《应用回归分析》课后题答案

《使用回归分析》部分课后习题答案
第一章回归分析概述
1.1 变量间统计关系和函数关系的区别是什么?
答:变量间的统计关系是指变量间具有密切关联而又不能由某一个或某一些变量
唯一确定另外一个变量的关系,而变量间的函数关系是指由一个变量唯一确定另
外一个变量的确定关系。
1.2 回归分析和相关分析的联系和区别是什么?
答:联系有回归分析和相关分析都是研究变量间关系的统计学课题。区别有 a.
在回归分析中,变量y称为因变量,处在被解释的特殊地位。在相关分析中,变
量x和变量y处于平等的地位,即研究变量y和变量x的密切程度和研究变量x
和变量y的密切程度是一回事。b.相关分析中所涉及的变量y和变量x全是随机
变量。而在回归分析中,因变量y是随机变量,自变量x可以是随机变量也可以
是非随机的确定变量。C.相关分析的研究主要是为了刻画两类变量间线性相关的
密切程度。而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归
方程进行预测和控制。
1.3 回归模型中随机误差项ε的意义是什么?
答:ε为随机误差项,正是由于随机误差项的引入,才将变量间的关系描述为
一个随机方程,使得我们可以借助随机数学方法研究y和x1,x2…..xp的关系,
由于客观经济现象是错综复杂的,一种经济现象很难用有限个因素来准确说明,
随机误差项可以概括表示由于人们的认识以及其他客观原因的局限而没有考虑
的种种偶然因素。
1.4 线性回归模型的基本假设是什么?
答:线性回归模型的基本假设有:1.解释变量x1.x2….xp是非随机的,观测值
xi1.xi2…..xip是常数。2.等方差及不相关的假定条件为{E(εi)=0 i=1,2…. Cov(εi,εj)={σ^2
3.正态分布的假定条件为相互独立。
4.样本容量的个数要多于解释变量的个数,
即n>p.
1.5 回归变量的设置理论根据是什么?在回归变量设置时应注意哪些问题?
答:理论判断某个变量应该作为解释变量,即便是不显著的,如果理论上无法判
断那么可以采用统计方法来判断,解释变量和被解释变量存在统计关系。应注意
的问题有:在选择变量时要注意和一些专门领域的专家合作,不要认为一个回归
模型所涉及的变量越多越好,回归变量的确定工作并不能一次完成,需要反复试算,最终找出最合适的一些变量。
1.6 收集,整理数据包括哪些内容?
答;常用的样本数据分为时间序列数据和横截面数据,因而数据收集的方法主要
有按时间顺序统计数据和在同一时间截面上统计数据,在数据的收集中,样本容
量的多少一般要和设置的解释变量数目相配套。而数据的整理不仅要把一些变量
数据进行折算差分甚至把数据对数化,标准化等有时还需注意剔除个别特别大或
特别小的“野值”。
1.7 构造回归理论模型的基本依据是什么?
答:选择模型的数学形式的主要依据是经济行为理论,根据变量的样本数据作出
解释变量和被解释变量之间关系的散点图,并将由散点图显示的变量间的函数关
系作为理论模型的数学形式。对同一问题我们可以采用不同的形式进行计算机模拟,对不同的模拟结果,选择较好的一个作为理论模型。 1.8 为什么要对回归模型进行检验? 答:我们建立回归模型的目的是为了使用它来研究经济问题,但如果马上就用这个模型去预测,控制,分析,显然是不够慎重的,所以我们必须通过检验才能确定这个模型是否真正揭示了被解释变量和解释变量之间的关系。 1.9 回归模型有那几个方面的使用?
答:回归模型的使用方面主要有:经济变量的因素分析和进行经济预测。 1.10 为什么强调运用回归分析研究经济问题要定性分析和定量分析相结合? 答:在回归模型的运用中,我们还强调定性分析和定量分析相结合。这是因为数理统计方法只是从事物外在的数量表面上去研究问题,不涉及事物质的规定性,单纯的表面上的数量关系是否反映事物的本质?这本质究竟如何?必须依靠专门的学科研究才能下定论,所以,在经济问题的研究中,我们不能仅凭样本数据估计的结果就不加分析地说长道短,必须把参数估计的结果和具体经济问题以及现实情况紧密结合,这样才能保证回归模型在经济问题研究中的正确使用。
第二章 一元线性回归
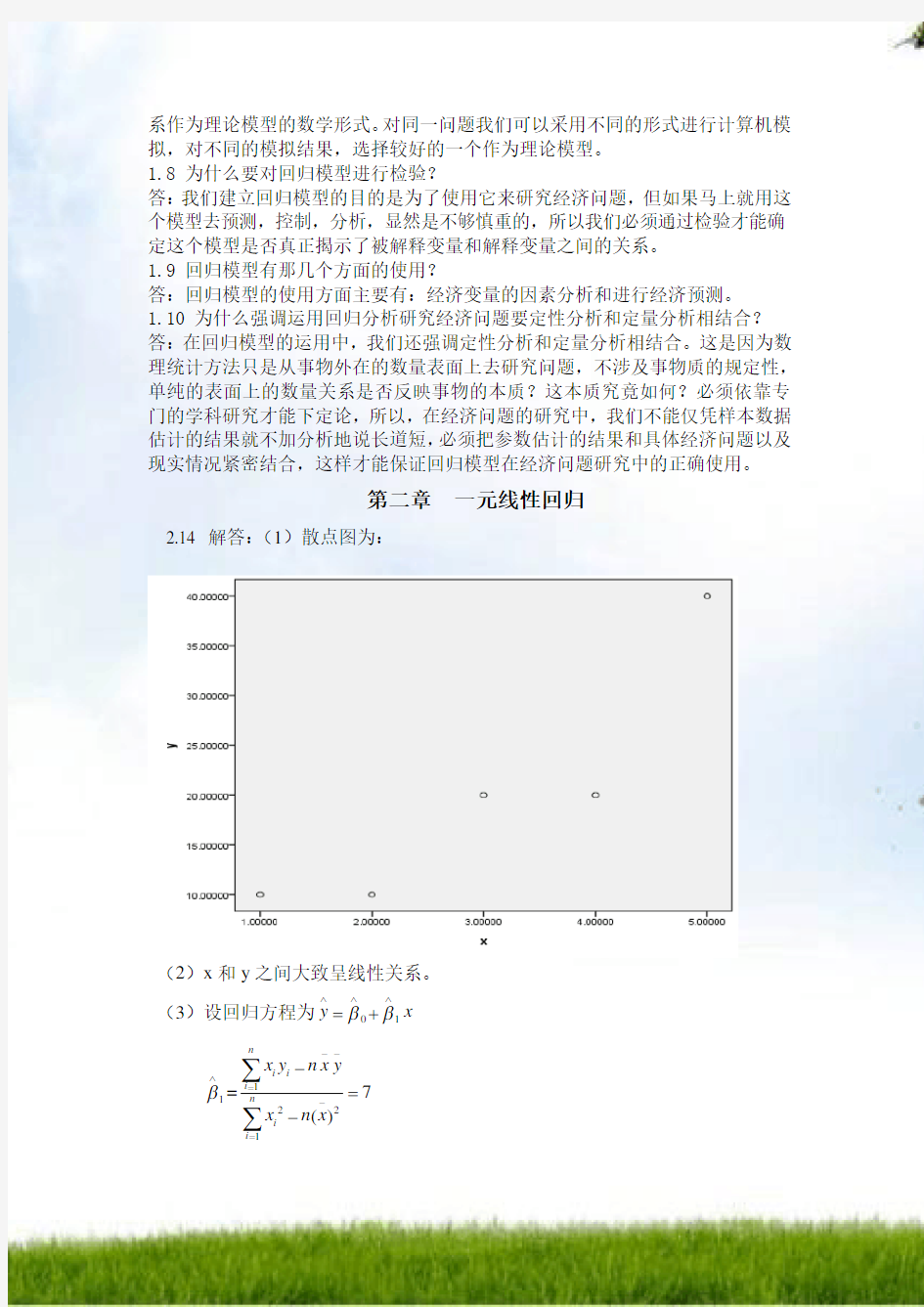
2.14 解答:(1)散点图为:
(2)x 和y 之间大致呈线性关系。 (3)设回归方程为01y x ββ∧
∧
∧
=+
1β∧
=
1
2
2
1
7()n
i i
i n
i
i x y n x y
x
n x --
=-
=-=-∑∑
0120731y x ββ-
∧-
=-=-?=-
17y x ∧
∴=-+可得回归方程为
(4)2
2
n
i=1
1()n-2i i y y σ∧∧=-∑ 2
n 01i=1
1(())n-2i y x ββ∧∧=-+∑
=222
22
13???+?+???+?+???
(
10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1
169049363
110/3=
++++=
1330 6.
13
σ∧=≈ (5)由于2
1
1(,
)xx
N L σββ∧
1112
()/xx
xx
L t L ββσσ
∧
∧
-=
=
服从自由度为n-2的t 分布。因而
1/2()|(2)1xx L P t n αββασ∧??-??<-=-??
