VFP6常用命令2
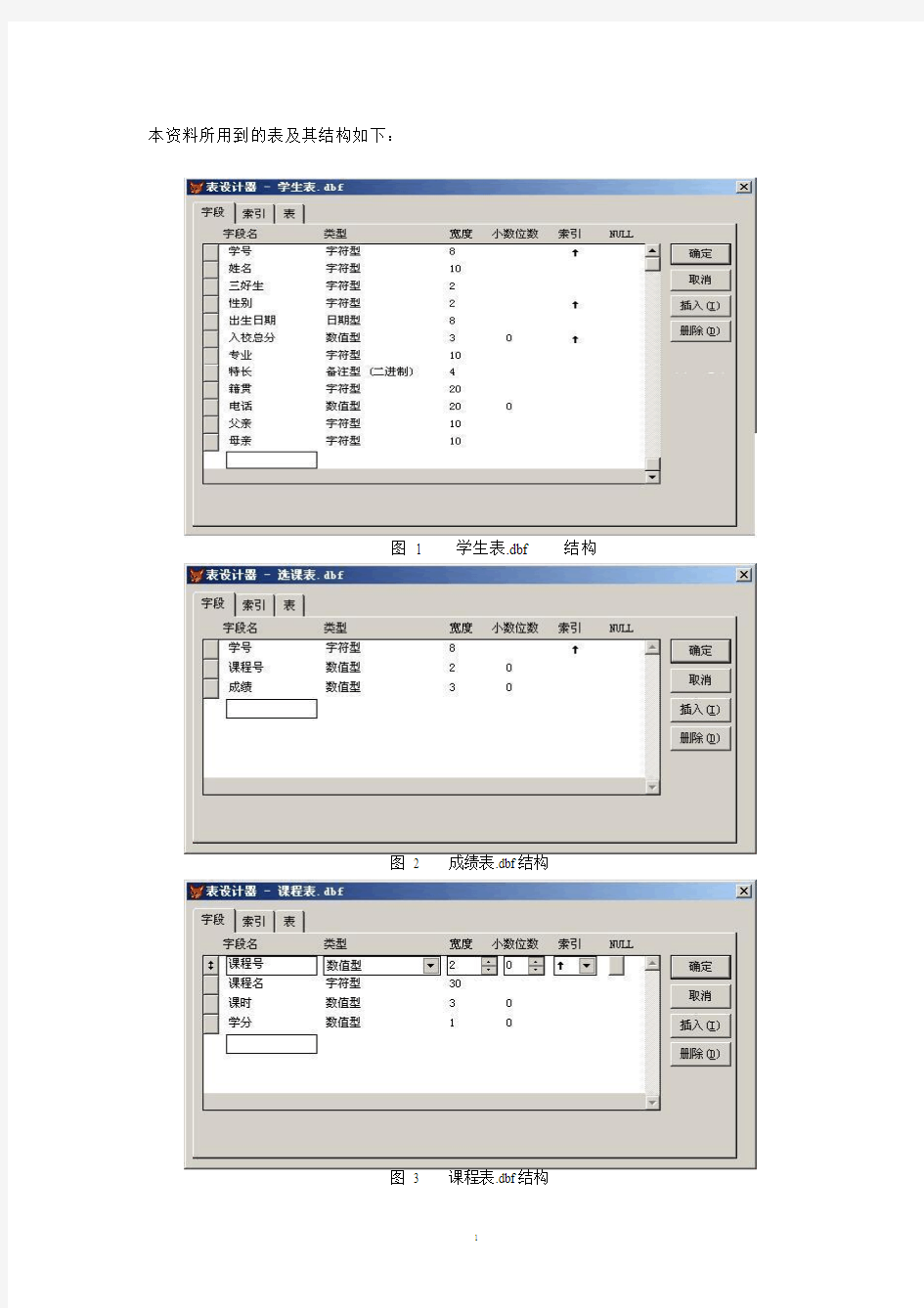

本资料所用到的表及其结构如下:
图 1 学生表.dbf 结构
图 2 成绩表.dbf 结构
图 3 课程表.dbf 结构
1、设置工作目录:set default to
命令格式:命令功能:
实例1:练习:set default to <目录名>
设置vfp 系统默认的工作目录(文件夹),以后存取文件均以该文件夹作为
默认文件夹。
set defa to d:\data ↙
打开vfp,然后观察此时的默认工作目录;再在D盘新建一文件夹:test,并设置该文件夹为vfp 的默认工作目录。
2、赋值语句:Store、=
Store 格式:Stroe <表达式> to <内存变量名表>
功能:将表达式的值赋给内存变量名表中的变量。实例1:store 100 to a1, a2 , b, c, num
=格式:<变量名>=<表达式>
功能:
注意:表达式与变量名顺序不能写反了。
3、输出命令:?、??
命令格式1:?<表达式列表>
命令格式2:??<表达式列表>
4、定义数组命令:dimension、declare
命令格式:命令功能:实例1:
实例2:dimension/declare <数组名1>[<下标上界1>[,<下标上界2]…]
定义一维数组或二维数组,每一维的下标一般从 1 开始。Dimension A(20),B(3,2) ↙
B(1,1)=10 ↙
B(1,2)=20 ↙
B(2,2)=30 ↙
B(6)=40 ↙
? B(1,1), B(1,2), B(2,2), B(3,2)
Dimension sz1(20),sz2(3,2) ↙
Store 10 to sz1
store “警察学院” to sz2(1,1)
sz2(3,2)=.F.
sz(2,1)=3.14159
如果数组元素没有赋值,则默认值为 .F.
