分类数据的快速筛选

还在一个个的查看和分类表格数据吗?筛选能帮助我们快速提取表格中的信息,提高效率。
工具/原料
wps
方法/步骤
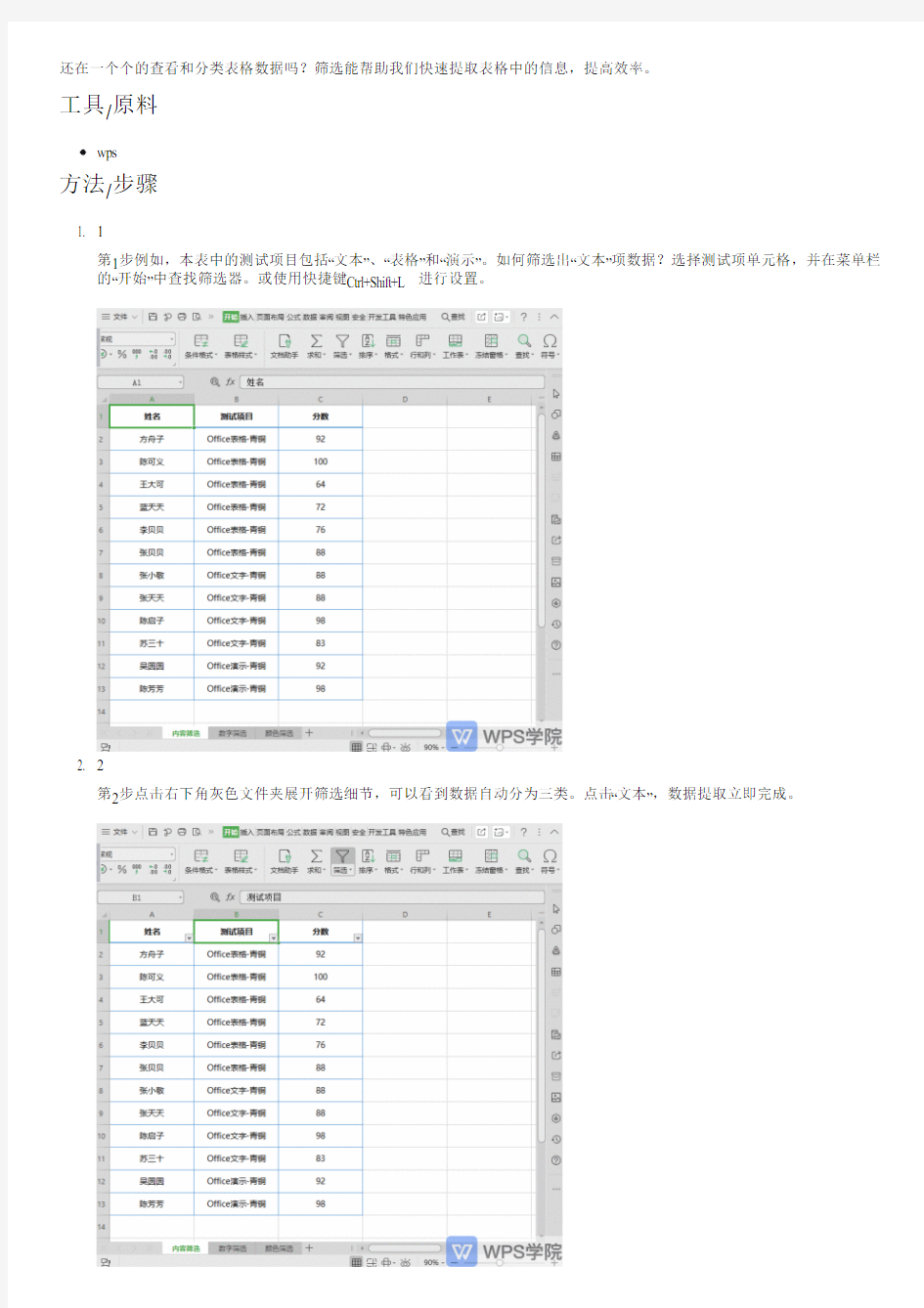
1. 1
第1步例如,本表中的测试项目包括“文本”、“表格”和“演示”。如何筛选出“文本”项数据?选择测试项单元格,并在菜单栏的“开始”中查找筛选器。或使用快捷键Ctrl+Shift+L进行设置。
2. 2
第2步点击右下角灰色文件夹展开筛选细节,可以看到数据自动分为三类。点击“文本”,数据提取立即完成。
3. 3
第3步在筛选过程中,也可以快速进行数字筛选,例如,提取得分大于90的测试数据。点击数字筛选器,选择大于90,筛选器立即完成!
4. 4
第4步如果表内容已用不同的颜色标记为不同类别的数据,则还可以选择按颜色过滤。首先设置筛选,展开筛选详细信息,选择“颜色筛选”,选择一种颜色,确定!