??
也即:1/2
11/2
(xx
xx
p t t L L ααβββ∧
∧
∧
∧
-<<+=1α-
可得111
95%333333
β∧
的置信度为的置信区间为(7-2.353,7+2.353)
即为:(2.49,11.5)
22
01()(,())xx
x N n L ββσ-
∧
+
00
002221()1()()xx
xx
t x x n L n L σσ
∧
∧
-
-
∧∧
=
=
++
服从自由度为n-2的t 分布。因而
00/22(2)11()xx P t n x n L αασ∧-
∧??????<-=-??????+
????
即2
20/200/21()1()()1xx
xx
x x p t t n L n L βσ
ββσα-
-
∧∧
∧
∧
-+<<++=- 可得195%7.77,5.77β∧
-的置信度为的置信区间为()
(6)x 和y 的决定系数2
2
1
2
1
()
490/6000.817()
n
i
i n
i
i y y r y y ∧-
=-=-=
=≈-∑∑
ANOV A
x
平方和
df
均方 F 显著性
组间
(组合) 9.000 2 4.500 9.000 .100 线性项
加权的 8.167 1 8.167 16.333 .056 偏差
.833 1 .833 1.667
.326
组内 1.000 2 .500
总数
10.000
4
由于(1,3)F F α>,拒绝0H ,说明回归方程显著,x 和y 有显著的线性关系。
(8)112
/xx
xx
L t L βσ
σ∧
∧
∧=
=
其中2
2
211
11()22n n
i i i i i e y y n n σ∧∧====---∑∑ 710 3.66
1333303
?=
=≈ /2 2.353t α= /23.66t t α=>
∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
(9)相关系数 1
2
1
1
()()
()()
n
i
i
xy i n
n
xx yy
i
i
i i x x y y L r L L x x y y -
-
=-
-
==--=
=
--∑∑∑
0.9041060060
=≈?
r 小于表中1%α=的相应值同时大于表中5%α=的相应值,∴x 和y 有显著的线性关系.
序号 x
y
y ∧
e
1 1 10 6 4
2 2 10 1
3 -3 3 3 20 20 0
4 4 20 27 -7 5
5
40
34
6
从图上看,残差是围绕e=0随机波动,从而模型的基本假定是满足的。
(11)当广告费0x =4.2万元时,销售收入028.4y =万元,
95%置信度为的置信区间 y 2σ∧∧
±近似为,即(17.1,39.7)
2.15 解答:
(1) 散点图为:
2)x
和y 之间大致呈线性关系。 (3)设回归方程为01y x ββ∧
∧
∧
=+
1β∧
=
12
2
1
(2637021717)
0.0036(71043005806440)
()n
i i
i n
i
i x y n x y
x
n x --
=-
=--=
=--∑∑
01 2.850.00367620.1068y x ββ-∧-
=-=-?=
0.10680.0036y x ∧
∴=+可得回归方程为
(4) 22
n
i=1
1()n-2i i y y σ∧∧=-∑ 2
n 01i=1
1(())n-2i y x ββ∧∧=-+∑
=0.2305
σ∧
=0.4801
(5) 由于2
1
1(,
)xx
N L σββ∧
1112
()/xx
xx
L t L ββσσ
∧
∧
-=
=
服从自由度为n-2的t 分布。因而
1/2()|(2)1xx L P t n αββασ∧??-??<-=-??
??
也即:1/2
11/2
(xx
xx
p t t L L ααβββ∧
∧
∧
∧
-<<+=1α-
可得195%β∧
的置信度为的置信区间为
0.4801/12978600.4801/1297860??(0.0036-1.860,0.0036+1.860)
即为:(0.0028,0.0044)
220
01()(,())xx
x N n L ββσ-
∧
+
00
002221()1()()xx
xx
t x x n L n L σσ
∧
∧
-
-
∧∧
=
=
++
服从自由度为n-2的t 分布。因而
00/22(2)11()xx P t n x n L αασ∧-
∧??????<-=-??????+
????
即2
20/200/21()1()()1xx
xx
x x p t t n L n L βσ
ββσα-
-
∧∧
∧
∧
-+<<++=- 可得195%0.3567,0.5703β∧
-的置信度为的置信区间为()
(6)x 和y 的决定系数 2
2
1
2
1
()
()
n
i
i n
i
i y y r y y ∧-
=-=-=
=
-∑∑16.82027
18.525
=0.908
(7)
ANOV A
x
平方和 df
均方 F 显著性
组间
(组合) 1231497.500 7 175928.214 5.302 .168 线性项
加权的 1168713.036 1 1168713.036 35.222 .027 偏差
62784.464 6 10464.077 .315
.885
组内 66362.500 2 33181.250
总数
1297860.000
9
由于(1,9)F F α>,拒绝0H ,说明回归方程显著,x 和y 有显著的线性关系。
(8) 112
/xx
xx
L t L βσ
σ∧
∧
∧=
=
其中2
2
211
11()22n n
i i i i i e y y n n σ∧∧====---∑∑ 0.003612978608.5420.04801
=
=
/2 1.895t α= /28.542t t α=>
∴接受原假设01:0,H β=认为1β显著不为0,因变量y 对自变量x 的一元线性回归成立。
(9) 相关系数 1
21
1
()()
()()
n
i
i
i n
n
xx yy
i i i i x x y y L r L L x x y y --
=-
-
==--=
=
--∑∑∑
0.9489129786018.525
=?
r 小于表中1%α=的相应值同时大于表中5%α=的相应值,∴x 和y 有显著的线性关系. 序号 x y y ∧
e 1 825 3.5 3.0768 0.4232
2 215 1 0.8808 0.1192
3 1070
4 3.9588 0.0412 4 550 2 2.0868 -0.0868
5 480 1 1.8348 -0.8348
6 920 3 3.4188 -0.4188
7 1350 4.5 4.968
8 -0.4668 8 325 1.5 1.2768 0.2232
9 670 3 2.5188 0.4812 10
1215
5
4.4808 0.5192
从图上看,残差是围绕e=0随机波动,从而模型的基本假定是满足的。
(11)001000 3.7x ∧
==新保单时,需要加班的时间为y 小时。
(12)00/200y (2)1y t n h αα∧
∧
±-+的置信概率为1-的置信区间精确为, 即为(2.7,4.7)
近似置信区间为:02y σ∧∧
±,即(2.74,4.66)
(13)可得置信水平为α1-的置信区间为0/200(2)y t n h α∧
∧
±-,即为(3.33,4.07). 2.16 (1)散点图为:
可以用直线回归描述y 和x 之间的关系. (2)回归方程为:12112.629 3.314y x ∧
=+ (3)
从图上可看出,检验误差项服从正态分布。
第三章多元线性回归
3.11 解:(1)用SPSS算出y,x1,x2,x3相关系数矩阵:
相关性
y x1 x2 x3 Pearson 相关性
y 1.000 .556 .731 .724 x1 .556 1.000 .113 .398 x2 .731 .113 1.000 .547 x3
.724 .398 .547 1.000
y . .048 .008 .009 x1 .048 . .378 .127 x2 .008 .378 . .051 x3
.009 .127 .051 . N
y 10 10 10 10 x1 10 10 10 10 x2 10 10 10 10 x3
10
10
10
10
所以r ~=
(2)所以三元线性回归方程为3447.122101.71754.328.348?x x x y
+++-= (3)由于决定系数R 方=0.708 R=0.898较大所以认为拟合度较高 (4)
Anova b
系数a
模型
非标准化系数 标准系数
t
Sig. B 的 95.0% 置信区间
相关性
共线性统计量 B
标准 误差 试用版
下限
上限
零阶
偏
部分
容差
VIF
1 (常量)
-348.2
80
176.459
-1.974
.096 -780.060
83.500
x1 3.754 1.933 .385 1.942 .100 -.977 8.485 .556 .621 .350 .825 1.211 x2 7.101 2.880 .535 2.465 .049
.053 14.149
.731 .709 .444 .687 1.455 x3
12.447
10.569
.277 1.178
.284 -13.415
38.310
.724
.433 .212
.586
1.708
a. 因变量: y
模型汇总
模型
R
R 方 调整 R 方
标准 估计的
误差 更改统计量
R 方更改
F 更改
df1
df2
Sig. F 更改
1
.898a
.806
.708
23.44188
.806
8.283
3
6
.015
a. 预测变量: (常量), x3, x1, x2。
模型平方和df 均方 F Sig.
1 回归13655.370 3 4551.790 8.283 .015a
残差3297.130 6 549.522
总计16952.500 9
a. 预测变量: (常量), x3, x1, x2。
b. 因变量: y
系数a
模型
非标准化系数标准系数
t Sig. B 的 95.0% 置信区
间相关性共线性统计量
B 标准误差试用版下限上限零阶偏部分容差VIF
1 (
常
量
)
-348.280 176.459 -1.974 .096 -780.060 83.500
x1 3.754 1.933 .385 1.942 .100 -.977 8.485 .556 .621 .350 .825 1.211 x2 7.101 2.880 .535 2.465 .049 .053 14.149 .731 .709 .444 .687 1.455 x3 12.447 10.569 .277 1.178 .284 -13.415 38.310 .724 .433 .212 .586 1.708 a. 因变量: y
验,应去除。
Anova b
模型平方和df 均方 F Sig.
