多元统计分析

作业一
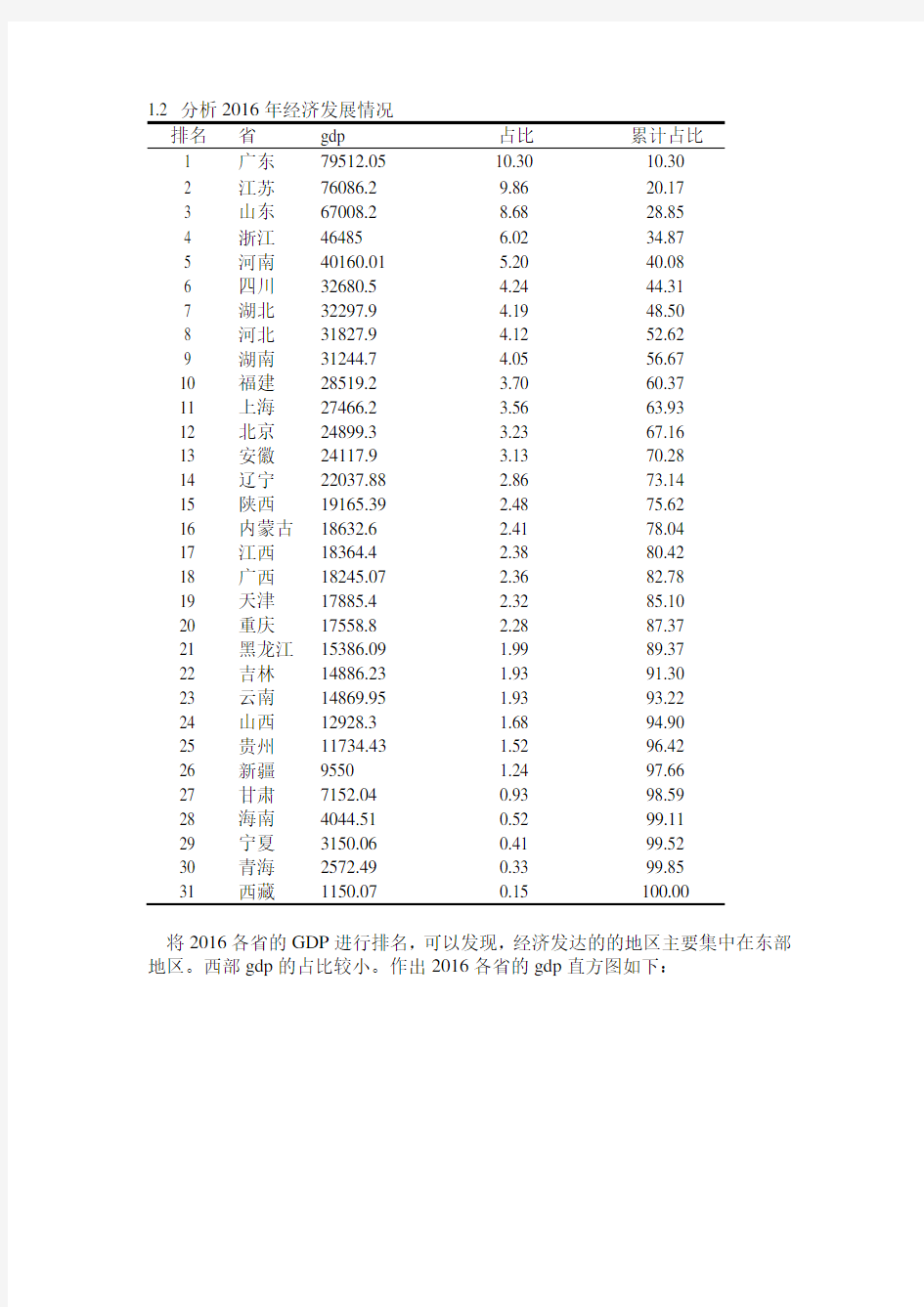
1.2 分析2016年经济发展情况
排名省gdp 占比累计占比
1 广东79512.05 10.30 10.30
2 江苏76086.2 9.86 20.17
3 山东67008.2 8.68 28.85
4 浙江4648
5 6.02 34.87
5 河南40160.01 5.20 40.08
6 四川32680.5 4.24 44.31
7 湖北32297.9 4.19 48.50
8 河北31827.9 4.12 52.62
9 湖南31244.7 4.05 56.67
10 福建28519.2 3.70 60.37
11 上海27466.2 3.56 63.93
12 北京24899.3 3.23 67.16
13 安徽24117.9 3.13 70.28
14 辽宁22037.88 2.86 73.14
15 陕西19165.39 2.48 75.62
16 内蒙古18632.6 2.41 78.04
17 江西18364.4 2.38 80.42
18 广西18245.07 2.36 82.78
19 天津17885.4 2.32 85.10
20 重庆17558.8 2.28 87.37
21 黑龙江15386.09 1.99 89.37
22 吉林14886.23 1.93 91.30
23 云南14869.95 1.93 93.22
24 山西12928.3 1.68 94.90
25 贵州11734.43 1.52 96.42
26 新疆9550 1.24 97.66
27 甘肃7152.04 0.93 98.59
28 海南4044.51 0.52 99.11
29 宁夏3150.06 0.41 99.52
30 青海2572.49 0.33 99.85
31 西藏1150.07 0.15 100.00
将2016各省的GDP进行排名,可以发现,经济发达的的地区主要集中在东部地区。西部gdp的占比较小。作出2016各省的gdp直方图如下:
作业二多元回归分析
2.1多元线性回归 2.1.1数据来源
《福建省统计年鉴-2017》 年份 商品零售价格指数y 农业生产资料价格指数x1 工业生产价格指数x2 工业生产者购进价格指数x3 固定资产投资
价格总指数x4 2000 98.9 97.4 100.5 112.4 100.2 2001 98 98.7 98.1 96.7 99.5 2002 98.3 99.9 97.6 97.6 99.7 2003 99.1 101.8 100.7 106.3 101.4 2004 102.7 112.5 102.6 113.3 103.4 2005 100.6 108.1 100.2 108.1 100.7 2006 100.5 100.9 99.2 103.9 102 2007 104.3 110.3 100.8 104.3 105.9 2008 105.7 123.6 102.7 110.2 105.9 2009 97.9 93.3 95.5 93.2 98 2010 103.4 102.4 103.2 107.7 103.3 2011 104.8 111.8 103.9 108 106.2 2012 101.8 103.3 98.7 97.7 100.3 2013 101.1 99.5 98.4 98.4 100.1 2014 101.1 99.5 98.6 98.3 100.4 2015 99.9 101.4 97 96.1 98.3 2016 100.7
100.2 99.1
98 100
2.1.2模型假设
商品的零售价格会受很多因素的影响,对于影响零售价格指数y 的影响现在仅考虑农业生产资料指数x1、工业生产价格指数x2、工业生产者购进价格指数x3、固定资产投资的影响x4。 2.1.3模型建立
为了大致分析y 与x1、x2、x3、x4,建立y 关于x1、x2、x3、x4的散点图,可以看出y 与X 呈现出较为明显的线性相关关系。由此可以建立y 关于x 的多元线性回归模型:
443322110x a x a x a x a a y ++++=
运用MatlabR2017a画y关于x的散点图如下:
2.1.4模型求解和分析
运用MatlabR2017a进行多元回归分析,使用命令为:
[b,bint,r,rint,stats]=regress(y,X,alpha)
在这里y是n*1的列向量,x是n*(m+1)的矩阵且第一列向量全是1,alpha 采用默认值0.05。将Excel的数据导入Matlab运行结果截图如下:
由计算结果可得:
参数参数估计值置信区间
a0 11.84 [-23.7566,47.4395]
a1 0.1304 [-0.0041,0.2648]
a2 0.5429 [-0.1834,1.2961]
a3 -0.1796 [-0.3628,0.0036]
a4 0.3945 [-0.1545,0.9432]
R2=0.8699 统计量观测值F=20.0540 检验值p=0.0000 误差方差估计=0.9995
可知y=11.84+0.1304x1+0.5429x2?0.1796x3+0.3945x4
以上结果的置信度为95%,R2=0.8699,F=20.0540,p=0.0000<0.05,可知回归模型成立。
分析其杠杆残差图如下:执行 rcoplot(r,rint)
由残差图可以看出,除第二个数据外,其它数据的残差离零点都较近,且残差的置信区间均包含零点,这说明回归模型y=11.84+0.1304x1+0.5429x2?0.1796x3+0.3945x4能较好的符合原始数据,而第二个数据为异常点。由模型可以看出对商量零售价格影响最大的是工业生产价格指数,工业生产价格指数每上升一个点,商品零售价格指数约上升0.5。
2.1.5逐步回归分析
运用Matlab采用逐步回归的方法对数据进行建模分析,命令为
stepwise(x,y,inmodel,alpha)
这里inmodel采取所有变量,alpha采用默认值,输如命令得到下图:
可以看出,四条线均为实线,无需对变量进行剔除,选中四条线,可以得到下图:
由图可知,模型结果同2.1.4中的模型,即:
y=11.84+0.1304x1+0.5429x2?0.1796x3+0.3945x4
2.2非线性回归
2.2.1数据来源
《福建省统计年鉴-2017》
年份工业总产值
(亿元)
能源生产量
(万吨标准煤)
年份
工业总产值
(亿元)
能源生产量
(万吨标准煤)
1981 87.76 493 1999 3479.84 1634.16
1982 95.77 522 2000 3994.86 1654.17
1983 103.97 609 2001 4398.08 1850.44
1984 131.11 641 2002 5260.2 1923.4
1985 173.13 690 2003 6616.61 1816.8
1986 205.1 724 2004 8544.5 1805.75
1987 265.87 806 2005 9995.89 2488.47
1988 388.85 918 2006 11855.68 2668.15
1989 488.96 950 2007 14425.06 2625.28
1990 531.49 966.52 2008 17141.44 2989.93
1991 658.86 854.43 2009 18681.48 2939.48
1992 915.51 1013.39 2010 23805.32 3260.42
1993 1522.37 1051.43 2011 30330.59 2802.72
1994 2128.61 1169.96 2012 32379.94 2989.65
1995 2638.52 1396.24 2013 36724.66 2739.76
1996 2840.51 1406.04 2014 41579.84 2924.01
1997 3066.76 1256.3 2015 43888.84 3566.6
1998 3218.51 1177 2016 47275.84 4490.8
2.2.2模型假设
工业生产总值会收到很多因素的影响,技术的进步会使得能源的利用率得到提高,假设工业生产总值与能源的生产量存在着非线性关系,作工业生产总值关于能源生产量的散点图如下,运用Matlab作散点图,命令为:scatter(x,y),得到的散点图如下:
由散点图可知,工业生产总值y 与能源生产量之间x 存在着非线性关系,设y 与x 存在着指数函数关系,即x b x a y **=。
2.2.3模型建立
由于是二维,可运用Matlab 的cftool 拟合工具箱对数据进行拟合,结果如下图所示:
由拟合结果可知,R 2为0.8016,拟合效果一般,SSE 为1132000000,RMSE 为5856,模型为:
x e y *001086.08.974=
作业三主成分分析与聚类分析3.1数据来源
《福建省统计年鉴——2017》
年份固定资产
投资(亿
元)
GDP(亿
元)
财政总
收入(亿
元)
工业总产
值(亿元)
第一
产业
(%)
第二
产业
(%)
第三
产业
(%)
GDP
增长
率
(%)
人均
GDP
(元)
社会消费
品零售总
额(亿元)
城镇居
民人均
可支配
收入
(元)
3.2主成分分析
经济发展系统包含11个指标:全社会固定资产投资(亿元)、全部工业总产值(亿元)、GDP总量(亿元)、财政总收入(亿元)主要反应福建省的经济规模和总量;第一产业、第二产业和第三产业比重主要反应福建省的经济结构;GDP增长率、人均GDP(元)、城镇居民恩格尔系数、社会消费品零售总额(亿元)主要反应福建省的经济效益。
主成分分析法是利用降维的思想,把多个指标转换为少数几个综合指标(即主成分),其中每个主成分都能够反应原始数据的大部分信息,且所含信息互不重叠。这里,运用MatlabR2017a进行主成分分析。
首先,需要对数据进行标准化处理,采用zscore函数,结果如下:
调用princomp函数函数对标准化处理后的数据进行主成分分析,由于princomp函数不返回贡献率,需要用协方差矩阵的特征值向量latent来计算,命令为explained = 100*latent/sum(latent)。为了直观,将处理后的数据储存在元胞数组中,命令如下:
处理结果如下:
由处理结果可知,第一主成分的贡献率达到78.91%,第二主成分贡献率为14.14%,累计贡献率为93.05%,超过85%,因此,只需提取前两个主成分。
由COEEF第一、二列可知:
y1=0.3332x1+0.3386x2+0.3380x30.3384x4+0.3077x5+0.2567x6 +0.1888x7+0.0786x8+0.3387x9+0.3372x10+0.3388x11 y2=0.1332x1+0.0346x2+0.0347x3+0.0126x4+0.3106x5+0.5009x6 +0.3537x7+0.0769x8+0.0222x9+0.0.0822x10+0.0163x11
3.3聚类分析
运用Matlab对数据进行分析,这里采用分部聚类法对福建省2000——2016的经济发展进行分析,对其发展的类型作一个简单的划分。
运用分步聚类对数据进行处理,首先寻找变量之间的相似性,这里运用pdlist计算相似矩阵,过程及谱系图如下:
X为原始数据,XZ为标准化处理后的数据。
由运行结果可以看出,当距离为0时,17年的经济情况各自为一类,当距离逐渐扩大时,17年的经济数据被依次聚类。从谱系图我们可以看出,经济情况距离最小的两年2000、2001年首先被聚为一类,选取聚类标准距离为1.4,可
以将2000—2017年的经济情况划分为三类:第一类为2000~2005年,第二类为2006~2014年,第三类为2015、2016年。
由福建省2000—2016年的gdp数据我们可以看出,福建省的经济逐年增长,通过聚类分析,我们可以将福建省在2000—2016年的经济水平大致划分为三个阶段,由于时间跨度较小,选取的指标体系也存在一定的局限性,以及缺乏科学的评判标准,因此,对福建省的经济发展水平的阶段划分存在一定的科学性,但是,从聚类的结果来看,一定程度上可以反映出2000—2006年福建省经济发展的阶段。
