计量经济学实验五 多重共线性的检验与修正 完成版
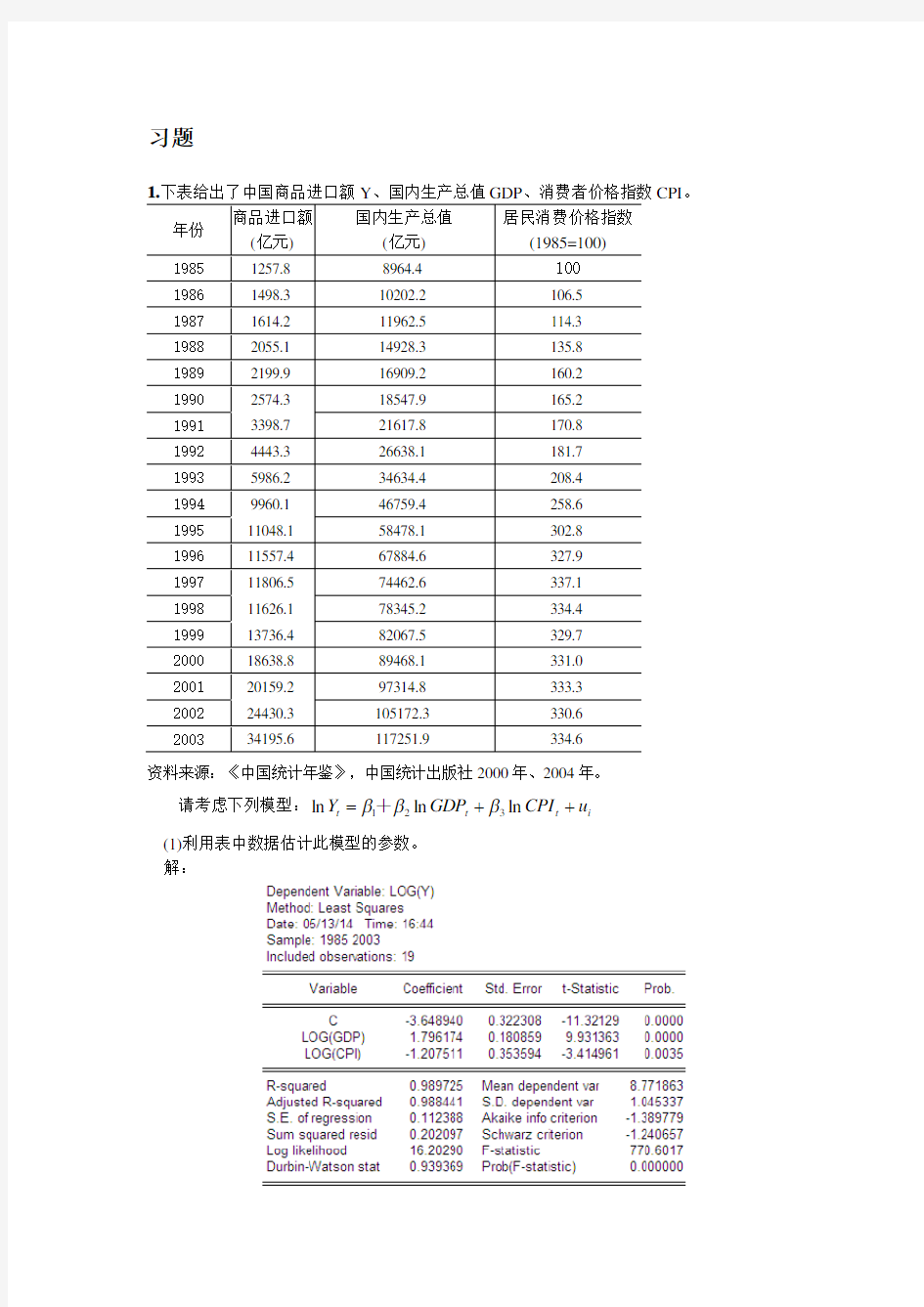

习题
CPI 。
资料来源:《中国统计年鉴》,中国统计出版社2000年、2004年。
请考虑下列模型:i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。 解:
ln 3.6489 1.796ln 1.2075ln t t t Y GDP CPI =--+
t= (-11.32) (9.93) (-3.415)
20.988770.6.0.1124R F S E ===
(2)你认为数据中有多重共线性吗?
多重共线性的检验 1)综合统计检验法
若 在OLS 法下:R 2与F 值较大,但t 检验值较小,则可能存在多重共线性。 2)简单相关系数检验
在Eviews 软件命令窗口中键入:COR GDP CPI
或在包含所有解释变量的数组窗口中点击View\Correlations ,其结果如图所示。由相关系数矩阵可以看出,解释变量之间的相关系数均为0.93以上,即解释变量之间是高度相关的。
GDP CPI GDP 1.000000 0.941303 CPI 0.941303
1.000000
3)判定系数检验法
当解释变量多余两个且变量之间呈现出较复杂的相关关系时,可以通过建立辅助回归模型来检验多重共线性。在Eviews 软件命令窗口中键入:
LS GDP C CPI
得到相应的回归结果,分析方程对应的F 值和T 值,来检验这些变量间是否相关以及相关联程度。
对应的回归结果如下图所示。
上述回归方程的F 检验值非常显著,方程回归系数的T 检验值表明:GDP 与CPI 的T 检验值较大,变量之间相关。
(3)进行以下回归:
i t t i t t i t t v CPI C C GDP v CPI B B Y v GDP A A Y 321221121ln ln ln ln ln ln ++=+=+=++
根据这些回归你能对数据中多重共线性的性质说些什么?
解:进行ls 检验,得到如下的三个结果:
ln 3.745 1.187ln t t Y GDP =-+
t= (-9.143) (30.6594)
20.981939.999.0.1434R F S E ===
ln 3.39 2.254ln t t Y CPI =-+
t= (-4.064) (14.63)
20.922213.93.0.2918R F S E ===
ln 0.1439
1.9273ln t t GDP CPI =+ t= (0.334) (24.21)
20.97586.337.0.15R F S E ===
数据中多重共线性的性质:单个解释变量也可以解释被解释变量,但是本题的两个解释变量之间的相关性较大,若在同一个线性方程中使用就会造成多重共线性。
(4)假设数据有多重共线性,但3
2??ββ和在5%水平上个别地显著,并且总的F 检验也是显著的。对这样的情形,我们是否应考虑共线性的问题?