1 回归12893.199
2 6446.600 11.117 .007a
残差4059.301 7 579.900
总计16952.500 9
a. 预测变量: (常量), x2, x1。
b. 因变量: y
系数a
模型
非标准化系数标准系数
t Sig. B 的 95.0% 置信区间相关性
共线性统计
量
B 标准误差试用版下限上限零阶偏部分容差VIF
1 (常量) -459.624 153.058 -3.003 .020 -821.547 -97.700
x1 4.676 1.816 .479 2.575 .037 .381 8.970 .556 .697 .476 .987 1.013 x2 8.971 2.468 .676 3.634 .008 3.134 14.808 .731 .808 .672 .987 1.013 a. 因变量: y
此时,我们发现x1,x2的显著性大大提高。
(7)x1:(-0.997,8.485) x2:(0.053,14.149) x3:(-13.415,38.310)
(8)****3277.02535.01385.0?x x x y
++= 残差统计量a
极小值 极大值 均值 标准 偏差 N
预测值 175.4748 292.5545 231.5000
38.95206 10 标准 预测值 -1.438 1.567 .000 1.000 10 预测值的标准误差 10.466 20.191 14.526 3.127 10 调整的预测值 188.3515 318.1067 240.1835 49.83914 10 残差 -25.19759
33.22549 .00000 19.14022
10 标准 残差 -1.075 1.417 .000 .816 10 Student 化 残差 -2.116 1.754 -.123 1.188 10 已删除的残差
-97.61523
50.88274 -8.68348 43.43220 10 Student 化 已删除的残差 -3.832 2.294 -.255 1.658 10 Mahal 。 距离 .894 5.777 2.700 1.555 10 Cook 的距离 .000 3.216 .486 .976 10 居中杠杆值 .099
.642
.300
.173
10
a. 因变量: y
(10)由于x3的回归系数显著性检验未通过,所以居民非商品支出对货运总量影响不大,但是回归方程整体对数据拟合较好
3.12 解:在固定第二产业增加值,考虑第三产业增加值影响的情况下,第一产业每增加一个单位,GDP 就增加0.607个单位。
在固定第一产业增加值,考虑第三产业增加值影响的情况下,第二产业每增加一个单位,GDP 就增加1.709个单位。
第四章 违背基本假设的情况
4.8
加权变化残差图上点的散步较之前的残差图,没有明显的趋势,点的散步较随机,因此加权最小二乘估计的效果较最小二乘估计好。
系数a
模型非标准化系数标准系数
B 标准误差试用版
t Sig.
1 (常量) -.831 .44
2 -1.882 .065
x .004 .000 .839 11.030 .000
a. 因变量: y
由SPSS计算得:y?=-0.831+0.004x
残差散点图为:
(2)由残差散点图可知存在异方差性
相关系数
x t Spearman 的 rho X 相关系数 1.000 .318*
Sig.(双侧). .021
N 53 53
T 相关系数.318* 1.000
Sig.(双侧).021 .
N 53 53 *. 在置信度(双测)为 0.05 时,相关性是显著的。
(3)
模型描述
因变量y
自变量 1 x
权重源x
幂值 1.500
模型: MOD_1.
ANOVA
平方和df 均方 F Sig.
回归.006 1 .006 98.604 .000
残差.003 51 .000
总计.009 52
系数
未标准化系数标准化系数
B 标准误试用版标准误
t Sig.
(常数)-.683 .298 -2.296 .026
x .004 .000 .812 .082 9.930 .000
所以:
y?-0.683+0.004x
系数a
模型非标准化系数标准系数
B 标准误差试用版
t Sig.
1 (常量) .58
2 .130 4.481 .000
x .001 .000 .805 9.699 .000
a. 因变量: yy
4.10 经济变量的滞后性会给序列带来自相关性。如前期消费额对后期消费额一般会有明显的影响,有时,经济变量的这种滞后性表现出一种不规则的循环运动,当经济情况处于衰退的低谷时,经济扩张期随之开始,这时,大多数经济时间序列上升的快一些。在经济扩张时期,经济时间数列内部有一种内在的动力,受此影响,时间序列一直上升到循环的顶点,在顶点时刻,经济收缩随之开始。因此,在这样的时间序列数据中,顺序观察值之间的相关现象是恨自然的。
4.11 当一个线性回归模型的随机误差项存在序列相关时,就违背了线性回归方程的基本假设,如果仍然直接用普通最小二乘估计未知参数,将会产生严重后果,
一般情况下序列相关性会带来下列问题:
(1)参数的估计值不再具有最小方差线性无偏性。
(2)均方误差MSE可能严重低估误差项的方差。
(3)容易导致对t值评价过高,常用的F检验和t检验失效。如果忽视这一点,可能导致得出回归参数统计检验为显著,但实际上并不显著的严重错误结论。
(4)当存在序列相关时,最小二乘估计量对抽样波动变得非常敏感。
(5)如果不加处理地运用普通最小二乘法估计模型参数,用此模型进行预测和进行结构分析将会带来较大的方差甚至错误的解释。
4.12 优点:DW检验有着广泛的使用,对很多模型能简单方便的判断该模型有无序列相关性,当DW的值在2左右时,则无需查表,即可放心的认为模型不存在序列的自相关性。
缺点:DW检验有两个不能确定的区域,一旦DW值落在这两个区域,就无法判断,这时,只有增大样本容量或选取其他方法;DW统计量的上、下界表要求n>15,这是因为如果样本再小,利用残差就很难对自相关的存在性作出比较正确的判断;DW检验不适合随机项具有高阶序列相关的检验。
4.13 解:
系数a
模型非标准化系数标准系数
t Sig.
B 标准误差试用版
1 (常量) -1.435 .24
2 -5.930 .000
x .176 .002 .999 107.928 .000
a. 因变量: y
y?=-1.435+0.176x
模型汇总b
模型
R R 方调整 R 方标准估计的误
差Durbin-Watson
1 .999a.998 .998 .09744 .663
a. 预测变量: (常量), x。
b. 因变量: y
DW=0.663 查DW分布表知:
L
d=0.95
所以DW<
L
d,故误差项存在正相关。
残差图为:
t
e随t的变化逐次变化并不频繁的改变符号,说明误差项存在正相关。(3) ?=1-0.5*DW=0.6685 计算得:
Y’x’7.39 44.90 7.65 45.80 6.84 40.69 8.00 48.50
7.79 46.85
8.26 49.45
7.96 48.47
8.28 50.04 7.90 48.03
8.49 51.17
7.88 47.26
8.77 52.33
8.93 52.69
9.32 54.95
9.29 55.54
9.48 56.77
9.38 55.83
9.67 58.00
9.90 59.22模型汇总b
模型
R R 方调整 R 方标准估计的误
差Durbin-Watson
1 .996a.993 .993 .07395 1.344
a. 预测变量: (常量), xx。
b. 因变量: yy
系数a
模型非标准化系数标准系数
t Sig.
