Teradata分析

1、 T eradata 优势 ,能否打数据并发 1)优势
以下是部分Teradata 客户数据仓库管理的内容,可说明Teradata 系统的强大处理能力: ?
多达千亿行数据的数据库表格 ?
每天数据加载超过30亿条记录 ?
每天捕获3000万笔客户交易 ?
每天为消费者在线提供150万种个性化产品和服务 ?
每小时处理100万次数据库查询 ?
每天响应1万个并发数据仓库用户 ? 业务查询响应时间仅为40-50毫秒
2)并发问题:
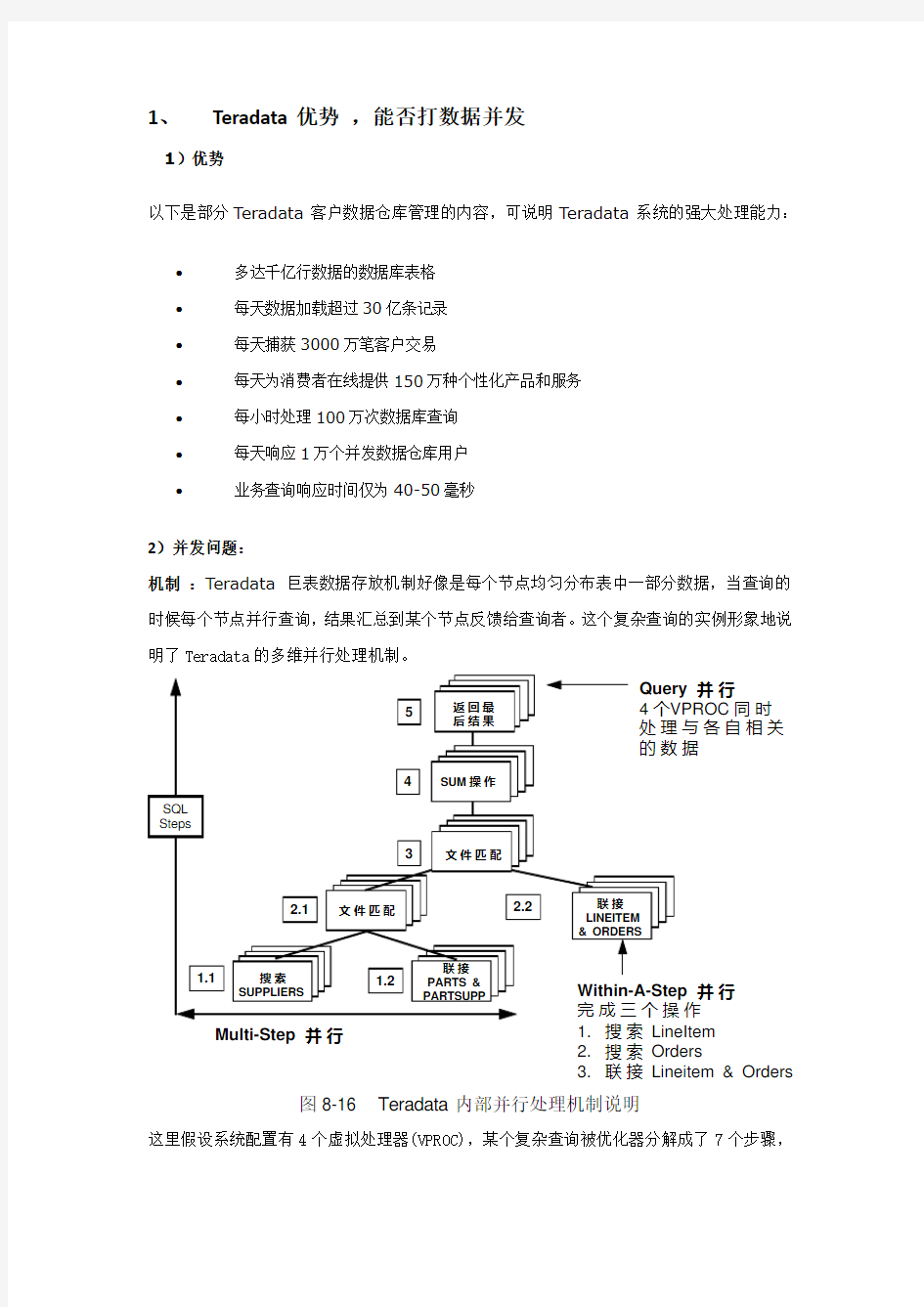
机制 :Teradata 巨表数据存放机制好像是每个节点均匀分布表中一部分数据,当查询的时候每个节点并行查询,结果汇总到某个节点反馈给查询者。这个复杂查询的实例形象地说明了Teradata 的多维并行处理机制。
M ulti-S tep 并 行
并 行 作1. 搜 索 LineItem
2. 搜 索 O rders
3. 联 接 Lineitem & O rders 并 行P R O C 同 时
与 各 自 相 关
据
图8-16 T eradata 内部并行处理机制说明
这里假设系统配置有4个虚拟处理器(VPROC),某个复杂查询被优化器分解成了7个步骤,
图中SUPPLIERS、PARTS、PARTSUPP等为数据库中表的名字。在每个步骤执行时,4个VPROC 同时处理与各自相关的数据块,例如搜索SUPPLIERS表,该表的记录是通过HASH算法均匀分布在四个VPROC各自负责的磁盘中的,搜索时4个VPROC将同时进行,把相关的记录搜索出来,这就是所谓的查询并行。
例子:
例如:使用NCR 5300服务器,2个节点,存储为2TB,RAID1,在业务高峰期,系统并发查询用户在300个以上,最高到1000个,此时系统响应速度有些缓慢大概业务查询响应时间30秒,峰值过后速度就加快了。主要进行的操作就是表之间的关联查询,4张表,每张6-7千万条记录,ETL加载的数据量不算太大。
2、T eradata内外部集建立原则
针对实际的应用,采用内外部集市可以有效的发挥起各自的优势:
1)松耦合原则
介于要将整个系统划分为数据和应用层,相互存在很多密切关联,在设计库表时要充分考虑数据和应用的相互影响,做到应用不影响到数据的处理,数据处理不直接针对应用的松耦合技术架构
2)任务明确原则
数据处理层和应用层在处理具体业务时,必然存在既可以在数据层处理有可以在应用层处理的问题,需要在设计时充分讨论业务需求,做到责任明确,任务单一,各负其责。
3、teradata比较oracle的优缺点
Teradata是专为数据仓库OLAP设计的,主要用来进行数据的综合分析和处理,
Oracle更多的适合联机事务处理的OLTP应用,针对DW 数据仓库从以下几个角度对teradata进行分析:
1、数据管理能力(Data Management)
数据自动分配
Teradata中只有一种基于HASH算法的数据分配机制,当要插入一条记录时,根据主索引计算出相应的AMP,该条记录即通过此AMP存到其对应的磁盘上。由于主索引值的不同,一个表的各条记录将通过各AMP均匀地分布到各个磁盘上。分配过程完全自动进行,不需要DBA干预,这一点和其它OLTP DBMS有很大的区别。Teradata的HASHING算法经过长期的发展,已经十分完善。它采用了一个类似矩阵的HASH MAP,将计算出来的HASH值通过此矩阵
的映射与AMP进行联系。这样,当重新配置AMP数时,只需要变动HASH MAP,速度非常快。
对于OLTP系统而言,其查询的特点是预先知道要回答什么样的问题,因此,DBA会根据业务问题的特点把数据按照相应的规律进行分配,例如把数据按照时间的不同分配到不同的硬盘上。这种由DBA手工进行的数据分配机制对OLTP系统而言是有意义的,也确实能提高系统性能。但对数据仓库系统来说,其查询往往比较复杂而且具有不确定性,不同的业务部门可能会提出各种不同的问题,如果再按照一种规律进行数据的分配,则有可能对某些问题系统的响应速度很快,而对另外一些问题的反应则很慢。
在Teradata数据库中,通过选择合适的主索引就可以保证数据在各磁盘上的自动均匀分配,使得其并行处理性能得以充分的发挥,特别适合于数据仓库环境下各种不确定的、动态的业务问题。另一方面,所有记录的插入、更新都按同样的HASHING算法进行,使得各磁盘上的数据总是混合存储而且是均衡的,不存在“有序”或者“无序”的概念,因而也就不存在数据库的重组问题(Reorganization)。对于传统的OLTP RDBMS而言,投产运行一段时间后系统性能常常因某种原因(如不断追加记录后造成数据存储不平衡)下降,这时就要考虑对数据库的重组。这是一项非常耗时而且需要经验丰富DBA参与的工作。在Teradata中,由于不存在数据库重组这类的工作,使得其管理十分简单。
2、系统管理能力(Data Administration)
Teradata易于管理
Teradata 数据库提供了一整套齐全的工具和功能,可对数据库操作、管理和维护进行控制,您只需通过一个普通的 Windows 用户界面——Teradata 管理器——即可使用这些工具和功能,包括:
?Teradata 备份、存档和恢复解决方案,结合了行业领先合作伙伴和 Teradata 专业技术的实力
?Teradata 仪表盘,用于状态和绩效统计
?管理工作站,用于对整个 Teradata 系统进行单点管理控制
?Teradata 动态工作量管理器,用于查询工作量管理情况
?Teradata 工作量分析器,用于查询绩效分析结果以及对工作量分组和资源分配提出的建议
3、扩充能力和适应能力(Platform Suitability & Scalability )
teradata线性可扩展能力
一般来说,当数据仓库投产以后,随着应用的增加,其数据量也增长得非常快,因此,数据仓库系统对扩展性的要求很高。可扩展包含两方面的含义,即硬件平台的可扩展和软件平台的可扩展,两者必须相互配合,相辅相成,任何一方存在瓶颈都会影响整个系统的扩充能力。Teradata的操作系统是Microsoft Windows NT/2000或者是NCR UNIX,如果使用Windows,则可用使用任何支持Windows的服务器,如果使用NCR UNIX,则只能使用NCR的MPP服务器。之所以存在这种限制的主要原因就在于扩展能力上,因为目前NCR的 MPP服务器是业界扩展能力最强的计算机系统,它配合Teradata,形成了扩展能力最强、并行处理能力最佳的数据仓库基础平台。
考虑一个系统的线性可扩展能力,可以从以下三个方面来进行评估:
?数据量增长时的线性度:当用户数据量成倍增加时,对于同一个系统(指硬件配置不变),响应时间是按比例线性增加的;
?硬件平台的线性度:对于同一个查询,当硬件平台的配置增加一倍时,响应时间应减少一半;
?并发用户增加时的线性:对于同一个系统,当并发用户的数目增加时,响应时间也按比例线性增加。
对基于Teradata实施的数据仓库系统的扩充是很容易的,可以采用现场升级(Field Upgrade)方式。下图举例说明了将一个四节点的系统扩充到六节点的情况,首先将新增加的两个节点通过BYNET与原系统联接,然后运行Teradata提供的一个名叫RECONFIG的工具,它将自动把原系统磁盘阵列中1/3的数据按照HASH算法均匀地分布到新节点所控制的磁盘中。这个过程完全自动进行,不需要DBA过多地干预。这个特性也是为什么说由Teradata 组成的数据仓库系统比较容易管理的原因之一。
转移1/3 的数据至 ...这里
图8-17 Teradata线性扩展说明
4、并发查询管理能力(Concurrent Query Management)
Teradata最显著的特色之一是其强大的并行处理能力,这也是为什么说它是数据仓库专用引擎的主要原因之一。其实现方式被称为多维并行处理机制,简单描述如下:
查询并行(Query并行):这种并行处理是基于上面介绍的HASHING数据分配机制实现的。
每个AMP都是一个VPROC,各自独立负责一部分数据的处理,相互之间没有关系,每个节点一般配置4至16个这样的VPROC。所有关系运算如表的搜索、索引检索、投影、选择、联接、聚集、排序等都是由各个VPROC并行进行的。
步内并行(Within-a-Step并行):一个SQL查询进入系统后,首先由优化器进行优化处理,分解成一些小的步骤(Step),然后再分发给各VPROC进行处理。一个步骤可能非常简单,如“搜索一个表并返回结果”,也可能非常复杂,如“按照某条件搜索两个表,然后联接,结果投影到某几个列,对它们加和(SUM)后返回结果”。象这种复杂查询将处理多个关系运算,每个关系运算在一个VPROC内将启动多个进程来实现并行处理,称为步内并行。
多步并行(Multi-Step并行):上面说过,一个SQL被分解成多个小的步骤,这些步骤的执行将同时进行,称为多步并行。优化器分解一个SQL查询请求的原则是尽可能使各步独立。在目前所有的DBMS产品中,只有Teradata实现了多步并行。
七天搞定SAS系列
七天搞定SAS系列 七天搞定SAS系列学习笔记。参考书籍:The Little SAS Book 七天搞定SAS(一):数据的导入、数据结构 标题有些噱头,不过这里的重点是: speak SAS in 7 days。也就是说,知识是现成的,我这里只是要学会如何讲这门语言,而不是如何边学SAS边学模型。顺便发现我最近喜欢写连载了,自从西藏回来后..... 之所以下定决定学SAS,是因为周围的人都在用SAS。为了和同事的沟通更有效率,还是多学一门语言吧。R再灵活,毕竟还是只有少数人能直接读懂。理论上语言是不应该成为障碍的~就像外语一样,多学一点总是好的,至少出门不发怵是不是? 最后一根稻草则是施老师传给我的一个link: https://www.360docs.net/doc/3a14454309.html,/articles/bi/3-career-secrets-for-data-scientist s-1101712/,据说有数据分析师的职业秘笈...我就忍不住去看了看。其中一句话还是蛮有启发的: 如果有人问你要学什么工具,是SAS,R,EXCEL,SQL,SPSS还是?直接回答:所有。 这个答案一方面霸气,一方面也是,何必被工具束缚呢? 