【原创】R语言svm决策树模型分析空气质量附代码数据
data=read.csv("air.csv",skip =1)
head(data)
## label X1 X2 X3 X4 X5 X6 X7 Y1 Y2 X8 X9 X10
## 1 北京 14 50 102 81 46965 3.6 203 186 124 23014.60 16410.54 2170. 50
## 2 天津 29 42 117 70 94867 3.1 142 216 104 16538.19 11946.88 1547. 00
## 3 石家庄 47 51 147 89 88167 4.3 148 180 123 5440.60 15848.00 1028. 84
## 4 太原 71 38 114 62 79456 3.1 131 230 94 2735.34 6999.00 367. 39
## 5 呼和浩特 34 39 103 43 55970 3.2 145 276 87 3090.52 17224.00 238. 58
## 6 沈阳 66 48 115 72 98871 2.2 155 207 107 7280.49 12948.00 730. 41
## X11 X12 X13 X14 X15
## 1 561.90 342.40 0.26 4542.64 0.20
## 2 273.62 229.03 0.18 7704.22 0.47
## 3 219.53 138.52 0.21 2452.40 0.45
## 4 113.30 161.88 0.31 1020.18 0.37
## 5 85.39 49.58 0.36 867.08 0.28
## 6 181.70 140.33 0.25 3474.18 0.48
# 分析分为两个部分
# 第一部分:
######################################################################
##### 数据导入与处理
######################################################################
data$Y1<-ifelse(data$Y1>365*0.8,'空气好','空气差')
## 构建因变量
data$Y1<-as.factor(data$Y1) ## 将因变量格式转为因子型
######################################################################
##### 构建训练集、测试集
##### 分层抽样,70%作为训练集,30%作为测试集
######################################################################
# library(sampling)
trainindex=sample(1:nrow(data),nrow(data)*0.7)
train<-data[trainindex, ] ## 去除price变量的训练集
test<-data[-trainindex, ] ## 去除price变量的测试集
# 根据空气的指标(x1~x7)将30个城市分成两类,y1用来检验分类的效果(可以将y1的指标转化成0,1来表示该城市空气好或坏);
# 初步打算使用决策树方法和SVM方法;
# 编程的步骤尽可能完善,从初始的数据预处理,数据可视化,到建模,检验,优化都不能缺少;
# 如果编程需要训练数据集和预测数据集,而个数太少,我可以提供前几年的数据作为训练(这个不知你需不需要)。
###################################################################### #####训练svm模型
###################################################################### # install.packages('e1071') ## 安装软件包
library(e1071) ## 加载软件包
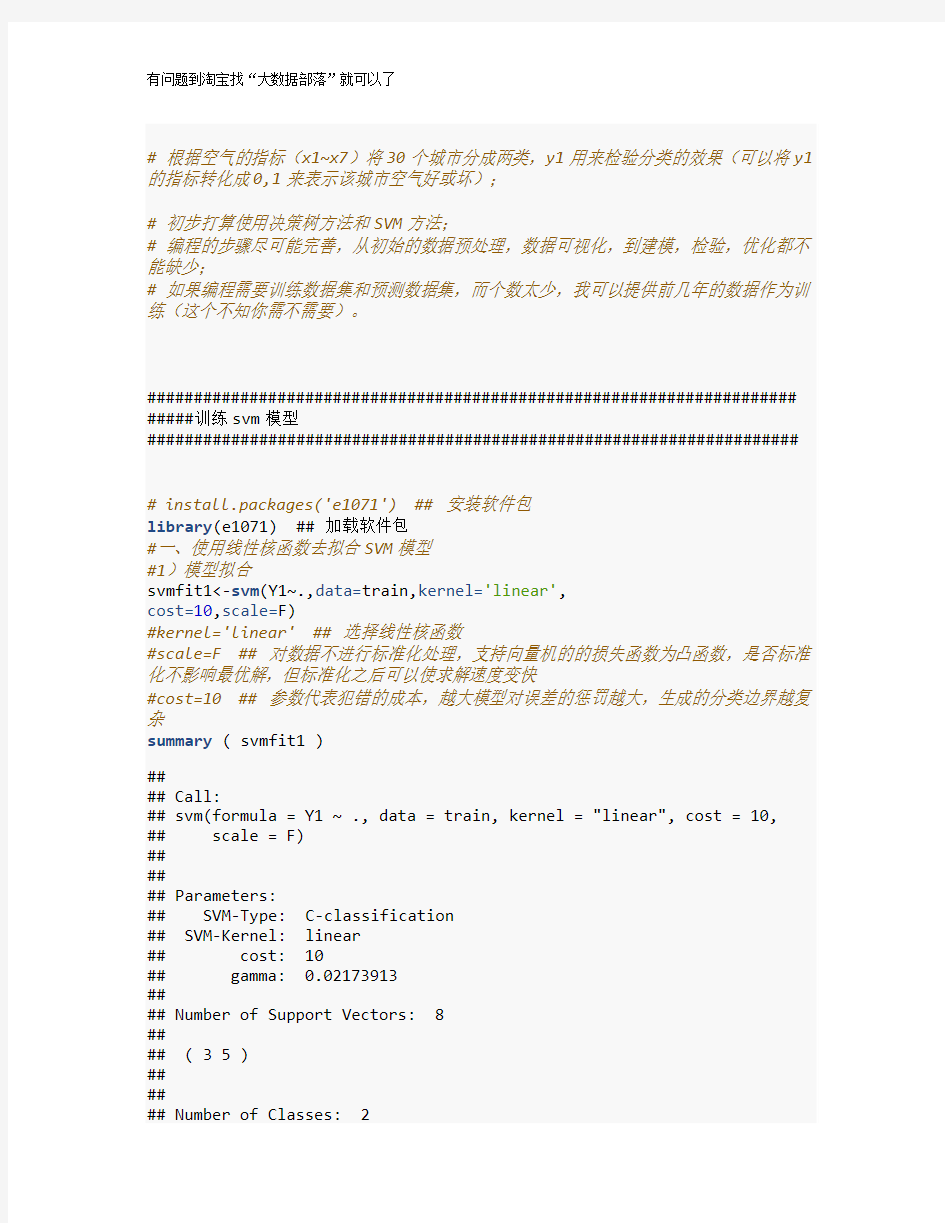
#一、使用线性核函数去拟合SVM模型
#1)模型拟合
svmfit1<-svm(Y1~.,data=train,kernel='linear',
cost=10,scale=F)
#kernel='linear' ## 选择线性核函数
#scale=F ## 对数据不进行标准化处理,支持向量机的的损失函数为凸函数,是否标准化不影响最优解,但标准化之后可以使求解速度变快
#cost=10 ## 参数代表犯错的成本,越大模型对误差的惩罚越大,生成的分类边界越复杂
summary ( svmfit1 )
##
## Call:
## svm(formula = Y1 ~ ., data = train, kernel = "linear", cost = 10,
## scale = F)
##
##
## Parameters:
## SVM-Type: C-classification
## SVM-Kernel: linear
## cost: 10
## gamma: 0.02173913
##
## Number of Support Vectors: 8
##
## ( 3 5 )
##
##
## Number of Classes: 2
## Levels:
## 空气差空气好
#2)对svmfit1模型进行改进,选择最优的cost值
set.seed (1) ## 设置种子,保证每次运行结果一致
tune.out<-tune(svm,Y1~.,data=train,
kernel ='linear',
ranges =list(cost=c(0.001 ,
0.01, 0.1, 1,5,10,100) ))
summary (tune.out )
##
## Parameter tuning of 'svm':
##
## - sampling method: 10-fold cross validation
##
## - best parameters:
## cost
## 0.1
##
## - best performance: 0.05
##
## - Detailed performance results:
## cost error dispersion
## 1 1e-03 0.30 0.2581989
## 2 1e-02 0.30 0.2581989
## 3 1e-01 0.05 0.1581139
## 4 1e+00 0.05 0.1581139
## 5 5e+00 0.05 0.1581139
## 6 1e+01 0.05 0.1581139
## 7 1e+02 0.05 0.1581139
best.mode1<-tune.out$best.model ## 得到最优模型
