插值算法与matlab代码

Matlab中插值函数汇总和使用说明
MATLAB中的插值函数为interp1,其调用格式为: yi= interp1(x,y,xi,'method')
其中x,y为插值点,yi为在被插值点xi处的插值结果;x,y为向量,'method'表示采用的插值方法,MA TLAB提供的插值方法有几种:'method'是最邻近插值,'linear'线性插值;'spline'三次样条插值;'cubic'立方插值.缺省时表示线性插值
注意:所有的插值方法都要求x是单调的,并且xi不能够超过x的范围。
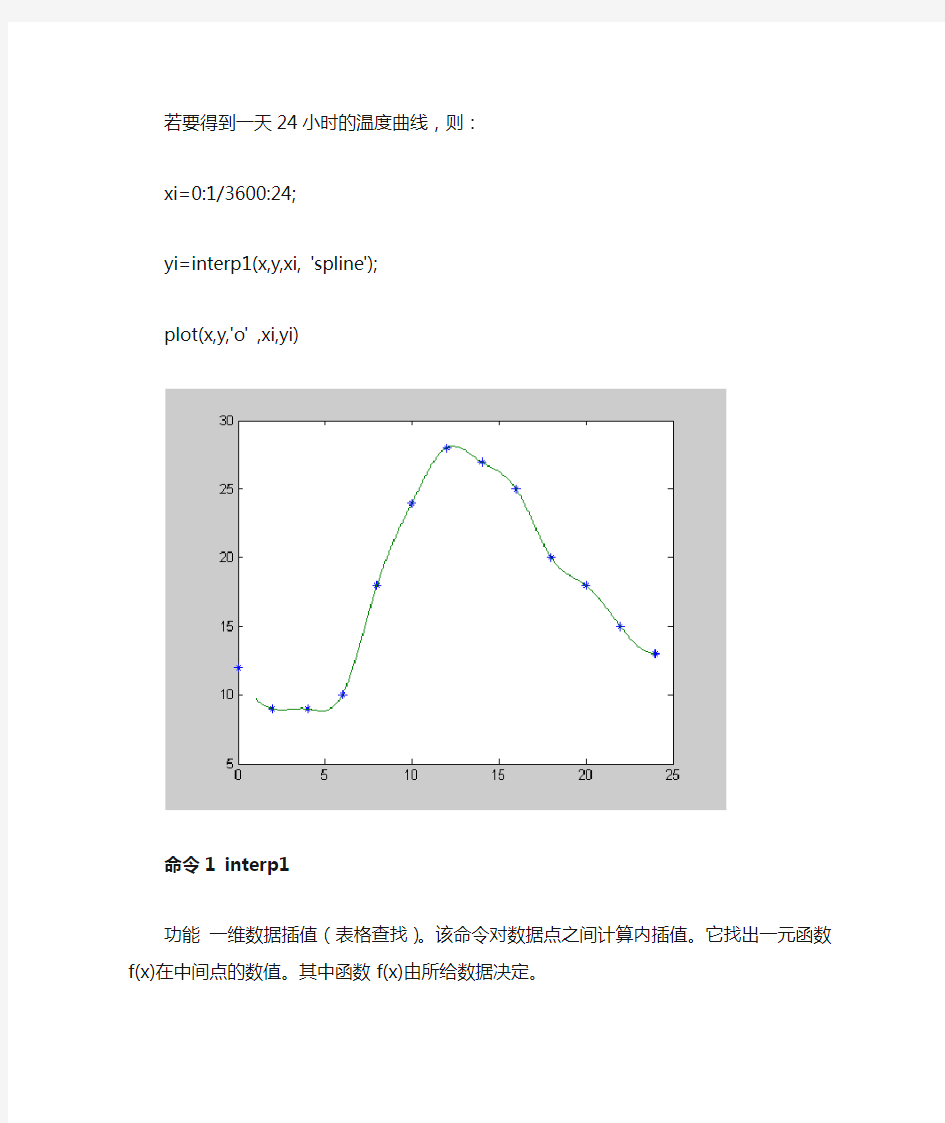
例如:在一天24小时内,从零点开始每间隔2小时测得的环境温度数据分别为12,9,9,10,18 ,24,28,27,25,20,18,15,13,
推测中午12点(即13点)时的温度.
x=0:2:24;
y=[12 9 9 10 18 24 28 27 25 20 18 15 13];
a=13;
y1=interp1(x,y,a,'spline')
结果为:27.8725
若要得到一天24小时的温度曲线,则:
xi=0:1/3600:24;
yi=interp1(x,y,xi, 'spline');
plot(x,y,'o' ,xi,yi)
命令1 interp1
功能一维数据插值(表格查找)。该命令对数据点之间计算内插值。它找出一元函数f(x)在中间点的数值。其中函数f(x)由所给数据决定。
x:原始数据点
Y:原始数据点
xi:插值点
Yi:插值点
格式
(1)yi = interp1(x,Y,xi)
返回插值向量yi,每一元素对应于参量xi,同时由向量x 与Y 的内插值决定。参量x 指定数据Y 的点。
若Y 为一矩阵,则按Y 的每列计算。yi 是阶数为length(xi)*size(Y,2)的输出矩阵。
(2)yi = interp1(Y,xi)
假定x=1:N,其中N 为向量Y 的长度,或者为矩阵Y 的行数。
(3)yi = interp1(x,Y,xi,method)
用指定的算法计算插值:
’nearest’:最近邻点插值,直接完成计算;
’linear’:线性插值(缺省方式),直接完成计算;
’spline’:三次样条函数插值。对于该方法,命令interp1 调用函数spline、ppval、mkpp、umkpp。这些命令生成一系列用于分段多项式操作的函数。命令spline 用它们执行三次样条函数插值;
’pchip’:分段三次Hermite 插值。对于该方法,命令interp1 调用函数pchip,用于对向量x 与y 执行分段三次内插值。该方法保留单调性与数据的外形;
’cubic’:与’pchip’操作相同;
’v5cubic’:在MATLAB 5.0 中的三次插值。
对于超出x 范围的xi 的分量,使用方法’nearest’、’linear’、’v5cubic’的插值算法,相应地将返回NaN。对其他的方法,interp1 将对超出的分量执行外插值算法。
(4)yi = interp1(x,Y,xi,method,'extrap')
对于超出x 范围的xi 中的分量将执行特殊的外插值法extrap。
(5)yi = interp1(x,Y,xi,method,extrapval)
确定超出x 范围的xi 中的分量的外插值extrapval,其值通常取NaN 或0。
例1
1.
2.>>x = 0:10; y = x.*sin(x);
3.>>xx = 0:.25:10; yy = interp1(x,y,xx);
4.>>plot(x,y,'kd',xx,yy)
复制代码
例2
1.
