6.计量资料的统计推断—t检验

6 计量资料的统计推断-t检验
t检验是以t分布为理论依据的假设检验方法,常用于正态总体小样本资料的均数比较,t检验统计量有三个不同的形式,适用于单因素设计的三种不同类型:①单个样本的均数与已知总体均数比较的检验,适用于单组设计,给出一组服从正态分布的定量观测数据和一个标准值(总体均值)的资料。②配对t检验,适用于配对设计。③成组t检验,适用于完全随机设计的两均数比较。
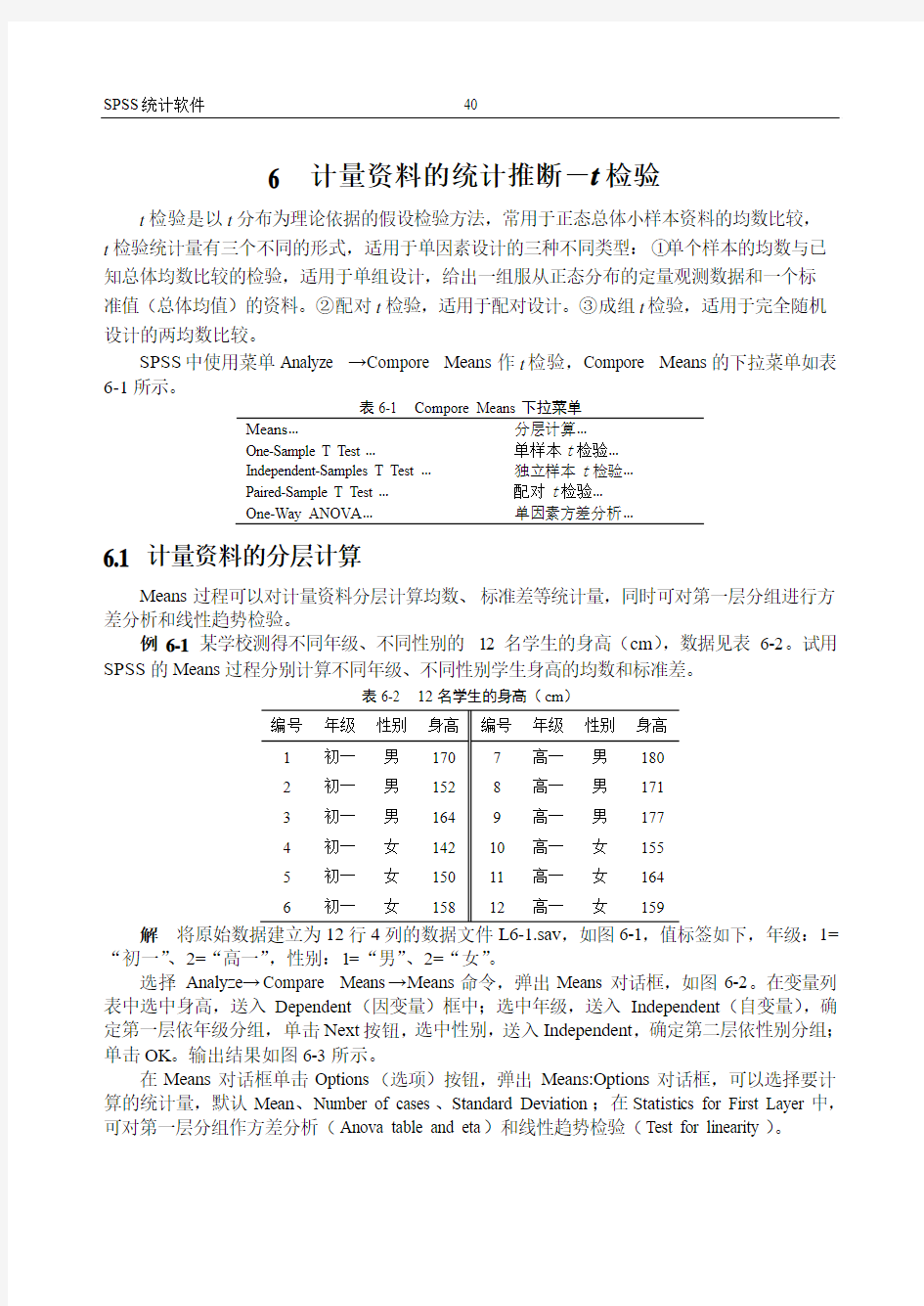
SPSS中使用菜单Analyze →Compore Means作t检验,Compore Means的下拉菜单如表6-1所示。
表6-1 Compore Means下拉菜单
Means…分层计算…
One-Sample T Test…单样本t检验…
Independent-Samples T Test…独立样本t检验…
Paired-Sample T Test…配对t检验…
One-Way ANOV A…单因素方差分析…
6.1 计量资料的分层计算
Means过程可以对计量资料分层计算均数、标准差等统计量,同时可对第一层分组进行方差分析和线性趋势检验。
例6-1某学校测得不同年级、不同性别的12名学生的身高(cm),数据见表6-2。试用SPSS的Means过程分别计算不同年级、不同性别学生身高的均数和标准差。
表6-2 12名学生的身高(cm)
解年级:1=“初一”、2=“高一”,性别:1=“男”、2=“女”。
选择Analyze→Compare Means→Means命令,弹出Means对话框,如图6-2。在变量列表中选中身高,送入Dependent(因变量)框中;选中年级,送入Independent(自变量),确定第一层依年级分组,单击Next按钮,选中性别,送入Independent,确定第二层依性别分组;单击OK。输出结果如图6-3所示。
在Means对话框单击Options(选项)按钮,弹出Means:Options对话框,可以选择要计算的统计量,默认Mean、Number of cases、Standard Deviation;在Statisti cs for First Layer中,可对第一层分组作方差分析(Anova table and eta)和线性趋势检验(Test for linearity)。
图6-1 数据文件L6-1.sav 图6-2 Means对话框
图6-3 例6-1计算结果图6-4 例6-2正态性检验结果
6.2 单样本t检验
单样本t检验是样本均数与已知总体均数比较的t检验,要求原始数据是一组服从正态分布的定量观测数据,原假设为H0:μ=μ0,μ0一般为理论值、标准值或经过大量观察所得的稳定值。
例6-2某中药厂用旧设备生产的六味地黄丸,丸重的均数是8.9克,更新设备后,从所生产的产品中随机抽取9丸,其重量为:9.2,10.0,9.6,9.8,8.6,10.3,9.9,9.1,8.9。问:设备更新后生产的丸药的平均重量有无变化?
