2015年统计术语与热点问题解答试卷及答案

统计术语与热点问题解答试卷及答案
多选题
判断题
统计学英语词汇
统计学英语词汇 发布: 2008-10-08 23:42 | 作者: zhou_209 | 来源: 6sigma品质网 统计学的一些英语词汇,希望对大家有用. A abscissa 横坐标 absence rate 缺勤率 absolute number 绝对数 absolute value 绝对值 accident error 偶然误差 accumulated frequency 累积频数 alternative hypothesis 备择假设 analysis of data 分析资料 analysis of variance(ANOVA) 方差分析 arith-log paper 算术对数纸 arithmetic mean 算术均数 assumed mean 假定均数 arithmetic weighted mean 加权算术均数 asymmetry coefficient 偏度系数 average 平均数 average deviation 平均差 B bar chart 直条图、条图 bias 偏性 binomial distribution 二项分布 biometrics 生物统计学 bivariate normal population 双变量正态总体 C cartogram 统计图
case fatality rate(or case mortality) 病死率 census 普查 chi-sguare(X2) test 卡方检验 central tendency 集中趋势 class interval 组距 classification 分组、分类 cluster sampling 整群抽样 coefficient of correlation 相关系数 coefficient of regression 回归系数 coefficient of variability(or coefficieut of variation) 变异系数collection of data 收集资料 column 列(栏) combinative table 组合表 combined standard deviation 合并标准差 combined variance(or poolled variance) 合并方差complete survey 全面调查 completely correlation 完全相关 completely random design 完全随机设计 confidence interval 可信区间,置信区间 confidence level 可信水平,置信水平 confidence limit 可信限,置信限 constituent ratio 构成比,结构相对数 continuity 连续性 control 对照 control group 对照组 coordinate 坐标 correction for continuity 连续性校正 correction for grouping 归组校正 correction number 校正数 correction value 校正值 correlation 相关,联系 correlation analysis 相关分析 correlation coefficient 相关系数 critical value 临界值 cumulative frequency 累积频率
2020年浙江统计术语与热点问题解读 考试及答案
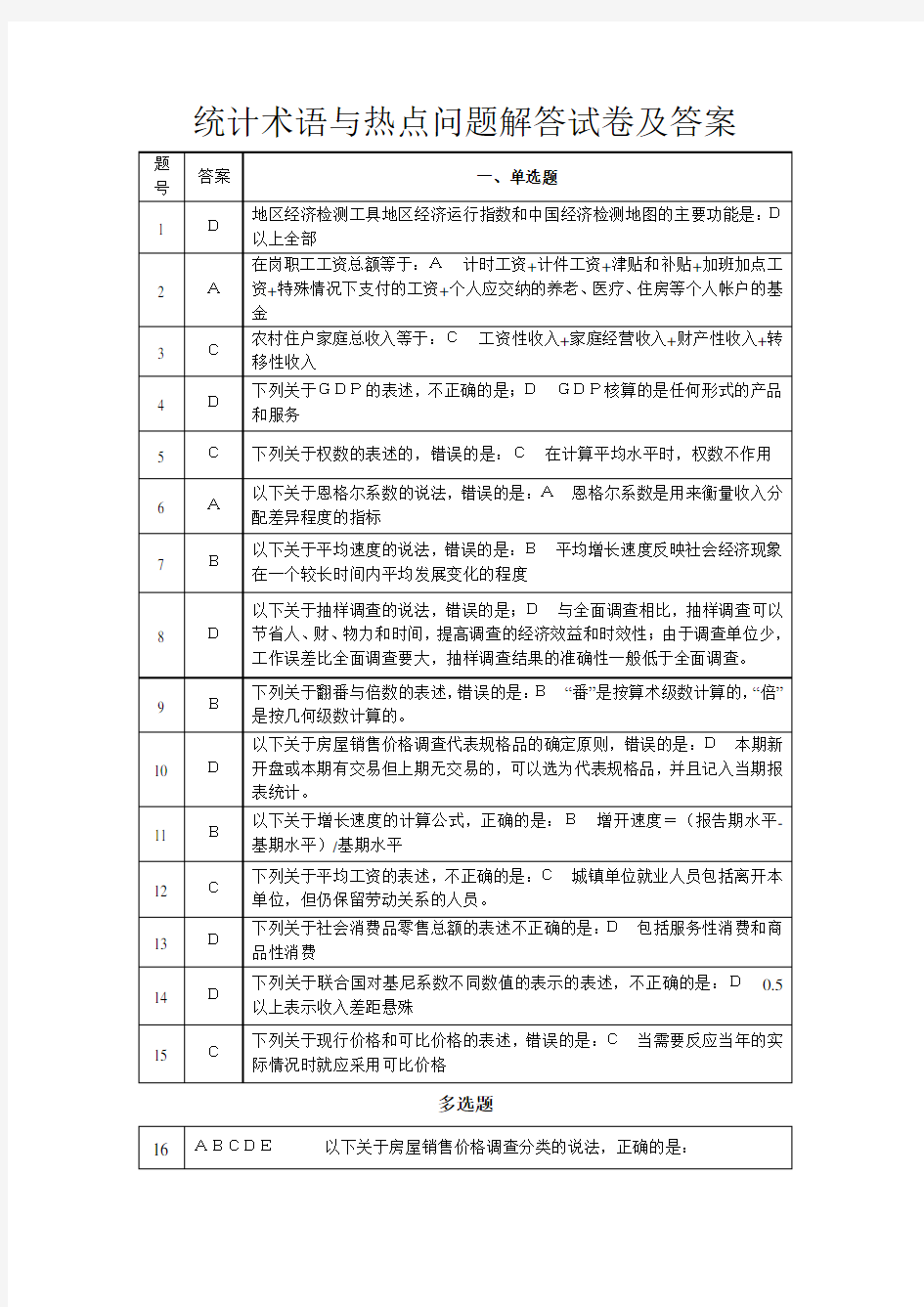
2020年浙江统计术语与热点问题解读 1.地区经济检测工具地区经济运行指数和中国经济检测地图的主要功能是(D)(3分) A.对某一地区的经济运行状态做出判断 B.经济走势的区际比较 C.直观地观察各地区经济运行状况间的差异 D.以上全部 2.在岗职工工资总额等于(A)(3分) A.计时工资+计件工资+奖金+津贴和补贴+加班加点工资+特殊情况下支付的工资+个人应交纳的养老、医疗、住房等个人账户的基金 B.计时工资+计件工资+奖金+津贴和补贴+加班加点工资+特殊情况下支付的工资 C.计时工资+加班加点工资+特殊情况下支付的工资+个人应交纳的养老、医疗、住房等个人账户的基金 D.奖金+津贴和补贴+加班加点工资+特殊情况下支付的工资+个人应交纳的养老、医疗、住房等个人账户的基金 3.农村住户家庭总收入等于(C)(3分) A.工资性收入+家庭经营收入+财产性收入 B.工资性收入+财产性收入+转移性收入 C.工资性收入+家庭经营收入+财产性收入+转移性收入 D.工资性收入+家庭经营收入+转移性收入 4.下列关于GDP的表述,不正确的是(D)(3分) A.GDP核算遵循“在地原则” B.在中国的外企属于中国常住单位,它提供的产品和服务包括在我国的GDP中 C.GDP以价值形式表示 D.GDP核算的是任何形式的产品和服务
