实验三-多元线性回归模型的估计和检验

实验报告
课程名称:计量经济学
实验项目:实验三多元线性回归模型的
估计和检验
实验类型:综合性□设计性□验证性
专业班别:
姓名:
学号:
实验课室:
指导教师:石立
实验日期:2014年5月12日
广东商学院华商学院教务处制一、实验项目训练方案
小组合作:是□否
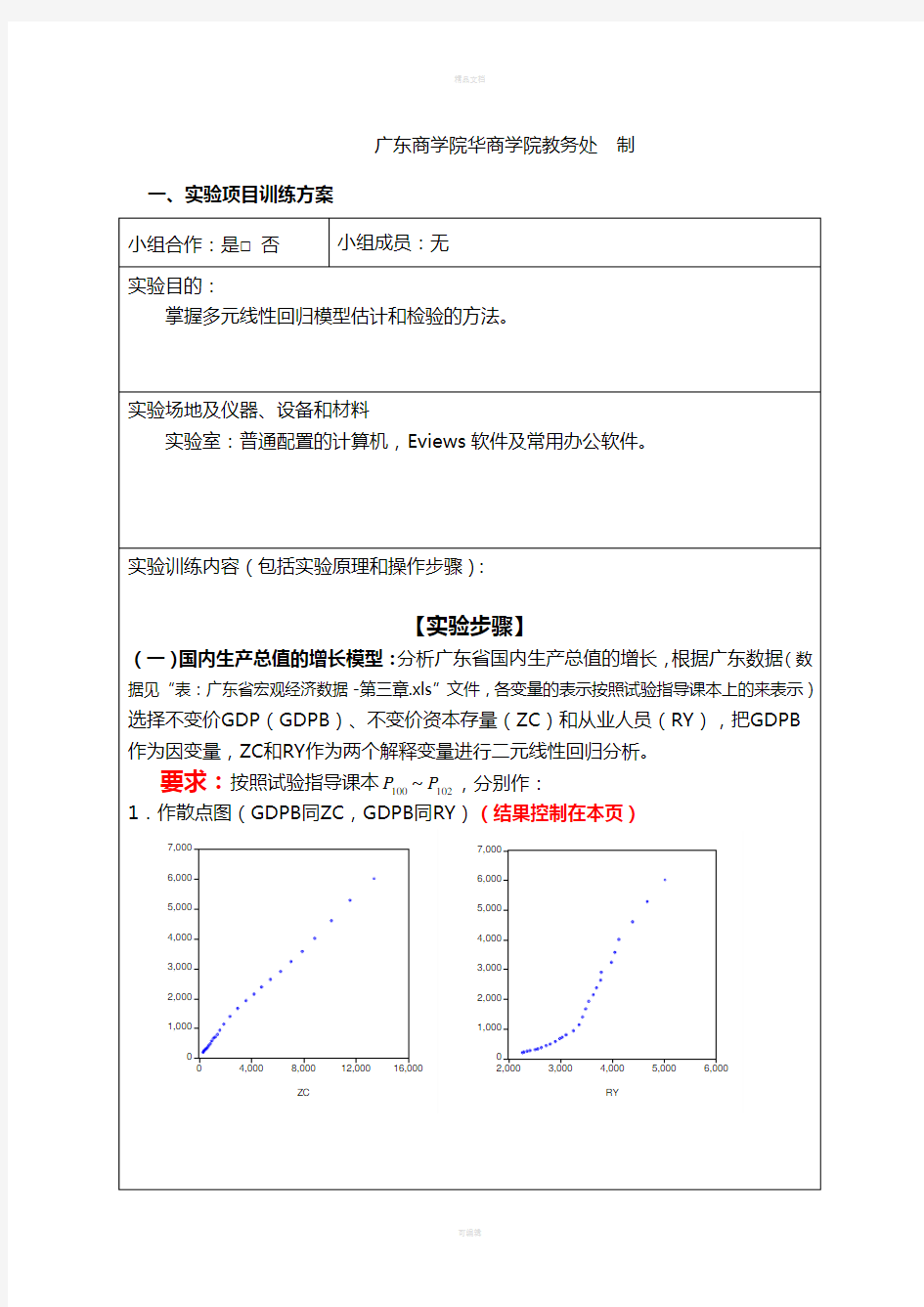
3.作GDPB同ZC和RY的多元线性回归,写出模型估计的结果,并分析模型检验是均否通过?(三个检验)(结果控制在本页)
得到的估计方程
GDPB=0.377170*ZC+0.353689*RY-800.5997
4.将建立的二元回归模型(GDPB同ZC和RY)同一元回归模型(GDPB同ZC、GDPB 同RY)相比较,分析优点。(结果控制在本页)
5.结合相关的经济理论,分析估计的二元回归模型的经济意义。(结果控制在本页)估计方程的判定系数人R2接近1;参数显著性t检验均大于2;方程显著性F检验显著。调整的判定系数为0.99085,比上面的一元回归有明显改善。
Null Hypothesis: Obs F-Statistic Prob.