这东西宜突击不宜拖延,所以还是集中搞定吧。七天应该是个不错的时间段。 大致分配如下: 1. 熟悉SAS的数据结构,如基本的向量,数据集,数组;熟悉基本的数据类型,如文本,数字。 2. 熟悉基本的数据输入与输出。 3. 熟悉基本的逻辑语句:循环,判断 4. 熟悉基本的数据操作:筛选行列,筛选或计算变量,合并数据集,计算基本统计量,转置 5. 熟悉基本的文本操作函数 6. 熟悉基本的计量模型函数 7. 熟悉基本的macro编写,局部变量与全局变量 其实这大概也是按照我常用的R里面完成的任务来罗列的。基本计划是完成就可以大致了解SAS的语法了,其他的高级功能现用现学吧。 书籍方面,中文的抢了同事的一本《SAS编程与数据挖掘商业案例》,英文的找了一本「Applied Econometrics Using The SAS System」和「The Little SAS Book」,先这么看着吧。 后知后觉的补充:其实这一系列笔记都是先写再发布的,主要是方便我调整顺序什么的。事实证明绝大多数时间我在看(或者更直接的,抄)「The Little SAS Book」这本书,姚老
OGG(oracle+GoldenGate)学习笔记
Oracle GoldenGate测试文档 1.Oracle GoldenGate介绍 (1) 2.Oracle GoldenGate For Oracle(windows 平台) 安装 (5) 3.数据库复制实施文档(DML) (7) 3.1准备工作 (7) 3.2配置GoldenGate (8) 3.2.1配置SourceDB的GoldenGate (8) 3.2.2 配置TargetDB的GoldenGate (9) 3.3 测试DML操作 (11) 4.GoldenGate Support DDL安装 (15) 5.玩玩GoldenGate (23) 1.Oracle GoldenGate介绍 GoldenGate TDM(交易数据管理)软件是一种基于日志的结构化数据复制软件,它通过解析源数据库在线日志或归档日志获得数据的增删改变化,再将这些变化应用到目标数据库,实现源数据库与目标数据库同步、双活。GoldenGate TDM 软件可以在异构的IT基础结构(包括几乎所有常用操作系统平台和数据库平台)之间实现大量数据亚秒一级的实时复制,其复制过程简图如下: 如上图所示,GoldenGate TDM的数据复制过程如下: 利用捕捉进程(Capture Process)在源系统端读取Online Redo Log或Archive Log,然后进行解析,只提取其中数据的变化如增、删、改操作,并将相关信息转换为GoldenGate TDM自定
义的中间格式存放在队列文件中。再利用传送进程将队列文件通过TCP/IP传送到目标系统。捕捉进程在每次读完log中的数据变化并在数据传送到目标系统后,会写检查点,记录当前完成捕捉的log位置,检查点的存在可以使捕捉进程在中止并恢复后可从检查点位置继续复制; 目标系统接受数据变化并缓存到GoldenGate TDM队列当中,队列为一系列临时存储数据变化的文件,等待投递进程读取数据; GoldenGate TDM投递进程从队列中读取数据变化并创建对应的SQL语句,通过数据库的本地接口执行,提交到数据库成功后更新自己的检查点,记录已经完成复制的位置,数据的复制过程最终完成。 由此可见,GoldenGate TDM是一种基于软件的数据复制方式,它从数据库的日志解析数据的变化(数据量只有日志的四分之一左右)。GoldenGate TDM将数据变化转化为自己的格式,直接通过TCP/IP网络传输,无需依赖于数据库自身的传递方式,而且可以通过高达9:1的压缩率对数据进行压缩,可以大大降低带宽需求。在目标端,GoldenGate TDM可以通过交易重组,分批加载等技术手段大大加快数据投递的速度和效率,降低目标系统的资源占用,可以在亚秒级实现大量数据的复制,并且目标端数据库是活动的 GoldenGate TDM提供了灵活的应用方案,基于其先进、灵活的技术架构可以根据用户需求组成各种拓扑结构,如图所示:
1019大数据笔记记录
一、大数据,云计算,AI概述 1、背景及来源 大数据的背景:20世纪开始,政府和各行业(如医疗、通信、交通、金融等)信息化的发展,积累了海量数据。而且目前数据增长速度越来越快。 如何实现对海量数据的存储、查询、分析,使之产生商业价值,是目前面临的主要挑战。 2、大数据的定义 目前没有统一的大数据的定义。 Gartner:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 麦肯锡:大数据指的是大小超出常规的数据库工具获取、存储、管理和分析能力的数据集。但它同时强调,并不是说一定要超过特定TB 值的数据集才能算是大数据。 维基百科:大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合. 总结成一句话、大数据实际上不是一项单一的技术,而是一个概念,一套技术,一个生态圈。 3、大数据的4大特征 第一个特征:数据量大(Volume). 第二个特征:数据类型繁多(Variety) 第三个特征:价值密度低(Value) 第四个特征是速度快、时效高(Velocity) 。 4、大数据生态圈 框架:Hadoop、Spark 集群管理:MapReduce、Yarn、Mesos 开发语言:Java、Python、Scala、Pig、Hive、SparkSQL。 数据库:NoSQL、HBase、Cassandra、Impala。 文件系统:HDFS、Ceph。 搜索系统:Elastic Search 采集系统:Flume、Sqoop、Kafka 流式处理:Spark Streaming、Storm 发行版:HortonWorks、Cloudera、MapR 集群管理:Ambari、大数据管理平台 机器学习:Spark MLLib、Mahout
