SPSS在数学建模中的应用

SPSS在数学建模中的应用
第一讲SPSS的一般应用
一、SPSS for Windows的界面介绍
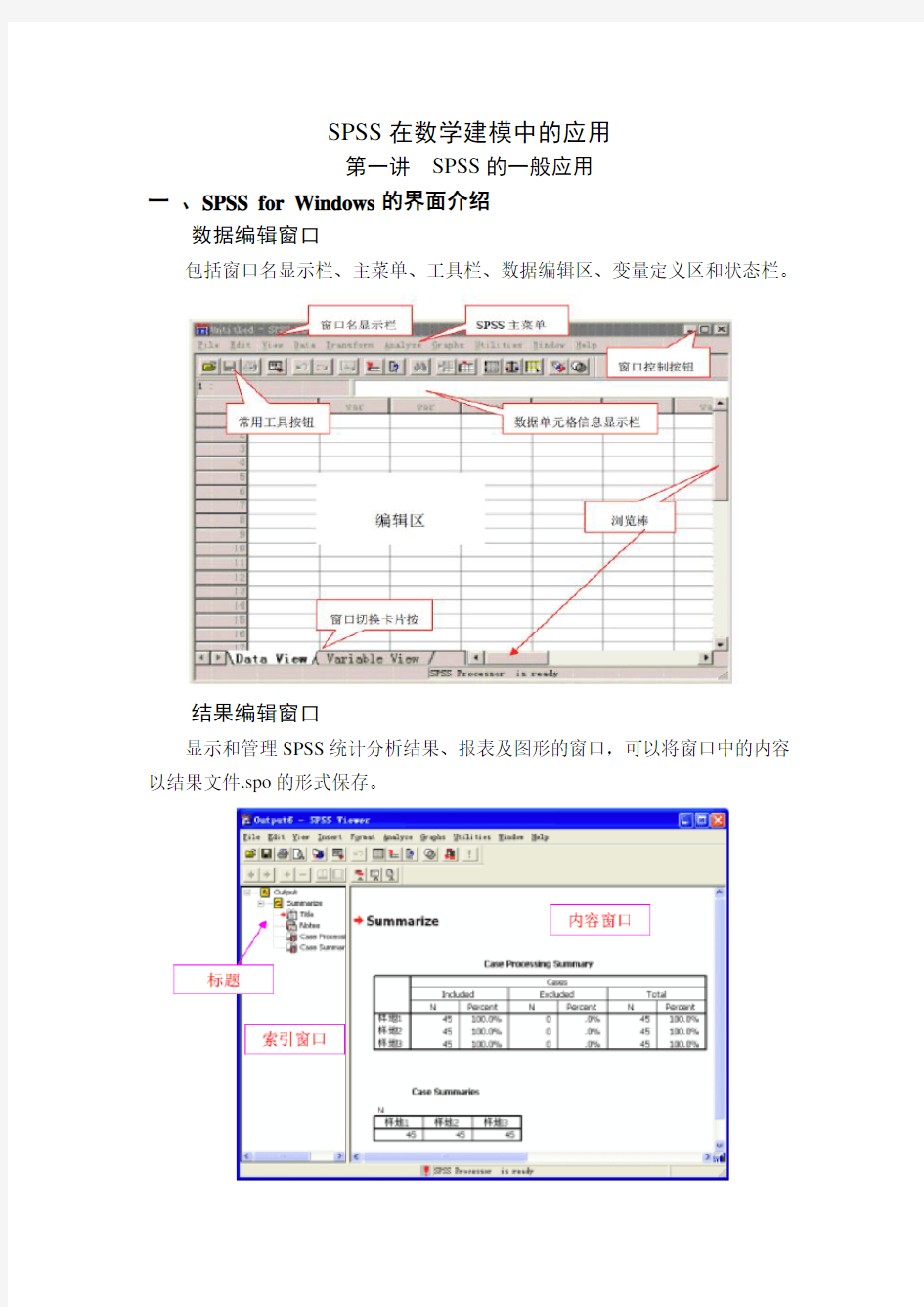
数据编辑窗口
包括窗口名显示栏、主菜单、工具栏、数据编辑区、变量定义区和状态栏。
结果编辑窗口
显示和管理SPSS统计分析结果、报表及图形的窗口,可以将窗口中的内容以结果文件.spo的形式保存。
二、建立数据文件
定义变量
1、单击数据编辑窗口左下方的“Variable View”标签或双击题头(Var),进入变量定义窗口。可定义:
变量名(Name)变量类型(Type)
变量长度(Width)小数点位数(Decimal)
变量标签(Label)变量值标签(Values)
缺失值的定义方式(Missing)
变量的显示宽度(Columns)
变量显示的对齐方式(Align)
变量的测量尺度(Measure)
2、定义变量名(Name)时,应注意:
1)变量名可为汉字或英文,英文的第一个字符必须为字母,后面可跟任意字母、数字、句点或@、#、_、$等;
2)变量名不能以句点结尾;
3)定义时应避免最后一个字符为下划线“_”(因为某些过程运行时自动创建的变量名的最后一个字符有可能为下划线);
4)变量的长度一般不能超过8个字符;
5)每个变量名必须保证是唯一的,不区分大小写。
常用的变量类型(Type)包括:数值型、字符串型、日期格式变量等。
数据录入
定义变量后,单击“Data View”,即可在数据编辑窗口中输入数据。
数据编辑
1)数据的排序:Data→Sort Cases…
2)数据的转置:Data→Transpose…
3)数据的聚合:Data→Aggregate Data
4)数据文件的拆分:Data→Split File
5)数据文件的合并:Data→Merge Files→Add Cases…/Add Variables
6)数据的转换:Transform→Compute…
数据文件的保存
1)选择“File”菜单的“Save”命令,可直接保存为SPSS默认的数据文件格式(*.sav)。
2)选择“File”菜单的“Save As”命令,弹出“Save Data As”对话框,可选择保存为Excel(*.xls)等文件格式。
调用其它数据文件
按照File→Open→Data…的顺序选择菜单项,打开“Open File”对话框。可以打开的文件格式除了SPSS(*.sav)外,还包括:Excel(*.xls)、数据文件(*.dat)和文本文件(*.txt)。
三、SPSS制图
主要通过“Graph”菜单中的选项来创建图形。
变量(Variable)分类与统计分析
要进行统计分析,离不开统计数据。在搜索数据之前,必须首先了解数据的种类。数据涉及到变量的取值,通常用变量的取值来描述数据。变量可按多种方法分类,这些分类有助于选择适当的统计分析方法作进一步的分析与研究。下面按三种方法对变量进行分类:按间隙分类、按作用分类和按测量尺度分类。
(一)按间隙(gaps)划分
根据一个变量紧挨着的两个观测值之间是否有间隙,可以把变量分为两类:离散型变量(discrete variable)和连续型变量(continuous variable)。更准确地说,当一个变量的任意两个可能取值之间没有其他取值时,该变量是离散的;当一个变量的任意两个可能取值之间还有其他可能取值时,该变量是连续的。例如,性别(设男性取值为0,女性取值为1)、企业数目、分组情况(设A 组取值为1,B 组取值为2 等)等为离散型变量;身高、体重、血压、GDP 等为连续型变量。
离散型变量与连续型变量