LB does not Granger Cause XFJ 26 7.19010 0.0042
XFJ does not Granger Cause LB 5.45516 0.0124
从散点图看它们之间具有线性关系,从因果关系检验看它们之间似乎具有双向因果关系。宏观经济中确实如此。进行一元线性回归如下:
得到回归方程
XFJ=0.986702*LB-75.99662
2.固定资产投资模型(结果控制在本页)
固定资产投资TZC显然取决于固定资产折旧ZJ、营业盈余YY和财政支出CZ,进行三元线性回归如下:
分别去掉一个解释变量进行三个二元线性回归如下:
从上面三个回归结果可以看出,只要固定资产折旧ZJ和财政支出CZ其中一个不在方程中,回归就能得到很好的拟合。现在暂且去最后一个回归方程来使用,方程为TZG=0.430093*YY+1.869278*CZ+20.91893
3.货物和服务净流出模型(结果控制在本页)
先考虑影响货物和服务净流出CK的因素为支出法的国内生产总值GDP,看散点图和因果关系检验。
-500
500
1,000
1,500
2,000
2,500
05,00010,00015,00020,00025,000
GDP
C
K
从散点图和因果关系检验看它们具有关系,进行一元线性回归如下:
在所有收集到的统计数据中,年利率LL是一个可以考虑引入的因素,引入LL进行二元线性回归如下:
最后得到回归方程
CK=0.88239*GDP-42.65989*LL+202.2173
4.存货增加模型(结果控制在本页)
存货增加TZC显然取决于城乡储蓄CX和商品零售价格指数PSL,进行二元线性回归如下:
方程为
TZC=0.030633*CX+1.780806*PSL-209.0546
SPSS实验报告_线性回归_曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
多元线性回归模型的案例分析
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下:
多元线性回归SPSS实验报告
回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
一元线性回归模型案例分析
一元线性回归模型案例分析 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表2.5的数据: 表2.52002年中国各地区城市居民人均年消费支出和可支配收入
计量经济学简单线性回归实验报告精编
实验报告 1. 实验目的随着中国经济的发展,居民的常住收入水平不断提高,粮食销售量也不断增长。研究粮食年销售量与人均收入之间的关系,对于探讨粮食年销售量的增长的规律性有重要的意义。 2. 模型设定 为了分析粮食年销售量与人均收入之间的关系,选择“粮食年销售量” 为被解释变量(用Y 表示),选择“人均收入”为解释变量(用X 表 示)。本次实验报告数据取自某市从1974 年到1987 年的数据(教材书上101页表3.11),数据如下图所示:
1粮食年销售量Y/万吨人均收入X/ rF1974[ 9& 45153.2 1975100.7190 pl1976102.8240.3 1977133. 95301.12 [61978140.13361 71979143.11420 8—1980146.15491.76「91981144.6501 101982148. 94529.2 1 11-1983158.55552. 72匸1984169. 68771.16 131985P 162.1481L8 14二1986170. 09988.43 1519871F& 691094.65为分析粮食年销售量与人均收入的关系,做下图所谓的散点图 从散点图可以看出粮食年销售量与人均收入大体呈现为线性关 系,可以建立如下简单现行回归模型: 3?估计参数