解这是单组计量资料分析,H0:μ=8.9,H1:μ≠8.9。以丸重为变量名,将原始数据建立为9行1列的数据文件。
1.用Explore过程进行正态性检验选择菜单Analyze →Descriptive Statistics→Explore,在弹出的Explore对话框中,将丸重送入Dependent框中;单击Plots按钮,在弹出的Plots对话框中选中Nomality plots with tests,单击Continue;单击OK。
主要输出结果见图6-4,可知,P=0.832>0.05,可认为丸重x服从正态分布。
2.用One-Sample T T est过程进行单样本t检验选择菜单Analyze →Compare Means→One-Sample T Test,在弹出的One-Sample T Test对话框中,选中丸重,将丸重送入上面的Test(检验变量)框中;在下面的Test(检验值)对话框中改系统默认值0为8.9,如图6-5所示;单击OK。
图6-5 One-Sample T Test对话框图6-6 单样本t检验计算结果
主要输出结果如图6-6,t=3.118,双侧P=0.014<0.05,按α=0.05水准拒绝H0,差异有统计学意义,可以认为设备更新后生产的丸药的平均重量有变化。样本均值=9.489>8.9,可以认为,设备更新后生产的丸药的平均重量大于设备更新前。
也可用置信区间推断,由95%Confidence Interval of the Difference(差值的95%CI)为(0.153,1.024),不含0(如果H0:μ=μ0成立,则差值的均数应为0),所以,按α=0.05水准,可以认为设备更新后生产的丸药的平均重量有变化。
6.3 两组配对样本t检验
配对t检验是将配对的两组相关资料转化为单组差值资料,适用于配对设计,要求成对数据的差值d服从正态分布。差值d不服从正态分布,应该选择非参数检验。
例6-3对12份血清分别用原方法(检测时间20分钟)和新方法(检测时间10分钟)测谷-丙转氨酶(nmol·S-1/L),结果见表6-3。问两法所得结果有无差别?
表6-3 12份血清的谷-丙转氨酶
编号 1 2 3 4 5 6 7 8 9 10 11 12
原法60 142 195 80 242 220 190 25 212 38 236 95
新法80 152 243 82 240 220 205 38 243 44 200 100 解这是配对比较,H0:μd=0,H1:μd≠0。以编号、原法和新法为变量名,将原始数据建立为12行3列的数据文件。
1.计算差值d选择菜单Transform→Compute V ariable,在Target V ariable框中输入d;选中原法,将其送入Numeric expression框中,单击运算键中的“-”,选中新法,将其送入Numeric expression框中;单击OK。数据文件中增加新变量d。
2.对差值d进行正态性检验步骤见例6-2。计算出的Shapiro-Wilk统计量,P=0.392>0.05,可认为配对差d服从正态分布。
3.进行配对t检验选择菜单Analyze → Compare Means→ Paired-Sample T Test,弹出的Paired-Sample T Test 对话框(见图6-7),选中原法和新法,将其送入Paired V ariables(配对变量)框中,单击OK。
主要输出结果如图6-8,t=-1.602,双侧P=0.137>0.05,按α=0.05水准不拒绝H0,差异无统计学意义,还不能认为两法测谷-丙转氨酶结果有差别。
图6-7 Paired-Sample T Test 对话框
图6-8 两组配对样本t检验计算结果
6.4 两组独立样本t检验
完全随机设计两组试验资料的分析,一般用成组t检验,推断两总体均数是否相等。要求两样本相互独立,总体均服从正态分布并且方差齐性。在两组均正态的条件下,满足方差齐性,用成组t检验(参数检验);不满足方差齐性,可用t′检验,也可用非参数检验。在正态性不满足的条件下,应该选择非参数检验,也可利用适当的变量变换,使达到正态性和方差齐性,再用t检验。
例6-4测定功能性子宫出血症中实热组与虚寒组的免疫功能,其淋巴细胞转化率如表6-4所示。比较实热组与虚寒组的淋巴细胞转化率均数是否不同。
表6-4 实热组与虚寒组的免疫功能淋巴细胞转化率
实热组0.709 0.755 0.655 0.705 0.723
虚寒组0.617 0.608 0.623 0.635 0.593 0.684 0.695 0.718 0.606 0.618
解这是成组比较。H0:μ1=μ2,H1:μ1≠μ2。以g表示分组(标签值:1=“实热组”、2=“虚寒组”),以x表示淋巴细胞转化率,将原始数据建立成2列15行的数据文件,如图6-9。
1.用Explore过程进行正态性检验选择菜单Analyze →Descriptive Statistics→Explore,在弹出的对话框中,将x送入Dependent框中,将g送入Factor List框中;单击Plots按钮,在弹出的Plots对话框中选中Normality plots with tests,单击Continue;单击OK。
运行后,两组的Shapiro-Wilk统计量分别为0.956、0.855,两组的P值分别为0.782、0.066,均>0.05,均服从正态分布。
2.做成组t 检验选择菜单Analyze → Compare Means→ Independent-Samples T Test,在弹出Independent-Samples T Test 对话框(见图6-10)中,将x选入Test(检验变量)框中,将g
选入Grouping(分组变量)框中;单击Define Groups(定义组),在两个Group框中分别键入1和2,单击Continue;单击OK。
图6-9 例6-4数据文件图6-10 Independent-Samples T Test 对话框主要输出结果如图6-11。先看Levene’s Test for Equality of V ariances(方差齐性Levene检验),若P>0.05,则选择Equal variances assumed(方差齐)的t检验结果;若P≤0.05,则选择Equal variances not assumed(方差不齐)的校正t 检验结果。t检验或校正t检验的P≤0.05时,认为两总体均数差异有统计学意义;P>0.05时,不能认为两总体均数差异有统计学意义。
本例,Levene’s Test for Equality of V ariances的统计量F=0.938,P =0.350>0.05,不能认为两组的总体方差不齐;t=3.093,双侧P=0.009<0.01,以α=0.01水准的双侧检验拒绝H0,两组的差异有统计意义。由1组(实热组)均数0.70940>2组(虚寒组)均数0.63970,可以认为实热组的淋巴细胞转化率均数高于虚寒组。
图6-11独立样本t检验计算结果
本章小结
本章首先介绍了用Meeans过程对计量资料分层计算的方法,然后,分别介绍了SPSS实现计量资料的单样本t检验、配对样本t检验和两组独立样本t检验的方法,在学习过程中,应熟悉各种方法需要的数据文件格式,掌握三种t检验的前提条件,熟练实现SPSS相应功能的操作步骤以及结果的解读与分析,达到灵活运用。
习题6
习题6-1表6-5中测得不同医院、不同组的12名患者的年龄(岁)。分别计算不同医院、不同组别患者年龄的均数和标准差。
表6-5 12名患者的年龄(岁)
习题6-2某医生测量了36名从事铅作业男性工人的血红蛋白含量,数据见表6-6。问从事铅作业男性工人的血红蛋白是否不同于正常成年男性平均值140g/L?
表6-6 从事铅作业男性工人的血红蛋白含量
112105172157165140137178116151171163
12913012513512810012612890113128129
881269617516011690103162129110127习题6-3为比较两种方法对乳酸饮料中脂肪含量测定结果是否不同,某人随机抽取了10份乳酸饮料制品,分别用两种方法测定,方法1:哥特里-罗紫法,方法2:脂肪酸水解法,测定结果见表6-7。问两种方法测定结果是否不同?
