周工作量统计表格范本
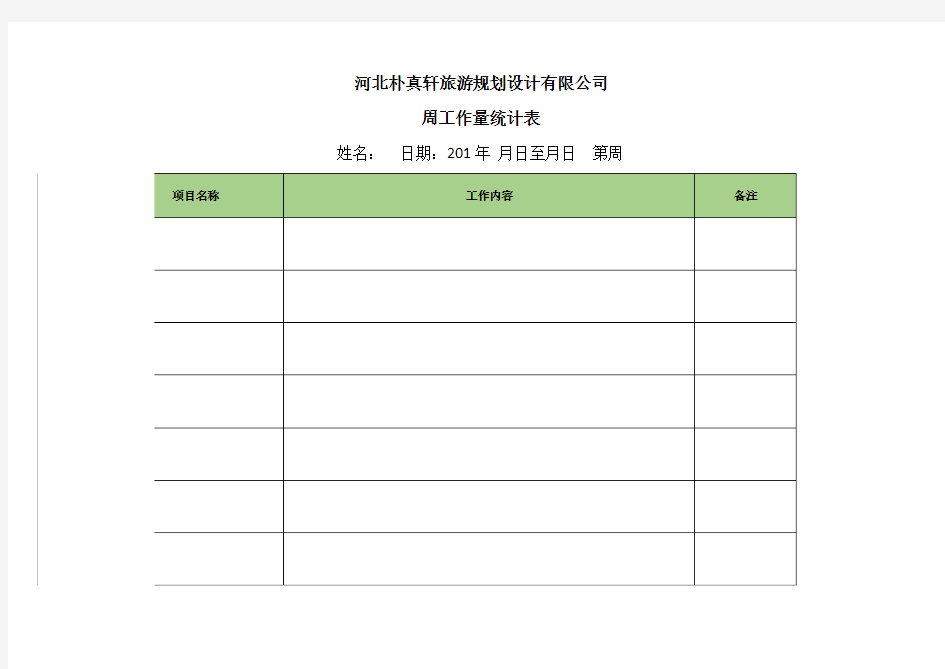
河北朴真轩旅游规划设计有限公司
周工作量统计表
姓名:日期:201年月日至月日第周
表格资料汇总常用统计方法
分类数据常用统计方法 在科研数据的统计分析中,经常会遇到分类数据。分类数据包括计数资料和等级资料,两者都是将观察指标分类(组),然后统计每一类(组)数目所得到的数据,区别是如果观察指标的分类是无序的则为计数资料,也叫定性资料或无序分类变量;如果观察指标的分类是有序的,则为等级资料,也叫有序分类数据。如调查某人群的血型分布,按照A 、B 、AB 与O 四型分组,计数所得该人群的各血型组的人数就是计数资料(因为A 、B 、AB 与O 血型之间是平等的,并没有度或量的差异);观察用某药治疗某病患者的疗效,以患者为观察单位,结果可分为治愈、显效、好转、无效四级,然后对该病的患者,分别计数治愈、显效、无效、好转的人数则为等级数据(因为无效的疗效最差、次之为好转、治愈的疗效最好,它们之间有度或者量的区别)。分类数据进行统计分析时要列成表格,根据表格中分组变量和指标变量的性质、样本含量(n )和理论频数(T )的大小以及分析的目的,所用的统计方法是不一样的。下面通过一些有代表性的例子来介绍分类数据常用的统计分析方法。 一、2×2表 2×2表也叫四格表。在实验研究中,将研究对象分为2组进行实验,实验只有2种可能的结果,如阳性与阴性,故叫2×2表;因为基本数据只有4个,所以也叫四格表。根据不同的实验安排,四格表又分为完全随机设计四格表和配对设计四格表。 表1 某抗生素的人群耐药性情况 用药史 不敏感 敏感 合计 耐药率(%) 曾服该药 180(174.10) 215(220.90) 395 45.57 未服该药 73(78.90) 106(100.10) 179 40.78 合计 253 321 574 44.08 表1 为完全随机设计四格表。其目的是要比较曾服该抗生素的人群和未曾服过该抗生素的人群,对该抗生素的耐药率有无差异。表格中的四个基本数据(也叫实际频数)分别为180、215、73、106;括号中的四个数据(174.10、220.90、78.90、100.10)为四个理论频数(T ),因40574>=n 且四个理论频数(T )均大于5,故应用Pearson 2 χ检验。经(SPSS 11.0,以下同)计算2 χ=1.145,P =0.285>0.05,故可认为曾服过该抗生素的人群和未曾服过该抗生素的人群对该抗生素的耐药率无差异。 表2 两个年级大学生的近视眼患病率比较 年级 近视 非近视 合计 近视率(%) 四年级 2(4.67) 26(23.33) 28 7.14 五年级 5(2.33) 9(11.69) 14 35.71 合计 7 35 42 16.67 表2也为完全随机设计四格表。虽4042>=n 但有两个格子的理论频数比1大比5小,此时需对2 χ 进行连续性校正(因为理论频数太小,会导致2 χ增大,易出现错误的有差异的结论)。经计算,连续性校正的c 2χ =3.621,P =0.057>0.05,可认为大学四年级与大学5年级学生近视眼的患病率无差异。如果不用 连续性校正的2 χ检验,则2 χ=5.486,P =0.019<0.05,则会得出五年级大学生近视眼的患病率高于四年级大学生的错误结论。 表3 两种疗法对腰椎间盘脱出症的疗效 疗法 治愈 未治愈 合计 治愈率(%) 新疗法 7 2 9 77.78 保守疗法 2 6 8 25.00 合计 9 8 17 52.94