Y t = ■? 1 2 X t ——I t 假定所建模型及其中的随机扰动项叫满足各项古典假定,可以 用OLS法估计其参数。 通过利用EViews对以上数据作简单线性回归分析,得出回归结果如下表所示: Dependent Variable Y Method: Least Squares Date 10/15/11 Time 14 49 Sample- 1 14 Included observations: 14 Variable Coefficient Std Error t-Statistic Prob C99 61349 6 431242 15 489000 0000 X0.0814700.010738 7.5071190.0000 R-squared0 827493Mean dependent var142 7129 Adjusted R-squared0 813123S.D. dependent var26.09805 S E of regression11 28200Akaike info criterion7 915858 Sum squared resid1527 403Schwarz criterion7 907152 Log likelihood-52.71101F-statisti c5756437 Durbin-V/atson stat0 638969Prob(尸-statistic)0 000006 可用规范的形式将参数估计和检验的结果写为: A Y t =99.61349+0.08147 X t (6.431242)(0.10738) t= (15.48900) (7.587119) R2=0.827498 F=57.56437 n=14 4?模型检验 (1).经济意义检验 A A 所估计的参数1=99.61349, 1 2=0.08147,说明人均收入每增加 1元,平均说来可导致粮食年销售量提高0.08147元。这与经济学中
多元线性回归分析预测法
多元线性回归分析预测法 (重定向自多元线性回归预测法) 多元线性回归分析预测法(Multi factor line regression method,多元线性回归分析法) [编辑] 多元线性回归分析预测法概述 在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。这时采用一元回归分析预测法进行预测是难以奏效的,需要采用多元回归分析预测法。 多元回归分析预测法,是指通过对两上或两个以上的自变量与一个因变量的相关分析,建立预测模型进行预测的方法。当自变量与因变量之间存在线性关系时,称为多元线性回归分析。 [编辑] 多元线性回归的计算模型[1] 一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释
因变量的变化,这就是多元回归亦称多重回归。当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。 设y为因变量,为自变量,并且自变量与因变量之间为线性关系时,则多元线性回归模型为: 其中,b0为常数项,为回归系数,b1为固定时,x1每增加一 个单位对y的效应,即x1对y的偏回归系数;同理b2为固定时,x2每增加一个单位对y的效应,即,x2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为: 其中,b0为常数项,为回归系数,b1为固定时,x2每增加一 个单位对y的效应,即x2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为: y = b0 + b1x1 + b2x2 + e 建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是: (1)自变量对因变量必须有显著的影响,并呈密切的线性相关; (2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的; (3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度; (4)自变量应具有完整的统计数据,其预测值容易确定。 多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和()为最小的前提下,用最小二乘法求解参数。以二线性回归模型为例,求解回归参数的标准方程组为 解此方程可求得b0,b1,b2的数值。亦可用下列矩阵法求得
SPSS多元线性回归分析实例操作步骤
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK.
第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.
