机器学习实验1-Fisher线性分类器设计

一、实验意义及目的
掌握Fisher分类原理,能够利用Matlab编程实现Fisher线性分类器设计,
熟悉基于Matlab算法处理函数,并能够利用算法解决简单问题。
二、算法原理
Fisher准则基本原理:找到一个最合适的投影周,使两类样本在该轴上投影之间的距离尽可能远,而每一类样本的投影尽可能紧凑,从而使分类效果为最佳。
内容:
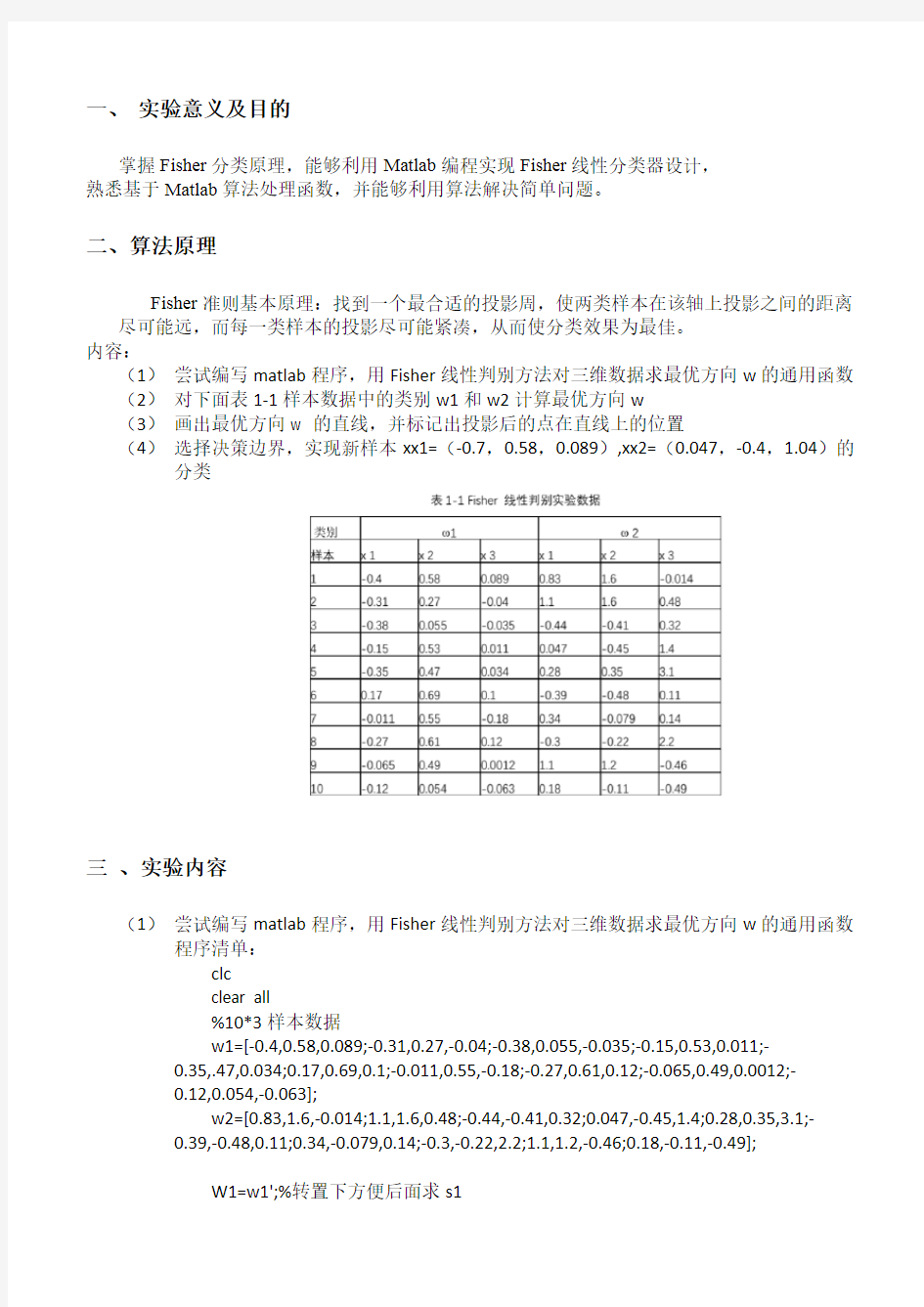
(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w
(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置
(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类
三、实验内容
(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数程序清单:
clc
clear all
%10*3样本数据
w1=[-0.4,0.58,0.089;-0.31,0.27,-0.04;-0.38,0.055,-0.035;-0.15,0.53,0.011;-
0.35,.47,0.034;0.17,0.69,0.1;-0.011,0.55,-0.18;-0.27,0.61,0.12;-0.065,0.49,0.0012;-
0.12,0.054,-0.063];
w2=[0.83,1.6,-0.014;1.1,1.6,0.48;-0.44,-0.41,0.32;0.047,-0.45,1.4;0.28,0.35,3.1;-
0.39,-0.48,0.11;0.34,-0.079,0.14;-0.3,-0.22,2.2;1.1,1.2,-0.46;0.18,-0.11,-0.49];
W1=w1';%转置下方便后面求s1
W2=w2';
m1=mean(w1);%对w1每一列取平均值结果为1*3矩阵
m2=mean(w2);%对w1每一列取平均值结果为1*3矩阵
S1=zeros(3);%有三个特征所以大小为3
S2=zeros(3);
for i=1:10%1到样本数量n
s1=(W1(:,i)-m1)*(W1(:,i)-m1)';
s2=(W2(:,i)-m2)*(W2(:,i)-m2)';
S1=S1+s1;
S2=S2+s2;
end
sw=S1+S2;
w_new=transpose(inv(sw)*(m1'-m2'));%这里m1m2是行要转置下3*3 X 3*1 =3*1 这里提前转置了下跟老师ppt解法公式其实一样
%绘制拟合结果数据画图用
y1=w_new*W1
y2=w_new*W2;
m1_new=w_new*m1';%求各样本均值也就是上面y1的均值
m2_new=w_new*m2';
w0=(m1_new+m2_new)/2%取阈值
%分类判断
x=[-0.7 0.047
0.58 -0.4
0.089 1.04 ];
m=0; n=0;
result1=[]; result2=[];
for i=1:2%对待观测数据进行投影计算
y(i)=w_new*x(:,i);
if y(i)>w0
m=m+1;
result1(:,m)=x(:,i);
else
n=n+1;
result2(:,n)=x(:,i);
end
end
%结果显示
display('属于第一类的点')
result1
display('属于第二类的点')
result2
figure(1)
scatter3(w1(1,:),w1(2,:),w1(3,:),'+r'),hold on
scatter3(w2(1,:),w2(2,:),w2(3,:),'sg'),hold on
scatter3(result1(1,:),result1(2,:),result1(3,:),'k'),hold on
scatter3(result2(1,:),result2(2,:),result2(3,:),'bd')
title('样本点及实验点的空间分布图')
legend('样本点w1','样本点w2','属于第一类的实验点','属于第二类的实验点')
figure(2)
title('样本拟合结果')
scatter3(y1*w_new(1),y1*w_new(2),y1*w_new(3),'b'),hold on
scatter3(y2*w_new(1),y2*w_new(2),y2*w_new(3),'sr')
(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w
(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置
最优方向w 的直线
投影后的位置
(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类
决策边界取法:
分类结果:
四、实验感想
通过这次实验,我学会了fisher线性判别相关的分类方法,对数据分类有了初步的认识,尽管在过程中有不少中间量不会算,通过查阅网络知识以及模式识别专业课ppt等课件帮助,我最终完成了实验,为今后继续深入学习打下良好基础。
用MATLAB解决线性代数问题实验报告
