用近邻函数法进行聚类与分类

用近邻函数法进行聚类与分类
汤宁SC08023110
一.实验原理
对应一个样本集中的任意两个样本xi和xj如果xi是xj的第I个近邻点,则定义xi对xj的近邻系数为I,记为d(i,j)=I.定义xi和xj简的近邻函数值为aij=d(i,j)+d(j,i)-2.样本间的近邻函数值越小,彼此越靠近,越相似。
算法步骤如下:
1.对于给定待分类的样本集合,计算距离矩阵D:
D(i,j)=d(xi,xj)
d(xi,xj)为xi和xj的欧式距离。
2.用D计算近邻系数矩阵M,元素Mij为xi对xj的近邻系数。
3.生成近邻函数矩阵L:
L(i,j)=Mij+Mji-2
并置L对角线上元素为2*N,如果xi和xj有连接,则L(i,j)为连接损失。
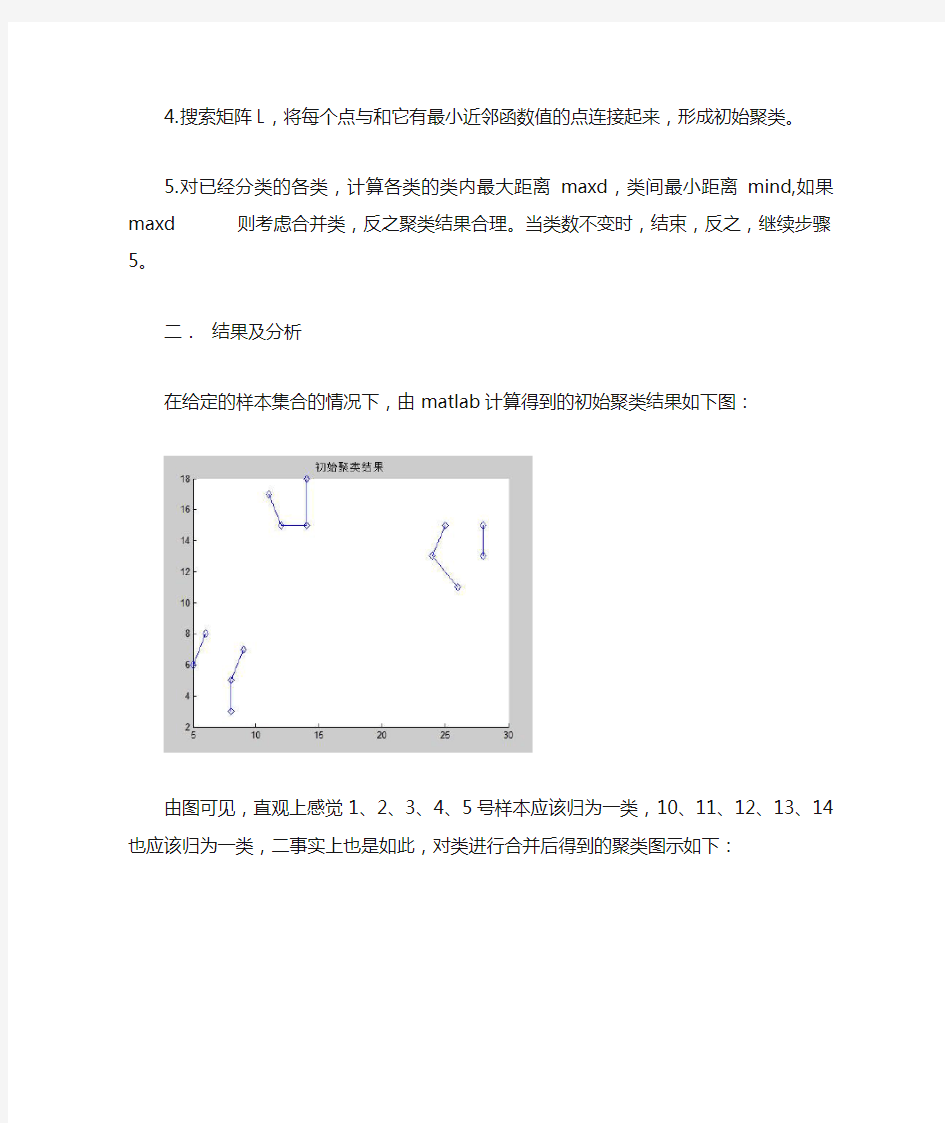
4.搜索矩阵L,将每个点与和它有最小近邻函数值的点连接起来,形成初始聚类。
5.对已经分类的各类,计算各类的类内最大距离maxd,类间最小距离mind,如果
maxd 二.结果及分析 在给定的样本集合的情况下,由matlab计算得到的初始聚类结果如下图: 由图可见,直观上感觉1、2、3、4、5号样本应该归为一类,10、11、12、13、14也应该归为一类,二事实上也是如此,对类进行合并后得到的聚类图示如下: 此为最终聚类结果,连在一起的点表示同为一类。 三.附件 Matlab程序文件prexp.m,直接运行,按照对话框的提示,返回matlab命令行模式按任意键就可以进行第二步的类合并,结果仍在figure1显示。Figure1相继显示上述图示结 果,程序包含了必要注释。 云南大学数学与统计学实验教学中心 实验报告 一、实验目的 能根据给出的训练集与测试集,用近邻法,k近邻法与剪辑近邻法, 重复剪辑近邻法给出测试集的分类结果并分别计算其错误率。 二、实验内容 画出近邻法的程序框图,对给定的分别存放在文件“riply_trn.mat”和”riply_tst.mat”中的两类样本训练集250个测试集1000个,试用近邻法,k近邻法与剪辑近邻法, 重复剪辑近邻法给出测试集的分类结果并分别计算其错误率。 三、实验环境 Windows XP Matlab6.5 四、实验过程 一、程序框图: 二、实验相关代码: (1)最近邻法 %计算错误率函数 function [P]=ZQL_func(ys,yr) load riply_tst; yr=y; n=size(ys,2); t=0; for i=1:n if ys(i)-yr(i)==0 t=t+1; end end P=1-t/n; %最近邻函数文件 function [ypd]=ZJL_func(Xtr,ytr,Xts,yts) [m1,n1]=size(Xtr); [m2,n2]=size(Xts); d=zeros(1,n1); ypd=zeros(1,n2); for i=1:n2 for j=1:n1 d(j)=(Xts(1,i)-Xtr(1,j))^2+(Xts(2,i)-Xtr(2,j))^2; %欧式距离end min=d(1); r=1; for t=2:n1 if d(t)<=min min=d(t); %计算最小距离(并保存下标值) r=t; end end ypd(i)=ytr(r); end %最近邻的m文件 load riply_trn; Xtr=X; ytr=y; load riply_tst; Xts=X; yts=y; [m,n]=size(Xts); yp=zeros(1,n); yp=ZJL_func(Xtr,ytr,Xts,yts); p=ZQL_func(yp,yts) (1)运行结果: (注:由于分类结果数据过于庞大在此不列出,只将错误率给出)p = 0.1500 (2)k近邻法 % k近邻法函数文件 function [P]= KJL(k) 语文总复习之词语归类 学习要求 学习词语归类方法,能按词语种类、属性、顺序进行逻辑归类,培养逻辑思维能力。 学习方法 按小学语言课文要求,词语归类译意风以下三种。 1、按词语类别、属性进行逻辑归类。 词语类别很多,有: (1)写人物的词语,如:男人、女人、学生、军人、工人、农民、老年人、中年人、少年等。 (2)写动物的词语,如:野兽——老虎、狮、鹿、象等;家畜——牛、马、羊、猪、狗等;飞禽——老鹰、乌鸦、喜鹊、燕子、天鹅、鹦鹉等;海里动物——海龟、海豹、鲸、鱼等。 (3)写植物的词语,如:树林、松树、杨树、白桦树、柳树、果树、水稻、玉米、大麦、小麦、蔬菜、菠菜、芥蓝、西红柿、大白菜等。 (4)写商品的词语,如:衣物、毛衣、布衣、衬衣、用具、脸盆、口盅、热水瓶、水杯等。 (5)写交通工具,如:汽车、火车、飞机、摩托车、轮船等。 此外,还有写建筑类,描写自然环境、天气、山川和其他各种各类等等。在这些词语中我们要学会按类别、属性进行分类,培养自己的逻辑思维能力。 写人物,按类别、属性进行逻辑归类可分为若干组。例如: A、人民、学生、军人、商人、工人、农民。“人民”与其他词语不同类,而是种属关系。 B、老年人、中年人、青年人、妇女、少年人、儿童、幼儿。“妇女”与其他词语不同一类。 C、爷爷、奶奶、爸爸、妈妈、少年、哥哥、姐姐、弟弟。“少年”与其他词语不同一类。 写动物,也可分为若干组词语,例如: A、狼、豹、老虎、大象、猴子、长颈鹿是同一类,“动物”、“野兽”与之是种属关系,就不同一类。 B、老鹰、鹤、猫头鹰、乌鸦、喜鹊是同一类,“鸟”、“飞禽”与之是种属关系,就不同一类。 