线性范围试验

实验5 线性范围试验
在光谱分析中,测定该实验条件下被测物质符合Beer定律的浓度范围(线性范围),是评价分析方法准确性和实用性的重要工作。通过线性范围测定,选择线性段作为该方法的分析范围,直线上任何一点的待测物浓度与吸光度的比值均为一常数,其斜率tanθ都相等,即
tanθ=,
此处的值称为校正常数,可用于计算测定结果。这样,可使具有临床意义的标本测定值都限定在此范围内,以保证测定结果的可靠。
线性误差表现为溶液的浓度与吸光度不成线性关系,出现正偏离或负偏离的现象。这种偏离,按Beer定律现象来自两个方面:一是溶液本身不符合Beer定律,这种现象叫做化学偏离;二是仪器本身各种因素的影响,使吸光度与浓度之间不成线性,这种现象叫仪器偏离,如杂光、有限带宽、检测器噪声、环境条件的变化、波长的变动、比色杯的误差、辐射光的非平行性、检测器本身的非线性等。因此,在做方法学线性范围评价实验时,良好的仪器性能是必须的。
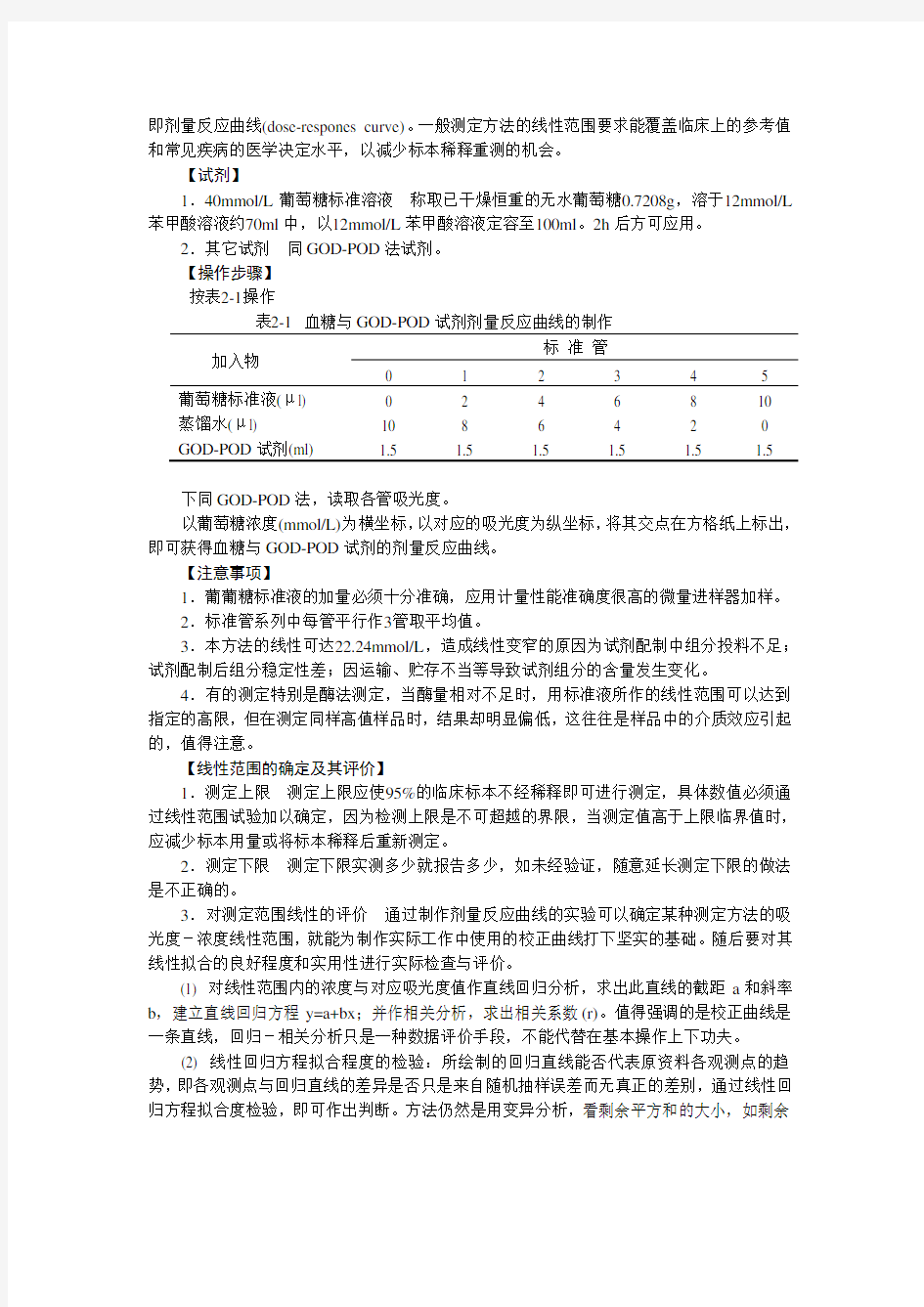
【原理】使用不同浓度的葡萄糖标准溶液,用GOD-POD法试剂测定各自的吸光度,以标准浓度为横坐标,以其对应的吸光度为纵坐标,在方格纸上作图,即可绘制出一条直线,即剂量反应曲线(dose-respones curve)。一般测定方法的线性范围要求能覆盖临床上的参考值和常见疾病的医学决定水平,以减少标本稀释重测的机会。
【试剂】
1.40mmol/L葡萄糖标准溶液称取已干燥恒重的无水葡萄糖0.7208g,溶于12mmol/L 苯甲酸溶液约70ml中,以12mmol/L苯甲酸溶液定容至100ml。2h后方可应用。
2.其它试剂同GOD-POD法试剂。
【操作步骤】
按表2-1操作
表2-1血糖与GOD-POD试剂剂量反应曲线的制作
加入物
标准管
0 1 2 3 4 5
葡萄糖标准液(μl) 0 2 4 6 8 10 蒸馏水(μl) 10 8 6 4 2 0 GOD-POD试剂(ml) 1.5 1.5 1.5 1.5 1.5 1.5
下同GOD-POD法,读取各管吸光度。
以葡萄糖浓度(mmol/L)为横坐标,以对应的吸光度为纵坐标,将其交点在方格纸上标出,即可获得血糖与GOD-POD试剂的剂量反应曲线。
【注意事项】
1.葡葡糖标准液的加量必须十分准确,应用计量性能准确度很高的微量进样器加样。
2.标准管系列中每管平行作3管取平均值。
3.本方法的线性可达22.24mmol/L,造成线性变窄的原因为试剂配制中组分投料不足;试剂配制后组分稳定性差;因运输、贮存不当等导致试剂组分的含量发生变化。
4.有的测定特别是酶法测定,当酶量相对不足时,用标准液所作的线性范围可以达到指定的高限,但在测定同样高值样品时,结果却明显偏低,这往往是样品中的介质效应引起的,值得注意。
【线性范围的确定及其评价】
1.测定上限测定上限应使95%的临床标本不经稀释即可进行测定,具体数值必须通过线性范围试验加以确定,因为检测上限是不可超越的界限,当测定值高于上限临界值时,应减少标本用量或将标本稀释后重新测定。
2.测定下限测定下限实测多少就报告多少,如未经验证,随意延长测定下限的做法是不正确的。
3.对测定范围线性的评价通过制作剂量反应曲线的实验可以确定某种测定方法的吸光度-浓度线性范围,就能为制作实际工作中使用的校正曲线打下坚实的基础。随后要对其线性拟合的良好程度和实用性进行实际检查与评价。
(1) 对线性范围内的浓度与对应吸光度值作直线回归分析,求出此直线的截距a和斜率b,建立直线回归方程y=a+bx;并作相关分析,求出相关系数(r)。值得强调的是校正曲线是一条直线,回归-相关分析只是一种数据评价手段,不能代替在基本操作上下功夫。
(2) 线性回归方程拟合程度的检验:所绘制的回归直线能否代表原资料各观测点的趋势,即各观测点与回归直线的差异是否只是来自随机抽样误差而无真正的差别,通过线性回归方程拟合度检验,即可作出判断。方法仍然是用变异分析,看剩余平方和的大小,如剩余
平方和()对总变异()的比值越小,说明Y的实际观测值与Y的估计值()越接近,曲线拟合越好。这种拟合度,可用相关指数()来表示。越接近于1.0,表明拟合度越高。
这里要注意的是必须由配得的回归方程直接算出的值计算。
(3) 使用高浓度和低浓度临床标本若干份进行实际的线性检查,理想的情况是该方法的分析范围的最高浓度上限应能使95%的临床标本不经稀释均能得到正确的测定结果。
SPSS实验报告_线性回归_曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
线性表实验报告
