数据模型期末考试复习要点(运筹和统计已完整)

数据、模型与决策期末考试复习要点
管理统计学部分(四道大题)
一、 描述性统计量
对应教材P53,1。详细步骤参见统计学作业解析. 给出一组数据,大约在20个左右。
1. 求样本均值、中位数、极差、众数。样本方差写出表达式,不需要计算结果。
2. 把样本分为若干组,且组距相同,作出列表数据和直方图。 二、 区间估计 对应教材P147,1. 查表294页最后一行。
注: μ的(1-α)×100%区间估计为
无论总体分布是什么,只要总体方差σ2 已知,并且n 充分大(通常n>30)。 例(P110)调查某大学教师家庭每月水电、煤气和电话费的支出情况,随机抽取100户,发现每月平均帐单为253元。设帐单上的付款数X 服从N(μ,σ2), σ=70元。求平均付款额μ的置信水平为95%的区间估计。
解:n=100, =253,σ=70,α=0.05, u 0.05/2=1.96, 故μ的置信水平为95%的区间
样本均值的抽样分布
x
x 2
()u n
αμ∈2
u
α
σd =
可由正态分布表查得
2
()
x u ασ
μ∈±
x
估计是[253±
±13.72 即
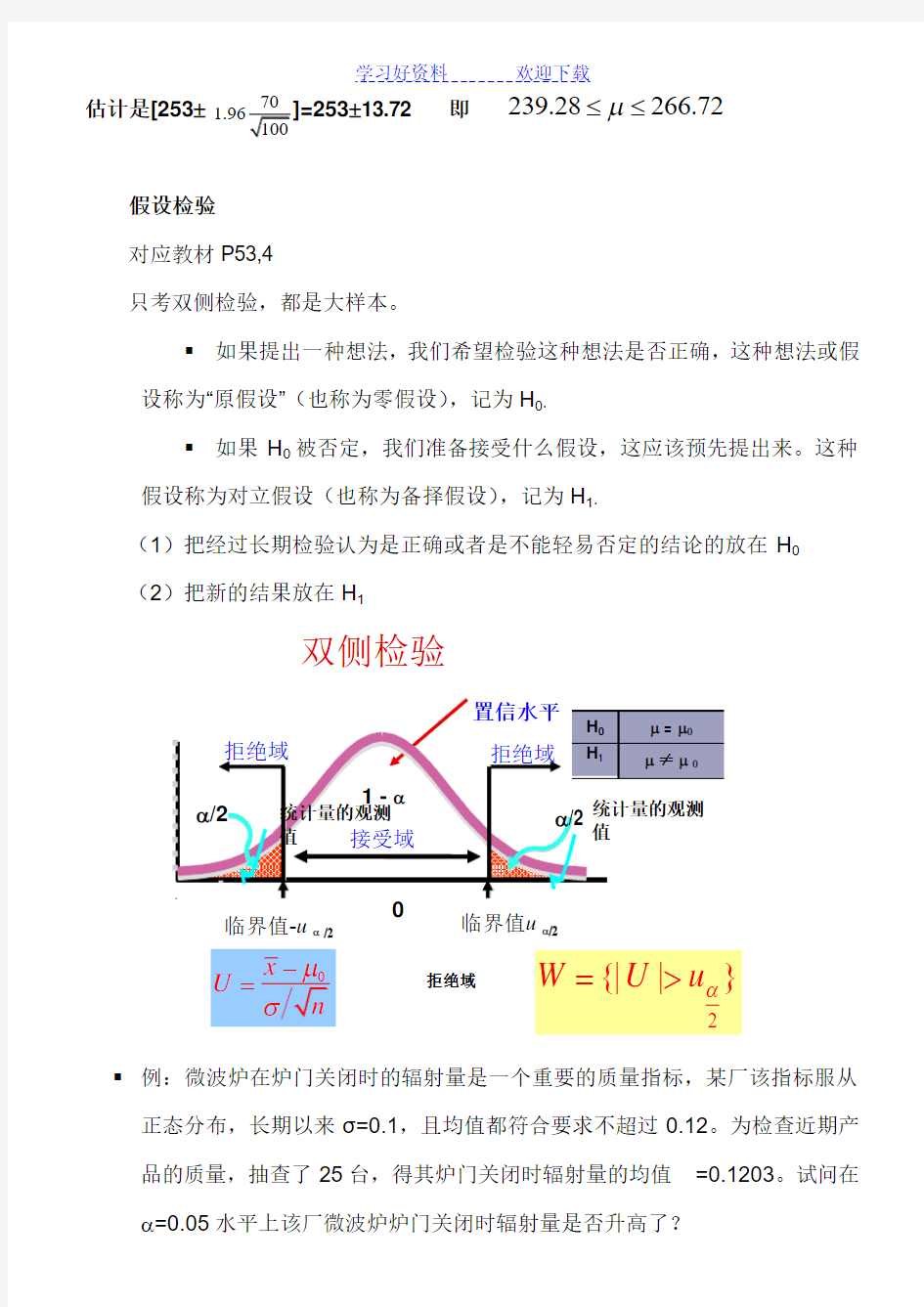
假设检验 对应教材P53,4
只考双侧检验,都是大样本。
? 如果提出一种想法,我们希望检验这种想法是否正确,这种想法或假设称为“原假设”(也称为零假设),记为H 0.
? 如果H 0被否定,我们准备接受什么假设,这应该预先提出来。这种假设称为对立假设(也称为备择假设),记为H 1.
(1)把经过长期检验认为是正确或者是不能轻易否定的结论的放在H 0 (2)把新的结果放在H 1
? 例:微波炉在炉门关闭时的辐射量是一个重要的质量指标,某厂该指标服从正态分布,长期以来σ=0.1,且均值都符合要求不超过0.12。为检查近期产品的质量,抽查了25台,得其炉门关闭时辐射量的均值 =0.1203。试问在α=0.05水平上该厂微波炉炉门关闭时辐射量是否升高了?