5. 5
第5步如果要取消筛选,只需再次点击“筛选”按钮。
END
数据分析的常见方法
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率\回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。 列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的
统计学名词解释汇总情况
1什么是统计学?统计方法可分为哪两大类?统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。方法有描述统计和推断统计两类 2统计数据可分为哪几种类型?不同类型数据各有什么特点?按采取计量尺度,分类、顺序、数值型数据;按统计数据收集方法,观测、实验数据;按被描述对象与时间关系,截面、时间序列数据 统计数据;按所采用的计量尺度不同分; (定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。 统计数据;按统计数据都收集方法分; 观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 实验数据:在实验中控制实验对象而收集到的数据。 统计数据;按被描述的现象与实践的关系分; 截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 3举例说明总体、样本、参数、统计量、变量这几个概念:对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。 4什么是有限总体和无限总体?举例说明 有限总体指总体的范围能够明确确定,而且元素的数目是有限可数的,如若干个企业构成的总体,一批待检查的灯泡。无限总体指总体包括的元素是无限不可数的,如科学实验中每个试验数据可看做是一个总体的一个元素,而试验可无限进行下去,因此由试验数据构成的总体是无限总体 5变量可分为哪几类? 变量可以分为分类变量,顺序变量,数值型变量。 变量也可以分为随机变量和非随机变量。经验变量和理论变量。
数据分析-分布类别
各种分布 泊松分布 Poisson分布,是一种统计与概率学里常见到的离散概率分布。 泊松分布的概率函数为: 泊松分布的参数λ是单位时间(或单位面积、单位体积)内随机事件的平均发生率。泊松分布适合于描述单位时间内随机事件发生的次数。 泊松分布的期望和方差均为 特征函数为: 泊松分布与二项分布 当二项分布的n很大而p很小时,泊松分布可作为二项分布的近似,其中λ为np。通常当n≧10,p≦0.1时,就可以用泊松公式近似得计算。 事实上,泊松分布正是由二项分布推导而来的。 泊松分布可作为二项分布的极限而得到。一般的说,若 ,其中n很大, p很小,因而不太大时,X的分布接近于泊松分布。这个事实有时可将较难计算的二项分布转化为泊松分布去计算。 应用示例 泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,某放射性物质发射出的粒子,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。 卡方分布 卡方分布( 分布)是概率论与统计学中常用的一种概率分布。n 个独立的标准
正态分布变量的平方和服从自由度为n 的卡方分布。卡方分布常用于假设检验和置信区间的计算。 若n个相互独立的随机变量ξ?、ξ?、……、ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和构成 一新的随机变量,其分布规律称为卡方分布(chi-square distribution),即分布(chi-square distribution),其中参数n称为自由度。正如正态分布中均值或方差不同就是另一个正态分布一样,自由度不同就是另一个分布。记为或者。 卡方分布与正态分布 卡方分布是由正态分布构造而成的一个新的分布,当自由度n很大时,分布 近似为正态分布。对于任意正整数x,自由度为 k的卡方分布是一个随机变量X 的机率分布。 期望和方差 分布的均值为自由度n,记为E( ) = n。分布的方差为2倍的自由度(2n),记为D( ) = 2n。 均匀分布 均匀分布(Uniform Distribution)是概率统计中的重要分布之一。 顾名思义,均匀,表示可能性相等的含义。 (1) 如果,则称X服从离散的均匀分布。 (2) 设连续型随机变量X的概率密度函数为,则称随机变
Excel中数据的排序、筛选与分类汇总
Excel中数据的排序、筛选与分类汇总 课程导入:通过前几次课公式和函数的系统学习,我们已经知道Excel电子表格具有强大的数据运算能力。但只有数据,而无法快速有效的查阅有效信息,这无疑是在做无用功,是一种资源的浪费。今天这次课我们将要学习Excel中的数据处理,真正对数据进行统计和分析。 引入实例:Excel在学生成绩统计中有独特的优势,能方便快速的进行学生成绩的各类统计,如能方便快捷的进行成绩的排序、分类汇总、数据的高效筛选、快速的进行学科及总分的分段统计等等。 要点:数据的处理重点从数据的排序、数据的筛选、数据的分类汇总入手。 教学内容一:数据排序和筛选 一、数据的排序:排序就是按某种规则排列数据以便分析。 排序的三种方式:a. “升序”排列,选中要排序列中的一个单元格,按按钮 b. “降序”排列,选中要排序列中的一个单元格,按按钮 c. 自定义排列,选择【数据】->【排序】,利用多个关键字进行复杂 排序。首先考虑的是“主要关键字”,当主要关键字排序出现相 同数据时,将按次要关键字再次排序,如果次要关键字还出现相 同数据时,可以按照第三关键字最后排序。 注意:如果Excel没能够正确地进行排序,可能是因为它没有正确地获取排序区域。特别应该注意的是,排序区域中不能够包含已合并的单元格。 教学实例一:《高一期末成绩分析》(排序) (1)打开D:\excel实例\操作一.xls,选择“高一期末成绩(排序)”。 (2)按总分进行数据排序。选定H列中的任意一个单元格(注意,不要选定H列,否则将只对H列排序),单击常用工具栏中的按钮,即从大到小排序。 (3)要求总分相同的学生按语数外总分降序排序,语数外总分相同的学生按照理综降序排序。选定表中任意单元格,单击【数据】->【排序】,指定主要关键字为总分,排序方式为降序;次要关键字为语数外,排序方式也为降序;第三关键字为理综,排序方式为降序。注意:若不想对标题行进行排序,那要选择“有标题行”。 (4)保存该文件。 操作后效果图如下:
统计学整理讲解
第1章 什么是统计学? 统计学是研究收集数据,整理数据,分析数据以及由数据分析得出结论的方法,简称为“数据的科学”。 统计滥用 ——不好的样本 ——过小的样本 ——误导性图表 ——局部描述 ——故意曲解 统计应用上的两个极端 ——不用或几乎不用统计 ——简单问题复杂化 随机性和规律性
当我们不能预测一件事情的结果时,这件事就和随机性联系起来了。 通过对看起来随机的现象进行统计分析,统计知识能够帮助我们把随机性归纳于可能的规律性中。统计从我们如何观察事物和事物本身如何真正发生这两个方面帮助我们理解随机性和规律 性的重要性。因此,统计可以看做是一项对随机性中的规律性的研究。 规律也表现出某种随机性。 在这种意义下来说,统计就成了对数据中的偏差问题的研究。根据作为统计基础的数学理论,我们可以确定一项调查中的某一比例有多大的随机性,以及在下一次的重复调查中,这个比例可能有多大的偏差。我们还可以指出,两个比例之间的差异是否大到了随机性本身所不能解释 的地步。 概率 概率是一个0到1之间的数,它告诉我们某一事件发生的机会有多大。 ?概率为统计学的第三个方面——如何从数据中得出结论——奠定了基石。 ?我们可能永远不能确定两个数字的差异是否超出了随机性本身所预期的范围,但是我们可以确定,这种差异发生的概率是大还是小。根据这个基本思想,在很多情况下,我们 可以得出关于我们所处的这个世界的重要结论。 变量(variable) 是指一个可以取两个或更多个可能值的特征、特质或属性。比如,性别是取两个值的变量,因 为一个人只可能是男性或女性。还有其它变量的例子,如人的寿命,体重,以及汽车每升汽油 所能行驶的距离,等等。 变量的值(value) 通常是对某一特定个体的度量,特定个体可能是指一个人,一个家庭,一个地区,或一个国家。表 1.1列出了一些变量、变量的取值及其所测量的个体的例子。从表中可知,性别变量是以人为个体的观测,孩子的数目是以家庭为个体的观测。
统计学基础课后全部详细答案与讲解
统计学第一至四章答案 第一章 一、思考题 1.统计学是收集、处理、分析、解释数据并从数据中得出结论的科 学。 统计方法可分为描述统计和推断统计。 2.统计数据的分类:按计量尺度:分类数据、顺序数据和数值型数据按获取数据的方式:观测数据和实验数据按数据与时间的关系:截面数据和时间序列数据特点:分类数据各类别之间是平等的并列关系,各类别之间的顺序可以任意改变;顺序数据的分类是有序的;数值型数据说明的是现象的数量特征,是定量数据;观测数据是通过调查或观测而收集到的数据,是在没有对事物进行人为控制的条件下得到的;实验数据是在实验中控制实验对象而收集到的数据;截面数据也称静态数据,描述的是现象在某一时刻的变化情况;时间序列数据也称动态数据,描述的是现象随时间的变化情况。 3.对武昌分校的全体教师进行工资调查,那么全体教师就是总体,从中抽取五十名教师进行调查,这五十名教师的集合就是样本,全体教师工资的总体平均值和总体标准差等描述特征的数值就是参数,五十名教师工资的样本平均值和样本标准差等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说教师的工资。 4.有限总体:指总体的围能够明确确定,而且元素的数目是有限可数的。例如:武昌分校10 级金融专业学生 无限总体:指总体所包含的元素是无限的、不可数的。例如:整个宇宙的星
球 5.变量可分为分类变量、顺序变量、数值型变量。同时数值型变量可分为离散型变量和连续型变量。 6.离散型变量只能取有限个值,而且其取值都以整位数断开,可以一一列举,例如“产品数量” 、“企业数”。连续型变量的取值指连续不断的,不能一一列举。例如“温度” 、“年龄”。 二、练习题 1.(1)数值型变量(2)分类变量(3)数值型变量 (4)顺序变量(5)分类变量 2.(1)这一研究的总体是IT 从业者,样本是从IT 从业者中抽取的1000 人,样本量是1000 (2)“月收入”是数值型变量 (3)“消费支付方式”是分类变量 3.(1)这一研究的总体是所有的网上购物者 (2)“消费者在网上购物的原因”是分类变量 第二章 一、思考题 1:答:1:普查的特点:①:普查通常是一次性的或周期性的; ②:普查一般需要规定统一的调查时间;③:普查的数据一般比 较准确;4:普查的使用围比较狭窄,只能调查一些最基本的、 特定的现象。2 :抽样调查的特点:①:经济性;②:时效性强; ③:适应面广;④:准确性高。
第14讲 数据的排序、筛选和分类汇总
