回归模型结果分析
回归模型结果分析
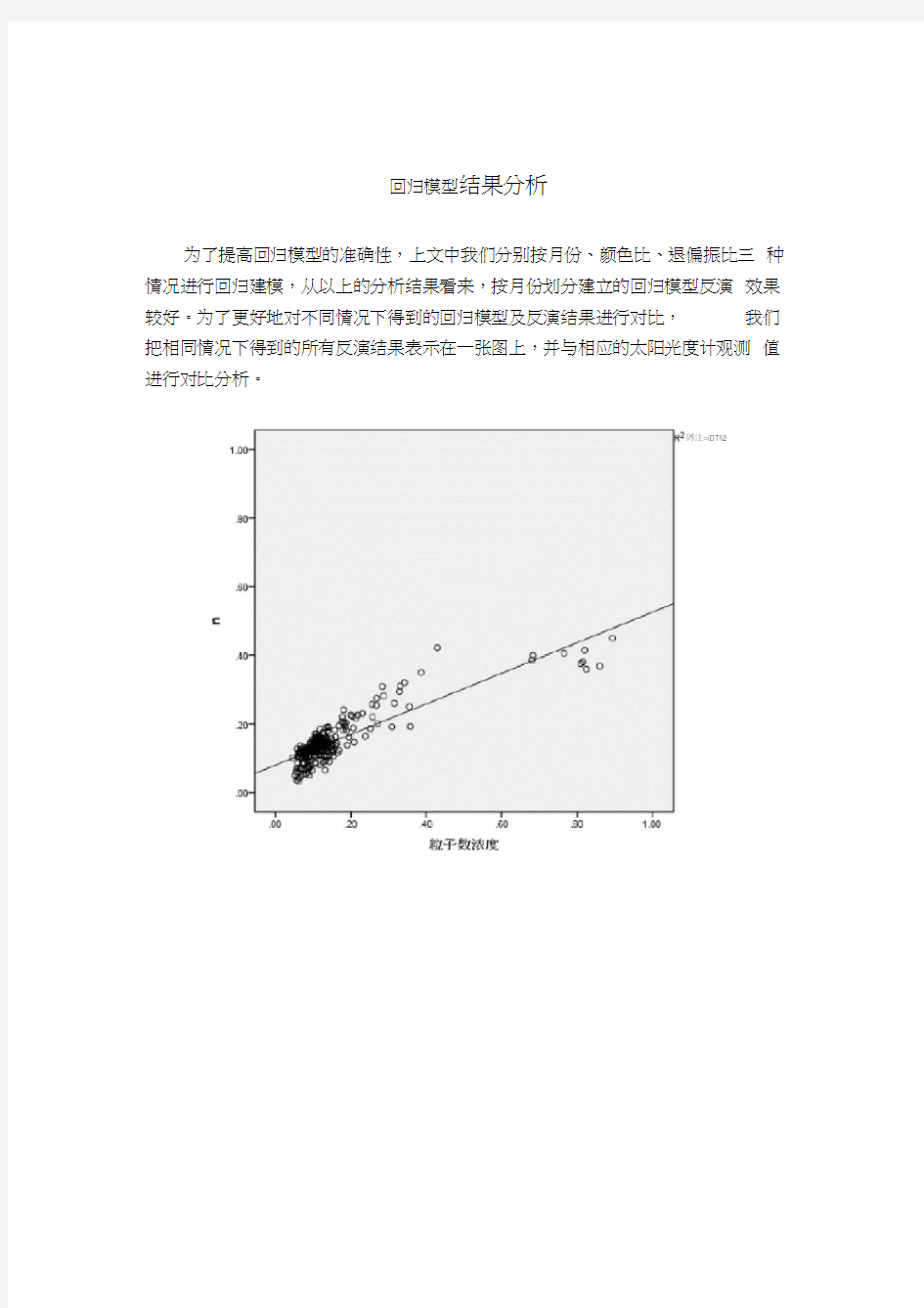
为了提高回归模型的准确性,上文中我们分别按月份、颜色比、退偏振比三种情况进行回归建模,从以上的分析结果看来,按月份划分建立的回归模型反演效果较好。为了更好地对不同情况下得到的回归模型及反演结果进行对比,我们把相同情况下得到的所有反演结果表示在一张图上,并与相应的太阳光度计观测值进行对比分析。
縛注=iDTfi2
■-■0L BC6 1.00-
.80-
I I
40 60
粒干数浓度
(c)
图4.1
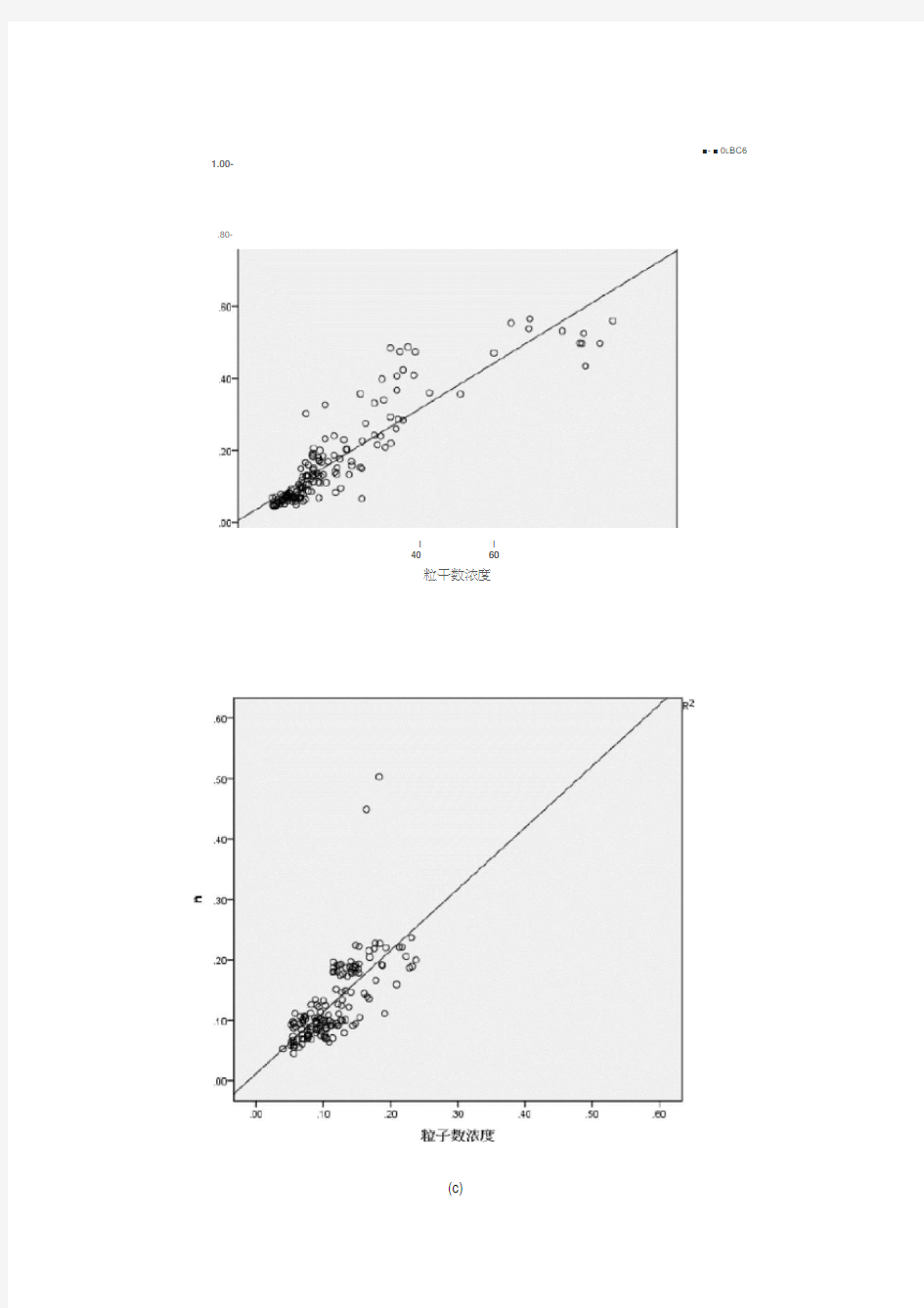
图4.1中(a)、(b)、(c)三幅图为分别按月份、颜色比和退偏振比建立回归模型后得出的所有颗粒物体积浓度的反演结果与相应太阳光度计观测值的对比分析图。图(a)数据的样本容量为250,图(b)和图(c)的样本容量为150, 虽然图(a)样本容量多,但是与图(b)和图(c)相比,图(a)中数据更为集中,大部分数据的反演结果与太阳光度计观测值接近,出现误差的数据少且误差小,图(c)的反演结果略优于图(b),总体来说按月份建立的颗粒物体积浓度的
回归模型最准确,而按颜色比建立的回归模型准确性较差。
=0 35
(a)
(b)
R?晞性=0 310 2flC-
1
有效:眦子半怪
(c)
图4.2
图4.2中(a)、(b)、(c)三幅图为分别按月份、颜色比和退偏振比建立回归模型后得出的所有有效粒子半径的反演结果与相应太阳光度计观测值的对比分析图。图(a)样本容量较多且数据比较集中,但有一部分数据反演结果明显偏小,严重影响了回归模型的准确性,图(b)数据较离散,部分数据误差大,线性相关系数较小,图(c)个别数据误差大,虽然数据集中程度没有图(a)好。但是数据横纵坐标的差异比其他两幅图小。在确定最优样本容量时,我们发现随着样本容量的增加,线性相关系数减小,所以在无法统一样本容量且线性相关系数差异不大的情况下无法确定在哪种情况下建立的回归模型最准确。所以在建立有效粒子半径的回归模型时,我们可以按月份建立回归模型,也可以按退偏振比建立回归模型。
回归模型分析
新疆财经大学 实验报告 课程名称:统计学 实验项目名称:回归模型分析 姓名: lili 学号: 20000000 班级:工商2011-2班 指导教师: 2014 年5 月
新疆财经大学实验报告
附:实验数据。
1、作散点图,加趋势线, 2、建立回归模型(用公式编辑器写),对模型进行统计检验。解释模型意义SUMMARY OUTPUT 回归统计 Multiple R 0.974111881 R Square 0.948893956 Adjusted R Square 0.947131679 标准误差527.4648386 观测值31 方差分析 df SS MS F Significance F 回归分析 1 149806425.5 149806426 538.4476 2.82E-20 残差29 8068355.522 278219.156 总计30 157874781.1 Coefficients 标准误差t Stat P-value Lower 95% Upper 95% Intercept 121.5246471 365.0193913 0.33292655 0.741585 -625.024 X Variable 1 1.270433698 0.054749518 23.2044728 2.82E-20 1.158458
RESIDUAL OUTPUT 观测值预测 Y 残差标准残差 1 14252.56 -369.959 -0.71338 2 10116.66 196.2382 0.378401 3 7032.43 206.6701 0.398516 4 6607.597 412.4032 0.795225 5 7006.005 6.895144 0.013296 6 7843.094 -602.494 -1.16177 7 7098.874 -93.6736 -0.18063 8 6493.004 185.8963 0.358458 9 14147.49 720.0062 1.388367 10 8644.356 618.1438 1.191949 11 12461.12 717.8799 1.384267 12 6555.382 244.618 0.47169 13 9467.216 532.2839 1.026388 14 6365.198 536.2019 1.033943 15 7832.295 567.6051 1.094497 16 6399.5 526.5002 1.015235 17 7697.502 -375.502 -0.72407 18 7871.17 -171.17 -0.33006 19 12363.8 16.59511 0.032 20 7443.669 