表6-7 脂肪含量测定结果(%)
编号 1 2 3 4 5 6 7 8 9 10 方法1 0.840 0.591 0.674 0.632 0.687 0.978 0.750 0.730 1.200 0.870 方法2 0.580 0.509 0.500 0.316 0.337 0.517 0.454 0.512 0.997 0.506 习题6-4某医师研究转铁蛋白测定对病毒性肝炎诊断的临床意义,测得12名正常人和15名病毒性肝炎患者血清转铁蛋白含量(μg/L),结果如表6-8所示。推断转铁蛋白测定对病毒性肝炎诊断的意义。
表6-8 血清转铁蛋白含量
265.4 271.5 284.6 291.3 254.8 275.9 281.7 268.6
正常人
264.1 273.2 270.8 260.5
256.9 235.9 215.4 251.8 224.7 228.3 231.1 253.0 患者
221.7 218.8 233.8 230.9 240.7 260.7 224.4
实验三 分类资料的统计描述与统计推断
实验三分类资料的统计描述与统计推断 一、下表为一抽样研究资料,试:(1)填补空白处数据;(2)根据最后三栏结果作简要分析。(3)试估计 该地死亡率、0~恶性肿瘤死亡率的置信区间。 某地各年龄组恶性肿瘤死亡情况 出高血压病人775人,试估计该市中年男性高血压患病率的95%置信区间。 三、一般而言,对某疾病采用常规治疗,其治愈率约为45%。现改用新的治疗方法,并随机抽取180名该 疾病患者进行了新疗法的治疗,治愈117人。问新治疗方法是否比常规疗法的效果好? 四、一般人群先天性心脏病的发病率为千分之八,某研究者为探讨母亲吸烟是否会增大其小孩的先天性心 脏病的发病危险,对一群20~25岁有吸烟嗜好的孕妇进行了生育观察,在她们生育的120名小孩中,经筛查有4人患了先天性心脏病。请作统计分析。 五、某院康复科用共鸣火花治疗癔症患者56例,有效者42例;心理辅导法治疗癔症患者40例,有效者 21例。问两种疗法治疗癔症的有效率有无差别? 六、用兰芩口服液治疗慢性咽炎患者34例,有效者31例;用银黄口服液治疗慢性咽炎患者26例,有效 者18例。问两药治疗慢性咽炎的有效率有无差别? 七、用甲乙两种方法检查已确诊的乳腺癌患者120名。甲法的检出率为60%,乙法的检出率为50%,甲乙 两法一致的检出率为35%,问甲、乙两法的检出率有无差别? 八、某研究者将腰椎间盘突出症患者1184例,随机分为三组,分别用快速牵引法、物理疗法和骶裂孔药 物注射法治疗,结果如下表。问三种疗法的有效率有无不同? 三种疗法治疗腰椎间盘突出有效率的比较 疗法有效无效合计 快速牵引法444 30 474 物理疗法323 91 414 骶裂孔药物注射法222 74 296 合计989 195 1184 九、思考题: 1、常用的相对数有哪些?应用相对数时应注意的事项? 2、率的标准误与率的抽样误差 3、简述二项分布、Poisson分布和正态分布的区别与联系。 4、总体率的区间估计方法 5、2x卡方检验的用途与基本思想 6、行?列表资料2x检验的注意事项 7、普通四格表资料2x检验的应用条件及其表格、检验公式、步骤等 8、配对四格表资料2x检验的应用条件及其表格、检验公式、步骤等 χ检验有何异同? 9、两样本率比较的z检验与2 10、对于四格表资料,如何正确选用检验方法? 11、资料的对比应注意其可比性,可比性指的是什么?试举两例说明
@2017.3.16-统计学-计量资料的统计描述方法
计量资料的统计描述方法 怎样表达一组数据? 描述计量资料的常用指标— A 、描述平均水平(中心位置): 均数X 、中位数和百分位数、几何均数G 、众数(mode ) B 、描述数据的分散程度: 标准差、四分位数间距、 变异系数、方差、全距 (一)均数mean 和标准差standard deviation 1. (算术)均数X 均数是描述一组计量资料平均水平或集中趋势的指标。 *直接计算公式: 应用条件:适用于对称分布,特别是正态分布资料。 2. 中位数(median )M 和百分位数(percentile ) A.中位数M 是将一组观察值从小到大排序后,居于中间位置的那个值或两个中间值的平均值。 应用条件: 12n X X X X X n n +++== ∑L
用于任何分布类型,包括偏态资料、两端数据无界限的资料。 计算: n 为奇数时-- n 为偶数时-- 9人数据:12,13,14, 14, 15, 15, 15, 17, 19天 B.百分位数 是将N 个观察值从小到大依次排列,再分成100等份,对应于X%位的数值即为第X 百分位数。中位数是第百分50位数。 四分位数间距(quartile range ) =第25百分位数(P25)~第75百分位数(P75)。 四分位数间距用于描述偏态资料的分散程度(代替标准差S ),包含了全部观察值的一半。 ) (天1552 19===+X X M 88451 22221415214.5() M X X X X ?? ==== ???+如果只调查了前八位中学生,则: +(+)(+)天
百分位数计算(频数表法): X L :第X 百分位数所在组段下限 L Σf :小于X L 各组段的累计频数 X i :第X 百分位数所在组段组距 n :总例数f x :所在组段频数 注:有的教材X= r ; L f ∑=C 例:求频数表的第25、第75百分位数(四分位数间距) 组段 频数f 累积频数∑f 56~ 2 2 59~ 5 7 62~ 12 19 ∑f 25 L 2565~ 15 34 P 25在此 68~ 25 59 71~ 26 85∑f 75 L 7574~ 19 104 P 75在此 77~ 15 119 80~ 10 129 83~85 1 130 合计 130 ① 确定Px 所在组段: P 25所在的组段:n X %=130×25%=32.5, 65~组最终的累积频数=34,32.5落在65~组段内;
实验二 定量资料的统计推断
实验二定量资料的统计推断 (总体均数的估计及t检验、z检验、F检验) 一、随机抽样调查上海市区男孩出生体重(kg),得下表数据,问 1、99%的男孩出生体重在什么范围? 2、全市男孩出生体重均数在什么范围? 3、某男孩出生体重为4.5kg ,怎样评价? 4、在这些男孩中随机抽样,根据正态分布理论抽到体重≤2.15(kg)的男孩的可能性 是多少? 5、在这些男孩中随机抽查10人,抽到出生体重均数为≤3.2(kg)的样本的可能性约有多少? 体重人数 2.0~ 1 2.2~ 2 2.4~ 5 2.6~ 10 2.8~ 12 3.0~ 24 3.2~ 23 3.4~ 22 3.6~ 17 3.8~ 7 4.0~ 3 4.2~ 2 4.4~4.6 1 二、将20名某病患者随机分为两组,分别用甲、乙两药治疗,测得治疗前后(治后一月)的血沉(㎜/小时)如下表。 病人号甲治疗前药治疗后1 2 3 4 5 6 7 8 9 10 20 23 16 21 20 17 18 18 15 19 16 19 13 20 20 14 12 15 13 13 病人号乙治疗前药治疗后1 2 3 4 5 6 7 8 9 10 19 20 19 23 18 16 20 21 20 20 16 13 15 13 13 15 18 12 17 14 1、甲、乙两药是否均有效? 2、甲、乙两药的疗效有无差别? 三、某地抽样调查了部分健康成人的红细胞数和血红蛋白量,结果如下表: 2、分别计算男、女两项指标的抽样误差。 3、试估计该地健康成年男、女红细胞数的均数。
