frequency函数用法

Frequency函数
函数定义:以一列垂直数组返回一组数据的频率分布。
语法:FREQUENCY(data_array,bins_array)
参数说明:data_array表示要对其频率进行计数的一组数值或对这组数值的引用。bins_array表示要将data_array中的值插入到的间隔数组或对间隔的引用。
函数说明
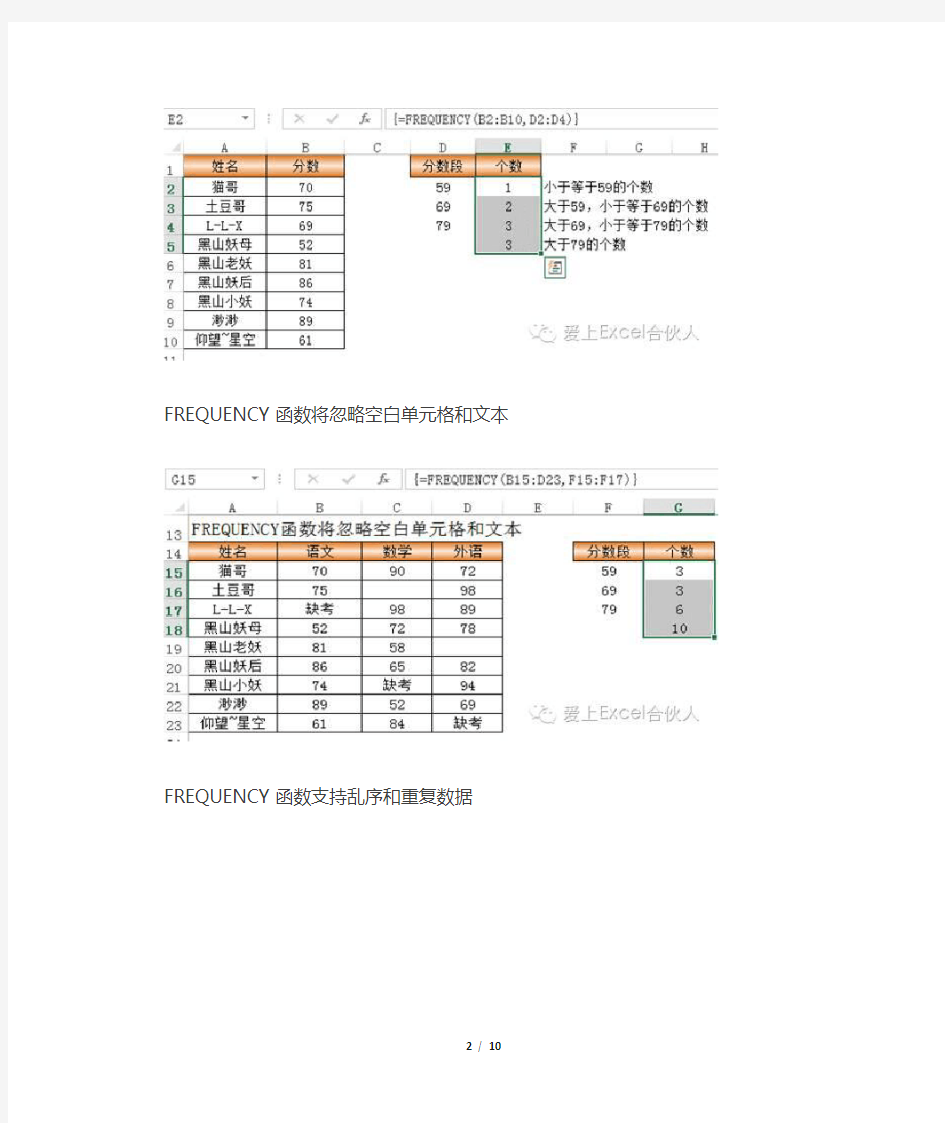
忽略空白单元格和文本
支持乱序和重复数据
对于返回结果为数组的公式,必须以数组公式的形式输入
函数应用实例
01 经典用法
FREQUENCY函数将忽略空白单元格和文本
FREQUENCY函数支持乱序和重复数据
02 分段统计
03 按给定区间统计数据个数
04 统计不重复的个数
第2参数总共有5个分隔点,那么就会返回6个结果,刚才我们
在上面上过,会多出一个结果,把=FREQUENCY(A3:A7,A3:A7)
抹黑,然后F9,得到{2;0;1;2;0;0},请大家数一下,是不是6个结果另外为什么中间出现一些零呢?,去看我们上面的7点中的
第3点:第2参数的分隔点有重复的分隔点,只显示第1次出现的,后面出现相同的分隔点全显示0
这样刚好我们要统计的个数就是结果里不等于0的个数
这个好说,因为我们知道0/0会报错,0不能作为除数
所以我们就就用0除以FREQUENCY(A3:A7,A3:A7)
得到公式=0/FREQUENCY(A3:A7,A3:A7)
把公式=0/FREQUENCY(A3:A7,A3:A7)抹黑,按F8得到下面的结果{0;#DIV/0!;0;0;#DIV/0!;#DIV/0!}
0/0报错
0/其它数据=0
这样0的个数就是我们要统计的个数,报错就是重复的
count函数是数值型的个数,不怕错误值,刚才对上我们现在的情况在=0/FREQUENCY(A3:A7,A3:A7)外面嵌套一个Count函数得到下面的公式
=COUNT((0/FREQUENCY(A3:A7,A3:A7)))
如果数据源是文本的话需要嵌套一个match函数。
根据FREQUENCY这个特点,.第2参数的分隔点有重复的分隔点,只显示第1次出现的,后面出现相同的分隔点全显示0
把公式=FREQUENCY(MATCH(A2:A6,A2:A6,),MATCH(A2:A6,A2:A6,))抹黑,F9 得到{2;0;2;0;1;0},第1次出现的是显示大于0,重复出现的显示0
然后我们用0除以它
FREQUENCY(MATCH(A2:A6,A2:A6,),MATCH(A2:A6,A2:A6,))
得到0和错误值,0/0报错,0/任意数=0
我们要的结果就是统计0的个数
再到外面嵌套一个count函数,就全部完成公式
=COUNT(0/FREQUENCY(MATCH(A2:A6,A2:A6,),MATCH(A2:A6,A2:A6,)))
05 提取不重复项
C2=LOOKUP(,0/FREQUENCY(0,ISNA(MATCH(A$2:A$11&"",C$1:C1,))-1),A$2:A3)&"", 06 单条件提取不重复项
E2=LOOKUP(,0/FREQUENCY(1,ISNA(MATCH(B$1:B$11,E$1:E1,))*(A$1:A$11=D$2)),B :B)&"",向下填充;
07 统计最大连续次数
C2=MAX(FREQUENCY(ROW(2:13),(A2:A13<>A3:A13)*ROW(2:13))) 08 查找最接近指定数值的数据
D3=LOOKUP(,0/FREQUENCY(0,(B2:B10-E3)^2),A2:A10)
或D4=LOOKUP(,0/FREQUENCY(0,ABS(B2:B10-E3)),A2:A10)
09 按指定次数生成重复数据
D2=LOOKUP(,0/FREQUENCY(ROW(A1),SUBTOTAL(9,OFFSET(B$1,,,ROW($1:$9)))), A:A)&"",向下填充
E2=LOOKUP(,0/FREQUENCY(ROW(A1),SUMIF(OFFSET(B$1,,,ROW($1:$9)),">0")),A: A)&"",向下填充
10 多条件不重复计数
F3=COUNT(0/FREQUENCY(ROW(A:A),MATCH(C2:C12,C2:C12,)*(B2:B12="东莞
")*(D2:D12>=6000)))-1
频数分布图的做法(函数法).