工作量统计报表
工作量统计报表 工作量统计报表 210赵鹏震工业分析091、牧医092班语文49 514刘淑荣工业分析091、牧医092班化学48 198李亚琴工业分析091、物理410 205王新兰园艺081、工业分析081.091数学49 213赵洪顺园艺081、工业分析081、091、资环091班体育29 229王贵宝工业分析091、牧医092班职业道德28 585李欣工业分析081、091、牧医092班社交礼仪28 208郝翠萍园艺091、资环091班、牧091班应用文写作49 181张洪红园艺091、资环091班高等数学410 409尚玫园艺091、资环091、牧091班英语49 422谢麦香园艺081、091、资环091班计算机基础610 498刘建忠园艺091、资环091、牧091班法律基础28 429朱江洁园艺091、资环091班测量学29 516段丽君园艺091、园林艺术28 436范晋芳资环091班资环概论49 434肖敏资环091班经济地理69 559段琳牧医091计算机基础68 197贾银凤牧医081、091、092体育210
395郭勤平牧医091动物生化49 233徐锐敏牧医092体育28 569贾建英牧医091解剖生理49 牧医081、各论6 201李新萍牧医081邓论210 398魏志贤牧医081禽病防治49 394温飞跃牧医081饲养210 402徐亚群工业分析091、化学实验48牧医092班解剖生理6 425高翠莲园艺091植生实验610 154武绛玲牧医091心理健康29 399贾朝阳牧医081牛羊病48 贾震虎牧医081兽医基础430
员工工作量分析报告
2009年5月份员工工作量分析报告 一、概述: 为了解公司员工5月份的实际工作量,提高员工工作方法,增强员工办事 效率,改善公司组织结构,合理利用人力成本。特进行本次调查分析,本次 分析辖营销部,拓展部,行政办,技术工程部(除施工人员),财务部,办事处。共计24人(新入职员工不例入分析范围)。以《周工作动态表》和《月 度工作完成情况表》为依据,对员工各项工作指标进行拆解并列出数据,采 用对比法进行图例分析。找准岗位特性,为下一步更好的进行员工工作量分 析确定模块及方法。 本次分析因为数据真实度和数据完成性有待进一步验证和加强,因此分析 结果只做为参考。 全公司详细分析数据见《5月份各员工工作量数据分析表》 二、分析方法: 1、本次分析采用工作量化分析法,即按照各部门岗位职责分解成: V:客户拜访(V isit)包括电话拜访和当面拜访所用时间; M:会议时间(M eeting)包括参与公司例会、甲方会议、工作安排、工作汇报、公司活动所用时间; R:工作准备时间(R eady)包括方案制作/修改、技术沟通、测试所用时间; C:工作洽谈、联系时间(C ontact)包括陪客户或公司上级聊天、询问、检查所用时间; E:应酬时间(E ntertainment)包括吃饭、活动、打牌等用于应酬时间; F:撰写时间(W rite)包括编撰各类报告、申请,及审核票据、填写各类日常表格、登/统计、分析等所用时间; S:履行岗位职责时间(S tatus)主要是行政、财务部人员履行本职岗位所
