正则表达式_打印版
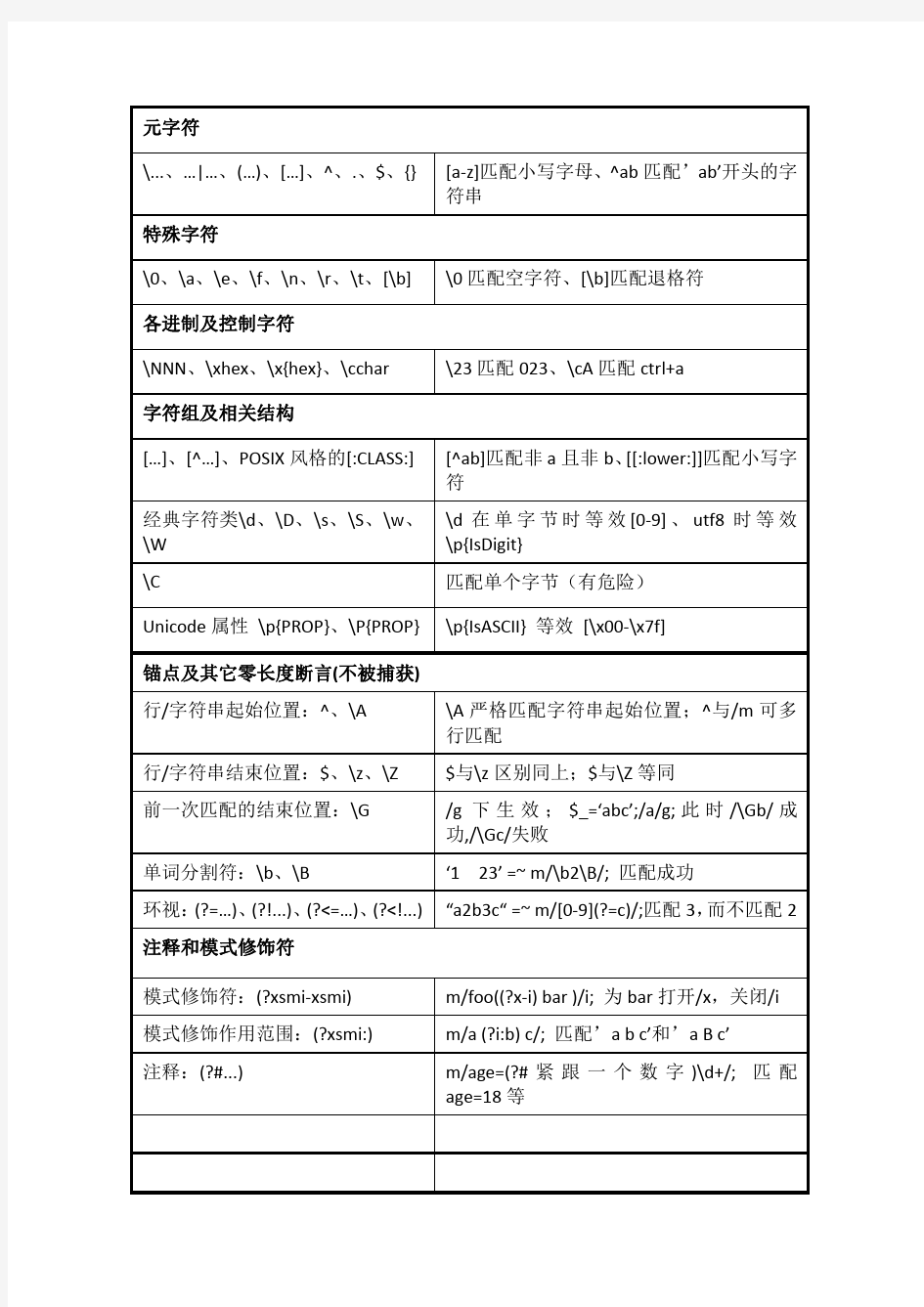
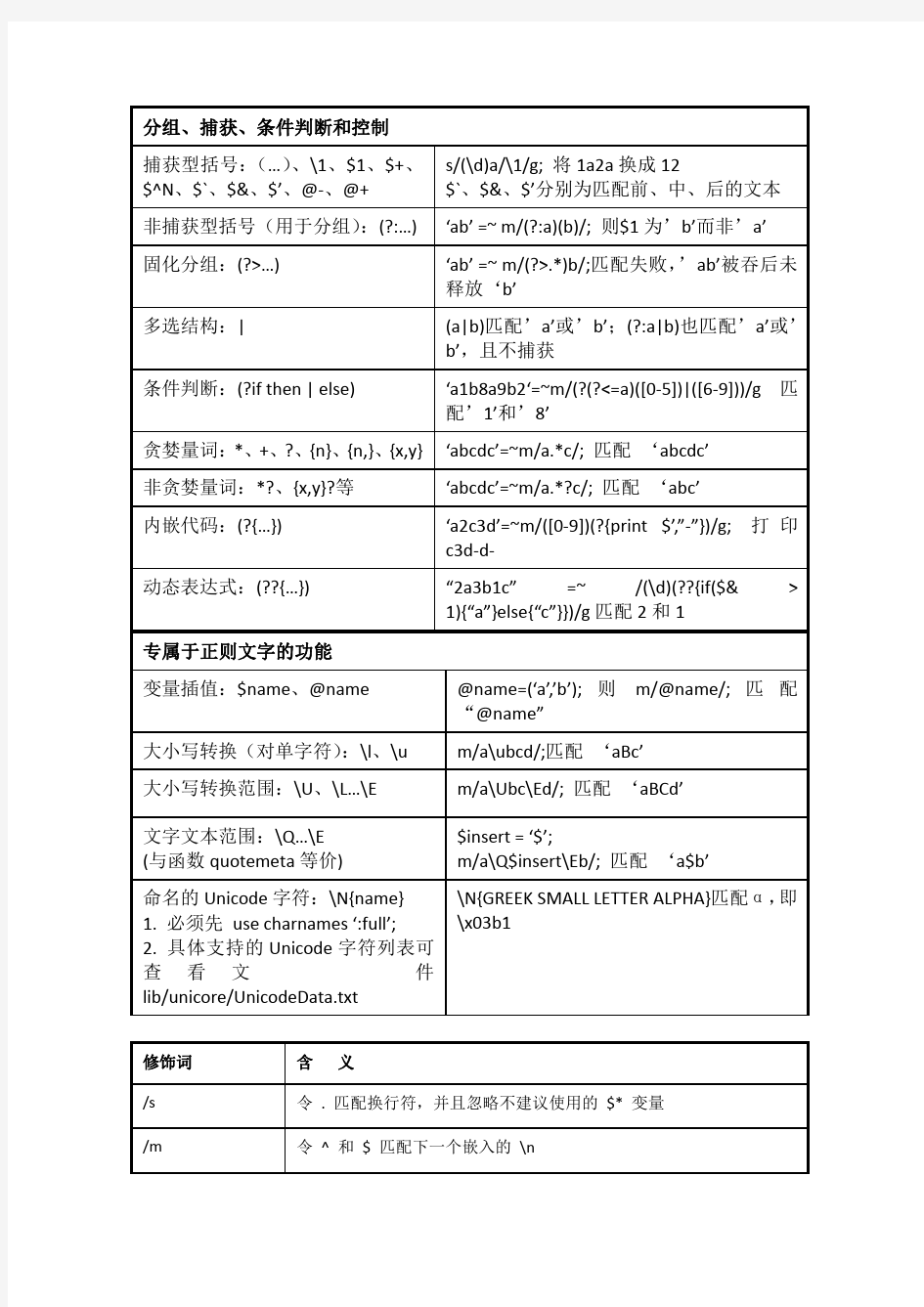
Find用法详解(含正则表达式)
Sed基础用法篇 刚开始接触linux,其实还是老实用vim来编辑文件,不过同样的过程重复多次,你就要想办法简化你的过程。sed绝对是一个好的命令或者工具,你不需要用vim打开文件就可以直接编辑(推荐掌握以下用法)。 1、删除行首空格 sed 's/^[ ]*//g' filename sed 's/^ *//g' filename sed 's/^[[:space:]]*//g' filename 2、行后和行前添加新行 行后:sed 's/pattern/&\n/g' filename 行前:sed 's/pattern/\n&/g' filename &代表pattern 3、使用变量替换(使用双引号) sed ‐e "s/$var1/$var2/g" filename 4、在第一行前插入文本 sed ‐i '1 i\插入字符串' filename 5、在最后一行插入 sed ‐i '$ a\插入字符串' filename
6、在匹配行前插入 sed ‐i '/pattern/ i "插入字符串"' filename 7、在匹配行后插入 sed ‐i '/pattern/ a "插入字符串"' filename 8、删除文本中空行和空格组成的行以及#号注释的行 grep ‐v ^# filename | sed /^[[:space:]]*$/d | sed /^$/d 9、要将目录/modules下面所有文件中的zhangsan都修改成list,可用如下命令:(注意备份原文件) sed ‐i 's/zhangsan/list/g' `grep zhangsan ‐rl /modules` Linux命令FIND详解 由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只你具有相应的权限。在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间(这里是指30G字节以上的文件系统)。 一、find 命令格式 1、find命令的一般形式为; find pathname ‐options [‐print ‐exec ‐ok ...]
