数据结构常见题型

数据结构常见解答题
1:二叉树性质3的证明 二叉树性质3::对任何一棵二叉树,若它含有n0 个叶子结点、n2 个度为 2 的结点,则必存在关系式:n0 = n2+1。
证明:设二叉树中结点总数为n ,n1为二叉树中度为1的结点数。则n=n0+n1+n2(1) 设二叉树中分支数目为B ,因为二叉树中的分支都是由度为1和度为2的结点发出,所以分支数目为:B=n1+2n2(2)
因为除根结点外,每个结点均对应一个进入它的分支,所以有:n=B+1。(3) 将(1)(2)代入(3)中,得n0+n1+n2=n1+2n2+1,整理后得n0=n2+1,故结论成立。 2:已知二叉树先序遍历序列和中序遍历序列画出二叉树(或是已知后序和中序) 例如
已知一棵二叉树的先序序列为A B C D E F G H I
中序序列为:B C A E D G H F I
试画出二叉树。
先序遍历是根左右,中序是左根右。
做法:先确定根结点,然后确定左子树的结点,和右子树结点,画出左右子树。
首先,由先序序列可知,结点A 是二叉树的根结点。其次,根据中序序列,在A 之前的所有结点都是根结点左子树的结点,在A 之后的所有结点都是根结点右子树的结点,由此得到图(a)所示的状态。然后,再对左子树进行分解,得知B 是左子树的根结点,又从中序序列知道,B 的左子树为空,B 的右子树只有一个结点C 。接着对A 的右子树进行分解,得知A 的右子树的根结点为D ;而结点D 把其余结点分成两部分,即左子树为E ,右子树为F 、G 、H 、I ,如图(b)所示。接下去的工作就是按上述原则对D 的右子树继续分解下去,最后得到如图(c)的整棵二叉树。
(a)
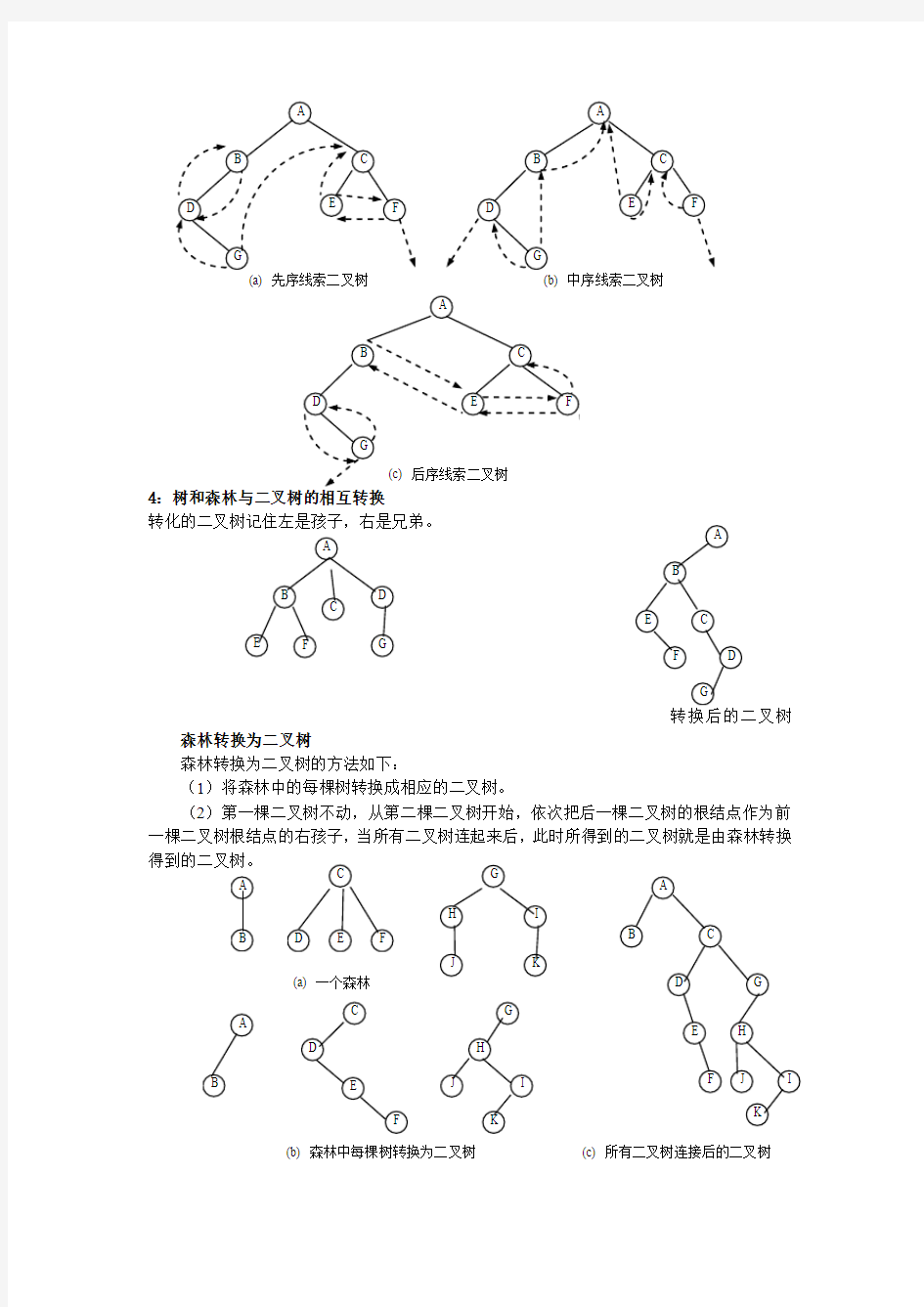
3:线索二叉树:
对下图所示的二叉树进行线索化。
将没有左孩子的结点用虚线指向遍历序列的前驱,将没有右孩子的结点用虚线指向遍历序列的后继。
中序线索与后序线索类似
4
转化的二叉树记住左是孩子,右是兄弟。
森林转换为二叉树
森林转换为二叉树的方法如下:
(1)将森林中的每棵树转换成相应的二叉树。
(2)第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树根结点的右孩子,当所有二叉树连起来后,此时所得到的二叉树就是由森林转换
(a) 一个森林
(b) 森林中每棵树转换为二叉树(c) 所有二叉树连接后的二叉树
5:赫夫曼树构造及赫夫曼编码 赫夫曼树构造:(1)由给定的n 个权值{W1,W2,…,Wn}构造n 棵只有一个叶结点的二叉树,从而得到一个二叉树的集合F ={T1,T2,…,Tn};
(2)在F 中选取根结点的权值最小和次小的两棵二叉树作为左、右子树构造一棵新的二叉树,这棵新的二叉树根结点的权值为其左、右子树根结点权值之和;
(3)在集合F 中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到集合F 中;(4)重复(2)(3)两步,直到F 中只剩下一棵二叉树时,这棵二叉树就是赫夫曼树。 例如: 假定用于通讯的电文仅有8个字母C1,C2,…,C8组成,各个字母在电文中出现的频率分别为5,25,3,6,10,11,36,4,试画出赫夫曼树并进行对这8个字母设计赫夫曼编码。
虽然赫夫曼树的带权
本题中各字母编码如下:c1:0110 c2:10 c3:0010 c4:0111 c5:000 c6:010 c7:11 c8:0011 6:邻接矩阵 所谓邻接矩阵(Adjacency Matrix )的存储结构, 就是用一维数组存储图中顶点的信息, 用矩阵表示图中各顶点之间的邻接关系。 假设图G =(V ,E )有n 个确定的顶点, 即V ={v 0,v 1,…,v n-1},则表示G 中各顶点相邻关系为一个n ×n 的矩阵,矩阵的元素为: A[i][j]=
若G 是网图,则邻接矩阵可定义为: A[i][j]=
其中,w ij 表示边(v i ,v j )或
例:
0 1 0 1
A = 1 0 1 1 0 1 0 0
1 1 0 0
一个无向图的邻接矩阵表示
∞ 9 6 3 ∞ 9 ∞ 4 5 ∞
A = 6 4 ∞ ∞ 7 3 5 ∞ ∞ 8 ∞ ∞ 7 8 ∞
一个网图的邻接矩阵表示
{ 1 若(v i ,v j )或
0 若(v i ,v j )或
{
w ij 若(v i ,v j )或
0或∞ 若(v i ,v j )或
c c 8 c 1
c
7
7:邻接表
给出上图无向图对应的邻接表表示。
vertex firstedge
图的邻接表表示
例如有向图
邻接表和逆邻接表为:
(a) 邻接表(b) 逆邻接表
8:已知有向图或无向图,给出深度优先遍历序列或广度优先遍历序列(生成树)
遍历序列要知道两点:初始点和存储结构,特别采用邻接表的存储结构表结点的顺序不同,得到的遍历序列可能不同。深度优先搜索可从图中某个顶点发v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
以上图为例,进行图的深度优先搜索。假设从顶点v1出发进行搜索,邻接点的顺序由小到大排列。在访问了顶点v1之后,找到第一个邻接点v2。因为v2未曾访问,则从v2出发进行搜索。依次类推,接着从v4 、v8 、v5 出发进行搜索。在访问了v5之后,由于v5
的邻接点都已被访问,则搜索回到 v8。由于同样的理由,搜索继续回到v4,v2直至v1,此时由于v1的另一个邻接点未被访问,则搜索又从v1到v3,再继续进行下去由此,得到的顶点访问序列为:
v1 →v2 →v4→v8→ v5 →v3→v6→v7
若进行广度优先搜索遍历,首先访问v1 和v1的邻接点v2和v3,然后依次访问v2 的邻接点v4 和v5 及v3 的邻接点v6和v7,最后访问v4 的邻接点v8。由于这些顶点的邻接点均已被访问,并且图中所有顶点都被访问,由些完成了图的遍历。得到的顶点访问序列为: v1→v2 →v3 →v4→ v5→ v6→ v7 →v8
由深度优先搜索得到的为深度优先生成树;由广度优先搜索得到的为广度优先生成树。
广度优先生成树
9
:最小生成树
Prim
算法的思想:从所有u
∈U ,v ∈V -U 的边中,选取具有最小权值的边(
u ,v
),将顶点v 加入集合U 中,将边(u ,v )加入集合T 中,如此不断重复,直到U
=V 时,最小生成树构造完毕,这时集合T 中包含了最小生成树的所有边。
Prim 算法可用下述过程描述,其中用w uv 表示顶点u 与顶点
v 边上的权值。
(1)U
={u1},T={}; (2)while (U ≠
V)do
(u ,v)
=min{w uv ;u ∈U ,v ∈V -U } T =T +{(u ,v)} U =U +{v} (3)结束。
图8.23 (a)所示的一个网图,按照Prim 方法,从顶点1出发,该网的最小生成树的产生过程如图
(b)、(c)、(d)、
(e)、(f)
和(g)所示。
(a) (b) (c)
(d)
(g) (h)
Prim 算法构造最小生成树的过程示意
按照Kruskal 方法构造最小生成树:按照网中边的权值由小到大的顺序,不断选取当前未被选取的边集中权值最小的边。依据生成树的概念,n 个结点的生成树,有n -1条边,故反复上述过程,直到选取了n -1条边为止,就构成了一棵最小生成树。
(a) (b) (c)
(d) (e) (f)
Kruskal 算法构造最小生成树的过程示意
10:拓扑排序
对AOV 网进行拓扑排序的方法和步骤是:
①从AOV 网中选择一个没有前驱的顶点(该顶点的入度为0)并且输出它; ②从网中删去该顶点,并且删去从该顶点发出的全部有向边; ③重复上述两步,直到剩余的网中不再存在没有前驱的顶点为止。 例: 求所有拓扑序列
v1 v3 v2 v4 v5 v6
v3 v4 v5 v6 v2 v4 v3 v5 v6 v2 v1 v3 v4 v5 v6
AOV 网 v4 v3 v5 v6
11:关键路径
(1)事件的最早发生时间ve[k]
ve[k]是指从源点到顶点的最大路径长度代表的时间。这个时间决定了所有从顶点发出的有向边所代表的活动能够开工的最早时间。根据AOE 网的性质,只有进入vk 的所有活
动< vj,vk>都结束时,vk代表的事件才能发生;而活动< vj, vk>的最早结束时间为ve[j]+dut(< vj, vk>)。所以计算vk发生的最早时间的方法如下:
ve[k]=0 vk是源点
ve[k]=Max{ve[j]+dut(< vj, vk>)} < vj, vk>∈p[k] 否则其中,p[k]表示所有到达vk的有向边的集合;dut(< vj, vk>)为有向边< vj,vk>上的权值。(2)事件的最迟发生时间vl[k]
vl[k]是指在不推迟整个工期的前提下,事件vk允许的最晚发生时间。设有向边< vk,vj>代表从vk出发的活动,为了不拖延整个工期,vk发生的最迟时间必须保证不推迟从事件vk出发的所有活动< vk,vj>的终点vj的最迟时间vl[j]。vl[k] 的计算方法如下:
vl[k]=ve[n] vk是汇点
vl[k]=Min{vl[j]-dut(< vk- vj>)} < vk, vj>∈s[k] 否则
其中,s[k]为所有从vk发出的有向边的集合。
(3)活动ai的最早开始时间e[i]
若活动ai是由弧
e[i]=ve[k]
(4)活动ai的最晚开始时间l[i]
活动ai的最晚开始时间指,在不推迟整个工程完成日期的前提下,必须开始的最晚时间。若由弧< vk,vj>>表示,则ai的最晚开始时间要保证事件vj的最迟发生时间不拖后。因此,应该有:
l[i]=vl[j]-dut(
根据每个活动的最早开始时间e[i]和最晚开始时间l[i]就可判定该活动是否为关键活动,也就是那些l[i]=e[i]的活动就是关键活动,而那些l[i]>e[i]的活动则不是关键活动,l[i]-e[i]的值为活动的时间余量。关键活动确定之后,关键活动所在的路径就是关键路径。
图8.37 一个AOE网实例
首先,按照(8-1)式求事件的最早发生时间ve[k]。
ve (1)=0
ve (2)=3
ve (3)=4
ve (4)=ve(2)+2=5
ve (5)=max{ve(2)+1,ve(3)+3}=7
ve (6)=ve(3)+5=9
ve (7)=max{ve(4)+6,ve(5)+8}=15
ve (8)=ve(5)+4=11
ve (9)=max{ve(8)+10,ve(6)+2}=21
ve (10)=max{ve(8)+4,ve(9)+1}=22
ve (11)=max{ve(7)+7,ve(10)+6}=28
其次,按照(8-2)式求事件的最迟发生时间vl[k]。
vl (11)= ve (11)=28
vl (10)= vl (11)-6=22
vl (9)= vl (10)-1=21
vl (8)=min{ vl (10)-4, vl (9)-10}=11
vl (7)= vl (11)-7=21
vl (6)= vl (9)-2=19
vl (5)=min{ vl (7)-8,vl (8)-4}=7
vl (4)= vl (7)-6=15
vl (3)=min{ vl (5)-3, vl (6)-5}=4
vl (2)=min{ vl (4)-2, vl (5)-1}=6
vl (1)=min{vl (2)-3, vl (3)-4}=0
再按照(8-3)式和(8-4)式求活动ai的最早开始时间e[i]和最晚开始时间l[i]。
活动a1 e (1)=ve (1)=0 l (1)=vl (2) -3 =3
活动a2 e (2)=ve (1)=0 l (2)=vl (3) - 4=0
活动a3 e (3)=ve (2)=3 l (3)=vl (4) - 2=13
活动a4 e (4)=ve (2)=3 l (4)=vl (5) - 1=6
活动a5 e (5)=ve (3)=4 l (5)=vl (5) - 3=4
活动a6 e (6)=ve (3)=4 l (6)=vl (6) - 5=14
活动a7 e (7)=ve (4)=5 l (7)=vl (7) - 6=15
活动a8 e (8)=ve (5)=7 l (8)=vl (7) - 8=13
活动a9 e (9)=ve (5)=7 l (9)=vl (8) - 4=7
活动a10 e (10)=ve (6)=9 l (10)=vl (9) - 2=19
活动a11 e (11)=ve (7)=15 l (11)=vl (11) - 7=21
活动a12 e (12)=ve (8)=11 l (12)=vl (10) - 4=18
活动a13 e (13)=ve (8)=11 l (13)=vl (9) - 10=11
活动a14 e (14)=ve (9)=21 l (14)=vl (10) -1=21
活动a15 e (15)=ve (10)=22 l (15)=vl (11) -6 =22 最后,比较e[i]和l[i]的值可判断出a2,a5,a9,a13,a14,a15是关键活动,关键路径如下图所示。
12:最短路径
例如,下图所示一个有向网图邻接矩阵为:
∞ ∞ 10 ∞ 30 100
∞ ∞ 5 ∞ ∞ ∞ ∞ ∞ ∞ 50 ∞ ∞ ∞ ∞ ∞ ∞ ∞ 10 ∞ ∞ ∞ 20 ∞ 60 ∞ ∞ ∞ ∞ ∞ ∞
一个有向网图G8及其邻接矩阵
施行Dijkstra 算法,则所得从v0 到其余各顶点的最短路径,以及运算过程中D 向量的13:折半查找判定树
从折半查找过程看,以表的中点为比较对象,并以中点将表分割为两个子表,对定位到的子表继续这种操作。所以,对表中每个数据元素的查找过程,可用二叉树来描述,称这个描述查找过程的二叉树为判定树。
例:有序表长度为10的折半查找判定树:范围是1-10,取中间的为5,所以根为5,左子树范围是1-4,画左子树,右子树范围是6-10,画右子树。
折半查找判定树 结点的比较次数就是结点所在层次数
ASLsucc=所有结点比较次数之和/关键字的个数=(1×1+2×2+3×4+4×3)/10 14:二叉排序树的构造
关键字序列为:63,90,70,55,67,42,98,83,10,45,58,则构造一棵二叉排序树的
9 7 4 2 1 8 10 5 3 6
过程如下:
φ
从空树开始建立二叉排序树的过程
ASLsucc=(1×1+2×2+3×4+4×4)/11 注意:二叉排序树中序遍历是递增有序序列 15哈希表的构造 1). 线性探测法
H i =(Hash(key)+d i ) mod m ( 1≤i < m ) 其中: Hash(key)为哈希函数 m 为哈希表长度 d i 为增量序列 1,2,……,m-1,且d i =i
例:关键字集为 {47,7,29,11,16,92,22,8,3},哈希表表长为11, Hash(key)=key mod 11,用线性探测法处理冲突,建表如下:
47、7、11、16、92均是由哈希函数得到的没有冲突的哈希地址而直接存入的; Hash(29)=7,哈希地址上冲突,需寻找下一个空的哈希地址:
由H 1=(Hash(29)+1) mod 11=8,哈希地址8为空,将29存入。另外,22、8同样在哈希地址上有冲突,也是由H 1找到空的哈希地址的; 而Hash(3)=3,哈希地址上冲突,由
