一个汉英机器翻译系统的设计与实现

一个汉英机器翻译系统的
计算模型与语言模型*
刘群+詹卫东++常宝宝++刘颖+
(+中国科学院计算技术研究所二室北京100080)
(++北京大学计算语言学研究所北京100871)
摘要:本文介绍我们所设计并实现的一个汉英机器翻译系统。在概要介绍本系统的主要目标和设计原则的基础上,着重说明系统的计算模型和语言模型,最后给出实验结果和进一步的打算。
关键词:自然语言处理机器翻译中文信息处理
一、引言
我国的机器翻译研究近年来取得了很大的发展。特别是英汉机器翻译系统的研制已经取得了较大的成功,达到了初步实用的阶段。相对而言,汉英机器翻译的研究却进展比较缓慢,离实用化还有相当的距离[1]。我们的目的是利用目前最新的计算机软件技术、相对成熟的机器翻译方法和先进的汉语语法理论,构造一个初步实用的汉英机器翻译系统。本文将对我们所开发的系统所采用的计算模型和语言模型作一个总体性的介绍,而不涉及过多的细节。
下面我们简要介绍一下本系统的几个主要设计原则:
⑴采用成熟的技术
我们的目的是构造一个真正实用的汉英机器翻译系统,因而在可供选择的若干技术路线面前,我们将尽量选用比较成熟的技术,而在现有技术难以解决问题时再尝试一些新技术。
⑵开放的体系结构
开放的体系结构主要体现在系统的实现上所采用的软件构件技术[8]。整个系统采用一些相对独立的软件构件组成,因而可以方便地对系统进行修改、维护和扩充。翻译的过程严格按照独立分析、独立生成的原则进行组织,每一阶段的算法相互独立,对其中一个阶段算法的修改不会对其他算法造成影响。
⑶方便的调试环境
本系统强调为语言工作者提供一个方便的调试环境。系统提供多窗口图形界面的知识库调试工具,支持课题组中多人同时通过网络对一个知识库进行操作。提供对翻译过程直观显示,用户可以清晰地看到翻译过程的每一步操作。提供翻译出错原因查找机制,用户
*本项目的研究受到863-306资助,合同号为863-306-03-06-2
可以轻松确定翻译出错的位置。
机器翻译系统可依据不同的标准进行分类,这些标准也刻划出本系统的一些基本特点:
(1) 规则方法与语料库方法
规则方法发展到今天,相对来说已比较成熟,但由于专家描述的规则知识通常颗粒度较大,不利于处理大量的细节,因而在处理大规模的开放语料时,遇到了难以克服的困难;而从预料库中获取的知识颗粒度较小,在自然语言处理的某些方面取得了成功,但纯粹基于语料库的的机器翻译系统,还没有比较成功的例子。本系统目前采用的是基于规则的技术,我们计划将其扩展成为一个规则方法与语料库方法相结合的系统。
(2) 转换方法与中间语言方法
从理论上说,在实现多种语言互译的机器翻译系统时,中间语言方法可以节省很多的工作量。但从已实现的系统来看,使用转换方法较易取得成功。本系统也采用转换方法。
(3) 确定性算法与不确定性算法
确定性算法的优点是算法较为简单,翻译速度快,缺点是不能提供回溯的能力,翻译过程任何一步的错误将导致整个翻译的失败。不确定算法刚好相反。本系统采用不确定性算法,翻译过程的每一步骤都是不确定的,都可以回溯。
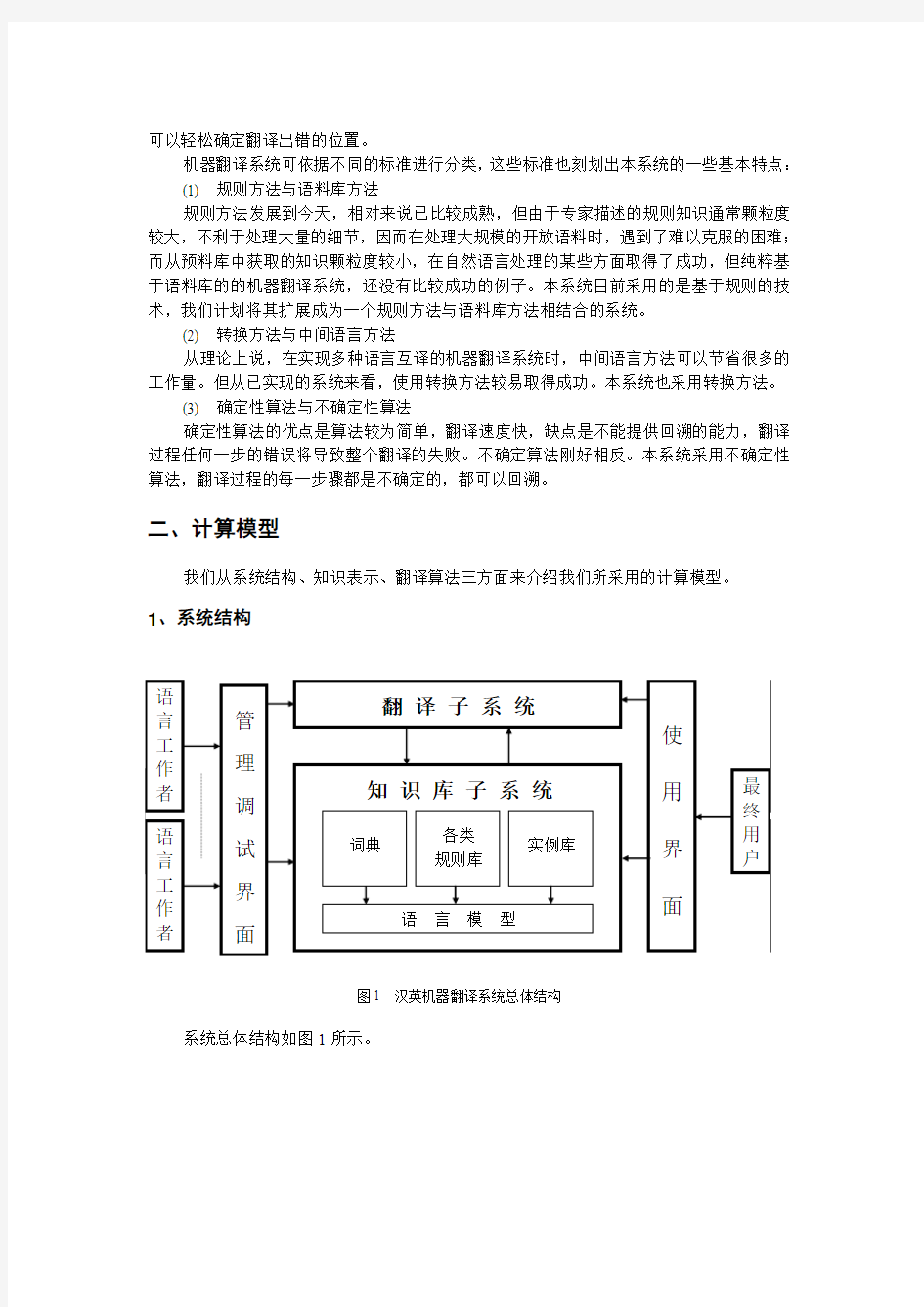
二、计算模型
我们从系统结构、知识表示、翻译算法三方面来介绍我们所采用的计算模型。
1、系统结构
图1 汉英机器翻译系统总体结构
系统总体结构如图1所示。
2、知识表示
机器翻译的过程可以看成是一个运用知识进行推理的过程。知识表示是这一过程的基础。我们把机器翻译中用到的知识表示形式分为内部知识和外部知识两类。其中外部知识是存放于知识库之中,由语言工作者进行管理的知识,如词典和各类规则库等,内部知识是翻译过程中临时生成的,用于描述所翻译的句子的语法语义特征的知识,如树形图、特征结构和语义网络等。
本系统的外部知识表示由知识库子系统进行处理。知识库包括一个语言模型、一部词典、多个规则库和一个实例库。
本系统设计的严格的语言模型起统帅作用,其中规定了本系统所使用的源语言和目标语言的词法模型、句法模型和语义模型,即词法、句法和语义的分类和各种属性描述。所有知识库中所用到的各种语言知识描述用的符号格式都必须符合语言模型中的规定。
整个系统使用一部双语词典。
多个规则库对应于翻译的各个步骤,每个步骤使用相应的规则库。每个规则库的具体格式各不相同,但基本上都采用“树结构+约束”的形式。在知识库的格式定义上,我们特别强调不仅要能描述全局性知识,也要能描述一些局部性的知识。因此我们特别强调词典的描述能力。例如,词典中的局部规则与全局规则具有完全相同的格式,在使用上局部规则优先于全局规则,这样特别有利处理一些与具体词相关的特殊用法。
实例库用于存放系统翻译过的句子及其相关信息。
本系统的内部知识表示形式包括线图(Chart)、树结构和特征网络三种形式。
线图源于Chart Parsing算法,是一种比较通用的语言内部结构表示方法,可以同时表示翻译过程中产生的大量词结点和短语结点,也可以适应多种不同的分析算法。
树结构是短语结构分析中最常用的一种表示方法,用于描述句法成分(包括词结点和短语结点)之间的组合关系。每个树结点对应于线图中的一个词结点或短语结点。我们所使用的树结构表示法中要求标出每个句法成分的中心子结点,用于处理属性值在句法成分之间的传播。
特征网络是本系统所使用的一种特有的知识表示方法。这种表示法融合了特征结构表示法[4]和语义网络表示法的一些特点并加以改进,以适合汉英机器翻译的需要。具体来说,特征网络表达具有以下特点:
1、一个特征网络由许多个互相关联的特征结点所组成;
2、一个特征结点是若干个特征的集合,一个特征是一个“属性-值”对;
3、属性分为简单、原子属性和关联属性两种,原子属性的值是一个原子,关联属性的值是另一个特征结点;
4、原子分为层次型、符号型、数值型、布尔型等多种类型,原子之间可以通过与、或、非等逻辑操作构成复杂原子,每一种类型的原子有不同的合一算法;
5、特征结点之间通过关联属性互相连接,这种连接可以构成回路,我们改进了合一算法,使得这种回路不至于在合一运算时造成死循环;
