东南大学编译原理词法分析器实验报告

词法分析设计
1. 实验目的
通过本实验的编程实践,了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。
2. 实验内容
用C++语言实现对C++语言子集的源程序进行词法分析。通过输入源程序从左到右对字符串进行扫描和分解,依次输出各个单词的内部编码及单词符号自身值;若遇到错误则显示“Error”,然后跳过错误部分继续显示;同时进行标识符登记符号表的管理。
3. 实验原理
本次实验采用NFA->DFA->DFA0的过程:
对待分析的简单的词法(关键词/id/num/运算符/空白符等)先分别建立自己的FA,然后将他们用产生式连接起来并设置一个唯一的开始符,终结符不合并。
待分析的简单的词法
(1)关键字:
"asm","auto","bool","break","case","catch","char","class","
const","const_cast"等
(2)界符(查表)
";",",","(",")","[","]","{","}"
(3)运算符
"*","/","%","+","-","<<","=",">>","&","^","|","++","--"," +=","-=","*=","/=","%=","&=","^=","|="
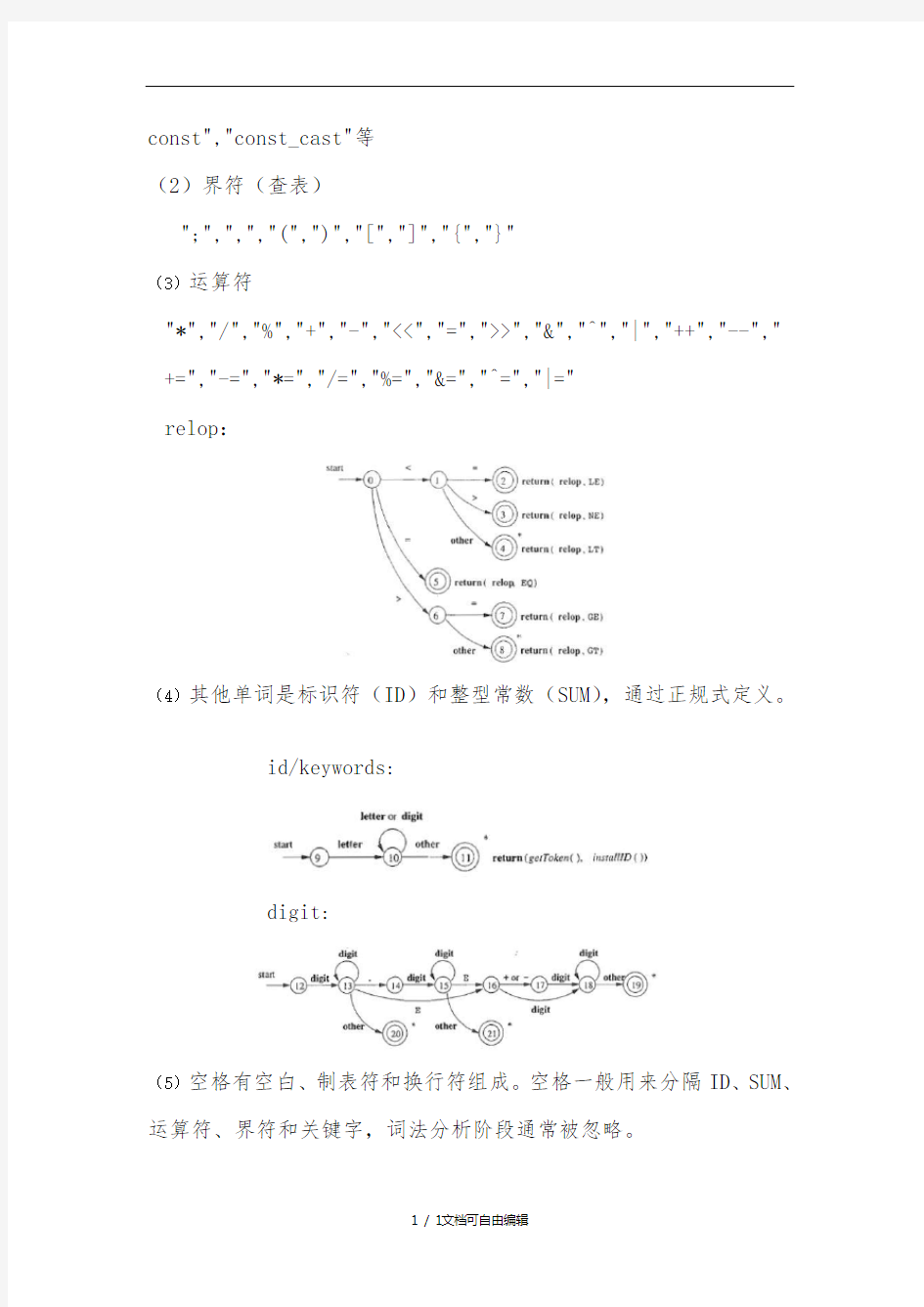
relop:
(4)其他单词是标识符(ID)和整型常数(SUM),通过正规式定义。 id/keywords:
digit:
(5)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
空白、制表符和换行符:
4. 相关自动机描述
DFA:
DFA0:
5.流程图
5. 核心数据结构描述
(1)生成的token序列由name、type、attr保存。
struct token{
string name;
string type;
int attr;
};
(2)本文的大多数数据结构都用map来保存,优点是查找方便,大大提高时间复杂度。
map
map
map
map
map
map
vector
6. 核心算法描述
(1)void addToken(string s,int type)s为找到的字符串,type 为可能类型。
将分析出来的token()序列添加到Token序列表中。如果是类型
为1,查看关键词表,若找到,其类型为关键词并将其以类型为关键词存储到Token表中;若未找到,则查找id表,若找到,说明该id 已经出现过,否则添加新的id到id表中,将该i字符串以类型为
id添加到Token表中。如果类型为2,在界符表中查找,如果找到以类型为界符存储到Token表中,同理其他几种类型。可能类型为1--5,如果出现其他类型表示是词法分析器中发现额错误,将错误信息记录下来。
void addToken(string s,int type)
{
switch(type){
case 1:
l_it=Keywords.find(s);
if (l_it!=Keywords.end()){
token t={s,"keywords",l_it->second};
Token.push_back(t);
}else{
l_it=id.find(s);
if (l_it==id.end())
{
id[s]=idNum;
token t={s,"id",idNum++};
Token.push_back(t);