正则表达式语法完整版
正则表达式基础知识 一个正则表达式就是由普通字符(例如字符a 到z)以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。如:
下面看几个例子: "^The":表示所有以"The"开始的字符串("There","The cat"等); "of despair$":表示所以以"of despair"结尾的字符串; "^abc$":表示开始和结尾都是"abc"的字符串——呵呵,只有"abc"自己了;"notice":表示任何包含"notice"的字符串。 '*','+'和'?'这三个符号,表示一个或一序列字符重复出现的次数。它们分别表示“没有或更多”,“一次或更多”还有“没有或一次”。下面是几个例子: "ab*":表示一个字符串有一个a后面跟着零个或若干个b。("a", "ab", "abbb",……);"ab+":表示一个字符串有一个a后面跟着至少一个b或者更多; "ab?":表示一个字符串有一个a后面跟着零个或者一个b; "a?b+$":表示在字符串的末尾有零个或一个a跟着一个或几个b。 也可以使用范围,用大括号括起,用以表示重复次数的范围。 "ab{2}":表示一个字符串有一个a跟着2个b("abb"); "ab{2,}":表示一个字符串有一个a跟着至少2个b; "ab{3,5}":表示一个字符串有一个a跟着3到5个b。
请注意,你必须指定范围的下限(如:"{0,2}"而不是"{,2}")。 还有,你可能注意到了,'*','+'和'?'相当于"{0,}","{1,}"和"{0,1}"。 还有一个'|',表示“或”操作: "hi|hello":表示一个字符串里有"hi"或者"hello"; "(b|cd)ef":表示"bef"或"cdef"; "(a|b)*c":表示一串"a""b"混合的字符串后面跟一个"c"; '.'可以替代任何字符: "a.[0-9]":表示一个字符串有一个"a"后面跟着一个任意字符和一个数字; "^.{3}$":表示有任意三个字符的字符串(长度为3个字符); 方括号表示某些字符允许在一个字符串中的某一特定位置出现: "[ab]":表示一个字符串有一个"a"或"b"(相当于"a|b"); "[a-d]":表示一个字符串包含小写的'a'到'd'中的一个(相当于"a|b|c|d"或者"[abcd]");"^[a-zA-Z]":表示一个以字母开头的字符串; "[0-9]%":表示一个百分号前有一位的数字; "[0-9]+":表示一个以上的数字; ",[a-zA-Z0-9]$":表示一个字符串以一个逗号后面跟着一个字母或数字结束。 你也可以在方括号里用'^'表示不希望出现的字符,'^'应在方括号里的第一位。(如:"%[^a-zA-Z]%"表 示两个百分号中不应该出现字母)。 为了逐字表达,必须在"^.$()|*+?{\"这些字符前加上转移字符'\'。 请注意在方括号中,不需要转义字符。
QT正则表达式QRegExp的解析
QRegExp正则表达式 2010-03-20 17:00 "^\d+$" //非负整数(正整数 + 0) "^[0-9]*[1-9][0-9]*$" //正整数 "^((-\d+)|(0+))$" //非正整数(负整数 + 0) "^-[0-9]*[1-9][0-9]*$" //负整数 "^-?\d+$" //整数 "^\d+(\.\d+)?$" //非负浮点数(正浮点数 + 0) "^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数 "^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮点数(负浮点数 + 0) "^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[ 1-9][0-9]*)))$" //负浮点数 "^(-?\d+)(\.\d+)?$" //浮点数 "^[A-Za-z]+$" //由26个英文字母组成的字符串 "^[A-Z]+$" //由26个英文字母的大写组成的字符串 "^[a-z]+$" //由26个英文字母的小写组成的字符串 "^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串 "^\w+$" //由数字、26个英文字母或者下划线组成的字符串 "^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址 "^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$" //url "^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$" // 年-月-日 "^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$" // 月/日/年 "^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z ]{2,4}|[0-9]{1,3})(]?)$" //Email "(d+-)?(d{4}-?d{7}|d{3}-?d{8}|^d{7,8})(-d+)?" //电话号码 "^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1 dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$" //IP地址 ^([0-9A-F]{2})(-[0-9A-F]{2}){5}$ //MAC地址的正则表达式 ^[-+]?\d+(\.\d+)?$ //值类型正则表达式 QRegExp是Qt的正则表达式类. Qt中有两个不同类的正则表达式. 第一类为元字符.它表示一个或多个常量表达式. 令一类为转义字符,它代表一个特殊字符. 一.元字符 . 匹配任意单个字符.例如, 1.3 可能是1. 后面跟任意字符,再跟3 ^ 匹配字符串首. 例如, ^12可能是123,但不能是312
正则表达式
