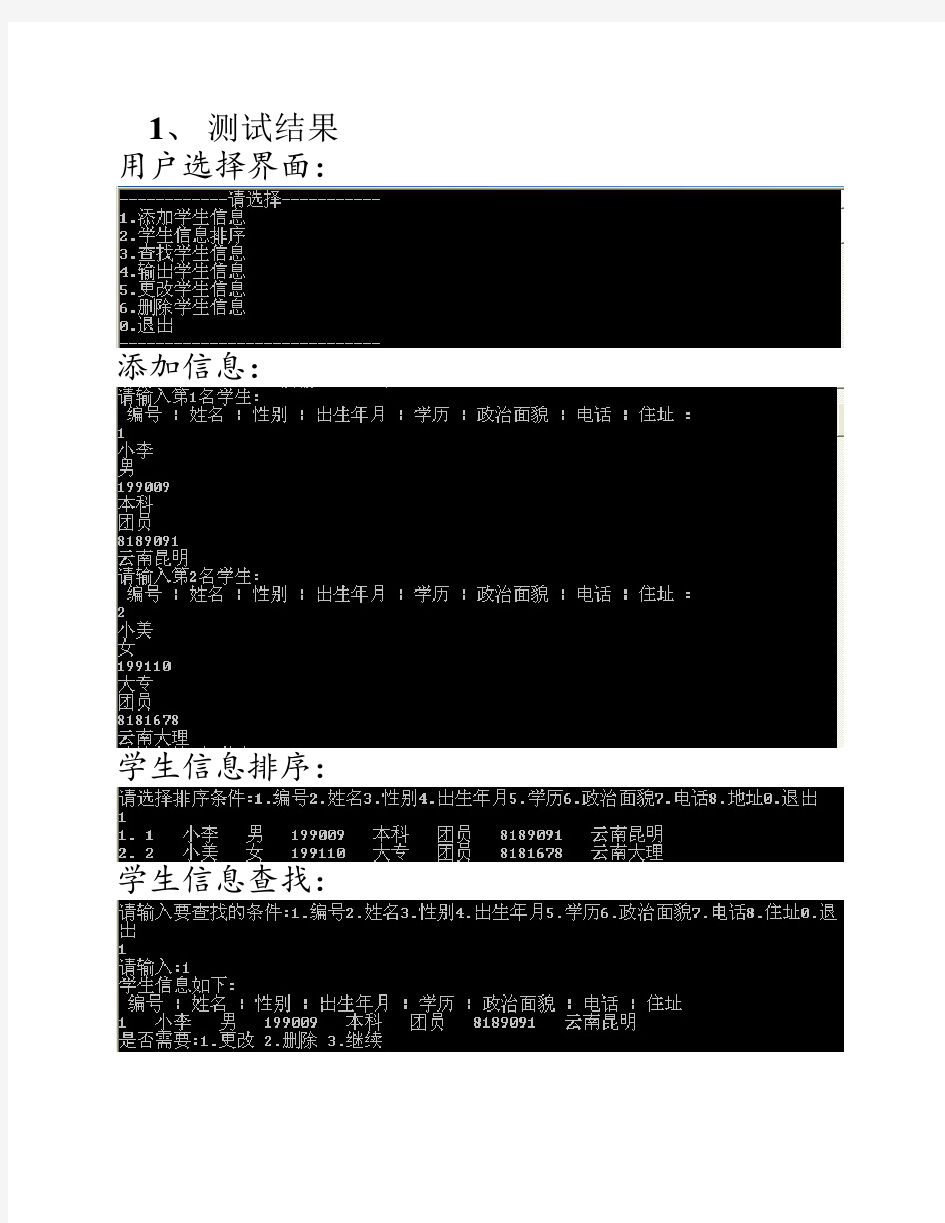
查找算法的设计与实现

《计算机算法设计与分析》习题及答案
《计算机算法设计与分析》习题及答案 一.选择题 1、二分搜索算法是利用( A )实现的算法。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 2、下列不是动态规划算法基本步骤的是( A )。 A、找出最优解的性质 B、构造最优解 C、算出最优解 D、定义最优解 3、最大效益优先是(A )的一搜索方式。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 4. 回溯法解旅行售货员问题时的解空间树是( A )。 A、子集树 B、排列树 C、深度优先生成树 D、广度优先生成树 5.下列算法中通常以自底向上的方式求解最优解的是(B )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法 6、衡量一个算法好坏的标准是( C )。 A 运行速度快 B 占用空间少 C 时间复杂度低 D 代码短 7、以下不可以使用分治法求解的是( D )。 A 棋盘覆盖问题 B 选择问题 C 归并排序 D 0/1背包问题 8. 实现循环赛日程表利用的算法是(A )。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 9.下面不是分支界限法搜索方式的是(D )。 A、广度优先 B、最小耗费优先 C、最大效益优先 D、深度优先 10.下列算法中通常以深度优先方式系统搜索问题解的是(D )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法
11.备忘录方法是那种算法的变形。( B ) A、分治法 B、动态规划法 C、贪心法 D、回溯法 12.哈夫曼编码的贪心算法所需的计算时间为(B )。 A、O(n2n) B、O(nlogn) C、O(2n) D、O(n) 13.分支限界法解最大团问题时,活结点表的组织形式是(B )。 A、最小堆 B、最大堆 C、栈 D、数组 14.最长公共子序列算法利用的算法是(B)。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 15.实现棋盘覆盖算法利用的算法是(A )。 A、分治法 B、动态规划法 C、贪心法 D、回溯法 16.下面是贪心算法的基本要素的是(C )。 A、重叠子问题 B、构造最优解 C、贪心选择性质 D、定义最优解 17.回溯法的效率不依赖于下列哪些因素( D ) A.满足显约束的值的个数 B. 计算约束函数的时间 C.计算限界函数的时间 D. 确定解空间的时间 18.下面哪种函数是回溯法中为避免无效搜索采取的策略(B ) A.递归函数 B.剪枝函数 C。随机数函数 D.搜索函数 19. (D)是贪心算法与动态规划算法的共同点。 A、重叠子问题 B、构造最优解 C、贪心选择性质 D、最优子结构性质 20. 矩阵连乘问题的算法可由( B )设计实现。 A、分支界限算法 B、动态规划算法 C、贪心算法 D、回溯算法 21. 分支限界法解旅行售货员问题时,活结点表的组织形式是( A )。
几种排序算法分析
《几种排序算法的分析》 摘要: 排序算法是在C++中经常要用到的一种重要的算法。如何进行排序,特别是高效率的排序是是计算机应用中的一个重要课题。同一个问题可以构造不同的算法,最终选择哪一个好呢?这涉及如何评价一个算法好坏的问题,算法分析就是评估算法所消耗资源的方法。可以对同一问题的不同算法的代价加以比较,也可以由算法设计者根据算法分析判断一种算法在实现时是否会遇到资源限制的问题。排序的目的之一就是方便数据的查找。在实际生活中,应根据具体情况悬着适当的算法。一般的,对于反复使用的程序,应选取时间短的算法;对于涉及数据量较大,存储空间较小的情况则应选取节约存储空间的算法。本论文重点讨论时间复杂度。时间复杂度就是一个算法所消耗的时间。算法的效率指的是最坏情况下的算法效率。 排序分为内部排序和外部排序。本课程结业论文就内部排序算法(插入排序,选择排序,交换排序,归并排序和基数排序)的基本思想,排序步骤和实现算法等进行介绍。 本论文以较为详细的文字说明,表格对比,例子阐述等方面加以比较和总结,通过在参加数据的规模,记录说带的信息量大小,对排序稳定的要求,关键字的分布情况以及算法的时间复杂度和空间复杂度等方面进行比较,得出它们的优缺点和不足,从而加深了对它们的认识和了解,进而使自己在以后的学习和应用中能够更好的运用。
