pe文件结构 入门 教程

三年前,我曾经写了一个手工打造可执行程序的文章,可是因为时间关系,我的那篇文章还是有很多模糊的地方,我一直惦记着什么时候再写一篇完美的,没想到一等就等了三年。因为各种原因直到三年后的今天我终于完成了它。现在把它分享给大家,希望大家批评指正。
我们这里将不依赖任何编译器,仅仅使用一个十六进制编辑器逐个字节的手工编写一个可执行程序。以这种方式讲解PE结构,通过这个过程读者可以学习PE结构中的PE头、节表以及导入表相关方面的知识。为了简单而又令所有学习程序开发的人感到亲切,我们将完成一个Hello World! 程序。功能仅仅是运行后弹出一个消息框,消息框的内容是Hello World!。
首先了解一下Win32可执行程序的大体结构,就是通常所说的PE结构。
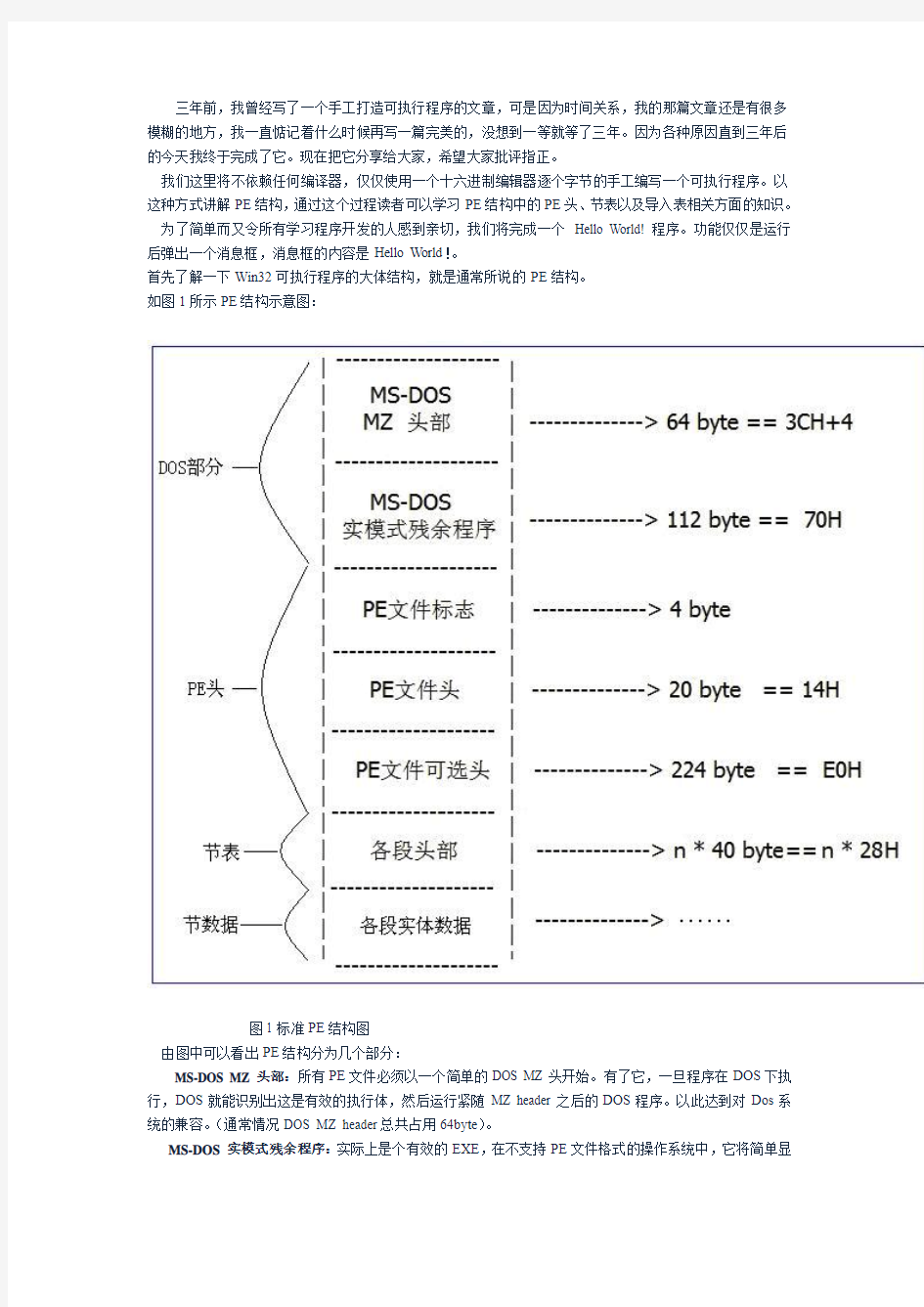
如图1所示PE结构示意图:
图1 标准PE结构图
由图中可以看出PE结构分为几个部分:
MS-DOS MZ 头部:所有PE文件必须以一个简单的DOS MZ 头开始。有了它,一旦程序在DOS下执行,DOS就能识别出这是有效的执行体,然后运行紧随MZ header 之后的DOS程序。以此达到对Dos系统的兼容。(通常情况DOS MZ header总共占用64byte)。
MS-DOS 实模式残余程序:实际上是个有效的EXE,在不支持PE文件格式的操作系统中,它将简单显
示一个错误提示,大多数情况下它是由汇编编译器自动生成。通常,它简单调用中断21h,服务9来显示字符串"This program cannot run in DOS mode"。(在我们写的程序中,他不是必须的,可以不予以实现,但是要保留其大小,大小为112byte,为了简洁,可以使用00来填充。)
PE文件标志:是PE文件结构的起始标志。(长度4byte, Windows程序此值必须为0x50450000)
PE文件头:是PE相关结构 IMAGE_NT_HEADERS 的简称,其中包含了许多PE装载器用到的重要域。执行体在支持PE文件结构的操作系统中执行时,PE装载器将从DOS MZ header中找到PE header的起始偏移量,跳过了MS-DOS 实模式残余程序,直接定位到真正的文件头PE header,长度20byte。
PE文件可选头:虽然它的名字是“可选头部”,但是请确信:这个头部并非“可选”,而是“必需”的。(长度 224byte )。
各段头部:又称节头部,一个Windows NT的应用程序典型地拥有9个预定义段(节),它们是“.text”、“.bss”、“.rdata”、“.data”、“.rsrc”、“.edata”、“.idata”、“.pdata”和“.debug”。一些应用程序不需要所有的这些段,同样还有些应用程序为了自己特殊的需要而定义了更多的段。(每个段头部占40byte,我们这里也不需要所有的段,仅需3个段。)
通常我们是将PE整个结构分成四个部分,把MS-DOS MZ 头部和MS-DOS 实模式残余程序作为第一部分,可以称他为DOS部分,而PE文件标志、PE文件头、PE文件可选头三个部分作为第二部分,称之为PE头部分,因为这部分才是Windows下真正需要的部分,所以从PE文件标志开始才是真正的PE部分。各段头部是第三部分,称之为节表。它详细描述了PE文件中各个节的详细信息。最后就是各个节的实体部分了,称为节数据。
以上仅仅是对PE结构各部分的大体讲解。接下来再手写这个Hello World!程序过程中,我将详细介绍每个部分的含义。
首先准备一下工具,一个十六进制编辑器足以。我们这里使用VC++ 6.0所携带的十六进制编辑器,您也可以使用如WinHex等十六进制编辑工具。
打开VC,选择文件,新建菜单项,然后选择一个二进制文件,单击确定。一切就绪了,下面就开始手写可执行程序,如图2所示:
图2 VC6.0下的十六进制编辑器
首先来完成“DOS MZ header”部分。“DOS MZ header”的功能前面已经讲过,在这里不再重述,直接实现他。“DOS MZ header”总共64byte,他对应的结构是IMAGE_DOS_HEADER ,在WINNT.H文件中有定义。通过这个结构我们可以看到,这64字节被分成19个成员,每个成员都有特殊的含义,与其说我们是在逐字节的手写可执行程序,倒不如说我们是在逐个成员的写。因为单独的一个字节并不一定具有什么意义。我们在学习过程中,就是要按照官方的定义,将整个部分拆分成若干个成员,然后逐个成员的去学习。
(提示: 如果安装有VC开发环境,那么在其安装目录下有一个头文件WINNT.H,在这个头文件中定义了所
有PE结构相关的各部分结构体。如图3所示:)
图3 VC安装目录下的WINNT.H头文件
使用VC开发环境打开此文件,然后按快捷键Ctrl+F输入IMAGE_DOS_HEADER进行搜索,如图4所示:
图4 VC下查找文件
单击Find Next按钮即可得到如下搜索结果,如图5所示:
图5
可以看出IMAGE_DOS_HEADER,结构体的定义如下:
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed WORD e_maxalloc; // Maximum extra paragraphs needed WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
按照它的定义,我们分别完成各个成员。
第一个成员(e_magic)是个WORD类型,占2个字节,它被用于表示一个MS-DOS兼容的文件类型,他的值是固定的0x5A4D,所以在十六进制编辑器中输入“4D5A”。
(注意:
因为我们是在十六进制编辑器下写数据,所以所有的数据格式都是十六进制式的。但是我们在开发环境中通常在数据前添加“0x”用来表示十六进制数 ,即:0x5A4D。而在十六进制编辑器中,直接写成“4D5A”即可。后面内容都照此规定书写。有一点需要说明,为什么十六进制值0x5A4D输入到十六进制编辑器中是4D5A呢?这是因为一个内存值,无论是占两个字节的WORD类型,还是占四个字节的DWORD类型等,如同我们学习数学中的十进制数值一样,都是有高低位之分的,从右向左位越来越高。然而在十六进制编辑器中,十六进制位是自左向右依次增高。因此按照高低位对齐的原则,值0x5A4D中,低位0x4D应该应该放到左边,0x5A应该放到右边。也就得到了编辑器中的4D5A。)
第2个成员到第18个成员总共58个字节,是对DOS程序环境的初始化等操作,对于我们这个程序来说,没什么影响,我们通通用“00”来填充。(如果您想对其进行详细了解,请查阅相关书籍。)
(提示:
我们在此不可能把PE结构所有的知识点都面面俱到,因为他十分的庞大。当然也没有必要对他作完全彻底的掌握,只需掌握关键的地方就可以了。以后我们都将把不影响程序执行的成员填充为零,这样做,一方面使程序看起来简洁,另一方面可以使您快速定位PE结构中要重点掌握的地方。)
第19(e_lfanew)个成员非常重要,他是一个LONG类型,占4个字节,用来表示“PE文件标志”在文件中的偏移,单位是byte。而从图5-1中可以看到“PE文件标志”紧随“MS-DOS 实模式残余程序”其后。知道这一点,我们就可以计算一下,我们的“DOS MZ header”总共64 byte,后面的“MS-DOS 实模式残余程序”占112 byte, 64 + 112 = 176 byte。但是要注意,我们这里的176是十进制的,转化成十六进制是0xB0。因为是4个字节,其余三位字节应该以00补齐,所以最终的值为0x000000B0。所以在我们的十六进制编辑器中按照高低对齐的原则应该填写“B0000000”。
接下来完成“MS-DOS 实模式残余程序”,笔者已经介绍,他是用在DOS下执行的,而我们所完成的HelloWorld程序是在win32下执行的。所以这里的内容并不影响我们程序的执行。因此这里直接用“00”来填充,注意总共112 byte。这两部分完成之后代码如图6所示:
图6 完成PE结构中Dos部分的编写
接下来便进入真正主题,开始写真正的PE结构部分:微软将“PE文件标志”,“PE文件头”,“PE文件可选头”这三个部分用一个结构来定义,即:IMAGE_NT_HEADERS32在WINNT.H中可以搜索其定义,定义如下:
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
可以看出这个结构含有3个成员:
第一个成员(Signature)表示“PE文件标志”,是一个DWORD类型,占4个字节,它是PE开始的标记,对于Windows程序这个值必须为0x00004550,所以编辑器中填写“50450000”。
第二个成员(FileHeader)表示“PE文件头”,他的类型是一个IMAGE_FILE_HEADER的结构。也就是说“PE文件头”的20个字节被定义为IMAGE_FILE_HEADER结构,定义如下:
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
这个结构具有7个成员:
成员1(Machine),占2个字节,表示PE文件运行所要求的CPU。对于Intel平台,该值是0x014C,所以编辑器中应该填写“4C01”。
成员2(NumberOfSections),占2个字节,表示PE文件中段(节)的总数,在我们这个程序中,计划完成3个段,(.text(代码段)、.rdata(只读数据段)、.data(全局变量数据段))。所以此处值是0x0003,因此填写“0300”。
成员3(TimeDateStamp),占4个字节,表示文件创建日期和时间,从1970.1.1 00:00:00以来的秒数,我们这里填“0000”即可。
成员4(PointerToSymbolTable),占4个字节,表示符号表的指针,主要用于调试,在这里填“0000”。
成员5(NumberOfSymbols),占4个字节,表示符号的数目,主要用于调试,在这里填“0000”。
成员6(SizeOfOptionalHeader),占2个字节,表示后面的“PE文件可选头”部分所占空间大小,我们已经知道“PE文件可选头”的大小是224 byte,转换成十六进制就是0xE0,此成员占两个字节,所以需要补齐一位00,即0x00E0。在编辑器中应该填写“E000”。
成员7(Characteristics),占2个字节,表示关于文件信息的标记,比如文件是exe还是dll。这个值实际上是二进制位进行或运算得到的值。各二进制位表示的意义如下:
Bit 0 :置1表示文件中没有重定向信息。每个段都有它们自己的重定向信息。这个标志在可执行文件中没有使用,在可执行文件中是用一个叫做基址重定向目录表来表示重定向信息的。
Bit 1 :置1表示该文件是可执行文件。
Bit 2 :置1表示没有行数信息;在可执行文件中没有使用。
Bit 3 :置1表示没有局部符号信息;在可执行文件中没有使用。
Bit 4 :未公开
Bit 7 :未公开
Bit 8 :表示希望机器为32位机。这个值永远为1。
Bit 9 :表示没有调试信息,在可执行文件中没有使用。
Bit 10:置1表示该程序不能运行于可移动介质中(如软驱或CD-ROM)。在这种情况下,OS必须把文件拷贝到交换文件中执行。
Bit 11:置1表示程序不能在网上运行。在这种情况下,OS必须把文件拷贝到交换文件中执行。
Bit 12:置1表示文件是一个系统文件例如驱动程序。在可执行文件中没有使用。
Bit 13:置1表示文件是一个动态链接库(DLL)。
Bit 14:表示文件被设计成不能运行于多处理器系统中。
Bit 15:表示文件的字节顺序如果不是机器所期望的,那么在读出之前要进行交换。在可执行文件中它们是不可信的(操作系统期望按正确的字节顺序执行程序)。