5.下列关于权数的表述,错误的是(C)(3分) A.是用来描述或反映个体对总体作用大小的数值 B.权数一般有绝对数形式和相对数形式 C.在计算平均水平时,权数不起作用 D.权数的选取与界定须严谨科学 6.以下关于恩格尔系数的说法,错误的是(A)(3分) A.恩格尔系数是用来衡量收入分配差异程度的指标 B.恩格尔系数是根据恩格尔定律计算的比例数 C.恩格尔系数=食品消费支出/生活消费支出*100% D.对恩格尔系数的使用个分析不能绝对化,还应当同时考虑程式化程度、食品加工、饮食业和食物本身结构变化等因素的影响。 7.以下关于平均速度的说法,错误的是(B)(3分) A.平均速度分为平均发展速度和平均增长速度 B.平均增长速度反映社会经济现象在一个较长时间内平均发展变化的程度 C.计算平均发展速度通常使用几何平均法 D.平均增长速度=平均发展速度-1 8.以下关于抽样调查的说法,错误的是(D)(3分) OA.抽样调查是按照随机的原则,从全部调查对象(总体)中,抽取一部分对象(样本)进行观察,并依据所获得的样本数据对全部调查对象的数量 特征做出具有一定可靠性的估计判断,从而实现对总体的认识的一种统计调查方法。B.随机原则是指在总体中抽取样本单位时完全排除主观意识的作用,不能有意识地抽取哪些单位或不抽取哪些单位,要保证总体中所有单位都 有被抽中的同等可能性。
(完整版)医学统计学第六版课后答案
第一章绪论 一、单项选择题 答案 1. D 2. E 3. D 4. B 5. A 6. D 7. A 8. C 9. E 10. D 二、简答题 1答由样本数据获得的结果,需要对其进行统计描述和统计推断,统计描述可以使数据更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。 2答医学统计学的基本内容包括统计设计、数据整理、统计描述和统计推断。统计设计能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。 3答统计描述结果的表达方式主要是通过统计指标、统计表和统计图,统计推断主要是计算参数估计的可信区间、假设检验的P 值得出相互比较是否有差别的结论。 4答统计量是描述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的指标可由“全体”数据算出。 5答系统误差、随机测量误差、抽样误差。系统误差由一些固定因素产生,随机测量误差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。 6答三个总体一是“心肌梗死患者”所属的总体二是接受尿激酶原治疗患者所属的总体三是接受瑞替普酶治疗患者所在的总体。 第二章定量数据的统计描述 一、单项选择题 答案 1. A 2. B 3. E 4. B 5. A 6. E 7. E 8. D 9. B 10. E 二、计算与分析 2
统计学名词解释
统计学名词解释 第一章绪论 1.随机变量:在统计学上,把取值之间不能预料到什么值的变量。 2.总体:又称母全体、全域,指具有某种特征的一类事物的全体。 3.个体:构成总体的每个基本单元称为个体。 4.样本:从总体中抽取的一部分个体,称为总体的一个样本。 5.次数:指某一事件在某一类别中出现的数目,又称为频数。 6.频率:又称相对次数,即某一事件发生的次数被总的事件数目除,亦即某一数据出现的次数被这一组数据总个数去除。 7.概率:某一事物或某一情在某一总体中出现的比率。 8.观测值:一旦确定了某个值。就称这个值为某一变量的观测值。 9.参数:又称为总体参数,是描述一个总体情况的统计指标。 10.统计量:样本的那些特征值叫做统计量,又称特征值。 第二章统计图表 1.统计表:是由纵横交叉的线条绘制,并将数据按照一定的要求整理、归类、排列、填写在内的一种表格形式。一般由表号、名称、标目、数字、表注组成。 2.统计图:一般采用直角坐标系,通常横轴表示事物的组别或自变量x,称为分类轴。纵轴表示事物出现的次数或因变量,称为数值轴。一般由图号及图题、图目、图尺、图形、图例、图组成。 3.简单次数分布表:依据每一个分数值在一列数据中出现的次数或总计数资料编制成的统计表,适合数据个数和分布范围比较小的时候用。 4.分组次数分布表:数据量很大时,应该把所有的数据先划分在若干区间,然后将数据按其数值大小划归到相应区域的组别内,分别统计各个组别中包括的数据个数,再用列表的形式呈现出来,适合数据个数和分布范围比较大的时候用。 5.分组次数分布表的编制步骤: (1)求全距 (2)定组距和组数 (3)列出分组组距 (4)登记次数 (5)计算次数 6.分组次数分布的意义: (1)优点:A.可将杂乱无章数据排列成序,以发现各数据的出现次数及分布状况。B.可显示一组数据的集中情况和差异情况等。 (2)缺点:原始数据不见了,从而依据这样的统计表算出的平均值会与用原始数据算出的值有出入,出现误差,即归组效应。 7.相对次数分布表:用频数比率或百分数来表示次数 8.累加次数分布表:把各组的次数由下而上,或由上而下加在一起。最后一组的累加次数等于总次数。 9.双列次数分布表:对有联系的两列变量用同一个表表示其次数分布。