1.五种排序算法的实例: 1.1.插入排序 1.1.1.直接插入排序 思路:将数组分为无序区和有序区两个区,然后不断将无序区的第一个元素按大小顺序插入到有序区中去,最终将所有无序区元素都移动到有序区完成排序。 要点:设立哨兵,作为临时存储和判断数组边界之用。 实现: Void InsertSort(Node L[],int length) { Int i,j;//分别为有序区和无序区指针 for(i=1;i
各个排序算法及其代码
常见排序算法的实现(一)→插入排序 插入排序是最简单最直观的排序算法了,它的依据是:遍历到第N个元素的时候前面的N-1个元素已经是排序好的了,那么就查找前面的N-1个元素把这第N 个元素放在合适的位置,如此下去直到遍历完序列的元素为止。 算法的复杂度也是简单的,排序第一个需要1的复杂度,排序第二个需要2的复杂度,因此整个的复杂度就是 1 + 2 + 3 + …… + N = O(N ^ 2)的复杂度。[详细内容] void insert_sort(int s[],int n) { int i,j,temp; for(i=1;i
对分查找算法及程序实现
对分查找算法及程序实现 一、设计思想 对分查找是计算机科学中的一个基础算法。对于一个基础算法的学习,同样可以让学生在一定的情境下,经历分析问题、确定算法、编程求解等用计算机解决问题的基本过程。本堂课以一个游戏暖场,同时激活学生的思维,引导学生去探索游戏或生活背后的科学原理。为了让学生在教师的引导下能自我解析算法的形成过程,本课分解了问题动作,找出问题的全部可能情况,在对全部可能情况总结归纳的情况下,得出对分查找的基础算法,最后在程序中得到实现,从而使学生建立起对分查找算法形成的科学逻辑结构。 二、教材分析 本课的课程标准内容: (一)计算机解决问题的基本过程(1)结合实例,经历分析问题、确定算法、编程求解等用计算机解决问题的基本过程,认识算法和程序设计在其中的地位和作用。 (三)算法与问题解决例举 C 查找、排序与问题解决 (2)通过实例,掌握使用数据查找算法设计程序解决问题的方法。 本课的《学科教学指导意见》内容: 基本要求:1.初步掌握对分查找算法。 2.初步掌握对分查找算法的程序实现。 教材内容:第二章算法实例 2.4.3对分查找和第五章5.4查找算法的程序实现,课题定为对分查找算法及程序实现,安排两个课时,第一课时着重是对分查找算
法的形成和初步程序实现,第二课时利用对分查找算法解决一些实际问题的程序实现,本教学设计为第一课时。 从《课程标准》和《学科教学指导意见》对本课教学内容的要求来看,要求学生能从问题出发,通过相应的科学步骤形成对分查找的算法。对学生来说,要求通过这一课时的学习能初步掌握或了解对分查找的前提条件、解决问题的对象,明确对分查找算法结构和对分查找的意义。 三、学情分析 学生应该已经掌握程序设计的基本思想,掌握赋值语句、选择语句、循环语句的基本用法和VB基本操作,这节课学生可能会遇到的最大问题是:如何归纳总结对分查找解决不同情况问题的一般规律,鉴于此,在教学中要积极引导学生采取分解动作、比较迁移等学习策略。 四、教学目标 知识与技能:理解对分查找的概念和特点,通过分步解析获取对分查找的解题结构,初步掌握对分查找算法的程序实现。 过程与方法:通过分析多种不同的可能情况,逐步归纳对分查找的基本思想和方法,确定解题步骤。 情感态度与价值观:通过实践体验科学解题的重要性,增强效率意识和全局观念,感受对分查找算法的魅力,养成始终坚持、不断积累才能获得成功的意志品质。 五、重点难点 教学重点和难点:分解并理解对分查找的过程。 六、教学策略与手段 1、教学线索:游戏引领---提出对分查找原理--- 解析对分查找的算法特征---实践解决问题。
第三节 排序和查找
