数据挖掘过程说明文档
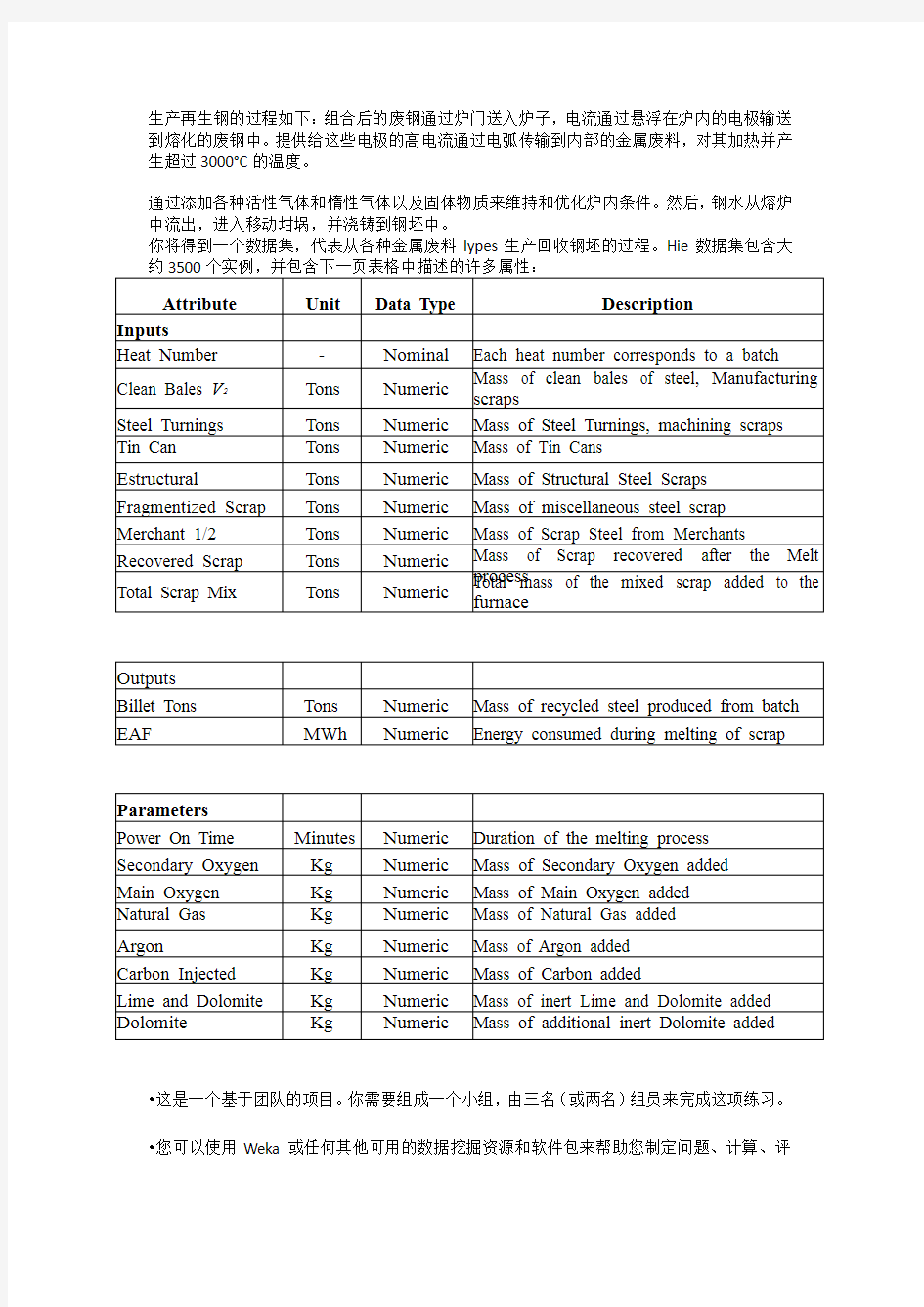

生产再生钢的过程如下:组合后的废钢通过炉门送入炉子,电流通过悬浮在炉内的电极输送到熔化的废钢中。提供给这些电极的高电流通过电弧传输到内部的金属废料,对其加热并产生超过3000°C的温度。
通过添加各种活性气体和惰性气体以及固体物质来维持和优化炉内条件。然后,钢水从熔炉中流出,进入移动坩埚,并浇铸到钢坯中。
你将得到一个数据集,代表从各种金属废料lypes生产回收钢坯的过程。Hie数据集包含大
?这是一个基于团队的项目。你需要组成一个小组,由三名(或两名)组员来完成这项练习。?您可以使用Weka或任何其他可用的数据挖掘资源和软件包来帮助您制定问题、计算、评
估等。
?您的团队绩效将完全根据团队的结果和您的报告进行评估。
?作为一个团队,您需要决定给定问题的性质;什么类型的数据挖掘问题公式适合解决此类问题;您的团队可以遵循什么样的基本数据挖掘过程;您的团队希望尝试什么类型的算法;以何种方式,您可以进一步利用或最大化您的性能,等等。
?您的团队应致力于涵盖讲座、教程中包含的领域,考虑预处理、特征选择、各种算法、验证、测试和性能评估方法。
?对于性能基准,建议您使用准确度和/或错误率作为评估指标。
?表现最好的球队将被宣布为本次迷你KDD杯冠军,并将获得10%的加分,最高100%满分。
数据挖掘流程:
一、数据建模
1. 数据获取
2. 数据分析
3. 数据预处理
二、算法建模
1. 模型构建
2. 模型检验
三、评估
一、数据建模
1.数据获取及分析
数据集:EAF_process_dataqqq.csv
根据《assignment 2》中,数据集的说明,可知:
输入数据:9个变量Heat Number
Clean Bales V2
Steel Turnings
Tin Can
Estructural Fragmentized Scrap Merchant 1/2 Recovered Scrap Total Scrap Mix
中间参数:8个Power On Time
Secondary Oxygen
Main Oxygen
Natural Gas
Argon
Carbon Injected
Lime and Dolomite
Dolomite
输出:
Billet Tons
EAF
在EAF_process_data中,列出21个变量。多出'Heat Number',Steel Grade'两个变量。
2. 数据预处理
1)数据规约:
(1)规定输入输出变量【特征选择】
【方案一】输出为单变量Billet Tons
【预测目标变量为数值,因此是监督学习,回归。可以利用回归、神经网络、深度学习等算法】
输入变量为:9个输入变量+8个中间参数
输出变量为:Billet Tons
具体含义:根据各种输入预测钢产量Billet Tons
【方案二】输出为单变量EAF
【预测目标变量为数值,因此是监督学习,回归。可以利用回归、神经网络、深度学习等算法】
输入变量为:9个输入变量+8个中间参数
输出变量为:EAF
具体含义:根据各种输入预测熔化废钢时消耗的数值能量EAF
【方案三】输出为单变量Steel Grade
【预测目标变量为类别,因此是监督学习,分类。可以利用分类、回归、神经网络、深度学习等算法】
输入变量为:9个输入变量+8个中间参数
输出变量为:Steel Grade
具体含义:根据各种输入预测钢类别Steel Grade
【方案四】输出为多变量Billet Tons 和EAF
【预测目标变量为数值,因此是监督学习,回归。可以利用回归、神经网络、深度学习等算法】
输入变量为:9个输入变量+8个中间参数
输出变量为:Billet Tons和EAF
具体含义:根据各种输入预测钢产量Billet Tons和能耗EAF
2)数据清洗:
(1)利用统计学方法观察数据分布:【可利用程序或者软件】
可根据EAF_process_data,依次观察每个变量分布情况,目的是看出是否有存在异常值【一般情况下,每个变量都应有一定的范围;或者说如果该变量为负值,则肯定异常,需删除】
以Estructural为例:
(2)查看数据中是否包含空值和特殊字符
若为空或者NAN,则需要处理。是删除整行数据还是用插值补空,需要根据具体情况再处理。
本数据集中无空值。
本数据集中包含特殊字符“?”,需将含有“?”的整行数据删除。
原数据集大小为:3493*21
经处理后大小为:3460*21
(3)现有数据是否合理
【因不知道每个变量的合理范围,因此此步无法执行】
3)数据降维
因《assignment 2》中已经列出输入、中间、输出变量
可根据相关性分析等数据统计方法,得到输入变量、中间变量和输出变量间的关系强弱。
【但个人认为本数据集中变量比较少,经相关性分析后,可将所有输入变量、中间变量均作为机器学习算法的输入,无需降维。】
二、算法建模
根据2.1.1中列出的方案分别建模。
因【方案一】和【方案二】均预测单个数值型变量,可利用同种建模方法。
现以【方案一】输出为Billet Tons为例。
1. 数据划分
将所有数据随机划分成训练集和测试,其中训练集占80%,测试集占20%。【传统划分数据集中,还应包含验证集,但此处将验证集和测试集合并】。
在运行算法前,将所有数据标准化处理。
2. 算法选择
可利用多种算法同时运行,选择评价指标最好的算法;也可选择神经网络,不断调参,得到最佳结果。
依据上述方案:
将多种算法同时运行,选择最佳算法。
将岭回归、随机梯度下降、SVR、随机森林等同时运行。根据评价指标(查准率、拟合程度R^2,MAE、MSE、RMSE)选择算法。发现各个算法评价指标均不理想。因此选择神经网络调参。
3. 性能评估
评价指标有查准率、拟合程度R^2,MAE、MSE、RMSE
查准率的定义为:预测值和实际值差小于8的个数/测试集数据个数
其中8,取的是Billet Tons'平均值146的5%
预测效果图如下,红色为实际,蓝色为预测。
数据仓库与及数据挖掘文本分类实验报告
2015-2016学年第1学期实验报告 课程名称:数据仓库与及数据挖掘实验名称:文本的分类 实验完成人: 姓名:学号:
日期: 2015年 12月 实验一:文本的分类 1.实验目的 1)掌握数据预处理的方法,对训练集数据进行预处理; 2)掌握文本建模的方法,对语料库的文档进行建模; 3)掌握分类算法的原理,基于有监督的机器学习方法,训练 文本分类器; 4)利用学习的文本分类器,对未知文本进行分类判别; 5)掌握评价分类器性能的评估方法 2.实验分工 独立完成 3.实验环境 基于Windows平台,使用eclipse开发。 4.主要设计思想 4.1实验工具介绍 Eclipse:一个开放源代码的/基于Java的可扩展开发平
台。就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境。Eclipse最早是由IBM开发的,后来IBM将Eclipse作为一个开放源代码的项目发布。现在Eclipse 在https://www.360docs.net/doc/5813660926.html,协会的管理与指导下开发。 4.2特征提取与表达方法的设计 在此次实验中,我考虑了CHI特征提取的方法来建立数据字典。详细步骤见5.3描述。根据CHI特征提取,最终建立成数据字典,数据字典记录在目录E:\DataMiningSample\docVector下的allDicWordCountMap.txt 文档中。 最终的特征向量表达方式为:文档类别标识_单词词频。如:alt.atheism_abstact 1.0。其中alt.atheism为此文本所属的类别,abstact为对应的单词,1.0为该单词的词频数。 4.3分类算法的选择 本次实验使用的是朴素贝叶斯分类算法,朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。即: Document) P(Document P(Category | | * nt) Category) )/P(Docume P(Category 朴素贝叶斯模型:
数据挖掘考试题库
1.何谓数据挖掘?它有哪些方面的功能? 从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程称为数据挖掘。相关的名称有知识发现、数据分析、数据融合、决策支持等。 数据挖掘的功能包括:概念描述、关联分析、分类与预测、聚类分析、趋势分析、孤立点分析以及偏差分析等。 2.何谓粒度?它对数据仓库有什么影响?按粒度组织数据的方式有哪些? 粒度是指数据仓库的数据单位中保存数据细化或综合程度的级别。粒度影响存放在数据仓库中的数据量的大小,同时影响数据仓库所能回答查询问题的细节程度。按粒度组织数据的方式主要有: ①简单堆积结构 ②轮转综合结构 ③简单直接结构 ④连续结构 3.简述数据仓库设计的三级模型及其基本内容。 概念模型设计是在较高的抽象层次上的设计,其主要内容包括:界定系统边界和确定主要的主题域。 逻辑模型设计的主要内容包括:分析主题域、确定粒度层次划分、确定数据分割策略、定义关系模式、定义记录系统。 物理数据模型设计的主要内容包括:确定数据存储结构、确定数据存放位置、确定存储分配以及确定索引策略等。在物理数据模型设计时主要考虑的因素有: 存取时间、空间利用率和维护代价等。 提高性能的主要措施有划分粒度、数据分割、合并表、建立数据序列、引入冗余、生成导出数据、建立广义索引等。 4.在数据挖掘之前为什么要对原始数据进行预处理? 原始业务数据来自多个数据库或数据仓库,它们的结构和规则可能是不同的,这将导致原始数据非常的杂乱、不可用,即使在同一个数据库中,也可能存在重复的和不完整的数据信息,为了使这些数据能够符合数据挖掘的要求,提高效率和得到清晰的结果,必须进行数据的预处理。 为数据挖掘算法提供完整、干净、准确、有针对性的数据,减少算法的计算量,提高挖掘效率和准确程度。
数据挖掘研究现状综述
数据挖掘 引言 数据挖掘是一门交叉学科,涉及到了机器学习、模式识别、归纳推理、统计学、数据库、高性能计算等多个领域。 所谓的数据挖掘(Data Mining)指的就是从大量的、模糊的、不完全的、随机的数据集合中提取人们感兴趣的知识和信息,提取的对象一般都是人们无法直观的从数据中得出但又有潜在作用的信息。从本质上来说,数据挖掘是在对数据全面了解认识的基础之上进行的一次升华,是对数据的抽象和概括。如果把数据比作矿产资源,那么数据挖掘就是从矿产中提取矿石的过程。与经过数据挖掘之后的数据信息相比,原始的数据信息可以是结构化的,数据库中的数据,也可以是半结构化的,如文本、图像数据。从原始数据中发现知识的方法可以是数学方法也可以是演绎、归纳法。被发现的知识可以用来进行信息管理、查询优化、决策支持等。而数据挖掘是对这一过程的一个综合性应用。
目录 引言 (1) 第一章绪论 (3) 1.1 数据挖掘技术的任务 (3) 1.2 数据挖掘技术的研究现状及发展方向 (3) 第二章数据挖掘理论与相关技术 (5) 2.1数据挖掘的基本流程 (5) 2.2.1 关联规则挖掘 (6) 2.2.2 .Apriori算法:使用候选项集找频繁项集 (7) 2.2.3 .FP-树频集算法 (7) 2.2.4.基于划分的算法 (7) 2.3 聚类分析 (7) 2.3.1 聚类算法的任务 (7) 2.3.3 COBWEB算法 (9) 2.3.4模糊聚类算法 (9) 2.3.5 聚类分析的应用 (10) 第三章数据分析 (11) 第四章结论与心得 (14) 4.1 结果分析 (14) 4.2 问题分析 (14) 4.2.1数据挖掘面临的问题 (14) 4.2.2 实验心得及实验过程中遇到的问题分析 (14) 参考文献 (14)
学习18大经典数据挖掘算法
