做 竞 品 分 析 的 四 大 流 程

做竞品分析的四大流程:
1.确定竞品分析的目的
2.筛选出目标产品
3.收集竞品资料
4.分析、输出竞品分析报告
以下就每个流程展开来讲:
一、确定竞品分析的目的
确定目的是做任何事情的前提。做竞品分析也是如此,我们大多数情况下做竞品分析,都是在做新的项目时,也有一些是在运营过程中遇到过不去坎时,会做些竞品分析,参考别人是如何跨过去的。不论哪个阶段的竞品分析,本质上都是为我们后续的工作做指引。
我当时做安卓桌面竞品分析时,正好是新项目立项,只确定了要做安卓桌面这个产品,至于里面具有的功能、用户的使用场景、频次、变现方式都不了解。当时做竞品分析的目的就是弄清楚市场的盘子有多大,每家的份额、优缺点和用户的喜好等。
重点是分析出各家产品的优缺点,这样我们做产品开发时,可以避其锋芒,攻其软肋,成功几率会大些。
二、筛选出目标产品
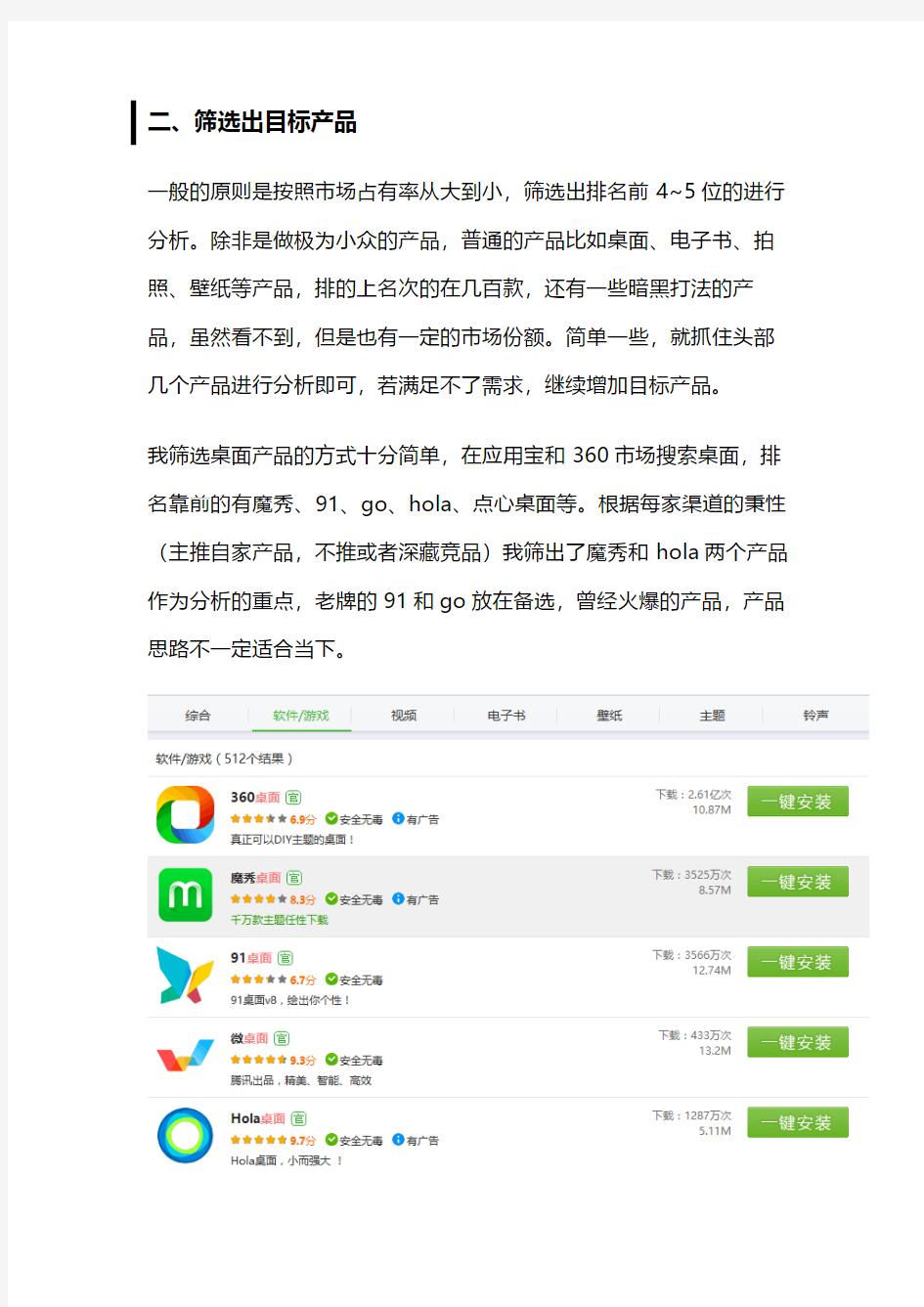
一般的原则是按照市场占有率从大到小,筛选出排名前4~5位的进行分析。除非是做极为小众的产品,普通的产品比如桌面、电子书、拍照、壁纸等产品,排的上名次的在几百款,还有一些暗黑打法的产品,虽然看不到,但是也有一定的市场份额。简单一些,就抓住头部几个产品进行分析即可,若满足不了需求,继续增加目标产品。
我筛选桌面产品的方式十分简单,在应用宝和360市场搜索桌面,排名靠前的有魔秀、91、go、hola、点心桌面等。根据每家渠道的秉性(主推自家产品,不推或者深藏竞品)我筛出了魔秀和hola两个产品作为分析的重点,老牌的91和go放在备选,曾经火爆的产品,产品思路不一定适合当下。
三、收集竞品资料
以上属于筹备阶段,接下来,才进入正题:材料的收集,这是重中之重。能让一个公司决胜于千里之外的就是信息了,我也见过有的公司因一两个有效策略而起死回生的例子,真正核心的信息,不一定能搜集到,但是普通信息收集齐全后,经过细致的分析,也是有可能获得有价值的信息。以下是我收集桌面竞品的几个信息来源。
亲自体验竞品是必不可少的一个环节。通过自己的亲身感受,对各个竞品有个大体的印象,各家的优缺点,一目了然,结合自家的实力,在体验的时候,基本上就确定了自家产品的大致方向。我体验了每个安卓桌面后,发现hola桌面与我们最初的构思比较接近,hola就成了接下来竞品分析的重中之重,也是我们用来对标的产品了。
我在做“老虎讲运营”公众号前,关注了至少100个公众号,每天必看,分析别人的更新频次、功能菜单,然后应用到自己的号上,才一撮而就,没有犯大的错误。
产品最核心的信息都体现在了产品简介里。我们之前做手游推广,产品简介的每个字,每句话都是改之又该的,把产品的卖点、特色、优
势都浓缩在了那几百字的产品简介里。所以,我在做安卓桌面竞品分析时,把hola、魔秀桌面的产品介绍单独复制出来,把重点标红以做分析。
此处很多人经常忽略掉,其实用户评论区的价值还是很大的。从中可以分析出用户的需求、痛点和该产品的问题所在。最重要的是摸清楚用户的需求,我在翻阅了几页用户评论后,了解到用户对安卓桌面的需求就是省空间、壁纸要好看。当我们去开发时,会着重优化这两块。
产品官网的价值主要是分析产品的发展路程和公司规模,从中可以评估出我们做出同样规模时需要投入的人力和时间,这些信息往往比较真实,可参考性大。
忽略这项即可。
咳咳,这个就比较有趣了,经常会收集到一些不为人所知的信息,就比如某个渠道经常推荐某个桌面,还以为是有进行付费推广的深度合作,后来知乎了解到原来是有参股,相当于是子公司。
这个就要看运气了,我之前有加过某个桌面的运营,作为同行交流了很多信息,当然这个交换是互相的,我提供了我们的变现思路,对方提供了他们的推广思路,互帮互助,大家都少走些弯路。
通过以上的几种路径,大概两周时间就可以把所需要的信息收集完全,接下来就是信息的处理环节了。另外收集信息的原则是:不论有无价值,先照单全收,分析时再取其精华,去其糟粕。
四、分析、输出竞品报告
材料分析时要先列好大纲,然后根据大纲填充信息。我做的桌面分析大纲是:产品名称、企业信息、产品简介、产品卖点、推广节奏、其他。将收集到的信息像贴标签一样,分门别类的放到各个模块去,信息筛选的过程就是一个分析的过程,有时候看到的信息和分析的结论可能会冲突,先不用理他,放进去即可。比如APUS桌面,很知名的一个桌面,在各个应用市场却没有怎么见到,后来看公司的策略才知道,人家是以海外为主,重点推广GP。
报告的输出无非是结论,里面包含整理的信息和最终的建议。有的公司要求用PPT,有的用WORD,还有的用脑图,各种形式都可以。我比较喜欢用EXCEL,把收集到的原始信息和报告都放到一个文档中去,在分享的时候,也可以拉出来原始信息大家讨论。
当然,我做的竞品分析实用为主,格式和外观略微差些,新人不建议用这种策略,毕竟能做出高大上的文档来,在老板面前也是可以加分的。
以上就是做一个竞品分析必备的四个环节,简单易懂,从价值的角度考虑,简单做完一个竞品分析,对接下来要走的方向基本上有了概念。我当时做完了桌面的竞品分析后,脑海中就有了一年后,我们产品的样子和规模,当下就是把想象变成现实就可以了。
所谓看的在多,不如做一遍,赶紧按照上面的步骤去做一个竞品分析吧,收获绝对超过你的想象。
手把手教你做竞品分析
手把手教你做竞品分析 什么是竞品?这里引用“苏杰”绕口令式的小结: 你的产品,在解决同样需求的时候会碰到同样的产品;解决同样需求的时候会碰到不同的产品;解决不同需求的时候会碰到不同的产品;解决不同层次需求的时候会碰到不同的产品。他们都是竞品。 那么,如何做竞品分析呢? 接下来,我以“为企鹅FM的后续发展方向提供辅助决策”为目的,来说明如何做竞品分析。竞争对手选择喜马拉雅FM。 一.明确竞品分析的目的 很多人在做竞品分析的时候,都是直接把竞品列上去,然后就开始分析了。这其实违背了一个很重要的设计思考原则:做一件事情首先要明白为什么要做,做的目的是什么,然后是你打算怎样去做。——刘津,《破茧成蝶》作者
本次竞品分析的目的:是为企鹅FM的后续发展方向提供辅助决策。 二.选择合适的竞品 如何选择合适的竞品? 1.搜索。渠道有:百度、知乎、易观智库、艾瑞网、微博、各大PM社区、36kr 等。如果有APP,上AppStore、各大安卓应用市场去搜关键词,对应推荐的一系列App都有可能是你的竞品,选择最符合自己定位的竞品。 2.善问。问同事、朋友,该领域的专业人士或去问答平台提问等,找出合适的竞品。 这里,我选择“喜马拉雅FM”为竞争对手的原因在于,目前市面上,按功能定位分,主要分为这五类: (图片来源于易观智库)