线性表实验报告 一、实验的目的要求 1、了解线性表的逻辑结构特性,以及这种结构特性在计算机内的两种存储结构。 2、掌握线性表的顺序存储结构的定义及其C语言实现。 3、掌握线性表的链式存储结构——单链表的定义及其C语言实现。 4、掌握线性表在顺序存储结构即顺序表中的各种基本操作。 5、掌握线性表在链式存储结构——单链表中的各种基本操作。 6、认真阅读和掌握实验的程序。 7、上机运行本程序。 8、保存和打印出程序的运行结果,并结合程序进行分析。 二、实验的主要内容 题目:请编制C语言,利用链式存储方式来实现线性表的创建、插入、删除和查找等操作。 具体地说,就是要根据键盘输入的数据建立一个单链表,并输出该单链表;然后根据屏幕 菜单的选择,可以进行数据的插入或删除,并在插入或删除数据后,再输出单链表;最后 在屏幕菜单中选择0,即可结束程序的运行。 三、解题思路分析 在链表中插入数据,不需要进行大量的数据移动,只需要找到插入点即可,可以采用后插入的算法,在插入点的后面添加结点。在链表中删除数据,先找到删除点,然后进行指针赋值操作。 四、程序清单 #include
LNode *L; LNode *creat_L(); void out_L(LNode *L); void insert_L(LNode *L,int i,ElemType e); ElemType delete_L(LNode *L,ElemType e); int locat_L(LNode *L,ElemType e); void main() {int i,k,loc; ElemType e,x; char ch; do{printf("\n"); printf("\n 1.建立单链表"); printf("\n 2.插入元素"); printf("\n 3.删除元素"); printf("\n 4.查找元素"); printf("\n 0.结束程序运行"); printf("\n================================"); printf("\n 请输入您的选择(1,2,3,4,0)"); scanf("%d",&k); switch(k) {case 1:{L=creat_L(); out_L(L); }break; case 2:{printf("\n请输入插入位置:"); scanf("%d",&i); printf("\n请输入要插入元素的值:");
多元线性回归SPSS实验报告
回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
g3.1100 12.4 正态分布、线性回归(1)
12.4 正态分布、线性回归 一、 知识梳理 1.正态分布的重要性 正态分布是概率统计中最重要的一种分布,其重要性我们可以从以下两方面来理解:一方面,正态分布是自然界最常见的一种分布。一般说来,若影响某一数量指标的随机因素很多,而每个因素所起的作用都不太大,则这个指标服从正态分布。 2.正态曲线及其性质 正态分布函数:22 ()2()x f x μσ-- = ,x ∈(-∞,+∞) 3.标准正态曲线 标准正态曲线N (0,1)是一种特殊的正态分布曲线,00()1()x x Φ-=-Φ,以及标准正态总体在任一区间(a ,b)内取值概率)()(a b P Φ-Φ=。 4.一般正态分布与标准正态分布的转化 由于一般的正态总体),(2σμN 其图像不一定关于y 轴对称,对于任一正态总体),(2σμN ,其取值小于x 的概率)( )(σ μ -Φ=x x F 。只要会用它求正态总体 ),(2σμN 在某个特定区间的概率即可。 5.“小概率事件”和假设检验的基本思想 “小概率事件”通常指发生的概率小于5%的事件,认为在一次试验中该事件是几乎不可能发生的。这种认识便是进行推断的出发点。关于这一点我们要有以下两个方面的认识:一是这里的“几乎不可能发生”是针对“一次试验”来说的,因为试验次数多了,该事件当然是很可能发生的;二是当我们运用“小概率事件几乎不可能发生的原理”进行推断时,我们也有5%的犯错误的可能。
课本是借助于服从正态分布的有关零件尺寸的例子来介绍假设检验的基本思想。进行假设检验一般分三步: 第一步,提出统计假设。课本例子里的统计假设是这个工人制造的零件尺寸服从正态分布),(2σμN ; 第二步,确定一次试验中的取值a 是否落入范围(μ-3σ,μ+3σ); 第三步,作出推断。如果a ∈(μ-3σ,μ+3σ),接受统计假设;如果 )3,3(σμσμ+-?a ,由于这是小概率事件,就拒绝统计假设。 6.相关关系 研究两个变量间的相关关系是学习本节的目的。对于相关关系我们可以从下三个方面加以认识:⑴相关关系与函数关系不同。函数关系中的两个变量间是一种确定性关系。相关关系是一种非确定性关系,即相关关系是非随机变量与随机变量之间的关系。 ⑵函数关系是一种因果关系,而相关关系不一定是因果关系,也可能是伴随关系。 ⑶函数关系与相关关系之间有着密切联系,在一定的条件下可以相互转化。 7.回归分析 本节所研究的回归分析是回归分析中最简单,也是最基本的一种类型——一元线性回归分析。 对于线性回归分析,我们要注意以下几个方面: ⑴回归分析是对具有相关关系的两个变量进行统计分析的方法。两个变量具有相关关系是回归分析的前提。 ⑵散点图是定义在具有相关系的两个变量基础上的,对于性质不明确的两组数据,可先作散点图,在图上看它们有无关系,关系的密切程度,然后再进行相关回归分析。