C、牛、羊、猪、狗、马属同一类,“家畜”与之是种属关系,就不同一类。 聚类分析 聚类(clustering)就是将数据对象分组成为多个类或簇(cluster),在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。相异度是基于描述对象的属性值来计算的。距离是经常采用的度量方式。聚类分析源于许多研究领域,包括数据挖掘,统计学,生物学,以及机器学习。 将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。在许多应用中,一个簇中的数据对象可以被作为一个整体来对待 “聚类的典型应用是什么?”在商业上,聚类能帮助市场分析人员从客户基本库中发现不同的客户群,并且用购买模式来刻画不同的客户群的特征。 聚类也能用于对Web 上的文档进行分类,以发现信息。作为一个数据挖掘的功能,聚类分析能作为一个独立的工具来获得数据分布的情况,观察每个簇的特点,集中对特定的某些簇作进一步的分析。此外,聚类分析可以作为其他算法(如分类等)的预处理步骤,这些算法再在生成的簇上进行处理 作为统计学的一个分支,聚类分析已经被广泛地研究了许多年,主要集中在基于距离的聚类分析。基于k-means(k-平均值),k-medoids(k-中心)和其他一些方法的聚类分析工具已经被加入到许多统计分析软件包或系统中,例如S-Plus,SPSS,以及SAS。 在机器学习领域,聚类是无指导学习(unsupervised learning)的一个例子。与分类不同,聚类和无指导学习不依赖预先定义的类和训练样本。由于这个原因,聚类是通过观察学习,而不是通过例子学习。 在概念聚类(conceptual clustering)中,一组对象只有当它们可以被一个概念描述时才形成一个簇。这不同于基于几何距离来度量相似度的传统聚类。概念聚类由两个部分组成:(1)发现合适的簇;(2)形成对每个簇的描述。在这里,追求较高类内相似度和较低类间相似度的指导原则仍然适用。 活跃的研究主题集中在聚类方法的可伸缩性,方法对聚类复杂形状和类型的数据的有效性,高维聚类分析技术,以及针对大的数据库中混合数值和分类数据的聚类方法。 数据挖掘对聚类的典型要求如下: 实例解析关键词聚类的方法策略 收藏到:1时间:2014-06-05 文章来源:马海祥博客访问次数:388 最近,马海祥接手了一个大型的网站,首先要做的就的对这个网站的流量来源进行分析,这其中最繁琐的莫过于对来源关键词的聚类整合了。 所谓关键词聚类就是以领域特征明显的词和短语作为聚类对象,在分类系统的大规模层级分类语料库中,利用独创的文本分类的特征提取算法进行词语的领域聚类,通过控制词语频率的影响,分别获取领域通用词和领域专类词。 所以,要想做好这类做关键词的聚类,就一定要有一些基础信息,基础数据作为背景。在此,我就借助马海祥博客的平台跟大家实例解析关键词聚类的方法策略: 1、百度商业词聚类模型 现在对于一些医疗SEO来说看行业新闻,大家经常讨论一个话题就是百度医疗行业的收入贡献比是多少?,其实,爆个大料给大家,在2005年甚至2006年之前,百度自己都不掌握这类数据。 当时百度有一个简单的客户分类,是客服提交的,然后我们看了一下消费的行业分布,结果显示超过50%属于其他分类,这个结果基本上就没法看了。 然后我就琢磨,用商业词能不能直接聚类为行业,当时我在产品部门,合作反欺诈点击的工程师是张怀亭,这是个算法高手,他当年的毕业论文就是关联规则和聚类算法,我就去请教他,他说了一堆,我大部分没听懂,但大概要点知道了一些,然后找他要了论文看了看,也没太看明白,凭借自己粗浅的理解我就动手了,然后这个还真做成了。 我的出发点就是假设客户本身具有行业属性(如果这个假设不存在,那就没辙了),我认为每个客户提交的关键词,彼此是有关联的。某两个关键词如果同时被不同的客户提交,其关联性就会随之增加,这个是最基本的一个定义,叫做共同推举数,也是最容易算的一个值。 但是仅仅依赖于共同推举数有一个问题,就是会导致很多词都和热门词关联,这是不合理的,我记得当时好像是某网上书城的推荐购买那一栏,明显都是热门书籍,似乎也是基于共同推举数做的关联。 问题1:A和B有50个共同推举,A和C有30个共同推举,但是B这个词是热门词,共有2000个客户提交;而C是冷门词,只有50个客户提交,请问A和B的关联度高还是A和C的关联度高? 问题2:客户1提交了10000个词(类似阿里真的是这么提交的);客户2提交了20个词,客户1所提交的10000个词的彼此关联度和客户2之间提交的是否一致? 考虑这两个问题,就需要做权值调整了,然后再计算词与词的关联值。那么,权值该怎么定呢? 高中化学-简单分类法及其应用分层练习 层级一 学业达标练 1.碳酸钠俗名纯碱,下面是对纯碱采用不同分类法的分类,其中正确的是( ) ①碱 ②含氧酸盐 ③钠盐 ④碳酸盐 A .①②③ B .①③④ C .①②④ D .②③④ 解析:选D 纯碱若采用交叉分类法分别属于含氧酸盐、钠盐、碳酸盐。 2.符合如图中阴影部分的物质是( ) A .NaHCO 3 B .Cu 2(OH)2CO 3 C .NaCl D .Na 2CO 3 解析:选D A 项属于酸式盐;B 项为碱式盐、铜盐;C 项不属于碳酸盐。 3.对于化学反应A +B===C +D 的下列说法中,正确的是( ) A .若生成物C 、D 有一种为单质,该反应一定是置换反应 B .若生成物C 、D 分别为两种沉淀,A 、B 有可能为盐和碱 C .