2.>> year = 1900:10:2010;
3.>> product = [75.995 91.972 105.711 123.203 131.669 150.697 179.323 203.212 226.505
4.249.633 256.344 267.893 ];
5.>>p1995 = interp1(year,product,1995)
6.>>x = 1900:1:2010;
7.>>y = interp1(year,product,x,'pchip');
8.>>plot(year,product,'o',x,y)
复制代码
插值结果为:
1.
2.p1995 =
3.252.9885
复制代码
命令2 interp2
功能二维数据内插值(表格查找)
格式
(1)ZI = interp2(X,Y,Z,XI,YI)
返回矩阵ZI,其元素包含对应于参量XI 与YI(可以是向量、或同型矩阵)的元素,即Zi(i,j) ←[Xi(i,j),yi(i,j)]。用户可以输入行向量和列向量Xi 与Yi,此时,输出向量Zi 与矩阵meshgrid(xi,yi)是同型的。同时取决于由输入矩阵X、Y 与Z 确定的二维函数Z=f(X,Y)。参量X 与Y 必须是单调的,且相同的划分格式,就像由命令meshgrid 生成的一样。若Xi 与Yi 中有在X 与Y范围之外的点,则相应地返回nan(Not a Number)。
(2)ZI = interp2(Z,XI,YI)
缺省地,X=1:n、Y=1:m,其中[m,n]=size(Z)。再按第一种情形进行计算。
(3)ZI = interp2(Z,n)
作n 次递归计算,在Z 的每两个元素之间插入它们的二维插值,这样,Z 的阶数将不断增加。interp2(Z)等价于interp2(z,1)。
(4)ZI = interp2(X,Y,Z,XI,YI,method)
用指定的算法method 计算二维插值:
’linear’:双线性插值算法(缺省算法);
’nearest’:最临近插值;
’spline’:三次样条插值;
’cubic’:双三次插值。
例3:
1.
2.>>[X,Y] = meshgrid(-3:.25:3);
3.>>Z = peaks(X,Y);
4.>>[XI,YI] = meshgrid(-3:.125:3);
5.>>ZZ = interp2(X,Y,Z,XI,YI);
6.>>surfl(X,Y,Z);hold on;
7.>>surfl(XI,YI,ZZ+15)
8.>>axis([-3 3 -3 3 -5 20]);shading flat
9.>>hold off
复制代码
例4:
1.
2.>>years = 1950:10:1990;
3.>>service = 10:10:30;
4.>>wage = [150.697 199.592 187.625
5.179.323 195.072 250.287
6.203.212 179.092 322.767
7.226.505 153.706 426.730
8.249.633 120.281 598.243];
9.>>w = interp2(service,years,wage,15,1975)
复制代码
插值结果为:
1.
2.w =
3.190.6288
复制代码
命令3 interp3
功能三维数据插值(查表)
格式
(1)VI = interp3(X,Y,Z,V,XI,YI,ZI)
找出由参量X,Y,Z决定的三元函数V=V(X,Y,Z)在点(XI,YI,ZI)的值。参量XI,YI,ZI 是同型阵列或向量。若向量参量XI,YI,ZI 是不同长度,不同方向(行或列)的向量,这时输出参量VI 与Y1,Y2,Y3 为同型矩阵。其中Y1,Y2,Y3 为用命令meshgrid(XI,YI,ZI)生成的同型阵列。若插值点(XI,YI,ZI)中有位于点(X,Y,Z)之外的点,则相应地返回特殊变量值NaN。(2)VI = interp3(V,XI,YI,ZI)
缺省地,X=1:N ,Y=1:M,Z=1:P ,其中,[M,N,P]=size(V),再按上面的情形计算。
(3)VI = interp3(V,n)
作n 次递归计算,在V 的每两个元素之间插入它们的三维插值。这样,V 的阶数将不断增加。interp3(V)等价于interp3(V,1)。
(4)VI = interp3(......,method) %用指定的算法method 作插值计算:
‘linear’:线性插值(缺省算法);
‘cubic’:三次插值;
‘spline’:三次样条插值;
‘nearest’:最邻近插值。
说明在所有的算法中,都要求X,Y,Z 是单调且有相同的格点形式。当X,Y,Z 是等距且单调时,用算法’*linear’,’*cubic’,’*nearest’,可得到快速插值。
例5
1.
2.>>[x,y,z,v] = flow(20);
3.>>[xx,yy,zz] = meshgrid(.1:.25:10, -3:.25:3, -3:.25:3);
4.>>vv = interp3(x,y,z,v,xx,yy,zz);
5.>>slice(xx,yy,zz,vv,[6 9.5],[1 2],[-2 .2]); shading interp;colormap cool
复制代码
命令4 interpft
功能用快速Fourier 算法作一维插值
格式
(1)y = interpft(x,n)
返回包含周期函数x 在重采样的n 个等距的点的插值y。若length(x)=m,且x 有采样间隔dx,则新的y 的采样间隔dy=dx*m/n。注意的是必须n≥m。若x 为一矩阵,则按x 的列进行计算。返回的矩阵y 有与x 相同的列数,但有n 行。
(2)y = interpft(x,n,dim)
沿着指定的方向dim 进行计算
命令5 griddata
功能数据格点
格式
(1)ZI = griddata(x,y,z,XI,YI)
用二元函数z=f(x,y)的曲面拟合有不规则的数据向量x,y,z。griddata 将返回曲面z 在点(XI,YI)处的插值。曲面总是经过这些数据点(x,y,z)的。输入参量(XI,YI)通常是规则的格点(像用命令meshgrid 生成的一样)。XI 可以是一行向量,这时XI 指定一有常数列向量的矩阵。类似地,YI 可以是一列向量,它指定一有常数行向量的矩阵。
(2)[XI,YI,ZI] = griddata(x,y,z,xi,yi)
返回的矩阵ZI 含义同上,同时,返回的矩阵XI,YI 是由行向量xi 与列向量yi 用命令meshgrid 生成的。
(3)[XI,YI,ZI] = griddata(.......,method)
用指定的算法method 计算:
‘linear’:基于三角形的线性插值(缺省算法);
‘cubic’:基于三角形的三次插值;
‘nearest’:最邻近插值法;
‘v4’:MATLAB 4 中的griddata 算法。
命令6 spline
功能三次样条数据插值
格式
(1)yy = spline(x,y,xx)
对于给定的离散的测量数据x,y(称为断点),要寻找一个三项多项式y = p(x) ,以逼近每对数据(x,y)点间的曲线。过两点(xi, yi) 和(xi+1, yi+1) 只能确定一条直线,而通过一点的三次多项式曲线有无穷多条。为使通过中间断点的三次多项式曲线具有唯一性,要增加两个条件(因为三次多项式有4 个系数):
a.三次多项式在点(xi, yi) 处有:p¢i(xi) = p¢i(xi) ;
b.三次多项式在点(xi+1, yi+1) 处有:p¢i(xi+1) = pi¢(xi+1) ;
c.p(x)在点(xi, yi) 处的斜率是连续的(为了使三次多项式具有良好的解析性,加上的条件);d.p(x)在点(xi, yi) 处的曲率是连续的;
对于第一个和最后一个多项式,人为地规定如下条件:
①.p¢1¢(x) = p¢2¢(x)
②.p¢n¢(x) = p¢n¢-1(x)
上述两个条件称为非结点(not-a-knot)条件。综合上述内容,可知对数据拟合的三次样条函数p(x)是一个分段的三次多项式:
ï ïî
ï ïí
ì
£ £
£ £
£ £
=
n n n+1
2 2 3
1 1 2
p (x) x x x
p (x) x x x
p (x) x x x
p(x)
L L L L
其中每段pi(x) 都是三次多项式。
该命令用三次样条插值计算出由向量x 与y 确定的一元函数y=f(x)在点xx 处的值。若参量y 是一矩阵,则以y 的每一列和x 配对,再分别计算由它们确定的函数在点xx 处的值。则yy 是一阶数为length(xx)*size(y,2)的矩阵。
(2)pp = spline(x,y)
返回由向量x 与y 确定的分段样条多项式的系数矩阵pp,它可用于命令ppval、unmkpp 的计算。
例6
对离散地分布在y=exp(x)sin(x)函数曲线上的数据点进行样条插值计算:
1.