学习18大经典数据挖掘算法 本文所有涉及到的数据挖掘代码的都放在了github上了。 地址链接: https://https://www.360docs.net/doc/5813660926.html,/linyiqun/DataMiningAlgorithm 大概花了将近2个月的时间,自己把18大数据挖掘的经典算法进行了学习并且进行了代码实现,涉及到了决策分类,聚类,链接挖掘,关联挖掘,模式挖掘等等方面。也算是对数据挖掘领域的小小入门了吧。下面就做个小小的总结,后面都是我自己相应算法的博文链接,希望能够帮助大家学习。 1.C4.5算法。C4.5算法与ID3算法一样,都是数学分类算法,C4.5算法是ID3算法的一个改进。ID3算法采用信息增益进行决策判断,而C4.5采用的是增益率。 详细介绍链接:https://www.360docs.net/doc/5813660926.html,/androidlushangderen/article/details/42395865 2.CART算法。CART算法的全称是分类回归树算法,他是一个二元分类,采用的是类似于熵的基尼指数作为分类决策,形成决策树后之后还要进行剪枝,我自己在实现整个算法的时候采用的是代价复杂度算法, 详细介绍链接:https://www.360docs.net/doc/5813660926.html,/androidlushangderen/article/details/42558235 3.KNN(K最近邻)算法。给定一些已经训练好的数据,输入一个新的测试数据点,计算包含于此测试数据点的最近的点的分类情况,哪个分类的类型占多数,则此测试点的分类与此相同,所以在这里,有的时候可以复制不同的分类点不同的权重。近的点的权重大点,远的点自然就小点。 详细介绍链接:https://www.360docs.net/doc/5813660926.html,/androidlushangderen/article/details/42613011 4.Naive Bayes(朴素贝叶斯)算法。朴素贝叶斯算法是贝叶斯算法里面一种比较简单的分类算法,用到了一个比较重要的贝叶斯定理,用一句简单的话概括就是条件概率的相互转换推导。 详细介绍链接:https://www.360docs.net/doc/5813660926.html,/androidlushangderen/article/details/42680161 5.SVM(支持向量机)算法。支持向量机算法是一种对线性和非线性数据进行分类的方法,非线性数据进行分类的时候可以通过核函数转为线性的情况再处理。其中的一个关键的步骤是搜索最大边缘超平面。 详细介绍链接:https://www.360docs.net/doc/5813660926.html,/androidlushangderen/article/details/42780439 6.EM(期望最大化)算法。期望最大化算法,可以拆分为2个算法,1个E-Step期望化步骤,和1个M-Step最大化步骤。他是一种算法框架,在每次计算结果之后,逼近统计模型参数的最大似然或最大后验估计。
数据挖掘中分类技术应用
分类技术在很多领域都有应用,例如可以通过客户分类构造一个分类模型来对银行贷款进行风险评估;当前的市场营销中很重要的一个特点是强调客户细分。客户类别分析的功能也在于此,采用数据挖掘中的分类技术,可以将客户分成不同的类别,比如呼叫中心设计时可以分为:呼叫频繁的客户、偶然大量呼叫的客户、稳定呼叫的客户、其他,帮助呼叫中心寻找出这些不同种类客户之间的特征,这样的分类模型可以让用户了解不同行为类别客户的分布特征;其他分类应用如文献检索和搜索引擎中的自动文本分类技术;安全领域有基于分类技术的入侵检测等等。机器学习、专家系统、统计学和神经网络等领域的研究人员已经提出了许多具体的分类预测方法。下面对分类流程作个简要描述: 训练:训练集——>特征选取——>训练——>分类器 分类:新样本——>特征选取——>分类——>判决 最初的数据挖掘分类应用大多都是在这些方法及基于内存基础上所构造的算法。目前数据挖掘方法都要求具有基于外存以处理大规模数据集合能力且具有可扩展能力。 神经网络 神经网络是解决分类问题的一种行之有效的方法。神经网络是一组连接输入/输出单元的系统,每个连接都与一个权值相对应,在将简单的单元连接成较复杂的系统后,通过并行运算实现其功能,其中系统的知识存储于网络结构和各单元之间的连接权中。在学习阶段,通过调整神经网络的权值,达到对输入样本的正确分类。神经网络有对噪声数据的高承受能力和对未经训练数据的模式分类能力。神经网
络概括性强、分类精度高,可以实现有监督和无监督的分类任务,所以神经网络在分类中应用非常广泛。 在结构上,可以把一个神经网络划分为输入层、输出层和隐含层(见图4)。网络的每一个输入节点对应样本一个特征,而输出层节点数可以等于类别数,也可以只有一个,(输入层的每个节点对应一个个的预测变量。输出层的节点对应目标变量,可有多个)。在输入层和输出层之间是隐含层(对神经网络使用者来说不可见),隐含层的层数和每层节点的个数决定了神经网络的复杂度。 除了输入层的节点,神经网络的每个节点都与很多它前面的节点(称为此节点的输入节点)连接在一起,每个连接对应一个权重Wxy,此节点的值就是通过它所有输入节点的值与对应连接权重乘积的和作为一个函数的输入而得到,我们把这个函数称为活动函数或挤压函数。如图5中节点4输出到节点6的值可通过如下计算得到:
学习资料:文本数据挖掘
学习资料:文本数据挖掘(Test Mining) 在当今世界,一个人或一个组织所获得的文本信息集合十分巨大,而且文本信息集合还在不断地更新和增加,信息检索等技术已不能适应当今文本信息处理的需要,因而,人们开始使用文本挖掘技术来解决这一难题。 1、定义 文本数据挖掘(Text Mining)是指从文本数据中抽取有价值的信息和知识的计算机处理技术。顾名思义,文本数据挖掘是从文本中进行数据挖掘(Data Mining)。从这个意义上讲,文本数据挖掘是数据挖掘的一个分支,由机器学习、数理统计、自然语言处理等多种学科交叉形成。 2、功能 文本挖掘可以对大量文档集合的内容进行总结、分类、聚类、关联分析等。 (1)文本总结 文本总结是指从文档中抽取关键信息,用简洁的形式对文档内容进行摘要或解释。用户不需要浏览全文就可以了解文档或文档集合的总体内容。文本总结在有些场合十分有用,例如,搜索引擎在向用户返回查询结果时,通常需要给出文档的摘要。目前,绝大部分搜索引擎采用的方法是简单地截取文档的前几行。 (2)文本分类与聚类 文本分类是指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别。这样,用户不但能够方便地浏览文档,而且可以通过限制搜索范围来使文档的查找更为容易。利用文本分类技术可以对大量文档进行快速、有效的自动分类。 文本聚类与文本分类的不同之处在于,聚类没有预先定义好主题类别,它的目标是将文档集合分成若干个簇,要求同一簇内文档内容的相似度尽可能地大,而不同簇间的相似度尽可能地小。 (3)关联分析 关联分析是指从文档集合中找出不同词语之间的关系。 3、典型应用方法——共词分析 共词分析法主要是对一对词两两统计其在同一篇文献中出现的次数, 以此为基础对这些词进行分层聚类, 揭示出这些词之间的亲疏关系, 进而分析它们所代表的学科和主题的结构变化。 其思想来源于文献计量学的引文耦合与共被引概念, 其中, 共被引指当两篇文献同时被后来的其他文献引用时, 则这两篇文献被称作共被引, 表明它们在研究主题的概念、理论或方法上是相关的。两篇文献共被引的次数越多, 它们的关系就越密切, 由此揭示文献之中的亲疏关系。 同理, 当一对能够表征某一学科领域研究主题或研究方向的专业术语( 一般为主题词或关键词) 在一篇文献中同时出现, 表明这两个词之间存在一定的关系, 同时出现的次数越多, 表明它们的关系越密切、距离越近。 共词分析通常可以分为3个步骤。