若生成物C 、D 是盐和水,则A 、B 一定是酸和碱 D .若生成物C 、D 是两种化合物,则A 、B 一定是化合物 解析:选B 由反应CO +CuO =====△ CO 2+Cu 知,A 项错误;由反应Ba(OH)2 +CuSO 4===BaSO 4↓+Cu(OH)2↓知,B 项正确;由反应CuO +H 2SO 4===CuSO 4+H 2O 知,C 项错误;由反应CH 4+2O 2点燃,CO 2+2H 2O 知,D 项错误。 4.Na 2O 、NaOH 、Na 2CO 3、NaCl 、Na 2SO 4可按某种标准划为同一类物质,下列分类标准正确的是(已知Na 2O 与水反应生成NaOH)( ) ①钠的化合物 ②能与硝酸反应的物质 ③可溶于水的物质 ④水溶液导电 ⑤钠盐 ⑥钠的含氧化合物 第2章k-近邻算法(kNN) 引言 本章介绍kNN算法的基本理论以及如何使用距离测量的方法分类物品。其次,将使用python从文本文件中导入并解析数据,然后,当存在许多数据来源时,如何避免计算距离时可能碰到的一些常见的错识。 2.1 k-近邻算法概述 k-近邻(k Nearest Neighbors)算法采用测量不同特征之间的距离方法进行分类。它的工作原理是:存在一个样本数据集合,并且样本集中每个数据都存在标签,即我们知道样本每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据的分类标签。一般来说,我们只选择样本数据集中前k 个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。 k-近邻算法的优点是精度高,对异常值不敏感,无数据输入假定;缺点是计算复杂度高、空间复杂度高。适用于数值和离散型数据。 2.1.1 准备知识:使用python导入数据 首先,创建名为kNN.py的python模块,然后添加下面代码: from numpy import * #引入科学计算包 import operator #经典python函数库。运算符模块。 #创建数据集 def createDataSet(): group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels=['A','A','B','B'] return group,labels 测试:>>> import kNN >>> group,labels=kNN.createDataSet() 注意:要将kNN.py文件放到Python27文件夹下,否则提示找不到文件。 2.2.2 实施kNN算法 使用k-近邻算法将每组数据划分到某个类中,其伪代码如下: 对未知类别属性的数据集中的每个点依次执行以下操作: 1.计算已知类别数据集中的点与当前点之间的距离; 2.按照距离递增交序排序; 3.选取与当前点距离最小的k个点; 4.确定前k个点所在类别的出现频率; 5.返回前k个点出现频率最高的类别作为当前点的预测分类。 用欧氏距离公式,计算两个向量点xA和xB之间的距离: 例如,点(0, 0)与(1, 2)之间的距离计算为: python函数classify()程序如下所示: 聚类和分类的区别 2008-10-22 19:57 分类(classification)是这样的过程: 它找出描述并区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。分类分析在数据挖掘中是一项比较重要的任务,目前在商业上应用最多。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个类中。分类和回归都可用于预测,两者的目的都是从历史数据纪录中自动推导出对给定数据的推广描述,从而能对未来数据进行预测。与回归不同的是,分类的输出是离散的类别值,而回归的输出是连续数值。二者常表现为决策树的形式,根据数据值从树根开始搜索,沿着数据满足的分支往上走,走到树叶就能确定类别。要构造分类器,需要有一个训练样本数据集作为输入。训练集由一组数据库记录或元组构成,每个元组是一个由有关字段(又称属性或特征)值组成的特征向量,此外,训练样本还有一个类别标记。一个具体样本的形式可表示为:(v1,v2,...,vn;c);其中vi表示字段值,c表示类别。分类器的构造方法有统计方法、机器学习方法、神经网络方法等等。不同的分类器有不同的特点。有三种分类器评价或比较尺度:1)预测准确度;2)计算复杂度;3)模型描述的简洁度。预测准确度是用得最多的一种比较尺度,特别是对于预测型分类任务。计算复杂度依赖于具体的实现细节和硬件环境,在数据挖掘中,由于操作对象是巨量的数据,因此空间和时间的复杂度问题将是非常重要的一个环节。对于描述型的分类任务,模型描述越简洁越受欢迎。另外要注意的是,分类的效果一般和数据的特点有关,有的数据噪声大,有的有空缺值,有的分布稀疏,有的字段或属性间相关性强,有的属性是离散的而有的是连续值或混合式的。目前普遍认为不存在某种方法能适合于各种特点的数据 聚类(clustering) 是指根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。它的目的是使得属于同一个簇的样本之间应该彼此相似,而不同簇的样本应该足够不相似。与分类规则不同,进行聚类前并不知道将要划分成几个组和什么样的组,也不知道根据哪些空间区分规则来定义组。其目的旨在发现空间实体的属性间的函数关系,挖掘的知识用以属性名为变量的数学方程来表示。