用时间以及各部门经理、主管用于部门人员管理所用时间; P:技术处理时间(P rocessing)主要是处理各类技术问题所用时间; T:培训时间(T raining)主要是授课人培训所用时间; D:路程时间(D istance)包括往返于工地、客户场所、出差旅途所用时间; O:其它时间(O ther)不属于上述范围内的时间,主要是指帮助别人工作所用时间。 2、以上分解时间,除D(路程时间)和O(其它时间)不计入有效工时,其余均列入有效工作时间。 3、优点: (1)工作分解量化分析,是激发员工工作责任感,紧迫感和积极性最有效的措施; (2)由于工作量化是通过数字和图表形式体现,其结果简单明了,直观性和可视性强,便于做纵横各项对比分析; (3)由于所有员工的工作量都用一样的量化考核标准进行考核计算,所以对员工评价更现公平、公正; (4)便于市场需求与现有人员配置的对比分析,从而能够及时准确地根据市场需求对人员进行调整。 三、5月份基本情况 1、本月共计31天,除“五一”、“瑞午”放假三天,周六、周日放假合计4.5天,31日未列入分析范围,因此本月个人有效工作日:19.5天,计8190小时。 2、本月有14人要求做出工作计划,共计划127项。 3、本月计划完成经济指标100万。 四、公司整体数据分析:
土建工程量计算表格(实用版)
工程名称:怡众置业3#房 序号定额编号分部分项工程数量单位计算式计算结果位置建筑面积#######m2 #NAME?0#NAME? 一、土石方工程 1平整场地#######m2 #NAME?0#NAME? 0.000#NAME? 2机械土方#######m3 #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? 3机械土方人工修边坡,三类土#######m3 #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? #NAME?0#NAME? 4基坑回填土m3 #NAME?0#NAME? 5基坑排水m2 #NAME?0#NAME? 6人工挖地槽,深1.5m以内m3 #NAME?0#NAME?
工程名称:怡众置业3#房 序号定额编号分部分项工程数量单位计算式计算结果位置1砖基础#######m3 #NAME?0#NAME? 2200厚砼空心砌块外墙m2 #NAME?0#NAME? 3200厚砼空心全外墙m2 #NAME?0#NAME? 4300厚砼空心外墙m2 #NAME?0#NAME? 5200厚加气砼内墙m2 #NAME?0#NAME? 6100厚加气砼内墙m2 #NAME?0#NAME? 8砖砌女儿墙m2 #NAME?0#NAME? 9零星砌体m3 #NAME?0#NAME? 三、混泥土及钢筋混泥土 1C25独立基础#######m3 J1#NAME?1*1*0.3*34#NAME? J2#NAME? 1.2*1.2*0.3*17#NAME? J3#NAME? 1.4*1.4*0.3*7#NAME? J4#NAME? 1.6*1.6*0.4*8#NAME? J5#NAME? 1.8*1.8*(0.3+0.1)#NAME? J6#NAME?2*2*(0.3+0.1)*14#NAME? J7#NAME? 2.2*2.2*(0.3+0.1)*2#NAME? J8#NAME? 2.4*2.4*(0.3+0.1)*23#NAME? J9#NAME? 2.6*2.6*(0.3+0.1)*8#NAME? J10#NAME? 2.8*2.8*(0.3+0.1)*7#NAME? J11#NAME?3*3*(0.3+0.1)*9#NAME?