B 标准误差试用版
1 (常量) -.303 .180 -1.684 .110
xx .173 .004 .996 49.011 .000 a. 因变量: yy
得回归方程 '?y
=-0.303+0.173x ’ 即:t y
?=-0.303+0.66851-t y +0.173(t x —0.66851-t x ) 模型汇总b
模型
R
R 方 调整 R 方
标准 估计的误
差 Durbin-Watson
1
.978a
.957
.955
.07449
1.480
a. 预测变量: (常量), x3。
b. 因变量: y3
系数a
模型
非标准化系数 标准系数 t Sig. B
标准 误差
试用版
1
(常量) .033 .026
1.273
.220 x3
.161
.008
.978
19.528
.000
a. 因变量: y3
△t y =0.033+0.161△t x
即:t y
?=0.033+1-t y +0.161(t x -1-t x ) (5)差分法的DW 值最大为1.48消除相关性最彻底,但是迭代法的σ
?值最小为0.07395,拟合的较好。 模型汇总b
模型
R
R 方 调整 R 方
标准 估计的误
差 Durbin-Watson
1
.541a
.293
.264
329.69302
.745
a. 预测变量: (常量), x2, x1。
b. 因变量: y
系数a
模型
非标准化系数 标准系数 t Sig. B
标准 误差 试用版
1
(常量) -574.062 349.271
-1.644
.107 x1 191.098 73.309 .345 2.607 .012 x2
2.045
.911
.297
2.246
.029
a. 因变量: y
回归方程为:y
?=-574.062+191.098x1+2.045x2 DW=0.745
(2)ρ
?=1-0.5*DW=0.6275 模型汇总b
模型
R
R 方 调整 R 方
标准 估计的误
差 Durbin-Watson
1
.688a
.474
.452
257.67064
1.716
a. 预测变量: (常量), x22, x12。
b. 因变量: y2
系数a
模型
非标准化系数 标准系数 t Sig. B
标准 误差
试用版
1
(常量) -179.668 90.337
-1.989
.052 x12 211.770 47.778 .522 4.432 .000 x22
1.434
.628
.269
2.283
.027
a. 因变量: y2
此时得方程:t y
?’=-179.668+211.77x1’+1.434x2’ 所以回归方程为:
)26275.02(434.1)16275.01(77.2116275.0668.179?1?11----+-++-=t t t t t t x x x x y y
模型汇总b
模型
R
R 方 调整 R 方
标准 估计的误
差 Durbin-Watson
1
.715a
.511
.490
283.79102
2.042
a. 预测变量: (常量), x23, x13。
回归分析测试题-21页文档资料
测试题 1.下列说法中错误的是() A.如果变量x与y之间存在着线性相关关系,则我们根据试验数据得到的点(i=1,2,3,…, n)将散布在一条直线附近B.如果两个变量x与y之间不存在线性相关关系,那么根据试验数据不能写出一个线性方程。 C.设x,y是具有线性相关关系的两个变量,且回归直线方程是,则叫回归系数 D.为使求出的回归直线方程有意义,可用线性相关性检验的方法判断变量x与y之间是否存在线性相关关系 2.在一次试验中,测得(x,y)的四组值分别是(1,2),(2,3),(3,4),(4,5),则y与 x之间的回归直线方程是() A.B. C.D. 3.回归直线必过点() A.(0,0)B. C. D. 4.在画两个变量的散点图时,下面叙述正确的是() A.预报变量在轴上,解释变量在轴上 B.解释变量在轴上,预报变量在轴上 C.可以选择两个变量中任意一个变量在轴上 D.可以选择两个变量中任意一个变量在轴上 5.两个变量相关性越强,相关系数r() A.越接近于0 B.越接近于1 C.越接近于-1 D.绝
对值越接近1 6.若散点图中所有样本点都在一条直线上,解释变量与预报变量的相关系数为() A.0 B.1 C.-1 D.-1或1 7.一位母亲记录了她儿子3到9岁的身高,数据如下表: 年龄(岁)3456789 身高(94.8104.2108.7117.8124.3130.8139.0由此她建立了身高与年龄的回归模型,她用这个模型预测儿子10岁时的身高, 则下面的叙述正确的是() A.她儿子10岁时的身高一定是145.83 B.她儿子10岁时的身高在145.83以上 C.她儿子10岁时的身高在145.83左右 D.她儿子10岁时的身高在145.83以下 8.两个变量有线性相关关系且正相关,则回归直线方程中, 的系数() A.B.C.D. 能力提升: 9.一个工厂在某年每月产品的总成本y(万元)与该月产量x(万件)之间有如下数据:
人教版四年级上册语文课后习题答案
四年级上册语文课后习题答案 1、《观潮》 1.让我们一起来想象“潮来前”、“潮来时”、“潮头过后”的景象,在交 流读后的感受。 答:“潮来前”的景象:江面上很平静,观潮人的心情急切。闷雷滚动、一条白线“潮来时”的景象:潮的声大,浪高,声如“山崩地裂”,形如“白色城墙”、“白色战马”。横贯江面 “潮头过后”的景象:潮头汹涌,漫天卷地,余威犹在,恢复平静,水位上涨。 2.我发现课文许多语句写得具体形象。找出来读一读,并谈谈对这些描 写的体会,在抄下来。 A 、宽阔的钱塘江横卧在眼前。 “横卧”一词具体形象地写出了钱塘江的宽阔。 B、再近些,只见白浪翻滚,形成一道两丈多高的白色城墙。 这句话把白浪比作白色城墙,从这个比喻中,我体会到大浪的浪潮很高、很宽、很壮观。 C、浪潮越来越近,犹如千万匹白色战马齐头并进,浩浩荡荡地飞奔而来。 这句话用比喻的修辞手法写出了大浪发出的巨响和浩大的声势。 4、《鸟的天堂》 1课文里五次提到鸟的天堂,为什么有的加了引号,有的没有加呢? 答:加引号的:引用别人说的话。 不加引号的:确实是的鸟的天堂、乐园。表明了作者对鸟的天堂的认同和赞叹. 2、读读下面的句子,体会画线部分: 我有机会看清它的真面目,真是一株大树,枝干的数目不可计数。 答:一株:说榕树只有“一株”,而不是“我”说的“许多株”,也不是“另一个朋友”说的“两株”。 枝干的数目不可计数:大榕树的枝干多,根多,“不可计数”是“没有办法清点、无法计算”的意思。“枝干的数目不可计数”的原因,是“枝上又生根,有许多根直垂到地上,伸进泥土里”。 那么多的绿叶,一簇堆在另一簇上面,不留一点儿缝隙。那翠绿的颜色,明亮的照耀着我们的眼睛,似乎每一片绿叶上都有一个新的生命在颤动。答:一簇堆在另一簇上面: 用堆可以表示出绿叶的茂盛,显出绿叶的多。 似乎每一片绿叶上都有一个新的生命在颤动: 作者从绿色中感受到有一种生命力在涌动,赞美榕树充满活力的蓬勃生机。 “起初周围是静寂的。后来忽然起了一声鸟叫。我们把手一拍,便看见一只大鸟飞了起来。接着又看见第二只,第三只。我们继续拍掌,树上就变得热闹了,到处都是鸟声,到处都是鸟影。大的,小的,花的,黑的,有的站在树枝上叫,有的飞起来,有的在扑翅膀。”
应用回归分析,第7章课后习题参考答案
第7章岭回归 思考与练习参考答案 7.1 岭回归估计是在什么情况下提出的? 答:当自变量间存在复共线性时,|X’X|≈0,回归系数估计的方差就很大,估计值就很不稳定,为解决多重共线性,并使回归得到合理的结果,70年代提出了岭回归(Ridge Regression,简记为RR)。 7.2岭回归的定义及统计思想是什么? 答:岭回归法就是以引入偏误为代价减小参数估计量的方差的一种回归方法,其统计思想是对于(X’X)-1为奇异时,给X’X加上一个正常数矩阵 D, 那么X’X+D接近奇异的程度就会比X′X接近奇异的程度小得多,从而完成回归。但是这样的回归必定丢失了信息,不满足blue。但这样的代价有时是值得的,因为这样可以获得与专业知识相一致的结果。 7.3 选择岭参数k有哪几种方法? 答:最优 是依赖于未知参数 和 的,几种常见的选择方法是: 岭迹法:选择 的点能使各岭估计基本稳定,岭估计符号合理,回归系数没有不合乎经济意义的绝对值,且残差平方和增大不太多;
方差扩大因子法: ,其对角线元 是岭估计的方差扩大因子。要让 ; 残差平方和:满足 成立的最大的 值。 7.4 用岭回归方法选择自变量应遵循哪些基本原则? 答:岭回归选择变量通常的原则是: 1. 在岭回归的计算中,我们通常假定涉及矩阵已经中心化和标准化了,这样可以直接比较标准化岭回归系数的大小。我们可以剔除掉标准化岭回归系数比较稳定且绝对值很小的自变量; 2. 当k值较小时,标准化岭回归系数的绝对值并不很小,但是不稳定,随着k的增加迅速趋近于零。像这样岭回归系数不稳定、震动趋于零的自变量,我们也可以予以剔除; 3. 去掉标准化岭回归系数很不稳定的自变量。如果有若干个岭回归系数不稳定,究竟去掉几个,去掉那几个,要根据去掉某个变量后重新进行岭回归分析的效果来确定。
应用回归分析填空题和答案