第14讲 数据的排序、筛选和分类汇总(先提问、讲解上节课的操作练习4、5、6、7) 我们已学了工作表中数据(如学生成绩)进行一些简单的统计和计算(如求总分、平均分)的方法,这一节我们将学习对数据表进行更多的管理和分析。 一、认识数据表: 在工作表中,我们可以输入各种文字、字符、数值、日期、公式和函数,以及各种修饰,其中有一种规则的数据内容组成一个规范的数据表(由数据列(字段)和数据行(记录)组成)。规范的数据表要求满足如下条件:(打开:“成绩按部门汇总”表演示) 1)规范的数据表由几列字段组成,每个字段的顶部是其列标题(称字段名); 2)每个字段中各单元格内容类型一致(如列标题是“姓名”下面单元格是文字组成的字符类型;列标题是“语文”下面单元格是分数组成的数值类型);(演示)3)规范的数据表和工作表中的其它信息之间至少留出一个空行和一个空列。以区分数据表和其它数据;(演示) 5)用第一行做字段名;每一行数据称为记录。(演示) 二、数据排序: 排序的目的是数据表中行(记录)按要求(按指定字段名—关键词)重新排列位置。 以“学生成绩示例.xls”中的“成绩统计示例”表)为例,: 1)选定数据表;(鼠标点击数据表中的任一单元格) 2)单击“数据”菜单中的“排序”命令,弹出“排序”对话框; 3)在上对话框中,输入排序要求(如:递增、递减、关键词的选定、是否包含标题?等)后,按“确定”即可。 排序也可以同时按主关键词、次关键词来排序;(演示)
提问1:对按“总分”排序“成绩统计示例”工作表,如何按总分加上名次? 提问2:按总分加上名次后,要求最终学号次序不变,再如何处理? 三、数据筛选: 当数据表中记录较多时,Excel可显示满足条件(筛选出)的记录,其它记录隐藏起来。 下面以“自动筛选”为例来看看如何进行记录(数据行)的筛选。 1、用“自动筛选”菜单进行筛选。 以“学生成绩示例.xls”中的“成绩按部门汇总”表)为例,演示。 方法:1)选定数据表;(鼠标点击数据表中的任一单元格) 2)单击“数据”菜单中的“筛选”项中的“自动筛选”命令,则字段名单元格出现箭头按钮。 3)单击要筛选的字段名旁箭头按钮,出现包含所有数据的选择列表,在选择列表中选择满足某个条件的数据即可。 (演示) 2.用“自定义”筛选条件进行筛选。 有时用户在进行筛选时,同一个项目下筛选条件有多个,此时仅用筛选箭头就不能实现了,Excel为我们提供了“自定义”筛选条件进行筛选。 以“学生成绩示例.xls”中的“成绩按部门汇总”表)为例,在“自动筛选”命令后,单击要筛选的字段名旁箭头按钮,出现包含所有数据的选择列表,在选择列表中选择“自定义”项,输入2个条件即可。(演示)。 3、关闭筛选 如果想取消“自动筛选”。可打开“数据”菜单,选择“筛选”,然后单击“自动筛选”命令即可。 四、分类汇总: 分类汇总是按某一字段分类统计(汇总)。如某工厂可按部门统计工资和、平均数等。
第八章 分类数据分析
第九章 列联分析 一、填空题 1、设R 为列联表的行数,C 为列联表的列数,则进行拟合优度检验时所用统计量2χ的自由度为 。 2、设0f 为列联表中观察值频数,e f 为期望值频数,则进行拟合优度检验时所用统计量2χ= 。 3、在列联分析中,观察值总数为n ,RT 为列联表中给定单元的行合计,CT 为给定单元列合计,则该给定单元频数期望值为 。 4、在列联分析中,观察值总数为500,列联表中给定单元的行合计数为140,列合计数为162,则该给定单元频数期望值为 。 5、在3×4列联分析中,统计量2 2 0()e e f f f χ-=∑(其中0f 为观测值频数,e f 为期望值频数)的自由度为____________。 6、对来自三个地区的原料质量进行检验时,先把它们分成三个等级,在随机抽取400间进行检验,经分析得知原料质量与地区之间的关系实现著的,现计算得2300χ=,则?相关系数等于 。 7、?相关系数是描述两个分类变量之间相关程度的统计量,它主要用于描述 的列联表数据。 8、若两个分类变量之间完全相关。则?相关系数的取值为 。 9、当列联表中两个变量相互独立时,计算的列联相关系数C= 。 10、利用2 χ分布进行独立性检验,要求样本容量必须足够大,特别是每个单元中的期望频数e f 不能过小,如果只有两个单元,则每个单元的期望频数必须 。 二、单项选择题 1、列联分析是利用列联表来研究( ) A 、两个分类变量的关系 B 、两个数值型变量的关系 C 、一个分类变量和一个数值型变量的关系 D 、连个数值型变量的分布 2、设R 为列联表的行数,C 为列联表的列数,则进行拟合优度检验时所用统计量2χ的自由度为( ) A 、R B 、 C C 、R ×C D 、(R-1)×(C-1) 3、若两个分类变量之间完全相关。则?相关系数的取值为( ) A 、0 B 、小于1 C 、大于1 D 、1=? 4、当列联表中两个变量相互独立时,计算的列联相关系数C ( ) A 、等于1 B 、大于1 C 、等于0 D 、小于0 5、利用2χ分布进行独立性检验,要求样本容量必须足够大,特别是每个单元中的期望频数e f 不能过小,如果只有两个单元,则每个单元的期望频数必须( ) A 、等于或大于1 B 、 C 值等于?值 C 、等于或大于5 D 、等于或大于10 6、一所大学准备采取一项学生上网收费的措施,为了解男女学生对这一措施的看法,分别抽取了150名男生和120名女生进行调查,得到结果如下: A 、48和39 B 、102和81 C 、15和14 D 、25和19 7、一所大学准备采取一项学生上网收费的措施,为了解男女学生对这一措施的看法,分别抽取了150名
统计学期末考试答案完整版
第一章绪论 一、填空题 1、根据统计方法的构成,可将统计学分为___描述统计________ 和_推断统计___________ 。 2、按照所采用的计量尺度不同,可以将统计数据分为___分类数据 ______ 、__顺序数据 ______ 和__ 数值型数据 ______ 。 3、按照数据的收集方法的不同,可将统计数据分为__观测数据_______ 和_实验数据 ________ 。 4、按照被描述的对象与时间的关系,可将统计数据分为_截面数据________ 和_时间序列数据 5、总体可分为____ 有限总体____ 和__无限总体 ______ 两种。 6、从总体中抽出的一部分元素的集合,称为__样本________ 。 7、参数是用来描述_总体特征 ________ 的概括性数字度量;而用来描述样本特征的概括性数 字度量,称为_统计量_______ 。 