误差修正模型

协整与误差修正模型
在处理时间序列数据时,我们还得考虑序列的平稳性。如果一个时间序列的均值或自协方差函数随时间而改变,那么该序列就是非平稳的。对于非平稳的数据,采用传统的估计方法,可能会导致错误的推断,即伪回归。若非平稳序列经过一阶差分变为平稳序列,那么该序列就为一阶单整序列。对一组非平稳但具有同阶的序列而言,若它们的线性组合为平稳序列,则称该组合序列具有协整关系。对具有协整关系的序列,我们算出误差修正项,并将误差修正项的滞后一期看做一个解释变量,连同其他反映短期波动关系的变量一起。建立误差修正模型。
建立误差修正模型的步骤如下:首先,对单个序列进行单根检验,进行单根检验有两种:ADF (Augument Dickey-Fuller )和DF(Dickey-Fuller)检验法。若序列都是同阶单整,我们就可以对其进行协整分析。在此我们只介绍单个方程的检验方法。对于多向量的检验参见Johensen 协整检验。我们可以先求出误差项,再建立误差修正模型,也可以先求出向量误差修正模型,然后算出误差修正项。补充一点的是,误差修正模型反映的是变量短期的相互关系,而误差修正项反映出变量长期的关系。下面我们给出案例分析。
案例分析
在此,我们考虑从1978年到2002年城镇居民的人均可支配收入income 与人均消费水平consume 的关系,数据来自于《中国统计年鉴》,如表8.1所示。根据相对收入假设理论,在一定时期,人们的当期的消费水平不仅与当期的可支配收入、而且受前期的消费水平的影响,具有一定的消费惯性,这就是消费的棘轮效应。从这个理论出发,我们可以建立如下(8.1)式的模型。同时根据生命周期假设理论,消费者的消费不仅与当期收入有关,同时也受过去各项的收入以及对将来预期收入的限制和影响。从我们下面的数据分析中,我们可以把相对收入假设理论与生命周期假设理论联系起来,推出如下的结果:当期的消费水平不仅与当期的可支配收入有关,而且还与前期的可支配收入、前两期的消费水平有关。在此先对人均可支配收入和人均消费水平取对数,同时给出如下的模型
t t t l i n c o m e l c o n s u m e l c o n s u m e 2110?+?+?=-
t=1,2,…,n (8.1) 如果当期的人均消费水平与当期的人均可支配收入及前期的人均消费水平均为一阶单
整序列,而它们的线性组合为平稳序列,那么我们可以求出误差修正序列,并建立误差修正模型,如下:
t ecm lconsume lincome lconsume t t t t 4131210βββββ++?+?+=?-- t=1,2,…,n (8.2)
t ecm = 12110--?-?-?-t t t lincome lconsume lconsume t=1,2,…,n (8.3)
从(8.2)式我们可以推出如下的方程:
t
lincome lincome lconsume lconsume lconsume t t t t t 4030123222131131)()()1(ββββββββββ+?-+?--+?--++=---(8.4)
在(8.2)中lc o n s u m e ?、 lincome ?分别为变量对数滞后一期的值,)1(-ecm 为误差修正项,如(8.3)式所示。(8.2)式为含有常数项和趋势项的形式,我们省略了只含趋势项
或常数项及二项均无的形式。
表8.1
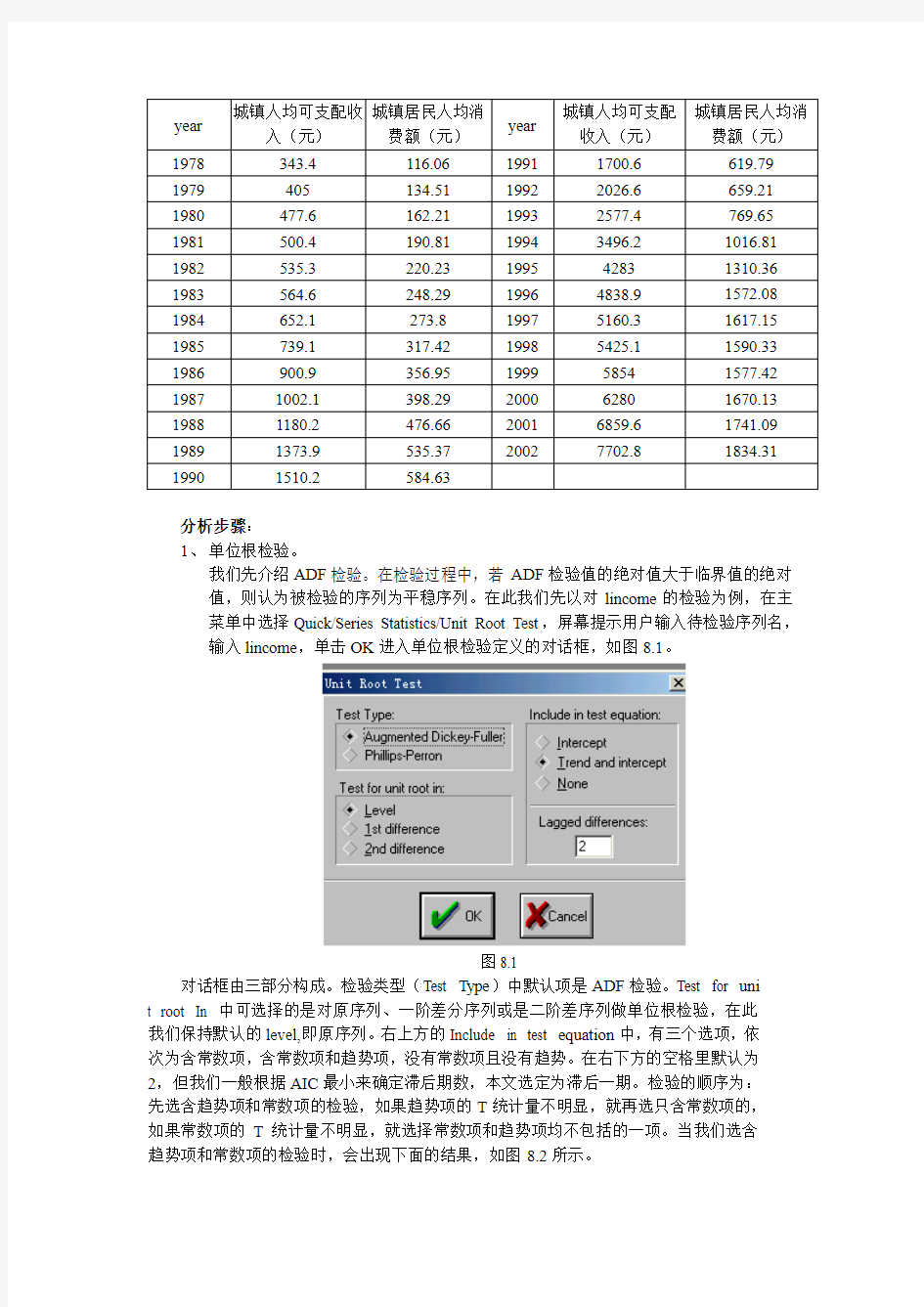
分析步骤:
1、单位根检验。
我们先介绍ADF检验。在检验过程中,若ADF检验值的绝对值大于临界值的绝对
值,则认为被检验的序列为平稳序列。在此我们先以对lincome的检验为例,在主
菜单中选择Quick/Series Statistics/Unit Root Test,屏幕提示用户输入待检验序列名,输入lincome,单击OK进入单位根检验定义的对话框,如图8.1。
图8.1
对话框由三部分构成。检验类型(Test Type)中默认项是ADF检验。Test for uni
t root In 中可选择的是对原序列、一阶差分序列或是二阶差序列做单位根检验,在此
我们保持默认的level,即原序列。右上方的Include in test equation中,有三个选项,依
次为含常数项,含常数项和趋势项,没有常数项且没有趋势。在右下方的空格里默认为
2,但我们一般根据AIC最小来确定滞后期数,本文选定为滞后一期。检验的顺序为:
先选含趋势项和常数项的检验,如果趋势项的T统计量不明显,就再选只含常数项的,
如果常数项的T统计量不明显,就选择常数项和趋势项均不包括的一项。当我们选含
趋势项和常数项的检验时,会出现下面的结果,如图8.2所示。
图8.2
在检验的结果输出窗口中,左上方为ADF检验值,右上方为1%、5%和10%的显著水平下的临界值,从图8.1中可以看出ADF统计的检验值为-3.117,其绝对值小于10%的显著水平的临界值–3.2856的绝对值。同时趋势值的T统计来看,在5%的水平下显著。注意,这里的T统计量不同于我们在做最小二乘时用的T统计值。这些T统计检验的临界值在Fuller(1976)中给出.从上面的分析我们可以认为该序列为非平稳的序列,且该序列有趋势项和常数项。在下文中我们会进行一步介绍只含常数项的和常数项与趋势项均不包括的ADF检验的过程。
在上面分析的基础上,我们回到图8.1的窗口,检验lincome差分一阶的平稳性。在图8.1中的Test for unit root In中选差分一阶,同时在Include in test equation 中选取含趋势项和常数项这一项,我们同样根据AIC和SC最小来选择滞后两期。此时会出现如下图8.3的结果:
图8.3
从上图中可以看出ADF的绝对值小于5%水平下的临界值的绝对值,大于10%的检验值的绝对值。但此时趋势项的T检验值不明显。所以我们回到图8.1的窗口,
在Include in test equation中选取含常数项这一项。其结果如下图8.4所示,结果显示ADF的绝对值为3.4546大于5%水平下的临界值的绝对值,此时常数项的T检验值为3.34572,大于在显著水平为5%水平下的T临界值为2.61,所以常数项T检验值很明显。我们认为lincome序列差分一阶后为平稳的。值得注意的是,我们在此选择10%为临界值来判断非平稳的情况,而选择5%的临界值来判断平稳的情况,也就是,当ADF检验值的绝对值大于5%水平下的临界的绝对值。