历史考题:语句DIME TM(3,5)定义的数组元素的个数是()(15)
练习:定义一个 4 行5 列的二维数组,数组名为Arr1,给元素赋值(第一个元素值为10,第四个元素值为20,第七个元素值为”hello”,最后一个元素
值为888)。
5、打开/关闭表命令:use、close all
命令格式1:命令功能:use<表文件名>[ exclusive | shared]
以独占或者共享方式打开指定的表(默认方式是exclusive(独占)),如果只
实例1:
实例2:
实例3:
练习:
命令格式2:命令功能:是单独的use 命令,则关闭当前表。
use D:\data\学生表shared ↙
set default to d:\data↙
use 学生表↙
use ↙
以独占的方式打开d:\data 里的教师表.dbf,然后关闭该表。close all
关闭所有的表及释放所有的内存变量。
6、查看记录命令:list/display
命令格式:命令功能:
list/display[范围][fields<字段名>][for<条件表达式>][to printer][to file<文
件名>][off]
在工作区窗口显示当前表中的记录,list 默认范围是all,若一屏显示不下,也不会暂停,直到显示完最后一条记录;display 默认范围是当前记录,如果使用display all,则分屏显示。
注意[范围]参数可以是:
all 表示全部记录
Next
Record
Rest 表示从当前记录起到最后一条记录为止的所有记录
实例1:Use 学生表↙
List fields 学号,姓名,入校总分↙
List for 性别=’男’↙
实例2:use 学生表↙
Display ↙
display all ↙
display all for 性别 .and. 入校总分>=500 ↙
display fields 学号,姓名,性别,入校总分for 性别='男'.and.入校总分>=500↙
练习1:练习2:练习3:练习4:分别用list 和display 命令显示所有女生记录(要求显示学号,姓名,性别,入校总分);
分别用list 和display 命令显示1988 年1 月 1 日前出生的学生记录;
list for 出生日期<{^1988-01-01}
分别用list 和display 命令显示目前年龄大于20 岁的学生记录(要求显示学号, 姓名,性别,入校总分);
list for (date()-出生日期)/365>20
用Disp 命令显示第四条记录后(含第四条记录)的所有记录
7、浏览记录命令:browse
命令格式:browse [fields<字段名表>] [for<条件>]
命令功能:在浏览窗口中显示满足条件的记录,缺省fields 参数则显示所有的字段。
实例1:练习:use 学生表↙
Browse ↙
Browse fields 学号,姓名,入校总分for 性别='男' ↙浏览侦查专业的所有成都籍女生记录的学号、姓名和入校总分。
比较:list、display 和browse 的区别
8、添加记录命令:append [blank]
命令格式:append [blank]
命令功能:不加参数blank,在已打开的表末尾添加一条空白记录,并显示要求立即输入数据;如果加参数blank,则在表末尾添加一条空白记录。
实例1:实例2:use 学生表↙append ↙
use 学生表↙append blank ↙
练习:在学生表的末尾再添加一条学号为x00101,姓名为李四的记录。
9、插入记录命令:insert
命令格式:insert [blank] [before]
命令功能:在当前表的当前记录后(缺省before 参数)或前(有before 参数)添加一条记录,并要求立即输入该条记录,如果有参数blank,则添加一条空白记录。
实例1:实例2:练习:use 学生表↙
go 4↙
insert ↙
use 学生表↙
go 4↙
insert blank before↙
操作上述两实例。
10、记录定位命令:go(绝对移动指针)、skip(相对当前记录而言移动指针)命令格式1:go top | bottom
命令功能:将当前表的记录指针移到第一条记录或表的最后一条记录
实例1:go bottom ↙
实例2:go top ↙
命令格式2:go <数值表达式>
命令功能:将当前表的记录指针移到记录号为数值表达式值的那条记录上。
实例1:实例2:Go 8 ↙
?Recno() ↙Display ↙x=3 ↙
Y=x**2 ↙Go y ↙Display ↙
命令格式3:skip [n]
命令功能:记录指针相对当前记录移动n 条记录,指向当前记录号加n 的那条记录上,n 若为正,则往前移动,如为负,则往后移;如果缺省参数n,相当于skip 1,
指针只移动一条记录位置。
实例3:go top ↙
Skip 5 ↙
?Recno()↙
Skip -3 ↙
?Recno()↙
练习:操作上述三实例,并注意观察结果。
11、修改记录命令:edit、replace
命令格式1:edit [范围] [fields<字段名表>] [for<条件>]
命令功能:在指定的记录范围内,修改满足条件的记录的指定字段的数据。
实例1:
实例2:练习:use 学生表↙
go 4 ↙
edit fields 学号,姓名↙
use 学生表↙
Edit all for 性别='女' .or. 入校总分<=500 ↙操作上述两实例,并观察结果。
命令格式2:replace [范围] <字段名1> with <表达式>,<字段名2> with <表达式>… ,<字段名n> with <表达式> [for<条件>]
命令功能:用表达式的值替换指定字段的值,此命令常用于数据的批量替换,注意,格式中的逗号可以用空格代替。
实例3:use 学生表↙
List for 三好生=’是’↙
Replace all 入校总分with 入校总分+20,籍贯with '四川泸州' for 三好生='是
' .and. 籍贯='泸州'↙
Display all for 三好生=’是’ ↙
实例4:use 学生表↙
Append blank ↙
Replace 学号with "00100",姓名with "张三" ,性别with '男',出生日期with
ctod("09/10/88"),入校总分with 450 ↙
练习:操作上述 4 实例,并浏览结果。
相关考题:将教师表中所有职称为“教授”的教授工资增加300 元的VFP 命令是( ) (Repl all 工资with 工资+300 for 职称=”教授”),注意,VFP 命令中的条件一般应该用For,不能用Where,而SQL 语句中的条件表示一定要用Where,二不能用For。
练习:操作上述 4 实例,并浏览结果。
注意:不要把with写成等号,还要注意字段类型,切记!!!另
外,此命令与SQL语句的Update命令功能相似,但语法格式不一
样。
12、逻辑删除命令:delete
命令格式:delete [范围] [for<条件>]
命令功能:逻辑删除指定范围内的满足条件的记录,配合set deleted on/off。
实例1:use 学生表↙
Browse for 入校总分<=300 ↙
Delete all for 入校总分<=300 ↙
Display all ↙
Set deleted on ↙
Display all ↙
历史考题:在VFP 中,如果逻辑删除数据表中的记录,则被删除的记录前应有删除标记符()。
练习:操作上述实例,并浏览结果。
13、恢复逻辑删除:recall
命令格式:recall [范围] [for<条件>]
命令功能:恢复指定范围内被逻辑删除的满足条件的记录。
实例1:use 学生表↙
Browse for 入校总分<=300 ↙
Recall all for 入校总分<=300 ↙
Display all for 入校总分<=300 ↙
练习:操作上述实例,并浏览结果。
14、物理删除命令:pack、zap
命令格式1:pack
命令功能:物理删除当前表中作了逻辑删除标记的记录,配合delete 命令使用。
实例1:练习:use 学生表↙
Browse for 入校总分<=300 ↙Delete all for 入校总分<=300 ↙Display all for 入校总分<=300 ↙Pack ↙
List for 入校总分<=300 ↙
操作上述实例,并观察结果。
命令格式2:zap
