主成分分析与聚类分析和判别分析

实验三主成分分析、聚类分析和判别分析
学院:地理科学学院专业:自然地理学
姓名:郭国洋
实验内容
(1)中国31个省份、直辖市、自治区(不包括港澳台)经济状况的7项指标。
(2)用主成分分析剖析出影响中国大陆经济状况的主要指标,并对中国大陆的经济综合实力进行排序。
(3)用主成分剖析出的指标,用聚类分析对中国大陆的经济状况进行评价,并对每类的经济综合状况进行评价。
(4)结合本题,谈谈聚类分析和主成分分析两种方法如何结合使用来分析问题。
实验目的
(1)巩固主成分和聚类分析的基本原理和方法步骤以及在实际分析中的意义。
(2)用SPSS软件完成地理的主成分分析和聚类分析。
第一部分主成分分析
1 实验数据
查阅2012年中国统计年鉴,数据表示2011年的指标。得到中国31个省份、直辖市、自治区(不含港澳台)的7项经济统计指标数据,包括:总人口/10^4人,城镇人口比例/%,第一产业总产值/10^8元,工业生产总值/10^8元,公共财政预算收入/10^8元,城乡居民储蓄余额/10^8元,城镇单位就业人员工资总额/10^8元。样本容量:31,变量:7,如图1。
。
2 实验步骤及分析
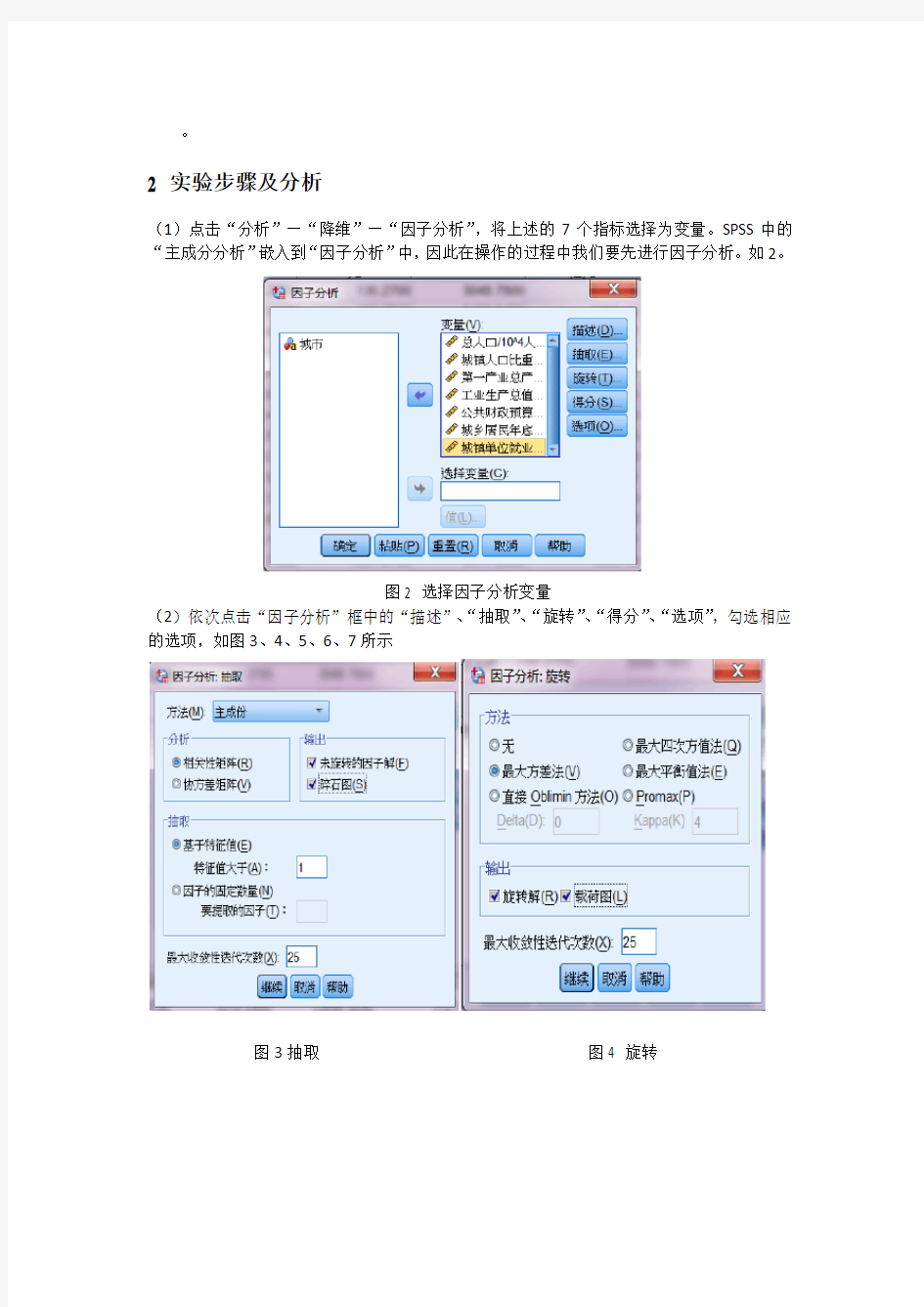
(1)点击“分析”—“降维”—“因子分析”,将上述的7个指标选择为变量。SPSS中的“主成分分析”嵌入到“因子分析”中,因此在操作的过程中我们要先进行因子分析。如2。
图2 选择因子分析变量
(2)依次点击“因子分析”框中的“描述”、“抽取”、“旋转”、“得分”、“选项”,勾选相应的选项,如图3、4、5、6、7所示
图3抽取图4 旋转
图4描述统计图5因子得分
图6选项图7旋转
(3)点击“确定”,得到相应的结果并分析。
图8 KMO和Bartlett检验
分析:
图8中,在进行因子分析之前,需要检验变量之间是否具备进行分析的条件。由图中
可知KMO值为0.787>0.5,说明数据变量之间具有结构效度,Sig<0.05,说明可以进行因子分析。
图9 公因子方差
分析:
图9是指全部公共因子对于变量的总方差做所的贡献,说明了全部公共因子反映出的原变量的信息的百分比。
例如:“总人口”的共同度是0.969,即提取的公因子对原变量的方差作出了96.9%的贡献。图9中我们知道提取公因子之后各个变量的数值都比较大,说明在变量空间转化为因子空间是,保存了比较多的信息,因此,因子分析的效果是显著的。
图10 解释的总方差
分析:
图10中可以看到各个特征值的贡献率以及累积贡献率。可见,在本次试验中,前两个因子的累积贡献率已达到93.667%。
图11 碎石图
分析:
图11横坐标为因子数,纵坐标为特征值,从图中可以看出前面两个因子的特征值比较大,都大于1,从第三个因子以后,折线平缓,因此,本次实验选择前面2个因子。
图12 因子载荷矩阵图13 旋转成分矩阵
分析:
在图12中我们发现工业生产总值、公共财政预算收入、城乡居民年底储蓄余额、城镇单位就业人员工资总额在第2个主因子的载荷值都比较低,不能对因子作出很好的解释。
本实验有必要对因子载荷矩阵实施旋转,得到图13的结果。用具有Kaiser标准化的正交旋转法旋转之后我们发现第一因子主要由“总人口、第一产业总产值、工业生产总值”决定,第二因子主要由“城镇人口比重、公共财政预算收入、储蓄余额、工资总额”决定。
图14 成份得分协方差矩阵
分析:图14的结果告诉我们两个因子之间是不相关的。
图15 成份得分系数矩阵
分析:
图15给出了因子得分系数矩阵,将公共因子表示成原始变量的线性组合,将公因子对变量做线性回归,得到系数的最小二乘估计就是所谓的因子得分系数。
图16 因子得分
分析:
根据估计出来的得分系数,可以计算因子得分,由于在图6的“因子得分”中勾选了“保存为变量”,在SPSS数据视图中出现的fac1_、fac_2就是变量的因子得分,如图16。
图17 因子载荷图
分析:
图17说明了我们提取了两个公因子,所以输出的是二位平面图,我们可以看到旋转后在主因子为坐标轴的二维平面上原变量的位置。
(3)计算主成分综合得分
点击“转换”—“计算变量”,输入目标变量——Z1、Z2(总得分)和数学表达式:Y=0.70643*FAC1_1+0.22545*FAC2_1
图18 计算变量
图19 因子总得分
分析:该图的列Z1、Z2代表主成分变量,由此可以相关的线性组合方程组。
(4)对31个观察量的综合得分进行排序
点击“数据”—“排序个案”,选择Y作为变量,选择“降序”,点击确定。如图20所示。
图20 综合得分排序
4 部分小结
在以上的操作过程中我们提取了两个公因子(主成分),发现两个主成分可以保存有原变量的93.188%的信息,因此我们认为主成分的提取是有效。“总人口、第一产业总产值、工业生产总值”可以由第一主成分代替,“城镇人口比重、公共财政预算收入、储蓄余额、工资总额”可以由第二主成分代替。在对因子载荷矩阵进行旋转之后,我们发现可以就不难建立因子模型,在得到因子得分后,就可以得到以两个组成分为变量的因子总得分,达到实验的要求和目的。本次实验是有效的。
第二部分聚类分析
1 实验原理
聚类分析,亦称群分析或点群分析,它是研究多要素事物分类问题的数量方法。其基本原理是,根据样本自身的属性,用数学方法按照某种相似性或差异性指标,定量地确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行聚类。
最近邻元素:也是最近距离法。定义类与类之间的距离为两类中最近的样品之间的距离。
2 实验步骤
(1)点击“分析”—“分类”—“系统聚类”,将上述的7个指标选择为变量。如图所示。
(2)依次点击“系统聚类分析”框中的“统计量”、“绘制”、“方法”、“保存”,勾选相应的选项,如图所示。方法选择:最近邻元素(最近距离法)、距离选择:欧式距离。