第三节排序和查找 一、教材分析 排序和查找算法是一种数据处理问题最常用的算法思想,在日常生活和学习过程中,经常需要对各种数据进行查找,而且总是希望要查找的数据井然有序,这样可以节约时间和精力,其实就是排序问题,在绝大多数情况下,查找是和排序紧密结合在一起的。本节在编写上力求前面体现排序和查找算法的基本思想,设计了一个典型的“运动员比赛成绩管理问题”,本节在设计上,就是让学生通过经历一个充分体现查找和排序的活动的算法分析设计过程,体验和感受相对比较简单的冒泡排序法和顺序查找法的基本思想,了解排序和查找的应用场合。在实践示例中通过与基本排序查找算法对比引入改良的算法选择排序法和二分查找法,让学生深入理解和掌握排序和查找算法的基本思想。通过运动会管理程序不同模块对数组的引用,让学生了解变量的作用范围。通过课堂三个教学活动的分析设计,让学生深入理解和体会模块化程序设计思想。排序和查找算法的原理与解析法和穷举法相比复杂了一些,如果通过大量的实践应用,也是很容易掌握的,在学习指引中有明确的描述。 在活动设计上,用到了两个“分析”和一个“实现”,旨在让学生重点关注冒泡法的分析过程和顺序查找法的分析过程,并在程序实现的过程中,体会变量的作用范围和两个分析子程序的调用过程,在宏观上渗透模块化程序设计思想。 1.教学活动一分析:分析比赛成绩排序算法并编写程序
3.教学活动三分析:实现运动会管理的应用程序
4.选择排序算法及示例分析: 选择排序算法是对冒泡排序算法的改进,通过下面的活动分析,旨在让学生在对比分析过程中掌握排序的基本思想。熟练掌握两种排序算法的使用过程及关键问题的处理过程,尤其是不同排序算法之间的排序原理的区别,决定了学生在今后解决实际问题中选择何种排序算法的重要依据,是学生算法分析素养的提升的关键环节。 示例:寻找一个数列中最小数的方法 查询过程:采用循环和选择程序结构,按顺序逐一比较数列中相邻的两个数,通过交换位置或记忆位置的方式,找到最小数。 5.二分查找算法及示例分析: 二分查找算法是对顺序查找算法的改进,通过下面的活动分析,旨在让学生在对比分析过程中掌握不同的查询思想。熟练掌握两种查询算法的使用过程及关键问题的处理过程,尤其是不同查询算法之间的查询分析过程的区别,决定了学生在今后解决实际问题中选择何种查询算法的重要依据,是学生算法分析素养的提升的关键环节。 示例:在有序数列A{3,16,20,27,35,39,46,48,55,73}中查找20和71
几种常见内部排序算法比较
常见内部排序算法比较 排序算法是数据结构学科经典的内容,其中内部排序现有的算法有很多种,究竟各有什么特点呢?本文力图设计实现常用内部排序算法并进行比较。分别为起泡排序,直接插入排序,简单选择排序,快速排序,堆排序,针对关键字的比较次数和移动次数进行测试比较。 问题分析和总体设计 ADT OrderableList { 数据对象:D={ai| ai∈IntegerSet,i=1,2,…,n,n≥0} 数据关系:R1={〈ai-1,ai〉|ai-1, ai∈D, i=1,2,…,n} 基本操作: InitList(n) 操作结果:构造一个长度为n,元素值依次为1,2,…,n的有序表。Randomizel(d,isInverseOrser) 操作结果:随机打乱 BubbleSort( ) 操作结果:进行起泡排序 InserSort( ) 操作结果:进行插入排序 SelectSort( ) 操作结果:进行选择排序 QuickSort( ) 操作结果:进行快速排序 HeapSort( ) 操作结果:进行堆排序 ListTraverse(visit( )) 操作结果:依次对L种的每个元素调用函数visit( ) }ADT OrderableList 待排序表的元素的关键字为整数.用正序,逆序和不同乱序程度的不同数据做测试比较,对关键字的比较次数和移动次数(关键字交换计为3次移动)进行测试比较.要求显示提示信息,用户由键盘输入待排序表的表长(100-1000)和不同测试数据的组数(8-18).每次测试完毕,要求列表现是比较结果. 要求对结果进行分析.
详细设计 1、起泡排序 算法:核心思想是扫描数据清单,寻找出现乱序的两个相邻的项目。当找到这两个项目后,交换项目的位置然后继续扫描。重复上面的操作直到所有的项目都按顺序排好。 bubblesort(struct rec r[],int n) { int i,j; struct rec w; unsigned long int compare=0,move=0; for(i=1;i<=n-1;i++) for(j=n;j>=i+1;j--) { if(r[j].key #include"stdio.h" #define LT(a,b) ((a)<(b)) #define LQ(a,b) ((a)>(b)) #define maxsize 20 typedef int keytype; typedef struct{ keytype