统计学术语中英文对照
统计学术语中英文对照Absolute deviation 绝对离差 Absolute number 绝对数 Absolute residuals 绝对残差 Acceleration array 加速度立体阵 Acceleration in an arbitrary direction 任意方向上的加速度Acceleration normal 法向加速度 Acceleration space dimension 加速度空间的维数 Acceleration tangential 切向加速度 Acceleration vector 加速度向量 Acceptable hypothesis 可接受假设 Accumulation 累积 Accuracy 准确度 Actual frequency 实际频数 Adaptive estimator 自适应估计量 Addition 相加
Addition theorem 加法定理 Additivity 可加性 Adjusted rate 调整率 Adjusted value 校正值 Admissible error 容许误差 Aggregation 聚集性 Alternative hypothesis 备择假设 Among groups 组间 Amounts 总量 Analysis of correlation 相关分析Analysis of covariance 协方差分析Analysis of regression 回归分析Analysis of time series 时间序列分析Analysis of variance 方差分析 Angular transformation 角转换 ANOVA (analysis of variance)方差分析
统计学专业名词中英对照
population 母体 sample 样本 census 普查 sampling 抽样 quantitative 量的 qualitative/categorical 质的 discrete 离散的 continuous 连续的 population parameters 母体参数 sample statistics 样本统计量 descriptive statistics 叙述统计学 inferential/inductive statistics 推论/归纳统计学levels of measurement 衡量尺度 nominal scale 名目尺度 ordinal scale 顺序尺度 interval scale 区间尺度 ratio scale 比例尺度 frequency distribution 次数分配 relative frequency 相对次数 range 全距 class midpoint 组中点 class limits 组限 class boundaries 组界 class width 组距 cumulative frequency (以下) 累加次数 decumulative frequency 以上累加次数 histogram 直方图 pie chart 饼图 ogive 肩形图 frequency polygon 多边形图 cumulative frequency polygon 累加次数多边形图box plot 盒须图 stem and leaf plot 枝叶图 measures of central tendency 中央趋势量数 mean 平均数 median 中位数 mode 众数 location measures 位置量数 percentile 百分位数 quartile 四分位数 decile 十分位数
统计学相关术语
统计学相关术语 1、概率(proability):度量一随机事件发生可能性大小的实数,其值介于0 与1 之间。一随机事件的慨率可看作在相同条件下重复试验时,该事件发生的频率的稳定值,也可看作对事件发生的相信程度。 2、统计学(statistics):主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进而进行推断和预测,为相关决策提供依据和参考。也就是收集、处理、分析、解释数据并从数据中得出结论的科学。主要又分为描述统计学和推断统计学。 3、描述统计(Descriptive statistics):描述统计是通过图表或数学方法,对数据资料进行整理、分析,并对数据的分布状态、数字特征和随机变量之间关系进行估计和描述的方法。目的是描述数据特征,找出数据的基本规律。描述统计分为集中趋势分析和离中趋势分析和相关分析三大部分。 4、推断统计(Inferential Statistics):推断统计是研究如何根据样本数据来推断总体数量特征的方法,它是在对样本数据进行描述的基础上,对统计总体的未知数量特征做出以概率形式表述的推断。主要包括参数估计与假设检验两种方法。 描述统计学和推断统计学的划分,一方面反映了统计方法发展的前后两个阶段,同时也反映了应用统计方法探索客观事物数量规律性的不同过程。 5、数值型数据(metric data):按数字尺度测量的观察值,结果表现为具体的数值,对事物的精确测度,例如:身高为175cm、168cm、183cm。 6、分类数据(categorical data) :只能归于某一类别的非数字型数据,对事物进行分类的结果,数据表现为类别,用文字来表述,例如,人口按性别分为男、女两类。 7、总体(population):所研究的全部个体(数据) 的集合,其中的每一个个体也称为元素。分为有限总体和无限总体:有限总体的范围能够明确确定,且元素的数目是有限的;无限总体
