贪心算法概论

贪心算法概论
贪心算法一般来说是解决“最优问题”,具有编程简单、运行效率高、空间
复杂度低等特点。是信息学竞赛中的一个有为武器,受到广大同学们的青睐。本
讲就贪心算法的特点作些概念上的总结。
一、贪心算法与简单枚举和动态规划的运行方式比较
贪心算法一般是求“最优解”这类问题的。最优解问题可描述为:有n个输入,它的解是由这n 个输入的某个子集组成,并且这个子集必须满足事先给定的条
件。这个条件称为约束条件。而把满足约束条件的子集称为该问题的可行解。这
些可行解可能有多个。为了衡量可行解的优劣,事先给了一个关于可行解的函数,称为目标函数。目标函数最大(或最小)的可行解,称为最优解。
a)求“最优解”最原始的方法为搜索枚举方案法(一般为回溯法)。
除了极简单的问题,一般用深度优先搜索或宽度优先搜索。通常优化方法为利用约束条件进行可行性判断剪枝;或利用目标函数下界(或上界),根据当前最
优解进行分枝定界。
b)其次现今竞赛中用的比较普遍的动态规划(需要满足阶段无后效性原则)。
动态规划主要是利用最最优子问题的确定性,从后向前(即从小规模向大规模)得到当前最优策略,从而避免了重复的搜索。
举例说明:求多段图的最短路径。
在图(1)中,我们省略了各线段的长度。
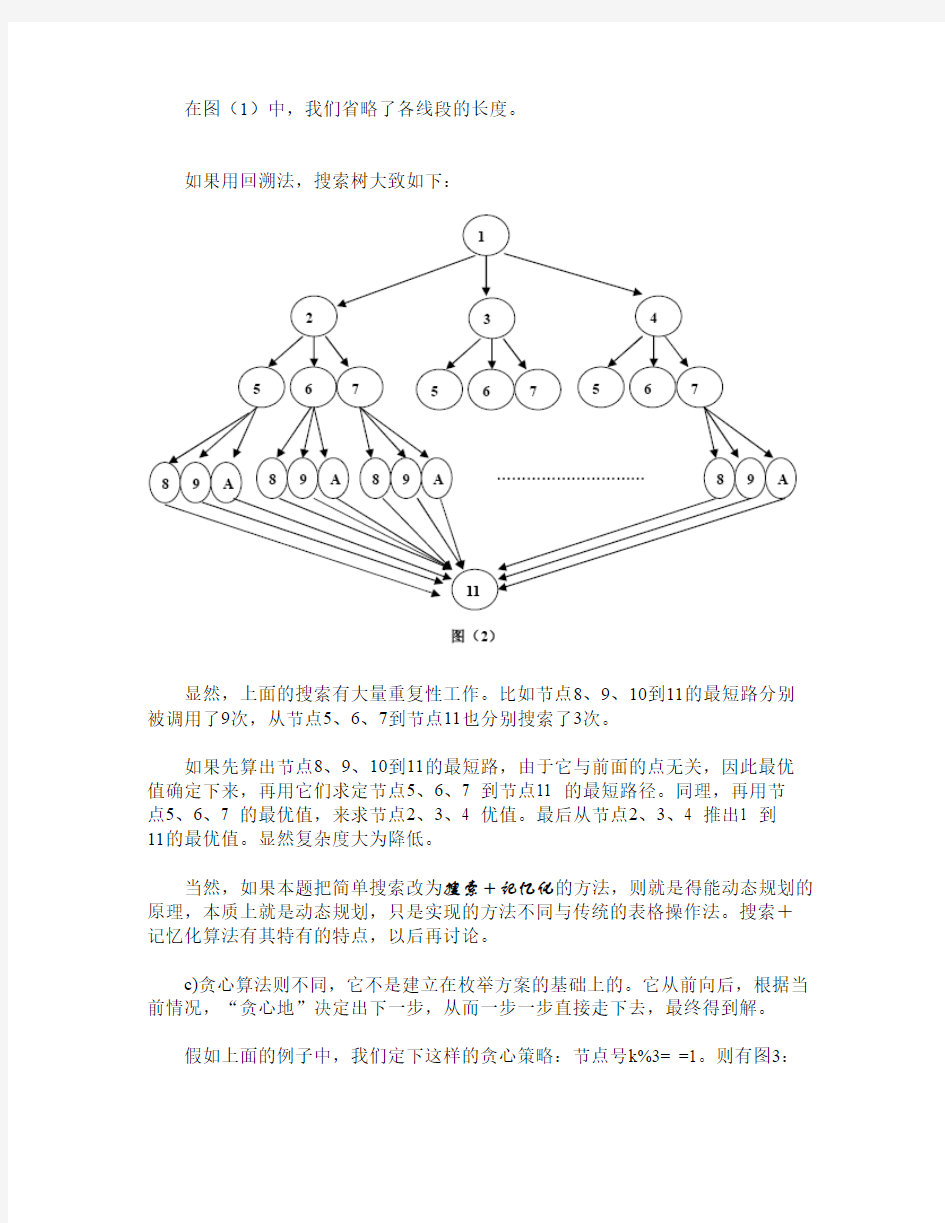
如果用回溯法,搜索树大致如下:
显然,上面的搜索有大量重复性工作。比如节点8、9、10到11的最短路分别被调用了9次,从节点5、6、7到节点11也分别搜索了3次。
如果先算出节点8、9、10到11的最短路,由于它与前面的点无关,因此最优值确定下来,再用它们求定节点5、6、7 到节点11 的最短路径。同理,再用节
点5、6、7 的最优值,来求节点2、3、4 优值。最后从节点2、3、4 推出1 到
11的最优值。显然复杂度大为降低。
当然,如果本题把简单搜索改为搜索+记忆化的方法,则就是得能动态规划的原理,本质上就是动态规划,只是实现的方法不同与传统的表格操作法。搜索+记忆化算法有其特有的特点,以后再讨论。
c)贪心算法则不同,它不是建立在枚举方案的基础上的。它从前向后,根据当前情况,“贪心地”决定出下一步,从而一步一步直接走下去,最终得到解。
假如上面的例子中,我们定下这样的贪心策略:节点号k%3= =1。则有图3:
显然,它只访问了节点1、4、7、10、11,工作量最少,效率最高。当然,对本题来说,它不能得到最优解―――最短路径。
从图3中可以看出,贪心算法是一种比动态规划更高效的算法。只是要保证得到最优解是贪心算法的关键。
贪心算法的一般框架为:
Procedure Greedy(A,n)//A问题有n个输入
Begin
Init(ans) //初始化
for i:=1 to n do
now=select(A) //按设计的标准选取一个“节点”
delete(A,now) //把A中的now删掉
if can(ans,now) then unio(ans,now) //如果可行性通过,放入解中。
end for
end;
二、贪心算法的关键――――正确性证明
动态规划要满足最优子结构原则,贪心算法呢?就目前的资料看,有个证明模型是“矩阵胚理论”,但要证明一个问题是矩阵胚,十分困难。并且也不常见
的可用贪心算法问题都能用矩阵胚来证明。因此,可以认为贪心算法的正确性证明是个难点。因此有些选手在没能证明时,也大胆设想结论应该是正确的。有时这难免会放错。
例如95年NOI中的“石子合并”一题:
例一、石子合并
试题:
在一个圆形操场的四周摆放N 堆石子(N≤100),现要将石子有次序地合并成一堆。规定每次只能选相邻的两堆合并成新的一堆,并将新的一堆的石子数,记为该次合并的得分。
编一程序,由文件读入堆数N 及每堆石子数(≤20)
选择一种合并石子的方案,使得做N-1 次合并,得分的总
和最小;选择一种合并石子的方案,使得做N-1 次合并,
得分的总和最大。
例如,图4所示的4堆石,每堆石子数(从最上面的
一堆数起,顺时针数)依次为4594。则3次合并得分总和
最小的方案为图5,得分总和最大的方案为图6。
输入数据
文件名由键盘输入,该文件内容为:
第1行为石子堆数N;
第2行为每堆石子数,每两个数之间用一个空格符分隔。
输出数据
输出文件名为output.txt ;
从第1 至第N 行为得分最小的合并方案。第N+1 行是空行。从第N+2 行 到第2N+1行是得分最大合并方案。
每种合并方案用N 行表示,其中第i 行(1≤i ≤N)表示第i 次合并前各堆石 子数(依顺时针次序输出,哪一堆先输出均可)。要求将待合并的两堆石子数以相 应的负数表示,以便标识。
输入输出示例:
当时这题是第一次出现,几乎有半数以上人都选择了贪心算法―――每次选 相邻和最小的两堆石子合并。
其实由于只能是相邻的两堆石子合并,并不能套用经典的哈夫曼树算法。本 题给的样例数据实际上是一个“陷阱”,造成了用贪心法即可解决的假象。
当一个贪心算法不能确定其正确性时,在使用之前,应该努力去证明它的不 正确性。而要证明不正确性,一种最简单的形式就是举一个反例。本例的反例见 图7。
常见的证明方法:
贪心算法的正确性证明虽然不容易,但一些常见的方法还是值得总结的。
a) 构造法
贪心算法的最小值为: (2+3)=5 (4+5)=9 (4+5)=9 (9+6)=15 (15+9)=24
5+9+9+15+24=62
另一种方法的最小值为: (2+4)=6 (3+4)=7 (5+6)=11 (7+6)=13 (11+13)=24
6+7+11+13+24=61
根据描述的算法,用贪心的策略,依次构造出一个解,可证明一定是
合法的解。即用贪心法找可行解。
b) 反证法
用贪心的策略,依次构造出一个解S1。假设最优解S2不同与S1,可
以证明是矛盾的。从而S1就是最优解。
c) 调整法
用贪心的策略,依次构造出一个解S1。假设最优解S2不同与S1,找
出不同之处,在不破坏最优性的前提下,逐步调整S2,最终使其变为S1。
从而S1也是最优解。
下面分别举例说明。
例2 士兵排队问题(1996 年中国队选拔赛)----构造法证明
试题:
有N 个士兵(1≤N≤26),编号依次为A,B,C,...。队列训练时,指挥官要把一些士兵从高到矮依次排成一行,但现在指挥官不能直接获得每个人的身高信息,只能获得“P1比P2高”这样的比较结果(P1,P2∈A,B,C,...,Z,记为P1>P2),如“A>B”表示A 比B高。