key; }RedType; typedef struct{ RedType r[maxsize+1]; int length; }Sqlist; //直接插入排序 void insertsort(Sqlist &L){ int i,j; for(i=2;i<=L.length;++i) if(LT(L.r[i].key,L.r[i-1].key)){ L.r[0]=L.r[i]; L.r[i]=L.r[i-1]; for(j=i-2;LT(L.r[0].key,L.r[j].key);--j) L.r[j+1]=L.r[j]; L.r[j+1]=L.r[0]; }//if }//insertsort //折半插入排序 void BInsertSort(Sqlist &L) { int i,j,low,high,m; for(i=2;i<=L.length;++i) { L.r[0]=L.r[i]; low=1; high=i-1; while(low<=high){ m=(low+high)/2; if(LT(L.r[0].key,L.r[m].key)) high=m-1; else low=m+1; }//while for(j=i-1;j>=high+1;--j) L.r[j+1]=L.r[j]; L.r[high+1]=L.r[0]; }//for §2.3《设计的基本原则》导学案 设计人:肥城六中郭建国 班级姓名组别教师评价 【学习目标】 知识与技能:(1)理解设计的基本原则; (2)理解设计的基本原则之间存在的相互关联、相互制约的关系; (3)初步学会用设计的基本原则来评价某个产品。 过程与方法:培养学生自主、合作、探究学习的能力。 情感态度与价值观:(1)辩证地看待设计原则间关系及设计中的人文因素; (2)增强面对技术世界的信心以及对个人、社会、环境的责任心。【学习重点】 理解设计的基本原则其及相互关系 【学习难点】 能初步应用设计的基本原则来评价某些产品 【课前自主预习案】 一、知识回顾: 1、设计是技术发展的,技术发展为设计创新提供了。 2、需要发明与革新,催化了发明与革新,从而促进了 技术的发展。任何新技术设计都是在上产生的。 3、技术与设计是相互依存,相互促进的,其闪亮的结合点是。 【课中探究案】 一、合作探究: 【学生思考】很多同学都对自己的座椅感到不满意,假设现在学校请来专家给你专门设计一把椅子,你有什么样的要求呢? 【小组讨论】各个小组展开讨论,举出一些设计成功的案例,说出它们遵循了什么样的科学原理? 【学生思考】从产品的实用性出发进行设计时,通过案例说明产品的功能是否越多越好?【小组讨论】从产品的实用性角度,对下面的水壶进行评价。 【学生思考】分析自行车、洗衣机和手机3个实例在哪些方面体现了创新性。 【提出问题】举出生活中一些技术设计的案例,说一下他们是从哪些地方考虑到安全性的? 【小组讨论】观察下面的儿童游乐设施,说一下它的设计从哪些角度考虑了安全性原则? 【学生思考】结合刚才的塑料椅案例,同学们分析一下:设计产品时应从哪些方面着手降低成本,体现经济原则? 【学生思考】相同功能的钟表,你会不会宁愿多花点钱也买外形漂亮一些的款式?产品的外观美是怎样来表达的? 【提出问题】你能举出日常生活中你见过的体现技术规范性原则的几个例子吗? 【学生思考】设计中该如何做才能实现可持续发展目标? 二、自主探究: 【小组讨论】我们已经学习了设计的8个原则,这些原则之间是怎样的一种关系?这些原则是独立存在的吗?这些原则能同时遵守吗? 【本节达标测试】 1、电话机发展好几代,从砖头式的手机到现代小巧玲珑、功能齐备的手机这都显示出手机设计的()原则 A、经济性 B、可持续发展 C、创新性 D、都不对 2、现代同学们可经常看到人们不再用绳捆扎啤酒(因为捆扎的啤酒有时瓶炸裂易伤人), 实验四查找算法的设计 一、实验目的 (1)理解静态查找和动态查找; (2)掌握顺序查找和二分查找的算法; (3)掌握二叉查找树的基本运算。 二、实验内容 (1)实现顺序查找的算法; (2)实现二分查找的算法; (3)实现二叉查找树的基本运算算法。 