SPSS线性回归分析案例
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: (
2010年中国各地区城市居民人均年消费支出和可支配收入
} 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 模型… R R方调整R方标准估计的误差 1.965a.93 2.930 a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) ~ 表3 相关性 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出 Y(元) .965 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
多元线性回归预测模型论文
多元线性回归统计预测模型 摘要:本文以多元统计分析为理论基础,在对数据进行统计分析的基础上建立多元线性回归模型并对未知量作出预测,为相关决策提供依据和参考。重点介绍了模型中参数的估计和自变量的优化选择及简单应用举例。 关键词:统计学;线性回归;预测模型 一.引言 多元线性回归统计预测模型是以统计学为理论基础建立数学模型,研究一个随机变量Y与两个或两个以上一般变量X 1,X 2,…,Xp 之间相依关系,利用现有数据,统计并分析,研究问题的变化规律,建立多元线性回归的统计预测模型,来预测未来的变化情况。它不仅能解决一些随机的数学问题,而且还可以通过建立适当的随机模型进而解决一些确定的数学问题,为相关决策提供依据和参考。 目前统计学与其他学科的相互渗透为统计学的应用开辟新的领域。并被广泛的应用在各门学科上,从物理和社会科学到人文科学,甚至被用来工业、农业、商业及政府部门。而多元线性回归是多元统计分析中的一个重要方法,被应用于众多自然科学领域的研究中。多元线性回归分析作为一种较为科学的方法,可以在获得影响因素的前提下,将定性问题定量化,确定各因素对主体问题的具体影响程度。 二.多元线性回归的基本理论 多元线性回归是多元统计分析中的一个重要方法,被广泛应用于众多自然科学领域的研究中。多元线性回归分析的基本任务包括:根据因变量与多个自变量的实际观测值建立因变量对多个自变量的多元线性回归方程;检验、分析各个自变量对因自变量的综合线性影响的显著性;检验、分析各个自变量对因变量的单纯线性影响的显著性,选择仅对因变量有显著线性影响的自变量,建立最优多元线性回归方程;评定各个自变量对因变量影响的相对重要性以及测定最优多元线性回归方程的偏离度等。由于多数的多元非线性回归问题都可以化为多元线性回归问题,所以这里仅讨论多元线性回归。许多非线性回归和多项式回归都可以化为多元线性回归来解决,因而多元线性回归分析有着广泛的应用。 2.1 多元线性回归模型的一般形式 设随机变量y 与一般变量12,, ,p x x x 线性回归模型为 01122...p p y x x x ββββε=+++++ (2.1) 模型中Y为被解释变量(因变量),而12,,,p x x x 是p 个可以精确测量并可控制的一般变 量,称为解释变量(自变量)。p =1时,(2.1)式即为一元线性回归模型,p 大于2时,(2.1)
多元线性回归模型案例
我国农民收入影响因素的回归分析 本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。?农民收入水平的度量常采用人均纯收入指标。影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。但可以归纳为以下几个方面:一是农产品收购价格水平。二是农业剩余劳动力转移水平。三是城市化、工业化水平。四是农业产业结构状况。五是农业投入水平。考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。 一、计量经济模型分析 (一)、数据搜集 根据以上分析,我们在影响农民收入因素中引入7个解释变量。即:2x -财政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。
资料来源《中国统计年鉴2006》。 (二)、计量经济学模型建立 我们设定模型为下面所示的形式: 利用Eviews 软件进行最小二乘估计,估计结果如下表所示: DependentVariable:Y Method:LeastSquares Sample: Includedobservations:19 Variable Coefficient t-Statistic Prob. C X1 X3 X4 X5 X6 X7 X8 R-squared Meandependentvar AdjustedR-squared 表1最小二乘估计结果 回归分析报告为: () ()()()()()()()()()()()()()()() 2345678 2? -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66 R Df DW F ====二、计量经济学检验 (一)、多重共线性的检验及修正 ①、检验多重共线性 (a)、直观法 从“表1最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4x6
matlab建立多元线性回归模型并进行显著性检验及预测问题