8、按取值的不同,数值型变量可分为_离散型变量 __________ 和_连续型变量 _______ 。 9、指标和标志的区别之一就是指标是说明__总体数量_______________________ 特征,而标志则是说明___总体单位_________________ 特征。 10、变量按其取值是否连续,有_离散型 ________ 变量和_连续型________ 变量之分。 11、统计分析方法有描述统计方法和推断统计两种。 12、按照所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和___数值型数 据__________ 。 13、数据分析是通过统计方法研究数据,其所有的方法可分为_描述统计_______________ 方法和 _____ 推断统计 _________ 方法。 14、用来描述样本特征的概括性数字度量称为统计量。 15、根据样本计算的用与推断总体特征的概括性度量称作指标。 16、若要研究某班学生的成绩,则统计总体是该班所有学生。 17、通过调查或观察得到的数据称为观测数据数据。
【周丽丽】《数据的查找、排序、筛选与分类汇总》教学设计及反思
课题:《数据的查找、排序、筛选与分类汇总》 学校及姓名:南航附属初级中学周丽丽 ■教材分析 《数据的查找、排序、筛选与分类汇总》是第4章《数据统计与分析》第3节《数据处理与统计》第2课时的内容。继公式与函数的学习之后,本节内容又进一步体现了Excel软件在处理和加工数据上的巨大优越性,实用性较强,在我们的日常学习、生活中有着重要的应用。是本章的重点内容也是本章的难点之一。■学情分析 经过前面几节课的学习,学生已经初步掌握Excel软件的基本操作,感受到了Excel软件在数据运算上的巨大优势,为本节课的学习打下了良好的基础。结合本节课学习内容,教师应联系生活实际,寻找贴近学生生活的素材,让学生能够学以致用,充分激发学生的学习积极性。 ■教学目标 1、知识与技能 (1)感知查找的作用,掌握查找的基本方法。 (2)了解记录单的概念与相关操作,了解在记录单中查找信息的基本方法。 (3)感知排序的作用,了解排序的一般过程,掌握排序的基本方法。 (4)感知筛选的作用,掌握单字段自动筛选的基本方法。 (5)感知分类汇总的作用,了解分类汇总的三要素,知道分类汇总操作的一般过程,掌握分类汇总的基本方法,知道分类汇总的注意项。 2、过程与方法 通过情境的创设,利用不同的问题让学生去思考找出问题答案的方法,寻找能够解决问题的Excel操作,感知查找、排序、筛选与分类汇总的作用。 3、情感态度与价值观 通过用excel操作技能去解决实际问题,找出问题答案的过程,体验成功的乐趣。 4、行为与创新 通过问题驱动,在学生寻求答案的过程中产生一种学习的内驱力。 ■课时安排 安排1课时。 ■教学重点与难点 教学重点:学会查找、排序、筛选和分类汇总的基本操作。 教学难点:1、关键字的选择 2、能够依据需求正确分析分类汇总的三要素,并正确实施分类汇总。 ■教学方法与手段 情境教学、任务驱动、直观启发式教学法、自主探究法 ■课前准备 教学课件、学件 ■教学过程
《统计学》重点归纳(20200625174335)
统计学》期末重点 1. 统计学的类型和不同类型的特点 统计数据;按所采用的计量尺度不同分; (1)(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述; (2)(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。它也是有类别的,但这些类别是有序的。 (3)(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。统计数据;按统计 数据都收集方法分; (4)观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。 (5)实验数据:在实验中控制实验对象而收集到的数据。统计数据;按被描述的现象与实践的关系分; (6)截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。 (7)时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。 2. 变量的题型 第10 页,习题1.1 (1)年龄:数值型变量 (2)性别:分类变量 (3)汽车产量:离散型变量 (4)员工对企业某项改革措施的态度(赞成、中立、反对):顺序变量 (5)购买商品时的支付方式(现金、信用卡、支票):分类变量 3.随机抽样(概率抽样)的抽样方式。 (1)简单随机抽样 (2)分层抽样:就是抽样单位按某种特征或者某种规则划分为不同的层,然后从不同的层中独立、随机地 抽取样本。将各层的样本结合起来,对总体目标量进行估计。 (3)整群抽样: (4)系统抽样 (5)多阶段抽样 分层抽样与整群抽样的区别:
分层抽样的层数就是样本容量;整群抽样的群中单位的个数就是样本容量 4.非概率抽样的几种类型 (1)方便抽样 (2)判断抽样 (3)自愿样本 (4)滚雪球抽样 滚雪球抽样往往用于对稀少群体的调查。在滚雪球抽样中,首先选择一组调查单位,对其实施调查后,再请他们提供另外一些属于研究总特的调查对象,调查人员根据调查线索,进行此后的调查。这个过程持续下去,就会形成滚雪球效应。 优点:容易找到那些属于特定群体的被调查者,调查成本也比较低。 (5)配额抽样 比较概率抽样和非概率抽样的特点,指出各自适用情况概率抽样:抽样时按一定的概率以随机原则抽取样本。每个单位别抽中的概率已知或可以计算,当用样本对总体目标量进行估计时,要考虑到每个单位样本被抽到的概率。技术含量和成本都比较高。如果调查目的在于掌握和研究对象总体的数量特征,得到总体参数的置信区间,就使用概率抽样。 非概率抽样:操作简单,时效快,成本低,而且对于抽样中的统计学专业技术要求不是很高。它适合探索性的研究,调查结果用于发现问题,为更深入的数量分析提供准备。它同样使用市场调查中的概念测试(不需要调查结果投影到总体的情况)。 5.数据预处理内容 数据审核(完整性和准确性;适用性和实效性),数据筛选和数据排序。 6.数据型数据的分组方法和步骤 分组方法:单变量值分组和组距分组,组距分组又分为等距分组和异距分组。分组步骤:(1)确定组数 (2)确定各组组距 3)根据分组整理成频数分布表 7.散点图与饼图的主要用途 饼图是用圆形及圆内扇形的角度来表示数值大小的图形,它主要用于表示一个样本(或总体)中各组成部分的数据占全部数据的比例,对于研究结构性问题十分有用。 散点图是描述变量之间关系的一种直观方法,从中可以大体上看出变量之间的关系形态及关系强度。
