化探数据处理成图过程

化探数据处理成图的过程
毕武1、2段新力1、2黄显义1、2袁小龙1、2彭仲秋1、2李永华1、2
1.乌鲁木齐金维图文信息科技有限公司,新疆,乌鲁木齐,830091
2.新疆地矿局物化探大队计算中心,新疆,昌吉,831100
0 前言
GeoIPAS软件用户群不断扩大,由于各用户对系统的熟悉程度不同,对软件功能了解不够,有必要分专题将GeoIPAS处理数据及成图过程做一系统总结,下面就化探数据处理成图的过程做一总结。
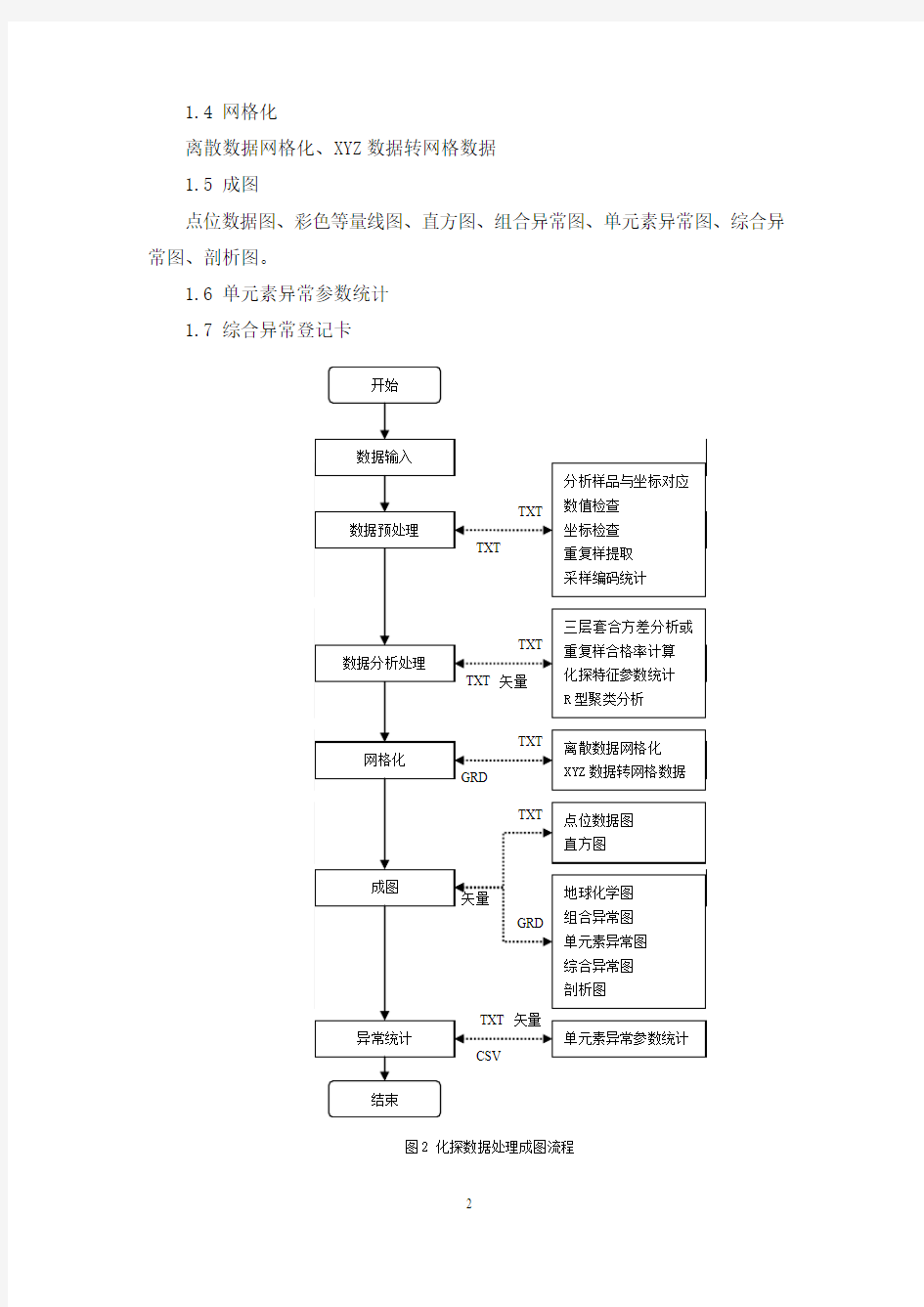
1 处理步骤
化探处理的成果包括:(1)参数统计表;(2)R型聚类分析-谱系图;(3)重复样三层套合方差分析或者重复样合格率计算结果;(4)点位数据图;(5)地球化学图;(6)直方图;(7)组合异常图;(8)综合异常图;(9)远景区划图;(10)单元素异常参数统计(附表册);(11)异常剖析(附图册);(12)综合异常登记卡(附表册)。
在GeoIPAS系统中,化探数据处理分为以下几个主要步骤:
1.1 数据检查
数值检查,坐标检查,重复样坐标检查。
1.2 分析处理
重复样三层套合方差分析、重复样合格率计算、化探特征参数统计、化探背景值分析、R型聚类分析、因子分析。
1.3 数据分析
数据变换;衬值、累加衬值;数据累加、累乘、比值;异常归一化。
1.4 网格化
离散数据网格化、XYZ数据转网格数据
1.5 成图
点位数据图、彩色等量线图、直方图、组合异常图、单元素异常图、综合异常图、剖析图。
1.6 单元素异常参数统计
1.7 综合异常登记卡
图2 化探数据处理成图流程
2 具体处理过程
2.1 数据检查
我们的数据处理工作从化验室提供的样品分析报告开始,项目要提供坐标和样品对应的分析数据,坐标我们一般取实际工作中的米单位,系统中默认东西向横坐标为X坐标,不加带号,南北向纵坐标为Y坐标,需要时还要提供样品对应的地质编码,我们拿到这个数据后首先进行数据检查,以确保数据中不出现写错、漏填、负数、0、>等字符,如果有这样的情况要找实验室给予纠正。数据准备好后,我们要把数据转换成TXT后缀的文本文件,这就做好了处理前的准备数据工作。
2.2 分析处理
2.2.1 重复样三层套合方差分析
一般是从分析样品的结果中挑出来重复样的分析值,每组四个样品,按如下顺序排列:
11 第一次采样第一次分析
12 第一次采样第二次分析
21 第二次采样第一次分析
22 第二次采样第二次分析
结果:
三层套合方差分析成果--元素:Cu
三层套合方差分析成果--元素:Au
查表:Fa0.05(18,19)=1.35 Fb0.05(19,38)=1.22
Cu:11.152 > 1.35 1.482 > 1.22 即:F1>Fa F2>Fb
Au:10.781 > 1.35 0.483 < 1.22 即:F1>Fa F2 说明:一般是F1>临界值,F2<临界值。 Fa>f0.05()理论值,说明采样与分析误差不显著,此次分析结果可靠, Fb>f0.05()理论值,说明采样与分析误差显著,且以采样误差为主。 例如报告中的描述: 先列一个表格说明所有元素的F1和F2; 重复样三层套合方差分析,39种元素F1值远超过临界值,说明采样与分析误差变化均低于区内地球化学自然变化,数据是可用的。F2值表现为两种情况,Ag、Pb、P、U、MgO、La等6个元素F2值小于临界值,说明采样误差不大于分析误差,以分析误差为主;其余33种元素F2值均大于临界值,说明误差应以采样误差为主。 2.2.2 地层编码统计 从样品相对应的地质图中自动读取地层的颜色号作为编码,实现每个样品的地层自动编码。 在GeoIPAS系统中的化探->化探特征参数统计->地层编码统计 其处理结果是在输入的数据文件中增加一列,过程是将坐标投影到地质图相应的投影参数上,以相同地层颜色来套取数据,取地层的颜色号为落入此地层的采样点的地层编码,所以要想一次做好,要先对地质图做个预处理,最好是按编码顺序,将颜色号改成相应的顺序号,比如Q的颜色改为1,N的颜色改为2,E 的颜色改为3,等等。相对应的出来的结果就是按顺序的地层编码了,可以直接用了,绘制的直方图也是这个顺序了。 2.2.3 化探特征参数统计 化探参数统计成果--元素:Cu 注:浓集克拉克值可以选用系统提供默认的,也可以直接输入用户所在不同 地区的浓集克拉克值。这个值可以保存为文件,以后导入使用。 2.2.4 R型聚类分析 从谱系图中可以看到,Cr、Ni、Co相关性最好,我们在做组合异常图时可以参考谱系图来做元素的组合,但这个也不能完全作为组合参考,我们通常还是以常用组合方式来做组合异常图,如:Cu-Pb-Zn;W-Sn-Mo;Cr-Ni-Co;Au-Ag-As-Sb。 