大数据时代读书笔记
大数据时代——读书笔记 一、引论 1.大数据时代的三个转变: 1.可以分析更多的数据,处理和某个现象相关的所有数据,而不是随机采样 2.不热衷于精确度 3.不热衷与寻找因果关系 2.习惯:用来决策的信息必须是少量而精确的。实际:数据量变大,数据处理速度变快, 数据不在精确 3.危险:不是隐私的泄露而是未来行动的预判 二、大数据时代的思维变革 1.原因:没有意识到处理大规模数据的能力,假设信息匮乏,发展一些使用少量信息的技 术(随机采样) 1.1086年末日审判书英国对人的记载 2.约翰·格朗特:统计学,采样分析精确性随着采样随机性上升而大幅上升,与样本数 量关系不大 3.1890年,穿孔卡片制表机,人口普查 4.随机采样有固有的缺陷 1.采样过程中存在偏差 2.采样不适合考察子类别 3.只能得出实现设计好的问题的结果 4.忽视了细节考察 2.全数据模式:样本=总体 1.通过异常量判断信用卡诈骗 2.大数据分析:不用随机抽样,而是采用所有数据。不是绝对意义而是相对意义。 (Xroom信用卡诈骗,日本相扑比赛) 3.多样性的价值(社区外联系很多》社区内联系很多) 3. 混杂性而非精确性 1. 葡萄树温度测量:数据变多,虽然可能有错误数据,但总体而言会更加精确。 2. 包容错误有更大好处 3. word语法检查:语料库》算法发展 4. google翻译:让计算机自己估算对应关系,寻找成千上万对译 结论:大数据的简单算法好过小数据的复杂算法 5. 大数据让我们不执著于也无法执着于精确 6. MIT的通货紧缩软件:即时的大数据 7. 标签:不精确 8. 想要获得大规模数据的好处,混乱是一种标准途经 9. 新的数据库:大部分数据是非结构化的,无法被利用 10. Hadoop:与mapreduce系统相对的开源式分布系统,输出结果不精确,但是非常快 结论:相比于依赖小数据和精确性的时代,大数据因为更强调数据的完整性和混杂性,帮助我们进一步接近事情的真相。“部分”和”确切“的吸引力是可以理解的。但是当我们的视野局限在我们可以分析和确定的数据上时,我们对世界的整体影响就会产生偏差和错误。不仅失去了尽力收集一切数据和活力,也失去了从不同角度观察时间的权利。三、不是因果是相关
oracle GoldenGate学习笔记
Oracle GoldenGate测试文档1.Oracle GoldenGate介绍 GoldenGate TDM(交易数据管理)软件是一种基于日志的结构化数据复制软件,它通过解析源数据库在线日志或归档日志获得数据的增删改变化,再将这些变化应用到目标数据库,实现源数据库与目标数据库同步、双活。GoldenGate TDM 软件可以在异构的IT基础结构(包括几乎所有常用操作系统平台和数据库平台)之间实现大量数据亚秒一级的实时复制,其复制过程简图如下: 如上图所示,GoldenGate TDM的数据复制过程如下: 利用捕捉进程(Capture Process)在源系统端读取Online Redo Log或Archive Log,然后进行解析,只提取其中数据的变化如增、删、改操作,并将相关信息转换为GoldenGate TDM自定义的中间格式存放在队列文件中。再利用传送进程将队列文件通过TCP/IP传送到目标系统。捕捉进程在每次读完log中的数据变化并在数据传送到目标系统后,会写检查点,记录当前完成捕捉的log位置,检查点的存在可以使捕捉进程在中止并恢复后可从检查点位置继续复制; 目标系统接受数据变化并缓存到GoldenGate TDM队列当中,队列为一系列临时存储数据变化的文件,等待投递进程读取数据; GoldenGate TDM投递进程从队列中读取数据变化并创建对应的SQL语句,通过数据库的本地接口执行,提交到数据库成功后更新自己的检查点,记录已经完成复制的位置,数据的复制过程最终完成。 由此可见,GoldenGate TDM是一种基于软件的数据复制方式,它从数据库的日志解析数据的变化(数据量只有日志的四分之一左右)。GoldenGate TDM将数据变化转化为自己的格式,直接通过TCP/IP网络传输,无需依赖于数据库自身的传递方式,而且可以通过高达9:1的压缩率对数据进行压缩,可以大大降低带宽需求。在目标端,GoldenGate TDM可以通
TeraData数据库学习笔记