表格汇总常用统计方法
分类数据常用统计方法 在科研数据得统计分析中,经常会遇到分类数据。分类数据包括计数资料与等级资料,两者都就是将观察指标分类(组),然后统计每一类(组)数目所得到得数据,区别就是如果观察指标得分类就是无序得则为计数资料,也叫定性资料或无序分类变量;如果观察指标得分类就是有序得,则为等级资料,也叫有序分类数据。如调查某人群得血型分布,按照A 、B 、AB 与O 四型分组,计数所得该人群得各血型组得人数就就是计数资料(因为A 、B 、AB 与O 血型之间就是平等得,并没有度或量得差异);观察用某药治疗某病患者得疗效,以患者为观察单位,结果可分为治愈、显效、好转、无效四级,然后对该病得患者,分别计数治愈、显效、无效、好转得人数则为等级数据(因为无效得疗效最差、次之为好转、治愈得疗效最好,它们之间有度或者量得区别)。分类数据进行统计分析时要列成表格,根据表格中分组变量与指标变量得性质、样本含量(n )与理论频数(T )得大小以及分析得目得,所用得统计方法就是不一样得。下面通过一些有代表性得例子来介绍分类数据常用得统计分析方法。 一、2×2表 2×2表也叫四格表。在实验研究中,将研究对象分为2组进行实验,实验只有2种可能得结果,如阳性与阴性,故叫2×2表;因为基本数据只有4个,所以也叫四格表。根据不同得实验安排,四格表又分为完全随机设计四格表与配对设计四格表。 表1 某抗生素得人群耐药性情况 用药史 不敏感 敏感 合计 耐药率(%) 曾服该药 180(174、10) 215(220、90) 395 45、57 未服该药 73(78、90) 106(100、10) 179 40、78 合计 253 321 574 44、08 表1 为完全随机设计四格表。其目得就是要比较曾服该抗生素得人群与未曾服过该抗生素得人群,对该抗生素得耐药率有无差异。表格中得四个基本数据(也叫实际频数)分别为180、215、73、106;括号中得四个数据(174、10、220、90、78、90、100、10)为四个理论频数(T ),因40574>=n 且四个理论频数(T )均大于5,故应用Pearson 2 χ检验。经(SPSS 11、0,以下同)计算2 χ=1、145,P =0、285>0、05,故可认为曾服过该抗生素得人群与未曾服过该抗生素得人群对该抗生素得耐药率无差异。 表2 两个年级大学生得近视眼患病率比较 年级 近视 非近视 合计 近视率(%) 四年级 2(4、67) 26(23、33) 28 7、14 五年级 5(2、33) 9(11、69) 14 35、71 合计 7 35 42 16、67 表2也为完全随机设计四格表。虽4042>=n 但有两个格子得理论频数比1大比5小,此时需对2 χ 进行连续性校正(因为理论频数太小,会导致2 χ增大,易出现错误得有差异得结论)。经计算,连续性校正得c 2χ =3、621,P =0、057>0、05,可认为大学四年级与大学5年级学生近视眼得患病率无差异。如果 不用连续性校正得2 χ检验,则2 χ=5、486,P =0、019<0、05,则会得出五年级大学生近视眼得患病率高于四年级大学生得错误结论。 表3 两种疗法对腰椎间盘脱出症得疗效 疗法 治愈 未治愈 合计 治愈率(%) 新疗法 7 2 9 77、78 保守疗法 2 6 8 25、00 合计 9 8 17 52、94
wps表格统计常用公式详解