双侧检验
临界值u α/2
临界值-u α /2
拒绝域
239.28266.72
μ≤≤
解:1)构造原假设和对立假设
H 0:μ≤0.12 ? H 1:μ>0.12 2)给定显著性水平α=0.05,故u α=1.645 3)计算
4)比较
三、 解释因子和趋势都有哪些成分。 答:因子成分:
1.长期趋势因子trend (T )
指时间序列在较长持续期内展现出来的总态势。具体表现为不断增加或不断减少的基本趋势,也可以表现为只围绕某一常数值波动而无明显增减变化的水平趋势。
2.季节因子 seasonal factor (S )
由于自然季节因素(气候条件)或人文习惯季节因素(节假日)的印象,时间序列随季节更替而呈现的周期性变动。周期长度有一年、一月、一周等。
3.循环因子 cyclical factor (C )
时间序列中出现以若干时段为周期上升与下降交替出现的循环往复运动,且周期长度可变。
4.随机因子
除去前述三种变动之后所剩余的一种变动,往往指那些事前无法预料的,由偶然因素或突发事件引起的不规则变动。
趋势成分:
0x =
=
.015
00.645,95%x u H αα=<.015=1故接受。
即在水平=0.05(置信度)下,该厂微波炉炉门关闭时辐射量没有增加。
1.线性趋势:用一元线性回归来描述。
2.非线性趋势,用滑动平均法来描述,其原理是用相对小的一段数据,找出平均值,以光滑原始序列的波动,然后滑到另一段上,每一小段的长短与观察的数据类型有关。
运筹学部分(四道大题)
一、线性规划模型建立
对应P2,例1.
将一个实际问题转化为线性规划模型有以下步骤:
1. 确定决策变量:决策变量是未知量,也是模型最重要的参数。
2. 确定目标函数:目标函数决定线性规划问题的优化方向,是线性规划
模型的重要组成部分。
3. 确定约束方程。
4. 变量取值限制,一般情况下,决策变量只取正值(非负值)。
二、线性规划综合运用
对应P90,11.以书上P1,2为例,最优单纯形表为
注:红字为对应的检验数。此最优表中非基变量检验数均小于0,故最优解唯一。
由来:前两个0:基变量的检验数为0
-5=0-(30*1+50*(-1/2))
-15=0-(30*(-2)+50*(3/2))
给出最优求解结果,解释经济意义。回答下列问题
1.影子价格是多少,为什么。
影子价格看单纯形法最后一行。影子价格代表对应的资源的边际贡献。表明某种资源每增加单位数量,最后效益所增加的数值。老师以课本中P2为例,单纯形法最后一行为对应检验数,其中最优解最后一行分别对应-5,-15,表明木工和油漆工对应的影子价格分别为5和15.其中-5和-15为所求最优解的检验数。
2.最优解是否唯一,依据是什么。
最优解判断标准:所有检验数<=0。非基变量检验数等于0时,解不唯一。老师以课本中P2为例,最优解最后一行对应检验数分别为0,0,-5,-15,所有检验数均<=0,教材中例子检验数<=0.非基变量就是不在最优解表格左边列表内的变量。教材里子中,最优表中,x2,x1为基变量,x3,x4为非基变量,此例中,非基变量检验数分别为-5,-15,不等于0,所以解唯一。
3.原料的利用情况。
资源利用情况看优化解那一行引入松弛变量的值。如果为正,说明有剩余,如果为0说明无剩余。此题中,将最优解代入标准型解得x3=0,x4=0.故资源无剩余。
三、求线性规划的对偶问题
对应P86,1.
1.两个问题中,一个是极大化,另一个是极小化;
2.一个问题的变量数等于另一问题的方程数,反之亦然;
3.一个问题的目标函数系数是另一个问题的约束方程右端常数,反之亦然;
4.两个问题的约束方程系数矩阵互为转置;
5.一个问题第几个变量的约束情况决定另一问题第几个方程不等式方向,反之亦然。
原问题(对偶问题)Max 对偶问题(原问题)Min
变≥0 约≥
≤0 ≤
量无约束束=
约≤变≥0
≥ ≤0
束= 量无约束
参考教材P62.
四、指派问题
对应P248.
第一步:变换系数矩阵,使其各行各列都有0元素,方法是将各行(列)减去其最小元素,再将各列(行)减去其最小元素。
第二步:试指派,试探能否找到n个独立0元素,将符合要求的作标记,方法是:从含0最少的行或列中任选个0加圈,记为◎,划去与◎同行列的其它0,记为Ф。重复这一步骤,直至所有的0都被加圈或划去。若◎的数目m=n,试指派成功,否则,转第三步。
第三步:检查当前系数矩阵中独立0元素是否不够n,若不是,说明试指派有误,重新指派;若是,转第四步。检查方法是作覆盖所有零元素的直线,直线根数就是独立0元素个数。
作最少直线覆盖所有0元素步骤:
1. 对无◎的行打√;
2.对√行中有0的列打√;
3.对√列中有◎的行打√;(从无到有)
4.重复(2)-(3),直至打不出√为止
对无√的行画横线,有√的列画纵线(从无到有),得最少直线。
若最少直线数L=n,返回第二步,否则,转第四步。
第四步:在当前系数矩阵中进一步增加0元素,方法是:从未被直线覆盖部分中找出最小元素,将所有√行减去该元素,所有√列加上该元素,返回第二步。
注:在变换系数矩阵时,先按行还是先按列,过程可能不同,
最后结果写法:
原始矩阵:
14 11 13 17
9 7 2 9
4 9 10 15
15 10 5 13
最优解矩阵:
0 0 1 0
0 1 0 0
0 0 0 1
1 0 0 0
最优(大)值:
Z=13+7+15+15=50
指派问题例题及步骤:
2 15 1
3 4
10 4 14 15
9 14 16 13
7 8 11 9
先做行变换,第1行最小值为2,第一行每个数减去2,
第2行最小值为4,第二行每个数减去4
第3行最小值为9,第三行每个数减去9
第4行最小值为7,第四行每个数减去7
得新矩阵
0 13 11 2
6 0 10 11
0 5 7 4
0 1 4 2
在做列变换,没出现0的列有第3列和第4列。第3列最小值为4,第四列最小值为2,第三列第四列分别减去4和2得:
0 13 7
6 6 9
5 3 2
0 1 0
不同行不同列圈0,同行同列的0划去。的上表。此例中0元素恰好为4,所以即是最优解。
老师上课修改数据,举了下面例题,
8 9 5 √
11 0 4
2 3 4
0 3 8 5 √
√
对无圈0的打钩,所以给第4行打钩。钩行有0列打钩,所以给第1列打钩。对钩列有0行打钩,所以给第一行打钩。至此全部标记完了。
对无√的行画横线,有√的列画纵线(从无到有),得最少直线。此例中无√的行为第2、3行,有√的列为第1列,画出3条线。
从未被直线覆盖的元素中找到最小元素,此题中除去直线覆盖的第2、3行,第1列,剩余数字为8 9 5 3 8 5,最小为3.