数据挖掘算法综述
数据挖掘方法综述 [摘要]数据挖掘(DM,DataMining)又被称为数据库知识发现(KDD,Knowledge Discovery in Databases),它的主要挖掘方法有分类、聚类、关联规则挖掘和序列模式挖掘等。 [关键词]数据挖掘分类聚类关联规则序列模式 1、数据挖掘的基本概念 数据挖掘从技术上说是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在的有用的信息和知识的过程。这个定义包括好几层含义: 数据源必须是真实的、大量的、含噪声的、发现的是用户感兴趣的知识, 发现的知识要可接受、可理解、可运用, 并不要求发现放之四海皆准的知识, 仅支持特定的发现问题, 数据挖掘技术能从中自动分析数据进行归纳性推理从中发掘出潜在的数据模式或进行预测, 建立新的业务模型帮助决策者调整策略做出正确的决策。数据挖掘是是运用统计学、人工智能、机器学习、数据库技术等方法发现数据的模型和结构、发现有价值的关系或知识的一门交叉学科。数据挖掘的主要方法有分类、聚类和关联规则挖掘等 2、分类 分类(Classification)又称监督学习(Supervised Learning)。监
督学习的定义是:给出一个数据集D,监督学习的目标是产生一个联系属性值集合A和类标(一个类属性值称为一个类标)集合C的分类/预测函数,这个函数可以用于预测新的属性集合(数据实例)的类标。这个函数就被称为分类模型(Classification Model),或者是分类器(Classifier)。分类的主要算法有:决策树算法、规则推理、朴素贝叶斯分类、支持向量机等算法。 决策树算法的核心是Divide-and-Conquer的策略,即采用自顶向下的递归方式构造决策树。在每一步中,决策树评估所有的属性然后选择一个属性把数据分为m个不相交的子集,其中m是被选中的属性的不同值的数目。一棵决策树可以被转化成一个规则集,规则集用来分类。 规则推理算法则直接产生规则集合,规则推理算法的核心是Separate-and-Conquer的策略,它评估所有的属性-值对(条件),然后选择一个。因此,在一步中,Divide-and-Conquer策略产生m条规则,而Separate-and-Conquer策略只产生1条规则,效率比决策树要高得多,但就基本的思想而言,两者是相同的。 朴素贝叶斯分类的基本思想是:分类的任务可以被看作是给定一个测试样例d后估计它的后验概率,即Pr(C=c j︱d),然后我们考察哪个类c j对应概率最大,便将那个类别赋予样例d。构造朴素贝叶斯分类器所需要的概率值可以经过一次扫描数据得到,所以算法相对训练样本的数量是线性的,效率很高,就分类的准确性而言,尽管算法做出了很强的条件独立假设,但经过实际检验证明,分类的效果还是
数据挖掘分类算法比较
数据挖掘分类算法比较 分类是数据挖掘、机器学习和模式识别中一个重要的研究领域。通过对当前数据挖掘中具有代表性的优秀分类算法进行分析和比较,总结出了各种算法的特性,为使用者选择算法或研究者改进算法提供了依据。 一、决策树(Decision Trees) 决策树的优点: 1、决策树易于理解和解释.人们在通过解释后都有能力去理解决策树所表达的意义。 2、对于决策树,数据的准备往往是简单或者是不必要的.其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。 3、能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。 4、决策树是一个白盒模型。如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。 5、易于通过静态测试来对模型进行评测。表示有可能测量该模型的可信度。 6、在相对短的时间内能够对大型数据源做出可行且效果良好的结果。 7、可以对有许多属性的数据集构造决策树。 8、决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小。 决策树的缺点: 1、对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。 2、决策树处理缺失数据时的困难。 3、过度拟合问题的出现。 4、忽略数据集中属性之间的相关性。 二、人工神经网络 人工神经网络的优点:分类的准确度高,并行分布处理能力强,分布存储及学习能力强,对噪声神经有较强的鲁棒性和容错能力,能充分逼近复杂的非线性关系,具备联想记忆的功能等。 人工神经网络的缺点:神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值;不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;学习时间过长,甚至可能达不到学习的目的。
基于机器学习的文本分类方法