实验三使用MATLAB解决线性代数问题学院:数计学院班级:1003班姓名:黄晓丹学号:1051020144 实验目的: 学习MATLAB有关线性代数运算的指令,主要学习运用MATLAB解决矩阵除法,线性方程组的通解,矩阵相似 对角化问题,以及解决投入产出分析等应用问题。 实验内容: 矩阵转置:A=[1 2;3 4];B=[4 3;2 1]; >> A',B' ans = 1 3 2 4 ans = 4 3 3 1 矩阵加减:A-B ans= -3 -1 1 3 矩阵乘法:A*B,A.*B(数组乘法)||比较矩阵乘法与数组乘法的区别ans= 8 5 20 13 ans= 4 6 6 4 矩阵除法:A\B,B./A ans=
-6 -5 5 4 ans= 4 1.5 0.6667 0.25 特殊矩阵生成:zeros(m,n)||生成m行n列的矩阵 ones(m,n)||生成m行n列的元素全为一的矩阵 eye(n)||生成n阶单位矩阵 rand(m,n)||生成m行n列[0 ,1]上均匀分布随 机数矩阵 zeros(2,3) ans = 0 0 0 0 0 0 >> ones(3,3) ans = 1 1 1 1 1 1 1 1 1 >> eye(3)
ans = 1 0 0 0 1 0 0 0 1 >> rand(2,4) ans = Columns 1 through 3 0.9501 0.6068 0.8913 0.2311 0.4860 0.7621 Column 4 0.4565 0.0185 矩阵处理:trace(A)||返回矩阵的迹 diag(A)||返回矩阵对角线元素构成的向量 tril(A)||提取矩阵的下三角部分 triu(A)||提取矩阵的上三角部分 flipud(A)||矩阵上下翻转 fliplr(A)||矩阵左右翻转 reshape(A,m,n)||将矩阵的元素重排成m行n列矩阵A=[1 2 3;4 5 6;7 8 9]; >> t=trace(A),d=diag(A),u=triu(A)
作业二基于Fisher准则线性分类器设计
作业二 F i s h e r 线性判别分类器 一 实验目的 本实验旨在让同学进一步了解分类器的设计概念,能够根据自己的设计对线性分类器有更深刻地认识,理解Fisher 准则方法确定最佳线性分界面方法的原理,以及Lagrande 乘子求解的原理。 二 实验条件 Matlab 软件 三 实验原理 线性判别函数的一般形式可表示成 0)(w X W X g T += 其中 根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为: )(211*m m S W W -=- 上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。另外,该式这种形式的运算,我们称为线性变换,其中21m m -式一个向量,1 -W S 是W S 的逆矩阵,如21m m -是d 维,W S 和 1-W S 都是d ×d 维,得到的*W 也是一个d 维的向量。 向量* W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量*W 的各分量值是对原d 维特征向量求加权和的权值。 以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量* W 的计算方法,但是判别函数中的另一项0W 尚未确定,一般可采用以下几种方法确定0W 如 或者 m N N m N m N W ~~~2 122110=++-= 或当1)(ωp 与2)(ωp 已知时可用 当W 0确定之后,则可按以下规则分类, 201 0ωω∈→-<∈→->X w X W X w X W T T
大数据挖掘weka大数据分类实验报告材料
一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff)
对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮:
Fisher分类器设计
Fisher分类器设计 班级:自092 姓名:刘昌元学号:099064370 一、实验目的: 1:根据fisher准则设计线性分类器 2:由fisher分类器训练样本数据 3:由fisher分类器测试样本观察出错率并与贝叶斯分类器的出错率比较判断两种分类器的性能优劣 4:将测试数据和决策面画在一张图上直观显示
三、实验所用函数: 类均值向量:∑=∈i xj j i x N M χ1 类内离散度矩阵:T i j i i xj j i M x M x S ))((--∑ ∈=χ 总类内离散度矩阵:21S S S w += 类间离散度矩阵:T b M M M M S ))((2121--= 最有投影方向:)(211 * M M S W w -=- 决策函数:0) (w x w x G T += 阈值:)(2 1210M w M w w T T +-= 四、实验结果: 1:得到参数:最有投影向量和阈值 2:利用分类器输入身高和体重数据得到性别分类(实验结果如下) w=[ 0.0012; 0.0003] threshold =0.2318
classify(165,56) 结果为“女” classify(178,70) 结果为“男”3:fisher准则分类器的出错率统计: 测试test1: 测试test2: 4:bayes分类器测试出错统计: 测试test1:
测试test2: 结论:很显然bayes分类器比fisher分类器准确率高的多。4:分类面决策图:
五、程序: 程序1:求最有投影方向和阈值 %程序功能:应用fisher分类方法,使用训练数据获得阈值和最佳变换向量(投影方向)% function fisher(boys,girls) %调用男生和女生的训练样本数据% A=boys.'; B=girls.'; [k1,l1]=size(A); [k2,l2]=size(B); M1=sum(boys); M1=M1.'; M1=M1/l1; %求男生身高与体重的均值% M2=sum(girls); M2=M2.'; M2=M2/l2; %求女生身高与体重的均值% S1=zeros(k1,k1); S2=zeros(k2,k2); for i=1:l1 S1=S1+(A(:,i)-M1)*((A(:,i)-M1).'); %求类内离散度矩阵S1% end for i=1:l2 S2=S2+(B(:,i)-M2)*((B(:,i)-M2).'); %求类内离散度矩阵S2% end for i=1:2 for j=1:2 Sw(i,j)=S1(i,j)+S2(i,j); %求总类内离散度矩阵Sw% end end w=inv(Sw)*(M1-M2) %求最有投影方向% wT=w.'; for i=1:l1 Y1(i)=wT(1,1)*A(1,i)+wT(1,2)*A(2,i); %由分类函数g(x)=wT*x求男生身高和体重的阈值% end for i=1:l2 Y2(i)=wT(1,1)*B(1,i)+wT(1,2)*B(2,i); %由分类函数g(x)=wT*x求女生身高和体重的阈值% end m1=sum(Y1)/l1; %阈值平均% m2=sum(Y2)/l2; %阈值平均% threshold=(l1*m1+l2*m2)/(l1+l2) %求fisher决策面的阈值%
贝叶斯实验报告
HUNAN UNIVERSITY 人工智能实验报告 题目实验三:分类算法实验 学生姓名匿名 学生学号2013080702xx 专业班级智能科学与技术1302班 指导老师袁进 一.实验目的 1.了解朴素贝叶斯算法的基本原理; 2.能够使用朴素贝叶斯算法对数据进行分类 3.了解最小错误概率贝叶斯分类器和最小风险概率贝叶斯分类器 4.学会对于分类器的性能评估方法 二、实验的硬件、软件平台 硬件:计算机 软件:操作系统:WINDOWS 10 应用软件:C,Java或者Matlab 相关知识点: 贝叶斯定理: 表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率,其基本求解公式为:
贝叶斯定理打通了从P(A|B)获得P(B|A)的道路。 直接给出贝叶斯定理: 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。 朴素贝叶斯分类的正式定义如下: 1、设为一个待分类项,而每个a为x的一个特征属性。 2、有类别集合。 3、计算。 4、如果,则。 那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做: 1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2、统计得到在各类别下各个特征属性的条件概率估计。即 3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: 因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
Matlab 使用之线性代数综合实例讲解
一、上机目的 1、培养学生运用线性代数的知识解决实际问题的意识、兴趣和能力; 2、掌握常用计算方法和处理问题的方法; 二、上机内容 1、求向量组的最大无关组; 2、解线性方程组; 三、上机作业 1、设A=[2 1 2 4; 1 2 0 2; 4 5 2 0; 0 1 1 7]; 求矩阵A列向量组的一个最大无关组. >> A=[2 1 2 4;1 2 0 2;4 5 2 0;0 1 1 7] A = 2 1 2 4 1 2 0 2 4 5 2 0 0 1 1 7 >> rref(A) ans = 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 所以矩阵A的列向量组的一个最大无关组就是它本身; 2、用Matlab解线性方程组 (1) >> A=[2 4 -6;1 5 3;1 3 2] A = 2 4 -6 1 5 3 1 3 2 >> b=[-4;10;5]
b = -4 10 5 >> x=inv(A)*b x = -3.0000 2.0000 1.0000 >> B=[3 41 -62;4 50 3;11 38 25] B = 3 41 -62 4 50 3 11 38 25 >> c=[-41;100;50] c = -41 100 50 >> x=inv(B)*c x = -8.8221 2.5890 1.9465 3、(选作)减肥配方的实现 设三种食物每100克中蛋白质、碳水化合物和脂肪的含量如下表,表中还给出了20世纪80年代美国流行的剑桥大学医学院的简捷营养处方。现在的问题是:如果用这三种食物作为每天的主要食物,那么它们的用量应各取多少才能全面准确地实现这个营养要求? 四、上机心得体会
matlab实验二