6、一个特征结点对应着句法分析中已经出现或可能出现的一个句法成分,而每一个句法成分(即句法树中的结点)一定有唯一的一个特征结点与之对应;
7、在一定的条件下,属性的值可以在特征结点之间进行传递;
8、特征结点之间实行真正的合一运算,而不是伪合一运算。
特征网络表示法作为一种最基本的知识表示方法在本系统中发挥着重要的作用,它基本上满足了我们在汉英机器翻译中描述各种复杂的语言现象的需要。
3、翻译算法
我们采用基于转换的翻译方法,遵循独立分析、独立生成的设计原则[3]。
具体的翻译流程下图2所示。
图2 翻译的流程
其中,汉语的词形分析阶段分为重叠词处理和切分两个步骤,汉语的切分采用双向最大匹配算法。出现切分歧义时,不做判断,保留到结构分析阶段进行处理。结构分析阶段采用改进的Chart Parsing算法[6]。转换阶段采用自顶向下与自底向上相结合的局部子树变换算法。结构生成阶段采用自底向上的局部子树变换算法和自顶向下的全局子树位移算法。
4、用户界面
用户界面包括使用界面和管理调试界面。由于本系统还处于开发阶段,我们着重开发了管理调试界面。对于一个实际的机器翻译系统来说,语言规则和词典的调试工作是非常重要的。一个良好的机器翻译系统管理调试界面,可以使语言工作者直观方便地进行语言规则和词典的调试,大大提高调试的效率,进而有效地提高语言知识库的质量。
本系统的管理调试界面分为知识库管理界面和翻译调试界面两部分。知识库管理界面帮助语言工作者对各知识库进行直观的创建、管理和查询等操作,翻译调试界面帮助语言工作者通过观察具体例句的翻译过程对语言知识库进行调试。系统依次以可视的图形显示源文正文、分析产生的每一个源文词语结点、源文短语结点、源文句法树、转换生成产生的译文句法树、译文词结点和最后的译文正文。语言工作者可以根据需要显示任何一个句法成分的产生过程及其对应的特征结点(属性和值)。
三、语言模型
在一个机器翻译系统中,计算模型决定了该系统的能力的极限,即该系统最好能翻译到什么程度;而语言模型则决定了该决定了这种极限能在多大程度上实现。没有好的语言模型,系统的计算模型再好,也不可能得到高质量的译文。
本系统采用以语法分析为主,以语义分析为辅的语言模型。
就汉英机器翻译系统而言,目前还没有专门适用于机器翻译的汉语语法模型。本系统采用的语言模型主要来源于北京大学计算语言学研究所研制的《现代汉语语法信息词典》[2](以下简称《词典》),并在该词典所采用的语言模型基础上修改扩充而成。
1、汉语词语分类和属性[10]
本系统所采用的汉语词语分类和属性取自于《词典》,并作了少量的改动。《词典》中将现代汉语词语(包括标点符号、语素、成语等)分为26类,我们只采用了其中的20类,并将其余6类归并到这些类中。《词典》中有大量的属性描述,我们根据机器翻译的需要对这些属性作了一定的取舍,并增加了少量新属性。本系统所使用的机器翻译词典就是在《词典》的基础上修改扩充而成。在使用中我们体会到,《词典》对现代汉语词语的分类合理,对词语语法功能的描述非常详尽,基本上能满足汉英机器翻译的需要。
2、汉语短语分类和属性[7,10]
对汉语短语的分类,我们继承了《词典》中对汉语词语分类时采用的“功能分类”思想,将短语(包括句子)分成np,vp,ap,tp,sp,dp,pp,mp,mcp,dj,fj,zj等12类。另外,我们还定义了内部结构、语气、被动、否定等短语属性。
我们认为,短语和汉语词语一样,采用按功能分类的思想,而不是按结构分类或按功能-结构混合分类,是符合机器翻译用汉语语法体系要求的。这是因为,功能反映了一种短语与其它短语互相结合的能力,而语法规则所描述的就是短语之间如何互相组合构成新的短语,因而采用功能分类是非常自然而贴切的。短语的结构从本质上说只是短语内部成分之间的组成关系,虽然结构对功能也有一定的影响,但它并不直接反映短语向外结合的能力。因此我们只是把短语的内部结构作为一种属性来对规则进行约束,而不是作为分类的依据。在实践中我们感觉到这种做法是恰当的,既不至于导致规则的描述能力不够,也不会产生大量的冗余规则。
总的来说,我们对汉语短语的认识要比我们对汉语词语的认识肤浅得多。在很多情况下,我们没有足够准确的属性来描述规则的约束条件,尤其是一些很常用的歧义结构,如np+np,vp+vp,np+vp等等。这尤其需要我们机器翻译研究工作者与语言学家共同努力,对汉语短语的语法功能进行更加深入的研究。
3、语义分类和属性[9]
本系统是一个以语法分析为主,语义分析为辅的系统。虽然如此,在本系统中,为消解句法分析和转换时的歧义,语义分析还是起着重要的作用。
本系统采用的语义模型主要包括语义分类和配价分析[5]两个方面。
我们制定了一个比较详尽的语义分类体系,对每一个汉语实词都要填写其相应的语义分类,而对于名词、动词、形容词三类词语还要填写配价数以及相应配价成分的语义类。在规则的约束条件中,对某些短语的组合规定了一定的配价关系,如果这种关系不能被满足,则合一失败。这样就排除了相当一部分由于搭配不当所造成的歧义。
四、实验结果和结论
我们对于3000个覆盖了现代汉语主要句型的汉语句子封闭集进行了调试,调试后翻译的正确率达到90%左右。目前我们所使用的汉语分析规则库中的规则不超过400条,词典中约有4000个汉语词条。
我们下一阶段将要进行的一项主要工作是词典的扩充,争取使之成为一个实用的系统。另一项工作是尝试引进语料库和统计的做法来帮助获取知识以提高翻译的准确率和效率。
参考文献:
[1] 段慧明,俞士汶,机器翻译评测报告,《计算机世界》报1996年3月25日,第183页
[2] 俞士汶等,《现代汉语语法信息词典》规格说明书,中文信息学报,第10卷,第2期,第1-22页,1996
年
[3] 冯志伟,自然语言机器翻译新论,语文出版社,1995
[4] Martin Kay, Unification in Grammar, In V.Dahi & P.Saint-Dizier(Ed.) Natural Language Understanding and
Logic Programming, North Holland, Amsterdam, The Netherlands.