基于机器学习算法的文本分类方法综述 摘要:文本分类是机器学习领域新的研究热点。基于机器学习算法的文本分类方法比传统的文本分类方法优势明显。本文综述了现有的基于机器学习的文本分类方法,讨论了各种方法的优缺点,并指出了文本分类方法未来可能的发展趋势。 1.引言 随着计算机技术、数据库技术,网络技术的飞速发展,Internet的广泛应用,信息交换越来越方便,各个领域都不断产生海量数据,使得互联网数据及资源呈现海量特征,尤其是海量的文本数据。如何利用海量数据挖掘出有用的信息和知识,方便人们的查阅和应用,已经成为一个日趋重要的问题。因此,基于文本内容的信息检索和数据挖掘逐渐成为备受关注的领域。文本分类(text categorization,TC)技术是信息检索和文本挖掘的重要基础技术,其作用是根据文本的某些特征,在预先给定的类别标记(label)集合下,根据文本内容判定它的类别。传统的文本分类模式是基于知识工程和专家系统的,在灵活性和分类效果上都有很大的缺陷。例如卡内基集团为路透社开发的Construe专家系统就是采用知识工程方法构造的一个著名的文本分类系统,但该系统的开发工作量达到了10个人年,当需要进行信息更新时,维护非常困难。因此,知识工程方法已不适用于日益复杂的海量数据文本分类系统需求[1]。20世纪90年代以来,机器学习的分类算法有了日新月异的发展,很多分类器模型逐步被应用到文本分类之中,比如支持向量机(SVM,Support Vector Machine)[2-4]、最近邻法(Nearest Neighbor)[5]、决策树(Decision tree)[6]、朴素贝叶斯(Naive Bayes)[7]等。逐渐成熟的基于机器学习的文本分类方法,更注重分类器的模型自动挖掘和生成及动态优化能力,在分类效果和灵活性上都比之前基于知识工程和专家系统的文本分类模式有所突破,取得了很好的分类效果。 本文主要综述基于机器学习算法的文本分类方法。首先对文本分类问题进行概述,阐述文本分类的一般流程以及文本表述、特征选择方面的方法,然后具体研究基于及其学习的文本分类的典型方法,最后指出该领域的研究发展趋势。 2.文本自动分类概述 文本自动分类可简单定义为:给定分类体系后,根据文本内容自动确定文本关联的类别。从数学角度来看,文本分类是一个映射过程,该映射可以是一一映射,也可以是一对多映射过程。文本分类的映射规则是,系统根据已知类别中若干样本的数据信息总结出分类的规律性,建立类别判别公式或判别规则。当遇到新文本时,根据总结出的类别判别规则确定文本所属的类别。也就是说自动文本分类通过监督学习自动构建出分类器,从而实现对新的给定文本的自动归类。文本自动分类一般包括文本表达、特征选取、分类器的选择与训练、分类等几个步骤,其中文本表达和特征选取是文本分类的基础技术,而分类器的选择与训练则是文本自动分类技术的重点,基于机器学习的文本分来就是通过将机器学习领域的分类算法用于文本分类中来[8]。图1是文本自动分类的一般流程。
文献综述_数据挖掘
数据挖掘简介 数据挖掘的任务 数据挖掘的任务就是从实例集合中找出容易理解的规则和关系。这些规则可以用于预测未来趋势、评价顾客、评估风险或简单地描述和解释给定的数据。通常数据挖掘的任务包括以下几个部分: 数据总结目的是对数据进行浓缩,给出它的紧凑描述。传统的也是最简单的数据总结方法是计算出数据库的各个字段上的求和值、平均值、方差值等统计值,或者用直方图、饼图等图形方式表示。数据挖掘主要关心从数据泛化的角度来讨论数据总结。数据泛化是一种把数据库中的有关数据从低层次抽象到高层次上的过程。数据泛化目前主要有两种技术:多维数据分析方法和面向属性的归纳方法。 多维数据分析方法是一种数据仓库技术,也称作联机分析处理(OLAP,onLineAnalysisProeess)。数据仓库是面向决策支持的、集成的、稳定的、不同时间的历史数据集合。决策的前提是数据分析。在数据分析中经常要用到诸如求和、总计、平均、最大、最小等汇集操作,这类操作的计算量特别大。因此一种很自然的想法是,把汇集操作结果预先计算并存储起来,以便于决策支持系统使用。存储汇集操作结果的地方称作多维数据库。多维数据分析技术已经在决策支持系统中获得了成功的应用,如著名的SAS数据分析软件包、Businessobject公司的决策支持系统Businessobjeet,以及IBM公司的决策分析工具都使用了多维数据分析技术。 采用多维数据分析方法进行数据总结,它针对的是数据仓库,数据仓库存储的是脱机的历史数据。为了处理联机数据,研究人员提出了一种面向属性的归纳方法。它的思路是,直接对用户感兴趣的数据视图(用一般的SQL查询语言即可获得)进行泛化,而不是像多维数据分析方法那样预先就存储好了泛化数据。方法的提出者对这种数据泛化技术称之为面向属性的归纳方法。原始关系经过泛化操作后得到的是一个泛化关系,它从较高的层次上总结了在低层次上的原始关系。有了泛化关系后,就可以对它进行各种深入的操作而生成满足用户需要的知识,如在泛化关系基础上生成特性规则、判别规则、分类规则,以及关联规则等。数据挖掘的分类 数据挖掘所能发现的知识有如下几种: .广义型知识,反映同类事物共同性质的知识; .特征型知识,反映事物各方面的特征知识; .差异型知识,反映不同事物之间属性差别的知识; .关联型知识,反映事物之间依赖或关联的知识; .预测型知识,根据历史的和当前的数据推测未来数据; .偏离型知识。揭示事物偏离常规的异常现象。 所有这些知识都可以在不同的概念层次上被发现,随着概念树的提升,从微观到中观再到宏观,以满足不同用户、不同层次决策的需要。例如,从一家超市的数据仓库中,可以发现的一条典型关联规则可能是“买面包和黄油的顾客十有八九也买牛奶”,也可能是“买食品的顾客几乎都用信用卡”,这种规则对于商家开发和实施客户化的销售计划和策略是非常有用的。 数据挖掘的方法 数据挖掘并非一个完全自动化的过程。整个过程需要考虑数据的所有因素和其预定的效用,然后应用最佳的数据挖掘方法。数据挖掘的方法很重要。在数据挖掘的领域里.有一点已经被广泛地接受,即不管你选择哪种方法,总存在着某种协定。因此对实际情况,应该具体分析,根据累积的经验和优秀的范例选择最佳的方法。数据挖掘中没有免费的午餐,也没
数据挖掘十大算法