2.3 网格化 2.3.1 工作比例尺与测网密度 DZ/T 0145-94土壤地球化学测量规范 从上表可以看到,化探在实际工作中一般和物探工作一起工作的常采用矩形网格,但在实际成图中却是用正方形网格的好,不用经过网格化处理,没有数据损失,也符合绘图的正方形网。 1:20万化探在全国范围已基本完成,只在新疆等高山区有少量的没有覆盖全,最常采用的是组合样,即:1点/4km2,少量的有单点样的,这主要用转网格数据的方式来将数据做网格化处理。单点样的网格化一般采用500×500到1000×1000的网格距,搜索半径3000×3000到5000×5000。组合样做转网格数据,注意起始坐标为奇数公里,间距为2000,然后要进行一次补空扩边处理,这主要是处理数据成图到图框边。 1:5万化探是现在化探普查的主要工作,一般在山区采用自由网的水系样,土壤测量一般用正方形网格采样, 1:1万化探作为1:5万化探异常检查的主要工作手段,常采用100×40的矩形网格,少量有100×20、200×40、150×40等加密或者抽稀采样。也有采用物探布设的测网非南北方向的测线。 2.3.2 下面用几个问题来具体说明。 问题1:1:5万土壤测量,网距330×300的怎么设置搜索半径和间距? 5万化探,网距500*500的,用GeoIPAS做地球化学图的时候,怎么设置搜索半径? 答:a、关于网格距,最好采用正方形网格,网格距为野外采样的点线距的 一半,比如野外采样为500×500,网格化的网格距选250×250就可以了,100×40的选为50×40或者50×50。 b、网格化的搜索半径选择需要一定的经验,建议你首先看看点位数据图,选择一个既能将所有数据联系起来,又不至于网格后把未采样区填充的参数,一般是网格距的2-3倍。 问题2:在进行1:5万化探采样时,乙类异常区采样密度设计为12个点/km2,丙、丁类异常区及其它基岩区采样密度设计为个8个点/km2,网格化时X Y 坐标的间距、行列数如何选? 答:一般1:5万化探点线距250×250米或者500×500米;搜索半径以满足丙、丁类异常区网格后只有个别空白区或者无空区,搜索半径一般1000×1000到2000×2000米;如果对网格化参数设置不太清楚,可以选择“计算网格化参数”;网格化后如果异常比较细碎零乱,可用数据预处理→二维数据滤波处理→周围点平均圆滑处理,X和Y方向点数选择3,原点倍数选择2-4倍。 问题3:请教如下问题. 1:2.5万土壤测量,线距250m ,点距40怎么设置搜索半径和间距? 答:搜索半径500*500,间距40*40或者50*40,注意最好与原始点位重叠. 问题4:1:1万化探,南北向测线,100×40网格距。 答:这样的数据本身符合网格数据的格式,只是以TXT文本格式保存,所以我们可以借助GeoIPAS软件的“数据预处理”→“数据格式转换”→“XYZ数据转为网格数据”功能,这里注意数据坐标的起始值、终止值和网格间距,网格间距就选择100×40,起始值和终止值要保证数据的原始点位都与网格点重合。这里有一个问题,就是有些项目用的是GPS坐标,不一定是与网格点位完全重合,一般我们建议用规则网的坐标。 圆滑方法:周围点平均圆滑;圆滑参数:X方向点数:3,Y方向点数:3,原点倍数:3 问题5:我的测网不是正南北向是45度方向,用咱们的软件进行网格化后变成正南北的,而且图幅形状不是原来测网的形状。请问这样的问题怎样解决? 1:1万化探,北西向测线,100×40网格距。 答:这样的数据虽然也是网格数据,但是经过旋转的测线方向与我们GRD 所定义的网格间距是有夹角的,最常采用的是离散数据网格化方法。离散数据网格化选择幂指数加权,指数因子:10;搜索范围:圆域,300米,网格化间距:40×40。 要用XYZ数据转网格数据的方式,就要知道测线的方位角,采样的点线号,起始坐标;利用点线号转换为实际点线距,然后再把点线距转为网格数据,成图后,统一处理,包括旋转方位角,然后平移到图上的起始坐标位置套图框。 2.3.3网格化成图的比较:三角剖分绘制的地化图,有被测线方向拉长的趋势,虽然其能保留原占坐标位的原始值,但成图结果不是很美观实用。距离平方导数加权和幂指数加权网格化,对数据的压制较大,异常线的形态较刻板。Kriging网格化选用了两种搜索范围,一种是圆域:300×300;一种是椭圆域:300×100,并且旋转45度。这两种方法整体上差异不大,只在局部的空区上表现出来不同,对数据的压制较小,异常的形态也保持较好,也是常选用的网格化方法,但其也有一个问题,就是对特高值边上的空区会处理出负值,这个不是我们希望得到的结果。 2.3.4经验:在处理1:1万化探数据时,可以根据测线方向和数据坐标点位的不同选择不同的数据处理方法,要遵循的一个原则是尽量使网格化后的坐标点位与原始数据坐标点位接近,网格化搜索的范围越小数据损失越小。