请编一程序,根据所得到的比较结果求出一种符合条件的排队方案。
注:比较结果中没有涉及到的士兵不参加排队
输入数据
比较结果从文本文件中读入(文件名由键盘输入),每个比较结果在文本文
件中占一行。
输出要求
若输入数据无解,打印“No Answer!”信息,否则从高到矮依次输出每一个士兵的编号,中间无分隔符,并把结果写入文本文件中,文件名由键盘输入。
输入输出示例
INPUT.TXT OUTPUT.TXT
A>B AFBD
B>D
F>D
显然用每次选“偏序中最高士兵”的贪心算法就可构造出一个可行解。这个
问题转就是“拓扑排序”问题。可这样证明:如果有解,就一定无环,因此每步贪心都一定能进行下去。
经典的“找欧拉回路”问题也类似。
例3 排队问题----反证法证明
试题:
在一个超市,有N 个人排队到一个柜台付款,已知每个人需要处理的时间为
Ti(0 输入数据 文本文件中第一行为一个正整数N≤10000,第二行有N个不超过1000的正整数Ti。 输出要求 只一个正整数:大家排队时间的最小总和。 输入输出示例 INPUT.TXT OUTPUT.TXT 4 67 5 10 8 7 本题的贪心算法为:N个数据从小到大排序,就是这N个人的最佳排序方案。求部分和的和即可得到答案。 反证法证明如下: 假设有最优解序列S1,S2,S3….,Sn,如果S1 不是最小的Tmin,不妨设 Sk=Tmin,将S1 与Sk对调。显然对Sk之后的人没影响,对Sk之前的人等待时 间都减少了(S1-Sk)>0。从而新的序列比原最优解序列好,矛盾! 固S1为最小时间。 同理可证S2是第二小的数,……。 证毕。 下面的调整法也有类似的思想,只是侧重点在“这样调整不会差”。 例4 切巧克力问题----调整法证明 试题 我们提供给你一块m*n 的巧克力(如图8 所示),你需要将这块巧克力切割成1*1 的单位巧克力。 具体来说,对于一块巧克力,你有两种切割的方法。一种是沿着某条竖线将巧克力切成两块,另外一种自然是沿着某条横线将巧克力切成两块。切割需要一定的花费,费用的计算与所切割的巧克力的大小没有关系,而只于沿着哪条线切割有关。我们将沿着横线切割的费用定义为y1、y2、……、y m-1;同样的,将沿着竖线切割的费用定义为x1、x2、……、x n-1。 现在,需要你计算的就是,怎样切才能使总费用最少? 在图8 中,如果我们先沿着横线将整块巧克力切成四块,然后对于每一小块,分别沿着竖线切割,那么总共的费用就是y1+ y 2+ y3+ ( x1+ x2+ x3+ x4) ? 4。 【输入格式】 输入文件chocolate.in 的第一行包含两个整数n,m(1 ≤ n,m ≤ 1000),表示巧克力的大 小。接下来的n-1行每行包含一个整数,分别表示沿竖线切割的费用(上图中x1,x2,……),接下来的m-1行也是每行包含一个整数,表示沿横线切割的费用(上图中的y1,y2,……)【输出格式】 输出文件chocolate.out 应该包含一个整数,表示你得到的最小切割费用。 样例输入样例输出 6 4 42 2 1 3 1 4 4 1 2 分析: 不妨设,Xi已经从大到小排序;Yi也同样。 如果把问题简化,只有横的切Xi或只有竖的切Yi,则显然和排队问题是一样的,可以用贪心算法。横、竖可以交错切呢? 对任意一种方案,只看其中横切的Xi 序列,如果不是从大到小排列,找到第一个违反有序原则的,设为Xp,找出应该在这个位置的――即后面不小于Xp 的Xq,把Xp与Xq对调,显然新方案会更好。如此,有 结论一: 任意最优方案在不改变竖切次序前提下,可调整成横切是有序的最优解。 同理,有 结论二: 任意最优方案在不改变横切次序前提下,可调整成竖切是有序的最优解。 综合结论一和结论二,有 结论三: 任意一种最优方案,可调整成横切、竖切都有序的最优解。 如此,可简单得到动态规划算法,时空复杂度约为O(106)。 上面虽然用了贪心算法的反证法解决了问题,但没有将贪心算法思想进行到底。我们可以进一步用调整法和反证法的思想,将最优解调整到不分横切、竖切,都是递减的。 简单证明如下: 设有最优方案序列XY[1..n+m],序列中任意两相邻项XY[i]和XY[i+1],记为 a和b,若a≤b,分三种情况考虑: (1) 若a、b同是横切,显然交换a、b不影响最优解; (2) 若a、b同是竖切,显然交换a、b也不影响最优解; (3) a和b不同,最交换a、b后,增加费用a,减少费用为b,共增加费用为 (a-b) ≤0,不会破坏最优性。 反复检查,最终调整为全部有序的最优解。 这样最终得到一个简单的算法:只要排序就可以了。 进一步,如果切过的巧克力可分别拿开,各自选方案切割。也可用调整法证明上面的方案也是最优解。 流水线调度问题 由于篇幅关系,后面的两节就简单列个提纲。 三、一些经典贪心算法问题 磁带最优存储 背包问题 有限期的作业排序 哈夫曼树 最小生成树---Prim算法 最小生成树---Kruskla算法 教室问题 四、贪心算法应用的多样性 (1)构造出次序 在众多的选择中,按预先设计的某种次序来确定当前要找的下一步选择。 单源最短路径:Dijkstra算法 最小生成树 (2)局部(阶段)正确 有时整个问题不能用贪心法,但我们确定了部分因素后,后面的方案就可以用贪心算法了。即通常简称:枚举+贪心 从汽车过沙漠到登山问题 (3)快速求得一“较好”可行解 前面提到的搜索枚举方案法中,要很多题都可通过贪心算法得到一个“较 优可行解”。有时甚至用“启发+随机化”多次贪心,能得到一个很好的上界(或下界)。 (4)快速分枝定界 接上面话题,在搜索过程中,有时也可以用贪心算法预测已有方案以后可能达到的最小值(或最大值),再用“当前最好解”进行分枝定界。 从原始背包问题到0/1背包 (5)对称性游戏 根据问题的特点,直接确定一步,保证次把必败状态留给对方。 圆桌放硬币游戏 取数游戏 贪心算法经典例题 发布日期:2009-1-8 浏览次数:1180 本资料需要注册并登录后才能下载! ·用户名密码验证码找回密码·您还未注册?请注册 您的账户余额为元,余额已不足,请充值。 您的账户余额为元。此购买将从您的账户中扣除费用0.0元。 