作业四马尔科夫预测与线性回归
4.1数据来源
计量地理学P147.某地区1965-2014年农业收成变化的转移情况,“1”代表丰收,“2”代表平收,“3”代表歉收。
年份状态年份状态年份状态
1965 1 1982 3 1996 3
1966 1 1983 3 1997 2
1967 2 1984 1 1998 1
1968 3 1982 3 1999 1
1969 2 1983 3 2000 2
1970 1 1984 1 2001 2
1971 3 1985 3 2002 3
1972 2 1986 3 2003 1
1973 1 1987 2 2004 2
1974 2 1988 1
1975 3 1989 1
1976 1 1990 3
1977 2 1991 2
1978 3 1992 2
1979 1 1993 1
1980 2 1994 2
1981 1 1995 1
4.2数据分析
运用Matlab对数据进行马尔科夫预测。
(1)求出状态转移概率矩阵
(2)对2015年农业收成状态进行预测
可以得到2005-2015年农业收成状态的概率预测值如下:
年份丰收平收签收
2005 0.5385 0.1538 0.3077
2006 0.3024 0.4148 0.2828
2007 0.3867 0.3335 0.2799
2008 0.3587 0.3590 0.2824
2009 0.3677 0.3510 0.2813
2010 0.3648 0.3535 0.2817
2011 0.3657 0.3527 0.2816
2012 0.3654 0.3529 0.2816
2013 0.3655 0.3528 0.2816
2014 0.3655 0.3529 0.2816
2015 0.3655 0.3529 0.2816
(3)终极状态概率预测
由分析结果可知,丰收、平手、歉收的终极状态概率分别为:0.3655、0.3529、0.2816,表明在经过无穷多次状态转移过后,丰收概率>平手概率>歉收概率。
4.2线性回归分析
4.2.1建立模型
生产I、II、III三种产品,都经过A,B两道工序加工。设备A工序有A1、A2两台设备,B工序有B1,B2,B3三台设备。已知产品I可在A,B任何一种设备上加工,产品II可在任一规格A设备上加工,但B工序只能在B2设备上加工,产品III两道工序只能在A2,B2设备上加工。加工单位产品所需工序时间及其有关数据如下表所示。应如何安排生产计划,使该厂获利最大。
解:对产品1来说,设以A1、A2完成A工序的产品分别为X1、X2,转入B工
序时,以B1、B2、B3完成B工序的产品分别为X3、X4、X5件;对产品2来
说,以A1、A2完成A工序的产品分别为X6、X7件,转入B工序时,以B1工
序的产品为X8件;对产品3来说,设以A2完成A工序的产品为X9件,则以
B2完成B工序的产品也为X9。可得:
maxZ= 1.25?0.25X1+X2+2?0.35(X6+X7)+ 2.8?0.5X9
?0.055X1+10X6?0.037X2+9X7+12X9
?0.066X3+8X8?0.114X4+11X9?0.05?7X5
=0.75X1+0.79X2-0.36X3-0.44X4-0.35X5+1.15X6+1.38X7-0.48X8+0.73X9
s.t.X1+X2=X3+X4+X5
X6+X7=X8
5X1+10X6<=6000;
7X2+9X7+12X9<=10000;
6X3+8X8<=4000;
4X4+11X9<=7000;
7X5<=4000;
X1,X2,X3,X4,X5,X6,X7,X8,X9>=0;
运用Matlab运行,建立M文件如下:
可得最优解为
X1=1200,X2=230,X3=0,X4=859,X5=571,X6=0,X7=500,X8=500,X9=324
此时最大利润为1147元。
二、建立模型,并用单纯形解法解模型
现有某一江段,沿江设有两个工厂,第一个工厂每日向江中排放的污染物为20个单位,第二个工厂每日排污量为14个单位。那些污染物在排入江中之前,曾作部分处理,每处理一个单位的污水处理费在第一个工厂为1000元,在第二个工厂为800元。两个工厂沿江分布的位置,见图。流经第一个工厂的河流在经过工厂以前未受污染的河流,其江水流量Q1为5M3/S,在第一个工厂到第二个工厂之间又有一小支流汇入,其流量Q2为2 M3/S。也未受污染。另外,第一个工厂排入江中的污染物在未到第二个工厂以前由于自净作用而自净掉20%。按国家城乡环保部的规定这条江对污染物的允许含量不得超过2个单位,既要满足江河的防治污染标准,又要使两个工厂因处理污水而花费的经费最少。试问这两个工厂需要处理的污水单位是多少?
▲ 工厂1 ▲工厂2
解:设X1和X2分别为第一个工厂和第二个工厂的污水处理单位,两个工厂所需要花费的污水处理费为1000X1+800X2,可得:
minZ=1000X1+800X2
20-X1<=10
-0.8(20-X1)-(14-X2)<=-14
10<=X1<=20
0<=X2<=14
令X1=X1-X3,X2=16-0.8X1
引入松弛变量X3、X4、X5、X6化为标准型:
minZ=1000X1+800X2
-X1+X3=-10
-0.8X1-X2+X4=-16
X1+X5=20
X2+X6=14
X1,X2>=0
建立M文件如下:
根据标准型,我们可以得到:
由此我们可以得到当x1=10,x2=8时为最优解,最小值为16400。
多元统计分析实例汇总
多元统计分析实例 院系:商学院 学号: 姓名:
多元统计分析实例 本文收集了2012年31个省市自治区的农林牧渔和相关农业数据,通过对对收集的数据进行比较分析对31个省市自治区进行分类.选取了6个指标农业产值,林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农村居民家庭经营耕地面积. 数据如下表: 一.聚类法
设定4个群聚,采用了系统聚类法.下表为spss分析之后的结果.
Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ 内蒙 5 -+ 吉林 7 -+ 云南 25 -+-+ 江西 14 -+ +-+ 陕西 27 -+-+ | 新疆 31 -+ +-+ 安徽 12 -+-+ | | 广西 20 -+ +-+ +-------+ 辽宁 6 ---+ | | 浙江 11 -+-----+ | 福建 13 -+ | 重庆 22 -+ +---------------------------------+ 贵州 24 -+ | | 山西 4 -+---+ | | 甘肃 28 -+ | | | 北京 1 -+ | | | 青海 29 -+ +---------+ | 天津 2 -+ | | 上海 9 -+ | | 宁夏 30 -+---+ | 西藏 26 -+ | 海南 21 -+ | 河北 3 ---+-----+ | 四川 23 ---+ | | 黑龙江 8 -+-+ +-------------+ | 湖南 18 -+ +---+ | | | 湖北 17 -+-+ +-+ +-------------------------+ 广东 19 -+ | | 江苏 10 -------+ | 山东 15 -----------+-----------+ 河南 16 -----------+
应用多元统计分析试题及答案
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
多元统计分析期末复习
多元统计分析期末复习 Document number:WTWYT-WYWY-BTGTT-YTTYU-2018GT
第一章: 多元统计分析研究的内容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X 均值向量: 随机向量X 与Y 的协方差矩阵: 当X=Y 时Cov (X ,Y )=D (X );当Cov (X ,Y )=0 ,称X ,Y 不相关。 随机向量X 与Y 的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X ,Y 为随机向量,A ,B 为常数矩阵 E (AX )=AE (X ); E (AXB )=AE (X )B; D(AX)=AD(X)A ’; Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. )' ,...,,(),,,(2121P p EX EX EX EX μμμ='= )')((),cov(EY Y EX X E Y X --=q p ij r Y X ?=)(),(ρ
(3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确),(~∑μP N X μ ∑ μ p X X X ,,,21 ),(~∑μP N X ),('A A d A N s ∑+μ) ()1(,,n X X X )',,,(21p X X X )' )(() ()(1X X X X i i n i --∑=n 1X μ∑μX ) 1,(~∑n N X P μ),1(∑-n W p X X
应用多元统计分析课后答案
应用多元统计分析课后答案 第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 2 1/21 (2)()p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
多元统计分析(最终版)
题目:研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。(注:要对方差齐性进行检验) 不同温度与不同湿度粘虫发育历期表 根据上述题目,分析结果如下。 一、相关理论概述 F检验与方差齐性检验 在方差分析的F检验中,是以各个实验组内总体方差齐性为前提的,因此,按理应该在方差分析之前,要对各个实验组内的总体方差先进行齐性检验。如果各个实验组内总体方差为齐性,而且经过F检验所得多个样本所属总体平均数差异显著,这时才可以将多个样本所属总体平均数的差异归因于各种实验处理的不同所致;如果各个总体方差不齐,那么经过F 检验所得多个样本所属总体平均数差异显著的结果,可能有一部分归因于各个实验组内总体方差不同所致。 但是,方差齐性检验也可以在F检验结果为多个样本所属总体平均数差异显著的情况下进行,因为F检验之后,如果多个样本所属总体平均数差异不显著,就不必再进行方差齐性检验。本文分析数据采用后一种方法,即先F检验再方差齐次性检验。
二、从单因子方差角度分析 (一)在假定相对湿度不变的情况下分析 1、假定相对湿度恒为40%,分析不同温度对粘虫发育历期的影响。如下表: 温度℃ 重复 25 27 29 31 1 100. 2 90.6 77.2 73.6 2 103. 3 91.7 85.8 73.2 3 98.3 94.5 81.7 76. 4 4 103.8 92.2 79.7 72. 5 Ti 405. 6 369 324.4 295.7 T 2 i 164511.36 136161 105235.36 87438.49 在本例中,r=4,m=4, n=16 , =1394.7, = 123413.4696 T 2 /n=(1394.7)2/ 16=121574.2556 (式1) ( 式2) (式3) S E =S T -S A =1839.214-1762.297=76.917 (式4) 数据的方差分析表见表1. 表1 粘虫发育历期方差分析表 粘虫发育历期 (相对湿度40%) 来源 平方和 df 均方 F 显著性 组间 1762.297 3 587.432 91.646 .000 组内 76.917 12 6.410 总数 1839.214 15 分析表1可知,F 0.05(3,12)=3.49,F 值=,91.646,F>F 0.05,P=0.000<0.05,说明在相对湿度为40%时,不同温度对粘虫发育历期有显著影响。同时,在方差齐次性检验中P=0.304>0.05,说明方差齐次性显著,如下表。以下方差齐次性检验于此类同,限于篇幅,直接得出结果,方差齐性检验 粘虫发育历期 Levene 统计量 df1 df2 显著性 1.351 3 12 .304 相关程序源代码附录如下:DATASET ACTIV ATE 数据集0. ONEW AY 粘虫发育历期 BY X2 /STA TISTICS HOMOGENEITY =493346.2105/4-121574.2556=1762.297 =123413.4696-121574.2556=1839.214
03第三篇 多元统计分析作业题
第三篇 多元统计分析作业题 1 证明题 1)已知ψ==A X E X Z T T T ,这里用到关系1-ψ=E A 。以二变量为例证明: 12*-Λ=ψ=A X A X Z T T T 1)(-=T T A X 。 式中X 为标准化原始变量矩阵,A 为载荷矩阵,Z 为非标准化主成分得分,Z *为标准化的因子得分,E 为单位化特征向量构成的矩阵即正交矩阵,Ψ为特征根的平方根的倒数构成的对角阵,Λ为特征根构成的对角阵,对于二变量有 ?????? ??=ψ21 /10 /1λλ, ?? ? ???=Λ21 00λλ. 2)对于二变量因子模型,我们有 ?? ?++=++=222221122 112211111εεu f a f a x u f a f a x . 试以 x 1为例证明1 2 22==+j x j j u h σ ,这里∑== p k kj j a h 1 2 22 21 211a a +=。 2 计算题 1)现有一组古生物腕足动物贝壳标本的两个变量:长度x 1和宽度x 2。所测数据如下(表2.1)。 要求: ① 利用Excel 对数据进行主成分分析。 ② 借助SPSS 对该数据进行主成分分析,并计算结果与Excel 的计算结果进行对比,理解各个表格所给参数的含义。 ③ 用本例数据验证证明题?的推导结果。 表2.1 古生物腕足动物贝壳标本数据 样品编号 长度x 1 宽度x 2 样品编号 长度x 1 宽度x 2 1 3 2 14 12 10 2 4 10 15 12 11 3 6 5 16 13 6 4 6 8 17 13 14 5 6 10 18 13 15 6 7 2 19 13 17 7 7 13 20 14 7 8 8 9 21 15 13 9 9 5 22 17 13