对于网格间距以小于等于最小的原始点距为准,如果要保留更多的细节,也可以将网格距减小一倍,如果图面太过零乱,可以用GeoIPAS的二维滤波处理的周围点平均圆滑处理,这里可以加大原点倍数,默认为2,可以选择3-5倍。所有这些处理方法可以先选择一个元素用不同的方法做出结果来比较一下确定效果最好的方法,记住处理参数然后再统一批处理。 2.4 成图 2.4.1图件编制的要求: a、土壤地球化学测量图件分两部分:基础图与推断解释图。 b、区域调查和普查工作的图件编制按化探区域调查有关规范执行。 c、图件编制必须符合地球化学勘查图式图例及用色标准规定。 d、成果报告需做交通测区位置图、实际材料图、等值线图、综合异常图及其它推断解释图。 2.4.2 彩色等量线图 问题1:有些异常为什么不标不上高值点? 答:这是因为网格化后成图时,最高的那一个等值线没有套住高值点的坐标位置。对这种情况一般我们只能用手动加注极值点,目前还没有太好的办法解决。程序只搜索那个最高的或者最低的等值线范围内的坐标点,然后从搜索的点中选择最大或者最小的进行标注。 加注后是一般删线,保证极值点在最高的或者最低的等值线范围内。有时点刚好在线边上也就不做处理了。加标注时,在MAPGIS工程中,加入点位数据图文件,将其设为关闭状态,先在等值线图上找到没标的地方,然后打开点位数据图,把相应的极值拷贝粘贴过来,然后修改子图+,-。 问题2:对于等值线高值的圈圈很密怎么处理? 答:对于等值线高值的圈圈很密可以减少或者帛稀特高值的画线间隔,不改变常量范围的等值线。另外,有时为了图面好看也可以处理一下特高值数据,我们在GeoIPAS系统中有这样的处理模块,就是压制一下特高值数据,然后网格化成图,可以视情况选用。 使用注意事项: (1)数据横坐标(东向距)不带投影带号。 (2)在绘制投影经纬网图框时,在原数据投影参数设置中输入正确的数据坐标单位和投影参数,通常高斯坐标数据的单位为米,比例尺为1。 (3)在选择标注原始极值时,必须选择正确的横坐标、纵坐标和元素名称或变量名称,否则极值标注将会出错。 2.4.3 直方图 生成直方图的流程为:首先选择数据文件,程序使用TXT格式数据,其次选定元素和组间隔,当选择绘制全区及各地层单元直方图时需要数据中有编码列,指定编码列,有地层编码文件则装入,没有就手动设置,最后设置剖面绘制起始值等设置,完成直方图绘制。 a、数据文件格式为TXT文本格式,数据要包含列标识,数据中必须包含地质编码。 b、直方图的最大分组数和起始值可以用户自己选择,并且每个地层编码可以分别进行设置。 c、地质编码相当于数字的地质图,将地质体用数字代表,每个样品都对应一个地质时代,当某个时代的样品个数少于30个时可以将其合并到其它地质单元中。 d、当用户没有编制地层编码文件时,可临时在编码窗口中挑选编码所在的地层。方法是双击“地层代号”下的空白行。 e、使用注意事项: (1)编码列必须选择正确。 (2)当修改直方图起始值时,小数点后第二次的正值的尾数为7,负值的尾数为3。 f、直方图绘图参数设置 (1)选择绘制对应形态曲线:即程序自动根据直方图勾绘是否属于正态分布的圆滑曲线; (2)柱体内填充颜色:即每个柱体内填充相应的颜色; (3)对于X刻度线,用户可以根据实际需要进行设置。 2.4.4 组合异常图 a、我们推荐在做组合异常图时,用单个元素来做,在MAPGIS工程中加入不同单个元素异常线文件来任意组合。 b、另外如果要做元素异常参数统计,推荐在MAPGIS中先对单元素异常进行 编辑整理压缩保存线文件后用单元素异常参数统计来做。 c、生成组合异常图的流程为:首先选择数据文件所在的路径,其次选择元素组合,然后进行异常统计设置,最后绘制图框完成组合异常图。 d、组合异常图使用的数据文件为Grd格式的网格数据,并且要求各元素网格化时的参数一致。 e、在数据列选择框中选择需组合的元素,每选择一个元素,在异常参数设置表中就会增加该元素,并提供系统缺省的异常下限值和线宽度、颜色等绘制参数,缺省的异常下限计算方法有累频和均值标准差两种方式,两种方式分别提供了弱、中、强3种选择,对累计频率而言弱、中、强分别对应了累计频率的85%、90%和95%,对均值标准差而言弱、中、强分别对应了平均值+2倍的离差、+2.3倍的离差和+2.7倍的离差,如果对系统提供的缺省下限值不满意,可以输入确定的异常下限值;每种元素异常对应的线颜色、线宽、线型均可在异常参数设置表中进行设置。 2.4.5 单元素异常图 单元素异常图使用的数据文件为Grd格式的网格数据,绘制方式有3种:直接用异常下限勾绘异常、采用异常衬度值勾绘异常和采用剩余异常值勾绘异常: a、直接用异常下限值勾绘异常,并以一定的含量等级划分出异常浓度外带、中带和内带。当数据为单一地质单元或数据基本符合正态分布时,按照全区异常下限值的1、2~4、3~8倍划分三个浓度带,勾绘异常外、中、内带。 