内容介绍>> 贪心算法经典例题 在求最优解问题的过程中,依据某种贪心标准,从问题的初始状态出发,直接去求每一步的最优解,通过若干次的贪心选择,最终得出整个问题的最优解,这种求解方法就是贪心算法。 从贪心算法的定义可以看出,贪心法并不是从整体上考虑问题,它所做出的选择只是在某种意义上的局部最优解,而由问题自身的特性决定了该题运用贪心算法可以得到最优解。 我们看看下面的例子 例1 均分纸牌(NOIP2002tg) [问题描述] 有 N 堆纸牌,编号分别为 1,2,…, N。每堆上有若干张,但纸牌总数必为 N 的倍数。可以在任一堆上取若干张纸牌,然后移动。移牌规则为:在编号为 1 堆上取的纸牌,只能移到编号为 2 的堆上;在编号为 N 的堆上取的纸牌,只能移到编号为 N-1 的堆上;其他堆上取的纸牌,可以移到相邻左边或右边的堆上。现在要求找出一种移动方法,用最少的移动次数使每堆上纸牌数都一样多。例如 N=4,4 堆纸牌数分别为: ①9 ②8 ③17 ④ 6 移动3次可达到目的: 从③取 4 张牌放到④(9 8 13 10) -> 从③取 3 张牌放到②(9 11 10 10)-> 从②取 1 张牌放到①(10 10 10 10)。 [输入]:键盘输入文件名。 文件格式:N(N 堆纸牌,1 <= N <= 100) A1 A2 … An (N 堆纸牌,每堆纸牌初始数,l<= Ai <=10000) [输出]:输出至屏幕。格式为:所有堆均达到相等时的最少移动次数。 [输入输出样例] a.in: 4 9 8 17 6 屏慕显示:3 算法分析:设a[i]为第i堆纸牌的张数(0<=i<=n),v为均分后每堆纸牌的张数,s为最小移到次数。 我们用贪心法,按照从左到右的顺序移动纸牌。如第i堆(0 《计算机算法设计与分析》习题及答案 一.选择题 1、二分搜索算法是利用(A )实现的算法。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 2、下列不是动态规划算法基本步骤的是(A )。 A、找出最优解的性质 B、构造最优解 C、算出最优解 D、定义最优解 3、最大效益优先是( A )的一搜索方式。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 4. 回溯法解旅行售货员问题时的解空间树是( A )。 A、子集树 B、排列树 C、深度优先生成树 D、广度优先生成树 5.下列算法中通常以自底向上的方式求解最优解的是( B )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法 6、衡量一个算法好坏的标准是(C )。 A 运行速度快 B 占用空间少 C 时间复杂度低 D 代码短 7、以下不可以使用分治法求解的是(D )。 A 棋盘覆盖问题 B 选择问题 C 归并排序 D 0/1背包问题 8. 实现循环赛日程表利用的算法是( A )。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 9.下面不是分支界限法搜索方式的是( D )。 A、广度优先 B、最小耗费优先 C、最大效益优先 D、深度优先 10.下列算法中通常以深度优先方式系统搜索问题解的是( D )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法 11.备忘录方法是那种算法的变形。(B ) A、分治法 B、动态规划法 C、贪心法 D、回溯法 12.哈夫曼编码的贪心算法所需的计算时间为( B )。 A、O(n2n) B、O(nlogn) C、O(2n) D、O(n) 13.分支限界法解最大团问题时,活结点表的组织形式是( B )。 A、最小堆 B、最大堆 C、栈 D、数组 14.最长公共子序列算法利用的算法是( B )。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 15.实现棋盘覆盖算法利用的算法是( A )。 A、分治法 B、动态规划法 C、贪心法 D、回溯法 16.下面是贪心算法的基本要素的是( C )。 A、重叠子问题 B、构造最优解 C、贪心选择性质 D、定义最优解 17.回溯法的效率不依赖于下列哪些因素( D ) A.满足显约束的值的个数 B. 计算约束函数的时间 C.计算限界函数的时间 D. 确定解空间的时间 18.下面哪种函数是回溯法中为避免无效搜索采取的策略( B ) A.递归函数 B.剪枝函数C。随机数函数 D.搜索函数 19. ( D )是贪心算法与动态规划算法的共同点。 贪心算法详解 贪心算法思想: 顾名思义,贪心算法总是作出在当前看来最好的选择。也就是说贪心算法并不从整体最优考虑,它所作出的选择只是在某种意义上的局部最优选择。当然,希望贪心算法得到的最终结果也是整体最优的。虽然贪心算法不能对所有问题都得到整体最优解,但对许多问题它能产生整体最优解。如单源最短路经问题,最小生成树问题等。在一些情况下,即使贪心算法不能得到整体最优解,其最终结果却是最优解的很好近似。 贪心算法的基本要素: 1.贪心选择性质。所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。 动态规划算法通常以自底向上的方式解各子问题,而贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。 对于一个具体问题,要确定它是否具有贪心选择性质,必须证明每一步所作的贪心选择最终导致问题的整体最优解。 2. 当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的 最优子结构性质是该问题可用动态规划算法或贪心算法求解的关键特征。 贪心算法的基本思路: 从问题的某一个初始解出发逐步逼近给定的目标,以尽可能快的地求得更好的解。当达到算法中的某一步不能再继续前进时,算法停止。 该算法存在问题: 1. 不能保证求得的最后解是最佳的; 2. 不能用来求最大或最小解问题; 3. 只能求满足某些约束条件的可行解的范围。 实现该算法的过程: 从问题的某一初始解出发; while 能朝给定总目标前进一步do 求出可行解的一个解元素; 由所有解元素组合成问题的一个可行解; 用背包问题来介绍贪心算法: 背包问题:有一个背包,背包容量是M=150。