(3)点击“确定”,得到相应的结果,如图所示。
分析:上图给出了样本处理的基本信息,包括样本数为31、含有缺失值的样本数为0以及百分比等。
聚类表
阶
群集组合
系数
首次出现阶群集
下一阶群集 1 群集 2 群集 1 群集 2
1 29 30 105579.860 0 0 2
2 21 29 689448.74
3 0 1 5
3 1
4 20 1002013.164 0 0 9
4 24 28 1067488.619 0 0 6
5 21 2
6 1213332.813 2 0 21
6 24 31 1281848.968 4 0 19
7 17 18 1459967.652 0 0 14
8 8 27 1609732.856 0 0 9
9 8 14 1776932.509 8 3 10
10 4 8 2101684.315 0 9 12
11 7 22 2137666.594 0 0 12
12 4 7 3536871.652 10 11 13
13 4 25 3884365.107 12 0 15
14 12 17 3992460.119 0 7 18
15 4 13 4004347.418 13 0 16
16 2 4 4201107.693 0 15 17
17 2 5 5300445.220 16 0 18
18 2 12 6083277.612 17 14 19
19 2 24 7278463.644 18 6 21
20 3 23 8849477.031 0 0 22
21 2 21 10623438.134 19 5 26
22 3 6 17010842.574 20 0 23
23 3 16 20454033.811 22 0 26
24 10 15 21802131.864 0 0 29
25 1 9 22829572.231 0 0 27
26 2 3 24845266.603 21 23 27
27 1 2 26060636.018 25 26 28
28 1 11 53341687.378 27 0 29
29 1 10 68613699.031 28 24 30
30 1 19 2.263E8 29 0 0
分析:
a.上表是聚类过程表,其中勒出了聚类中观测量或者合并的顺序。试验中共有31个观测量,经过30步的聚类,所有的观测量被合并为1类。
b.第一步,首先将距离最近的29、30号观测量合并为一类G1(首次出现阶聚类中,群集1=群集2=0),出现复聚类的下一阶段为第二步。
c.第二步是将21号样品并入G1类中(首次出现阶聚类中,群集1=0、群集2=1),形成G2类,下一阶段的复聚类将出现在第4步。以此类推。
d.随着聚类进程,系数的数值一直在增大,说明聚类刚开始的时候样品或者类间的差异比较小,聚类结束时,类与类的差异变得比较大,体现了聚类分析的基本思想。
分析:
a.上面两图分别为冰柱图和树状图。二者表达的内容是一样的,区别在于:首先是表达形式上的差距,其次是树状图可以读出样品或者观测量的距离,而冰柱图却没有这个功能。因此,本实验就分析树状图。
b.假定,将31个观测量分为2类:第1类是广东,第2类为其他城市。此时的距离为25。
假定,将31个观测量分为3类:第1类是广东,第2类为江苏和山东,第3类为其他城市,此时的距离范围可以为14到23。
假定,将31个观测量分为5类的情况:第1类是广东,第2类是江苏和山东,第3类是浙江、第4类是北京和上海。第5类为其它城市。
假定,将31个观测量分为8类的情况:第1类是广东,第2类是江苏和山东,第3类是浙江,第4类上海,第5类是北京,第6类是河南,第7类是辽宁,第8类是为其他城市。
实验总结
本次实验中国31个省份、直辖市、自治区(不包括港澳台)经济状况的7项指标,样
本容量31,进行了主成分和聚类分析,实验过程步骤清晰,得出的结果有效。
进行主成分分析后,总人口、第一产业总产值、工业总产值用第一主成分代表;说明了第一产业和工业这样的劳动密集型产业需要大量的劳动力投入,人口的多少一定程度上决定了第一产业和工业的总产值。城镇人口比重、公共财政预算内收入、城乡居民年底储蓄余额、城镇单位人员工资总额用第二主成分代表。四者中经济成分比较明显。
用成分得分计算得到总分,即综合得分,并对其排序,得到综合这7个影响因子下的综合实力的顺序。广东居首,江苏、浙江分别在3、7,西藏、青海、宁夏排在最后,而上海、北京、天津的排在23、25、27。对比这些城市GDP总体指标下的排名,经济发达的上海、北京、天津等城市的综合排名矛盾。说明在不同的经济指标影响下,城市的综合实力也收到影响。因此在对一个事物进行分析时,我们要认清楚影响事物的主要因子是哪些,起到了影响程度怎么样,才能分析更加到位。
根据聚类分析的结果可知,大体上广东单独为一类,北京和上海为一类,浙江和江苏为一类,其他城市为一类。说明了在同一类中的城市在经济发展过程中受到相似的因子影响,说明了主成分分析的结果和聚类分析的结果在一定程度上能够吻合。
在分类的结果中也可以发现,大体上经济特别发达的城市为一类、东部沿海城市为一类、其他的中部城市和西部城市为一类,从树状图中也可以知道,三类之间的距离最大为23左右,说明中国经济发展内部差异还是比较大,结果和中国实际的经济发展状况相似。
第三部分判别分析
1 实验内容
国家分类与判别。数据来源于联合国开发计划署(UN-DP)发表的《2000年人类发展报告》。 UN-DP的人类发展报告采用出生时预期寿命、成人识字率、人均GDP等的指标将全世界的国家分为三类。指标选取三个:出生时预期寿命、成人识字率和人均GDP。
2 实验数据
原数据来源于联合国开发计划署(UN-DP)发表的《2000年人类发展报告》。如
图1.