图8.4
同时我们也可以用命令来执行单位根检验,格式如下:
uroot(lags,options,h) series_name
其中,lags指式中滞后的阶数,options中可以选三个c、t和n,其中c代表含趋势项,t代表含趋势项和常数项,n代表不含趋势项也不含常数项。H表示采用pp检验,series_name即为序列名。
DF检验相当于ADF检验中的不含趋势项的常数项的情况。我们在此不再叙述。
2、协整检验。
在上面的例子中我们分析出城镇居民可支配收入为一阶单整序列,同时我们采用同样的分析方法,可知城镇居民的人均消费支出也为一阶单整。由此,可以对序列进行协整估计。
用变量lgdp对变量lm2进行普通最小二乘回归,在主窗口命令行中输入:
ls lconsume c lconsume(-1) lincome
回车得到回归模型的估计结果,如图8.5所示。
图8.5
此时系统会自动生成残差,我们令残差为ecm,命令如下:
ecm=resid
对残差项进行单位根检验,滞后期为1,结果如表8.2所示,从表中可以看出,残差序列为平稳序列,该协整关系成立。
表8.2
3、误差修正模型。
上面的分析可以证明序列lconsume、lincome及lconsme(-1)之间存在协整关系,故可以建立ecm(误差修正模型)。先分别对序列lconsume、lincome及lconsme(-1)进行一阶差分,然后对误差修正模型进行估计。在主窗口命令行中输入:ls d(lconsume) c d(lincome) d(lconsume(-1)) ecm(-1)
此时的常数项系数不明显,我们去掉常数项后再进行回归,结果如下图8.6所示
图8.6
从上式可以看出上式中的T检验值均显著,误差修正项的系数为-0.252,这说明长期均衡对短期波动的影响不大。
下面我们短期会给出另一种估计方式。我们可以直接进行估计,命令为:
ls lconsume c lincome lconsume(-1) lconsume(-2) lincome(-1)
结果如下图8.7所示:
图8.7
比较两种估计方法的结果,可知,第二种估计方法的拟合优度要好于第一种的拟合优度。但第一种方法似乎比第二种方法更能说明经济问题,因为没有差分的模型表现的是长期的均衡关系,而差分后的方程则反映了短期波动的决定情况,其中的误差项反映了长期均衡对短期波动的影响。注意,我们同样可以根据前面的(8.1)、(8.2)及(8.3)式,把第一种方法通过代数变换,转换成第二种形式,在此我们省略了变换过程。
误差修正模型实例(精)
一、误差修正模型的构造 对于yt的(1,1阶自回归分布滞后模型: 在模型两端同时减yt-1,在模型右端,得: 其中,,,。 记(5-5) 则(5-6) 称模型(5-6)为“误差修正模型”,简称ECM。 二、误差修正模型的含义 如果yt ~ I(1,x t ~ I(1,则模型(5-6)左端,右端,所以只有当yt和x t协整、即yt和x t之间存在长期均衡关系时,式(5-5)中的ecm~I(0,模型(5-6)两端的平稳性才会相同。 当yt和x t协整时,设协整回归方程为:
它反映了yt与x t的长期均衡关系,所以称式(5-5)中的ecm t-1是前一期的“非均衡误差”,称误差修正模型(5-6) 中的是误差修正项,是 修正系数,由于通常 ,这样;当ecm t-1 >0时(即出现正误差),误差修正项< 0,而ecm t-1 < 0时(即出现负误差), > 0,两者的方向恰好相反,所以,误差修正是一个反向 调整过程(负反馈机制)。 误差修正模型有以下几个明确的含义: 1.均衡的偏差调整机制 2.协整与长期均衡的关系 3.经济变量的长期与短期变化模型 长期趋势模型: 短期波动模型: 三、误差修正模型的估计 建立ECM的具体步骤为: 1.检验被解释变量y与解释变量x(可以是多个变量)之间的协整性; 2.如果y与x存在协整关系,估计协整回归方程,计算残差序列e t:
3.将e t-1作为一个解释变量,估计误差修正模型: 说明: (1)第1步协整检验中,如果残差是确定趋势过程,可以在第2步的协整回归方程中加入趋势变量; (2)第2步可以估计动态自回归分布滞后模型: 此时,长期参数为: 协整回归方程和残差也相应取成: , (3)第2步估计出ECM之后,可以检验模型的残差是否存在长期趋势和自相关性。如果存在长期趋势,则在ECM中加入趋势变量。如果存在自相关性,则在ECM的右端加入 误差修正项的滞后期一般也要作相应 调整。 如取成以下形式:
误差修正模型
第二节 误差修正模型(Error Correction Model ,ECM ) 一、误差修正模型的构造 对于y t 的(1,1)阶自回归分布滞后模型: t t t t t y x x y εβββα++++=--12110 在模型两端同时减y t-1,在模型右端10-±t x β,得: t t t t t t t t t t t t t x y x x y x y x x y εααγβεββββαββεββββα+--+?=+---+--+?=+-+++?+=?------)(]) 1()1()[1()1()(1101012120120121100 其中,12-=βγ,)1/()(200ββαα-+=,)1/(211ββα-=。 记 11011-----=t t t x y ecm αα (5-5) 则 t t t t ecm x y εγβ++?=?-10 (5-6) 称模型(5-6)为“误差修正模型”,简称ECM 。 二、误差修正模型的含义 如果y t ~ I(1),x t ~ I(1),则模型(5-6)左端)0(~I y t ?,右端)0(~I x t ?,所以只有当y t 和x t 协整、即y t 和x t 之间存在长期均衡关系时,式(5-5)中的ecm~I(0),模型(5-6)两端的平稳性才会相同。 当y t 和x t 协整时,设协整回归方程为: t t t x y εαα++=10 它反映了y t 与x t 的长期均衡关系,所以称式(5-5)中的ecm t -1