命令功能:物理删除当前表中所有的记录,但保留表结构。
例1:use 学生表↙
Browse ↙
Zap ↙
List ↙
历史考题:在当前打开的表中物理删除带有删除标记记录的命令是()练习:操作上述实例,并观察结果。
15、物理排序命令:sort
围][for<条件>][fields<字段名表>]
命令功能:对当前表中指定范围内的满足条件的记录进行物理排序,排序后的结果存入新表,参数/a 表示升序(默认),/d 表降序,/c 表示字母不区分大小写。
实例1:use 学生表↙
Sort to 新学生表on 入校总分/d,学号/a for "
四川"$籍贯fields 学号,姓名,
性别,入校总分↙
Use 新学生表↙
List ↙
练习:按照学号升序排列学生表中的入校总分大于450 的女生记录,生成的排序表为xsb.dbf。
16、建立索引命令:index
建立结构复合索引:index on <索引表达式> tag [索引名] [for <条件>] [ascending]
[descending][candidate]
命令功能:实例1:练习:对当前表中满足条件的记录,按照索引表达式建立结构复合索引,参数ascending 表示按索引表达式值建立升序索引,descending 则表建立降序索引,candidate 表示建立候选索引,缺省为普通索引。
use 学生表↙
Index on 入校总分tag rxzf ascending ↙
list↙
index on str(入校总分)+学号tag zfxh ↙
list ↙
按照姓名对学生表建立降序索引,索引标记为xm(建立好后,打开表设计器,注意观察索引一项里是不是多了一个名称为xm 的索引),还要注意观察当前目录下是不是多了一个文件名为学生表.cdx 的文件。
建立非结构复合索引:index on <索引表达式> tag [索引名] of <索引文件名>[for <条件>]
[ascending][descending][candidate]
命令功能:
实例:
练习:
建立单索引:index on <索引表达式> to<索引文件名> [for <条件>]
命令功能:实例1:练习:
历史考题:
对当前表中满足条件的记录,按照索引表达式建立单索引,注意单索引一般是升序排列。
use 学生表↙
Index on 入校总分to zfdsy.idx ↙
list↙
按照姓名对学生表建立降序索引,索引文件名为zfdsy,注意观察当前目录里是不是多了一个文件名为zfdsy.idx 的索引文件。
Visual FoxPro 中索引文件分为单一索引文件和复合索引文件,复合索引文
数据库表专有的索引类型是()。
索引的类型有:主索引、候选索引、普通索引、唯一索引17、设置主控索引:set order to
命令格式1:命令功能:
实例1:set order to tag <索引名>
设置结构复合索引里的某个索引标记为主控索引,设置好之后,表的显示顺序则按主控索引的顺序显示。
use 学生表↙
List ↙
Set order to tag rxzf ↙
list↙
命令格式2:set index to <索引文件名> tag of <索引文件名> 命令功能:
实例:
练习:
命令格式3:set index to <索引文件名>
命令功能:实例2:
练习:设置单索引为主控索引。
use 学生表↙
set index to zfdsy ↙
list ↙
操作上述两实例,注意观察结果。
18、更新索引命令:reindex
命令格式:命令功能:实例1:reindex
当表更新之后,使用该命令强制更新索引文件,以保证表与索引同步。use 学生表↙
Append ↙
Reindex ↙
list ↙
练习:修改某条记录,然后更新索引。
19、顺序查询命令:locate
命令格式:命令功能:实例1:locate [范围][for<条件>]
……
continue
在当前表中,从指定范围的第一条记录开始,查找满足条件的记录,当找到之后,将记录指针指向满足条件的第一条记录(此时found()函数的值为真,eof()函数值为假,若没找到,则found()函数值为假,eof()值为真);配合continue 语句可继续查找下一条满足条件的记录。
use 学生表↙
Locate all for '北京'$籍贯 .and. 入校总分>=500 ↙
Display ↙
Continue ↙
Display ↙
练习:用locate 命令查找年龄大于25 岁的学生记录。
20、索引查询命令:seek
……
skip
命令格式:seek <表达式>
命令功能:在索引已经打开的情况下,查询表中满足表达式的记录,找到之后,把记录指针指向第一条满足条件的记录,如果找到多条记录,可以使用skip 实现继续
查找。
实例1:use 学生表↙
Index on 姓名tag xm ↙
Seek “张三”↙
Display ↙
练习:操作上述实例。
21、计数命令:count
命令格式:count [范围] [for<条件>] [to <内存变量> ]
命令功能:统计当前表中指定范围内符合条件的记录个数,并可以把结果存入内存变量。
实例1:Use 学生表↙
Count all for 入校总分>500 .and. 三好生=’是’to total1 ↙
Count to total2 ↙
?total1,total2 ↙
练习:统计籍贯是四川的学生人数。
22、求和命令:sum
命令格式:sum[范围] [数字型字段][for<条件>] [to <内存变量> ]
命令功能:对当前表中指定范围内符合条件的记录的数值型字段按列求和,并可把结果存入内存变量。
实例1:练习:use 学生表↙
Sum all 入校总分for 性别=’男’ to zf ↙?zf ↙
统计非三好生的入校总分。
23、求平均命令:average
命令格式:average [范围] [数字型字段][for<条件>] [to <内存变量> ]
命令功能:对当前表中指定范围内符合条件的记录的数值型字段按列求平均,并可把结果存入内存变量。
实例1:use 学生表↙
average all 入校总分for 性别=’男’ to pjf ↙
?pjf ↙
练习:求女生的入校平均分。
24、计算命令:calculate
命令格式:calculate [范围] [表达式][for<条件>] [to <内存变量> ]
命令功能:在打开的表中,计算表达式的值,并在工作区中显示出来。
实例1:练习:use 学生表↙
Calculate max(入校总分),min(入校总分),cnt(),sum(入校总分),avg((date()-出生日期)/365) 操作上述实例,并观察结果。
25、汇总命令:total
命令格式:total on <关键字段名> to 汇总文件名[范围] [for<条件>] fields<数字型字段>
命令功能:在当前表中,对指定范围内满足条件的记录按关键字段名分类汇总求和,并把汇总结果存入新表。注意,汇总之前,必须按关键字排序或建立索引。
实例1:use 学生表↙
Index on 性别tag xb ↙
total on 性别to 汇总文件fields 入校总分↙
use 汇总文件↙
list ↙
练习:按照性别对侦查专业的学生的入校总分分类汇总。
26、工作区选择:select
命令格式:select <工作区号或别名>
命令功能:选择指定的工作区。
实例1:use 学生表↙
Select 2 ↙
Use 成绩表alias cjb ↙
Select 3 ↙
Use 课程表↙
Select cjb ↙
List ↙
历史考题:多表操作中,已经在2,3,5 号工作区上打开了多个表,此时执行select 0,选择的当前工作区号是()
27、表之间关联::set relation to
命令格式:set relation to <关联表达式1> into <别名>[,<关联表达式2> into <别名>…][additive]
命令功能:以当前表为父表,与一个或多个子表建立临时多对一关联。注意:被关联的子表须按照关联关键字建立索引,参数addtive 表示建立新关联时保留当前父表
和其它子表的关联,单独的set relation to 命令将取消父表与其它子表的关联关
系。
如果要建立一对多关联,还要使用命令:set skip to [<表别名1>,[<表别名2>]…]
指明多方。
实例1:实例2:练习:通过学生表、选课表、课程表显示所有学生的课程成绩,要求显示出学号、姓名、课程名及成绩字段(选课表为“多”方,是父表,学生表、课程表为“一”方,是子表)。