b、采用异常衬度值勾绘异常,当数据为两个以上的多个母体分布时,可依多个母体分别统计出的衬值,统一确定衬度异常下限,勾绘异常。并以衬度异常下限的1、2~4、3~8倍划分三个异常浓度分带。 c、采用剩余异常值勾绘异常,以求得普查区区域背景趋势面,然后用原始数据减去该点的背景趋势值所获得的剩余异常值作图。当求得剩余异常值后,以正剩余异常值确定剩余异常下限,并以一定的倍数勾绘正剩余异常及浓度分区。在应用剩余异常值制作异常图时,应对求取地球化学背景趋势面的方法进行试验、研究,以确保圈出的异常具有明确的找矿指示意义。 2.4.6 剖析图 GeoIPAS做异常剖析图有两种方法:地化图切剖析图和GRD数据生剖析图。 首先都要准备好切剖析图的矩形框,这个可以用MAPGIS中线编辑绘制矩形线,将异常包括进去。 a、地化图切剖析图 在GeoIPAS中做,利用地化图切剖析图模块,添加地质图和地化图的MAPGIS 文件,然后设置地质图的投影参数,导入裁剪框,设置裁剪框的投影参数,选择文件时,将地质图放在第一个位置,选择结果文件目录,进行排版设置,确定后进行裁剪,裁剪结果就组成一个完整的剖析图MAPGIS工程。 推荐在MAPGIS中做,可以用剖析图的裁剪框,做成一个区,然后在MAPGIS 地质图编辑中用工程裁剪,把地质图和地化图的裁剪结果文件加入到剖析图工程中,进行排版,组成一个完整的剖析图MAPGIS工程,第一个位置放地质图。 b、GRD数据生剖析图 推荐在GeoIPAS中用GRD数据生剖析图,地质图可在MAPGIS中用工程裁剪 得到,裁剪框也用MAPGIS中线编辑绘制矩形线得到。 要注意的是有三处设置投影参数的地方,源数据投影参数就是GRD文件的,生成的结果剖析图的投影参数,以及裁剪框的投影参数,选择排列好剖析的图顺序,可以生成规范要求的三级浓度分带的剖析图。 2.5 单元素异常参数统计 GeoIPAS中有两种方式: a、在组合异常图时,选择上“异常参数统计”输入原始数据文件名以及坐标,选择一个或者多个网格化后的GRD文件,选择异常下限,以及最后一列的统计元素名,然后计算出明码文件的同时还会产生一个结果文件+pSta.csv的属性 文件,如结果文件名是Ag(.wal .wat),那么属性文件名AgpSta.csv,这个文件就是和异常对应的参数统计,GeoIPAS同时也在结果线文件上挂接好属性。 b、由异常线来做异常参数统计 做元素异常参数统计时,我们推荐用组合异常图把每一个元素的异常生成出来,在生图时选择不套图框,不绘比例尺,然后在MAPGIS中编辑对异常线做处理。具体包括:删除小的异常线,闭合被图框或工区边角截断的异常线,连接并闭合被空区截断的线,使元素异常个数与实际统计的物理数一致,然后按编排的异常顺序号修改线的ID号,并压缩保存线文件 (MAPGIS编辑子系统中,在左边工程文件栏内,点右键,选择压缩保存工程,就把所有编辑状态的文件都压缩保存了) ,然后将这个异常线文件作为输入,在化探->单元素异常参数统计中统计异常参数,注意设置线文件投影参数,这个就是我们生成异常线时的参数,还需要设置数据文件的投影参数。运行后就会有一个CSV的结果,其中包括“元素名-编号”列,如Au-1,就和我们的异常编号对应一致,可以直接当作单元素异常参数统计附表了,同时元素异常线上也挂接好属性了。 单元素异常的参数,包括:异常点数、异常面积、异常的平均值、异常的对数平均值(几何平均值)、异常内样品最大值、异常标准离差、异常衬度、异常规模、异常NAP,同时进行了排序。 单元素异常参数统计 15 化探数据处理成图的过程 毕武12段新力12黄显义12袁小龙12彭仲秋12李永华12 1?乌鲁木齐金维图文信息科技有限公司,新疆,乌鲁木齐, 830091 2?新疆地矿局物化探大队计算中心,新疆,昌吉, 831100 0前言 GeolPAS 软件用户群不断扩大,由于各用户对系统的熟悉程度不同,对软件 功能 了解不够,有必要分专题将GeolPAS 处理数据及成图过程做一系统总结,下 面就化探数据处理成图的过程做一总结。 数据输入 *数据预处理 I I I II 「图件绘「输出… 图1金维地学信息处理研究应用系统 (GeolPAS )图件制作流程 1处理步骤 化探处理的成果包括:(1)参数统计表;(2)R 型聚类分析-谱系图;(3)重复 样三层套合方差分析或者重复样合格率计算结果;(4)点位数据图;(5)地球化学 图;(6)直方图;(7)组合异常图;(8)综合异常图;(9)远景区划图;(10)单元素 异常参数统计(附表册);(11)异常剖析(附图册);(12)综合异常登记卡(附表册)。 在GeolPAS 系统中,化探数据处理分为以下几个主要步骤: 1.1数据检查 数值检查,坐标检查,重复样坐标检查。 