341.3307 0.658178 21 7111.959 147.341 0.284113 22 9164.599 -1070.9 -2.06498 23 7490.04 -448.14 -0.86414 24 6408.901 160.099 0.308714 25 7774.109 -130.509 -0.25166 26 10342.54 -1577.04 -3.04097 27 7362.997 -462.997 -0.89278 28 6852.282 -195.082 -0.37617 29 6982.121 -236.821 -0.45665 30 6893.317 -362.817 -0.69961 31 7260.6 -39.5998 -0.07636 y=β0+β1x y=121.225+1.27X 3、求相关系数与方向说明数意 根据以上的结果,0《r≤1,这表明x与y之间正线性相关,因为r=0.9741可视为高度相关;
数学建模——回归分析
回归分析——20121060025 吕佳琪 企业编号生产性固定资产价值(万元)工业总产值(万元) 1318524 29101019 3200638 4409815 5415913 6502928 7314605 812101516 910221219 1012251624 合计65259801 (2)建立直线回归方程; (3)计算估价标准误差; (4)估计生产性固定资产(自变量)为1100万元时总产值(因变量)的可能值。解: (1)画出散点图,观察二变量的相关方向 x=[318 910 200 409 415 502 314 1210 1022 1225]; y=[524 1019 638 815 913 928 605 1516 1219 1624]; plot(x,y,'or') xlabel('生产性固定资产价值(万元)') ylabel('工业总产值(万元)') 由图形可得,二变量的相关方向应为直线 (2)
x=[318 910 200 409 415 502 314 1210 1022 1225]; y=[524 1019 638 815 913 928 605 1516 1219 1624]; X = [ones(size(x))', x']; [b,bint,r,rint,stats] = regress(y',X,0、05); b,bint,stats b = 395、5670 0、8958 bint = 210、4845 580、6495 0、6500 1、1417 stats = 1、0e+004 * 0、0001 0、0071 0、0000 1、6035 上述相关系数r为1,显著性水平为0 Y=395、5670+0、8958*x (3) 计算方法:W=((Y1-y1)^2+……+(Y10-y10)^2)^(1/2)/10 利用SPSS进行回归分析:
回归模型结果分析
回归模型结果分析 为了提高回归模型的准确性,上文中我们分别按月份、颜色比、退偏振比三种情况进行回归建模,从以上的分析结果看来,按月份划分建立的回归模型反演效果较好。为了更好地对不同情况下得到的回归模型及反演结果进行对比,我们把相同情况下得到的所有反演结果表示在一张图上,并与相应的太阳光度计观测值进行对比分析。 (a)
(b) (c)
图4.1 图4.1中(a)、(b)、(c)三幅图为分别按月份、颜色比和退偏振比建立回归模型后得出的所有颗粒物体积浓度的反演结果与相应太阳光度计观测值的对比分析图。图(a)数据的样本容量为250,图(b)和图(c)的样本容量为150,虽然图(a)样本容量多,但是与图(b)和图(c)相比,图(a)中数据更为集中,大部分数据的反演结果与太阳光度计观测值接近,出现误差的数据少且误差小,图(c)的反演结果略优于图(b),总体来说按月份建立的颗粒物体积浓度的回归模型最准确,而按颜色比建立的回归模型准确性较差。 (a)
(b) (c)图4.2
图4.2中(a)、(b)、(c)三幅图为分别按月份、颜色比和退偏振比建立回归模型后得出的所有有效粒子半径的反演结果与相应太阳光度计观测值的对比分析图。图(a)样本容量较多且数据比较集中,但有一部分数据反演结果明显偏小,严重影响了回归模型的准确性,图(b)数据较离散,部分数据误差大,线性相关系数较小,图(c)个别数据误差大,虽然数据集中程度没有图(a)好。但是数据横纵坐标的差异比其他两幅图小。在确定最优样本容量时,我们发现随着样本容量的增加,线性相关系数减小,所以在无法统一样本容量且线性相关系数差异不大的情况下无法确定在哪种情况下建立的回归模型最准确。所以在建立有效粒子半径的回归模型时,我们可以按月份建立回归模型,也可以按退偏振比建立回归模型。
应用回归分析