将所有√行减去该元素,所有√列加上该元素。
第2 3行各减3,
-3 5 6 2
11 0 0 4
2 3 4 0
-3 0 5 2
第1列各加3得
5 6 2
14 0 4
5 3 4
5 2
此时,不同行不同列被圈的0数量为4。得到最优解矩阵为(把被圈的0替换为1,其余写0)
1 0 0 0
0 0 1 0
0 0 0 1
0 1 0 0
把为1位置上的原始矩阵上的数字相加,即得到指派问题的最优解。
2017旅游数据报告
中国旅游研究院、携程发布《2017出境旅游大数据报告》 中国日报3月1日电 3月1日,中国旅游研究院、携程旅游集团联合发布《中国游客中国名片,消费升级品质旅游——2017 年中国出境旅游大数据报告》。双方专家团队基于全年旅游业数据,结合携程3亿会员以及业内规模最大的跟团游、自由行订单数据,对全年出境游情况和游客行为进行了全面监测。 报告数据显示,2017年中国公民出境旅游突破1.3亿人次,花费达1152.9亿美元,保持世界第一大出境旅游客源国地位。出境旅游呈现“消费升级、品质旅游”的特征与趋势。选择升级型、个性化的旅游产品,深度体验目的地的游客占比提升。出国目的也从观光购物转向享受海外优质生活环境和服务。出境旅游已成为衡量中国城市家庭和年轻人幸福度的一大标准。 中国旅游研究院院长戴斌表示,在“一带一路”倡议、“旅游年”推动下,旅游合作更加紧密,跨越国境的旅行越来越便利。走出国门旅游,更像是“串门儿”,去别人的城市住上几天,换另一种生活方式。游客越来越强调对城市生活方式的体验,目的地则成为本地居民与游客共享的生活空间。中国游客就是行走的中国名片,丰富着世界对中国人和中国的认识。 一、1.3亿人次,花费1152.9亿美元,蝉联世界第一大出境旅游客源国
中国旅游研究院、国家旅游局数据中心发布的数据显示,2017年全年,中国公民出境旅游13051万人次,比上年同期增长7.0%。中国已连续多年保持世界第一大出境旅游客源国地位。 国人出境旅游花了多少钱?根据中国旅游研究院测算,2017年我国国际旅游支出达1152.9亿美元,相比2016年1098亿美元增长5%。 在线旅游平台和手机端成为中国旅游者的首选。根据携程旅游集团的统计,每5个中国出境游客人中,就至少有1位是在携程上进行的预订。 (数据来源:中国旅游研究院、国家旅游局数据中心) 我国已成为越来越多国家最大的客源国。据报告统计,中国已经成为泰国、日本、韩国、越南、柬埔寨、俄罗斯、马尔代夫、印尼、朝鲜、南非等10个国家的第
excel函数公式大全excelXX怎样使用函数公式统计出勤率
excel函数公式大全excelXX怎样使用函数公式统计出勤率 Excel中经常需要用到公式进行计算出勤率,统计出勤率的公式具体该如何使用呢?对于新手来说还是有一定难度,怎么办?下面是由分享的excel统计出勤率公式的用法,以供大家阅读和学习。 1:首先我们知道需要用到vlookup函数,那么先介绍一下使用vlookup函数的几个参数,vlookup是判断引用数据的函数,它总共有四个参数,依次是: 1、判断的条件 2、跟踪数据的区域 3、返回第几列的数据 4、是否精确匹配 2:根据以上参考,和上述在总表显示问题的实际需求,在总表相应单元格输入这个公式是: =VLOOKUP($C3,'xx.01工业'!$D4:$P260,3,FALSE)
3:总表里包含12个月的小表。可用分级来隐藏或显示。 =VLOOKUP($C3,'xx.01工业'!$D4:$P260,3,FALSE) 详细说明一下,在此vlookup函数例子中各个参数的使用说明: 4:C3是判断的条件,也就是说分表和总表中名字相同者,即总表假别列对应的数据和分表中名字列C列的数据相同方能引用; 5:xx.01工业'!$D4:$P260是数据跟踪的区域,因为需要引用的数据在P列,所以跟踪的区域至少在P列,xx.01工业'!是不同表间引用所用的表名称,和标志是表间引用的!符号,$是绝对引用(关于绝对引用可以参考这里),$D4:$P260表明从D4到P260单元格的数据区域,如果数据区域不止P26,那么可以直接使用D:P,这样虽然方便但是有风险,因为如果xx.01工业表的下方还有其它数据,就有可能出现问题; 6:3这是返回什么数的列数,如上图的事假是第3列,所以应该是3,如果要求病假的数值,那么此处应该是4 7:最后是否绝对引用,如果是就输入true如果是近似即可满足条件那么输入false(近似值主要用于带小数点的财务、运算等)
旅游数据报告分析月
2016上半年旅游数据报告分析 一、上半年旅游统计数据报告 2016年上半年,我国旅游市场规模稳步扩大,继续领跑宏观经济:国内旅游22.36亿人次,比上年同期增长10.47%;入出境旅游1.27亿人次,增长4.1%;上半年实现旅游总收入2.25万亿元,增长12.4%。 (一)上半年国内旅游人数增长10.47% 根据国内旅游抽样调查结果,2016年上半年,国内旅游人数22.36亿人次,比上年同期增长10.47%。其中,城镇居民15.17亿人次,增长13.55%;农村居民7.19亿人次,增长4.51%。国内旅游收入1.88万亿元,增长13.72%。其中城 。 镇居民花费1.48万亿元,增长15.13%;农村居民花费0.40亿元,增长8.84% (二)上半年入境旅游人数和入境过夜旅游人数分别增长3.8%和4.3% 2016年1-6月,入境旅游人数6787万人次,比上年同期增长3.8%。其中:外国人1347万人次,增长9.0%;香港同胞4003万人次,增长2.2%;澳门同胞1158万人次,增长3.5%;台湾同胞279万人次,增长5.8%。入境旅游人数按照入境方式分,船舶占3.4%,飞机占16.0%,火车占0.8%,汽车占21.5%,徒步占58.3%。 2016年1-6月,入境过夜旅游人数2887万人次,增长4.3%。其中:外国人1036万人次,增长6.8%;香港同胞1369万人次,增长2.3%;澳门同胞236万人次,增长3.5%;台湾同胞246万人次,增长6.0%。 (三)上半年国际旅游收入达570亿美元