Select 1 ↙
Use 学生表↙
Index on 学号tag xh ↙
Select 2 ↙
Use 课程表↙
Index on 课程号tag kch ↙
Select 3 ↙
Use 选课表↙
Set relation to 学号into a,课程号into b↙
List 学号,a->姓名,b->课程名,成绩↙
通过学生表、选课表显示所有学生的课程成绩,要求显示出姓名、课程号及成绩字段。(学生表为“一”方,是父表,选课表为“多”方,为子表。)
Close all ↙
sele 1 ↙
USE 学生表↙
sele 2 ↙
USE 选课表↙
index on 学号tag xh ↙
sele 1 ↙
set rela to 学号into b ↙
set skip to b ↙
list 姓名,b->课程号,b->成绩↙
操作上述两实例,观察并分析结果。
28、表记录复制到数组:scatter… to…
命令格式:scatter [fields<字段名表>] to <数组名>[memo]
命令功能:将当前记录的字段值按字段名表顺序依次赋给指定数组的各元素,如果带参数memo,则将备注型字段一起复制。
实例1:use 学生表↙
Go bottom ↙
Dimension A(12) ↙
scatter to A memo ↙
?A(1),A(2),A(3),A(4),A(5),A(6),A(7) ↙
实例2:use 学生表↙
Go 6 ↙
Dimension B(5) ↙
scatter fields 学号,姓名,入校总分,性别,籍贯to B ↙
?B(1),B(2),B(3),B(4),B(5) ↙
练习:操作上述两实例。
29、数组数据添加到表里:gather from…
命令格式:gather from <数组名>[fields <字段名表>]
命令功能:用数组数据依次修改当前记录的字段值。
实例1:use 学生表↙
Append blank ↙
Dimension A(4) ↙
A(1)=”x00018”↙
A(2)=”test”↙
A(3)=”是”↙
A(4)=”女”↙
Gather from A fields 学号,姓名,三好生,性别↙
List ↙
练习:操作上述两实例。
30、表复制命令:copy to
命令格式:copy to <新表名>[<范围>][fields <字段名表>[for <条件>]
命令功能:将当前表的数据和表结构全部或部分复制到新文件表里。
实例1:use 学生表↙
Copy to stu1
copy to stu2 fields 学号,姓名,性别,籍贯,入校总分for 性别='女'↙
Use stu1↙
List
Use stu2
List ↙
练习:操作上述实例并观察结果。
31、表结构复制命令:copy structure to
命令格式:copy structure to <新文件名> fields [<字段名列表>]
命令功能:将当前表的结构全部或部分复制到新文件表里。
另:
Clear 命令(清除工作区)
Clear all 命令(从内存中释放所有的内存变量和数组以及所有用户自定义的菜单栏, 菜单, 和窗口的定义。CLEAR ALL 也能关闭所有表,包括所有相关的索引, 格式文件和备注文件, 并
选择 1 号工作区。CLEAR ALL 不释放系统内存变量。)
说明:本资料仅列出了Vfp最常用的命令及其最常用的功能,如果要弄清每条
命令的详尽格式及用法,请查Vfp命令手册。
CAD常用命令汇总及详解
CAD中有哪些命令?我们可以把它们分为几类。一类是绘图类,二类是编辑类,三类是设置类,四类是其它类,包括标注、视图等。我们依次分析。 第一类,绘图类。常用的命令有: Line 直线 Xline 构造线 mline 双线 pline 多义线 rectang 矩形 arc 圆弧 circle 圆 hatch 填充 boundary 边界 block 定义块 insert 插入快 第二类,编辑类。常用的命令有: Matchprop 特性匹配 Hatchedit 填充图案编辑 Pedit 多义线编辑 Erase 擦除 Copy 拷贝 Mirror 镜像 Offset 平移 Array 阵列 Move 移动 Rotate 旋转 Scale 缩放 Stretch 拉伸 Lengthen 拉长 Trim 裁减 Extend 延伸 Break 打断 Fillet 倒圆角 Explode 炸裂 Align 对齐 Properties 属性
绘图工具栏: 直线(L):全称(line) 在屏幕上指定两点可画出一条直线。也可用相对坐标 或者在正交模式打开的情况下,直接给实际距离鼠标拖动来控制方向 构造线(XL):全称(xline) H为水平V为垂直O为偏移A为角度B为等分一个角度。 多段线(PL):全称(pline) 首先在屏幕上指定一点,然后有相应提示: 指定下一个点或[圆弧(A)/半宽(H)/长度(L)/放弃(U)/宽度(W)]。可根据需要来设置。 其中“圆弧”指定宽度可画任意角度圆弧;“半宽”指多段线的一半宽度,即如要高线宽为10,则5;“长度”给相应的值,则画出相应长度的多段线;“放弃”指放弃一次操作;“宽度”指多段线的宽度 多边形(pol):全称(polygon) 所绘制多边形为正多边形,边数可以自己设 E:根据边绘制多边形也可根据圆的半径利用外切和内接来画正多边形 矩形(REC):全称(rectang) 点击矩形工具后出现下列提示: 指定第一个角点或[倒角(C)/标高(E)/圆角(F)/厚度(T)/宽度(W)] 其中“倒角”是将90度直角的两条边割去一点。变成一个斜角。“标高”是空间上的意义可以在三视图当中展现出来,标高是相对的;“圆角”:即是将四个直角边倒成半径为X的圆角;“厚度”:空间上的意义,可在Z轴上表现出来“宽度”:平面空间的概念,指矩形四边的宽度。 圆弧(ARC或A):默认为3点画圆弧,成弧方向为逆时针,画优弧半径给负值。绘图菜单中有如下选项: 起点、圆心、端点; 起点、圆心、角度; 起点、圆心、长度; 起点、端点、角度; 起点、端点、方向; 起点、端点、半径; 圆心、起点、端点; 圆心、起点、角度; 圆心、起点、长度;
常用的系统状态查询命令
常用的系统状态查询命令 # lsdev –C –s scsi 列出各个SCSI设备的所有相关信息:如逻辑单元号,硬件地址及设备文件名等。 # ps -ef 列出正在运行的所有进程的各种信息:如进程号及进程名等。 ps aux查看进程信息 # netstat -rn 列出网卡状态及路由信息等。 # netstat -in 列出网卡状态及网络配置信息。 # df -k 列出已加载的逻辑卷及其大小信息。 #top 查看系统应用信息,如CPU、内存使用率。按u,输入用户名则可监视用户;按k然后输入特定进程PID可关闭此进程,输入信号代码15关闭进程,输入信号代码9强行关闭。 # mount 列出已加载的逻辑卷及其加载位置。 # ntsysv 选择启动服务 # uname -a 列出系统ID 号,系统名称,OS版本等信息。 # hostname 列出系统网络名称。 # lsvg –l rootvg,lsvg –p rootvg 显示逻辑卷组信息,如包含哪些物理盘及逻辑卷等。 # lslv –l datalv,lslv –p datalv 显示逻辑卷各种信息,如包含哪些盘,是否有镜像等。 八网络故障定位方法 网络不通的诊断过程: ifconfig 查看网卡是否启动 (up) netstat –i 查看网卡状态 Ierrs/Ipkts 和 Oerrs/Opkts是否>1% ping自己网卡地址 (ip 地址) ping其它机器地址,如不通,在其机器上用diag检测网卡是否有问题。 在同一网中, subnetmask 应一致。 网络配置的基本方法: (1) 如需修改网络地址、主机名等,一定要用 chdev 命令 # chdev –l inet0 –a hostname=myhost # chdev -l en0 -a netaddr='9.3.240.58' -a netmask=255.255.255.0’ (2) 查看网卡状态:# lsdev –Cc if
(完整版)CAD最常用命令大全(实用版)