当前,聚类技术正在蓬勃发展,涉及范围包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及市场营销等领域,聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题。常见的聚类算法包括:K-均值聚类算法、K-中心点聚类算法、CLARANS、BIRCH、CLIQUE、DBSCAN等。 简单分类法及其应用(教案) 一、教学目标 (1)知识与技能 a.复习初中所学基本概念,在了解纯净物、混合物、单质、化合物、氧化物、酸、碱、盐等概念的基础上,能够从物质的组成与性质角度对物质进行分类。 b.了解常见物质及变化的分类方法,能够用不同的方法对化学物质及其变化进行分类。 (2)过程与方法 通过本课时的启发式教学,学生的组内讨论来培养学生发现问题,分析问题,解决问题的综合能力。 (3)情感态度与价值观 让每一个学生能够成功地选择一种分类方法,对自己所熟悉的知识进行分类,亲身感受到分类方法对于化学科学研究和化学学习的重要作用,并能够学以致用。 二、教学重难点 重点:掌握本课分类方法后为后续学习将会带来很大方便。因此常见化学物质及其变化的分类方法是本课的重点。 难点:学生从初中单一分类法中走出来如何进入本课的新情境,掌握新方法是本课教学的难点。 三、教学过程 (一)创设情景,导入新课 问:如果有一个学生家长问你,要你帮他找他的孩子,你怎么问这位家长?l来帮助他找到他的孩子。 学生活动:寻找生活中的其它分类实例 (二)通过情景,探求新知 化学中有哪些分类方法? 活动1:对明星进行分类 讨论什么是交叉分类法,说出他的特点与优点 巩固练习1 :请对下列物质进行交叉分类 练习2:请对下列化学反应进行交叉分类 活动2:看生物类别的分类 讨论什么是树状分类法,说出他的特点与优点 巩固练习3:将O2、Cu、H2SO4、Ba(OH)2、KNO3、CO2、空气进行树状分类 (二)利用情景,巩固新知 练习4:请分别以钙和碳为例,用化学方程式表示下列转化关系 (四)小结与巩固 1 反思:是否认同学习和利用分类法对学习化学有帮助;是否认同掌握方法比死记硬背更有效呢? 2 巩固练习 下列每组中都有一种物质与其他物质在分类上不同,试分析每组中物质的组成规律,将这种物质找出来。 (1)空气N2 HCl CuSO4·5H2O (2)SO3 KOH H2NaCl (3)H3PO4H2SiO3 HCl H2SO4(4)NaCl Na2SO4Na2CO3 BaCO3 3 作业;1 、P25实践活动第一问 2 P29第1、2题 词 单音词(由一个音节构成的词,如:牛、走、大) 双声词:澎湃、琵琶单纯词(由一个语素构成)联绵词叠韵词:彷徨、蹒跚 其他:芙蓉、茉莉 复音词(由两个或两个以上音节构成)音译词:幽默、咖啡 拟声词:哗啦、叮当 叠音词:猩猩、蛐蛐 前加式:老虎、老师 词根连接词缀构成的合成词后加式:学者、职员 前后均加式:可靠性 合成词(由几个语素构成)并列式:劳动、买卖 偏正式:足球、钢笔 补充式:缩小、提高 词根相互融合构成的合成词陈述式:日食、眼馋 支配式:化石、管家 名量式:花朵、纸张 重叠式:娃娃、星星 并列关系:披坚执锐、防微杜渐、失之东隅,收之桑榆 承接关系:见异思迁、先斩后奏、皮之不存、毛将焉附 目的关系:削足适履、守株待兔、杀一儆百 因果关系:水滴石穿、水落石出、失之毫厘,谬之千里 主谓关系:毛遂自荐、杞人忧天、夜郎自大、叶公好龙成语动宾关系:不见经传、顿开茅塞、如丧考妣 动补关系:轻如鸿毛、退避三舍、无动于衷、荒谬绝伦 动宾补关系:问道于盲、贻笑大方、拒人千里 连动关系:画蛇添足、抱薪救火、亡羊补牢 兼语关系:请君入瓮、令人生畏、引狼入室、化险为夷 偏正关系:衣冠禽兽、扶摇直上、孜孜不倦、一丘之貉 划分词类的几个问题: ◆怎样区别时间名词和时间副词 1)能在前面加上“在”“从”“到”等介词的是时间名词,不能加的是时间副词。如“立刻”“马上”“正在”“早已”“从来”“即将”都不 能加,是时间副词;“最近”“现在”“目前”“早上”“从前”“将来”都能加,则是时间名词。 2)看能否修饰名词。能修饰名词的是时间名词,不能修饰名词的是时间副词。如:能说“刚才的情况”,不能说“刚 刚的情况”;能说“过去的报纸”,不能说“曾经的报纸”。这里“刚才”“过去”是时间名词,“刚刚”“曾经”是时间副词。3)看能否受形容词修饰。能受形容词修饰的是时间名词,不能受形容词修饰的是时间副词。如:能说“光荣的过 去”,不能说“光荣的已经”;能说“幸福的未来”,不能说“幸福的将要”。这里“过去”“未来”是时间名词,“已经”“将要”是时间副词。 ◆怎样区分副词和形容词 副词和形容词都可以修饰动词和形容词,作状语,容易相混,可从下面四方面去辨别: 1)形容词能修饰名词,而副词一般不能。如“一致”可以修饰“意见”,“一律”则不能;可以说“突然的想法”,但不能说 “忽然的想法”“居然的想法”。 2)看能否受“很”字修饰。形容词能受“很”字修饰,副词则不能。可以说“很突然”,不能说“很忽然”“很居然”;可以说“很 努力”,不能说“很竭力”“很极力”。因此,“一致”“突然”“努力”是形容词,“一律”“忽然”“居然”“竭力”“极力”是副词。 3)形容词可以作谓语,副词不能。如:可以说“情况太突然了”,不能说“情况太忽然了”。 4)形容词可以单独回答问题,副词一般不能(“不”例外)。 一、层次聚类 1、层次聚类的原理及分类 1)层次法(Hierarchical methods)先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。