实例用数组公式: FREQUENCY 以一列垂直数组返回某个区域中数据的频率分布。例如,使用函数FREQUENCY 可以计算在给定的分数范围内测验分数的个数。由于函数FREQUENCY 返回一个数组,所以必须以数组公式的形式输入。 语法 FREQUENCY(data_array,bins_array) Data_array 为一数组或对一组数值的引用,用来计算频率。如果data_array 中不包含任何数值,函数FREQUENCY 返回零数组。(注:就是你想看分布的那些原始数据) Bins_array 为间隔的数组或对间隔的引用,该间隔用于对data_array 中的数值进行分组。如果bins_array 中不包含任何数值,函数FREQUENCY 返回data_array 中元素的个数。(注:就是你想用来分原始数据档的那些序列数,这个要自己根据需要先做好,备用) 说明 在选定相邻单元格区域(该区域用于显示返回的分布结果)后,函数FREQUENCY 应以数组公式的形式输入。 返回的数组中的元素个数比bins_array(数组)中的元素个数多1。返回的数组中所多出来的元素表示超出最高间隔的数值个数。例如,如果要计算输入到三个单元格中的三个数值区间(间隔),请一定在四个单元格中输入FREQUENCY 函数计算的结果。多出来的单元格将返回data_array 中大于第三个间隔值的数值个数。 函数FREQUENCY 将忽略空白单元格和文本。 对于返回结果为数组的公式,必须以数组公式的形式输入。 示例 本示例假设所有测验分数都为整数。 如果您将示例复制到空白工作表中,可能会更易于理解该示例。 操作方法 创建空白工作簿或工作表。 分数分段点 79 70 85 79 78 89 85 50 81 95 88 97 注:分数那一列拷贝到从A2-A10的部分,分段点列拷贝到B2-B5 公式说明(结果) =FREQUENCY(A2:A10,B2:B5) 分数小于等于70 的个数(1) 成绩介于71-79 之间的个数(2) 成绩介于80-89 之间的个数(4) 成绩大于等于90 的个数(2) 注释示例中的公式必须以数组公式的形式输入。将示例复制到空白工作表之后,请选中从公式单元格开始的单元格区域 A13:A16。按 F2,再按 Ctrl+Shift+Enter。如果公式未以数组公式的形式输入,则
C语言函数手册(DOC)
一、字符测试函数 isupper()测试字符是否为大写英文字 ispunct()测试字符是否为标点符号或特殊符号isspace()测试字符是否为空格字符 isprint()测试字符是否为可打印字符 islower()测试字符是否为小写字母 isgraphis()测试字符是否为可打印字符 isdigit()测试字符是否为阿拉伯数字 iscntrl()测试字符是否为ASCII码的控制字符isascii()测试字符是否为ASCII码字符 isalpha()测试字符是否为英文字母 isalnum()测试字符是否为英文或数字 isxdigit()测试字符是否为16进制数字 二、字符串操作函数 strtok()字符串分割函数 strstr()字符串查找函数 strspn()字符查找函数 strrchr()定位字符串中最后出现的指定字符 strpbrk()定位字符串中第一个出现的指定字符strncpy()复制字符串 strncat()字符串连接函数 strncasecmp()字符串比较函数(忽略大小写) strlen()字符串长度计算函数 strdup()复制字符串 strcspn()查找字符串 strcpy()复制字符串 strcoll()字符串比较函数(按字符排列次序) strcmp()字符串比较函数(比较字符串) strchr()字符串查找函数(返回首次出现字符的位置) strcat()连接字符串 strcasecmp()字符串比较函数(忽略大小写比较字符串) rindex()字符串查找函数(返回最后一次出现的位置) index()字符串查找函数(返回首次出现的位置) toupper()字符串转换函数(小写转大写) tolower()字符串转换函数(大写转小写) toascii()将整数转换成合法的ASCII码字符 strtoul()将字符串转换成无符号长整型数
在Excel中使用FREQUENCY函数统计各分数段人数