解:应该考虑。此时3
2??ββ和并不反映各自与被解释变量之间的结构关系,而是反映它们对被解释变量的共同影响,所以各自的参数已经失去了应有的经济含义。所以不能根据变量
的参数显著及F 检验的显著来判断没有共线性的情况出现。如果模型的经济意义明显不合理,我们就要考虑是否有多重共线性的问题出现并予以相应的解决方法来现出多重共线性的影响。
2. 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费总量Y (万吨标准煤)、国内生产总值(亿元)X1(代表经济发展水平)、国民总收入(亿元)X2(代表收入水平)、工业增加值(亿元)X3、建筑业增加值(亿元)X4、交通运输邮电业增加值(亿元)X5(代表产业发展水平及产业结构)、人均生活电力消费 (千瓦小时)X6(代表人民生活水平提高)、能源加工转换效率(%)X7(代表能源转换技术)等在1985-2002年期间的统计数据,具体如下:
资料来源:《中国统计年鉴》2004、2000年版,中国统计出版社。
要求:
(1) 建立对数线性多元回归模型 解:
(2) 如果决定用表中全部变量作为解释变量,你预料会遇到多重共线性的问题吗?为什么? 解:存在多重共线性,ls 的结果显示R 2与F 值较大,但t 检验值较小,考虑多重共线性的存在。
(3) 如果有多重共线性,你准备怎样解决这个问题?明确你的假设并说明全部计算。 解:逐步回归:
2
ln 7.02ln 1 4.873ln 2 1.389ln 30.0477ln 40.0388ln 50.5187ln 60.443ln 7 2.6876
(1.2986)(0.9724)( 1.867)(0.2531)(0.2096)( 1.93)(0.57)(0.5732)0.98173.8y x x x x x x x t R F =--+--++=----==
1
从中可以看出,除lnx7与lnx1 lnx2 lnx3 lnx4 lnx5 lnx6的相关系数不超过0.93外,其余各变量两两之间的相关系数均超过了0.93,说明这些变量均高度相关。 2)、建立基本的一元线性方程:被解释变量对每一个解释变量进行初始回归(得到回归的结果如图所示),选取拟合优度最高的首先进入方程;根据经济理论分析和回归结果,可知中国能源消费总量Y 和国内生产总值(亿元)X1关联度最大,所以建立基本的一元回归方程:
1Y X αβε=++
Ls lny c lnx1:
Ls lny c lnx2:
Ls lny c lnx3:
Ls lny c lnx4:
Ls lny c lnx5:
Ls lny c lnx6:
1
2ln 9.1630.236ln (73.1914)(0.9607419.78...509)
04R DW Y X ===+2
2ln 9.1840.234ln (73.3964)(0.96014319.63..0.49)89R DW Y X ===+3
2ln 9.5680.2188ln (83.71)(0.95158.2..047.4557)R DW Y X ==+=4
2ln 10.090.2018ln (116.876)0.95(2178..0..50999
86)R D X W Y ==+=5
2ln 10.007380.215ln (112.490.9548..0.97)(18476.)1Y X R DW =+==6
2ln 10.380.3029ln (137.17)0.946..0.(16.7416
4)8Y X R DW =+==
Ls lny c lnx7:
3)、将其他解释变量分别导入上述初始回归模型,寻找最佳回归方程(如表所示):
7
2ln 4.7567 3.879ln (0.7788)(2.6835)0.31..0.4139
D Y R W X ===-+-
讨论:
第一步:在初始模型中加入lnx2,模型拟合优度提高,但变量未通过t 检验;
第二步:去掉lnx2,引入lnx3,模型拟合优度提高了,但是变量的显著性均未通过t 检验,
且参数的符号不合理(从直观上看,工业增加值越大,中国能源消费总量也应该越大,lnx3前的系数应该为正数);
第三步:去掉lnx3,引入lnx4,不止模型的拟合优度降低了,变量的显著性也未通过检验,
lnx3前的系数符号仍然不合理;
第四步:去掉lnx4,引入lnx5,模型的拟合优度稍微提高了一点,但是变量均未通过检验,
变量的符号仍然不合理;
第五步:去掉lnx5,引入lnx6,模型的拟合优度提高了,但是变量的显著性未通过t 检验; 第六步:去掉lnx6,引入lnx7,模型的拟合优度未明显提高,且变量的显著性均未通过t
检验。
第二步到第六步表明,lnx2到lnx7是多余的,且通过7个变量的相关系数表可以看出,这
些变量之间高度相关。因此,最终的中国能源消费总量的函数关系式为:
1
2ln 9.1630.236ln (73.1914)0.96(01974.79)8391.62
R F Y X ===+
3.经济理论指出,家庭消费指出Y 不仅取决于可支配收入1X ,还决定于个人财富2X ,即可设定如下回归模型:
i i i i X X Y μβββ++=22110+
试根据下表的资料进行回归分析,并说明估计的模型是否可靠,给出你的分析。
解:
(1)、首先画出Y 与两个变量的线性图:
(2)、进行ls 估计:
(3)、ls 的结果显示R 2与F 值较大,但t 检验值较小,考虑多重共线性的存在。 (4)、进行逐步回归以消除多重共线性:
1)、逐步回归:
cor x1 x2得到2
从中可以看出,两变量之间的相关系数超过了0.93,说明这两个变量高度相关。 2)、建立基本的一元线性方程:被解释变量对每一个解释变量进行初始回归(得到回归的结果如图所示),选取拟合优度最高的首先进入方程;根据经济理论分析和回归结果,可知中国能源消费总量Y 和国内生产总值(亿元)X1关联度最大,所以建立基本的一元回归方程:
1Y X αβε=++
Ls y c x1:
Ls y c x2:
3)、将其他解释变量分别导入上述初始回归模型,寻找最佳回归方程(如表所示):
2245.5158+0.568410.00582(3.5314)(0.7938)(-0.083)0.962 D.W.=2.7
y x x t R =-==1
2244.54550.509t=(3.8128)(14.24320.962.. 2.6)8
R DW Y X ===+22ln 238.99490.0499ln t=
(3.5448)(13.620.9587.. 2.35)9
R DW Y X ===+
讨论:在初始模型中加入lnx2,模型拟合优度未明显提高,且变量未通过t 检验;表明,x2是多余的,且通过2个变量的相关系数表可以看出,这些变量之间高度相关。因此,最终的中国能源消费总量的函数关系式为:
12244.54550.509t=(3.8128)(14.24320.962.. 2.6)
8
R DW Y X ===+
《计量经济学》第四章精选题及答案