对于我们的程序,因为它是可执行程序,所以Bit 1必须置为1,其他位按照需要置位即可。在我们的程序中只需将第二位置1表示是可执行程序。也就得到二进制值“0000000000000010”,将其转换为十六进制形式为0x02,而该成员占两个字节,补齐一位00由此得到成员7的值为0x0002。因此在编辑器中填写“0200”。如果是dll,那么得到的二进制值应该是“0010000000000000”,转换成十六进制为0x2000。如果填写编辑器中应该填写“0020”。
第三个成员(OptionalHeader),表示“PE文件可选头”,他的类型是一个IMAGE_OPTIONAL_HEADER32结构。也就是说PE文件头的224个字节被定义为IMAGE_OPTIONAL_HEADER32结构,其结构定义如下: typedef struct _IMAGE_OPTIONAL_HEADER {
//
// Standard fields.
//
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
//
// NT additional fields.
//
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
该结构总共具有31个成员,我们分别实现它:
成员1(Magic),占2个字节,表示文件的格式,值为0x010B表示.EXE文件,为0x0107表示ROM 映像,因为我们写的是一个可执行程序,所以此处应该填写“0B01”。
成员2(MajorLinkerVersion),占1个字节,表示链接器的主版本号,此值不会影响程序的执行,我们这里填充零,此值为“00”。
成员3(MinorLinkerVersion),占1个字节,表示链接器的幅版本号,此值不会影响程序的执行,我们这里填充零,此值为“00”。
成员4(SizeOfCode),占4个字节,表示可执行代码的长度,此值不会影响程序的执行,我们这里填充零,此值为“00000000”。
成员5(SizeOfInitializedData),占4个字节,表示初始化数据的长度(数据段)。此值不会影响程序的执行,我们这里填充零,此值为“00000000”。
成员6(SizeOfUninitializedData),占4个字节,表示未初始化数据的长度(bss段)。此值不会影响程序的执行,我们这里填充零,此值为“00000000”。
(说明:
在介绍成员7之前,有必要了解一个很重要的知识------文件映射到内存。在可执行程序运行之前,PE加载器将把PE文件加载到进程空间的内存中去,并且初始化每个段实体。那么加载到内存中的哪个地址去呢?这将由IMAGE_OPTIONAL_HEADER32结构的成员10的值指出加载的起始地址(又叫基地址)。这个值通常是“00400000”,那么PE文件的首地址“00000”就被映射到内存地址“00400000”处,那么相对于文件偏移10个字节的地址为“00010”,被映射到内存后的偏移也应该是10个字节,映射后的地址应该为“00400010”。PE加载器就是按照此种方法将文件映射到内存中的。)
成员7(AddressOfEntryPoint),4个字节,表示代码入口的RV A地址。
(说明:
RVA是指PE加载器将文件映射到内存后,某个物理地址距离加载基址的偏移地址。)
所谓代码的入口是指程序从这儿开始执行。成员7实际上是PE装载器准备运行的PE文件中的第一条指令的RV A值。若您要改变整个程序执行的流程,可以将该值指定到新的RV A,这样新RV A处的指令首先被执行。
知道成员7的含义后,我们又如何来填充它呢?如何得知我们的程序将使用哪个地址作为入口呢?前面已经提到,一般在PE文件中总会有个.text段,这个段通常是用来填写代码的。按照一般规律,我们也将实现这么一个段,将我们这个程序中的所有代码指令写到此段中。我们在完成此程序的代码时,是从.text段起始地址开始写起。所以.text段的起始地址就将是我们程序的入口地址。那么又出现另外一个问题,如何得到.text段的起始地址呢?在PE结构中,所有段都对应有一个段头部,而在段头部中将指定该段的起始地址。那么这个值要等待我们完成.text头部后才能够得到,所以此处首先用“aaaaaaaa”填写,待完成.text 段头部后再计算填写它。
成员8(BaseOfCode),4个字节,表示可执行代码起始位置。当然就是.text段的首地址,此值不会影响程序的执行,我们这里填充零,此值为“00000000”。
成员9(BaseOfData),4个字节,表示初始化数据的起始位置,此值不会影响程序的执行,我们这里填充零,此值为“00000000”。
成员10(ImageBase),4个字节,就是上面所讲的文件映射到内存后的基地址。PE文件的优先装载地址。通常为0x00400000。因为PE装载器默认情况下优先将尝试把文件装到虚拟地址空间的0x00400000处。字眼“优先”表示若该地址区域已被其他模块占用,那PE装载器会选用其他空闲地址。我们这里的值设为“00004000”。
成员11(SectionAlignment),4个字节,表示段加载后在内存中的对齐方式,即内存中节对齐的粒度。例如,如果该值是4096 (1000h),那么每节的起始地址必须是4096的倍数。若第一节从401000h开始,大小是10个字节,下一个节并不是从401011开始,因为要经过节对齐,那么下一节必定从402000h开始,即使401000h和402000h之间还有很多空间没被使用。因为Windows管理内存采用分页管理的方式,而每页的大小为4k,也就是1000h。一般情况下程序的内存节对齐粒度都为0x00001000,我们这个值也填充为“00100000”。
成员12(FileAlignment),4个字节,表示段在文件中的对齐方式。文件中节对齐的粒度。例如,如果该值是(200h),,那么每节的起始地址必须是512(十六进制为200h)的倍数。若第一节从文件偏移量200h 开始且大小是10个字节,则下一节必定位于偏移量400h处。即使偏移量512和1024之间还有很多空间没被使用。一般情况下程序的文件节对齐粒度都为200h,所以我们在此将此值设为“00020000”。
成员13(MajorOperatingSystemVersion),2个字节,表示操作系统主版本号,此值不会影响程序的执行,我们这里填充零,此值为“0000”。
成员14(MinorOperatingSystemVersion),2个字节,表示操作系统副版本号,此值不会影响程序的执行,我们这里填充零,此值为“0000”。
成员15(MajorImageVersion),2个字节,表示程序主版本号,此值不会影响程序的执行,我们这里填充零,此值为“0000”。
成员16(MinorImageVersion),2个字节,表示程序副版本号,此值不会影响程序的执行,我们这里填充零,此值为“0000”。
成员17(MajorSubsystemVersion),2个字节,表示子系统主版本号。win32子系统版本。PE文件是专门为Win32设计的,该子系统版本必定是4.0,那么此处值为“04”。
成员18(MinorSubsystemVersion),2个字节,表示子系统副版本号,根据上面所说,此值应为“00”。
成员19(Win32VersionValue),2个字节,此值一般为“00”。
成员20(SizeOfImage),4个字节,表示程序载入内存后占用内存的大小(单位字节),即等于所有段的长度之和---------所有头和节经过节对齐处理后的大小。我们知道,我们文件PE结构总长小于1000h,但是内存中的对齐粒度是1000h,所以PE结构被映射后要占1000h,尽管很多空间没有使用,另外我们有3个段,每个段的长度小于1000h,但是被映射后同样要占1000h,所以总共占用内存的大小为1000h + 3 * 1000h = 4000h,因此此值为“00400000”。
成员21(SizeOfHeaders),4个字节,表示所有文件头的长度之和(从文件开始到第一个段之间的大小)。所有头即PE头加所有节表头的大小,也就等于文件尺寸减去文件中所有节的尺寸。可以以此值作为PE文件第一节的文件偏移量。那么我们怎么得到这个值呢?我们的PE文件头总大小为:64 + 112 + 4 + 20 + 224 = 424,3个节表头的总大小 3 * 40 =120。424 + 120 = 544 byte 转化成十六进制为220h,那么此值就填写220h吗?不是的,因为我们文件中的对齐粒度是200h,那么220h经过文件对齐后实际上要占用400h的空间,所以此值为“00040000”。
成员22(CheckSum),4个字节,表示校验和。它仅用在驱动程序中,在可执行文件中可能为0。它的计算方法Microsoft没有公开,在imagehelp.dll中的CheckSumMappedFile()函数可以计算它,此处我们设为填充零,此值为“00000000”。
成员23(Subsystem),2个字节,表示NT子系统,可能是以下的值:
IMAGE_SUBSYSTEM_NA TIVE (1) 不需要子系统。用在驱动程序中。
IMAGE_SUBSYSTEM_WINDOWS_GUI(2) WIN32 graphical程序(它可用AllocConsole()来打开一个控制台,但是不能在一开始自动得到)。
IMAGE_SUBSYSTEM_WINDOWS_CUI(3) WIN32 console程序(它可以一开始自动建立)。
IMAGE_SUBSYSTEM_OS2_CUI(5) OS/2 console程序(因为程序是OS/2格式,所以它很少用在PE)。 IMAGE_SUBSYSTEM_POSIX_CUI(7) POSIX console程序。
Windows程序总是用WIN32子系统,所以只有2和3是合法的值。也就是说此值必须为2或3,如果是3,那么程序运行后会自动打开一个控制台,我们为了看一下效果,这里设为3,此值为“0300”。
成员24(DllCharacteristics),2个字节,表示Dll属性,我们这里填充零,此值为“0000”。
成员25(SizeOfStackReserve),4个字节,保留堆栈大小,我们这里填充零,此值为“00000000”。
成员26(SizeOfStackCommit),4个字节,启动后实际申请的堆栈数,可随实际情况变大,我们这里填充零,此值为“00000000”。
成员27(SizeOfHeapReserve),4个字节,保留堆大小,我们这里填充零,此值为“00000000”。
成员28(SizeOfHeapCommit),4个字节,实际堆大小,我们这里填充零,此值为“00000000”。
成员29(LoaderFlags),4个字节,装载标志,我们这里填充零,此值为“00000000”。
成员30(NumberOfRvaAndSizes),4个字节,在讲这个成员之前,我们应该先了解
成员31,成员31实际上是一个IMAGE_DATA_DIRECTORY结构的数组,成员30的值就是表示该数组的大小。通常有16个元素,也就是十六进制的0x00000010,所以此值填为:“10000000”。 IMAGE_DA TA_DIRECTORY结构定义如下:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DA TA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
成员31(DataDirectory),128个字节,上面说过他是一个IMAGE_DA TA_DIRECTORY结构的数组,通常具有16个元素。
IMAGE_DATA_DIRECTORY结构有两个成员,各占4个字节,也就得到成员31的总大小:2 * 4 * 16 = 128byte。16个元素中每个元素代表一个目录表,每个目录表表示的目录如下:
IMAGE_DIRECTORY_ENTRY_EXPORT (0) 导出目录,用于DLL
IMAGE_DIRECTORY_ENTRY_IMPORT (1) 导入目录
IMAGE_DIRECTORY_ENTRY_RESOURCE (2) 资源目录
IMAGE_DIRECTORY_ENTRY_EXCEPTION (3) 异常目录
IMAGE_DIRECTORY_ENTRY_SECURITY (4) 安全目录
IMAGE_DIRECTORY_ENTRY_BASERELOC (5) 重定位表
IMAGE_DIRECTORY_ENTRY_DEBUG (6) 调试目录
IMAGE_DIRECTORY_ENTRY_COPYRIGHT (7) 描述版权串
IMAGE_DIRECTORY_ENTRY_GLOBALPTR (8) 机器值
IMAGE_DIRECTORY_ENTRY_TLS (9) 本地线程存储目录
IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG (10) 载入配置目录
IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (11) 绑定导入表目录
IMAGE_DIRECTORY_ENTRY_IA T (12) 输入地址表目录
IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT(13) 延迟加载导入描述目录
IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR(14) COM 运行时描述目录
是不是所有的目录表都要关心呢?其实要把这些目录表都研究清楚是个很大的课题,对于我们这个程序,只需关心第2个元素,导入目录,它标识了我们的程序从其他模块导入的函数信息。因为我们要显示一个消息框,所以要导入user32.dll库中的MessageBoxA函数。程序要正常退出,又要导入kernel32.dll库中的ExitProcess函数。因此需要构造这个目录表。然而上面已说明每个目录是一个IMAGE_DATA_DIRECTORY 结构,该结构具有两个成员,第一个成员表示目录表的起始RV A地址,第二个成员表示目录表的长度。我们将把这个目录表构造到.rdata段中,所以暂时先不填写。但是要留出空位来,为了记住该位置,我们先都填写为a,即:“aaaaaaaa”,“aaaaaaaa”。注意因为要文件对齐,所以其余的统统添零直到地址1a7h处。此时完成的代码如图7所示:
图7 完成PE结构中的PE头部分
接下来完成各段头部,又称为节表。一个程序中用到的所有代码、资源、全局数据等信息分布在各个节中,而各个节的信息,如节加载位置,节大小,节属性等信息都由紧跟PE头之后的节表所指出。它实际上就是紧挨着 PE 头的一个结构数组,该数组成员的数目由 file header (IMAGE_FILE_HEADER) 结构中 NumberOfSections 域的域值来决定。节表结构又命名为 IMAGE_SECTION_HEADER。
我们这里有3个段,.text(代码段), .rdata(只读数据段),data(全局变量数据段)。每段是一个IMAGE_SECTION_HEADER 结构,具有10个成员。IMAGE_SECTION_HEADER结构定义如下:typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
首先我们来完成.text段。
成员1(Name),8个字节,表示该节的名称,我们这里该节的名字为.text,那么此值应该是他的ASKII 码值应该为“2E74657874000000”。
成员2(VirtualSize),4个字节,表示该节数据映射到内存后所占字节数。在这里是指有效代码所占的字节数。稍后我们将把程序的执行代码指令写入到文件中,总共有多少字节的指令需要那时计算,我们也可以提前将代码准备好并计算出长度将其填写。笔者已经计算完毕,将写入26h个字节的代码。所以此时仍然将此值设为“26000000”。我们也可以填写26h经过内存对齐后的值,即“00100000”。
成员3(VirtualAddress),4个字节,表示在.text段映射到内存中的起始地址,那么这个值如何得来呢?我们知道.text是紧跟PE结构后的,然后整个PE头结构映射到内存后占的大小为1000h(因为PE头本身结构小于1000h个字节,而经过内存对齐后便为1000h),那么此值便得到了,为0x00001000,因此此处填写“00100000”。这个时候我们已经可以完成前面遗留的一个问题,再填写IMAGE_OPTIONAL_HEADER32结构的第七个成员的时候,它实际上是程序的入口地址,当时已经讲解此入口地址实际就是.text段的起始地址,所以可以将此处的“aaaaaaaa”更改为“00100000”。
(提示
程序的入口地址并不一定就代码段.text的起始位置。读者只需知道IMAGE_OPTIONAL_HEADER32结构的第7个成员所表示的含义是程序的入口地址。它通常是由编译器生成的。因为我们没有使用编译器,而是要手工打造一个可执行程序,所以所有的成员值都要自己来安排。只要按照PE结构的要求,安排合理即可。因此我们可以把代码的起始地址随意安排什么地方,只要安排的那个地址刚好又是我们保存的程序执行代码的入口即可。我们为了方便将其放在.text段的起始地址处。)
成员4(SizeOfRawData),4个字节,表示.text段在文件中所占的大小。因为我们的实际代码只有26h 个字节,那么这个值可以填写“26000000”,也可以填写此值经过文件对齐后的值即200h,所以也可以填写此值为“00020000”。
成员5(PointerToRawData),4个字节,表示.text段在文件中的起始地址,上面已经计算过PE文件的总长度为400h,他实际上也就是.text的起始偏移地址,此值为“00040000”。
成员6(PointerToRelocations),7(PointerToLinenumbers),8(NumberOfRelocations),9(NumberOfLinenumbers),均占4个字节,都仅用于目标文件,我们这里用零来填充。
成员10(Characteristics),4个字节。包含标记以指示节属性,比如节是否含有可执行代码、初始化数据、未初始数据,是否可写、可读等。这个值实际上是二进制位进行或运算得到的值。各二进制位表示的意义如下:
bit 5 (IMAGE_SCN_CNT_CODE),置1,节内包含可执行代码。
bit 6 (IMAGE_SCN_CNT_INITIALIZED_DATA)置1,节内包含的数据在执行前是确定的。
bit 7 (IMAGE_SCN_CNT_UNINITIALIZED_DATA) 置1,本节包含未初始化的数据,执行前即将被初始化为0。一般是BSS.
bit 9 (IMAGE_SCN_LNK_INFO) 置1,节内不包含映象数据除了注释,描述或者其他文档外,是一个目标文件的一部分,可能是针对链接器的信息。比如哪个库被需要。
bit 11 (IMAGE_SCN_LNK_REMOVE) 置1,在可执行文件链接后,作为文件一部分的数据被清除。
bit 12 (IMAGE_SCN_LNK_COMDAT) 置1,节包含公共块数据,是某个顺序的打包的函数。
bit 15 (IMAGE_SCN_MEM_FARDATA) 置1,不确定。
bit 17 (IMAGE_SCN_MEM_PURGEABLE) 置1,节的数据是可清除的。
bit 18 (IMAGE_SCN_MEM_LOCKED) 置1,节不可以在内存内移动。
bit 19 (IMAGE_SCN_MEM_PRELOAD)置1,节必须在执行开始前调入。
bits 20 to 23指定对齐。一般是库文件的对象对齐。
bit 24 (IMAGE_SCN_LNK_NRELOC_OVFL) 置1,节包含扩展的重定位。
bit 25 (IMAGE_SCN_MEM_DISCARDABLE) 置1,进程开始后节的数据不再需要。
bit 26 (IMAGE_SCN_MEM_NOT_CACHED) 置1,节的数据不得缓存。
bit 27 (IMAGE_SCN_MEM_NOT_PAGED) 置1,节的数据不得交换出去。
bit 28 (IMAGE_SCN_MEM_SHARED) 置1,节的数据在所有映象例程内共享,如DLL的初始化数据。
bit 29 (IMAGE_SCN_MEM_EXECUTE) 置1,进程得到“执行”访问节内存。
bit 30 (IMAGE_SCN_MEM_READ) 置1,进程得到“读出”访问节内存。
bit 31 (IMAGE_SCN_MEM_WRITE)置1,进程得到“写入”访问节内存。
在我们这里,因为这是代码段,所以bit 5 (IMAGE_SCN_CNT_CODE)位要置1,一般代码段都含有初始化数据,那么bit 6 (IMAGE_SCN_CNT_INITIALIZED_DATA)位要置1,又因为代码段的代码可以执行的,所以bit 29 (IMAGE_SCN_MEM_EXECUTE) 位要置1,那么这3个二进制位进行或运算最终得到的二进制值为
“00100000000000000000000001100000”,将其转换为十六进制值为0x20000060,所以此处应该填写“60000020”。
到此整个.text头编写完毕,按照上面的方法,分别填写.rdata段和.data段。因为要文件对齐,所以后面的代码用零补齐,直到3ffh。
PE加载器根据节表加载程序的过程是这样的:读取 IMAGE_FILE_HEADER 的 NumberOfSections域,得到文件中节的数目。读取IMAGE_OPTIONAL_HEADER32的SizeOfHeaders 域值,将其作为节表的文件偏移,并以此定位节表。遍历整个结构数组检查各成员值。对于每个结构,读取PointerToRawData域值并定位到该文件偏移量。然后再读取SizeOfRawData域值来决定映射内存的字节数。将VirtualAddress域值加上ImageBase域值等于节起始的虚拟地址。然后把节映射进内存,并根据Characteristics域值设置属性。遍历整个数组,直至所有节都已处理完毕。
(提示
感染型病毒经常通过增加节来达到感染正常文件的目的。因为感染正常文件需要添加病毒代码,病毒最常用的方法是新建一个节,然后将病毒代码放置在新建的节中,然后修改程序入口地址使其指向病毒代码。这样程序运行以后首先运行的是病毒代码,等病毒代码运行完毕才会跳转到被感染程序的原始入口地址处执行。)
最后的编写结果如图8所示:
图8 完成各个节表
至此,我们已经完成了PE头结构的编写。为了让我们写的程序可以运行,我们还要完成.text(代码段), .rdata(只读数据段),data(全局变量数据段)三个段的实体部分。
首先编写.text段,他紧接着PE结构后面。前面已经说过,.text段中存放所有可执行的指令代码(机器码)。我们可以通过先编写汇编指令(调用MessageBoxA和ExitProcess两个函数),然后反汇编出机器代码抄到这里就可以了。我们的程序功能是弹出一个消息框,这需要用到MessageBoxA函数,当用户单击确定以后程序要退出,这又需要用到ExitProcess函数。这两个函数调用的汇编代码如下:
push 0 ; MessageBoxA的第四个参数,即消息框的风格,这里传入0。
push ???? ;第三个参数,消息框的标题字符串所在的地址,需要计算。
push ???? ;第二个参数,消息框的内容字符串所在的地址,需要计算。
push 0 ;第一个参数,消息框所属窗口句柄,这里填0。
call ????;调用MessageBoxA,实际是跳转到该函数的跳转指令所在地址
push 0 ;ExitProcess函数的参数,程序退出码,传入0.