统计学简答题35734
1、解释描述统计和推断统计(练习卷答案) (1)描述统计是研究数据收集、处理、汇总、图表描述、概括与分析等统计方法,内容有收集数据、整理数据、展示数据、描述性分析。 (2)推断统计是研究如何利用样本数据来推断总体特征的统计学方法、包含参数估计、假设检验。 2、统计数据可分为哪几种类型?不同类型的数据各有什么特点? 按照所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据 特点: 分类数据是只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,是用文字来表述的。 顺序数据是只能归于某一有序类别的非数字型数据。顺序数据虽然也是类别,但这些类别是有序的。 数值型数据是按数字尺度测量的观察值,其结果表现为具体的数值。现实中所处理的大多数是数值型数据。 按照统计数据的收集方法,可以将其分为观测数据和实验数据。 特点: 观测数据是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制条件下得到的,有关社会经济现象的统计数据几乎都是观测数据。 实验数据则是在实验中控制实验对象而收集到的数据。自然科学领域的大多数数据都为实验数据。 按照被描述的现象与时间关系,可以将其分为截面数据和时间序列数据。 特点: 截面数据是在相同或近似相同的时间点上收集的数据,这类数据通常是在不同空间上获得的,用来描述现象在某一时刻的变化情况。 时间序列数据是在不同时间收集到的数据,这列数据是按时间顺序收集得到的,
用于所描述现象随时间变化的情况。 3、解释分类数据、顺序数据和数值型数据的含义。 分类数据是只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,是用文字来表述的。 顺序数据是只能归于某一有序类别的非数字型数据。顺序数据虽然也是类别,但这些类别是有序的。 数值型数据是按数字尺度测量的观察值,其结果表现为具体的数值。现实中所处理的大多数是数值型数据。 4、变量可分为哪几类? 分类变量(是说明事物类别的一个名称,其取值是分类数据) 顺序变量(是说明事物有序类别的一个名称,其取值是顺序数据) 数值型变量(是说明事物数字特征的一个名称,其取值是数值型数据)可分为离散型变量(只能取可数值的变量,它只能取有限个值而且其取值都以整位数断开,可以一一列举)、连续型变量(可以在一个或多个区间中取任何值的变量,它的取值是连续不断的,不能一一列举) 第二章:数据的搜集 1、比较概率抽样和非概率抽样的特点。列举说明什么情况下什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。(练习卷答案) (1)概率抽样也称随机抽样,是指遵循随机原则进行的抽样,总体中每个单位都有一定的机会被选入样本。样本统计量的理论分布是存在的,可以根据调查的结果对总体的有关参数进行估计。 (2)非概率抽样是指抽取样本时不是依据随机原则,而是根据研究目的对数据的要求,采用某种方式从总体中抽出部分单位对其实施调查。样本统计量的分布是不确切的,无法使用样本的几个对总体相应的参数进行推断。 (3)如果调查的目的在于掌握研究对象总体的数量特征,得到总体参数的置信
大学《统计学》课后作业及答案
1.1什么是统计学? 统计学是一门研究随机现象,以推断为特征的方法论科学,“由部分推及全体”的思想贯穿于统计学的始终。具体地说,它是研究如何搜集、整理、分析反映事物总体信息的数字资料,并以此为依据,对总体特征进行推断的原理和方法。用统计来认识事物的步骤是:研究设计—>抽样调查—>统计推断—>结论。这里,研究设计就是制定调查研究和实验研究的计划,抽样调查是搜集资料的过程,统计推断是分析资料的过程。显然统计的主要功能是推断,而推断的方法是一种不完全归纳法,因为是用部分资料来推断总体。 增加定义:是关于收集、整理、分析和解释统计数据的科学,是一门认识方法论性质的科学,其目的是探索数据内在的数量规律性,以达到对客观事物的科学认识。统计学是收集、分析、表述和解释数据的科学 1.2解释描述统计和推断统计 描述统计学(Descriptive Statistics)研究如何取得反映客观现象的数据,并通过图表形式对所收集的数据进行加工处理和显示,进而通过综合概括与分析得出反映客观现象的规律性数量特征。内容包括统计数据的收集方法、数据的加工处理方法、数据的显示方法、数据分布特征的概括与分析方法等。 推断统计学(1nferential Statistics)则是研究如何根据样本数据去推断总体数量特征的方法,它是在对样本数据进行描述的基础上,对统计总体的未知数量特征做出以概率形式表述的推断。 描述统计学和推断统计学的划分,一方面反映了统计方法发展的前后两个阶段,同时也反映了应用统计方法探索客观事物数量规律性的不同过程。 统计研究过程的起点是统计数据,终点是探索出客观现象内在的数量规律性。