在Excel中使用FREQUENCY函数统计各分数段人数 用Excel怎样统计出学生成绩各分数段内的人数分布呢?很多文章都推荐使用CountIF 函数,可是每统计一个分数段都要写一条函数,十分麻烦。例如,要在C58:C62内统计显示C2:C56内小于60分、60至70之间、70至80之间、80至90之间、90至100之间的分数段内人数分布情况,要输入以下5条公式: 1. 在C58内输入公式统计少于60分的人数:=CountIF(C2:C56,"<60") 2. 在C59内输入公式统计90分至100之间的人数:=CountIF(C2:C56,">=90") 3. 在C60内输入公式统计80至90之间的人数:=CountIF(C2:C56,">=80")-CountIF(C2:C56,">=90"), 4. 在C61内输入公式统计70到80之间的人数:=CountIF(C2:C56,">=70")-CountIF(C2:C56,">=80"), 5. 在C62内输入公式统计60到70之间的人数:=CountIF(C2:C56,">=60")-CountIF(C2:C56,">=70")。 如果要把0至10之间、10至20之间、20至30……90至100之间这么多个分数段都统计出来,就要写上十条公式了。可见用COUNTIF()函数效率并不高。 其实,Excel已经为我们提供了一个进行频度分析的FreQuency数组函数,它能让我们用一条数组公式就轻松地统计出各分数段的人数分布。 FREQUENCY函数说明如下: -------------------------------------------------- 语法: FREQUENCY(data_array,bins_array) 参数: data_array:需要进行频率统计的一组数。 bins_array:为间隔的数组,该间隔用于对data_array中的数值进行分组。 返回值: 以一列垂直数组返回某个区域中数据的频率分布。例如,使用函数FREQUENCY 可以计算在给定的分数范围内测验分数的个数。 注: 1、返回的数组中的元素个数比bins_array(数组)中的元素个数多1。所多出来的元素表示超出最高间隔的数值个数。 2、由于返回结果为数组,必须以数组公式的形式输入。即给定FREQUENCY的参数
输入和输出函数的区别
输入输出函数区别如下: 一、printf 、sprintf、fprintf的区别 1.1 都是把格式好的字符串输出,只是输出的目标不一样: 1)、printf,是把格式字符串输出到标准输出(一般是屏幕、控制台,可以重定向),是和标准输出文件(stdout)关联的; 原型为: int printf(const char *format[,argument]...); 2)、sprintf,是把格式字符串输出到指定的字符串中,所以参数比printf多一个char*。这是目标字符串地址; 原型为:int sprintf(char *buffer,const char *format[,argument]...); 3)、fprintf,是把格式字符串输出到指定文件设备中,fprintf是格式化输出到一个stream,通常是到文件,所以参数比printf多一个文件指针FILE*; 原型为:int fprintf(FILE *stream,const char *format[,argument]...); 1.2. Fprintf c语言把文件看作一个字符(字节)的序列,即由一个一个字符(字节)的数据顺序组成。根据数据的组成形式,可分为ASCLL文件和二进制文件。ASCLL文件又称为文本文件(text),它的每个字节放一个ASCLL代码,代表一个字符。二进制文件是内存中的数据按其在内在中的存储形式原样输出到磁盘上存放。 1).fprintf(fp,"%d",buffer);是将格式化的数据写入文件; fprintf(文件指针,格式字符串,输出表列); fwrite(&buffer,sizeof(int),1,fp); 是以二进位方式写入文件 fwrite(数据,数据类型大小(字节数),写入数据的最大数据,文件指针); 由于fprintf写入是,对于整数来说,一位站一个字节, 比如1,占1个字节; 10,占2个字节; 100,占3个字节; 10000,占5个字节;所以文件的大小会随数据的大小而改变,对大数据空间占用很大。而fwrite是按二进制写入,所以写入数据所占空间是根据数据类型来确定,比如int的大小为4个字节(一般32位下),那么整数10所占空间为4个字节,100/10000所占空间也是4个字节,所以二进制写入比格式化写入更省空间。因此, 对于1 2 3 4 5 6 7 8 9 0 十个整数,用fprintf写入时,占10个字节;而用fwrite写入时,占40个字节。 对于100 101 102 103 104 105 106 107 108 109 110 这十个整数,用fprintf写入时,占30个字节;而用fwrite写入时,占40个字节。 对于10000 10100 10200 10300 10400 10500 10600 10700 10800 10900 1 1000 这十个整数,用fprintf写入时,占50个字节;而用fwrite写入时,还是