call ????;调用ExitProcess,实际是跳转到该函数的跳转指令所在地址
jmp ????;跳转到MessageBoxA的真正地址处。
jmp ????;跳转到ExitProcess的真正地址处。
首先计算MessageBoxA两个字符串参数的地址,实际上是两个字符串,“消息框”和“HelloWorld !”。这
两个串需要保存到文件中,我们设计将其存放在.data(全局变量数据段)。这个段位于.rdata段之后,那么可以计算它的起始内存地址,PE头1000h,.text段只有26h字节,内存对齐后为1000h,.data(只读数据段)是准备用来完成导入表的段,它肯定也不会超过1000h,所以对齐后应为1000h,因此紧随其后的.rdata的起始内存地址应该在偏移为:
1000h+1000h+1000h=3000h处,程序的基址为400000h,故此得到.rdata的绝对内存地址为:
0x00400000+0x00003000=0x00403000。我们将“消息框”字符串放于此处,该字符串占7个字符,那么紧随其后的“Hello World !”字符串的地址应该为0x00403000+7=0x00403007。
所以修正以上汇编代码为:
push 0 ; MessageBoxA的第四个参数,即消息框的风格,这里传入0。
push 0x403000 ;第三个参数,消息框的标题字符串所在的地址。
push 0x403007 ;第二个参数,消息框的内容字符串所在的地址。
push 0 ;第一个参数,消息框所属窗口句柄,这里填0。
call ????;调用MessageBoxA,实际是跳转到该函数的跳转指令所在地址。
push 0 ;ExitProcess函数的参数,程序退出码,传入0.
call ????;调用ExitProcess,实际是跳转到该函数的跳转指令所在地址。
jmp ????;跳转到MessageBoxA的真正地址处。
jmp ????;跳转到ExitProcess的真正地址处。
其次需要计算MessageBoxA和ExitProcess两个函数所在地址,这个需要完成.rdata段的导入表才可以得到。所以首先用200h个00将.text段填充,待完成.rdata段后再返过来完成它。
接下来完成.rdata段,这个段非常重要,也非常繁琐。因为我们要手工打造导入表。通常导入表是由编译器生成的,其生成规则遵循IMAGE_IMPORT_DESCRIPTOR结构。IMAGE_IMPORT_DESCRIPTOR结构的定义如下:
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RV A to original unbound IA T (PIMAGE_THUNK_DATA)
};
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RV A to IA T (if bound this IA T has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
前面曾介绍这个程序我们只用完成数据目录数组的第二个元素-------导入表目录,然而此目录值我们当时没有填写,当时添充的是“aaaaaaaa”作为标记,现在我们要一并解决这个问题。前面已经说过,每个数据目录具有两个成员,第一个成员表示目录表的起始RV A地址,第二个成员表示目录表的长度。对于我们这个导入表目录来说,他指的就是导入表了,导入表实际上是一个IMAGE_IMPORT_DESCRIPTOR 结构数组,每个结构包含PE文件从某一个DLL库引入函数的相关信息。例如,我们这个程序将从2个DLL库中导入函数,那么这个数组就有2个成员,同时该数组以一个全零的成员结尾。每一个IMAGE_IMPORT_DESCRIPTOR结构具有5个成员,都是DOWRD类型,因此每个IMAGE_IMPORT_DESCRIPTOR结构的大小为4*5=20byte。因此整个导入表的大小应该为(2+1)
*20=60byte。转换成十六进制也就是0x3C。这样也就得到了导入表的大小,现在可以将导入表目录的第二个成员修改过来,将“aaaaaaaa”替换为0x0000003c,也就是在编辑器中输入“3c000000”。接下来看导入目录的第一个成员如何计算,它是导入表的起始地址的RV A值,我们计划将导入表放到.rdata段,并且自.rdata段起始地址处开始。那么导入表的起始地址也就是.rdata段的起始地址。.rdata紧随.text段之后,那么它的起始地址偏移应该为PE头的大小1000h+.text的大小1000h即2000h。现在可以将导入表目录的第一个成员修改过来,将“aaaaaaaa”替换为“00200000”。
之后的工作就是手工打造一个导入表。导入表在文件中的位置也同样是.rdata段的起始地址处,文件地址应该为PE头的400h+.text段的200h即600h处。我们打造导入表同样也要遵循IMAGE_IMPORT_DESCRIPTOR结构,该结构有5个成员:
成员1,4个字节,他实际上是指向一个 IMAGE_THUNK_DATA 结构数组的RV A,而IMAGE_THUNK_DATA 结构数组记录所有从某个.dll库中导入的所有函数名称的RV A。实际上它是指从某个DLL文件中导入的所有函数名称所在地址的地址表,该地址表由一个全零DWORD值0x00000000结束。因此我们需要构造这样一个表。首先需要把导入的所有函数名称依次保存到某个位置,然后计算其RV A去构造函数名称地址表。
为了紧凑,我们可以将每个函数名和动态库名字符串放在导入表之后。前面已经计算得到导入表的长度为0x3c,那么字符串的位置应该保存到文件中的地址为:600h(导入表的起始文件偏移地址)+3ch(导入表长度)= 63ch处。在这里准备填写所有字符串的AscII码。首先输入“MessageBoxA”字符串,这里有一点要注意,一个PE程序在导入函数的时候可以按照函数名来导入,也就是我们准备采取的方式,也可以按照函数序号导入。函数序号在各个动态库的导出表中可以查询到。该序号是一个WORD类型的值。无论是否我们以序号方式导入都要保留其位置,也就是在“MessageBoxA”字符串前应该预留一个WORD值的位置。因为我们并不是按照函数序号的方式导入,所以这里可以填写任意值,我们就填写0x0000。然后紧接其后写入“MessageBoxA”字符串,注意字符串要以一个字节的0x00结尾。如果还导入了其他函数,那么依次输入那些被导入的函数名AscII值即可。最后输入导入库名的AscII值,即“user32.dll”字符串。这样我们完成了一个导入库的名称表,紧随其后以相同方式完成另一个导入库,即“ExitProcess”字符串和“kernel32.dll”字符串。在导入表后输入的内容如下:
“00004D657373616765426F7841007573657233322E646C6C0080004578697450726F63657373006B65726E65 6C33322E646C6C00”。
如图9所示:
图9 导入表用到的字符串
完成函数名称表后就可以构造函数名称地址表。紧随名称表之后,函数名称表起始地址为文件偏移63ch处,长度是34h。所以其后的函数名称地址表的起始应该为:63ch+34h==670h。函数名称地址表中保存了从某一个DLL库中导入的所有函数名称所在内存地址的RV A值,并且以一个0x00000000作结束。导入了几个DLL库,那么就有几个函数名称地址表。我们这里总共导入了两个DLL库,那么就有两个函数名称地址表。我们分别完成它。首先是user32.dll库中导入了MessageBoxA,因为函数名称表已经构造完毕,所以我们可以得到它的文件偏移,是63ch,怎样由文件偏移计算得到RV A值呢?这取决于内存对齐粒度和文件对齐粒度。PE加载器将PE文件加载入内存是按照内存对其粒度进行加载的。让们看看从文件首到0x063C处内容如何加载入内存。首先PE头经过文件对齐占400h,而此部分内容经过内存对齐加载入内存后占1000h。然后是.text节经文件对齐占200h,而此节内容经过内存对齐加载如内存后占1000h,也就是说文件偏移600h
对应内存RV A是2000h,因此文件地址0x63C对应的RV A应该是0x203C。所以函数名称地址表中填写0x0000203C,即“3C200000”,user32.dll库中只导入了一个函数,所以后面填写一个全零的DWORD值0x00000000,即“00000000”表示结束。接着完成kernel32.dll库的导入函数地址表。由函数名称表中可以得到被导入的ExitProcess的文件偏移为0x655。它对应的RV A值为0x2055,那么紧随前一个函数名称地址表填写“55200000”,由于也只导入了一个函数,所以后面填写全零的DWORD值表示此表的结束。这样完成了整个导入表所需的两个库函数名称地址表,如图10所示:
图10导入名称地址表
由此可知user32.dll库函数名称地址表的起始文件偏移为0x670,对应的RV A值为0x2070。而kernel32.dll 库函数的名称地址表的起始文件偏移为0x678,对应的RV A值为0x2078。此时可以完成关于user32.dll库的导入表的第一个成员,就是指由user32.dll库导入的函数名称地址表起始地址的RV A值,应该是0x2070,因为此成员占4个字节,所以编辑器中应该填写“70200000”。
成员2,成员3各4各字节,用处不大,我们用零填充。
成员4,4个字节,是指向DLL名字的RV A。由user32.dll导入函数名称表可以得知此DLL名称所在地址的文件偏移为0x64A,对应的RV A值应该为0x204A,所以此成员应该填写0x0000204A,即“4A200000”。成员5,4个字节,指向一个 IMAGE_THUNK_DA TA 结构数组的RV A,同成员1一样。但是此IMAGE_THUNK_DATA 数组结构含义确和成员1完全不同。它将保存所有导入函数的真实调用地址。换句话说实际上它也指向一个地址表,这个地址不再像成员1一样是函数名称地址表,而是函数真实调用地址表,这个表又称为导入地址表,简称为IA T。既然这个表存放的是函数调用的真实地址,在设计PE文件时还没有得到导入函数的调用地址,所以无法填写此表。该表由PE文件被装载到内存时,PE加载器获得导入函数的真实地址来填充这个表。同样这个表以一个全零的DWORD作为结束标志。同样为了紧凑,我们将函数调用地址表安排在函数名称地址表之后,函数名称地址表的起始文件偏移是0x670,总共0x10个字节,那么其后的函数调用地址表的起始文件偏移为0x670+0x10=0x680。转换为RV A应该为0x2080,所以成员5应该填写“80200000”。