企鹅FM和喜马拉雅FM均侧重于做音频分享型平台。所以,我优先选择“喜马拉雅FM”为竞争对手来做详细的竞品分析,找出其做的好的,可以借鉴的地方。 两款APP的iOS版首页总览: 三.竞品分析的三个方面 竞品分析主要包括三个方面:用户分析、功能分析和数据分析,三者需同步进行。界面及交互研究这里不具体展开。 1.用户分析 用户分析包含:核心用户、主流用户和用户构成比例三个部分。 1)核心用户
【EXCEL】数据分析那些事(菜鸟入门必看)
Q1:我现在的工作有一点数据分析的模块,自从上微薄后了解到还有专门从事数据分析工作,我现在想做这一行,但是经验、能力都还是菜鸟中的菜鸟,请问成为一名数据分析师还有需要哪些准备? A:很简单,我们可以看一下国内知名互联网数据分析师的招聘要求,进行自我对照,即可知道需要做哪些准备。 数据分析师职位要求: 1、计算机、统计学、数学等相关专业本科及以上学历; 2、具有深厚的统计学、数据挖掘知识,熟悉数据仓库和数据挖掘的相关技术,能够熟练地使用SQL; 3、三年以上具有海量数据挖掘、分析相关项目实施的工作经验,参与过较完整的数据采集、整理、分析和建模工作; 4、对商业和业务逻辑敏感,熟悉传统行业数据挖掘背景、了解市场特点及用户需求,有互联网相关行业背景,有网站用户行为研究和文本挖掘经验尤佳; 5、具备良好的逻辑分析能力、组织沟通能力和团队精神; 6、富有创新精神,充满激情,乐于接受挑战。 Q2:对数据分析有浓厚兴趣,希望从事数据分析、市场研究相关工作,但听说对学历要求较高,请问我是否要读研,读研的话应该读哪个方向? A:读研要看自身情况,但可明确:专业不是问题,本科学历就够。关键是兴趣与能力,以及自身的努力,兴趣是学习成长最好的老师! 当然如果是在校生考上研究生的话那是最好,如果考不上可以先工作,等你工作有经验了,你就知道哪方面的知识是自己需要,要考哪方面的研究生,也就更有方向性。 Q3:那么如何培养对数据分析的兴趣呢? A:建议如下: 1、先了解数据分析是神马? 2、了解数据分析有何用?可解决什么问题? 3、可以看看啤酒与尿布等成功数据分析案例; 4、关注数据分析牛人微博,听牛人谈数据分析(参考Q1的三个链接); 5、多思考,亲自动手分析实践,体验查找、解决问题的成就感; 6、用好搜索引擎等工具,有问题就搜索,你会有惊喜发现; 7、可以看看@李开复老师写的《培养兴趣:开拓视野,立定志向》; 有网友说:让数据分析变的有趣的方法是,把自己想象成福尔摩斯,数据背后一定是真相!Q4:我有点迷茫,是练好技能再找工作,还是找一个数据分析助理之类的要求不是特别高的工作,在工作中提升? A:建议在工作中进行学习实践,这才是最好的提升。看那么多书,没有实践都是虚的。 Q5:我是做电商的,对于数据分析这块,您有什么好的软件工具类推荐吗? A:做数据分析首先是熟悉业务及行业知识,其次是分析思路清晰,再次才是方法与工具,切勿为了方法而方法,为工具而工具!不论是EXCEL、SPSS还是SAS,只要能解决问题的工具就是好工具。 问题的高效解决开始于将待解决问题的结构化,然后进行系统的假设和验证。分析框架可以帮助我们:1、以完整的逻辑形式结构化问题;2、把问题分解成相关联的部分并显示它们之间的关系;3、理顺思路、系统描述情形/业务;4、然后洞察什么是造成我们正在解决的问题的原因。
EXCEL之手把手教你如何做合同明细表
EXCEL之手把手教你如何做合同明细表摘要:EXCEL 合同明细表目录链接 目录 1. EXCEL合同台账的管理作用 2. 合同台账框架 2.1 目录表 2.2 单个合同明细表 2.3 空模板 2.4 下拉箭头清单 3. 合同台账中使用的EXCEL的功能及作用 4. 操作流程 4.1空模板页面和下拉菜单制作 4.2新建合同文档 4.3 合同执行阶段数据录入 4.4 合同执行完毕
以下为正文: 1. EXCEL合同台账的管理作用 1.1 统一企业的EXCEL合同台账格式,方便录入各项合同数据;1.2 建立合同目录清单,分类罗列,执行状态一目了然; 1.3 动态登记合同执行过程中的每一个数据,促进合同执行和合同数据高度统一; 1.4 合同执行完毕后,打印作为合同封面留底,便于查看或审核书面合同执行情况; 1.5 本文只针对企业的采购合同做管理台账,如有需要,可根据此模板制作企业的销售合同台账。 2. 合同台账框架 2.1 目录表 2.1.1 作用:合同的清单,并可实现分类呈现和汇总; 2.1.2 格式如下:
2.2 单个合同明细表: 2.2.1 作用:合同的清单,记录合同的各项静态信息,在执行过程中,记录每一条合同的动态信息,; 2.2.2 格式如下:
2.3 空模板: 2.3.1 作用:新增合同时,以此合同为空白模板复制建档; 2.3.2 格式如下:
2.4 下拉箭头清单 2.4.1 作用:作为部门、费用类别、合同类别下拉清单设置用途; 2.4.2 格式如下:
3. 合同台账中使用的EXCEL的功能及作用 3.1 超链接:用于文档页面间转换,便于目录和单个合同股明细来回的切换; 3.2 移动或复制:用于文档复制,新建合同清单,复制空模板,建立一个新的模板格式的页面: 3.3 定义名称:设置下拉菜单的清单时,可以跨页面使用; 3.4 if函数:用于判断合同执行的状态; 3.5 查找替换:用于设置跨页面取数公式时,替换公式中的一部分数据。 4. 操作流程
微博项目资料整理
利用周末的时间,做了微博相关资料的整理,和大家共同分享(附件:有相关的论文可供参考)。 一、微博内容挖掘 主要技术支撑:文本挖掘技术 相关理论模型topic model。 其中包含两个主要的模型:分别为PLSA模型和LDA模型. 1.1 PLSA模型 LSA:潜在语义分析 PLSA:概率潜在语义分析 1. 引子 Bag-of-Words 模型是NLP和IR领域中的一个基本假设。在这个模型中,一个文档(document)被表示为一组单词(word/term)的无序组合,而忽略了语法或者词序的部分。BOW在传统NLP领域取得了巨大的成功,在计算机视觉领域(Computer Vision)也开始崭露头角,但在实际应用过程中,它却有一些不可避免的缺陷,比如: 1.稀疏性(Sparseness): 对于大词典,尤其是包括了生僻字的词典,文档稀疏性不可避免; 2.多义词(Polysem): 一词多义在文档中是常见的现象,BOW模型只统计单词出现的次数,而忽略了他们之 间的区别; 3.同义词(Synonym): 同样的,在不同的文档中,或者在相同的文档中,可以有多个单词表示同一个意思; 从同义词和多义词问题我们可以看到,单词也许不是文档的最基本组成元素,在单词与文档之间还有一层隐含的关系,我们称之为主题(Topic)。