Excel表格中的一些基本函数使用方法
Excel表格中的一些基本函数使用方法 一、输入三个“=”,回车,得到一条双直线; 二、输入三个“~”,回车,得到一条波浪线; 三、输入三个“*”或“-”或“#”,回车,惊喜多多; 在单元格内输入=now()显示日期 在单元格内输入=CHOOSE(WEEKDAY(I3,2),"星期一","星期二","星期三","星期四","星期五","星期六","星期日") 显示星期几 Excel常用函数大全 1、ABS函数 函数名称:ABS 主要功能:求出相应数字的绝对值。 使用格式:ABS(number) 参数说明:number代表需要求绝对值的数值或引用的单元格。 应用举例:如果在B2单元格中输入公式:=ABS(A2),则在A2单元格中无论输入正数(如100)还是负数(如-100),B2中均显示出正数(如100)。 特别提醒:如果number参数不是数值,而是一些字符(如A等),则B2中返回错误值“#VALUE!”。 2、AND函数 函数名称:AND 主要功能:返回逻辑值:如果所有参数值均为逻辑“真(TRUE)”,则返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。
使用格式:AND(logical1,logical2, ...) 参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。 应用举例:在C5单元格输入公式:=AND(A5>=60,B5>=60),确认。如果C5中返回TRUE,说明A5和B5中的数值均大于等于60,如果返回FALSE,说明A5和B5中的数值至少有一个小于60。 特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。 3、AVERAGE函数 函数名称:AVERAGE 主要功能:求出所有参数的算术平均值。 使用格式:AVERAGE(number1,number2,……) 参数说明:number1,number2,……:需要求平均值的数值或引用单元格(区域),参数不超过30个。 应用举例:在B8单元格中输入公式: =AVERAGE(B7:D7,F7:H7,7,8),确认后,即可求出B7至D7区域、F7至H7区域中的数值和7、8的平均值。 特别提醒:如果引用区域中包含“0”值单元格,则计算在内;如果引用区域中包含空白或字符单元格,则不计算在内。 4、COLUMN 函数 函数名称:COLUMN 主要功能:显示所引用单元格的列标号值。
sscanf,sscanf_s及其相关用法
sscanf,sscanf_s 及其相关用法 #include
excel函数学习教程可资借鉴的学习步骤(精)
函数学习教程可资借鉴的学习步骤 第一部分:函数与公式基础 第1集:公式与运算符 什么是公式?函数?怎么在EXCEL里进行计算?如果你和我当初一样菜,那就老老实实的从这一集学起吧。认识一下公式的种类、学习使用加减乘除、乘方、开方等运算符。 第2集:相对引用与绝对引用 为什么公式复制时A1会变成A2,公式拖动时能不能不变化呢?可有时。。。又需要变化。这个。。怎么才能让它变就变,不让它变就老实的呆着呢?学会引用方式,A1的72变就逃不出你的手心了。 第3集:公式的调试与操作技巧 公式常出错、咋快速找出错误?合并单元格大小不一,怎么复制?公式怎么隐藏起来?可恶的“不能更改数组的一部分”提示,不让我更改公式。掌握公式的调试与操作技巧,是你学习函数公式前必须打好的基础。 第二部分:逻辑与判断函数 第4集:IF函数 单条件、混合条件、多条件、区间条件的判断,IF很给力,配合AND和OR两个小助手,这些都可以帮你实现。 第5集:信息类函数 ISODD判断奇偶、ISNUMBER判断数字、ISTEXT判断文本、ISERROR判断错误值、实在不行还有TYPE函数。日期与数学竟然也可以用CELL函数判断。还有什么不能判断的?
