语义分析器

重庆大学课程设计报告课程设计题目:简单编译器的设计与实现
学院:计算机学院
专业班级:计算机科学与技术2班
年级:2010级
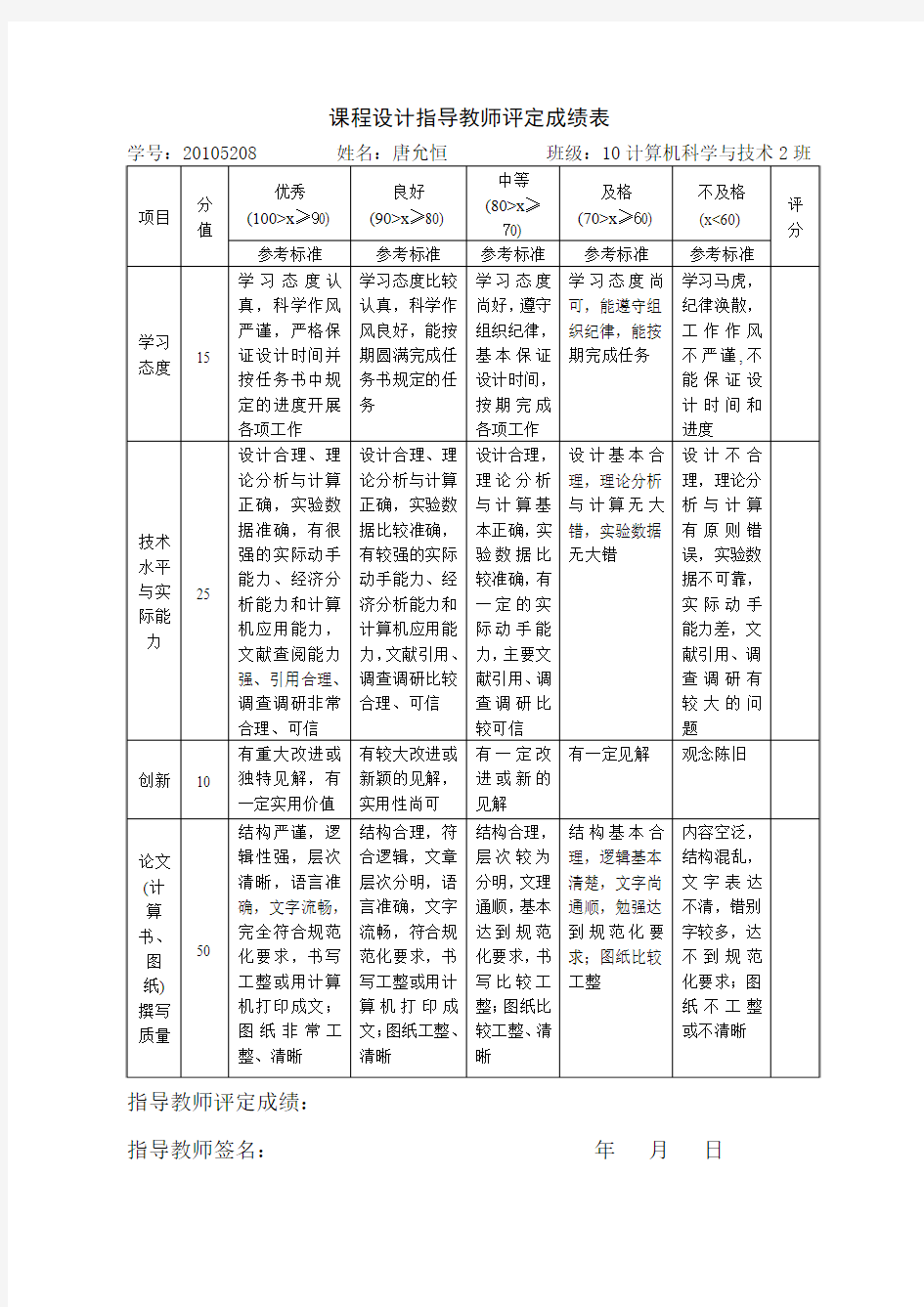
姓名:唐允恒,张楠
学号:20105208,20105333
完成时间:2013 年 6 月12 日成绩:
指导教师:张敏
重庆大学教务处制
指导教师评定成绩:
指导教师签名:年月日
指导教师评定成绩:
指导教师签名:年月日
重庆大学本科学生课程设计任务书
简单编译器设计与实现
目录
(一)目录 (1)
(二)简单编译器分析与设计 (2)
(1)简单编译器需求分析 (3)
(2)词法分析器的设计 (3)
1.词法表设计 (3)
2.token串取法简单流程图 (3)
(3)语法分析器的设计 (4)
1.算符优先文法设计 (4)
2.符号优先表 (6)
(4)语义分析器的设计 (6)
1.简单四元式分析 (6)
2.简单四元式的实现 (6)
(三)关键代码以及算法 (7)
(1)词法分析器的关键算法 (7)
(2)语法分析器的关键算法 (7)
(3)四元产生式的关键算法 (8)
(四)系统测试 (9)
(1)用例测试 (9)
(2)差错处理 (10)
(3)设计自我评价 (10)
(五)运行效果 (11)
(六)总结 (13)
简单编译器分析与设计
简单编译器需求分析
编写目的
《编译原理》是一门实践性较强的软件基础课程,为了学好这门课程,必须在掌握理论知识的同时,加强上机实践。本课程设计的目的就是要达到理论与实际应用相结合,使同学们能够根据编译程序的一般原理和基本方法,通过具体语言的编译程序的编写,掌握编译程序的主要实现技术,并养成良好的程序设计技能。
设计背景
此项目是开发一个C++语言编辑器,完成编辑C++语言源程序,对C++语言源程序进行高亮显示、错误处理、代码重排版、显示当前文件的函数列表和跳转、成对括号、语句块标识的功能,同时描述了编译器执行每个步骤流程。
在词法分析,语法分析和语义分析等方面加深对课程基本内容的理解。同时,在程序设计方法以及上机操作等基本技能和科学作风方面受到比较系统和严格的训练。
对一个c++语言的子集编制一个编译程序,主要包括以下步骤:
词法分析
设计、编制并调试简单的C++语言的词法分析程序
语法分析
编制一个语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析。
语义分析
采用语法制导翻译原理,将语法分析所识别的语法成分变换成四元式形式的中间代码序列。
词法分析器的设计
词法表设计
以对程序进行简单分析,容易得到需要提取的token串,对token串进行简单分类,可以得到相应词法表,该词法表在代码中的实现采用数组的形式,共分为标识符,常量,关键字,符号几大类,关键字和符号具体分类如下:
char *key[6]={"break","continue","return","cout","endl","cin"};//关键字
char *def[3]={"int","char","string"};//定义关键字
char *proc[4]={"while","if","for","else"};//过程关键字
char *logic[2]={"&&","||"};逻辑运算符
char *comp[6]={"<=",">=","==","<",">","!="};//比较符
char *assi[6]={"+=","-=","*=","/=","%=","="};//赋值运算符
char *bd[7]={";","(",")","{","}","\"","'"};//标点
char *sym[6]={"$","&","_","#",">>","<<"};//特殊符号
char *mathtic[6]={"%","+","-","*","^","/"};//运算符
char *selfgrow[2]={"++","--"}; //自增符
token串取法简单流程图
语法分析器的设计
算符优先文法设计
对于c++程序,很多功能的实现复杂,操作繁琐,所以我们精简c++语言的语法分析,该语法分析器主要针int,char,string类型的操作符进行定义,赋值,表达式,逻辑运算式以及输入输出语句进行识别和分析,而程序体则可以识别while,if else 和for语句。基本涵盖了面向过程程序能够用到的循环判断和选择过程。
步骤1:Token串取法进行了细分和削减(只对需要识别的Token串词法分析)将词法分析器完善,将标识符以及其对应的类型分别存入数组中以方便识别,对token 串命名,把token串后的名字作为终结符进行语法分析。
对应终结符
<标识符>
<字符常量>(‘s’,’&’……)
<字符串常量>
<数字常量>(12,0.231……)
<比较符>(==,!=,<=,>=,<,>)
<赋值符号>(+=,-=,=)
<运算符>(+,-,*,/,%,^)//不区分优先级
<逻辑运算符>(||,&&)
<自增符号>(++,--)
<标点符号以及输入输出符号> 保留cout,cin,; ( ) { } << >> <过程关键字> 保留for,while,if,else
由于cout,cin,for,while,if,else,return搭配固定,把这几个关键字的Token也看作终结符。
步骤2:定义一般文法:(根据一般C++语言描述,非算符优先文法)
<程序>(P)::= <定义语句>(D); <程序>(P)|<赋值语句>;<程序>(P)|<输入输出语句>(IO);<程序>(P)|<过程关键字>{程序(P)}
<定义语句>(D)::=<定义符号>【<标识符>| <赋值语句>】
<赋值语句>(S)::=<标识符><赋值符><表达式>(E)|<标识符><赋值符>
<表达式>(E)::=<算术表达式>(M1)|<字符串常量>|<字符常量>
<算术表达式>(M1)::=<算术表达式><运算符><算术表达式>|M2
M2::=( <算术表达式>)|<标识符>|<数字常量>
<输入输出语句>::=cin>><标识符>|cout<<<表达式>【<
<过程>::=<过程关键字><程序>
<过程关键字>::=for(<赋值语句>;<判定语句>;<赋值语句>)|If(<判定语句>)|E lse if(<判定语句>)|E lse|W hile(<判定语句>)//循环for,while,选择判断if,else
步骤3:根据一般文法改写成相应的算符优先文法
P::=D; |S;|IO; |J; |I; |PP*
|
*D::=D
|D
|D
Es::=(Es) |Es
En::=(En) |En
Ec::=(Ec)* |Ec
I::=
S::= Es
J::=J
Cs::=
Cn::=
Cc::=
IO::=
IO <<
*注:该文法定义同类型符号之间才能进行各项操作。