需要指出的是,由于分析的需要,离散型变量经常作为连续型变量处理。而连续型变量也可以作为离散型变量处理,如可以把“血压”变量分为“低”、“中”、“高”三组变为离散型变量。
(二)按作用划分
根据一个变量在分析时的作用,可以把变量分为因变量(dependent variable)或自变量(independent variable)。如果一个变量由其他变量来描述,该变量称为因变量或反应量(response variable);如果一个变量与其他变量一起用于描述因变量,该变量称为自变量或预测变量(predictor variable)。例如,在分析家庭收入、性别等因素对消费支出的影响时,收入变量和性别变量是自变量,消费支出变量是因变量。
一个变量是因变量还是自变量,与统计分析的目的有关。同一个变量在某种分析中作为因变量,而在其它分析中可能作为自变量。
(三)根据测量尺度划分
根据变量测量精度不同,可把变量由低到高分为四种尺度:定类变量、定序变量、定距变量和定比变量。
1、定类变量
定类变量又称为名义(nominal)变量。这是一种测量精确度最低、最粗略的基于“质”因素的变量,它的取值只代表观测对象的不同类别,例如“性别”变量、“职业”变量等都是定类变量。定类变量的取值称为定类数据或名义数据。定类数据的其同特点是用不多的名称来加以表达,并由被研究变量每一组出现的次数及其总计数所组成,这种数据是枚举性的,即由计数一一而得。唯一适合于定类数据的数学关系是“等价关系”。因而,在定类数据中,同一组内各单位是等价的,同时若更换各不同组的符号并不会改变数据原有的基本信息。因此,最常用来综合定类数据的统计量是频数、比率或百分比等。
2、定序变量
定序变量又称为有序(ordinal)变量、顺序变量,它的取值的大小能够表示观测对象的某种顺序关系(等级、方位或大小等),也是基于“质”因素的变量。例如,“最高学历”变量的取值是:1—小学及以下、2—初中、3—高中、中专、技校、4—大学专科、5—大学本科、6—研究生以上。由小到大的取值能够代表学历由低到高。定序变量的取值称为定序数据或有序数据。适合于定序数据的数学关系是“大于(>)”和“小于(<)”关系。在定序数据中,同一组内各单位是等价的,相邻组之间的单位是不等价的,它们存在“大于”或“小于”的关系。而且,并进行保序变换(或称单调变换),则不改变数据原有的基本信息即等级顺序。最适合用于综合定序数据取值的集中趋势的统计量是中位数。
3、定距变量
定距变量又称为间隔(interval)变量,它的取值之间可以比较大小,可以用加减法计算出差异的大小。例如,“年龄”变量,其取值60 与20 相比,表示60 岁比20 岁大,并且可以计算出大40 岁(60-20)。定距变量的取值称为定距数据或间隔数据。定距数据是一些真实的数值,具有公共的、不变的测定单位,可以进行加减乘除运算。定距数据的基本特点是两个相同间隔的数值的差异相等,例如,年龄的60 岁与50 岁之差等于40 岁与30 岁之差。对于定距数据,不仅可以规定“等价关系”以及“大于关系”和“小于关系”,而且也可以规定任意两个相同间隔的比值或差值。如果将每个数值分别乘以一个正的常数再加上一个常数,即进行正线性变换,并不影响定距数据原有的基本信息。因此,常用的统计量如均值、标准差、相关系数等都可直接用于定距数据。
4、定比变量
定比变量又称为比率(ratio)变量,它与定距变量意义相近,细微差别在于定距变量中的“0”值只表示某一取值,不表示“没有”。例如,人的身高就是一个定比变量,如果身高值为“0”米,则表示这个人不存在。而定比变量的“0”值表示“没有”。而在测定温度的摄氏表中,0oC 并不表示没有温度,因为还有在零点以下的温度。定比变量的取值称为定比数据或比率数据。定比数据也同样可进行算术运算和线性变换等。通常对定距变量和定比变量不需再加以区别,两者统称为定距变量或间隔变量。