2.>>x = [0 2 4 5 8 12 12.8 17.2 19.9 20]; y = exp(x).*sin(x);
3.>>xx = 0:.25:20;
4.>>yy = spline(x,y,xx);
5.>>plot(x,y,'o',xx,yy)
复制代码
命令7 interpn
功能n 维数据插值(查表)
格式
(1)VI = interpn(X1,X2,,,Xn,V,Y1,Y2,?,Yn) %返回由参量X1,X2,…,Xn,V 确定的n 元函数V=V(X1,X2,…,Xn)在点(Y1,Y2,…,Yn)处的插值。参量Y1,Y2,…,Yn 是同型的矩阵或向量。若Y1,Y2,…,Yn 是向量,则可以
是不同长度,不同方向(行或列)的向量。它们将通过命令ndgrid生成同型的矩阵,再作计算。若点(Y1,Y2,…,Yn) 中有位于点(X1,X2,…,Xn)之外的点,则相应地返回特殊变量NaN。
VI = interpn(V,Y1,Y2,?,Yn) %缺省地,X1=1:size(V,1),X2=1:size(V,2),… ,
Xn=1:size(V,n),再按上面的情形计算。
VI = interpn(V,ntimes) %作ntimes 次递归计算,在V 的每两个元素之间插入它们的n 维插值。这样,V 的阶数将不断增加。interpn(V)
等价于interpn(V, 1)。
VI = interpn(?,method) %用指定的算法method 计算:
‘linear’:线性插值(缺省算法);
‘cubic’:三次插值;
‘spline’:三次样条插值法;
‘nearest’:最邻近插值算法。
命令8 meshgrid
功能生成用于画三维图形的矩阵数据。
格式[X,Y] = meshgrid(x,y) 将由向量x,y(可以是不同方向的)指定的区域[min(x),max(x) ,min(y) ,max(y)] 用直线x=x(i),y=y(j) (i=1,2,…,length(x) ,j=1,2,…,length(y))进行划分。这样,得到了length(x)*length(y)个点,
这些点的横坐标用矩阵X 表示,X 的每个行向量与向量x 相同;这些点的纵坐标用矩阵Y 表示,Y 的每个列向量与向量y 相同。其中X,Y可用于计算二元函数z=f(x,y)与三维图形中xy 平面矩形定义域的划分或
曲面作图。
[X,Y] = meshgrid(x) %等价于[X,Y]=meshgrid(x,x)。
[X,Y,Z] = meshgrid(x,y,z) %生成三维阵列X,Y,Z,用于计算三元函数v=f(x,y,z)或三维容积图。
例7
1.[X,Y] = meshgrid(1:3,10:14)
复制代码
计算结果为:
1.X =
2. 1 2 3
3. 1 2 3
4. 1 2 3
5. 1 2 3
6. 1 2 3
7.Y =
8.10 10 10
9.11 11 11
10.12 12 12
11.13 13 13
12.14 14 14
复制代码
命令9 ndgrid功能生成用于多维函数计算或多维插值用的阵列
格式[X1,X2,…,Xn] = ndgrid(x1,x2,…,xn) %把通过向量x1,x2,x3…,xn 指定的区域转换为数组x1,x2,x3,…,xn 。这样,得到了length(x1)*length(x2)*…*length(xn)个点,这些点的第一维坐标用矩阵X1 表
示,X1 的每个第一维向量与向量x1 相同;这些点的第二维坐标用矩阵X2 表示,X2 的每个第二维向量与向量x2 相同;如此等等。
其中X1,X2,...,Xn 可用于计算多元函数y=f(x1,x2,...,xn)以及多维插值命令用到的阵列。[X1,X2,...,Xn] = ndgrid(x) %等价于[X1,X2,...,Xn] = ndgrid(x,x, (x)
命令10 table1
功能一维查表
格式Y = table1(TAB,X0) %返回用表格矩阵TAB 中的行线性插值元素,对X0(TAB的第一列查找X0)进行线性插值得到的结果Y。矩阵TAB 是第一列包含
关键值,而其他列包含数据的矩阵。X0 中的每一元素将相应地返回一线性插值行向量。矩阵TAB 的第一列必须是单调的。
例8
1.
2.>>tab = [(1:4)' hilb(4)]
3.>>y = table1(tab,[1 2.3 3.6 4]) 复制代码
查表结果为:
1.