我们在写文章时,首先想到的是文章的主题,然后才根据主题选择合适的单词来表达自己的观点。在BOW模型中引入Topic的因素,成为了大家研究的方向,这就是我们要讲的Latent Semantic Analysis (LSA) 和 probabilitistic Latent Semantic Analysis (pLSA), 2. LSA简介 已知一个文档数据集及相应的词典,采用BOW模型假设,我们可以将数据集表示为一个的共生矩阵,,其中, 表示词典中的第j个单词在第i个文档中出现的次数。 LSA的基本思想就是,将document从稀疏的高维Vocabulary空间映射到一个低维的向量空间,我们称之为隐含语义空间(Latent Semantic Space). 如何得到这个低维空间呢,和PCA采用特征值分解的思想类似,作者采用了奇异值分解(Singular Value Decomposition)的方式来求解Latent Semantic Space。标准的SVD可以写为:
用定性数据分析包 RQDA tm 进行文本挖掘
用定性数据分析包RQDA tm进行文本挖掘 Written by Benson Ye (bensonye@https://www.360docs.net/doc/536807373.html,) Revised by Ronggui Huang (ronggui.huang@https://www.360docs.net/doc/536807373.html,) First reversion 2010-07-22 Last revision 2010-08-03 在对访谈内容或剧本、小说部分内容进行文本挖掘时,如果用不断的剪粘保存的方法非常繁琐而且容易漏掉一些内容。好在黄荣贵开发的RQDA包可以进行文档管理和内容编码及提取,大大方便了利用tm包进行文本挖掘,既提高了效率又提高了准确性,下面举一个小例子: 对(人民网>> 时政>> 时政专题>> 网友进言)中的公安部回应进行分析 相关链接:https://www.360docs.net/doc/536807373.html,/GB/8198/138817/index.html 1、安装RQDA包、tm包和中文分词软件; > install.packages(c("rJava","tm", "gsubfn")) > install.packages(c("RQDA","RQDAtm"),repos="https://www.360docs.net/doc/536807373.html,",type='source') 2、装载RQDA包并建立一个新的工程项目; > library(RQDAtm) 3、输入相关文本文件;
4、进行编码和作标记; 5、双击想要提取的编码即可提取相关文本;
6、运行下面下载的程序进行文本提取、转换、分词、文本挖掘工作。 (以上步骤的结果为RQDA2tm_example.rqda),可直接打开该文件继续如下步骤。 > gg <- RQDA2tm("公安部回应" ) > summary(gg) A corpus with 26 text documents The metadata consists of 2 tag-value pairs and a data frame Available tags are: create_date creator Available variables in the data frame are: MetaID cid fid selfirst selend fname > inspect(gg) ----------------------------------------------- > ## 去掉多余空格####
基于情感文本挖掘和分析的系统设计
摘要:如何对网络中大量的文本数据进行挖掘和分析是大数据应用一个热点的问题,本文提供一种对文本数据进行挖掘和分析的新思路。以汽车口碑的文本数据为例,将采集的数据存入sql server 2008数据库,采用自然语言处理的方法处理数据,结合最大熵算法和支持向量机(support vector machine, svm)算法对数据进一步挖掘和分析。 关键词:文本分析;数据挖掘;汽车大数据;svm 一、研究背景 情感文本挖掘和分析是自然语言处理中的一个研究领域[1]。如何有效地挖掘网络情感文本中的数据,是当今网络舆情分析所面临的关键问题。[2]本文借鉴现有的研究成果,提出一种基于最大熵算法结合svm的文本情感分析新思路,设计出一个基于情感文本挖掘和分析的系统。 二、基于情感文本挖掘和分析的系统设计 (一)数据的采集 (二)数据的预处理 本系统创新地运用了hashset类来存储不重复的对象[3];采用基于ansj的分词算法进行中文分词;使用基于哈工大停用词表的改进型停用词表进行停用词过滤操作。 (三)特征词的提取 针对“知网情感词典”和“台湾大学简体中文极性词典ntusd”合并后的词典,我们通过人工添加新词的方法构建更合理的情感词典,提取评论的特征词。 (四)文本向量化 为了使计算机处理文本数据,我们需要将数据进行向量化。本文使用了著名的权值计算方法――词频-逆向文档频率(term frequency?cinverse document frequency , tf-idf[4])实现汽车口碑的向量化。tf-idf是一种统计方法,用以评估特征词对于汽车口碑中情感倾向的重要程度。 tfidf的主要思想是:如果某个词或短语在一篇文章中出现的频率tf高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。特征词的重要性随著它在文件中出现的次数成正比增加,但同时会随著它在语料库中出现的频率成反比下降。 (五)情感分析 1基于最大熵算法的情感分类 这里我们使用的是softmax回归模型,逻辑回归(softmax)是最大熵对应类别为两类时的特殊情况 [5]。在softmax回归中,类型标记y可以取k个不同的值。于是,对于我们的训练集便有。首先计算softmax回归概率值,其中是模型的参数。这一项对概率分布进行归一化,所有概率之和为1。然后添加一个权重衰减项来修改原代价函数,让参数值保持比较小的状态,这个衰减项会惩罚过大的参数值,得到新的代价函数,利用求偏导数,求最小化,从而实现一个可用的softmax回归模型。 2基于svm的情感细粒度分析 假设存在训练样本,可以被某个超平面没有差错地分开,其中,m为样本个数,为n维实数空间,是分类间隔。因此和两类最近的样本点距离最大的分类超平面称为最优超平面。在条件下对求解一下最大的函数值,为拉格朗日乘子,再根据公式求解最优分类函数,是偏移量,是是共轭表达。从而得到svm分类器[6]。 三、结果分析 本文对网上7种车型的口碑进行爬取,利用最大熵算法的softmax分类器进行情感倾向分类得到结果如下。