该文法并非完全按照算符优先文法要求,因为存在符号间优先级矛盾和非终结符之间直接相连(PP)的情况,比如)在过程标识符后面和在算术表达式后面与标识符和常量的优先关系矛盾,对于这种特殊情况只能进行手动识别。
步骤4:写出文法的分析表和规约规则并导入程序中:(完整规约规则在代码中查看)int change(){
/*程序语句规约*/
else if(strcmp(stack1[stk1],"S;")==0)
{shift<<"规约:"<<"P=S;"< else if(strcmp(stack1[stk1],"T;")==0) {shift<<"规约:"<<"P=T;"< else if(strcmp(stack1[stk1],"J;")==0) {shift<<"规约:"<<"P=J;"< else if(strcmp(stack1[stk1],"I;")==0) {shift<<"规约:"<<"P=I;"< else if(strcmp(stack1[stk1],"O;")==0) {shift<<"规约:"<<"P=O;"< else if(strcmp(stack1[stk1],"while(J)")==0) {shift<<"规约:"<<"P=while(J)P"< { shift<<"规约:"<<"P=if(J)P"< else if(strcmp(stack1[stk1],"elseP")==0) {shift<<"规约:"<<"P=elseP"< else if(strcmp(stack1[stk1],"{P}")==0) {shift<<"规约:"<<"P={P}"< else{return 0;} } 符号优先表 Ctrl+点击查看:符号优先表 数组形式导入到代码中:int pri[29][29]={……} 语义分析器的设计 简单四元式分析 语法分析是对符号栈的操作,而语义分析要根据语法分析的顺序对数据栈进行同步操作,进而通过一系列算法产生四元式。 所以,我们首先定义了数据栈保存源码信息,并实现所有操作与符号栈同步(即同类数组下标采用统一标识符),定义如下: char stack1[1000][100],stack2[1000][100],stack3[1000][100];//语法栈(2是Input String,1是真正 规约栈,3是算法中间需要暂存1的栈) char stack_1[1000][100],stack_2[1000][100],stack_3[1000][100];//数据栈 然后对语法分析中的规约过程进行分析,发现在规约赋值语句,判断语句,算术运算,逻辑运算时会产生四元式。 所以当规约以上几种语句时保存数据栈中规约部分的数据到规约栈内,规约栈定义如下: char stack[1000][100]; 这样就按语法分析规约顺序将数据操作代码存入了,并且数组下标就是相应四元式的标号。 接下来就是回填,具体分析在下面关键代码算法中分析。 关键代码以及算法 词法分析器的关键算法: void IsSign(){…} 关于符号的判定为读取一个字符,调用Judge(int a,int b,char c[],char d[])判定具体类型;其中双符号判定原则是向后判定一位确定是否为双符号。 void IsNum(){…} 关于常量的判定为读取连续的数字;其中小数的判定原则是当读入一个”.”时继续向后读 void IsChar(){…} 关于字符的判定为读取连续的字母,比较关键字。若非关键字就判定为标识符,会在符号表中查找相应的表项,并且在定义语句中将定义的标识符,类型,值,所在定义行添加至字符表。 void Judge(int a,int b,char c[],char d[]){…} 对符号具体类型判定的函数。 语法分析器的关键算法 在词法分析的基础上,将每次提取的Token的类型(词法分析过程)替换成相应的标识符存入stack2[1000][100]栈中(移近-规约时的Input String),通过符号优先表进行移进规约判定,根据导入的规则判定如何规约。 注:规约的原则:自规约栈顶向栈底逐个添加,判定能否规约,能规约则规约!!void push(char a[],int s,char b[]) 压栈操作,a[]压入符号栈,b[]压入数据栈(同步),s代表压入几号栈 void pop(int s) 弹栈操作,s代表弹出栈的号 void save(int s) stack1,stack3互存的操作(s为1则将stack3存入stack1,3则将stack1 存入stack3)在stack1判定规约前先保存数据到stack3,若无法规约,则 取暂存器中数据。 int get_pri(char a[]) 将字符类型替换成相应的数据,以便在符号表中查到相应的优先级。int change() 存放规约规则的函数。由replace()调用 void replace() 每当需要规约时调用replace()进行能规约则规约操作。 语义分析的关键算法 在词法分析执行的每一步都会将单个数据Token串按序存入数据栈并通过语法分析的pop和push函数进行数据符号同步。 当规约赋值,算术运算,逻辑运算,判定语句时保存至stack。数组下标就是相应四元式的标号。 需要特别留意的是在规约判断语句时要预留两个四元式位置,因为判定语句才会出现在if,else,while,for等需要跳转的循环语句中!!多预留的位置是(j,_,_,*)一类的四元式。 有缺陷的回填算法: 我们所采用的回填算法只针对if,else不带{}的形式,因为我们判定while 执行完毕的位置是}的出现位置(可以确定while执行完毕时所产生的四元式编号),但是若if,和else也采用{},则导致混乱(也就是说if else的函数范围只有下一句)其具体算法规则是: 1.根据产生stack数组大小n+1,定义为空即代表执行完毕n+1:NULL 2.当规约if(J)时,将当前四元产生式的编号n1+1(即(j,_,_,null))存入“if”栈中,并且将当前四元式n1的跳转位置定义为n1+2即:(j*,a,b,n1+2)。若继续出现规约if(J)时则继续压入栈中,当出现一个else,提取当前四元产生式编号ux+1(即下条产生式编号),回填至”if”栈顶号所代表的的四元式中的null。 3.当规约while(J)时,与if类似存入一个”while”栈,并且置当前四元式s的跳转位置为null待回填即s:(j*,a,b,null),当出现一个“}”时,则记录当前四元式编号n +1(即“}”前的最后一条四元式已执行完毕添加的一个跳回while 判定语句的位置(j,_,_,null)),此时将”while”栈中的数据编号回填至n+1号四元式的null,并将n+2回填至s号的四元式null. 4.