第四章:多重共线性 二、简答题 1、导致多重共线性的原因有哪些? 2、多重共线性为什么会使得模型的预测功能失效? 3、如何利用辅回归模型来检验多重共线性? 4、判断以下说法正确、错误,还是不确定?并简要陈述你的理由。 (1)尽管存在完全的多重共线性,OLS 估计量还是最优线性无偏估计量(BLUE )。 (2)在高度多重共线性的情况下,要评价一个或者多个偏回归系数的个别显著性是不可能的。 (3)如果某一辅回归显示出较高的2 i R 值,则必然会存在高度的多重共线性。 (4)变量之间的相关系数较高是存在多重共线性的充分必要条件。 (5)如果回归的目的仅仅是为了预测,则变量之间存在多重共线性是无害的。 12233i i i Y X X βββ=++ 来对以上数据进行拟合回归。 (1) 我们能得到这3个估计量吗?并说明理由。 (2) 如果不能,那么我们能否估计得到这些参数的线性组合?可以的话,写出必要的计 算过程。 6、考虑以下模型: 23 1234i i i i i Y X X X ββββμ=++++ 由于2X 和3 X 是X 的函数,那么它们之间存在多重共线性。这种说法对吗?为什么? 7、在涉及时间序列数据的回归分析中,如果回归模型不仅含有解释变量的当前值,同时还含有它们的滞后值,我们把这类模型称为分布滞后模型(distributed-lag model )。我们考虑以下模型: 12313233i t t t t t Y X X X X βββββμ---=+++++ 其中Y ——消费,X ——收入,t ——时间。该模型表示当期的消费是其现期的收入及其滞后三期的收入的线性函数。 (1) 在这一类模型中是否会存在多重共线性?为什么? (2) 如果存在多重共线性的话,应该如何解决这个问题? 8、设想在模型 12233i i i i Y X X βββμ=+++ 中,2X 和3X 之间的相关系数23r 为零。如果我们做如下的回归:
计量经济学实验报告完整版
计量经济学实验报告集团标准化办公室:[VV986T-J682P28-JP266L8-68PNN]
3.3 3.3 经调查研究发现,家庭书刊消费受家庭收入及户主受教育年数的影响,表 3.6为对某地区部分家庭抽样调查得到的样本数据。 (1T )的多 元线性回归:123i i i i u Y X T βββ=+++ 利用样本数据估计模型的参数,对模型加以检验,分析所估计模型的经济意义和 作用。 步骤: 1.打开EViews6,点“File ”“New ”“Workfile ”。选择 “Unstructured/Unda=ted ”在Observations 后输入18,点击ok 。 2. 在命令行输入:DATA Y X T ,回车。将数据复制粘贴到Group 中的表格中。 3. 建立数据关系图为初步观察数据的关系,在命令行输入命令:sort Y ,从而实现数据Y 的递增排序。 4. 在数据表“group ”中点“view/graph/line ”,最后点击确定,出现序列Y 、X 、T 的线性图。 5. OLS 估计参数,点击主界面菜单Quick\Estimate Equation ,弹出对话框,如下图。在其中输入Y c X T ,点确定即可得到回归结果。
经济意义:家庭月平均收入每增加1元,家庭书刊消费将增加0.08645元。户主受教育年数每增加1年,家庭书刊消费平均将增加52.3703元。 作用:显示出各解释变量在其他解释变量不变的情况下,对被解释变量的影响情况。 (2)作家庭书刊消费(Y )对户主受教育年数(T )的一元回归,获得残差E1;再作家庭月平均收入(X )对户主受教育年数(T )的一元回归,并获得残差E2。 Y 对T 的一元回归: 步骤: 1. 打开EViews6,点“File ”“New ”“Workfile ”。选择 “Unstructured/undated”,在Observations 后输入样本容量个数:18。 2. 在命令行输入:DATA Y T ,回车,将数据复制粘贴到Group 中的表格中。 3. 作散点图在命令行输入命令:SCAT T Y 。 4. 在主菜单中点“Quick ”“Estimate Equation ”,在 Specification 中输入 Y C T ,点“确定”。 E1=resid X 对T 的一元回归: 步骤: 1. 打开EViews6,点“File ”“New ”“Workfile ”。选择 “Unstructured/undated”,在Observations 后输入样本容量个数:18。 2. 在命令行输入:DATA X T ,回车,将数据复制粘贴到Group 中的表格中。 3. 作散点图在命令行输入命令:SCAT T X 。 4. 在主菜单中点“Quick ”“Estimate Equation ”,在 Specification 中输入 X C T ,点“确定”。 E2=resid (3)作残差E1对残差E2的无截距项的回归:212i E E v α=+ ,估计其参数。 步骤1.打开EViews6,点“File ”“New ”“Workfile ”。选择 “Unstructured/Unda=ted ”在Observations 后输入18,点击ok 。 2. 在命令行输入:DATA E1 E2,回车。将数据复制粘贴到Group 中的表格 中。 3. 采用OLS 估计参数在主界面命令框栏中输入 ls E1 E2,然后回车,即可得到参数的估计结果。 由结果可知1=-6.3351+0.08645*2E E
计量经济学课后习题
计量经济学课后习题 1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。 计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 5.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 4.如何缩小置信区间?(P46) 由上式可以看出(1).增大样本容量。样本容量变大,可使样本参数估计量的标准差减小;同时,在同样置信水平下,n越大,t分布表中的临界值越小。(2)提高模型的拟合优度。因为样本参数估计量的标准差和残差平方和呈正比,模型的拟合优度越高,残差平方和应越小。 1.为什么计量经济学模型的理论方程中必须包含随机干扰项? (经典模型中产生随机误差的原因) 答:计量经济学模型考察的是具有因果关系的随机变量间的具体联系方式。由于是随机变量,意味着影响被解释变量的因素是复杂的,除了解释变量的影响外,还有其他无法在模型中独立列出的各种因素的影响。这样,理论模型中就必须使用一个称为随机干扰项的变量宋代表所有这些无法在模型中独立表示出来的影响因素,以保证模型在理论上的科学性。 3.一元线性回归模型的基本假设主要有哪些? 违背基本假设的模型是否不可以估计? 答:线性回归模型的基本假设有两大类:一类是关于随机干扰项的,包括零均值,同方差,不序列相关,满足正态分布等假设;另一类是关于解释变量的,主要有:解释变量是非随机的,若是
(完整版)多重共线性检验与修正.doc