2.>>tab = [(1:4)' hilb(4)]
3.>>y = table1(tab,[1 2.3 3.6 4])
数据插值和函数逼近 MATLAB实现
数据插值和函数逼近 1 数据插值 由已知样本点,以数据更为平滑为目标,求出其他点处的函数 值。在信号处理与图像处理上应用广泛。 求解方法: y1=interp1(x,y,x1,'方法') z1=interp2(x,y,z,x1,y1,'方法') 1.1 一维数据的插值 例:假设样本点来自x e x x x f x sin )53()(52-+-=,进行插值处理,得到平 例:草图样条曲线功能。 function sketch() x=[]; y=[]; gca; hold on; axis([0 1,0 1]); while 1 [x0,y0,button]=ginput(1);
if(isempty(button)) break; end; x=[x x0]; y=[y y0]; plot(x,y,'*'); end; xx=[x(1):(x(end)-x(1))/100:x(end)]; yy=interp1(x,y,xx,'spline'); plot(xx,yy,x,y,'*'); end 1.2 二维网格数据的插值 例3:假设样本点来自xy y x e x x z ----=2 2)2(2,进行插值处理,得到平滑的曲
1.3 二维一般分布数据的插值 例4:假设样本点来自xy y x e x x z ----=22)2(2,进行插值处理,得到平滑的曲 2 样条插值函数逼近 由已知样本点,求能对其较好拟合的函数表达式。 求解方法: S=csapi(x,y); % 定义一个三次样条函数类 S=spapi(k,x,y); % 定义一个k 次B 样条函数类 ys=fnval(S,xs); % 计算插值结果 fnplt(S); % 绘制插值结果 例:从)sin(x y =中取样本点,计算三次样条函数。
matlab插值法实例
Several Typical Interpolation in Matlab Lagrange Interpolation Supposing: If x=175, while y=? Solution: Lagrange Interpolation in Matlab: function y=lagrange(x0,y0,x); n=length(x0);m=length(x); for i=1:m z=x(i); s=0.0; for k=1:n p=1.0; for j=1:n if j~=k p=p*(z-x0(j))/(x0(k)-x0(j)); end end s=p*y0(k)+s; end y(i)=s; end input: x0=[144 169 225] y0=[12 13 15] y=lagrange(x0,y0,175) obtain the answer: x0 = 144 169 225 y0 = 12 13 15 y = 13.2302
Spline Interpolation Solution : Input x=[ 1 4 9 6];y=[ 1 4 9 6];x=[ 1 4 9 6];pp=spline(x,y) pp = form: 'pp' breaks: [1 4 6 9] coefs: [3x4 double] pieces: 3 order: 4 dim: 1 output : pp.coefs ans = -0.0500 0.5333 -0.8167 1.0000 -0.0500 0.0833 1.0333 2.0000 -0.0500 -0.2167 0.7667 4.0000 It shows the coefficients of cubic spline polynomial , so: S (x )=, 169,3)9(1484.0)9(0063.0)9(0008.0,94,2)4(2714.0)4(0183.0)4(0008 .0, 41,1)1(4024.0)1(0254.0)1(0008.0232 3 23≥≤+-+---≥≤+-+---≥≤+-+---x x x x x x x x x x x x Newton’s Interpolation Resolve 65 Solution: Newton’s Interpolation in matlab : function yi=newint(x,y,xi); n=length(x); ny=length(y); if n~=ny error end Y=zeros(n);Y(:,1)=y';
三次样条插值---matlab实现
计算方法实验—三次样条插值 机电学院075094-19 苏建加 20091002764 题目:求压紧三次样条曲线,经过点(-3,2),(-2,0),(1,3),(4,1),而且一阶导 数边界条件S'(-3)=-1;S'(4)=1。 解:首先计算下面的值: 记 1--=j j j x x h ; 1++=j j j j h h h u ;1=+j j u λ ; ?? ????????---+=-++++-j j j j j j j j j j j h y y h y y h h x x x f 1111 111],,[ ;M j =)(''j x s ;],,[611+-=j j j j x x x f d ; h1=-2-(-3)=1;h2=1-(-2)=3;h3=4-1=3; u1=1/4;u2=3/6; d1=6/4*(3/3-(-2)/1)=4.5;d2=6/6*(-2/3-3/3)=-5/3; 由于边界条件S'(-3)=-1;S'(4)=1,得到如下 式子: d0=6/1*(-2/1-(-1))=-6; d3=6/3*(1-(-2)/3)=10/3; 所以得到4个含参数m0~m3 的线性代数方程组为: 2.0000 1.0000 0 0 m0 0.2500 2.0000 0.7500 0 m1 0 0.5000 2.0000 0.5000 m2 0 0 1.0000 2.0000 m3 利用matlab 求解方程得: m = -4.9032 3.8065 -2.5161 2.9247 所以 S1(x)=-0.8172*(-2-x)^3+ 0.6344*(x+3)^3+2.8172*(-2-x)-0.6344*(x+3) x ∈[-3,-2] S2(x)=0.2115*(1-x)^3 -0.1398*(x+2)^3- 1.9032*(1-x)+ 2.2581*(x+2) x ∈[-2,1] S3(x)=-0.1398*(4-x)^3+0.1625(x-1)^3+ 2.2581*(4-x)-1.1290*(x-1) x ∈[1,4] 化简后得:S1(x)=1.4516*x^3 + 10.6128*x^2 + 23.4836*x + 16.1288 x ∈[-3,-2] S2(x)=-0.3513x^3-0.2043x^2+1.8492x+1.7061 x ∈[-2,1] S3(x)=0.3023x^3-2.1651x^2+3.8108x+1.0517 x ∈[1,4] 画图验证:
聚类分析Matlab程序实现