第五章 自变量选择对回归参数的估计有何影响 答:全模型正确而误用选模型时,我们舍去了m-p 个自变量,用剩下的p 个自变量去建立选模型,参数估计值是全模型相应参数的有偏估计。选模型正确而误用全模型时,参数估计值是选模型相应参数的有偏估计。 自变量选择对回归预测有何影响 (一)全模型正确而误用选模型的情况 估计系数有偏,选模型的预测是有偏的,选模型的参数估计有较小的方差,选模型的预测残差有较小的方差,选模型预测的均方误差比全模型预测的方差更小。 (二)选模型正确而误用全模型的情况 全模型的预测值是有偏的,全模型的预测方差的选模型的大,全模型的预测误差将更大。 如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣 答:应该用自由度调整复决定系数达到最大的准则。当给模型增加自变量时,复决定系数也随之增大,然而复决定系数的增大代价是残差自由度的减小,自由度小意味着估计和预测的可靠性低。应用自由度调整复决定系数达到最大的准则可以克服样本决定系数的这一缺点,把2 R 给予适当的修正,使得只有加入“有意义”的变量时,经过修正的样本决定系数才会增加,从而提高预测的精度。 试述前进法的思想方法。 解:主要是变量由少到多,每次增加一个,直至没有可引入的变量为止。 具体做法是:首先将全部m 个自变量,分别对因变量y 建立m 个一元线性回归方程,并分别计算这m 个一元回归方程的m 个回归系数的F 检验值,记为 111 12{,,,} m F F F ,选其最大者 1111 12max{,, ,} j m F F F F =,给定显著性水平α,若 1(1,2) j F F n α≥-,则首先将 j x 引入回 归方程,假设 1 j x x =。其次,将 12131(,),(,),,(,)m y x x x x x x 分别与建立m-1个二元线性 回归方程,对这m-1个回归方程中 23,, ,m x x x 的回归系数进行F 检验,计算F 值,记为 222 23{,, ,} m F F F ,选其最大的记为 2222 23max{,, ,} j m F F F F =,若 2(1,3) j F F n α≥-,则 接着将j x 引入回归方程。以上述方法做下去。直至所有未被引入方程的自变量的F 值均小
多元线性回归模型的案例分析
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下:
数学建模之回归分析法
什么是回归分析 回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。 回归分析之一多元线性回归模型案例解析 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:(数据可以先用excel建立再通过spss打开) 点击“分析”——回归——线性——进入如下图所示的界面:
回归分析方法
第八章 回归分析方法 当人们对研究对象的内在特性和各因素间的关系有比较充分的认识时,一般用机理分析方法建立数学模型。如果由于客观事物内部规律的复杂性及人们认识程度的限制,无法分析实际对象内在的因果关系,建立合乎机理规律的数学模型,那么通常的办法是搜集大量数据,基于对数据的统计分析去建立模型。本章讨论其中用途非常广泛的一类模型——统计回归模型。回归模型常用来解决预测、控制、生产工艺优化等问题。 变量之间的关系可以分为两类:一类叫确定性关系,也叫函数关系,其特征是:一个变量随着其它变量的确定而确定。另一类关系叫相关关系,变量之间的关系很难用一种精确的方法表示出来。例如,通常人的年龄越大血压越高,但人的年龄和血压之间没有确定的数量关系,人的年龄和血压之间的关系就是相关关系。回归分析就是处理变量之间的相关关系的一种数学方法。其解决问题的大致方法、步骤如下: (1)收集一组包含因变量和自变量的数据; (2)选定因变量和自变量之间的模型,即一个数学式子,利用数据按照最小二乘准则计算模型中的系数; (3)利用统计分析方法对不同的模型进行比较,找出与数据拟合得最好的模型; (4)判断得到的模型是否适合于这组数据; (5)利用模型对因变量作出预测或解释。 应用统计分析特别是多元统计分析方法一般都要处理大量数据,工作量非常大,所以在计算机普及以前,这些方法大都是停留在理论研究上。运用一般计算语言编程也要占用大量时间,而对于经济管理及社会学等对高级编程语言了解不深的人来说要应用这些统计方法更是不可能。MATLAB 等软件的开发和普及大大减少了对计算机编程的要求,使数据分析方法的广泛应用成为可能。MATLAB 统计工具箱几乎包括了数理统计方面主要的概念、理论、方法和算法。运用MATLAB 统计工具箱,我们可以十分方便地在计算机上进行计算,从而进一步加深理解,同时,其强大的图形功能使得概念、过程和结果可以直观地展现在我们面前。本章内容通常先介绍有关回归分析的数学原理,主要说明建模过程中要做的工作及理由,如模型的假设检验、参数估计等,为了把主要精力集中在应用上,我们略去详细而繁杂的理论。在此基础上再介绍在建模过程中如何有效地使用MATLAB 软件。