H 1=(Hash(3)+1) mod 11=4 仍然冲突; H 2=(Hash(3)+2) mod 11=5 仍然冲突;
H 3=(Hash(3)+3) mod 11=6 找到空的哈希地址,存入。
ASLsucc=(1+2+1+1+1+4+1+2+2)/9
2)链地址法
设哈希函数得到的哈希地址域在区间 [0,m-1]上,以每个哈希地址作为一个指 针,指向一个链,建立m 个空链表,由哈希函数对关键码转
换后,映射到同一哈希地址i 的同义词均加入到i 链表中。
例:关键字序列为 47,7,29,11,16,92,22,8,3,50,37,89, 21,
哈希函数为 Hash(key)=key mod 11 表长为11 ASLsucc=(1×9+2×4)/13 63
63 90
70
90 63 70
90 63 55
70 90 63 55
67
70
90 63 55 67
42
70
90 63 55 67 42
98
70 90 63 55 67 83 98 42 70 90 63 55 67
83
98 10
42 42 98 70 90 63
45
55 83
67
10 58 42 98 70 90 63
45
55 83
67
10
17:希尔排序:
1. 选择一个步长序列t1,t2,…,t k,其中t i>t j,t k=1;
2. 按步长序列个数k,对序列进行k趟排序;
3. 每趟排序,根据对应的步长t i,将待排序列分割成若干长度为m的子序列,分别对各子表进行直接插入排序。仅步长因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度。
例待排序列为 39,80,76,41,13,29,50,78,30,11,100,7,41,86。
步长因子分别取5、3、1,则排序过程如下:
p=5 39 80 76 41 13 29 50 78 30 11 100 7 41 86
└─────────┴─────────┘
└─────────┴──────────┘
└─────────┴──────────┘
└─────────┴──────────┘
└─────────┘
子序列分别为{39,29,100},{80,50,7},{76,78,41},{41,30,86},{13,11}。第一趟排序结果:
p=3 29 7 41 30 11 39 50 76 41 13 100 80 78 86
└─────┴─────┴─────┴──────┘
└─────┴─────┴─────┴──────┘
└─────┴─────┴──────┘
子序列分别为{29,30,50,13,78},{7,11,76,100,86},{41,39,41,80}。
第二趟排序结果:
p=1 13 7 39 29 11 41 30 76 41 50 86 80 78 100
此时,序列基本“有序”,对其进行直接插入排序,得到最终结果:
7 11 13 29 30 39 41 41 50 76 78 80 86 100
18:快速排序
例:一趟快排序过程示例
r[1] r[2] r[3] r[4] r[5] r[6] r[7] r[8] r[9] r[10] 存储单元
49 14 38 74 96 65 8 49 55 27 记录中关键码
low=1;high=10;设置两个搜索指针, r[0]=r[low];支点记录送辅助单元,
□ 14 38 74 96 65 8 49 55 27 ↑ ↑ low high 第一次搜索交换
从high 向前搜索小于r[0].key 的记录,得到结果
27 14 38 74 96 65 8 49 55 □ ↑ ↑ low high 从low 向后搜索大于r[0].key 的记录,得到结果
27 14 38 □ 96 65 8 49 55 74 ↑ ↑ low high 第二次搜索交换
从high 向前搜索小于r[0].key 的记录,得到结果
27 14 38 8 96 65 □ 49 55 74 ↑ ↑ low high
从low 向后搜索大于r[0].key 的记录,得到结果
27 14 38 8 □ 65 96 49 55 74 ↑ ↑ low high 第三次搜索交换
从high 向前搜索小于r[0].key 的记录,得到结果
27 14 38 8 □ 65 96 49 55 74 ↑↑ low high
从low 向后搜索大于r[0].key 的记录,得到结果
27 14 38 8 □ 65 96 49 55 74 ↑↑ low high low=high ,划分结束,填入支点记录
27 14 38 8 49 65 96 49 55 74 19 建堆
例 53 36 30 91 47 12 24 85判断是否为堆,若不是堆,则调整为大根堆
不是堆
调整:从?n/2?处开始调整,即91开始筛选
36
30 91 47 24 12 53 85
8个结点的初始状态
堆排序:对n 个元素的序列进行堆排序,先将其建成堆,以根结点与第n 个结点交换;
调整前n-1个结点成为堆,再以根结点与第n-1个结点交换;重复上述操作,直到整个序列有序。
36 30 91 47 24 12 53 85 .从第4个结点开始 筛选,筛选91 36
30 91 47 24 12 53 85
对第3个结点开始 筛选,筛选30
91
30 85 47 24 12 53 36
对36进行筛选
85 30 53 47 24 12
91
36
.对53进行筛选
数据结构常见笔试题
1.栈和队列的共同特点是(只允许在端点处插入和删除元素) 2.栈通常采用的两种存储结构是(线性存储结构和链表存储结构) 3.链表不具有的特点是(B) A.不必事先估计存储空间 B.可随机访问任一元素 C.插入删除不需要移动元素 D.所需空间与线性表长度成正比 4.用链表表示线性表的优点是(便于插入和删除操作) 5.在单链表中,增加头结点的目的是(方便运算的实现) 6.循环链表的主要优点是(从表中任一结点出发都能访问到整个链表) 7.线性表若采用链式存储结构时,要求内存中可用存储单元的地址(D) A.必须是连续的 B.部分地址必须是连续的 C.一定是不连续的 D.连续不连续都可以 8.线性表的顺序存储结构和线性表的链式存储结构分别是(随机存取的存储结构、顺序存取的存储结构) 9.具有3个结点的二叉树有(5种形态) 10.设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的 结点数为(13)(n 0 = n 2 +1) 11.已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是(cedba) 12.若某二叉树的前序遍历访问顺序是abdgcefh,中序遍历访问顺序是dgbaechf,则其后序遍历的结点访问顺序是(gdbehfca) 13.数据库保护分为:安全性控制、完整性控制、并发性控制和数据的恢复。