何晓群多元统计分析(数据)
第二章数据 行业公司简称净资产 收益 率% 总资产 报酬 率% 资产负 债率% 总资产周 转率 流动资 产周转 率 已获利 息倍数 销售增 长率% 资本积 累率% 电力、煤气及水的生产和供应业深能源A16.8512.35 42.32 0.37 1.78 7.18 45.73 54.54 深南电A2215.30 46.51 0.76 1.77 15.67 48.11 19.41 富龙热力8.977.98 30.56 0.17 0.58 10.43 17.80 9.44 穗恒运A10.258.99 40.44 0.46 2.46 5.06 11.06 1.09 粤电力A20.8120.00 35.87 0.43 1.25 34.89 24.77 12.67 韶能股份8.867.52 27.59 0.24 0.84 20.59 -3.50 54.02 惠天热电10.987.94 49.30 0.36 0.69 12.43 16.88 3.52 原水股份8.858.88 36.20 0.13 0.41 8.53 -11.49 2.44 大连热电9.037.41 46.89 0.28 0.79 6.86 16.23 -1.52 龙电股份12.078.70 16.81 0.28 0.68 29.75 4.11 63.06 华银电力 6.85 6.12 41.93 0.24 0.65 4.38 11.20 3.80 房地行业长春经开9.8510.50 31.23 0.34 0.40 17.13 18.05 7.18 兴业房产 1.07 1.52 66.91 0.21 0.24 1.53 -31.93 1.08 金丰投资19.447.01 73.34 0.26 0.30 7.02 71.22 12.73 新黄浦7.61 5.92 39.64 0.16 0.17 4.20 14.77 7.91 浦东金桥 4.24 3.99 37.30 0.20 0.25 3.98 -9.24 4.69 外高桥 1.673 1.92 49.05 0.03 0.05 1.06 -21.74 0.24 中华企业8.78 6.28 57.42 0.17 0.19 3.58 75.29 2.93 渝开发A0.2 2.24 63.40 0.09 0.15 1.07 -12.56 0.29 辽房天8.12 3.98 69.10 0.10 0.72 2.65 -35.83 3.16 粤宏远A0.42 1.16 37.42 0.09 0.15 1.59 19.18 0.43 ST中福 5.17 6.62 65.48 0.16 0.21 1.33 -19.91 23.74 倍特高新0.72 2.76 65.39 0.30 0.42 1.24 8.40 0.70 三木集团 5.99 4.53 65.17 0.74 0.88 4.14 75.36 0.87 寰岛实业0.420.20 24.03 0.02 0.03 -8.18 -71.33 0.42 中关村9.32 4.48 67.76 0.32 0.37 16.42 -29.42 4.09 信息技术 业中兴通讯18.7811.09 69.15 0.93 1.08 4.79 80.80 23.27 长城电脑14.949.48 45.53 1.14 1.85 9.51 34.47 35.93 青鸟华光9.7888.70 36.67 0.28 0.39 13.11 28.36 7.87 清华同方15.919.08 34.19 0.85 1.19 15.61 98.92 95.66 永鼎光缆9.48.67 32.75 0.79 1.25 13.49 41.75 6.33 宏图高科14.577.96 65.86 0.76 0.94 3.95 54.45 15.71 海星科技 4.06 3.35 36.49 0.48 0.60 4.64 -16.28 1.69 方正科技27.4816.69 57.13 2.51 2.87 7.40 63.27 32.02
matlab与应用多元统计分析
多元统计分析中的应用研究 , 摘要:许多实际问题往往需要对数据进行统计分析,建立合适的统计模型,过去一般采用SAS 、SPSS软件分析,本文给出 Matlab软件在多元统计分析上的应用, 主要介绍Matlab 在聚类分析、判别分析、主成份分析上的应用,文中均给以实例, 结果令人满意。 关键词:Matlab软件;聚类分析;主成份分析 Research for application of Multivariate Statistical Analysis Abstract:Many practice question sometimes need Statistical Analysis to data.,and establish appropriate Statistical model SAS and SPSS software were commonly used in foretime ,this paper give the application of Matlab software in Multivariate Statistical Analysis,mostly introduce the application of Matlab software in priciple component analysis and cluster analysis and differentiate analysis.The example are given in writing and the result are satisfaction. Key words: Matlab software; cluster analysis; priciple component analysis 0 引言 许多实际问题往往需要对数据进行多元统计分析, 建立合适的模型, 在多元统计分析方面, 常用的软件有SAS 、SPSS 、S-PLUS等。我们在这里给出Matlab在多元统计分析上的应用, 在较早的版本中, 统计功能不那么强大, 而在Matlab6.x版本中, 仅在统计工具中的功能函数就达200多个, 功能已足以赶超任何其他专用的统计软件,在应用上Matlab具有其他软件不可比拟的操作简单,接口方便, 扩充能力强等优势, 再加上Matlab的应用范围广泛, 因此可以预见其在统计应用上越来越占有极其重要的地位,下面用实例给出Matlab 在聚类分析、主成份分析上的应用。 1 聚类分析 聚类分析法是一门多元统计分类法,其目的是把分类对象按一定规则分成若干类,所分成的类是根据数据本身的特征确定的。聚类分析法根据变量(或样品或指标)的属性或特征的相似性,用数学方法把他们逐步地划类,最后得到一个能反映样品之间或指标之间亲疏关系的客观分类系统图,称为谱系聚类图。 聚类分析的步骤有:数据变换,计算n个样品的两两间的距离,先分为一类,在剩下的n-1个样品计算距离,按照不同距离最小的原则,增加分类的个数,减少所需要分类的样品的个数,循环进行下去,直到类的总个数为1时止。根
(整理)多元统计分析各章的电子版数据.