1.2分析处理 重复样三层套合方差分析、重复样合格率计算、化探特征参数统计、化探背 景值分析、R 型聚类分析、因子分析。 1.3数据分析 原测数据 重磁数据处理 电法数据处理 化探数据处理 数学地质数据处理 水文地质数据处理 数据变换;衬值、累加衬值;数据累加、累乘、比值;异常归一化。 1.4网格化 离散数据网格化、XYZ数据转网格数据 1.5成图 点位数据图、彩色等量线图、直方图、组合异常图、单元素异常图、综合异常图、剖析图。 1.6单元素异常参数统计 1.7综合异常登记卡 图2化探数据处理成图流程 2具体处理过程 内蒙古扎赉特旗东芒合矿和哈拉街吐矿 化探数据处理及图件编制方法 1 化探数据质量评价的数据处理(分矿区) ⑴统计重采样和重分析抽查样所占样品总数的比例 比例 = (重采样和重分析抽查样数/工作样总数)100% ⑵作出SSPS数据文件 将重采样和重分析样分别作成SSPS数据文件。文件中列出项目为: ①重采抽查样重采样号元素含量相应的工作样号元素含量 ②重分析抽查样重分析样号元素含量相应的工作样号元素含量 ⑶计算各元素相对误差 重采样和重分析抽查样相对误差均按RE(%) = |C1-C2|/0.5×(C1+C2)×100%计算。 C1为重采样或重分析抽查样的分析含量 C2为重采样或重分析抽查样的相应的工作样的分析含量 | |为绝对值 RE(%)≤30%为合格,>30为超差(不合格);(Au:RE(%)≤50%为合格,>50为超差) ⑷计算各元素的合格率 η= (抽查样品中合格的样品数/抽查样品的总数)100% 合格率(η)应>80%,即这批样品的分析结果是可信的。 ⑸列表表示检查或分析质量结果 表××化探重采样抽查各元素的合格率(%) Cu Pb Zn Cr Ni Co Sn V Ag Ti 2 矿区地球化学特征研究的数据处理(以哈拉街吐为例) ⑴作出SSPS数据文件 作出下列SSPS数据文件: ①文件1:整个矿区数据文件; ②文件2:矿区地层数据文件; ③文件3:矿区岩浆岩数据文件; ④文件4 :下二叠统大石寨组(P1d)数据文件; ⑤文件5 :下白垩统大磨拐河含煤组(K1d)数据文件; ⑥文件6 :华力西晚期侵入岩数据文件; ⑦文件7 :燕山期早期侵入岩数据文件; ⑧文件8 :燕山期晚期侵入岩数据文件; ⑨文件9:已知矿附近一定范围数据文件 每一数据文件的内容项目包括: 序号野外号 X坐标 Y坐标各元素的含量 ⑵整个矿区和各地质单元(各地层、各岩浆岩)样品各元素含量特征统计 统计的参数包括: ①元素含量平均值; ②最大值; ③最小值; ④标准离差; ⑤变化系数(标准离差/含量平均值); ⑥浓度克拉克值(元素含量平均值/该元素的克拉克值) 整个矿区和各地质单元统计结果含量平均值、最小值、最大值用表表示。 ⑶整个矿区和各地质单元样品各元素的概率分布特征统计 ①标准离差 ②峰度 ③偏度 ④概率分布曲线特征 ⑷矿区各地层样品各元素的局域丰度和蚀变-矿化叠加系数特征统计 根据地球化学过程的基本定律(A.B.Vstelius,1960),一个矿区地层中元素的“丰度”应该是沉积岩沉积成岩时的初始平均含量,而不应包括后期岩浆、蚀变、矿化作用等地质作用造成的元素含量的增赢或亏损。而矿区内局部地区地层中元素的“局域丰度”,至少应排除最后蚀变-成矿作用叠加的那一部分元素的含量。若本区各地层中元素概率分布及其偏度和峰度特征表明元素呈偏对数正态分布。这说明地层中多数元素都受到了后期不同程度的蚀变-成矿作用的叠加。据此,剔除了不服从正态分布的超差样品(即含量大 化探数据处理及图件编制 第二节分析方法及质量评述 一、分析方法 本次扫面和异常查证的全部样品均交由四川省地矿局华阳地矿检测中心测试,根据任务书要求共分析测试元素14种。 样品从加工到测试到质量监控均按中华人民共和国地质矿产行业标准DZ0130-1994《地质矿产实验室测试质量管理规范》、ISSN-1870《1?5万区域地质调查及地球化学样品分析方法及质量管理指导性规程》和2002年新疆地勘局试验管理科《1?5万化探样品分析质量过程管理规则报告》进行。14种元素的分析方法见表3,3。 二、技术要求 1、报出率 十四种元素的总报出率应大于95%。 2、外检样 对已测试样品,测试单位按照3%的比率进行外检。 3、分析质量检查及质量监控方案 为了有重点地监控元素的分析质量,实验室在送样单位确定的分析元素中,要再选择若干种主要监控元素并根据这些元素在本省制备的全部GRS二级标样中选择四个在元素含量范围及基体组成均为合适的GRD二级标样作为本图幅质量检查监控之用。主要监控元素和二级标样的选择均应和送样单位协商进行。每一大批样品测定完毕后,应将数据交给质量管理人员,对每一小批中插入的四个二级标样及四个重复分析(内部检查)样进行统计计算,并及时绘制日常质量监控图,在日常金的分析工作中,必须进行不小于10%的内检抽查。