其中类与类的距离的计算方法有:最短距离法,最长距离法,中间距离法,类平均法等。比如最短距离法,将类与类的距离定义为类与类之间样本的最短距离。 层次聚类算法根据层次分解的顺序分为:自下底向上和自上向下,即凝聚的层次聚类算法和分裂的层次聚类算法(agglomerative和divisive),也可以理解为自下而上法(bottom-up)和自上而下法(top-down)。自下而上法就是一开始每个个体(object)都是一个 类,然后根据linkage寻找同类,最后形成一个“类”。自上而下法就是反过来,一开始所有个体都属于一个“类”,然后根据linkage排除异己,最后每个个体都成为一个“类”。这两种路方法没有孰优孰劣之分,只是在实际应用的时候要根据数据特点以及你想要的“类”的个数,来考虑是自上而下更快还是自下而上更快。至于根据Linkage判断“类” 的方法就是最短距离法、最长距离法、中间距离法、类平均法等等(其中类平均法往往被认为是最常用也最好用的方法,一方面因为其良好的单调性,另一方面因为其空间扩张/浓缩的程度适中)。为弥补分解与合并的不足,层次合并经常要与其它聚类方法相结合,如循环定位。 2)Hierarchical methods中比较新的算法有BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies利用层次方法的平衡迭代规约和聚类)主要是在数据量很大的时候使用,而且数据类型是numerical。首先利用树的结构对对象集进行划分,然后再利用其它聚类方法对这些聚类进行优化;ROCK(A Hierarchical Clustering Algorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering Algorithm Using Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂度很高,O(n^2)。 2、层次聚类的流程 凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。这里给出采用最小距离的凝聚层次聚类算法流程: (1) 将每个对象看作一类,计算两两之间的最小距离; (2) 将距离最小的两个类合并成一个新类; (3) 重新计算新类与所有类之间的距离; (4) 重复(2)、(3),直到所有类最后合并成一类。 大类中类小类细目 (21)服装 1.机织面料服装(10)棉布服装(01)普通棉布男服装 (03)普通棉布女服装 (05)普通棉布童服装 (07)棉布婴儿服装 (09)棉布学生服装 (11)棉布职业服装 (13)棉布民族服装 (99)其他棉布服装材料螺钉直径螺钉头形状表面处理 1—不锈钢2—黄铜3—铜1—直径0.5 2—直径1.0 3—直径1.5 1—圆头 2—平头 3—六角形头 4—方形头 1—未处理 2—镀铬 3—镀锌 4—上漆 表8-3 螺钉选用面及类目编码 商品编码类型 数字型(顺序型、层次型、平行型) 字母形 数字-字母混合型 条形码 顺序型,数列长度完全一致,按在分类体系中先后出现的次序,依次给与编码。 如罐头制品:猪000-099,牛羊100-199,禽类200-299,鱼300-399, 红烧400-499,虾、水产500-599,糖、水果罐头600-699,果浆700-799, 蔬菜800-899,其它类900-999。 层次型,按商品类目在分类体系中的层级顺序,依次赋予对应的数字代码,整个编码分为4个层级,由8位数字代码组成,其中1、2位数字为第1个层次,表示大类,3、4位数字为第2个层级,表示中类,5、6位数字为第3个层级表示小类,7、8位数字为第4个层级表示品种。最大优点是商品隶属关系清晰,层次鲜明,逻辑性强。 代码代码A 门累 01 01 10 01 第一层,农业产品 第二层,粮食作物 第三层,小麦 第四层,冬小麦 字母型用一个或若干个字母表示商品代码的编码方法,一般按字母顺序编码,大写字母表示商品大类,小写字母表示其他类目。 数字、字母混合 用英文字母表示门类、8位阿拉伯数字分别代表大类、中类、小类和品种4个层次。 A 03 10 25 01 门类,农林牧渔 大类人工饲养动物、捕猎 中类人工饲养动物、下水及副产品 小类蛋类 品种鸡蛋 B 42 01 10 13 门类,医药商品 大类,中药材 中类,植物类中草药 小类,根茎类小药材 品种,川贝 用近邻函数法进行聚类与分类 汤宁SC08023110 一.实验原理 对应一个样本集中的任意两个样本xi和xj如果xi是xj的第I个近邻点,则定义xi对xj的近邻系数为I,记为d(i,j)=I.定义xi和xj简的近邻函数值为aij=d(i,j)+d(j,i)-2.样本间的近邻函数值越小,彼此越靠近,越相似。 算法步骤如下: 1.对于给定待分类的样本集合,计算距离矩阵D: D(i,j)=d(xi,xj) d(xi,xj)为xi和xj的欧式距离。 2.用D计算近邻系数矩阵M,元素Mij为xi对xj的近邻系数。 3.生成近邻函数矩阵L: L(i,j)=Mij+Mji-2 并置L对角线上元素为2*N,如果xi和xj有连接,则L(i,j)为连接损失。 4.搜索矩阵L,将每个点与和它有最小近邻函数值的点连接起来,形成初始聚类。 5.对已经分类的各类,计算各类的类内最大距离maxd,类间最小距离mind,如果 maxd 此为最终聚类结果,连在一起的点表示同为一类。 