(注意:
虽然函数调用地址最终由PE加载器来填充,我们只需指定该表的位置。但是由于该表以全零的DWORD 值作为结束标记。所以如果我们开始也填充全零将使PE加载器填充失败,所以我们需要随便填入一个非零值,这里笔者填入0x00000011。之后再填写结束标记0x00000000。紧随其后是第二导入库的函数调用地址表,导入了几个函数就需要填写几个非零的DWORD值,然后填写结束标记0x00000000。最终完成的导入函数调用地址表如图11所示:)
图 11 IA T
至此,完成了导入表中的关于导入库user32.dll的部分,按照相同的方法继续完成关于导入库kernel32.dll 部分。最终导入表如图12所示:
图 12 导入表
.rdata的其余部分用00填充,直到文件偏移0x800处。
最后是.data段,这个段非常简单,就是MessageBoxA所需的参数,消息框的标题和内容:即“消息框”、“Hello World !”两个字符串的AscII值。其余部分用00填充,直到0xA00处。如图13所示:
图 13 导入表
最后我们继续完成.text段的程序执行代码。代码如下:
push 0 ; MessageBoxA的第四个参数,即消息框的风格,这里传入0。
push 0x403000 ;第三个参数,消息框的标题字符串所在的地址。
pe文件格式
PE文件格式详解(一)――基础知识 什么是PE文件格式: 我们知道所有文件都是一些连续(当然实际存储在磁盘上的时候不一定是连续的)的数据组织起来的,不同类型的文件肯定组织形式也各不相同;PE文件格式便是一种文件组织形式,它是32位Wind ow系统中的可执行文件EXE以及动态连接库文件DLL的组织形式。为什么我们双击一个EXE文件之后它就会被Window运行,而我们双击一个DOC文件就会被Word打开并显示其中的内容;这说明文件中肯定除了存在那些文件的主体内容(比如EXE文件中的代码,数据等,DOC文件中的文件内容等)之外还存在其他一些重要的信息。这些信息是给文件的使用者看的,比如说EXE文件的使用者就是Window,而DOC文件的使用者就是Word。Window可以根据这些信息知道把文件加载到地址空间的那个位置,知道从哪个地址开始执行;加载到内存后如何修正一些指令中的地址等等。那么PE文件中的这些重要信息都是由谁加入的呢?是由编译器和连接器完成的,针对不同的编译器和连接器通常会提供不同的选项让我们在编译和 联结生成PE文件的时候对其中的那些Window需要的信息进行设定;当然也可以按照默认的方式编译连接生成Window中默认的信息。例如:WindowNT默认的程序加载基址是0x40000;你可以在用VC连接生成EXE文件的时候使用选项更改这个地址值。在不同的操作系统中可执行文件的格式是不同的,比如在Linux上就有一种流行的ELF格式;当然它是由在Linux上的编译器和连接器生成的,
所以编译器、连接器是针对不同的CPU架构和不同的操作系统而涉及出来的。在嵌入式领域中我们经常提到交叉编译器一词,它的作用就是在一种平台下编译出能在另一个平台下运行的程序;例如,我们可以使用交叉编译器在跑Linux的X86机器上编译出能在Arm上运行的程序。 程序是如何运行起来的: 一个程序从编写出来到运行一共需要那些工具,他们都对程序作了些什么呢?里面都涉及哪些知识需要学习呢?先说工具:编辑器-》编译器-》连接器-》加载器;首先我们使用编辑器编辑源文件;然后使用编译器编译程目标文件OBJ,这里面涉及到编译原理的知识;连接器把OBJ文件和其他一些库文件和资源文件连接起来生成EXE文件,这里面涉及到不同的连接器的知识,连接器根据OS的需要生成EXE文件保存着磁盘上;当我们运行EXE文件的时候有W indow的加载器负责把EXE文件加载到线性地址空间,加载的时候便是根据上一节中说到的PE文件格式中的哪些重要信息。然后生成一个进程,如果进程中涉及到多个线程还要生成一个主线程;此后进程便开始运行;这里面涉及的东西很多,包括:PE文件格式的内容;内存管理(CPU内存管理的硬件环境以及在此基础上的OS内存管理方式);模块,进程,线程的知识;只有把这些都弄清楚之后才能比较清楚的了解这整个过程。下面就让我们先来学习PE文件格式吧。
读书笔记之建筑结构设计快速入门-第二版(刘铮)
P24 1.1.3如何初估各种结构构件的截面尺寸 主动记忆一些常识性的工程数据,比如梁板的跨高比,剪力墙墙厚,平时注意积累分析,多问多算,大工程做细,小工程做精。 1.1.3熟记民用建筑设计荷载 (1)多高层住宅楼(商品房),二次装修改造的荷载,落棉荷载一般取值2.0kN/m2。 (2)3个2.0kN/m2 表1 一般民用住宅荷载经验取值 楼面做法自重(2.0kN/m2)轻质隔墙自重(2.0kN/m2)活荷载取值(2.0kN/m2) 2.0 2.0 2.0 (3)对于住宅和办公的屋面,如没有特殊保温防水做法要求,一般屋面恒荷载在4.0 kN/m2左右,与实际不会有太大出入;对于屋面活荷载,不上人时0.5 kN/m2,上人时为2.0 kN/m2。 1.2.3 “次要让位于主要”的原则—明确哪些钢筋的位置对结构设计来说更重要 1.3.1 钢筋的三种连接方式—焊接、搭接、机械连接“孰优孰劣” 对于结构重要的部位,《高层建筑混凝土结构技术规程》(JGJ3-2002)规定钢筋的连接宜采用机械连接,而之前规范规定为焊接,改的原因是焊接会使被焊钢筋变脆,在抗震的重要部位,反而变成了“最坏”的做法。 机械连接分为邓强连接和不等强连接,I级为等强连接,II、III级则为不等强连接,主要是针对“钢筋接头处的强度是否大于钢筋母材强度”而言的。 设计可依据《钢筋机械连接通用技术规程》(JGJ 107-2003)中相关的规定,选择与受力情况相匹配的接头。 I级接头:套筒挤压、镦粗接头、剥肋滚螺纹。 剪力墙之水平与竖向分布筋,因钢筋较细,不是抗震的关键部位,适合采用搭接的方式,
不宜采用机械接头。 搭接接头应满足: (1)选择正确的搭接部位; (2)有足够的搭接长度; (3)搭接部位的箍筋间距加密至满足要求。 (4)有足够的混凝土强度与足够的保护层厚度。 如能满足这4款要求,搭接是一种比较好接头方式,而且往往是最省工的方法。但其缺点: (1)在抗震构件的内力较大部位,当构件承受反复荷载时,有滑动的可能; (2)在构件钢筋较密集时,采用搭接方法将使浇捣混凝土较为困难。 当受拉钢筋直径大于28mm,受压钢筋直径大于32mm时,不宜采用搭接。
中文版word基础教程
W o r d 2003基础教程 编 撰 花 椒 文 刀 版权归属:中国盲文出版社信息无障碍中心盲人挚友聊天室 前 言 结合阳光读屏软件强大的Word 朗读功能, 由信息无障碍中心开办的于2008年11月至 2009年3 月,推出在线《Word2003基础讲座》。同期,我们将讲座内容编纂成册,免费提供给 阳光软件的广大用户,以便查阅。 本教程用Word2003编写, 您可以通过单击目录快速跳转到需要查阅的文本,具体操作方法是:用上下光标逐行朗读目录,听到您想查阅的条目后,按下 Ctrl+小键盘的斜杠键,这样,光标会自动跳转到目录对应的文本,以方便您的查阅,同时,在阅读过程中,教程所提及的所有操作,您均可在当前窗口尝试,当然,为了保持教程的完整,建议您在关闭本 教程时选择不保存修改。 本教程由阳光软件免费提供,版权归属中国盲文出版社信息无障碍中心盲人挚友聊天室, 请勿用于商业用途,违者必究。
目录 第一章 初识中文版Word2003 中文版word2003是微软公司推出的中文版office2003软件套装中的重要组成部分,它具有 强大的文本编辑和文件处理功能,是实现无纸化办公和网络办公不可或缺的应用软件之一。 第一节安装、启动和退出程序 一、安装程序 安装word2003和安装其它软件并无二致,需要说明一下的是光盘版的安装。当您将中文版 office2003光盘放入光驱后,请不要自动播放,因为自动播放会弹出图形化的安装界面,读 屏软件无法操作。您可以在插入光盘后,打开“我的电脑”找到CD驱动器,application键 弹出快捷菜单,通过“打开(O)菜单”来打开光盘,然后在列表中选中office文件夹,打开 以后,列表中出现几个文件夹,由于版本不同,文件夹数量和名称可能会略有区别,不过没 关系,在这些文件夹中寻找setup.exe并回车执行,您就能顺利地用键盘完成安装操作了。 二、启动程序 按下Windows键弹出“「开始」菜单”,展开“所有程序(P)菜单”后。上下光标到 “MicrosoftOffice子菜单”,右光标展开该子菜单后,上下光标找到 “MicrosoftOfficeWord2003菜单”回车即可启动Word程序。另外,当您在资源管理器中选 择任意一个后缀名为.doc的文档回车时,计算机也会为您启动word程序,同时打开您选中 的文档。 三、退出程序 在程序窗口按下快捷键:“Alt+F4”是退出程序最简便的方法。当然您还可以在程序窗口按下 Alt键激活菜单栏,下光标展开“文件(F)子菜单”并找到到“退出(X)菜单”回车,或在程 序窗口按下“Alt+空格”弹出控件菜单,上下光标找到“关闭(c)菜单”回车即可退出程序。
PE文件头解析大全
PE可选头部 PE可执行文件中接下来的224个字节组成了PE可选头部。虽然它的名字是“可选头部”,但是请确信:这个头部并非“可选”,而是“必需”的。OPTHDROFFSET宏可以获得指向可选头部的指针: PEFILE.H #define OPTHDROFFSET(a) ((LPVOID)((BYTE *)a + \ ((PIMAGE_DOS_HEADER)a)->e_lfanew + \ SIZE_OF_NT_SIGNATURE + \ sizeof(IMAGE_FILE_HEADER))) 可选头部包含了很多关于可执行映像的重要信息,例如初始的堆栈大小、程序入口点的位置、首选基地址、操作系统版本、段对齐的信息等等。IMAGE_OPTIONAL_HEADER结构如下: WINNT.H typedef struct _IMAGE_OPTIONAL_HEADER { // // 标准域 // USHORT Magic; UCHAR MajorLinkerVersion; UCHAR MinorLinkerVersion; ULONG SizeOfCode; ULONG SizeOfInitializedData; ULONG SizeOfUninitializedData; ULONG AddressOfEntryPoint; ULONG BaseOfCode; ULONG BaseOfData; // // NT附加域 // ULONG ImageBase; ULONG SectionAlignment;