图1 实验数据
3 实验原理
(1)判别分析是根据地理对象的一些数量特征,来判别其类型归属的一种统计方法。
(2)判别分析的作用即对已分好的类型进行合理性检验、判别某地地理类型的归属问题和确定区域界线、评价各要素特征值在判别分析中贡献率的大小。
(3)判别分析与聚类分析既有相同之处,又有差别。相同处在于:都能确定地理类型;不同点在于:判别分析兼有判别和分类的两种性质,但以判别为主,判别分析必须事先已知类型为前提,而聚类分析则不必事先已知类型,类型的划分是聚类的结果。
4 实验目的
(1)通过本次实验了解判别分析的基本思想,理解判别分析与聚类分析的区别和联系。
(2)理解判别函数在判别分析过程中所起的作用,对判别分析结果做出合理的统计学和实际含义的解释。
5实验步骤
(1)导入数据,定义变量,在“类别”中用1表示高人类发展水平,2表示中等人类发展水平,0表示待判别,并定义为数值格式。如图2所示。
图2
(2)点击“分析”—“分类”—“判别”,分别选择分组变量(定义范围最小值为1,最大值为2)、自变量,选择“一起输入自变量”如图3,图4,图5.
图3
图4
图5
(3)分别点击“统计量”、“分类”和“保存”,勾选相应的选项,
6数据处理结论及分析
分析案例处理摘要
未加权案例N 百分比
有效14 77.8
排除的缺失或越界组代码 4 22.2
至少一个缺失判别变量0 .0
0 .0
缺失或越界组代码还有至少一个缺失
判别变量
合计 4 22.2
合计18 100.0
由上图我们可以看出参加判别分析的观测量为18,其中有效观测量数为14,有效观测量占总数的77.8%。
组均值的均等性的检验
Wilks 的 Lambda F df1 df2 Sig.
出生时预期寿命.395 18.397 1 12 .001
成人识字率.943 .720 1 12 .413
人均GDP .162 61.889 1 12 .000
组均值的均等性的检验
Wilks 的 Lambda
F df1
df2
Sig.
出生时预期寿命 .395 18.397 1 12 .001 成人识字率 .943
.720
1 1
2 .413
由组均值相等的检验表可知,出生时预期寿命和人均GDP 两个变量类内均值检验的显著性概率(sig )都小于0.05,且Wiiks Lamabda 的值都比较接近0,说明除了成人识字率外,其余变量之间类内均值都存在显著差异,可以进行判别分析。
汇聚的组内矩阵a
出生时预期寿命
成人识字率
人均GDP
协方差
出生时预期寿命 8.376 18.818 4401.042 成人识字率 18.818 182.960 16182.267 人均GDP
4401.042 16182.267
16874782.000
相关性
出生时预期寿命
1.000 .481 .370 成人识字率 .481 1.000 .291 人均GDP
.370
.291
1.000
a. 协方差矩阵的自由度为 12。
汇聚的组内矩阵分为两部分,即自变量间合并的协方差矩阵和自变量间相关系数矩阵。其中,协方差矩阵的自由度为12,从相
关系数值可知,各变量之间的线性相关关系都不显
著。
从检验结果图可以看出,Sig 的值为0.015小于0.1,所以我们认为判别分
析是显著的,说明判错率将很小。而图中箱的M 值为22.319小于0.05,说明在该显著性水平下各类协方差矩阵相等,可以进行Bayes 检验。
检验结果
箱的 M 22.319 F
近似。 2.646
df1 6
df2
795.195
Sig.
.015
对相等总体协方差矩阵的零假设进行检
验。
,方差的百分比和累积百分比都是100%,相关系数为0.924。
分析:这是对判别函数的显著性检验,其中Wiiks 的Lamabda 值为0.147,非常小,卡方为20.127,较大,自由度为3,Sig 为
0.000,因此认为判别函数有效。
分析:从左图的数据中我们可以得到一个标注化的典型判别式函数即Y=0.331X1-0.324X2+0.915X3,右图表示的判别变量与判别函数之间的相关性,由数值可知,“人均GDP ”与判别函数的关系最为密切,贡献率最大。
结构矩阵
函数 1
人均GDP .943 出生时预期寿命 .514 成人识字率
.102
判别变量和标准化典型判别式函数之间的汇聚组间相关性
按函数内相关性的绝对大小排序的变量。
标准化的典型判别式函数系数
函数 1
出生时预期寿命 .331 成人识字率 -.324 人均GDP
.915
典型判别式函数系数
函数 1
出生时预期寿命 .114 成人识字率 -.024 人均GDP
.000
分析:上图表示我们可以得到一个未标准化的判别函数即Y=-8.874+0.114X1-0.024X2,所以我们可以将变量带入计算判别分进行分类。右图为各类别重心的位置,通过计算各观测值与重心的距离,观测值的分类以距离最小值作为标准。
分类函数系数
类别
1 2
出生时预期寿命10.911 10.395
成人识字率-.512 -.404
人均GDP -.001 -.002
(常量) -385.613 -344.181
Fisher 的线性判别式函数
F1=-385.613+10.911X1-0.512X2-0.001X3,F2=-344.181+10.395X1-0.404X2-0.002X3。将自变量的数值带入上述的判别函数中,计算出函数值,哪个函数值比较大就可以判别该变量属于哪一从上图我们可以看到全部的18个观测量都被采用,没有缺失值或者其他原因被排除掉。
分析:其中DIS_1为类别显示,DIS_1_1和DIS_1_2分别表示带入判别函数后的判别分。可知,类别1的判别分较大,类别2的判别分较小。原始数据中有一个判别错误即“阿根廷”,说明阿根廷的判别条件可能处在两个类别的中间地(常量) -8.874
非标准化系数
组质心处的函数
类别
函数
1
1 2.574
2 -1.931
在组均值处评估的非标准化典
型判别式函数
分类处理摘要
已处理的18
已排除的缺失或越界组代码0
至少一个缺失判别变量0
用于输出中18
带。
7 实验体会
通过本次实验,能够对判别分析和聚类分析进行比较,掌握二者之间的异同点;更加深入地了解和掌握了判别分析的操作过程。
主成分分析和聚类分析报告
北京建筑工程学院 理学院信息与计算科学专业实验报告 课程名称《数据分析》实验名称《主成分分析和聚类分析》实验地点:基础楼C-423日期__2016.5.5_____ 姓名张丽芝班级信131 学号201307010108___指导教师王恒友成绩 【实验目的】 (1)熟悉利用主成分分析进行数据分析,能够使用SPSS软件完成数据的主成分分析; (2)熟悉利用聚类分析进行数据分析,能够运用主成分分析的结果,做进一步分析,如聚类分析、回归分析等,能够使用SPSS软件完成该任务。 【实验要求】 根据各个题目的具体要求,分别运用SPSS软件完成实验任务。 【实验内容】 1、表4.9(数据见exercise4_5.txt)给出了1991年我国30个省市、城镇居民的月平均消 费数据,所考察的八个指标如下:(单位均为元/人) X1: 人均粮食支出;X2:人均副食支出; X3: 人均烟酒茶支出;X4: 人均其他副食支出; X5:人均衣着商品支出;X6: 人均日用品支出; X7: 人均燃料支出;X8: 人均非商品支出。 (1)求样本相关系数矩阵R。 (2)从R出发做主成分分析,求出各主成分的贡献率及前两个主成分的累积贡献率; 2、(1)对题1中的数据,按照原有的八个指标,对30个省份进行聚类,给出分为3
类的聚类结果。 (2)利用题1得到的前2个主成分指标,分别按最短距离法(最近邻居距离)、最长距离法(最远邻居距离)、类平均距离法(组间平均距离)、重心距离法;其中距离均采用欧式平方距离,对样本进行谱系聚类分析,并画出谱系聚类图;给出分为3类的聚类结果。并与(1)的结果进行比较 【实验步骤】(此部分主要包括实验过程、方法、结果、对结果的分析、结论等) 1 1) 2) 表:方差贡献率和累计贡献率
主成分分析、聚类分析、因子分析的基本思想及优缺点