为满足在一个较大范围的成矿远景区 带内的1?5万图幅的拼接,应对分析的准确度进行检查和考核,为此实验室应在每一个1?5万普查化探项目完成后,分析8个GSD一级标样一次,痕金分析也应用金标样作准确度检查。准确度和精密度计算结果应符合表3,2的要求。 4、微量金 由于金元素在自然界中的均匀度和赋存状态对分析检测影响比较大,为确保金元素的分析质量,化验室特采用两种监控措施: 第一,在每一分析批次的50个样品中插入两个国家?级标准物质GBW系列,用以计算实测值与推荐值之间的对数偏差: ΔlgC,lgC,lgC; 定值实测值 第二,该地区样品分析结果结束或阶段性结束后,再对高、低异常点进行随机抽样检查约20%. 5、?级标样 为严格监控各元素的分析质量,实验室选取了四个不同含量的GRD系列监控样,每批次50个样品密码插入一组,与样品同时分析。然后计算四个监控样实际测定值与监控样定值之间的平均对数偏差X和对数标准差λ(统计结果见表3,2),其计算公式如下: L n ,lgC,i,1 ΔlgC,lg C-lgCX,L定值测定值 n n22(,lgC)-nX,L,1iλ, n,1 6、重复分析样编码 重复采样及重复分析样的编码,两个二级监控样的密码空号均由野外采样单位确定。同时野外采样单位负责重复采样和重复分析结果的方差分析。 三、质量评述 1、报出率 化探数据处理成图的过程 毕武1、2段新力1、2黄显义1、2袁小龙1、2彭仲秋1、2李永华1、2 1.乌鲁木齐金维图文信息科技有限公司,新疆,乌鲁木齐,830091 2.新疆地矿局物化探大队计算中心,新疆,昌吉,831100 0 前言 GeoIPAS软件用户群不断扩大,由于各用户对系统的熟悉程度不同,对软件功能了解不够,有必要分专题将GeoIPAS处理数据及成图过程做一系统总结,下面就化探数据处理成图的过程做一总结。 1 处理步骤 化探处理的成果包括:(1)参数统计表;(2)R型聚类分析-谱系图;(3)重复样三层套合方差分析或者重复样合格率计算结果;(4)点位数据图;(5)地球化学图;(6)直方图;(7)组合异常图;(8)综合异常图;(9)远景区划图;(10)单元素异常参数统计(附表册);(11)异常剖析(附图册);(12)综合异常登记卡(附表册)。 在GeoIPAS系统中,化探数据处理分为以下几个主要步骤: 1.1 数据检查 数值检查,坐标检查,重复样坐标检查。 1.2 分析处理 重复样三层套合方差分析、重复样合格率计算、化探特征参数统计、化探背景值分析、R型聚类分析、因子分析。 1.3 数据分析 数据变换;衬值、累加衬值;数据累加、累乘、比值;异常归一化。 1.4 网格化 离散数据网格化、XYZ数据转网格数据 1.5 成图 点位数据图、彩色等量线图、直方图、组合异常图、单元素异常图、综合异常图、剖析图。 1.6 单元素异常参数统计 1.7 综合异常登记卡 图2 化探数据处理成图流程 2 具体处理过程 2.1 数据检查 我们的数据处理工作从化验室提供的样品分析报告开始,项目要提供坐标和样品对应的分析数据,坐标我们一般取实际工作中的米单位,系统中默认东西向横坐标为X坐标,不加带号,南北向纵坐标为Y坐标,需要时还要提供样品对应的地质编码,我们拿到这个数据后首先进行数据检查,以确保数据中不出现写错、漏填、负数、0、>等字符,如果有这样的情况要找实验室给予纠正。数据准备好后,我们要把数据转换成TXT后缀的文本文件,这就做好了处理前的准备数据工作。 2.2 分析处理 2.2.1 重复样三层套合方差分析 一般是从分析样品的结果中挑出来重复样的分析值,每组四个样品,按如下顺序排列: 11 第一次采样第一次分析 12 第一次采样第二次分析 21 第二次采样第一次分析 22 第二次采样第二次分析 结果: 三层套合方差分析成果--元素:Cu 三层套合方差分析成果--元素:Au 查表:Fa0.05(18,19)=1.35 Fb0.05(19,38)=1.22 Cu:11.152 > 1.35 1.482 > 1.22 即:F1>Fa F2>Fb Au:10.781 > 1.35 0.483 < 1.22 即:F1>Fa F2 MAPG IS 数字高程模拟系统在化探数据处理中的应用 何明华 (甘肃省地勘局第一地质矿产勘查院,甘肃天水 741020) 摘要:地球化学普查水系沉积物测量和土壤测量数据具有三维特征。利用MAPGIS 数字高程模拟系统绘制普查区金、银、铜等元素的点位图、原始数据图、地球化学图,不仅缩短了数据处理的周期,而且保证了空间数据的精确性,具有较强的实用性。关键词:数据高程系统;处理;化探;数据 中图分类号:P 208 文献标识码:B 文章编号:1001-358X(2005)02-0013-03 随着计算机数据处理能力的不断提高,自动测量仪器广泛使用以及制图技术的发展,一种全新的数字描述地理现象的方法)))数字高程模型(DT M )日渐普及。