处理节点(node)、用于节点间通信的内部高速互联(InterConnection)和数据存储介质(一般是磁盘阵列)。每个节点都是SMP结构的单机,节点的物理和逻辑结构如图1所示单个节点就是一个就是一个smp 处理单元,一台多CPU或多核的计算机。硬件包括CPU、内存、用于安装操作系统和应用软件的本地磁盘,与外界交互的网卡及bynet端口;节点网卡一种是与IBM MainFrame链接的Channel Adapter,另一种是局域网网卡,通常一个节点只有一种网卡,但有很多块网卡,分别用于不同的连接(比如:备份等)和冗余。 多个节点一起构成MPP系统,多个节点之间的内部高速互联时通过BYNET的硬件实现 Shared Nothing Architecture The Teradata Database virtual processors, or vprocs (which are the PEs and AMPs), share the components of the nodes (memory and cpu). The main component of the "shared-nothing" architecture is that each AMP manages its own dedicated portion of the system's disk space (called the vdisk) and this space is not shared with other AMPs. Each AMP uses system resources independently of the other AMPs so they can all work in parallel for high system performance overall. Modul-2 一个关系数据库是存储在关系数据库管理系统里的相关联的表的集合。“管理系统”这个词,指的是一个关系数据库需要软件来提供象事物处理完整性、安全性和日志的功能。Teradata是一个关系数据库管理系统。 关系数据库不用访问路径去查找数据,数据通过数据值来连接。数据连接由一个列与另外一个表中的
冰与火之歌 读书之《权利的游戏》读后感1000字
冰与火之歌读书之《权利的游戏》读后感 1000字 导读:读书笔记冰与火之歌读书之《权利的游戏》读后感1000字,仅供参考,如果觉得很不错,欢迎点评和分享。 冰与火之歌——读书心得之《权利的游戏》读后感1000字: 把今天的随想说完了,那我就来写读书笔记。 这一篇文章是讲《权利的游戏》为什么会在全球这么火,而且为什么会被誉为神作? 文章是从社交网络模型为出发点和切入点,即是以探索书中和电视剧中所展示的社会关系来写的。作者认为,权利的游戏之所以好看,即使在第七季夜王突变投枪手,最强谋略家小指头沦为北境第一大混子,囧雪和姑姑突然被爱情撞了腰还擦了火花等等,但是却还是会让人觉要看下去。原因在于什么? 作者认为是,他讲了一个好故事。这个好故事的原则的有三:让”主角“意想不到的死亡;让“配角”连珠成线的加让“阵营”有理有据的反转。 先说第一个,我记得我看第一季的时候我以为北狼家族的艾德·史塔克会是主角但是随着剧情的发展,怎么感觉“主角”要被抹脖子了?在最后一集之前我还以为放心吧,肯定会活下去的,在刑场上肯定会有人来救的,但是没有想到,到最后一集还是哎呦我去,把
艾德给抹脖子了。我怀着震惊和不甘开始了第二季,发现大儿子罗伯领兵起义开起“五王之战”,哦!原来他才是主角,但是到第三季,他、他媳妇、他老娘都!没!了!然后就是各种主角被杀,我发现主角死的几率比配角的还大,以后拍电视剧的都不敢当主角了。 但是,这只是一种直观的感受,作者提出几个问题,第一,这个主角是真的主角吗?第二,在大部分故事中主角都是有主角光环的,因为主角是所有线索的一条线,一旦主角死了,故事就没有连载的继续了。那为什么冰火可以让主角不断地去死呢?我再想如果当年的工藤新一在娱乐场被一棒子敲死的话,柯南也就不会连载十几年了吧。 作者为此做了一个统计,把存在已经出版了的五本英文原版里面的人物利用社会关系模型做了一个统计,最后得到的结果是琼恩和提利昂的关系的密度最大,读后感.所以在看电视的时候有这样的一种感觉,作者做完统计之后更加深了判断。虽然狼爸,狼少主,鹿国王等人的排名都很靠前,但是和他们相似的还有很多,所以他们就可以安心的领盒饭了。但是为什么,他们虽然不是真正的主角他们死的时候我们还是感到惊讶? 这和作者马丁的写作方式有关,冰火采用的是每个章节都以一个角色的视角来叙述,而狼爸在第一部中出场时间战了大多数,因此确实容易被认为是真主角。 虽然,不是真的主角,他占得戏份也多,为什么说砍就砍呢?这就涉及到第二个原则,让“配角”连珠成线的加戏。简单来说,作者建立一个庞大复杂的人物线,少一个人根本不影响叙事虽然去掉这些
人工神经网络学习总结笔记