怎么制作个人简历表格
怎么制作个人简历表格 篇一:手把手教您如何用word做个人简历 手把手教您用word修改、制作一个完整的个人简历 如果您自己不会设计模板,您可以自己到网上下载一个模板,但是一般情况下这个模板都不会太令人满意,也许因为内容太少,也许因为封面页不够清新。无论怎样,您只需要选择一个您喜欢的样式就好,然后本文章会教您如何根据这个样式将个人简历变成世界上独一无二的简历。如果您自己心中已经设想了一个漂亮的模板,但是对于某些word的技巧尚不能熟练掌握,那么这篇文章也可以帮助您。 现在,我以车辆工程专业为例,模拟一个学生制作个人简历的过程。 一、下载模板 注意问题:根据自己的专业性质选择适合的模板,一般都不能太花哨,此时您无需在意简历里面的内容是否与你想要填写的一致,也无需在意添加照片的位置是否刚好是一寸,也无需在意模板的封面页是不是太丑。 假如您心中的模板(以下称其为黑简历)应该包括以下内容: 但是您下载的中意的模板(以下称其为蓝简历)却是这样的: 所以您需要修改的内容包括:1、将蓝简历中基本信息对应的表格进行调整,并且加入放照片的框框 2、将蓝简历中后面每一个表格的标题更改成您希望的名称
注意:更改表格行列数、添加文字不难,但是添加之后表格会跳行,会出现表格之间间距不同导致不美观的问题,所以您必须合理安排每个表格的大小以及表格内文字的多少,使同一个表格尽量在一页里面,必要时交换两个表格的位置。二、删添模板内容 1、先不管放照片的地方。因为黑简历中个人信息有10项,所以我们先将蓝简历的基本信息表格制作成5行4列的样式,也就是删除后四行。 蓝简历变为: ()按住玫红框框里的标志,改变表格长宽,使其保持原来的长度,否则后面的表格会往上移,不美观。 现在再解决照片的问题,首先要添加列,但是如果您现在右击表格→插入→列(在右侧),您会发现表格变得很乱,并且添加的不是一列而是两列,原因是该表格最顶端还有一行(上图黑框区域所圈),这一行在您看来是为了美观,但它却有四列,且与下面没有对齐,导致添加列会出现异常,所以,建议删除该行,以后再添加。删除该行后再添加列,基本信息表格变为: 点击表格工具→合并单元格 现在存放照片的框框已经有了,但问题是照片不是刚好能放进去,如果您先添加图片再来调整框框的大小,您会发现这样行不通,因为图片无法任意移动。解决办法是:添加一个一寸大小的矩形形状,再将照片填充进去,最后根据装有照片的矩形的大小,来调整框框的大小,具体步骤:
用激情打造语文教学的卓越课堂
用激情打造语文教学的卓越课堂 语文课堂的魅力要靠激情打造。 激情是语文的底色,是语文教学的生命。?激情是语文课堂的魅力。是唤醒、释放与引导学生激情的主阵地。是实现语文在强烈的情感共鸣和审美愉悦中,让学生得到知的丰富,美的陶冶、情的升华的需要。 缺少激情的语文课堂,注定是苍白乏力的,是无力在学生的心灵留下印迹的。 怎样创设富有激情的有效语文课堂呢? 一、激情源于导语 罗丹说,艺术就是感情。语文教学这门艺术同样也离不开感情。我就利用导语的情感因素来奠定课堂情感基调,去叩击学生的心扉,引导他们进入课文情景,使情与景偕,情与理融。四年级课文中的《桂花雨》是一篇回忆童年生活的文章。我的导语是这样设计的:童年是美好的,在每个人记忆的花园里,总会有一些常开不败的花朵,给人留下永久的回忆。同学们,你有过在雨中嬉戏的经历吗?(学生回答)可是你有过在桂花雨中陶醉的经历吗?现在请你们闭上眼睛想一想:每当桂花盛开时,满树生香,花香随风飘逸,弥漫四方,一切都沉浸在花香里。你抱住那桂花树,使劲地摇,尽情地摇,任由桂花像雨点一样纷纷落下来。落在你的头上、脸上、肩上、身上、脚上,落得满身都是。你沐浴在香甜的桂花雨中,整个人都陶醉了,你忘情地喊着:“啊!真像下雨,好香的雨啊!”然后我让他们睁开眼睛顺势引入新课:“今天,就让我们一起走进台湾女作家琦君的童年,去感受一场美丽的桂花雨,和作家共同分享童年的欢乐。” 这段导语从学生已有的生活经验切入,然后用充满感情的语言为学生描述了摇桂花的场景,激起学生对作者童年生活的向往,也唤起学生已有的情感体验,学生的情绪一下子被调动起来了,教学也因为学生的入情而进入了积极的状态。好的导语就是教师精心打造的一把金钥匙,以它放射出的独特光芒,开启了学生智慧与情感的闸门,引领学生走入求知的神圣境界。 二、激情藏于文本 语文教材中许多典范的文本给教师的再创造留下了无限的空间,足以让我们激情奔放,游目骋怀。《观潮》的壮美与豪放,《怀念母亲》的凄婉与伤情,《桥》的悲壮与激昂,《詹天佑》的忠贞与赤诚,《穷人》所彰显的人性的光辉、《地震中的父与子》所表露的父子深情,这些文质兼美的文章,无不浸透着作者情与感的结晶,灵与肉的凝聚,神与思的升华。语文教师倘若不以教学的智慧去挖掘,去表现,不以自己的激情去引发,去点燃,就难以把学生从一个知识的高峰引入另一个知识的高峰,就难以让学生达到心灵境界的一个又一个升华。
清楚自己的产品再去做竞品分析
清楚自己的产品再去做 竞品分析 Document number:BGCG-0857-BTDO-0089-2022
知己知彼——清楚自己的产品去做竞品分析 正所谓“知己知彼,百战不殆”。做产品也是如此。互联网的一些事 知己,意味着知道自己产品的定位是什么,核心竞争力在哪里,产品定义是什么等等。 知彼,简单的说就是清楚竞争对手的情况。知彼是建立在知己的前提下:清楚自己的产品,才会知道对应的竞品有哪些。但是并不是说知己,就一定会知彼。这就免不了要深入的做竞品分析,才能更懂对方。互联网的一些事不客气的说,现在很多产品经理,包括交互设计师,既不知己,也不知彼。很多人还停留在先盲目照抄竞品,再增加其他功能的思维框框里。 交互设计师也是如此,立场不坚定就很容易被PM牵着走。最近我做了一个内容型页面,接到需求文档后(更准确的说应该是一个文摘集锦),然后就开始排版了。但是越做越觉得不靠谱,在一些关键点上和PM有分歧,但又总讨论不出来结果。最后我恍然大悟:是因为前期漏掉了很多必要的工作。 首先,应该明确这个页面的目的是什么这个页面可以为用户创造什么样的价值