数据挖掘十大算法 数据挖掘十大算法—K 近邻算法 k -近邻算法是基于实例的学习方法中最基本的,先介绍基于实例学习的相关概念。 一、基于实例的学习。 1、已知一系列的训练样例,很多学习方法为目标函数建立起明确的一般化描述;但与此不同,基于实例的学习方法只是简单地把训练样例存储起来。 从这些实例中泛化的工作被推迟到必须分类新的实例时。每当学习器遇到一个新的查询实例,它分析这个新实例与以前存储的实例的关系,并据此把一个目标函数值赋给新实例。 2、基于实例的方法可以为不同的待分类查询实例建立不同的目标函数逼近。事实上,很多技术只建立目标函数的局部逼近,将其应用于与新查询实例邻近的实例,而从不建立在整个实例空间上都表现良好的逼近。当目标函数很复杂,但它可用不太复杂的局部逼近描述时,这样做有显著的优势。 3、基于实例方法的不足: (1)分类新实例的开销可能很大。这是因为几乎所有的计算都发生在分类时,而不是在第一次遇到训练样例时。所以,如何有效地索引训练样例,以减少查询时所需计算是一个重要的实践问题。(2)当从存储器中检索相似的训练样例时,它们一般考虑实例的所有属性。如果目标概念仅依赖于很多属性中的几个时,那么真正最“相似”的实例之间很可能相距甚远。 二、k-近邻法基于实例的学习方法中最基本的是k -近邻算法。这个算法假定所有的实例对应于n 维欧氏空间?n 中的点。一个实例的最近邻是根据标准欧氏距离定义的。更精确地讲,把任意的实例x 表示为下面的特征向量:其中a r (x ) 表示实例x 的第r 个属性值。那么两个实例x i 和x j 间的距离定义为d (x i , x j ) ,其中: 说明: 1、在最近邻学习中,目标函数值可以为离散值也可以为实值。 2、我们先考虑学习以下形式的离散目标函数。其中V 是有限集合 {v 1,... v s }。下表给出了逼近离散目标函数的k-近邻算法。 3、正如下表中所指出的,这个算法的返回值f' (x q ) 为对f (x q ) 的估计,它就是距离x q 最近的k 个训练样例中最普遍的f 值。 4、如果我们选择k =1,那么“1-近邻算法”
大数据时代的空间数据挖掘综述
第37卷第7期测绘与空间地理信息 GEOMATICS &SPATIAL INFORMATION TECHNOLOGY Vol.37,No.7收稿日期:2014-01-22 作者简介:马宏斌(1982-),男,甘肃天水人,作战环境学专业博士研究生,主要研究方向为地理空间信息服务。 大数据时代的空间数据挖掘综述 马宏斌1 ,王 柯1,马团学 2(1.信息工程大学地理空间信息学院,河南郑州450000;2.空降兵研究所,湖北孝感432000) 摘 要:随着大数据时代的到来,数据挖掘技术再度受到人们关注。本文回顾了传统空间数据挖掘面临的问题, 介绍了国内外研究中利用大数据处理工具和云计算技术,在空间数据的存储、管理和挖掘算法等方面的做法,并指出了该类研究存在的不足。最后,探讨了空间数据挖掘的发展趋势。关键词:大数据;空间数据挖掘;云计算中图分类号:P208 文献标识码:B 文章编号:1672-5867(2014)07-0019-04 Spatial Data Mining Big Data Era Review MA Hong -bin 1,WANG Ke 1,MA Tuan -xue 2 (1.Geospatial Information Institute ,Information Engineering University ,Zhengzhou 450000,China ; 2.Airborne Institute ,Xiaogan 432000,China ) Abstract :In the era of Big Data ,more and more researchers begin to show interest in data mining techniques again.The paper review most unresolved problems left by traditional spatial data mining at first.And ,some progress made by researches using Big Data and Cloud Computing technology is introduced.Also ,their drawbacks are mentioned.Finally ,future trend of spatial data mining is dis-cussed. Key words :big data ;spatial data mining ;cloud computing 0引言 随着地理空间信息技术的飞速发展,获取数据的手 段和途径都得到极大丰富,传感器的精度得到提高和时空覆盖范围得以扩大,数据量也随之激增。用于采集空间数据的可能是雷达、红外、光电、卫星、多光谱仪、数码相机、成像光谱仪、全站仪、天文望远镜、电视摄像、电子 显微镜、CT 成像等各种宏观与微观传感器或设备,也可能是常规的野外测量、人口普查、土地资源调查、地图扫描、 地图数字化、统计图表等空间数据获取手段,还可能是来自计算机、 网络、GPS ,RS 和GIS 等技术应用和分析空间数据。特别是近些年来,个人使用的、携带的各种传感器(重力感应器、电子罗盘、三轴陀螺仪、光线距离感应器、温度传感器、红外线传感器等),具备定位功能电子设备的普及,如智能手机、平板电脑、可穿戴设备(GOOGLE GLASS 和智能手表等),使人们在日常生活中产生了大量具有位置信息的数据。随着志愿者地理信息(Volunteer Geographic Information )的出现,使这些普通民众也加入到了提供数据者的行列。 以上各种获取手段和途径的汇集,就使每天获取的 数据增长量达到GB 级、 TB 级乃至PB 级。如中国遥感卫星地面站现在保存的对地观测卫星数据资料达260TB ,并以每年15TB 的数据量增长。比如2011年退役的Landsat5卫星在其29年的在轨工作期间,平均每年获取8.6万景影像,每天获取67GB 的观测数据。而2012年发射的资源三号(ZY3)卫星,每天的观测数据获取量可以达到10TB 以上。类似的传感器现在已经大量部署在卫 星、 飞机等飞行平台上,未来10年,全球天空、地空间部署的百万计传感器每天获取的观测数据将超过10PB 。这预示着一个时代的到来,那就是大数据时代。大数据具有 “4V ”特性,即数据体量大(Volume )、数据来源和类型繁多(Variety )、数据的真实性难以保证(Veracity )、数据增加和变化的速度快(Velocity )。对地观测的系统如图1所示。 在这些数据中,与空间位置相关的数据占了绝大多数。传统的空间知识发现的科研模式在大数据情境下已经不再适用,原因是传统的科研模型不具有普适性且支持的数据量受限, 受到数据传输、存储及时效性需求的制约等。为了从存储在分布方式、虚拟化的数据中心获取信息或知识,这就需要利用强有力的数据分析工具来将