4、该地正常成年男、女血红蛋白含量有无差别? 5、该地成年男、女两项血液指标是否均低于上表地标准值? 四、为研究某药物的抑癌作用,使一批小白鼠致癌后,按完全随机设计的方法随机分为四组,A 、B 、C 三个试验组和一个对照组,分别接受不同的处理,A 、B 、C 三个试验组,分别注射0.5m1、1.0m1和1.5m1 30%的注射液,对照组不用药。经一定时间以后,测定四组小白鼠的肿瘤重量(g),测量结果见下表。问不同剂量药物注射液的抑癌作用有无差别?如有差别,请用SNK-q 检验方法作多重比较。 某药物对小白鼠抑癌作用(肿瘤重量,g)的试验结果 五、为研究注射不同剂量雌激素对大白鼠子宫重量的影响,取4窝不同种系的大白鼠,每窝3只,随机地分配到3个组内接受不同剂量雌激素的注射,然后测定其子宫重量,结果见下表。问注射不同剂量的雌激素对大白鼠子宫重量是否有影响? 如有影响,请用Dunnett-t 检验方法作多重比较。 大白鼠注射不同剂量雌激素后的子宫重量(g) 大白鼠 种系 雌激素剂量(μg/100g) 0.25 0.5 0.75 A 108 112 142 B 46 64 116 C 70 96 134 D 43 65 98 六、思考题及名词解释 1、试述正态分布、z 分布及t 分布的联系和区别。 2、均数的可信区间与参考值范围有何不同?试比较95%参考值范围与95%总体均数可信区间。 3、抽样分布(数理统计)的中心极限定理的内容是什么? 4、试举例说明标准差与标准误(即均数的标准差)的区别与联系。 对照组 试 验 组 A B C 3.6 3.0 0.4 3.3 4.5 2.3 1.8 1.2 4.2 2.4 2.1 1.3 4.4 1.1 4.5 2.5 3.7 4.0 3.6 3.1 5.6 3.7 1.3 3.2 7.0 2.8 3.2 0.6 4.1 1.9 2.1 1.4 5.0 2.6 2.6 1.3 4.5 1.3 2.3 2.1
看医统学习题(计数资料)
《医学统计学习题》计数资料 5、有资料如下表: 甲、乙两个医院某传染病各型治愈率 病型 患者数治愈率(%)甲乙甲乙 普通型300 100 60.0 65.0 重型100 300 40.0 45.0 暴发型100 100 20.0 25.0 合计500 500 48.0 45.0 由于各型疾病的人数在两个医院的内部构成不同,从内部看,乙医院各型治愈率都高于甲医院,但根据栏的结果恰好相反,纠正这种矛盾现象的统计方法是: A、重新计算,多保留几位小数 B、对率进行标准化 C、对各医院分别求平均治愈率 D、增大样本含量,重新计算 6、5个样本率作比较,χ2>χ20.01,4,则在α=0.05检验水准下,可认为: A、各总体率不全等 B、各总体率均不等 C、各样本率均不等 D、各样本率不全等 7、两个独立小样本计量资料比较的假设检验,首先应考虑: A、用t检验 B、用Wilcoxon秩和检验 C、t检验或Wilcoxon秩和检验均可 D、资料符合t检验还是Wilcoxon秩和检验条件 13.对三行四列表资料作 2检验,自由度等于 A. 1 B. 2 C. 3 D. 6 E. 12 14. 根据下述资料,则 病情 病人数治愈数治愈率(%)病人数治愈数治愈率(%)轻型40 36 90 60 54 90 重型60 42 70 40 28 70 合计100 78 78 100 82 82 A. 乙疗法优于甲疗法 B. 甲疗法优于乙疗法 C. 甲疗法与乙疗法疗效相等 D. 此资料甲、乙疗法不能比较 E. 以上都不对15.在实际工作中,同质是指()。 A.被研究指标的非实验影响因素均相同。B.研究对象的测量指标无误差。 C.被研究指标的主要影响因素相同。D.研究对象之间无个体差异。E.以上都对。答案 5、有资料如下表: 甲、乙两个医院某传染病各型治愈率 病型 患者数治愈率(%)甲乙甲乙
作业与参考标准答案ch第三部分计数资料统计描述和统计推断
作业与参考标准答案ch第三部分计数资料统计描述和统计推断
————————————————————————————————作者:————————————————————————————————日期:
《医学统计学》 【教材】倪宗瓒主编.医学统计学.北京;高等教育出版 社.2004. 【作业】教材附录二 【习题解答】 第三单元 计数资料的统计描述和统计推断 分析计算题 3.1 解: (1) 100%= ?同年该年龄组死亡人数 年龄组死亡人数构成比某年某年龄组死亡总数 %39.1%1001802 25 ~0=?= 岁组死亡人数构成比 余类推; 10000010= ?同年该年龄组死亡人数 死亡率万某年某年龄组平均人口数 010000010 3.3610?=25 ~岁组死亡率= 万万745000 余类推; 岁组死亡率 各年龄组死亡率 相对比~0= 04.1336 .380 .43~30== 岁组相对比 余类推。 各年龄组死亡人数构成比、死亡率和相对比计算结果见表3.1.1。 表3.1.1 某地某年循环系统疾病死亡资料 年龄组 /岁 平均人口数 循环系统 死亡人数 死亡人数构成比 /% 死亡率 (1/10万) 相对比 (各年龄组死亡率/0~组死亡率)
0~ 745000 25 1.39 3.36 — 30~ 538760 236 13.10 43.80 13.04 40~ 400105 520 28.86 129.97 38.68 50~ 186537 648 35.96 347.38 103.39 60~ 52750 373 20.70 707.11 210.45 合 计 1923152 1802 100.00 93.70 — (2) 死亡人数构成比是指某年龄组死亡人数与各年龄组死亡人口总数之比,说明总死亡人数中各年龄组死亡人数所占的比重; 死亡率是指某年实际死亡数与该年可能发生死亡人数(本题即为该年平均人口数)之比,用以说明死亡发生的频率或强度; 相对比用以说明各年龄组死亡率是0~岁组死亡率的几倍或几分之几。 3.2解:因为甲、乙两医院某传染病的类型构成明显不同,且疾病类型对该病的治疗效果有影响,故应进行标准化,再比较两医院的治愈率。根据本题资料,以两医院合计病人数为标准人口,采用直接标准化法。 表3.2.1 直接法计算甲、乙两医院某传染病标准化治愈率/% 类型 标准病人数 N i 甲医院 乙医院 原治愈率/% p i 预期治愈人数 N i p i 原治愈率/% p i 预期治愈人数 N i p i 普通型 552 59.9 331 65.2 360 重 型 552 39.9 220 44.9 248 暴发型 252 19.8 50 25.4 64 合 计 1356 48.4 601( i i N p ∑) 45.4 672( i i N p ∑) 甲医院某传染病标准化治愈率:601 100%44.3%1356p '=?=甲 乙医院某传染病标准化治愈率:672100%49.6%1356p '=?=乙 可以看出,经标准化后乙医院的该传染病的治愈率高于甲医院。
计量复习资料详解