summary ( best.mode1 )
##
## Call:
## best.tune(method = svm, train.x = Y1 ~ ., data = train, ranges = lis t(cost = c(0.001,
## 0.01, 0.1, 1, 5, 10, 100)), kernel = "linear")
##
##
## Parameters:
## SVM-Type: C-classification
## SVM-Kernel: linear
## cost: 0.1
## gamma: 0.02173913
##
## Number of Support Vectors: 11
## ( 5 6 )
##
##
## Number of Classes: 2
##
## Levels:
## 空气差空气好
#3)模型评估
ypred<-predict(best.mode1,test)
table(predict=ypred,ture=test$Y1)
## ture
## predict 空气差空气好
## 空气差 6 1
## 空气好 0 2
###################################################################### #####训练decision tree模型
######################################################################
library(rpart)
# grow tree
fit <-rpart(Y1 ~.-label-Y1,
method="class", data=data)
printcp(fit) # display the results
##
## Classification tree:
## rpart(formula = Y1 ~ . - label - Y1, data = data, method = "class") ##
## Variables actually used in tree construction:
## [1] X4
##
## Root node error: 9/30 = 0.3
##
## n= 30
##
## CP nsplit rel error xerror xstd
## 1 0.88889 0 1.00000 1.00000 0.27889
## 2 0.01000 1 0.11111 0.22222 0.15181
plotcp(fit) # visualize cross-validation results
summary(fit) # detailed summary of splits
## Call:
## rpart(formula = Y1 ~ . - label - Y1, data = data, method = "class") ## n= 30
##
## CP nsplit rel error xerror xstd
## 1 0.8888889 0 1.0000000 1.0000000 0.2788867
## 2 0.0100000 1 0.1111111 0.2222222 0.1518067
##
## Variable importance
## X4 X6 X3 Y2 X2 X8
## 23 18 16 16 14 14
##
## Node number 1: 30 observations, complexity param=0.8888889
## predicted class=空气差 expected loss=0.3 P(node) =1
## class counts: 21 9
## probabilities: 0.700 0.300
## left son=2 (20 obs) right son=3 (10 obs)
## Primary splits:
## X4 < 50 to the right, improve=10.800000, (0 missing)
## X6 < 1.45 to the right, improve=10.690910, (0 missing)
## Y2 < 74.5 to the right, improve= 8.947826, (0 missing)
## X3 < 75.5 to the right, improve= 8.917460, (0 missing)
## X2 < 35.5 to the right, improve= 7.213636, (0 missing)
## Surrogate splits:
## X6 < 1.45 to the right, agree=0.933, adj=0.8, (0 split)
数据分析算法与模型一附答案
精品文档 数据分析算法与模型模拟题(一) 一、计算题(共4题,100分) 1、影响中国人口自然增长率的因素有很多,据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据 人口自然增长率国民总收入居民消费价格指数增长人均GDP 年份(元)率((亿元) CPI(%。))% 1366 15037 1988 15.73 18.8 1519 1989 18 17001 15.04 1644 18718 1990 14.39 3.1 1893 21826 3.4 1991 12.98 2311 26937 11.6 6.4 1992 2998 35260 14.7 11.45 1993 4044 48108 1994 24.1 11.21 5046 17.1 10.55 59811 1995 5846 70142 1996 10.42 8.3 6420 10.06 1997 2.8 78061 -0.8 1998 9.14 83024 6796 8.18 7159 1999 88479 -1.4 7858 2000 0.4 7.58 98000 精品文档. 精品文档
剖析大数据分析方法论的几种理论模型