第二章数据
第三章数据
例3-1 X1 职工标准工资收入 X5 单位得到的其他收入 X2 职工奖金收入 X6 其他收入 X3 职工津贴收入 X7 性别 X4 其他工资性收入 X8 就业身份 X1 X2 X3 X4 X5 X6 X7 X8 540.00 0.0 0.0 0.0 0.0 6.00 男国有1137.00 125.00 96.00 0.0 109.00 812.00 女集体1236.00 300.00 270.00 0.0 102.00 318.00 女国有1008.00 0.0 96.00 0.0 86.0 246.00 男集体1723.00 419.00 400.00 0.0 122.00 312.00 男国有1080.00 569.00 147.00 156.00 210.00 318.00 男集体1326.00 0.0 300.00 0.0 148.00 312.00 女国有1110.00 110.00 96.00 0.0 80.00 193.00 女集体1012.00 88.00 298.00 0.0 79.00 278.00 女国有1209.00 102.00 179.00 67.00 198.00 514.00 男集体1101.00 215.00 201.00 39.00 146.00 477.00 男集体 例3-3 English Norwegian Danish Dutch German French One En en een ein un Two To to twee zwei deux Three Tre tre drie drei trois Four Fire fire vier vier quatre Five Fem fem vijf funf einq Six Seks seks zes sechs six seven Sju syv zeven siebcn sept Eight Ate otte acht acht huit Nine Ni ni negen neun neuf Ten Ti ti tien zehn dix Spanish Italian Polish Hungarian Finnish Uno uno jeden egy yksi Dos due dwa ketto kaksi Tres tre trzy harom kolme cuatro quattro cztery negy neua Cinco cinque piec ot viisi Seix sei szesc hat kuusi Siete sette siedem het seitseman Ocho otto osiem nyolc kahdeksau nueve nove dziewiec kilenc yhdeksan Diez dieci dziesiec tiz kymmenen 例3-4
多元统计分析复习整理
一、聚类分析的基本思想: 我们认为,所研究的样品或指标之间存在着程度不同的相似性。根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间的相似程度的统计量,以这些统计量为划分类型的依据,把一些相似程度较大的样品聚合为一类,把另一些彼此之间相似程度较大的样品又聚合到另外一类。把不同的类型一一划分出来,形成一个由小到大的分类系统。最后,用分群图把所有的样品间的亲疏关系表示出来。 二、聚类分析的方法 系统聚类法、模糊聚类法、K-均值法、有序样品的聚类、分解法、加入法 三、系统聚类法的种类 最短距离法、最长距离法、重心法、类平均法、离差平方和法 四、判别分析的基本思想 判别分析用来解决被解释变量是非度量变量的情形,预测和解释影响一个对象所属类别。识别一个个体所属类别的情况下有着广泛的应用 判别分析将对象进行分析,通过人们选择的解释变量来预测或者解释每个对象的所属类别。 五、判别分析的假设条件 判别分析的假设条件之一是每一个判别变量不能是其他判别变量的线性组合;判别分析的假设之二是各组变量的协方差矩阵相等。判别分析最简单和最常用的形式是采用线性判别函数。判别分析的假设之三是各判别变量之间具有多元正态分布,即每个变量对于所有其他变量的固定值有正态分布。当违背该假设时,计算的概率将非常的不准确。 六、判别分析的方法 距离判别法、Bayes判别法、Fisher判别法、逐步判别法
七、距离判别法的判别准则 设有两个总体1G 和2G ,x 是一个p 维样品,若能定义样品到总体1G 和2G 的距离d (x ,1G )和d (x ,2G ),则用如下规则进行判别:若样品x 到总体1G 的距离小于到总体2G 的距离,则认为样品x 属于总体1G ,反之,则认为样品x 属于总体样品x 属于总体2G ,若样品x 到总体1G 和2G 的距离相等,则让它待判。 八、Fisher 判别的思想 Fisher 判别的思想是投影,将k 组p 维数据投影到某一个方向,使的它们的投影与组之间尽可能地分开。 九、Bayes 判别的思想 Bayes 统计的思想是:假定对研究的对象已有一定的认识,常用先验概率分布来描述这种认识,然后我们取得一个样本,用样本来修正已有的认识,得到后验概率分布,各种统计推断都通过后验概率分布来进行。将Bayes 统计的思想用于判别分析,就得到Bayes 判别。 十、判别分析的方法和步骤 1.判别分析的对象 2.判别分析的研究设计 3.判别分析的假定 4.估计判别模型和评估整体拟合 5.结果的解释 6.结果的验证 十一、提取主成分的原则 1.累计方差贡献率大于85%, 2.特征根大于1 ,3碎石图特征根的变化趋势。 十二、因子分析的步骤 1.根据研究问题选取原始变量。 2.对原始变量进行标准化并求其相关阵,分析变量之间的相关性。 3.求解初始公共因子及因子载荷矩阵。 4.因子旋转。 5.因子得分。 6.根据因子得分值进行进一步分析。
多元统计分析论文
多元统计分析实践论文 院系:理学院 专业:统计学 年级:2010 姓名:樊恩泽 学号:20101004005
我国城镇居民人均消费支出的多元统计分析 樊恩泽 摘要:本文本文综合了主成分因子分析与系统聚类分析,先进行主成分因子分析, 再用进行聚类分析。采用2011年我国31个省、市、自治区城镇居民人均消费支出数据,首先利用主成分因子分析的方法, 找出影响我国城镇居民人均消费支出的主成分, 计算各样本的主成分得分;其次运用系统聚类分析法,对各地区人均消费水平进行分类,结果表明,系统聚类分析法得到的结果也较好;最后对于扩大国内消费提出相关建议。 关键词:主成分分析聚类分析居民人均消费支出 1、引言 人均消费支出指居民用于满足家庭日常生活消费的全部支出,包括购买实物支出和服务性消费支出。消费支出按商品和服务的用途可分为食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住、杂项商品和服务等八大类。人均消费支出是社会消费需求的主体,是拉动经济增长的直接因素,是体现居民生活水平和质量的重要指标。 本文选取2011年我国城镇居民人均消费支出数据,主要利用三种统计方法进行分析:主成分分析法、聚类分析法。将全国31个省、市、自治区进行分类和排序,并与人们实际观察到的情况进行比较。 1.1主成分分析 主成分分析是将分量相关的原始变量, 借助于一个正交变换转化为不相关的新变量, 并以方差作为信息量的测度, 对新变量进行降维, 取累计贡献率大的若干成分作为主成分。这些主成分能够反映原始变量的绝大部分信息, 它们通常表示为原始变量的某种线性组合。