数据结构实验一题目一线性表实验报告
北京邮电大学电信工程学院 数据结构实验报告 实验名称:实验1——线性表 学生姓名: 班级: 班内序号: 学号: 日期: 1.实验要求 1、实验目的:熟悉C++语言的基本编程方法,掌握集成编译环境的调试方法 学习指针、模板类、异常处理的使用 掌握线性表的操作的实现方法 学习使用线性表解决实际问题的能力 2、实验内容: 题目1: 线性表的基本功能: 1、构造:使用头插法、尾插法两种方法 2、插入:要求建立的链表按照关键字从小到大有序 3、删除 4、查找 5、获取链表长度 6、销毁 7、其他:可自行定义 编写测试main()函数测试线性表的正确性。 2. 程序分析 2.1 存储结构 带头结点的单链表
2.2 关键算法分析 1.头插法 a、伪代码实现:在堆中建立新结点 将x写入到新结点的数据域 修改新结点的指针域 修改头结点的指针域,将新结点加入链表中b、代码实现: Linklist::Linklist(int a[],int n)//头插法 {front=new Node; front->next=NULL; for(int i=n-1;i>=0;i--) {Node*s=new Node; s->data=a[i]; s->next=front->next; front->next=s; } } 2、尾插法
a、伪代码实现:a.在堆中建立新结点 b.将a[i]写入到新结点的数据域 c.将新结点加入到链表中 d.修改修改尾指针 b、代码实现: Linklist::Linklist(int a[],int n,int m)//尾插法 {front=new Node; Node*r=front; for(int i=0;i
数据结构实验报告——线性表
实验报告:线性表的基本操作 实验1:实现顺序表各种基本运算的算法 一、实验目的 学会并运用顺序表存储结构及各种运算。 二、实验环境 VC++6.0 三、实验准备 (1) 复习课件中理论知识 (2)练习课堂所讲的例子 四、实验内容 编写一个程序实现SqList.cpp,实现顺序表基本运算,并在此基础上设计个主程序exp1.cpp,完成如下功能: (1)初始化顺序表L; (2)依次插入a、b、c、d、e元素; (3)输出顺序表L; (4)输出顺序表L长度; (5)判断顺序表L是否为空: (6)输出顺序表L的第3个元素; (7)输出元素a的位置; (8)在第4个位置上插入f元素; (9)输出顺序表L; (10)删除顺序表L的第3 个元素; (11)输出顺序表L; (12)顺序表L; 五、实验步骤 1、构造一个空的线形表并分配内存空间 Status InitList_Sql(SqList &L) {L.elem=(ElemType*)malloc(LIST_INIT_SIZE*sizeof(ElemType)); if(!L.elem) exit(OVERFLOW); L.length=0; L.listsize=LIST_INIT_SIZE; return OK; } 2、求线性表的长度 Status ListLength(SqList L) { return L.length; } 3、线性表清空 void ClearList(SqList &L){ L.length = 0; } 4、在顺序线形表 L 中第 i 个位置之前插入新的元素 e Status ListInsert_Sq(SqList &L,int i,ElemType e)
计量经济学简单线性回归实验报告精编
实验报告 1. 实验目的随着中国经济的发展,居民的常住收入水平不断提高,粮食销售量也不断增长。研究粮食年销售量与人均收入之间的关系,对于探讨粮食年销售量的增长的规律性有重要的意义。 2. 模型设定 为了分析粮食年销售量与人均收入之间的关系,选择“粮食年销售量” 为被解释变量(用Y 表示),选择“人均收入”为解释变量(用X 表 示)。本次实验报告数据取自某市从1974 年到1987 年的数据(教材书上101页表3.11),数据如下图所示:
1粮食年销售量Y/万吨人均收入X/ rF1974[ 9& 45153.2 1975100.7190 pl1976102.8240.3 1977133. 95301.12 [61978140.13361 71979143.11420 8—1980146.15491.76「91981144.6501 101982148. 94529.2 1 11-1983158.55552. 72匸1984169. 68771.16 131985P 162.1481L8 14二1986170. 09988.43 1519871F& 691094.65为分析粮食年销售量与人均收入的关系,做下图所谓的散点图 从散点图可以看出粮食年销售量与人均收入大体呈现为线性关 系,可以建立如下简单现行回归模型: 3?估计参数