多少年来,许多的编程语言和工具都包含对正则表达式的支持,.NET基础类库中包含有一个名字空间和一系列可以充分发挥规则表达式威力的类,而且它们也都与未来的Perl 5中的规则表达式兼容。 此外,regexp类还能够完成一些其他的功能,例如从右至左的结合模式和表达式的编辑等。 在这篇文章中,我将简要地介绍System.Text.RegularExpression中的类和方法、一些字符串匹配和替换的例子以及组结构的详细情况,最后,还会介绍一些你可能会用到的常见的表达式。 应该掌握的基础知识 规则表达式的知识可能是不少编程人员“常学常忘”的知识之一。在这篇文章中,我们将假定你已经掌握了规则表达式的用法,尤其是Perl 5中表达式的用法。.NET的regexp类是Perl 5中表达式的一个超集,因此,从理论上说它将作为一个很好的起点。我们还假设你具有了C#的语法和.NET架构的基本知识。 如果你没有规则表达式方面的知识,我建议你从Perl 5的语法着手开始学习。在规则表达式方面的权威书籍是由杰弗里?弗雷德尔编写的《掌握表达式》一书,对于希望深刻理解表达式的读者,我们强烈建议阅读这本书。 RegularExpression组合体 regexp规则类包含在System.Text.RegularExpressions.dll文件中,在对应用软件进行编译时你必须引用这个文件,例如: csc r:System.Text.RegularExpressions.dll foo.cs 命令将创建foo.exe文件,它就引用了System.Text.RegularExpressions文件。 名字空间简介 在名字空间中仅仅包含着6个类和一个定义,它们是: Capture: 包含一次匹配的结果; CaptureCollection: Capture的序列; Group: 一次组记录的结果,由Capture继承而来; Match: 一次表达式的匹配结果,由Group继承而来; MatchCollection: Match的一个序列; MatchEvaluator: 执行替换操作时使用的代理; Regex: 编译后的表达式的实例。 Regex类中还包含一些静态的方法: Escape: 对字符串中的regex中的转义符进行转义; IsMatch: 如果表达式在字符串中匹配,该方法返回一个布尔值; Match: 返回Match的实例; Matches: 返回一系列的Match的方法; Replace: 用替换字符串替换匹配的表达式; Split: 返回一系列由表达式决定的字符串; Unescape:不对字符串中的转义字符转义。
《易语言“正则表达式”详细教程》
《易语言“正则表达式”教程》 本文改编自多个文档,因此如有雷同,不是巧合。 “正则表达式”的应用范围越来越广,有了这个强大的工具,我们可以做很多事情,如搜索一句话中某个特定的数据,屏蔽掉一些非法贴子的发言,网页中匹配特定数据,代码编辑框中字符的高亮等等,这都可以用正则表达式来完成。 本书分为四个部分。 第一部分介绍了易语言的正则表达式支持库,在这里,大家可以了解第一个正则表达式的易语言程序写法,以及一个通用的小工具的制作。 第二部分介绍了正则表达式的基本语法,大家可以用上述的小工具进行试验。 第三部分介绍了用易语言写的正则表达式工具的使用方法。这些工具是由易语言用户提供的,有的工具还带有易语言源码。他们是:monkeycz、零点飞越、寻梦。 第四部分介绍了正则表达式的高级技巧。 目录 《易语言“正则表达式”教程》 (1) 目录 (1) 第一章易语言正则表达式入门 (3) 一.与DOS下的通配符类似 (3) 二.初步了解正则表达式的规定 (3) 三.一个速查列表 (4) 四.正则表达式支持库的命令 (5) 4.1第1个正则表达式程序 (5) 4.2第2个正则表达式例程 (7) 4.3第3个例程 (8) 4.4一个小型的正则工具 (9) 第二章揭开正则表达式的神秘面纱 (11) 引言 (12) 一.正则表达式规则 (12) 1.1普通字符 (12) 1.2简单的转义字符 (13) 1.3能够与“多种字符”匹配的表达式 (14) 1.4自定义能够匹配“多种字符”的表达式 (16) 1.5修饰匹配次数的特殊符号 (17) 1.6其他一些代表抽象意义的特殊符号 (20) 二.正则表达式中的一些高级规则 (21) 2.1匹配次数中的贪婪与非贪婪 (21)
很完整的一篇正则表达式总结
1、正则表达式-完结篇---工具类开发--- ? 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 '/.+/', 'email'=> '/^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/', 'url'=> '/^http(s?):\/\/(?:[A-za-z0-9-]+\.)+[A-za-z]{2,4}(?:[\/ \?#][\/=\?%\-&~`@[\]\':+!\.#\w]*)?$/', 'currency'=> '/^\d+(\.\d+)?$/', 'number'=> '/^\d+$/', 'zip'=> '/^\d{6}$/', 'integer'=> '/^[-\+]?\d+$/', 'double'=> '/^[-\+]?\d+(\.\d+)?$/',
5 1 6 1 7 1 8 1 9 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2'english'=> '/^[A-Za-z]+$/', 'qq'=> '/^\d{5,11}$/', 'mobile'=> '/^1(3|4|5|7|8)\d{9}$/', ); //定义其他属性 private$returnMatchResult=false; //返回类型判断 private$fixMode=null; //修正模式 private$matches=array(); //存放匹配结果 private$isMatch=false; //构造函数,实例化后传入默认的两个参数 public function __construct($returnMatchResult=false,$fixMode=null){ $this->returnMatchResult=$returnMatchResult; $this->fixMode=$fixMode; } //判断返回结果类型,为匹配结果matches还是匹配成功与否isMatch,并调用返回方法 private function regex($pattern,$subject){ if(array_key_exists(strtolower($pattern), $this->validate)) $pattern=$this->validate[$pattern].$this->fixMode; //判断后再连接上修正模式作为匹配的正则表达式 $this->returnMatchResult ?