是前一期的“非均衡误差”,称误差修正模型(5-6)中的1-t ecm γ是误差修正项,12-=βγ是修正系数,由于通常1||2<β,这样 0<γ; 当ecm t -1 >0时(即出现正误差),误差修正项1-t ecm γ< 0,而ecm t -1 < 0时(即出现负误差),1-t ecm γ> 0,两者的方向恰 好相反,所以,误差修正是一个反向调整过程(负反馈机制)。 误差修正模型有以下几个明确的含义: 1.均衡的偏差调整机制 2.协整与长期均衡的关系 3.经济变量的长期与短期变化模型 长期趋势模型: t t t x y εαα++=10 短期波动模型: t t t t ecm x y εγβ++?=?-10 三、误差修正模型的估计 建立ECM 的具体步骤为: 1.检验被解释变量y 与解释变量x (可以是多个变量)之间的协整性; 2.如果y 与x 存在协整关系,估计协整回归方程,计算残差序列e t : t t t x y εβα++=0 t t t x y e 0??βα--= 3.将e t-1作为一个解释变量,估计误差修正模型: t t t t v e x y ++?=?-10γβ 说明: (1)第1步协整检验中,如果残差是确定趋势过程,可以在第2步的协整回归方程中加入趋势变量; (2)第2步可以估计动态自回归分布滞后模型: t i t i i t i t y x y εβαα∑∑+++=-- 此时,长期参数为: ∑∑-=)1(i i βαθ 协整回归方程和残差也相应取成:
协整检验及误差修正模型实验指导
协整检验及误差修正模型实验指导 一、实验目的 理解经济时间序列之间的理论关系,并学会用统计方法验证他们之间的关系。学会验证时间序列存在的不平稳性,掌握ADF检验平稳性的方法。认识不平稳的序列容易导致虚假回归问题,掌握为解决虚假回归问题引出的协整检验,协整的概念和具体的协整检验过程。协整描述了变量之间的长期关系,为了进一步研究变量之间的短期均衡是否存在,掌握误差纠正模型方法。 二、实验内容及要求 1、实验内容 用Eviews来分析1982年到2002年中国居民实际消费支出的对数序列和中国居民实际可支配收入的对数序列{}之间的关系。内容包括: (1)对两个对数序列分别进行ADF平稳性检验; (2)进行二者之间的协整关系检验; (3)若存在协整关系,建立误差修正模型ECM。 2、实验要求 (1)在认真理解本章内容的基础上,通过实验掌握ADF检验平稳性的方法; (2)掌握具体的协整检验过程,以及误差修正模型的建立方法; (3)能对宏观经济变量间的长期均衡关系进行分析。 三、实验指导 1、对两个数据序列分别进行平稳性检验: (1)做时序图看二者的平稳性 在workfile中按住ctrl选择要检验的二变量,击右键,选择open—as group,此时他们可以作为一个数据组被打开。点击“View”―“graph”—“line”,得到两个序列的时序图。 给出两个序列的时序图。 从上图可以看出两个序列都呈上升趋势,显然不平稳,但二者有大致相同的增长和变化趋势,说明二者可能存在协整关系。但若要证实二者有协整关系,必须先看二者的单整阶数,如果都是一阶单整,则可能存在协整关系,若单整地阶数不相同,则需采取差分的方式,
协整检验及误差修正模型实验指导
实验八 协整检验及误差修正模型实验指导 一、实验目的 理解经济时间序列之间的理论关系,并学会用统计方法验证他们之间的关系。学会验证时间序列存在的不平稳性,掌握ADF 检验平稳性的方法。认识不平稳的序列容易导致虚假回归问题,掌握为解决虚假回归问题引出的协整检验,协整的概念和具体的协整检验过程。协整描述了变量之间的长期关系,为了进一步研究变量之间的短期均衡是否存在,掌握误差纠正模型方法。 二、基本概念 设随机向量t X 中所含分量均为d 阶单整,记为t X I(d ):。如果存在一个非零向量β,使得随机向量()~t t Y X I d b =-β,0b >,则称随机向量t X 具有d ,b 阶协整关系,记为t X CI(d ,b ):,向量β被称为协整向量。特别地,t y 和t x 为随机变量,并且t y ,~(1)t x I ,当01()~I(0)t t t y x εββ=-+,即t y 和t x 的线性组合与I(0)变量有相同的统计性质,则称t y 和t x 是协整的,()01,ββ称为协整系数。更一般地,如果一些I(1)变量的线性组合是I(0),那么我们就称这些变量是协整的。 三、实验内容及要求 1、实验内容 用Eviews5.1来分析1978年到2002年中国农村居民对数生活费支出序列{ln }t y 和对数人均纯收入{ln t x }序列之间的关系。内容包括: (1)对两个对数序列分别进行ADF 平稳性检验; (2)进行二者之间的协整关系检验; (3)若存在协整关系,建立误差纠正模型ECM 。 2、实验要求 (1)在认真理解本章内容的基础上,通过实验掌握ADF 检验平稳性的方法; (2)掌握具体的协整检验过程,以及误差纠正模型的建立方法; (3)能对宏观经济变量间的长期均衡关系进行分析。 四、实验指导 1、对两个数据序列分别进行平稳性检验: (1)做时序图看二者的平稳性 首先按前面介绍的方法导入数据,在workfile 中按住ctrl 选择要检验的二变量,击右键,选择open —as group ,此时他们可以作为一个数据组被打开。 点击“View ”―“graph ”—“line ”,对两个序列做时序图见图8-1,两个序列都呈上升趋势,显然不平稳,但二者有大致相同的增长和变化趋势,说明二者可能存在协整关系。但若要证实二者有协整关系,必须先看二者的单整阶数,如果都是一阶单整,则可能存在协整关系,若单整地阶数不相同,则需采取差分的方式,将他们变成一阶单整序列。 图8-1 ln t x 和ln t y 时序图
第5章 动态回归与误差修正模型(案例)汇总
例:(file: break2)东北、华北、华东、华中21省市1993和1998年耕地面积(land ,百万公顷)和农业产值(Y , 百亿元)数据见图(已取对数)。用圆圈表示的观测点为1993年数据,用三角表示的观测点为1998年数据。大体看各省市1998年耕地面积比1993年耕地面积略有减少,产值却都有增加。以1993和1998年数据为两个子样本,以42个数据为总样本,求得残差平方和见下表 -10 12 3 -2 -1 1 2 3 LOG(LAND) LOG(Y93)LOG(Y98) -10 1 2 3 -2 -1 1 2 3 LOG(LAND) LOG(Y93)LOG(Y98) 样本容量 残差平方和 相应自由度 回归系数 1 T = 42 SSE T = 14.26 T - k = 40 2 n 1= 21 SSE 1 = 4.37 n 1 - k = 19 α1 3 n 2= 21 SSE 2 = 3.76 n 2 - k = 19 β1 注:三次回归的模型形式Lnout t = β0 +β1 Lnland t + u t 。 因为, F = ) 2/()(/)]([2121k T SSE SSE k SSE SSE SSE T -++-= 38 /)76.337.4(2 /)]76.337.4(26.14[++-= 14.33 > F (1, 40) = 7.31