有7个物品,物品可以分割成任意大小。要 求尽可能让装入背包中的物品总价值最大,但不能超过总容量。 贪心方法:总是对当前的问题作最好的选择,也就是局部寻优。最后得到整体最优。 应用:1:该问题可以通过“局部寻优”逐步过渡到“整体最优”。贪心选择性质与“动态规划”的主要差别。 2:最优子结构性质:某个问题的整体最优解包含了“子”问题的最优解。 代码如下: #include for(i=1;i<=n;i++) goods[i].X=0; cu=M; //背包剩余容量 for(i=1;i 4.5 哈夫曼编码 哈夫曼编码是一种被广泛应用而且非常有效的数据压缩技术,哈夫曼根据字符在文件中出现的不同频率来建立一个用0,1串表示各字符的最优编码树(称为哈夫曼树),它的设计也是贪心选择的一个典型例子。 例假设有一个包含10000个只含a,b,c,d,e,f字符的数据文件,各字符在文件中出现的频率见下4.5.1表 表 4.5.1 若采用等长编码,则需3位二进制数位来表示6个字符,这种方法要用30000位来表示整个文件。若采用变长编码,则整个文件只需 (45×1+13×3+12×3+16×3+9×4+5×4) ×100=22400 位 也就是说压缩了 (30000-22400)÷30000×100%≥25% 。实际上,这就是这个文件的最优编码方案了 4.5.1 前缀码 我们对每一字符规定一个0,1串作为其代码,并要求任一字符代码都不是其他字符代码的前缀,这样的编码简称为前缀码。在4.5.1表中的两种编码都是前缀码。由于任一字符代码都不是其他字符代码的前缀,所以译码方法非常简单。为了在译码过程中方便地取出编码的前缀,我们可以用二叉树作为前缀码的数据结构。在表示前缀码的二叉树中,树叶代表给定的字符,并将每个字符的前缀码看作是从树根到代表该字符的树叶的一条道路。代码中每一位的0或1分别作为指示某结点到左儿子或右儿子的路标。如图4-1中的两棵二叉树是表4.5.1中两种编码方案所对应的数据结构。 图 4-1 前缀码的二叉树表示 容易看出,表示最优编码方案所对应的前缀码的二叉树总是一棵完全二叉树,即树中任一结点都有2个儿子。而定长编码方案不是最优的,其编码的二叉树不是一棵完全二叉树。在一般情况下,若C是编码字符集,包含有n个字符,则表示其最优前缀码的二叉树中恰好有n个叶子。每个叶子对应于字符集中一个字符,且该二叉树恰好有n - 1个内部结点。 4.6 最小生成树 设G= (V ,E )是一个无向连通图,即一个网络。给 E 的每一条边(v, w )赋于一个权。如果G 的一个子图G ˊ是一棵包含G 的所有顶点的树,则称G ˊ为G 的生成树。生成树上各边权的总和称为该生成树的代价。在G 的所有生成树中,代价最小的生成树称为G 的最小生成树。 网络的最小生成树在实际中有着广泛的应用。在不同的背景下,边的权可以代表不同的含义,比如,两点间的距离,两点间的公路造价等等。例如,在设计通信网络时,用图的顶点表示城市,用边(v, w )的权表示建立城市v 和城市w 的之间的通信线路所需的费用,则最小生成树就给出了建立通信网络的最经济的方案。 用贪心算法设计策略可以设计出构造最小生成树的有效算法。本节中要介绍的构造最小生成树的Prim 算法和Kruskal 算法都可以看作是应用贪心算法设计策略的典型例子。 4.6.1 Prim 算法 设G= (V ,E )是一个连通带权图,V={1 ,2 ,···,n} ,二维数组W 的元素W[i][j] 表示边(i ,j )的权。构造G 的一棵最小生成树的Prim 算法的基本思想是:首先置S={1} , 【贪心算法】思想 & 基本要素 & 贪心算法与局部最优 & 贪心算法与动态规划的区别 & 运用贪心算法求解问题 首先我们先代入问题来认识一下贪心算法涉及的问题 找钱问题 给顾客找钱,希望找零的钞票尽可能少,零钱种类和数量限定 找钱问题满足最优子结构 最快找零(贪心):为得到最小的找零次数,每次最大程度低减少零额活动安排问题 设个活动都需要使用某个教室,已知它们的起始时间和结束时间,求合理的安排使得举行的活动数量最多 贪心:使得每次安排后,教室的空闲时间最多 解决过程如下: 贪心算法求得的相容活动集是最大的 第一步:证明最优解中包含结束时间最早的活动 设相容集 A 是一个最优解,其结束最早的活动为 a,则 ( A - { a }) U { 1 } 也是一个最优解 第二步:证明去掉结束时间最早的活动后,得到的子问题仍是最优的:反证法 理解贪心算法 贪心算法总是做出当前最好的选择 贪心选择的依据是当前的状态,而不是问题的目标 贪心选择是不计后果的 贪心算法通常以自顶向下的方法简化子问题 贪心算法求解的问题具备以下性质 贪心选择性质:问题的最优解可以通过贪心选择实现 最优子结构性质:问题的最优解包含子问题的最优解 贪心选择性质的证明 证明问题的最优解可以由贪心选择开始 即第一步可贪心 证明贪心选择后得到的子问题满足最优子结构 即步步可贪心 背包问题 问题描述:给定 n 个物品和一个背包。物品 i 的重量为 Wi ,价值为 Vi ,背包的容量为 c ,问如何选择物品或物品的一部分,使得背包中物品的价值最大? 当 n = 3 ,c = 50 0-1背包问题:装入物品2、3,最大价值220 背包问题:装入物品1、2和2-3的物品3,最大价值240(贪心算法)贪心算法无法求解0-1背包问题,按贪心算法,0-1背包问题将装入物品1和2 贪心与局部最优 思考:为什么0-1背包可以用动态规划?而不能用贪心算法 贪心易陷入局部最优 基于贪心算法与最小路径的基因组组装优化问题 摘要 随着人类基因组计划的实施和飞速发展,基因组测序拼接作为生物信息学的核有着极其重要的应用价值。新的测序技术大量涌现,产生的reads 长度更短,数量更多,覆盖率更大,能直接读取的碱基对序列长度远小于基因组长度。本文通过如何在保证组装序列的连续性、完整性和准确性的同时设计耗时短、内存小的组装算法,建立数学模型来解决基因组组装问题。 针对问题一,首先,利用相应的软件对原基因组G 进行切割,利用全基因鸟枪法测序对切割后的短基因进行测序,得到较小的基因组j i G ,通过对比多条任意切割后相似的基因组j i G 从而找出个别碱基对存在的识别错误。