一般地,定类变量和定序变量用于描述定性数据,属于定性变量;而定距变量和定比变量用于描述定量数据,属于定量变量。
同其他分类标准一样,一个变量在不同分析中可当作不同尺度的变量。例如,“年龄”在某些分析中(如回归分析)当作定距变量,而在另外一些分析中(如方差分析)可通过分组作为定类变量处理。
另外,较高尺度的变量包含了较低尺度变量的性质。定序变量包含了定类变量的所有特征,定距变量同时包含了定序变量和定类变量的特征。这种性质允许在分析数据时把一些较高尺度变量作为较低尺度变量处理。例如,定距变量可当作定类变量或定序变量看待,而定序变量可作为定序变量分析。
以上通过三种不同方法对变量进行分类。这些分类是可以重叠的。一个变量可能是离散型变量、自变量、定类变量(如“最高学历”),也可能是连续型变量、因变量、定距变量(如“血压”)。按间隙分类和按测量尺度分类的重叠。
变量分类的重叠
因为自变量与因变量是根据分析目的而不是按变量本身性质来划分的,所以上图中没有包括这种分类。从上图可以看出,定类变量必须是离散变量,而定距变量和定序变量可以是离散变量或连续变量;连续变量必须是定序变量或定距变量。例如,变量“性别”是离散变量又是定类变量;变量“年龄”可当作定距变量、连续变量,也可以作为定类变量、离散变量。
二、统计分析方法的分类与选择
对数据进行统计分析时,选择正确的分析方法是非常重要的。选择统计分析方法时,必须考虑许多因素,主要有:(1)统计分析的目的,(2)所用变量的特征,(3)对变量所作的假定,(4)数据的收集方法(即抽样过程)。选择统计分析方法时一般考虑前两个因素就足够了。
(一)根据统计分析目的不同进行分类
统计分析方法根据统计分析目的的不同,可以分成四大类:相关分析方法、结构简化方法、分类分析方法、预测决策方法。
(二)根据变量特征的不同进行分类
根据变量的分类不同分类方法,把变量分为因变量、自变量以及定量变量、定性变量,可把统计分析方法一一进行归类,这是正确选择统计分析方法的一种有效方法。
数学建模题目及其答案
数学建模疾病的诊断 现要你给出疾病诊断的一种方法。 胃癌患者容易被误诊为萎缩性胃炎患者或非胃病者。从胃癌患者中抽取5人(编号为1-5),从萎缩性胃炎患者中抽取5人(编号为6-10),以及非胃病者 中抽取5人(编号为11-15),每人化验4项生化指标:血清铜蓝蛋白( X)、 1 蓝色反应( X)、尿吲哚乙酸(3X)、中性硫化物(4X)、测得数据如表1 2 所示: 表1. 从人体中化验出的生化指标 根据数据,试给出鉴别胃病的方法。
论文题目:胃病的诊断 摘要 在临床医学中,诊断试验是一种诊断疾病的重要方法。好的诊断试验方法将对临床诊断的正确性和疾病的治疗效果起重要影响。因此,对于不同疾病不断发现新的诊断试验方法是医学进步的重要标志。传统的诊断试验方法有生化检测、DNA检测和影像检测等方法。而本文则通过利用多元统计分析中的判别分析及SPSS软件的辅助较好地解决了临床医学中胃病鉴别的问题。在临床医学上,既提高了临床诊断的正确性,又对疾病的治疗效果起了重要效果,同时也减轻了病人的负担。 判别分析是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。 其基本原理是按照一定的判别准则,建立一个或多个判别函数,用研究对象的大量资料确定判别函数中的待定系数,并计算判别指标。 首先,由判别分析定义可知,只有当多个总体的特征具有显著的差异时,进行判别分析才有意义,且总体间差异越大,才会使误判率越小。因此在进行判别分析时,有必要对总体多元变量的均值进行是否不等的显著性检验。 其次,利用判别分析中的费歇判别和贝叶斯判别进行判别函数的建立。 最后,利用所建立的判别函数进行回判并测得其误判率,以及对其修正。 