三.附件 Matlab程序文件prexp.m,直接运行,按照对话框的提示,返回matlab命令行模式按任意键就可以进行第二步的类合并,结果仍在figure1显示。Figure1相继显示上述图示结 果,程序包含了必要注释。 词语部分练习题 一、按词语的概念从大到小排列下列词语。 1.公共汽车车交通工具汽车 2.双色圆珠笔圆珠笔文具笔 3.苹果树果树植物树 4.昆虫动物蚊子生物 5.小钢刀小刀刀旧小钢刀 6.字典工具书《新华字典》中文字典 7.男人男孩子小学二年级男生人 8.小学语文课本书语文书书籍 二、找出下面每组词中不是同一类的词,在下面划上横线。 1.骨科儿科内科外科财务科 2.手枪步枪冲锋枪机关枪玩具枪 3.屋子桌子椅子柜子床 4.工人青年农民教师解放军 5.法语外语英语日语俄语 6.汽油柴油机油煤油菜油 三、把下面的词按要求分类。 1.浓眉大眼凝视魁梧端详忐忑不安胆颤心惊目不转睛懊悔喜悦苍老东张西望容光焕发 ①表示“看”的词语有: ②表示外貌的词语有: ③表示心理活动的词语有: 2.刻舟求剑舍己为人视死如归自相矛盾千山一碧崇山峻岭守株待兔花红柳绿拾金不昧 ①表现人物品质的词语有: ②描写自然景物的词语有: ③说明某种道理的词语有: 四、将下列词语补充完整,然后按类别写在横线上。 1.()发()颜翠色()流愁眉不()()()若失一()不染()烛夜游 神采()()一()千里 ①描写人物外貌的: ②描写人物神态的: ③描写人物动作的: ④描写景物的: 2.奋不()身弄()作()()()向荣 好高()远神机()算()()其谈 高瞻远()阴谋()计 褒义词: 贬义词: 五、在括号里填出相对应的词语。 热闹对城市正如安静对()()对白天正如黑暗对夜晚 节约对光荣正如浪费对()()对秋天正如温暖对春天 清澈对泉水正如混浊对()寒冷对冬大正如()对夏天 喧闹对大街正如僻静对()勤劳对丰收正如懒惰对() 团结对安定正如分裂对()信任对朋友正如怀疑对() 批评对缺点正如表扬对()马对牲畜正如鸡对() 宽阔对马路正如狭窄对()高耸对山峰正如低陷对() 凶猛对老虎正如柔弱对()铁对矿藏正如蜘蛛对() 微笑对高兴正如流泪对()(1) 雨天对潮湿正如晴天对()(2) 摇头对反对正如点头对()(3) 勤奋对聪明正如懒惰对()(4) 旧社会对痛苦正如新社会对()(5) 豺狼对残忍正如羔羊对()4、在括号里填上恰当的答案 (1)节约对光荣正如浪费对()。 (2)春天对耕耘正如秋天对()。 (3)夏天对炎热正如冬天对()。 (4)勤劳对富裕正如懒惰对()。 (5)轮船对大海正如飞机对()。 (6)汽车对运输正如渔网对()。 六、选出与每组示例关系最相似的词。(在序号上打“√”) 1.字典:学习工具 A.地理:数学B.树木:森林C.皮鞋:衣服D.电冰箱:电器2.猴子:动物 A.上衣:袜子B.菊花:植物C.西瓜:瓜地D.树枝:树3.马:牲畜 A.西瓜:瓜地B.蜘蛛:琥珀C.铁:矿藏D.鸡:家禽4.船:运输 A.笔:写字B.布:纺织C.棉花:染料D.飞机:降落5.医生:病人 A.爸爸:工人B.教养员:幼儿C.老师:学生D.朋友:邻居6.树枝:树 A.蔬菜:水果B.课本:书包C.茶杯:茶具D.袜子:衣服7.学校:学生 A.奶奶:孙子B.机器:工人C.商店:顾客D.医生:病人8.老师:学生 A.农民:土地B.医生:病房C.营业员:顾客D.老板:学徒9.药物:治病 A.枪:武器B.报刊:画报C.大脑:思考D.纸:簿本10.向日葵:葵花子 A.稻谷:麦子B.西瓜:瓜地C.棉花:皮棉D.学校:操场11.人:营养 A.果实:果树B.书本:书包C.作物:肥料D.教室:学校12.剪刀:布匹 A.锯子:水泥B.锯子:木材C.锯子:椅子D.锯子:砖头 、按一定的顺序把下列每组词语排列起来。 (1)工具书书字典小学生字典 分类(classification ): 它找出描述并区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。分类分析在数据挖掘中是一项比较重要的任务, 目前在商业上应用最多。分类的目的是学会一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个类中。分类和回归都可用于预测,两者的目的都是从历史数据纪录中自动推导出对给定数据的推广描述,从而能对未来数据进行预测。与回归不同的是,分类的输出是离散的类别值,而回归的输出是连续数值。二者常表现为决策树的形式,根据数据值从树根开始搜索,沿着数据满足的分支往上走,走到树叶就能确定类别。要构造分类器,需要有一个训练样本数据集作为输入。训练集由一组数据库记录或元组构成,每个元组是一个由有关字段(又称属性或特征)值组成的特征向量,此外,训练样本还有一个类别标记。一个具体样本的形式可表示为:(v1,v2,...,vn; c);其中vi表示字段值,c表示类别。分类器的构造方法有统计方法、机器学习方法、神经网络方法等等。不同的分类器有不同的特点。有三种分类器评价或比较尺度:1)预测准确度;2)计算复杂度;3)模型描述的简洁度。预测准确度是用得最多的一种比较尺度,特别是对于预测型分类任务。计算复杂度依赖于具体的实现细节和硬件环境,在数据挖掘中,由于操作对象是巨量的数据,因此空间和时间的复杂度问题将是非常重要的一个环节。对于描述型的分类任务,模型描述越简洁越受欢迎。另外要注意的是,分类的效果一般和数据的特点有关,有的数据噪声大,有的有空缺值,有的分布稀疏,有的字段或属性间相关性强,有的属性是离散的而有的是连续值或混合式的。