没有学过这部分数学知识的读者可以不深究其数学原理,只要知道回归分析的目的,按照相应方法通过软件显示的图形或计算所得结果表示什么意思,那么,仍然可以学到用回归模型解决实际问题的基本方法。包括:一元线性回归、多元线性回归、非线性回归、逐步回归等方法以及如何利用MATLAB 软件建立初步的数学模型,如何透过输出结果对模型进行分析和改进,回归模型的应用等。 8.1 一元线性回归分析 回归模型可分为线性回归模型和非线性回归模型。非线性回归模型是回归函数关于未知参数具有非线性结构的回归模型。某些非线性回归模型可以化为线性回归模型处理;如果知道函数形式只是要确定其中的参数则是拟合问题,可以使用MATLAB 软件的curvefit 命令或nlinfit 命令拟合得到参数的估计并进行统计分析。本节主要考察线性回归模型。 8.1.1 一元线性回归模型的建立及其MATLAB 实现 其中01ββ,是待定系数,对于不同的,x y 是相互独立的随机变量。 假设对于x 的n 个值i x ,得到 y 的n 个相应的值i y ,确定01ββ,的方法是根据最小二乘准则,要使 取最小值。利用极值必要条件令 01 0,0Q Q ββ??==??,求01ββ,的估计值01??ββ,,从而得到回归直线01 ??y x ββ=+。只不过这个过程可以由软件通过直线拟合完成,而无须进行繁杂的运算。
回归分析在数学建模中的应用
摘要 回归分析和方差分析是探究和处理相关关系的两个重要的分支,其中回归分析方法是预测方面最常用的数学方法,它是利用统计数据来确定变量之间的关系,并且依据这种关系来预测未来的发展趋势。本文主要介绍了一元线性回归分析方法和多元线性回归分析方法的一般思想方法和一般步骤,并且用它们来研究和分析我们在生活中常遇到的一些难以用函数形式确定的变量之间的关系。在解决的过程中,建立回归方程,再通过该回归方程进行预测。 关键词:多元线性回归分析;参数估计;F检验
回归分析在数学建模中的应用 Abstract Regression analysis and analysis of variance is the inquiry and processing of the correlation between two important branches, wherein the regression analysis method is the most commonly used mathematical prediction method, it is the use of statistical data to determine the relationship between the variables, and based on this relationship predict future trends. introduces a linear regression analysis and multiple linear regression analysis method general way of thinking and the general steps, and use them to research and analysis that we encounter in our life, are difficult to determine as a function relationship between the variables in the solving process, the regression equation is established by the regression equation to predict. Keywords:Multiple linear regression analysis; parameter estimation;inspection II
简述回归分析的概念与特点
简述回归分析的概念与特点 回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。 方差齐性 线性关系 效应累加 变量无测量误差 变量服从多元正态分布 观察独立 模型完整(没有包含不该进入的变量、也没有漏掉应该进入的变量) 误差项独立且服从(0,1)正态分布。 现实数据常常不能完全符合上述假定。因此,统计学家研究出许多的回归模型来解决线性回归模型假定过程的约束。 研究一个或多个随机变量Y1 ,Y2 ,…,Yi与另一些变量X1、X2,…,Xk之间的关系的统计方法。又称多重回归分析。通常称Y1,Y2,…,Yi为因变量,X1、X2,…,Xk为自变量。回归分析是一类数学模型,特别当因变量和自变量为线性关系时,它是一种特殊的线性模型。最简单的情形是一个自变量和一个因变量,且它们大体上有线性关系,这叫一元线性回归,即模型为Y=a+bX+ε,这里X是自变量,Y是因变量,ε是随机误差,通常假定随机误差的均值为0,方差为σ^2(σ^2大于0)σ2与X的值无关。