PYTHON正则表达式模块RE讲解
2re模块的基本函数 在上面的说明中,我们已经对re模块的基本函数‘findall’很熟悉了。当然如果光有findall 的话,很多功能是不能实现的。下面开始介绍一下re模块其它的常用基本函数。灵活搭配使用这些函数,才能充分发挥Python正则式的强大功能。 首先还是说下老熟人findall函数吧 findall(rule,target[,flag]) 在目标字符串中查找符合规则的字符串。 第一个参数是规则,第二个参数是目标字符串,后面还可以跟一个规则选项(选项功能将在compile函数的说明中详细说明)。 返回结果结果是一个列表,中间存放的是符合规则的字符串。如果没有符合规则的字符串被找到,就返回一个空列表。 2.1使用compile加速 compile(rule[,flag]) 将正则规则编译成一个Pattern对象,以供接下来使用。 第一个参数是规则式,第二个参数是规则选项。 返回一个Pattern对象 直接使用findall(rule,target)的方式来匹配字符串,一次两次没什么,如果是多次使用的话,由于正则引擎每次都要把规则解释一遍,而规则的解释又是相当费时间的,所以这样的效率就很低了。如果要多次使用同一规则来进行匹配的话,可以使用https://www.360docs.net/doc/1215301382.html,pile函数来将规则预编译,使用编译过返回的Regular Expression Object或叫做Pattern对象来进行查找。 >>>s='111,222,aaa,bbb,ccc333,444ddd' >>>rule=r’\b\d+\b’ >>>compiled_rule=https://www.360docs.net/doc/1215301382.html,pile(rule) >>>compiled_rule.findall(s) ['111','222'] 可见使用compile过的规则使用和未编译的使用很相似。compile函数还可以指定一些规则标志,来指定一些特殊选项。多个选项之间用’|’(位或)连接起来。 I IGNORECASE忽略大小写区别。 L LOCAL字符集本地化。这个功能是为了支持多语言版本的字符集使用环境的,比如在转义符\w,在英文环境下,它代表[a-zA-Z0-9],即所以英文字符和数字。如果在一个法语环境下使用,缺省设置下,不能匹配"é"或"?"。加上这L选项和就可以匹配了。不过这个对于中文环境似乎没有什么用,它仍然不能匹配中文字符。 M MULTILINE多行匹配。在这个模式下’^’(代表字符串开头)和’$’(代表字符串结尾)将能够匹配多行的情况,成为行首和行尾标记。比如 >>>s=’123456\n789012\n345678’ >>>rc=https://www.360docs.net/doc/1215301382.html,pile(r’^\d+’)#匹配一个位于开头的数字,没有使用M选项 >>>rc.findall(s) ['123']#结果只能找到位于第一个行首的’123’ >>>rcm=https://www.360docs.net/doc/1215301382.html,pile(r’^\d+’,re.M)#使用M选项 >>>rcm.findall(s) ['123','789','345']#找到了三个行首的数字
正则表达式7
Java正则表达式详解 仙人掌工作室 如果你曾经用过Perl或任何其他内建正则表达式支持的语言,你一定知道用正则表达式处理文本和匹配模式是多么简单。如果你不熟悉这个术语,那么“正则表达式”(Regular Expression)就是一个字符构成的串,它定义了一个用来搜索匹配字符串的模式。 许多语言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能。那么Java又怎样呢?本文写作时,一个包含了用正则表达式进行文本处理的Java规范需求(Specification Request)已经得到认可,你可以期待在JDK的下一版本中看到它。 然而,如果现在就需要使用正则表达式,又该怎么办呢?你可以从https://www.360docs.net/doc/1215301382.html,下载源代码开放的Jakarta-ORO库。本文接下来的内容先简要地介绍正则表达式的入门知识,然后以Jakarta-ORO API为例介绍如何使用正则表达式。 一、正则表达式基础知识 我们先从简单的开始。假设你要搜索一个包含字符“cat”的字符串,搜索用的正则表达式就是“cat”。如果搜索对大小写不敏感,单词“catalog”、“Catherine”、“sophisticated”都可以匹配。也就是说: 1.1句点符号 假设你在玩英文拼字游戏,想要找出三个字母的单词,而且这些单词必须以“t”字母开头,以“n”字母结束。另外,假设有一本英文字典,你可以用正则表达式搜索它的全部内容。要构造出这个正则表达式,你可以使用一个通配符——句点符号“.”。这样,完整的表达式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,还匹配“t#n”、“tpn”甚至“t n”,还有其他许多无意义的组合。这是因为句点符号匹配所有字符,包括空格、Tab字符甚至换行符: 1.2方括号符号 为了解决句点符号匹配范围过于广泛这一问题,你可以在方括号(“[]”)里面指定看来有意义的字符。此时,只有方括号里面指定的字符才参与匹配。也就是说,正则表达式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因为在方括号之内你只能匹配单个字符 1.3“或”符号
正则表达式
正则表达式
目录
1. 引言 2. 基本语法 3. sed 4. awk 5. 练习:在 C 语言中使用正则表达式
1. 引言
以前我们用 grep 在一个文件中找出包含某些字符串的行,比如在头文件中找出一个宏定义. 其实 grep 还可以找出符合某个模式(Pattern)的一类字符串.例如找出所有符合 xxxxx@xxxx.xxx 模式的字符串(也就是 email 地址),要求 x 字符可以是字母,数字,下划 线,小数点或减号,email 地址的每一部分可以有一个或多个 x 字符,例如 abc.d@https://www.360docs.net/doc/1215301382.html,, 1_2@987-6.54,当然符合这个模式的不全是合法的 email 地址,但至少可以做一次初步筛选, 筛掉 a.b,c@d 等肯定不是 email 地址的字符串.再比如,找出所有符合 yyy.yyy.yyy.yyy 模 式的字符串(也就是 IP 地址),要求 y 是 0-9 的数字,IP 地址的每一部分可以有 1-3 个 y 字 符. 如果要用 grep 查找一个模式,如何表示这个模式,这一类字符串,而不是一个特定的字符串 呢?从这两个简单的例子可以看出,要表示一个模式至少应该包含以下信息: 字符类(Character Class):如上例的 x 和 y,它们在模式中表示一个字符,但是取 值范围是一类字符中的任意一个. 数量限定符(Quantifier): 邮件地址的每一部分可以有一个或多个 x 字符,IP 地址 的每一部分可以有 1-3 个 y 字符 各种字符类以及普通字符之间的位置关系:例如邮件地址分三部分,用普通字符@和. 隔开,IP 地址分四部分,用.隔开,每一部分都可以用字符类和数量限定符描述.为 了表示位置关系,还有位置限定符(Anchor)的概念,将在下面介绍.