本文利用SPSS软件实现了对总体间给类变量的均值是否不等的显著性检验并根据样本建立了相应的费歇判别函数和贝叶斯判别函数,最后进行了回判并测得了误判率,从而获得了在临床诊断中模型,给临床上的诊断试验提供了新方法和新建议。 关键词:判别分析;判别函数;Fisher判别;Bayes判别 一问题的提出 在传统的胃病诊断中,胃癌患者容易被误诊为萎缩性胃炎患者或非胃病患者,为了提高医学上诊断的准确性,也为了减少因误诊而造成的病人死亡率,必须要找出一种最准确最有效的诊断方法。为诊断疾病,必须从人体中提取4项生化指标进行化验,即血清铜蓝蛋白、蓝色反应、尿吲哚乙酸、中性硫化物。但是,从人体中化验出的生化指标,必须要确定一个精准的指标来判断疾病所属的类型。设想,使用判别分析法,利用SPSS 软件对各个变量进行系统的分析,使该问题得到有效地解决。
数学建模__SPSS_典型相关分析
典型相关分析 在对经济问题的研究和管理研究中,不仅经常需要考察两个变量之间的相关程度,而且还经常需要考察多个变量与多个变量之间即两组变量之间的相关性。典型相关分析就是测度两组变量之间相关程度的一种多元统计方法。 典型相关分析计算步骤 (一)根据分析目的建立原始矩阵 原始数据矩阵 ?? ????????? ???nq n n np n n q p q p y y y x x x y y y x x x y y y x x x 2 1 2 1 222212221 1121111211 (二)对原始数据进行标准化变化并计算相关系数矩阵 R = ?? ? ? ??22211211 R R R R 其中11R ,22R 分别为第一组变量和第二组变量的相关系数阵,12R = 21 R '为第一组变量和第二组变量的相关系数 (三)求典型相关系数和典型变量 计算矩阵=A 111-R 12R 122-R 21R 以及矩阵=B 122-R 21R 1 11-R 12R 的特征值和特征向量,分 别得典型相关系数和典型变量。 (四)检验各典型相关系数的显著性 第五节 利用SPSS 进行典型相关分析 第一步,录入原始数据,如下表:X1 X2 X3 X4 X5 分别代表多孩率、综合节育率、初中及以上受教育程度的人口比例、人均国民收入和城镇人口比例。
1、点击“Files→New→Syntax”打开如下对话框。 2、输入调用命令程序及定义典型相关分析变量组的命令。如图
输入时要注意“Canonical correlation.sps”程序所在的根目录,注意变量组的格式和空格。 第三步,执行程序。用光标选择这些命令,使其图黑,再点击运行键,即可得到所有典型相关分析结果。
数学建模中SPSS运用
1.偏度(skewness) g1 0,则可以认为分布是对称的;若g1>0,则认为分布有右偏态;若g1<0,认为分布有左偏态 2.峰度(kurtosis) 它以正态分布为标准,比较两侧极端数据分布的情况。对于正态分布有g2=0;若g2>0,表示数据中有较多远离均值的极端数据;若g2<0,则均值两侧极端数据较少。 1命令位置:分析\描述统计\频率(Frequencis)\统计量(Statistics) 适合求分位点,一般情况下是首选命令 2.分析\描述统计\描述统计(Descriptive) 此命令可以完成数据的标准化,并把结果以变量的形式存放在数据文件上 Z分数一般小数可以先行转化为T分数 操作:转换(transform)→计算变量 是否服从正态分布 方法: ?定性方法 ?观察偏度和峰度 ?画直方图 ?QQ图:散点基本在直线上,可以认为服从正态分布 ?可靠方法:单样本KS检验 操作:图形->旧对话框 3.假设检验的步骤 提出原假设(零假设)H0; 确定适当的检验统计量; 计算检验统计量的值发生的概率(P值); 给定显著性水平a; 作出统计决策。 