[5] 沈阳,郑定欧主编,《现代汉语配价语法研究》,北京大学出版社,1995
[6] Gazdar G., Mellish C., Natural Language Processing in Lisp, Addison-Welsley Publishing Company, 1989
[7] 俞士汶,关于计算语言学的若干研究,语言与文字应用,1993年第3期
[8] 刘群,张祥,基于软件构件的机器翻译研究方法,待发表
[9] 常宝宝,詹卫东,一个汉英机器翻译系统中的语义处理框架,待发表
[10] 詹卫东,刘群,语义分类在汉英机器翻译中的作用及其存在的问题,待发表
致谢:
本课题是在中国科学院计算技术研究所张祥研究员领导下开展的,并得到了北京大学计算语言学研究所俞士汶教授的悉心指导和大力支持。前后参加过本课题并作出重要贡献的还有北京大学计算语言学研究所的周强、陶晓鹏和中国科学院计算技术研究所的叶煜、王斌等同学和同事。在此一并向他们表示衷心的感谢。
机器翻译技术的现状及发展
机器翻译技术的现状及发展 篇一:翻译技术领域的现状与展望 翻译技术领域的现状与展望 作者/王华伟闫栗丽 翻译技术在中国的发展起步相对较晚,但近年来随着中国在全球化进程中扮演着越来越重要的角色,催生了对翻译技术发展的强烈需求。中国翻译行业在借鉴国外同行经验的基础上,于2007~2008年间在翻译技术领域取得了一系列成就,也还存在一些亟需改进的方面,而这也势必对我国的翻译行业产生深远的影响。 1. 国家政策的扶持和行业协会的推动 翻译技术的发展直接关乎整个翻译行业的翻译质量及效率,具备巨大的行业经济效益。对此,科技部、财政部都给与了足够的重视并拨出专项资金进行扶持。在 2008年的科技型中小企业技术创新基金扶持计划中,中文及多语种处理软件及基于先进语言学理论的中文翻译软件等赫然在列。而中国译协也在 2008年的第 18届世界翻译大会上专门辟出了翻译工具、术语管理和翻译标准等分论坛,着力推动翻译技术的探讨与发展。 2. 词典型翻译软件百花齐放 词典是使用范围最广的工具,它以使用便利的优势,几乎占据了每个计算机的桌面,无论语言学习者还是专业翻译人员,几乎都是必备工具。词典的发展从最早的单机版本发展至今,已经有很多种产品
类型,我们可以见到的有:电子词典、在线词典、手机词典等。“金山词霸”的网络版本“爱词霸”在这两年获得了长足的发展,如爱词霸网络释义、谷歌金山词霸等一系列特色功能的相继推出,将词典型翻译软件的应用领域从传统的桌面计算机拓展到网络、手机等,并取得了显著的成功。另外,类似Google这样的搜索引擎,因为信息量大,检索便利而成为很多专业翻译人员查词的重要辅助工具。 值得一提的是,最新推出的基于用户发布词汇的词典编撰系统之前的词典都是以各大出版社公开发行的词典中的词条作为主要数据库来源,为用户提供查询上的便利。但是传统出版词典的方式存在发布周期长、词汇更新慢的缺陷。互联网的出现,加快了信息传播的速度,也提高了用户对新词更新的速度要求,为了方便新词汇的发布,词典编纂系统也就应运而生了。这是一种基于用户的词典发布系统,用户可自由发起词典编纂项目,自发组织人员参与项目,发起人可以按照需要给小组成员分配不同的权限,将词汇添加等基本工作和审核人员明确区分,既确保了词典的专业性,也实现了专业语料的适时更新和发布。 3. 机器翻译应用软件融入普通网民生活 谷歌语言工具的推出打破了互联网语言的藩篱,用户可以方便简捷地将目标语言的网页转化成自己的母语进行浏览。事实上,这也是机器翻译软件的一个应用领域,而国内的相关软件如金山快译等,专注于为普通网民提供更为友好的英中日网站浏览体验,并在亚洲语言的机器翻译应用方面积累了大量的经验。其他如华建等长期从事机器
机械设计外文翻译(中英文)
机械设计理论 机械设计是一门通过设计新产品或者改进老产品来满足人类需求的应用技术科学。它涉及工程技术的各个领域,主要研究产品的尺寸、形状和详细结构的基本构思,还要研究产品在制造、销售和使用等方面的问题。 进行各种机械设计工作的人员通常被称为设计人员或者机械设计工程师。机械设计是一项创造性的工作。设计工程师不仅在工作上要有创造性,还必须在机械制图、运动学、工程材料、材料力学和机械制造工艺学等方面具有深厚的基础知识。如前所诉,机械设计的目的是生产能够满足人类需求的产品。发明、发现和科技知识本身并不一定能给人类带来好处,只有当它们被应用在产品上才能产生效益。因而,应该认识到在一个特定的产品进行设计之前,必须先确定人们是否需要这种产品。 应当把机械设计看成是机械设计人员运用创造性的才能进行产品设计、系统分析和制定产品的制造工艺学的一个良机。掌握工程基础知识要比熟记一些数据和公式更为重要。仅仅使用数据和公式是不足以在一个好的设计中做出所需的全部决定的。另一方面,应该认真精确的进行所有运算。例如,即使将一个小数点的位置放错,也会使正确的设计变成错误的。 一个好的设计人员应该勇于提出新的想法,而且愿意承担一定的风险,当新的方法不适用时,就使用原来的方法。因此,设计人员必须要有耐心,因为所花费的时间和努力并不能保证带来成功。一个全新的设计,要求屏弃许多陈旧的,为人们所熟知的方法。由于许多人墨守成规,这样做并不是一件容易的事。一位机械设计师应该不断地探索改进现有的产品的方法,在此过程中应该认真选择原有的、经过验证的设计原理,将其与未经过验证的新观念结合起来。 新设计本身会有许多缺陷和未能预料的问题发生,只有当这些缺陷和问题被解决之后,才能体现出新产品的优越性。因此,一个性能优越的产品诞生的同时,也伴随着较高的风险。应该强调的是,如果设计本身不要求采用全新的方法,就没有必要仅仅为了变革的目的而采用新方法。 在设计的初始阶段,应该允许设计人员充分发挥创造性,不受各种约束。即使产生了许多不切实际的想法,也会在设计的早期,即绘制图纸之前被改正掉。只有这样,才不致于堵塞创新的思路。通常,要提出几套设计方案,然后加以比较。很有可能在最后选定的方案中,采用了某些未被接受的方案中的一些想法。
人工智能与机器翻译习题答案.doc