若进一步假定随机误差遵从正态分布,就叫做正态线性模型。一般的情形,差有k个自变量和一个因变量,因变量的值可以分解为两部分:一部分是由自变量的影响,即表示为自变量的函数,其中函数形式已知,但含一些未知参数;另一部分是由于其他未被考虑的因素和随机性的影响,即随机误差。当函数形式为未知参数的线性函数时,称线性回归分析模型;当函数形式为未知参数的非线性函数时,称为非线性回归分析模型。当自变量的个数大于1时称为多元回归,当因变量个数大于1时称为多重回归。 回归分析的主要内容为:①从一组数据出发确定某些变量之间的定量关系式,即建立数学模型并估计其中的未知参数。估计参数的常用方法是最小二乘法。②对这些关系式的可信程度进行检验。③在许多自变量共同影响着一个因变量的关系中,判断哪个(或哪些)自变量的影响是显著的,哪些自变量的影响是不显著的,将影响显著的自变量选入模型中,而剔除影响不显著的变量,通常用逐步回归、向前回归和向后回归等方法。④利用所求的关系式对某一生产过程进行预测或控制。回归分析的应用是非常广泛的,统计软件包使各种回归方法计算十分方便。
数学建模回归分析多元回归分析
1、 多元线性回归 在回归分析中,如果有两个或两个以上的自变量,就称为多元回归。事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。 在实际经济问题中,一个变量往往受到多个变量的影响。例如,家庭消费支出,除了受家庭可支配收入的影响外,还受诸如家庭所有的财富、物价水平、金融机构存款利息等多种因素的影响,表现在线性回归模型中的解释变量有多个。这样的模型被称为多元线性回归模型。(multivariable linear regression model ) 多元线性回归模型的一般形式为: 其中k 为解释变量的数目,j β (j=1,2,…,k)称为回归系数(regression coefficient)。上式也被称为总体回归函数的随机表达式。它的非随机表达式为: j β也被称为偏回归系数(partial regression coefficient)。 2、 多元线性回归计算模型 多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和(Σe)为最小的前提下,用最小二乘法或最大似然估计法求解参数。 设( 11 x , 12 x ,…, 1p x , 1 y ),…,( 1 n x , 2 n x ,…, np x , n y )是一个样本, 用最大似然估计法估计参数: 达 到最小。
把(4)式化简可得: 引入矩阵: 方程组(5)可以化简得: 可得最大似然估计值:
3、Matlab 多元线性回归的实现 多元线性回归在Matlab 中主要实现方法如下: (1)b=regress(Y, X ) 确定回归系数的点估计值 其中 (2)[b,bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检 验回归模型 ①bint 表示回归系数的区间估计. ②r 表示残差 ③rint 表示置信区间 ④stats 表示用于检验回归模型的统计量,有三个数值:相关系数r2、F 值、与F 对应的 概率p 说明:相关系数r2越接近1,说明回归方程越显著;F>F1-alpha(p,n-p-1) 时拒绝H0,F 越大,说明回归方程越显著;与F 对应的概率p<α 时拒绝H0,回归模型成立。 ⑤alpha 表示显著性水平(缺省时为0.05) (3)rcoplot(r,rint) 画出残差及其置信区间
数学建模-回归分析-多元回归分析
1、 多元线性回归在回归分析中,如果有两个或两个以上的自变量,就称为 多元回归。事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。 在实际经济问题中,一个变量往往受到多个变量的影响。例如,家庭消费支出,除了受家庭可支配收入的影响外,还受诸如家庭所有的财富、物价水平、金融机构存款利息等多种因素的影响,表现在线性回归模型中的解释变量有多个。这样的模型被称为多元线性回归模型。(multivariable linear regression model ) 多元线性回归模型的一般形式为: 其中k 为解释变量的数目,j β (j=1,2,…,k)称为回归系数(regression coefficient)。上式也被称为总体回归函数的随机表达式。它的非随机表达式为: j β也被称为偏回归系数(partial regression coefficient)。 2、 多元线性回归计算模型 多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和(Σe)为最小的前提下,用最小二乘法或最大似然估计法求解参数。 设( 11 x , 12 x ,…, 1p x , 1 y ),…,( 1 n x , 2 n x ,…, np x , n y )是一个样本, 用最大似然估计法估计参数: 达 到最小。