主成分分析:利用降维(线性变换)的思想,在损失很少信息的前提下把多个指标转化为几个综合指标(主成分),用综合指标来解释多变量的方差- 协方差结构,即每个主成分都是原始变量的线性组合,且各个主成分之间互不相关,使得主成分比原始变量具有某些更优越的性能(主成分必须保留原始变量90%以上的信息),从而达到简化系统结构,抓住问题实质的目的综合指标即为主成分。 求解主成分的方法:从协方差阵出发(协方差阵已知),从相关阵出发(相关阵R已知)。(实际研究中,总体协方差阵与相关阵是未知的,必须通过样本数据来估计) 注意事项:1. 由协方差阵出发与由相关阵出发求解主成分所得结果不一致时,要恰当的选取某一种方法; 2. 对于度量单位或是取值范围在同量级的数据,可直接求协方差阵;对于度量单位不同的指标或是取值范围彼此差异非常大的指标,应考虑将数据标准化,再由协方差阵求主成分; 3.主成分分析不要求数据来源于正态分布; 4. 在选取初始变量进入分析时应该特别注意原始变量是否存在多重共线性的问题(最小特征根接近于零,说明存在多重共线性问题)。 优点:首先它利用降维技术用少数几个综合变量来代替原始多个变量,这些综合变量集中了原始变量的大部分信息。其次它通过计算综合主成分函数得分,对客观经济现象进行科学评价。再次它在应用上侧重于信息贡献影响力综合评价。 缺点:当主成分的因子负荷的符号有正有负时,综合评价函数意义就不明确。命名清晰性低。 聚类分析:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。 。其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。 常用聚类方法:系统聚类法,K-均值法,模糊聚类法,有序样品的聚类,分解法,加入法。 注意事项:1. 系统聚类法可对变量或者记录进行分类,K-均值法只能对记录进行分类;2. K-均值法要求分析人员事先知道样品分为多少类;
SPSS聚类分析和判别分析论文
S P S S聚类分析和判别分析 论文 Prepared on 22 November 2020
基于聚类分析的我国城镇居民消费结构实证分析摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍存在较大差别。文章选用8个城镇居民消费结构统计指标,采用欧式距离平方和离差平方和法,对我国31个省、直辖市及自治区的2013年城镇居民消费结构进行聚类分析和比较研究。这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。 关键词:消费结构;聚类分析;判别分析;政策建议; 一、引言 近年来,随着我国经济的快速发展,城镇居民的收入不断增加,并且在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变化,结构不合理现象也得到了一定程度的调整。但是,由于各地区的经济发展不平衡及原有经济基础的差异,使各地区的消费结构仍存在着明显差别。为了进一步改善消费结构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和谐增长提供决策依据。 二、消费结构的数据分析 消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替代、制约的关系。就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需求结构,体现一国或各地区的经济发展水平和居民生活状况。 (一)数据来源 为了更加深入地了解我国城镇居民消费结构,先利用2013年全国数据(如表1所示),对全国31个省、直辖市、自治区进行聚类分析。分析采用选用了城镇居民食品、衣着、居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和服务八项指标,分别用来反映较高、中等、较低居民消费结构。
主成分分析、聚类分析、因子分析的基本思想及优缺点
注意事项:1. 系统聚类法可对变量或者记录进行分类,K-均值法只能对记录进行分类; 2. K-均值法要求分析人员事先知道样品分为多少类; 3. 对变量的多元正态性,方差齐性等要求较高。应用领域:细分市场,消费行为划分,设计抽样方案等 优点:聚类分析模型的优点就是直观,结论形式简明。 缺点:在样本量较大时,要获得聚类结论有一定困难。由于相似系数是根据被试的反映来建立反映被试间内在联系的指标,而实践中有时尽管从被试反映所得出的数据中发现他们之间有紧密 的关系,但事物之间却无任何内在联系,此时,如果根据距离或相似系数得出聚类分析的结果,显然是不适当的,但是,聚类分析模型本身却无法识别这类错误。 因子分析:利用降维的思想,由研究原始变量相关矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子。(因子
分析是主成分的推广,相对于主成分分析,更倾向于描述原始变量之间的相关关系),就是研究如何以最少的信息丢失,将众多原始变量浓缩成少数几个因子变量,以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。 求解因子载荷的方法:主成分法,主轴因子法,极大似然法,最小二乘法,a因子提取法。 注意事项:5. 因子分析中各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。 应用领域:解决共线性问题,评价问卷的结构效度,寻找变量间潜在的结构,内在结构证实。 优点:第一它不是对原有变量的取舍,而是根据原始变量的信息进行重新组合,找出影响变量的共同因子,化简数据;第二,它通过旋转使得因子变量更具有可解释性,命名清晰性高。 缺点:在计算因子得分时,采用的是最小二乘法,此法有时可能会失效。 判别分析:从已知的各种分类情况中总结规律(训练出判别函数),当新样品进入时,判断其与判别函数之间的相似程度(概率最大,距离最
系统工程 主成分分析及聚类分析
泛珠三角区域物流发展水平综合评价研究 资料来源:吴晓燕. 泛珠三角区域物流发展水平综合评价研究 泛珠三角区域是我国最主要的经济发达地区之一,也是现代物流最为强劲的“增长极”,具有优越的地理、交通与经济区位优势。但是区域内有发达省份,也有不发达省份,有沿海的省份,也有内陆省份,有东部省份,也有西部省份,彼此之间存在不同的优势和劣势。因此对泛珠三角区域物流发展水平进行评估与分析,有利于明确广东、福建、江西、广西、海南、湖南、四川、云南、贵州九省(区)的区域物流发展现状及差异,找出区域间的优势互补项目,为区域内物流资源有效利用和合理共享、促进区域物流一体化发展提供方向和依据。 评价区域物流综合发展水平是一项很复杂的工作。选择并构建区域物流发展水平综合评价指标体系是评价的关键。因此选择指标构建评价指标体系,必须以综合评价目的为依据,对所要考察的事物进行认真分析,寻找出影响评价对象的因素,从中选出若干主要因素,构建成综合评价指标体系。在多指标综合评价中,如果指标选择不当,再好的综合评价方法也会出现差错,甚至完全失败。 区域物流发展水平评价指标体系实际上就是利用具体的指标将区域物流所包括的功能、区域物流的内涵、特征具体化、层次化的统计描述和综合评价。为了合理评估区域物流发展综合水平,我们主要选取6个一级评价指标,20个次级评价指标对其进行评估,具体结构如下表:
表1 区域物流发展水平评价指标体系 1、社会经济发展类 经济发展是区域物流发展的基础保障,一个地区雄厚的经济基础有利于该物流的加速发展。一般来说,区域物流发展水平与区域的经济发展水平成正比。因此,我们考虑GDP和人均GDP两个次级指标,他们综合反映了物流发展的社会经济基础。 2、生产、消费流通类 从物流需求源考虑,农业、制造业等产业中的物流需求主要是生产资料的位移、储存和流通加工等,这类产业的物流需求与各行业的产量产值存在正比关系,物流需求是商品需求的派生物,与消费品销售,生产资料市场直接相关,商品市场的规模直接决定物流需求的大
判别分析及聚类分析