而对于基因组中存在的重复片段可以通过两个read 之间的DNA 片段的长度满足一定的分布规律即pared end read 来解决。 接下来对比任意两个11 1m n read 和3 2 2 m n read 是否相等,通过MATLAB 软件建立n m 阶的关联矩阵,最后利用图论中的最短路径方法使更多的基因组能拼接在一起,尽可能使拼接出来的基因组在原基因组的覆盖率达到最大。 针对问题二,先把附件给出的数据提取出来导入MATLAB 中,再结合问题一给出的模型对基因组进行重组,从而得到新的基因。 最后,基于对基因组组装的研究,为使重组基因能更接近原基因序列,对问题一提出模型进行合理性的评价。 关键词:基因组组装 全基因鸟枪法测序 贪心算法 最短路径 一、问题的重述 1.1问题背景 快速和准确地获取生物体的遗传信息对于生命科学研究具有重要的意义。对每个生物体来说,基因组包含了整个生物体的遗传信息,这些信息通常由组成基因组的DNA或RNA分子中碱基对的排列顺序所决定。获得目标生物基因组的序列信息,进而比较全面地揭示基因组的复杂性和多样性,成为生命科学领域的重要研究内容。 1.2问题提出 确定基因组碱基对序列的过程称为测序(sequencing)。测序技术始于20世纪70年代,伴随着人类基因组计划的实施而突飞猛进。从第一代到现在普遍应用的第二代,以及近年来正在兴起的第三代,测序技术正向着高通量、低成本的方向发展。尽管如此,目前能直接读取的碱基对序列长度远小于基因组序列长度,因此需要利用一定的方法将测序得到的短片段序列组装成更长的序列。通常的做法是,将基因组复制若干份,无规律地分断成短片段后进行测序,然后寻找测得的不同短片段序列之间的重合部分,并利用这些信息进行组装。例如,若有两个短片段序列分别为 ATACCTT GCTAGCGT GCTAGCGT AGGTCTGA 则有可能基因组序列中包含有ATACCTT GCTAGCGT AGGTCTGA这一段。当然,由于技术的限制和实际情况的复杂性,最终组装得到的序列与真实基因组序列之间仍可能存在差异,甚至只能得到若干条无法进一步连接起来的序列。对组装效果的评价主要依据组装序列的连续性、完整性和准确性。连续性要求组装得到的(多条)序列长度尽可能长;完整性要求组装序列的总长度占基因组序列长度的比例尽可能大;准确性要求组装序列与真实序列尽可能符合。 利用现有的测序技术,可按一定的测序策略获得长度约为50–100个碱基对的序列,称为读长(reads)。基因组复制份数约为50–100。基因组组装软件可根据得到的所有读长组装成基因组,这些软件的核心是某个组装算法。常用的组装算法主要基于OLC(Overlap/Layout/Consensus)方法、贪婪图方法、de Bruijn 图方法等。一个好的算法应具备组装效果好、时间短、内存小等特点。新一代测序技术在高通量、低成本的同时也带来了错误率略有增加、读长较短等缺点,现有算法的性能还有较大的改善空间。 具体解决问题如下: 问题一:试建立数学模型,设计算法并编制程序,将读长序列组装成基因组。你的算法和程序应能较好地解决测序中可能出现的个别碱基对识别错误、基因组中存在重复片段等复杂情况。 问题二:现有一个全长约为120,000个碱基对的细菌人工染色体(BAC),采用Hiseq2000测序仪进行测序,测序策略以及数据格式的简要说明见附录一和附录二,测得的读长数据见附录三,测序深度(sequencing depth)约为70×,即基因组每个位置平均被测到约70次。试利用你的算法和程序进行组装,并使之具有良好的组装效果。 摘要:作业和测试的自动组卷是在线形成性考核系统的核心内容。本文在深入研究贪心算法的基础上,提出了基于贪心算法的自动组卷算法,分析了题库和作业库的约束条件,实现了快速高效的组卷过程。最后给出具体实例加以论证。该算法已经成功应用于实际的在线形成性考核系统中。 关键词:贪心算法;在线形成性考核;约束条件;组卷 一、引言目前,常用的自动组卷算法有随机选取算法、回溯试探算法、蛮力法和遗传算法等,这些算法对在线考试系统确实具有一定的应用价值,但这些方法生成的作业卷和测试卷在试卷的科学性和合理性上考虑较少。在综合研究以上各种算法的优缺点后,保证达到较好时间效率和空间效率的基础上,采用贪心算法为核心和随机选取算法为辅助的组卷算法,应用于在线形成性考核系统在线作业和在线测试中,能够达到较好的组卷效果,并且达到教学辅助效果。决定组卷效率和作业卷质量的主要因素有两个:一是题库和作业库的结构;二是组卷算法的设计。二、贪心算法简介贪心算法建议通过一系列步骤来构造问题的解,每一步对目前构造的部分解做一个扩展,直到获得问题的完整解为止。在每一步中,它要求“贪婪”地选择最佳操作,并希望通过一系列局部的最优选择,能够产生一个全局的最优解。贪心算法一般可以快速得到满意的解,因为它省去了为找最优解要穷尽所有可能而必须耗费的大量时间。贪心算法的基本要素。一是贪心选择性质。所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素。贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。对于一个具体问题,要确定它是否具有贪心选择性质,必须证明每一步所作的贪心选择最终导致问题的整体最优解。二是最优子结构性质。当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题可用贪心算法求解的关键特征。在题库组卷问题中,其最优子结构性质表现为:若a是对于e的题库组卷问题包含试题1的一个最优解,则相容作业卷集合a′= a-{1}是对于e′= {i∈e:si≥f1}的题库组卷问题的一个最优解。三、基于贪心算法的在线形成性考核系统组卷算法1、在线形成性考核系统结构在线形成性考核是指对学生学习过程的测评,是对学生课程学习的阶段性考核,是加强教学过程管理、检验学习效果的重要措施。在该系统中,管理员模块主要负责数据导入导出和系统维护,按照学生的课程注册信息绑定学生的班级、课程、辅导教师及恢复误删除成绩;教师模块完成课程形成性考核方案设计,作业题设计,查询考核内容,作业管理,作业批阅,查询批阅结果,删除已批阅但学生要求重做的作业成绩,学生信息管理,查询作业完成情况,到课率录入;学生模块主要功能是查看形考方案、主持教师、辅导教师、导学教师,在线作业,在线测试,作业成绩及反馈查询。