第三部分:计数、求和及数学函数 第6集:COUNT和COUNTA函数 在EXCEL函数里,简单总是相对的,这两个函数简单不?简单,难不?难!想真正的灵活应用,还真要需要一些实战经验。本集除了介绍几个小应用,也给大家提供一个在数组公式中应用的实例。为学习函数数组打打基础。 第7集:SUM函数 会用EXCEL的同学,都会用这个函数。你用过可以多表合并的SUM吗?你会用它巧设含有数个小计的累计数吗?还是那句话,函数简单,学会灵活应用还是需要下点功夫的。 第8集:COUNTIF函数 每次给企业培训,这个函数总是会重点推荐,因为它太。。。太重要了,看看它可以实现的功能你会不会已对它垂涎欲滴。两个表格核对、提取唯一值、删除重复的行、防止重复录入、限制录入的内容、根据条件统计个数..它的作用真是罄竹难书。。。。 第9集:SUMIF函数 SUMIF你会了,根据条件求和你会吗?曾经菜鸟时的我,学会了这个函数几近疯狂。它竟然可以帮我自动实现了供货商的往来账的自动汇总,不用再一个个的手工加了。那个激动啊.....别笑我,那时我就是这么的菜.... 第10集:SUMPRODUCT函数 萨达姆不绕打他的,这个函数真让我无语。你你怎么可以这样,即可以多条件计数、又可以多条件求和,竟然还可以多条件模糊求和。这让自诩功能强大的COUNTIF和SUMIF函数情何以堪啊....
Excel中函数的使用方法
各函数使用方法大全 Excel函数使用方法 1、ABS函数 主要功能:求出相应数字的绝对值。 使用格式:ABS(number) 参数说明:number代表需要求绝对值的数值或引用的单元格。 应用举例:如果在B2单元格中输入公式:=ABS(A2),则在A2单元格中无论输入正数(如100)还是负数(如-100),B2中均显示出正数(如100)。 特别提醒:如果number参数不是数值,而是一些字符(如A等),则B2中返回错误值“#VALUE!”。 2、AND函数 主要功能:返回逻辑值:如果所有参数值均为逻辑“真(TRUE)”,则返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。 使用格式:AND(logical1,logical2, ...) 参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。 应用举例:在C5单元格输入公式:=AND(A5>=60,B5>=60),确认。如果C5中返回TRUE,说明A5和B5中的数值均大于等于60,如果返回FALSE,说明A5和B5中的数值至少有一个小于60。 特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。 3、AVERAGE函数 主要功能:求出所有参数的算术平均值。 使用格式:AVERAGE(number1,number2,……) 参数说明:number1,number2,……:需要求平均值的数值或引用单元格(区域),参数不超过30个。 应用举例:在B8单元格中输入公式:=AVERAGE(B7:D7,F7:H7,7,8),确认后,即可求出B7至D7区域、F7至H7区域中的数值和7、8的平均值。 特别提醒:如果引用区域中包含“0”值单元格,则计算在内;如果引用区域中包含空白或字符单元格,则不计算在内。 4、COLUMN 函数 主要功能:显示所引用单元格的列标号值。 使用格式:COLUMN(reference) 参数说明:reference为引用的单元格。
人力资源常用EXCEL函数汇总
1、利用身份证号码提取员工性别信息 我国新一代的18 位身份证号码有一个很明显的特征,身份证号的倒数第2 位是奇数,为男性,否则是女性。根据这一特征,利用MID 和TRUNC两个函数判断员工的性别,而不必逐个输入,这样既避免了输入的烦琐工作,又保证了数据的正确性 操作步骤: 在单元格区域E3:E19 中输入员工的身份证号码。 MID 返回文本字符串中从指定位置开始指定数目的字符,该数目由用户指定。格式:MID(text,start_num,num_chars)。参数:text(文本)代表要提取字符的文本字符串;start_num(开始数值)代表文本中要提取字符的位置,文本中第1 个字符的start_num 为1,以此类推;num_chars(字符个数)指定MID 从文本中返回字符的个数。
函数TRUNC 的功能是将数字的小数部分截去,返回整数。格式:TRUNC(number,num_digits)。参数:number(数值)需要截尾取整的数字。num_digits(阿拉伯数字)用于指定取整精度的数字,num_digits 的默认值为0。 2、利用身份证号码提取员工出生日期信息 利用身份证号码来提取员工的出生日期,既准确又节省时间。具体操作步骤如图