ULONG FileAlignment; USHORT MajorOperatingSystemVersion; USHORT MinorOperatingSystemVersion; USHORT MajorImageVersion; USHORT MinorImageVersion; USHORT MajorSubsystemVersion; USHORT MinorSubsystemVersion; ULONG Reserved1; ULONG SizeOfImage; ULONG SizeOfHeaders; ULONG CheckSum; USHORT Subsystem; USHORT DllCharacteristics; ULONG SizeOfStackReserve; ULONG SizeOfStackCommit; ULONG SizeOfHeapReserve; ULONG SizeOfHeapCommit; ULONG LoaderFlags; ULONG NumberOfRvaAndSizes; IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]; } IMAGE_OPTIONAL_HEADER, *PIMAGE_OPTIONAL_HEADER; 如你所见,这个结构中所列出的域实在是冗长得过分。为了不让你对所有这些域感到厌烦,我会仅仅讨论有用的——就是说,对于探究PE文件格式而言有用的。 标准域 首先,请注意这个结构被划分为“标准域”和“NT附加域”。所谓标准域,就是和UNIX可执行文件的COFF 格式所公共的部分。虽然标准域保留了COFF中定义的名字,但是Windows NT仍然将它们用作了不同的目的——尽管换个名字更好一些。 ·Magic。我不知道这个域是干什么的,对于示例程序EXEVIEW.EXE示例程序而言,这个值是0x010B
建筑结构设计步骤
1、首先是柱网的布置,这一阶段你可以理解为概念设计,你要大概确定哪些位置需要布置柱,如果是某些对室内空间有要求的建筑,比如住宅,你还需要确定是布矩形柱还是L型柱或者T型柱,这一阶段你可以先不确定柱的尺寸,只要先确定哪些位置需要布置柱就行了。具体怎么布你需要查一查规范,这个我在这里也很难说清楚,一般主要是首先在保证结构尽量规整(比如框架尽可能要形成闭合体系,就是围成一个矩形)的基础上,根据建筑的使用要求再进行调整(比如有的地方不能放柱)。 2、确定梁的位置。一般没意外的话墙下尽可能要有梁,柱网没有形成闭合体系的地方要通过梁把两个闭合体系连接成一个整体,楼板跨度过大的地方要设置次梁,楼板开洞处板洞要用梁围合,梁不能凭空搭接,梁的两端要么搭在柱上,要么搭在别的梁上。以上两部分算概念设计,确实有规范可循,但主要靠经验,你可以查一查《建筑抗震设计规范》、《混凝土结构设计规范》 3、梁柱尺寸的确定,柱截面尺寸估算你可以根据轴压比公式来估算,不会的话百度下很多的,比较长我不细说了。梁高主要根据跨度取,我也不说多复杂了,主梁一般取1/10不到,次梁取1/12,梁宽你一般取200~350之间,高宽比最好不要大于2,主梁你可以外围的梁取250宽,中部的取300,次梁取200~250,比如一块7*9最边上的板,外部9米长的跨度部分取800*250,内部的取800*300,7米跨度部分外部的取600*250,内部的取600*300,9米跨一半的地方搭根次梁取500*250。 4、建模,其实前面3点已经是在PKPM里建模做了,第四部主要是加荷载,比如墙的重量转化成梁上的线荷载,板上的面层转化成楼面恒载等等,具体不细说了。然后楼层组装,设定建筑的一些系数,最后去SATWE里计算,然程序自动给你配筋 5、出施工图了,用梁平法和柱平法把施工图出出来让后根据制图规范改吧。 6、JCCAD里做基础,地质报告看看好,系数设好,布基础、地梁,导荷载,然后自动计算,写了好多了也不细说了,主要在1、2、3里给你讲下最开始怎么从梁柱的布置入手。 一、起因 与钢、混凝土、砌体等材料相比,土属于大变形材料,当荷载增加时,随着地基变形的相应增长,地基承载力也在逐渐加大,很难界定出一个真正的“极限值”,而根据现有 理论的、半理论半经验的或经验的承载力计算公式,可以得出不同的值。因此,地基极限承载力的确定,实际上没有一个可以通用的界定标准,也没有一个可以适用于一切土类的计算公式,主要依赖于根据工程经验所定下的界限和相应的安全系数加以调整,考虑一个满足工程要求的地基承载力值。它不仅与土质、土层埋藏顺序有关,而且与基础底面的形状、大小、埋深、上部结构对变形的适应程度、地下水位的升降、地区经验的差别等等有关,不能作为土的工程特性指标。 另一方面,建筑物的正常使用应满足其功能要求,常常是承载力还有潜力可挖,而变形已达到或超过正常使用的限值,也就是由变形控制了承载力。以往的工程实践证明,绝大多数地基事故皆由地基变形过大且不均匀造成。 因此,根据传统习惯,地基设计所选用的承载力通常是在保证地基稳定的前提下,使建筑
民用建筑结构设计中的基础设计
民用建筑结构设计中的基础设计 摘要:在民用建筑结构基础设计过程中,其设计技术复杂,设计质量还直接关 系着整个建筑的质量水平的高低。所以,设计人员在实际的基础设计中,应该重 视地基基础设计工作,不断探究设计要求,充分考虑各种因素对基础设计产生的 影响,并且提出有效的措施解决问题,从而提升民用建筑的质量,保障人们的生 命安全,推动我国建筑行业长远的发展。 关键词:民用建筑;结构设计;基础设计 1 民用建筑结构设计要求 1.1 上部结构 在整个民用建筑工程中,是由上部结构和基础地基部分组成,地基基础和上部结构相互 促进作用,共同受力协调。上部结构的设计,不仅关系着地基的承载力,更关系着整个建筑 体的质量与安全。因此,在地基基础设计过程中,要充分的考虑上部结构的强度和刚度,不 同的上部结构对地基基础变形的使用能力也不同。所以,设计人员在深入了解上部结构刚度 特征后,要制定出合理的地基基础形式和结构设计方案。 1.2 地理条件 在民用建筑在进行基础设计前,应该充分的对现场进行勘察和研究,深入的掌握地质资料。同时,掌握建筑场地的交通、供电、排水等情况。不同的建筑物,需要根据不同的地基 方案进行不同的基础改造,并且工程造价和施工难度也不一样。通常情况下,会选择地理条 件优越的地基,简单的施工方式,让设计更符合经济合理的原则。其次,特殊的工程需要在 特定的地形上建设,比如地基强度不稳定或者压缩性较大,无法满足设计要求,则需要按照 不同的情况对地基进行特殊的处理,通过各种处理和优化,来提高地基的稳定性和强度,从 而减少地基变形,为建筑整体质量目标和要求奠定基础保障。同时,再选择建筑地基时,应 该尽量避免滑坡现象的地段。由于地震等其他自然因素的影响,会导致地基受到影响,产生 变形,从而影响建筑体的安全。 1.3 施工环境因素 民用建筑在基础设计过程中,由于天然地基无法满足沉降量和承载力的设计要求,往往 采用桩基础。在城市建筑体密集的地方,桩基础作业带来的环境危害非常多,不仅会影响到 工程的造价和进度,还会对整个工程的质量和安全产生影响。尤其是桩基础施工会对周围环 境造成严重的破坏,如:噪音污染、环境污染等等,甚至还会造成不可挽回的损失。 2 建筑物建设过程中的常见基础形式 2.1 墙下条形基础 在相关的结构基础设计上需要完成有关的研究工作,最大程度的满足其具体的使用需求,在相关的研究来说,墙下需要使用条形基础构建,整体的建设上需要完成混凝土来打基础, 对于混凝土来说其有较强的耐久性,同时在经过相关的使用之后要确保其能够满足实际发展 需求,并且对于较低的建筑物当中,相关的优势就是需要进行合理的造价安排,对于相关建 设来说,主要的优势就是造价较低,综合的满足操作便利的问题,所以对于工程的全面建设 来说,需要结合实际情况因地制宜的对整体刚度进行改进。
Scratch2.0入门中文使用教程
儿童编程 SCRATCH2.0入门中文使用教程 目录: 1. Scratch的简介 第1课下载与安装 第2课初识Scratch 2.Scratch基础课程 第3课让角色动一动 第4课键盘控制 第5课迷宫程序 第6课会飞的巫婆 第7课三角形的面积 第8课造型切换---人物走动 第9课移动人物教师进阶使用 第10课判断人物位置 3. Scratch进阶课程--打蝙蝠 3-1 第一节课 3-2 第二节课 3-3 第三节课
4. scratch进阶课程2-打地鼠 4-1 设计背景、铁锤及地鼠 4-2 撰写地鼠的程序 4-3 撰写铁锤程序 4-4 分数的计算 5. 接球游戏 5-1 设计球部份的程序 5-2 人物部份的程序 5-3 程序计分 5-4 扣分的构想 6.如何分享SCRATCH作品 7.如何把sb2文件转化成swf格式的flash文件
SCRATCH2.0入门中文使用教程 1. Scratch的简介 Scratch是 MIT (麻省理工学院) 发展的一套新的程序语言,可以用来创造交互式故事、动画、游戏、音乐和艺术。很适合8岁以上儿童使用,目前1.4版已经完全支持中文界面,更方便使用,完全不用背指令,使用积木组合式的程序语言,让学习变得更轻松,并充满乐趣。 官方网站:https://www.360docs.net/doc/418183514.html,/ 目前已经推出2.0版本,支持在线和离线模式。 由于国外网站速度较慢,gateface门面,已经集成了scratch的程序,所以只要安装了伽卡他卡电子教室(15.5以上版本)或这个gateface5.5以上版本,都有scratch,不用另外安装。(伽卡他卡电子教室集成了gateface,scratch在gateface的门面编辑器里,点击相应按钮,就可以启动scratch) Gateface门面中,集成的是离线程序,可以不用登录scratch网站,在本机使用。搜索伽卡他卡电子教室或者gateface都可以到官网或者华军下载。 分享SCRATCH作品的方法: 方法1:放到网站共享。SCRATCH网站,可以上传sb2格式的文件,这样,别人通过访问SCRATCH网站来访问你的作品,需要在SCRATCH
房屋建筑结构设计中的基础设计方案的相关研究