统计学名词解释超级大全
统计学名词解释超级大全第一章导论 统计学:一门阐明如何去采集、整理、显示、描述、分析数据和由数据得出结论的一系列概念、原理、原则、方法和技术的科学,是一门独立的、实用性很强的通用方法论科学。 教育统计学:专门研究如何搜集、整理、分析在心理和教育方面对实验或调查所获得的数字资料,如何根据这些资料所传递的信息,进行数学推论,找出客观规律的一门科学。 描述统计:对实验或调查所获得的数据加以整理(如制表、绘图),并计算其各种代表量数(如集中量数、差异量数、相关量数等),其基本思想是平均,如在集中量数中将原始数据进行平均,在差异量数中将离均差进行平均,在相关量数中将积差进行平均等等。 推断统计:又称抽样统计。它是根据对部分个体进行观测所得到的信息,通过概括性的分析、论证,在一定可靠程度上去推测相应团体。换言之,就是根据已知的情况推测未知情况。 实验设计:研究如何更加合理、有效地获得观测资料,如何更正确、更经济、更有效地达到实验目的,以揭示试验中各种变量关系的实验计划。 统计常态法则:从总体中随机抽取一部分个体所组成的样本,差不多可以保持总体的特征。这种样本特性保持着总体特性的现象叫做统计常态法则。 小数永存法则:第一个样本中所表现出的特性,在其他样本中也会存在,这就是小数永存法则。此处“小数”是指小数量的意思。 大量惰性原则:某一事物的某一性质或状态,在反复观察或试验中是保持不变的。
有效数字:指能影响测量准确性的数字。 变量:又称随机变量。具有变异性的数据。三个特性,离散型,变异性,规律性。 数据:某个数值一旦被取定了,则称这个数值为随机变量的一个观察值。即数据。 总体:性质相同的一类事物的全体。 个体:构成总体的每一基本单位或单元。 样本:总体抽出的部分个体。 参数:表示总体特征的量数。 统计量:直接从样本计算出的量数,代表样本的特征。 名称变量:指一事物与其他事物在属性、类别上不同。 顺序变量:事物的某一属性的多少或大小按顺序排列起来的变量。既无相等的单位又无绝对的零点的变量。 等距变量:只具有相等的单位,而没有绝对的零点的变量。 比率变量:既有相等的单位,又有绝对的零点的变量。 连续变量:指取值可以是某区间内任一数值的随机变量,它是指测量单位之间可以划分成无限多个细小单位,其数字形式多取小数。 离散变量:指测量单位之间不能再细分的数字资料,其数字形式常取整数。 计数数据:计算人或物的个数所获得的数据。 度量数据:用一定的测量工具或测量标准测量时所获得的数据。 指标:表明总体数量特征的概念和具体数值,又称统计指标,它是把各个个体的特征加总起来的综合结果。
统计学词汇中英文对照完整版
统计学词汇中英文对照完整版 Absolute deviation, 绝对离差 Absolute number, 绝对数 Absolute residuals, 绝对残差 Acceleration array, 加速度立体阵 Acceleration in an arbitrary direction, 任意方向上的加速度Acceleration normal, 法向加速度 Acceleration space dimension, 加速度空间的维数Acceleration tangential, 切向加速度 Acceleration vector, 加速度向量 Acceptable hypothesis, 可接受假设 Accumulation, 累积 Accuracy, 准确度 Actual frequency, 实际频数 Adaptive estimator, 自适应估计量 Addition, 相加 Addition theorem, 加法定理 Additive Noise, 加性噪声 Additivity, 可加性 Adjusted rate, 调整率 Adjusted value, 校正值 Admissible error, 容许误差 Aggregation, 聚集性 Alpha factoring,α因子法 Alternative hypothesis, 备择假设 Among groups, 组间 Amounts, 总量 Analysis of correlation, 相关分析 Analysis of covariance, 协方差分析 Analysis Of Effects, 效应分析 Analysis Of Variance, 方差分析 Analysis of regression, 回归分析 Analysis of time series, 时间序列分析 Analysis of variance, 方差分析 Angular transformation, 角转换 ANOVA (analysis of variance), 方差分析 ANOVA Models, 方差分析模型 ANOVA table and eta, 分组计算方差分析 Arcing, 弧/弧旋 Arcsine transformation, 反正弦变换 Area 区域图 Area under the curve, 曲线面积 AREG , 评估从一个时间点到下一个时间点回归相关时的误差