第二,我们如何为用户创造价值是通过我们的臆想去教育用户还是向用户展示他可能关心的内容如果选择后者的话如何确定哪些内容是他关心的第三,根据用户可能关心的内容,我们应该提供哪些内容模块第四,这些模块的优先级是什么这些都确定好了,才开始做排版布局的工作。 为什么出现这样的问题因为这个内容丰富的页面,PM只给了半天的时间,在这种环境压力下,交互设计师很容易迷失自己,把专业的流程统统抛到脑后,而只想着如何按时完成任务。 由这个页面,我的思维延伸到了整个产品上:我们做这个产品的时候知道自己的核心竞争力是什么吗知道如何甩开竞争对手吗我们了解会有哪些人使用我们的产品且这些人的期望是怎样的他们会如何使用我们的产品我们的产品能满足他们的需求吗对于这样一个业务复杂的专业产品,我们认真的研究过竞品吗我们真正了解这个行业的特性以及用户的需求吗 一切都是否定的。只是简单看看几个竞品,就凭借经验和感觉去勾画一个产品是远远不够的。越到后期,就越觉得心里没底。在设计的过程中,总是会不经意的发现新的设计质量不错的竞品,让我备感压力。也许靠着公司的牌子和广告资源,做的再烂也有人埋单。但这毕竟是短期的,不仅这个产品救不活,就连公司的品牌形象都会逐渐被透支。 产品设计已逐渐接近尾声,而我作为一个交互设计师,却说不出几个竞品的名称,也不了解竞品的情况,真是非常惭愧。我回想这一个多月,到底都做了些什么为什么要对时间妥协为什么不能以专业的素养来向产品方建议正确的流程呢大家其实都非常想把事情做好,但是往往被眼前的限制冲昏了头脑。
文本挖掘
文本挖掘简述 摘要:文本挖掘是数据挖掘的一个重要分支, 其应用前景十分广泛。本文对文本挖掘的 基本概念和主要内容进行介绍, 并且说明了挖掘的过程以及它的应用领域和它与其他相关 领域的关系。 关键词: 文本挖掘; 数据挖掘; 文本分类 目前随着信息技术的快速发展, 特别是网络的普及, 以文本形式表示的信息越来越多, 如何 在纷繁芜杂的信息海洋中找到自己需要的有用信息, 具有广泛的应用背景和实用价值。文本挖掘作为从浩瀚的文本数据中发现潜在的有价值知识的一种有效技术, 已经成为近年来的 研究热点, 研究人员对文本挖掘技术进行了大量的研究, 但这些研究大部分是在英文环境 下进行的, 对中文的研究却很少。以下介绍了文本挖掘的主要内容, 挖掘过程以及与其它领域关系。 1. 文本挖掘概述 ( 1) 定义 文本挖掘的定义: 文本挖掘是指从大量文本的集合C 中发现隐含的模式P。如果将C 看作输入, 将P 看作输出, 那么文本挖掘的过程就是从输入到输出的一个映射N: Cy P。 ( 2) 包括的内容 1. 文本分类:文本分类指按照预先定义的主题类别, 为文档集合中的每个文档确定一个类别。这样用户不但能够方便地浏览文档, 而且可以通过限制搜索范围来使查询文档更容易、快捷。目前, 用于英文文本分类的分类方法较多, 用于中文文本分类的方法较少, 主要有朴素贝叶 斯分类, 向量空间模型以及线性最小二乘LLSF。 2.文本聚类文本分类是将文档归入到己经存在的类中, 文本聚类的目标和文本分类是一 样的, 只是实现的方法不同。文本聚类是无教师的机器学习, 聚类没有预先定义好的主题类别, 它的目标是将文档集合分成若干个簇, 要求同一簇内文档内容的相似度尽可能大, 而不 同簇间的相似度尽可能小。Hearst 等人的研究已经证明了/ 聚类假设0 , 即与用户查询相 关的文档通常会聚类得比较靠近, 而远离与用户查询不相关的文档。目前, 有多种文本聚类算法, 大致可以分为两种类型: 以G) HAC 等算法为代表的层次凝聚法和以K. means 等算 法为代表的平面划分法。 3. 文本结构分析:为文本结构进行分析是为了更好地理解文本的主题思想, 了解文本所 表达的内容以及采用的方式。最终结果是建立文本的逻辑结构, 即文本结构树, 根结点是文本主题, 依次为层次和段落。 4.Web 文本数据挖掘:在Web 迅猛发展的同时, 不能忽视“信息爆炸”的问题, 即信息极大丰富而知识相对匮乏。据估计,web 已经发展成为拥有3 亿个页面的分布式信息空间。在这些大量、异质的Web 信息资源中, 蕴含着具有巨大潜在价值的知识。这样就需要一种 工具使人们能够从Web 上快速、有效的发现资源和知识。 2. 文本挖掘过程 ( 1) 特征表示及预处理
【推荐】清楚自己的产品再去做竞品分析
知己知彼——清楚自己的产品去做竞品分析正所谓“知己知彼,百战不殆”。做产品也是如此。互联网的一些事 知己,意味着知道自己产品的定位是什么,核心竞争力在哪里,产品定义是什么等等。 知彼,简单的说就是清楚竞争对手的情况。知彼是建立在知己的前提下:清楚自己的产品,才会知道对应的竞品有哪些。但是并不是说知己,就一定会知彼。这就免不了要深入的做竞品分析,才能更懂对方。互联网的一些事 不客气的说,现在很多产品经理,包括交互设计师,既不知己,也不知彼。很多人还停留在先盲目照抄竞品,再增加其他功能的思维框框里。 交互设计师也是如此,立场不坚定就很容易被PM牵着走。最近我做了一个内容型页面,接到需求文档后(更准确的说应该是一个文摘集锦),然后就开始排版了。但是越做越觉得不靠谱,在一些关键点上和PM有分歧,但又总讨论不出来结果。最后我恍然大悟:是因为前期漏掉了很多必要的工作。 首先,应该明确这个页面的目的是什么?这个页面可以为用户创造什么样的价值? 第二,我们如何为用户创造价值?是通过我们的臆想去教育用户?还是向用户展示他可能关心的内容?如果选择后者的话如何确定哪些内容是他关心的? 第三,根据用户可能关心的内容,我们应该提供哪些内容模块?第四,这些模块的优
先级是什么?这些都确定好了,才开始做排版布局的工作。 为什么出现这样的问题?因为这个内容丰富的页面,PM只给了半天的时间,在这种环境压力下,交互设计师很容易迷失自己,把专业的流程统统抛到脑后,而只想着如何按时完成任务。 由这个页面,我的思维延伸到了整个产品上:我们做这个产品的时候知道自己的核心竞争力是什么吗?知道如何甩开竞争对手吗?我们了解会有哪些人使用我们的产品且这些人的期望是怎样的?他们会如何使用我们的产品?我们的产品能满足他们的需求吗?对于这样一个业务复杂的专业产品,我们认真的研究过竞品吗?我们真正了解这个行业的特性以及用户的需求吗? 一切都是否定的。只是简单看看几个竞品,就凭借经验和感觉去勾画一个产品是远远不够的。越到后期,就越觉得心里没底。在设计的过程中,总是会不经意的发现新的设计质量不错的竞品,让我备感压力。也许靠着公司的牌子和广告资源,做的再烂也有人埋单。但这毕竟是短期的,不仅这个产品救不活,就连公司的品牌形象都会逐渐被透支。 产品设计已逐渐接近尾声,而我作为一个交互设计师,却说不出几个竞品的名称,也不了解竞品的情况,真是非常惭愧。我回想这一个多月,到底都做了些什么?为什么要对时间妥协?为什么不能以专业的素养来向产品方建议正确的流程呢?大家其实都非常想把事情做好,但是往往被眼前的限制冲昏了头脑。 亡羊补牢,未为晚也!明天,开始和PM商谈竞品分析事宜!
【原创附代码】R语言用之进行文本挖掘与分析