在线形成性考核系统结构如图1所示。图1 在线形成性考核系统结构2、题库设计首先需要确定的是试题组织的方式。为了保证达标原则、全面性原则和主要性原则,最好将试题库与具体的知识内容进行关联,也即以课程知识点为核心组织试题库。然后就要考虑试题本身固有的特性参数,主要有题型、试题内容、答案、难度系数等。难度系数是试题难易程度的指标,也是试卷生成中的一个重要参数,它可以由教师录入试题时给定,并且在同一门课程中要坚持相同的标准,并且难度标准初始设定时要充分考虑到所要测试学生的程度范围。难度系数一般用等级来表示, 在五级难度系数中, 一级难度为最低, 五级难度为最高。题型分为客观题和主观题。客观题分单项选择题、多项选择选、判断题和填空题,主观题分计算题、简答题和论述题。3、作业库设计组卷方式可以按需求由主持老师进行客观题和主观题自由组卷。客观题在学生完成并提交成功后,系统自动阅卷并给出成绩。主观题在学生完成并提交后,由辅导老师阅 从贪心算法的定义可以看出,贪心法并不是从整体上考虑问题,它所做出的选择只是在某种意义上的局部最优解,而由问题自身的特性决定了该题运用贪心算法可以得到最优解。 我们看看下面的例子 例1 均分纸牌(NOIP2002tg) [问题描述] 有 N 堆纸牌,编号分别为 1,2,…, N。每堆上有若干张,但纸牌总数必为 N 的倍数。可以在任一堆上取若干张纸牌,然后移动。移牌规则为:在编号为 1 堆上取的纸牌,只能移到编号为 2 的堆上;在编号为 N 的堆上取的纸牌,只能移到编号为 N-1 的堆上;其他堆上取的纸牌,可以移到相邻左边或右边的堆上。现在要求找出一种移动方法,用最少的移动次数使每堆上纸牌数都一样多。例如 N=4,4 堆纸牌数分别为: ①9 ②8 ③17 ④6 移动3次可达到目的: 从③取 4 张牌放到④(9 8 13 10) -> 从③取 3 张牌放到②(9 11 10 10)-> 从②取 1 张牌放到①(10 10 10 10)。 [输入]:键盘输入文件名。 文件格式:N(N 堆纸牌,1 <= N <= 100) A1 A2 … An (N 堆纸牌,每堆纸牌初始数,l<= Ai <=10000) [输出]:输出至屏幕。格式为:所有堆均达到相等时的最少移动次数。 [输入输出样例] : 4 9 8 17 6 屏慕显示:3 算法分析:设a[i]为第i堆纸牌的张数(0<=i<=n),v为均分后每堆纸牌的张数,s为最小移到次数。 我们用贪心法,按照从左到右的顺序移动纸牌。如第i堆(0 贪心算法的基本思想是找出整体当中每个小的局部的最优解,并且将所有的这些局部最优解合起来形成整体上的一个最优解。因此能够使用贪心算法的问题必须满足下面的两个性质: 1.整体的最优解可以通过局部的最优解来求出; 2.一个整体能够被分为多个局部,并且这些局部都能够求出最优解。使用贪心算法当中的两个典型问题是活动安排问题和背包问题。 在对问题求解时,总是作出在当前看来是最好的选择。也就是说,不从整体上加以考虑,它所作出的仅仅是在某种意义上的局部最优解(是否是全局最优,需要证明)。 特别注意:若要用贪心算法求解某问题的整体最优解,必须首先证明贪心思想在该问题的应用结果就是最优解!! 以经典的活动安排为例: 1、若A是E的最优解,那么E-A 也是问题的最优解,在余下的问题里,继续拿最早结束的; 2、拿可以开始的最早结束。(所以要按结束时间排序一次,然后把可以开始的选择上,然后继续向后推) 贪心子结构是独立的(往往用标志判断而已),不同于动态规划(后面每一边的计算要用到前一步的值,另外开辟空间来保存) 贪心算法的基本步骤: 1、从问题的某个初始解出发。 2、采用循环语句,当可以向求解目标前进一步时,就根据局部最优策略,得到一个部分解,缩小问题的范围或规模。 3、将所有部分解综合起来,得到问题的最终解。 如最经典的活动安排问题,按结束时间从小到大排序,这样找出第一个节目后,剩下的节目已经是最safe的子结构了,再从子结构中最最早结束但又不和上一次观看的节目有冲突的节目 void arrange(int s[],int f[],bool A[],int n) { A[0] = true; int lastSelected = 0; for (int i = 1;i 贪心算法的应用实例 例2.排队问题 【题目描述】 在一个医院B 超室,有n个人要做不同身体部位的B超,已知每个人需要处理的时间为ti,(0 贪心算法 1.喷水装置(一) 描述 现有一块草坪,长为20米,宽为2米,要在横中心线上放置半径为Ri的喷水装置,每个喷水装置的效果都会让以它为中心的半径为实数Ri(0 对于每一组输入,输出最多能够安排的活动数量。 每组的输出占一行 样例输入 2 2 1 10 10 11 3 1 10 10 11 11 20 样例输出 1 2 提示注意:如果上一个活动在T时间结束,下一个活动最早应该在T+1时间开始。 解题思路:这是一个贪心法中选择不相交区间的问题。先对活动结束时间从小到大排序,排序的同时活动的起始时间也要跟着变化。而且,结束时间最小的活动一定会安排,不然这段时间就白白浪费了。后一个活动的起始时间如果比前一个活动的结束时间大,即两个活动没有相交时间,就把这个活动也安排上。就这样一直找到结束时间最大的,输出时间数目即可。排序时可用下面的方法,排序的同时起始时间也跟着变了。 如果输入 0 6 3 4 1 9 2 8 则排序后的结果就是 3 4 0 6 2 8 1 9 Sample Output 3 5 大学计算机考试模拟题(理工类) 一、简答题(本题共6个小题,每小题5分,共30分) 1. 什么是信息社会?信息社会的主要特征是什么?P32 第4题参见P13 P14 2. 什么是CPU,简述CPU的基本组成和功能P108 第18.(1) 参见P77 3. 什么是操作系统?简述操作系统的主要功能。P109 第24题参见P89 4. 人类问题求解的一般思维过程是什么?简要说明参见P112图3-1 描述 5. 什么是枚举法?说明枚举法的优缺点。参见P113第6段, P132穷举法 6. 什么是浏览器/服务器(B/S)三层体系结构,画图并简要说明。P340第10题参见P316 P276 二、单项选择题(本题共20个小题,每小题1分,共20分) 1. 下列容不属于信息素养(Information Literacy)的是 A.