判别分析(Discriminant Analysis) 一、概述: 判别问题又称识别问题,或者归类问题。 判别分析是由Pearson于1921年提出,1936年由Fisher首先提出根据不同类别所提取的特征变量来定量的建立待判样品归属于哪一个已知类别的数学模型。 根据对训练样本的观测值建立判别函数,借助判别函数式判断未知类别的个体。 所谓训练样本由已知明确类别的个体组成,并且都完整准确地测量个体的有关的判别变量。 训练样本的要求:类别明确,测量指标完整准确。一般样本含量不宜过小,但不能为追求样本含量而牺牲类别的准确,如果类别不可靠、测量值不准确,即使样本含量再大,任何统计方法语法弥补这一缺陷。 判别分析的类别很多,常用的有:适用于定性指标或计数资料的有最大似然法、训练迭代法;适用于定量指标或计量资料的有:Fisher二类判别、Bayers多类判别以及逐步判别。半定量指标界于二者之间,可根据不同情况分别采用以上方法。 类别(有的称之为总体,但应与population的区别)的含义——具有相同属性或者特征指标的个体(有的人称之为样品)的集合。如何来表征相同属性、相同的特征指标呢? 同一类别的个体之间距离小,不同总体的样本之间距离大。 距离是一个原则性的定义,只要满足对称性、非负性和三角不等式的函数就可以称为距 绝对距离 马氏距离:(Manhattan distance) 设有两个个体(点)X与Y(假定为一维数据,即在数轴上)是来自均数为μ,协方差阵为∑的总体(类别)A的两个个体(点),则个体X与Y的马氏距离为 (,)X与总体(类别)A的距离D X Y= (,) 为D X A= 明考斯基距离(Minkowski distance):明科夫斯基距离 欧几里德距离(欧氏距离) 二、Fisher两类判别 一、训练样本的测量值 A类训练样本
主成分和聚类分析
4实证过程与结果 4.1主成分与聚类分析 首先通过SPSS软件对环境污染的相应指标进行主成分分析,得到:提取Y1、Y2、Y3和Y4四个主成分,其累积贡献率已经达到,超过80%,代表所有环境污染指标的绝大部分信息。Y1偏向于解释工业氢氧化物排放量,Y2偏向于解释生活烟尘排放量,Y3偏向于解释生活废水排放量,Y4偏向于解释工业二氧化硫排放量。 然后,根据主成分分析结果,用Z=0.43226*Y1+0.21911*Y2+0.10380*Y3+ 0.06519*Y4计算综合得分,见下表1。 表1环境污染地区的主成分综合得分表 序号地区Z 排名序号地区Z 排名 1 北京0.863 5 17 武汉-0.116 13 2 天津 1.088 4 18 长沙-0.841 28 3 石家庄0.455 6 19 广州-0.373 19 4 太原0.209 8 20 南宁-0.519 24 5 呼和浩特-0.052 12 21 海口-1.29 31 6 沈阳-0.273 1 7 22 重庆 2.767 1 7 长春-0.257 16 23 成都-0.451 20 8 哈尔滨 2.489 2 24 贵阳-0.331 18 9 上海 1.979 3 25 昆明-0.552 26 10 南京-0.232 15 26 拉萨-1.275 30 11 杭州0.175 9 27 西安0.357 7 12 合肥-0.5 21 28 兰州-0.514 23 13 福州-0.525 25 29 西宁0.004 11 14 南昌-0.949 29 30 银川-0.702 27 15 济南0.022 10 31 乌鲁木齐-0.502 22 16 郑州-0.152 14 最后将环境污染的综合得分作为个案进行层次聚类分析,将31个地区分为5类,如表2。
聚类分析与判别分析区别
聚类分析与判别分析区别1 2 聚类分析和判 3 别分析就是这样的分类方法 4 , 5 目前它们已经成为 6 比较标准的数据分类方法。 7 我们常说 8 “物以类聚、 9 人以群分” 10 , 11 就是聚类分 12 析和判别分析最简单、 13 14 最朴素的阐释 15 , 16 并且这一成 17 语也道明了这两种方法的区别与联系 , 18 19 都是分类 20 技术 , 21 22 但它们是分别从不同的角度来对事物分类 的 23 24 , 25 或者说 , 26 27 是两种互逆的分类方式。聚类分析与 28 判别分析都是多元统计中研究事物分类的基本方 29 法 30 , 31 但二者却存在着较大的差异。 32 一、 33 聚类分析与判别分析的基本概念 34 1 35 、 36 聚类分析 37 又称群分析、 38 点群分析。 39 根据研究对象特征对 40 研究对象进行分类的一种多元分析技术 , 41 42 把性质
相近的个体归为一类 1 2 , 3 使得同一类中的个体都具 4 有高度的同质性 5 , 6 不同类之间的个体具有高度的 异质性。 7 8 根据分类对象的不同分为样品聚类和变量聚类。9 2 、 10 11 判别分析 12 是一种进行统计判别和分组的技术手段。根 13 据一定量案例的一个分组变量和相应的其他多元14 变量的已知信息 15 , 16 确定分组与其他多元变量之间 17 的数量关系 18 , 19 建立判别函数 , 20 21 然后便可以利用这一 22 数量关系对其他未知分组类型所属的案例进行判23 别分组。 24 判 25 别 26 分 27 析 28 中 29 的 30 因 变 31 32 量 33 或 34 判 35 别 36 准 则 37 38 是 39 定 类 40 41 变 42 量 , 43 44 而自变量或预测变量基本上是定距变量。
主成分和聚类分析
4实证过程与结果 主成分与聚类分析 首先通过SPSS软件对环境污染的相应指标进行主成分分析,得到: 提取Y 1、Y 2 、Y 3 和Y 4 四个主成分,其累积贡献率已经达到,超过80%,代表 所有环境污染指标的绝大部分信息。Y 1偏向于解释工业氢氧化物排放量,Y 2 偏向 于解释生活烟尘排放量,Y 3偏向于解释生活废水排放量,Y 4 偏向于解释工业二氧 化硫排放量。 然后,根据主成分分析结果,用Z=*Y 1+*Y 2 +*Y 3 + *Y 4 计算综合得分,见下表1。 表1 环境污染地区的主成分综合得分表 序号地区Z排名序号地区Z排名1北京517武汉13 2天津418长沙28 3石家庄619广州19 4太原820南宁24 5呼和浩特1221海口31 6沈阳1722重庆1 7长春1623成都20 8哈尔滨224贵阳18 9上海325昆明26 10南京1526拉萨30 11杭州927西安7 12合肥2128兰州23 13福州2529西宁11 14南昌2930银川27 15济南1031乌鲁木齐22 16郑州14 最后将环境污染的综合得分作为个案进行层次聚类分析,将31个地区分为5类,如表2。 表2 各地区污染分类 分类污染情况地区 1轻度污染海口、拉萨
2比较轻度污染合肥、乌鲁木齐、福州、南宁、兰州、,昆明、成都、银川、南昌、长沙、沈阳、长春、南京、广州、贵阳、郑州、武汉、济南、西宁、呼和浩特 3污染情况一般太原、杭州、石家庄、西安 4污染比较严重北京、天津 5污染十分严重上海、哈尔滨、重庆 主成分分析和聚类分析在SPSS中的操作过程 打开SPSS,“文件-打开-数据”,选中excel,如下图结果。 首先将变量标准化,“分析-描述统计-描述”,将变量全部选入对话框,点上“将标准化得分另存为变量(Z)”,结果如下。
全国各省经济的聚类分析及判别分析
全国各省经济的聚类分析及判别分析 唐鹏钧(DY1001109) 摘要:利用SPSS软件对全国31个省、直辖市、自治区(浙江、湖南、甘肃除外)的主要经济指标进行聚类分析,将其经济分成4种类型,并对浙江、湖南、甘肃进行类型判别分析。通过这两个方法对全国各省进行经济分类。本文选取了7项经济指标作为决定经济类型的影响因素,各项数据均来自2010年国家统计年鉴。分析结果表明:北京市和上海市为第一类经济类型;江苏省和山东省为第三类型;广东省为第四类经济;其他25个省、直辖市、自治区均属于第二类型。 关键词:聚类分析、判别分析、经济类型 0引言 聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称。它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。系统聚类分析又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。 判别分析是根据多种因素(指标)对事物的影响来实现对事物的分类,从而对事物进行判别分类的统计方法。判别分析适用于已经掌握了历史上分类的每一个类别的若干样品,希望根据这些历史的经验(样品),总结出分类的规律性(判别函数)来指导未来的分类。 聚类分析与判别分析都是研究分类的,但是它们有所区别: (1)聚类分析一般寻求客观的分类方法,在进行聚类分析以前,对总体到底有几种类型并不知道。判别分析则是在总体类型划分已知,在各总体分布或来自总体训练样本的基础上,对当前的新样本判定它们属于哪个总体。 (2)两类方法的建立的模型不一样,因此在处理某些特定的问题时,就会得