matlab建立多元线性回归模型并进行显着性检验及预测问题 例子; x=[143 145 146 147 149 150 153 154 155 156 157 158 159 160 162 164]'; X=[ones(16,1) x]; 增加一个常数项Y=[88 85 88 91 92 93 93 95 96 98 97 96 98 99 100 102]'; [b,bint,r,rint,stats]=regress(Y,X) 得结果:b = bint = stats = 即对应于b的置信区间分别为[,]、[,]; r2=, F=, p= p<, 可知回归模型y=+ 成立. 这个是一元的,如果是多元就增加X的行数! function [beta_hat,Y_hat,stats]=regress(X,Y,alpha) % 多元线性回归(Y=Xβ+ε)MATLAB代码 %? % 参数说明 % X:自变量矩阵,列为自变量,行为观测值 % Y:应变量矩阵,同X % alpha:置信度,[0 1]之间的任意数据 % beta_hat:回归系数 % Y_beata:回归目标值,使用Y-Y_hat来观测回归效果 % stats:结构体,具有如下字段 % =[fV,fH],F检验相关参数,检验线性回归方程是否显着 % fV:F分布值,越大越好,线性回归方程越显着 % fH:0或1,0不显着;1显着(好) % =[tH,tV,tW],T检验相关参数和区间估计,检验回归系数β是否与Y有显着线性关系 % tV:T分布值,beta_hat(i)绝对值越大,表示Xi对Y显着的线性作用% tH:0或1,0不显着;1显着 % tW:区间估计拒绝域,如果beta(i)在对应拒绝区间内,那么否认Xi对Y显着的线性作用 % =[T,U,Q,R],回归中使用的重要参数 % T:总离差平方和,且满足T=Q+U % U:回归离差平方和 % Q:残差平方和 % R∈[0 1]:复相关系数,表征回归离差占总离差的百分比,越大越好% 举例说明 % 比如要拟合y=a+b*log(x1)+c*exp(x2)+d*x1*x2,注意一定要将原来方程线化% x1=rand(10,1)*10; % x2=rand(10,1)*10; % Y=5+8*log(x1)+*exp(x2)+*x1.*x2+rand(10,1); % 以上随即生成一组测试数据 % X=[ones(10,1) log(x1) exp(x2) x1.*x2]; % 将原来的方表达式化成Y=Xβ,注意最前面的1不要丢了
(完整word版)多元线性回归模型案例分析
多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据
设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024
计量经济学多元线性回归、多重共线性、异方差实验报告记录
计量经济学多元线性回归、多重共线性、异方差实验报告记录
————————————————————————————————作者:————————————————————————————————日期:
计量经济学实验报告
多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β 1 X 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元
多元线性回归实例分析
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除)
多元线性回归模型实验报告
多元线性回归模型实验报告 13级财务管理 101012013101 蔡珊珊 【摘要】首先做出多元回归模型,对于解释变量作出logx等变换,选择拟合程度最高的模型,然后判断出解释变量之间存在相关性,然后从检验多重线性性入手,由于解释变量之间有的存在严重的线性性,因此采用逐步回归法,将解释变量进行筛选,保留对模型解释能力较强的解释变量,进而得出一个初步的回归模型,最后对模型进行异方差和自相关检验。 【操作步骤】1.输入解释变量与被解释变量的数据 2.作出回归模型
R^2=0.966951 DW=0.626584 F-statictis=241.3763 ②我们令y1=log(consumption),x4=log(people),x5=log(price),x6=log(retained),x7= log(gdp), 作出回归模型
② 发现拟合程度很高,也通过了F检验与T检验。但是我们首先检查模型的共线性 发现x4与x6,x4与x7,x6与x7存在很强的共线性,对模型会造成严重影响。
目前暂用模型y1=10.55028-3.038439x4-0.236518x5+2.647396x6-0.557805x7,我们将陆续进行调整。 3.分别作出各解释变量与被解释变量之间的线性模型
①作出汽车消费量与汽车保有量之间的线性回归模型 R^2=0.956231 DW=0.147867 F-statistic=786.4967
因为prob小于α置信度,则可说明β1不明显为零。经济意义存在 Y1^=4.142917 + 0.761197x6 (8.283960) (28.04455)
一元线性回归分析实验报告
一元线性回归在公司加班制度中的应用 院(系): 专业班级: 学号姓名: 指导老师: 成绩: 完成时间:
一元线性回归在公司加班制度中的应用 一、实验目的 掌握一元线性回归分析的基本思想和操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境 SPSS21.0 windows10.0 三、实验题目 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经10周时间,收集了每周加班数据和签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示 y 3.5 1.0 4.0 2.0 1.0 3.0 4.5 1.5 3.0 5.0 2. x 与y 之间大致呈线性关系? 3. 用最小二乘法估计求出回归方程。 4. 求出回归标准误差σ∧ 。 5. 给出0 β∧与1 β∧ 的置信度95%的区间估计。 6. 计算x 与y 的决定系数。 7. 对回归方程作方差分析。 8. 作回归系数1 β∧ 的显著性检验。 9. 作回归系数的显著性检验。 10.对回归方程做残差图并作相应的分析。