规定一些特殊语法表示字符类,数量限定符和位置关系,然后用这些特殊语法和普通字符一 起表示一个模式,这就是正则表达式(Regular Expression).例如 email 地址的正则表达式 可以写成[a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.[a-zA-Z0-9_.-]+,IP 地址的正则表达式可以 写成[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}.下一节介绍正则表达式的语法, 我们先看看正则表达式在 grep 中怎么用.例如有这样一个文本文件 testfile:
192.168.1.1
第 1 页 共 10 页
Java中的正则表达式+--++示例详解
Java中的正则表达式 众所周知,在程序开发中,难免会遇到需要匹配、查找、替换、判断字符串的情况发生,而这些情况有时又比较复杂,如果用纯编码方式解决,往往会浪费程序员的时间及精力。因此,学习及使用正则表达式,便成了解决这一矛盾的主要手段。 大家都知道,正则表达式是一种可以用于模式匹配和替换的规范,一个正则表达式就是由普通的字符(例如字符a到z)以及特殊字符(元字符)组成的文字模式,它用以描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。 自从jdk1.4推出java.util.regex包,就为我们提供了很好的JAVA正则表达式应用平台。 因为正则表达式是一个很庞杂的体系,所以我仅例举些入门的概念,更多的请参阅相关书籍及自行摸索。 \\ 反斜杠 \t 间隔 ('\u0009') \n 换行 ('\u000A') \r 回车 ('\u000D') \d 数字等价于[0-9] \D 非数字等价于[^0-9] \s 空白符号 [\t\n\x0B\f\r] \S 非空白符号 [^\t\n\x0B\f\r] \w 单独字符 [a-zA-Z_0-9] \W 非单独字符 [^a-zA-Z_0-9] \f 换页符 \e Escape \b 一个单词的边界 \B 一个非单词的边界 \G 前一个匹配的结束 ^为限制开头 ^java 条件限制为以Java为开头字符 $为限制结尾 java$ 条件限制为以java为结尾字符 .为限制一个任意字符 java.. 条件限制为java后除换行外任意两个字符 加入特定限制条件「[]」 [a-z] 条件限制在小写a to z范围中一个字符 [A-Z] 条件限制在大写A to Z范围中一个字符 [a-zA-Z] 条件限制在小写a to z或大写A to Z范围中一个字符 [0-9] 条件限制在小写0 to 9范围中一个字符
C#正则表达式之Regex类用法详解
C#正则表达式之Regex类用法详解 正则表达式的本质是使用一系列特殊字符模式,来表示某一类字符串,正则表达式无疑是处理文本最有力的工具,而.NET提供的Regex类实现了验证正则表达式的方法。 Regex类表示不可变(只读)的正则表达式。它还包含各种静态方法,允许在不显式创建其他类的实例的情况下使用其他正则表达式类。 正则表达式基础概述 什么是正则表达式 在编写字符串的处理程序时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。 通常,我们在使用WINDOWS查找文件时,会使用通配符(*和?)。如果你想查找某个目录下的所有Word文档时,你就可以使用*.doc进行查找,在这里,*就被解释为任意字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂。 一、C#正则表达式符号模式
说明: 由于在正则表达式中“\”、“?”、“*”、“^”、“$”、“+”、“(”、“)”、“|”、“{”、“[”等字符已经具有一定特殊意义,如果需要用它们的原始意义,则应该对它进行转义,例如希望在字符串中至少有一个“\”,那么正则表达式应该这么写:\\+。
二、在C#中,要使用正则表达式类,请在源文件开头处添加以下语句: 复制代码代码如下: using Syst https://www.360docs.net/doc/1215301382.html, ressions; 三、RegEx类常用的方法 1、静态Match方法 使用静态Match方法,可以得到源中第一个匹配模式的连续子串。 静态的Match方法有2个重载,分别是 Regex.Match(string input,string pattern); Regex.Match(string input,string pattern,RegexOptions options); 第一种重载的参数表示:输入、模式 第二种重载的参数表示:输入、模式、RegexOptions枚举的“按位或”组合。 RegexOptions枚举的有效值是: Complied表示编译此模式 CultureInvariant表示不考虑文化背景 ECMAScript表示符合ECMAScript,这个值只能和IgnoreCase、Multiline、Complied连用ExplicitCapture表示只保存显式命名的组 IgnoreCase表示不区分输入的大小写 Ign https://www.360docs.net/doc/1215301382.html, pace表示去掉模式中的非转义空白,并启用由#标记的注释Multiline表示多行模式,改变元字符^和$的含义,它们可以匹配行的开头和结尾 None表示无设置,此枚举项没有意义 RightToLeft表示从右向左扫描、匹配,这时,静态的Match方法返回从右向左的第一个匹配Singleline表示单行模式,改变元字符.的意义,它可以匹配换行符
Perl+正则表达式讲解
Perl正则表达式讲解 摘自《Perl编程详解》目录:
9.3.1原则1 正则表达式有三种形式:匹配、替换和转换。 在表 9-1 中列有三种正则表达式运算符。 接下来对每一个表达式给出详尽解释。 匹配:m/ Java 正则表达式 表达式意义: 1.字符 x 字符 x。例如a表示字符a \\ 反斜线字符。在书写时要写为\\\\。(注意:因为java在第一次解析时,把\\\\解析成正则表达式\\,在第二次解析时再解析为\,所以凡是不是1.1列举到的转义字符,包括1.1的\\,而又带有\的都要写两次) \0n 带有八进制值 0的字符 n (0 <= n <= 7) \0nn 带有八进制值 0的字符 nn (0 <= n <= 7) \0mnn 带有八进制值 0的字符 mnn(0 <= m <= 3、0 <= n <= 7) \xhh 带有十六进制值 0x的字符 hh \uhhhh 带有十六进制值 0x的字符 hhhh \t 制表符 ('\u0009') \n 新行(换行)符 ('\u000A') \r 回车符('\u000D') \f 换页符 ('\u000C') \a 报警 (bell) 符('\u0007') \e 转义符 ('\u001B') \c x 对应于 x 的控制符 2.字符类 [abc] a、b或 c(简单类)。例如[egd]表示包含有字符e、g或d。 [^abc] 任何字符,除了 a、b或 c(否定)。例如[^egd]表示不包含字符e、g或d。 [a-zA-Z] a到 z或 A到 Z,两头的字母包括在内(范围) [a-d[m-p]] a到 d或m到 p:[a-dm-p](并集) [a-z&&[def]] d、e或 f(交集) [a-z&&[^bc]] a到 z,除了 b和 c:[ad-z](减去) [a-z&&[^m-p]] a到 z,而非m到 p:[a-lq-z](减去) 3.预定义字符类(注意反斜杠要写两次,例如\d写为\\d)任何字符 (与行结束符可能匹配也可能不匹配) \d 数字:[0-9] \D 非数字: [^0-9] \s空白字符:[ \t\n\x0B\f\r] \S 非空白字符:[^\s] \w 单词字符:[a-zA-Z_0-9] \W 非单词字符:[^\w] 4.POSIX 字符类(仅 U S-ASCII)(注意反斜杠要写两次,例如\p{Lower}写为\\p{Lower}) \p{Lower} 小写字母字符:[a-z]。 \p{U pper} 大写字母字符:[A-Z] \p{A SCII} 所有 A SCII:[\x00-\x7F] \p{A lpha} 字母字符:[\p{Lower}\p{U pper}] \p{Digit} 十进制数字:[0-9] \p{A lnum} 字母数字字符:[\p{A lpha}\p{Digit}] \p{P unc t} 标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ \p{Graph} 可见字符:[\p{A lnum}\p{Punc t}] \p{P rint} 可打印字符:[\p{Graph}\x20] JAVA 正则表达式4种常用的功能下面简单的说下它的4种常用功能: 查询: 以下是代码片段: String str="abc efg ABC"; String regEx="a|f"; //表示a或f Pattern p=https://www.360docs.net/doc/1215301382.html,pile(regEx); Matcher m=p.matcher(str); boolean rs=m.find(); 如果str中有regEx,那么rs为true,否则为flase。如果想在查找时忽略大小写,则可以写成Pattern p=https://www.360docs.net/doc/1215301382.html,pile(regEx,Pattern.CASE_INSENSITIVE); 提取: 以下是代码片段: String regEx=".+\(.+)$"; String str="c:\dir1\dir2\name.txt"; Pattern p=https://www.360docs.net/doc/1215301382.html,pile(regEx); Matcher m=p.matcher(str); boolean rs=m.find(); for(int i=1;i<=m.groupCount();i++){ System.out.println(m.group(i)); } 以上的执行结果为name.txt,提取的字符串储存在m.group(i)中,其中i最大值为 m.groupCount(); 分割: 以下是代码片段: String regEx="::"; Pattern p=https://www.360docs.net/doc/1215301382.html,pile(regEx); String[] r=p.split("xd::abc::cde"); 执行后,r就是{"xd","abc","cde"},其实分割时还有跟简单的方法:String str="xd::abc::cde"; String[] r=str.split("::"); 替换(删除): 以下是代码片段: String regEx="a+"; //表示一个或多个a Pattern p=https://www.360docs.net/doc/1215301382.html,pile(regEx); Matcher m=p.matcher("aaabbced a ccdeaa"); String s=m.replaceAll("A"); 结果为"Abbced A ccdeA" 如果写成空串,既可达到删除的功能,比如: String s=m.replaceAll(""); 结果为"bbced ccde" 附: \D 等於[^0-9] 非数字 \s 等於[ \t\n\x0B\f ] 空白字元 \S 等於[^ \t\n\x0B\f ] 非空白字元 \w 等於[a-zA-Z_0-9] 数字或是英文字 \W 等於[^a-zA-Z_0-9] 非数字与英文字 正则表达式语法 正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。模式描述在搜索文本时要匹配的一个或多个字符串。 正则表达式示例 常用正则表达式: 整数或者小数:^[0-9]+\.{0,1}[0-9]{0,2}$只能输入数字:"^[0-9]*$"。 只能输入n位的数字:"^\d{n}$"。 只能输入至少n位的数字:"^\d{n,}$"。 只能输入m~n位的数字:。"^\d{m,n}$" 只能输入零和非零开头的数字:"^(0|[1-9][0-9]*)$"。 只能输入有两位小数的正实数:"^[0-9]+(.[0-9]{2})?$"。 只能输入有1~3位小数的正实数:"^[0-9]+(.[0-9]{1,3})?$"。 只能输入非零的正整数:"^\+?[1-9][0-9]*$"。 只能输入非零的负整数:"^\-[1-9][]0-9"*$。 只能输入长度为3的字符:"^.{3}$"。 只能输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。 只能输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。 只能输入由26个小写英文字母组成的字符串:"^[a-z]+$"。 只能输入由数字和26个英文字母组成的字符串:"^[A-Za-z0-9]+$"。 只能输入由数字、26个英文字母或者下划线组成的字符串:"^\w+$"。 验证用户密码:"^[a-zA-Z]\w{5,17}$"正确格式为:以字母开头,长度在6~18之间,只能包含字符、数字和下划线。 验证是否含有^%&',;=?$\"等字符:"[^%&',;=?$\x22]+"。 