所以两个年度21省市的农业生产发生了很大变化。
案例1:开滦煤矿利润影响因素的实证分析(1903-1940,动态分布滞后模型,file:LH1) (发表在《学术论坛》,2003.1, p. 88-90) 1000 2000300040005000600005 10 15 20 25 30 35 40 销煤量 x1 图 1 开滦煤矿销煤量变化曲线(x 1, 1903-1940) 2 4681012141605 10 15 20 25 30 35 40 吨煤售价 X2 图2 开滦煤矿吨煤售价变化曲线(x 2, 1903-1940)
ECM误差修正模型
协整与误差修正模型 在处理时间序列数据时,我们还得考虑序列的平稳性。如果一个时间序列的均值或自协方差函数随时间而改变,那么该序列就是非平稳的。对于非平稳的数据,采用传统的估计方法,可能会导致错误的推断,即伪回归。若非平稳序列经过一阶差分变为平稳序列,那么该序列就为一阶单整序列。对一组非平稳但具有同阶的序列而言,若它们的线性组合为平稳序列,则称该组合序列具有协整关系。对具有协整关系的序列,我们算出误差修正项,并将误差修正项的滞后一期看做一个解释变量,连同其他反映短期波动关系的变量一起。建立误差修正模型。 建立误差修正模型的步骤如下:首先,对单个序列进行单根检验,进行单根检验有两种:ADF (Augument Dickey-Fuller )和DF(Dickey-Fuller)检验法。若序列都是同阶单整,我们就可以对其进行协整分析。在此我们只介绍单个方程的检验方法。对于多向量的检验参见Johensen 协整检验。我们可以先求出误差项,再建立误差修正模型,也可以先求出向量误差修正模型,然后算出误差修正项。补充一点的是,误差修正模型反映的是变量短期的相互关系,而误差修正项反映出变量长期的关系。下面我们给出案例分析。 案例分析 在此,我们考虑从1978年到2002年城镇居民的人均可支配收入income 与人均消费水平consume 的关系,数据来自于《中国统计年鉴》,如表8.1所示。根据相对收入假设理论,在一定时期,人们的当期的消费水平不仅与当期的可支配收入、而且受前期的消费水平的影响,具有一定的消费惯性,这就是消费的棘轮效应。从这个理论出发,我们可以建立如下(8.1)式的模型。同时根据生命周期假设理论,消费者的消费不仅与当期收入有关,同时也受过去各项的收入以及对将来预期收入的限制和影响。从我们下面的数据分析中,我们可以把相对收入假设理论与生命周期假设理论联系起来,推出如下的结果:当期的消费水平不仅与当期的可支配收入有关,而且还与前期的可支配收入、前两期的消费水平有关。在此先对人均可支配收入和人均消费水平取对数,同时给出如下的模型 t t t lincome lconsume lconsume 2110?+?+?=- t=1,2,…,n (8.1) 如果当期的人均消费水平与当期的人均可支配收入及前期的人均消费水平均为一阶单整序列,而它们的线性组合为平稳序列,那么我们可以求出误差修正序列,并建立误差修正模型,如下: t ecm lconsume lincome lconsume t t t t 4131210βββββ++?+?+=?-- t=1,2,…,n (8.2) t ecm = 12110--?-?-?-t t t lincome lconsume lconsume t=1,2,…,n (8.3) 从(8.2)式我们可以推出如下的方程: t lincome lincome lconsume lconsume lconsume t t t t t 4030123222131131)()()1(ββββββββββ+?-+?--+?--++=---(8.4) 在(8.2)中lconsume ?、 lincome ?分别为变量对数滞后一期的值,)1(-ecm 为误差修正项,如(8.3)式所示。(8.2)式为含有常数项和趋势项的形式,我们省略了只含趋
stata-误差修正模型讲解
误差修正模型: 如果用两个变量,人均消费y 和人均收入x (从格林的数据获得)来研究误差修正模型。 令z=(y x )’,则模型为: t t k i i t t z p z A z επ+?++=?-=-∑11 10 其中,'αβπ= 如果令1=k ,即滞后项为1,则模型为 t t t t z p z A z επ+?++=?--1110 实际上为两个方程的估计: t t t t t y t x p y p x b y b a y 1112111112111ε+?+?+++=?---- t t t t t x t x p y p x b y b a x 2122121122121ε+?+?+++=?---- 用ols 命令做出的结果: gen t=_n tsset t time variable: t, 1 to 204 gen ly=L.y (1 missing value generated) gen lx=L.x (1 missing value generated) reg D.y ly lx D.ly D.lx Source | SS df MS Number of obs = 202 -------------+------------------------------ F( 4, 197) = 21.07 Model | 37251.2525 4 9312.81313 Prob > F = 0.0000 Residual | 87073.3154 197 441.996525 R-squared = 0.2996 -------------+------------------------------ Adj R-squared = 0.2854 Total | 124324.568 201 618.530189 Root MSE = 21.024 ------------------------------------------------------------------------------ D.y | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- ly | .0417242 .0187553 2.22 0.027 .0047371 .0787112 lx | -.0318574 .0171217 -1.86 0.064 -.0656228 .001908 ly | D1. | .1093189 .082368 1.33 0.186 -.0531173 .2717552 lx | D1. | .0792758 .0566966 1.40 0.164 -.0325344 .1910861 _cons | 2.533504 3.757158 0.67 0.501 -4.875909 9.942916 这是t t t t t y t x p y p x b y b a y 1112111112111ε+?+?+++=?----的回归结果,其中y a =2.5335,