在这一过程中,如果搜集到的是总体数据(如普查数据),则经过描述统计之后就可以达到认识总体数量规律性的目的了;如果所获得的只是研究总体的一部分数据(样本数据),要找到总体的数量规律性,则必须应用概率论的理论并根据样本信息对总体进行科学的推断。 1.3 统计数据可分为哪几种类型?不同类型的统计数据各有什么特点? 1.分类数据:由定类尺度计量形成,表现为类别,通常用文字表述,但不区分顺序。 2.顺序数据:由定序尺度计量形成,表现为类别,通常用文字表述,但有顺序。 3.数值型数据:由定距尺度和定比尺度计量形成,说明的是现象的数量特征,通常用数值来表现。也称为定量数据或数量数据。数据类型的不同,可采用不同的统计方法来处理和分析。 1.4解释分类数据、顺序数据和数值型数据的含义。 分类数据和顺序数据说明的是事物的品质特征,通常是用文字来表述的,其结果表现为类别,因而也称为定性数据或品质数据。 数值型数据说明的是现象的数量特征,通常是用数值来表现的,因而也可称为定量数据或数量数据. 1.5 举例说明总体、样本、参数、统计量、变量这几个概念。
《EXCEL中数据的排序、筛选与分类》教学设计
《EXCEL中数据的排序、筛选与分类》教学设计 《EXCEL中数据的排序、筛选与分类汇总》教学设计 一、教学目标: 1、知识与技能。 ①理解查排序、筛选、分类汇总的意义。 ②掌握数据排序、筛选、分类汇总的方法。 ③能利用这些操作解决实际生活中的数据管理与分析的问题。 ④培养学生自主、协作学习的能力。 2、过程与方法。 本节课的操作主要围绕“高一年级成绩表”进行,让学生以自主探究和互助学习的方式,处理与自己有关的数据,激发学生求知欲,同时还采用小组形式,让学生合作学习,互相帮助,共同进步,这 样符合学生的心理,学生在轻松快乐中学到新知识。教师在教学过 程中起引导作用,主要给学生提出任务和适时引导,以任务驱动模 式让学生进行有目的的学习。 3、情感、态度、价值观。 ①培养学生信息管理意识,知道使用EXCEL能规范、高效地管理数据,激发学生学习EXCEL的兴趣。 ②初步培养学生分析问题、解决问题的能力,以及勇于克服困难的精神。 ③通过实践练习,增强学生合作意识,提高学生利用信息技术解决学习、生活中问题的能力。 二、重点:
1、基本的数据排序。 2、数据的自动筛选。 3、数据的分类汇总。 三、难点: 1、数据的复杂排序。 2、数据的多条件筛选。 四、教学方法: 任务驱动法、协作学习法、分层教学法。 五、教学过程: (一)复习导入新课。 1、今天,在上课之前,你们的班主任交给班长一个作业,请班长来说一下作业的内容是什么? 生:我这里有本次月考高一的各科成绩,老师交给我四个任务: (1)计算每个同学的总分; (2)将成绩按总分高低的顺序排序; (3)查找出所有“总分”不小于560分的同学; (4)计算每一个班级的语文平均分; 2、请看第一个任务,同学们根据我们上节课学习过的内容来完成。(请同学演示) (二)新授: 后面的三个任务就是我们本节课所要学习内容。 1、排序
统计学资料及课后习题答案
第1章统计与统计数据 一、学习指导 统计学是处理和分析数据的方法和技术,它几乎被应用到所有的学科检验领域。本章首先介绍统计学的含义和应用领域,然后介绍统计数据的类型及其来源,最后介绍统计中常用的一些基本概念。本章各节的主要内容和学习要点如下表所示。 章节主要内容学习要点 1.1 统计及其应用领域什么是统计学④概念:统计学,描述统计,推断统计。统计的应用领域 ④统计在工商管理中的应用。 ④统计的其他应用领域。 1.2 数据的类型分类数据、顺序数据、数值 型数据 ④概念:分类数据,顺序数据,数值型数据。 ④不同数据的特点。 观测数据和实验数据④概念:观测数据,实验数据。 截面数据和时间序列数据④概念:截面数据,时间序列数据。 1.3 数据来源数据的间接来源 ④统计数据的间接来源。 ④二手数据的特点。 数据的直接来源 ④概念:抽样调查,普查。 ④数据的间接来源。 ④数据的收集方法。 调查方案设计④调查方案的内容。 数据质量 ④概念。抽样误差,非抽样误差。 ④统计数据的质量。 1.4 统计中的几个基本概念总体和样本④概念:总体,样本。 参数和统计量④概念:参数,统计量。 变量 ④概念:变量,分类变量,顺序变量,数值 型变量,连续型变量,离散型变量。 二、主要术语 1. 统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。 2. 描述统计:研究数据收集、处理和描述的统计学分支。 3. 推断统计:研究如何利用样本数据来推断总体特征的统计学分支。 4. 分类数据:只能归于某一类别的非数字型数据。 5. 顺序数据:只能归于某一有序类别的非数字型数据。 6. 数值型数据:按数字尺度测量的观察值。 7. 观测数据:通过调查或观测而收集到的数据。 8. 实验数据:在实验中控制实验对象而收集到的数据。 9. 截面数据:在相同或近似相同的时间点上收集的数据。 10. 时间序列数据:在不同时间上收集到的数据。
Excel:只对筛选后的结果进行求值
Excel :只对筛选后的结果进行求值 SUBTOTAL 返回列表或数据库中的分类汇总。通常,使用“数据”选项卡上“大纲”组中的“分类汇总”命令更便于创建带有分类汇总的列表。一旦创建了分类汇总,就可以通过编辑 SUBTOTAL 函数对该列表进行修改。 语法 SUBTOTAL (function_num , ref1, ref2, ...) Function_num 为 1 到 11(包含隐藏值)或 101 到 111(忽略隐藏值)之间的数字,指定使用何种函数在列表中进行分类汇总计算。 Function_num (包含隐藏值) Function_num (忽略隐藏值) 函数 1 101 AVERAGE 2 102 COUNT 3 103 COUNTA 4 104 MAX 5 105 MIN 6 106 PRODUCT 7 107 STDEV 8 108 STDEVP