论文题目:R语言用之进行文本挖掘与分析 摘要:要分析文本内容,最常见的分析方法是提取文本中的词语,并统计频率。频率能反映词语在文本中的重要性,一般越重要的词语,在文本中出现的次数就会越多。词语提取后,还可以做成词云,让词语的频率属性可视化,更加直观清晰。本文利用R语言对2016年政府工作报告进行文本挖掘与分析并使用词云是该报告可视化,统计词频,用图片方式短时间看透文章的重点。 关键词:文本挖掘;R语言;2016政府工作报告;词云;可视化 Abstract:To analyze text content, the most common method of analysis is to extract the words in the text and to count the frequency. After extraction, can also be made word cloud, so that the frequency of the word attribute visualization, more intuitive and clear. This paper uses the R language to carry on the text mining and analysis to the government work report in 2016 and use the word cloud to visualize the report, to count word frequency, and to see the focus of the article in a short time. Key words:Text mining; R language; 2016 government work report; word cloud; visualization
手把手教你做年报
年报操作指引 2017年度市场主体年报工作开始啦! 具体时间:江苏省2017年度市场主体年报工作于2018年1月1日开始,6月30日结束。2017年12月31日前设立登记的市场主体,应当报送2017年度年报。 具体影响:企业未按时年报和公示信息隐瞒真实情况、弄虚作假,将被工商(市场监管)部门列入经营异常名录(满三年将被列入严重违法企业名单),并向社会公示影响其信用,在政府采购、工程招投标、国有土地出让、授予荣誉称号、银行贷款、企业招工、催收货款、办理房产抵押登记等工作中予以限制或禁入,并在各部门业务中联动受限,会因“一处违规”,而“处处受限”。 企业年报具体步骤(个体户步骤类似) 第一步:建议使用火狐浏览器,否则即使能进入年报填写,最终不一定能提交。
首先进入“常州市工商行政管理局官网主页”(https://www.360docs.net/doc/536807373.html,/),点击“国家企业信用公示系统(江苏)”(如下图所示红圈处),再点击“年报入口”进入国家企业信用信息公示系统(江苏)主页(https://www.360docs.net/doc/536807373.html,/index.html)(如下图所示红圈处),点击“企业信息填报”,如下图所示红圈处,进入登录界面。
第二步:市场主体有两种方式登录公示系统进行年报。一种方式为“工商联络员”登录,另一种方式为电子营业执照登录。采取“工商联络员”登录方式的,如已注册过“工商联络员”,输入“统一社会信用代码/注册号”和“工商联络员身份证号”,凭手机验证码登录填报。未注册过“工商联络员”的企业,需指定一名负责本单位年报公示工作的工商联络员,先在公示系统按照页面提示进行“联络员注册”,注册成功后,回到登录页面进行登录。需输入统一社会信用代码、联络员身份证号码、验证码登录。验证码通过点击“获取验证码”按钮,发往注册的联络员手机号码获得,目前一个手机号24小时之内只能获取5个验证码;已通过登记机关领取电子营业执照的可以通过“电子营业执照”方式登录,输入PIN码和验证码即可。 已注册过“工商联络员”的市场主体若要更换原先注册的“工商联络员”的,必须在登录公示系统之前完成“联络员变更”,新任“工商联络员”需取得原“工商联络员”的注册信息(姓名、证件号码、手机号码等),经系统完成准确性和匹配性判断,校验后方能变更。
用 Python 做文本挖掘的流程_光环大数据python培训
https://www.360docs.net/doc/536807373.html, 用 Python 做文本挖掘的流程_光环大数据python培训 收集数据 数据集。如果是已经被人做成数据集了,这就省去了很多麻烦事 抓取。这个是 Python 做得最好的事情,优秀的包有很多,比如scrapy,beautifulsoup等等。 预处理(对这里的高质量讨论结果的修改,下面的顺序仅限英文) 去掉抓来的数据中不需要的部分,比如 HTML TAG,只保留文本。结合beautifulsoup 和正则表达式就可以了。pattern.web 也有相关功能。 处理编码问题。没错,即使是英文也需要处理编码问题!由于 Python2 的历史原因,不得不在编程的时候自己处理。英文也存在 unicode 和 utf-8 转换的问题,中文以及其他语言就更不用提了。这里有一个讨论,可以参考,当然网上也有很多方案,找到一个适用于自己的最好。 将文档分割成句子。 将句子分割成词。专业的叫法是 tokenize。 拼写错误纠正。pyenchant 可以帮你!(中文就没有这么些破事!) POS Tagging。nltk 是不二选择,还可以使用 pattern。 去掉标点符号。使用正则表达式就可以。 去掉长度过小的单词。len<3 的是通常选择。 去掉 non-alpha 词。同样,可以用正则表达式完成 /W 就可以。 转换成小写。 去掉停用词。Matthew L. Jockers 提供了一份比机器学习和自然语言处理中常用的停词表更长的停词表。中文的停词表可以参考这个。 lemmatization/stemming。nltk 里面提供了好多种方式,推荐用wordnet 的方式,这样不会出现把词过分精简,导致词丢掉原型的结果,如果实在不行,也用 snowball 吧,别用 porter,porter 的结果我个人太难接受了,
在twitter中做文本挖掘进行股市预测的论文