函数TEXT 功能是将数值转换为指定数字格式表示的文本。格式:TEXT(value,format_text)。参数:value(数值)指数值、计算结果为数字值的公式,或对包含数字值的单元格的引用;format_text(文本格式)为【单元格格式】对话框中【数字】选项卡上【分类】文本框中的文本形式 的数字格式。函数LEN 功能是返回文本字符串中的字符数。格式:LEN(text)。参数:text 表示要查找的文本,空格将作为字符进行计数。 3、计算员工年龄 企业中的职务变动和员工的年龄有密切的关系,员工年龄随着日期变化而变动,借助于函数YEAR 和TODAY 可以轻松输入。 选择单元格区域F3:F19,单击【开始】选项卡,在【数字】组中单击
FREQUENCY函数说明
FREQUENCY函数说明 计算数值在某个区域内的出现频率,然后返回一个垂直数组。例如,使用函数FREQUENCY 可以在分数区域内计算测验分数的个数。由于函数 FREQUENCY 返回一个数组,所以它必须以数组公式的形式输入。 语法 FREQUENCY(data_array,bins_array) Data_array 是一个数组或对一组数值的引用,您要为它计算频率。如果 data_array 中不包含任何数值,函数 FREQUENCY 将返回一个零数组。 Bins_array 是一个区间数组或对区间的引用,该区间用于对 data_array 中的数值进行分组。如果 bins_array 中不包含任何数值,函数 FREQUENCY 返回的值与 data_array 中的元素个数相等。 说明:在选择了用于显示返回的分布结果的相邻单元格区域后,函数 FREQUENCY 应以数组公式的形式输入。返回的数组中的元素个数比 bins_array 中的元素个数多 1 个。多出来的元素表示最高区间之上的数值个数。例如,如果要为三个单元格中输入的三个数值区间计数,请务必在四个单元格中输入 FREQUENCY 函数获得计算结果。多出来的单元格将返回 data_array 中第三个区间值以上的数值个数。 函数 FREQUENCY 将忽略空白单元格和文本。如果公式的返回结果为数组,该公式必须以数组公式的形式输入。本示例假设所有测验分数都是整数。 请选择从公式单元格开始的区域 A13:A16。按 F2,再按 Ctrl+Shift+Enter。如果公式未以数组公式的形式输入,则返回的结果为 1。 若分段数组无序,则分段情况不变,但显示规律是:假设分段数组为a\b\c\d\e\f\g。则A位置显示<=A的部分,B位置显示<=B的部分……依此类推,F位置显示<=F的部分,G位置显示<=G的部分,最后显示>最大数的部分。
sscanf函数
Sscanf 函数 sscanf() - 从一个字符串中读进与指定格式相符的数据. 函数原型: Int sscanf( string str, string fmt, mixed var1, mixed var2 ... ); int scanf( const char *format [,argument]... ); 说明: sscanf与scanf类似,都是用于输入的,只是后者以屏幕(stdin)为输入源,前者以固定字符串为输入源。 其中的format可以是一个或多个{%[*] [width] [size]type | ' ' | '\t' | '\n' | 非%符号} 注: 1、* 亦可用于格式中, (即%*d 和%*s) 加了星号(*) 表示跳过此数据不读入. (也就是不把此数据读入参数中) 2、{a|b|c}表示a,b,c中选一,[d],表示可以有d也可以没有d。 3、width表示读取宽度。 4、参数的size: 常用的有hh表示单字节size,h表示2字节size,其他详见man sscanf或msdn 5、type :这就很多了,就是%s,%d之类。 控制字符说明 %c 一个单一的字符 %d 一个十进制整数
%i 一个整数 %e, %f, %g 一个浮点数 %o 一个八进制数 %s 一个字符串 %x 一个十六进制数 %p 一个指针 %n 一个等于读取字符数量的整数 %u 一个无符号整数 %[] 一个字符集 %% 一个精度符 6、特别的:%*[width] [{h | l | I64 | L}]type 表示满足该条件的被过滤掉,不会向目标参数中写入值 支持集合操作: %[a-z] 表示匹配a到z中任意字符,贪婪性(尽可能多的匹配) %[aB'] 匹配a、B、'中一员,贪婪性 %[^a] 匹配非a的任意字符,贪婪性 还是用例子说话: #include
sscanf()用法详细介绍
sscanf()用法详细介绍 1.名称 函数原型: int sscanf( const char *, const char *, ...); int sscanf(const char *buffer,const char *format,[argument ]...); buffer存储的数据 format格式控制字符串 argument 选择性设定字符串 sscanf会从buffer里读进数据,依照format的格式将数据写入到argument里。 2.头文件 #include