1.在计算机中,算法是指(解题方案的准确而完整的描述) 2.算法一般都可以用哪几种控制结构组合而成(顺序、选择、循环) 3.算法的时间复杂度是指(算法执行过程中所需要的基本运算次数) 4.算法的空间复杂度是指(执行过程中所需要的存储空间) 5.算法分析的目的是(分析算法的效率以求改进) 6.下列叙述正确的是(C) A.算法的执行效率与数据的存储结构无关 B.算法的空间复杂度是指算法程序中指令(或语句)的条数 C.算法的有穷性是指算法必须能在执行有限个步骤之后终止 D.算法的时间复杂度是指执行算法程序所需要的时间 7.数据结构作为计算机的一门学科,主要研究数据的逻辑结构、对各种数据结构进行的运算,以及(数据的存储结构) 8.数据结构中,与所使用的计算机无关的是数据的(C) A.存储结构 B.物理结构 C.逻辑结构 D.物理和存储结构 9.下列叙述中,错误的是(B) A.数据的存储结构与数据处理的效率密切相关 B.数据的存储结构与数据处理的效率无关 C.数据的存储结构在计算机中所占的空间不一定是连续的 D.一种数据的逻辑结构可以有多种存储结构 10.数据的存储结构是指(数据的逻辑结构在计算机中的表示) 11.数据的逻辑结构是指(反映数据元素之间逻辑关系的数据结构) 12.根据数据结构中各数据元素之间前后件关系的复杂程度,一般将数据结构分为(线性结构和非线性结构) 13.下列数据结构具有记忆功能的是(C) A.队列 B.循环队列 C.栈 D.顺序表 14.递归算法一般需要利用(栈)实现。 15.由两个栈共享一个存储空间的好处是(节省存储空间,降低上溢发生的机率)
数据结构习题
数据结构习题及解析 第6 章树和二叉树 基础知识题 6.1①已知一棵树边的集合为 {
高中化学选修三选修物质结构与性质第三章第章常见晶体结构晶胞分析归纳整理总结
个六元环共有。每个六元环实际拥有的碳原子数为 ______个。C-C键夹角:_______。C原子的杂化方式是______ SiO2晶体中,每个Si原子与个O原子以共价键相结合,每个O原子与个Si 原子以共价键相结合,晶体中Si原子与O原子个数比为。晶体中Si原子与Si—O键数目之比为。最小环由个原子构成,即有个O,个Si,含有个Si-O键,每个Si原子被个十二元环,每个O被个十二元环共有,每个Si-O键被__个十二元环共有;所以每个十二元环实际拥有的Si原子数为_____个,O原子数为____个,Si-O键为____个。硅原子的杂化方式是______,氧原子的杂化方式是_________. 知该晶胞中实际拥有的Na+数为____个 Cl-数为______个,则次晶胞中含有_______个NaCl结构单元。 3. CaF2型晶胞中,含:___个Ca2+和____个F- Ca2+的配位数: F-的配位数: Ca2+周围有______个距离最近且相等的Ca2+ F- 周围有_______个距离最近且相等的F——。 4.如图为干冰晶胞(面心立方堆积),CO2分子在晶胞中的位置为;每个晶胞含二氧化碳分子的个数为;与每个二氧化碳分子等距离且最近的二氧化
碳分子有个。 5.如图为石墨晶体结构示意图, 每层内C原子以键与周围的个C原子结合,层间作用力为;层内最小环有 _____个C原子组成;每个C原子被个最小环所共用;每个最小环含有个C原子,个C—C键;所以C原子数和C-C键数之比是_________。C原子的杂化方式是__________. 6.冰晶体结构示意如图,冰晶体中位于中心的一个水分子 周围有______个位于四面体顶角方向的水分子,每个水分子通过 ______条氢键与四面体顶点上的水分子相连。每个氢键被_____个 水分子共有,所以平均每个水分子有______条氢键。 7.金属的简单立方堆积是_________层通过_________对 _________堆积方式形成的,晶胞如图所示:每个金属阳离子的 配位数是_____,代表物质是________________________。 8.金属的体心立方堆积是__________层通过 ________对________堆积方式形成的,晶胞如图: 每个阳离子的配位数是__________.代表物质是 _____________________。
数据结构期末考试题及答案
数据结构期末考试题及答案 、选择题 1.在数据结构中, 从逻辑上能够把数据结构分为 A. 动态结构和静态结构 B .紧凑结构和非紧凑结构 C.线性结构和非线性结构 D .内部结构和外部结构 2. 数据结构在计算机内存中的表示是指 A.数据的存储结构 B.数据结构 C.数据的逻辑结构 D.数据元素之间的关系 3. 在数据结构中, 与所使用的计算机无关的是数据的 结构。 A.逻辑 B.存储 C.逻辑和存储 D.物理 4. 在存储数据时, 一般不但要存储各数据元素的值, 而且还 要存储C A. 数据的处理方法 B. 数据元素的类型 C.数据元素之间的关系 D.数据的存储方法 5.在决定选取何种存储结构时般不考虑A 。 A. 各结点的值如何 B. 结点个数的多少 C.对数据有哪些运算 D.所用的编程语言实现这种结构是否方便。 6.以下说法正确的是 A. 数据项是数据的基本单位
B. 数据元素是数据的最小单位 C. 数据结构是带结构的数据项的集合 D. —些表面上很不相同的数据能够有相同的逻辑结构7.算法分析的目的是C , 算法分析的两个主要方面是A 。 (1) A.找出数据结构的合理性 和输出的关系 C. 分析算法的效率以求改进 档性 ( 2) A .空间复杂度和时间复杂度 C. 可读性和文档性 性 8. 下面程序段的时间复杂度是 s = 0; for( I = 0; i v n; i + + ) for( j = 0; j v n; j ++ ) s +二B[i][j]; sum = s ; 9. 下面程序段的时间复杂度是 for( i = 0; i v n; i + + ) for( j = 0; j v m; j ++ ) B .研究算法中的输入 C .分析算法的易读性和文 B .正确性和简明性D .数据复杂性和程序复杂 O( n2) 。 O( n*m) 。
数据结构习题库
知识点: 01.绪论 02.顺序表 03.链表 04.栈 05.链队列 06.循环队列 07.串 08.数组的顺序表示 09.稀疏矩阵 10.广义表 11.二叉树的基本概念 12.二叉树遍历、二叉树性质 13.树、树与二叉树的转换 14.赫夫曼树 15.图的定义、图的存储 16.图的遍历 17.图的生成树 18.静态查找(顺序表的查找、有序表的查找) 19.动态查找(二叉排序树、平衡树、B树) 20.哈希查找 21.插入排序(直接插入、折半插入、2路插入、希尔排序)22.选择排序(简单选择、树形选择、堆排序) 23.快速排序、归并排序
101A1(1).数据的逻辑结构是(A)。 A.数据的组织形式 B.数据的存储形式 C.数据的表示形式 D.数据的实现形式 101A1(2).组成数据的基本单位是(C)。 A.数据项 B.数据类型 C.数据元素 D.数据变量 101B1(3).与顺序存储结构相比,链式存储结构的存储密度(B)。 A.大 B.小 C.相同 D.以上都不对 101B2(4).对于存储同样一组数据元素而言,(D)。 A.顺序存储结构比链接结构多占空间 B.在顺序结构中查找元素的速度比在链接结构中查找要快 C.与链接结构相比,顺序结构便于安排数据元素 D.顺序结构占用整块空间而链接结构不要求整块空间101B2(5).下面程序的时间复杂度为(B)。 x=0; for(i=1;i
经典数据结构面试题(含答案)