剖析大数据分析方法论的几种理论模型 做大数据分析的三大作用,主要是:现状分析、原因分析和预测分析。什么时候开展什么样的数据分析,需要根据我们的需求和目的来确定。 作者:佚名来源:博易股份|2016-12-01 19:10 收藏 分享 做大数据分析的三大作用,主要是:现状分析、原因分析和预测分析。什么时候开展什么样的数据分析,需要根据我们的需求和目的来确定。 利用大数据分析的应用案例更加细化的说明做大数据分析方法中经常用到的几种理论模型。 以营销、管理等理论为指导,结合实际业务情况,搭建分析框架,这是进行大数据分析的首要因素。大数据分析方法论中经常用到的理论模型分为营销方面的理论模型和管理方面的理论模型。 管理方面的理论模型: ?PEST、5W2H、时间管理、生命周期、逻辑树、金字塔、SMART原则等?PEST:主要用于行业分析 ?PEST:政治(Political)、经济(Economic)、社会(Social)和技术(Technological) ?P:构成政治环境的关键指标有,政治体制、经济体制、财政政策、税收政策、产业政策、投资政策、国防开支水平政府补贴水平、民众对政治的参与度等。?E:构成经济环境的关键指标有,GDP及增长率、进出口总额及增长率、利率、汇率、通货膨胀率、消费价格指数、居民可支配收入、失业率、劳动生产率等。?S:构成社会文化环境的关键指标有:人口规模、性别比例、年龄结构、出生率、死亡率、种族结构、妇女生育率、生活方式、购买习惯、教育状况、城市特点、宗教信仰状况等因素。
?T:构成技术环境的关键指标有:新技术的发明和进展、折旧和报废速度、技术更新速度、技术传播速度、技术商品化速度、国家重点支持项目、国家投入的研发费用、专利个数、专利保护情况等因素。 大数据分析的应用案例:吉利收购沃尔沃 大数据分析应用案例 5W2H分析法 何因(Why)、何事(What)、何人(Who)、何时(When)、何地(Where)、如何做(How)、何价(How much) 网游用户的购买行为: 逻辑树:可用于业务问题专题分析
数据分析建模简介
数据分析建模简介 观察和实验是科学家探究自然的主要方法,但如果你有数据,那么如何让这些数据开口说话呢?数据用现代人的话说即信息,信息的挖掘与分析也是建模的一个重要方法。 1.科学史上最有名的数据分析例子 开普勒三定律 数据来源:第谷?布拉赫(1546-1601,丹麦人),观察力极强的天文学家,一辈子(20年)观察记录了750颗行星资料,位置误差不超过0.67°。 观测数据可以视为实验模型。 数据处理:开普勒(1571-1630,德国人),身体瘦弱、近视又散光,不适合观天,但有一个非常聪明的数学头脑、坚韧的性格(甚至有些固执)和坚强的信念(宇宙是一个和谐的整体),花了16年(1596-1612)研究第谷的观测数据,得到了开普勒三定律。 开普勒三定律则为唯象模型。 2.数据分析法 2.1 思想 采用数理统计方法(如回归分析、聚类分析等)或插值方法或曲线拟合方法,对已知离散数据建模。 适用范围:系统的结构性质不大清楚,无法从理论分析中得到系统的规律,也不便于类比,但有若干能表征系统规律、描述系统状态的数据可利用。 2.2 数据分析法 2.2.1 基础知识 (1)数据也称观测值,是实验、测量、观察、调查等的结果,常以数量的形式给出; (2)数据分析(data analysis)是指分析数据的技术和理论; (3)数据分析的目的是把隐没在一大批看来杂乱无章的数据中的信息集中、萃取和提炼出来,以找出所研究对象的内在规律;
(4)作用:在实用中,它可帮助人们作判断,以采取适当行动。 (5)实际问题所涉及的数据分为: ①受到随机性影响(随机现象)的数据; ②不受随机性影响(确定现象)的数据; ③难以确定性质的数据(如灰色数据)。 (6)数理统计学是一门以收集和分析随机数据为内容的学科,目的是对数据所来自的总体作出判断,总体有一定的概率模型,推断的结论也往往一概率的形式表达(如产品检验合格率)。 (7)探索性数据分析是在尽量少的先验假定下处理数据,以表格、摘要、图示等直观的手段,探索数据的结构及检测对于某种指定模型是否有重大偏离。它可以作为进一步分析的基础,也可以对数据作出非正式的解释。 实验者常常据此扩充或修改其实验方案(作图法也该法的重要方法,如饼图、直方图、条形图、走势图或插值法、曲线(面)拟合法等)。 2.2.2 典型的数据分析工作步骤 第一步:探索性数据分析 目的:通过作图、造表、用各种形式的方程拟合、计算某些特征量等手段探索规律性的可能形式,即往什么方向和用何种方式去寻找和揭示隐含在数据中的规律性。 第二步:模型选定分析 目的:在探索性分析的基础上,提出一类或几类可能的模型(如进一步确定拟合多项式(方程)的次数和各项的系数)。 第三步:推断分析 目的:通常用数理统计或其它方法对所选定的模型或估计的可靠程度或精确程度作出推断(如统计学中的假设检验、参数估计、统计推断)。3.建模中的概率统计方法 现实世界存在确定性现象和随机现象,研究随机现象主要由随机数学来承担,随机数学包括十几个分支,但主要有概率论、数理统计、试验设计、贝叶
业绩数据分析模型(终审稿)
业绩数据分析模型 TPMK standardization office【 TPMK5AB- TPMK08- TPMK2C- TPMK18】
营销总经理的业绩数据分析模型--营销总经理的工作模型(一) 前言 营销总经理这个职位压力大而且没有安全 感——天气变化、竞品动态、本品产品质量、 公司的战略方向、费用投入、经销商的突然变 化、行业动荡、上游采购成本等等诸多因素影 响业绩。营销行业没有常胜将军,但是这个行业以成败论英雄。 营销总经理这个职位事情多而且杂乱琐碎:营销总经理要遥控管理庞大的营销团队,服务于全国几千万家经销商和终端。工作千头万绪,哪怕每天干25个小时,工作还是俄罗斯方块一样堆积。 压力和杂务干扰之下,就容易迷失,做营销总经理需要热情、能力、经验、更需要固化的可复制的工作模型,帮助自己脱身庶务,联系市场实际,提升管理绩效。 营销总经理工作模型一:数据分析模型 一、营销总经理数据分析流程概述 数据分析好像“业绩体检报告”,告诉营销总经理哪里有问题。营销总经理要每天按照固定的数据分析模型对当日发货量、累计业绩进度、发货客户数、
发货品项数、产品结构、区域结构等关键指标进行全方位多维次的实时监控。随时关注整体业绩达成的数量和质量。 如果公司整体业绩分析没问题就下延看区域业绩有没问题,没问题就结束分析。如果公司整体业绩有问题;就要思考有没有特殊原因——比如:天气下雨造成三天发货量下滑,天晴后业绩会恢复。公司上半月集中力量乡镇市场压货,所以低价产品业绩上升高价产品业绩下滑是计划内正常现象。如果没有特殊原因,确实属于业绩异常,就要立刻从这个指标着手深度分析:通常是从产品、区域、客户三条主线来研究。发现问题产品(哪个产品需要重点管理)、发现问题区域(哪个区域需要重点巡查)、发现问题客户(哪个重点零售ka系统重点经销商的业绩不正常)。除非问题非常严重,一般营销总经理的数据分析下延到直接下级(大区或者省区层面)即可,然后要求问题区域的大区经理做出解释,拿出整改方案。大区省区经理再做区域内数据分析,寻找问题产品、问题片区和问题经销商。 数据分析得出结论就找到了管理重点,接下来营销总经理要采取针对性有的放失的管理动作——比如立刻去巡检重点问题区域、要求问题区域限期改善、更改当月的促销投入或者产品价格、设立新的工作任务(比如乡镇铺货)等等,整个分析流程图示如下:
数据分析和数据建模
数据分析和数据建模 大数据应用有几个方面,一个是效率提升,帮助企业提升数据处理效率,降低数据存储成本。另外一个是对业务作出指导,例如精准营销,反欺诈,风险管理以及业务提升。过去企业都是通过线下渠道接触客户,客户数据不全,只能利用财务数据进行业务运营分析,缺少围绕客户的个人数据,数据分析应用的领域集中在企业内部经营和财务分析。 大数据应用有几个方面,一个是效率提升,帮助企业提升数据处理效率,降低数据存储成本。另外一个是对业务作出指导,例如精准营销,反欺诈,风险管理以及业务提升。过去企业都是通过线下渠道接触客户,客户数据不全,只能利用财务数据进行业务运营分析,缺少围绕客户的个人数据,数据分析应用的领域集中在企业内部经营和财务分析。 数字时代到来之后,企业经营的各个阶段都可以被记录下来,产品销售的各个环节也被记录下来,客户的消费行为和网上行为都被采集下来。企业拥有了多维度的数据,包括产品销售数据、客户消费数据、客户行为数据、企业运营数据等。拥有数据之后,数据分析成为可能,企业成立了数据分析团队整理数据和建立模型,找到商品和客户之间的关联关系,商品之间关联关系,另外也找到了收入和客户之间的关联关系。典型的数据分析案例如沃尔玛啤酒和尿布、蛋挞和手电筒,Target的判断16岁少女怀孕都是这种关联关系的体现。
关联分析是统计学应用最早的领域,早在1846年伦敦第二次霍乱期间,约翰医生利用霍乱地图找到了霍乱的传播途径,平息了伦敦霍乱,打败了霍乱源于空气污染说的精英,拯救了几万人的生命。伦敦霍乱平息过程中,约翰医生利用了频数分布分析,建立了霍乱地图,从死亡案例分布的密集程度上归纳出病人分布同水井的关系,从而推断出污染的水源是霍乱的主要传播途径,建议移除水井手柄,降低了霍乱发生的概率。 另外一个典型案例是第二次世界大战期间,统计分析学家改造轰炸机。英美联盟从1943年开始对德国的工业城市进行轰炸,但在1943年年底,轰炸机的损失率达到了英美联盟不能承受的程度。轰炸军司令部请来了统计学家,希望利用数据分析来改造轰炸机的结构,降低阵亡率,提高士兵生还率。统计学家利用大尺寸的飞机模型,详细记录了返航轰炸机的损伤情况。统计学家在飞机模型上将轰炸机受到攻击的部位用黑笔标注出来,两个月后,这些标注布满了机身,有的地方标注明显多于其他地方,例如机身和侧翼。有的地方的标注明显少于其他地方,例如驾驶室和发动机。统计学家让军火商来看这个模型,军火商认为应该加固受到更多攻击的地方,但是统计学家建议对标注少的地方进行加固,标注少的原因不是这些地方不容易被击中,而是被击中的这些地方的飞机,很多都没有返航。这些标注少的地方被击中是飞机坠毁的一个主要原因。军火商按照统计学家的建议进行了飞机加固,大大提高了轰炸机返航的比率。以二战著名的B-17轰炸机为例,其阵亡率由26%降到了7%,帮助美军节约了几亿美金,大大提高了士兵的生还率。 一数据分析中的角色和职责 数据分析团队应该在科技部门内部还在业务部门内部一直存在争议。在业务部门内部,对数据场景比较了解,容易找到数据变现的场景,数据分析对业务提升帮助较大,容易出成绩。但是弊端是仅仅对自己部门的业务数据了解,分析只是局限独立的业务单元之内,在数据获取的效率上,数据维度和数据视角方面缺乏全局观,数据的商业视野不大,对公司整体业务的推动发展有限。业务部门的数据分析团队缺少数据技术能力,无法利用最新的大数据计算和分析技术,来实现数
【数据分析技术系列】之用户画像数据建模方法
【数据分析技术系列】 之用户画像数据建模方法 目录 一、什么是用户画像? (1) 二、为什么需要用户画像 (1) 三、如何构建用户画像 (2) 3.1数据源分析 (2) 静态信息数据 (3) 动态信息数据 (3) 3.2目标分析 (3) 3.3数据建模方法 (4) 四、总结: (6)
从1991年Tim Berners-Lee发明了万维网(World Wide Web)开始到2011年,互联网真正走向了一个新的里程碑,进入了“大数据时代”。经历了12、13两年热炒之后,人们逐渐冷静下来,更加聚焦于如何利用大数据挖掘潜在的商业价值,如何在企业中实实在在的应用大数据技术。伴随着大数据应用的讨论、创新,个性化技术成为了一个重要落地点。相比传统的线下会员管理、问卷调查、购物篮分析,大数据第一次使得企业能够通过互联网便利地获取用户更为广泛的反馈信息,为进一步精准、快速地分析用户行为习惯、消费习惯等重要商业信息,提供了足够的数据基础。伴随着对人的了解逐步深入,一个概念悄然而生:用户画像(UserProfile),完美地抽象出一个用户的信息全貌,可以看作企业应用大数据的根基。 一、什么是用户画像? 男,31岁,已婚,收入1万以上,爱美食,团购达人,喜欢红酒配香烟。 这样一串描述即为用户画像的典型案例。如果用一句话来描述,即:用户信息标签化。 如果用一幅图来展现,即: 二、为什么需要用户画像 用户画像的核心工作是为用户打标签,打标签的重要目的之一是为了让人能够理解并且方便计算机处理,如,可以做分类统计:喜欢红酒的用户有多少?喜
欢红酒的人群中,男、女比例是多少?也可以做数据挖掘工作:利用关联规则计算,喜欢红酒的人通常喜欢什么运动品牌?利用聚类算法分析,喜欢红酒的人年龄段分布情况? 大数据处理,离不开计算机的运算,标签提供了一种便捷的方式,使得计算机能够程序化处理与人相关的信息,甚至通过算法、模型能够“理解” 人。当计算机具备这样的能力后,无论是搜索引擎、推荐引擎、广告投放等各种应用领域,都将能进一步提升精准度,提高信息获取的效率。 三、如何构建用户画像 一个标签通常是人为规定的高度精炼的特征标识,如年龄段标签:25~35岁,地域标签:北京,标签呈现出两个重要特征:语义化,人能很方便地理解每个标签含义。这也使得用户画像模型具备实际意义。能够较好的满足业务需求。如,判断用户偏好。短文本,每个标签通常只表示一种含义,标签本身无需再做过多文本分析等预处理工作,这为利用机器提取标准化信息提供了便利。 人制定标签规则,并能够通过标签快速读出其中的信息,机器方便做标签提取、聚合分析。所以,用户画像,即:用户标签,向我们展示了一种朴素、简洁的方法用于描述用户信息。 3.1 数据源分析 构建用户画像是为了还原用户信息,因此数据来源于:所有用户相关的数据。 对于用户相关数据的分类,引入一种重要的分类思想:封闭性的分类方式。如,世界上分为两种人,一种是学英语的人,一种是不学英语的人;客户分三类,高价值客户,中价值客户,低价值客户;产品生命周期分为,投入期、成长期、成熟期、衰退期…所有的子分类将构成了类目空间的全部集合。 这样的分类方式,有助于后续不断枚举并迭代补充遗漏的信息维度。不必担心架构上对每一层分类没有考虑完整,造成维度遗漏留下扩展性隐患。另外,不同的分类方式根据应用场景,业务需求的不同,也许各有道理,按需划分即可。 本文将用户数据划分为静态信息数据、动态信息数据两大类。