1 Twitter mood predicts the stock market. Johan Bollen 1, ,Huina Mao 1, ,Xiao-Jun Zeng 2. :authors made equal contributions. Abstract —Behavioral economics tells us that emotions can profoundly affect individual behavior and decision-making.Does this also apply to societies at large,i.e.can societies experience mood states that affect their collective decision making?By extension is the public mood correlated or even predictive of economic indicators?Here we investigate whether measurements of collective mood states derived from large-scale Twitter feeds are correlated to the value of the Dow Jones Industrial Average (DJIA)over time.We analyze the text content of daily Twitter feeds by two mood tracking tools,namely OpinionFinder that measures positive vs.negative mood and Google-Pro?le of Mood States (GPOMS)that measures mood in terms of 6dimensions (Calm,Alert,Sure,Vital,Kind,and Happy).We cross-validate the resulting mood time series by comparing their ability to detect the public’s response to the presidential election and Thanksgiving day in 2008.A Granger causality analysis and a Self-Organizing Fuzzy Neural Network are then used to investigate the hypothesis that public mood states,as measured by the OpinionFinder and GPOMS mood time series,are predictive of changes in DJIA closing values.Our results indicate that the accuracy of DJIA predictions can be signi?cantly improved by the inclusion of speci?c public mood dimensions but not others.We ?nd an accuracy of 87.6%in predicting the daily up and down changes in the closing values of the DJIA and a reduction of the Mean Average Percentage Error by more than 6%.Index Terms —stock market prediction —twitter —mood analysis. I.I NTRODUCTION S TOCK market prediction has attracted much attention from academia as well as business.But can the stock market really be predicted?Early research on stock market prediction [1],[2],[3]was based on random walk theory and the Ef?cient Market Hypothesis (EMH)[4].According to the EMH stock market prices are largely driven by new information,i.e.news,rather than present and past prices.Since news is unpredictable,stock market prices will follow a random walk pattern and cannot be predicted with more than 50percent accuracy [5]. There are two problems with EMH.First,numerous studies show that stock market prices do not follow a random walk and can indeed to some degree be predicted [5],[6],[7],[8]thereby calling into question EMH’s basic assumptions.Sec-ond,recent research suggests that news may be unpredictable but that very early indicators can be extracted from online social media (blogs,Twitter feeds,etc)to predict changes in various economic and commercial indicators.This may conceivably also be the case for the stock market.For example,[11]shows how online chat activity predicts book sales.[12]uses assessments of blog sentiment to predict movie sales.