wps Excel表格公式大全 来源:郭志煌的日志 1、查找重复内容公式:=IF(COUNTIF(A:A,A2)>1,"重复","")。 2、用出生年月来计算年龄公式:=TRUNC((DAYS360(H6,"2009/8/30",FALSE))/360,0)。 3、从输入的18位身份证号的出生年月计算公式:=CONCATENATE(MID(E2,7,4),"/",MID(E2,11,2),"/",MID(E2,13,2))。 4、从输入的身份证号码内让系统自动提取性别,可以输入以下公式: =IF(LEN(C2)=15,IF(MOD(MID(C2,15,1),2)=1,"男","女"),IF(MOD(MID(C2,17,1),2)=1,"男","女"))公式内的“C2”代表的是输入身份证号码的单元格。 1、求和: =SUM(K2:K56) ——对K2到K56这一区域进行求和; 2、平均数: =AVERAGE(K2:K56) ——对K2 K56这一区域求平均数; 3、排名: =RANK(K2,K$2:K$56) ——对55名学生的成绩进行排名; 4、等级: =IF(K2>=85,"优",IF(K2>=74,"良",IF(K2>=60,"及格","不及格")))
5、学期总评: =K2*0.3+M2*0.3+N2*0.4 ——假设K列、M列和N列分别存放着学生的“平时总评”、“期中”、“期末”三项成绩; 6、最高分: =MAX(K2:K56) ——求K2到K56区域(55名学生)的最高分; 7、最低分: =MIN(K2:K56) ——求K2到K56区域(55名学生)的最低分; 8、分数段人数统计: (1) =COUNTIF(K2:K56,"100") ——求K2到K56区域100分的人数;假设把结果存放于K57单元格; (2) =COUNTIF(K2:K56,">=95")-K57 ——求K2到K56区域95~99.5分的人数;假设把结果存放于K58单元格; (3)=COUNTIF(K2:K56,">=90")-SUM(K57:K58) ——求K2到K56区域90~94.5分的人数;假设把结果存放于K59单元格; (4)=COUNTIF(K2:K56,">=85")-SUM(K57:K59) ——求K2到K56区域85~89.5分的人数;假设把结果存放于K60单元格; (5)=COUNTIF(K2:K56,">=70")-SUM(K57:K60) ——求K2到K56区域70~84.5分的人数;假设把结果存放于K61单元格; (6)=COUNTIF(K2:K56,">=60")-SUM(K57:K61) ——求K2到K56区域60~69.5分的人数;假设把结果存放于K62单元格; (7) =COUNTIF(K2:K56,"<60") ——求K2到K56区域60分以下的人数;假设把结果存放于K63单元格; 说明:COUNTIF函数也可计算某一区域男、女生人数。 如:=COUNTIF(C2:C351,"男") ——求C2到C351区域(共350人)男性人数;
wps表格统计常用公式详解
wps表格统计常用公式详解
wps Excel表格公式大全 来源:郭志煌的日志 1、查找重复内容公式:=IF(COUNTIF(A:A,A2)>1,"重复","")。 2、用出生年月来计算年龄公式:=TRUNC((DAYS360(H6,"2009/8/30",FALSE))/360,0)。 3、从输入的18位身份证号的出生年月计算公式:=CONCATENATE(MID(E2,7,4),"/",MID(E2,11,2),"/",MID(E2, 13,2))。 4、从输入的身份证号码内让系统自动提取性别,可以输入以下
公式: =IF(LEN(C2)=15,IF(MOD(MID(C2,15,1),2)=1,"男","女"),IF(MOD(MID(C2,17,1),2)=1,"男","女"))公式内的“C2”代表的是输入身份证号码的单元格。 1、求和: =SUM(K2:K56) ——对K2到K56这一区域进行求和; 2、平均数: =AVERAGE(K2:K56) ——对K2 K56这一区域求平均数; 3、排名: =RANK(K2,K$2:K$56) ——对55名学生的成绩进行排名; 4、等级: =IF(K2>=85,"优",IF(K2>=74,"良",IF(K2>=60,"及格","不及格"))) 5、学期总评: =K2*0.3+M2*0.3+N2*0.4 ——假设K列、M列和N列分别存放着学生的“平时总评”、“期中”、“期末”三项