统计学名词解释及公式
第1章统计与统计数据 一、学习指导 统计学是处理和分析数据的方法和技术,它几乎被应用到所有的学科检验领域。本章首先介绍统计学的含义和应用领域,然后介绍统计数据的类型及其来源,最后介绍统计中常用的一些基本概念。本章各节的主要内容和学习要点如下表所示。 概念:统计学,描述统计,推断统计。 统计在工商管理中的应用。 统计的其他应用领域。 概念:分类数据,顺序数据,数值型数据。 不同数据的特点。 概念:观测数据,实验数据。 概念:截面数据,时间序列数据。 统计数据的间接来源。 二手数据的特点。 概念:抽样调查,普查。 数据的间接来源。 数据的收集方法。 调查方案的内容。 概念。抽样误差,非抽样误差。 统计数据的质量。 概念:总体,样本。 概念:参数,统计量。 概念:变量,分类变量,顺序变量,数值 型变量,连续型变量,离散型变量。 二、主要术语 1.统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。 2.描述统计:研究数据收集、处理和描述的统计学分支。 3.推断统计:研究如何利用样本数据来推断总体特征的统计学分支。 4.分类数据:只能归于某一类别的非数字型数据。 5.顺序数据:只能归于某一有序类别的非数字型数据。 6.数值型数据:按数字尺度测量的观察值。 7.观测数据:通过调查或观测而收集到的数据。 8.实验数据:在实验中控制实验对象而收集到的数据。 9.截面数据:在相同或近似相同的时间点上收集的数据。 10.时间序列数据:在不同时间上收集到的数据。
11.抽样调查:从总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推 断总体特征的数据收集方法。 12.普查:为特定目的而专门组织的全面调查。 13.总体:包含所研究的全部个体(数据)的集合。 14.样本:从总体中抽取的一部分元素的集合。 15.样本容量:也称样本量,是构成样本的元素数目。 16.参数:用来描述总体特征的概括性数字度量。 17.统计量:用来描述样本特征的概括性数字度量。 18.变量:说明现象某种特征的概念。 19.分类变量:说明事物类别的一个名称。 20.顺序变量:说明事物有序类别的一个名称。 21.数值型变量:说明事物数字特征的一个名称。 22.离散型变量:只能取可数值的变量。 23.连续型变量:可以在一个或多个区间中取任何值的变量。 四、习题答案 1.D 2.D 3.A 4.B 5.A 6.D 7.C 8.B 9.A 10.A 11.C、12.C 13.B 14.A 15.C 16.D 17.C 18.A 19.C 20.D 21.A 22.C 23.C 24.B 25.D 26.C 27.B 28.D 29.A 30.D 31.A 32.B 33.C 34.A 35.A 36.A 37.D 38.B 39.B 40.C 41.C 42.D 43.C 44.D 45.A 46.B 47.C 48.A 49.C 50.D 51.A 52.C 53.D 54.A 55.B
医学统计学试题:第4题【15分】__回归分析
四、回归分析 15分 可能涉及范围:多元线性回归、logistic 回归。要求: 1、提供某一资料,选择统计分析方法 2、偏回归系数、标准偏回归系数、决定系数、校正决定系数、OR 等常用指标的意义与应用 3、列回归方程 例 27名糖尿病人的血清总胆固醇、甘油三脂、空腹胰岛素、糖化血红蛋白、空腹血糖的测量值如下表: (1)欲分析影响空腹血糖浓度的有关因素,宜采用什么统计分析方法?多元线性回归分析 (2)已知甘油三酯(X2)、胰岛素(X3)和糖化血红蛋白(X4)是主要影响因素,现欲比较上述因素对血糖浓度的相对影响强度,应计算何种指标? 标准偏回归系数可用来比较各自变量Xj 对Y 的影响强度,有统计意义下,回归系数绝对值越大,对Y 的作用越大。 SPSS 输出的多元回归分析结果中给出的各变量的标准偏回归系数, 比较三个标准偏回归系数:甘油三脂0.354: 胰岛素0.360: 糖化血红蛋白0.413≈1:1.02:1.17(倍) 糖化血红蛋白对血糖的影响强度大小依次为:糖化血红蛋白X4、胰岛素X3、甘油三脂X2 (3)分析其回归模型的好坏宜选用何种指标?校正决定系数( R 2 a )作为评价标准 一般说决定系数(R 2)越大越优,但由于R 2是随自变量的增加而增大,因此,不能简单地以R 2 作为评价标准, 而是用校正决定系数( R 2a )作为评价标准。 R 2 a 不会随无意义的自变量增加而增大。 (4)根据给出SPSS 结果,做出正确的结论。 空腹血糖浓度与总胆固醇无关,与甘油三脂、空腹胰岛素、糖化血红蛋白线性相关。 (5)列出回归方程。最优回归方程为:432663.0287.0402.05.6?X X X y +-+= Model Summary(最终模型的拟合优度检验验表)相关分析