问题: 选取粮食生产为例,由经济学理论和实际可以知道,影响粮食生产y 的因素有:农业化肥施 用量x1,粮食播种面积x2,成灾面积x3,农业机械总动力x4,农业劳动力x5,由此建立以下方程: y=β0+β1x1+β2x2+β3x3+β4x4+β5x5,相关数据如下: 解: 1、检验多重共线性 (1)在命令栏中输入: ls y c x1 x2 x3 x4 x5,则有; 可以看到,可决系数R2 和 F 值都 很高,二自变量x1 到 x5 的 t 值 均较小,并且x4 和 x5 的 t 检验 不显著,说明方程很可能存在多 重共线性。 (2)对自变量做相关性分析: 将x1—— x5 作为组打开, view —— covariance analysis—— correlation ,结果如下: 可以看到x1 和 x4 的相关系数 为 0.96,非常高,说明原模型 存在多重共线性
2、多重共线性的修正 (1)逐步回归法 第一步:首先确定一个基准的解释变量,即从 x1, x2, x3, x4, x5 中选择解释 y 的最好的一个建 立基准模型。分别用 x1, x2, x3, x4, x5 对 y 求回归,结果如下: 从上面 5 个输出结果可以知道,y 对 x1 的可决系数R2=0.89(最高),因此选择 第一个方程作为基准回归模型。即: Y = 30867.31062 + 4.576114592* x1 在基准模型的基础上,逐步将x2, x3 等加入到模型中, 加入 x2,结果:
拟合优度R2=0.961395 ,显著提高; 并且参数符号符合经济常识,且均显著。 所以将模型修改为: Y= -44174.52+ 4.576460*x1+ 0.672680*x2 再加入 x3,结果: 拟合优度R2=0.984174 ,显著提高; 并且参数符号符合经济常识(成灾面积越大,粮食产 量越低),且均显著。 所以将模型修改为: Y=-12559.35+5.271306*x1+0.417257*x2-0.212103*x3 再加入 x4,结果: 拟合优度R2=0.987158 ,虽然比上一次拟 合提高了; 但是变量x4 的系数为 -0.091271 ,符号不 符合经济常识(农业机械总动力越高, 粮食产量越高),并且 x4 的 t 检验不显著。 因此应该从模型中剔除x4。
计量经济学习题及答案
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。
所有计量经济学检验方法(全)
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R - ==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数)1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方 和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 )1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临 界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t 检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0 给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 统计量 )1(~1??? ----'--= k n t k n c S t ii i i i i i e e βββββ 在(1-α)的置信水平下βi 的置信区间是 ( , ) ββααββ i i t s t s i i -?+?2 2 ,其中,t α/2为显著性 水平为α、自由度为n-k-1的临界值。 五、异方差检验 1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程: i ji i X f e ε+=)(~2 或 i ji i X f e ε+=)(|~|
Eviews计量经济学三大检验(精品文档)_共14页
作业1 我们有1978-2007年我国财政收入,国内生产总值,财政支出和商品零售价格指数的年度数据。请用Eview 进行回归分析。 (1(根据回归结果分析模型的经济意义(包含模型的显著性,拟合优度,系数 的显著性,系数的经济意义) 建立模型,做OLS 估计,得结果图一,列表如下: 4 3283175.57898859.0003271.0558.6399X X X Y ++--=∧ ) 0636.20)(065848.0)(012559.0)(836.2132(SE ) 882456.2)(65061.13)(260476.0-)(000492.3-(t = 997046.02=R 996705.02=R 845 .2924=F 模型整体显著性较高(F 检验十分显著),可决系数2 R 和调整的可决系数较大,即样本回归方程对样本观测值拟合较好。t 检验显示2X 的系数不显著(p 值>0.05,不能拒绝β=0的原假设),3X 和4X 的系数显著(p 值<0.05,拒绝β=0的原假设)。 从模型的经济意义来看,财政支出、商品零售价格指数与财政收入成正相关,国内生产总值与财政收入成负相关,不符合客观经济规律,可能与模型变量的选取有关。考虑对模型进行对数变换,结果为图二。 4 32ln 128427.1ln 631090.0ln 448496.0946444.6ln X X X Y +++-=∧ ) 610249.0)(160929.0)(141418.0)(853146.2(SE
) 849127.1)(921549.3)(171412.3)(434662.2(t -= 987673.02=R 986251.02=R 3969 .694=F 对数变换后模型整体显著性较高(F 检验十分显著,p 值=0.00<<0.05), 可决系数2 R 和调整的可决系数略有下降,模型可解释98.63%的因变量变化。t 检验显示4ln X 的系数不显著(p 值=0.0758>0.05,不能拒绝β=0的原假设),2ln X 和3ln X 的系数显著(p 值<0.05,拒绝β=0的原假设)。 从模型的经济意义来看,国内生产总值、财政支出、商品零售价格指数与财政收入均成正相关,符合客观经济规律。在其他条件不变的情况下,国内生产总值每增加1%,财政收入平均增加0.448496%;在其他条件不变的情况下,财政支出每增加1%,财政收入平均增加0.631090%。 (2(分别用F 检验,Wald, LR, LM 检验检验: “财政收入和商品零售价格指数 的边际效应之合为1”是否成立。 (要求:清将必要的Eviews 输出结果放在作业中,并做必要的解释)Wald 检验: 在限制条件中输入c(3)+c(4)=1,得出的结果图三,t 检验F 检验卡方检验p 值均小于0.05,拒绝原假设,即认为财政支出与商品零售价格指数之和为一不成立。 F 检验: 受限条件为,回归模型为143=+ββ4433221X X X y ββββ+++=∧ 可得受限模型为) (4332214--X X X X y βββ++=∧ 对受限模型进行OLS 估计,结果见表4.可得,而无约束14599615=R RSS 模型的,又,代入F 检验统计量: 11076606=U RSS 4,30,1===k n q