其他的四元式是没有跳转项的 系统测试 用例测试: 用例代码如下: 用例1:用例2: string d="是水仙花数"; string d="是水仙花数"; int i=10; int i=10; while(i<=999){ while(i<=999){ if(i==i) cout< else i=i; char k='s'; char k='s'; int a1=i/100; int a1=i/100; int b2=i/10%10; int b2=i/10%10; int ac=i%10; int ac=i%10; if(a1^3+b2^3+ac^3==i) if(a1^3+b2^3+ac^3==i) cout< else else cout< } } Result: Result: 差错处理 *语法分析器识别完毕后,若栈stack1得到了#P#则证明程序成功且无错的识别。 *若栈中出现#P#和其他的一些未能识别的符号,则说明在某处文法没有相应的规约规则。 *若栈中只出现开始的#而没有结束#,则说明在某个位置的终结与后一个位置的终结符之间不存在优先关系,并能够根据提示找到这两个终结符。 *经过多次测试发现当出现标识符重定义和存在未定义的标识符的时候,程序会出现卡死状况,所以在进行语法分析器之前会对上述两种情况进行预处理,即在语法分析过程中发现错误,终止程序。 *当【if,else】【{,}】【while,}】对不相同时会造成四元式产生卡死,但是对词法分析和语法分析不造成影响 设计自我评价 优点: *对简单的程序编译过程基本完善,对能够识别的程序都能产生正确输出结果。 *程序框架结构(过程模块化)、文法的设计清晰明了,对于理解编译器的执行原理有很好的帮助作用。 *语法分析清晰明了,每步操作都有保存在移进-规约.Txt文档中。 *对变量不兼容的错误有很好的处理,比如标识符的类型定义混乱时会报错。在运算表达式中出现不兼容的标识符同样能够发现。 *对于错误能够指出其位置,方便修改。 *添加许多栈存储数据,有利于查询、添加、修改。 *输出结果界面清晰易懂。 不足: *语法分析文法并未按照严格的算符优先文法(前面有具体说明),部分文法通过手动操作实现,容易产生未知错误。 *文法对算术表达式符号优先级统一规划,没有细分各个算术运算符的优先顺序,导致产生的四元式不区分各符号的先后顺序。 *对于待识别的程序限制太多(例如if else必须成对出现,即使else什么也不做)。*回填算法的缺陷(具体描述如上)。 *编译器在除上述已处理错误外,肯定存在一些未知的BUG,因为识别过程复杂,使用的算法函数调用频繁,不利于维护更新。 运行结果 Ctrl+点击打开Token串 Ctrl+点击打开移进-规约 Ctrl+点击打开字符表 以上是正确程序的输出,当把int b2=i/10%10; 改为int b2=k/10%10则会输出: 即规约k/10时出现了问题。 当把int b2=i/10%10; 改为int b2=f/10%10则会输出: 此次课程设计,毫无疑问对我的帮助是非常巨大的。一直以来,我对编译原理这门课程比较感兴趣,因为在学习这门课程之前我对编译器的概念仅仅停留在认知阶段(即高级语言转换成PC机能够识别的语言),以为像C++的编译器是与VS开发平台直接相连的,也很奇怪为什么编译器不能够识别所有错误,也很好奇它是如何工作的。就这样带着疑问开始了我的编译原理的旅程。 刚开始接触编译原理,我对文法和产生式之类的毫无概念,也觉得学习起来有些艰难,不过直到第一个实验结束,才开始对文法有一个较为清晰的认识。充分说明实践对于理论的重要性,而课程设计便是对这学期理论学习的升华总结吧。 我感觉编译原理这门课程最大的收获并不在于它本身的实用性,更多的是让我在编代码的时候能够理解编译器如何“理解”我的代码,而有意识的将容易出错的地方避开,即使出错了也能够很快找出错误的根结所在,这对于我来说是一个很值得开心也让我感受到编译原理的真正的价值所在。 这次课程设计给我的最大感受就是:累!编译器所使用的算法并不困难(虽然我的回填算法非常烂,但是更多的是我认为是我经验不足导致的),但是工作量是非常巨大的。抛开BUG不谈,仅仅编写一个识别最简单程序的编译器,30*30的符号优先表已经把我弄得焦头烂额,这让我非常沮丧,也让我意识到我要走的路还很长,学习计算机科学仅仅靠头脑真的是不够用的。同时也对编写各大语言的编译器的团队佩服不已,毕竟人力有时尽,可以想象这些程序员需要耗费多少心血来完成这些编译器。 课程设计给我的第二感受是:考虑问题要全面。这一点在编写编译器时特别突出,因为很多次失败都是因为某些细节没有考虑到(比如文法少一个产生式,比如某个token串没取到)。当提示错误的时候,往往感到非常愕然,但是仅仅需要多想一步,或许就能成功了。这一点让我明白了:编写程序代码的每个阶段都需要认真,或许因为你的一个疏忽,导致后面的程序无法工作,回炉重造,得不偿失。 最后,我认为我该感谢张老师的悉心教导,否则我可能要花很长时间才能完全理解编译原理的整个过程。 计科二班 唐允恒 本次课程设计,通过词法,语法,语义的分析完成了一个简单编译器额实现。在这个过程中,遇到了许多困难,token串进行移进和规约以及first 与last集的计算,以及对输入与分析栈的设计,最后通过查找资料解决了这些基本问题。 通过这个课程设计,将这学期从编译原理课堂中学习的知识运用到实际中去了,加深了对编译原理的理解与应用。 计科二班 张楠 语义分析实验报告 一、实验目的: 通过上机实习,加深对语法制导翻译原理的理解,掌握将语法分析所识别的语法成分变换为中间代码的语义翻译方法。 二、实验要求: 采用递归下降语法制导翻译法,对算术表达式、赋值语句进行语义分析并生成四元式序列。 三、算法思想: 1、设置语义过程。 (1)emit(char *result,char *ag1,char *op,char *ag2) 该函数的功能是生成一个三地址语句送到四元式表中。 四元式表的结构如下: struct { char result[8]; char ag1[8]; char op[8]; char ag2[8]; }quad[20]; (2) char *newtemp() 该函数回送一个新的临时变量名,临时变量名产生的顺序为T1,T2,… char *newtemp(void) { char *p; char m[8]; p=(char *)malloc(8); k++; itoa(k,m,10); strcpy(p+1,m); p[0]=’t’; return(p); } 2、函数lrparser 在原来语法分析的基础上插入相应的语义动作:将输入串翻译成四元式序列。在实验中我们只对表达式、赋值语句进行翻译。 四、源程序代码: #include 报表语义模型(数据加工:返回结果集方式) 数据加工方式:1.返回查询SQL ; 2.返回结果集DataSet;3.返回数据表。 实现方式基本一致,可以参照系统原有报表语义模型 一、新建报表查询入口类,初始化报表字段 1.