误差修正模型案例
大型作业报告 课程名称计量经济学 课程代码142102601 题目误差修正模型 专业经济学 班级2010271 成员陈晓燕
上海电力学院经济与管理学院
计量经济学大型作业评分表 备注: 课程设计报告的质量70%,分4个等级: 1、按要求格式书写,计算正确,方案合理,内容完整,绘图规范整洁,符合任务书的要求35-40 2、按要求格式书写,计算较正确,有少量错误,方案较合理,内容完整,绘图较规范整洁,基本符合任务书的要求26-34 3、基本按要求格式书写,计算较正确,有部分错误,方案较合理,内容基本完整,绘图不规范整洁,基本符合任务书的要求15-25 4、基本按要求格式书写,计算错误较多,方案不合理,内容不完整,绘图不规范整洁,不符合任务书的要求0-14 工作态度30%,分4个等级: 1、很好,积极参与,答疑及出勤情况很好16-20 2、良好,比较能积极参与,答疑情况良好但有少量缺勤记录,或答疑情况
一般但出勤情况良好11-15 3、一般,积极性不是很高,基本没有答疑记录,出勤情况较差6-10 4、欠佳,不认真投入,且缺勤很多,也没有任何答疑记录0-5 实验报告 一、实验目的与要求 1、掌握时间序列的ADF平稳性检验; 2、掌握双变量的Engel-Granger检验; 3、掌握双变量的误差修正模型; 4、熟练使用Eviews软件建立误差修正模型。 二、实验内容 依据1978-2010年我国人均消费和人均GDP的数据,完成以下内容。 1、对实验数据进行单位根检验; 2、利用E-G两步法对实验数据进行协整检验; 3、根据实验数据的关系,建立误差修正模型,估计并进行解释。 三、实验步骤 (1)收集数据
误差修正模型.
第二节误差修正模型(Error Correction Model,ECM) 一、误差修正模型的构造 对于yt的(1,1阶自回归分布滞后模型: 在模型两端同时减yt-1,在模型右端,得: 其中,,,。 记(5-5) 则(5-6) 称模型(5-6)为“误差修正模型”,简称ECM。 二、误差修正模型的含义 如果yt ~ I(1,xt ~ I(1,则模型(5-6)左端 ,右端,所以只有当yt和xt协整、即yt 和xt之间存在长期均衡关系时,式(5-5)中的 ecm~I(0,模型(5-6)两端的平稳性才会相同。 当yt和xt协整时,设协整回归方程为:
它反映了yt与xt的长期均衡关系,所以称式(5-5)中的ecmt-1是前一期的“非均衡误差”,称误差修正模型(5-6)中的是误差修正项,是修正系数,由于通常 ,这样;当ecmt-1 >0时(即出现正误差),误差 修正项< 0,而ecmt-1 < 0时(即出现负误差), > 0,两者的方向恰好相反,所以,误差修正是一个反向 调整过程(负反馈机制)。 误差修正模型有以下几个明确的含义: 1.均衡的偏差调整机制 2.协整与长期均衡的关系 3.经济变量的长期与短期变化模型 长期趋势模型: 短期波动模型: 三、误差修正模型的估计 建立ECM的具体步骤为: 1.检验被解释变量y与解释变量x(可以是多个变量)之间的协整性; 2.如果y与x存在协整关系,估计协整回归方程,计算残差序列e t:
3.将e t-1作为一个解释变量,估计误差修正模型: 说明: (1)第1步协整检验中,如果残差是确定趋势过程,可以在第2步的协整回归方程中加入趋势变量; (2)第2步可以估计动态自回归分布滞后模型: 此时,长期参数为: 协整回归方程和残差也相应取成: , (3)第2步估计出ECM之后,可以检验模型的残差是否存在长期趋势和自相关性。如果存在长期趋势,则在ECM中加入趋势变量。如果存在自相关性,则在ECM的右端加入的滞后项来消除自相关性,误差修正项的滞后期一般也要作相应调整。如取成以下形式: 由于模型中的各项都是平稳变量,所以可以用t检验判断各项的显著性,逐个剔除其中不显著的变量,当然误差修正项要尽可能保留。
协整检验及误差修正模型实验指导(精)
实验八协整检验及误差修正模型实验指导 一、实验目的 理解经济时间序列之间的理论关系,并学会用统计方法验证他们之间的关系。学会验证时间序列存在的不平稳性,掌握ADF检验平稳性的方法。认识不平稳的序列容易导致虚假回归问题,掌握为解决虚假回归问题引出的协整检验,协整的概念和具体的协整检验过程。协整描述了变量之间的长期关系,为了进一步研究变量之间的短期均衡是否存在,掌握误差纠正模型方法。 二、基本概念 设随机向量中所含分量均为阶单整,记为。如果存在一个非零向量,使得随机向量,,则称随机向量具有阶协整关系,记为 ,向量被称为协整向量。特别地,和为随机变量,并且,,当,即和的线性组合与变量有相同的统计性质,则称和是协整的,称为协整系数。更一般地,如果一些变量的线性组 合是,那么我们就称这些变量是协整的。 三、实验内容及要求 1、实验内容 用Eviews5.1来分析1978年到2002年中国农村居民对数生活费支出序列和对数人均纯收入{}序列之间的关系。内容包括: (1)对两个对数序列分别进行ADF平稳性检验; (2)进行二者之间的协整关系检验; (3)若存在协整关系,建立误差纠正模型ECM。 2、实验要求 (1)在认真理解本章内容的基础上,通过实验掌握ADF检验平稳性的方法; (2)掌握具体的协整检验过程,以及误差纠正模型的建立方法; (3)能对宏观经济变量间的长期均衡关系进行分析。 四、实验指导 1、对两个数据序列分别进行平稳性检验: (1)做时序图看二者的平稳性