2019年1计量经济学作业多重共线性p171.doc复习进程
2019年1计量经济学作业多重共线性 p171.d o c
计量经济学作业 ——多重共线性P171 8.下表是被解释变量Y,解释变量X1,X2,X3,X4的时间序列观测值: 时间序列观测值表 3 6.5 47.5 5.2 108 86 4 7.1 49.2 6.8 100 100 5 7.2 52.3 7.3 99 107 6 7.6 58.0 8. 7 99 111 7 8.0 61.3 10.2 101 114 8 9.0 62.3 14.1 97 116 9 9.0 64.7 17.1 93 119 10 9.3 66.8 21.3 102 121 (1)采用适当的方法检验多重共线性。 (2)多重共线性对参数估计值有何影响? (3)用Frisch法确定一个较好的回归模型。 解:(1)采用参数估计值的统计检验法检验多重共线性。 用OLS最小二乘法,估计被解释变量Y与解释变量X1,X2,X3,X4的样本方程,如下所示:
图1-1 在Eviews中建立样本回归模型 图1-2 样本回归模型数据表 输入被解释变量与解释变量: 图1-3 整体样本回归模型建立
用最小二乘法求得结果如下所示: 图1-4 Eviews的结果分析一元线性样本回归方程为: 1.拟合优度检验 由上表可知,样本可决系数为: R-squared=0.978915 修正样本可决系数为: Adjusted-squared=0.962046 即
计算结果表明,估计的样本回归方程较好的拟合了样本观测值。 2.F检验 提出检验的原假设为 对立假设为 由图1-4,得F统计量为 F-statistic=58.03254 对于给定的显著性水平α=0.05,查出分子自由度为4,分母自由度为5的F分布上侧分位数F0.05(4,5)=5.19。因为 F=58.03254>5.19,所以否定H0,总体回归方程显著。 3.t检验 提出检验的原假设为 由上表可知,t统计量为 β0的t-statistic=1.975329 β1的t-statistic=1.149646 β2的t-statistic=2.401806 β3的t-statistic=-0.662938
计量经济学考试重点整理
计量经济学考试重点整理 第一章: P1:什么是计量经济学?由哪三组组成? 定义:“用数学方法探讨经济学可以从好几个方面着手,但任何一个方面都不能和计量经济学混为一谈。计量经济学与经济统计学绝非一码事;它也不同于我们所说的一般经济理论,尽管经济理论大部分具有一定的数量特征;计量经济学也不应视为数学应用于经济学的同义语。经验表明,统计学、经济理论和数学这三者对于真正了解现代经济生活的数量关系来说,都是必要的,但本身并非是充分条件。三者结合起来,就是力量,这种结合便构成了计量经济学。” P9:理论模型的设计主要包含三部分工作,即选择变量,确定变量之间的数学关系,拟定模型中待估计参数的数值范围。 P12:常用的样本数据:时间序列,截面,虚变量数据 P13:样本数据的质量(4点) 完整性;准确性;可比性;一致性 P15-16:模型的检验(4个检验) 1、经济意义检验 2、统计检验 拟合优度检验 总体显著性检验 变量显著性检验 3、计量经济学检验 异方差性检验 序列相关性检验 共线性检验 4、模型预测检验 稳定性检验:扩大样本重新估计 预测性能检验:对样本外一点进行实际预测 P16计量经济学模型成功的三要素:理论、方法和数据。 P18-20:计量经济学模型的应用 1、结构分析 经济学中的结构分析是对经济现象中变量之间相互关系的研究。 结构分析所采用的主要方法是弹性分析、乘数分析与比较静力分析。 计量经济学模型的功能是揭示经济现象中变量之间的相互关系,即通过模型得到弹性、乘数等。 2、经济预测 计量经济学模型作为一类经济数学模型,是从用于经济预测,特别是短期预测而发展起来的。 计量经济学模型是以模拟历史、从已经发生的经济活动中找出变化规律为主要技术手段。 对于非稳定发展的经济过程,对于缺乏规范行为理论的经济活动,计量经济学模型预测功能失效。 模型理论方法的发展以适应预测的需要。
计量经济学名词解释
1、计量经济学 计量经济学是一门从数量上研究物质资料的生产、交换、分配、消费等经济关系和经济活动规律及其应用的科学。 2、数据质量 数据满足明确或隐含需求程度的指标 3、相关分析 主要研究变量之间的相互关联程度,用相关系数表示。包括简单相关和多重相关(复相关)。 4、回归分析(Regression Analysis) 研究一个变量(因变量)对于一个或多个其他变量(解释变量)的数量依存关系。其目的在于根据已知的解释变量的数值来估计或预测因变量的总体平均值。 5.内生变量 指由模型系统内决定的变量,取值在系统内决定 6、面板数据 时间序列数据和截面数据的混合 7.异方差: 总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差。如果这一假定不满足,则称线性回归模型存在异方差性。 8.自相关 自相关是在时间序列资料中按时间顺序排列的观测值之间的相关或在横截面资料中按空间顺序排列的观测值之间的相关 9.多重共线性 解释变量之间存在完全的线性关系或近似的线性关系。解释变量存在完全的线性关系叫完全多重共线;解释变量之间存在近似的线性关系叫不完全多重共线。 10.虚拟变量 虚拟变量:在建立模型时,有一些影响经济变量的因素无法定量描述 构造只取“0”或“1”的人工变量,通常称为虚拟变量,记为D 11.平稳序列 是指时间序列的统计规律不会随着时间的推移而发生变化。
12.伪回归 所谓“伪回归”,是指变量间本来不存在相依关系,但回归结果却得出存在相依关系的错误结论。 13.协整 所谓协整,是指多个非平稳变量的某种线性组合是平稳的 14.前定变量 所有的外生变量和滞后的内生变量。前定变量=外生变量+滞后内生变量+滞后外生变量 15.恰好识别 恰好识别:能够唯一地估计出结构参数值。 16.结构式模型 体现经济理论中经济变量之间的关系结构的联立方程模型,称为结构式模型17.过度识别 过度识别:结构参数的估计值具有多个确定值 18.自回归模型 自回归模型:指模型中的解释变量仅是X 的当期值与被解释变量Y 的若干期滞后值,它由于被解释变量的滞后期值对被解释变量现期做了回归,故叫做自回归模型。 利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型。 19.拟合优度2R:拟合优度检验:指检验模型对样本观测值的拟合程度 20.修正的拟合优度2R 二、.