数学建模步骤
数学建模的基本步骤 一、数学建模题目 1)以社会,经济,管理,环境,自然现象等现代科学中出现的新问题为背景,一般都有一个比较确切的现实问题。 2)给出若干假设条件: 1. 只有过程、规则等定性假设; 2. 给出若干实测或统计数据; 3. 给出若干参数或图形等。 根据问题要求给出问题的优化解决方案或预测结果等。根据问题要求题目一般可分为优化问题、统计问题或者二者结合的统计优化问题,优化问题一般需要对问题进行优化求解找出最优或近似最优方案,统计问题一般具有大量的数据需要处理,寻找一个好的处理方法非常重要。 二、建模思路方法 1、机理分析根据问题的要求、限制条件、规则假设建立规划模型,寻找合适的寻优算法进行求解或利用比例分析、代数方法、微分方程等分析方法从基本物理规律以及给出的资料数据来推导出变量之间函数关系。 2、数据分析法对大量的观测数据进行统计分析,寻求规律建立数学模型,采用的分析方法一般有: 1). 回归分析法(数理统计方法)-用于对函数f(x)的一组观测值(xi,fi)i=1,2,…,n,确定函数的表达式。 2). 时序分析法--处理的是动态的时间序列相关数据,又称为过程统计方法。 3)、多元统计分析(聚类分析、判别分析、因子分析、主成分分析、生存数据分析)。 3、计算机仿真(又称统计估计方法):根据实际问题的要求由计算机产生随机变量对动态行为进行比较逼真的模仿,观察在某种规则限制下的仿真结果(如蒙特卡罗模拟)。 三、模型求解: 模型建好了,模型的求解也是一个重要的方面,一个好的求解算法与一个合
适的求解软件的选择至关重要,常用求解软件有matlab,mathematica,lingo,lindo,spss,sas等数学软件以及c/c++等编程工具。 Lingo、lindo一般用于优化问题的求解,spss,sas一般用于统计问题的求解,matlab,mathematica功能较为综合,分别擅长数值运算与符号运算。 常用算法有:数据拟合、参数估计、插值等数据处理算法,通常使用spss、sas、Matlab作为工具. 线性规划、整数规划、多元规划、二次规划、动态规划等通常使用Lindo、Lingo,Matlab软件。 图论算法,、回溯搜索、分治算法、分支定界等计算机算法, 模拟退火法、神经网络、遗传算法。 四、自学能力和查找资料文献的能力: 建模过程中资料的查找也具有相当重要的作用,在现行方案不令人满意或难以进展时,一个合适的资料往往会令人豁然开朗。常用文献资料查找中文网站:CNKI、VIP、万方。 五、论文结构: 0、摘要 1、问题的重述,背景分析 2、问题的分析 3、模型的假设,符号说明 4、模型的建立(局部问题分析,公式推导,基本模型,最终模型等) 5、模型的求解 6、模型检验:模型的结果分析与检验,误差分析 7、模型评价:优缺点,模型的推广与改进 8、参考文献 9、附录 六、需要重视的问题 数学建模的所有工作最终都要通过论文来体现,因此论文的写法至关重要:
业绩数据分析模型
营销总经理的业绩数据分析模型--营销总经理的工作模型(一) 前言 营销总经理这个职位压力大而且没有安全感—— 天气变化、竞品动态、本品产品质量、公司的战略方向、 费用投入、经销商的突然变化、行业动荡、上游采购成 本等等诸多因素影响业绩。营销行业没有常胜将军,但 是这个行业以成败论英雄。 营销总经理这个职位事情多而且杂乱琐碎:营销总 经理要遥控管理庞大的营销团队,服务于全国几千万家 经销商和终端。工作千头万绪,哪怕每天干25个小时, 工作还是俄罗斯方块一样堆积。 压力和杂务干扰之下,就容易迷失,做营销总经理需要热情、能力、经验、更需要固化的可复制的工作模型,帮助自己脱身庶务,联系市场实际,提升管理绩效。 营销总经理工作模型一:数据分析模型 一、营销总经理数据分析流程概述 数据分析好像“业绩体检报告”,告诉营销总经理哪里有问题。营销总经理要每天按照固定的数据分析模型对当日发货量、累计业绩进度、发货客户数、发货品项数、产品结构、区域结构等关键指标进行全方位多维次的实时监控。随时关注整体业绩达成的数量和质量。 如果公司整体业绩分析没问题就下延看区域业绩有没问题,没问题就结束分析。如果公司整体业绩有问题;就要思考有没有特殊原因——比如:天气下雨造成三天发货量下滑,天晴后业绩会恢复。公司上半月集中力量乡镇市场压货,所以低价产品业绩上升高价产品业绩下滑是计划内正常现象。如果没有特殊原因,确实属于业绩异常,就要立刻从这个指标着手深度分析:通常是从产品、区域、客户三条主线来研究。发现问题产品(哪个产品需要重点管理)、发现问题区域(哪个区域需要重点巡查)、发现问题客户(哪个重点零售ka系统重点经销商的业绩不正常)。除非问题非常严重,一般营销总经理的数据分析下延到直接下级(大区或者省区层面)即可,然后要求问题区域的大区经理做出解释,拿出整改方案。大区省区经理再做区域内数据分析,寻找问题产品、问题片区和问题经销商。 数据分析得出结论就找到了管理重点,接下来营销总经理要采取针对性有的放失的管理动作——比如立刻去巡检重点问题区域、要求问题区域限期改善、更改当月的促销投入或者产品价格、设立新的工作任务(比如乡镇铺货)等等,整个分析流程图示如下:
空间数据分析模型
第7 章空间数据分析模型 7.1 空间数据 按照空间数据的维数划分,空间数据有四种基本类型:点数据、线数据、面数据和体数据。 点是零维的。从理论上讲,点数据可以是以单独地物目标的抽象表达,也可以是地理单元的抽象表达。这类点数据种类很多,如水深点、高程点、道路交叉点、一座城市、一个区域。 线数据是一维的。某些地物可能具有一定宽度,例如道路或河流,但其路线和相对长度是主要特征,也可以把它抽象为线。其他的 线数据,有不可见的行政区划界,水陆分界的岸线,或物质运输或思想传播的路线等。 面数据是二维的,指的是某种类型的地理实体或现象的区域范围。国家、气候类型和植被特征等,均属于面数据之列。 真实的地物通常是三维的,体数据更能表现出地理实体的特征。一般而言,体数据被想象为从某一基准展开的向上下延伸的数,如 相对于海水面的陆地或水域。在理论上,体数据可以是相当抽象的,如地理上的密度系指单位面积上某种现象的许多单元分布。 在实际工作中常常根据研究的需要,将同一数据置于不同类别中。例如,北京市可以看作一个点(区别于天津),或者看作一个面 (特殊行政区,区别于相邻地区),或者看作包括了人口的“体”。 7.2 空间数据分析 空间数据分析涉及到空间数据的各个方面,与此有关的内容至少包括四个领域。 1)空间数据处理。