1.2聚类分析 聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类的分析技术。 在市场研究领域,聚类分析主要应用方面是帮助我们寻找目标消费群体,运用这项研究技术,我们可以划分出产品的细分市场,并且可以描述出各细分市场的人群特征,以便于客户可以有针对性的对目标消费群体施加影响,合理地开展工作 2、数据来源及处理 2.1统计思想 主成分因子分析的基本思想是通过对变量相关系数矩阵内部结构的研究,找出能控制所以变量的少数几个随机变量去描述多个变量之间的相关关系,并依据相关性的大小将变量分组,使得同组内的变量之间相关性较高,不同组的变量相关性较低。每组代表一个基本结构,这个基本结构成为公共因子。对于所研究的问题试图用最小个数的不可观测的所谓公共因子的线性函数与特殊因子之和来描述原来可观测的每一个变量。 下表是要进行处理的31个省市的城镇居民人均消费支出的相关原始数据,数据来源于《2011中国统计年鉴》。 X1:食品x2:衣着x3:居住x4:家庭用品x5:交通通信x6:文教娱乐x7:医疗保健 表1
多元统计分析重点归纳.归纳.docx
多元统计分析重点宿舍版 第一讲:多元统计方法及应用;多元统计方法分类(按变量、模型、因变量等) 多元统计分析应用 选择题:①数据或结构性简化运用的方法有:多元回归分析,聚类分析,主成分分析,因子分析 ②分类和组合运用的方法有:判别分析,聚类分析,主成分分析 ③变量之间的相关关系运用的方法有:多元回归,主成分分析,因子分析, ④预测与决策运用的方法有:多元回归,判别分析,聚类分析 ⑤横贯数据:{因果模型(因变量数):多元回归,判别分析相依模型(变量测度):因子分析,聚类分析 多元统计分析方法 选择题:①多元统计方法的分类:1)按测量数据的来源分为:横贯数据(同一时间不同案例的观测数据),纵观数据(同样案例在不同时间的多次观测数据) 2)按变量的测度等级(数据类型)分为:类别(非测量型)变量,数值型(测量型)变量 3)按分析模型的属性分为:因果模型,相依模型 4)按模型中因变量的数量分为:单因变量模型,多因变量模型,多层因果模型 第二讲:计算均值、协差阵、相关阵;相互独立性 第三讲:主成分定义、应用及基本思想,主成分性质,主成分分析步骤 主成分定义:何谓主成分分析 就是将原来的多个指标(变量)线性组合成几个新的相互无关的综合指标(主成分),并使新的综合指标尽可能多地反映原来的指标信息。 主成分分析的应用 :(1)数据的压缩、结构的简化;(2)样品的综合评价,排序 主成分分析概述——思想:①(1)把给定的一组变量X1,X2,…XP ,通过线性变换,转换为一组不相关的变量Y1,Y2,…YP 。(2)在这种变换中,保持变量的总方差(X1,X2,…Xp 的方差之和)不变,同时,使Y1具有最大方差,称为第一主成分;Y2具有次大方差,称为第二主成分。依次类推,原来有P 个变量,就可以转换出P 个主
多元统计分析
多元统计分析 > data1=matrix(c(260,200,240,170,270,205,190,200,250,200,225,210,170,270,190,280,310,270,25 0,260,75,72,87,65,110,130,69,46,117,107,130,125,64,76,60,81,119,57,67,135,40,34,45,39,39,34, 27,45,21,28,36,26,31,33,34,20,25,31,31,39,18,17,18,17,24,23,15,15,20,20,11,17,14,13,16,18,15, 8,14,29),20,4) > data2=matrix(c(310,310,190,225,170,210,280,210,280,200,200,280,190,295,270,280,240,280,37 0,280,122,60,40,65,65,82,67,38,65,76,76,94,60,55,125,120,62,69,70,40, 30,35,27,34,37,31,37,36,30,40,39,26,33,30,24,32,32,29,30,37,21,18,15,16,16,17,18,17,23,17,20, 11,17,16,21,18,20,20,20,17),20,4) > data3=matrix(c(320,260,360,295,270,380,240,260,260,295,240,310,330,345,250,260,225,345,36 0,250,64,59,88,100,65,114,55,55,110,73,114,103,112,127,62,59,100,120,107,117,39,37,28,36,32 ,36,42,34,29,33,38,32,21,24,22,21,34,36,25,36,17,11,26,12,21,21,10,20,20,21,18,18,11,20,16,19, 30,18,23,16),20,4) 1.对单个分量进行检验 对第一个分量进行检验,看其是否服从正态分布,利用的是Q-Q图检验法: > x<-rbind(data1,data2,data3) > x<-sort(x[,1]) > x [1] 170 170 170 190 190 190 190 200 200 200 200 200 205 210 210 210 225 225 [19] 225 240 240 240 240 250 250 250 250 260 260 260 260 260 260 270 270 270 [37] 270 270 280 280 280 280 280 280 280 295 295 295 310 310 310 310 320 330 [55] 345 345 360 360 370 380 > p<-c() > for(i in 1:60){ + pi[i]=(i-0.5)/60} > q<-c() > for(i in 1:60){ + q[i]=qnorm(pi[i])} > plot(q,x)
第三章 多元统计分析(3)
第三章多元统计分析 §4 聚类分析 分类是人类认识世界的方式,也是管理世界的有效手段。在科学研究中非常重要,许多科学的研究都是从分类研究出发的。没有分类就没有效率;没有分类,这个世界就没有秩序。瑞典博物学家林奈(Carl von Linnaeus, 1707-1778)因为对植物的分类成就被后人誉为“分类学之父”,后人评价说“上帝创世,林奈分类”——能与上帝的名字并列的人不多,另一个著名的科学家是牛顿。由此可见分类成果的重要性。最初分类都是定性了,后来随着科学的发展产生了定量分类技术,包括基于统计学的聚类方法和基于模糊数学的聚类技巧。本节主要讲述统计学意义的数字分类方法思想和过程。 1 聚类的分类 分类研究的成果的重要性决定了方法的重大实践意义。在任何一门语言的语法学中,都要对词词汇进行分类,词汇分类可以根据词性:名词,动词,形容词……;英文还可以根据首字母分类:ABCD……;汉字则还可以根据笔划,如此等等。在生物学中,将生物划分为:界,门,纲,目,科,属,种。