第一章 一、现代地理学发展史上的计量运动 ⑴、计量运动的萌芽: 舍弗尔等人对区域学派的批评与否定,拉开了现代地理学发展史上的计量运动的帷幕。 计量运动主要是由美国地理学家发起的,形成了3大学派: ①艾奥瓦的经济派。代表人物是舍弗尔、麦卡尔蒂。受杜能、廖什、克里斯塔勒等区位论学者影响很深,极力倡导建立地理学法则,着重探讨经济区位现象间相互内在联系及其组合类型。 ②威斯康星的统计派。代表人物是威弗尔、罗宾逊、东坎和仇佐里,以经典著作《统计地理学》为代表作,主要特征是发展和应用统计分析方法。 ③普林斯顿的社会物理学派。代表人物是司徒瓦特(J.Q. Stewart)。该派把物理学原理应用于社会现象的研究之中,发展了理论地理学中的引力模型、位势模型、空间相互作用模式。 ⑵、计量运动的飞速发展: 加里森(W. L. Garrison) 及其领导的华盛顿小组首次把地理学的理论和方法建立在定量的基础上,编写了第一本《计量地理学》教材,率先在华盛顿大学举办了地理计量方法研讨班,培养了大批现代地理学名家。 美国区域科学协会组织了大量的学术活动,编辑出版了《区域科学年鉴》,成为美国计量运动的源地之一。瑞典学者哈格斯特朗积极组织瑞典和美国的地理学家交流学术思想,大大促进了计量运动向全世界的扩散。 ⑶、计量运动中涌现的著名学派、组织和学术刊物: 英国以乔莱(R.J. Chorley)、哈格特(P. Haggett)和哈威(D. Harvey)等为代表的剑桥学派; 1964年国际地理学联合会(IGU)设立的地理计量学方法委员会; 1967年英国地理学会设立的地理教学采用模型和计量技术委员会; 1968年日本成立的计量地理学研究委员会,1973年又改称理论、计量地理学委员会; 1963年英国出版的《地理学计量资料杂志》和1969年美国出版的《地理分析——国际理论地理学》杂志。 二、地理计量化的表现: ⑴、古代地理学和近代地理学中的数学方法限于定量地描述、记载和解释。 ⑵、现代地理学中运用数学方法,是为了深入地进行定量化研究,揭示地理现象发生、发展的内在机制及运动规律,从而为地理系统的预测及优化调控提供科学依据。 三、计量地理学的发展经历了那几个阶段: 第一阶段(20世纪50年代末期到60年代末期) 把统计学方法引入地理学研究领域,构造一系列统计量来定量地描述地理要素的分布特征,应用各种概率分布函数、方差等简单的统计特征回归分析方法。分布中心、区域形状、地理要素分布的集中和离散程度等都有了定量指标,许多地理要素间的相关关系,也可以进行定量地表示。 第二阶段(20世纪60年代末期到70年代末期) 多元统计分析方法和电子计算机技术在地理学研究中广泛应用。以电子计算
第六章分类资料的统计推断
1不满足正态近似条件,所以采用直接计算概率法。 H0:加维生素C的治愈率与不加相同,即π=π0=0.6 H1:加维生素C的治愈率高于不加维生素C,即π>π0 α=0.05 P(X≤8)=1-P(X≥9)=1-P(X=9)-P(X=10)=1-C109*0.69*0.41-C1010*0.610*0.40= 0.9536>0.05 不拒绝H0,差别无统计学意义,可以认为加维生素C的治愈率与不加相同。 2满足正态近似条件,采用正态近似法。 H0:经健康教育后的高血压患病率与以前相同,即π=π0=0.6 H1:经健康教育后的高血压患病率比以前降低,即π<π0 单侧α=0.05 u==4.9453536 u>u0.05,单侧=1.64 p<0.05,拒绝H0,接受H1,差别有统计学意义,可以认为经健康教育后的高血压患病率与以前有差别。 3①建立检验假设和确定检验水准 H0:男女大学生HBV感染对其心理影响相同,即π1 =π2 H1:男女大学生HBV感染对其心理影响不同,即π1≠π2 检验水准α=0.05 ②计算检验统计量 χ2=(ad-bd)2*n/(a+b)(c+d)(a+c)(b+d) =(250*213-246*320)/(250+320)(246+213)(250+246)(320+213)=9.651 ν=1 ③确定p值 查χ2届值表,得p<0.05 ④统计推断 按α=0.05水准,拒绝H O,接受H1,差别有统计学意义,可以认为HBV感染对不同性别的大学生在心理行为方面的影响不同。 4①建立检验假设和确定检验水准 H0:两组的治愈率相等,即π1 =π2 H1:两组的治愈率不等,即π1≠π2 检验水准α=0.05
6.计量资料的统计推断—t检验
6 计量资料的统计推断-t检验 t检验是以t分布为理论依据的假设检验方法,常用于正态总体小样本资料的均数比较,t检验统计量有三个不同的形式,适用于单因素设计的三种不同类型:①单个样本的均数与已知总体均数比较的检验,适用于单组设计,给出一组服从正态分布的定量观测数据和一个标准值(总体均值)的资料。②配对t检验,适用于配对设计。③成组t检验,适用于完全随机设计的两均数比较。 SPSS中使用菜单Analyze →Compore Means作t检验,Compore Means的下拉菜单如表6-1所示。 表6-1 Compore Means下拉菜单 Means…分层计算… One-Sample T Test…单样本t检验… Independent-Samples T Test…独立样本t检验… Paired-Sample T Test…配对t检验… One-Way ANOV A…单因素方差分析… 6.1 计量资料的分层计算 Means过程可以对计量资料分层计算均数、标准差等统计量,同时可对第一层分组进行方差分析和线性趋势检验。 例6-1某学校测得不同年级、不同性别的12名学生的身高(cm),数据见表6-2。试用SPSS的Means过程分别计算不同年级、不同性别学生身高的均数和标准差。 表6-2 12名学生的身高(cm) 解年级:1=“初一”、2=“高一”,性别:1=“男”、2=“女”。 选择Analyze→Compare Means→Means命令,弹出Means对话框,如图6-2。在变量列表中选中身高,送入Dependent(因变量)框中;选中年级,送入Independent(自变量),确定第一层依年级分组,单击Next按钮,选中性别,送入Independent,确定第二层依性别分组;单击OK。输出结果如图6-3所示。 在Means对话框单击Options(选项)按钮,弹出Means:Options对话框,可以选择要计算的统计量,默认Mean、Number of cases、Standard Deviation;在Statisti cs for First Layer中,可对第一层分组作方差分析(Anova table and eta)和线性趋势检验(Test for linearity)。
分类资料的统计分析A型选择题-30页精选文档
第十章分类资料的统计分析 A型选择题 1、下列指标不属于相对数的是() A、率 B、构成比 C、相对比 D、百分位数 E、比 2、表示某现象发生的频率或强度用 A 构成比 B 观察单位 C 相对比 D 率 E 百分比 3、下列哪种说法是错误的() A、计算相对数尤其是率时应有足够数量的观察单位数或观察次数 B、分析大样本数据时可以构在比代替率 C、应分别将分子和分母合计求合计率或平均率 D、相对数的比较应注意其可比性 E、样本率或构成比的比较应作假设检验 4、以下哪项指标不属于相对数指标( ) A.出生率
