哈夫曼编码译码器实验报告

实验报告
哈夫曼编码及译码
班级:软件工程一班
学号:2220141524
姓名:孙正涛1 问题描述
1.设计一个利用哈夫曼算法的编码和译码系统,重复地显示并处理以下项目,直到选择退出为止。
(1) 将权值数据存放在数据文件(文件名为data.txt,位于当前目录中);
(2) 分别采用动态和静态存储结构; 初始化:键盘输入字符集大小n、n个字符和n个权值,建立哈夫曼树;
(3) 编码:利用建好的哈夫曼树生成哈夫曼编码;输出编码;
设计要求:
(1) 符合课题要求,实现相应功能;
(2) 要求界面友好美观,操作方便易行;
(3) 注意程序的实用性、安全性。
2 需求分析
编写此软件是为了实现一个利用哈夫曼算法的编码和译码系统。比如,再利用电报进行通讯时,需要将文字转换成由二进制的字符组成的字符串。比如需传送的电文为“A B A C C D A”假设将A,B,C,D分别编码为00、01、10、11.则上述电文遍为100,总长度为14位。但是在传送过程中,总希望长度能够尽可能的短,于是我们想采用长度不等的编码。但是这种编码必须遵循:任何一个字符的编码都不是另一个字符编码的前缀。
对此软件的要求:能够正确的使得对于输入的字符进行编码以及译码,并且是的在译码过程中不会出错,同时能够将编码以及译码的结果正确的存入文件当中。
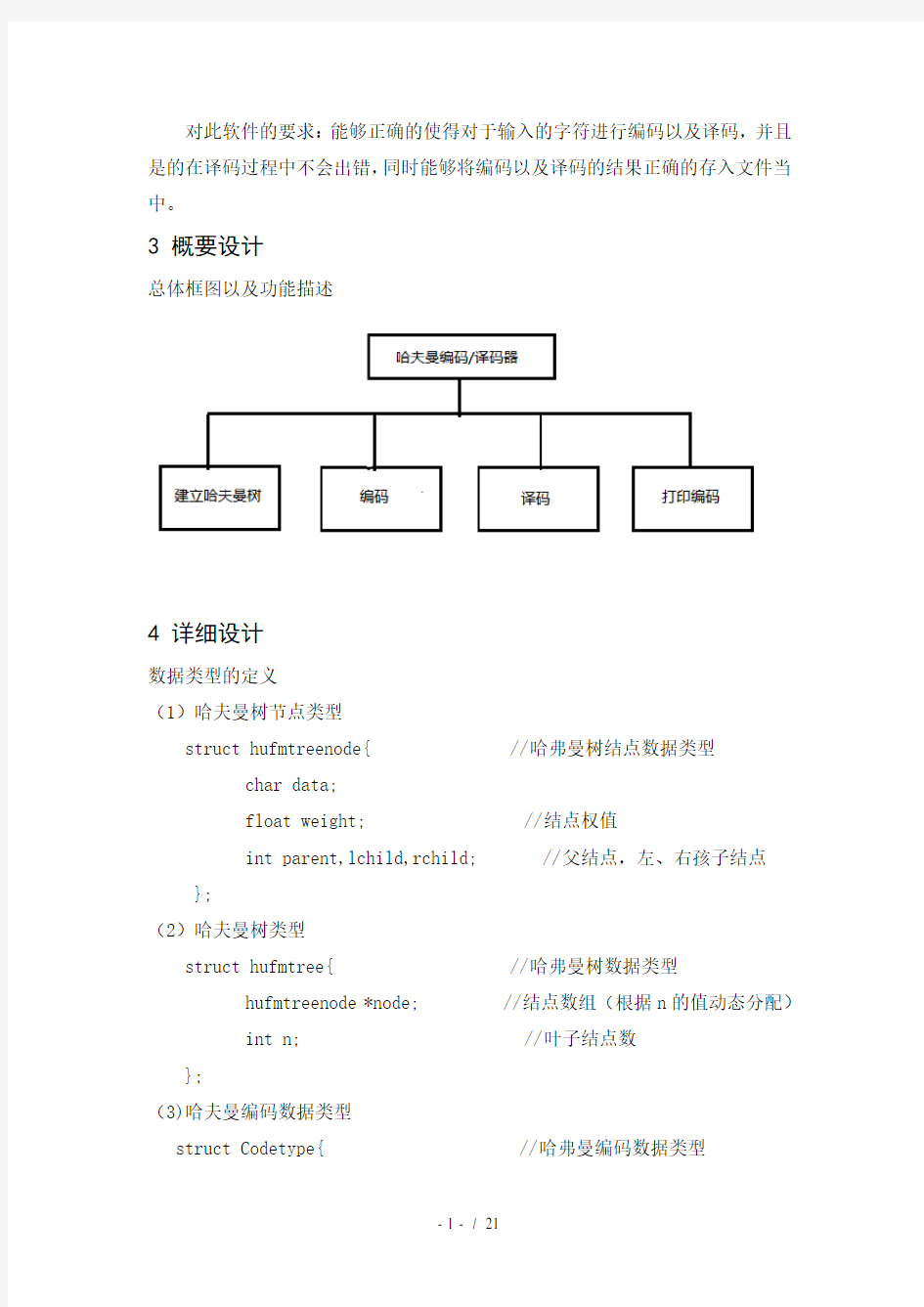
3 概要设计
总体框图以及功能描述
4 详细设计
数据类型的定义
(1)哈夫曼树节点类型
struct hufmtreenode{ //哈弗曼树结点数据类型 char data;
float weight; //结点权值
int parent,lchild,rchild; //父结点,左、右孩子结点
};
(2)哈夫曼树类型
struct hufmtree{ //哈弗曼树数据类型 hufmtreenode *node; //结点数组(根据n的值动态分配) int n; //叶子结点数