2、产生式系统有哪些类型? 1正向、逆向、双向产生式系统 2可交换的产生式系统 3可分解的产生式系统 3、试举例说明不可撤|口|搜索方法的基本思想? 这种方法相当于沿着单独一条路搜索下去,利用问题给出的局部知识决定如何选取规则, 就是说根据当前可靠的局部知识选一条可应用规则并作用于当前综合数据库。接着再根据新状态继续选取规则,搜索过程一直进行,不必考虑撤回用过的规则。 9、试说明产生式系统规则不一致的原因及解决方法。 原因:规则集中存在的不一致是影响系统性能的重要因素之一。系统建立初期,由于规则集较小,内容也比较简单,设计人员能对每一条规则的条件和结论部分反复推敲和精心构造,这类问题容易防止。但随着时间的推移,新的规则不断加入,规则集合越来越大,内容也越来越丰富,这时规则间的相互影响和相互联系就随之变得复杂。在此情况下,规则的不一致就将自然产生, 解决:(1) 对于循环规则,可构造规则集的IF-THEN图,从起始规则的条件部分开始搜索,如果搜索过程中遇到的THEN部分已在前面出现,就可以中断搜索,规则集中包含的循环规则子集合需设计人员检查,解决; (2)对于冲突规则,构造IF-IF表,对规则集内有相同的IF规则子句构造规则树,形成推理图。同时建立THEN-THEN表用以判断是否有冲突规则出现。对相同IF部分的规则继续用它的各自THEN部分作为其它可以匹配的IF前提条件,递归地构造,如发现两个推理图上分别有节点在THEN-THEN表上是矛盾的,则检测出冲突规则,人工予以解决。 (3)对冗余规则和从属规则的检查类似于冲突规则链的方法.不同之处是前者在推理图中的遍历是试图发现有THEN部分等价的两条规则。 1、机器翻译主要有娜些方法?这些方法各有什么特点? 1基于分析和转换的机器翻译方法 这样的方法有两个特点:一是面向源语言分析,因为源语言中的一个句子已经由句法、语义分析等阶段分析完毕,生成了关于源语言句子的某种中间表示,转换以这种源语言中间表示作为输入;二是直接转换,即对于S表示,直接给出译文形式,一般不需要在目标语言内再作进一步转换,Tl~Tj可以直接包括目标语言的词汇,也可以是对应于Sl~Si的译文组块。 2基于中间语言的翻译方法 基于中间语言的机器翻译方法主要有两个优点。首先,独立的中间表示形式为多语种之间的互译的实现提供了一种经济有效的途径。假设要对N种语言进行互译,则有N*(N.1)个语言对。不同方向的翻译是不同的语言对。此时如果采用基于转换的方法,因为把一种语言翻译成另一种语言都需要一个不同的转换机制(或模块),所以N火(N?l)个语言对共需要N*(N-1)个独立的转换机制。而采用中间语言的方法,由于对每一种语言只需实现将该种语言翻译成中间语言和把中间语言翻译成该种语言的目标语言这样两个模块,所以总共只需要2N个模块。其次,中间语言不仅是对基于中间语言的机器翻译方法这一特定目的有意义, 同时,作为一种通用的自然语言表示,也值得深入研究。 4.1.3基于统计的机器翻译方法 基于统计的机器翻译方法,一般不要任何语言学知识,它的基木原理是实现源语言词汇到目标语言浏汇的映射。其思路受到语音识别研究的启发,因而应用了类似的方法来实现。研究者用
搭建属于自己的机器翻译系统
搭建属于自己的机器翻译系统——MTI专业“技术小白”走进小牛翻译开源社区的心得 搭建属于自己的机器翻译系统 ——MTI专业“技术小白”走进小牛翻译开源社区的心得首先,自我介绍一下。我是一个MTI(翻译硕士)专业、没有计算机编程背景、没有机器翻译理论基础的菜鸟,任职于一家网络科技公司的市场部门,之前的工作中需要做些翻译工作,有时候求助百度翻译、有道翻译等免费的机器翻译系统来解决问题,但是对于一些涉及我们商业机密的数据,由于担心泄密,只能借助于有道词典查查词,然后再自己形成翻译结果。很早之前我就想,要是能有自己的机器翻译系统就好了。 我心目中的翻译技术大牛、对外经贸大学的崔启亮老师曾在微博中给MTI的学生提建议,“学好翻译技术,有前途。对于仍在迷茫MTI的同学,我建议学机器翻译设计与开发,走出迷茫。”非常非常幸运的是,我一个东大毕业的同学告诉我,东北大学自然语言处理实验室(国内搞机器翻译最好的团队之一)联合沈阳雅译网络技术有限公司推出了“小牛翻译开源社区”,社区中有一项内容,就是教不懂机器翻译的人学习“快速搭建自己的机器翻译系统”。于是,我走进社区,按照社区里的相关说明,亲身体验了搭建过程。下面,我想谈谈这个被誉为“目前国内首个以机器翻译为核心的交流平台”的菜鸟级用户体验。 小牛翻译开源社区里提供了统计机器翻译开源系统的全部代码。我了解了一下,NiuTrans开源系统在国际上比较有名,据说是目前国际上能够支持统计机器翻译模型最全的两套统计机器翻译系统之一(另一套是爱丁堡大学的Moses)。这些内容对MT(机器翻译)的专业学者应该很有用吧,但是对于我这个非科班出身的人来说,其实会完全忽略这部分内容。我还是讲讲我在社区里的真正收获——快速搭建实用的机器翻译系统。 一、搭建过程详细说明 需要说明的是,我是在在网页指导与人工指导下才在自己的电脑(Windows7 64位系统,硬盘500G,内存8G)上成功搭建机器翻译系统的。解释一下为什么我不仅看了网页上操作指导,还需要人工指导。身为“技术小白”的我,虽然网页上的操作指导写的很规范,但是第一次接触这么“高大上”的东西,还是有点小紧张的。于是,我加入了小牛翻
机器在线翻译与人工翻译的比较
现如今大家各个国家的人群交流的越来越多,以至于语言自然而然的要学习的更多,如果机器翻译也就是“一点翻译”与人工翻译摆在一起,大家都知道选择人工翻译,因为人工翻译准确性高并且是根据文章上下文进行翻译的,那机翻真的没有优点了么,错,机翻的优点有很多,比如单词准确性高,面对偏僻的词汇也是可以翻译的,翻译语句的时候虽然不是很精准,但是对于了解语言的我们来说也可以根据翻译进行大致的了解,话不多说,简单的来介绍一下如何在线翻译吧。 步骤一:我们要先在电脑上准备好需要进行翻译的文件,最好是将其添加至桌面上,或路径不复杂的文件框内,同时还需要借助电脑浏览器搜索一点翻译,进入相关的界面。 步骤二:通过搜索可以看到“一点翻译“在百度里面的页面,进入在线翻译的界面后,我们就可以在页面的中心位置通过上传文档按钮进入文档翻译的选项页面了。
步骤三:进入文档翻译的选项页面后,我们可以先对上传文档按钮上方的一些选项进行修改(也就是下图里面的选项)这样可以帮助我们更好的实现翻译。 步骤四:上面的选项修改好后,我们就可以开始将准备好的文件添加进来了,可通过点击上传文档按钮或者是拖拽的方式将文件添加进来。
步骤五:文件添加进来后,可再次去翻译的自定义选项是否修改好,若确定修改好后,就可以通过开始翻译按钮,对PDF文件进行翻译了。 步骤六:翻译的时间根据翻译的文件的大小来定制,耐心等待文件翻译结束后,我们可以通过预览按钮对翻译后的文件进行预览,也可以直接将翻译后的文件下载到电脑上进行保存。
在线翻译与人工翻译最大的优点是速度快,方便,准确性高,如果不是相对了解很透的语句的话建议在“一点翻译”内进行在线翻译,小编已经尝试过了,感觉蛮好的哦。