首先按前面介绍的方法导入数据,在workfile中按住ctrl选择要检验的二变量,击右键,选择open—as group,此时他们可以作为一个数据组被打开。 点击“View”―“graph”—“line”,对两个序列做时序图见图8-1,两个序列都呈上升趋势,显然不平稳,但二者有大致相同的增长和变化趋势,说明二者可能存在协整关系。但若要证实二者有协整关系,必须先看二者的单整阶数,如果都是一阶单整,则可能存在协整关系,若单整地阶数不相同,则需采取差分的方式,将他们变成一阶单整序列。 图8-1 和时序图 (2)用ADF检验分别对序列和进行单整检验 双击每个序列,对其进行ADF单位根检验,有两种方法。方法一:“view”—“unit root test”;方法二:点击菜单中的“quick”―“series statistic”―“unit root test”。序列和都有 明显的上升趋势,采用带常数项和趋势项的模型进行检验,见图8-2,对对数序列的原水平进行带趋势项和常数项的ADF检验,采用SC准则自动选择滞后阶数,检验结果见图8-3和8-4,在0.05的显著性水平下,都接受存在一个单位根的原假设,说明这两个序列都不平稳。
实验报告二——误差修正模型的建立与分析
实验报告(二)——误差修正模型(ECM)的建立与分析 一、单位根检验: 1、绘制cons与GDP的时间序列图: 从时间序列图中可以看出,cons与GDP随时间增加都呈上升趋势,表现出非平稳性。 2、对cons进行单位根检验: 先选择对原序列(level)进行单位根检验,根据cons与GDP的时间序列图的走势,选择trend and intercept的检验方法,在maximum lags中填写ADF 检验方法的滞后期为0,从上表中可以看出,P值为0.9888,大于0.05的显著性水平,说明原序列是非平稳的。
选择cons的一阶差分(1st)和trend and intercept,从上表中可以看出,经过一阶差分后,P值(=0.5099)仍然没有通过0.05的置信水平检验,说明是不平稳的,需要继续改进。 再试用ADF检验,在滞后期(maximum lags)中填入8,选择一阶差分和trend and intercept,得出上表,可以看出P值=0.0801,大于0.05,没有通过0.05的置信水平检验,说明是不平稳的,需要继续改进。
再试用ADF检验,在滞后期(maximum lags)中填入6,选择二阶差分和trend and intercept,得出上表,可以看出P值=0.0137,小于0.05,通过0.05的置信水平检验,说明是平稳的。 3、对GDP进行单位根检验:
先选择对原序列(level)进行单位根检验,根据cons与GDP的时间序列图的走势,选择trend and intercept的检验方法,在maximum lags中填写ADF 检验方法的滞后期为0,从上表中可以看出,P值为1.0000,大于0.05的显著性水平,说明原序列是非平稳的。 选择GDP的一阶差分(1st)和trend and intercept,从上表中可以看出,经过一阶差分后,P值(=0.5574)仍然没有通过0.05的置信水平检验,说明是不平稳的,需要继续改进。
误差修正模型ECM
Error Correction Model 用EVIEWS怎么做 一、利用EG两步法做协整检验。在两个变量情况下(设为Y、X),包括两序列单整检验、两变量最小二乘法回归并得到残差序列并命名为e、对e作单位根检验。 二、在证明Y、X两序列间存在协整后,才可以建立ECM。其中,误差修正项ecm的值就是之前的回归模型的残差序列e。 三、直接输入以下命令: ls y c y(-1) x x(-1) 得到的估计结果在实际预测时比较方便,不过需要计算得到ecm项的系数。 四、也可以直接输入以下命令: ls y c x e(-1) 其中,e(-1)项的系数就是ecm项的系数。这个模型的优点是直观,但是不便于预测。 五、两种估计是等价的。 六、建议参考阅读易丹辉:《数据分析与EViews应用》,中国统计出版社2002年版。(也许有新版也不一定) 对于误差修正模型,需要先建立一个模型,然后进行回归分析,分析它的短期均衡关系。 操作:举个例子说,比如试图建立y对y(-1)和x的误差修正模型。 STEP1 建立长期关系 ls y c y(-1) x STEP2 对残差进行单位根检验来检验协整关系 ecm=resid uroot(10,h) ecm STEP3 建立误差修正模型 ls d(y) c d(y(-1)) d(x) ecm(-1)
教程:
案例1 上面的分析可以证明序列lconsume、lincome及lconsme(-1)之间存在协整关系,故可以建立ecm(误差修正模型)。先分别对序列lconsume、lincome及lconsme(-1)进行一阶差分,然后对误差修正模型进行估计。在主窗口命令行中输入: ls d(lconsume) c d(lincome) d(lconsume(-1)) ecm(-1) 此时的常数项系数不明显,我们去掉常数项后再进行回归,结果如下图8.6所示 图8.6 从上式可以看出上式中的T检验值均显著,误差修正项的系数为-0.252,这说明长期均衡对短期波动的影响不大。 下面我们短期会给出另一种估计方式。我们可以直接进行估计,命令为:
协整检验及误差修正模型定稿版
协整检验及误差修正模 型 HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】
协整检验及误差修正模型 设随机向量t X 中所含分量均为d 阶单整,记为t X I(d )。如果存在一个非零向量β,使得随机向量()~t t Y X I d b =-β,0b >,则称随机向量t X 具有d ,b 阶协整关系,记为t X CI(d ,b ),向量β被称为协整向量。特别地,t y 和t x 为随机变量,并且t y , ~(1)t x I ,当01()~I(0)t t t y x εββ=-+,即t y 和t x 的线性组合与I(0)变量有相同的统计性质,则称t y 和t x 是协整的,()01,ββ称为协整系数。更一般地,如果一些I(1)变量的线性组合是I(0),那么我们就称这些变量是协整的。 用Eviews5.1来分析1978年到2002年中国农村居民对数生活费支出序列{ln }t y 和对数人均纯收入{ln t x }序列之间的关系。 1、对两个数据序列分别进行平稳性检验: (1)做时序图看二者的平稳性 首先按前面介绍的方法导入数据,在workfile 中按住ctrl 选择要检验的二变量,击右键,选择open —as group ,此时他们可以作为一个数据组被打开。 点击“View ”―“graph ”—“line ”,对两个序列做时序图见图8-1,两个序列都呈上升趋势,显然不平稳,但二者有大致相同的增长和变化趋势,说明二者可能存在协整关系。但若要证实二者有协整关系,必须先看二者的单整阶数,如果都是一阶单整,则可能存在协整关系,若单整地阶数不相同,则需采取差分的方式,将他们变成一阶单整序列。 图8-1 ln t x 和ln t y 时序图