数据加工查询业务处理接口的定义: package 票据信息查询/票据池额度查询接口 * * @author 温燕荣WYR * @date 2014-04-15 */ public interface IFbmQueryPaperBillService { /** * 票据信息查询 * @param context * @return * @throws BusinessException */ public DataSet queryPaperBillInfo(IContext context) throws Exception; /** * 票据池额度查询接口 * @param context * @return * @throws BusinessException */ public DataSet queryPaperBillPoolLimit(IContext context) throws Exception; } 2.数据加工入口类,初始化报表字段 package 票据池额度查询入口类 * * @author 温燕荣WYR * @date 2014-04-15 */ public class QueryPaperPoolLimitService { private static final MetaData metaData; public QueryPaperPoolLimitService(){ super(); } /** * 获得结果集 * * @param context 报表界面查询传进来的参数(查询条件=值,系统一些默认参数等)* @return */ public static DataSet queryPJCAmt(IContext context)throws Exception { ookup DataSet resultDataSet = (context); setPrecision(resultDataSet); return resultDataSet; } etFields()) { if () == { (300); } } } /** * 获得票据池额度元数据(相当于代码写一个元数据) * * @return */ public static MetaData getPJCAmtrMetaData(){ return metaData; } } 二、数据加工业务处理 hangeQueryPaperBillPoolVO(hashmap); 编译技术 班级网络0802 学号3080610052姓名叶晨舟 指导老师朱玉全2011年 7 月 4 日 一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为 “把字句”的语义分析 孙志景 我们这里所要讲的句式指的是一种比较有特色的动词性谓语句——把字句。把字句是用介词“把”将谓语动词支配关涉的对象提到动词前面的句子,它是现代汉语中很重要、很有特色的句式。其形式是“主语+(把+宾语)+谓词性词语”。 在现代汉语中,句子是语言运用的基本单位,它由词、词组(短语)构成,能表达一个完整的意思,如告诉别人一件事,提出一个问题,表示要求或者制止,表示某种感慨,表示对一段话的延续或省略。句子和句子中间有较大停顿。它的结尾应该用上句号、问号、省略号、或感叹号。 我们这里所要讲的句式指的是一种比较有特色的动词性谓语句——把字句。把字句是用介词“把”将谓语动词支配关涉的对象提到动词前面的句子,它是现代汉语中很重要、很有特色的句式。其形式是“主语+(把+宾语)+ 谓词性词语”。把字句强调的是对某物的处理结果。把字句是一种有特色的句子,那么这种句式到底有什么特点呢?第一,谓语动词大多数是表动作的及物动词,并且在语义上能支配把字后边的词语。及物动词一般后面都可以接宾语。例如:他把书看完了。“看”是及物动词,在语义平面“书”是“看”的受事。当然,这里的“书”可以被“看”所支配。又例如:“我踩到了石头”一句就不能改成了把字句,这里的“踩”对“石头”没有支配能力。第二,谓语动词(特别市单音节词)的后面或前面通常都有一些别的词语。例如:他把作业做完了。动词“做”的后面加了“完了”一词,表示一种结果,作业完成了。同时,又例:我把论文认真地审查了一遍。这个句子中,谓语动词前面加了“认真地”修饰动词,表明一种态度;而谓语动词的后面也加了“一遍”表示一种频率或者一个量。当然,有些谓语动词本身含结果意义,如“采纳、接受、拒绝、说服”等,这类动词如果前面有某些状语,后面可以没有别的词语。例如:董事会已经把她的建议采纳了。“已经”一词表示一种完成的结果,同时 采纳也有一定的结果含义,那么动词后面可以不用加词语。第三,“把”字后面的词语所代表的事物一般是定指的,是上下文出现过或交际双方都知道的。上例中的“作业、话、论文”都是定指的。有时候“把”字后面的词语包含有“一个、几个”之类的词语,但说话人认为所指的对象或范围仍是明确的。例如:我们把一个强大的中国带入了二十一世纪。这里的“中国”这个当然是特指,而后面的“一个”也是特指的,是大家都知道的,所表示的物象是明确的。第四,如果句中有否定副词或助动词,则出现在“把”字前面。例如:他没有把话说清楚。这里的“没有”要放在把字的前面。其实,看到这个特点,我想起了英文中的一个词“think”,跟我们这个把字句的这个否定特点很相似,都是将否定词放在前面。 前面都是在讨论“把”字句一些特点,下面我们就要讲讲把字句的作用。首先,语用表达的需要:强调动作的处置结果。这种把字句有不用把字的相对格式。例如:他推翻了原计划。//他把原计划推翻了。把字句就是把大家的焦点聚焦在句末,聚焦在谓语动词上,是大家能够更好地理解句意。在这个例子中强调的是已然的处置结果推翻了。又例:我明天可以看完这本书。//我明天可以把这本书看完。这里强调的是未然的处置结果看完。当然,也有一些“把”字句强调动作的致使结果,这种把字句的谓语中心通常是不及物动词或形容词。例如:繁忙的工作把他累垮了。其次,是在使用过程中结构上的需要。同时它们没有其相对格式。这里,有三种情况:第一,动词紧接着补语,不允许宾语将它跟动词隔开,这种情况一般用把字短语。例如:他把自行车放在车棚里。(“放”与“在……”关系密切)。第二,动词带双宾语,其中的一个或两个宾语都比较复杂,放在一起累赘拖沓,这种情况一般用“把”字把直接宾语提前。例如:我们把那封最后的通牒式的信退还给了他们。第三,动词后有“为、 编译原理实验一 姓名:朱彦荣 学号:20132184 专业:软件工程2 实验题目:词法分析完成语言:C/C++ 上级系统:VC++6.0 日期:2015/11/7 词法分析 设计题目:手工设计c语言的词法分析器 (可以是c语言的子集) 设计容: 处理c语言源程序,过滤掉无用符号,判断源程序中单词的合法性,并分解出正确的单词,以二元组形式存放在文件中。 