SSCANF与STRINGSTREAM函数的用法总结
sscanf与stringstream函数的用法总结 在按tab为分隔符读取文件的时候,遇到了很多问题,c++不像java、C#对字符串游很好的操作,我在查了很多资料,查到了sscanf和stringstream函数,这两个函数对上述问题可以很好的解决。 在读取字符串时,sscanf和stringstream非常强大,尤其是当以某个字符为分隔符读入字符串,并把分割后字符串转换成double或者int时,这两个函数的优势就体现出来,以下是我看了很多资料后,总结的一些用法。 sscanf是一个运行时函数,原形很简单: int sscanf(const char*buffer,const char*format[,argument]...); 它强大的功能体现在对format的支持,以及类型转换上。 其中的format可以是一个或多个{%[*][width][{h|l|I64|L}]type|''|'\t'|'\n'|非%符号}, 注:{a|b|c}表示a,b,c中选一,[d],表示可以有d也可以没有d。 width:宽度,一般可以忽略,用法如: const char sourceStr[]="hello,world"; char buf[10]={0}; sscanf(sourceStr,"%5s",buf);//%5s,只取5个字符 cout< Linux下常用C语言字符串操作函数 stroul, strdup snprintf() atio C中常用字符串操作函数 #include C 中scanf ( ) 函数用法心得 我觉得,在输入输出函数中,scanf()函数,应该是最麻烦的,有时它给我们的结果很可笑,但是一定是一原因的.... 首先声明一下,这篇日志不是介绍scanf()中各种格式符用法的文章(没有这个必要,但是大家一定要会用). 我尝试了很多种输入,包括一些错误的练习,曾经对scanf()由迷茫转向清醒,又由清醒再次转向迷茫......不知道何时是个尽头,谁让C如此高深呢? 在这里贴出来,也是想让自己时而不时能看到,也想知道自己的理解是否有错,错在哪里(所以我就厚着脸皮,放在上面了). 注意, 键盘缓冲区与输入有着密切的关系,并且, 类型匹配对输入也极为重 要!! 下面进入主题: scanf对流的操作遵从类型匹配操作原则,如果类型不匹配,它将不读取输入流。因此输入流将滞留,如果输入流不空,scanf不会等待用户输入,直接从缓冲区中输入. 但是,scanf() 怎样匹配? stdin又是什么? 在网上搜到的关于匹配的非常少,有些细节原因还是找不到. 所以,我自作主张的下了点结论: 例: scanf("%d,%d",&i,&j); 输入:12 ,13回车但是,j!=13. //注意,12后有一个空格,why? 原因:我解释为,在scanf()中,格式字符串中普通字符(不包括空白字符)实行的是严格匹配,因为格式串中%d后面是一个 ',' ,因此输入中数字12后必须为一个','. scanf("1123%s",&str); 输入:1123aaabb 时str为aaabb,但是,输入24aabbdd时, 会出错,因为1123必须进行严格匹配. 另外: scanf("%d\n",&i); printf("i=%d",i); 要怎么输入才能输出: i=12 ? 它不是你想像中的那样,有机会尝试一下吧! 一些样例: scanf()是一个有返回值的函数,它的返回值是什么?怎么样利用这个特性? scanf()中的匹配原则: 在本文第五点具体说明... scanf()中各种数据格式匹配的开始条件,结束条件 . 如: %d ,\n等类型输入结束条件. frequency函数的使用方法 答:我们在工作中经常会遇到计算连续次数最大的问题,计算连续次数最常用的函数就是FREQUENCY,下面就这个函数在计算连续次数的应用做一个详细图解。 首先,我们需要了解一下FREQUENCY函数的计算原理。 FREQENCY(数据区域,用于设置区间分隔点的数组) 作用: 简单的说就是在设置好的各个数值区间内,存在几个数。(频率分布) 例:A列有35,45,68,78,75,90,要分别计算 0~60、61~80、80以上这三个区域分别有几个数。公式就可以这样写。 =FREQUENCY(A1:A6,B1:B2) 分析: 虽然我们要设置三个区域,我们只需要设置两个数即可,即60和80,它就代表着0~60 、61~80、大于80三个区间。也就是说FR EQUENCY上函数返回的结果总比第二个参数的数字个数大1个。 