2. Matlab程序 2.1 一次聚类法 X=[11978 12.5 93.5 31908;…;57500 67.6 238.0 15900]; T=clusterdata(X,0.9) 2.2 分步聚类 Step1 寻找变量之间的相似性 用pdist函数计算相似矩阵,有多种方法可以计算距离,进行计算之前最好先将数据用zscore 函数进行标准化。 X2=zscore(X); %标准化数据 Y2=pdist(X2); %计算距离 Step2 定义变量之间的连接 Z2=linkage(Y2); Step3 评价聚类信息 C2=cophenet(Z2,Y2); //0.94698 Step4 创建聚类,并作出谱系图 T=cluster(Z2,6); H=dendrogram(Z2); Matlab提供了两种方法进行聚类分析。 一种是利用 clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法; 另一种是分步聚类:(1)找到数据集合中变量两两之间的相似性和非相似性,用pdist函数计算变量之间的距离;(2)用 linkage函数定义变量之间的连接;(3)用 cophenetic函数评价聚类信息;(4)用cluster函数创建聚类。 1.Matlab中相关函数介绍 1.1 pdist函数 调用格式:Y=pdist(X,’metric’) 说明:用‘metric’指定的方法计算 X 数据矩阵中对象之间的距离。’ X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n。 metric’取值如下: ‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离; ‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离; ‘minkowski’:明可夫斯基距离;‘cosine’: ‘correlation’:‘hamming’: ‘jaccard’:‘chebychev’:Chebychev距离。 1.2 squareform函数 调用格式:Z=squareform(Y,..) 说明:强制将距离矩阵从上三角形式转化为方阵形式,或从方阵形式转化为上三角形式。 1.3 linkage函数 调用格式:Z=linkage(Y,’method’) 说明:用‘method’参数指定的算法计算系统聚类树。 Y:pdist函数返回的距离向量;
MATLAB数值实验一(数据的插值运算及其应用完整版)
佛山科学技术学院 实 验 报 告 课程名称 数值分析 实验项目 插值法与数据拟合 专业班级 机械工程 姓 名 余红杰 学 号 10 指导教师 陈剑 成 绩 日 期 月 日 一、实验目的 1、学会Lagrange 插值、牛顿插值和三次样条插值等基本插值方法; 2、讨论插值的Runge 现象 3、学会Matlab 提供的插值函数的使用方法,会用这些函数解决实际问题。 二、实验原理 1、拉格朗日插值多项式 2、牛顿插值多项式 3、三次样条插值 三、实验步骤 1、用MATLAB 编写独立的拉格朗日插值多项式函数 2、用MATLAB 编写独立的牛顿插值多项式函数 3、用MATLAB 编写独立的三次样条函数(边界条件为第一、二种情形) 4、已知函数在下列各点的值为: 根据步骤1,2,3编好的程序,试分别用4次拉格朗日多项式4()L x 、牛顿插值多项式4()P x 以及三次样条函数()S x (自然边界条件)对数据进行插值,并用图给出 {(,),0.20.08,0,1,2, ,10i i i x y x i i =+=},4()L x 、4()P x 和()S x 。 5、在区间[-1,1]上分别取10,20n =用两组等距节点对龙格函数 2 1 (),(11)125f x x x = -≤≤+作多项式插值,对不同n 值,分别画出插值函数及()f x 的图形。 6、下列数据点的插值
可以得到平方根函数的近似,在区间[0,64]上作图。 (1)用这9个点作8次多项式插值8()L x 。 (2)用三次样条(第一边界条件)程序求()S x 。 7、对于给函数2 1 ()125f x x = +在区间[-1,1]上取10.2(0,1, ,10)i x i i =-+=,试求3次 曲线拟合,试画出拟合曲线并打印出方程,与第5题的结果比较。 四、实验过程与结果: 1、Lagrange 插值多项式源代码: function ya=lag(x,y,xa) %x 所有已知插值点 %y 插值点对应函数值 %xa 所求点,自变量 %ya 所求点插值估计量 ya=0; mu=1; %初始化 %循环方式求L 系数,并求和: for i = 1:length(y) for j = 1:length(x) if i ~= j mu = mu * (xa - x(j) ) / ( x(i) - x(j) ); else continue end end ya = ya + y(i) * mu ; mu = 1; end 2、Newton 源代码: function ya = newton(x,y,xa) %x 所有已知插值点 %y 插值点对应函数值 %xa 所求点,自变量 %ya 所求点插值估计量 %建立系数零矩阵D 及初始化:
Matlab中插值函数汇总和使用说明
MATLAB中的插值函数 命令1:interp1 功能:一维数据插值(表格查找)。该命令对数据点之间计算内插值。它找出一元函数f(x)在中间点的数值。其中函数f(x)由所给数据决定。 x:原始数据点 Y:原始数据点 xi:插值点 Yi:插值点 格式 (1) yi = interp1(x,Y,xi) 返回插值向量yi,每一元素对应于参量xi,同时由向量x 与Y 的内插值决定。参量x 指定数据Y 的点。若Y 为一矩阵,则按Y 的每列计算。yi 是阶数为length(xi)*size(Y,2)的输出矩阵。 (2) yi = interp1(Y,xi) 假定x=1:N,其中N 为向量Y 的长度,或者为矩阵Y 的行数。 (3) yi = interp1(x,Y,xi,method) 用指定的算法计算插值: ’nearest’:最近邻点插值,直接完成计算; ’linear’:线性插值(缺省方式),直接完成计算; ’spline’:三次样条函数插值。对于该方法,命令interp1 调用函数spline、ppval、mkpp、umkpp。这些命令生成一系列用于分段多项式操作的函数。命令spline 用它们执行三次样条函数插值; ’pchip’:分段三次Hermite 插值。对于该方法,命令interp1 调用函数pchip,用于对向量x 与y 执行分段三次内插值。该方法保留单调性与数据的外形; ’cubic’:与’pchip’操作相同; ’v5cubic’:在MATLAB 5.0 中的三次插值。 对于超出x 范围的xi 的分量,使用方法’nearest’、’linear’、’v5cubic’的插值算法,相应地将返回NaN。对其他的方法,interp1 将对超出的分量执行外插值算法。 (4)yi = interp1(x,Y,xi,method,'extrap') 对于超出x 范围的xi 中的分量将执行特殊的外插值法extrap。 (5)yi = interp1(x,Y,xi,method,extrapval) 确定超出x 范围的xi 中的分量的外插值extrapval,其值通常取NaN 或0。
MATLAB三次样条插值之三弯矩法
MATLAB三次样条插值之三弯矩法 首先说这个程序并不完善,为了实现通用(1,2,…,n)格式解题,以及为调用追赶法程序,没有针对节点数在三个以下的情况进行分类讨论。希望能有朋友给出更好的方法。 首先,通过函数 sanwanj得到方程的系数矩阵,即追赶法方程的四个向量参数,接下来调用 追赶法(在intersanwj函数中),得到三次样条分段函数系数因子,然后进行多项式合并得 到分段函数的解析式,程序最后部分通过判断输入值的区间自动选择对应的分段函数并计算改 点的值。附:追赶法程序 chase %%%%%%%%%%%%%% function [newv,w,newu,newd]=sanwj(x,y,x0,y0,y1a,y1b) % 三弯矩样条插值 % 将插值点分两次输入,x0 y0 单独输入 % 边值条件a的二阶导数 y1a 和b的二阶导数 y1b,这里建议将y1a和y1b换成y2a和 y2b,以便于和三转角代码相区别 n=length(x);m=length(y); if m~=n error('x or y 输入有误,再来'); end v=ones(n-1,1);u=ones(n-1,1);d=zeros(n-1,1); w=2*ones(n+1); h0=x(1)-x0; h=zeros(n-1,1); for k=1:n-1 h(k)=x(k+1)-x(k); end v(1)=h0/(h0+h(1)); u(1)=1-v(1); d(1)=6*((y(2)-y(1))/h(1)-(y(1)-y0)/h0)/(h0+h(1)); % for k=2:n-1 v(k)=h(k-1)/(h(k-1)+h(k)); u(k)=1-v(k); d(k)=6*((y(k+1)-y(k))/h(k)-(y(k)-y(k-1))/h(k-1))/(h(k-1)+h(k)); end newv=[v;1]; newu=[1;u]; d0=6*((y(1)-y0)/h0-y1a)/h0;