空间数据处理的概念常出现在地理信息系统中,通常指的是空间分析。就涉及的内容而言,空间数据处理更多的偏重于空间位置及其关系的分析和管理。 2)空间数据分析。空间数据分析是描述性和探索性的,通过对大量的复杂数据的处理来实现。在各种空间分析中,空间数据分析是 重要的组成部分。空间数据分析更多的偏重于具有空间信息的属性数据的分析。 3)空间统计分析。使用统计方法解释空间数据,分析数据在统计上是否是“典型”的,或“期望”的。与统计学类似,空间统计分析与空间数据分析的内容往往是交叉的。 4)空间模型。空间模型涉及到模型构建和空间预测。在人文地理中,模型用来预测不同地方的人流和物流,以便进行区位的优化。在自然地理学中,模型可能是模拟自然过程的空间分异与随时间的变化过程。空间数据分析和空间统计分析是建立空间模型的基础。 7.3 空间数据分析的一些基本问题 空间数据不仅有其空间的定位特性,而且具有空间关系的连接属性。这些属性主要表现为空间自相关特点和与之相伴随的可变区域 单位问题、尺度和边界效应。传统的统计学方法在对数据进行处理时有一些基本的假设,大多都要求“样本是随机的”,但空间数据可能不一定能满足有关假设,因此,空间数据的分析就有其特殊性(David,2003 )。
数据分析算法与模型(一)(附答案)
数据分析算法与模型模拟题(一) 一、计算题(共4题,100分) 1、影响中国人口自然增长率的因素有很多,据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据 年份人口自然增长率 (%。) 国民总收入 (亿元) 居民消费价格指数增长 率(CPI)% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040
数学建模各种分析方法
现代统计学 1.因子分析(Factor Analysis) 因子分析的基本目的就是用少数几个因子去描述许多指标或因素之间的联系,即将相关比较密切的几个变量归在同一类中,每一类变量就成为一个因子(之所以称其为因子,是因为它是不可观测的,即不是具体的变量),以较少的几个因子反映原资料的大部分信息。 运用这种研究技术,我们可以方便地找出影响消费者购买、消费以及满意度的主要因素是哪些,以及它们的影响力(权重)运用这种研究技术,我们还可以为市场细分做前期分析。 2.主成分分析 主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的。主成分分析一般很少单独使用:a,了解数据。(screening the data),b,和cluster analysis一起使用,c,和判别分析一起使用,比如当变量很多,个案数不多, 直接使用判别分析可能无解,这时候可以使用主成份发对变量简化。(reduce dimensionality)d,在多元回归中,主成分分析可以帮助判断是否存在共线性(条件指数),还可以用来处理共线性。 主成分分析和因子分析的区别 1、因子分析中是把变量表示成各因子的线性组合,而主成分分析中则是把主成分表示成个变量的线性组合。 2、主成分分析的重点在于解释个变量的总方差,而因子分析则把重点放在解释各变量之间的协方差。 3、主成分分析中不需要有假设(assumptions),因子分析则需要一些假设。因子 分析的假设包括:各个共同因子之间不相关,特殊因子(specific factor)之间 也不相关,共同因子和特殊因子之间也不相关。 4、主成分分析中,当给定的协方差矩阵或者相关矩阵的特征值是唯一的时候,的主成分一般是独特的;而因子分析中因子不是独特的,可以旋转得到不同的因子。 5、在因子分析中,因子个数需要分析者指定(spss根据一定的条件自动设定,只要是特征值大于1的因子进入分析),而指定的因子数量不同而结果不同。在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分。 和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势。大致说来,当需要寻找潜在的因子,并对这些因子进行解释的时候,更加倾向于使用因子分析,并且借助旋转技术帮助更好解释。而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这中情况也可以使用因子得分做到。所以这中区分不是绝对的。 总得来说,主成分分析主要是作为一种探索性的技术,在分析者进行多元数据分析之前,用主成分分析来分析数据,让自己对数据有一个大致的了解是非常重要的。主成分分析一般很少单独使用:a,了解数据。(screening the data),b,
10大经典数据分析模型
模型分析法就是依据各种成熟的、经过实践论证的管理模型对 问题进行分析的方法。 在长时间的企业管理理论研究和实践过程中,将企业经营管理中一些经典的相关关系以一个固定模型的方式描述出来,揭示企业系统内部很多本质性的关系,供企业用来分析自己的经营管理状况,针对企业管理出现的不同问题,能采用最行之有效的模型分析 往往可以事半功倍。 1、波特五种竞争力分析模型 波特的五种竞争力分析模型被广泛应用于很多行业的战略制定。波特认为在任何行业中,无论是国内还是国际,无论是提供产品还是提供服务,竞争的规则都包括在五种竞争力量内。 这五种竞争力就是 1.企业间的竞争 2.潜在新竞争者的进入 3.潜在替代品的开发 4.供应商的议价能力 5.购买者的议价能力 这五种竞争力量决定了企业的盈利能力和水平。 竞争对手
企业间的竞争是五种力量中最主要的一种。只有那些比竞争对手的战略更具优势的战略才可能获得成功。为此,公司必须在市场、价格、质量、产量、功能、服务、研发等方面建立自己的核心竞争优势。 影响行业内企业竞争的因素有:产业增加、固定(存储)成本/附加价值周期性生产过剩、产品差异、商标专有、转换成本、集中与平衡、信息复杂性、竞争者的多样性、公司的风险、退出壁垒等。 新进入者 企业必须对新的市场进入者保持足够的警惕,他们的存在将使企业做出相应的反应,而这样又不可避免地需要公司投入相应的资源。 影响潜在新竞争者进入的因素有:经济规模、专卖产品的差别、商标专有、资本需求、分销渠道、绝对成本优势、政府政策、行业内企业的预期反击等。 购买者 当用户分布集中、规模较大或大批量购货时,他们的议价能力将成为影响产业竞争强度的一个主要因素。 决定购买者力量的因素又:买方的集中程度相对于企业的集中程度、买方的数量、买方转换成本相对企业转换成本、买方信息、后向整合能力、替代品、克服危机的能力、价格/购买总量、产品差异、品牌专有、质量/性能影响、买方利润、决策者的激励。 替代产品 在很多产业,企业会与其他产业生产替代品的公司开展直接或间接的斗争。替代品的存在为产品的价格设置了上限,当产品价格超过这一上限时,用户将转向其他替代产品。 决定替代威胁的因素有:替代品的相对价格表现、转换成本、客户对替代品的使用倾向。 供应商 供应商的议价力量会影响产业的竞争程度,尤其是当供应商垄断程度比较高、原材料替代品比较少,或者改用其他原材料的转换成本比较高时更是如此。 决定供应商力量的因素有:投入的差异、产业中供方和企业的转换成本、替代品投入的现状、供方的集中程度、批量大小对供方的重要性、与产业总购买量的相关成本、投入对成本和特色的影响、产业中企业前向整合相对于后向整合的威胁等。 2、SWOT分析模型