};
(3)哈夫曼编码数据类型
struct Codetype{ //哈弗曼编码数据类型
char *bits; //编码流数组,
int start;//编码实际在编码流数组里的开始位置
}
5 测试分析
(1)打开源文件统计各字符及权值信息并存入data.txt文件中
(2)将统计出的权值信息进行哈夫曼编码
(3)将编码内容存入Code文件中
(4)将Code文件中的内容译码
(5)成功译码把原字符信息存入DeCode文件中
(6)输入各字符及其权值
(7)将各字符的权值信息进行哈夫曼编码
(7)根据编码再进行译码工作
6 课程设计总结
课程设计是培养学生综合运用所学知识,发现,提出,分析和解决实际问题,锻炼实践能力的重要环节,是对学生实际工作能力的具体训练和考察过程.随着科学技术发展的日新日异,当今计算机应用在生活中可以说得是无处不在。因此作为二十一世纪的大学来说掌握计算机开发技术是十分重要的。
回顾起此次课程设计,至今我仍感慨颇多,的确,自从拿到题目到完成整个编程,从理论到实践,在整整一个星期的日子里,可以学到很多很多的的东西,同时不仅可以巩固了以前所学过的知识,而且学到了很多在书本上所没有学到过的知识。通过这次课程设计使我懂得了理论与实际相结合是很重要的,只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能真正为社会服务,从而提高自己的实际动手能力和独立思考的能力。在设计的过程中遇到问题,这毕竟独立做的,难免会遇到过各种各样的问题,同时在设计的过程中发现了自己的不足之处,对以前所学过的知识理解得不够深刻,掌握得不够牢固,比如说结构体……通过这次课程设计之后,一定把以前所学过的知识重新温故。
这次课程设计终于顺利完成了,在设计中遇到了很多编程问题,最后在谢老师的辛勤指导下,终于游逆而解。同时,在李玉蓉老师的《软件工程导论》
课上我学得到很多实用的知识,在次我表示感谢!同时,对给过我帮助的所有同学和各位指导老师再次表示忠心的感谢!