主成分分析,聚类分析比较
主成分分析、聚类分析的比较与应用
主成分分析、聚类 分析的比较与应用 摘要:主成分分析、聚类分析是两种比较有价值的多元统计方法,但同时也是在使用过程中容易误用或混淆的几种方法。本文从基本思想、数据的标准化、应用上的优缺点等方面,详细地探讨了两者的异同,并且 举例说明了两者在实际问题中的应用。 关键词:spss、主成分分析、聚类分析
一、基本概念 主成分分析就是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。综合指标即为主成分。所得出的少数几个主成分,要尽可能多地保留原始变量的信息,且彼此不相关。因子分析是研究如何以最少的信息丢失,将众多原始变量浓缩成少数几个因子变量,以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。 聚类分析是依据实验数据本身所具有的定性或定量的特征来对大量的数据进行分组归类以了解数据集的内在结构,并且对每一个数据集进行描述的过程。其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。 二、基本思想的异同 (一)共同点 主成分分析法和因子分析法都是用少数的几个变量(因子) 来综合反映原始变量(因子) 的主要信息,变量虽然较原始变量少,但所包含的信息量却占原始信息的85 %以上,所以即使用少数的几个新变量,可信度也很高,也可以有效地解释问题。并且新的变量彼此间互不相关,消除了多重共线性。这两种分析法得出的新变量,并不是原始变量筛选后剩余的变量。在主成分分析中,最终确定的新变量是原始变量的线性组合,如原始变量为x1 ,x2 ,. . . ,x3 ,经过坐标变换,将原有的p个相关变量xi 作线性变换,每个主成分都是由原有p 个变量线性组合得到。在诸多主成分Zi中,Z1 在方差中占的比重最大,说明它综合原有变量的能力最强,越往后主成分在方差中的比重也小,综合原信息的能力越
SPSS聚类分析和判别分析论文
基于聚类分析的我国城镇居民消费结构实证分析 摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍 存在较大差别。文章选用8个城镇居民消费结构统计指标,采用欧式距离平方和离差平 方和法,对我国31个省、直辖市及自治区的2013年城镇居民消费结构进行聚类分析和 比较研究。这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国 各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。 关键词:消费结构;聚类分析;判别分析;政策建议; 一、引言 近年来,随着我国经济的快速发展,城镇居民的收入不断增加,并且在国家连续出台 住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济 政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变 化,结构不合理现象也得到了一定程度的调整。但是,由于各地区的经济发展不平衡及 原有经济基础的差异,使各地区的消费结构仍存在着明显差别。为了进一步改善消费结 构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区 城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握 各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和 谐增长提供决策依据。 二、消费结构的数据分析 消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替 代、制约的关系。就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费 支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需 求结构,体现一国或各地区的经济发展水平和居民生活状况。 (一)数据来源 为了更加深入地了解我国城镇居民消费结构,先利用2013年全国数据(如表1所示), 对全国31个省、直辖市、自治区进行聚类分析。分析采用选用了城镇居民食品、衣着、 居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和 服务八项指标,分别用来反映较高、中等、较低居民消费结构。 表1 各地区城镇居民家庭平均每人全年消费支出 (2013年)
主成分和聚类分析
4实证过程与结果 4、1主成分与聚类分析 首先通过SPSS软件对环境污染的相应指标进行主成分分析,得到: 提取Y1、Y2、Y3与Y4四个主成分,其累积贡献率已经达到,超过80%,代表所有环境污染指标的绝大部分信息。Y1偏向于解释工业氢氧化物排放量,Y2偏向于解释生活烟尘排放量,Y3偏向于解释生活废水排放量,Y4偏向于解释工业二氧化硫排放量。 然后,根据主成分分析结果,用Z=0、43226*Y1+0、21911*Y2+0、10380*Y3+ 0、06519*Y4计算综合得分,见下表1。 表1 环境污染地区的主成分综合得分表 序号地区Z 排名序号地区Z 排名 1 北京0、863 5 17 武汉-0、116 13 2 天津1、088 4 18 长沙-0、841 28 3 石家庄0、455 6 19 广州-0、373 19 4 太原0、209 8 20 南宁-0、519 24 5 呼与浩特-0、052 12 21 海口-1、29 31 6 沈阳-0、273 1 7 22 重庆2、767 1 7 长春-0、257 16 23 成都-0、451 20 8 哈尔滨2、489 2 24 贵阳-0、331 18 9 上海1、979 3 25 昆明-0、552 26 10 南京-0、232 15 26 拉萨-1、275 30 11 杭州0、175 9 27 西安0、357 7 12 合肥-0、5 21 28 兰州-0、514 23 13 福州-0、525 25 29 西宁0、004 11 14 南昌-0、949 29 30 银川-0、702 27 15 济南0、022 10 31 乌鲁木齐-0、502 22 16 郑州-0、152 14 最后将环境污染的综合得分作为个案进行层次聚类分析,将31个地区分为5类,如表2。 表2 各地区污染分类 分类污染情况地区
聚类分析、判别分析、主成分分析、因子分析
聚类分析、判别分析、主成分分析、因子分析 主成分分析与因子分析的区别 1. 目的不同:因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和仅对某一个变量有作用的特殊因子线性组合而成,因此就是要从数据中控查出对变量起解释作用的公共因子和特殊因子以及其组合系数;主成分分析只是从空间生成的角度寻找能解释诸多变量变异的绝大部分的几组彼此不相关的新变量(主成分)。 2. 线性表示方向不同:因子分析是把变量表示成各公因子的线性组合;而主成分分析中则是把主成分表示成各变量的线性组合。 3. 假设条件不同:主成分分析中不需要有假设;因子分析的假设包括:各个公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关。 4. 提取主因子的方法不同:因子分析抽取主因子不仅有主成分法,还有极大似然法,主轴因子法,基于这些方法得到的结果也不同;主成分只能用主成分法抽取。 5. 主成分与因子的变化:当给定的协方差矩阵或者相关矩阵的特征值唯一时,主成分一般是固定的;而因子分析中因子不是固定的,可以旋转得到不同的因子。 6. 因子数量与主成分的数量:在因子分析中,因子个数需要分析者指定(SPSS 根据一定的条件自动设定,只要是特征值大于1的因子主可进入分析),指定的因子数量不同而结果也不同;在主成分分析中,成分的数量是一定的,一般有几个变量就有几个主成分(只是主成分所解释的信息量不等)。 7. 功能:和主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。当然,这种情况也可以使用因子得分做到,所以这种区分不是绝对的。 1 、聚类分析 基本原理:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。 常用聚类方法:系统聚类法,K-均值法,模糊聚类法,有序样品的聚类,分解法,加入法。