把(4)式化简可得: 引入矩阵: 方程组(5)可以化简得: 可得最大似然估计值:
3、Matlab 多元线性回归的实现 多元线性回归在Matlab 中主要实现方法如下: (1)b=regress(Y, X ) 确定回归系数的点估计值 其中 (2)[b,bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检 验回归模型 ①bint 表示回归系数的区间估计. ②r 表示残差 ③rint 表示置信区间 ④stats 表示用于检验回归模型的统计量,有三个数值:相关系数r2、F 值、与F 对应的 概率p 说明:相关系数r2越接近1,说明回归方程越显著;F>F1-alpha(p,n-p-1) 时拒绝H0,F 越大,说明回归方程越显著;与F 对应的概率p<α 时拒绝H0,回归模型成立。 ⑤alpha 表示显著性水平(缺省时为0.05) (3)rcoplot(r,rint) 画出残差及其置信区间
(完整版)逻辑回归模型分析见解
1.逻辑回归模型 1.1逻辑回归模型 考虑具有p个独立变量的向量,设条件概率为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为 (1.1) 上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。 其中。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有 (1.2) 定义不发生事件的条件概率为 (1.3) 那么,事件发生与事件不发生的概率之比为 (1.4) 这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。因为0
得到的概率。在同样条件下得到的条件概率为。于是,得到一个观测值的概率为 (1.6) 因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。 (1.7) 上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数,使上式取得最大值。 对上述函数求对数 (1.8) 上式称为对数似然函数。为了估计能使取得最大的参数的值。 对此函数求导,得到p+1个似然方程。 (1.9) ,j=1,2,..,p. 上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森(Newton-Raphson)方法进行迭代求解。 1.3牛顿-拉斐森迭代法 对求二阶偏导数,即Hessian矩阵为 (1.10) 如果写成矩阵形式,以H表示Hessian矩阵,X表示 (1.11) 令
计量经济学Eviews简单线性回归模型的建立与分析应用实验报告
实验一:简单线性回归模型的建立与分析应用 【实验目的】 1、熟悉计量经济学软件包EViews的界面和基本操作; 2、掌握计量经济学分析实际经济问题的具体步骤; 3、掌握简单线性回归模型的参数估计、统计检验、预测的基本操作方法; 4、理解简单线性回归模型中参数估计值的经济意义。 【实验类型】综合型 【实验软硬件要求】计量经济学软件包EViews、微型计算机 【实验内容】 为研究深圳市地方预算内财政收入(Y)与地区生产总值(X)的关系,建立简单线性回归模型,现根据深圳市统计局网站的相关信息,得到统计数据如下表: 请按照下列步骤完成实验一,每个步骤要写出操作过程: (1)打开EViews,新建适当的工作文件夹; 打开Eviews后,依次点击File-New-Workfile,新建一个时间序列数据(Dated-regular frequencied)类型的文件,频率选择年度(Annual),键入起止日期1990-2008(如图一),点击ok,新建工作文件夹完成(如图二)
(图一) (图二) (2)在工作文件夹中新建变量X和Y,并输入数据; 依次点击Objects-New Object,对象类型选择序列(Series),并输入序列名Y(如图三),点击OK,重复以上操作,新建系列对象X。新建系列对象完成后如(图四) 按住ctrl并同时选定X和Y,用鼠标右击选择open—as group,点击Edit +/-开始编辑,输入数据,数据输入完毕再点击Edit+/-一次。数据输入后如(图五)。
(图三) (图四)
(图五) (3)生成X和Y的自然对数序列,保存在工作文件夹中,命名为lnX和lnY; 依次点击Objects-Generate Sereies,出现Generate Series by Equation 窗口,在Enter equation窗口中输入公式:lnY=log(Y)点击ok,重复以上操作,输入:lnX=log(X) 创建序列lnX。(如图六) (图六) (4)求X和Y的描述统计量的值,写出操作过程并画出相应表格; 依次点击Quick-Group Statistics—Descriptive Statistics-Common sample,打开Series List窗口,输入x y,点击ok,输出结果(如图七)