注: 必须搞清楚原假设(零假设)是什么 应该知道检验所用统计量服从什么分布 会根据软件求得的p值(sig.),作出判断 即:p<0.05,拒绝原假设; P>0.05, 接受原假设. 4.单样本KS检验法:单样本KS检验-非参方法 操作:分析――>非参数检验――>旧对话框 5.列联表分析:判明所考察的各属性之间有无关联,即是否独立。(利用交叉表分析) 转化为一个假设检验问题,构造检验统计量卡方 1)设置权重变量! 数据\加权个案 操作:分析->描述统计->交叉表->统计量->卡方 6.1均值比较 单样本t检验:目的:检验单个变量的均值是否与给定的常数(总体均值)之间是否存在显著差异。 要求样本来自的总体服从或近似服从正态分布。H0:总体均值和指定检验值之间不存在显著差异。 ?两独立样本t检验:目的:利用来自两个总体的独立样本,推断两个总体的均值是否存在显著 性差异;样本来自的总体服从或近似服从正态分布,H0:两总体均值之间不存在显著差异 Analyze――>compare――>independent-sample t test――>
SPSS在数学建模中的应用
SPSS在数学建模中的应用 第一讲SPSS的一般应用 一、SPSS for Windows的界面介绍 数据编辑窗口 包括窗口名显示栏、主菜单、工具栏、数据编辑区、变量定义区和状态栏。 结果编辑窗口 显示和管理SPSS统计分析结果、报表及图形的窗口,可以将窗口中的内容以结果文件.spo的形式保存。
二、建立数据文件 定义变量 1、单击数据编辑窗口左下方的“Variable View”标签或双击题头(Var),进入变量定义窗口。可定义: 变量名(Name)变量类型(Type) 变量长度(Width)小数点位数(Decimal) 变量标签(Label)变量值标签(Values) 缺失值的定义方式(Missing) 变量的显示宽度(Columns) 变量显示的对齐方式(Align) 变量的测量尺度(Measure) 2、定义变量名(Name)时,应注意: 1)变量名可为汉字或英文,英文的第一个字符必须为字母,后面可跟任意字母、数字、句点或@、#、_、$等; 2)变量名不能以句点结尾; 3)定义时应避免最后一个字符为下划线“_”(因为某些过程运行时自动创建的变量名的最后一个字符有可能为下划线); 4)变量的长度一般不能超过8个字符; 5)每个变量名必须保证是唯一的,不区分大小写。 常用的变量类型(Type)包括:数值型、字符串型、日期格式变量等。 数据录入 定义变量后,单击“Data View”,即可在数据编辑窗口中输入数据。 数据编辑 1)数据的排序:Data→Sort Cases… 2)数据的转置:Data→Transpose… 3)数据的聚合:Data→Aggregate Data 4)数据文件的拆分:Data→Split File 5)数据文件的合并:Data→Merge Files→Add Cases…/Add Variables 6)数据的转换:Transform→Compute…
数学建模spss.时间预测,心得总结和实例
《一周总结,底稿供参考》 我们通过案例来说明: 假设我们拿到一个时间序列数据集:某男装生产线销售额。一个产品分类销售公司会根据过去10 年的销售数据来预测其男装生产线的月销售情况。 现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行! 大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。 当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!