应用回归分析:填空 (1) 回归分析是处理变量间_______关系的一种数理统计方法,若变量间具有线性关系,则称相应的回归分析为____________;若变量间不具有线性关系,就称相应的回归分析为___________________。 (2) 现代统计学中研究统计关系的两个重要分支是_________和_____________。 (3) 回归模型的建立是基于回归变量的样本统计数据,常用的样本数据分为___ ___________________和______________________。 (4) 回归模型通常应用于______________________、____________________和_____________________等方面。 (5) 最小二乘法的基本特点是使回归值与_________________________平方和为最小,最小二乘法的理论依据是___________________________。 (6) 多元线性回归模型ε β += X Y ,回归参数β的最小二乘估计为 β ?=_________________________。 (7) 设线性回归模型参数向量β(p+1维)的最小二乘估计为β?,c 为p+1维常数向量,则______________是____________的最小方差线性无偏估计。 (8) 在线性回归分析中,最小二乘估计的性质有______________; _____ _____________和____________________等。 (9) 多元线性回归模型n i x x y i ip p i i ,,2,1,110 =++++=εβββ,误差项 ()n i i ,,2,1, =ε需满足的markov Gauss -假设为: (a):________________________________________; (b):________________________________________; (c):_________________________________________。 (10) 对回归方程做显著性检验时,可以用P 值代替检验统计量值,作出拒绝或接受原假设的决定:当P_______α时,接受0H ;当P________α时,拒绝0H 。 (11) 在p 元线性回归中,确定随机变量y 与自变量12,,,p x x x 间是否有线性
应用回归分析第三章课后习题整理
y1 1 x11 x12 x1p 0 1 3.1 y2 1 x21 x22 x2p 1 + 2 即y=x + yn 1 xn1 xn2 xnp p n 基本假定 (1) 解释变量x1,x2…,xp 是确定性变量,不是随机变量,且要求 rank(X)=p+1 n 注 tr(H) h 1 3.4不能断定这个方程一定很理想,因为样本决定系数与回归方程中 自变量的数目以及样本量n 有关,当样本量个数n 太小,而自变量又较 多,使样本量与自变量的个数接近时, R 2易接近1,其中隐藏一些虚 假成分。 3.5当接受H o 时,认定在给定的显著性水平 下,自变量x1,x2, xp 对因变量y 无显著影响,于是通过x1,x2, xp 去推断y 也就无多大意 义,在这种情况下,一方面可能这个问题本来应该用非线性模型去描 述,而误用了线性模型,使得自变量对因变量无显著影响;另一方面 可能是在考虑自变量时,把影响因变量y 的自变量漏掉了,可以重新 考虑建模问题。 当拒绝H o 时,我们也不能过于相信这个检验,认为这个回归模型 已经完美了,当拒绝H o 时,我们只能认为这个模型在一定程度上说明 了自变量x1,x2, xp 与自变量y 的线性关系,这时仍不能排除排除我 们漏掉了一些重要的自变量。 3.6中心化经验回归方程的常数项为0,回归方程只包含p 个参数估计 值1, 2, p 比一般的经验回归方程减少了一个未知参数,在变量较 SSE (y y)2 e12 e22 1 2 1 E( ) E( - SSE* - n p 1 n p n 2 [D(e) (E(e ))2 ] 1 n (1 1 n 2 en n E( e 1 1 n p 1 1 n p 1 1 "1 1 n p 1 J (n D(e) 1 (p 1)) 1_ p 1 1 1 n p 1 2 2 n E(e 2 ) (1 h ) 2 1 1.1回归分析的基本思想及其初步应用 一、选择题 1. 某同学由x 与y 之间的一组数据求得两个变量间的线性回归方程为y bx a =+,已知:数据x 的平 均值为2,数据 y 的平均值为3,则 ( ) A .回归直线必过点(2,3) B .回归直线一定不过点(2,3) C .点(2,3)在回归直线上方 D .点(2,3)在回归直线下方 2. 在一次试验中,测得(x,y)的四组值分别是A(1,2),B(2,3),C(3,4),D(4,5),则Y 与X 之间的回归直线方程为( )A . y x 1=+ B . y x 2=+ C . y 2x 1=+ D. y x 1=-3. 在对两个变量x ,y 进行线性回归分析时,有下列步骤: ①对所求出的回归直线方程作出解释; ②收集数据(i x 、i y ) ,1,2i =,…,n ; ③求线性回归方程; ④求未知参数; ⑤根据所搜集的数据绘制散点图 如果根据可行性要求能够作出变量,x y 具有线性相关结论,则在下列操作中正确的是( ) A .①②⑤③④ B .③②④⑤① C .②④③①⑤ D .②⑤④③① 4. 下列说法中正确的是( ) A .任何两个变量都具有相关关系 B .人的知识与其年龄具有相关关系 C .散点图中的各点是分散的没有规律 D .根据散点图求得的回归直线方程都是有意义的 5. 给出下列结论: (1)在回归分析中,可用指数系数2 R 的值判断模型的拟合效果,2 R 越大,模型的拟合效果越好; (2)在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好; (3)在回归分析中,可用相关系数r 的值判断模型的拟合效果,r 越小,模型的拟合效果越好; (4)在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域中,说明这样的模型比较合适.带状区域的宽度越窄,说明模型的拟合精度越高. 以上结论中,正确的有( )个. A .1 B .2 C .3 D .4 6. 已知直线回归方程为2 1.5y x =-,则变量x 增加一个单位时( ) A.y 平均增加1.5个单位 B.y 平均增加2个单位 C.y 平均减少1.5个单位 D. y 平均减少2个单位 7. 下面的各图中,散点图与相关系数r 不符合的是( ) 1 第三章化学动力学基础课后习题参考答案 2解:(1)设速率方程为 代入数据后得: 2.8×10-5=k ×(0.002)a (0.001)b ① 1.1×10-4=k ×(0.004)a (0.001)b ② 5.6×10-5=k ×(0.002)a (0.002)b ③ 由②÷①得: 2a =4 a=2 由③÷①得: 2b =2 b=1 (2)k=7.0×103(mol/L)-2·s -1 速率方程为 (3)r=7×103×(0.0030)2×0.0015=9.45×10-5(mol ·L -1·s -1) 3解:设速率方程为 代入数据后得: 7.5×10-7=k ×(1.00×10-4)a (1.00×10-4)b ① 3.0×10-6=k ×(2.00×10-4)a (2.00×10-4)b ② 6.0×10-6=k ×(2.00×10-4)a (4.00×10-4)b ③ 由③÷②得 2=2b b=1 ②÷①得 22=2a ×21 a=1 k=75(mol -1·L ·s -1) r=75×5.00×10-5×2.00×10-5=7.5×10-8(mol ·L -1·s -1) 5解:由 得 ∴△Ea=113.78(kJ/mol ) 由RT E a e k k -=0得:9592314.81078.11301046.5498.03?=?==??e ke k RT E a 9解:由阿累尼乌斯公式:RT E k k a 101ln ln -=和RT E k k a 202ln ln -=相比得: ∴ 即加催化剂后,反应速率提高了3.4×1017倍 因△r H θm =Ea(正) -Ea(逆) Ea(逆)=Ea(正)-△r H θm =140+164.1=304.1(kJ/mol) 10解:由)11(ln 2 112T T R Ea k k -=得: )16001(314.8102621010.61000.1ln 2 384T -?=??-- T 2=698(K ) 由反应速率系数k 的单位s-1可推出,反应的总级数为1,则其速率方程为 r=kc(C 4H 8) 对于一级反应,在600K 下的)(1014.110 10.6693.0693.0781s k t ?=?== - ) ()(2O c NO kc r b a =)()(107223O c NO c r ?=) ()(355I CH c N H C kc r b a =)11(ln 2112T T R E k k a -=)627 15921(314.8498.081.1ln -=a E ) /(75.41046.5656314.81078.113903s mol L e e k k RT E a ?