(整理)多重共线性的检验与修正
附件二:实验报告格式(首页) 山东轻工业学院实验报告成绩 课程名称计量经济学指导教师实验日期 2013-5-25 院(系)商学院专业班级实验地点二机房 学生姓名学号同组人无 实验项目名称多重共线性的检验与修正 一、实验目的和要求 掌握Eviews软件的操作和多重共线性的检验与修正 二、实验原理 Eviews软件的操作和多重共线性的检验修正方法 三、主要仪器设备、试剂或材料 Eviews软件,计算机 四、实验方法与步骤 (1)准备工作:建立工作文件,并输入数据: CREATE EX-7-1 A 1974 1981; TATA Y X1 X2 X3 X4 X5 ; (2)OLS估计: LS Y C X1 X2 X3 X4 X5; (3)计算简单相关系数 COR X1 X2 X3 X4 X5 ; (4)多重共线性的解决 LS Y C X1; LS Y C X2; LS Y C X3; LS Y C X4; LS Y C X5; LS Y C X1 X3; LS Y C X1 X3 X2; LS Y C X1 X3 X4; LS Y C X1 X3 X5; 五、实验数据记录、处理及结果分析 (1)建立工作组,输入以下数据: 98.45 560.20 153.20 6.53 1.23 1.89 100.70 603.11 190.00 9.12 1.30 2.03 102.80 668.05 240.30 8.10 1.80 2.71 133.95 715.47 301.12 10.10 2.09 3.00 140.13 724.27 361.00 10.93 2.39 3.29
计量经济学实验报告 (3)
1.背景 经济增长是指一个国家生产商品和劳务能力的扩大。在实际核算中,常以一国生产的商品和劳务总量的增加来表示,即以国民生产总值(GDP)和国内生产总值的的增长来计算。 古典经济增长理论以社会财富的增长为中心,指出生产劳动是财富增长的源泉。现代经济增长理论认为知识、人力资本、技术进步是经济增长的主要因素。 从古典增长理论到新增长理论,都重视物质资本和劳动的贡献。物质资本是指经济系统运行中实际投入的资本数量.然而,由于资本服务流量难以测度,在这里我们用全社会固定资产投资总额(亿元)来衡量物质资本。中国拥有十三亿人口,为经济增长提供了丰富的劳动力资源。因此本文用总就业人数(万人)来衡量劳动力。居民消费需求也是经济增长的主要因素。 经济增长问题既受各国政府和居民的关注,也是经济学理论研究的一个重要方面。在1978—2008年的31年中,我国经济年均增长率高达9.6%,综合国力大大增强,居民收入水平与生活水平不断提高,居民的消费需求的数量和质量有了很大的提高。但是,我国目前仍然面临消费需求不足问题。 本文将以中国经济增长作为研究对象,选择时间序列数据的计量经济学模型方法,将中国国内生产总值与和其相关的经济变量联系起来,建立多元线性回归模型,研究我国中国经济增长变动趋势,以及重要的影响因素,并根据所得的结论提出相关的建议与意见。用计量经济学的方法进行数据的分析将得到更加具有说服力和更加具体的指标,可以更好的帮助我们进行预测与决策。因此,对我国经济增长的计量经济学研究是有意义同时也是很必要的。 2.模型的建立 2.1 假设模型
为了具体分析各要素对我国经济增长影响的大小,我们可以用国内生产总值(Y )这个经济指标作为研究对象;用总就业人员数(1X )衡量劳动力;用固定资产投资总额(2X )衡量资本投入:用价格指数(3X )去代表消费需求。运用这些数据进行回归分析。 这里的被解释变量是,Y :国内生产总值, 与Y-国内生产总值密切相关的经济因素作为模型可能的解释变量,共计3个,它们分别为: 1X 代表社会就业人数, 2X 代表固定资产投资, 3X 代表消费价格指数, μ代表随机干扰项。 模型的建立大致分为理论模型设置、参数估计、模型检验、模型修正几个步骤。如果模型符合实际经济理论并且通过各级检验,那么模型就可以作为最终模型,可以进行结构分析和经济预测。 国内生产总值 经济活动人口 全社会固定资产投资 居民消费价格指数 1992年 26,923.48 66,782.00 8,080.10 106.4 1993年 35,333.92 67,468.00 13,072.30 114.7 1994年 48,197.86 68,135.00 17,042.10 124.1 1995年 60,793.73 68,855.00 20,019.30 117.1 1996年 71,176.59 69,765.00 22,913.50 108.3 1997年 78,973.03 70,800.00 24,941.10 102.8 1998年 84,402.28 72,087.00 28,406.20 99.2 1999年 89,677.05 72,791.00 29,854.70 98.6 2000年 99,214.55 73,992.00 32,917.70 100.4 2001年 109,655.17 73,884.00 37,213.50 100.7 2002年 120,332.69 74,492.00 43,499.90 99.2 2003年 135,822.76 74,911.00 55,566.61 101.2 2004年 159,878.34 75,290.00 70,477.43 103.9 2005年 184,937.37 76,120.00 88,773.61 101.8 2006年 216,314.43 76,315.00 109,998.16 101.5
计量经济学检验汇总
最全计量经济学检验汇总 现代计量经济学的检验包括以下三个大类: §1.1 系数检验 一、Wald 检验——系数约束条件检验 Wald 检验没有把原假设定义的系数限制加入回归,通过估计这一无限制回归来计算检验统计量。Wald 统计量计算无约束估计量如何满足原假设下的约束。如果约束为真,无约束估计量应接近于满足约束条件。 考虑一个线性回归模型:εβ+=X y 和一个线性约束:0:0=-r R H β,R 是一个已知的k q ?阶矩阵,r 是q 维向量。Wald 统计量在0H 下服从渐近分布)(2q χ,可简写为: )())(()(112r Rb R X X R s r Rb W -'''-=-- 进一步假设误差ε独立同时服从正态分布,我们就有一确定的、有限的样本F-统计量 q W k T u u q u u u u F /) /(/)~~(=-''-'= u ~是约束回归的残差向量。F 统计量比较有约束和没有约束计算出的残差平方和。如果约束有效,这两个残差平方和差异很小,F 统计量值也应很小。EViews 显示2χ和F 统计量以及相应的p 值。 假设Cobb-Douglas 生产函数估计形式如下: εβα+++=K L A Q log log log (1) Q 为产出增加量,K 为资本投入,L 为劳动力投入。