数据挖掘算法
数据挖掘的10大经典算法 国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2006年12月评选出了数据挖掘领域的十大经典算法:C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART. 不仅仅是选中的十大算法,其实参加评选的18种算法,实际上随便拿出一种来都可以称得上是经典算法,它们在数据挖掘领域都产生了极为深远的影响。 1. C4.5 C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进: 1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足; 2) 在树构造过程中进行剪枝; 3) 能够完成对连续属性的离散化处理; 4) 能够对不完整数据进行处理。 C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在 构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。 2. The k-means algorithm 即K-Means算法 k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割,k < n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。 3. Support vector machines 支持向量机,英文为Support Vector Machine,简称SV机(论文中一般简称SVM)。它是一种監督式學習的方法,它广泛的应用于统计分类以及回归分析中。支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。一个极好的指南是C.J.C Burges的《模式识别支持向量机指南》。van der Walt 和 Barnard 将支持向量机和其他分类器进行了比较。 4. The Apriori algorithm
文本数据挖掘及其应用
文本数据挖掘及其应用
文本数据挖掘及其应用 摘要:随着Internet上文档信息的迅猛发展,文本分类成为处理和组织大量文档数据的关键技术。本文首先对文本挖掘进行了概述包括文本挖掘的研究现状、主要内容、相关技术以及热点难点进行了探讨,然后通过两个例子简单地说明了文本挖掘的应用问题。 关键词:文本挖掘研究现状相关技术应用 1 引言 随着科技的发展和网络的普及,人们可获得的数据量越来越多,这些数据多数是以文本形式存在的。而这些文本数据大多是比较繁杂的,这就导致了数据量大但信息却比较匮乏的状况。如何从这些繁杂的文本数据中获得有用的信息越来越受到人们的关注。“在文本文档中发现有意义或有用的模式的过程"n1的文本挖掘技术为解决这一问题提供了一个有效的途径。而文本分类
技术是文本挖掘技术的一个重要分支,是有效处理和组织错综复杂的文本数据的关键技术,能够有效的帮助人们组织和分流信息。 2 文本挖掘概述 2.1文本挖掘介绍 数据挖掘技术本身就是当前数据技术发展的新领域,文本挖掘则发展历史更短。传统的信息检索技术对于海量数据的处理并不尽如人意,文本挖掘便日益重要起来,可见文本挖掘技术是从信息抽取以及相关技术领域中慢慢演化而成的。 1)文本挖掘的定义 文本挖掘作为数据挖掘的一个新主题引起了人们的极大兴趣,同时它也是一个富于争议的研究方向。目前其定义尚无统一的结论,需要国内外学者开展更多的研究以进行精确的定义,类似于我们熟知的数据挖掘定义。我们对文本挖掘作如下定义。 定义 2.1.1 文本挖掘是指从大量文本数据中抽取事先未知的可理解的最终可用的信息或知识的过程。直观地说,当数据挖掘的对象完全由文本这种数据类型组成时,这个过程就称为文
《文本数据挖掘》教学大纲
文本数据挖掘教学大纲 课程名称:文本数据挖掘 学分:2 总学时:32 理论学时:24 实验学时:8 先修课程:数据库原理与应用、Python高级语言编程、数据结构 适用专业: 数据工程专业 开课学期:第六学期 01课程性质、定位和教学目标 课程性质:文本数据挖掘是数据工程专业的必修课程,本课程以文本数据挖掘为主要内容,讲述实现文本数据挖掘的各主要功能、挖掘算法和应用,并通过对实际数据的分析更加深入地理解常用的文本数据挖掘模型。 课程定位:“文本数据挖掘技术导论”是针对数据工程专业的专业技术课程,同时也是该专业的核心课程,也是本专业创业创新教育课程。在学生专业培养中起到至关重要的作用。 教学目标:通过“文本数据挖掘技术导论”课程的教学,使学生理解文本数据挖掘的基本概念和方法,学习和掌握中的文本数据挖掘的经典方法。使学生能够借助Python高级语言编程工具进行具体文本数据的挖掘分析。 02教学内容与要求 第一章绪论 【教学目的与要求】 了解文本挖掘研究背景、意义及国内外研究现状,掌握文本挖掘的概念,了解文本挖掘主要研究领域,了解文本挖掘在制药企业应用案例。 【教学内容】 1.1 文本挖掘研究背景及意义 1.2 文本挖掘的国内外研究现状 1.3 文本挖掘概述 1.4 文本挖掘的过程 1.5 文本挖掘在制药企业应用案例 【教学重点与难点】 重点:文本挖掘研究背景、意义国内外研究现状、文本挖掘概念 难点:文本挖掘的过程 【教学手段】 利用网络环境、多媒体课件,案例教学、实理一体化教学方法等
【课后作业】 1. 文本挖掘与数据挖掘有何联系和区别? 2. 目前文本挖掘的领域主要涉及到哪些? 第二章文本切分及特征词选择 【教学目的与要求】 掌握文本数据采集的常用方法、了解中文语料库与词典,熟练掌握文本切分和文本特征词选择的方法,熟练掌握Python Jieba分词模块及其用法。 【教学内容】 2.1 文本数据采集 2.2 语料库与词典简介 2.3 文本切分 2.4 文本特征词选择 2.5 Python Jieba分词模块及其用法 【教学重点与难点】 重点:文本切分、文本特征词选择、Python Jieba分词模块及其用法 难点:Python Jieba分词模块及其用法 【教学手段】 利用网络环境、多媒体课件,案例教学、实理一体化教学方法等 【课后作业】 1 利用现代汉语语料库进行一段中文文本的汉语分词、词性自动标注、字频统计和词频统计。 2 用Python实现双向最大匹配的算法。 3 利用jieba进行一段中文文本的三种模式的分词。 第三章文本表示模型 【教学目的与要求】 熟练掌握文本预处理的常用方法、掌握向量模型、概率模型和主题概率模型的概念及Python的实现。 【教学内容】 3.1 文本预处理 3.2 向量空间模型 3.3 概率模型