三、算法思想与算法描述 1、顺序查找,在顺序表R[0..n-1]中查找关键字为k的记录,成功时返回找到的记录位置,失败时返回-1,具体的算法如下所示: int SeqSearch(SeqList R,int n,KeyType k) { int i=0; while(i return mid; if(R[mid].key>k) high=mid-1; else low=mid+1; } return -1; } 四、实验步骤与算法实现 #include 数据结构实验 报告 实验题目:几种基本排序算法的实现 :耀 班级:计嵌151 学号:1513052017 一、实验目的 实现直接插入排序,冒泡排序,简单选择排序,快速排序,希尔排序,堆排序等6种常用部排序算法,比较各算法的比较次数和移动次数。 二、数据结构设计 (1)设计待排序记录的存储结构。 (2)设计待排序数据的存储结构。 (3)输入:待排序数据的数据个数和数据可由键盘输入,也可由程 序生成伪随机数,以菜单方式选择上述排序方法中的一个,并指明输出第几趟排序的结果。 (4)输出:各趟排序结果或指定趟的排序结果,以及对应的关键字 比较次数和移动次数。 三、算法设计与N-S图 算法设计: 编写一个主函数main(),在主函数中设计一个简单的菜单,分别调用6种部排序算法。 为了对各种排序算法的性能进行比较,算法中的主要工作是在已知算法的适当位置插入对关键字的比较次数和移动次数的计数操作。为 此,可设立一个实现排序算法中的关键字比较的函数;设立一个实现排序算法中的关键字移动的函数;设立一个实现排序算法中的关键字交换的函数,从而解决比较次数和移动次数的统计问题。 数据的输入也可以通过菜单选择输入方式:键盘输入或由伪随机数程序生成数据,以便随时更换排序数据,并按照不同要求对排序数据进行排序,输出排序的结果以及对应的关键字比较次数和移动次数。对于测试数据,算法中可以考虑几组数据的典型性,如正序,逆序和不同程度等,以取得直观的感受,从而对不同算法进行比较。 四、程序清单 #include 存档编号: 西安******** 课程设计说明书 设计题目: 查找算法性能分析 系别:计算机学院 专业:计算机科学 班级:计科*** 姓名:王*** (共页) 2015年01月07 日 ***** 计算机科学专业课程设计任务书 姓名:*** 班级:计科**** 学号:**** 指导教师:**** 发题日期:2015-01-05 完成日期:2015-01-09 一需求分析 1.1问题描述 查找又称检索,是指在某种数据结构中找出满足给定条件的元素。查找是一种十分有用的操作。而查找也有内外之分,若整个查找过程只在内存中进行称为内查找;若查找过程中需要访问外存,则称为外查找,若在查找的同时对表做修改运算(插入或删除),则相应的表成为动态查找表,反之称为静态查找表。 由于查找运算的主要运算是关键字的比较,所以通常把查找过程中对关键字的平均比较次数(也叫平均查找长度)作为一个查找算法效率优劣的标准。 平均查找程度ASL定义为: ASL=∑PiCi(i从1到n) 其中Pi代表查找第i个元素的概率,一般认为每个元素的查找概率相等,Ci代表找到第i个元素所需要比较的次数。 查找算法有顺序查找、折半查找、索引查找、二叉树查找和散列查找(又叫哈希查找),它们的性能各有千秋,对数据的存储结构要求也不同,譬如在顺序查找中对表的结果没有严格的要求,无论用顺序表或链式表存储元素都可以查找成功;折半查找要求则是需要顺序表;索引表则需要建立索引表;动态查找需要的树表查找则需要建立建立相应的二叉树链表;哈希查找相应的需要建立一个哈希表。 1.2基本要求 (1)输入的形式和输入值的范围; 在设计查找算法性能分析的过程中,我们调用产生随机数函数: srand((int)time(0)); 产生N个随机数。 注:折半查找中需要对产生的随机数进行排序,需要进行排序后再进行输入,N<50; (2)输出形式; 查找算法分析过程中,只要对查找算法稍作修改就可以利用平均查找 数据挖掘十大经典算法,你都知道哪些? 当前时代大数据炙手可热,数据挖掘也是人人有所耳闻,但是关于数据挖掘更具体的算法,外行人了解的就少之甚少了。 数据挖掘主要分为分类算法,聚类算法和关联规则三大类,这三类基本上涵盖了目前商业市场对算法的所有需求。而这三类里又包含许多经典算法。而今天,小编就给大家介绍下数据挖掘中最经典的十大算法,希望它对你有所帮助。 一、分类决策树算法C4.5 C4.5,是机器学习算法中的一种分类决策树算法,它是决策树(决策树,就是做决策的节点间的组织方式像一棵倒栽树)核心算法ID3的改进算法,C4.5相比于ID3改进的地方有: 1、用信息增益率选择属性 ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(shang),一种不纯度度量准则,也就是熵的变化值,而 C4.5用的是信息增益率。