热点统计与概率含答案
热点8统计与概率 (时间:loo 分钟 总分:loo 分) 一、选择题(本大题共10小题,每小题3分,共30分,在每小题给出的四个选项中,只有 一个是符合题目要求的) 1. 一组数据5, 5, 6, x , 7 7, 8,已知这组数据的平均数是 6,则这组数据的中位数是 () A . 7 B . 6 C . 5. 5 D . 5 2. 检测1 000名学生的身高,从中抽出 50名学生测量,在这个问题中,50名学生的身高是 () A .个体 B .总体 C .样本容量 3. 下列事件为必然事件的是( ) A .买一张电影票,座位号是偶数; C .百米短跑比赛,一定产生第一名; 4. 一次抽奖 活动中,印发的奖券有 10 000张 张,三等奖200张,鼓励奖680张,那么第 () D .总体的样本 B ?抛掷一枚普通的正方体骰子 1点朝上 D .明天会下雨 其中特等奖2张,一等奖20张,?二等奖98 ? 位抽奖者(仅买一张奖券) ?中奖的概率为 5. 某校把学生的笔试、实践能力、成长记录三项成绩分别按 50%、20%、30%?的比例计入 学期总评成绩,90分以上为优秀,甲、乙、丙三人的各项成绩(单位:分)如下表,学 期总评成 绩优秀的是( ) A .甲 B .乙、丙 C .甲、乙 D .甲、丙 6. 甲、乙两个样本的方差分别是 s 甲2=6.06, s 乙 2 =14.31,由此可反映出( ) A .样本甲的波动比样本乙的波动大; B. 样本甲的波动比样本乙的波动小; C. 样本甲的波动与样本乙的波动大小一样; D .样本甲和样本乙的波动大小关系不确定 1 7. 已知一组数据X 1, X 2, X 3, X 4, X 5的平均数是2,方差为一,那么另一组数据 3X 1-2, 3X 2-2 , 3 3X 3-2, 3X 4-2, 3X 5-2的平均数和方差分别是( ) 1 A . 2,— 3 &某班一次数学测验 则这个班此次测验的众数为( ) 1 1 1 A . B . C . 10 50 500 1 D . 5 000 2 B . 2, 1 C . 4, D . 4, 3 3 ,其成绩统计如下
医学统计学第三版第四章课后习题答案
2. ANOVA 实验结果 Sum of Squares df Mean Square F Sig. Between Groups 43.194 3 14.398 13.697 .000 Within Groups 37.842 36 1.051 Total 81.036 39 Multiple Comparisons Dependent Variable: 实验结果 Dunnett t (2-sided)a (I) 分组(J) 分组Mean Difference (I-J) Std. Error Sig. 95% Confidence Interval Lower Bound Upper Bound 0.5 对照组-2.15000*.45851 .000 -3.2743 -1.0257 1.0 对照组- 2.27000*.45851 .000 - 3.3943 -1.1457 1.5 对照组-2.66000*.45851 .000 -3.7843 -1.5357 F=13.697 P=0.000004 P A=0.000113 P B=0.000051 P C=0.000004均小于0.001 根据完全随机资料的方差分析,按α=0.05水准,拒绝H0,接受H1,认为四组治疗组小白鼠的肿瘤重量总体均数不全相等,即不同剂量药物注射液的抑癌作用有差别。 3. Tests of Between-Subjects Effects Dependent Variable: 重量 Source Type III Sum of Squares df Mean Square F Sig. Hypothesis 99736.333 1 99736.333 58.489 .005 Error 5115.667 3 1705.222a 治疗 Hypothesis 6503.167 2 3251.583 44.867 .000 Error 434.833 6 72.472b 分组 Hypothesis 5115.667 3 1705.222 23.529 .001 Error 434.833 6 72.472b F:44.867 23.529 P:0.000246 0.001020<0.01 根据随机区组资料的方差分析,按α=0.05水准,拒绝H0,接受H1,三组注射不同剂量雌激素的大白鼠子宫重量总体均数不全相等,即注射不同剂量的雌激素对大白鼠子宫重量有影响 5.