目前普遍认为不存在某种方法能适合于各种特点的数据。 聚类(clustering): 是指根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。它的目的是使得属于同一个簇的样本之间应该彼此相似,而不同簇的样本应该足够不相似。与分类规则不同,进行聚类前并不知道将要划分成几个组和什么样的组,也不知道根据哪些空间区分规则来定义组。其目的旨在发现空间实体的属性间的函数关系,挖掘的知识用以属性名为变量的数学方程来表示。当前,聚类技术正在蓬勃发展,涉及范围包括数据挖掘、统计学、机器学习、空间数据库技术、生物学以及市场营销等领域,聚类分析已经成为数据挖掘研究领域中一个非常活跃的研究课题。常见的聚类算法包括:K-均值聚类算法、K-中心点聚类算法、CLARANS、BIRCH、CLIQUE、DBSCAN等。 教学板块 人 板块一 生活中的分类及分类定义 任务1.1 认识并能举出生活中的各种分类,体会并感受生活中的分类意义。 任务1.2 认识并理解分类的标准及重要性,明确分类的定义 活动1.1,1:进行“记忆游戏”,看同学们在20s 内可以记住多少个屏幕上的内容 活动1.1.2:例举生活中的各种分类的例子,感受分类的意义 活动2,1.1:例举生活中衣物整理的例子,看同学如何整理分类? 活动 2.1.2:学生讨论在生活中如何将物质进行分类的?并学习物质分类的定义。 板块二 化学中的常用分 类 任务2.1 感受单一分类方法的缺点和不足 任务2.2 掌握交叉分类方法,并能正确的应用两种方法对物质进行分类 任务2.4 思考并回顾化学中常用的分类方法,以及理解这节课对物质分类活动2.1.1 :对K 2SO 4 、Na 2CO 3、K 2CO 3、Na 2SO 4这四种物质分类。 活动2.2.:1:给体育明星进行连线 活动2.2.2:用交叉法对K 2SO 4 、Na 2CO 3、K 2CO 3、Na 2SO 进行连线,分类 活动2.4,1:回顾这节课所学的分类方法,体会分类标准及意义。 任务2.3 掌握树状分类方法,并能正确的应用两种方法对物质进行分类 活动2.3.:1:回忆初中所学习的各种物质类别的概念。 活动 2.3.:2:学习树状分类法,并对物质、纯净物、单质、化合物、氧化物、酸、碱、盐、混合物这几个概念进行分类 物质的分类(课时一) §2.1物质的分类——简单分类法及其应用教学设计 课题简单分类法及其应用课型新知识课 授课人授课班级 教材分析本节教学内容位于新课标人教版高中化学必修1第二章《化学物质及其变化》第一节《物质的分类》。课标在本节的要求是“能根据物质的组成和性质对物 质进行分类,并尝试用不同的方法对物质进行分类”。 简单分类法是新课程背景下化学教学教材所增添的“新”内容之一。在初高中 的学习中,贯穿中学化学的学习,对中学化学的教学起到了“承前启后”的作 用。学生既可以对初中所学的化学知识进行分类整理,又可以在学生掌握科学 的方法后对以后的化学知识进行更加系统和有效地学习。从新课程内容编排的 角度看,新课程以元素及其化合物的类别作为知识编排的一条主线,每一种类 别的元素及其化合物都是从典型的元素及其化合物作为切入点展开,这样可以 举一反三,让学生的学习变得更加具有调理型。通过本章节的学习,学生对科 学分类方法有了更深刻的认识,也有利于学生自身科学素养的培养。以共性的 角度出发来学习化学,学生会对化学知识体系的建构更加完备。 学生分析教学对象是高一的学生,有一定的生活经验和知识基础,并已经有了生活中对很多事物是分类的概念。在初中化学的学习中,学生已掌握了四种基本反应, 以及酸、碱、盐、氧化物等化学的基本内容,但却没有概括过这些物质间所存 在的共性,以及物质与物质间的转化规律。由此学生对初中学习的基本反应的 本质以及物质的概念还未完全的掌握。通过物质的分类这节课的学习,学生可 以将初中化学学习的知己进行归纳与总结,形成系统的分类观,由此更有利于 对高中化学的学习。 【知识与技能】 1.能根据物质的组成和性质对物质进行分类; 2.学习几种分类方法,并掌握交叉分类法和树状分类法; 3.可根据物质之间的变化规律对一些简单的基本化学反应分类。 【过程与方法】 1.通过学生对日常生活中对物质的分类方法,运用观察,比较,归纳的方法, 词语的归类或排列 (一)多义词复习指导 一字多义、一词多义是汉语言的一大特点。在小学阶段,只要学生了解这一特点,并能在理解词语的基本义的基础上,联系语言环境理解词语的引申义和比喻义。 【建议】 1、从学习能力与习惯培养入手,让学生养成查阅字典的习惯,培养能正确选择词义的能力。 2、在培养学生的阅读理解能力过程中提高学生解词水平。 3、结合词语的近义词、反义词,逐步提高对一词多义的认识。 【复习中应注意以下几点】 ⑴根据《课程标准》的要求,“认识3500个左右常用汉字,能正确工整地书写汉字,有一定的速度。”这是学生最基本的语文素养之一。因此必须重视对字、词的复习。 ⑵查字典的能力是帮助学生学习字词的重要能力,是必须掌握的技能,也是学生今后学习和工作中经常运用的技能。因此,不仅应学会音序查字法、部首查字法,还应学会数笔画查字法。复习中应结合学生的情况经常运用,逐步养成习惯,但不必过多的进行专门的练习。 ⑶查字典的重点和难点是确定部首及选择解释。对此应结合课文中的字词进行指导,解决学生的疑难问题,并作必要的练习。 ⑷词语复习的重点是理解和运用。对常用词语和课文中的重点词语,应采用各种形式让学生进行运用。