实验2 MATLAB数值计算、符号运算功能 一、实验目的 1、掌握建立矩阵、矩阵分析与处理的方法。 2、掌握线性方程组的求解方法。 3、掌握数据统计和分析方法、多项式的常用运算。 4、掌握求数值导数和数值积分、常微分方程数值求解、非线性代数方程数值求解的方法。 5、掌握定义符号对象的方法、符号表达式的运算法则及符号矩阵运算、符号函数极限及导数、符号函数定积分和不定积分的方法。 二、预习要求 (1)复习4、5、6章所讲内容; (2)熟悉MATLAB中的数值计算和符号运算的实现方法和主要函数。 三、实验内容 1、已知 29618 20512 885 A -?? ?? =?? ?? - ?? ,求A的特征值及特征向量,并分析其数学意义。 >> A=[-29,6,18;20,5,12;-8,8,5]; >> [V,D]=eig(A) V = 0.7130 0.2803 0.2733 -0.6084 -0.7867 0.8725 0.3487 0.5501 0.4050 D = -25.3169 0 0 0 -10.5182 0 0 0 16.8351 V为A的特征向量,D为A的特征值,3个特征值是-25.3169、10.5182和16.8351。 >> A*V ans = -18.0503 -2.9487 4.6007 15.4017 8.2743 14.6886 -8.8273 -5.7857 6.8190 >> V*D
ans = -18.0503 -2.9487 4.6007 15.4017 8.2743 14.6886 -8.8273 -5.7857 6.8190 经过计算,A*V=V*D 。 2、 不用rot90函数,实现方阵左旋90°或右旋90°的功能。例如,原矩阵为A ,A 左旋后得到B ,右旋后得到C 。 147102581136912A ????=??????,101112789456123B ??????=??????,321654987121110B ??????=?????? 提示:先将A 转置,再作上下翻转,则完成左旋90°;如将A 转置后作左右翻转,则完成右旋转90°,可用flipud 、fliplr 函数。 >> a=[1 4 7 10;2 5 8 11;3 6 9 12] a= 1 4 7 10 2 5 8 11 3 6 9 12 >> B=rot90(a) B = 10 11 12 7 8 9 4 5 6 1 2 3 >>C= rot90(s,3) C= 3 2 1 6 5 4 9 8 7 12 11 10
Bayes分类器设计
实验一 Bayes 分类器设计 【实验目的】 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。 【实验条件】 Matlab 软件 【实验原理】 根据贝叶斯公式,给出在类条件概率密度为正态分布时具体的判别函数表达式,用此判别函数设计分类器。数据随机生成,比如生成两类样本(如鲈鱼和鲑鱼),每个样本有两个特征(如长度和亮度),每类有若干个(比如50个)样本点,假设每类样本点服从二维正态分布,随机生成具体数据,然后估计每类的均值与协方差,在下列各种情况下求出分类边界。先验概率自己给定,比如都为0.5。如果可能,画出在两类协方差不相同的情况下的分类边界。 若第一类的样本为{}12,,n x x x ,则第一类均值的估计为1 1?n k k x n μ==∑,协方差的估计为1 1???()()n T k k k x x n μμ=∑=--∑。则在两类协方差不相同的情况下的判别函数为: 判别边界为g1(x)-g2(x)=0,是一条一般二次曲线(可能是椭圆、双曲线、抛物线等)。 【实验内容】 1、 自动随机生成两类服从二维正态分布的样本点 2、 计算两类样本的均值和协方差矩阵 3、 按照两类协方差不相同情况下的判别函数,求出判别方程曲线。 4、 通过修改不同的参数(均值、方差、协方差矩阵),观察判别方程曲线的变化。 【实验程序】 clear all; close all;
samplenum = 50;%样本的个数 n1(:,1) = normrnd(8,4,samplenum,1);%产生高斯分布的二维随机样本,第一个参数为均值,第二个为方差 n1(:,2) = normrnd(6,4,samplenum,1);%产生高斯分布的二维随机样本,第一个参数为均值,第二个为方差 n2(:,1) = normrnd(14,4,samplenum,1);%产生高斯分布的二维随机样本,第一个参数为均值,第二个为方差 n2(:,2) = normrnd(16,4,samplenum,1);%产生高斯分布的二维随机样本,第一个参数为均值,第二个为方差 scatter(n1(1:samplenum,1),n1(1:samplenum,2),'ro');%画出样本 hold on scatter(n2(1:samplenum,1),n2(1:samplenum,2),'g*');%画出样本 u1 = mean(n1);%计算第一类样本的均值 e1=0; for i=1:20 e1 = e1+(n1(i,:)-u1)'*(n1(i,:)-u1);%计算协方差矩阵 end; u2 = mean(n2);%计算第二类样本的均值 e2=0; for i=1:20 e2 = e2+(n2(i,:)-u2)'*(n2(i,:)-u2);%计算协方差矩阵 end; e2=e2/20;%计算协方差矩阵 e1=e1/20;%计算协方差矩阵 %-------------通过改变条件来完成不同的曲线--------- % e2 = e1; %-------------------------------------------------- u1 = u1'; u2 = u2'; scatter(u1(1,1),u1(2,1),'b+');%画出样本中心 scatter(u2(1,1),u2(2,1),'b+');%画出样本中心 line([u1(1,1),u2(1,1)],[u1(2,1),u2(2,1)]); %画出样本中心连线 %求解分类方程 W1=-1/2*inv(e1); w1=inv(e1)*u1; w10=-1/2*u1'*inv(e1)*u1-1/2*log(det(inv(e1)))+log(0.5);%假设w1的先验概率为0.5 W2=-1/2*inv(e2); w2=inv(e2)*u2; w20=-1/2*u2'*inv(e2)*u2-1/2*log(det(inv(e2)))+log(0.5);% 假设w2的先验概率为0.5 syms x y; fn = [x,y]*(W1-W2)*[x,y]'+(w1-w2)'*[x,y]'+w10-w20; ezplot(fn,[0,30]);
Matlab线性代数实验指导书
Matlab线性代数实验指导书 理学院线性代数课程组 二零零七年十月
目录 一、基础知识 (1) 1.1、常见数学函数 (1) 1.2、系统在线帮助 (1) 1.3、常量与变量 (2) 1.4、数组(矩阵)的点运算 (3) 1.5、矩阵的运算 (3) 二、编程 (4) 2.1、无条件循环 (4) 2.2、条件循环 (5) 2.3、分支结构 (5) 2.4、建立M文件 (6) 2.5、建立函数文件 (6) 三、矩阵及其运算 (7) 3.1、矩阵的创建 (7) 3.2、符号矩阵的运算 (11) 四、秩与线性相关性 (14) 4.1、矩阵和向量组的秩以及向量组的线性相关性 (14) 4.2、向量组的最大无关组 (14) 五、线性方程的组的求解 (16) 5.1、求线性方程组的唯一解或特解(第一类问题) (16) 5.2、求线性齐次方程组的通解 (18) 5.3、求非齐次线性方程组的通解 (19) 六、特征值与二次型 (22) 6.1、方阵的特征值特征向量 (22) 6.2、正交矩阵及二次型 (23)
一、基础知识 1.1常见数学函数 函数数学计算功能函数数学计算功能 abs(x) 实数的绝对值或复数的幅值floor(x) 对x朝-∞方向取整acos(x) 反余弦arcsinx gcd(m,n) 求正整数m和n的最大公约数acosh(x) 反双曲余弦arccoshx imag(x) 求复数x的虚部angle(x) 在四象限内求复数x的相角lcm(m,n)求正整数m和n的最小公倍 自然对数(以e为底数) asin(x) 反正弦arcsinx log(x) 常用对数(以 10 为底数) asinh(x) 反双曲正弦arcsinhx log10(x) atan(x) 反正切arctanx real(x) 求复数 x 的实部atan2(x,y) 在四象限内求反正切rem(m,n) 求正整数m和n的m/n之余数atanh(x) 反双曲正切arctanhx round(x) 对x四舍五入到最接近的整数 符号函数:求出 x 的符号ceil(x) 对x朝+∞方向取整 sign(x) conj(x) 求复数x的共轭复数 sin(x) 正弦sinx 反双曲正弦sinhx cos(x) 余弦cosx sinh(x) cosh(x) 双曲余弦coshx sqrt(x) 求实数x的平方根exp(x) 指数函数e x tan(x) 正切tanx fix(x) 对 x 朝原点方向取整 tanh(x) 双曲正切tanhx 如:输入 x=[-4.85 -2.3 -0.2 1.3 4.56 6.75],则: ceil(x)= -4 -2 0 2 5 7 fix(x) = -4 -2 0 1 4 6 floor(x) =-5 -3 -1 1 4 6 round(x) = -5 -2 0 1 5 7 1.2 系统的在线帮助 1.2.1 help 命令: 1.当不知系统有何帮助内容时,可直接输入 help以寻求帮助: >> help(回车) 2.当想了解某一主题的内容时,如输入: >> help syntax (了解Matlab的语法规定) 3.当想了解某一具体的函数或命令的帮助信息时,如输入: >> help sqrt (了解函数sqrt的相关信息) 1.2.2 lookfor 命令 现需要完成某一具体操作,不知有何命令或函数可以完成,如输入: >> lookfor line (查找与直线、线性问题有关的函数) 1.3 常量与变量
matlab-线性分类器的设计doc