cad命令大全 L, *LINE 直线 ML, *MLINE 多线(创建多条平行线) PL, *PLINE 多段线 PE, *PEDIT 编辑多段线 SPL, *SPLINE 样条曲线 SPE, *SPLINEDIT 编辑样条曲线 XL, *XLINE 构造线(创建无限长的线) A, *ARC 圆弧 C, *CIRCLE 圆 DO, *DONUT 圆环 EL, *ELLIPSE 椭圆 PO, *POINT 点 DCE, *DIMCENTER 中心标记 POL, *POLYGON 正多边形 REC, *RECTANG 矩形 REG, *REGION 面域 H, *BHATCH 图案填充 BH, *BHATCH 图案填充 -H, *HATCH HE, *HATCHEDIT 图案填充...(修改一个图案或渐变填充)SO, *SOLID 二维填充(创建实体填充的三角形和四边形)*revcloud 修订云线 *ellipse 椭圆弧 DI, *DIST 距离 ME, *MEASURE 定距等分 DIV, *DIVIDE 定数等分
DT, *TEXT 单行文字 T, *MTEXT 多行文字 -T, *-MTEXT 多行文字(命令行输入) MT, *MTEXT 多行文字 ED, *DDEDIT 编辑文字、标注文字、属性定义和特征控制框ST, *STYLE 文字样式 B, *BLOCK 创建块... -B, *-BLOCK 创建块...(命令行输入) I, *INSERT 插入块 -I, *-INSERT 插入块(命令行输入) W, *WBLOCK “写块”对话框(将对象或块写入新图形文件)-W, *-WBLOCK 写块(命令行输入) -------------------------------------------------------------------------------- AR, *ARRAY 阵列 -AR, *-ARRAY 阵列(命令行输入) BR, *BREAK 打断 CHA, *CHAMFER 倒角 CO, *COPY 复制对象 CP, *COPY 复制对象 E, *ERASE 删除 EX, *EXTEND 延伸 F, *FILLET 圆角 M, *MOVE 移动 MI, *MIRROR 镜像 LEN, *LENGTHEN 拉长(修改对象的长度和圆弧的包含角)
hadoop基本命令_建表-删除-导数据
HADOOP表操作 1、hadoop简单说明 hadoop 数据库中的数据是以文件方式存存储。一个数据表即是一个数据文件。hadoop目前仅在LINUX 的环境下面运行。使用hadoop数据库的语法即hive语法。(可百度hive语法学习) 通过s_crt连接到主机。 使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。 2、使用hive 进行HADOOP数据库操作
3、hadoop数据库几个基本命令 show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。 usezb_dim; show tables;
4、在hadoop数据库上面建表; a1: 了解hadoop的数据类型 int 整型; bigint 整型,与int 的区别是长度在于int; int,bigint 相当于oralce的number型,但是不带小数点。 doubble 相当于oracle的numbe型,可带小数点; string 相当于oralce的varchar2(),但是不用带长度; a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。 create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)
row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符 a2.1 查看建表结构: describe A2.2 往表里面插入数据。 由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
ORACLE SQLPLUS 常用命令及解释
Oracle SQLPlus常用命令及解释 1.@ 执行位于指定脚本中的SQLPlus语句。可以从本地文件系统或Web服务器中调用脚本。可以为脚本中的变量传递值。在iSQL*Plus中只能从Web服务器中调用脚本。 2.@@ 执行位于指定脚本中的SQL*Plus语句。这个命令和@(“at”符号)命令功能差不多。在执行嵌套的命令文件时它很有用,因为它会在与调用它的命令文件相同的路径或url中查找指定的命令文件。在iSQL*Plus中只支持url形式。 3./ 执行保存在SQL缓冲区中的最近执行的SQL命令或PL/SQL块。在SQL*Plus命令行中,可在命令提示符或行号提示符使用斜线(/)。也可在iSQL*Plus的输入区中使用斜线(/)。斜线不会列出要执行的命令。 4.ACCEPT 可以修改既有变量,也可定义一个新变量并等待用户输入初始值,读取一行输入并保存到给出的用户变量中。ACCEPT在iSQL*Plus中不可用。 5.APPEND 把指定文本添加到SQL缓冲区中当前行的后面。如果text的最前面包含一个空格可在APPEND和text间输入两个空格。如果text的最后是一个分号,可在命令结尾输入两个分号(SQL*Plus会把单个的分号解释为一个命令结束符)。APPEND 在iSQL*Plus中不可用。 6.ARCHIVE LOG 查看和管理归档信息。启动或停止自动归档联机重做日志,手工(显示地)归档指定的重做日志,或者显示重做日志文件的信息。 7.ATTRIBUTE 为对象类型列的给定属性指定其显示特性,或者列出单个属性或所有属性的当前显示特性。 8.BREAK 分开重复列。指定报表中格式发生更改的位置和要执行的格式化动作(例如,在列值每次发生变化时跳过一行)。只输入BREAK而不包含任何子句可列出当前的BREAK定义。 9.BTITLE 在每个报表页的底部放置一个标题并对其格式化,或者列出当前BTITLE定义。
UNIX系统常用命令
UNIX系统常用命令 UNIX系统常用命令格式: command [flags] [argument1] [argument2] ... 其中flags以-开始,多个flags可用一个-连起来,如ls -l -a 与ls -la相同。 根据命令的不同,参数分为可选的或必须的;所有的命令从标准输入接受输入,输出结果显示在标准输出,而错误信息则显示在标准错误输出设备。可使用重定向功能对这些设备进行重定向。 命令在正常执行结果后返回一个0值,如果命令出错可未完全完成,则返回一个 非零值(在shell中可用变量$?查看). 在shell script中可用此返回值作为控制逻辑的一部分。 注:不同的UNIX版本的flags可能有所不同。 1、与用户相关的命令 1.1 login (在LINUX Redhat下此命令功能与Solaris/BSD不同,执行login会退出当前任务). login: Password: 相关文件: 在下面的这些文件中设定shell运行时必要的路径,终端类型,其他变量或特殊程序. $HOME/.profile (Bourne shell, sh, bash) $HOME/.cshrc (csh, tcsh) $HOME/.tcshrc (tcsh) /etc/passwd文件中列出每个用户的shell /etc/csh.cshrc /etc/csh.login /etc/profile (Bourne shell, bash) /etc/login (Bourne shell, bash) csh: /etc/csh.cshrc和$HOME/.cshrc每次执行都会读取, 而/etc/csh.login和$HOME/.login只有注册shell才执行 修改相应文件后使用 source .cshrc使能相关修改,如果修改了path则 还需使用rehash刷新可执行文件hash表。 tcsh: $HOME/.tcshrc, 没有些文件读取.cshrc sh: /etc/profile和$HOME/.profile注册shell bash: /etc/profile和$HOME/.bash_profile注册shell读取 .bashrc交互式非注册shell才读取。
CASS常用命令大全