B .某病发病率 C .某病潜伏期的百分位数 D .死因构成比 E .女婴与男婴的性别比 5、计算麻疹疫苗接种后血清检查的阳转率,分母为( ). A.麻疹易感人群 B.麻疹患者数 C.麻疹疫苗接种人数 D.麻疹疫苗接种后的阳转人数 E.年均人口数 6、某病患者120人,其中男性114人,女性6人,分别占95%与5%,则结论为( ). A.该病男性易得 B.该病女性易得 C.该病男性、女性易患率相等 D.尚不能得出结论 E.以上均不对 7、某地区某重疾病在某年的发病人数为0α,以后历年为1α,2α,…,n α,则该疾病发病人数的年平均增长速度为( )。 A. 1 ...10+++n n ααα B. 110+??n n ααα C.n n 0 α α
D.n n 0 α α -1 E. 10 -a a n 8、按目前实际应用的计算公式,婴儿死亡率属于( )。 A. 相对比(比,ratio ) B. 构成比(比例,proportion ) C. 标准化率(standardized rate ) D. 率(rate ) E 、以上都不对 9、某年某地乙肝发病人数占同年传染病人数的9.8%,这种指标是 A .集中趋势 B .时点患病率 C .发病率 D .构成比 E .相对比 10、构成比: A.反映事物发生的强度 B 、反映了某一事物内部各部分与全部构成的比重 C 、既反映A 也反映B D 、表示两个同类指标的比 E 、表示某一事物在时间顺序上的排列 11、构成比之重要特点是各组成部分的百分比总和: A.必大于1
统计学计量的统计描述方法
计量资料的统计描述方法 怎样表达一组数据? 描述计量资料的常用指标— A、描述平均水平(中心位置): 均数X、中位数和百分位数、几何均数G、众数(mode) B、描述数据的分散程度: 标准差、四分位数间距、变异系数、方差、全距 (一)均数mean和标准差standard deviation 1. (算术)均数X 均数是描述一组计量资料平均水平或集中趋势的指标。 *直接计算公式: 应用条件:适用于对称分布,特别是正态分布资料。 2. 中位数(median)M和百分位数(percentile) A.中位数M 是将一组观察值从小到大排序后,居于中间位置的那个值或两个中间值的平均值。 应用条件: 用于任何分布类型,包括偏态资料、两端数据无界限的资料。 计算: n为奇数时-- n为偶数时-- 9人数据:12,13,14, 14, 15, 15, 15, 17, 19天 B.百分位数 是将N个观察值从小到大依次排列,再分成100等份,对应于X%位的数
值即为第X 百分位数。中位数是第百分50位数。 四分位数间距(quartile range ) = 第25百分位数(P25)~第75百分位数(P75)。 四分位数间距用于描述偏态资料的分散程度(代替标准差S ),包含了全部观察值的一半。 百分位数计算(频数表法): X L :第X 百分位数所在组段下限 L Σf :小于X L 各组段的累计频数 X i :第X 百分位数所在组段组距 n :总例数 f x :所在组段频数 注:有的教材X= r ; L f =C 例:求频数表的第25、第75百分位数(四分位数间距) 组段 频数f 累积频数∑f 56~ 2 2 59~ 5 7 62~ 12 19 ∑f 25 L 25 65~ 15 34 P 25在此 68~ 25 59 71~ 26 85 ∑f 75 L 75 74~ 19 104 P 75在此 77~ 15 119 80~ 10 129 83~85 1 130 合 计 130 ① 确定Px 所在组段: P 25所在的组段:n X %=130×25%=32.5, 65~组最终的累积频数=34,32.5落在65~组段内; P 75所在的组段:n X %=130×75%=97.5, 此值落在74~组段 ② 确定Px 所在组段的X L 、X i 、f x 、L Σf ③ P 25=65+3x[(130x25%-19)/15]=65.90 P 75=74+3x[(130x75%-85)/19]=74.66
第六章分类资料的统计推断(pdf 6)
第六章 分类资料的统计推断 分类资料中最常用的统计方法是2χ检验,确切概率法,另外还有秩和检验。秩和检验在后一章介绍,本章重点介绍2χ检验,其它方法简略讲述。 6.1 四格表资料2χ检验 例 6.1 某医院治疗慢性肾炎病人,其中用西药治疗79例,有效者63人,有效率79.75%,用中药治疗54例,有效者47人,有效率87.04%,问两种药物治疗慢性肾炎有效率是否相同? 处理 有效 无效 西药组 63 16 中药组 47 7 具体步骤: 1. 数据录入 设变量group 代表处理组(西药组为1,中药组为2),变量effect 代表是否有效(有效为1,无效为0),变量f 代表频数,即例数。如西药组有效例数为63,则group 为1,effect 为1,freq 为63。数据格式如图6.1。 2.统计分析 首先依次选取Data -weight Cases ,展开对话框如图6.2,选择Weight cases by ,将freq 选入Frequency Variable :框,即赋予权重;然后依次选取Analyze -Descriptive Statistics -Crosstabs ,展开对话框如图6.3,将group 选入Rows 框,effect 选入Columns 框,或相反; 该对话框下方有三个按钮:Statistics 、Cells 和Format ,现将其子对话框选项介绍如下: Statistics 选择要输出的统计量,常用的有2χ(Chi -square )、Pearson 相关系数
χ(McNemar)(Correlations)、Kappa系数(Kappa)、相对危险度(Risk)、配对2 等。 Cells指定多维分布表中显示实际频数、理论频数、行列及全部百分比和残差等。 Format指定行顺序(升序或降序)。 在对话框下方还有两个选项:Display Clustered Bar Charts(输出直方图)和Suppress Tables(不输出多维分布表)。 本例仅计算2 χ,单击Statistics,弹出对话框如图6.4,选取Chi-square。返回主对话框,单击OK提交执行。 χ检验数据格式 图6.1 2
练习二 计量资料的区间估计与t检验