协整与误差修正模型计算实验
协整与误差修正模型 武汉大学经济学系数量经济学教研室《实践教改项目组》编制 在处理时间序列数据时,我们还得考虑序列的平稳性。如果一个时间序列的均值或自协方差函数随时间而改变,那么该序列就是非平稳的。对于非平稳的数据,采用传统的估计方法,可能会导致错误的推断,即伪回归。若非平稳序列经过一阶差分变为平稳序列,那么该序列就为一阶单整序列。对一组非平稳但具有同阶的序列而言,若它们的线性组合为平稳序列,则称该组合序列具有协整关系。对具有协整关系的序列,我们算出误差修正项,并将误差修正项的滞后一期看做一个解释变量,连同其他反映短期波动关系的变量一起。建立误差修正模型。 建立误差修正模型的步骤如下:首先,对单个序列进行单根检验,进行单根检验有两种:ADF (Augument Dickey-Fuller )和DF(Dickey-Fuller)检验法。若序列都是同阶单整,我们就可以对其进行协整分析。在此我们只介绍单个方程的检验方法。对于多向量的检验参见Johensen 协整检验。我们可以先求出误差项,再建立误差修正模型,也可以先求出向量误差修正模型,然后算出误差修正项。补充一点的是,误差修正模型反映的是变量短期的相互关系,而误差修正项反映出变量长期的关系。下面我们给出案例分析。 案例分析 在此,我们考虑从1978年到2002年城镇居民的人均可支配收入income 与人均消费水平consume 的关系,数据来自于《中国统计年鉴》,如表8.1所示。根据相对收入假设理论,在一定时期,人们的当期的消费水平不仅与当期的可支配收入、而且受前期的消费水平的影响,具有一定的消费惯性,这就是消费的棘轮效应。从这个理论出发,我们可以建立如下(8.1)式的模型。同时根据生命周期假设理论,消费者的消费不仅与当期收入有关,同时也受过去各项的收入以及对将来预期收入的限制和影响。从我们下面的数据分析中,我们可以把相对收入假设理论与生命周期假设理论联系起来,推出如下的结果:当期的消费水平不仅与当期的可支配收入有关,而且还与前期的可支配收入、前两期的消费水平有关。在此先对人均可支配收入和人均消费水平取对数,同时给出如下的模型 t t t l i n c o m e l c o n s u m e l c o n s u m e 2110?+?+?=- t=1,2,…,n (8.1) 如果当期的人均消费水平与当期的人均可支配收入及前期的人均消费水平均为一阶单 整序列,而它们的线性组合为平稳序列,那么我们可以求出误差修正序列,并建立误差修正模型,如下: t ecm lconsume lincome lconsume t t t t 4131210βββββ++?+?+=?-- t=1,2,…,n (8.2) t ecm = 12110--?-?-?-t t t lincome lconsume lconsume t=1,2,…,n (8.3) 从(8.2)式我们可以推出如下的方程: t lincome lincome lconsume lconsume lconsume t t t t t 4030123222131131)()()1(ββββββββββ+?-+?--+?--++=---(8.4) 在(8.2)中lc o n s u m e ?、 lincome ?分别为变量对数滞后一期的值,)1(-ecm 为误差修正项,如(8.3)式所示。(8.2)式为含有常数项和趋势项的形式,我们省略了只含趋势项
协整检验及误差修正模型
协整检验及误差修正模型 设随机向量t X 中所含分量均为d 阶单整,记为t X I(d ):。如果存在一个非零向量β,使得随机向量()~t t Y X I d b =-β,0b >,则称随机向量t X 具有d ,b 阶协整关系,记为t X CI(d ,b ):,向量β被称为协整向量。特别地,t y 和t x 为随机变量,并 且t y ,~(1)t x I ,当01()~I(0)t t t y x εββ=-+,即t y 和t x 的线性组合与I(0)变量有相同的统计性质,则称t y 和t x 是协整的,()01,ββ称为协整系数。 更一般地,如果一些I(1)变量的线性组合是I(0),那么我们就称这些变量是协整的。 用Eviews5.1来分析1978年到2002年中国农村居民对数生活费支出序列{ln }t y 和对数人均纯收入{ln t x }序列之间的关系。 1、对两个数据序列分别进行平稳性检验: (1)做时序图看二者的平稳性 首先按前面介绍的方法导入数据,在workfile 中按住ctrl 选择要检验的二变量,击右键,选择open —as group ,此时他们可以作为一个数据组被打开。 点击“View ”―“graph ”—“line ”,对两个序列做时序图见图8-1,两个序列都呈上升趋势,显然不平稳,但二者有大致相同的增长和变化趋势,说明二者可能存在协整关系。但若要证实二者有协整关系,必须先看二者的单整阶数,如果都是一阶单整,则可能存在协整关系,若单整地阶数不相同,则需采取差分的方式,将他们变成一阶单整序列。 图8-1 ln t x 和ln t y 时序图 (2)用ADF 检验分别对序列ln t x 和ln t y 进行单整检验 双击每个序列,对其进行ADF 单位根检验,有两种方法。方法一:“view ”—“unit root test ”;方法二:点击菜单中的“quick ”―“series statistic ”―
协整方程(CE)与误差修正模型(VECM)