回归模型的残差分析
回归模型的残差分析 山东 胡大波 判断回归模型的拟合效果是回归分析的重要内容,在回归分析中,通常用残差分析来判断回归模型的拟合效果。下面具体分析残差分析的途径及具体例子。 一、 残差分析的两种方法 1、差分析的基本方法是由回归方程作出残差图,通过观测残差图,以分析和发现观测数据中可能出现的错误以及所选用的回归模型是否恰当;在残差图中,残差点比较均匀地落在水平区域中,说明选用的模型比较合适,这样的带状区域的宽度越窄,说明模型的拟合精度越高,回归方程的预报精度越高。 2、可以进一步通过相关指数∑∑==--- =n i i n i i i y y y y R 1 2 1 2 ^ 2 )()(1来衡量回归模型的拟合效果,一般 规律是2 R 越大,残差平方和就越小,从而回归模型的拟合效果越好。 二、 典例分析: 例1、某运动员训练次数与运动成绩之间的数据关系如下: 试预测该运动员训练47次以及55次的成绩。 解答:(1)作出该运动员训练次数x 与成绩y 之间的散点图,如图1所示,由散点图可 知,它们之间具有线性相关关系。 (2)列表计算: 由上表可求得875.40,25.39==y x , 126568 1 2 =∑=i i x ,137318 1 2=∑=i i y ,
131808 1 =∑=i i i y x ,所以∑∑==---= 8 1 2 8 1 )() )((i i i i i x x y y x x β.0415.188 1 2 28 1≈--= ∑∑==i i i i i x x y x y x 00302.0-≈-=x y βα,所以回归直线方程为.00302.00415.1^ -=x y (3)计算相关系数 将上述数据代入∑∑∑===---= 8 1 8 1 2 22 2 8 1 ) 8)(8(8i i i i i i i y y x x y x y x r 得992704.0=r ,查表可知 707.005.0=r ,而05.0r r >,故y 与x 之间存在显着的相关关系。 (4)残差分析: 作残差图如图2,由图可知,残差点比较均匀地分布在水平带状区域中,说明选用的模型比较合适。 计算残差的方差得884113.02 =σ ,说明预报的精度较高。 (5)计算相关指数2 R 计算相关指数2 R =0.9855.说明该运动员的成绩的差异有98.55%是由训练次数引起的。 (6)做出预报 由上述分析可知,我们可用回归方程 .00302.00415.1^ -=x y 作为该运动员成绩的预报值。 将x =47和x =55分别代入该方程可得y =49和y =57, 故预测运动员训练47次和55次的成绩分别为49和57. 点评:一般地,建立回归模型的基本步骤为: (1)确定研究对象,明确哪个变量是解释变量,哪个变量是预报变量; (2)画出确定好的解释变量和预报变量的散点图,观察它们之间的关系(如是否存在线性关系等); (3)由经验确定回归方程的类型(如我们观察到数据呈线性关系,则选用线性回归方程y =bx +a ); (4)按一定规则估计回归方程中的参数(如最小二乘法); (5)得出结果后分析残差图是否有异常(个别数据对应残差过大,或残差呈现不随机的规律性等等),若存在异常,则检查数据是否有误,或模型是否合适等。 例2、某城区为研究城镇居民月家庭人均生活费支出和月人均收入的相关关系,随机抽取
应用回归分析-课后习题参考复习资料
自变量选择与逐步回归 5章第思考与练习参考答案 5.1 自变量选择对回归参数的估计有何影响? 答:回归自变量的选择是建立回归模型得一个极为重要的问题。如果模型中丢掉了重要的自变量, 出现模型的设定偏误,这样模型容易出现异方差或自相关性,影响回归的效果;如果模型中增加了不必要的自变量, 或者数据质量很差的自变量, 不仅使 得建模计算量增大, 自变量之间信息有重叠,而且得到的模型稳定性较差,影响回归模型的应用。 5.2自变量选择对回归预测有何影响? 答:当全模型(m元)正确采用选模型(p元)时,我们舍弃了个自变量,回归系数的最小二乘估计是全模型相应参数的有偏估计,使得用选模型的预测是有偏的,但由于选模型的参数估计、预测残差和预测均方误差具有较小的方差,所以全模型正确而误用选模型有利有弊。当选模型(p元)正确采用全模型(m元)时,全模型回归系数的最小二乘估计是相应参数的有偏估计,使得用模型的预测是有偏的,并且全模型的参数估计、预测残差和预测均方误差的方差都比选模型的大,所以回归自变量的选择应少而精。 5.3 如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣?