=??==??--36.40298314.810)140240(ln 32112=??-=-=RT E E k k a a 1712104.3ln ?=k k 部编版四年级下册语文课后习题参考答案第1课古诗词三首 2.读下面的诗句,说说你眼前浮现出了怎样的情景。 〔答案〕“儿童急走追黄蝶,飞入菜花无处寻。”描绘了儿童捕蝶的欢快场景。 “日长篱落无人过,惟有蜻蜓蛱蝶飞。”让我们看到农民早出晚归的场景,蛱蝶飞又让我们感受到静中有动的情景。 “大儿锄豆溪东,中儿正织鸡笼。最喜小儿亡赖,溪头卧剥莲蓬。”大儿子在溪东豆地里锄草,二儿子在家里编织鸡笼,三儿子只知任意地调皮玩耍,躺卧在溪边剥莲蓬吃。 第2课乡下人家 1.朗读课文,想象画面。如果给课文配画,你觉得可以画几幅?试着给每幅画取个名字。 〔答案〕7幅,屋前搭瓜架、门前种鲜花、屋后春笋冒、院里鸡觅食、河中鸭嬉戏、门前吃晚饭、夜静催眠曲。 2.你对课文描写的哪一处景致最感兴趣?和同学交流。 〔答案〕描写门前五颜六色的花和雨后春笋的景致我最感兴趣,本来是朴素的乡下,可是门前这些五彩缤纷的花朵、雨后的春笋又给本来朴素的乡下带来了勃勃生机,读完以后让我也向往乡下这样恬静安逸的生活。 3.读句子,再从课文中找出像这样写得生动形象的句子,抄写下来。 〔答案〕他们的屋后倘若有一条小河,那么在石桥旁边,在绿树荫下,会见到一群鸭子游戏水中,不时地把头扎到水下去觅食。天边的红霞,向晚的微风,头上飞过的归巢的鸟儿,都是他们的好友,它们和乡下人家一起,绘成了一幅自然、和谐的田园风景画。秋天到了,纺织娘寄住在他们屋前的瓜架上。月明人静的夜里,它们便唱起歌来:“织,织,织,织啊!织,织,织,织啊!”那歌声真好听,赛过催眠曲,让那些辛苦一天的人们,甜甜蜜蜜地进入梦乡。 选做 你眼里的乡村景致是怎样的?用一段话写下来。 〔答案〕大树也绿,小草也茂盛,花朵也艳丽,田园的风光真是美。近处,一棵棵大杨树挺直身板,抬起头,密密麻麻的绿叶里闪过一丝丝日影。远远地看去,这些杨树就像一名名威武的保卫者。小草又嫩又绿,茂密的草地就像一大块碧绿的地毯,躺在软软的绿地上,比躺在沙发上还要舒服。那的野花不是一般的香,在千里之外都可以闻到。每一朵花都神气十足地仰起头。每个人家的门前都有一块可爱的菜地,种有茄子、黄瓜、辣子、豇豆、草莓等蔬菜水果。从高处往下看,那些蔬菜水果就像一个个精英士兵,你就像那位大将军,准备率领十万精英去攻打敌人的城池。晚上,无数颗星星眨着眼睛,等我们睡着,星星才肯离开…… 乡下的田园风光真是美不胜收,哪里的景色都比不上田园风光的美丽。 第3章 多元线性回归 思考与练习参考答案 3.1 见教材P64-65 3.2 讨论样本容量n 与自变量个数p 的关系,它们对模型的参数估计有何影响? 答:在多元线性回归模型中,样本容量n 与自变量个数p 的关系是:n>>p 。如果n<=p 对模型的参数估计会带来很严重的影响。因为: 1. 在多元线性回归模型中,有p+1个待估参数β,所以样本容量的个数应该大于解释变量的个数,否则参数无法估计。 2. 解释变量X 是确定性变量,要求()1rank p n =+ 1、对于一元线性回归01(1,2,...,)i i i y x i n ββε=++=,()0i E ε=,2 var()i εσ=, cov(,)0()i j i j εε=≠,下列说法错误的是 (A)0β,1β的最小二乘估计0?β,1 ?β 都是无偏估计; (B)0β,1β的最小二乘估计0?β,1?β对1y ,2y ,...,n y 是线性的; 2、在回归分析中若诊断出异方差,常通过方差稳定化变化对因变量进行变换. 如果误差方差与因变量y 的期望成正比,则可通过下列哪种变换将方差常数化 (A) 1 y ; (C) ln(1)y +;(D)ln y . 3、下列说法错误的是 (A)强影响点不一定是异常值; (B)在多元回归中,回归系数显着性的t 检验与回归方程显着性的F 检验是等价的; (C)一般情况下,一个定性变量有k 类可能的取值时,需要引入k-1个0-1型自变量; (D)异常值的识别与特定的模型有关. 4、下面给出了4个残差图,哪个图形表示误差序列是自相关的 (A) (C) 5 应用回归分析试题(一) (C)0β,1β的最小二乘估计0?β,1 ?β之间是相关的; (D)若误差服从正态分布,0β,1β的最小二乘估计和极大似然估计是不一样的. (A) (B) (C) (D) 二、填空题(每空2分,共20分) 1、考虑模型y X βε=+,2var()n I εσ=,其中:X n p '?,秩为p ',2 0σ>不一定 已知,则?β =__________________, ?var()β=___________,若ε服从正态分布,则 22 ?()n p σ σ'-:___________,其中2?σ 是2σ的无偏估计. 2、下表给出了四变量模型的回归结果: 则残差平方和=_________,总的观察值个数=_________,回归平方和的自由度=________. 3、已知因变量y 与自变量1x ,2x ,3x ,4x ,下表给出了所有可能回归模型的AIC 值,则最优子集是_____________________. 4、在诊断自相关现象时,若0.66DW =,则误差序列的自相关系数ρ的估计值=_____ ,若存在自相关现象,常用的处理方法有迭代法、_____________、科克伦-奥克特迭代法. 5、设因变量y 与自变量x 的观察值分别为12,,...,n y y y 和12,,...,n x x x ,则以* x 为折点的 折线模型可表示为_____________________. 三、(共45分)研究货运总量y (万吨)与工业总产值1x (亿元)、农业总产值2x (亿元)、居民非商品支出3x (亿元)的线性回归关系.观察数据及残差值i e 、学生化残差i SRE 、 第一章 单自由度系统 1、1 总结求单自由度系统固有频率的方法与步骤。 单自由度系统固有频率求法有:牛顿第二定律法、动量距定理法、拉格朗日方程法与能量守恒定理法。 1、 牛顿第二定律法 适用范围:所有的单自由度系统的振动。 解题步骤:(1) 对系统进行受力分析,得到系统所受的合力; (2) 利用牛顿第二定律∑=F x m && ,得到系统的运动微分方程; (3) 求解该方程所对应的特征方程的特征根,得到该系统的固有频率。 2、 动量距定理法 适用范围:绕定轴转动的单自由度系统的振动。 解题步骤:(1) 对系统进行受力分析与动量距分析; (2) 利用动量距定理J ∑=M θ &&,得到系统的运动微分方程; (3) 求解该方程所对应的特征方程的特征根,得到该系统的固有频率。 3、 拉格朗日方程法: 适用范围:所有的单自由度系统的振动。 解题步骤:(1)设系统的广义坐标为θ,写出系统对于坐标θ的动能T 与势能U 的表达式;进一步写求出拉格朗日函数的表达式:L=T-U ; (2)由格朗日方程 θθ ??- ???L L dt )(&=0,得到系统的运动微分方程; (3) 求解该方程所对应的特征方程的特征根,得到该系统的固有频率。 4、 能量守恒定理法 适用范围:所有无阻尼的单自由度保守系统的振动。 解题步骤:(1)对系统进行运动分析、选广义坐标、写出在该坐标下系统的动能T 与势能U 的表达式;进一步写出机械能守恒定理的表达式 T+U=Const (2)将能量守恒定理T+U=Const 对时间求导得零,即 0) (=+dt U T d ,进一步得到系统的运动微分方程; (3) 求解该方程所对应的特征方程的特征根,得到该系统的固有频率。 1、2 叙述用衰减法求单自由度系统阻尼比的方法与步骤。 用衰减法求单自由度系统阻尼比的方法有两个:衰减曲线法与共振法。 方法一:衰减曲线法。 求解步骤:(1)利用试验测得单自由度系统的衰减振动曲线,并测得周期与相邻波峰与波谷的幅值i A 、1+i A 。 (2)由对数衰减率定义 )ln( 1 +=i i A A δ, 进一步推导有 2 12ζ πζδ-= , 部编版四年级语文上册课后习题参考答案 第一课《观潮》 一、说说课文是按照什么顺序描写钱塘江大潮的,你的头脑中浮现出怎样的画面,选择印象最深和同学交流。 答:课文按潮前,潮时,潮过后的顺序观察描写钱塘江大潮。 “潮前”的景象:江面上很平静,观潮人的心情急切。闷雷滚动、一条白线“潮时”的景象:潮的声大,潮头有数丈之高,声如“山崩地裂”,形如“白色城墙”、“白色战马”,横贯江面。给人的印象就是如巨雷般的大潮像千军万马席地而卷,在呐喊、嘶鸣中奔。狂潮拍石,如同几里岸边同时金钟齐鸣。 “潮头过后”的景象:潮头汹涌,漫天卷地,余威犹在,恢复平静,水位上涨。 我印象最深的是“潮时”的景象:那条白线很快地向我们移,逐渐拉长,变粗,横贯江面。再近些,只见白浪翻滚,形成一堵两丈多高的水墙。浪潮越越近,犹如千万匹白色战马齐头并进,浩浩荡荡地飞奔而;那声音如同山崩地裂,好像大地都被震得颤动起。霎时,潮头奔腾西去,可是余波还在漫天卷地般涌,江面上依旧风号浪吼。 二、读下面这首诗,从课文中找出与诗的内容相关的句子。 浪淘沙唐·刘禹锡 八月涛声吼地,头高数丈触山回。 须臾却入海门去,卷起沙堆似雪堆。 与诗的内容相关的句子: 那条白线很快地向我们移,逐渐拉长,变粗,横贯江面。再近些,只见白浪翻滚,形成一堵两丈多高的水墙。 