产品数据分析建模方案
产品数据分析建模方案 一、概述 建设背景 对于企业在人才管理上的问题:不能有效的发现自己的人才储备落后于行业的发展,在职员工可能存在上面异常的方面,更好的规划薪酬范围,让员工在个人岗位上获得满足感。依据能力制定合理的薪酬范围。依据行业画像,个人能力画像,提供分层数据,做决策展示。项目经理对人才的选拔。 建设目标 通过建立大数据体系下的数据挖掘平台,分析业务数据,为我们的客户提供更好的决策,并开发可视化模块,将结果展示给我们的客户,并且确定经营方向,做好推广工作。 二、需求分析 数据来源 主要的数据来源之一是现有的数据库数据,接通到大数据平台进行分析,还有一部分外部数据,使用爬虫爬的数据,实时更新每日的趋势展示,另外一部分从业者的信息,能否通过购买其它合作企业的信息,满足分析需求。 数据提取整体思路,算法需求设计 行业信息展示的数据提取,主要是为了展示某职位在行业的各个特征维度下的占比,比方说以地域来划分行业对当前职业的需求饼
图。某职位在每个行业的每日需求趋势。每个行业对某主要需求的职位的技能词云统计。洞悉趋势 薪酬预测的数据,需要职位的分类信息,以及每个分类下的每日整体数据,包括最大值,最小值,平均值。以预测这一部分数据为指导,通过数据分析是手段,找到相关的特征信息,比方说,每日上线的从业者,每日简历的更新次数,发布新需求的企业个数等等作为特征,由数据挖掘工程师进行抽取。人才倾斜,造成竞争力处于行业底层 客户画像展示将从业者对当前行业投递的简历信息聚合,进行多维度的展示,并对聚集的数据,进行算法分层,提供一个标签输入栏,输入标签数据,获得从业者在分层系统。客户当前的行业画像展示,由人才构成图,工资趋势,行业的趋势,每年发布招聘的行业个数的变化,新公司名称的个数。行业招的岗位分布情况。 三、建设方案 数据挖掘算法系统框架图参考
数据分析及建模实验报告.doc
学生学号实验课成绩 学生实验报告书 实验课程名称数据分析与建模 开课学院 指导教师姓名 学生姓名 学生专业班级 2015 —2016 学年第 1 学期
实验报告填写规范 1、实验是培养学生动手能力、分析解决问题能力的重要环节;实验报告是反映实验教学水 平与质量的重要依据。为加强实验过程管理,改革实验成绩考核方法,改善实验教学效果,提高学生质量,特制定本实验报告书写规范。 2、本规范适用于管理学院实验课程。 3、每门实验课程一般会包括许多实验项目,除非常简单的验证演示性实验项目可以不写实 验报告外,其他实验项目均应按本格式完成实验报告。在课程全部实验项目完成后,应按学生姓名将各实验项目实验报告装订成册,构成该实验课程总报告,并给出实验课程成绩。 4、学生必须依据实验指导书或老师的指导,提前预习实验目的、实验基本原理及方法,了 解实验内容及方法,在完成以上实验预习的前提下进行实验。教师将在实验过程中抽查学生预习情况。 5、学生应在做完实验后三天内完成实验报告,交指导教师评阅。 6、教师应及时评阅学生的实验报告并给出各实验项目成绩,同时要认真完整保存实验报 告。在完成所有实验项目后,教师应将批改好的各项目实验报告汇总、装订,交课程承担单位(实验中心或实验室)保管存档。
画出图形 由图x=4时,y最大等于1760000 (2)求关于所做的15%假设的灵敏性 粗分析: 假设C=1000 即给定r y=f(x)=(1500-100x)1000(1+rx)=-100000rx^2+1500000rx-100000x+1500000 求导,f’(x)=-200000rx+1500000r-100000,令f’(x)=0,可得相应x值,x=(15r-1)/2r Excel画出相应图形
数据分析与数据建模.doc
数据分析与数据建模 ——信息资源规划(IRP)系列讲座之六 我们前面讲的信息资源规划“建立两种模型和一套标准”的工作,是分两个阶段完成的:第一阶段需求分析,第二阶段系统建模。上一讲介绍功能需求分析和建模,这一讲介绍数据需求分析和建模。 从用户视图开始的数据需求分析 我们讲过,用户视图(User View)是一些数据的集合,它反应了最终用户对数据实体的看法,包括单证、报表、账册和屏幕格式等。威廉·德雷尔(William Durell)主张基于用户视图做数据需求分析,认为所谓的“数据流”实际上就是用户视图的流动。采用这一思路进行数据需求分析,可大大简化传统的实体-关系(E-R)分析方法,有利于发挥业务分析员的知识经验。 用户视图的分析过程,就是调查研究和规范化表达用户视图的过程,包括掌握用户视图的标识、名称、流向等概要信息和用户视图的组成信息。例如,用户视图标识“D041309”是按一定的规则编码的,其名称是“材料申报单”,而其组成是: 序号数据项/元素名称数据项/元素定义 01 NY 年月 02 DWBM 单位编码 03 CLBM 材料编码 04 SL 数量 05 YTDM 用途代码 一个制造厂的人力资源、生产管理、物资采购、产品销售等职能域,一般都有几十个至几百个用户视图,一个制造厂的人力资源、生产管理、物资采购、产品销售等职能域,一般都有几十个至几百个用户视图,对它们进行如上例的分析和规范化表述,实际上是一次从未做过的、工作量较大的数据流梳理的基础工作,对全面把握信息需求有重要意义。尤其系统分析设计人员在业务人员提供所需的信息内容的基础上,按照数据结构规范化理论,对需要存储的用户视图结构做标准化的“范式”重新组织,可以直接为数据库的规划设计做好准备。
【数据分析技术系列】之数据建模的几大模式
【数据分析技术系列】 之数据建模的几大模式 目录 第一,目标律:业务目标是所有数据解决方案的源头。 (1) 第二,知识律:业务知识是数据挖掘过程每一步的核心。 (1) 第三,准备律:数据预处理比数据挖掘其他任何一个过程都重要。 2第四,试验律(NFL律:NO FREE LUNCH):对于数据挖掘者来说,天下没有免费的午餐,一个正确的模型只有通过试验(EXPERIMENT)才能被发现。 (3) 第五,模式律(大卫律):数据中总含有模式。 (4) 第六,洞察律:数据挖掘增大对业务的认知。 (5) 第七,预测律:预测提高了信息泛化能力。 (6) 第八,价值律:数据挖掘的结果的价值不取决于模型的稳定性或预测的准确性。 (6) 第九,变化律:所有的模式因业务变化而变化。 (7)