MATLAB实现FCM 聚类算法
本文在阐述聚类分析方法的基础上重点研究FCM 聚类算法。FCM 算法是一种基于划分的聚类算法,它的思想是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。最后基于MATLAB实现了对图像信息的聚类。 第 1 章概述 聚类分析是数据挖掘的一项重要功能,而聚类算法是目前研究的核心,聚类分析就是使用聚类算法来发现有意义的聚类,即“物以类聚” 。虽然聚类也可起到分类的作用,但和大多数分类或预测不同。大多数分类方法都是演绎的,即人们事先确定某种事物分类的准则或各类别的标准,分类的过程就是比较分类的要素与各类别标准,然后将各要素划归于各类别中。确定事物的分类准则或各类别的标准或多或少带有主观色彩。 为获得基于划分聚类分析的全局最优结果,则需要穷举所有可能的对象划分,为此大多数应用采用的常用启发方法包括:k-均值算法,算法中的每一个聚类均用相应聚类中对象的均值来表示;k-medoid 算法,算法中的每一个聚类均用相应聚类中离聚类中心最近的对象来表示。这些启发聚类方法在分析中小规模数据集以发现圆形或球状聚类时工作得很好,但当分析处理大规模数据集或复杂数据类型时效果较差,需要对其进行扩展。 而模糊C均值(Fuzzy C-means, FCM)聚类方法,属于基于目标函数的模糊聚类算法的范畴。模糊C均值聚类方法是基于目标函数的模糊聚类算法理论中最为完善、应用最为广泛的一种算法。模糊c均值算法最早从硬聚类目标函数的优化中导出的。为了借助目标函数法求解聚类问题,人们利用均方逼近理论构造了带约束的非线性规划函数,以此来求解聚类问题,从此类内平方误差和WGSS(Within-Groups Sum of Squared Error)成为聚类目标函数的普遍形式。随着模糊划分概念的提出,Dunn [10] 首先将其推广到加权WGSS 函数,后来由Bezdek 扩展到加权WGSS 的无限族,形成了FCM 聚类算法的通用聚类准则。从此这类模糊聚类蓬勃发展起来,目前已经形成庞大的体系。 第 2 章聚类分析方法 2-1 聚类分析 聚类分析就是根据对象的相似性将其分群,聚类是一种无监督学习方法,它不需要先验的分类知识就能发现数据下的隐藏结构。它的目标是要对一个给定的数据集进行划分,这种划分应满足以下两个特性:①类内相似性:属于同一类的数据应尽可能相似。②类间相异性:属于不同类的数据应尽可能相异。图2.1是一个简单聚类分析的例子。
蚁群算法TSP问题matlab源代码
function [R_best,L_best,L_ave,Shortest_Route,Shortest_Length]=ACATSP(C,NC_max,m,Alpha,Beta ,Rho,Q) %%===================================================== ==================== %% ACATSP.m %% Ant Colony Algorithm for Traveling Salesman Problem %% ChengAihua,PLA Information Engineering University,ZhengZhou,China %% Email:aihuacheng@https://www.360docs.net/doc/3b18577468.html, %% All rights reserved %%------------------------------------------------------------------------- %% 主要符号说明 %% C n个城市的坐标,n×4的矩阵 %% NC_max 最大迭代次数 %% m 蚂蚁个数 %% Alpha 表征信息素重要程度的参数 %% Beta 表征启发式因子重要程度的参数 %% Rho 信息素蒸发系数 %% Q 信息素增加强度系数 %% R_best 各代最佳路线 %% L_best 各代最佳路线的长度 %%===================================================== ==================== %%第一步:变量初始化 n=size(C,1);%n表示问题的规模(城市个数) D=zeros(n,n);%D表示完全图的赋权邻接矩阵 for i=1:n for j=1:n if i~=j D(i,j)=max( ((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5,min(abs(C(i,3)-C(j,3)),144- abs(C(i,3)-C(j,3))) );%计算城市间距离 else D(i,j)=eps; end D(j,i)=D(i,j); end end Eta=1./D;%Eta为启发因子,这里设为距离的倒数 Tau=ones(n,n);%Tau为信息素矩阵 Tabu=zeros(m,n);%存储并记录路径的生成 NC=1;%迭代计数器 R_best=zeros(NC_max,n);%各代最佳路线
matlab实现数值分析插值及积分
Matlab实现数值分析插值及积分 摘要: 数值分析(numerical analysis)是研究分析用计算机求解数学计算问题的数值计算方法及其理论的学科,是数学的一个分支,它以数字计算机求解数学问题的理论和方法为研究对象。在实际生产实践中,常常将实际问题转化为数学模型来解决,这个过程就是数学建模。学习数值分析这门课程可以让我们学到很多的数学建模方法。 分别运用matlab数学软件编程来解决插值问题和数值积分问题。题目中的要计算差值和积分,对于问题一,可以分别利用朗格朗日插值公式,牛顿插值公式,埃特金逐次线性插值公式来进行编程求解,具体matlab代码见正文。编程求解出来的结果为:=+。 其中Aitken插值计算的结果图如下: 对于问题二,可以分别利用复化梯形公式,复化的辛卜生公式,复化的柯特斯公式编写程序来进行求解,具体matlab代码见正文。编程求解出来的结果为: 0.6932 其中复化梯形公式计算的结果图如下:
问题重述 问题一:已知列表函数 表格 1 分别用拉格朗日,牛顿,埃特金插值方法计算。 问题二:用复化的梯形公式,复化的辛卜生公式,复化的柯特斯公式计算积分,使精度小于5。 问题解决 问题一:插值方法 对于问题一,用三种差值方法:拉格朗日,牛顿,埃特金差值方法来解决。 一、拉格朗日插值法: 拉格朗日插值多项式如下: 首先构造1+n 个插值节点n x x x ,,,10 上的n 插值基函数,对任一点i x 所对应的插值基函数 )(x l i ,由于在所有),,1,1,,1,0(n i i j x j +-=取零值,因此)(x l i 有因子 )())(()(110n i i x x x x x x x x ----+- 。又因)(x l i 是一个次数不超过n 的多项式,所以只 可能相差一个常数因子,固)(x l i 可表示成: )())(()()(110n i i i x x x x x x x x A x l ----=+- 利用1)(=i i x l 得:
三次样条插值的Matlab实现(自然边界和第一边界条件)
(第一边界条件)源代码:function y=yt1(x0,y0,f_0,f_n,x)_____________(1) %第一类边界条件下三次样条插值; %xi所求点; %yi所求点函数值; %x已知插值点; %y已知插值点函数值; %f_0左端点一次导数值; %f_n右端点一次导数值; n = length(x0); z = length(y0); h = zeros(n-1,1); k=zeros(n-2,1); l=zeros(n-2,1); S=2*eye(n); fori=1:n-1 h(i)= x0(i+1)-x0(i); end fori=1:n-2 k(i)= h(i+1)/(h(i+1)+h(i)); l(i)= 1-k(i);