房屋建筑结构设计中的基础设计方案的相关研究 发表时间:2019-11-12T14:19:45.507Z 来源:《防护工程》2019年13期作者:王超 [导读] 在房屋建筑结构设计当中,基础设计是最为重要的一环,直接影响着房屋建筑的经济性和房屋质量。本文对房屋建筑结构设计的各个细节进行有效的分析。 王超 北京首钢国际工程技术有限公司北京 100043 摘要:在房屋建筑结构设计当中,基础设计是最为重要的一环,直接影响着房屋建筑的经济性和房屋质量。本文对房屋建筑结构设计的各个细节进行有效的分析。 关键词:房屋建筑基础设计;设计因素;设计要点 引言 建筑市场正处于一个日益增长的状态之中,高层建筑的质量成为了人们更加关注的话题。房屋质量问题是国家以及社会都比较重视的问题之一,如果房屋的质量不达标,存在安全隐患的话,就可能对人们的居住质量产生一定影响,严重的话还会威胁到人们的生命财产安全。而保证建筑建设质量的最重要因素就是基础设计以及建设质量,现阶段要做的就是对高层建筑的基础设计方案进行不断的优化创新,使得基础建设质量能够达到相关标准,从而使整个基础结构的稳定性得到保障。 1 房屋建筑结构设计中的基础设计因素 1.1 基础设计中的上部结构 房屋建筑结构中的上部结构在施工中运用的是哪种形式、建筑中要求的墙体厚度,都能够直接影响到基础类型、埋深以及截面积等因素,所以,上部结构是基础设计过程中要反复考虑的主要因素。究其原因是因为,上部结构的选择的建设高度以及墙体的厚度,选择的类型不同,就会出现不同的荷载,则建设结果也会出现不同,对基础的沉降、稳定性以及抗变形的能力所要求的强度也是各不相同的,所以对房屋建筑结构设计中进行基础设计的时候要考虑周全。 1.2 基础设计中的地质条件 房屋建筑中的地质条件,基本上决定了基础设计方案中的承载能力,房屋建筑中地质条件的范围很广,其原因也很多,但是其中有两个条件对房屋建筑中的基础设计影响是最大的:(1)地基持力层的条件,地基持力层是和基础相互关联的土层,这个土层是支持且承受房屋建筑负荷的主要部分,所以,持力层土质的特点、压缩模量、持力层的承受能力等的实际情况必须是房屋建筑基础设计中的重要考虑原因;(2)桩基穿过土层的状态,也是需要注意的条件,包括土层当中地下水的分布实际情况以及桩基穿越的能力等,基础的选型过程中需要把这些因素完全考虑进去。 1.3 基础设计中的施工环境 施工环境包括自然形成的环境与人工造成的环境,自然环境中有环境温度与抗震质量等,因为组成基础施工的材料基本都是钢筋混凝土,所以如果施工环境的温度要是过于低的话,非常容易出现施工地基基础开裂的现象,所以房屋建设基础设计的时候,要全方位的考虑好低温施工的有效的应对措施。而抗震质量影响基础建设的原因是需不需要抗震缝,还有抗震缝需求的数量以及安置位置。人工环境对基础设计的影响有以下几个方面:(1)建筑施工过程里难免会有很多的震动,为了确保以后的房屋建筑的可靠性,所以在施工初期就要把这些问题考虑好;(2)如果房屋建筑过程中需要打桩,桩基在进土的时候会把土向桩基周围挤压,让周围的土层产生一定的应力,从而改变周边建筑物基础的受力情况,基础设计的时候要尽量避免这种影响。 2 房屋建筑结构设计中基础设计的设计要点 不管什么类型的建筑,在基础设计工作开展之前需要利用相关资料掌握其大致情况,需要了解的资料包括有地质资料和建筑上部结构资料。由于建筑体不同部位的作用以及重要性都是有所区别的,所以对资料的要求也是有所差别的,尤其是在对建筑进行资料收集时,对资料的详细程度以及准确度的要求更高。在基础设计方案制定的过程中,要根据施工区域的地质情况对可能产生的施工问题进行预测,并针对问题制定相应的解决方案。在基础研究工作开展中,主要就是对土层的分布、地下水的活动规律以及对周围的建筑物进行调查。 2.1 独立的基础设计 独立的基础设计理念分为两种,分别是柔性以及刚性,在进行独立基础设计的时候,要结合当地施工的地基土质特点,例如说:地基土压实密度很大而且压缩性比较强的话,那么施工的时候最好就要运用刚性的独立基础设计,如果当地施工的地基土质特点是其他情况的话就采用柔性基础,目的是为了有效的避免由于地基土的压缩从而引发的不均局沉降。由于我国现阶段大多数的民建工程所运用的是独立基础设计的方法,且这种设计方法还具有非常好的发展空间。多数情况的时候独立基础设计方法大面积的运用在柱下基础当中,然后与浇筑混凝土一起浇筑,从而形成了一个整体。还要把柱荷载的偏心距作为接下来判断的根据,从而来判断出断面是采用矩形还是方形。 2.2 桩基础的设计 因为桩基础设计方法的荷载承受能力比较强,一般这种情况下,房屋建筑当中上部结构有几率会出现承载能力不足的情况,则要在进行基础设计类型选择加固的时候,采用桩基础设计的预防措施。桩基础设计由于桩身的部位比较长,所以能够将建筑结构的上部荷载全部转到土层深处,从而能够有效的控制地基发生沉降的问题,在桩基础设计的正中部位进行加密布桩,从而延长中部桩的长度,有效调节房屋建筑结构设计中桩基础设计的承重能力。 2.3 箱形以及筏型基础设计要点 箱型或者是筏板形基础的使用情况是,主要用于地基土承载能力不平均,或者是高层建筑建设对于地基基础承受力要求很大的场合。除此之外,如果在房屋建设中,有地下室的情况下,也可以运用筏板基础,让其发挥出基础的作用,又可以作为地下室的地面使用。箱型基础和筏形基础设计的主要难点区别为箱型基础与筏形基础设计其中一个需要降低基础整体弯曲应力而另一个不需要,所以,可以把上部结构与基础看为一体。除此之外,箱形基础和筏形基础都是大体积的混凝土,如果在气温较低的状态下进行施工的时候,比较容易出现温度裂缝,所以在设计的时候要充分的考虑在施工计划之内,可以采用设计伸缩缝来处理这种现象,防止由于温度变化产生的变形,其宽度
浅谈建筑结构基础设计的一般方法
浅谈建筑结构基础设计的一般方法 发表时间:2014-10-08T14:47:37.687Z 来源:《工程管理前沿》2014年第9期供稿作者:顾小睿张建峰[导读] 建筑结构基础是整个建筑物的重要组成部分,它与整个建筑物的安全息息相关。 顾小睿中科院建筑设计研究院有限公司 张建峰中煤科工集团重庆设计研究院有限公司 摘要:近年来,我国经济社会飞速发展,建筑业也取得了日新月异的发展和进步,各种功能的建筑物被大量兴修,建筑物的体型结构也越来越复杂,高层建筑物越来越多。为了适应高层建筑结构的需要,有必要优化建筑结构基础的设计工作,采取相应的策略来提高设计水平。文章主要结合建筑业发展的实际情况,探讨分析了建筑结构基础设计问题,并提出了相应的优化建筑结构基础设计的策略,希望能够引起人们对这一问题的进一步关注,在实践应用中发挥指导作用。 关键词:建筑结构基础设计优化 一、引言 建筑结构基础是整个建筑物的重要组成部分,它与整个建筑物的安全息息相关。尤其是随着建筑物高度的不断增加,建筑结构基础的地位和作用更加凸显。建筑工程的主要目的是经济和安全,这两者不能缺少其中的任何一项。而要达到这二者的统一,在工程设计和建设中,必须采取相应策略,优化建筑物的结构基础,在保证建筑结构安全的前提下也获得经济效益。 二、建筑结构基础设计的基本要求 结构基础设计,具体来说,需要满足以下几个方面的要求。 1、安全性。建筑物与人们的生产和生活息息相关,安全性是建筑结构基础设计必须考虑的因素。如果只是片面的强调结构基础设计的优化,而忽视建筑结构的安全性,那么所做的一切努力都没有任何意义。因为,如果建筑物没有满足安全这一基本要求的话,必然给人们的生命财产安全带来巨大的损失。所以,建筑结构基础设计必须满足安全性的要求。 2、经济性。经济性是市场经济条件下对建筑结构基础设计提出的新的要求,它主要是指在建筑结构基础设计当中,尽量节省成本,优化资源配置,合理利用各种材料,以达到节省成本,提高建筑项目工程经济效益的目的。 3、环保性。环保性是人们对建筑结构基础设计提出的更高的要求,它要求选用环保材料,通过合理布局来实现可持续发展的理念,降低能源资源消耗,实现人与自然和谐相处。 三、建筑结构基础设计的一般方法 1、建筑基础方案选择。 在整个建筑结构设计中,基础的合理选型和布置是相当重要的部分。对于同一种场地地基,可以有多种基础形式可以选择,不同的基础形式,它的施工难度和工程造价是不一样的。因此,在基础选型的时候,要综合考虑多方面的因素,合理选择,寻求最优目标。 1) 以准确的岩土工程勘察资料为依据。包括场地工程地质条件、岩石物理力学性质、地基承载力、地下水位、场地土动力学参数等,这些资料是方案合理设计的基础,必须进行科学合理的分析。通过资料的分析,再综合考虑上部结构的形式,最终确定合理的建筑基础形式和布置。 2) 基础的形式和布置应考虑基础与上部结构的相互作用。通常情况下,建筑结构设计是将上部结构和基础分离开来,各作单独的考虑,对他们分别进行力学分析。而事实表明,这种方法存在着较大的局限性,计算所得到的基底应力和基础沉降量与实际测量值存在着很大的差别。所以,基础问题的解决不能只关注基础,还应该考虑基础与上部结构的相互作用。在结构设计的时候,应该注意到上部结构次应力、开裂等不良情况的发生,将上部结构和基础进行综合考虑,从二者的相互联系出发,选择合理的方案。 3) 基础形式的选择须对经济性和施工周期作综合考虑通常情况下,考虑到经济性,高层建筑设计人员习惯于采用梁筏式基础。近年来,平板式筏基得到较多的应用。平板基础虽然含钢量略大于梁筏基础,但施工工期更短,埋置深度较浅,综合经济性优于后者。 2、基础结构的计算。 伴随着计算机技术在基础结构计算中的运用,基础设计取得了快速的发展和进步,计算精确度得到提高,计算的可靠性也更高。然而,我们在充分发挥计算机计算优势的同时,应该明确知道,结构设计程序是被动的计算过程,在计算中可能会出现差错,所以还需要注意以下几个问题。 1) 提高对电算结果自主判断的能力。有时候,设计图纸的错误是工程师过分依赖计算机所致,因而,工程师或者设计人员应改变这种情况,在设计时,对相关数据和计算结果进行反复的核对和审查,避免计算错误而影响结构设计。尤其是对基础设计的荷载数据、受力简图更要加强审核,确保不发生差错。 2) 合理采用计算模型。计算程序与现实有一定的差距,软件公司常对不同的结构构件提供了不同的软件模型。例如PKPM软件在基础计算时,提供了“按普通弹性地基梁计算”、 “按上部结构为刚性的弹性地基梁计算”、“按SATWE或TAT上部刚度进行地基梁计算”等多种不同的计算模型可供选用,工程师须根据上部结构刚度、竖向构件跨度、基础构件的跨高比等作出合理选择,不可一概而论。 3) 正确采用计算参数。在计算过程中,计算参数的不同将会导致计算结果的不同,但是,并不是所有的计算结果都在结构基础设计中适用,例如在地下室深度相同时,采用箱基和条基的埋置深度相差很远。所以,工程师和设计人员要根据不同的基础形式,填写正确的计算参数。 3、合理采用材料强度。在钢筋混凝土基础中,混凝土标号不必取得太高。混凝土强度过高,如高于C35,水泥用量也将相应增加,在混凝土凝固过程中的收量和水化热等不利影响也会增大。如果养护不够的大面积基础,很容易出现裂缝。由于基础构件是以受弯为主,要选用高强度的钢筋,以减少钢筋的用量。总之,要重视材料的恰当选择,提高材料的利用率,降低造价,取得好的效益。 4、对《规范》的正确理解和应用。《规范》是优化设计的基础和指南,在实际工作中必须严格执行相关的规定。一方面,对《规范》中的相关条文要进行深入的学习,深刻领会其中的内涵,并将此作为设计准则,根据具体的设计对象、设计环境、构件特点等,并根据设计的要求,进行科学合理的设计。另一方面,要高度重视《规范》中的构造措施。在实践中,一些工程师过分强调计算结果,却忽视设计环境,从而导致结构设计的安全性和经济性受到损害。
手工构造典型PE文件