练习二计量资料的区间估计与t检验 一、思考题 1以t检验为例, 简述假设检验的一般步骤。 2配对资料有哪几种情形?请举例说明。 3 标准差与标准误之间的联系与区别是什么? 4 可信区间与正常值范围的联系与区别是什么? 5 试述统计推断包括的主要内容。 6如果配对设计的资料用成组设计的方法处理假设检验,结果如何? 二、最佳选择题 1减少均数的抽样误差的可行方法之一是: A. 严格执行随机抽样 B .增大样本含量 C. 设立对照 D. 选一些处于中间状态的个体 2 增大样本含量,理论上可使其变小的是: A. 样本的变异系数 B. 样本的标准差 C. 均数的抽样误差 D. 样本均数 3 两小样本均数比较,当方差不齐时,可选择: A.t’检验 B.t检验 C.F检验 D. 2检验 4样本均数比较的t检验,P<0.05,按α=0.05水准,认为两总体均数不同。此时若推断有错,则犯第Ⅰ类错误的概率P: A. P>0.05 B. P<0.05 C. P=0.05 D. P=β, 而β未知 5 由t分布可知,自由度υ越小,t分布的峰越矮,尾部翘得越高,故正确的是: A. t0.05,5>t0.05,1 B. t0.05,5=t0.05,1 C. t0.05,1>t0.01,1 D. t0.05,1>t0.05,5 6多个样本均数间两两比较时,若采用t检验的方法,则会出现的情况是: A. 结果与q检验相同 B. 结果比q检验更合理 C. 可能出现假阴性的结果 D. 可能出现假阳性的结果 7两组数据中的每个变量值减去同一常数后作两个样本均数差异的t检验, A. t值变小 B. t值变大 C. t值不变 D. t值变小或变大 8对于配对(或成对)t检验和成组t检验,下列哪一种说法是错误的: A. 对于配对设计的资料应作配对t检验,如果作成组t检验,不但不合理,而且 平均起来统计效率降低 B. 成组设计的资料用配对t检验,不但合理,而且平均起来可以提高统计效率 C. 成组设计的资料,无法用配对t检验 D. 作配对或成组t检验,应根据原始资料的统计设计类型而定 9在两样本均数差别的t检验中,事先估计并确定合适的样本含量的一个重要作用是: A. 控制Ⅰ型错误概率的大小 B. 可以消除Ⅰ型错误
实习2 定量资料的统计推断1
实习二 定量资料的统计推断 一、目的要求 1、掌握抽样误差、标准误、可信区间的概念及计算; 2、熟悉t 分布; 3、掌握假设检验的基本原理、有关概念(如I 、II 类错误)及注意事项; 4、掌握t 检验和u 检验的适用条件、基本步骤等。 二、主要内容 (一)基本概念 1.抽样误差 2.可信区间 (二)t 分布 1.以0为中心,左右对称的单峰分布; 2.t 分布曲线是一簇曲线,其形态与自由度v 的大小有关。自由度v 越小,则t 值越分散,曲线越低平;自由度v 逐渐增大时,t 分布逐渐逼近u 分布(标准正态分布);当v 趋于∞时,t 分布即为u 分布。 (三)总体均数的估计 1、点估计 2、区间估计 ①σ未知且n 较小:(/2X X t S αν-,,/2v X X t S α+,) ②σ未知但n 足够大:(/2X X u S α-,/2X X u S α+) ③σ已知:(X u X σα2/-,X u X σα2/+) (四)假设检验的步骤及有关概念 1、基本思想:小概率事件和反证法 2、基本步骤 (1)建立检验假设,确立检验水准 (2)选择检验方法,计算检验统计量 (3)确定P 值,下结论 P <α,拒绝H 0,接受H 1,差异有统计学意义,可以认为……不同。
P>α,不拒绝H0,差异无统计学意义,尚不能认为……不同。 3、两类错误: Ⅰ型错误是拒绝了实际上成立的H0,也称为“弃真”错误,用α表示。统计推断时,根据研究者的要求来确定。 Ⅱ型错误是不拒绝实际上不成立的H0,也称为“存伪”错误,用β表示。但β值的大小一般很难确切估计,只有已知样本含量n、两总体参数的差值δ以及检验水准α的条件下,才能估算出β的大小。 4、注意事项 (五)t检验和u检验 1、t检验的应用条件:独立性;σ未知且n较小时,要求样本来自正态分布总体;两样本均数比较时,还要求两样本所属总体的方差齐性。 2、u检验的应用条件:独立性;σ未知但n足够大(如n>100)或σ已知。 3、t检验与u检验,检验统计量的计算: 三、SPSS操作演示 1、单样本t检验 2、两独立样本t检验 3、两配对样本t检验 四、课堂讨论 1.根据以下案例资料回答问题:在对两组药物治疗某心血管病的临床试验研究中,选择了140例受试对象,得到如下结果:
计数资料的统计学分析 (1)
[模拟] 计数资料的统计学分析 A型题题干在前,选项在后。有A、B、C、D、E五个备选答案其中只有一个为最佳答案。 第1题: 计数资料又称如下哪一种资料 A.数量资料 B.抽样资料 C.普查资料 D.调查资料 E.定性资料 参考答案:E 答案解析: 第2题: 计数资料是指将观察单位按下列哪一种分组计数所得的资料 A.数量 B.体重 C.含量 D.属性或类型或品质 E.放射性计数 参考答案:D 答案解析: 第3题: 计数资料的初步分析常常要用下列哪些相对数 A.频数 B.频数和频率指标 C.率、构成比和相对比 D.构成指标和相对比 E.比和构成比 参考答案:C 答案解析: 第4题: 频率指标,它说明某现象发生的如下哪一种
B.强度 C.比重大小 D.例数 E.各组的单位数 参考答案:B 答案解析: 第5题: 构成指标,它说明一事内部各组成部分所占的如下哪一种大小 A.比重 B.强度 C.频数 D.频率 E.例数 参考答案:A 答案解析: 第6题: 对480人进行老年性白内障普查,分60岁一、70岁一和80岁一三个年龄组受检人数分别为300、150和30人,白内障例数分别为150、90和24人。回答70岁一年龄组的患病率(%)是多少 A.5 B.50 C.60 D.80 E.20 参考答案:C 答案解析: 第7题: 对1000人进行老年性白内障普查,分50岁一和60岁一两个年龄组,受检人数分别为480人和520人,白内障例数分别为120人和280人。回答患者50岁一年龄构成比(%)是多少 A.53.9 B.12 C.30 D.28
参考答案:C 答案解析: 第8题: 在计数资料计算相对数时,应注意如下哪些问题 A.分母不宜过大 B.可比性 C.随机性 D.分母不宜过小 E.分母宜中 参考答案:D 答案解析: 第9题: 在计数资料进行相对数间比较时,应注意如下哪些问题 A.分母不宜太小 B.可比性 C.可用频率指标代替构成指标 D.随机性和正态分布 E.其可比性和遵循随机抽样 参考答案:E 答案解析: 第10题: X2检验是要计算检验统计量X2值、X2值是反应如下哪种情况 A.实际频数大于理论频数 B.理论频数大于实际频数 C.实际频率和理论频率的吻合程度 D.实际频数和理论频数的吻合程度 E.实际频率大于理论频率 参考答案:D 答案解析: 第11题: X2值愈大,则X2值的概率P值如下哪种情况
假设检验的基本步骤
假设检验的基本步骤 (三)假设检验的基本步骤 统计推断 1.建立假设检验,确定检验水准 H0和H1假设都是对总体特征的检验假设,相互联系且对立。 H0总是假设样本差别来自抽样误差,无效/零假设 H1是来自非抽样误差,有单双侧之分,备择假设。 检验水准,a=0.05 检验水准的含义 2.选定检验方法,计算检验统计量 选择和计算检验统计量要注意资料类型和实验设计类型及样本量的问题, 一般计量资料用t检验和u检验; 计数资料用χ2检验和u检验。 3.确定P值,作出统计推理 P≤a ,拒绝H0,接受H1 P> a,按a=0.05水准,不拒绝H0,无统计学意义或显著性差异 假设检验结论有概率性,无论使拒绝或不拒绝H0,都有可能发生错误 (四)两均数的假设检验(各种假设检验方法的适用条件及假设的特点、计算公式、自由度确定以及确定概率P值并做出推断结论) u检验适用条件 t检验适用条件 t检验和u检验 1.样本均数与总体均数比较 2.配对资料的比较/成组设计的两样本均数的比较 配对设计的情况:3点 3. 两个样本均数的比较 (1)两个大样本均数比较的u检验 (2)两个小样本均数比较的t检验 (五)假设检验的两类错误及注意事项(Ⅰ和Ⅱ类错误) 1.两类错误 拒绝正确的H0称Ⅰ型错误-弃真,用检验水准α表示,α=0.05,犯I型错误概率为0.05,理论上平均每100次抽样有5次发生此类错误; 接受错误的H0称Ⅱ型错误-存伪。用β表示,(1-β)为检验效能或把握度,意义为两总体有差异,按α水准检出差别的能力,1-β=0.9,若两总体确有差别,理论上平均每100次抽样有90次得出有差别的结论。 两者的关系:α愈大β愈小;反之α愈小β愈大。 2.假设检验中的注意事项 (1)随机化:代表性和均衡可比性 (2)选用适当的检验方法 (3)正确理解统计学意义 (4)结论不绝对 (5)单侧与双侧检验的选择 四.分类变量资料的统计描述