线性分类器设计 1 问题描述 对“data1.m ”数据,分别采用感知机算法、最小平方误差算法、线性SVM 算法设计分类器,分别画出决策面,并比较性能。(注意讨论算法中参数设置的影响。) 2 方法描述 2.1 感知机算法 线性分类器的第一个迭代算法是1956年由Frank Rosenblatt 提出的,即具有自学习能力的感知器(Perceptron )神经网络模型,用来模拟动物或者人脑的感知和学习能力。这个算法被提出后,受到了很大的关注。感知器在神经网络发展的历史上占据着特殊的位置:它是第一个从算法上完整描述的神经网络,是一种具有分层神经网络结构、神经元之间有自适应权相连接的神经网络的一个基本网络。 感知器的学习过程是不断改变权向量的输入,更新结构中的可变参数,最后实现在有限次迭代之后的收敛。感知器的基本模型结构如图1所示: 图1 感知器基本模型 其中,X 输入,Xi 表示的是第i 个输入;Y 表示输出;W 表示权向量;w0是阈值,f 是一个阶跃函数。 感知器实现样本的线性分类主要过程是:特征向量的元素x1,x2,……,xk 是网络的输入元素,每一个元素与相应的权wi 相乘。,乘积相加后再与阈值w0相加,结果通过f 函数执行激活功能,f 为系统的激活函数。因为f 是一个阶跃函数,故当自变量小于0时,f= -1;当自变量大于0时,f= 1。这样,根据输出信号Y ,把相应的特征向量分到为两类。 然而,权向量w 并不是一个已知的参数,故感知器算法很重要的一个步骤即是寻找一个合理的决策超平面。故设这个超平面为w ,满足: 12 *0,*0,T T w x x w x x ωω>?∈
贝叶斯分类实验报告doc
贝叶斯分类实验报告 篇一:贝叶斯分类实验报告 实验报告 实验课程名称数据挖掘 实验项目名称贝叶斯分类 年级 XX级 专业信息与计算科学 学生姓名 学号 1207010220 理学院 实验时间: XX 年 12 月 2 日 学生实验室守则 一、按教学安排准时到实验室上实验课,不得迟到、早退和旷课。 二、进入实验室必须遵守实验室的各项规章制度,保持室内安静、整洁,不准在室内打闹、喧哗、吸烟、吃食物、随地吐痰、乱扔杂物,不准做与实验内容无关的事,非实验用品一律不准带进实验室。 三、实验前必须做好预习(或按要求写好预习报告),未做预习者不准参加实验。四、实验必须服从教师的安排和指导,认真按规程操作,未经教师允许不得擅自动用仪器设备,特别是与本实验无关的仪器设备和设施,如擅自动用
或违反操作规程造成损坏,应按规定赔偿,严重者给予纪律处分。 五、实验中要节约水、电、气及其它消耗材料。 六、细心观察、如实记录实验现象和结果,不得抄袭或随意更改原始记录和数据,不得擅离操作岗位和干扰他人实验。 七、使用易燃、易爆、腐蚀性、有毒有害物品或接触带电设备进行实验,应特别注意规范操作,注意防护;若发生意外,要保持冷静,并及时向指导教师和管理人员报告,不得自行处理。仪器设备发生故障和损坏,应立即停止实验,并主动向指导教师报告,不得自行拆卸查看和拼装。 八、实验完毕,应清理好实验仪器设备并放回原位,清扫好实验现场,经指导教师检查认可并将实验记录交指导教师检查签字后方可离去。 九、无故不参加实验者,应写出检查,提出申请并缴纳相应的实验费及材料消耗费,经批准后,方可补做。 十、自选实验,应事先预约,拟订出实验方案,经实验室主任同意后,在指导教师或实验技术人员的指导下进行。 十一、实验室内一切物品未经允许严禁带出室外,确需带出,必须经过批准并办理手续。 学生所在学院:理学院专业:信息与计算科学班级:信计121
主观贝叶斯实验报告
主观贝叶斯实验报告 学生姓名 程战战 专业/班级 计算机91 学 号 09055006 所在学院 电信学院 指导教师 鲍军鹏 提交日期 2012/4/26
根据初始证据E 的概率P (E )及LS 、LN 的值,把H 的先验概率P (H )更新为后验概率P (H/E )或者P(H/!E)。在证据不确定的情况下,用户观察到的证据具有不确定性,即0 作业6 编程题实验报告 (一)实验内容: 编程实现朴素贝叶斯分类器,假设输入输出都是离散变量。用讲义提供的训练数据进行试验,观察分类器在 121.x x m ==时,输出如何。如果在分类器中加入Laplace 平滑(取?=1) ,结果是否改变。 (二)实验原理: 1)朴素贝叶斯分类器: 对于实验要求的朴素贝叶斯分类器问题,假设数据条件独立,于是可以通过下式计算出联合似然函数: 12(,,)()D i i p x x x y p x y =∏ 其中,()i p x y 可以有给出的样本数据计算出的经验分布估计。 在实验中,朴素贝叶斯分类器问题可以表示为下面的式子: ~1*arg max ()()D i y i y p y p x y ==∏ 其中,~ ()p y 是从给出的样本数据计算出的经验分布估计出的先验分布。 2)Laplace 平滑: 在分类器中加入Laplace 平滑目的在于,对于给定的训练数据中,有可能会出现不能完全覆盖到所有变量取值的数据,这对分类器的分类结果造成一定误差。 解决办法,就是在分类器工作前,再引入一部分先验知识,让每一种变量去只对应分类情况与统计的次数均加上Laplace 平滑参数?。依然采用最大后验概率准则。 (三)实验数据及程序: 1)实验数据处理: 在实验中,所用数据中变量2x 的取值,对应1,2,3s m I === 讲义中所用的两套数据,分别为cover all possible instances 和not cover all possible instances 两种情况,在实验中,分别作为训练样本,在给出测试样本时,输出不同的分类结果。 2)实验程序: 比较朴素贝叶斯分类器,在分类器中加入Laplace 平滑(取?=1)两种情况,在编写matlab 函数时,只需编写分类器中加入Laplace 平滑的函数,朴素贝叶斯分类器是?=0时,特定的Laplace 平滑情况。 实现函数:[kind] =N_Bayes_Lap(X1,X2,y,x1,x2,a) 输入参数:X1,X2,y 为已知的训练数据; x1,x2为测试样本值; a 为调整项,当a=0时,就是朴素贝叶斯分类器,a=1时,为分类器中加入Laplace 平滑。 输出结果:kind ,输出的分类结果。 