数据建模指的是对现实世界各类数据的抽象组织,确定数据库需管辖的范围、数据的组织形式等直至转化成现实的数据库。将经过系统分析后抽象出来的概念模型转化为物理模型后,在visio或erwin等工具建立数据库实体以及各实体之间关系的过程。数据挖掘是利用业务知识从数据中发现和解释知识(或称为模式)的过程,这种知识是以自然或者人工形式创造的新知识。 当前的数据挖掘形式,是在20世纪90年代实践领域诞生的,是在集成数据挖掘算法平台发展的支撑下适合商业分析的一种形式。也许是因为数据挖掘源于实践而非理论,在其过程的理解上不太引人注意。20世纪90年代晚期发展的跨行业数据挖掘标准流程,逐渐成为数据挖掘过程的一种标准化过程,被越来越多的数据挖掘实践者成功运用和遵循。 虽然‘跨行业数据挖掘标准流程’能够指导如何实施数据挖掘,但是它不能解释数据挖掘是什么或者为什么适合这样做。在本文中将阐述提出数据挖掘的九种准则或“定律”以及另外其它一些熟知的解释。开始从理论上来解释数据挖掘过程。 第一,目标律:业务目标是所有数据解决方案的源头。 定义了数据挖掘的主题:数据挖掘关注解决业务业问题和实现业务目标。数据挖掘主要不是一种技术,而是一个过程,业务目标是它的的核心。没有业务目标,没有数据挖掘(不管这种表述是否清楚)。因此这个准则也可以说成:数据挖掘是业务过程。 第二,知识律:业务知识是数据挖掘过程每一步的核心。 这里定义了数据挖掘过程的一个关键特征。CRISP-DM的一种朴素的解读是业务知识仅仅作用于数据挖掘过程开始的目标的定义与最后的结果的实施,这将错过数据挖掘过程的一个关键属性,即业务知识是每一步的核心。 商业理解必须基于业务知识,所以数据挖掘目标必须是业务目标的映射(这种映射也基于数据知识和数据挖掘知识); 数据理解使用业务知识理解与业务问题相关的数据,以及它们是如何相关的; 数据预处理就是利用业务知识来塑造数据,使得业务问题可以被提出和解答(更详尽的第三条—准备律); 建模是使用数据挖掘算法创建预测模型,同时解释模型和业务目标的特点,也就是说理解它们之间的业务相关性; 评估是模型对理解业务的影响; 实施是将数据挖掘结果作用于业务过程。
利用大数据分析应用案例剖析大数据分析方法论的几种理论模型
利用大数据分析应用案例剖析大数据分析方法论的几种理论模型 做大数据分析的三大作用,主要是:现状分析、原因分析和预测分析。什么时候开展什么样的数据分析,需要根据我们的需求和目的来确定。 利用大数据分析的应用案例更加细化的说明做大数据分析方法中经常用到的几种理论模型。以营销、管理等理论为指导,结合实际业务情况,搭建分析框架,这是进行大数据分析的首要因素。大数据分析方法论中经常用到的理论模型分为营销方面的理论模型和管理方面的理论模型。 管理方面的理论模型: PEST、5W2H、时间管理、生命周期、逻辑树、金字塔、SMART原则等 PEST:主要用于行业分析 PEST:政治(Political)、经济(Economic)、社会(Social)和技术(Technological)P:构成政治环境的关键指标有,政治体制、经济体制、财政政策、税收政策、产业政策、投资政策、国防开支水平政府补贴水平、民众对政治的参与度等。 E:构成经济环境的关键指标有,GDP及增长率、进出口总额及增长率、利率、汇率、通货膨胀率、消费价格指数、居民可支配收入、失业率、劳动生产率等。 S:构成社会文化环境的关键指标有:人口规模、性别比例、年龄结构、出生率、死亡率、种族结构、妇女生育率、生活方式、购买习惯、教育状况、城市特点、宗教信仰状况等因素。T:构成技术环境的关键指标有:新技术的发明和进展、折旧和报废速度、技术更新速度、技术传播速度、技术商品化速度、国家重点支持项目、国家投入的研发费用、专利个数、专利保护情况等因素。 大数据应用案例:沃尔玛
5W2H分析法 何因(Why)、何事(What)、何人(Who)、何时(When)、何地(Where)、如何做(How)、何价(How much) 网游用户的购买行为:
数据分析_最常用的数据分析模型
https://www.360docs.net/doc/7610946751.html, 数据分析_最常用的数据分析模型 数据分析_最常用的数据分析模型。光环大数据了解到,随着数据的重要性的凸显,越来越多的公司已经认识到数据对于公司的经营是十分重要的。所以绝大部分企业都有专门的BI部门进行初步的数据加工、分析,以周报表的形式汇总给管理层做为日常数据所需以及企业决策使用。 为大家介绍两个最常用的数据分析模型。 AARRR模型: Acquisition(获取)、Activation(活跃)、Retention(留存)、Revenue(收益)、Refer(传播) 获取用户(Acquisition) 如何获取用户?线上通过网站通过SEO,SEM,app通过市场首发、ASO等方式获取。还有运营活动的H5页面,自媒体等方式。线下通过地推和传单进行获取用户。 提高活跃度(Activation) 来了用户后,通过运营价格优惠、编辑内容等方式进行提高活跃度。把内容做多,商品做多,价格做到优惠,但需要控制在成本至上的有生长空间。这样的用户是最有价值进行活跃。 产品策略上,除了提供运营模块和内容深化。进行产品会员激励机制成长体制进行活跃用户。不仅商品优惠的,VIP等标示的ICON,对于长业务流程,进行流程激励体制,产品策略更具多元化。
https://www.360docs.net/doc/7610946751.html, 提高留存率(Retention) 提高活跃度的,有了忠实的用户,就开始慢慢沉淀下来了。运营上,采用内容,相互留言等社区用户共建UCG,摆脱初期的PCG模式。电商通过商品质量,O2O通过优质服务提高留存。这些都是业务层面的提高留存。 产品模式上,通过会员机制的签到和奖励的机制去提高留存。包括app推送和短信激活方式都是激活用户,提高留存的产品方式。 通过日留存率、周留存率、月留存率等指标监控应用的用户流失情况,并采取相应的手段在用户流失之前,激励这些用户继续使用应用。 获取收入(Revenue) 获取收入其实是应用运营最核心的一块。即使是免费应用,也应该有其盈利的模式。 收入来源主要有三种:付费应用、应用内付费、以及广告。付费应用在国内的接受程度很低,包括GooglePlayStore在中国也只推免费应用。在国内,广告是大部分开发者的收入来源,而应用内付费目前在游戏行业应用比较多。 前面所提的提高活跃度、提高留存率,对获取收入来说,是必需的基础。用户基数大了,收入才有可能上量。 自传播(Refer) 以前的运营模型到第四个层次就结束了,但是社交网络的兴起,使得运营增加了一个方面,就是基于社交网络的病毒式传播,这已经成为获取用户的一个新途径。这个方式的成本很低,而且效果有可能非常好;唯一的前提是产品自身要足够好,有很好的口碑。