.栈通常采用的两种存储结构是______________________ .用链表表示线性表的优点是_______________________ 8.在单链表中,增加头结点的目的是___________________ 9.循环链表的主要优点是________________________- 12.线性表的顺序存储结构和线性表的链式存储结构分别是__________________________ 13.树是结点的集合,它的根结点数目是_____________________ 14.在深度为5的满二叉树中,叶子结点的个数为_______________ 15.具有3个结点的二叉树有(_____________________ 16.设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的结点数为____________________ 17.已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是____________________________ 18.已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为______________________ 19.若某二叉树的前序遍历访问顺序是abdgcefh,中序遍历访问顺序是dgbaechf,则其后序遍历的结点访问顺序是_______________________ 20.数据库保护分为:安全性控制、完整性控制、并发性控制和数据的恢复。 在计算机中,算法是指_______________________ 算法一般都可以用哪几种控制结构组合而成_____________________ .算法的时间复杂度是指______________________ 5. 算法的空间复杂度是指__________________________ 6. 算法分析的目的是__________________________
Python常见数据结构整理
Python常见数据结构整理 2014年10月15日tenking阅读23 次 Python中常见的数据结构可以统称为容器(container)。序列(如列表和元组)、映射(如字典)以及集合(set)是三类主要的容器。 一、序列(列表、元组和字符串) 序列中的每个元素都有自己的编号。Python中有6种内建的序列。其中列表和元组是最常见的类型。其他包括字符串、Unicode字符串、buffer对象和xrange对象。下面重点介绍下列表、元组和字符串。 1、列表 列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。 (1)、创建 通过下面的方式即可创建一个列表: 1 2 3 4list1=['hello','world'] print list1 list2=[1,2,3] print list2 输出: […hello?, …world?] [1, 2, 3] 可以看到,这中创建方式非常类似于javascript中的数组。(2)、list函数
通过list函数(其实list是一种类型而不是函数)对字符串创建列表非常有效: 1 2list3=list("hello") print list3 输出: […h?, …e?, …l?, …l?, …o?] 2、元组 元组与列表一样,也是一种序列,唯一不同的是元组不能被修改(字符串其实也有这种特点)。(1)、创建 1 2 3 4 5 6t1=1,2,3 t2="jeffreyzhao","cnblogs" t3=(1,2,3,4) t4=() t5=(1,) print t1,t2,t3,t4,t5 输出: (1, 2, 3) (…jeffreyzhao?, …cnblogs?) (1, 2, 3, 4) () (1,)从上面我们可以分析得出: a、逗号分隔一些值,元组自动创建完成; b、元组大部分时候是通过圆括号括起来的; c、空元组可以用没有包含内容的圆括号来表示; d、只含一个值的元组,必须加个逗号(,);(2)、tuple函数
数据结构题型样例
一、选择题 (1)下列程序段的时间复杂度 D ; for(i=0;i (8) 在散列储存中,装填应子α的值越大存取元素时发生冲突的可能性就(1) 当α的值越小存取元素时发生冲突的可能性就(2)。 A (1)越大(2)越大 B (1)越小(2)越小 C (1)越小(2)越大 D(1)越大(2)越小 (9)快速排序方法在情况下最不利于发挥其长处。 A.要排序的数据量太大; B.要排序的数据中含有多个相同值; C.要排序的数据已基本有序; D.要排序的数据个数为奇数。 (10)线性表最常用的查找方法有三种。其中,一种适用于很少进行查找,但内容又经常需要变化的线性表;另一种适用于经常进行查找,但内容又 很少变化的线性表;第三种适用于既希望较快查找而内容又需动态变化 的线性表。它们依次分别为。 A.分块查找、折半查找和顺序查找 B.折半查找、顺序查找和分块查找 C.顺序查找、分块查找和折半查找 D.顺序查找、折半查找和分块查找 二、简要回答下列问题: 1)试画出下列数据结构的图示并列出空表(栈)的条件 (1)单链表;(2)双向循环链表;(3)链栈。 2)顺序存储结构的循环队列q,其空队列和满队列的条件分别是什么? 3)在直接插入排序、快速排序、合并排序、基数排序中哪些排序方法是不稳定的,并举例说明。 4)以数据集{7,19,2,6,32,3,21,10}为权值构造一棵哈夫曼树,并计算其带权路径长度。 5)无向图G1和有向图G2的顶点数均为n则G2至多有几条弧,G1最少有几条边。 栈和队列的共同特点是__________________________ .栈通常采用的两种存储结构是______________________ .用链表表示线性表的优点是_______________________ 8.在单链表中,增加头结点的目的是___________________ 9.循环链表的主要优点是________________________- 12.线性表的顺序存储结构和线性表的链式存储结构分别是 __________________________ 13.树是结点的集合,它的根结点数目是_____________________ 14.在深度为5的满二叉树中,叶子结点的个数为_______________ 15.具有3个结点的二叉树有(_____________________ 16.设一棵二叉树中有3个叶子结点,有8个度为1的结点,则该二叉树中总的结点数为____________________ 17.已知二叉树后序遍历序列是dabec,中序遍历序列是debac,它的前序遍历序列是 ____________________________ 18.已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为______________________ 19.若某二叉树的前序遍历访问顺序是abdgcefh,中序遍历访问顺序是dgbaechf,则其后序遍历的结点访问顺序是_______________________ 20.数据库保护分为:安全性控制、完整性控制、并发性控制和数据的恢复。 在计算机中,算法是指_______________________ 算法一般都可以用哪几种控制结构组合而成_____________________ .算法的时间复杂度是指______________________ 5. 算法的空间复杂度是指__________________________ 6. 算法分析的目的是__________________________ 几种常见的排序算法之比较 2010-06-20 14:04 数据结构课程 摘要: 排序的基本概念以及其算法的种类,介绍几种常见的排序算法的算法:冒泡排序、选择排序、插入排序、归并排序、快速排序、希尔排序的算法和分析它们各自的复杂度,然后以表格的形式,清晰直观的表现出它们的复杂度的不同。在研究学习了之前几种排序算法的基础上,讨论发现一种新的排序算法,并通过了进一步的探索,找到了新的排序算法较之前几种算法的优势与不足。 关键词:排序算法复杂度创新算法 一、引言 排序算法,是计算机编程中的一个常见问题。