第一次练习 教学要求:熟练掌握Matlab 软件的基本命令和操作,会作二维、三维几何图形,能够用Matlab 软件解决微积分、线性代数与解析几何中的计算问题。 补充命令 vpa(x,n) 显示x 的n 位有效数字,教材102页 fplot(‘f(x)’,[a,b]) 函数作图命令,画出f(x)在区间[a,b]上的图形 在下面的题目中m 为你的学号的后3位(1-9班)或4位(10班以上) 1.1 计算30sin lim x mx mx x →-与3 sin lim x mx mx x →∞- syms x limit((902*x-sin(902*x))/x^3) ans = 366935404/3 limit((902*x-sin(902*x))/x^3,inf) ans = 0 1.2 cos 1000 x mx y e =,求''y syms x diff(exp(x)*cos(902*x/1000),2) ans = (46599*cos((451*x)/500)*exp(x))/250000 - (451*sin((451*x)/500)*exp(x))/250 1.3 计算 22 11 00 x y e dxdy +?? dblquad(@(x,y) exp(x.^2+y.^2),0,1,0,1) ans = 2.1394 1.4 计算4 2 2 4x dx m x +? syms x int(x^4/(902^2+4*x^2)) ans = (91733851*atan(x/451))/4 - (203401*x)/4 + x^3/12 1.5 (10)cos ,x y e mx y =求 syms x diff(exp(x)*cos(902*x),10) ans = -356485076957717053044344387763*cos(902*x)*exp(x)-3952323024277642494822005884*sin(902*x)*exp(x) 1.6 0x =的泰勒展式(最高次幂为4). 用Matlab学习线性代数__行列式 实验目的理解行列式的概念、行列式的性质与计算 Matlab函数det 实验内容 前面的四个练习使用整数矩阵,并演示一些本章讨论的行列式的性质。最后两个练习演示我们使用浮点运算计算行列式时出现的不同。 理论上将,行列式的值应告诉我们矩阵是否是奇异的。然而,如果矩阵是奇异的,且计算其行列式采用有限位精度运算,那么由于舍入误差,计算出的行列式的值也许不是零。一个计算得到的行列式的值很接近零,并不能说明矩阵是奇异的甚至是接近奇异的。此外,一个接近奇异的矩阵,它的行列式值也可能不接近零。 1.用如下方法随机生成整数元素的5阶方阵: A=round(10*rand(5)) 和B=round(20*rand(5))-10 用Matlab计算下列每对数。在每种情况下比较第一个是否等于第二个。(1)det(A) ==det(A T) (2)det(A+B) ;det(A)+det(B) (3)det(AB)==det(A)det(B) (4)det(A T B T) ==det(A T)det(B T) (5)det(A-1)==1/det(A) (6)det(AB-1)==det(A)/det(B) > A=round(10*rand(5)); >> B=round(20*rand(5))-10; >> det(A) ans = 5972 >> det(A') ans 5972 >> det(A+B) ans = 36495 >> det(A)+det(B) ans = 26384 >> det(A*B) ans = 4 >> det(A)*det(B) ans = 4 >> det(A'*B') ans = 4 >> det(A')*det(B') ans = 4 >> det(inv(A)) ans = 0.00016745 >> 1/det(A) ans = 0.00016745 >> det(A*inv(B)) ans = 0.29257 >> det(A)/det(B) ans = 0.29257 >> 2.n阶的幻方阵是否奇异?用Matlab计算n=3、4、5、…、10时的det(magic(n))。看起来发生了什么?验证当n=24和25时,结论是否仍然成立。【当n为奇数时,det(magic(n))不为0;当n为偶数时,det(magic(n))为0;】>> det(magic(3)) ans = -360 >> det(magic(4)) ans = >> det(magic(5)) ans = 5070000 基于Fisher准则线性分类器设计 专业:电子信息工程 学生:子龙 学号:201316040117 一、实验类型 设计型:线性分类器设计(Fisher 准则) 二、实验目的 本实验旨在让同学进一步了解分类器的设计概念,能够根据自己的设计对线性分类器有更深刻地认识,理解Fisher 准则方法确定最佳线性分界面方法的原理,以及Lagrande 乘子求解的原理。 三、实验条件 matlab 软件 四、实验原理 线性判别函数的一般形式可表示成 0)(w X W X g T += 其中 ????? ??=d x x X Λ1?????? ? ??=d w w w W Λ21 根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类样本投影尽可能密集的要求,用以评价投影方向W 的函数为: 2 2 2122 1~~)~~()(S S m m W J F +-= )(211 *m m S W W -=- 上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。