附录(源程序清单)
#include
#include
#include
#define MAXVAL 10000.0
struct hufmtreenode{//哈弗曼树结点数据类型
char data;
double weight;//结点权值
int parent,lchild,rchild;//父结点,左、右孩子结点
};
struct hufmtree{//哈弗曼树数据类型
hufmtreenode *node;//结点数组(根据n的值动态分配)
int n;//叶子结点数
};
struct Codetype{//哈弗曼编码数据类型
char *bits;//编码流数组,n为为哈夫曼树中叶子结点的数目,编码的长度不可能超过n
int start;//编码实际在编码流数组里的开始位置
};
void SortHufmtree(hufmtree *tree){//将哈夫曼树n个叶子结点由大到小排序int i,j,k;
hufmtreenode temp;
if (tree==NULL)
return;
for (i=0;i
{
k=i;
for(j=i+1;j
if (tree->node[j].weight>tree->node[k].weight) k=j;
if (k!=i)
{
temp=tree->node[i];
tree->node[i]=tree->node[k];
tree->node[k]=temp;
}
}
}
Codetype* HuffmanCode(hufmtree *tree){//哈弗曼编码的生成int i,j,p,k;
Codetype *code;
if (tree==NULL)
return NULL;
code=(Codetype*)malloc(tree->n*sizeof(Codetype));
for (i=0;i
{
printf("%c ",tree->node[i].data);//打印字符信息
code[i].bits=(char*)malloc(tree->n*sizeof(char));
code[i].start=tree->n-1;
j=i;
p=tree->node[i].parent;
while(p!=-1){
if (tree->node[p].lchild==j)
code[i].bits[code[i].start]='0';
else
code[i].bits[code[i].start]='1';
code[i].start--;
j=p;
p=tree->node[p].parent;
}
for (k=code[i].start+1;k
printf("%c",code[i].bits[k]);
printf("\n");
}
return code;
}
hufmtree* BuildHuffmanTree(hufmtree *tree){//构建叶子结点已初始化的哈夫曼树
//tree中所有叶子结点已初始化
int i,j,p1,p2,m;
float small1,small2;
m=2*(tree->n)-1;
for (i=tree->n;i { tree->node[i].parent=-1; tree->node[i].lchild=-1; tree->node[i].rchild=-1; tree->node[i].weight=0.0; } for (i=tree->n;i { small1=small2=MAXVAL; for (j=0;j<=i-1;j++) { if (tree->node[j].parent==-1 && tree->node[j].weight<=small1) { small1=tree->node[j].weight; p1=j; } } for (j=0;j<=i-1;j++) { if (tree->node[j].parent==-1 && tree->node[j].weight<=small2 && (j!=p1)) { small2=tree->node[j].weight; p2=j; } } tree->node[p1].parent=tree->node[p2].parent=i; tree->node[i].weight=tree->node[p1].weight+tree->node[p2].weight; tree->node[i].lchild=p1; tree->node[i].rchild=p2; } return tree; } hufmtree* CreateHuffmanTreeFromSourceFile(){//通过解析源文件建立哈夫曼树 FILE *textfile,*datafile; char ch,source[100]; int i,j=0,n=0; float count[128]; //用于统计字符在源文件中出现的次数,27表示26个英文字母和1个空格字符 hufmtree *tree; //打开一个源文件 printf("\n请输入源文件所在路径:\n"); scanf("%s",source); if ((text(source,"r"))==NULL){ printf("\n找不到文件%s\n",source); return NULL; } for(i=0;i<128;i++) count[i]=0; //对源文件中各字符的个数统计 ch=fgetc(textfile); while(!feof(textfile)){ for(i=0;i<128;i++) if (ch==char(i)){ count[i]++; break; } ch=fgetc(textfile); } //将统计结果写入权值信息文件data.txt中,并构建哈夫曼树 data("f:\\data.txt","w"); for (i=0;i<128;i++)