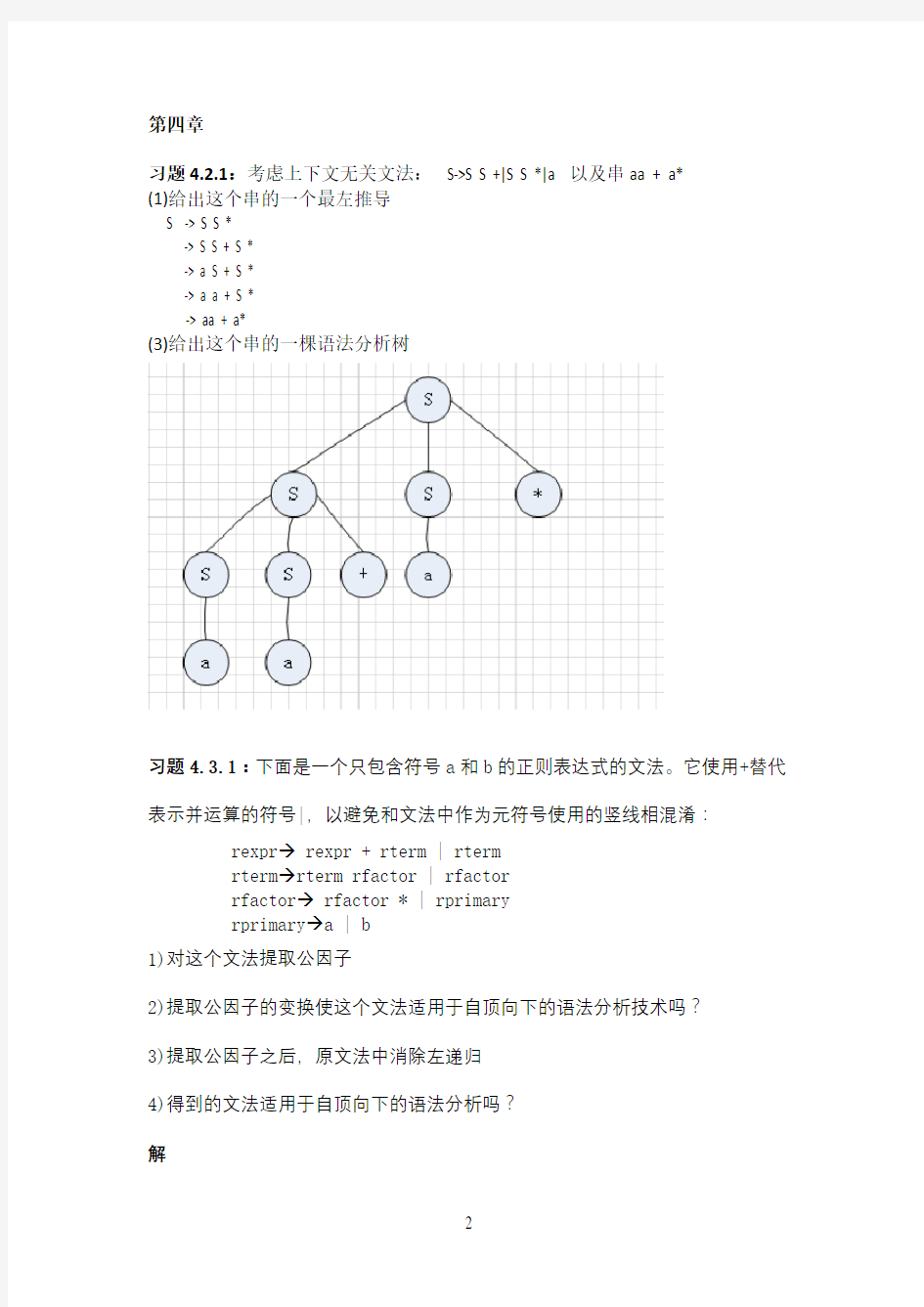
习题4.2.1:考虑上下文无关文法: S->S S +|S S *|a 以及串aa + a*
(1)给出这个串的一个最左推导
S -> S S *
-> S S + S *
-> a S + S *
-> a a + S *
-> aa + a*
(3)给出这个串的一棵语法分析树
习题4.3.1:下面是一个只包含符号a和b的正则表达式的文法。它使用+替代表示并运算的符号|,以避免和文法中作为元符号使用的竖线相混淆:
rexpr→ rexpr + rterm | rterm
rterm→rterm rfactor | rfactor
rfactor→ rfactor * | rprimary
rprimary→a | b
1)对这个文法提取公因子
2)提取公因子的变换使这个文法适用于自顶向下的语法分析技术吗?
3)提取公因子之后,原文法中消除左递归
4)得到的文法适用于自顶向下的语法分析吗?
解
1)提取左公因子之后的文法变为
rexpr→ rexpr + rterm | rterm
rterm→rterm rfactor | rfactor
rfactor→ rfactor * | rprimary
rprimary→a | b
2)不可以,文法中存在左递归,而自顶向下技术不适合左递归文法
3)消除左递归后的文法
rexpr -> rterm rexpr’
rexpr’-> + rterm rexpr’|ε
rterm-> rfactor rterm’
rterm’-> rfactor rterm’|ε
rfactor-> rprimay rfactor’
rfactor’-> *rfactor’|ε
rprimary-> a | b
4)该文法无左递归,适合于自顶向下的语法分析
习题4.4.1:为下面的每一个文法设计一个预测分析器,并给出预测分析表。可能要先对文法进行提取左公因子或消除左递归
(3)S->S(S)S|ε
(5)S->(L)|a L->L,S|S
解
(3)
①消除该文法的左递归后得到文法
S->S’
S’->(S)SS’|ε
②计算FIRST和FOLLOW集合
FIRST(S)={(,ε} FOLLOW(S)={),$}
FIRST(S’)={(,ε} FOLLOW(S’)={),$}
③构建预测分析表
①消除该文法的左递归得到文法 S->(L)|a
L->SL’
L’->,SL’|ε
②计算FIRST与FOLLOW集合
FIRST(S)={(,a} FOLLOW(S)={ ),, ,$}
FIRST(L)={(,a} FOLLOW(L)={ ) }
FIRST(L’)={,,ε} FOLLOW(L’)={ ) }
③构建预测分析表
习题4.4.4 计算练习4.2.2的文法的FIRST和FOLLOW集合3)S S(S)S|ε