信息意识B.信息知识 C.分析能力D.信息道德 2. 阿兰·麦席森·图灵(Alan Mathison Turing)对计算机科学的发展做出了巨大贡献,下列说法不正确的是 A.图灵是著名的数学家、逻辑学家、密码学家,被称为计算机科学之父。 B.图灵最早提出关于机器思维的问题,被称为人工智能之父。 C.图灵创立了二进制。 D.“图灵奖”是为奖励那些对计算机科学研究与推动计算机技术发展有卓越贡献的杰出科学家而设立的。 3. 最早的机械式计算机“加法器”的发明人是 A.帕斯卡B.巴贝奇 C.莱布尼茨D.布尔 4. 巴贝奇的“分析机”到他终生都没有制造出来,下列说确的是() A.设计原理有错误B.设计精度不够 C.设计图纸不够完善D.机械加工的工艺水平达不到它要求的精度 5. 以集成电路为基本元件的第三代计算机出现的时间为()。A.1965—1969B.1964—1975 C.1960—1969D.1950—1970 6. 在计算机中,引入16进制,主要目的是()。 A.计算机中的数据存储采用16进制 B.计算机中的数据运算采用16进制 C.缩短2进制字串的长度 D.计算机的存地址采用16进制编制 7. 设计算机字长为16位,采用补码表示,可表示的整数的取值围是()。A.0~65535B.-32767~32767 C.-32768~32767D.-32767~32768 8. 下列叙述中,正确的是( )。 A.所有十进制小数都能准确地转换为有限位二进制小数 B.汉字的计算机码就是国标码 C.所有二进制小数都能准确地转换为十进制小数 D.存储器具有记忆能力,其中的信息任何时候都不会丢失 9. 关于微处理器,下列说法错误的是() A、微处理器就是微机的CPU,由控制器运算器和存储器组成。 B、微处理器不包含存储器。 C、微处理器执行CPU控制部件和算术逻辑部件的功能。 D、微处理器与存储器和外围电路芯片组成微型计算机。 10. 关于操作系统,下列叙述中正确的是()。 Computer Knowledge and Technology 电脑知识与技术软件设计开发本栏目责任编辑:谢媛媛第6卷第35期(2010年12月)基于贪心算法的0-1背包问题 陈曦 (九江学院,江西九江332005) 摘要:贪心算法是解决问题的一种算法,因其解决问题时具有简单性、直观性和高效性而备受青睐。当待解决的问题具有最优子结构和贪心选择性质时,就可以考虑用贪心算法求解。0-1背包问题是计算机问题中一个普遍的问题,文章中详述了用贪心算法如何解决0-1背包问题。并得出用贪心算法求解此问题能得到最优解。 关键词:0-1背包;贪心算法;动态规划中图分类号:TP312文献标识码:A 文章编号:1009-3044(2010)35-10061-02 Based on the Greedy Algorithm of 0-1Knapsack Problems CHEN Xi (Jiujiang University,Jiujiang 332005,China) Abstract:The greedy algorithm is the solution to the problem of an algorithm,because of its solving problems with simplicity,intuitive and the efficiency is favour.When un-solved problems that have the most YouZi structure and moment-the greedy-choice properties,can con -sider to use greedy algorithm.0-1knapsack problems in computer problems is a common problem in the text,was described by the greedy algorithm to solve 0-1knapsack problems.And obtained by greedy algorithm for solving this problem can obtain optimal solutions.Key words:0-1knapsack;greedy algorithm;dynamic programming 1算法设计与分析是一门集应用性、创造性、实践性为一体的综合性极强的课程[1-2] 一个高效的程序不仅需要“编程技巧”,更需要合理的数据组织和清晰高效的算法。当一个问题具有最优子结构时,根据其具体情况可以用动态规划算法或者贪心算法来求解,但是问题同时具有贪心选择性质时,选择贪心算法更优,贪心算法通常会给出一个简单、直观和高效的解法[3]。 贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,它所做出的仅是在某种意义上的局部最优解。贪心算法并不是对所有问题都能得到整体最优解,但对范围相当广泛的许多问题它能产生整体最优解或者是整体最优解的近似解。 作为一种算法设计技术,贪心法是一种简单的方法。与动态规划法一样,贪心法也经常用于解决最优化问题。不过与动态规划法不同的是,贪心法在解决问题的策略上是仅根据当前已有的信息做出选择,而且一旦做出了选择,不管将来有什么结果,这个选择都不会改变。这种局部最优选择并不能保证总能获得全局最优解,但是通常能得到较好的近似最优解。例如,平时购物找钱时,为使找回的零钱的硬币数量最少,从最大面值的币种开始,按递减的顺考虑各币种,先尽量用大面值的币种,当不足大面值币种的金额时才去考虑下一种较小的面值的币种。这就是在采用贪心算法。这种方法在这里总是最优,因为银行对其发行的硬币种类和硬币面值的巧妙安排。如果只有面值分别为1,5,和11单位的硬币,而希望找回总额为15单位的硬币,按贪心算法,应找1个11单位面值的硬币和4个1单位面值的硬币,共找回5个硬币,但是最优的解答应是3个5单位面值的硬币。 1.1贪心算法解题思路 贪心算法[4]是经常用到的一种解题方法,往往在解决最优问题时都可以用贪心算法求解。其解题思路为: 1)建立数学模型来描述问题。 2)把求解的问题分成若干子问题。 3)对每一对问题求解,得到子问题的局部最优解。 