Y t = ■? 1 2 X t ——I t 假定所建模型及其中的随机扰动项叫满足各项古典假定,可以 用OLS法估计其参数。 通过利用EViews对以上数据作简单线性回归分析,得出回归结果如下表所示: Dependent Variable Y Method: Least Squares Date 10/15/11 Time 14 49 Sample- 1 14 Included observations: 14 Variable Coefficient Std Error t-Statistic Prob C99 61349 6 431242 15 489000 0000 X0.0814700.010738 7.5071190.0000 R-squared0 827493Mean dependent var142 7129 Adjusted R-squared0 813123S.D. dependent var26.09805 S E of regression11 28200Akaike info criterion7 915858 Sum squared resid1527 403Schwarz criterion7 907152 Log likelihood-52.71101F-statisti c5756437 Durbin-V/atson stat0 638969Prob(尸-statistic)0 000006 可用规范的形式将参数估计和检验的结果写为: A Y t =99.61349+0.08147 X t (6.431242)(0.10738) t= (15.48900) (7.587119) R2=0.827498 F=57.56437 n=14 4?模型检验 (1).经济意义检验 A A 所估计的参数1=99.61349, 1 2=0.08147,说明人均收入每增加 1元,平均说来可导致粮食年销售量提高0.08147元。这与经济学中
正态分布和线性回归
专题:正态分布和线性回归 一、 基础知识回顾 1 ( x )2 1. 正态分布:若总体密度曲线就是或近似地是函数 f ( x) e 2 2 的图象 2 , x, 其中:π是圆周率; e 是自然对数的底; x 是随机变量的取值 , 为正态分布的平均值; 是 正态分布的标准差.这个总体是无限容量的抽样总体,其分布叫做正态分布.正态分布由参 数 , 唯一确定,记作 ~ N ( , 2 ) ,E( )= ,D( )= 2 . 2. 函数 f(x) 图象被称为正态曲线 . (1) 从形态上看,正态分布是一条单峰、对称呈钟形的曲线,其对称轴为 x=μ,并在 x=μ时 .... .......... 取最大值 。(2) 从 x=μ点开始,曲线向正负两个方向递减延伸,不断逼近 x 轴,但永不与 x .... 轴相交,因此说曲线在正负两个方向都是以 x 轴为渐近线的 ,(3) 当μ的值一定时 , σ越大,曲线越“矮胖”,总体分布越分散;σ越小,曲线越“高”.总体分布越集中. 3. 把 ~ N (0,1) 即μ =0, σ=1 称为标准正态分布,这样的正态总体称为标准正态总体 , 其密度函 1 1 x 2 数为 f ( x) e 2 2 ,x ∈(- ∞,+∞) ,相应的曲线称为标准 正 态曲线. 4. 利用标准正态分布表可求得标准正态总体在某一区间内取 值 的概率 . (1) 对于标准正态总体 N (0,1) , ( x 0 ) 是总体取值小于 x 0 的概率,即: ( x 0 ) P(x x 0 ) , 其中 x 0 0 ,其值可以通过 “标准正态分布表” 查得,也就是图中阴影部分的面积,它表示 总体取值小于 x 0 的概率. (2) 标准正态曲线关于 y 轴对称。因为当 x 0 0 时, ( x 0 ) P(x x 0 ) ; 而当 x 0 0 时,根据正态曲线的性质可得: ( x 0 ) 1 ( x 0 ) ,并且可以求得在任一区间(x 1 , x 2 ) 内 取值的概率: P(x 1 x x 2 ) ( x 2 ) ( x 1 ) , 显然Φ(0)=0.5. 5. 对于任一正态总体 ~ N ( , 2 ) , 都可以通过 使之标准化 ~ N (0,1) , 那么 , P( x )=P( < x )= ( x ) ,求得其在某一区间内取值的概率 . 例如: ~ N(1,4), 那么 , 设 = 1 , 则 ~ N (0,1) , 有 P( <3)=P( <1)= (1)=0.8413. 2 6. Φ(1)=0.8413 、Φ (2)=0.9772 、Φ(3)=0.9987 二、例题
线性表逆置(顺序表)实验报告