2016年1-6月,国际旅游收入570亿美元,比上年同期增长5.3%。其中:外国人在华花费310亿美元,增长6.9%;香港同胞在内地花费151亿美元,增长2.3%;澳门同胞在内地花费38亿美元,增长3.5%;台湾同胞在大陆花费72亿美元,增长6.0%。 (四)上半年入境外国游客亚洲占比63.7%,以观光休闲为目的游客占31.2% 2016年1-6月,入境外国游客人数1347万人次,亚洲占63.7%,美洲占12.4%,欧洲占18.9%,大洋洲占2.9%,非洲占2.0%,其他国家占0.1%。其中:按照年龄分,14岁以下人数占3.8%,15-24岁占7.7%,25-44岁占45.8%,45-64岁占36.6%,65岁以上占6.1%;按性别分,男占64.5%,女占35.5%;按目的分,会议/商务占20.2%,观光休闲占31.2%,探亲访友占3.4%,服务员工占14.8%,其他占30.4%。 2016年1-6月,按入境旅游人数排序,我国主要客源市场前17位国家如下:韩国、日本、美国、越南、俄罗斯、菲律宾、蒙古、马来西亚、新加坡、印度、泰国、加拿大、澳大利亚、德国、印度尼西亚、英国、法国。 (五)上半年中国公民出境旅游人数达5903万人次 1-6月累计,中国公民出境旅游人数5903万人次,比上年同期增长4.3%。 二、下半年旅游经济形势分析 (一)旅游消费走势 1、国内旅游继续保持两位数的增速 旅游业将继续领跑宏观经济。我国经济进入结构深度调整的关键期,传统货币政策和财政政策效应弱化,经济增速将缓慢筑底,企稳后继续呈“L”型走势。在此背景下,旅游一枝独秀的地位将更加明显。 旅游需求升级空间更加凸显。目前,观光、休闲等传统旅游消费稳定发展,度假旅游受制于供给缺口、休假时长偏短、多数地区经济发展水平偏低等原因,消费升级、拉动经济和就业增长的效应将更加明显。虽然三季度开始极端天气频发,观光休闲和度假旅游需求均受到不同程度抑制,但是下半年将会出现恢复性增长。 2、入境旅游有望达到4%的良好增长势头 在人民币贬值、空气质量改善、外围目的地恐怖活动频发等因素推动下,入境旅游由前几年的衰退周期转为复苏周期的基础进一步稳固。下半年入境旅游人次增长有望突破4%,国际旅游收入增长超过5%。 3、出境旅游维持4%左右的增速
数据统计员个人工作总结范文
数据统计员个人工作总结范文 数据统计是否具有准确性,直接决定着单位、企业决策与管理是否科学、高效的问题。以下是为大家精心整理的数据统计员个人工作总结范文,欢迎大家阅读,供您参考。 数据统计员个人工作总结范文 过去的一年在领导和同事们的悉心关怀和指导下,通过自身的不懈努力,在工作上取得了一定的成果,但也存在了诸多不足,现将过去一年的工作情况总结如下: 一、公司领导高度重视,统计工作逐步完善。 近年来,公司领导高度重视统计工作,在统计体制改革、人员力量配备、经费保障等方面采取了很多措施,增加了统计工作人员,健全完善了统计工作体系,进一步夯实了统计基础建设,确保统计数据源头工作质量。 二、扎实做好统计基层基础工作。 近年来,围绕ldquo;人员专职化、台账规范化、管理制度化、调查法制化、手段现代化、经费有保障rdquo;的ldquo;五化一有rdquo;目标,进一步完善统计工作制度,夯实基层基础工作。统计工作部门具备独立的办公场所,同时配备了微机、打印机、办公桌椅等,确保统计工作的顺利进行。建立统计工作管理制度和统计人员管理制度,包括综合统计管理制度;建立原始记录和统计台帐、统计报表管理制度;建立数据管理制度和数据质量检查、控制制度;建立统计资料
归档及保密制度;建立企业各级专兼职统计、记录人员的岗位责任制等。 三、按时完成统计工作,为公司领导经营决策提供准确依据。 我们严格执行国家统计报表制度,认真做好各项年定报的贯彻落实。统计人员认真学习《统计法》和统计报表有关规章制度,虚心向统计局有关领导学者学习,主动采用科学的统计方法,系统地调查研究,对待每一个统计数字和统计调查分析,都一丝不苟,严肃认真,确保统计数据的质量,及时收集、掌握重要经济指标,通过静态和动态、纵向和横向的比较分析,充分了解公司的经济运行态势,提高统计分析水平,从而为促进公司经营管理目标的实现和公司领导经营决策、促进经济发展提供科学依据。 四、统计法制建设不断完善,数据质量不断提高。 统计数据质量是统计工作的核心所在。我们坚持实事求是,弘扬求真务实精神,努力提高基层数据质量。规范基础工作,确保源头数出有据。统计报表有关数据直接从企业原始记录、统计台账、会计报表取得的,报表数据和有关记录项目保持一致;统计报表有关数据以企业原始记录、统计台账、会计报表相关数据加工后取得的,以企业原始记录、统计台账、会计报表为依据。 五、建立规范的统计台账,保证源头统计数据质量。 建立规范的、统一的、可核查的统计台账,是统计基础建设的一项重要内容,是保证统计源头数据质量的一个重要抓手。统计台账依据原始记录和相关数据,按照统计指标的含义填写,统计报表的数据
MATLAB空间面板数据模型操作介绍
MATLAB空间面板数据模型操作简介 MATLAB安装:在民主湖资源站上下载MA TLAB 2009a,或者2010a,按照其中的安装说明安装MATLAB。(MATLAB较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局: 首先我们说一下MA TLAB处理空间面板数据时,数据文件是怎么布局的,熟悉eviews的同学可能知道,eviews中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中“1-94”“1-95”“1-96”“1-97”中,1是省份的代号,94,95,96,97表示年份,eviews是将每个省份的数据放在一起,再将所有省份堆放在一起。 与eviews不同,MATLAB处理空间面板数据时,面板数据的布局是(在excel中说明):先排放一个横截面上的数据(即某年所有省份的数据),再将不同年份的横截面按时间顺序堆放在一起。如图:
这里需要说明的是,MA TLAB中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。 二、数据的输入: MATLAB与excel链接:在excel中点击“工具→加载宏→浏览”,找到MA TLAB的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为:C:\Programfiles\MATLAB\R2009a\toolbox\exlink,点击excllink.xla即可完成excel与MATLAB的链接。这样的话excel中的数据就可以直接导入MATLAB中形成MATLAB的数据文件。操作完成后excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB”即表示我们希望excel 与MATLAB实现链
中国旅游市场统计数据梳理