end %对于第一种边界条件: k = [1;k];_______________________(2) l = [l;1];_______________________(3) %构建系数矩阵S: fori = 1:n-1 S(i,i+1) = k(i); S(i+1,i) = l(i); end %建立均差表: F=zeros(n-1,2); fori = 1:n-1 F(i,1) = (y0(i+1)-y0(i))/(x0(i+1)-x0(i)); end D = zeros(n-2,1); fori = 1:n-2 F(i,2) = (F(i+1,1)-F(i,1))/(x0(i+2)-x0(i)); D(i,1) = 6 * F(i,2); end %构建函数D: d0 = 6*(F(1,2)-f_0)/h(1);___________(4)
matlab实现Kmeans聚类算法
题目:matlab实现Kmeans聚类算法 姓名吴隆煌 学号41158007
背景知识 1.简介: Kmeans算法是一种经典的聚类算法,在模式识别中得到了广泛的应用,基于Kmeans的变种算法也有很多,模糊Kmeans、分层Kmeans 等。 Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans 的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定标记样本调整类别中心向量。K均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 Kmeans在某种程度也可以看成Meanshitf的特殊版本,Meanshift 是一种概率密度梯度估计方法(优点:无需求解出具体的概率密度,直接求解概率密度梯度。),所以Meanshift可以用于寻找数据的多个模态(类别),利用的是梯度上升法。在06年的一篇CVPR文章上,证明了Meanshift方法是牛顿拉夫逊算法的变种。Kmeans 和EM算法相似是指混合密度的形式已知(参数形式已知)情况下,利用迭代方法,在参数空间中搜索解。而Kmeans和Meanshift相似是指都是一种概率密度梯度估计的方法,不过是Kmean选用的是特殊的核函数(uniform kernel),而与混合概率密度形式是否已知无关,是一种梯度求解方式。 k-means是一种聚类算法,这种算法是依赖于点的邻域来决定哪些
点应该分在一个组中。当一堆点都靠的比较近,那这堆点应该是分到同一组。使用k-means,可以找到每一组的中心点。 当然,聚类算法并不局限于2维的点,也可以对高维的空间(3维,4维,等等)的点进行聚类,任意高维的空间都可以。 上图中的彩色部分是一些二维空间点。上图中已经把这些点分组了,并使用了不同的颜色对各组进行了标记。这就是聚类算法要做的事情。 这个算法的输入是: 1:点的数据(这里并不一定指的是坐标,其实可以说是向量) 2:K,聚类中心的个数(即要把这一堆数据分成几组) 所以,在处理之前,你先要决定将要把这一堆数据分成几组,即聚成几类。但并不是在所有情况下,你都事先就能知道需要把数据聚成几类的。但这也并不意味着使用k-means就不能处理这种情况,下文中会有讲解。 把相应的输入数据,传入k-means算法后,当k-means算法运行完后,该算法的输出是: 1:标签(每一个点都有一个标签,因为最终任何一个点,总会被分到某个类,类的id号就是标签) 2:每个类的中心点。 标签,是表示某个点是被分到哪个类了。例如,在上图中,实际上
matlab插值(详细 全面)
Matlab中插值函数汇总和使用说明 MATLAB中的插值函数为interp1,其调用格式 为: yi= interp1(x,y,xi,'method') 其中x,y为插值点,yi为在被插值点xi处的插值结果;x,y为向量, 'method'表示采用的插值方法,MATLAB提供的插值方法有几种: 'method'是最邻近插值, 'linear'线性插值; 'spline'三次样条插值; 'cubic'立方插值.缺省时表示线性插值 注意:所有的插值方法都要求x是单调的,并且xi不能够超过x的范围。 例如:在一天24小时内,从零点开始每间隔2小时测得的环境温度数据分别为 12,9,9,10,18 ,24,28,27,25,20,18,15,13, 推测中午12点(即13点)时的温度. x=0:2:24; y=[12 9 9 10 18 24 28 27 25 20 18 15 13]; a=13; y1=interp1(x,y,a,'spline') 结果为: 27.8725 若要得到一天24小时的温度曲线,则: xi=0:1/3600:24; yi=interp1(x,y,xi, 'spline'); plot(x,y,'o' ,xi,yi)
命令1 interp1 功能一维数据插值(表格查找)。该命令对数据点之间计算内插值。它找出一元函数f(x)在中间点的数值。其中函数f(x)由所给数据决定。 x:原始数据点 Y:原始数据点 xi:插值点 Yi:插值点 格式 (1)yi = interp1(x,Y,xi) 返回插值向量yi,每一元素对应于参量xi,同时由向量x 与Y 的内插值决定。参量x 指定数据Y 的点。 若Y 为一矩阵,则按Y 的每列计算。yi是阶数为length(xi)*size(Y,2)的输出矩阵。(2)yi = interp1(Y,xi) 假定x=1:N,其中N 为向量Y 的长度,或者为矩阵Y 的行数。 (3)yi = interp1(x,Y,xi,method) 用指定的算法计算插值: ’nearest’:最近邻点插值,直接完成计算; ’linear’:线性插值(缺省方式),直接完成计算; ’spline’:三次样条函数插值。对于该方法,命令interp1 调用函数spline、ppval、mkpp、umkpp。这些命令生成一系列用于分段多项式操作的函数。命令spline 用它们执行三次样条函数插值; ’pchip’:分段三次Hermite 插值。对于该方法,命令interp1 调用函数pchip,用于对
三次样条插值的MATLAB实现
MATLAB 程序设计期中考查 在许多问题中,通常根据实验、观测或经验得到的函数表或离散点上的信息,去研究分析函数的有关特性。其中插值法是一种最基本的方法,以下给出最基本的插值问题——三次样条插值的基本提法: 对插值区间[]b a ,进行划分:b x x x a n ≤
最短距离聚类的matlab实现-1(含聚类图-含距离计算)
最短距离聚类的matlab实现-1 【2013-5-21更新】 说明:正文中命令部分可以直接在Matlab中运行, 作者(Yangfd09)于2013-5-21 19:15:50在MATLAB R2009a(7.8.0.347)中运行通过 %最短距离聚类(含距离计算,含聚类图) %说明:此程序的优点在于每一步都是自己编写的,很少用matlab现成的指令, %所以更适合于初学者,有助于理解各种标准化方法和距离计算方法。 %程序包含了极差标准化(两种方法)、中心化、标准差标准化、总和标准化和极大值标准化等标准化方法, %以及绝对值距离、欧氏距离、明科夫斯基距离和切比雪夫距离等距离计算方法。 %==========================>>导入数据<<============================== %变量名为test(新建一个以test变量,双击进入Variable Editor界面,将数据复制进去即可)%数据要求:m行n列,m为要素个数,n为区域个数(待聚类变量)。 % 具体参见末页测试数据。 testdata=test; %============================>>标准化<<=============================== %变量初始化,m用来寻找每行的最大值,n找最小值,s记录每行数据的和 [M,N]=size(testdata);m=zeros(1,M);n=9999*ones(1,M);s=zeros(1,M);eq=zeros(1,M); %为m、n和s赋值 for i=1:M for j=1:N if testdata(i,j)>=m(i) m(i)=testdata(i,j); end if testdata(i,j)<=n(i) n(i)=testdata(i,j); end s(i)=s(i)+testdata(i,j); end eq(i)=s(i)/N; end %sigma0是离差平方和,sigma是标准差 sigma0=zeros(M); for i=1:M for j=1:N sigma0(i)=sigma0(i)+(testdata(i,j)-eq(i))^2; end end sigma=sqrt(sigma0/N);