数字高程模型(DT M )是利用已有的观测数据经过专业处理产生,利用计算机自动产生各类专业地学图件并进行专业分析。MAPGIS 地理信息系统是集数字制图、数据库管理及空间分析为一体的空间信息系统。随着该系统在地质勘查部门的进一步推广和应用,地质找矿和地质勘查技术方法和手段有了进一步的提高。在地球化学普查中,利用MAPG I S 数字地面高程模拟系统绘制普查区金、银、铜等金属元素的点位图、原始数据图、地球化学图,不仅提高了地质工作人员的工作效率,缩短了工作时间,而且保证了空间数据的精确性。1 化探数据的特征 地球化学普查的主要目的是在勘查区域内查明成矿有利地段以及与找矿有关的地球化学特征,圈出 各类区域性异常及成矿有利的远景区,寻找目标靶区,为进一步开展其它地质勘查工作提供依据。通常采用的化探方法主要有:水系沉积物测量和土壤测 量,工作精度为1:5万,采样密度一般为4-8个点/km 2 。采样点在勘查区分布比较均匀(图1) [1] 。 图1 设计采样点分布图 水系沉积物测量和土壤测量数据具有三维特征,即采样点平面坐标及每一个采样点样品经过化验得出的金、银、铜、铅、锌等金属元素的含量,平面坐标由地质人员利用GPS 全球定位系统采集。数据结构见(表1) 表1 水系沉积物测量数据一览表 采样点号 样品编号 采样点坐标Au Ag Cu Pb X Y w(10-6)w(10-6)w(10-2)w(10-2)88c 13821650440470117010812511261588d 23821080440530114010342114241289c 33821300440721110010772317221289d 43822078440789117010872415231490c 53821850440920313010492211311290d 63822230440500018011352512221589a 73822800440850110010662219211888b 83822330441240113010962517221680c 938219504412502011012582513261789b 103822870441280119010902414321890a 11 3822650 441680 113 01158 2516 3513 13 第2期2005年6月 矿 山 测 量M I NE SURVEYI NG No 12 June 12005 地球化学数据 处理与图件编制方法流程 一、指导思想 成矿地质背景地球化学研究就是从地球化学特征出发,借助已建立的地球化学信息提取技术,充分利用地球化学调查所获得的海量数据信息,提取有关反应成矿地质背景条件的地球化学信息,并编制相应地球化学图及相应的推断解释图件,为资源潜力评价有关成矿地质背景的研究提供地球化学支撑。 二、工作内容 (一)基础图件 成矿地质背景条件的地球化学信息提取首先是要编制有关基础地球化学图件。主要有: 1. 39种元素(化合物)地球化学图 2. 地球化学组合异常图 3. 地球化学综合异常图 (二)解释推断图件 地球化学解释推断图件,内容包括: 1. 地球化学推断解译地质图 2. 地球化学找矿预测图 三、工作方法 (一)数据校正处理 由于区域地球化学数据受地理景观、采样介质、分析手段的影响,不可避免的产生明显的系统误差,尤其是涉及到区域性的化探数据,这种误差更为突出。因此,在各省进行数据处理与专题地球化学图编制之前,有必要分别对各元素进行系统误差的处理,以便能更好地反映地质现象和矿产信息。误差处理主要针对图幅间(包括分析批次)明显的系统分析误差(必须处理)和地质景观环境差异影响解释的效果(根据解释的需要确定)。 1. 系统误差特征及处理原则 (1)分析误差源,所展示的数据误差与周边数据值具有明显的台阶状。 (2)数据误差在空间上具有区域性特点,区域、图幅或分析批次。 (3)在数据值的分布上,掩盖了地球化学特征和地质特征展布的延续性和规律性。 (4)在数据处理方法上,尽可能地选择线性校正,通过简单的计算可以复原数据。 2. 系统误差处理步骤 (1)按原始点位采用符号分级的方式生成元素的符号图,分级方法采用累计频率方式。 (2)通过校正图示窗浏览原始数据全图,确定具有明显的数据台阶区域,区域的确定原则是由区域->图幅->批次;采用图形编辑工具,在图上直接圈定要处理的区域(用面的方式表示)。 (3)确定局部图幅和分析批次范围产生的系统误差,校正单元由系统提供的工具直接在显示窗中勾绘,确定完所有需要校正单元,各校正单元的ID需设定为唯一。 (4)建立校正单元与处理数据表空间位置索引关系。 (5)确定各单元的校正值或校正系数,主要方法是与单元周边数据进行对比分析,部分规律性较复杂的单元可以通过统计规律确定,同时还需考虑地球化学分布的整体空间分布趋势和地质背景; 计算方法推荐采用:V ai=A V i+B 其中:V ai为校正点校正后数据,A为校正系数,V i为校正点原始数据,B 校正常数。A与B值的确定参照校正单元周边数据单元(正常的数据单元)确定,可以由经验判断,也可通过统计规律确定。 (6)数据校正,可采用SQL语言操作模式或应用软件系统提供的专用工具,按确定的校正值对各校正单元逐一进行计算。 元。 (5)单元校正计算,以基准单元为基础,应用归一化方法调整其他单元的数据值。计算方法推荐采用: V aij=V ij×(V j/V r) 其中V aij为第j个单元的第i个数据校正结果值,V ij为第j个单元的第i个原始数据,V j为第j个单元的平均值,V r基准单元的平均值。 V j和V r也可分别换为计算单元和基准单元的中位数。 一、指导思想 成矿地质背景地球化学研究就是从地球化学特征出发,借助已建立的地球化学信息提取技术,充分利用地球化学调查所获得的海量数据信息,提取有关反应成矿地质背景条件的地球化学信息,并编制相应地球化学图及相应的推断解释图件,为资源潜力评价有关成矿地质背景的研究提供地球化学支撑。 二、工作内容 (一)基础图件 成矿地质背景条件的地球化学信息提取首先是要编制有关基础地球化学图件。主要有: 1. 单元素(化合物)地球化学图 2. 地球化学组合异常图 3. 地球化学综合异常图 (二)解释推断图件 地球化学解释推断图件,内容包括: 1. 地球化学推断解译地质图 2. 地球化学找矿预测图 三、工作方法 (一)数据校正处理 1|数据检查的必要性,因为实验室的分析报告还是手工输入的,还是存在录入错误的,我们重点检查的是“>”,数据中间的空格等录入错误问题;另外还有畸变检查,数据的特大值,比如超过10倍变差,一般对这样的分析值实验室会很重视的,你也可以提出让他们再确认一下,做到心中有数。另一类错误可能会是我们录入样号或者坐标时出现的错误,如:“56b” 写成“56 b”,程序是以空格分开数据的,数据如果写成这样就会产生错误结果,有时在完成处理后才可能发现,这样一来我们前面的工作就作废了。所以数据检查是非常必要的。 2|异常下限值的确定采用逐渐剔除法:①计算全区各元素原始数据的均值(X)和标准偏差(S);②按X1+3S1的条件剔除一批高值后获得一个新数据集,再计算此数据集的均值(X2)和标准偏差(S2);③重复第二步,直至无特高值点存在,求出最终数据集的均值(X)和标准偏差(S),则X做为背景平均值,S为标准离差,T(异常下限值)= X (背景平均值)+2S(标准离差)求出理论异常下限值,再结合地球化学等量线、地质背景及圈定效果确定出实用异常下限值。 3|重复样样品合格率统计野外重采样品以密码样形式插入样品中进行了分析,结果(C2)与第一次分析结果(C1)进行了比对。计算两次分析值之间的相对偏差(RE%),具体计算采用如下公式:RE%= |(C1-C2)︳/(C1+C2)×100%,当RE<33.3% 时为合格,合格率=合格样品/总样品数×100%。总合格率大于80%。 推荐软件:GeoExpl,MapGIS, Geoipas1.64 .Suffer (二)坐标投影变换 在坐标投影变换和成图时经常出现的是将“源数据投影参数”的单位、比例尺弄错的情况,比如把数据直接转换成结果投影的单位等,这些是不需要做的,我们一般工作默认用的投影参数就是我们的地图参数,比如“投影平面直角坐标,北京54,高斯-克吕格投影坐标系”或者“投影平面直角坐标,西安80,高斯-克吕格投影坐标系”,实际工作的坐标单位一般用米,比如我们要成5万图,那参数设置就是: 源数据投影参数,比例尺:1,坐标单位:米,21度带 结果投影参数,比例尺:50000,坐标单位:毫米,21度带 推荐软件:GeoExpl,MapGIS ,Geoipas1.64 (三)数据网格化 离散数据网格化处理是空间数据插值的一种,即把无规则分布的空间数据内插为规则分布的空间数据集。网格数据是编制地球化学图件的重要数据源。 网格化处理一般包括这样几个过程:①空间几何属性的确定;②插值方法(模型)的选择;③空间数据的探索分析,包括对数据的均值、方差、协方差、独立性和变异函数的估计等;④插值方法评价;⑤重新选择内插方法,直到合理。 网格化数据处理中要确定主要参数包括: 1. 网格距:根据采样密度确定,一般网格距应与采样密度一致; 2. 数据搜索半径:一般选择网格距的2.5倍; 3. 数据计算模式:最近点或距离指数加权;化探数据处理成图过程
化探数据处理方法
化探数据处理及图件编制
化探数据处理成图过程.
MAPGIS数字高程模拟系统在化探数据处理中的应用
化探数据处理与编图流程
最新最详细化探数据处理与编图流程