2009-06-08 11:38:40 https://www.360docs.net/doc/418183514.html, 来源:黑客防线 一直以来都在学习PE文件结构,从不敢轻视,但是即使如此还是发现自己在这方面有所不足,于是便想到了用纯手工方式打造一个完整的可执行的PE文件。在这期间我也查了大量资料,但是这些资料都有一个通病就是不... 一直以来都在学习PE文件结构,从不敢轻视,但是即使如此还是发现自己在这方面有所不足,于是便想到了用纯手工方式打造一个完整的可执行的PE文件。在这期间我也查了大量资料,但是这些资料都有一个通病就是不完整,看雪得那个只翻译了一部分,加解密技术内幕介绍的更是笼统,而且是打造一个只有180字节的PE文件,是高手们茶余饭后的怡情小游戏。 鉴于此,心想为什么不自己摸索着手工打造一个完整些的呢?一是加强一下自己对于PE文件的了解,二是写出一篇参考性比较强的文章,给有志于在此发展的朋友们铺一铺路,也算是干了一件利国利民的好事。 对于手工打造PE文件,我个人认为至少要分为三篇文章来阐述,每篇相对独立,合起来形成一个相对的体系。第一篇文章(也就是本文)用来介绍怎样用手工打造一个最典型、最简单的PE文件,而后两篇文章的问世还要引用潘爱民先生的一句话“还需要时日与机缘”。 本文介绍的PE文件手工编辑方式,是本着以下三个原则所写的,望读者注意: 1、完整性:对于手工打造PE文件所不需注意的字段也进行了必要的介绍,因此整文可能显得非常臃肿。 2、典型性:完全按照典型的PE文件结构构造,因此对于某些不常见的PE文件结构有一定差距。 3、易学性:对于字段之间的逻辑关系进行了比较细致的介绍,因此对于一部分底子比较好的读者来说可能显得有些啰嗦。 为了方便各位阅读与查阅,我将文章分成了三各部分,以便各位读者各取所需,不用把宝贵的精力浪费在查找上。 1、PE文件整体信息,提供了一个剖析PE文件的图表,以便于读者对于PE文件有一个整体的了解,并监督自己的工作进度。 2、对于重点字段的介绍,以及字段之间的逻辑关系,建议首先从这里开始看。 3、手工构造PE文件字段清单,此清单包含构造一个完整PE文件的每一个字节,跟着这个清单走就可以构造一个PE文件。 对于第一次手工打造PE文件的朋友们来说,你们可以以“一、整体性息”为大纲,并参考第三部分一块一块的慢慢打造,如果有不懂的地方就去看第二部分。 选读:为什么要手工打造PE文件? 我们知道,往往从一个系统可执行文件结构上,就可以看整个操作系统的一些特性。也就是说PE里有Windows操作系统结构与运行机理的影子。由此可见,PE文件必然是一个非常庞杂且逻辑复杂的结构,那么为什么我们还要“自取其辱”来手工制造一个PE文件呢?这就要从PE文件的重要性说起了。 我们现今组成Windows大家庭的主要成员就是PE文件了,里面包括EXE、DLL、OCX、SYS等一切最有价值的文件都是PE文件格式,出于对版权的考虑或对某种技术的渴求,任何一种与Windows系统相关的行为最终都要归集到这里--PE文件。 特别是对于想学习加壳、破解、搞虚拟机的朋友们来说,熟知PE文件结构更是必不可少的基本功! 但也正是由于PE文件的复杂性,我们才要采取一些特别的办法来攻克它,其中手工打造PE文件就是一条捷径。 你可以想像一下,如果你都可以手工打造PE文件的话,那么对于PE文件的了解更是
土木工程建设中建筑结构基础设计
土木工程建设中建筑结构基础设计 摘要:近年来随着我国经济社会的不断发展,也进一步的推动了土木工程建设 的发展。而在土木工程建设过程中建筑结构基础设计作为其重要的一部分并对整 个工程的质量都具有非常重要的作用。 关键词:土木工程;结构基础;设计 1建筑结构基础设计的重要作用 1.1保证施工安全 建筑结构基础设计事关土木工程施工的安全,所以在对土木工程基础结构进 行设计时必须要做到选型正确以及加强设计的合理性,并且最大程度的提高土木 工程施工的安全系数。例如,如果在设计的过程中其基础结构设计的不够科学、 合理,那么势必会给土木工程建筑的承载能力造成一定的影响并最终会造成建筑 物的墙面出现裂开或者是不均匀的下沉等情况。 1.2缩短施工工期 结构设计的合理性可以确保施工的合理性,确保土木工程的各项施工工序得 以有序开展,从而避免出现中途返工的不良现象。而且,还能够进行人力、物力 和财力合理安排,大大缩短土木工程的建设工期,为顺利完成工程施工任务提供 有利的保障。 1.3提高经济效益 合理的结构基础设计还能够为企业创造出更高的社会效益以及经济效益。通 过对相关项目调查研究表明,在土木工程建设中其结构基础设计在全项目造价中 占有将近20%的成本,如果是针对一些较复杂并且大型的项目工程其占有的比例 将会更大。 2建筑结构基础设计存在的问题 2.1建筑结构基础中地基基础问题 第一类问题:地基质量方面的重视程度不足,导致地基的质量和承载力达不 到标准施工要求;第二类问题:如果施工建筑所处位置为斜坡,容易忽视对其实 施的地基稳定性的验算,开展施工后,很容易出现返工问题,施工工作不能一次 顺利完成;第三类问题:如果建筑工程的地基不够硬实,出现在设计方面的问题 表现为,容易忽视对地基承载力和沉降问题的思考,基础设计同实际施工融合程 度较低,正常施工受到影响。 2.2承重柱截面高度设计的问题 在对这部分进行设计时,容易忽视建筑整体的抗震能力是比较常见的问题, 如果设计人员没有站在整体的角度上进行思考与设计,使得截面面积较小,极易 导致结构的承载能力无法达到要求与标准,影响后期的施工与正常使用,甚至导 致结构出现裂开等问题,存在一定的安全隐患。同时,基础设计的不合理,也极 易导致结构耐久性的降低,对建筑整体的抗震能力也会产生一定的不利影响,一 旦发生地震等灾害,极易对建筑产生严重的不利影响。 2.3构造柱与承重柱设计部分的问题 构造柱和承重柱设计的问题主要缘由设计师在设计的过程中并没有将这两者 进行充分的思考,从而致使设计不够科学、合理,以至于最终影响到了整个项目 的正常施工。与此同时如果不加以制止,将会给使用者的安全性带来一定的影响。
pe文件结构 入门 教程
三年前,我曾经写了一个手工打造可执行程序的文章,可是因为时间关系,我的那篇文章还是有很多模糊的地方,我一直惦记着什么时候再写一篇完美的,没想到一等就等了三年。因为各种原因直到三年后的今天我终于完成了它。现在把它分享给大家,希望大家批评指正。 我们这里将不依赖任何编译器,仅仅使用一个十六进制编辑器逐个字节的手工编写一个可执行程序。以这种方式讲解PE结构,通过这个过程读者可以学习PE结构中的PE头、节表以及导入表相关方面的知识。为了简单而又令所有学习程序开发的人感到亲切,我们将完成一个Hello World! 程序。功能仅仅是运行后弹出一个消息框,消息框的内容是Hello World!。 首先了解一下Win32可执行程序的大体结构,就是通常所说的PE结构。 如图1所示PE结构示意图: 图1 标准PE结构图 由图中可以看出PE结构分为几个部分: MS-DOS MZ 头部:所有PE文件必须以一个简单的DOS MZ 头开始。有了它,一旦程序在DOS下执行,DOS就能识别出这是有效的执行体,然后运行紧随MZ header 之后的DOS程序。以此达到对Dos系统的兼容。(通常情况DOS MZ header总共占用64byte)。 MS-DOS 实模式残余程序:实际上是个有效的EXE,在不支持PE文件格式的操作系统中,它将简单显
示一个错误提示,大多数情况下它是由汇编编译器自动生成。通常,它简单调用中断21h,服务9来显示字符串"This program cannot run in DOS mode"。(在我们写的程序中,他不是必须的,可以不予以实现,但是要保留其大小,大小为112byte,为了简洁,可以使用00来填充。) PE文件标志:是PE文件结构的起始标志。(长度4byte, Windows程序此值必须为0x50450000) PE文件头:是PE相关结构 IMAGE_NT_HEADERS 的简称,其中包含了许多PE装载器用到的重要域。执行体在支持PE文件结构的操作系统中执行时,PE装载器将从DOS MZ header中找到PE header的起始偏移量,跳过了MS-DOS 实模式残余程序,直接定位到真正的文件头PE header,长度20byte。 PE文件可选头:虽然它的名字是“可选头部”,但是请确信:这个头部并非“可选”,而是“必需”的。(长度 224byte )。 各段头部:又称节头部,一个Windows NT的应用程序典型地拥有9个预定义段(节),它们是“.text”、“.bss”、“.rdata”、“.data”、“.rsrc”、“.edata”、“.idata”、“.pdata”和“.debug”。一些应用程序不需要所有的这些段,同样还有些应用程序为了自己特殊的需要而定义了更多的段。(每个段头部占40byte,我们这里也不需要所有的段,仅需3个段。) 通常我们是将PE整个结构分成四个部分,把MS-DOS MZ 头部和MS-DOS 实模式残余程序作为第一部分,可以称他为DOS部分,而PE文件标志、PE文件头、PE文件可选头三个部分作为第二部分,称之为PE头部分,因为这部分才是Windows下真正需要的部分,所以从PE文件标志开始才是真正的PE部分。各段头部是第三部分,称之为节表。它详细描述了PE文件中各个节的详细信息。最后就是各个节的实体部分了,称为节数据。 以上仅仅是对PE结构各部分的大体讲解。接下来再手写这个Hello World!程序过程中,我将详细介绍每个部分的含义。 首先准备一下工具,一个十六进制编辑器足以。我们这里使用VC++ 6.0所携带的十六进制编辑器,您也可以使用如WinHex等十六进制编辑工具。 打开VC,选择文件,新建菜单项,然后选择一个二进制文件,单击确定。一切就绪了,下面就开始手写可执行程序,如图2所示:
pe文件格式
pe文件格式:PE文件格式(1) 疯狂代码 https://www.360docs.net/doc/418183514.html,/ ?:http:/https://www.360docs.net/doc/418183514.html,/Waigua/Article60255.html 介绍说明:希望本文能够对初级入门CRACKER有定帮助翻译存在疏漏或者不准确希望来信指出感谢您指导!感谢看雪为我们提供这个交流平台让我们技术和时俱进!! 前言: PE("portableexecutable")文件格式是针对MSwindowsNT,windows95and win32s可执行 2进制代码(DLLsandprograms)在windowsNT内,驱动也是这个格式也可以用于对象文件和库 这个格式是Microsoft设计并在1993经过TIS(toolerfacestandard)委员会 (Microsoft,Intel,Borland,Watcom,IBM等)标准化了它基于在UNIX和VMS上运行对象文件和可执行文件COFF"commonobjectfileformat"格式 win32SDK包括个头文件