区别就在于一个是信息增益,一个是信息增益率。 2、在树构造过程中进行剪枝,在构造决策树的时候,那些挂着几个元素的节点,不考虑最好,不然容易导致过拟。 3、能对非离散数据和不完整数据进行处理。 该算法适用于临床决策、生产制造、文档分析、生物信息学、空间数据建模等领域。 二、K平均算法 K平均算法(k-means algorithm)是一个聚类算法,把n个分类对象根据它们的属性分为k类(kn)。它与处理混合正态分布的最大期望算法相似,因为他们都试图找到数据中的自然聚类中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。 从算法的表现上来说,它并不保证一定得到全局最优解,最终解的质量很大程度上取决于初始化的分组。由于该算法的速度很快,因此常用的一种方法是多次运行k平均算法,选择最优解。 k-Means 算法常用于图片分割、归类商品和分析客户。 三、支持向量机算法 支持向量机(Support Vector Machine)算法,简记为SVM,是一种监督式学习的方法,广泛用于统计分类以及回归分析中。 SVM的主要思想可以概括为两点: (1)它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分; (2)它基于结构风险最小化理论之上,在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。 四、The Apriori algorithm Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,其核心是基于两阶段“频繁项集”思想的递推算法。其涉及到的关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支 需 求 分 析 报 告 课程设计题目:排序算法实现与演示系统专业:计算机科学与技术 班级: 姓名: 一.问题的提出 1.1编写目的 排序在人们的日常生活和学习、科研、生产等各个方面有着重要的应用。因此掌握常用的排序算法是很必要的。此次设计拟开发一个排序算法演示系统,以提高对排序算法的掌握程度。 本系统实现各种内部排序:直接插入排序、冒泡排序、直接选择排序、希尔排序、快速排序、堆排序、归并排序演。用户可以选择排序算法以演示输入数据在该排序算法下的排序过程。 1.2项目背景 课程设计题目:排序算法实现与演示系统 本课题的指导老师: 本课题的任务开发者: 该设计系统与其他系统的关系:相辅相成,紧密相关 1.3定义 文档中所用到的专业术语: 1.4参考资料 [1] 李云清,杨庆红.数据结构(C语言版).北京:人民邮电出版社,2004. [2]严蔚敏,吴伟民.数据结构(C语言版).北京:清华大学出版.1997. [3] 苏光奎,李春葆.数据结构导学.北京:清华大学出版.2002. [4] 周海英,马巧梅,靳雁霞.数据结构与算法设计.北京:国防工业出版社,2007. [5] 张海藩. 软件工程导论. 北京:清华大学出版社.2003. 随着计算机的普及,数据结构的应用与开发也深入我们的生活学习当中,其中排序算法也影响极深,通过这次排序算法的实现,希望更多人可以学会并运用排序算法。 二.任务概述 2.1目标 了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力; 初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能; 提高综合运用所学的理论知识和方法独立分析和解决问题的能力; 训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。 2.2运行环境 Microsoft Visual C++ 2008 2.3用户的特点 排序算法实现与演示系统使用者:具有一定的计算机操作能力和知识。 系统调用人员:具有很高的专业知识水平,理解排序算法实现与演示系统的运行机制,可以对开放代码进行阅读和分析,以完成其系统独特的需求。 2.4条件与限制 课程设计代码编写测试时间短、技术力量弱,设备具有约束性。 三.数据描述 .1 算法分类 十种常见排序算法可以分为两大类: ?比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。 ?非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。 0.2 算法复杂度 0.3 相关概念 ?稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。 ?不稳定:如果a原本在b的前面,而a=b,排序之后a 可能会出现在b 的后面。 ?时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。 ?空间复杂度:是指算法在计算机 内执行时所需存储空间的度量,它也是数据规模n的函数。 1、冒泡排序(Bubble Sort) 冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。 1.1 算法描述 ?比较相邻的元素。如果第一个比第二个大,就交换它们两个; ?对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数; ?针对所有的元素重复以上的步骤,除了最后一个; ?重复步骤1~3,直到排序完成。 1.2 动图演示 1.3 代码实现 ? 2、选择排序(Selection Sort) 选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 2.1 算法描述 n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下: ?初始状态:无序区为R[1..n],有序区为空; ?第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1..i-1]和R(i..n)。该趟排序从当前无序区中-选出关键字最小的记录R[k],将它与无序区的第1个记录R交换,使R[1..i]和R[i+1..n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区; ?n-1趟结束,数组有序化了。 2.2 动图演示 2.3 代码实现 ? #include int indegree; //入度 }VexNode; //顶点边定义 typedef struct LGraph { VexNode vex_array[Max]; //顶点数组 int vexnum; //图中顶点数 }LGraph; /*函数功能:图的创建 入口参数:图G 返回值:无 */ void Creat_G(Graph *G) { char v; int i=0; int j=0; G->vexnum=0; printf("输入说明。。。有权值请输入权值,无权值请输入1,无边请输入0\n"); printf("\n请输入所有顶点(不超过20个,按‘#’结束输入):\n"); do{ printf("输入第%d 个顶点:",G->vexnum+1); scanf(" %c",&v); G->vex_array[G->vexnum].data = v; G->vexnum++; }while(v!='#'); G->vexnum--; printf("输入邻接矩阵(%d * %d):",G->vexnum,G->vexnum); for(i=0; i 3.2 设计的一般原则说课稿 一、说教材 1.教材分析 本节课是第三章“设计过程、原则及评价”第二节“设计的一般原则”。这节内容有两个方面要求:一是理解设计的一般原则及其之间相互关系;二是初步学会用设计的一般原则评价某个技术产品。本节课由设计的创新原则、实用原则、经济原则、美观原则、道德原则、技术规范原则、可持续发展原则七个一般原则组成。 分析课本可以看出,本节内容是全章的重点,也是下一章开始学生进行具体的设计活动体验时,各环节需要遵守的基本准则。学生通过对设计的一般原则及原则之间关系的理解,不仅可以为“能制定符合一般原则和相关设计规范的完整设计方案”作知识准备,而且可以更有效地把握设计的过程,并进行设计的评析。 设计原则既是设计应遵循的标准和规范,同时又是技术评价的基本手段和尺度。“设计的一般原则”则是设计活动经过长期检验所整理出来的合理化现象,其内涵成为通用技术课程思想方法的核心,也成为通用技术课程教学的重点之一。在了解了“技术世界中的设计”之后,通过“设计的一般过程”的初步体验,进入“设计的一般原则”的学习,体现了通用技术课程独具匠心的安排,对后续课程内容的学习具有指导作用,对于提高学生的技术素养有着重要的意义。 