9 109 SUM 10 110 VAR 11 111 VARP Ref1、ref2为要进行分类汇总计算的1 到254 个区域或引用。 说明 ?如果在ref1, ref2,…中有其他的分类汇总(嵌套分类汇总),将忽略这些嵌套分类汇总,以避免重复计算。 ?当function_num 为从1 到11 的常数时,SUBTOTAL 函数将包括通过“隐藏行”命令所隐藏的行中的值,该命令位于“工作表”选项卡上“单元格”组中“格式”命令的“隐藏和取消隐藏”子菜单下面。当您要对列表中的隐藏和非隐藏数字进行分类汇总时,请使用这些常数。当 function_num 为从101 到111 的常数时,SUBTOTAL 函数将忽略通 过“隐藏行”命令所隐藏的行中的值。当您只对列表中的非隐藏数字进行分类汇总时,请使用这些常数。 ?SUBTOTAL 函数忽略任何不包括在筛选结果中的行,不论使用什么function_num 值。 ?SUBTOTAL 函数适用于数据列或垂直区域。不适用于数据行或水平区域。 例如,当function_num 大于或等于101 时需要分类汇总某个水平区域 时,例如SUBTOTAL(109,B2:G2),则隐藏某一列不影响分类汇总。但是隐藏分类汇总的垂直区域中的某一行就会对其产生影响。
图表数据信息型试题归类分析
图表数据信息型试题归类分析 湖北省公安县教研室 朱敬华 来源:2009 年上半年《试题与研究》 一、图表数据信息型试题分类 目前主要从两个方面:一是根据题解的目的要求可分为(1)探究物质的结构类;(2)测定某组分的含量类;(3)优选混和物分离方法类;(4)寻求某种性质变化规律类;(5)综合计算类等。二是依据数据的性质或数据的产生,分为(1)实测数据类。该类数据一般通过化学实验或科研方法实际测定,主要是求解物质的组成或含量,或寻求物质性质变化规律; (2)物质的溶解度或溶度积常数(Ksp )类。利用物质的溶解度不同制取新物质或分离混和物;(3)物质的熔点、沸点、密度类。探求制取物质的方案或探寻用物理方法分离物质的方法;(4)物质固有的性质数据(如键长、键能、键角、电负性、电离能等)类。这类数据题一般设计为探讨物质的性质,诸如物质的稳定性、氧化性、还原性等;(5)化学平衡与化学反应速率类。主要设计的题有比较化学反应速率快慢和化学平衡移动有关的计算和判断题; (6)数学建模类。将某组数据设计成数学计算题模式,用数学方法求解。本文摘要选析几种图表数据类信息题,供大家揣摩此题信息题的处理方法。 二、图表数据信息型试题分析法 1.流程图信息分析法 流程图题已经成为近年高考题中的主流题型,让学生了解流程图的分析方法是提高非选择题得分的必要措施。 研究近三年各种版本的的工业流程题大家可以发现,试题往往通过对某种重要化工产品的工业生产流程简图分析, 考察考生对元素周期表结构,元素化合物等的重要性质,化学反应原理、热化学方程式的含义与计算、产率计算,物质制备、提纯等常见实验操作的作用的理解与应用能力,并通过对副产物利用和废液处理的设问考察学生对环境保护意识、绿色化学知识的理解和应用,试题常以化学原理和化学实验基本操作进行综合设计和设问。 例3.聚合氯化铝是一种新型、高效絮凝剂和净水剂,其单体是液态的碱式氯化铝 [Al 2(OH)n Cl 6-n ]。 本实验采用铝盐溶液水解絮凝法制备碱式氯化铝。其制备原料为分布广、价格廉的高岭土,化学组成为:Al 2O 3(25%~34%)、SiO 2(40%~50%)、Fe 2O 3(0.5%~3.0%)以及少量杂质和水分。已知氧化铝有多种不同的结构,化学性质也有差异,且一定条件下可相互转化;高岭土中的氧化铝难溶于酸。制备碱式氯化铝的实验流程如下: 根据流程图回答下列问题: (1)“煅烧”的目的是________________。 (2)配制质量分数15%的盐酸需要200mL30%的浓盐酸(密度约为 1.15g/cm 3)和 _______g 蒸馏水,配制用到的仪器有烧杯、玻璃棒、______________。 (3)“溶解”过程中发生反应的离子方程式为__________。 (4)加少量铝粉的主要作用是_____________________ 。 Al 2(OH)n Cl 6-n
数据筛选和分类汇总例题
数据筛选例题 筛选是在数据清单中快速查找具有特定条件的记录,筛选后清单中只包含符合条件的记录。 筛选分自动筛选和高级筛选。 自动筛选练习: 1、在工作表“某公司人员情况表”中,自动筛选出职称为高工的所有记录; 2、显示全部数据; 3、在工作表“某公司人员情况表”中,自动筛选出事业部工资在5500以上(包含5500)的所有男职工的记录; 4、在工作表“某公司人员情况表”中,自动筛选出年龄大于等于30并且小于等于45的硕士或博士的所有记录。 高级筛选练习: 1、在工作表“某公司人员情况表”中,利用高级筛选功能筛选出事业部工资在5500以上(包含5500)的所有男职工的记录; 2、在工作表“某公司人员情况表”中,利用高级筛选功能筛选出年龄大于等于30并且小于等于45的硕士或博士的所有记录。 解释:高级筛选方式主要用于多字段条件的筛选。使用高级筛选必须先建立一个条件区域。条件区域的第一行是所有作为筛选条件的字段名,这些字段名必须与数据清单中的字名完全一样。条件区域的其他行输入筛选条件,“与”关系的条件必须出现在同一行内,“或”关系的条件不能出现在同一行内。条件区域与数据清单区域不能连
接,须用空行隔开。 分类汇总是对数据内容进行分析的一种方法。Excel分类汇总是对工作表中数据清单的内容进行分类,然后统计同类记录的相关信息,包括求和、计数、平均值、最大值、最小值等。 数据分类汇总例题: 在工作表“某公司人员情况表”中,汇总计算各部分基本工资的平均值(分类字段为“部门”,汇总方式为“平均值”,汇总项为“基本工资”),汇总结果显示在数据下方。 解释:分类汇总只能对数据清单进行,数据清单的第一行必须有列标题。进行分类汇总前,必须根据分类汇总的数据类对数据清单进行排序。