注意:因为这个是一个数组函数,所以在输入时要选取大于分段点的一个的单元格数量,输入公式,按CTRL+SHIFT+ENTER结束输入。 了解了FREQUENCY的计算原理,下面我们书归正题,看一下它在计算最大连续数中的应用。还是先看例子吧。 例:如下图所示,B列中含1的表示张三的已签到,留 空的为未签到。要求计算张三最大连续签到的次数。 解题过程及思路: 第一步:从上图我们可以看到,各个连续的1被空行分隔成了多个独立的连续区域。要想计算连续1的个数,我们先要判断空行的位置。即: 第二步:从第一步的结果,我们发现,我们要想计算每一个连续1区域的个数,就演变成了3之前有几个数,4~8之间有几个数,8~11之间有几个数。这不正好是FREQUENCY计算根据分段点计算各个分段区间的个数模式了吗?。分段点就是这些空行的序数,分段数据源是1~12的连续数字。如下图所示: scanf格式控制的完整格式: % * m l或h 格式字符 ①格式字符与printf函数中的使用方式相同,以%d、%o、%x、%c、%s、%f、%e,无%u格式、%g格式。 ②可以指定输入数据所占列宽,系统自动按它截取所需数据。如: scanf(“%3d%3d”,&a,&b); 输入:123456 系统自动将123赋给a,456赋给b。 ③%后的“*”附加说明符,用来表示跳过它相应的数据。例如: scanf(“%2d%*3d%2d”,&a,&b); 如果输入如下信息:1234567。将12赋给a,67赋给b。第二个数据”345”被跳过不赋给任何变量。 ④输入数据时不能规定精度,例如: scanf(“%7.2f”,&a); 是不合法的,不能企图输入:12345.67而使a的值为12345.67。 ------------------相关------------------- 输入数据流分隔 ①根据格式字符的含义从输入流中取得数据,当输入流中数据类型与格式字符要求不符时,就认为这一项结束。如: scanf(“%d%c%f”,&a,&b,&c); 如果输入如下信息: 1234r1234.567 则scanf函数在接收数据时发现”r”类型不匹配,于是把”1234”转换成整型赋值给a,把”r”赋给变量b,最后把”1234.567”转换成实型数据赋给c。 ②根据格式项中指定的域宽分隔出数据项。如语句:scanf(“%2d%3f%4f”,&a,&b,&c); 如果输入如下信息: 123456789012345 则scanf函数在接收数据时根据域宽把12赋值给a,345赋值给b,6789赋值给c。 ③隐示分隔符。空格、跳格符(’\t’)、换行符(’\n’)都是C语言认定的数据分隔符。 ④显示分隔符。在scanf函数的两个格式说明项间有一个或多个普通字符,那么在输入数据时,在两个数据之间也必须以这一个或多个字符分隔。如语句:scanf(“a=%d,b=%f,c=%f”,&a,&b,&c); 巧用Frequency函数统计各分数段人数在组织学生考试之后,经常要进行一下成绩分析,其中各分数段人数是很重要的一项指标,它可以让任课老师了解学生对知识掌握的情况。在1690社区体验版中,提供了一个新的函数,叫Frequency,它可以让我们快捷地得到各分数段的人数。下面来看一个成绩表: 首先,我们要给出分段的界值。本例中,我们在分段一栏给出了分段的界值(59.9、69.9、79.9、89.9、100,如果成绩没有小数,也可以设置为59、69、79、89、100),即我们要统计小于等于59.9的人数、大于59.9且小于等于69.9的人数、……、大于89.9且小于等于100的人数。 其次,选中E2:E6区域,用于存放各分数段的为数,公式也就是在此输入。 然后,将光标定位到编辑栏,输入公 式“=FrequencyA2:A10,D2:D6”,按下组合键Ctrl+Shift+Enter,选中的区域中自动给出了各分数段的人数! 说明: 1、函数Frequency()是一个频数函数,统计各区间的频数,它有两个参数,用逗号分开。第一个参数是要进行统计的数据,如本例中的学生成绩,第二个参数是分组的依据,也就是分段的界值。 2、函数Frequency()返回的是一列数值,要用数组公式的形式输入,因此,在输入时,要选中输出结果的区域,在编辑栏输入完公式后按下组合键Ctrl+Shift+Enter,使之成为数组公式(公式会自动加上花括号,可不要手工输入花括号哟)。 3、上面的公式还可以改为{=FREQUENCYB2:B10, {59.9,69.9,79.9,89.9,100}},其中函数的第二个参数用常量数组来代替上面的界值区域,这样就可以将统计数据的左边一列改成合适的标题了。 #includeLinux下常用C语言字符串操作函数
C语言 中scanf详解
frequency函数的使用方法
scanf 和 sscanf
巧用Frequency函数统计各分数段人数
sscanf,sscanf_s及其相关用法