统计学符号及读音【爆款】.docx
统计学符号意义及读音 按照国家标准GB3358-82《统计学名词及符号》的有关规定书写,常用如下: (1) 样本的算术平均数用英文小与x (中位数仍用M) ; (2) 标准差用英文小与s; (3) 标准误用英文小写Sx; (4) t检验用英文小写t; (5) F检验用英文大写F; (6) 卡方检验用希文小写字X2; (7) 相关系数用英文小写r; (8) 白由度用希文小写u; (9) 概率用英文大写P (P值前应给出具体检验值,如t值、字2值、q 值等)。 以上符号均用斜体。 拉丁字母 假定均数X样本均数Y Y变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值 Y样本均数 希腊字母
符号名称符号名称 α检验水准,显著性水准;第一类错误的概率1-α可信度,置信度 β第二类错误的概率;总体回归系数1-β检验效能,把握度 ν(n′)自由度π总体率 μ总体均数ρ总体相关系数 Σ求和的符号σ总体标准差 σ2总体方差χ2χ2检验的统计量 符号名称符号名称 A X2检验中的实际频数A,b,c,d四格表中的实际频 a样本回归直线在Y轴上的截距b样本回归系数 C校正数;常量;x2检验中的列(栏)数CI可信区间 -------------------------------------------------------------------------------- CL可信限CV变异系数 -------------------------------------------------------------------------------- d两数之差值d差值的均数 f(X)连续型分布密度函数,密度f观察频数,实际频数 G几何均数;对数似然比检验的统计量H调和均数;H检验的统计量 Hg检验假设,无效假设H1备择假设 i组距;行次L下限
统计学名词解释汇总
统计学名词解释汇总 WTD standardization office【WTD 5AB- WTDK 08- WTD 2C】
1什么是统计学?统计方法可分为哪两大类?统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。方法有描述统计和推断统计两类2统计数据可分为哪几种类型?不同类型数据各有什么特点?按采取计量尺度,分类、顺序、数值型数据;按统计数据收集方法,观测、实验数据;按被描述对象与时间关系,截面、时间序列数据 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述; (定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分;
截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 3举例说明总体、样本、参数、统计量、变量这几个概念:对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 4什么是有限总体和无限总体?举例说明 有限总体指总体的范围能够明确确定,而且元素的数目是有限可数的,如若干个企业构成的总体,一批待检查的灯泡。无限总体指总体包括的元素是无限不可数的,如科学实验中每个试验数据可看做是一个总体的一个元素,而试验可无限进行下去,因此由试验数据构成的总体是无限总体 5变量可分为哪几类? 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。 6举例说明离散型变量和连续型变量
统计201802文字:2018统计热点问题解读考试试题及答案
1.多产业法人单位在划分行业时( )? (4分) A. 应根据单位从事的主要活动确定其行业性质 B. 应按其下属产业活动单位从事的经济活动分别划分行业 C. 应根据法人单位的三个条件,将所有法人单位逐一分开,再按照不同的要求划分行业 2.消费者信心指数的经济作用不包括( )? (4分) A. 判断宏观经济的发展变化 B. 影响消费者对消费-储蓄的决策 C. 预测市场的变化 D. 为政府部门决策提供依据 3. ( )是根据企业家对当前企业生产经营状况所作出的定性判断和对未来发展变化作出的预期而编制的景气指数? (4分) A. 企业家信心指数 B. 企业景气指数 C. 单项景气指数 4.以下哪项不是R&D包括的活动( )? (4分) A. 实验研究 B. 基础研究 C. 应用研究 D. 试验研究 5.以下哪个领域不能列入社会发展状况( )? (4分) A. 人口发展 B. 公共服务 C. 知识水平 D. 社会和谐 6.以下哪一项不能列入CPI与普通百姓感受不一致的原因( )? (4分) A. 个体与总体不一致 B. 权数对消费结构的影响 C. 个人承受力的不同 D. 绝对价格与价格指数的不同 7. B to C指( )? (4分) A. 企业对企业的电子商务交易 B. 企业对个人的电子商务交易 C. 个人对个人的电子商务交易 8. ( )年起,国家统计局正式建立私营单位抽样调查制度,把私营单位也纳入工资统计调查的范围? (4分) A. 2008 B. 2009 C. 2010 D. 2011 9.关于固定资本形成总额的说法错误的是( )? (4分) A. 固定资本形成总额不包括土地购置费、旧设备购置费和旧建筑物购置费 B. 固定资本形成总额不包括城镇和农村非农户50万元以下项目的固定资产投资 C. 固定资本形成总额包括商品房销售增值 D. 固定资本形成总额还包括无形固定资本形成总额 10. 经济学家称( )为拉动国民经济增长的“三驾马车”? (4分) A. 投资需求、消费需求和进口 B. 投资需求、固定资产投资、净出口 C. 投资需求、社会消费品零售总额、净出口 D. 投资需求、消费需求和净出口 11.下列关于工业总产值和工业销售产值的表述正确的是( )? (6分) A. 工业总产值与工业销售产值的计算价格和计算方法是一致的 B. 工业总产值与工业销售产值的实物量基础不同 C. 工业总产值与工业销售产值都包括自制半成品、在制品期末期初差额价值 D. 工业销售产值的计算基础是工业产品的销售总量,工业总产值的计算基础是工业产品的生产总量 12.固定资本形成总额与全社会固定资产投资额的区别在于( )? (6分) A. 全社会固定资产投资额包括土地购置费、旧设备购置费和旧建筑物购置费,固定资本形成总额则不包括这