实验一:线性表逆置(顺序表)实验报告 (一)问题的描述: 实现顺序表的逆置算法 (二)数据结构的设计: 顺序表是线性表的顺序存储形式,因此设计如下数据类型表示线性表: typedef struct { ElemType *elem; /* 存储空间基址*/ int length; /* 当前长度*/ int listsize; /* 当前分配的存储容量(以sizeof(ElemType)为单位) */ }SqList; (三)函数功能、参数说明及概要设计: 1.函数Status InitList(SqList *L) 功能说明:实现顺序表L的初始化 算法设计:为顺序表分配一块大小为LIST_INIT_SIZE的储存空间 2.函数int ListLength(SqList L) 功能说明:返回顺序表L长度 算法设计:返回顺序表中的length变量 3.函数Status ListInsert(SqList *L,int i,ElemType e) 功能说明:将元素e插入到顺序表L中的第i个节点 算法设计:判断顺序表是否已满,已满则加空间,未满则继续,将元素e插入到第i个元素之前,并将后面的元素依次往后移 4.函数Status ListTraverse(SqList L,void(*vi)(ElemType*)) 功能说明:依次对L的每个数据元素调用函数vi() 算法设计:依次对L的每个数据元素调用函数vi() 5.函数void Exchange(SqList *L) 功能说明:实现顺序表L的逆置 算法设计:用for循环将顺序表L中的第i个元素依次与第(i+length)个元素交换6.函数void print(ElemType *c) 功能说明:打印元素c 算法设计:打印元素c 2. (四)具体程序的实现
数据结构线性表的应用实验报告
实验报告 课程名称____数据结构上机实验__________ 实验项目______线性表的应用____________实验仪器________PC机___________________ 系别_____电子信息与通信学院___ 专业________ ___ 班级/学号______ __ 学生姓名______ ___________ 实验日期_______________________ 成绩_______________________ 指导教师_______________________
实验一.线性表的应用 1.实验目的:掌握线性链表的存储、运算及应用。利用链 表实现一元多项式计算。 2.实验内容: 1)编写函数,实现用链表结构建立多项式; 2)编写函数,实现多项式的加法运算; 3)编写函数,实现多项式的显示; 4)测试:编写主函数,它定义并建立两个多项式,显示 两个多项式,然后将它们相加并显示结果。变换测试用的多项式,检查程序的执行结果。 选做内容:修改程序,选择实现以下功能: 5)多项式求值:编写一个函数,根据给定的x值计算并 返回多项式f(x)的值。测试该函数(从终端输入一个x的值,调用该函数并显示返回结果)。 6)多项式相减:编写一个函数,求两个多项式相减的多 项式。 7)多项式相乘:编写一个函数,求两个多项式的乘积多 项式。 3.算法说明: 1)多项式的建立、显示和相加算法见讲义。可修改显示 函数,使输出的多项式更符合表达规范。
2)多项式减法:同次项的系数相减(缺项的系数是0)。 例如a(x)=-5x2+2x+3,b(x)= -4x3+3x,则a(x)-b(x) =4x3-5x2-x+3。提示:a(x)-b(x) = a(x)+(-b(x))。 3)多项式乘法:两个多项式的相乘是“系数相乘,指数 相加”。算法思想是用一个多项式中的各项分别与另 一个多项式相乘,形成多个多项式,再将它们累加在 一起。例如,a(x)=-5x2+2x+3,b(x)=-4x3+3x,则 a(x)*b(x) = (-4x3)*(-5x2+2x+3)+(3x)*(-5x2+2x+3) = (20x5-8x4-12x3) + (-15x3+6x2+9x) = 20x5-8x4-27x3+6x2+9x。 4.实验步骤: 根据实验报告的要求,我对文件夹里的C文件进行了丰 富和修改,步骤如下: 链表结构建立多项式: typedef struct polynode { float coef; //系数 int exp; //指数 struct polynode *next; //下一结点指针 } PNode; 编写函数,实现多项式的加法运算; PNode * PolyAdd (PNode *f1, PNode *f2) //实现加法功能。
正态分布和线性回归