在日常的数据处理中,面对纷繁的数据,我们也许有成百上千种要求,因此只有当数据经过恰当的排序后,才能更符合用户的要求。因此,在过去的数十载里,程序员们为我们留下了几种经典的排序算法,他们都是智慧的结晶。本文将带领读者探索这些有趣的排序算法,其中包括介绍排序算法的某些基本概念以及几种常见算法,分析这些算法的时间复杂度,同时在最后将介绍我们独创的一种排序方法,以供读者参考评判。 二、几种常见算法的介绍及复杂度分析 1.基本概念 1.1稳定排序(stable sort)和非稳定排序 稳定排序是所有相等的数经过某种排序方法后,仍能保持它们在排序之前的相对次序,。反之,就是非稳定的排序。 比如:一组数排序前是a1,a2,a3,a4,a5,其中a2=a4,经过某种排序后为 a1,a2,a4,a3,a5, 则我们说这种排序是稳定的,因为a2排序前在a4的前面,排序后它还是在a4的前面。假如变成a1,a4,a2,a3,a5就不是稳定的了。 1.2内排序( internal sorting )和外排序( external sorting) 在排序过程中,所有需要排序的数都在内存,并在内存中调整它们的存储顺序,称为内排序;在排序过程中,只有部分数被调入内存,并借助内存调整数在外存中的存放顺序排序方法称为外排序。 数据结构经典例题 1.设计一个算法将L拆分成两个带头节点的单链表L1和L2。 void split(LinkList *&L,LinkList *&L1,LinkList *&L2) { LinkList *p=L->next,*q,*r1; //p指向第1个数据节点 L1=L; //L1利用原来L的头节点 r1=L1; //r1始终指向L1的尾节点 L2=(LinkList *)malloc(sizeof(LinkList));//创建L2的头节点 L2->next=NULL; //置L2的指针域为NULL while (p!=NULL) { r1->next=p; //采用尾插法将*p(data值为ai)插入L1中 r1=p; p=p->next; //p移向下一个节点(data值为bi) q=p->next; //由于头插法修改p的next域,故用q保存*p的后继节点 p->next=L2->next; //采用头插法将*p插入L2中 L2->next=p; p=q; //p重新指向ai+1的节点 } r1->next=NULL; //尾节点next置空 } 2.查找链表中倒数第k个位置上的节点(k为正整数)。若查找成功,算法输出该节点的data域的值,并返回1;否则,只返回0。 typedef struct LNode {int data; struct LNode *link; } *LinkList; int Searchk(LinkList list,int k) { LinkList p,q; int count=0; p=q=list->link; while (p!=NULL) { if (count 《数据结构》期中考试题答案 一、填空题(20分,每题2分) 1.逻辑结构、存储结构 2.便于插入和删除操作 3.方便运算的实现 4.算法执行过程中所需要的基本运算次数 5.存储结构 6.q.next=p.next ; p.next=q 7.递归算法 8.抽象类或接口 二、选择题(30分,每题2分) AACBB BDDCB AACAC 三、问答题(50分,每题10分) 1.什么是栈和队列?两者有何异同? 答:栈和队列都属于线性表结构,它们是两种特殊的线性表,栈的插入和删除操作都在线性表的一端进行,所以栈的特点是“后进先出”;而队列的插入和删除操作分别在线性表的两端进行,所以队列的特点是“先进先出”。 2.采用顺序存储结构的栈和队列,在进行插入、删除操作时需要移动数据元素吗?为什么? 答:采用顺序存储结构的栈和队列,在进行插入、删除操作时不需要移动数据元素,因为栈和队列均不能进行中间插入、删除操作。 3.什么是队列的假溢出?为什么顺序存储结构队列会出现假溢出?怎样解决队列的假溢出问题?链式存储结构队列会出现假溢出吗? 答:顺序队列,当入队的元素个数(包括已出队元素)超过数组容量时,队列尾下标越界,数据溢出。此时,由于之前已有若干元素出队,数组前部已空出许多存储单元,所以,这种溢出并不是因存储空间不够而产生的,称之为假溢出。 顺序队列之所以会产生假溢出现象,是因为顺序队列的存储单元没有重复使用机制。解决的办法是将顺序队列设计成循环结构。 链式存储结构队列不会出现假溢出。因为每次元素入队,都要申请新结点,数据不会溢出。 4.答案:(1) (a2, a4, …, ) (2)将单链表中偶数结点位置的元素值写入顺序表list 5.数据的存储结构有哪两种,各有什么特点? 答:数据存储结构的基本形式有两种:顺序存储结构和链式存储结构。 顺序存储结构使用一组连续的内存单元依次存放数据元素,元素在内存中的物理存储次序与它们的逻辑次序相同。 链式存储结构使用若干地址分散的存储单元存储数据元素,逻辑上相邻的数据元素在物理位置上不一定相邻,数据元素间的关系需要采用附加信息特别指定。 #include"stdio.h" #define LT(a,b) ((a)<(b)) #define LQ(a,b) ((a)>(b)) #define maxsize 20 typedef int keytype; typedef struct{ keytype key; }RedType; typedef struct{ RedType r[maxsize+1]; int length; }Sqlist; //直接插入排序 void insertsort(Sqlist &L){ int i,j; for(i=2;i<=L.length;++i) if(LT(L.r[i].key,L.r[i-1].key)){ L.r[0]=L.r[i]; L.r[i]=L.r[i-1]; for(j=i-2;LT(L.r[0].key,L.r[j].key);--j) L.r[j+1]=L.r[j]; L.r[j+1]=L.r[0]; }//if }//insertsort //折半插入排序 void BInsertSort(Sqlist &L) { int i,j,low,high,m; for(i=2;i<=L.length;++i) { L.r[0]=L.r[i]; low=1; high=i-1; while(low<=high){ m=(low+high)/2; if(LT(L.r[0].key,L.r[m].key)) high=m-1; else low=m+1; }//while for(j=i-1;j>=high+1;--j) L.r[j+1]=L.r[j]; L.r[high+1]=L.r[0]; }//for 几种常见晶体结构分析文档编制序号:[KK8UY-LL9IO69-TTO6M3-MTOL89-FTT688] 几种常见晶体结构分析 河北省宣化县第一中学 栾春武 邮编 075131 栾春武:中学高级教师,张家口市中级职称评委会委员。河北省化学学会会员。市骨干教师、市优秀班主任、模范教师、优秀共产党员、劳动模范、县十佳班主任。 联系电话: E-mail : 一、氯化钠、氯化铯晶体——离子晶体 由于离子键无饱和性与方向性,所以离子晶体中无单个分子存在。阴阳离子在晶体中按一定的规则排列,使整个晶体不显电性且能量最低。离子的配位数分析如下: 离子数目的计算:在每一个结构单元(晶胞)中,处于不同位置的微粒在该单元中所占的份额也有所不同,一般的规律是:顶点上的微粒属于该 单元中所占的份额为18,棱上的微粒属于该单元中所占的份额为1 4,面上 的微粒属于该单元中所占的份额为1 2,中心位置上(嚷里边)的微粒才完 全属于该单元,即所占的份额为1。 