人工神经网络学习总结笔记 主要侧重点: 1.概念清晰 2.进行必要的查询时能从书本上找到答案 第一章:绪论 1.1人工神经网络的概述 “认识脑”和“仿脑”:人工智能科学家在了解人脑的工作机理和思维的本质的基础上,探索具有人类智慧的人工智能系统,以模拟延伸和扩展脑功能。我认为这是人工神经网络研究的前身。 形象思维:不易被模拟 人脑思维抽象推理 逻辑思维:过程:信息概念最终结果 特点:按串行模式 人脑与计算机信息处理能力的不同点: 方面类型人脑计算机 记忆与联想能力可存储大量信息,对信息有 筛选、回忆、巩固的联想记 忆能力无回忆与联想能力,只可存取信息 学习与认知能力具备该能力无该能力 信息加工能力具有信息加工能力可认识 事物的本质与规律仅限于二值逻辑,有形式逻辑能力,缺乏辩证逻辑能力 信息综合能力可以对知识进行归纳类比 和概括,是一种对信息进行 逻辑加工和非逻辑加工相 结合的过程 缺乏该能力 信息处理速度数值处理等只需串行算法就能解决的应用问题方便,计算 机比人脑快,但计算机在处理文字图像、声音等类信息的 能力远不如人脑 1.1.2人脑与计算机信息处理机制的比较 人脑与计算机处理能力的差异最根本的原因就是信息处理机制的不同,主要有四个方面 方面类型人脑计算机 系统结构有数百亿神经元组成的神经 网络由二值逻辑门电路构成的按串行方式工作的逻辑机器 信号形式模拟量(特点:具有模糊性。离散的二进制数和二值逻辑容易被机器模拟的思维方式
难以被机器模拟)和脉冲两种 形式 形式 信息储存人脑中的信息分布存储于整个系统,所存储的信息是联想式 的 有限集中的串行处理机制信息处理机制高度并行的非线性信息处理系统 (体现在结构上、信息存储上、信 息处理的运行过程中) 1.1.3 人工神经网络的概念:在对人脑神经网络的基本认识的基础上,用数理方法从信息处理的角度对人脑神经网络进行抽象,并建立某种简化模型,称之为人工神经网络,是对人脑的简化、抽象以及模拟,是一种旨在模仿人脑结构及其功能的信息处理系统。 其他定义:由非常多个非常简单的处理单元彼此按某种方式相互连接而形成的计算系统,外部输入信息之后,系统产生动态响应从而处理信息。 它是由许多简单的并行工作的处理单元组成的系统,其功能会因网络结构、连接强度以及各单元的处理方式的不同而不同 1.3神经网络的基本特点与功能 基本特点:1、结构特点:信息处理的并行性、信息存储的分布性、信息处理单元的互联性、结构的可塑性。神经网络内在的并行性与分布性表现在其信息的存储于处理都是空间上分布、时间上并行的。 2、性能特点:高度的非线性、良好的容错性和计算的非精确性。 3、能力特征:自学习、自组织(重构)与自适应性。 神经网络的基本功能:1、联想记忆:自联想记忆与异联想记忆 2、非线性映射 3、分类与识别 4、优化计算 5、知识处理 第二章人工神经网络建模基础 2.1~2.2 讲述了生物神经系统以及生物神经网络的建模基础 神经元所产生的信息是具有电脉冲形式的神经冲动,脉冲的宽度和幅度相同,但是间隔是随机变化的。 人脑中,外界的刺激不同可以改变神经元之间的突触关系,即突触厚膜电位的方向以及大小,从突触信息传递的角度来看,表现为放大倍数和极性的变化。 空间整合的概念(BP29)信息整合这一段中 阀值特性:我认为阀值特性即静息电位必须上升到一定数值范围即超过阀值电位之后,神经元才会产生兴奋,信息才能以脉冲的形式得到传递。 所谓的时间整合,如果由一个脉冲所引起的突触膜后电位很小,只有在持续时间内当另一脉冲到达的时候,总的突触膜后电位增大。 2.3 人工神经元模型 人工神经网络是在现代神经生物学研究基础上提出的模拟生物的过程,反映人脑某些特性的一种计算结构,是人脑神经系统的一种抽象、简化和模拟而不是对它的真实描写。神经网络的基本器件是神经元和突触。人工神经网络当中的神经元是处理单元,也称之为节点。人工神经元是对生物神经元的信息处理过程的抽象模拟,通过数学语言对其进行描述,对其结构和功能进行模拟,用模型图予以表达。 2.3.1 神经元的建模
大数据营销-丽莎(读书笔记简约版)
营销职能正在经历重大转型,数据驱动型营销。 创造力价值评估的要点在于转变。 数据毛球的不断变大,洞察力的价值被混乱所掩埋。企业高层需要转型。 第一部我们是怎么到这的 第一章走出传统营销的阴影 数据分析的投资?CEO是否会认可会意识到重要性,应对“数字”冲击(将公司与客户用新的方式联系) 趋势:客户对个人信息控制权的索取,基于相互信任和体验共享的基础上进行价值传递。数据驱动型营销工作:驱动客户参与为目标,在洞悉结构性和多元结构性公司数据(大数据)的基础上进行的搜集、分析和执行。 《teradata全球数据驱动型营销调查报告》 第二章为什么市场营销已经过时 1、企业内部障碍阻止了大数据。 2、营销人员面对的6大障碍: 战术营销(而不是战略营销) 需要转向战略,借助数据洞察力指导决策,这样更加能更加以客户为中心,会引发创新。传统的营销很多时候是战术的,往往也会被认为是摆设。即,需要将客户与公司的收益联系起来,证明营销部门的价值。 人工营销管理 琐碎的营销事宜占据了大部分时间(例如各种文字和图片)几乎没有时间去规划。总是和一些无关紧要的事情纠缠。公司没有对营销部门确定量化的指标。现在营销业务应该是管理监控组合资产包含财务人力跨业务和跨区域项目,营销内容和测量的知识产权。需要有效标准化管理这些高价值资产,增加营收,提高竞争优势。 孤立的数据与实时互动需求 零售渠道被消费者当作试用渠道而不是购买渠道,“销售展厅”,如何避免?个性化营销,每位顾客如何会选择店面,优惠措施等,愿意为优越体验付费,现在客户更有意愿分享消费体验,改善体验,整合数据,互动客户。 市场营销价值不清晰 用数据证明团队的价值。价值营收。数据、流程和文案均可以证明自身价值。 缺乏人才和培训 缺乏技能数据分析,计算分析,预测模型,统计学课程。 散乱与经常缺失的数据 分散孤立的数据形成杂乱的数据环境——数据毛球