人民币实际有效汇率对我国经济影响的实证研究 巴曙松,王群2009-09-29 摘要:本文试从理论上给出实际汇率变动对产业结构调整的三种传导途径,并从有效汇率的角度出发,通过协整模型、Granger因果检验和脉冲响应方法对实际有效汇率对我国产业、就业结构的影响进行实证分析。结果表明,人民币实际有效汇率的升值提升了我国第三产业的比重并增加了该产业就业人数,在一定程度上促进了农村劳动力的转移,同时相应地对第二产业的就业造成了负面影响。总体上来看,人民币有效汇率的上升将有助于长期改善我国的产业结构,但短期会造成一定的就业压力。 关键词:实际汇率,产业结构,就业结构,传导途径 2008年以来,伴随着次级抵押贷款危机下全球金融市场的动荡,我国经济不仅面临着恶劣的国际环境、国内经济增长的周期性回落,同时还面临着以产业重组、产业升级和放松管制为重点的产业结构调整。随着近年来我国对外贸易依存度的不断上升,产业结构调整的动力则不可忽略地受到对外贸易部门发展的影响。实际汇率作为一种非贸易品和贸易品相对价格,则是影响外贸企业的重要因素之一,从而影响了不同产业之间的资源配置,进而对产业结构的调整产生影响。因此,在开放型经济条件下,实际汇率成为考察国内产业结构和就业结构调整的重要影响因素之一。而对该影响作用的分析和研究,不仅有助于加深对产业结构调整的宏观把握,而且将对汇率政策的制定起到一定的指导作用。另外,在2005年7月21日我国实行了汇率制度改革以后,如何通过人民币有效汇率这一衡量人民币整体水平的汇率指标来把握汇率政策,也引起了学者的普遍关注和研究,本文正是依据人民币实际有效汇率的数据,分析人民币的升值对我国产业结构和就业结构带来的影响。 一、研究背景
误差修正模型实例
一、误差修正模型的构造 对于y t 的(1,1)阶自回归分布滞后模型: t t t t t y x x y εβββα++++=--12110 在模型两端同时减y t-1,在模型右端10-±t x β,得: t t t t t t t t t t t t t x y x x y x y x x y εααγβεββββαββεββββα+--+?=+---+--+?=+-+++?+=?------)(]) 1()1()[1()1()(1101012120120121100 其中,12-=βγ,)1/()(200ββαα-+=,)1/(211ββα-=。 记 11011-----=t t t x y ecm αα (5-5) 则 t t t t ecm x y εγβ++?=?-10 (5-6) 称模型(5-6)为“误差修正模型”,简称ECM 。 二、误差修正模型的含义 如果y t ~ I(1),x t ~ I(1),则模型(5-6)左端)0(~I y t ?,右端)0(~I x t ?,所以只有当y t 和x t 协整、即y t 和x t 之间存在长期均衡关系时,式(5-5)中的ecm~I(0),模型(5-6)两端的平稳性才会相同。 当y t 和x t 协整时,设协整回归方程为: t t t x y εαα++=10 它反映了y t 与x t 的长期均衡关系,所以称式(5-5)中的ecm t -1是前一期的“非均衡误差”,称误差修正模型(5-6)中的1-t ecm γ是误差修正项,12-=βγ是修正系数,由于通常1||2<β,这样
0<γ;当ecm t -1 >0时(即出现正误差),误差修正项1-t ecm γ< 0, 而ecm t -1 < 0时(即出现负误差),1-t ecm γ> 0,两者的方向恰 好相反,所以,误差修正是一个反向调整过程(负反馈机制)。 误差修正模型有以下几个明确的含义: 1.均衡的偏差调整机制 2.协整与长期均衡的关系 3.经济变量的长期与短期变化模型 长期趋势模型: t t t x y εαα++=10 短期波动模型: t t t t ecm x y εγβ++?=?-10 三、误差修正模型的估计 建立ECM 的具体步骤为: 1.检验被解释变量y 与解释变量x (可以是多个变量)之间的协整性; 2.如果y 与x 存在协整关系,估计协整回归方程,计算残差序列e t : t t t x y εβα++=0 t t t x y e 0??βα--= 3.将e t-1作为一个解释变量,估计误差修正模型: t t t t v e x y ++?=?-10γβ 说明: (1)第1步协整检验中,如果残差是确定趋势过程,可以在第2步的协整回归方程中加入趋势变量; (2)第2步可以估计动态自回归分布滞后模型: t i t i i t i t y x y εβαα∑∑+++=-- 此时,长期参数为: ∑∑-=)1(i i βαθ 协整回归方程和残差也相应取成: t t x y θ=, t t t x y e θ?-= (3)第2步估计出ECM 之后,可以检验模型的残差是
实验四:协整检验及误差修正模型实验报告
课程论文 (2016 / 2017学年第 1 学期) 课程名称应用时间序列分析 指导单位经济学院 指导教师易莹莹 学生姓名班级学号 学院(系) 经济学院专业经济统计学
实验四协整检验及误差修正模型实验指导 一、实验目的: 理解经济时间序列之间的理论关系,并学会用统计方法验证他们之间的关系。学会验证时间序列存在的不平稳性,掌握ADF 检验平稳性的方法。认识不平稳的序列容易导致虚假回归问题,掌握为解决虚假回归问题引出的协整检验,协整的概念和具体的协整检验过程。协整描述了变量之间的长期关系,为了进一步研究变量之间的短期均衡是否存在,掌握误差纠正模型方法。 二、基本概念: 设随机向量t X 中所含分量均为d 阶单整,记为t X I(d ) 。 如果存在一个非零向量β,使得随机向量()~t t Y X I d b =-β,0b >,则称随机向量t X 具有d ,b 阶协整关系,记为 t X CI(d,b ) , 向量β被称为协整向量。特别地,t y 和t x 为随机变量,并且t y ,~(1)t x I ,当01()~I(0)t t t y x εββ=-+,即t y 和t x 的线性组合与I(0)变量有相同的统计性质,则称 t y 和t x 是协整的,()01,ββ称为协整系数。 更一般地,如果一些I(1)变量的线性组合是I(0),那么我们就称这些变量是协整的。 三、实验任务: 1、实验内容 用Eviews 来分析1992年到1998年中国城镇居民生活费支出序列和人均可支配收入序列之间的关系。内容包括: (1)对两个对数序列分别进行ADF 平稳性检验; (2)进行二者之间的协整关系检验; (3)若存在协整关系,建立误差纠正模型ECM 。 2、实验要求 (1)在认真理解本章内容的基础上,通过实验掌握ADF 检验平稳性的方法; (2)掌握具体的协整检验过程,以及误差纠正模型的建立方法; (3)能对宏观经济变量间的长期均衡关系进行分析。 四、实验要求: 实验过程描述(包括变量定义、分析过程、分析结果及其解释、实验过程遇到的问题及体会)。 实验题:1992年到1998年中国城镇居民生活费支出序列和人均可支配收入序列之间的关系。