成绩; 6、最高分:=MAX(K2:K56) ——求K2到K56区域(55名学生)的最高分; 7、最低分:=MIN(K2:K56) ——求K2到K56区域(55名学生)的最低分; 8、分数段人数统计: (1) =COUNTIF(K2:K56,"100") ——求K2到K56区域100分的人数;假设把结果存放于K57单元格; (2) =COUNTIF(K2:K56,">=95")-K57 ——求K2到K56区域95~99.5分的人数;假设把结果存放于K58单元格; (3)=COUNTIF(K2:K56,">=90")-SUM(K57:K58) ——求K2到K56区域90~94.5分的人数;假设把结果存放于K59单元格;
表格资料汇总常用统计方法
表格资料汇总常用统计方法-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
分类数据常用统计方法 在科研数据的统计分析中,经常会遇到分类数据。分类数据包括计数资料和等级资料,两者都是将观察指标分类(组),然后统计每一类(组)数目所得到的数据,区别是如果观察指标的分类是无序的则为计数资料,也叫定性资料或无序分类变量;如果观察指标的分类是有序的,则为等级资料,也叫有序分类数据。如调查某人群的血型分布,按照A、B、AB 与O四型分组,计数所得该人群的各血型组的人数就是计数资料(因为A、B、AB与O血型之间是平等的,并没有度或量的差异);观察用某药治疗某病患者的疗效,以患者为观察单位,结果可分为治愈、显效、好转、无效四级,然后对该病的患者,分别计数治愈、显效、无效、好转的人数则为等级数据(因为无效的疗效最差、次之为好转、治愈的疗效最好,它们之间有度或者量的区别)。分类数据进行统计分析时要列成表格,根据表格中分组变量和指标变量的性质、样本含量(n)和理论频数(T)的大小以及分析的目的,所用的统计方法是不一样的。下面通过一些有代表性的例子来介绍分类数据常用的统计分析方法。 一、2×2表 2×2表也叫四格表。在实验研究中,将研究对象分为2组进行实验,实验只有2种可能的结果,如阳性与阴性,故叫2×2表;因为基本数据只有4个,所以也叫四格表。根据不同的实验安排,四格表又分为完全随机设计四格表和配对设计四格表。 表1 某抗生素的人群耐药性情况 用药史不敏感敏感合计耐药率(%) 曾服该药180(174.10) 215(220.90) 395 45.57 未服该药73(78.90) 106(100.10) 179 40.78 合计253 321 574 44.08 表1 为完全随机设计四格表。其目的是要比较曾服该抗生素的人群和未曾服过该抗生素的人群,对该抗生素的耐药率有无差异。表格中的四个基本数据(也叫实际频数)分别为180、215、73、106;括号中的四个数据(174.10、220.90、78.90、100.10)为四个理论频数(T),因40 n且四个理论频数(T)均大于5,故应用Pearson2χ检验。经(SPSS 574> = 11.0,以下同)计算2χ=1.145,P=0.285>0.05,故可认为曾服过该抗生素的人群和未曾服过该抗生素的人群对该抗生素的耐药率无差异。 表2 两个年级大学生的近视眼患病率比较 年级近视非近视合计近视率(%) 四年级2(4.67) 26(23.33) 28 7.14 五年级5(2.33) 9(11.69) 14 35.71 合计7 35 42 16.67 表2也为完全随机设计四格表。虽40 42> n但有两个格子的理论频数比1大比5小,此 = 时需对2χ进行连续性校正(因为理论频数太小,会导致2χ增大,易出现错误的有差异的结论)。经计算,连续性校正的c2χ=3.621,P=0.057>0.05,可认为大学四年级与大学5年级