则应使用如果所建模型主要用于预测,答:统计量达到最小的1 / 8 准则来衡量回归方程的优劣。 5.4 试述前进法的思想方法。 答:前进法的基本思想方法是:首先因变量Y对全部的自变量 x12建立m个一元线性回归方程, 并计算F检验值,选择偏回归平方和显著的变量(F值最大且大于临界值)进入回归方程。每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的两变量变量(F值最大且大于临界值)进入回归方程。在确定引入的两个自变量以后,再引入一个变量,建立m-2个三元线性回归方程,计算它们的F检验值,选择偏回归平方和显著的三个变量(F值最大)进入回归方程。不断重复这一过程,直到无法再引入新的自变量时,即所有未被引入的自变量的F检验值均小于F检验临界值F α(11),回归过程结束。 5.5 试述后退法的思想方法。 答:后退法的基本思想是:首先因变量Y对全部的自变量x12建立一个m元线性回归方程, 并计算t检验值和F检验值,选择最不显著(P值最大且大于临界值)的偏回归系数的自变量剔除出回归方程。每一步只剔除一个变量,再建立m-1元线性回归方程,计算t检验值和F检验值,剔除偏回归系数的t检验值最小(P值最大)的自变量,再建立新的回归方程。不断重复这一过
数学建模实验 ——曲线拟合与回归分析
曲线拟合与回归分析 1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下: (1)说明两变量之间的相关方向; (2)建立直线回归方程; (3)计算估计标准误差; (4)估计生产性固定资产(自变量)为1100万元时的总资产 (因变量)的可能值。 解: (1)工业总产值是随着生产性固定资产价值的增长而增长的,存 在正向相关性。 用spss回归 (2)spss回归可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示: .0+ y =x 896 . 395 567 (3)spss回归知标准误差为80.216(万元)。 (4)当固定资产为1100时,总产值为: (0.896*1100+395.567-80.216~0.896*1100+395.567+80.216) 即(1301.0~146.4)这个范围内的某个值。 MATLAB程序如下所示: function [b,bint,r,rint,stats] = regression1 x = [318 910 200 409 415 502 314 1210 1022 1225]; y = [524 1019 638 815 913 928 605 1516 1219 1624]; X = [ones(size(x))', x']; [b,bint,r,rint,stats] = regress(y',X,0.05); display(b); display(stats); x1 = [300:10:1250]; y1 = b(1) + b(2)*x1; figure;plot(x,y,'ro',x1,y1,'g-');
初中数学数学论文线性回归分析的数学模型
线性回归分析的数学模型 在实际问题中常常遇到简单的变量之间的关系,我们会遇到多个变量同处于一个过程之中,它们之间互相联系、互相制约.这些问题中最简单的是线性回归.线性回归分析是对客观事物数量关系的分析,是一种重要的统计分析方法,被广泛的应用于社会经济现象变量之间的影响因素和关联的研究.由于客观事物的联系错综复杂经济现象的变化往往用一个变量无法描述,故本篇论文在深入分析一元线性回归及数学模型的情况下,又详细地介绍了多元线性回归方程的参数估计和其显著性检验等.全面揭示了这种复杂的依存关系,准确测定现象之间的数量变动.以提高预测和控制的准确度. 本文中详细的阐述了线性回归的定义及其线性模型的简单分析并应用了最小二乘法原理.具体介绍了线性回归分析方程参数估计办法和其显著性检验.并充分利用回归方程进行点预测和区间预测. 但复杂的计算给分析方法推广带来了困难,需要相应的操作软件来计算回归分析求解操作过程中的数据.以提高预测和控制的准确度.从而为工农业生产及研究起到强有力的推动作用. 关键词:线性回归;最小二乘法;数学模型 目录 第一章前言 (1) 第二章线性模型 (2) 第一节一元线性模型 (2) 第二节多元线性模型 (4) 第三章参数估计 (5) 第一节一元线性回归方程中的未知参数的估计 (5) 第二节多元线性回归模型的参数估计 (8) 第四章显著性检验 (13) 第一节一元线性回归方程的显著性检验 (13) 第二节多元线性回归方程的显著性检验 (20) 第五章利用回归方程进行点预测和区间预测 (21) 第六章总结 (26) 致谢 (27) 参考文献………………………………………………………………………… 第一章前言
8选择回归模型 拔高难度 讲义
选择回归模型 知识讲解 回归分析 1、回归分析的侧重点应先求回归直线方程,并进行相应的估计预测,但这类的题数据的处理与计算量可能很大,学习中应谨慎把握. 对于独立性检验问题,应以K2的计算与临界值的比较来判断分类变量的相关与无关为主. 2、线性回归分析是统计中的一个重要内容,随着新课标的实施和新课程高考改革的不断深入,这部分的内容也将回越来越受到重视. 非线性回归问题有时并不给出经验公式,这时候我们可以画出已知数据的散点图,把它与必修模块数学1中学过的各种函数(幂函数、指数函数、对数函数、二次函数等)图象比较,挑选一种跟这些点拟合最好成的函数,然后采取适当的置换,把问题化为线性回归问题,使其得到解决。 3、回归直线方程求解需要复杂的运算,随着新课程标准的继续实施和新课程高考改革的不断深入,考查同学们数据处理能力,特别是运用计算器等现代技术工具对进行数据处理的能力,将是改革的方向之一. 有关理论要求同学们理解,但公式也不需要死记硬背. 典例精讲 一.选择题(共11小题) 1.(2018秋?曾都区校级期中)某公司为了增加其商品的销售利润,调查了该商品投入的广告费用x与销售利润y的统计数据如表,由表中数据得线性回归),则下列结论中错误的是(方程=x+ 3256(万元)广告费用x 11579(万元)销售利润y B.y>A.0与x正相关 0C.回归直线过点(4,8<)D. 与当天气温y春2018?邢台期末)如表是某饮料专卖店一天卖出奶茶的杯数2. (的线性回归方程y关于xx(单位:℃)的对比表,已知由表中数据计算得到x),+27,则相应于点(1020)的残差为(为= 510152025℃气温/ 1420161426杯数 1.D.C.﹣A1.﹣B0.50.5