中国旅游市场统计数据梳理 从实用的角度出发,本文对国家旅游局发布的2005至2010年旅游统计数据(部分年度数据有缺失)进行了梳理,整理出了一些基础数据,其中也参考了同期国家统计局的个别数据。最后,本文对入境游的一些数据也进行了简单梳理,仅供参考。 一、2005至2010年中国居民出游规模数据整理 在过去的10年时间里,中国居民国内旅游人次增长了236.73%,所创造的旅游收入增长了448.1%,表1. 为2005年至2011年的国内旅游规模数据统计。 表1. 2005至2011年国内旅游规模统计数据汇总 年度 国内出游人数(亿人次) 国内旅游收入(亿元人民币) 旅游总收入(亿元人民 币) 2011 26.40 19306.00 22500 2010 21.03 12579.77 15700 2009 19.02 10183.69 12900 2008 17.12 8749.30 11600 2007 16.10 7770.62 10957 2006 13.94 6229.74 8935 2005 12.12 5285.86 7686 出境方面,2011年总的出境人数为7025万人次,其中因私出境者占91.27%,达到了6412万人次。2011年因私出境者在总体出境者的比例比十年期增长了59.45%,见表2. 二、中国居民旅游行为宏观数据整理 表2. 2005-2011年中国居民出境人数及结构统计 年度 总出境人数(万人次) 因私出境人数(万人次) 因私出境占比 2011 7025.00 6412.00 91.27% 2010 5738.65 5150.90 89.76% 2009 4765.63 4220.97 88.57% 2008 4584.44 4013.12 87.54% 2007 4095.40 3492.40 85.28% 2006 3452.36 2879.91 83.42% 2005 3102.63 2514.00 81.03%
数据统计工作总结
数据统计工作总结 篇一:统计工作总结 统计工作总结 准确的统计信息是公司领导正确决策的基础,没有准确的统计数据,就无法准确反映公司经济运行情况及存在的问题,也就无法对经济形势做出正确的判断和决策,不能按照统计部门的要求保质保量按时报送。近年来,公司领导高度重视统计工作,配备得当人员,相关部门配合顺畅有序,公司的统计工作水平得到了显著提高。统计工作总结如下: (一) 公司在统计体制改革、人员力量配备、经费保障等方面采取了很多措施,增加了统计工作人员,健全完善了统计工作体系,进一步夯实了统计基础建设,确保统计数据源头的工作质量。指定公司领导主抓统计工作,制定了《财务信息采集使用管理暂行办法》、《财务报告编制管理办法》等与统计工作有关的规章制度,为做好统计工作保驾护航。 (二) 扎实做好统计基层基础工作。围绕“人员专职化、台账规范化、管理制度化、调查法制化、手段现代化、经费有保障”的“五化一有”目标,夯实统计基础工作。各统计部门均具备独立的办公场所,同时配备了优良的微机、打印机、办公桌椅等,确保统计工作的顺利进行。逐步完善统计工作考核制度和岗位责任制度,理顺了原始记录和统计台帐、统计报表信息使用、数据审核等流程;建立了统计资料归档
及保密措施。 (三) 按时完成统计工作。公司严格执行国家统计报表制度,统计人员认真学习《统计法》和统计报表有关的规章制度,虚心向统计局有关领导专家学习,积极采用科学的统计方法,系统地调查研究,对待每一个统计数字和统计调查分析,严肃认真,确保统计数据的质量,及时收集、掌握重要经济指标,通过静态和动态、纵向和横向的比较分析,充分反映公司的经济运行态势,提高统计分析的水平,为促进公司经营管理目标的实现和公司领导经营决策、经济发展提供了科学依据。 (四) 公司领导严格要求提高统计数据的准确性。统计数据质量是统计工作的核心所在,公司坚持实事求是,弘扬求真务实精神,努力提高各部门的数据质量,规范基础工作,确保源头数据真实有效。统计报表有关数据直接从公司原始记录、统计台账、会计报表中取得,报表数据和有关记录项目能够保持一致,保证统计报表资料的真实完整。 (五) 公司重视统计资料管理工作,报表档案管理科学化。公司按照统计信息化的要求,运用计算机处理企业统计数据的采集、汇总、分析和上报工作。每年结合企业的现实情况,完善各项档案管理制度,制定档案管理考核规定,统计台账分门别类地进行登记、整理,年终汇总表册存档,坚持从严规范、从细抓起,狠抓档案的归档率、完整率、准确
面板数据的计量方法
1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输出结果中没有公共截距项。 (2)时刻固定效应模型。 时刻固定效应模型就是对于不同的截面(时刻点)有不同截距的模型。如果确知
全国旅游人数统计
2005年:我国入境旅游人数12029.23万人次,国内旅游人数12.12亿人次 2006年中国国内旅游人数预计达到13.8亿人次,入境旅游人数可望突破1.24亿人次2007年:我国入境旅游人数13187.33万人次,国内旅游人数16.10亿人次 2008年国内旅游人数17.12亿人次 2009年国内旅游人数 2010年,我国国内旅游人数达21亿人次,比上年增长10.6%; 2011年国内旅游人数将达到25.5亿,入境旅游将达到1.38亿人次 2011五一黄金周,全国出游达到1.79亿人次,同比增长22.7%,达到历史最高水平。去年五一出游达1.46亿人次后,今年五一出游人数再创记录。据国家统计局、国家旅游局统计,五一黄金周全国出游达到1.79亿人次,同比增长22.7%;旅游收入736亿元人民币,同比增长25.8%。其中,纳入全国假日旅游统计预报体系的北京等39个重点旅游城市,接待游客6214万人次,比去年同期有所增长;纳入全国假日旅游统计预报的119个直报景区(点)共接待2231万人次,门票收入9.1亿元,同比分别增长9%和10.9%。全国假日办认为,在全国出游人数达历史最高的情况下,旅游市场总体上保持了安全有序。由于各景区采取了扩容、调整开放时间等措施,全国大多数景区的接待均在最佳和最大接待量之间,只有少部分景区在高峰接待时段超过了最大接待容量。由于铁路动车组的开行和直通旅游专列、临客的大量增加,以及民航和公路交通积极组织、加大运力,旅游客运总体通畅,没有出现大范围的游客滞留和交通堵塞。 2005年,“五一”黄金周期间,在全国接待的1.46亿人次旅游者中,过夜旅游者(仅限于住在宾馆饭店和旅馆招待所)为3884万人次,一日游游客为1.07亿人次,其中北京、天津、承德、秦皇岛、沈阳、大连、长春、吉林、哈尔滨、上海、南京、无锡、苏州、杭州、宁波、黄山、厦门、南昌、瑞金、青岛、洛阳、武汉、长沙、张家界、韶山、广州、深圳、桂林、海口、三亚、重庆、成都、广安、贵阳、遵义、昆明、西安、延安、银川等39个重点旅游城市,“五一”黄金周期间共接待游客5225万人次,其中过夜旅游者(口径同上)为1379万人次,一日游游客为3846万人次, 2006年,5月黄金周,为国际国内的旅游人数总体8167万。其中有2310万(为过夜旅游者)一日游为4464万人次重点在39个城市。。 2007年5月黄金周,国际国内的人数达到1。03亿,其中过夜的有近5419万, 2008年,5月黄金周,因地震灾区影响,下降了部分旅游人数,7738万。其中有5305万是过夜旅游者 2009年,现在没有统计完全。。