11.该公司预测下一周签发新保单01000 x=张,需要的加班时间是多少? 12.给出0y的置信度为95%的精确预测区间。 13.给出 () E y的置信度为95%的区间估计。 四、实验过程及分析 1.画散点图 如图是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以看出,数据均匀分布在对角线的两侧,说明x和y之间线性关系良好。 2.最小二乘估计求回归方程
用SPSS 求得回归方程的系数01,ββ分别为0.118,0.004,故我们可以写出其回归方程如下: 0.1180.004y x =+ 3.求回归标准误差σ∧ 由方差分析表可以得到回归标准误差:SSE=1.843 故回归标准误差: 2= 2SSE n σ∧-,2σ∧=0.48。 4.给出回归系数的置信度为95%的置信区间估计。 由回归系数显著性检验表可以看出,当置信度为95%时:
一般线性回归分析案例
一般线性回归分析案例 1、案例 为了研究钙、铁、铜等人体必需元素对婴幼儿身体健康的影响,随机抽取了30个观测数据,基于多员线性回归分析的理论方法,对儿童体内几种必需元素与血红蛋白浓度的关系进行分析研究。这里,被解释变量为血红蛋白浓度(y),解释变量为钙(ca)、铁(fe)、铜(cu)。 表一血红蛋白与钙、铁、铜必需元素含量 (血红蛋白单位为g;钙、铁、铜元素单位为ug) case y(g)ca fe cu 17.0076.90295.300.840 27.2573.99313.00 1.154 37.7566.50350.400.700 48.0055.99284.00 1.400 58.2565.49313.00 1.034 68.2550.40293.00 1.044 78.5053.76293.10 1.322 88.7560.99260.00 1.197 98.7550.00331.210.900 109.2552.34388.60 1.023 119.5052.30326.400.823 129.7549.15343.000.926 1310.0063.43384.480.869 1410.2570.16410.00 1.190 1510.5055.33446.00 1.192 1610.7572.46440.01 1.210 1711.0069.76420.06 1.361 1811.2560.34383.310.915 1911.5061.45449.01 1.380 2011.7555.10406.02 1.300 2112.0061.42395.68 1.142 2212.2587.35454.26 1.771 2312.5055.08450.06 1.012 2412.7545.02410.630.899 2513.0073.52470.12 1.652 2613.2563.43446.58 1.230
多元线性回归模型的案例讲解
多元线性回归模型的案 例讲解 Document number:NOCG-YUNOO-BUYTT-UU986-1986UT
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/ 千克 X/元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/ 千克 X/元 P 1/(元/千克) P 2/(元/千克) P 3/(元/ 千克) 1980 397 1992 911 1981 413 1993 931 1982 439 1994 1021 1983 459 1995 1165 1984 492 1996 1349 1985 528 1997 1449 1986 560 1998 1575 1987 624 1999 1759 1988 666 2000 1994 1989 717 2001 2258 1990 768 2002 2478 1991 843 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下:
所以,回归方程为: 123ln 0.73150.3463ln 0.5021ln 0.1469ln 0.0872ln Y X P P P =-+-++ 由上述回归结果可以知道,鸡肉消费需求受家庭收入水平和鸡肉价格的影响,而牛肉价格和猪肉价格对鸡肉消费需求的影响并不显着。 验证猪肉价格和鸡肉价格是否有影响,可以通过赤池准则(AIC )和施瓦茨准则(SC )。若AIC 值或SC 值增加了,就应该去掉该解释变量。 去掉猪肉价格P 2与牛肉价格P 3重新进行回归分析,结果如下: Variable Coefficient Std. Error t-Statistic Prob.?? C LOG(X) LOG(P1) R-squared ????Mean dependent var Adjusted R-squared ????. dependent var . of regression ????Akaike info criterion Sum squared resid ????Schwarz criterion Log likelihood ????F-statistic Durbin-Watson stat ????Prob(F-statistic)