写近、反义词,选词填空是常见的形式,还有造句,联词成文,词语搭配等都应当让学生进行练习。 (二)成语复习指导 为了突出成语的重要,特将成语单独作为一部分。成语是汉语中的精粹,是人们长期以来习用的简洁、精辟的固定词组或短句。汉语中的成语常常由四个字组成,一般都有出处。许多成语都有一个生动有趣、富含哲理的故事,如:杯弓蛇影、天衣无缝、一鸣惊人等。因此,学习成语不仅能积累词汇,而且能增强阅读、理解水平,了解历史,拓宽知识面,另外如果能恰当地使用它,会使语言更精练,更形象生动,提高我们的写作水平。 【教学建议】 1、依据教材,回忆并引导学生梳理小学阶段学习过的成语,在此过程中培养学生的学习能力。 2、以语文活动课形式,交流课外学习的常用成语,并达到引导学生注重平时阅读积累和学以致用的目的。 3、设计一些学生喜闻乐见的成语练习,让学生在练习中增强兴趣,如:成语竞猜、成语接龙、成语对联等游戏性练习。 2、可以利用教室中的板报和学习园地,辟成语学习的专栏,由学生编稿、组稿,让学生真正成为学习的主人。 关键词共词分析、聚类分析和多维尺度分析 功能: 1、寻找近几年研究热点(热点图),为论文的选题做准备 2、直接为论文服务 方法举例: 关键词:自闭症 研究工具:Bicomb共词分析软件、、excel、中国知网(CNKI) 研究进程: A:中国知网(官网)-左上“资源总库”-左上“中国学术期刊网络出版总库” 主题:自闭症,年限范围:2000-2014,来源类别:全选-检索 每页显示:50-一页页全选后再删除一定不要研究的文献-尽量多选择文献(最好全部) 导出/参考文献-全选-导出-自定义(支持需输出更多文献信息)-全选-导出-保存-txt 打开txt-编辑-全部替换(前面英文删除)-另存为txt-编码:ANSI【多操作几遍,不然提取不出来或会出现00000,而不是00000,00001,00002等】 B:书目共现分析系统-增加(右上角)-项目编号:1-格式类型:cnki中文txt-提取-选择文档-关键字段:关键词-提取(红色)-统计-关键字:关键词-∑统计-矩阵-关键字:关键词-≥5≤280-词篇矩阵-生成-导出至txt-保存 C:打开SPSS-文件-打开文本数据-下一步-删除第一行-度量标准:“名义”变为“度量”-分析-分类-系统聚类-V1标准个案-V2到Vn变量-统计量:选择“合并进程表”“相似性矩阵”-绘制:树状图-方法(二分类-Ochiai)-结果:近似矩阵(最大的表格)导出到excel-多维尺度分析【树状图如果是虚线,可能是spss版本问题或其他问题】 D:SPSS-excel导入-打开数据-excel-删除第一行-删除1:、2:、3:、4:、5:、、、-复制粘贴到变量视图-度量标准:“名义”变为“度量”-字符串变为数值【第一个分类不要改字符串】-分析-度量-多维尺度最后一个ALSCAL-变量移动-从数据创建距离-度量(E)-标准化:Z 得分-选项:组图 什么是面分类法[1] 面分类法是将要分类的事物或对象的若干个属性或特征视为若干个面,每个面又可以分成彼此独立的若干类目,使用时根据需要将这些面中的类目组合在一起,形成一个复合类目。 面分类法结构[1] 面分类法的基本原则[2] 在选用面分类法时,应遵循以下几条基本原则: (1)根据需要,选择分类对象本质的属性或特征作为分类对象的各个“面”; (2)不同“面”的类目不应相互交叉,也不能重复出现; (3)每个“面”有严格的固定位置; (4)“面”的选择以及位置的确定,应根据实际需要而定。 面分类法的优缺点[2] 面分类的主要优点是分类结构上具有较大的柔性,即分类体系中任何一个”面”内类目的变动,不会影响其它”面”,而且可以对”面”进行增删。再有,”面”的分类结构可根据任意”面”的组合方式进行检索,这有利于计算机的信息处理。 面分类的主要缺点是不能充分利用编码空间。例如,在上面的服装分类中,纯毛男式连衣裙的搭配是毫无意义的,在实际编制代码体系时,到底采用哪一种分类方法,要根据课题中需要解决的问题而定。有时,还可根据事物的特征,在一个分类体系中,同时运用线分类法和面分类法。 面分类法 面分类法也称平行分类法,它是把拟分类的商品集合总体。根据其本身固有的属性或特征,分成相互之间没有隶属关系的面,每个面都包含一组类目。将某个面中的一种类目与另一个面的一种类目组合在一起,即组成一个复合类目。面分类法具有类目可以较大量地扩充、结构弹性好、不必预先确定好最后的分组、适用于计算机管理等优点,但也存在不能充分利用容量、组配结构太复杂、不便于手工处理等缺点。 面分类法则将整形码分为若干码段,一个码段定义事物的一重意义,需要定义多重意义就可以采用多个码段。这种代码的数值当然也可以在数轴上找到表达,然而,一根数轴却只能约束一重意义上父类与子类的从属关系,多重意义的约束就要用多根数轴来实现,也就是说一个码段对应一根数轴。面分类是若干个线分类的合成。 基于这一理解,线分类法应该属于1维分类法,面分类法则为2维或多维的分类法。 现实生活中,面分类法的应用可谓广泛,以大家熟悉的15位的身份证号码为例:第一段(前6位)近邻法与剪辑近邻法
语文总复习之词语归类
最全的聚类知识
实例解析关键词聚类的方法策略
高中化学-简单分类法及其应用分层练习
k近邻分类算法
聚类和分类的区别
简单分类法及其应用
中文词语的分类
(完整word版)各种聚类算法介绍及对比
线分类法、面分类法例子
用近邻函数法进行聚类与分类
词语归类练习题
聚类与分类的区别
简单分类法及其应用
词语的归类或排列
关键词共词分析、聚类分析和多维尺度分析
信息分类法