专题:正态分布和线性回归 一、 基础知识回顾 1.正态分布: 若总体密度曲线就是或近似地是函数()2 2 ()2(),,x f x x μσ--=∈-∞+∞的图象 其中:π是圆周率;e 是自然对数的底;x 是随机变量的取值,μ为正态分布的平均值;σ是正态分布的标准差.这个总体是无限容量的抽样总体,其分布叫做正态分布.正态分布由参数μ,σ唯一确定,记作ξ~2(,)N μσ,E(ξ)=μ,D(ξ)=2σ. 2.函数f(x)图象被称为正态曲线. (1)从形态上看,正态分布是一条单峰、对称呈钟形的曲线,其对称轴为....x=..μ.,并在...x=..μ.时. 取最大值.... 。(2)从x=μ点开始,曲线向正负两个方向递减延伸,不断逼近x 轴,但永不与x 轴相交,因此说曲线在正负两个方向都是以x 轴为渐近线的,(3)当μ的值一定时, σ越大,曲线越“矮胖”,总体分布越分散;σ越小,曲线越“高”.总体分布越集中. 3. 把ξ~(0,1)N 即μ=0,σ=1称为标准正态分布,这样的正态总体称为标准正态总体,其密度函 数为21 2 ()x f x -=,x ∈(-∞,+∞),相应的曲线称为标准正态曲线. 4.利用标准正态分布表可求得标准正态总体在某一区间内取值的概率. (1)对于标准正态总体(0,1)N ,)(0x Φ是总体取值小于0x 的概率,即:)()(00x x P x <=Φ, 其中00>x ,其值可以通过“标准正态分布表”查得,也就是图中阴影部分的面积,它表示总体取值小于0x 的概率. (2)标准正态曲线关于y 轴对称。因为当00>x 时,)()(00x x P x <=Φ; 而当00 一.实验名称 1.线性表基本操作; 2.处理约瑟夫环问题 二.试验目的: 1.熟悉C语言的上机环境,掌握C语言的基本结构。 2.定义单链表的结点类型。 3.熟悉对单链表的一些基本操作和具体的函数定义。 4.通过单链表的定义掌握线性表的链式存储结构的特点。 5.熟悉对单链表的一些其它操作。 三.实验内容 1.编制一个演示单链表初始化、建立、遍历、求长度、查询、插入、删除等操作的程序。 2.编制一个能求解除约瑟夫环问题答案的程序。 实验一线性表表的基本操作问题描述: 1. 实现单链表的定义和基本操作。该程序包括单链表结构类型以及对单链表操作 的具体的函数定义 程序中的单链表(带头结点)结点为结构类型,结点值为整型。 /* 定义DataType为int类型*/ typedef int DataType; /* 单链表的结点类型*/ typedef struct LNode {DataType data; struct LNode *next; }LNode,*LinkedList; LinkedList LinkedListInit() //初始化单链表 void LinkedListClear(LinkedList L) //清空单链表 int LinkedListEmpty(LinkedList L)//检查单链表是否为空 void LinkedListTraverse(LinkedList L)//遍历单链表 int LinkedListLength(LinkedList L)//求单链表的长度 /* 从单链表表中查找元素*/ LinkedList LinkedListGet(LinkedList L,int i) /* 从单链表表中查找与给定元素值相同的元素在链表中的位置*/ int LinkedListLocate(LinkedList L, DataType x) void LinkedListInsert(LinkedList L,int i,DataType x) //向单链表中插入元素 /* 从单链表中删除元素*/ void LinkedListDel(LinkedList L,DataType x) 计量经济学多元线性回归、多重共线性、异方差实验报告记录 ————————————————————————————————作者:————————————————————————————————日期: 计量经济学实验报告 多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β 1 X 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元 Ch4 正态性假定: 经典正态线性回归模型 对于模型 i i i u X Y ++=21ββ (4.1) 我们首先讨论扰动的分布。 i u 4.1. 的概率分布 i u 没有分布假设,不可能对参数估计量作出任何推断,也不可能对任何有关总体的假定作出检验 4.2. 的概率分布假定为正态分布 i u 经典正态线性回归假定具有正态分布,且 i u 均值: 0)(=i u E 方差: ,表示对每一个,方差相同 22)(σ=i u E i u 协方差 j i u u j i ≠=0),cov( 概率密度函数: 22 221 )(σ π σi u i e u f ?= 概率分布函数 ∫ ∞ ??=x i i du e u F i 22221 )(σ μπ σ 上述假定采取记为 2~(0,i u NID )σ (4.2) 简称为为独立同分布。其分布特征如图所示. i u 正态分布特征: 为什么假定为正态分布? 1. 