(完整版)统计学里的符号与缩写
统计方法通用符号与缩写(1)本表仅包括统计的通用符号。 (2)参数用希腊字母表示,统计量用拉丁字母表示。 (3)英文术语(名词)的缩写,不用缩写点。 (4)符号上有短横“-”者表示平均。 (5)符号上有“^”者表示估计值。 (6)同一字母在不同场合可代表不同意义。 拉丁字母
f(X)连续型分布密度函数,密度 f 观察频数,实际频数 G 几何均数;对数似然比检验的统计量H 调和均数;H检验的统计量 Hg 检验假设,无效假设H1 备择假设 i 组距;行次L 下限 M 中位数N 有限总体含量;各样本含量的总和n 样本含量;各样本含量的总和P 概率 P(1)单侧检验的概率P(2)双侧检验的概率 Px 第x百分位数P 样本率 R 极差;样本复相关系数;x2检验中的行数r 样本相关系数 RR 相对危险度s 样本标准差 S2 样本方差sb 样本回归系数的标准误 S02 合并样本方差sd (样本)差值的标准差 s-d (样本)差值均数的标准误sp 样本率的标准误 Sp1-p2 两样本率差的标准误sX 样本均数的标准误 SD 标准差SE 标准误 T X2检验的理论频数;Wilcoxon秩和检验的统计量t t检验的统计量 u 标准正态变量;标准正态(离)差;u检验的统计 量 X 变量;变量值,观察值;回归中的自变量 x X变换后的变量或变量值Xi 变量X的第i个观察值;第i个变量XO 假定均数X 样本均数
Y 变量;变量值,观察值;回归中的应(因)变量y Y变换后的变量或变量值Y 样本均数 希腊字母 符号名称符号名称 α检验水准,显著性水准;第一类错误的概率1-α可信度,置信度β第二类错误的概率;总体回归系数1-β检验效能,把握度ν(n′)自由度π总体率 μ总体均数ρ总体相关系数 Σ求和的符号σ总体标准差 σ2总体方差χ2χ2检验的统计量
《统计分析与SPSS的应用(第五版)》课后练习标准答案(第2章)
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第2章SPSS数据文件的建立和管理 1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么? SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。 ●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的 统计指标。 ●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总 后的数据。 2、什么是SPSS的个案?什么SPSS的变量? 个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。 变量:数据编辑器窗口中的一列。 3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明? 默认的变量名:VAR------;默认的变量类型:数值型。 变量名标签和变量值标签可增强统计分析结果的可读性。 4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料? 产品类型体重变化情况 明显减轻无明显变化 第一种产品2719 第二种产品20 33 问:在SPSS中应如何组织该数据? 数据文件如图所示: 5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值? 缺失值分为用户缺失值(User Missing Value)和系统缺失值(System Missing
Value)。用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“?”。在变量视图中定义。 6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。如何在SPSS中指定变量的计算尺度? 变量类型包括:数值型(身高)、定序型(受教育程度)以及定类型(性别)。在变量视图中定义。 7、有一份关于居民储蓄调查的模拟数据存储在Excel中,文件名为“居民储蓄调查数据.xls”。该数据的第一行是变量名,格式如下图所示。请将该份数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签。(该份数据的具体含义见Excel文件的后半部分) 【文件(F)】→【打开(O)】→【数据(A)】→文件类型选“Excel(*.xls,…)”,文件名选“居民储蓄调查数据.xls”→【打开】→选中“从第一行数据读取变量名”,在“范围” 中输入“A1:Q283”→【确定】→在“变量视图”窗口,调整A1变量的宽度,输入变量名标签和变量值标签→在主菜单窗口选定【文件(F)】→【保存】→选择保存路径,保存类型为“sav”,文件名为“居民储蓄调查数据”→【保存】. 8、现有股民投资状况调查的文本数据,文件名为“股民投资数据.txt”。其中各变量的含义和编码见文件“股民投资数据.xls”。请将该文本数据读入SPSS,并定义变量名标签和变量值标签。其中各变量取值为9的均为用户缺失值,请加以定义说明。(注:本调查问卷中涉及多选项问题,以及多选项问题的编码等,可先忽略。) 【文件(F)】→【打开文本数据(D)】→【数据(A)】→文件类型选“Text(*.txt,…)”,文件名选“股民投资数据.txt”,【打开】→在“您的文本文件与预定义的格式匹配吗?”中选“否”,【下一步】→在“变量名称是否包括在文件的顶部”中选“是”,【下一步】→在“第一个数据个案从哪个行号开始”中输入“2”,其他默认,【下一步】→【下一步】→在“数据格式”中输入“字符串”,接着在弹出的窗口输入“4”,【下一步】→默认各选项,【完成】→在主菜单窗口选定【文件(F)】→【保存】→选择保存路径,保存类型为“sav”,文件名为“股民投资数据”→【保存】.