Excel利用函数进行数据计算(教案)
Excel利用函数进行数据计算(教案) ——制作歌手大奖赛成绩统计表 (执教人:信息技术教研组王荔虹) [课题] Excel利用函数进行数据计算 [教学内容] Excel数据的函数运算 [教学对象] 1、子江中学初一(1)班。 2、对Excel有了初步的认识。 [教学目标] 知识目标:1、了解函数的定义、组成和使用方法; 2、掌握SUM、A VERAGE、MAX、MIN等几种函数的使用方法; 3、了解设置单元格格式的基本方法; 4、学会利用函数进行简单的计算。 过程与方法:通过对Excel运用公式与函数运算的对比,能够在实际运用中正确选择和使用何种方法进行数据处理。 情感目标:体验应用公式和函数解决问题的优势。,感受计算机的优势,增强学生学习计算机的兴趣。[教学重点] 掌握SUM、A VERAGE、MAX、MIN等几种函数的使用方法。 [教学难点] 1、理解函数的参数和函数参数的格式。 2、函数中的选定数据范围(包括连续和不连续)。 [教学方法] 1、创设情境法:教师创设好Excel的故事导入情境,激发学生的学习兴趣。 2、游戏讲授法:通过有趣的游戏环节,讲解Excel中什么是函数,通过故事内容中的数据让学生区分公式运算与函数运算。 3、任务驱动法:根据布置任务的具体要求,利用习得的知识经验进行迁移学习,从而达到相应的教学目标。 4、自主探究法:分小组结合书本、教师提示,自主探究、合作学习相应的教学目标。 [教学准备] 1、教师准备:提供Excel运算的辅助材料,如练习、导入材料等。 2、学生准备:课前分好小组。 3、教学环境:多媒体网络教室。 [课时] 1课时 [教学过程]
面板数据的计量方法
面板数据的计量方法 1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输
Excel表格公式使用基本操作及excel表格计算公式大全、使用技巧
Excel 部分函数列表. AND “与”运算,返回逻辑值,仅当有参数的结果均为逻辑“真(TRUE)”时返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。条件判断AVERAGE 求出所有参数的算术平均值。数据计算 COLUMN 显示所引用单元格的列标号值。显示位置 CONCATENATE 将多个字符文本或单元格中的数据连接在一起,显示在一个单元格中。字符合并 COUNTIF 统计某个单元格区域中符合指定条件的单元格数目。条件统计 DATE 给出指定数值的日期。显示日期 DATEDIF 计算返回两个日期参数的差值。计算天数 DAY 计算参数中指定日期或引用单元格中的日期天数。计算天数 DCOUNT 返回数据库或列表的列中满足指定条件并且包含数字的单元格数目。条件统计 FREQUENCY 以一列垂直数组返回某个区域中数据的频率分布。概率计算 IF 根据对指定条件的逻辑判断的真假结果,返回相对应条件触发的计算结果。条件计算 INDEX 返回列表或数组中的元素值,此元素由行序号和列序号的索引值进行确定。数据定位 INT 将数值向下取整为最接近的整数。数据计算 ISERROR 用于测试函数式返回的数值是否有错。如果有错,该函数返回TRUE,反之返回FALSE。逻辑判断 LEFT 从一个文本字符串的第一个字符开始,截取指定数目的字符。截取数据LEN 统计文本字符串中字符数目。字符统计 MATCH 返回在指定方式下与指定数值匹配的数组中元素的相应位置。匹配位置MAX 求出一组数中的最大值。数据计算 MID 从一个文本字符串的指定位置开始,截取指定数目的字符。字符截取 MIN 求出一组数中的最小值。数据计算 MOD 求出两数相除的余数。数据计算 MONTH 求出指定日期或引用单元格中的日期的月份。日期计算 NOW 给出当前系统日期和时间。显示日期时间 OR 仅当所有参数值均为逻辑“假(FALSE)”时返回结果逻辑“假(FALSE)”,否则都返回逻辑“真(TRUE)”。逻辑判断 RANK 返回某一数值在一列数值中的相对于其他数值的排位。数据排序 RIGHT 从一个文本字符串的最后一个字符开始,截取指定数目的字符。字符截取 SUBTOTAL 返回列表或数据库中的分类汇总。分类汇总 SUM 求出一组数值的和。数据计算 SUMIF 计算符合指定条件的单元格区域内的数值和。条件数据计算 TEXT 根据指定的数值格式将相应的数字转换为文本形式数值文本转换 TODAY 给出系统日期显示日期 VALUE 将一个代表数值的文本型字符串转换为数值型。文本数值转换VLOOKUP 在数据表的首列查找指定的数值,并由此返回数据表当前行中指定列处
六步学会用做空间计量回归详细步骤
与MATLAB链接: Excel: 选项——加载项——COM加载项——转到——没有勾选项 2. MATLAB安装目录中寻找toolbox——exlink——点击,启用宏 E:\MATLAB\toolbox\exlink 然后,Excel中就出现MATLAB工具
(注意Excel中的数据:) 3.启动matlab (1)点击start MATLAB (2)senddata to matlab ,并对变量矩阵变量进行命名(注意:选取变量为数值,不包括各变量)
(data表中数据进行命名) (空间权重进行命名) (3)导入MATLAB中的两个矩阵变量就可以看见
4.将elhorst和jplv7两个程序文件夹复制到MATLAB安装目录的toolbox文件夹 5.设置路径:
6.输入程序,得出结果 T=30; N=46; W=normw(W1); y=A(:,3);