深度文本匹配综述_庞亮
网络出版时间:2016-09-20 21:04:43 网络出版地址:https://www.360docs.net/doc/5813660926.html,/kcms/detail/11.1826.TP.20160920.2104.006.html 第39卷计算机学报Vol. 39 深度文本匹配综述 庞亮1),2)3)兰艳艳1)2) 徐君1)2) 郭嘉丰1)2) 万圣贤1),2)3) 程学旗1)2) 1)(中国科学院网络数据科学与技术重点实验室北京 100190) 2)(中国科学院计算技术研究所,北京 100190) 3)(中国科学院大学,北京100190) 摘要自然语言理解的许多任务,例如信息检索、自动问答、机器翻译、对话系统、复述问题等等,都可以抽象成文本匹配问题。过去研究文本匹配主要集中在人工定义特征之上的关系学习,模型的效果很依赖特征的设计。最近深度学习自动从原始数据学习特征的思想也影响着文本匹配领域,大量基于深度学习的文本匹配方法被提出,我们称这类模型为深度文本匹配模型。相比于传统方法,深度文本匹配模型能够从大量的样本中自动提取出词语之间的关系,并能结合短语匹配中的结构信息和文本匹配的层次化特性,更精细地描述文本匹配问题。根据特征提取的不同结构,深度文本匹配模型可以分为三类:基于单语义文档表达的深度学习模型、基于多语义文档表达的深度学习模型和直接建模匹配模式的深度学习模型。从文本交互的角度,这三类模型具有递进的关系,并且对于不同的应用,具有各自性能上的优缺点。本文在复述问题、自动问答和信息检索三个任务上的经典数据集上对深度文本匹配模型进行了实验,比较并详细分析了各类模型的优缺点。最后本文对深度文本模型未来发展的若干问题进行了讨论和分析。 关键词文本匹配;深度学习;自然语言处理;卷积神经网络;循环神经网络 中图法分类号TP18 论文引用格式: 庞亮,兰艳艳,徐君,郭嘉丰,万圣贤,程学旗,深度文本匹配综述,2016,V ol.39,在线出版号No. 128 Pang Liang,Lan Yanyan,Xu Jun,Guo Jiafeng,Wan Shengxian ,Cheng Xueqi,A Survey on Deep Text Matching,2016,V ol.39,Online Publishing No.128 A Survey on Deep Text Matching Pang Liang 1),2)3)Lan Yanyan 1)2) Xu Jun 1)2) Guo Jiafeng 1)2)Wan Shengxian 1),2)3) Cheng Xueqi 1)2) 1)(CAS Key Lab of Network Data Science and Technology, Beijing100190) 2)(Institute of Computing Technology, Chinese Academy of Sciences, Beijing100190) 3)(University of Chinese Academy of Sciences, Beijing 100190) Abstract Many problems in natural language processing, such as information retrieval, question answering, machine translation, dialog system, paraphrase identification and so on, can be treated as a problem of text ——————————————— 本课题得到国家重点基础研究发展计划(973)(No. 2014CB340401, 2013CB329606)、国家自然科学基金重点项目(No.61232010, 61472401, 61425016, 61203298)、中国科学院青年创新促进会(No. 20144310,2016102)资助.庞亮(通讯作者),男,1990年生,博士,学生,计算机学会(CCF)学生会员(59709G),主要研究领域为深度学习与文本挖掘.E-mail: pangliang@https://www.360docs.net/doc/5813660926.html,.兰艳艳,女,1982年生,博士,副研究员,计算机学会(CCF)会员(28478M),主要研究领域为统计机器学习、排序学习和信息检索.E-mail: lanyanyan@https://www.360docs.net/doc/5813660926.html,.徐君,男,1979年生,博士,研究员,计算机学会(CCF)会员, 主要研究领域为信息检索与数据挖掘.E-mail: junxu@https://www.360docs.net/doc/5813660926.html,.郭嘉丰,男,1980年生,博士,副研究员,计算机学会(CCF)会员, 主要研究领域为信息检索与数据挖掘.E-mail: guojiafeng@https://www.360docs.net/doc/5813660926.html,.万圣贤,男,1989年生,博士,学生,主要研究领域为深度学习与文本挖掘.E-mail: wanshengxian@https://www.360docs.net/doc/5813660926.html,.程学旗,男,1971年生,博士,研究员,计算机学会(CCF)会员, 主要研究领域为网络科学、互联网搜索与挖掘和信息安全等.E-mail: cxq@https://www.360docs.net/doc/5813660926.html,.