JDBC学习笔记
JDBC基础 1.JDBC类结构 DriverManager:它是一个工厂类,用来生产Driver对象的这个类的结构设计模式为工厂方法。 Driver:这是驱动程序对象的接口,它指向一个实实在在的数据库驱动程序对象。 Connection:这个接口可以制向一个数据库连接对象。 Statement:用于执行静态的SQL语句的接口,通过Connection中的createStatement方法得到的。 PreparedStatement:表示预编译的 SQL 语句的对象。 Resultset:用于指向结果集对象的接口,结果集对象是通过Statement中的execute等方法得到的。 2.使用JDBC访问数据库的步骤 (1)得到数据库驱动程序 通常使用Class类的forName()静态方法来加载驱动。例如: Class.forName("org.gjt.mm.mysql.Driver");//加载MySQL的JDBC驱动程序 (2)创建数据库连接 使用:DriverManager.getConnection(String url, String user, String password)创建数据库连接对象,例如: String DBURL="jdbc:mysql://127.0.0.1:3306/java";//数据库连接地址 Connection con = DriverManager.getConnection(DBURL,"root","lizhiwei");//得到连接(3)执行SQL语句 ?通过Connection对象创建Statement对象。Connection创建Statement的方法有如下3个:createSatement():创建基本的Statement对象。 prepareStatement(String sql):根据传入的sql语句创建预编译的Statement对象。 prepareCall(String sql):根据传入的sql语句创建CallableStatement对象。 ?createSatement()的使用: Statement st = con.createStatement();// 得到用于执行静态SQL语句的对象 ResultSet rs = st.executeQuery("select * from Person");// 执行查询,得到结果集对象 while (rs.next()) { System.out.print(rs.getInt("pid")+"\t"); System.out.print(rs.getInt("id")+"\t"); System.out.println(rs.getString("name")); } ?prepareStatement(String sql)的使用: PreparedStatement ps=con.prepareStatement("select * from Person where pid>?"); ps.setInt(1, 3);//向第一个“?”设置值 ResultSet rs=ps.executeQuery();//执行查询,得到结果集对象 while (rs.next()) { System.out.print(rs.getInt("pid")+"\t"); System.out.print(rs.getInt("id")+"\t"); System.out.println(rs.getString("name")); } (4)得到结果集 使用Statement执行Sql语句。所有的Statement都有如下3个方法来执行sql语句:execute():可以执行任何sql语句,但比较麻烦。 executeUpdate():主要用于执行DML和DDL语句。执行DML语句返回受sql语句影响的行数。 executeQuery():只能执行查询语句,执行后返回代表查询结果的ResultSet对象 (5)对结果集做相应的处理(增,删,改,查) 操作结果集。如果执行的sql语句是查询语句,则执行结果将返回一个ResultSet对象,该对象里保存了sql语句查询的结果。程序可以通过操作该ResultSet对象来取出查询结果。ResultSet 对象主要提供了如下两类方法: next()、previous()、first()、last()、beforeFirst()、afterLast()、absolute()等移动记录指针的方法。 getXxx()方法获取记录指针指向行、特定列的值。该方法既可以使用列索引作为参数,也可以使用列名作为参数。 (6)关闭资源 释放资源的顺序是ResultSet, Statement,Connection;Connection在使用完成后,必须关闭,ResultSet, Statement无所谓,只要Connection关闭了,它们也会被自动关闭(但资源不是立即被释放)。Connection的使用原则是尽量晚创建,尽量早的释放。在关闭资源异常的情况下,应该将资