蚁群算法matlab程序代码
先新建一个主程序M文件ACATSP.m 代码如下: function [R_best,L_best,L_ave,Shortest_Route,Shortest_Length]=ACATSP(C,NC_max,m,Alpha,Beta,Rho,Q) %%================================================== ======================= %% 主要符号说明 %% C n个城市的坐标,n×2的矩阵 %% NC_max 蚁群算法MATLAB程序最大迭代次数 %% m 蚂蚁个数 %% Alpha 表征信息素重要程度的参数 %% Beta 表征启发式因子重要程度的参数 %% Rho 信息素蒸发系数 %% Q 表示蚁群算法MATLAB程序信息素增加强度系数 %% R_best 各代最佳路线 %% L_best 各代最佳路线的长度 %%================================================== =======================
%% 蚁群算法MATLAB程序第一步:变量初始化 n=size(C,1);%n表示问题的规模(城市个数) D=zeros(n,n);%D表示完全图的赋权邻接矩阵 for i=1:n for j=1:n if i~=j D(i,j)=((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5; else D(i,j)=eps; % i = j 时不计算,应该为0,但后面的启发因子要取倒数,用eps(浮点相对精度)表示 end D(j,i)=D(i,j); %对称矩阵 end end Eta=1./D; %Eta为启发因子,这里设为距离的倒数 Tau=ones(n,n); %Tau为信息素矩阵 Tabu=zeros(m,n); %存储并记录路径的生成
MATLAB三次样条插值之三转角法
非常类似前面的三弯矩法,这里的sanzhj函数和intersanzhj作用相当于前面的sanwanj和intersanwj,追赶法程序通用,代码如下。 %%%%%%%%%%%%%%%%%%% function [newu,w,newv,d]=sanzhj(x,y,x0,y0,y1a,y1b) % 三转角样条插值 % 将插值点分两次输入,x0 y0 单独输入 % 边值条件a的一阶导数 y1a 和b的一阶导数 y1b n=length(x);m=length(y); if m~=n error('x or y 输入有误,再来'); end v=ones(n-1,1); u=ones(n-1,1); d=zeros(n-1,1); w=2*ones(n-1,1); h0=x(1)-x0; h=zeros(n-1,1); for k=1:n-1 h(k)=x(k+1)-x(k); end v(1)=h0/(h0+h(1)); u(1)=1-v(1); d(1)=3*(v(1)*(y(2)-y(1))/h(1)+u(1)*((y(1)-y0))/h0); % for k=2:n-1 v(k)=h(k-1)/(h(k-1)+h(k)); u(k)=1-v(k); d(k)=3*(v(k)*(y(k+1)-y(k))/h(k)+u(k)*(y(k)-y(k-1))/h(k-1)); end d(1)=d(1)-u(1)*y1a; d(n-1)=d(n-1)-v(n-1)*y1b; newv=v(1:n-2,:); newu=u(2:n-1,:); %%%%%%%%%%%% function intersanzhj(x,y,x0,y0,y1a,y1b) % 三转角样条插值
数学实验05聚类分析---用matlab做聚类分析
用matlab做聚类分析 Matlab提供了两种方法进行聚类分析。 一种是利用clusterdata函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法; 另一种是分步聚类:(1)找到数据集合中变量两两之间的相似性和非相似性,用pdist函数计算变量之间的距离;(2)用linkage函数定义变量之间的连接;(3)用cophenetic函数评价聚类信息;(4)用cluster函数创建聚类。1.Matlab中相关函数介绍 1.1pdist函数 调用格式:Y=pdist(X,’metric’) 说明:用‘metric’指定的方法计算X数据矩阵中对象之间的距离。’X:一个m×n的矩阵,它是由m个对象组成的数据集,每个对象的大小为n。 metric’取值如下: ‘euclidean’:欧氏距离(默认);‘seuclidean’:标准化欧氏距离; ‘mahalanobis’:马氏距离;‘cityblock’:布洛克距离; ‘minkowski’:明可夫斯基距离;‘cosine’: ‘correlation’:‘hamming’: ‘jaccard’:‘chebychev’:Chebychev距离。 1.2squareform函数 调用格式:Z=squareform(Y,..)
说明:强制将距离矩阵从上三角形式转化为方阵形式,或从方阵形式转化为上三角形式。 1.3linkage函数 调用格式:Z=linkage(Y,’method’) 说明:用‘method’参数指定的算法计算系统聚类树。 Y:pdist函数返回的距离向量; method:可取值如下: ‘single’:最短距离法(默认);‘complete’:最长距离法; ‘average’:未加权平均距离法;‘weighted’:加权平均法; ‘centroid’:质心距离法;‘median’:加权质心距离法; ‘ward’:内平方距离法(最小方差算法) 返回:Z为一个包含聚类树信息的(m-1)×3的矩阵。 1.4dendrogram函数 调用格式:[H,T,…]=dendrogram(Z,p,…) 说明:生成只有顶部p个节点的冰柱图(谱系图)。 1.5cophenet函数 调用格式:c=cophenetic(Z,Y) 说明:利用pdist函数生成的Y和linkage函数生成的Z计算cophenet相关系数。 1.6cluster函数 调用格式:T=cluster(Z,…) 说明:根据linkage函数的输出Z创建分类。
(完整版)Matlab学习系列13.数据插值与拟合
13. 数据插值与拟合 实际中,通常需要处理实验或测量得到的离散数据(点)。插值与拟合方法就是要通过离散数据去确定一个近似函数(曲线或曲面),使其与已知数据有较高的拟合精度。 1.如果要求近似函数经过所已知的所有数据点,此时称为插值问 题(不需要函数表达式)。 2.如果不要求近似函数经过所有数据点,而是要求它能较好地反 映数据变化规律,称为数据拟合(必须有函数表达式)。 插值与拟合都是根据实际中一组已知数据来构造一个能够反映数据变化规律的近似函数。区别是:【插值】不一定得到近似函数的表达形式,仅通过插值方法找到未知点对应的值。【拟合】要求得到一个具体的近似函数的表达式。 因此,当数据量不够,但已知已有数据可信,需要补充数据,此时用【插值】。当数据基本够用,需要寻找因果变量之间的数量关系(推断出表达式),进而对未知的情形作预测,此时用【拟合】。
一、数据插值 根据选用不同类型的插值函数,逼近的效果就不同,一般有:(1)拉格朗日插值(lagrange插值) (2)分段线性插值 (3)Hermite (4)三次样条插值 Matlab 插值函数实现: (1)interp1( ) 一维插值 (2)intep2( ) 二维插值 (3)interp3( ) 三维插值 (4)intern( ) n维插值 1.一维插值(自变量是1维数据) 语法:yi = interp1(x0, y0, xi, ‘method’) 其中,x0, y0为原离散数据(x0为自变量,y0为因变量);xi为需要插值的节点,method为插值方法。 注:(1)要求x0是单调的,xi不超过x0的范围; (2)插值方法有‘nearest’——最邻近插值;‘linear’——线性插值;‘spline’——三次样条插值;‘cubic’——三次插值;