另外,该式这种 形式的运算,我们称为线性变换,其中21m m -式一个向量,1 -W S 是W S 的逆矩阵,如21m m -是d 维,W S 和1-W S 都是d ×d 维,得到的* W 也是一个d 维的向量。 向量* W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量* W 的各分量值是对原d 维特征向量求加权和的权值。 以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量* W 的计算方法,但是判别函数中的另一项0W 尚未确定,一般可采用以下几种方法确定0W 如 2 ~~2 10m m W +-= 或者 m N N m N m N W ~~~2 12 2110=++- = 或当1)(ωp 与2)(ωp 已知时可用 []??????-+-+=2)(/)(ln 2 ~~212 1210N N p p m m W ωω …… 当W 0确定之后,则可按以下规则分类, 2 010ωω∈→->∈→->X w X W X w X W T T 使用Fisher 准则方法确定最佳线性分界面的方法是一个著名的方法,尽管提出该方法的时间比较早,仍见有人使用。 五、实验容 已知有两类数据1ω和2ω二者的概率已知1)(ωp =0.6,2)(ωp =0.4。 1ω中数据点的坐标对应一一如下: 《模式识别》实验报告 ---最小错误率贝叶斯决策分类 一、实验原理 对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为 11 22 11()exp ()()2(2)T d p π-??=--∑-???? ∑x x μx μ 式中,12,,,d x x x ????=x 是d 维行向量,12,,,d μμμ????=μ 是d 维行向量,∑是d d ?维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。 本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数 ()(|)(), 1,2,3i i i g p P i ωω==x x (3个类别) 其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。 由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。 我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为 112 2 ()1()exp ()(),1,2,32(2)T i i d P g i ωπ-?? = -∑=???? ∑ x x -μx -μ 对上式右端取对数,可得 111()()()ln ()ln ln(2)222 T i i i i d g P ωπ-=-∑+-∑-i i x x -μx -μ 上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。则判别函数()i g x 可简化为以下形式 111 ()()()ln ()ln 22 T i i i i g P ω-=-∑+-∑i i x x -μx -μ 合肥学院 2018—2019学年第2学期 线性代数及应用 (模块) 实验报告 实验名称:线性代数MATLAB实验 实验类别:综合性 设计性□验证性 专业班级: 17通信工程(2)班 实验时间: 9-12周 组别:第组人数 3人 指导教师:牛欣成绩: 完成时间: 2019年 5 月9日 一. 小组成员 姓名学号具体分工 汪蔚蔚(组长) 1705022025 A报告最后的整合,编写,案例四的计算与应用 以及案例一的计算与证明 陶乐 1 1705022009 C案例二,化学方程式配平问题 程赢妹1505022036 A案例三,应用题灰度值的计算问题 二. 实验目的 1、案例一利用MATLAB进行线性代数计算,求出矩阵B 2、案例二利用MATLAB计算出每一个网格数据的值,然后每一个网格数据的值乘以256以后进行归一化处理,根据每个网格中的灰度值,绘制出灰度图像。 3、案例三利用MATLAB完成对化学方程式进行配平的应用 4、案例四利用MATLAB求极大线性无关组,并表示出其余向量 三. 实验内容 1、案例一: 0,1,0 ,=1,0,0, 0,0,0 A B AB BA A B ?? ?? =?? ?? ?? 已知矩阵和矩阵满足乘法交换律,即且求矩阵。 2、案例二 配平下列化学方程式: 3、案例三: 3*32 0.81.21.70.20.3 0.6021.61.20.6. 1MATLAB 2256MATLAB 给定一个图像的个方向上的灰度叠加值:沿左上方到右 下方的灰度叠加值依次为,,,,;沿右上方到左下 方的灰度叠加值依次为,。,,, )建立可以确定网络数据的线性方程组,并用求解 )将网络数据乘以,再取整,用绘制该灰度图像统计学习_朴素贝叶斯分类器实验报告
南邮MATLAB数学实验答案(全)
用Matlab学习线性代数_行列式
基于-Fisher准则线性分类器设计
《模式识别》实验报告-贝叶斯分类
线性代数MATLAB仿真实验报告