巴比情结与机器翻译系统的研发
巴比情结与机器翻译系统的研发 [摘要]重建巴比塔的情结促使科学家和语言学家联合起来试图利用计算机来进行自然语言的翻译和转换工作。介绍了机器翻译的起源,论述了基于规则和基于语料库的机器翻译系统的特点和实例,探讨了目前机器翻译系统的缺陷及其将来研发方向。 [关键词]巴比情结机器翻译机器翻译系统的研发基于规则基于语料库 一、前言 《圣经》旧约中“创世纪”里巴比塔的故事发生在远古时代,但从那时到现在多少代人以来,人们还在不断地怀有一种情结,构筑同一个梦想:重建巴比塔,让世界各地操不同语言的人通过一种有效的方式可以任意沟通起来。不过构筑语言的“巴比塔”绝非易事,因为虽然大多数语言有共性,但是其差异却很巨大。这种浓厚的巴比情结积聚已久,人们长期无法释怀。20世纪中期计算机的诞生又让人们萌生了新的希望,促使科学家和语言学家联合起来试图利用计算机来进行自然语言的翻译和转换工作,这就是机器翻译。 机器翻译是用计算机把一种语言(源语)翻译成另外一种语言(目标语)的一门新学科,涉及到语言学、计算机科学、数学等许多领域,是典型的多边缘交叉学科。多年以来,人们在不断孜孜追求,对不同种类的机器翻译系统进行了研发,希冀找到一个适当方法解决语言之间的快速和准确翻译问题。虽然时光发展到二十一世纪,计算机早已渗透到人们生活的方方面面,计算机技术的发展和运用已经达到了一个令人瞠目的程度,但是机器翻译却依然没有达到理想的水平。机器翻译研究涉及到很多方面,由于文章篇幅限制,本文将集中讨论机器翻译系统的研发。 二、机器翻译的起源 用机器来进行翻译的理念最早可以追溯到古希腊时代,他们提出各种方案来替代种类繁多而形式各异的自然语言,其中就有用机械手段来分析语言的问题。20世纪30 年代,法国人阿尔楚尼明确提出用机器来进行语言翻译的设想。1933年,前苏联发明家特洛扬斯基设计了机械方法把一种语言翻译成另一种语言的机器,但由于当时技术水平的限制,他的翻译机没有制成。 1946年世界上第一台电子计算机诞生,它惊人的运算速度启发了人们考虑翻译技术的革新问题。有关机器翻译的设想从那时起开始活跃起来,当时许多科学家相信可以通过对计算机编程实现“人工智能”。冷战开始后,当时美国情报部门需要大量的有关前苏联的情报,由于情报是俄文资料,需要进行大量的俄英翻译,而由于人工翻译速度慢,需要进行机器的快速翻译。在此时代背景下,Andrew Booth有幸得到了洛克菲勒基金的资助进行语言翻译的研究。Booth和Weaver
一个汉英机器翻译系统的设计与实现
一个汉英机器翻译系统的 计算模型与语言模型* 刘群+詹卫东++常宝宝++刘颖+ (+中国科学院计算技术研究所二室北京100080) (++北京大学计算语言学研究所北京100871) 摘要:本文介绍我们所设计并实现的一个汉英机器翻译系统。在概要介绍本系统的主要目标和设计原则的基础上,着重说明系统的计算模型和语言模型,最后给出实验结果和进一步的打算。 关键词:自然语言处理机器翻译中文信息处理 一、引言 我国的机器翻译研究近年来取得了很大的发展。特别是英汉机器翻译系统的研制已经取得了较大的成功,达到了初步实用的阶段。相对而言,汉英机器翻译的研究却进展比较缓慢,离实用化还有相当的距离[1]。我们的目的是利用目前最新的计算机软件技术、相对成熟的机器翻译方法和先进的汉语语法理论,构造一个初步实用的汉英机器翻译系统。本文将对我们所开发的系统所采用的计算模型和语言模型作一个总体性的介绍,而不涉及过多的细节。 下面我们简要介绍一下本系统的几个主要设计原则: ⑴采用成熟的技术 我们的目的是构造一个真正实用的汉英机器翻译系统,因而在可供选择的若干技术路线面前,我们将尽量选用比较成熟的技术,而在现有技术难以解决问题时再尝试一些新技术。 ⑵开放的体系结构 开放的体系结构主要体现在系统的实现上所采用的软件构件技术[8]。整个系统采用一些相对独立的软件构件组成,因而可以方便地对系统进行修改、维护和扩充。翻译的过程严格按照独立分析、独立生成的原则进行组织,每一阶段的算法相互独立,对其中一个阶段算法的修改不会对其他算法造成影响。 ⑶方便的调试环境 本系统强调为语言工作者提供一个方便的调试环境。系统提供多窗口图形界面的知识库调试工具,支持课题组中多人同时通过网络对一个知识库进行操作。提供对翻译过程直观显示,用户可以清晰地看到翻译过程的每一步操作。提供翻译出错原因查找机制,用户 *本项目的研究受到863-306资助,合同号为863-306-03-06-2
机器翻译技术介绍
机器翻译技术介绍
常宝宝 北京大学计算语言学研究所 chbb@https://www.360docs.net/doc/274904646.html,
什么是机器翻译
研究目标:研制出能把一种自然语言(源语言)的文 本翻译为另外一种自然语言(目标语言)的文本的计 算机软件系统。 制造一种机器,让使用不同语言的人无障碍地自由交 流,一直是人类的一个梦想。 随着国际互联网络的日益普及,网上出现了以各种语 言为载体的大量信息,语言障碍问题在新的时代又一 次凸显出来,人们比以往任何时候都更迫切需要语言 的自动翻译系统。 但机器翻译是一个极为困难的研究课题,无论目前对 它的需求多么迫切,全自动高质量的机器翻译系统 (FAHQMT)仍将是人类一个遥远的梦。
机器翻译的基本方法
机器翻译的基本方法 ? 基于规则的机器翻译方法 ? 直接翻译法 ? 转换法 ? 中间语言法 ? 基于语料库的机器翻译方法 ? 基于统计的方法 ? 基于实例的方法 ? 混合式机器翻译方法
目前没有任何 一种方法能实现机 器翻译的完美理 想,但在方法论方 面的探索已经使得 人们对机器翻译问 题的认识更加深 刻,而且也确实带 动了不少不那么完 美但尚可使用的产 品问世。
20世纪90年代以前,机器翻译方法的主流一直是基于规则的方 法,不过,统计方法后来居上,目前似乎已成主流方法,从学术 研究的角度看,更是如此。(Google translate)
机器翻译的基本方法
20世纪90年代以前,机器翻译方法的主流一直是基于 规则的方法,因此基于规则的方法也称为传统的机器 翻译方法。 直接翻译法 ? 逐词进行翻译,又称逐词翻译法(word for word translation) ? 无需对源语言文本进行分析 ? 对翻译过程的认识过渡简化,忽视了不同语言之间 在词序、词汇、结构等方面的差异。 ? 翻译效果差,属于早期过时认识,现已无人采用 How are you ? 怎么 是 你 ? How old are you ? 怎么 老 是 你 ?