1.CASS屏幕菜单不见了? 答: 如果关掉了,打开CAD设置,显示屏幕菜单就可以了,如果最小化了,拉下来就行了 2.我在cass5.1中画的图怎么保存不了,会出对话框说: 写入/关闭文件时出错? 答: 选取有用的图纸内容,用cass5.1的窗口存盘或多边形存盘功能将图纸另存为另一文件。 3.CASS5.0中在图幅整饰中,为什么不能完全删除图框外实体? 答南方CASS在图纸分幅中,确实存在一些问题,特别是采用批量分幅,还存在分幅后缺这少那的问题。其中: 1、一部份是操作者的问题,在分幅时要求图纸全屏显示,关闭对象捕捉等; 2、一部份是软件平台AUTOCAD本身存在,如图幅边有不可分割的字体、块等; 3、还有是CASS软件存在的缺陷,特别是在CASS5.1以前的版本。实际上这个问题南方公司早就注意到了,在推出的最新版6.1中问题就较少。 建议楼主使用南方CASS新版。 4.如何从cass的界面切换到autocad的界面? 答: 在CASSxx,按下例选项操作既可: 文件-AUTOCAD系统配置-配置-UNNAMED PROFILE-置为当前-确定。
5.在cass软件上怎么才能显示点号呀 答: 数据文件上的点号有的话,通过展点就可以了 6.断面图文字不能修改,表格也没法修改,整个断面及表格、文字就像一个块,且不能打断。是什么原因? 答: 把编辑里的编组选择关闭即可 7.在CASS6.0中成图时为什么高程点位与数据不能分开,当数据压盖地物时不好只移位数据而点位不变?在CASS6.0的“编辑”中“图层控制”子菜单中为什么象“实体层→当前层”等好多菜单命令都是无效命令? 答: 在cass6.1中将“文件-cass6.1参数配置-地物绘制-展点注记”设为分置即可分开。 8.CASS6.0使用问题请问来自何方: CASS6.0制图时,高程注记和高程点(如: . 350)是否为一个块?不能对其进行编辑,如我想移动"350",而又不移动".",利用软件怎样操作才能做到? 答: 在绘图处理里有“打散高程注记”,用它将高程注记和点位打散就可以移动和编辑了。 9.为什么CASS5.1在改变当前比例尺时,问是否改变符号大小,选2不改变时,那些坎线,坟墓等地物还是会变大或变小呢?有时会很难看答:
(完整word版)汇编语言常用指令大全,推荐文档
MOV指令为双操作数指令,两个操作数中必须有一个是寄存器. MOV DST , SRC // Byte / Word 执行操作: dst = src 1.目的数可以是通用寄存器, 存储单元和段寄存器(但不允许用CS段寄存器). 2.立即数不能直接送段寄存器 3.不允许在两个存储单元直接传送数据 4.不允许在两个段寄存器间直接传送信息 PUSH入栈指令及POP出栈指令: 堆栈操作是以“后进先出”的方式进行数据操作. PUSH SRC //Word 入栈的操作数除不允许用立即数外,可以为通用寄存器,段寄存器(全部)和存储器. 入栈时高位字节先入栈,低位字节后入栈. POP DST //Word 出栈操作数除不允许用立即数和CS段寄存器外, 可以为通用寄存器,段寄存器和存储器. 执行POP SS指令后,堆栈区在存储区的位置要改变. 执行POP SP 指令后,栈顶的位置要改变. XCHG(eXCHanG)交换指令: 将两操作数值交换. XCHG OPR1, OPR2 //Byte/Word 执行操作: Tmp=OPR1 OPR1=OPR2 OPR2=Tmp 1.必须有一个操作数是在寄存器中 2.不能与段寄存器交换数据 3.存储器与存储器之间不能交换数据. XLAT(TRANSLATE)换码指令: 把一种代码转换为另一种代码. XLAT (OPR 可选) //Byte 执行操作: AL=(BX+AL) 指令执行时只使用预先已存入BX中的表格首地址,执行后,AL中内容则是所要转换的代码. LEA(Load Effective Address) 有效地址传送寄存器指令 LEA REG , SRC //指令把源操作数SRC的有效地址送到指定的寄存器中. 执行操作: REG = EAsrc 注: SRC只能是各种寻址方式的存储器操作数,REG只能是16位寄存器 MOV BX , OFFSET OPER_ONE 等价于LEA BX , OPER_ONE MOV SP , [BX] //将BX间接寻址的相继的二个存储单元的内容送入SP中 LEA SP , [BX] //将BX的内容作为存储器有效地址送入SP中 LDS(Load DS with pointer)指针送寄存器和DS指令 LDS REG , SRC //常指定SI寄存器。 执行操作: REG=(SRC), DS=(SRC+2) //将SRC指出的前二个存储单元的内容送入指令中指定的寄存器中,后二个存储单元送入DS段寄存器中。
Hadoop 集群基本操作命令-王建雄-2016-08-22
Hadoop 集群基本操作命令 列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help (注:一般手动安装hadoop大数据平台,只需要创建一个用户即可,所有的操作命令就可以在这个用户下执行;现在是使用ambari安装的dadoop大数据平台,安装过程中会自动创建hadoop生态系统组件的用户,那么就可以到相应的用户下操作了,当然也可以在root用户下执行。下面的图就是执行的结果,只是hadoop shell 支持的所有命令,详细命令解说在下面,因为太多,我没有粘贴。) 显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name (注:可能有些命令,不知道什么意思,那么可以通过上面的命令查看该命令的详细使用信息。例子: 这里我用的是hdfs用户。) 注:上面的两个命令就可以帮助查找所有的haodoop命令和该命令的详细使用资料。
创建一个名为 /daxiong 的目录 $ bin/hadoop dfs -mkdir /daxiong 查看名为 /daxiong/myfile.txt 的文件内容$ bin/hadoop dfs -cat /hadoop dfs -cat /user/haha/part-m-00000 上图看到的是我上传上去的一张表,我只截了一部分图。 注:hadoop fs <..> 命令等同于hadoop dfs <..> 命令(hdfs fs/dfs)显示Datanode列表 $ bin/hadoop dfsadmin -report
$ bin/hadoop dfsadmin -help 命令能列出所有当前支持的命令。比如: -report:报告HDFS的基本统计信息。 注:有些信息也可以在NameNode Web服务首页看到 运行HDFS文件系统检查工具(fsck tools) 用法:hadoop fsck [GENERIC_OPTIONS]
SAP系统常用命令介绍
SAP系统常用命令介绍 1、系统配置常用命令 所谓系统配置命令,通常包含系统操作配置、系统传输配置、系统自定义内容配置等相关命令。系统配置的范围很广,这里介绍的系统配置不包括模块配置内容,主要是系统层面的相关配置命令。常用的操作命令主要包含以下几种。 (1)系统传输配置命令:SE09/SE10、STMS (2)系统后台参数配置命令:SPRO (3)系统信息发布命令:SM02 (4)目标集团参数配置命令:SCC4 2、后台维护常用命令 在SAP系统中,普通用户常常因为权限不够导致很多事项无法处理,需要通过管理员在后台对相应的主数据及参数进行修改设置。这里主要介绍以下几个常用的后台维护命令。 (1)批处理命令:SCAT (2)定义后台作业命令:SM36 (3)查看后台作业命令:SM37 3、程序编辑常用命令 程序编辑属于SAP系统开发的一个重要组成部分,SAP系统本身带有ABAP语言编辑器,可以提供强大的自开发程序功能。这里介绍程序编辑通常使用的相关命令。一般来说,程序编辑常用到的命令有以下3各。 (1)程序编辑器命令:SE38 (2)韩式编辑器命令:SE37 (3)对象浏览器命令:SE80 4、表间维护常用命令: (1)SAP系统中的数据都是存储在不同的表空间中。对于这些表的查询、修改及数据整理,SAP提供有相应的操作命令。常用的表间维护命令主要包括以下几种。 (1)ABAP数据字典命令:SE11 (2)维护表视图命令:SM30 5、用户及权限控制常用命令 在SAP系统中对于用户及权限的控制是非常严格的,权限参数、权限、用户的管理,均有一套专有的体系。这里介绍用户及权限控制常用的命令,包括以下几种。 (1)权限创建及修改命令:PFCG (2)用户创建及配置命令:SU01 (3)用户批量处理命令:SU10
CAD常用命令大全