1.氯化钠晶体中每个Na +周围有6个Cl -,每个Cl -周围有6个Na +,与一个Na +距离最近且相等的Cl -围成的空间构型为正八面体。每个Na +周围与其最近且距离相等的Na +有12个。见图1。 图1 图2 NaCl 晶胞中平均Cl-个数:8×1 8 + 6× 1 2 = 4;晶胞中平均Na+个数:1 + 12×1 4 = 4 因此NaCl的一个晶胞中含有4个NaCl(4个Na+和4个Cl-)。 2.氯化铯晶体中每个Cs+周围有8个Cl-,每个Cl-周围有8个Cs+,与一个Cs+距离最近且相等的Cs+有6个。 晶胞中平均Cs+个数:1;晶胞中平均Cl-个数:8×1 8 = 1。 因此CsCl的一个晶胞中含有1个CsCl(1个Cs+和1个Cl-)。 二、金刚石、二氧化硅——原子晶体 1.金刚石是一种正四面体的空间网状结构。每个C 原子以共价键与4个C原子紧邻,因而整个晶体中无单 个分子存在。由共价键构成的最小环结构中有6个碳原 子,不在同一个平面上,每个C原子被12个六元环共用,每C—C键共6 个环,因此六元环中的平均C原子数为6× 1 12 = 1 2 ,平均C—C键数为 6×1 6 = 1。 C原子数: C—C键键数= 1:2; C原子数: 六元环数= 1:2。 2.二氧化硅晶体结构与金刚石相似,C被Si代替,C与C之间插 氧,即为SiO 2晶体,则SiO 2 晶体中最小环为12环(6个Si,6个O), 图3 CsCl 晶 图4 金刚石晶 习题一 一、填空题 1. 算法具有有穷性、确定性、可行性、输入和输出五大特征。 2. 数据结构的内容包括以下三个方面:数据元素、数据关系和运算集合。 3. 数据结构的存储结构分为顺序、链式、索引、散列。 4. 评价算法性能的标准主要从算法执行时间和空间两方面考虑。 5. 在线性结构、树形结构和图状结构中,数据元素之间分别存在着1对1 、1对多和多对多关系。 二、分析题 2.设n为整数,分析下列程序段中,用*标明的语句的语句频度及时间复杂度。(1)for(n =1;n<=10;n++) *s=s+n; (2) for(i =1;i<=n;i++) *s=s+n; (3) for(i =1;i<=n;i++) for(j=1;j<=n;j++) *s=s+n (4) for(i =1;i<=n;i++) for(j=1;j<=i ;j++) *s=s+n; (5)for(i =1;i<=n;i++) for(j=1;j<=n;j++) { c[i][j]=0; for(k=1;k<=n;k++) *c[i][j]=c[i][j]+a[i][k]*b[k][j]; } 习题二 3.填空题 1.在顺序表中,逻辑上相邻的元素,其物理位置上一定相邻。 2.在单链表中,逻辑上相邻的元素,其物理位置上不一定相邻。 3.设单链表中,指针p指向结点s,若要删除s之后的结点(若存在),则需修改指针的操作为P=s->next;s->next=s->next->next;free(p); 。 4.在一个长度为n的顺序表中,如果要删除第i个元素,需移动n-i+1 个元素。 二、选择题 1.某线性表中最常用的操作是存取序号为i的元素和在最后进插入和删除运算,则采用(C )存储方式的时间性能最好。 A.双向链表 B.双向顺环链表 C.顺序表 D.单向顺环链表 2.在一个单链表中,已知q结点是p结点的前驱结点,若在p和q之间插入s结点,则需执行( C )。 A.s->next=p->next;p->next=s B.p->next=s->next;s->next=p C.q->next=s;s->next=p D.p->next=s;s->next=q 第二章作业 2-1 常见的金属晶体结构有哪几种它们的原子排列和晶格常数有什么特点 V、Mg、Zn 各属何种结构答:常见晶体结构有 3 种:⑴体心立方:-Fe、Cr、V ⑵面心立方:-Fe、Al、Cu、Ni ⑶密排六方:Mg、Zn -Fe、-Fe、Al、Cu、Ni、Cr、 2---7 为何单晶体具有各向异性,而多晶体在一般情况下不显示出各向异性答:因为单晶体内各个方向上原子排列密度不同,造成原子间结合力不同,因而表现出各向异性;而多晶体是由很多个单晶体所组成,它在各个方向上的力相互抵消平衡,因而表现各向同性。第三章作业3-2 如果其它条件相同,试比较在下列铸造条件下,所得铸件晶粒的大小;⑴金属模浇注与砂模浇注;⑵高温浇注与低温浇注;⑶铸成薄壁件与铸成厚壁件;⑷浇注时采用振动与不采用振动;⑸厚大铸件的表面部分与中心部分。答:晶粒大小:⑴金属模浇注的晶粒小⑵低温浇注的晶粒小⑶铸成薄壁件的晶粒小⑷采用振动的晶粒小⑸厚大铸件表面部分的晶粒小第四章作业 4-4 在常温下为什么细晶粒金属强度高,且塑性、韧性也好试用多晶体塑性变形的特点予以解释。答:晶粒细小而均匀,不仅常温下强度较高,而且塑性和韧性也较好,即强韧性好。原因是:(1)强度高:Hall-Petch 公式。晶界越多,越难滑移。(2)塑性好:晶粒越多,变形均匀而分散,减少应力集中。(3)韧性好:晶粒越细,晶界越曲折,裂纹越不易传播。 4-6 生产中加工长的精密细杠(或轴)时,常在半精加工后,将将丝杠吊挂起来并用木锤沿全长轻击几遍在吊挂 7~15 天,然后再精加工。试解释这样做的目的及其原因答:这叫时效处理一般是在工件热处理之后进行原因用木锤轻击是为了尽快消除工件内部应力减少成品形变应力吊起来,是细长工件的一种存放形式吊个7 天,让工件释放应力的时间,轴越粗放的时间越长。 4-8 钨在1000℃变形加工,锡在室温下变形加工,请说明它们是热加工还是冷加工(钨熔点是3410℃,锡熔点是232℃)答:W、Sn 的最低再结晶温度分别为: TR(W) =(~×(3410+273)-273 =(1200~1568)(℃)>1000℃ TR(Sn) =(~×(232+273)-273 =(-71~-20)(℃) <25℃ 所以 W 在1000℃时为冷加工,Sn 在室温下为热加工 4-9 用下列三种方法制造齿轮,哪一种比较理想为什么(1)用厚钢板切出圆饼,再加工成齿轮;(2)由粗钢棒切下圆饼,再加工成齿轮;(3)由圆棒锻成圆饼,再加工成齿轮。答:齿轮的材料、加工与加工工艺有一定的原则,同时也要根据实际情况具体而定,总的原则是满足使用要求;加工便当;性价比最佳。对齿轮而言,要看是干什么用的齿轮,对于精度要求不高的,使用频率不高,强度也没什么要求的,方法 1、2 都可以,用方法 3 反倒是画蛇添足了。对于精密传动齿轮和高速运转齿轮及对强度和可靠性要求高的齿轮,方法 3 就是合理的。经过锻造的齿坯,金属内部晶粒更加细化,内应力均匀,材料的杂质更少,相对材料的强度也有所提高,经过锻造的毛坯加工的齿轮精度稳定,强度更好。 4-10 用一冷拔钢丝绳吊装一大型工件入炉,并随工件一起加热到1000℃,保温后再次吊装工件时钢丝绳发生断裂,试分析原因答:由于冷拔钢丝在生产过程中受到挤压作用产生了加工硬化使钢丝本身具有一定的强度和硬度,那么再吊重物时才有足够的强度,当将钢丝绳和工件放置在1000℃炉内进行加热和保温后,等于对钢丝绳进行了回复和再结晶处理,所以使钢丝绳的性能大大下降,所以再吊重物时发生断裂。 4-11 在室温下对铅板进行弯折,越弯越硬,而稍隔一段时间再行弯折,铅板又像最初一样柔软这是什么原因答:铅板在室温下的加工属于热加工,加工硬化的同时伴随回复和再结晶过程。