人工智能与机器翻译期末复习题
一、名词解释(5X3‘)15’ 1.兼类(P121):一个单词既可以作名词动词又可以作其他词类 2.机器翻译:用计算机软件代替人做的书面翻译 3.组合型歧义:一个字与前面的字成词,与后面的字成词,合起来也成词。 4.交集型歧义(P117):一个字与前面的字成词,与后面的字也成词。 5.人工智能:用计算机硬件、软件模拟人的行为,解决人类目前尚未认识清楚的问题。 6.人工智能软件的三大技术:知识表示、知识推理、知识获取。 7.语料库:单词、短语和句子组成的数据库。 8.知识工程:包括人工智能软件技术的工程。(知识工程是以知识为基础的系统,就是 通过智能软件而建立的专家系统) 9.深度学习:一步一步在丰富起来的特征规律引导下,由浅入深完成推理的方法。 10.语用分析:分析成语和习惯用语的方法。 二、题解P36 例2.1 、2.2 例2.1 设有下列语句: (1)高山比他父亲出名。 (2)刘水是计算机系的一名学生,但他不喜欢编程序。 (3)人人爱劳动。 为了用谓词公式表示这些语句,应先定义谓词: BIGGER(x,y):x比y出名 COMPUTER(x):x是计算机系的学生 LIKE(x,y):x喜欢y LOVE(x,y):x爱y M(x):x是人 定义函数father(x)表示从x到其父亲的映射此时可用谓词公式把上述三个语句表示为:(1)BIGGER(高山,father(x)) (2)COMPUTER(刘水)∧∽LIKE(刘水,程序) (3)(?x)(M(x) →LOVE(x,劳动)) 例2.2 设有下列语句: (1)自然数都是大于零的整数。 (2)所有整数不是偶数就是奇数。 (3)偶数除以2是整数。 定义谓词如下: N(x):x是自然数 I(x):x是整数 E(x):x是偶数 O(x):x是奇数 GZ(x):x大于零 另外,用函数S(x)表示x除以2。此时,上述三个句子可用谓词公式表示为: (?x)(N(x) →GZ(x)∧I(x)) (?x)(I(x) →E(x)∨O(x)) (?x)(E(x) →I(S(x))) 三、论述(4X5‘)20’ 1.阐述深度、广度、代价驱动搜索方法。(P68) 答:广度优先搜索法:对全部节点沿广度进行横向扫描,按各节点生成的先后次序,
费森尤斯透析机中英翻译
费森尤斯透析机中英翻译 1、set cond limit设置浓度界限 2、treatment mode 治疗模式 2.2sequ dialysis 单超 2.3SN click clock 单针 2.4Rei nfusio n 回血 2.5Needle Adj pqro 2.7 Ret to mai nprg 回主菜单 3、Alarm limit报警界限 3.1Arterion limit 动脉压界限 3.2Venous limit静脉压界限 3.3TMP limit跨膜压界限 3.4回主菜单 4、Bloodflow calc 4.1Eff bloodflow有效血流量 4.2Total bld volume 总血流量 4.3clear total vulume清除总血流量数据 4.4回主菜单 5、system parameter系统参数 5.1brishtness亮度(调节光标亮度) 5.2Auto-o n ptogram
5.3key click 按键音 5.4status CDS 5.6回主菜单 6、clock sett in gs 闹钟设置 6.1system clock 系统钟 6.2Automatic on 6.3回主菜单 7、treatment param 治疗参数 7.1Reset UF data重设超滤数据 7.2show ISO data显示单超数据 7.3Reset ISO data重设单超数据 7.4show eff time显示有效时间 7.5clear eff time清除有效时间 7.6Dialysate flow 透析液流速 机器版面中英翻译 On/Off 机器开关;Rinse 冲洗;Hotrinst 热冲洗; Disinfection 消毒;Single Needle 单针;Test 自检;Prime 预冲;Dialysis Start 开始透析;Reset Alarm 报警 复位;Alarm Tone Mute 报警消音;Air Detector 空气报警; Blood Leak 漏血报警;Arterial Pressure动脉监测; Venous Pressure静脉监测;TMP 跨膜压监测; Ultrafiltration 超滤菜单;UF Volume 现除水量(ml); Reset Volume 数值归零;UF Rate 除水速度(ml/h);UF Goal 总除 水量(ml);Time Left 剩余除水时间(h:min);UF On/Off 除水开关;UF Prog 超
机器翻译
机器翻译 1 概述 机器翻译(machine translation),又称为自动翻译,是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,一般指自然语言之间句子和全文的翻译。它是自然语言处理(Natural Language Processing)的一个分支,与计算语言学(Computational Linguistics )、自然语言理解( Natural Language Understanding)之间存在着密不可分的关系。 2 国内外现状 机器翻译思想的萌芽关于用机器来进行语言翻译的想法,远在古希腊时代就有人提出过了。在17世纪,一些有识之士提出了采用机器词典来克服语言障碍的想法。笛卡(Descartes)和莱布尼兹(Leibniz)都试图在统一的数字代码的基础上来编写词典。在17世纪中叶,贝克(Cave Beck)、基尔施(Athanasius Kircher)和贝希尔(Johann JoachimBecher)等人都出版过这类的词典。由此开展了关于“普遍语言”的运动。维尔金斯(JohnWilkins)在《关于真实符号和哲学语言的论文》(An Essay towards a Real Character andPhilosophical Language, 1668)中提出的中介语(Interlingua)是这方面最著名的成果,这种中介语的设计试图将世界上所有的概念和实体都加以分类和编码,有规则地列出并描述所有的概念和实体,并根据它们各自的特点和性质,给予不同的记号和名称。本世纪三十年代之初,亚美尼亚裔的法国工程师阿尔楚尼(G.B. Artsouni)提出了用机器来进行语言翻译的想法,并在1933年7月22日获得了一项“翻译机”的专利,叫做“机械脑”(mechanical brain)。这种机械脑的存储装置可以容纳数千个字元,通过键盘后面的宽纸带,进行资料的检索。阿尔楚尼认为它可以应用来记录火车时刻表和银行的帐户,尤其适合于作机器词典。在宽纸带上面,每一行记录了源语言的一个词项以及这个词项在多种目标语言中的对应词项,在另外一条纸带上对应的每个词项处,记录着相应的代码,这些代码以打孔来表示。机械脑于1937年正式展出,引起了法国邮政、电信部门的兴趣。但是,由于不久爆发了第二次世界大战,阿尔楚尼的机械脑无法安装使用。1903年,古图拉特(Couturat)和洛(Leau)在《通用语言的历史》一书中指出,德国学者里格(W. Rieger) 曾经提出过一种数字语(Zifferngrammatik),这种语法加上词典的辅助,可以利用机械将一种语言翻译成其他多种语言,首次使用了“机器翻译” (德文是ein mechanisches Uebersetzen)这个术语。 真正对机器翻译进行研究应该说是从布恩和韦弗开始的。他们研究的是自动词典万, 从1954年1月7日公开展示的IBM701型计算机开始, 机器翻译进人一个繁荣发展的时期。从那时起, 很多国家都投人了大量的人力、物力从事这方面的研究和开发。随着 Internet 的普遍应用,世界经济一体化进程的加速以及国际社会交流的日渐频繁,传统的人工作业的方式已经远远不能满足迅猛增长的翻译需求,人们对于机器翻译的需求空前增长,机器翻译迎来了一个新的发展机遇。国际性的关于机器翻译研究的会议频繁召开,中国也取得了前所未有的成就,相继推出了一系列机器翻译软件,例如“译星” 、“雅信” 、“通译” 、“华建”等。在市场需求的推动下,商用机器翻译系统迈入了实用化阶段,走进了市场,来到了用户面前。 中国机器翻译研究起步于1957年,是世界上第4个开始搞机器翻译的国家,60年代中期以后一度中断,70年代中期以来有了进一步的发展。现在,中国社会科学院语言研究所、中国科学技术情报研究所、中国科学院计算技术研究所、黑龙江大学、哈尔滨工业大学等单位都