设计目的: 了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程。 结果要求:课程设计报告。 完成日期:第十五周提交报告 一.分析 要想手工设计词法分析器,实现C语言子集的识别,就要明白什么是词法分析器,它的功能是什么。词法分析是编译程序进行编译时第一个要进行的任务,主要是对源程序进行编译预处理(去除注释、无用的回车换行找到包含的文件等)之后,对整个源程序进行分解,分解成一个个单词,这些单词有且只有五类,分别是标识符、保留字、常数、运算符、界符。以便为下面的语法分析和语义分析做准备。可以说词法分析面向的对象是单个的字符,目的是把它们组成有效的单词(字符串);而语法的分析则是利用词法分析的结果作为输入来分析是否符合语法规则并且进行语法制导下的语义分析,最后产生四元组(中间代码),进行优化(可有可无)之后最终生成目标代码。可见词法分析是所有后续工作的基础,如果这一步出错,比如明明是‘<=’却被拆分成‘<’和‘=’就会对下文造成不可挽回的影响。因此,在进行词法分析的时候一定要定义好这五种符号的集合。下面是我构造的一个C语言子集。 第一类:标识符 letter(letter | digit)* 无穷集 第二类:常数 (digit)+ 无穷集 第三类:保留字(32) auto break case char const continue default do double else enum extern float for goto if int long register return short signed sizeof static struct switch typedef union unsigned void volatile while 第四类:界符‘/*’、‘//’、 () { } [ ] " " ' 等 第五类:运算符 <、<=、>、>=、=、+、-、*、/、^、等 对所有可数符号进行编码: . 编译原理实验专业:13级网络工程 语法分析器1 一、实现方法描述 所给文法为G【E】; E->TE’ E’->+TE’|空 T->FT’ T’->*FT’|空 F->i|(E) 递归子程序法: 首先计算出五个非终结符的first集合follow集,然后根据五个产生式定义了五个函数。定义字符数组vocabulary来存储输入的句子,字符指针ch指向vocabulary。从非终结符E函数出发,如果首字符属于E的first集,则依次进入T函数和E’函数,开始递归调用。在每个函数中,都要判断指针所指字符是否属于该非终结符的first集,属于则根据产生式进入下一个函数进行调用,若first集中有空字符,还要判断是否属于该非终结符的follow集。以分号作为结束符。 二、实现代码 头文件shiyan3.h #include #include int a=0; cout<<"按1结束程序"< 词法分析器实验报告 词法分析器设计 一、实验目的: 对C语言的一个子集设计并实现一个简单的词法分析器,掌握利用状 态转换图设计词法分析器的基本方法。利用该词法分析器完成对源程 序字符串的词法分析。输出形式是源程序的单词符号二元式的代码, 并保存到文件中。 二、实验内容: 1. 设计原理 词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号。 理论基础:有限自动机、正规文法、正规式 词法分析器(Lexical Analyzer) 又称扫描器(Scanner):执行词法分析的程序 2. 词法分析器的功能和输出形式 功能:输入源程序、输出单词符号 程序语言的单词符号一般分为以下五种:关键字、标识符、常数、运算符,界符 3. 输出的单词符号的表示形式: 单词种别用整数编码,关键字一字一种,标识符统归为一种,常数一种,各种符号各一种。 4. 词法分析器的结构 单词符号 5. 状态转换图实现 三、程序设计 1.总体模块设计 /*用来存储目标文件名*/ string file_name; /*提取文本文件中的信息。*/ string GetText(); /*获得一个单词符号,从位置i开始查找。并且有一个引用参数j,用来返回这个单词最后一个字符在str的位置。*/ string GetWord(string str,int i,int& j); /*这个函数用来除去字符串中连续的空格和换行 int DeleteNull(string str,int i); /*判断i当前所指的字符是否为一个分界符,是的话返回真,反之假*/ bool IsBoundary(string str,int i); /*判断i当前所指的字符是否为一个运算符,是的话返回真,反之假*/ bool IsOperation(string str,int i); 概率潜在语义模型综述 信息检索本质上是语义检索, 而传统信息检索系统都是基于独立词索引, 因此检索效果并不理想. 概率潜在语义索引是一种新型的信息检索模型, 它在潜在语义索引模型思想的基础上, 通过EM迭代算法将词向量和文档向量投影到一个低维空间, 消减了词和文档之间的语义模糊度, 使得文档之间的语义关系更为明晰。论述了概率潜在语义索引的理论基础, 探讨了隐含语义索引在信息处理处理中的应用。 标签:信息检索;潜在语义索引;SVD分解;概率潜在语义索引 1 简介 传统的信息检索模型可归为三类:布尔模型、向量空间模型和概率模型。它们都分别把文本和查询表示为索引词的集合,尽管使用了不同的方法,但本质上均为某种形式的索引词的匹配,而没有进一步做语义上的分析。自然语言中存在大量的同义词、多义词,这分别对传统检索模型的召回率和准确率有不利的影响。检索系统要求用户提供足够多精确、无歧义的关键词才有可能得到所需要的信息,这大大增加了系统使用的难度。为了进行更自然更人性化的查询,检索系统必须能够处理自然语言中的同义、多义现象,进行语义上的分析。 潜在语义分析(LSA)是一种发现潜在语义并分析文档、词和语义三者之间关系的方法。其主要思想是通过统计分析来发现文档中词与词之间存在的某种潜在的语义结构,并且使用这些潜在的语义结构来表示词和文本。 虽然潜在语义分析在信息检索领域取得了令人满意的效果,但是它存在几个缺陷:首先由于潜在语义分析过程中奇异值分解的物理意义不够明确,较难控制词义聚类的效果;此外这个算法的空间和时间复杂度太大,在目前的计算机硬件条件下很难实际适应实际应用。 针对潜在语义分析的这些缺陷,Hoffmann 提出了一种新的方法-概率潜在语义分析(PLSA),该方法使用概率模型来表示“文档—潜在语义—关键词”三者之间的关系,文档和关键词都可以映射到同一个语义空间,这样,文档和文档以及文档和关键词之间的相似度都可以通过计算语义空间上的夹角而得以量化。 2 潜在语义索引(LSI) 潜在语义索引(Latent Semantic Indexing) 是S. T. Dumais)等人提出的。