越弯越硬是由于位错大量增加而引起的加工硬化造成,而过一段时间又会变软是因为室温对于铅已经是再结晶温度以上,所以伴随着回复和再结晶过程,等轴的没有变形晶粒取代了变形晶粒,硬度和塑性又恢复到了未变形之前。第五章作业 5-3 一次渗碳体、二次渗碳体、三次渗碳体、共晶渗碳体、共析渗碳体异同答:一次渗碳体:由液相中直接析出来的渗碳体称为一次渗碳体。二次渗碳体:从 A 中析出的渗碳体称为二次渗碳体。三次渗碳体:从 F 中析出的渗碳体称为三次渗碳体共晶渗碳体:经共晶反应生成的渗碳体即莱氏体中的渗碳体称为共晶渗碳体共析渗碳体:经共析反应生成的渗碳体即珠光体中的渗 现在的公司招聘,都要笔试面试.如果你不是那种编程功底非常深厚的人,又不好好准备一番,在笔试面试中往往会处于被动局面.虽然有些笔试题是故意为难我们,有点钻牛角尖.但是很多笔试题面试题确实能够很好地看出我们的基础. 在这里,我就略去那些钻牛角尖的题.从csdn论坛我近半年的收集中选出10道有代表性的题目,难度基本上是逐渐加大.对数组,指针,数据结构,算法,字符串,文件操作等问题都有覆盖.主要以c语言的实现为主,也有c++的题.大家可以先做做这10道题,测试一下自己的水平. 1. 下面这段代码的输出是多少(在32位机上). char *p; char *q[20]; char *m[20][20]; int (*n)[10]; struct MyStruct { char dda; double dda1; int type ; }; MyStruct k; printf("%d %d %d %d",sizeof(p),sizeof(q),sizeof(m),sizeof(n),sizeof(k)); 2. (1) char a[2][2][3]={{{1,6,3},{5,4,15}},{{3,5,33},{23,12,7}} }; for(int i=0;i<12;i++) printf("%d ",_______); 在空格处填上合适的语句,顺序打印出a中的数字 (2) char **p, a[16][8]; 问:p=a是否会导致程序在以后出现问题?为什么? 答:p是char**类型,而a是char[16][8]类型。经过退化,a可以作为一个指针右值,类型为char(*)[8],或者在参数列表中表达为char[][8]。char**指针和char(*)[8]不是完全兼容的指针,无法无条件地相互转换。编译器应该对p = a 这种试图进行隐式转换的表达式产生一个警告(C)或错误(C++)。 从语言层面来说,p 和 a 具有不同的类型,表达式p = a 体现了错误的语义。 从实现层面上来看,由于C/C++的数组长度不是一个左值,多维数组实际上只是数组的数组,换用不兼容的指针类型指向的对象和数组可能占用相同的存储器单元(线性地址空间的边界一致),那么不一定会出现和预期不符的问题。但在参数传递等情况下,这个问题很容易复杂化。 事实上,LZ的问题是使用者对语言的误用。解决方法就是保证p为char(*)[8]类型: char(*p)[8]; char a[16][8]; p = &a; 或者(尤其是在数组大小需要改变的情况下)不要使用内置的静态数组,用指针和表达数组大小的整数来实现动态数组。---- LS linxxx3 错误,尽管这里a 和p 在语言实现(目标代码)中一般不保留类型信息而体现行为一致性,语言本身也允许相同的访问方式,但在编译期a 冗余了的类型比p 更严格,a 不只是指针,本质是不同的。 第19卷 第12期2003年12月 甘肃科技 G ansu Science and T echnology Vol.19 No.12 Dec. 2003 字符串处理中常用的几种数据结构及其性能分析 郑丽英1,李永昶2 (1.兰州交通大学信息与电气工程学院,甘肃兰州 730070;2.兰州交通大学机电工程学院,甘肃兰州 730070) 摘 要:许多计算机应用涉及字符串处理。为了提高处理效率,设计一个好的数据结构十分重要。分析了几种常用的字符串数据结构及其性能,重点分析了数据结构T rie及其三种形式的结构特性。关键词:T rie;数据结构;索引 中图分类号:TP311 1 前言 许多计算机应用都涉及到对一个非常大的字符串集合的有效管理。例如,从档案管理、文献目录查找、地理信息索引到Web上大量的文本信息处理等等,都涉及到对一个非常大的字符串集合的管理。显然,如何有效管理大的字符串集合的首要问题是如何存储和组织它们即选择一个合适的数据结构。在实际中为一个应用选择一个好的数据结构取决于许多因素,如存储需求、查找速度、是否在内存、是否要求有序存储等等。已有许多用于字符串管理的数据结构,下面将分别进行分析和讨论。 2 常用的字符串数据结构 2.1 BST树 BST树((Binary Search T ree,即二叉搜索树)是最简单且最直观的一种。在一棵BST树中,每一个结点存储一个字符串和两个分别指向左右孩子结点的指针。在BST树中查找一个给定的字符串的过程是:首先和根结点的字符串比较,若相等则查找成功。若不相等则按比较结果决定沿左分支或右分支继续比较。BST树的结构性能主要取决于树的形态,与输入字符串集的排列有关。假设字符串集合的分布是稳定的、且常用词的集合是已知的且常用词分布在根结点的附近,则BST结构是相当快的,如果字符串集合的分布不稳定,特别地如果是有序的,BST的性能最差(为O(n)),BST退化为一棵单枝树。因此,BST特别不适合有序排列的输入字符串集合。 2.2 BST树的变种 实际应用中,有许多BST的变种。如AV L-树和红-黑树及splay树等,它们与BST树的不同在于插入字符串的过程中重组树的结构,保持树的近似平衡,从而保证不会出现单枝树。但是,AV L-树和红-黑树结构的不足在于每一个结点中要保存附加的信息位(AV L-树中2位,红-黑树中1位)。另一方面,由于重组树的结构使一些经常存取的关键词聚集在树的根附近。并且,在不经常作插入运算的情况下,保持树的平衡的代价相对较低。因此保持树的平衡所带来的好处相对于BST树来说可以抵消由于插入运算引起的附加时间。S play树是另一种BST树的变种。其特点是:每一次搜索,都要将操作的结点通过一系列的结点旋转即splaying 运算将结点移到根结点的附近。这样使得一些经常存取的关键词总在根的附近,以便在后续查找中可以快速找到。但是,这种结构也有明显的不足。相对于BST树,一棵S play树需要较多的存储空间(每一个结点中要存储一个指向双亲的指针),其次, S playing运算本身比较复杂。在实际的应用中,应该根据实际的应用需求选择合适的结构。 2.3 Hash表 字符串处理中常用的另外一种数据结构是哈希表(Hash table)。哈希表是一种直接计算记录存放地址的方法,它在关键码(字符串)与存储位置之间直接建立映像。当采用链式哈希表结构、位方式的哈希函数、不要求字符串集合有序存储时,哈希表结构及其查找技术性能最佳。由于哈希表中的字符串通常是随机地分布在表中,不是有序的,在某些要求字符串有序存储(如索引维护及前缀查找)的应用中,不适合采用哈希表。 2.4 T rie树 T rie树是一种有效的字符串处理数据结构,广泛地用于自然语言处理、模式匹配、IP路由表以及文本压缩等。 T rie是一种树型数据结构,用于存储字符串,可以实现字符串的快速查找。有三种类型的trie:标准trie,压缩trie,后缀trie; ?标准trie经典数据结构面试题(含答案)
数据结构中几种常见的排序算法之比较
数据结构经典例题
数据结构期中笔试题答案
数据结构各种常用排序算法综合
几种常见晶体结构分析
数据结构习题
常见的金属晶体结构
csdn数据结构笔试题汇总
字符串处理中常用的几种数据结构及其性能分析