CAD常用命令大全 CAD 一、绘图工具栏中的绘图命令(英文名)及命令快捷键 1、直线(line) L 2、参照线又叫结构线(xline)XL: 1)平行。 2)垂直。 3)角度:反方向的角输入负值。 4)二等分(角的平分线):顶、角、角。 5)偏移:前题是必须先有一个参照线存在。 3、多线(mline)ML: 1、对正: 1)上:在光标下绘制多线。。 2)无(中):将光标作为原点绘制多线。 3)下:在光标上绘制多线。 4)比例:多线之间的全局宽度。 5)样式:系统外的样式。(需外挂) 4、多段线(pline)PL: 1)圆弧:将弧线段添加到多段线中。 2)闭合:在当前位置到多段线起点之间绘制一条直线段以闭合多线段。 3)半宽:指定宽多段线线段的中心到其一边的宽度。 4)取消:U。删除最近一次添加到多段线上的直线段 5)长度:以前一段线段相同的角度并按指定长度(也可用鼠标指定角度方向、长度)
绘制直线段。如果前一线段为圆弧,AutoCAD将绘制一条直线段与弧线段相切。 6)宽度:指定下一条直线段的宽度。 5、多边形(polygon)POL:(有3到1024条等长边的封闭多线段) 6、矩形(rectang)REC: 1)倒角: 2)圆角: 3)宽度:指定矩形线的宽度。 7、圆弧(arc)A:默认下有三种画法(共11种画法)常用的画法是:起点、端点、方向。 圆(circle)C:默认下有三种画法。 8、样条曲线(spline)SPL 9、椭圆(ellipse)EL: 1)中心点:通过指定的中心点来创建椭圆。 2)轴端点:通过指定两个端点来创建椭圆。 3)椭圆弧:先确定了椭圆,再根据此椭圆样式来编辑弧的大小。 10、插入块(insert)I: 1)输入块的名称。 2)选择路径: A:插入点 B:缩放比例 C:旋转 注:上面三项的可选择“在屏幕上指定”。在没有选择的情况下,插入时会按原来定
Hadoop命令大全
Hadoop命令大全 Hadoop配置: Hadoop配置文件core-site.xml应增加如下配置,否则可能重启后发生Hadoop 命名节点文件丢失问题:
1、列出所有Hadoop Shell支持的命令 $ bin/hadoop fs -help 2、显示关于某个命令的详细信息 $ bin/hadoop fs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoop namenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh bin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止DataNode守护进程。 9、在分配的JobTracker上,运行下面的命令停止Map/Reduce: $ bin/stop-mapred.sh bin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上停止TaskTracker守护进程。 10、启动所有 $ bin/start-all.sh 11、关闭所有 $ bin/stop-all.sh DFSShell 10、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 11、创建一个名为 /foodir 的目录 $ bin/hadoop dfs -mkdir /foodir 12、查看名为 /foodir/myfile.txt 的文件内容 $ bin/hadoop dfs -cat /foodir/myfile.txt
CMD常用命令大全(最新整理)
说起cmd大家都很熟悉吧很有用哦这里我为大家接扫常见的命令 dos命令[只列出我们工作中可能要用到的] cd\ '返回到根目录 cd.. '返回到上一级目录 1、cd 显示当前目录名或改变当前目录。 2、dir 显示目录中的文件和子目录列表。 3、md 创建目录。 4、del 删除一或数个文件。 5、chkdsk 检查磁盘并显示状态报告。 6、cacls 显示或者修改文件的访问控制表(ACL) 7、copy 将一份或多份文件复制到另一个位置。 8、date 修改日期 9、format 格式化磁盘 10、type 显示文本文件的内容。 11、move 移动文件并重命名文件和目录。 12、expand 展开一个或多个压缩文件。 13、ren 重命名文件。 14、attrib 显示或更改文件属性。 15、time 显示或设置系统时间。 16、at at命令安排在特定日期和时间运行命令和程序。要使用AT 命令,计划服务必须已在运行中。 17、net [user],[time],[use] 多,自己去查 18、netstat 显示协议统计和当前tcp/ip连接 19、nbtstat 基于NBT(net bios over tcp/ip)的协议统计和当前tcp/ip连接 20、route 操作和查看网络路由表 21、ping 就不说了,大家都熟悉吧 22、nslookup 域名查找 23、edit 命令行下的文本编辑器 24、netsh强大的命令行下修改tcp/ip配置的工具 25、fdisk 相信现在用的人比较少了,不过在没有其他工具的情况,他还是有用的 更多: attrib 设置文件属性 ctty 改变控制设备 defrag 磁盘碎片整理 doskey 调用和建立DOS宏命令 debug 程序调试命令
(完整版)hadoop常见笔试题答案
Hadoop测试题 一.填空题,1分(41空),2分(42空)共125分 1.(每空1分) datanode 负责HDFS数据存储。 2.(每空1分)HDFS中的block默认保存 3 份。 3.(每空1分)ResourceManager 程序通常与NameNode 在一个节点启动。 4.(每空1分)hadoop运行的模式有:单机模式、伪分布模式、完全分布式。 5.(每空1分)Hadoop集群搭建中常用的4个配置文件为:core-site.xml 、hdfs-site.xml 、mapred-site.xml 、yarn-site.xml 。 6.(每空2分)HDFS将要存储的大文件进行分割,分割后存放在既定的存储块 中,并通过预先设定的优化处理,模式对存储的数据进行预处理,从而解决了大文件储存与计算的需求。 7.(每空2分)一个HDFS集群包括两大部分,即namenode 与datanode 。一般来说,一 个集群中会有一个namenode 和多个datanode 共同工作。 8.(每空2分) namenode 是集群的主服务器,主要是用于对HDFS中所有的文件及内容 数据进行维护,并不断读取记录集群中datanode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。 9.(每空2分) datanode 在HDFS集群中担任任务具体执行角色,是集群的工作节点。文 件被分成若干个相同大小的数据块,分别存储在若干个datanode 上,datanode 会定期向集群内namenode 发送自己的运行状态与存储内容,并根据namnode 发送的指令进行工作。 10.(每空2分) namenode 负责接受客户端发送过来的信息,然后将文件存储位置信息发 送给client ,由client 直接与datanode 进行联系,从而进行部分文件的运算与操作。 11.(每空1分) block 是HDFS的基本存储单元,默认大小是128M 。 12.(每空1分)HDFS还可以对已经存储的Block进行多副本备份,将每个Block至少复制到 3 个相互独立的硬件上,这样可以快速恢复损坏的数据。 13.(每空2分)当客户端的读取操作发生错误的时候,客户端会向namenode 报告错误,并 请求namenode 排除错误的datanode 后,重新根据距离排序,从而获得一个新的的读取路径。如果所有的datanode 都报告读取失败,那么整个任务就读取失败。14.(每空2分)对于写出操作过程中出现的问题,FSDataOutputStream 并不会立即关闭。 客户端向Namenode报告错误信息,并直接向提供备份的datanode 中写入数据。备份datanode 被升级为首选datanode ,并在其余2个datanode 中备份复制数据。 NameNode对错误的DataNode进行标记以便后续对其进行处理。 15.(每空1分)格式化HDFS系统的命令为:hdfs namenode –format 。 16.(每空1分)启动hdfs的shell脚本为:start-dfs.sh 。 17.(每空1分)启动yarn的shell脚本为:start-yarn.sh 。 18.(每空1分)停止hdfs的shell脚本为:stop-dfs.sh 。 19.(每空1分)hadoop创建多级目录(如:/a/b/c)的命令为:hadoop fs –mkdir –p /a/b/c 。 20.(每空1分)hadoop显示根目录命令为:hadoop fs –lsr 。 21.(每空1分)hadoop包含的四大模块分别是:Hadoop common 、HDFS 、