浪潮越越近,犹如千万匹白色战马齐头并进,浩浩荡荡地飞奔而;那声音如同山崩地裂,好像大地都被震得颤动起。 第二课《走月亮》 一、阿妈牵着我“我”走过“月光闪闪的溪岸”,“细细的溪水,流着山草和野花的香味,流着月光……”你的头脑中浮出了怎样的画面?课文中还有哪些画面给你留下了深刻的印象?和同学交流。 提示:山草、野花、月光倒映在溪水里,随着溪水流动着,就像是“流着山草、野花的香味,流着月光”。这里用了暗喻的手法,把阿妈比作美丽的月亮,牵着那些闪闪烁烁的小星星,也就是“我”在天上走着。这样写形象生动,写出阿妈对我的种种启示和引导,让读者更具体地了解我和阿妈走月亮的含义。 画面:迷人的秋夜,阿妈牵着“我”,在月光下,沿着乡间的小路,沿着小溪走着走着……人和美丽的月光、潺潺的流水、芳香的山草、野花,构成了一幅美妙的乡村夜景图。 给我留下了深刻印象的画面还有:“秋虫唱着,夜鸟拍打着翅膀,鱼儿跃出水面,泼剌声里银光一闪…….从果园那边飘了果子的甜香。是雪梨,还是火把梨?还是紫葡萄?都有,月光下,在坡头上那片果园里,这些好吃的果子挂满枝头。沟水汩汩,很满意的响着。是啊,旁边就是它浇灌过的田地。在这片地里我们种过油菜,种过蚕豆。我在豆田里找过兔草。我把蒲公英吹得飞啊,飞,飞得 第4章违背基本假设的情况 思考与练习参考答案 4.1 试举例说明产生异方差的原因。 答:例4.1:截面资料下研究居民家庭的储蓄行为 Y i=β0+β1X i+εi 其中:Y i表示第i个家庭的储蓄额,X i表示第i个家庭的可支配收入。 由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以εi的方差呈现单调递增型变化。 例4.2:以某一行业的企业为样本建立企业生产函数模型 Y i=A iβ1K iβ2L iβ3eεi 被解释变量:产出量Y,解释变量:资本K、劳动L、技术A,那么每个企业所处的外部环境对产出量的影响被包含在随机误差项中。由于每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。这时,随机误差项ε的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。 4.2 异方差带来的后果有哪些? 答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果: 1、参数估计量非有效 2、变量的显著性检验失去意义 3、回归方程的应用效果极不理想 总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。 4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。 答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差 的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。 加权最小二乘法的方法: 4.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。 答:运用加权最小二乘法消除多元线性回归中异方差性的思想与一元线性回归的类似。多元线性回归加权最小二乘法是在平方和中加入一个适当的权数i w ,以调整各项在平方和中的作用,加权最小二乘的离差平方和为: ∑=----=n i ip p i i i p w x x y w Q 1211010)( ),,,(ββββββ (2) 加权最小二乘估计就是寻找参数p βββ,,,10 的估计值pw w w βββ?,,?,?10 使式(2)的离差平方和w Q 达极小。所得加权最小二乘经验回归方程记做 22011 1 ???()()N N w i i i i i i i i Q w y y w y x ββ===-=--∑∑22 __ 1 _ 2 _ _ 02 222 ()() ?()?1 11 1 ,i i N w i i i w i w i w w w w w kx i i i i m i i i m i w x x y y x x y x w kx x kx w x σβββσσ==---=-= = ===∑∑1N i =1 1表示=或 人教版四年级数学上册练习题及答案 一、直接写出下面各题得数. 8×8+52÷4 160+40÷ ×125 ×6×8÷26×8 二、把下面运算中不正确的地方改过来. 1.÷25×2.600× =800÷25× =600× ==24000 三、把下面各组式子列成综合算式. 1.3280÷16=202.23×16=368 205×10=2050625-368=257 6000-2050=3950 1028÷257=4 四、计算下面各题. 1.280+840÷24×5 2.85× 3.58870÷ 4.80400- 五、装订车间每人每小时装订课本640册,照这样计算,12人8小时装订课本多少册? 六、汽车队开展节约用油活动,12辆车一年共节约汽油7200千克,平均每辆车每个月节约汽油多少千克? 七、一部电话机售价320元,一台“彩电”的售价是电话机售价的8倍,一台电脑的售价比“彩电”售价的3倍还多1000元,一台电脑多少元? 八、两个车间生产零件,5天后甲车间生产1520个零件,乙车间生产1280个零件,若每天工作8小时,乙车间比甲车间每小时少生产多少个零件? 参考答案 三、1.6000-3280÷16×10 2.1028÷ 四、1.45.2975 3.40.76042 五、640×12×8=1440 六、7200÷12÷12=50 七、320×8×3+1000=8680 八、÷=6 综合能力训练 一、填空. 1.学校有足球24个,是篮球的3倍,学校有足球,篮球共个. 2.甲数是15,乙数比甲数的2倍多3,乙数比甲数多..甲、乙两数的平均数是14,乙、丙两数的平均数是18,甲、丙两数的平均数是16.甲、乙、丙三数的平均数是. 应用回归分析试题(一) 1、对于一元线性回归y 0i X i i(i 1,2,..., n),E(J 0 , var( J cov( i, j) 0(i j),下列说法错误的是 (A) 0,1的最小一乘估计? '0, ?都是无偏估计; (B) 0,1的最小一乘估计? 0, Q ?对y,y2,... ,y n是线性的; (C) 0,1的最小一乘估计 ? , ?之间是相关的; (D)若误差服从正态分布,0,1的最小二乘估计和极大似然估计是不一样的 2、在回归分析中若诊断出异方差,常通过方差稳定化变化对因变量进行变换.如果误差方差与因变量y的期望成正比,则可通过下列哪种变换将方差常数化 1 (A) - ;(B) “ ;(C) ln( y 1) ;(D) In y. y 、 3、下列说法错误的是 (A) 强影响点不一定是异常值; (B) 在多元回归中,回归系数显着性的t检验与回归方程显着性的F检验是等价的; (C) 一般情况下,一个定性变量有k类可能的取值时,需要引入k-1个0-1型自变量; (D) 异常值的识别与特定的模型有关. 4、下面给岀了4个残差图,哪个图形表示误差序列是自相关的 (A) (B) (C) (D) 5、下列哪个岭迹图表示在某一具体实例中最小二乘估计是适用的 (A) (B) (C)(D) 二、填空题(每空2分,共20分) 2 2 1、考虑模型y X ,var( ) I n,其中X : n p,秩为p,0不一定 已知,则 ? ________________ , var ( ?) _________ ,若 服从正态分布,则 2、下表给岀了四变量模型的回归结果: 则残差平方和= ___________ ,总的观察值个数 = ___________ ,回归平方和的自由度 = ________ . 3、已知因变量 y 与自变量X i ,X 2, X 3,X 4,下表给岀了所有可能回归模型的 AIC 值,则最 优子集是 _______________________ . 4、 在诊断自相关现象时,若 DW 0.66,则误差序列的自相关系数 的估计值= _______ ,若 存在自相关现象,常用的处理方法有迭代法、 _____________ 、科克伦-奥克特迭代法. 5、 设因变量y 与自变量X 的观察值分别为 y 「y 2,..., y n 和x 1, x 2 ,..., x n ,则以x *为折点的折 线模型可表示为 ________________________ . 三、(共45分)研究货运总量y (万吨)与工业总产值x 1 (亿元)、农业总产值x 2 (亿元)、 居民非商品支岀X 3 (亿元)的线性回归关系.观察数据及残差值e i 、学生化残差SRE i 、删除 学生化残差SRE (i )、库克距离D i 、杠杆值ch ii 见表 (n P)?2 ___________ ,其中?2是2的无偏估计 第六章 化学动力学习题答案 1. 某放射性元素经14天后,活性降低了%。试求:(1)该放射性元素的半衰期;(2)若要分解掉90%,需经多长时间 解:放射性元素的衰变符合一级反应规律。 设反应开始时,其活性组分为100%,14天后,剩余的活性组分为100%%,则: A,031A,011100 ln ln 5.0710d 14100 6.85 c k t c x --===?