判别分析和聚类分析
第9章 判别分析和聚类分析 §9.1 判别分析问题的一般形式 在生产、科研和日常生活中,我们经常会遇到判别分类的问题。在这些问题中,已经知道研究对象可以分为几个类别,而且对这些类别已经作了一些观测,取得了一批样本数据。要求从已知的样本观测数据出发,建立一种判别方法,当我们取得一个新的样品时,可以根据这个样品的观测值,判定它属于哪一类,这种做法就称为判别分析(Discriminant Analysis )。 例1 岩石分类 从某矿床取得14块已知是铀矿石的样品和14块已知是围岩的样品,分别测定其中7种成分的含量,取得了一批观测数据: 要求建立一种判别方法,当我们从这个矿床取得一个新的岩石样品时,可以通过测定这个样品中7种成分的含量,判定它是铀矿石还是围岩。 例2 精神病的诊断(Rao 和Slater ,1949) 对114个处于焦虑状态的病人,33个患癔病的病人,32个有精神变态的病人,17个有强迫观念的病人,5个有变态人格的病人,以及55个正常人,分别进行3种精神病测试,得到测试分数1X ,2X 和3X 。 要求根据上述已知的测试数据,建立一种诊断方法,使得我们可以对一个新来的求诊者进行这3种精神病测试,根据测试得到的分数1X ,2X 和3X ,判断出求诊者是否正常,如果不正常,诊断出他患有哪一类精神病。 例3 (全国数学建模竞赛2000年A 题)DNA 序列分类 对于A,B 两种不同的DNA ,给出了20个类别已知的DNA 序列样品,其中1号~10号序列属于A 类,11号~20号序列属于B 类。另外还有20个类别未知的DNA 序列样品。 要求建立一种判别方法,判别出类别未知的DNA 序列样品属于哪一类。
聚类分析,因子分析
主成分分析,聚类分析,因子分析的基本思想以及他们各自的优缺点。 主成分分析就是将多项指标转化为少数几项综合指标,用综合指标来解释多变量的方差- 协方差结构。综合指标即为主成分。所得出的少数几个主成分,要尽可能多地保留原始变量的信息,且彼此不相关。 因子分析是研究如何以最少的信息丢失,将众多原始变量浓缩成少数几个因子变量,以及如何使因子变量具有较强的可解释性的一种多元统计分析方法。 聚类分析是依据实验数据本身所具有的定性或定量的特征来对大量的数据进行分组归类以了解数据集的内在结构,并且对每一个数据集进行描述的过程。其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。 三种分析方法既有区别也有联系,本文力图将三者的异同进行比较,并举例说明三者在实际应用中的联系,以期为更好地利用这些高级统计方法为研究所用有所裨益。 二、基本思想的异同 (一) 共同点 主成分分析法和因子分析法都是用少数的几个变量(因子) 来综合反映原始变量(因子) 的主要信息,变量虽然较原始变量少,但所包含的信息量却占原始信息的85 %以上,所以即使用少数的几个新变量,可信度也很高,也可以有效地解释问题。并且新的变量彼此间互不相关,消除了多重共线性。这两种分析法得出的新变量,并不是原始变量筛选后剩余的变量。在主成分分析中,最终确定的新变量是原始变量的线性组合,如原始变量为x1 ,x2 ,. . . ,x3 ,经过坐标变换,将原有的p个相关变量xi 作线性变换,每个主成分都是由原有p 个变量线性组合得到。在诸多主成分Zi 中,Z1 在方差中占的比重最大,说明它综合原有变量的能力最强,越往后主成分在方差中的比重也小,综合原信息的能力越弱。因子分析是要利用少数几个公共因子去解释较多个要观测变量中存在的复杂关系,它不是对原始变量的重新组合,而是对原始变量进行分解,分解为公共因子与特殊因子两部分。公共因子是由所有变量共同具有的少数几个因子;特殊因子是每个原始变量独自具有的因子。对新产生的主成分变量及因子变量计算其得分,就可以将主成分得分或因子得分代替原始变量进行进一步的分析,因为主成分变量及因子变量比原始变量少了许多,所以起到了降维的作用,为我们处理数据降低了难度。 聚类分析的基本思想是: 采用多变量的统计值,定量地确定相互之间的亲疏关系,考虑对象多因素的联系和主导作用,按它们亲疏差异程度,归入不同的分类中一元,使分类更具客观实际并能反映事物的内在必然联系。也就是说,聚类分析是把研究对象视作多维空间中的许多点,并合理地分成若干类,因此它是一种根据变量域之间的相似性而逐步归群成类的方法,它能客观地反映这些变量或区域之间的内在组合关系[3 ]。聚类分析是通过一个大的对称矩阵来探索相关关系的一种数学分析方法,是多元统计分析方法,分析的结果为群集。对向量聚类后,我们对数据的处理难度也自然降低,所以从某种意义上说,聚类分析也起到了降维的作用。 (二) 不同之处
学生成绩的主成分分析和聚类分析
学生成绩的主成分分析和聚类分析 摘要 运用主成分分析方法和聚类分析方法,对高校学生的综合成绩进行评价。避免传 统方法在综合评价中对指标的主观选择及对权重的主观判断,使权重的分配更合理, 尽可能地减少重叠信息的不良影响,克服变量之间的多重相关性,简化系统分析。 关键词:主成分分析;综合评价;聚类分析 Principal Component and Cluster Analysis in Students’Grades Abstract Using principal component analysis and cluster analysis method to evaluate College students’comprehensive performance.Avoid the traditional method of Comprehensive Evaluation that will give rise to choice subjective indicators and subjectively judge right weight. So there is a more reasonable distribution of right weight.Possible to reduce duplication of information that causes the adverse effects.Overcome the multiple variables related to simplify analysis. K ey words:principal component analysis,comprehensive evaluation,cluster analysis 1引言 学生的学习成绩是学校、工作单位选拔人才的重要依据,更是学生衡量自己知识掌握程度的重要标准。因此,对成绩进行科学评价的问题显得尤为重要。假如每人只有一科分数,排出名次即可。但实际上,每个学生都有几科甚至几十科分数。这就需要对这些数据进行加工整理分析并提取出有关这N个学生的有用信息,即多指标统计分析问题。显然,指标越多越复杂,因此,自然希望通过对原有指标数据的科学的加工、整理,将问题的指标数尽可能地减少、压缩。所以,我们希望能用较少的几个新的综合指标,来代替原由的
聚类分析与判别分析