其基本思想是文本中的词与词之间存在某种联系,即存在某种潜在的语义结构,因此采用统计的方法来寻找该语义结构,并且用语义结构来表示词和文本。这样的结果可以达到消除词之间的相关性,化简文本向量的目的。潜在语义索引的算法基于矩阵的奇异值分解 词法分析器实验报告 词法分析器实验报告实验目的: 设计、编制、调试一个词法分析子程序,识别单词,加深对词法分析原理的理 解。 实验要求: 该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立 意义的单词,即基本保留字、标识符、常数、运算符、分界符五大类。并依次输出 各个单词的内部编码及单词符号自身值。 (一)实验内容 (1)功能描述:对给定的程序通过词法分析器弄够识别一个个单词符号,并以二 元式(单词种别码,单词符号的属性值)显示。而本程序则是通过对给定路径的文件 的分析后以单词符号和文字提示显示。 (2)程序结构描述: 函数调用格式: 函数调用格式函数名(实在参数表 ) Switch(m)、 isKey(String string)、isLetter(char c)、实参 isDigit(char c)、isOperator(char c) isKey(String string)、isLetter(char c)、调作为表达式 isDigit(char c)、isOperator(char c) 用 方 作为语句 getChar()、judgement()、 法 函数的递归调用 isOperator(char c) 、isLetter(char c)、isDigit(char c) 参数含义: 1 String string;存放读入的字符串 String str; 存放暂时读入的字符串 char ch; 存放读入的字符 int rs 判断读入的文件是否为空 char []data 存放文件中的数据 int m;通过switch用来判断字符类型, 函数之间的调用关系图: main Complier..judgement isOperate() M=0 getChar( ) isDigit() M=4 For(ch ) isLet ter() M=2 Switch(m) isKey() M=3 函数功能: Judgement()判断输入的字符并输出单词符号,返回值为空; getChar() 读取文件的,返回值为空; isLetter(char c) 判断读入的字符是否为字母的,返回值为Boolean类型; switch (m) 判断跳转输出返回值为空; isOperator(char c)判断是否为运算符的,返回值为Boolean类型; isKey(String string)判断是否为关键字的,返回值为Boolean类型; isDigit(char c) 判断读入的字符是否为数字的,返回值为Boolean类型。测试结果: PL/0 语言编译器分析实验 一、实验目的 通过阅读与解析一个实际编译器(PL/0语言编译器)的源代码,加深对编译阶段(包括词法分析、语法分析、语义分析、中间代码生成等)和编译系统软件结构的理解,并达到提高学生学习兴趣的目的。 二、实验要求 (1)要求掌握基本的程序设计技巧(C语言)和阅读较大规模程序源代码的能力; (2)理解并掌握编译过程的逻辑阶段及各逻辑阶段的功能; (3)要求能把握整个系统(PL/0语言编译器)的体系结构,各功能模块的功能,各模块之间的接口; (4)要求能总结出实现编译过程各逻辑阶段功能采用的具体算法与技 三、实验报告 pl/0语言是pascal语言的一个子集,我们这里分析的pl/0的编译程序包括了对pl/0语言源程序进行分析处理、编译生成类pcode代码,并在虚拟机上解释运行生成的类pcode代码的功能。 pl/0语言编译程序采用以语法分析为核心、一遍扫描的编译方法。词法分析和代码生成作为独立的子程序供语法分析程序调用。语法分析的同时,提供了出错报告和出错恢复的功能。在源程序没有错误编译通过的情况下,调用类pcode 解释程序解释执行生成的类pcode代码。 词法分析子程序分析: 词法分析子程序名为getsym,功能是从源程序中读出一个单词符号(token),把它的信息放入全局变量sym、id和num中,语法分析器需要单词时,直接从这三个变量中获得。(注意!语法分析器每次用完这三个变量的值就立即调用getsym 子程序获取新的单词供下一次使用。而不是在需要新单词时才调用getsym过程。)getsym过程通过反复调用getch子过程从源程序过获取字符,并把它们拼成单词。getch过程中使用了行缓冲区技术以提高程序运行效率。 词法分析器的分析过程: 调用getsym时,它通过getch过程从源程序中获得一个字符。如果这个字符是字母,则继续获取字符或数字,最终可以拼成一个单词,查保留字表,如果查到为保留字,则把sym变量赋成相应的保留字类型值;如果没有查到,则这个单词应是一个用户自定义的标识符(可能是变量名、常量名或是过程的名字),把sym 置为ident,把这个单词存入id变量。查保留字表时使用了二分法查找以提高效率。如果getch获得的字符是数字,则继续用getch获取数字,并把它们拼成一个整数,然后把sym置为number,并把拼成的数值放入num变量。如果识别出其它合 用友软件股份有限公司 商业分析平台语义模型红皮书 版本:V6.0.0.20120227 目录 一、前言 (3) 1.概念 (3) 2.定位 (3) 二、结构 (3) 1.应用模型 (3) 2.语义模型 (4) a) 定义形态 (4) b) 执行流程 (6) c) 数据形态 (6) 3.语义提供者 (7) a) 接口 (7) b) 扩展 (9) 4.函数 (13) a) 函数解析 (13) b) 函数扩展 (13) 5.参数 (15) a) 参数定义 (16) b) 参数引用 (16) c) 参数设置 (16) 6.宏变量 (18) 7.描述器 (19) 8.数据加工 (20) 9.物化策略 (23) 10.复合语义模型 (24) 11.语义上下文 (28) 三、语义模型的管理 (31) 1.对象管理 (31) 2.环境配置 (34) 四、功能扩展 (41) 1.扩展语义提供者 (41) 2.扩展业务函数 (42) 3.使用数据加工 (42) 4.自定义执行策略 (42) 五、附录 (43) 1.入门 (43) 2.语义模型API (48) 3.语义函数 (50) 4.其他函数 (50) 5.脚本引擎 (52) 6.针对查询引擎的改进 (52) 一、前言 1.概念 SMART,即Semantic Modeling for Analysis Report Toolkit, 分析报表语义建模工具。 2.定位 语义模型把面向技术的数据,组织成面向业务的数据,供业务人员查询分析使用 二、结构 1.应用模型 上图为语义模型应用结构图。