中心极限定理 独立同分布随机变量X i , 其均值为μ, 方差为σ2, 则: )/,(/2 n N n X X n i σμ??→?=∞ →∑ )1,0() (/N X n n X z n ??→??= ?= ∞ →σ μσμ 正是中心极限定理,为的正态假设提供了理论支持。 i u 2. 正态变量所具有的性质: 线性变换仍为正态变量,分布函数仅有两个参数即均值和方差。 4.3.正态假定下OLS 估计量的性质 用OLS 方法所得到的估计量,在正态假定下具有性质: )2,1(?=i i β1. 无偏性; 2. 最小方差; 3. 一致性,即随着样本个数的无限增大,估计量将收敛于它们的真值。用公式表示 {} 01?lim >= 数据结构实验报告全集 实验一线性表基本操作和简单程序 1.实验目的 (1)掌握使用Visual C++ 上机调试程序的基本方法; (2)掌握线性表的基本操作:初始化、插入、删除、取数据元素等运算在顺序存储结构和链表存储结构上的程序设计方法。 2.实验要求 (1)认真阅读和掌握和本实验相关的教材内容。 (2)认真阅读和掌握本章相关内容的程序。 (3)上机运行程序。 (4)保存和打印出程序的运行结果,并结合程序进行分析。 (5)按照你对线性表的操作需要,重新改写主程序并运行,打印出文件清单和运行结果 实验代码: 1)头文件模块 #include >验目的 掌握顺序栈的基本操作:初始化栈、判栈空否、入栈、出栈、取栈顶数据元素等运算以及程序实现方法。 2.实验要求 (1)认真阅读和掌握和本实验相关的教材内容。 (2)分析问题的要求,编写和调试完成程序。 (3)保存和打印出程序的运行结果,并分析程序的运行结果。 3.实验内容 利用栈的基本操作实现一个判断算术表达式中包含圆括号、方括号是否正确配对的程序。具体完成如下: (1)定义栈的顺序存取结构。 (2)分别定义顺序栈的基本操作(初始化栈、判栈空否、入栈、出栈等)。 (3)定义一个函数用来判断算术表达式中包含圆括号、方括号是否正确配对。其中,括号配对共有四种情况:左右括号配对次序不正确;右括号多于左括号;左括号多于右括号;左右括号匹配正确。 (4)设计一个测试主函数进行测试。 (5)对程序的运行结果进行分析。 实验代码: #include < > #define MaxSize 100 typedef struct { int data[MaxSize]; int top; }SqStack; 多元线性回归模型实验报告 13级财务管理 101012013101 蔡珊珊 【摘要】首先做出多元回归模型,对于解释变量作出logx等变换,选择拟合程度最高的模型,然后判断出解释变量之间存在相关性,然后从检验多重线性性入手,由于解释变量之间有的存在严重的线性性,因此采用逐步回归法,将解释变量进行筛选,保留对模型解释能力较强的解释变量,进而得出一个初步的回归模型,最后对模型进行异方差和自相关检验。 【操作步骤】1.输入解释变量与被解释变量的数据 2.作出回归模型 R^2=0.966951 DW=0.626584 F-statictis=241.3763 ②我们令y1=log(consumption),x4=log(people),x5=log(price),x6=log(retained),x7= log(gdp), 作出回归模型 ② 发现拟合程度很高,也通过了F检验与T检验。但是我们首先检查模型的共线性 发现x4与x6,x4与x7,x6与x7存在很强的共线性,对模型会造成严重影响。 目前暂用模型y1=10.55028-3.038439x4-0.236518x5+2.647396x6-0.557805x7,我们将陆续进行调整。 3.分别作出各解释变量与被解释变量之间的线性模型 ①作出汽车消费量与汽车保有量之间的线性回归模型 R^2=0.956231 DW=0.147867 F-statistic=786.4967 因为prob小于α置信度,则可说明β1不明显为零。经济意义存在 Y1^=4.142917 + 0.761197x6 (8.283960) (28.04455) 正态分布和线性回归 高考要求 1.了解正态分布的意义及主要性质 2.了解线性回归的方法和简单应用 知识点归纳 1.正态分布密度函数: 2 2 () 2 () x f x μ σ - - =,(σ>0,-∞<x<∞) 其中π是圆周率;e是自然对数的底;x是随机变量的取值;μ为正态分布的均值;σ是正态分布的标准差.正态分布一般记为) , (2 σ μ N 2.正态分布) , (2 σ μ N)是由均值μ和标准差σ唯一决定的分布 例1、下面给出三个正态总体的函数表示式,请找出其均值μ和标准差σ.(1)2 2 2 1 ) ( x e x f- = π ,(-∞<x<+∞) (2 ) 2 (1) 8 () x f x - - =,(-∞<x<+∞) 解:(1)0,1 (2)1,2 3.正态曲线的性质:正态分布由参数μ、σ唯一确定,如果随机变量ξ~N(μ,σ2),根据定义有:μ=Eξ,σ=Dξ。 