系数假设检验时,加入约束1=+βα。 为进行Wald 检验,选择View/Coefficient Tests/Wald-Coefficient Restrictions ,在编辑对话框中输入约束条件,多个系数约束条件用逗号隔开。约束条件应表示为含有估计参数和常数(不可以含有序列名)的方程,系数应表示为c(1),c(2)等等,除非在估计中已使用过一个不同的系数向量。 为检验规模报酬不变1=+βα的假设,在对话框中输入下列约束:c(2)+c(3)=1 二、遗漏变量检验 这一检验能给现有方程添加变量,而且询问添加的变量对解释因变量变动是否有显著作用。原假设 0H 是添加变量不显著。 选择View/Coefficient Tests/Omitted Variables —Likehood Ration ,在打开的对话框中,列出检验统计量名,用至少一个空格相互隔开。例如:原始回归为 LS log(q) c log(L) log(k) ,输入:K L ,EViews 将显示含有这两个附加解释变量的无约束回归结果,而且显示假定新变量系数为0的检验统计量。 三、冗余变量 冗余变量检验可以检验方程中一部分变量的统计显著性。更正式,可以确定方程中一部分变量系数是否为0,从而可以从方程中剔出去。只有以列出回归因子形式,而不是公式定义方程,检验才可以进行。 选择View/Coefficient Tests/Redundant Variable —likelihood Ratio ,在对话框中,输入每一检验的变量名,相互间至少用一空格隔开。例如:原始回归为: Ls log(Q) c log(L) log(K) K L ,如果输入K L ,EViews 显示去掉这两个回归因子的约束回归结果,以及检验原假设(这两个变量系数为0)的统计量。 §1.2 残差检验 一、相关图和Q —统计量 在方程对象菜单中,选择View/Residual Tests/Correlogram-Q-Statistics ,将显示直到定义滞后阶数的残差自相关性和偏自相关图和Q-统计量。在滞后定义对话框中,定义计算相关图时所使用的滞后数。如果残差不存在序列相关,在各阶滞后的自相关和偏自相关值都接近于零。所有的Q -统计量不显著,并且有大
计量经济学实验四、五
实验四 序列相关的检验与修正 实验目的 1、理解序列相关的含义后果、 2、学会序列相关的检验与消除方法 实验内容 利用下表资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 表3 我国城乡居民储蓄存款与GDP 统计资料(1978年=100) 一、模型的估计 0、准备工作。建立工作文件,并输入数据。 1、相关图分析 SCAT X Y 相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数等不同形式,进而加以比较分析。 2、估计模型,利用LS 命令分别建立以下模型 ⑴线性模型: LS Y C X x y 5075.9284.14984?+-=
=t (-6.706) (13.862) 2R =0.9100 F =192.145 S.E =5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX x y ln 9588.20753.8?ln +-= =t (-31.604) (64.189) 2R =0.9954 F =4120.223 S.E =0.1221 3、选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这种函数形式设置是不当的。而且,这个模型的拟合优度也较双对数模型低,所以又可舍弃线性模型。双对数模型具有很高的拟合优度,因而初步选定回归模型为双对数回归模型。 二、模型自相关的检验 1.图示法 其一,残差序列e t 的变动趋势图。菜单:Quick→Graph→line ,在对话框中输入resid ;或者用命令操作,直接在命令行输入:line X 。 其二,作e t-1和e t 之间的散点图。菜单:Quick→Graph→Scatter ,在对话框中输入resid(-1) resid ;或者用命令操作,直接在命令行输入:scat resid(-1) resid 。 2.DW 检验 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22,U d =1.42,而0<0.7062=DW 计量经济学实验报告成绩 课程名称计量经济学指导教师苏卫东实验日期 2014-6-24 院(系)财政与金融学院专业班级金融二专实验地点实验楼八机房 学生姓名单一芳学号 201212041018 同组人无 实验项目名称多重共线性的检验与修正 一、实验目的和要求 1、理解多重共线性的含义与后果 2、掌握Eviews软件的操作和多重共线性的检验与修正 二、实验原理 Eviews软件的操作和多重共线性的检验修正方法 三、主要仪器设备、试剂或材料 Eviews软件,计算机 四、实验方法与步骤 1、准备工作:建立工作文件,并输入数据 CREATE A 1974 1981; DATA Y X1 X2 X3 X4 X5 2、OLS估计: LS Y C X1 X2 X3 X4 X5; 3、计算简单相关系数 COR X1 X2 X3 X4 X5 4、多重共线性的解决 LS Y C X1; LS Y C X2; LS Y C X3; LS Y C X4; LS Y C X5; LS Y C X1 X3; LS Y C X1 X3 X2; LS Y C X1 X3 X4; LS Y C X1 X3 X5 五、实验数据记录、处理及结果分析 1、建立工作组,输入以下数据: obs Y X1 X2 X3 X4 X5 1974 98.45 560.2 153.2 6.53 1.23 1.89 1975 100.7 603.11 190 9.12 1.3 2.03 1976 102.8 668.05 240.3 8.1 1.8 2.71 1977 133.95 715.47 301.12 10.1 2.09 3 1978 140.13 724.27 361 10.93 2.39 3.29 1979 143.11 736.13 420 11.85 3.9 5.24 1980 146.15 748.91 497.16 12.28 5.13 6.83 1981 144.6 760.32 501 13.5 5.47 8.36 1982 148.94 774.92 529.2 15.29 6.09 10.07 1983 158.55 785.3 552.72 18.1 7.97 12.57 1984 169.68 795.5 771.16 19.61 10.18 15.12 