这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH 和DATE(时间标签)。 接下来:为了帮我们找到适当的模型,最好先绘制时间序列。时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。另外,我们需要弄清以下几点: ?此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝??此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在? 这时候我们就可以看到时间序列图了! 我们看到:此序列显示整体上升趋势,即序列值随时间而增加。上升趋势似乎将持续,即为线性趋势。此序列还有一个明显的季节特征,即年度高点在十二月。季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。时间序列预测模型的建立是一个不断尝试和选择的过程。 spss提供了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA 指数平滑法 指数平滑法有助于预测存在趋势和/或季节的序列,此处数据同时体现上述两种特征。创建最适当的指数平滑模型包括确定模型类型(此模型是否需要包含趋势和/或季节),然后获取最适合选定模型的参数。
数学建模spss-时间预测-心得总结及实例
《一周总结,底稿供参考》我们通过案例来说明:一个产品分类销售公司会根据过假设我们拿到一个时间序列数据集:某男装生产线销售额。年的销售数据来预测其男装生产线的月销售情况。去10 个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也年12010现在我们得到了个历史数据才行!要24但你必须知道时间的原则上讲数据中没有时间变量,实际上也不需要时间变量,大家看到,起点和时间间隔。当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标 记!.
这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。 MONTH、定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER 和DATE(时间标签)。时间序列的可视化检查通常可接下来:为了帮我们找到适当的模型,最好先绘制时间序列。以很好地指导并帮助我们进行选择。另外,我们需要弄清以下几点:此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝???如果是,那么这种季节的波动是随时间而加剧还是持续稳定存季节变化此序列是否显示? 在?
这时候我们就可以看到时间序列图了! 我们看到:此序列显示整体上升趋势,即序列值随时间而增加。上升趋势似乎将持续,即为线性趋势。此序列还有一个明显的季节特征,即年度高点在十二月。季节变化显示随上升序。是乘法季节模型而不是加法季节模型列而增长的趋势,表明 此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。时间序列预测模型的建立是一个不断尝试和选择的过程。 spss提供了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA
全国大学生数学建模竞赛C题国家奖一等奖优秀论文
全国大学生数学建模竞赛C题国家奖一等奖优 秀论文 TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-
脑卒中发病环境因素分析及干预 摘要 本文主要讨论脑卒中发病环境因素分析及干预问题。根据题中所给出的数据,利用SPSS20 软件进行相关性统计分析,分别对各气象因素进行单因素分析,进而建立后退法线性回归分析模型,得到脑卒中与气压、气温、相对湿度之间的关系。同时在广泛收集各种资料并综合考虑环境因素,对脑卒中高危人群提出预警和干预的建议方案。 首先,利用SPSS20软件,从患病人群的性别、年龄、职业进行统计分析,得到2007-2010年男性患病人数高于女性,且男性所占比例有逐年下降趋势,女性则有上升趋势,因此,性别比例呈减小趋势。