机器翻译和人工翻译-大学英语作文
学术英语作文 机器翻译是否会代替人工翻译 In the past decades, artificial intelligence has brought the light of reform to many areas, translation industry included. The new reform brought us machine translation. As an increasing popular topic, it has inspired people to think that maybe one day, they no longer need to learn foreign languages because machine translation will replace human translation. Though it is not 100% correct, there remains some reasonality within. Last year, A research team from Microsoft claimed that their machine translation (MT) system has achieved the level of professional human translators when it comes to general news report. Meanwhile, Google Translate tool has surpassed the proficiency of some advanced learners. And on Baidu World Conference, Yanhong Li showcased a real-time translation developed by his company. A trend revealed by all those tech giants’ news——an accurate and real-time translation by machine is promising in the future. Meanwhile, new techniques emerge constantly, accelerating the smartness and depth of machine learning. Taking neural network for example……(待补充70词) Thus, In the coming future, there’s no need for comm on people to learn foreign languages. Once the translation machines are smart and powerful enough to deal with academic environment and daily life while also portable to be carried with, people will use them to travel, study and live all around the world without language barriers. It will just look like the scenery in the movie The Wondering Earth -- Astronauts from various countries talk in their mother tongue. At the same time, a mini equipment installed in their suits translate their words. However, if you
中英文在线翻译
英文翻译中文在线翻译 英文翻译中文在线翻译 (一)促进经济平稳较快发展 1. Promoting steady and robust economic development 扩大内需特别是消费需求是我国经济长期平稳较快发展的根本立足点,是今年工作的重点。 Expanding domestic demand, particularly consumer demand, which is essential to ensuring China’s long -term, steady, and robust economic development, is the focus of our economic work this year. 着力扩大消费需求。加快构建扩大消费的长效机制。大力调整收入分配格局,增加中低收入者收入,提高居民消费能力。完善鼓励居民消费政策。大力发展社会化养老、家政、物业、医疗保健等服务业。鼓励文化、旅游、健身等消费,落实好带薪休假制度。积极发展网络购物等新型消费业态。支持引导环保建材、节水洁具、节能汽车等绿色消费。
扩大消费信贷。加强城乡流通体系和道路、停车场等基础设 施建设。加强产品质量安全监管。改善消费环境,维护消费 者合法权益。 We will work hard to expand consumer demand. We will move faster to set up a permanent mechanism for boosting consumption. Wewill vigorously adjust income distribution, increase the incomes of low-and middle- income groups, and enhance people ’s ability to consume. We will improve policies that encourage consumption. We will vigorously develop elderly care, domestic, property management, medical and healthcare services. We will encourage consumer spending on cultural activities, tourism, and fitness; and implement the system of paid vacations. We will actively develop new forms of consumption such as online shopping; support and guide the consumption of green goods such as environmentally friendly building materials, water-saving sanitation products, and energy-efficient vehicles; and expand consumer credit. We will improve the urban-rural logistics system and infrastructural facilities, such as roads and parking lots, strengthen supervision over product quality and
机器翻译技术的探讨