x=A(:,[4,6]); xconstant=ones(N*T,1); [nobs K]=size(x); results=ols(y,[xconstant x]); vnames=strvcat('logcit','intercept','logp','logy'); prt_reg(results,vnames,1); sige=*((nobs-K)/nobs); loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*'* % The (robust)LM tests developed by Elhorst LMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 解释 每一行分别表示:
MATLAB空间面板数据模型操作介绍
MATLAB 空间面板数据模型操作简介 MATLAB 安装: 在民主湖资源站上下载 MA TLAB 2009a ,或者 2010a ,按照其中的安装说明 安装 MATLAB 。( MATLAB 较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局 首先我们说一下 MA TLAB 处理空间面板数据时,数据文件是怎么布局的,熟悉 eviews 的同学 可能知道, eviews 中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间 序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中 “1-94”“1-95” “1-96” “ 1-97”中, 1是省份的代号, 94,95,96,97 表示年份, eviews 是将每个省 份的数据放在一起,再将所有省份堆放在一起。 与 eviews 不同, MATLAB 处理空间面板数据时,面板数据的布局是(在 excel 中说明): 先排 放一个横截面上的数据(即某年所有省份的数据) ,再将不同年份的横截面按时间顺序堆放在一起。 如图:
这里需要说明的是, MA TLAB 中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。二、数据的输入: MATLAB 与 excel链接:在 excel中点击“工具→加载宏→浏览” ,找到 MA TLAB 的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为: C:\Programfiles\MATLAB\R2009a\toolbox\exlink ,点击 excllink.xla 即可完成 excel 与 MATLAB 的链接。这样的话 excel 中的数据就可以直接导入 MATLAB 中形成 MATLAB 的数据文件。操作完成后 excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB ”即表示我们希望 excel 与
数据计算公式
统计数据计算公式 (1)表中、人员、床位、门急诊人次、实际开放总床日数、实际占用总床口数、出院者占用总床日数、出院人数。等基本数字的填列口径参照卫生部统计报表制度。 (2)"出院者平均住院天数"=出院者占用总床日+出院人数 (3)"药品平均日消耗"=药品费/日历天数 (4)"药品收入占医药收入比重"=药品收入/(药品收入+医疗收入)x100% (5)"药品综合差价率"=药品平均迸销差价/药品平均占用额*100% (6)"严药品周转天数"=日历天数*药品平均占用额/药品费 (7)"每职工平均门诊人次"=门急诊人次/平均职工人数 (8)"每职工平均住院床日"=实际占用总床日/平均职工人数 (9)"严每职工平均业务收入"=(医疗收入+药品收入+其他收入)/平均职工人数 (10)"存货周转次数"=(卫生材料费+其他材料赞+低值易耗品)/存货平均占用额 (11)"每床位占用固定资产"=固定资产/实际开放床位数 (12)"病床使用率"=实际占用总床日/实际开放总床日x100% (13)"病床周转次数"=出院人数/平均开放床位 (14)"固定资产增长率"=(固定资产期末数/固定资产期初数-l)x100% (15)"净资产增长率"=(净资产期末数/净资产期初数-l)x100% (16)"流动资产收益率"=(净资产累计增加数-财政补助收入)/流动资产平均占用额x100% (17)"固定资产收益率"=(净资产累计增加数-财政补助收入)/固定资产平均占用额x100% (18)"净资产收益率"=(净资产累计增加数-财政补助收入)/净资产平均占用额x100% (19)"百元固定资产医疗收入"=医疗收入/固定资产x100 (20)"百元业务收入积累率=(修购基金+收支结余-财政补助收入)/业务收入x100 (21)"资产负债率"=负债总额/资产总额x100% (22)"流动比率"=流动资产/流动负债·
2013年春节黄金周旅游统计报告(含各省统计数据)
2013年春节黄金周旅游统计报告 根据国家旅游局、国家统计局联合制定的《黄金周旅游信息统计调查制度》的要求,全国31个省、自治区、直辖市分别对辖区内春节黄金周的接待规模和 效益进行了统计调查。经国家旅游局、国家统计局汇总,结果如下:(一)今年春节黄金周期间,全国共接待游客2.03亿人次,比上年春节黄 金周增长15.1%;实现旅游收入1170.6亿元,增长15.4%。 (二)在全国接待的2.03亿人次中,过夜游客(仅限于住在宾馆饭店和旅 馆招待所)为4825万人次;一日游游客为1.55亿人次。北京、天津、承德、 秦皇岛、沈阳、大连、长春、吉林、哈尔滨、上海、南京、无锡、苏州、杭州、宁波、黄山、厦门、南昌、瑞金、青岛、洛阳、武汉、长沙、张家界、韶山、 广州、深圳、桂林、海口、三亚、重庆、成都、广安、贵阳、遵义、昆明、西安、延安、银川等39个重点旅游城市,共接待游客7643万人次,其中过夜游 客为1299万人次;一日游游客为6344万人次。 (三)在春节黄金周期间实现的1170.6亿元旅游收入中,民航客运收入57.2 亿元;铁路客运收入27.3亿元。39个重点旅游城市实现旅游收入441.9亿元,其他地区实现旅游收入644.2亿元。 全国各级旅游部门结合本地特点和民俗特色,推出了各种旅游节庆活动。北京、山东、上海、广东、陕西、江苏、云南等地推出了城市庙会、迎春灯会、新年祈福、迎春花展等传统民俗节庆活动;黑龙江、吉林、辽宁、新疆、内蒙古、山西等地推出了以冰雪为主题的节庆活动。