4)把子问题的解局部最优解合成原来解问题的一个解。 实现该算法的过程: 从问题的某一初始解出发; while 能朝给定总目标前进do 求出可行解的一个元素; 由所有解元素组合成问题的一个可行解。 虽然贪心算法有时并不能得到最优解,但是经过证明贪心算法能提高问题的解决效率。 收稿日期:2010-10-15 作者简介:陈曦(1982-),女,江西九江人,讲师,硕士,主要研究方向为计算机应用。 E-mail:xsjl@https://www.360docs.net/doc/218186427.html, https://www.360docs.net/doc/218186427.html, Tel:+86-551-56909635690964ISSN 1009-3044Computer Knowledge and Technology 电脑知识 与技术Vol.6,No.35,December 2010,pp.10061-1006210061 贪心算法求解汽车加油问题 1 引言 随着科学的发展,人们生活中面临的大数据量越来越多。生活的快节奏要求人们对这些庞大的数据进行简单快速的处理,在这种实际需求的背景下,计算机算法设计得到了飞速发展,线性规划、动态规划、贪心策略等一系列运筹学模型越来越多被应用到计算机算法学中。 当一个问题具有最优子结构性质和贪心选择性质时,可用动态规划法来解决。但是贪心算法通常会给出一个更简单、直观和高效的解法。贪心算法通过一系列的选择来得到一个问题的解。尽管贪心算法对许多问题不能总是产生整体最优解,但对诸如最短路径问题、最小生成树问题,以及哈夫曼编码问题等具有最优子结构和贪心选择性质的问题却可以获得整体最优解,而且所给出的算法一般比动态规划算法更加简单、直观和高效[1]。 2 贪心算法 2.1 贪心算法概述 贪心算法又称贪婪算法,是指在求解问题时,总是做出在当前看来是最好的选择,也就是说,贪心算法并不要求从整体上最优考虑,它所作的仅是在某种意义上的局部最优选择。当然,希望贪心算法得到的最终结果也是整体最优的。贪心算法并不是对所有问题都能得到整体最优解,但对范围相当广泛的许多问题它能产生整体最优解或者是整体最优解的近似解。 贪心算法可以简单描述为:对一组数据进行排序,找出最小值,进行处理,再找出最小值,再处理。也就是说贪心算法是一种在每一步选择中都采取在当前状态下最好或最优的选择,从而希望得到结果是最好或最优的算法。 贪婪算法是一种对某些求最优解问题的更简单、更迅速的设计技术。用贪婪法设计算法的特点是一步一步地进行,常以当前情况为基础根据某个优化测度作最优选择,而不考虑各种可能的整体情况,它省去了为找最优解要穷尽所有可能而必须耗费的大量时间,它采用自顶向下,以迭代的方法做出相继的贪心选择,每做一次贪心选择就将所求问题简化为一个规模更小的子问题, 通过每一步贪心选择,可得到问题的一个最优解,虽然每一步上都要保证能获得局部最优解,但由此产生的全局解有时不一定是最优的。 贪婪算法是一种改进了的分级处理方法。其核心是根据题意选取一种量度标准。然后将这多个输入排成这种量度标准所要求的顺序,按这种顺序一次输入一个量。如果这个输入和当前已构成在这种量度意义下的部分最佳解加在一起不能产生一个可行解,则不把此输入加到这部分解中。这种能够得到某种量度意义下最优解的分级处理方法称为贪婪算法。 对于一个给定的问题,往往可能有好几种量度标准。初看起来,这些量度标准似乎都是可取的,但实际上,用其中的大多数量度标准作贪婪处理所得到该量度意义下的最优解并不是问题的最优解,而是次优解。因此,选择能产生问题最优解的最优量度标准 智能算法30个案例分析 【篇一:智能算法30个案例分析】 智能算法是我们在学习中经常遇到的算法,主要包括遗传算法,免 疫算法,粒子群算法,神经网络等,智能算法对于很多人来说,既 爱又恨,爱是因为熟练的掌握几种智能算法,能够很方便的解决我 们的论坛问题,恨是因为智能算法感觉比较“玄乎”,很难理解,更 难用它来解决问题。 因此,我们组织了王辉,史峰,郁磊,胡斐四名高手共同写作 matlab 智能算法,该书包含了遗传算法,免疫算法,粒子群算法, 鱼群算法,多目标pareto 算法,模拟退火算法,蚁群算法,神经网络,svm 等,本书最大的特点在于以案例为导向,每个案例针对一 个实际问题,给出全部程序和求解思路,并配套相关讲解视频,使 读者在读过一个案例之后能够快速掌握这种方法,并且会套用案例 程序来编写自己的程序。本书作者在线,读者和会员可以向作者提问,作者做到有问必答。 本书和目录如下:基于遗传算法的tsp算法(王辉) tsp (旅行商问题—traveling salesman problem),是典型的np 完全问题,即其 最坏情况下的时间复杂性随着问题规模的增大按指数方式增长,到 目前为止不能找到一个多项式时间的有效算法。遗传算法是一种进 化算法,其基本原理是仿效生物界中的“物竞天择、适者生存” 的演 化法则。遗传算法的做法是把问题参数编码为染色体,再利用迭代 的方式进行选择、交叉以及变异等运算来交换种群中染色体的信息,最终生成符合优化目标的染色体。实践证明,遗传算法对于解决 tsp 问题等组合优化问题具有较好的寻优性能。 基于遗传算法和非线性规划的函数寻优算法(史峰)遗传算法提供 了求解非线性规划的通用框架,它不依赖于问题的具体领域。遗传 算法的优点是将问题参数编码成染色体后进行优化,而不针对参数 本身,从而不受函数约束条件的限搜索过程从问题解的一个集合开始,而不是单个个体,具有隐含并行搜索特性,大大减少陷入局部 最小的可能性。而且优化计算时算法不依赖于梯度信息,且不要求 目标函数连续及可导,使其适于求解传统搜索方法难以解决的大规模、非线性组合优化问题。 用于模式分类、模式识别等方面.但 bp 算法收敛速度慢,且很容易 陷入局部极小点,而遗传算法具有并行搜索、效率高、不存在局部贪心算法经典例题
计算机算法设计与分析习题和答案解析
贪心算法详解分析
背包问题的贪心算法
常见的贪心算法问题
贪 心 算 法
基于贪心算法与最短路径的基因组组装最优拼接问题---1411
基于贪心算法的在线形成性考核系统组卷研究
贪心算法的应用
贪心算法
贪心算法的应用实例
贪心算法练习题
大学计算机基础mooc习题集整理(含答案解析)
基于贪心算法的0_1背包问题
贪心算法结课论文
智能算法30个案例分析