语义模型通过语义提供者,可以将多个数据源的数据进行整合。 2. 语义模型 定义形态 下图展示了语义模型的内部结构, 语义模型主要由以下几部分构成: 1.1 元数据 词法分析设计 1. 实验目的 通过本实验的编程实践,了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。 2. 实验内容 用C++语言实现对C++语言子集的源程序进行词法分析。通过输入源程序从左到右对字符串进行扫描和分解,依次输出各个单词的内部编码及单词符号自身值;若遇到错误则显示“Error”,然后跳过错误部分继续显示;同时进行标识符登记符号表的管理。 3. 实验原理 本次实验采用NFA->DFA->DFA0的过程: 对待分析的简单的词法(关键词/id/num/运算符/空白符等)先分别建立自己的FA,然后将他们用产生式连接起来并设置一个唯一的开始符,终结符不合并。 待分析的简单的词法 (1)关键字: "asm","auto","bool","break","case","catch","char","class"," const","const_cast"等 (2)界符(查表) ";",",","(",")","[","]","{","}" (3)运算符 "*","/","%","+","-","<<","=",">>","&","^","|","++","--"," +=","-=","*=","/=","%=","&=","^=","|=" relop: (4)其他单词是标识符(ID)和整型常数(SUM),通过正规式定义。 id/keywords: digit: (5)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 词法分析器实验报告 一、实验目的及要求 本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。 运行环境: 硬件:windows xp 软件:visual c++6.0 二、实验步骤 1.查询资料,了解词法分析器的工作过程与原理。 2.分析题目,整理出基本设计思路。 3.实践编码,将设计思想转换用c语言编码实现,编译运行。 4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。 三、实验内容 本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。标识符、常数是在分析过程中不断形成的。 对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。 输出形式例如:void $关键字 流程图、程序流程图: 程序: #include 实验三语法分析 309 科3 李君林 一.实验目的: 通过使用、剖析和扩充TINY语言的语义分析程序,掌握编译器的语义分析程序的构造方法。 二.实验内容 (一)运行TINY的语义分析程序 (二)扩充TINY的语法分析程序 提示: 考虑作用域(如:函数)和数组时可能需要修改符号表。 三.实验步骤 1.先读懂TINY语义程序(相关联的文件:) (1)buildSymtab(syntaxTree); 充TINY的语法分析程序 本次实验我首先将源程序实现的功能改成符合C_MINUS的符号表与类型检测 然后加入没申明调用与数组调用错误即数组没申明而调用数组类型。 四.实验结果 1.正确的测试程序 /**/ int gcd (int u,int v[]) { if(v==0) return u; else return gcd(v,u); } void main(void) { int x;int y; read x; x=y=2; while(x>0) y=y-1; write y; return (gcd(x,y)); } /**/ 运行结果: 经检验测试程序代码无语义错误2.错误测试程序 /**/ int gcd (int u,int v[]) { if(v==0) return u; else return gcd(v,u); } void main(void) { int x;int y; read x; t=1; x=y=2; x[2]=2; while(x>0) y=y-1; write y; return (gcd(x,y)); } /**/ 实验结果: 编译原理语法分析器实验报告 班级: 学号: 姓名: 实验名称语法分析器 一、实验目的 1、根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。 2、本次实验的目的主要是加深对自上而下分析法的理解。 二、实验内容 [问题描述] 递归下降分析法: 0.定义部分:定义常量、变量、数据结构。 1.初始化:从文件将输入符号串输入到字符缓冲区中。 2.利用递归下降分析法分析,对每个非终结符编写函数,在主函数中调用文法开始符号的函数。 LL(1)分析法: 模块结构: 1、定义部分:定义常量、变量、数据结构。 2、初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体等); 3、运行程序:让程序分析一个text文件,判断输入的字符串是否符合文法定义的规则; 4、利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式 符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示简 单的错误提示。 [基本要求] 1. 对数据输入读取 2. 格式化输出分析结果 2.简单的程序实现词法分析 public static void main(String args[]) { LL l = new LL(); l.setP(); String input = ""; boolean flag = true; while (flag) { try { InputStreamReader isr = new InputStreamReader(System.in); BufferedReader br = new BufferedReader(isr); System.out.println(); System.out.print("请输入字符串(输入exit退出):"); input = br.readLine(); } catch (Exception e) { e.printStackTrace(); } if(input.equals("exit")){ flag = false; }else{ l.setInputString(input); l.setCount(1, 1, 0, 