Oracle GoldenGate学习笔记(简体、繁体)
Oracle GoldenGate 测试文档 https://www.360docs.net/doc/3a14454309.html,
1.Oracle GoldenGate介绍 GoldenGate TDM(交易资料管理)软体是一种基于日志的结构化资料複製软体,它通过解析源资料库在线日志或归档日志获得资料的增删改变化,再将这些变化应用到目标资料库,实现源资料库与目标资料库同步、双活。GoldenGate TDM 软体可以在异构的IT基础结构(包括几乎所有常用作业系统平台和资料库平台)之间实现大量资料亚秒一级的即时複製,其複製过程简图如下: 如上图所示,GoldenGate TDM的资料複製过程如下: 利用捕捉进程(Capture Process)在源系统端读取Online Redo Log或Archive Log,然后进行解析,只提取其中资料的变化如增、删、改操作,并将相关资讯转换爲GoldenGate TDM 自定义的中间格式存放在伫列文件中。再利用传送进程将伫列文件通过TCP/IP传送到目标系统。捕捉进程在每次读完log中的资料变化并在资料传送到目标系统后,会写检查点,记录当前完成捕捉的log位置,检查点的存在可以使捕捉进程在中止并恢复后可从检查点位置继续複製; 目标系统接受资料变化并缓存到GoldenGate TDM伫列当中,伫列爲一系列临时存储资料变化的文件,等待投递进程读取资料; GoldenGate TDM投递进程从伫列中读取资料变化并创建对应的SQL语句,通过资料库的本地介面执行,提交到资料库成功后更新自己的检查点,记录已经完成複製的位置,资料的複製过程最终完成。 由此可见,GoldenGate TDM是一种基于软体的资料複製方式,它从资料库的日志解析资料的变化(资料量只有日志的四分之一左右)。GoldenGate TDM将资料变化转化爲自己的格式,直接通过TCP/IP网路传输,无需依赖于资料库自身的传递方式,而且可以通过高达9:1的压缩率对资料进行压缩,可以大大降低带宽需求。在目标端,GoldenGate TDM可以通过
teradataSQL学习笔记
13.15.23.24.25.26.28.29 什么时候要在表名前加数据库的名字,为什么要加 不加的时候当前默认数据库为什么是DWMART_BWCM A:这是可以设置的。 FORMAT不好用 A:这是可以设置的。 TITLE vs AS A:能用哪个用哪个。 单引号 vs 双引号 A:都用单引号,保险。 P118.数据存储属性。包括下面各项: 1000字节;经过compress之后,可能就变成2字节,或者远远比原来所占存储空间更小的内存。 但是!compress的过程是消耗系统资源的,也就是会对执行效率有一定的影响。所以是否使用compress就是效率和空间的一个权衡过程。
-Ch 10 内连接- ?INNER JOIN。。。ON 后面的条件应该用主键连接,为避免连接结果中数据重复。 eg. sel b.DIVIDEID,b.REPASSETTYPEID_ON,b.REPASSETTYPEID_ON_DESC ,co unt(*) from dwmart_bwcm.N_exposures a inner join dwmart_rwa.fc_check_exposure_divide_315b on a.ACCOUNTREFCD=b.ACCOUNTREFCD where a.timeid=20130630 and a.SOURCEID=9 and a.ASSETTYPEID=20 and a.ACCOUNTING_SUBJECT in ('3125','3126') and b.timeid=20130630 and b.DIVIDEID=9 group by1,2,3 order by1,2,3; sel ab.DIVIDEID,ab.REPASSETTYPEID_ON,ab.REPASSETTYPEID_ON_DESC ,count(*) from dwmart_rwa.fc_check_exposure_divide_315ab where timeid=20130630 and ab.ACCOUNTREFCD in (sel A. ACCOUNTREFCD from dwmart_bwcm.N_exposures a where a.timeid=20130630 and a.SOURCEID=9 and a.ASSETTYPEID=20 and a.ACCOUNTING_SUBJECT in ('3125','3126') group by1) and ab.DIVIDEID=9 group by1,2,3 order by1,2,3; 解释:两个查询结果的COUNT(*)不一样,因为第一个语句块中的内连接字段ACCOUNTREFCD不是表的主键,该字段内存在重复数据,所以内连接的结果有重复数据,导致计数结果不一致。 ?SELF JOIN 什么时候要用自连接? 【一般能看到的例子就是以下两种】