只能输入汉字:"^[\u4e00-\u9fa5]{0,}$" 验证Email地址:"^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([- .]\w+)*$"。 验证InternetURL:"^http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?$"。 验证电话号码:"^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$"正确格式为:"XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX"。 验证11位的手机号:/^1[3|5][0-9]\d{4,8}$/ 验证身份证号(15位或18位数字):"^\d{15}|\d{18}$"。 验证一年的12个月:"^(0?[1-9]|1[0-2])$"正确格式为:"01"~"09"和"1"~"12"。 验证一个月的31天:"^((0?[1-9])|((1|2)[0-9])|30|31)$"正确格式为;"01"~"09"和"1"~"31"。匹配中文字符的正则表达式: [\u4e00-\u9fa5] 今天想用正则表达式来获取收到的http报文中的content-length字段的值的时候,无意中发现一篇用tcl语言写的文章,觉得很不错。所以转载。 一、介绍 追根溯源,正则表达式是在1956年的时候,人类最早研究神经网络的产物,但随着时间的流逝,几乎所有编程语言都加入了对它的支持,hoho~其实这个东西也是程序员开发中比较有名的一个难点。但是不要以为它只能用于程序开发,在Unix/Linux系统管理中它也有极为广泛的应用。 不要认为正则表达式很可怕,用直白的话来说,正则表达式就是利用26个英文字符与一些特殊符号的配合来进行文字内容比对的方法,绝大部分情况下,26个英文字符都代表它们本身,但在特殊符号的辅助下,这些英文字符也会有其他的含义,正则表达式比较困难的地方,也就在这种字符的2义性上面,这篇文档中对于这种具有字符2义性的地方,都会有专门的标注和说明。 如果用过Dos/Windows/Linux中的通配符,就可以理解正则表达式的作用了,通配符用*号匹配任意多的任意字符,用?号匹配任意的一个字符,正则表达式有更加复杂的一套匹配系统,可以用来匹配几乎所有希望匹配的文字内容。 二、文档约定 本文档中的所有实例,都是在以下环境中调试和运行的: 操作系统: CentOS4.1 (Linux 2.6.9-11) 编程语言: TCL8.4 文本编辑器: VIM6.3.46 文档格式约定: 实例的解释性文字,使用华文楷体小四号蓝色字体显示 实例的解释性文字 系统或程序输出,使用浅蓝色底纹表示 特别需要注意和标注的地方,将以笑脸符号专门表示 ?看我可爱吗? 三、基本正则表达式 正则表达式中,26个英文字符代表它们本身,但是下面表格中的特殊字符则赋予了更多不同的含义,一定要记住它们,因为它们是一切正则表达式的基础并不真正是一个正则表达式,但是对于 用正则表达式难于处理的数据常使用它来进行操纵。因 此,tr/[0-9]/9876543210.组成1223456789,987654321 等字符串。 通过使用=~(用英语讲:does ,与“进行匹配”同) 和!~(英语:doesn't ,与“不匹配”同)把这些表达式捆绑 到标量上。作为这种类型的例子,下面我们给出六个示例 正则表达式及相应的定义: $scalar $scalarName =~ s/a/b;Name =~ s/a/b;Name =~ s/a/b; # substitute the character a for b, and return true if this can happern # substitute the character a for b, and return true if this can happern $scalarName =~ m/a;$scalarName =~ m/a; # does the scalar $scalarName have an a in it? # does the scalar $scalarName have an a in it? ~ tr/A $scalarName =~ tr/A--Z/a Z/a--# translate all capital letter with lower case ones, and retur z/; # translate all capital letter with lower case ones, and return ture n ture if this happens if this happens $scalarName !~ s/a/b/;$scalarName !~ s/a/b/; # substitute the character a for b, and return false if this indeed happens.happens. $scalarName !~ m/a/;$scalarName !~ m/a/; # does the scalar $scalarName match the character a? Return false if it does.if it does. $scalarName !~ tr/0$scalarName !~ tr/0--9/a 9/a--j/;j/; # translate the digits for the letters a thru j, and return false if this happens.if this happens. 如果我们输入像 horned toad =~ m/toad/ 这样的代码,则出现图 9-1 所示情况: 另外,如果读者正在对特定变量 $_ 进行匹配(读者可能在while 循环,map 或grep 中使用),则可以不用!~和=~。因而,以下所有代码都会合法: my @elemente = (' al' ,' a2' ,my @elemente = (' al' ,' a2' ,' a3' ,' a4' ,' a5' );' a3' ,' a4' ,' a5' );' a3' ,' a4' ,' a5' ); foreach (@elements) {s/a/b/;}foreach (@elements) {s/a/b/;} 程序使 @elements 等于b 1,b2.b3,b4,b5。另外: while(<$FD>) {print if (m/ERBOR/);} while(<$FD>) {print if (m/ERBOR/);} JAVA正则表达式语法
JAVA 正则表达式4种常用的功能
正则表达式语法及常用规则
Tcl正则表达式详解