春节假期开始之后,全国大部分景点景区游客数量明显增加,特别是短途 出游数量增长,游客出行热情较高。城市周边的民俗游、休闲游、自驾游、乡 村游明显升温。逛庙会、品美食、泡温泉、滑雪等参与性强、适合全家活动的 项目受到游客青睐。 东北地区的冰雪旅游和南方地区的避寒旅游是春节黄金周长线旅游的热门 之选,哈尔滨、长春、沈阳、大连、厦门、海口、三亚等地受到游客青睐。春 节7天哈尔滨共接待游客309.38万人次,同比增长3.76%,过夜游客占 19.2%。 根据全国团队旅游服务管理系统提供的信息,2013年春节黄金周期间旅行 社组织中国内地(大陆)在境外游客超出400万人次,同比上涨14%,赴亚洲 目的地的超过90%。黄金周7天日均出游人数42万人次,2月10日(初一)、11日(初二)分别达到最高峰值61万人次;日均境外游客人数超过230万人次,2月12日(初三)达到最高峰值256万人次。2013年春节黄金周期间最热门出境游目的地国家和地区是泰国、韩国、香港、澳门和台湾。
空间面板数据计量经济分析
空间面板数据计量经济分析 空间面板数据计量经济分析 *以上分别介绍了区域创新过程中空间效应(依赖性和异质性)的空间计量检测,以及纳入空间效应的计量模型的估计方法——空间常系数回归模型(空间滞后模型,SLM 和空间误差模型,SEM )和空间变系数回归模型(地理加权回归模型,GWR );同时还介绍和分析了面板数据(Panel Data )计量经济学方法的估计和检验。 *可以看出,目前的空间计量经济学模型使用的数据集主要是截面数据,只考虑了空间单元之间的相关性,而忽略具有时空演变特征的时间尺度之间的相关性,这显然是一个美中不足。 *Anselin (1988)也认识到这一点。当然,大多学者通过将多个时期截面数据变量计算多年平均值的办法来综合消除时间波动的影响和干扰,但是这种做法仍然造成大量具有时间演变特征的创新行为信息的损失,从而无法科学和客观地认识和揭示具有时空二维特征的研发与创新过程的真实机制。*面板数据(Panel Data )计量经济模型作为目前一种前沿的计量经济估计技术,由于其可以综合创新行为变量时间尺度的信息和截面(地域空间)单元的信息,同时集成考虑了时间相关性和空间(截面)相关性,因而能够科学而客观地反映受到时空交互相关性作用的创新行为的特征和规律,是定量揭示研发、知识溢出与区域创新相互作用关系的有效方法。但是,限于在所有时刻对所有个体(空间)均相等的假定(即不考虑空间效应),面板数据计量经济学理论也有其美中不足之处,具有很大的改进余地。 *鉴于空间计量经济学理论方法和面板数据计量经济学理论方法各有所长,把面板数据模型的优点和空间计量经济学模型的特点有机结合起来,构建一个综合考虑了变量时空二维特征和信息的空间面板数据计量经济模型,则是一种新颖的研究思路。以下根据空间计量经济模型和标准的面板数据模型[1]的建模思路,提出空间面板数据(Spatial Panel Data Model ,SPDM )模型的建模思路和过程。 [1]与动态面板数据模型的建模思路类似,只要施加一些假定,引入因变量的滞后项,则为空间动态面板数据模型。 空间滞后面板数据计量分析 *考虑一个标准的面板数据模型: it it it it it y αx βμ=++*如果将变量的真实的区域空间自相关性(依赖性)(Anselin &Florax ,1995)考虑到创新行为中来,这种创新行为的空间自相关性可以视为区域创新过程中的一种外部溢出形式,这样则可以设定如下模型: it it it it it it y αWy x βμρ=+++*上式为空间滞后面板数据(Spatial Lag Panel Data Model ,SLPDM )计量经济模型。其中,是创新的空间滞后变量,主要度量在地理空间上邻近地区的外部知识溢出,是一个区域在地理上邻近的区域在时期创新行为变量的加权求和。 空间误差面板数据计量分析 *如果在创新行为的空间依赖性存在误差扰动项中来测度邻近地区创新因变量的误差冲击对本地区创新行为的影响程度,则可以通过空间误差模型的空间依赖性原理可得: it it it it it y αx βμ=++it it it W μλμε=+*上式即为空间误差面板数据(Spatial Error Panel Data Model ,SEPDM )计量经济模型。其中,参数衡量了样本观察值的误差项引进的一个区域间溢出成分。 *因为已经在面板数据模型中考虑了创新行为变量的空间依赖性,因此采用一般面板数据模型的估计技术如OLS 或GLS 等将具有良好的估计效果。如果能够综合考虑面板数据模型中的一些假定,如时间加权(Period Weights )或截面加权(Cross-section Weights ),则可获得更加符合创新现实的估计结果。
空间计量经济学模型归纳
空间计量经济学模型 空间相关性是指 () ,i j y f y i j =≠即i y 与j y 相关 模型可表示为() (),1i j j i i y f y x i j βε=++≠ 其中,()f 为线性函数,(1)式的具体形式为 () ()2,0,2i ij j i i i i j y a y x N βεεδ≠=++∑ 如果只考虑应变量空间相关性,则(2)式变为(3)式 ()()21 ,0,,1,2...3n i ij j i i i y W y N i n ρεεδ==+=∑ 式中 1 n ij j i W y =∑为空间滞后算子,ij W 为维空间权重矩阵n n W ?中的元素,ρ为待估的空间自相 关系数。0ρ≠,存在空间效应 (3)式的矩阵形式为() ()2 1,0,4u n y Wy N I ρεδ?= (4)式称为一阶空间自回归模型,记为FAR 模型 当在模型中引入一系列解释变量X 时,形式如下 () ()2,0,5n y Wy X N I ρβεεδ=++ (5)式称为空间自回归模型,记为SAR 模型 当个体间的空间效应体现在模型扰动项时有 () ()21,,0,6u n y X u u Wu N I βλεδ?=+= (6)式成为空间误差模型,记为SEM 模型 当应变量与扰动项均存在空间相关时有 () ()2121,,0,7u n y W y X u u W u N I ρβλεεδ?=++=+ (7)式称为一般空间模型,记为SAC 模型 当0X =且20W =时,SAC →FAR ;当20W =时,SAC →SAR 当10W =时,SAC →SEM 当空间相关性还体现在解释变量上时,则有 () ()2,0,8n y Wy X WXr N I ρβεεδ=+++ (8)式成为空间杜宾模型,记为SDM 模型