2.教学目标 1. 知识与技能目标: (1)通过对实例的分析、归纳,得出设计的一般原则。 (2)理解设计的一般原则。 2. 过程与方法目标 (1)通过对典型案例的分析,理解各设计原则实现的途径和方法。 (2)通过引导学生以自主、合作、探究的学习方式学习,让学生在探究中自主建构知识。 3. 情感态度和价值观目标 (1)培养学生的独立思考能力和创新能力,培养学生的团队意识及学会与他人交流观点的能力。 (2)增强学生对技术设计中人文因素的理解,提高学生审美情趣和技术素养,增强面对技术世界的信心以及对个人、社会、环境的责任心。 3.教学重难点 理解各设计原则实现的途径和方法。 二、说教法 本节课教学主要采用导学式小组合作学习的教学方法完成教学任务,即各个环节均以学生为主体,教师为主导,引导学生进行自主、合作、探究的学习方式学习,让学生在探究中自主建构知识,在设计中发现问题,在活动中体验原则。 三、说学法 作为设计的一般原则的组成部分,七个原则是不可分割的。但是,作为一个学习过程,需要分步学习。因此课堂教学的总体思路为:总分总模式。具体的主要教学思路为:第一课时——购买手机(引入情景)→合作探究 计算机算法设计与分析习 题及答案 Prepared on 24 November 2020 《计算机算法设计与分析》习题及答案 一.选择题 1、二分搜索算法是利用( A )实现的算法。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 2、下列不是动态规划算法基本步骤的是( A )。 A、找出最优解的性质 B、构造最优解 C、算出最优解 D、定义最优解 3、最大效益优先是(A )的一搜索方式。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 4. 回溯法解旅行售货员问题时的解空间树是( A )。 A、子集树 B、排列树 C、深度优先生成树 D、广度优先生成树 5.下列算法中通常以自底向上的方式求解最优解的是(B )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法 6、衡量一个算法好坏的标准是( C )。 A 运行速度快 B 占用空间少 C 时间复杂度低 D 代码短 7、以下不可以使用分治法求解的是( D )。 A 棋盘覆盖问题 B 选择问题 C 归并排序 D 0/1背包问题 8. 实现循环赛日程表利用的算法是(A )。 A、分治策略 B、动态规划法 C、贪心法 D、回溯法 9.下面不是分支界限法搜索方式的是(D )。 A、广度优先 B、最小耗费优先 C、最大效益优先 D、深度优先 10.下列算法中通常以深度优先方式系统搜索问题解的是(D )。 A、备忘录法 B、动态规划法 C、贪心法 D、回溯法 11.备忘录方法是那种算法的变形。( B ) A、分治法 B、动态规划法 C、贪心法 D、回溯法 12.哈夫曼编码的贪心算法所需的计算时间为(B )。 A、O(n2n) B、O(nlogn) C、O(2n) D、O(n) 13.分支限界法解最大团问题时,活结点表的组织形式是(B )。 A、最小堆 B、最大堆 C、栈 D、数组 14.最长公共子序列算法利用的算法是(B)。 A、分支界限法 B、动态规划法 C、贪心法 D、回溯法 15.实现棋盘覆盖算法利用的算法是(A )。 A、分治法 B、动态规划法 C、贪心法 D、回溯法 16.下面是贪心算法的基本要素的是(C )。 A、重叠子问题 B、构造最优解 C、贪心选择性质 D、定义最优解 17.回溯法的效率不依赖于下列哪些因素( D ) A.满足显约束的值的个数 B. 计算约束函数的时间 C.计算限界函数的时间 D. 确定解空间的时间 18.下面哪种函数是回溯法中为避免无效搜索采取的策略(B ) A.递归函数 B.剪枝函数 C。随机数函数 D.搜索函数 19. (D)是贪心算法与动态规划算法的共同点。数据结构各种常用排序算法综合
通用技术课程设计的基本原则-学生导学案
查找算法
10.1几种基本排序算法的实现
数据结构查找算法课程设计
十 大 经 典 排 序 算 法 总 结 超 详 细
排序算法的实现与演示需求分析报告
十大经典排序算法
各种排序算法C语言实现
高中通用技术苏教版 必修1 第三章 设计过程、原则及评价 第2节 设计的一般原则 说课稿
计算机算法设计与分析习题及答案