Cad常用命令及使用方法
Cad常用命令及使用方法 一、绘图命令 直线:L 用法:输入命令L/回车/鼠标指定第一点/输入数值(也就是指定第二点)/回车(这时直线就画出来了)/回车(结束命令) 射线:RAY 用法:输入命令RAY/回车/鼠标指定射线起点/指定通过点/回车(结束命令) 构造线:XL 用法:输入命令XL/回车/鼠标指定构造线起点/指定通过点/回车(结束命令) 多段线:PL 用法1:同直线命令 用法2:输入命令PL/回车/指定起点/输入W(绘制带有宽度的线)/回车/指定线起点宽度/回车/指定线结束点宽度/回车/输入数值(线的长度值)/回车(结束命令) 正多边形:POL 用法:输入命令POL/回车/指定边数/回车/鼠标指定正多边形的中心点/输入选项(C外切于圆;I内接于圆)/回车/输入半径/回车(结束命令) 矩形:REC 用法1:输入命令REC/回车/鼠标指定第一角点/指定第二角点 用法2:输入命令REC/回车/输入C(绘制带有倒角的矩形)/回车/输入第一倒角值/回车/输入第二倒角值/回车/鼠标指定第一角点/指定第二角点 用法3:输入命令REC/回车/输入F(绘制带有圆角的矩形)/回车/输入圆角半径/回车/指定第一角点/指定第二角点 圆弧:A 用法:输入命令A/回车/指定圆弧起点/指定圆弧中点/指定圆弧结束点 (绘制圆弧的方法有11种,可参考绘图菜单---圆弧选项) 圆:C 用法:输入命令C/回车/鼠标指定圆心/输入半径值/回车(命令结束) (绘制圆的方法有6种,可参考绘图菜单---圆选项) 样条曲线:SPL 用法:输入命令SPL/回车/鼠标指定要绘制的范围即可/需要三下回车结束命令 椭圆:EL
Windows操作系统常用命令与蓝屏代码
Windows操作系统常用命令及蓝屏代码 一域控管理工具 1 dcpromo------- 安装域控制器 2 dsa.msc-------打开AD用户和计算机 3 dssite.msc-------打开AD站点和服务 4 domain.msc-------打开AD域和信任关系 5 dnsmgmt.msc-------打开DNS服务器 6 services.msc------- 打开服务 7 MMC-------(管理控制台) 8 compmgmt.msc------- 计算机管理控制台 9 devmgmt.msc------- 设备管理器控制台 10 diskmgmt.msc------- 磁盘管理器控制台 11 eventvwr.msc------- 日志管理器控制台 12 fsmgmt.msc------- 共享文件夹控制台 13 gpedit.msc------- 组策略管理控制台 14 iis6.msc iis-------管理控制台 15 lusrmgr.msc------- 本地账户管理控制台 16 napclcfg.msc------- NAP管理控制台 17 printmanagement.msc------- 打印管理控制台 18 rsop.msc------- 组策略结果集控制台 19 wf.msc------- 防火墙管理控制台 20 lusrmgr.msc------- 本机用户和组 21 devmgmt.msc-------设备管理器 22 rsop.msc-------组策略结果集 23 secpol.msc-------本地安全策略 24 services.msc-------本地服务设置
ADB 常用命令合集
ADB 常用命令合集 ADB (Android Debug Bridge) 说明:下面一些命令需要有root权限才能执行成功 快速启动dos窗口执行adb: 1. adb.exe所在路径添加到系统环境变量Path中 2. 配置快捷键启动dos 进入C:\WINDOWS\system32目录下,找到cmd.exe. 右击菜单 "发送到" -> 桌面快捷方式。 在桌面上右击"快捷方式到 cmd.exe" -> "属性" -> "快捷方式"页 -> 光标高亮"快捷键" -> 按下自定义快捷键 (如:Ctrl + Alt + Z) 任何情况下,按下Ctrl + Alt + Z启动dos窗口就可以执行adb命令了 -----------查看设备连接状态系列----------- adb get-serialno 获取设备的ID和序列号serialNumber adb devices 查询当前计算机上连接那些设备(包括模拟器和手机),输出格式: [serialNumber] [state] adb get-state 查看模拟器/设施的当前状态. 说明: 序列号[serialNumber]——由adb创建的一个字符串,这个字符串通过自己的控制端口
Hadoop最全面试题整理(附目录)
Hadoop面试题目及答案(附目录) 选择题 1.下面哪个程序负责HDFS 数据存储。 a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 答案C datanode 2. HDfS 中的block 默认保存几份? a)3 份b)2 份c)1 份d)不确定 答案A 默认3 份 3.下列哪个程序通常与NameNode 在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker 答案D 分析:hadoop 的集群是基于master/slave 模式,namenode 和jobtracker 属于master,datanode 和tasktracker 属于slave,master 只有一个,而slave 有多个SecondaryNameNode 内存需求和NameNode 在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode 运行在不同的机器上。 JobTracker 和TaskTracker JobTracker 对应于NameNode,TaskTracker 对应于DataNode,DataNode 和NameNode 是针对数据存放来而言的,JobTracker 和TaskTracker 是对于MapReduce 执行而言的。mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:jobclient,JobTracker 与TaskTracker。 1、JobClient 会在用户端通过JobClient 类将应用已经配置参数打包成jar 文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker 创建每一个Task(即MapTask 和ReduceTask)并将它们分发到各个TaskTracker 服务中去执行。 2、JobTracker 是一个master 服务,软件启动之后JobTracker 接收Job,负责调度Job 的每一个子任务task 运行于TaskTracker 上,并监控它们,如果发现有失败的task 就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。 3、TaskTracker 是运行在多个节点上的slaver 服务。TaskTracker 主动与JobTracker 通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需要运行在HDFS 的DataNode 上。 4. Hadoop 作者 a)Martin Fowler b)Kent Beck c)Doug cutting 答案C Doug cutting 5. HDFS 默认Block Size a)32MB b)64MB c)128MB 答案:B 6. 下列哪项通常是集群的最主要瓶颈 a)CPU b)网络c)磁盘IO d)内存 答案:C 磁盘 首先集群的目的是为了节省成本,用廉价的pc 机,取代小型机及大型机。小型机和大型机