0); l.setFenxi(); System.out.println(); System.out.println("分析过程"); System.out.println("----------------------------------------------------------------------"); System.out.println(" 步骤| 分析栈 | 剩余输入串| 所用产生式"); System.out.println("----------------------------------------------------------------------"); boolean b = l.judge(); System.out.println("----------------------------------------------------------------------"); if(b){ System.out.println("您输入的字符串"+input+"是该文法的一个句子"); }else{ System.out.println("您输入的字符串"+input+"有词法错误!"); (此文档为word格式,下载后您可任意编辑修改!) 编译技术 班级网络0802 学号 姓名叶晨舟 指导老师朱玉全 2011年 7 月 4 日 一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为 IF i>0 i= 1; 实验三语义分析程序实现 一、实验设计 在实现词法、语法分析程序的基础上,编写相应的语义子程序,进行语义处理,加深对语法制导翻译原理的理解,进一步掌握将语法分析所识别的语法范畴变换为某种中间代码(四元式)的语义分析方法。 基本实验题目:对文法G2[<算术表达式>]中的产生式添加语义处理子程序,完成运算对象是简单变量(标识符)和无符号数的四则运算的计值处理,将输入的四则运算转换为四元式形式的中间代码。 语法制导翻译模式是在语法分析的基础上,增加语义操作来实现的,实际上是对前后文无关文法的一种扩展。一般而言,首先需要根据进行的语义分析工作,完成对给定文法的必要拆分和语义动作的编写,从而为每一个产生式都配备相应的语义子程序,以便在进行语法分析的同时进行语义解释。即在语法分析过程中,每当用一个产生式进行推导或归约时,语法分析程序除执行相应的语法分析动作之外,还要调用相应的语义子程序,以便完成生成中间代码、查填有关表格、检查并报告源程序中的语义错误等工作。每个语义子程序需指明相应产生式中各个符号的具体含义,并规定使用该产生式进行分析时所应采取的语义动作。这样,语法制导翻译程序在对源程序从左到右进行的一遍扫描中,既完成语法分析任务,又完成语义分析和中间代码生成方面的工作。本实验要求从编译器的整体设计出发,重点通过对实验二中语法分析程序的扩展,完成一个编译器前端程序的编写、调试和测试工作,形成一个将源程序翻译为中间代码序列的编译系统。 二、程序代码 在词法分析和语法分析的基础上,完成了语义的分析,同样采用了头文件的形式,在VC++6.0中运行 #include 语法分析器的设计实验报告 一、实验内容 语法分析程序用LL(1)语法分析方法。首先输入定义好的文法书写文件(所用的文法可以用LL(1)分析),先求出所输入的文法的每个非终结符是否能推出空,再分别计算非终结符号的FIRST集合,每个非终结符号的FOLLOW集合,以及每个规则的SELECT集合,并判断任意一个非终结符号的任意两个规则的SELECT 集的交集是不是都为空,如果是,则输入文法符合LL(1)文法,可以进行分析。对于文法: G[E]: E->E+T|T T->T*F|F F->i|(E) 分析句子i+i*i是否符合文法。 二、基本思想 1、语法分析器实现 语法分析是编译过程的核心部分,它的主要任务是按照程序的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行词法检查,为语义分析和代码生成作准备。这里采用自顶向下的LL(1)分析方法。 语法分析程序的流程图如图5-4所示。 语法分析程序流程图 该程序可分为如下几步: (1)读入文法 (2)判断正误 (3)若无误,判断是否为LL(1)文法 (4)若是,构造分析表; (5)由句型判别算法判断输入符号串是为该文法的句型。 三、核心思想 该分析程序有15部分组成: (1)首先定义各种需要用到的常量和变量; (2)判断一个字符是否在指定字符串中; (3)读入一个文法; (4)将单个符号或符号串并入另一符号串; (5)求所有能直接推出&的符号; (6)求某一符号能否推出‘& ’; (7)判断读入的文法是否正确; (8)求单个符号的FIRST; (9)求各产生式右部的FIRST; (10)求各产生式左部的FOLLOW; (11)判断读入文法是否为一个LL(1)文法; (12)构造分析表M; (13)句型判别算法; (14)一个用户调用函数; (15)主函数; 下面是其中几部分程序段的算法思想: 1、求能推出空的非终结符集 Ⅰ、实例中求直接推出空的empty集的算法描述如下: void emp(char c){ 参数c为空符号 char temp[10];定义临时数组 int i; for(i=0;i<=count-1;i++)从文法的第一个产生式开始查找 { if 产生式右部第一个符号是空符号并且右部长度为1, then将该条产生式左部符号保存在临时数组temp中 将临时数组中的元素合并到记录可推出&符号的数组empty中。 } Ⅱ、求某一符号能否推出'&' int _emp(char c) { //若能推出&,返回1;否则,返回0 int i,j,k,result=1,mark=0; char temp[20]; temp[0]=c; temp[1]='\0'; 存放到一个临时数组empt里,标识此字符已查找其是否可推出空字 如果c在可直接推出空字的empty[]中,返回1 for(i=0;;i++) { if(i==count) return(0); 找一个左部为c的产生式 j=strlen(right[i]); //j为c所在产生式右部的长度 if 右部长度为1且右部第一个字符在empty[]中. then返回1(A->B,B可推出空) if 右部长度为1但第一个字符为终结符,then 返回0(A->a,a为终结符) else编译原理语义分析实验报告——免费!
2019年NC数据加工做语义模型(DOC)
编译原理词法分析器语法分析器实验报告
把字句的语义特征
词法分析实验报告
编译原理实验报告(语法分析器)
词法分析器实验报告
概率潜在语义模型综述
词法分析器实验报告
PL 0 语言编译器分析实验报告
语义模型红皮书
东南大学编译原理词法分析器实验报告
词法分析器实验报告
语义分析实验报告
编译原理语法分析器实验报告
编译原理词法分析器语法分析器实验报告
河北工业大学语义分析实验报告
语法分析器实验报告