机器翻译技术的探讨 六院五队-徐允鹏-12060143 摘要随着国际交流的日益增多,在计算机、互联网等相关技术日新月异的基础上,机器翻译的技术与应用得到了蓬勃发展。本文详细探讨了基于规则的机器翻译方法、基于语料库的机器翻译方法和混合式机器翻译方法,并讲述了机器翻译的评估方法,最后介绍了机器翻译技术的最新进展。 关键词:机器翻译;基于规则;语料库;评估方法 1.机器翻译概述 随着国际化交流的普遍性,信息通信的日益膨胀,高效的处理不同领域各种语言之间的互译已成为当代人们的普遍需求。翻译是解决自然语言之间通信障碍最直接最有效的方法。传统的翻译工作都是通过专业翻译人员完成,利用语言学知识进行自然语言之间的互译,帮助人们实现信息通信。伴随着计算机技术的成熟与自然语言处理技术的不断进步,利用机器翻译系统帮助人们快速获取外文信息代替人工翻译已成为一种必然的趋势。 机器翻译(machine translation),又称为自动翻译,是利用计算机把一种自然源语言转变为另一种自然目标语言的过程,一般指自然语言之间句子和全文的翻译。它是自然语言处理(Natural Language
Processing)的一个分支,与计算语言学(Computational Linguistics )、自然语言理解(Natural Language Understanding)之间存在着密不可分的关系[1]。 机器翻译是21世纪要解决的科技难题之一,主要困难是自然语言在各个层次上的歧义性。研究机器翻译具有重要的实践意义和理论意义。国际间的合作与交流,语言的差异是一个非常重要的障碍,各行各业的人们面对大量他们不熟悉的语言的文档资料,如果单纯的依靠人工翻译,这些日益的待翻译材料将是一种非常沉重的负担,而机器翻译可大幅度减轻这种负担。同时,机器翻译对于了解人类语言和思维的基本机制,探讨人工智能技术有着重要的意义。 2.机器翻译方法 人们一直在寻求更好的解决机器翻译问题的方法,目前机器翻译方法主要有基于规则的机器翻译,基于语料库的机器翻译和混合式机器翻译方法。 2.1基于规则的机器翻译方法 2.1.1基于分析和转换的机器翻译方法 人作翻译时,把一个源语言句子译成目标语言句子,设计到四个基本操作:目标语言单词的检索、调序、删词、增词;机器翻译系统的过程包括检索、分析、转换和生成主要四个阶段,这被称为基于分析和转换的机器翻译系统,也被认为是模拟人类翻译活动最恰当的机
中英文翻译机器人
中英文翻译机器人 机器人工业机器人是在生产环境中用以提高生产效率的工具,它能做常规的装配线工作,或能做那些对于工人来说是危险的工作,例如,第一代工业机器人是用来在核电站中更换核燃料棒,如果人去做这项工作,将会遭受有害放射线的辐射。工业机器人亦能工作在装配线上将小元件装配到一起,如将电子元件安装在电路印刷板,这样,工人就能从这项乏味的常规工作中解放出来。机器人也能按程序要求用来拆除炸弹,辅助残疾人,在社会的很多应用场合履行职能。机器人可以认为是将手臂末端的工具、传感器和(或)手爪移到程序指定位置的一种机器。当机器人到达位置后,他将执行某种任务。这些任务可以是焊接、密封、机器装料、拆卸以及装配工作。除了编程以及系统的开停之外,这些工作可以在无人干预下完成。如下叙述的是机器人系统基本术语:机器人是一个可编程、多功能的机器手,通过给要完成的不同任务编制各种动作,它可以移动零件、材料、工具以及特殊装置。这个基本定义引导出后续段落的其他定义,从而描绘出一个完整的机器人系统。预编程位置点是机器人为完成工作而必须跟踪的轨迹。在某些位置点上机器人将停下来做某写操作,如装配零件、喷涂油漆或焊接。这些预编程点贮存在机器人的贮存器中,并为后续的连续操作所调用,而且这些预编程点像其他程序数据一样,可在日后随工作需要而变化。因而,正是这种可编程的特征,一个工业机器人很像一台计算机,数据可在这里储存、后续调用与编辑。机械手上机器人的手臂,它使机器人能弯曲、延伸、和旋转,提供这些运动的是机器手的轴,亦是所谓的机器人的自由度。一个机器人能有3—16 轴,自由度一词总是与机器人轴数相关。工具和手爪不是机器人自身组成部分,但它们安装在机器人手臂末端的附件。这些连在机器人手臂末端的附件可使机器人抬起工件、点焊、刷漆、电弧焊、钻孔、打毛刺以及根据机器人的要求去做各种各样的工作。机器人系统还可以控制机器人的工作单元,工作单元是机器人执行任务所处的整体环境,包括控制器、机械手、工作平台、安全保护装置或者传输装置。所有这些为保证机器人完成自己任务而必需的装置都包括在这一工作单元中。另外,来自外设的信号与机器人通讯,通知机器人何时装配工件、取工件或放工件到传输装置上。机器人系统有三个基本部件:机械手、控制器和动力源。A.机械手机械手做机器人系统中粗重工作,它包括两个部分:机构和附件,机械手也有联接附件基座,图 1 表示了一机器人基座与附件之间的联接情况。图 1 机械手基座通常在工作区域的地基上,有时基座也可以移动,在这种情况下基座安装在导轨或轨道上,允许机械手从一个位置移动到另外一个位置。正如前面所提到的那样,附件从机器人基座上延伸出来,附件就是机器人的手臂,它可以是直接型,也可以是轴节型手臂,轴节型手臂也是大家所知的关节型手臂。机械臂使机械手产生各轴的运动。这些轴连在一个安装基座上,然后再连到托架上,托架确保机械手停留在某一位置。在手臂的末端上,连接着手腕(图1),手腕由辅助轴和手腕凸缘组成,手腕是让机器人用户在手腕凸缘上安装不同工具来做不同种工作。机械手的轴使机械手在某一区域内执行任务,我们将这个区域为机器人的工作单元,该区域的大小与机器手的尺寸相对应,(图2)列举了一个典型装配机器人的工作单元。随着机器人机械结构尺寸的增加。工作单元的范围也必须相应增加。图2 机械手的运动由执行元件或驱动系统来控制。执行元件或驱动系统允许个轴在工作单元内运动。驱动系统可用电气、液压和气压动力,驱动系统所产生的动力经机构转变为机械能,驱动系统与机械传动链相匹配。有链、齿轮和滚珠丝杠组成的机械传动链驱动着机器人的各轴。 B. 控制器机器人控制器是工作单元的核心。控制器储存着预编程序供调用、控制外设,及与厂内计算进行通讯以满足产品经常更新的需要。控制器用于控制机器手运动和在工作单元内控制机器人外设。用户可通过手持的示教盒将机械手运动的程序编入控制器。这些信息储存在控制器的存储器中以备后续调用,控制器储存了机器人系统的所有编程数据,它能储存几个不同的程序,并且所有这些程序均能编辑。控制器要求能够在工作单元内外设进行通信。例如控制器有一个输入端,它能标识某
人工智能与机器翻译.
人工智能与机器翻译(A,B 卷 七个大题:1. 名词解释 2.题解 3.智能知识 4.机器翻译方法 5. 技术阐述 6.分析题 7.应用题 A. 名词解释 : a. 机器翻译 :计算机程序做人的翻译。 b. 兼类 :一个单词既可以作名词动词又可以作其它词类。 c. 人工智能软件技术 :知识表示,知识推理,知识学习。 d. 人工智能 :用计算机模拟人的行为。 e. 交集型歧义 :一个字和前面的字可以成词,跟后面的字也可以成词。 f. 组合型歧义 :一个字可以和前面的字成词也可以同后面的字成词,连起来也可以成词。 g. 语法分析 :分析一句话的语法含义。 h. 语料库 :单词,短语,句子的集合。 i. 自然语言理解 :用计算机程序去理解一篇文章的含义。 B. 题解 : 第二章 P36 2-1,2-2 例 2.1 设有下列语句: (1 高山比他父亲出名。 (2 刘水是计算机系的一名学生,但他不喜欢编程序。
(3 人人爱劳动。 为了用谓词公式表示这些语句,应先定义谓词: BIGGER(x,y:x比 y 出名 COMPUTER(x:x是计算机系的学生 LIKE(x,y:x喜欢 y LOVE(x,y:x爱 y M(x:x是人 定义函数 father(x表示从 x 到其父亲的映射此时可用谓词公式把上述三个语句表示为: (1 BIGGER(高山, father(x (2 COMPUTER(刘水∧∽ LIKE (刘水,程序 (3 (任意 x (M(x->LOVE(x,劳动 例 2.2 设有下列语句: (1 自然数都是大于零的整数。 (2 所有整数不是偶数就是奇数。 (3 偶数除以 2是整数。 定义谓词如下: N(x:x是自然数 I(x:x是整数