-- 312 ln 2/ln 2/(5.0710)136.7d t k -==?= A,03A,0A,0111ln ln 454.2d 0.9 5.071010.9 c t k c c -===-?- 2.已知某药物在体内的代谢过程为某简单级数反应,给某病人在上午8时注射该药物,然后分别经过不同时刻t 测定药物在血液中的浓度c (以mmol?L -1表示),得到如下数据: t / h 4 8 12 16 c/(mmol?L -1) 如何确定该药物在体内代谢过程的反应级数该反应的速率常数和半衰期分别是多少 解:此题可用尝试法求解反应级数。先求出不同时刻的ln c : t / h 4 8 12 16 ln c ? ? ? ? 以ln c 对t 作图,得一直线,相关系数为,所以此为一级反应,即n=1。 直线的斜率为?,则有此反应的速率常数为;半衰期1/2ln 2 7.24h t k ==。 3.蔗糖在酸催化的条件下,水解转化为果糖和葡萄糖,经实验测定对蔗糖呈一 级反应的特征: 122211261266126H C H O H O C H O C H O + +??→+ 蔗糖(右旋) 果糖(右旋) 葡萄糖(左旋) 部编版四年级语文下册课后习题参考答案 第1课古诗词三首 2.读下面的诗句,说说你眼前浮现出了怎样的情景。 〔答案大家找〕“儿童急走追黄蝶,飞入菜花无处寻。”描绘了儿童捕蝶的欢快场景。 “日长篱落无人过,惟有蜻蜓蛱蝶飞。”让我们看到农民早出晚归的场景,蛱蝶飞又让我们感受到静中有动的情景。 “大儿锄豆溪东,中儿正织鸡笼。最喜小儿亡赖,溪头卧剥莲蓬。”大儿子在溪东豆地里锄草,二儿子在家里编织鸡笼,三儿子只知任意地调皮玩耍,躺卧在溪边剥莲蓬吃。 第2课乡下人家 1.朗读课文,想象画面。如果给课文配画,你觉得可以画几幅?试着给每幅画取个名字。 〔答案大家找〕 7幅,屋前搭瓜架、门前种鲜花、屋后春笋冒、院里鸡觅食、河中鸭嬉戏、门前吃晚饭、夜静催眠曲。 2.你对课文描写的哪一处景致最感兴趣?和同学交流。 〔答案大家找〕描写门前五颜六色的花和雨后春笋的景致我最感兴趣,本来是朴素的乡下,可是门前这些五彩缤纷的花朵、雨后的春笋又给本来朴素的乡下带来了勃勃生机,读完以后让我也向往乡下这样恬静安逸的生活。 3.读句子,再从课文中找出像这样写得生动形象的句子,抄写下来。 〔答案大家找〕他们的屋后倘若有一条小河,那么在石桥旁边,在绿树荫下,会见到一群鸭子游戏水中,不时地把头扎到水下去觅食。天边的红霞,向晚的微风,头上飞过的归巢的鸟儿,都是他们的好友,它们和乡下人家一起,绘成了一幅自然、和谐的田园风景画。秋天到了,纺织娘寄住在他们屋前的瓜架上。月明人静的夜里,它们便唱起歌来:“织,织,织,织啊!织,织,织,织啊!”那歌声真好听,赛过催眠曲,让那些辛苦一天的人们,甜甜蜜蜜地进入梦乡。 选做 你眼里的乡村景致是怎样的?用一段话写下来。 〔答案大家找〕大树也绿,小草也茂盛,花朵也艳丽,田园的风光真是美。近处,一棵棵大杨树挺直身板,抬起头,密密麻麻的绿叶里闪过一丝丝日影。远远地看去,这些杨树就像一名名威武的保卫者。小草又嫩又绿,茂密的草地就像一大块碧绿的地毯,躺在软软的绿地上,比躺在沙发上还要舒服。那的野花不是一般的香,在千里之外都可以闻到。每一朵花都神气十足地仰起头。每个人家的门前都有一块可爱的菜地,种有茄子、黄瓜、辣子、豇豆、草莓等蔬菜水果。从高处往下看, 应用回归分析试题(二) 一、选择题 1. 在对两个变量x , y 进行线性回归分析时,有下列步骤: ①对所求出的回归直线方程作出解释;②收集数据(X i 、),1,2,…, n ;③ 求线性回归方程;④求未知参数; ⑤根据所搜集的数据绘制 散点图。 如果根据可行性要求能够作出变量x ,y 具有线性相关结论,则在下列 操作中正确的是(D ) A .①②⑤③④ B .③②④⑤① C .②④③①⑤ D .②⑤④③① 2. 下列说法中正确的是(B ) A .任何两个变量都具有相关关系 B .人的知识与其年龄具有相关关系 C .散点图中的各点是分散的没有规律 D .根据散点图求得的回归直线方程都是有意义的 3. 下面的各图中,散点图与相关系数r 不符合的是(B ) \ 4 yi i .? — | 5. 在画两个变量的散点图时,下面哪个叙述是正确的 (B ) (A) 预报变量在x 轴上,解释变量在y 轴上 (B) 解释变量在x 轴上,预报变量在y 轴上 (C) 可以选择两个变量中任意一个变量在 X 轴上 (D) 可以选择两个变量中任意一个变量 二、 填空题 m 丄 1. y 关于m 个自变量的所有可能回归方程有-一1个。 2. H 是帽子矩阵,贝S tr(H)=p+1。 3. 回归分析中从研究对象上可分为一元和多元。 4. 回归模型的一般形式是 y ° 1X 1 2X 2 p X p 。 5. Cov(e) 2(l H) (e 为多元回归的残差阵)。 三、 叙述题 1.引起异常值消除的方法(至少5个)? 答案:异常值消除方法: (1) 重新核实数据; (2) 重新测量数据; (3) 删除或重新观测异常值数据; (4) 增加必要的自变量; 则正确的叙述是(D ) A .身咼一定是145.83cm C .身高低于145.00cm B .身高超过146.00cm D .身高在145.83cm 左右 统编版语文四年级下册教材课后题参考答案 第1课古诗词三首 2.读下面的诗句,说说你眼前浮现出了怎样的情景。 〔答案大家找〕“儿童急走追黄蝶,飞入菜花无处寻。”描绘了儿童捕蝶的欢快场景。 “日长篱落无人过,惟有蜻蜓蛱蝶飞。”让我们看到农民早出晚归的场景,蛱蝶飞又让我们感受到静中有动的情景。 “大儿锄豆溪东,中儿正织鸡笼。最喜小儿亡赖,溪头卧剥莲蓬。”大儿子在溪东豆地里锄草,二儿子在家里编织鸡笼,三儿子只知任意地调皮玩耍,躺卧在溪边剥莲蓬吃。 第2课乡下人家 1.朗读课文,想象画面。如果给课文配画,你觉得可以画几幅?试着给每幅画取个名字。 〔答案大家找〕 7幅,屋前搭瓜架、门前种鲜花、屋后春笋冒、院里鸡觅食、河中鸭嬉戏、门前吃晚饭、夜静催眠曲。 2.你对课文描写的哪一处景致最感兴趣?和同学交流。 〔答案大家找〕描写门前五颜六色的花和雨后春笋的景致我最感兴趣,本来是朴素的乡下,可是门前这些五彩缤纷的花朵、雨后的春笋又给本来朴素的乡下带来了勃勃生机,读完以后让我也向往乡下这样恬静安逸的生活。 3.读句子,再从课文中找出像这样写得生动形象的句子,抄写下来。 〔答案大家找〕他们的屋后倘若有一条小河,那么在石桥旁边,在绿树荫下,会见到一群鸭子游戏水中,不时地把头扎到水下去觅食。天边的红霞,向晚的微风,头上飞过的归巢的鸟儿,都是他们的好友,它们和乡下人家一起,绘成了一幅自然、和谐的田园风景画。秋天到了,纺织娘寄住在他们屋前的瓜架上。月明人静的夜里,它们便唱起歌来:“织,织,织,织啊!织,织,织,织啊!”那歌声真好听,赛过催眠曲,让那些辛苦一天的人们,甜甜蜜蜜地进入梦乡。 选做 你眼里的乡村景致是怎样的?用一段话写下来。 〔答案大家找〕大树也绿,小草也茂盛,花朵也艳丽,田园的风光真是美。近处,一棵棵大杨树挺直身板,抬起头,密密麻麻的绿叶里闪过一丝丝日影。远远地看去,这些杨树就像一名名威武的保卫者。小草又嫩又绿,茂密的草地就像一大块碧绿的地毯,躺在软软的绿地上,比躺在沙发上还要舒服。那的野花不是一般的香,在千里之外都可以闻到。每一朵花都神气十足地仰起头。每个人家的门前都有一块可爱的菜地,种有茄子、黄瓜、辣子、豇豆、草莓等蔬菜水果。从高处往下看,那些蔬菜水果就像一个个精英士兵,你就像那位大将军,准备率领十万精英去攻打敌人的城池。晚上,无数颗星星眨着眼睛,等我们睡着,星星才肯离开…… 乡下的田园风光真是美不胜收,哪里的景色都比不上田园风光的美丽。 第3课天窗 1.默读课文。说说天窗在哪儿,为什么要开天窗。 〔答案大家找〕大人们在屋顶开一个小方洞,装一块玻璃板,这就是天窗了。为的是在大风大雨,北风呼呼的冬天可以让屋子里有光亮不会像地洞那样黑了。 2.在什么样的情况下,小小的天窗成了孩子们“唯一的慰藉”?找出相关句子体会体会,再有感情地读一读。 〔答案大家找〕夏天阵雨来了时,孩子们顶喜欢在雨里跑跳,仰着脸看闪电,然而大人们偏就不许。“到屋里来啊!”跟着木板窗的关闭,孩子们也就被关在地洞似的屋里了。晚上,当你被逼着上床去“休息”的时候,也许你还忘不了月光下的草地河滩。在这些情况下天窗就是唯一的慰藉了。 3.读句子,回答括号里的问题。 〔答案大家找〕 (1)“扫荡”让我们感受到外面风雨的猛烈。因为我们可以透过这小小的天窗发挥无穷的想象,想象着外面猛烈的风雨,这要比真实的感受大十倍百倍。 (2) 从那小小的天窗,孩子们可以想象卜落卜落跳的雨滴,还能想象会唱歌的夜莺,霸气十足的猫头鹰,这些从“无”到“有”,从“虚”到“实”都是孩子们从无穷的想象中得来的。回归分析练习题(有答案)
第三章化学动力学基础课后习题参考答案
部编版四年级下册语文课后习题参考答案
应用回归分析-第3章课后习题参考答案
应用回归分析试卷
结构动力学习题解答一二章
【精品】部编版四年级语文上册课后习题参考答案
应用回归分析,第4章课后习题参考答案
人教版四年级数学上册练习题及答案
应用回归分析试题套
化学动力学习题参考答案
新部编四年级下册语文课后习题参考答案(全册)
应用回归分析试题二
最新部编统编版四年级下册语文课后习题参考答案