1985 162.14 804.8 811.8 17.22 11.79 18.25 1986 170.09 814.94 988.43 18.6 11.54 20.59 1987 178.69 828.73 1094.65 23.53 11.68 23.37 2、OLS估计 LS Y C X1 X2 X3 X4 X5 Dependent Variable: Y Method: Least Squares Date: 06/24/14 Time: 18:45 Sample: 1974 1987 Included observations: 14 Variable Coefficient Std. Error t-Statistic Prob. C -3.650950 30.00144 -0.121692 0.9061 X1 0.125752 0.059087 2.128275 0.0660 X2 0.072656 0.037445 1.940317 0.0883 X3 2.681426 1.258639 2.130418 0.0658 X4 3.405866 2.444896 1.393052 0.2011 X5 -4.430561 2.194164 -2.019248 0.0781 R-squared 0.970397 Mean dependent var 142.7129 《计量经济学》实验报告一,数据 二,理论模型的设计 解释变量:可支配收入X 被解释变量:消费性支出Y 软件操作: (1)X与Y散点图 从散点图可以粗略的看出,随着可支配收入的增加,消费性支出也在增加,大致呈线性关系。因此,建立一元线性回归模型: 01i i i Y X ββμ=++ (2)对模型做OLS 估计 OLS 估计结果为 272.36350.7551Y X ∧ =+ 011.705732.3869t t == 20.9831.. 1.30171048.912R DW F === 三,模型检验 从回归估计结果看,模型拟合较好,可决系数为0.98,表明家庭人均年可消费性支出变化的98.31%可由支配性收入的变化来解释。 t 检验:在5%的显著性水平下1β不显著为0,表明可支配收入增加1个单位,消费性支出平均增加0.7551单位。 1,预测 现已知2018年人均年可支配收入为20000元,预测消费支出预测值为 0272.36350.75512000015374.3635Y =+?= E(X)=6222.209,Var(X)=1994.033 则在95%的置信度下,E( Y)的预测区间为(874.28,16041.68) 2,异方差性检验 对于经济发达地区和经济落后地区,消费支出的决定因素不一定相同甚至差异很大。如经济越落后储蓄率越高,可能出现异方差性问题。 G-Q检验 对样本进行处理,X按从大到小排序,去掉中间4个,分为两组数据, 128 n n ==分别回归 1615472.0RSS = 2126528. 3R S S = 于是的F 统计量: ()() 12811 4.86811RSS F RSS --==-- 在5%的想著想水平下,0.050.05(6,6) 4.28,(6,6)F F F =>,即拒绝无异方差性假设,说明模型存在异方差性。 时间 地点 实验题目 多重共线性的诊断与修正 一、实验目的与要求: 要求目的:1、对多元线性回归模型的多重共线性的诊断; 2、对多元线性回归模型的多重共线性的修正。 二、实验内容 根据书上第四章引子“农业的发展反而会减少财政收入”,1978-2007年的财政收入,农业增加值,工业增加值,建筑业增加值等数据,运用EV 软件,做回归分析,判断是否存在多重共线性,以及修正。 三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等) (一)模型设定及其估计 经分析,影响财政收入的主要因素,除了农业增加值,工业增加值,建筑业增加值以外,还可能与总人口等因素有关。研究“农业的发展反而会减少财政收入”这个问题。 设定如下形式的计量经济模型:i Y =1β+2β2X +3β3X +4β4X +5β5X +6β6X +7β7X +i μ 其中,i Y 为财政收入CS/亿元;2X 为农业增加值NZ/亿元;3X 为工业增加值GZ/亿元;4X 为建筑业增加值JZZ/亿元;5X 为总人口TPOP/万人;6X 为最终消费CUM/亿元;7X 为受灾面积SZM/千公顷。 图1: 1978~2007年财政收入及其影响因素数据 年份 财政收入CS/亿元 农业增加值NZ/亿元 工业增加值GZ/亿元 建筑业 增加值 JZZ/亿 元 总人口 TPOP/万 人 最终消费 CUM/亿元 受灾面 积SZM/ 千公顷 1978 1132.3 1027.5 1607 138.2 96259 2239.1 50790 1979 1146.4 1270.2 1769.7 143.8 97542 2633.7 39370 1980 1159.9 1371.6 1996.5 195.5 98705 3007.9 44526 1981 1175.8 1559.5 2048.4 207.1 100072 3361.5 39790 1982 1212.3 1777.4 2162.3 220.7 101654 3714.8 33130 1983 1367 1978.4 2375.6 270.6 103008 4126.4 34710 1984 1642.9 2316.1 2789 316.7 104357 4846.3 31890 1985 2004.8 2564.4 3448.7 417.9 105851 5986.3 44365 1986 2122 2788.7 3967 525.7 107507 6821.8 47140 1987 2199.4 3233 4585.8 665.8 109300 7804.6 42090 1988 2357.2 3865.4 5777.2 810 111026 9839.5 50870 1989 2664.9 4265.9 6484 794 112704 11164.2 46991 1990 2937.1 5062 6858 859.4 114333 12090.5 38474 1991 3149.48 5342.2 8087.1 1015.1 115823 14091.9 55472 1992 3483.37 5866.6 10284.5 1415 117171 17203.3 51333 1993 4348.95 6963.8 14188 2266.5 118517 21899.9 48829 1994 5218.1 9572.7 19480.7 2964.7 119850 29242.2 55043多重共线性的检验与修正
计量经济学实验报告
EViews计量经济学实验报告-多重共线性的诊断与修正