正态曲线具有以下性质: (1)曲线在x轴的上方,与x轴不相交。 (2)曲线关于直线x =μ对称。 (3)曲线在x =μ时位于最高点。 (4)当x <μ时,曲线上升;当x >μ 时,曲线下降。并且当曲线向左、 右两边无限延伸时,以x 轴为渐近线,向它无限靠近。 (5)当μ一定时,曲线的形状由σ确定。σ越大,曲线越“矮胖”,表示总体越分散;σ越小,曲线越“瘦高”,表示总体的分布越集中。 五条性质中前三条较易掌握,后两条较难理解,因此应运用数形结合的原则,采用对比教学 4.标准正态曲线:当μ=0、σ=l 时,正态总体称为标准正态总体,其 相应的函数表示式是2 221)(x e x f - = π ,(-∞<x <+∞) 其相应的曲线称为标准正态曲线 标准正态总体N (0,1)在正态总体的研究中占有重要的地位 任何正态分布的概率问题均可转化成标准正态分布的概率问题 5.标准正态总体的概率问题: 对于标准正态总体N (0,1),)(0x Φ是总体取值小于0x 的概率, 即 )()(00x x P x <=Φ, 其中00>x ,图中阴影部分的面积表示为概率0()P x x < 只要有标准正态 分布表即可查表解决.从图中不难发现:当00 实验报告 实验一线性表 实验目的: 1.理解线性表的逻辑结构特性; 2.熟练掌握线性表的顺序存储结构的描述方法,以及在该存储结构下的基本操作;并能灵活运用; 3.熟练掌握线性表的链表存储结构的描述方法,以及在该存储结构下的基本操作;并能灵活运用; 4.掌握双向链表和循环链表的的描述方法,以及在该存储结构下的基本操作。 实验原理: 线性表顺序存储结构下的基本算法; 线性表链式存储结构下的基本算法; 实验内容: 2-21设计单循环链表,要求: (1)单循环链表抽象数据类型包括初始化操作、求数据元素个数操作、插入操作、删除操作、取消数据元素操作和判非空操作。 (2)设计一个测试主函数,实际运行验证所设计单循环链表的正确性。 2-22 .设计一个有序顺序表,要求: (1)有序顺序表的操作集合有如下操作:初始化、求数据元素个数、插入、删除和取数据元素。有序顺序表与顺序表的主要区别是:有序顺序表中的数据元素按数据元素值非递减有序。 (2)设计一个测试主函数,实际运行验证所设计有序顺序表的正确性。 (3)设计合并函数ListMerge(L1,L2,L3),功能是把有序顺序表L1和L2中的数据元素合并到L3,要求L3中的数据元素依然保持有序。并设计一个主函数,验证该合并函数的正确性。 程序代码: 2-21(1)头文件LinList.h如下: typedef struct node { DataType data; struct node *next; }SLNode; /*(1)初始化ListInitiate(SLNode * * head)*/ void ListInitiate(SLNode * * head) { /*如果有内存空间,申请头结点空间并使头指针head指向头结点*/ if((*head=(SLNode *)malloc(sizeof(SLNode)))==NULL)exit(1); 实验报告 课程名称:数据结构与算法分析 实验名称:链表的实现与应用 实验日期:班级:数媒1401 姓名:范业嘉学号 08 一、实验目的 掌握线性表的链式存储结构设计与基本操作的实现。 二、实验内容与要求 ⑴定义线性表的链式存储表示; ⑵基于所设计的存储结构实现线性表的基本操作; ⑶编写一个主程序对所实现的线性表进行测试; ⑷线性表的应用:①设线性表L1和L2分别代表集合A和B,试设计算法求A和B的并集C,并用 线性表L3代表集合C;②(选做)设线性表L1和L2中的数据元素为整数,且均已按值非递减有序排列,试设计算法对L1和L2进行合并,用线性表L3保存合并结果,要求L3中的数据元素也按值非递减有序排列。 ⑸设计一个一元多项式计算器,要求能够:①输入并建立多项式;②输出多项式;③执行两个多项式相加;④执行两个多项式相减;⑤(选做)执行两个多项式相乘。 三、数据结构设计 1.按所用指针的类型、个数、方法等的不同,又可分为: 线性链表(单链表) 静态链表 循环链表 双向链表 双向循环链表 2.用一组任意的存储单元存储线性表中数据元素,用指针来表示数据元素间的逻辑关系。 四、算法设计 1.定义一个链表 void creatlist(Linklist &L,int n) { int i; Linklist p,s; L=(Linklist)malloc(sizeof(Lnode)); p=L; L->next=NULL; for(i=0;i线性表实验报告
计量经济学多元线性回归、多重共线性、异方差实验报告记录
计量经济学ch4 正态假定 经典线性回归模型
数据结构实验报告全集
多元线性回归模型实验报告
高三数学正态分布和线性回归(知识点和例题)
数据结构线性表实验报告
线性表的链式存储结构实验报告