统计学-计量资料的统计描述方法
计量资料得统计描述方法 怎样表达一组数据? 描述计量资料得常用指标— A 、描述平均水平(中心位置): 均数X 、中位数与百分位数、几何均数G 、众数(mode) B 、描述数据得分散程度: 标准差、四分位数间距、 变异系数、方差、全距 (一)均数mean 与标准差standard deviation 1、 (算术)均数X 均数就是描述一组计量资料平均水平或集中趋势得指标。 *直接计算公式: 12n X X X X X n n +++= = ∑ 应用条件:适用于对称分布,特别就是正态分布资料。 2、 中位数(median )M 与百分位数(percentile) A 、中位数M 就是将一组观察值从小到大排序后,居于中间位置得那个值或两个中间值得平均值。 应用条件: 用于任何分布类型,包括偏态资料、两端数据无界限得资料。 计算: n 为奇数时-- 1 ( )2 n M X += n 为偶数时--
( )(1)2212n n M X X +? ?=+ ? ?? 9人数据:12,13,14, 14, 15, 15, 15, 17, 19天 B 、百分位数 就是将N 个观察值从小到大依次排列,再分成100等份,对应于 X%位得数值即为第X 百分位数。中位数就是第百分50位数。 四分位数间距(quartile range) = 第25百分位数(P25)~第75百分位数(P75)。 四分位数间距用于描述偏态资料得分散程度(代替标准差S),包含了全部观察值得一半。 百分位数计算(频数表法): (%) X X X L X i P L nX f f =+-∑ X L :第X 百分位数所在组段下限 L Σf :小于X L 各组段得累计频数 X i :第X 百分位数所在组段组距 n :总例数 f x :所在组段频数 注:有得教材X= r ; L f ∑=C ) (天1552 19===+X X M 88451 22221415214.5() M X X X X ?? ==== ???+如果只调查了前八位中学生,则: +(+)(+)天
第三单元 计数资料的统计描述和统计推断(第一部分)
第三单元计数资料的统计描述和统计推断 【习题】 分析计算题 3.1 某地某年循环系统疾病死亡资料如表18。 表18 某地某年循环系统疾病死亡资料 年龄组/岁平均人口数 循环系统 死亡人数 死亡人数构成比 /% 死亡率 (1/10万) 相对比 (各年龄组死亡率 /0~组死亡率) 0~745000 25 30~538760 236 40~400105 520 50~186537 648 60~52750 373 合计1923152 1802 (1) 请根据以上数据计算各年龄组死亡人数构成比、死亡率和相对比。 (2) 分析讨论各指标的含义。 3.2 请就表19资料比较甲、乙两个医院某传染病的治愈率/%。 表19 甲、乙两院某传染病治愈率(%)的比较 类型 甲医院乙医院 病人数治愈数治愈率/% 病人数治愈数治愈率/% 普通型414 248 59.9 138 90 65.2 重型138 55 39.9 414 186 44.9 暴发型126 25 19.8 126 32 25.4 合计678 328 48.4 678 308 45.4 3.3 传统疗法治疗某病,其病死率为30%,治愈率为70%。今用某种新药治疗该病10人,结果有1人死亡。问该新药的治疗效果是否优于传统疗法(单侧)。
3.4 甲、乙两地各抽样调查1万名妇女,结果甲地卵巢癌患病人数100人,乙地卵巢癌患病人数80人,请问甲乙两地妇女的卵巢癌患病率是否不同。 3.5 对甲地一个由40名新生儿组成的随机样本进行某病的基因检测,结果阳性2例。据此资料,估计该地此病的基因总体携带率的95%可信区间。 3.6 已知一般人群中慢性气管炎患病率为9.7%,现调查了300名吸烟者,发现其中有63人患有慢性气管炎,试推断吸烟人群慢性气管炎患病率是否高于一般人群。 3.7 研究者取4mL某饮料进行细菌培养,得细菌数60个,试估计平均每1mL 饮料中细菌数的均值和标准差,并估计平均每1mL饮料中细菌数的95%可信区间。 3.8 分别从两种饮料中各取10mL样品进行细菌培养,甲饮料培养细菌440个,乙饮料培养细菌300个,问两种饮料中细菌数有无差别。 3.9 若某地区1998年新生儿腭裂发生率为2.15‰ ,1999年在此地区抽样调查1000名新生儿,发现腭裂1例,问此地区1999年腭裂发生率是否比1998年低。 3.10 对某地区居民饮用水进行卫生学检测中,随机抽查1mL水样,经培养获大肠杆菌菌落2个,试估计该地区水中平均每毫升所含大肠杆菌菌落的95%可信区间。 3.11 将80例均为初治的乳腺癌患者随机分配到甲乙两种治疗方案中,每组各40例,甲方案31例有效,乙方案14例有效,问两种治疗方案的有效率有无差别? 3.12 为了解某中药治疗原发性高血压的疗效,将44名高血压患者随机分为两组。实验组用该药加辅助治疗,对照组用安慰剂加辅助治疗,观察结果如表20,问该药治疗原发性高血压是否有效? 表20 两种疗法治疗原发性高血压的疗效 分组例数有效有效率/% 实验组23 21 91.30 对照组21 5 23.81
.3.16-统计学-计量资料的统计描述方法
计量资料的统计描述方法 怎样表达一组数据 描述计量资料的常用指标 一 A 、 描述平均水平(中心位置): 均数X 、中位数和百分位数、几何均数 G 、众数(mode ) B 、 描述数据的分散程度: 标准差、四分位数间距、变异系数、方差、全距 (一)均数 mea n 和标准差 1.(算术)均数X 均数是描述一组计量资料平均水平 或集中趋势的指标。 直接计算公式: 应用条件:适用于对称分布,特别是正态分布资料 2.中位数(median ) M 和百分位数(percentile ) A.中位数M 是将一组观察值从小到大排序后,居于中间位置的那个值或两个 中间值的平均值。 应用条件: 用于任何分布类型,包括偏态资料、两端数据无界限的资料。 计算: sta ndard deviati on X ! X 2 L X n
n 为奇数时-- M x (= n 为偶数时-- M X 9 1 X 5 15(天) 2 如果只调查了前八位中学生,贝y : M X 8+ X 8 2 (X 4+ X )2 (14+15)/2 14.5(天) ?+ 1 * 2 2 B.百分位数 是将N 个观察值从小到大依次排列,再分成 100等份,对应于 X%位的数值即为第X 百分位数。中位数是第百分50位数。 四分位数间距 (quartile range / =第25百分位数(P25)?第75百分位数(P75)。 四分位数间距用于描述偏态资料的分散程度(代替标准差S ),包 含了全部观察值的一半。 1 — X 门 X 门 2 (2) (2 1) 9 人数据:12, 13, 14, 14, 15, 15, 15, 17, 19 天