[15]predict future product sales using a Probabilistic Latent Semantic Analysis (PLSA)model to extract indicators of sentiment from blogs.In addition,Google search queries have been shown to provide early indicators of disease infection rates and consumer spending [14].[9]investigates the relations between breaking ?nancial news and stock price changes.Most recently [13]provide a ground-breaking demonstration of how public sentiment related to movies,as expressed on Twitter,can actually predict box of?ce receipts. Although news most certainly in?uences stock market prices,public mood states or sentiment may play an equally important role.We know from psychological research that emotions,in addition to information,play an signi?cant role in human decision-making [16],[18],[39].Behavioral ?nance has provided further proof that ?nancial decisions are sig-ni?cantly driven by emotion and mood [19].It is therefore reasonable to assume that the public mood and sentiment can drive stock market values as much as news.This is supported by recent research by [10]who extract an indicator of public anxiety from LiveJournal posts and investigate whether its variations can predict S&P500values. However,if it is our goal to study how public mood in?uences the stock markets,we need reliable,scalable and early assessments of the public mood at a time-scale and resolution appropriate for practical stock market https://www.360docs.net/doc/536807373.html,rge surveys of public mood over representative samples of the population are generally expensive and time-consuming to conduct,cf.Gallup’s opinion polls and various consumer and well-being indices.Some have therefore proposed indirect assessment of public mood or sentiment from the results of soccer games [20]and from weather conditions [21].The accuracy of these methods is however limited by the low degree to which the chosen indicators are expected to be correlated with public mood. Over the past 5years signi?cant progress has been made in sentiment tracking techniques that extract indicators of public mood directly from social media content such as blog content [10],[12],[15],[17]and in particular large-scale Twitter feeds [22].Although each so-called tweet ,i.e.an individual user post,is limited to only 140characters,the aggregate of millions of tweets submitted to Twitter at any given time may provide an accurate representation of public mood and sentiment.This has led to the development of real-time sentiment-tracking indicators such as [17]and “Pulse of Nation”1. In this paper we investigate whether public sentiment,as expressed in large-scale collections of daily Twitter posts,can be used to predict the stock market.We use two tools to measure variations in the public mood from tweets submitted 1https://www.360docs.net/doc/536807373.html,/home/amislove/twittermood/ a r X i v :1010.3003v 1 [c s .C E ] 14 O c t 2010