利用聚类分析和判别分析对我国各省市经济发展状况的分析 统计081 许建霞 089114284 摘要:转变经济发展方式是我国未来经济发展过程中一项重要而十分艰巨的任务,《中共中央关于制定国民经济和社会发展第十二个五年规划的建议》更是提出“十二五”时期要以加快转变经济发展方式为主线。要实现这一转变,它与调整经济结构是高度相关、相辅相成的,其中,产业结构的转型升级更是经济发展方式转变的体现和依托。当前我国经济发展方式粗放与面临着的诸多结构性矛盾,在很大程度上根源于我国经济发展过程中的“三个过度和一个缺失”,即:经济增长过度依赖投资、全球分工中过度依赖加工制造环节和加工贸易、竞争战略过度依赖成本价格,而产业链和价值链中研发设计、营销、品牌和供应链管理等高端环节缺失。要加快转变经济发展方式,就必须改变上述“三个过度和一个缺失”,促进产业结构转型升级,这也关系到当前战略性新兴产业发展是否能够摆脱过去发展模式,走出一条可持续发展的道路。 关键词: 聚类分析 判别分析 经济发展 一.研究背景 我国产业结构基本上分享了经济的增长效应,但协调效应、分配效应和就业效应不理想,环境效应问题比较突出,并且在总体上具有名义高度化较快而实际高度化不足的特征,我们必须紧紧抓住机遇,承担起历史使命,把加快经济发展方式转变作为深入贯彻落实科学发展观的重要目标和战略举措,毫不动摇地加快经济发展方式转变,不断提高经济发展质量和效益,不断提高我国经济的国际竞争力和抗风险能力,使我国发展质量越来越高、发展空间越来越大、发展道路越走越宽。 二.方法介绍 1.聚类分析方法介绍 聚类分析是从事物数量上的特征出发对事物进行分类,是事物分类学和多元统计技术结合的结果,是一种较为粗糙的,理论并非完善的分析方法,但是其使用简便,分类效果较好,其内容也在不断丰富中,是常用的数据探索性分析工具。 聚类分析(Cluster Analysis )又称为集群分析,其分析的基本思想是依照事物的数值特征,来观察各样品之间的亲疏关系。而样品之间的亲疏关系则是由样品之间的距离来衡量的,一旦样品之间的距离定义之后,则把距离近的样品归为一类 。聚类分析既可以对样品聚类,又可以对变量聚类,样品聚类也称为Q 型聚类,变量聚类也称为R 型聚类。本文先采用样品聚类,然后再采用变量聚类。 2.判别分析方法介绍 费希尔判别的基本思想是投影。将k 组m 元数据投影到某一个方向,使得投影后组与组之间尽可能地分开。而衡量组与组之间是否分开的方法借助于一元方差分析的思想。利用方差分析的思想来导出判别函数,这个函数可以是线性的,也可以是很一般的函数。因线性判别函数在实际应用中最方便,本节仅讨论线性判别函数的导出。 设从总体),,1(k t G t 分别抽取m 元样本如下:
聚类分析与判别分析实验报告
多元统计分析实验报告 ——研究房价与人民生活水平的关系 一、实验目的 本文旨在研究全国各省市住宅型商品房的平均价格水平,同时分析各省市住宅型商品房平均销售价格与其人民生活水平的关系。本文将用各省市人均GDP、城镇居民人均可支配收入、农村居民人均纯收入三个变量来衡量各省市的人民生活水平。住宅型商品房平均销售价格应该与人民生活水平成正相关关系。接下来,本文不仅要根据2012年全国各省市住宅型商品房平均销售价格如表1-1进行聚类分析和判别分析,还会根据2012年全国各省市人民生活水平数据如表1-2进行聚类分析与判别分析,观察房价较高的省市与人民生活水平较高的省市是否相符合,用以评价各省市房地产市场的定价是否符合该省市人民生活水平。 表1-1 2012年全国各省市住宅型商品房平均销售价格(元/平方米) 地区X 地区X 北京16553.48 湖南3669.63 天津8009.58 广东7667.89 河北4141.96 广西3909.83 山西3690.88 海南7811.26 内蒙古3656.41 重庆4804.80 辽宁4717.21 四川4959.19 吉林3875.10 贵州3695.36 黑龙江3725.51 云南3861.01 上海13869.88 西藏2982.19 浙江10679.69 甘肃3376.08 安徽4495.12 陕西4803.05 福建8365.92 青海3692.21 江西4381.18 宁夏3620.77 山东4556.63 新疆3593.82 河南3511.26 江苏6422.85 湖北4668.00 其中,X表示住宅型商品房平均销售价格。 数据来源:国家统计局、各省市统计部门官方网站。 表1-2 2012年全国各省市人民生活水平数据单位:元
多元统计分析之判别分析
第六章 判别分析 §6.1 什么是判别分析 判别分析是判别样品所属类型的一种统计方法,其应用之广可与回归分析媲美。 在生产、科研和日常生活中经常需要根据观测到的数据资料,对所研究的对象进行分类。例如在经济学中,根据人均国民收入、人均工农业产值、人均消费水平等多种指标来判定一个国家的经济发展程度所属类型;在市场预测中,根据以往调查所得的种种指标,判别下季度产品是畅销、平常或滞销;在地质勘探中,根据岩石标本的多种特性来判别地层的地质年代,由采样分析出的多种成份来判别此地是有矿或无矿,是铜矿或铁矿等;在油田开发中,根据钻井的电测或化验数据,判别是否遇到油层、水层、干层或油水混合层;在农林害虫预报中,根据以往的虫情、多种气象因子来判别一个月后的虫情是大发生、中发生或正常; 在体育运动中,判别某游泳运动员的“苗子”是适合练蛙泳、仰泳、还是自由泳等;在医疗诊断中,根据某人多种体验指标(如体温、血压、白血球等)来判别此人是有病还是无病。总之,在实际问题中需要判别的问题几乎到处可见。 判别分析与聚类分析不同。判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。对于聚类分析来说,一批给定样品要划分的类型事先并不知道,正需要通过聚类分析来给以确定类型的。 正因为如此,判别分析和聚类分析往往联合起来使用,例如判别分析是要求先知道各类总体情况才能判断新样品的归类,当总体分类不清楚时,可先用聚类分析对原来的一批样品进行分类,然后再用判别分析建立判别式以对新样品进行判别。 判别分析内容很丰富,方法很多。判别分析按判别的组数来区分,有两组判别分析和多组判别分析;按区分不同总体的所用的数学模型来分,有线性判别和非线性判别;按判别时所处理的变量方法不同,有逐步判别和序贯判别等。判别分析可以从不同角度提出的问题,因此有不同的判别准则,如马氏距离最小准则、Fisher 准则、平均损失最小准则、最小平方准则、最大似然准则、最大概率准则等等,按判别准则的不同又提出多种判别方法。本章仅介绍四种常用的判别方法即距离判别法、Fisher 判别法、Bayes 判别法和逐步判别法。 §6.2 距离判别法 基本思想:首先根据已知分类的数据,分别计算各类的重心即分组(类)的均值,判别准则是对任给的一次观测,若它与第i 类的重心距离最近,就认为它来自第i 类。 距离判别法,对各类(或总体)的分布,并无特定的要求。 1 两个总体的距离判别法 设有两个总体(或称两类)G 1、G 2,从第一个总体中抽取n 1个样品,从第二个总体中抽取n 2个样品,每个样品测量p 个指标如下页表。 今任取一个样品,实测指标值为),,(1'=p x x X ,问X 应判归为哪一类? 首先计算X 到G 1、G 2总体的距离,分别记为),(1G X D 和),(2G X D ,按距离最近准则
聚类分析与判别分析实验报告范例
上海电力学院 《应用多元统计分析》——判别分析与聚类分析 学院: 姓名: 学号: 2016年4月
我国部分城市经济发展水平的聚类分析 和判别分析 摘要:本文基于《中国统计年鉴》(2012年版)统计数据,寻找评价城市经济发展水平的指标,包括第二三产业发展水平、固定投资额、社会消费零售总额和进出口贸易交流五个指标,利用统计软件SPSS综合考虑各指标,对所选城市进行K-Means 聚类分析,利用Fisher 线性判别待判城市类型,进一步验证所建模型的有效性。 关键字:聚类分析,判别分析,SPSS,城市经济发展水平 1,引言 经过改革开放后三十多年的长足进展,中国城市化已步入中期阶段,步伐加快,质量显著提高。同时,中国城市化又处于周期转折点上,上一周期行将结束,下一周期将要开始。2011年中国城市化率首次突破50%,意味着中国城镇人口首次超过农村人口,中国城市化进入关键发展阶段,这必将引起深刻的社会变革。 根据2011年4月公布的第六次人口普查数据,2010年中国居住城镇的人口接近6.6亿人,城镇化率达到49.68%,全国已有近一半的人口居住在城镇,这意味着中国将进入城镇时代。在过去30多年中,中国的城市化发展取得了很大成绩。然而,总体上中国的城市化道路是城市化滞后于工业化的非均衡道路;是土地城市化快于人口城市化的非规整道路;是以抑制农村、农业、农民的经济利益来支持城市发展,导致不能兼顾效率和公平的非协调道路;是片面追求城市发展的数量和规模,而以生态环境损失为代价的非持续道路;是以生产要素的高投入,而不是投入少、产值高、依靠科技拉动经济增长的非集约道路。传统的城市化存在着诸多弊端,中国未来的城市化必须走出一条具有自身特色的新型城市化道路。 具体而言,中国城市经济发展水平受限于地理、环境、资源以及国家政策等因素的影响,我国不同区域的城市化进程尚存在很大差异。2012年中国城市发展报告中指出,从区域角度看,目前沿海一带城市发展起步早,与国际贸易交流往来频率高,经济发展水平较高,西部地区受到国家政策的大力扶持,表现出了强劲的增长势头,西部主要城市经济发展水平仅次于沿海发达地区,而中部地区