例如白菜(种)属于油菜属、十字花科、十字花目、双子叶植物纲、被子植物亚门、种子植物门、植物界;老虎(种)则属于猫属、猫科、食肉目、哺乳动物纲、脊椎动物亚门、脊索动物门、动物界。这样,整个世界的生物就可以建立一个等级谱系,根据这个谱系,我们可以比较容易地判断那些生物已经认识了,哪些生物尚未发现,哪些生物已经灭绝了。如果发现了新的生物,就可以方便地将其归类。在天文学中,天体可以根据视觉区域分类,也可以根据发光性质与光谱特征进行分类。在地理学中,城市既可以根据地域空间分类,也可以根据城市的职能进行分类。 表3-3-1 各种生物在分类学上的位置举例 位置白菜虎 界植物界动物界 门种子植物门脊索动物门 亚门被子植物亚门脊椎动物亚门 纲双子叶植物纲哺乳动物纲 目十字花目食肉目 科十字花科猫科 属油菜属猫属 种白菜虎 当我们走进一家图书馆,如果它们的图书没有分类编目,我们要找到一本图书与大海捞针没有什么区别。分类的方式也会影响工作的效率。书店的图书一般根据科学门类进行分类摆设,但有一段时间一家书店改为按照出版单位进行分类排列,结果读者很难找到所需图书,这家原本效益挺好的书店很快收到了消极影响。 早期的分类,一般根据事物的属性与特征进行划分,属于定性分类的范畴。随着人们认识的深入和研究对象复杂程度的增加,单纯的定性分类方法就不能满足要求了,于是产生了定量分类技术,即所谓数字分类。本节要讲述的就是根据多个指标进行数字分类的一种多元
多元统计分析
作业一
1.2 分析2016年经济发展情况 排名省gdp 占比累计占比 1 广东79512.05 10.30 10.30 2 江苏76086.2 9.86 20.17 3 山东67008.2 8.68 28.85 4 浙江4648 5 6.02 34.87 5 河南40160.01 5.20 40.08 6 四川32680.5 4.24 44.31 7 湖北32297.9 4.19 48.50 8 河北31827.9 4.12 52.62 9 湖南31244.7 4.05 56.67 10 福建28519.2 3.70 60.37 11 上海27466.2 3.56 63.93 12 北京24899.3 3.23 67.16 13 安徽24117.9 3.13 70.28 14 辽宁22037.88 2.86 73.14 15 陕西19165.39 2.48 75.62 16 内蒙古18632.6 2.41 78.04 17 江西18364.4 2.38 80.42 18 广西18245.07 2.36 82.78 19 天津17885.4 2.32 85.10 20 重庆17558.8 2.28 87.37 21 黑龙江15386.09 1.99 89.37 22 吉林14886.23 1.93 91.30 23 云南14869.95 1.93 93.22 24 山西12928.3 1.68 94.90 25 贵州11734.43 1.52 96.42 26 新疆9550 1.24 97.66 27 甘肃7152.04 0.93 98.59 28 海南4044.51 0.52 99.11 29 宁夏3150.06 0.41 99.52 30 青海2572.49 0.33 99.85 31 西藏1150.07 0.15 100.00 将2016各省的GDP进行排名,可以发现,经济发达的的地区主要集中在东部地区。西部gdp的占比较小。作出2016各省的gdp直方图如下:
多元统计分析对应分析
多元统计分析对应分析
学生实验报告 学院:统计学院 课程名称:多元统计分析 专业班级:统计123班 姓名:叶常青 学号: 0124253
学生实验报告 学生姓名叶常青学号0124253 同组人 实验项目对应分析的上机操作 □必修□选修□演示性实验□验证性实验□操作性实验□综合性实验实验地点实验仪器台号 指导教师李燕辉实验日期及节次 一、实验目的及要求: 目的熟悉和掌握对应分析的原理和上机操作方法 内容及要求本次操作就父母与孩子的受教
育程度的关系进行对应分析,分别对父亲与孩子和母亲与孩子的受教育程度做对应分析,最后再对输出结果进行详细的分析。 二、仪器用具: 仪器名称 规格/型号 数 量 备注 计算机 1 有网络环境 SPSS 软件 1 三、实验方法与步骤: 打开GSS93 subset .sav 数据,对变量Degree 与变量padeg 和madeg 进行对应分析,依次选择 分析→降维 …进入 对应分析 对话框,进行进行如下设置, 便可输出想要的数据的:
四、实验结果与数据处理: 按照上述方法和步骤得出以下输出结果. 对父亲受教育程度与孩子受教育程度的关系进行分析如下: 表1 对应表 Father' s Highest Degree R's Highest Degree Le ss than HS Hi gh school Jun ior college B achel or G radua te 有 效边 际 LT High School 15 6 30 8 29 4 5 2 5 5 63
High School 27 24 8 34 7 9 3 7 4 25 Junior College 1 11 2 8 3 2 5 Bachelo r 6 43 7 4 7 1 8 1 21 Graduat e 3 22 3 2 7 1 6 7 1 有效边际 19 3 63 2 75 2 06 9 9 1 205 表2 摘要 维数奇 异值 惯 量 卡 方 S ig. 惯量 比例 置信 奇异值 解 释 累 积 标 准差 相 关 2 1 . 400 . 160 . 846 . 846 . 025 . 256 2 . 164 . 027 . 142 . 988 . 026
多元统计分析整理版.
1、主成分分析的目的是什么? 主成分分析是考虑各指标间的相互关系,利用降维的思想把多个指标转换成较少的几个相互独立的、能够解释原始变量绝大部分信息的综合指标,从而使进一步研究变得简单的一种统计方法。它的目的是希望用较少的变量去解释原始资料的大部分变异,即数据压缩,数据的解释。常被用来寻找判断事物或现象的综合指标,并对综合指标所包含的信息进行适当的解释。 2、主成分分析基本思想? 主成分分析就是设法将原来指标重新组合成一组新的互相无关的几个综合指标来代替原来指标。同时根据实际需要从中选取几个较少的综合指标尽可能多地反映原来的指标的信息。 设p 个原始变量为 ,新的变量(即主成分) 为 , 主成分和原始变量之间的关系表示为 ? 3、在进行主成分分析时是否要对原来的p 个指标进行标准化?SPSS 软件是否能对数据自动进行标准化?标准化的目的是什么? p 21p x x x ,,, 21p ,21p y y y ,,, 21
需要进行标准化,因为因素之间的数值或者数量级存在较大差距,导致较小的数被淹没,导致主成分偏差较大,所以要进行数据标准化; 进行主成分分析时SPSS可以自动进行标准化; 标准化的目的是消除变量在水平和量纲上的差异造成的影响。 求解步骤 ?对原来的p个指标进行标准化,以消除变量在水平和量纲上的影响 ?根据标准化后的数据矩阵求出相关系数矩阵 ?求出协方差矩阵的特征根和特征向量 ?确定主成分,并对各主成分所包含的信息给予适当的解释 版本二:根据我国31个省市自治区2006年的6项主要经济指标数据,表二至表五,是SPSS的输出表,试解释从每张表可以得出哪些结论,进行主成分分析,找出主成分并进行适当的解释:(下面是SPSS的输出结果,请根据结果写出结论) 表一:数据输入界面 表二:数据输出界面a)