分析不同年龄段患病人数,得到患病高峰期为75-77岁之间,且青少年比例逐年呈增长趋势,可见患病比例趋于年轻化。同时在不同的职业中,农民发病人数最多,教师,渔民,医务人员,职工,离退人员的发病人数较少。 其次,由题中所给数据先进行单因素分析,剔除对脑卒中影响不显着的因素,得出气温、气压、相对湿度对脑卒中的影响程度大小,进而采用后退法线性回归分析建立模型,利用SPSS20对数据进行分析,求得脑卒中发病率与气温、气压、相对湿度之间的关系。即发病率与平均温度成正相关,与最高温度成负相关,发病率与平均气压成正相关,与最低气压成负相关,与平均相对湿度成负相关,与最小相对湿度成正相关。 最后,通过查找资料发现,影响脑卒中的因素有两类,一类是不可干预因素,如年龄、性别、家族史,另一类是可干预因素,如高血压、高血脂、糖尿病、肥胖、抽烟、酗酒等因素。分析这些因素,建立双变量因素分析模型,并结合问题1和问题2,对高危人群提出预警和干预的建议方案。 关键词脑卒中单因素分析后退法线性回归分析双变量因素分析 一问题的重述 脑卒中(俗称脑中风)是目前威胁人类生命的严重疾病之一,它的发生是一个漫长的过程,一旦得病就很难逆转。这种疾病的诱发已经被证实与环境因素,包括气温、湿度之间存在密切的关系。对脑卒中的发病环境因素进行分析,其目的是为了进行疾病的风险评估,对脑卒中高危人群能够及时采取干预措施,也让尚未得病的健康人,或者亚健康人了解自己得脑卒中风险程度,进行自我保护。同时,通过数据模型的建立,掌握疾病发病率的规律,对于卫生行政部门和医疗机构合理调配医务力量、改善就诊治疗环境、配置床位和医疗药物等都具有实际的指导意义。 数据(见Appendix-C1)来源于中国某城市各家医院2007年1月至2010年12月的脑卒中发病病例信息以及相应期间当地的逐日气象资料(Appendix-C2)。请你们根据题目提供的数据,回答以下问题: 1.根据病人基本信息,对发病人群进行统计描述。 2.建立数学模型研究脑卒中发病率与气温、气压、相对湿度间的关系。 3.查阅和搜集文献中有关脑卒中高危人群的重要特征和关键指标,结合1、2中所得结论,对高危人群提出预警和干预的建议方案。 二问题分析
学生成绩分析数学建模
2012年暑期培训数学建模第二次模拟 承诺书 我们仔细阅读了数学建模联赛的竞赛规则。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括、电子、网上咨询等)与本队以外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其它公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们愿意承担由此引起的一切后果。 我们的参赛报名号为: 参赛队员(签名) : 队员1: 队员2: 队员3:
2012年暑期培训数学建模第二次模拟 编号专用页 参赛队伍的参赛:(请各个参赛队提前填写好):竞赛统一编号(由竞赛组委会送至评委团前编号): 竞赛评阅编号(由竞赛评委团评阅前进行编号):
2012年暑期培训数学建模第二次模拟 题目学生成绩的分析问题 摘要 本文针对大学高数和线代,概率论成绩进行建模分析,主要用到统计分析的知识及SPSS软件,建立了方差分析、单因素分析、相关性分析等相关模型,从而分析两个专业、四门课程成绩的显著性,以及课程之间的相关性。最后利用分析结论表明了我们对大学数学学习的看法。 问题一:每门课程两个专业的差异性需要进行多个平均数间的差异显著性检验,首先应该对数据进行正态分布检验,结论是各个专业的分数都服从正态分布,之后可以根据Kolmogorov-Smirnov 检验(K-S检验)原理,利用SPSS软件进行单因素方差分析,得出方差分析表,进行显著性检验,最后得出的结论是高数1、高数2、线代和概率这四科成绩在两个专业中没有显著性差异。 问题二:对于甲乙两个专业分别分析,应用问题一的模型,以每个专业不同班级的高数一、高数二、线代和概率平均数为自变量,同第一问相同的做法,得到两个专业中不同学科之间没有显著差异。 问题三:我们通过对样本数据进行Spss的“双变量相关检验”得出相关系数值r、影响程度的P值,从而来分析出高数1、高数2与概率论、现代的相关性。 问题四:利用上面数据,得到各专业课程的方差和平均值,再通过对各门课程的分析,利用分析结论表明了我们对大学数学学习的看法。 关键词:单因素方差分析、方差分析、相关分析、 spss软件、