一个简单的C语言编译器

一个简单的C语言编译器
一.小组成员
朱嘉俊(3991102161)计算机996
王筱(3991102168)计算机996
朱杭(3991102162)计算机996
朱林(3991102094)计算机994
二.运行方式
在DOS环境下运行:
Cminus.exe
三.概述
经过一段时间的学习,我们在初步掌握了编译器的基本原理以后,设计了一个具有基本编译功能的编译器。该编译器接受类C语言语法的源代码输入,输出结果是PC机的汇编源代码。在捆绑了宏汇编编译器Masm后,即可直接生成MSDOS下的二进制可执行文件。为方便起见,以下简称为C—语言编译器。
本编译器实现了基本高级语言所必须的语法要素,包括简单变量声明、函数的实现、整数和字符串运算、条件判断语句和循环语句及跳转语句、基本代数运算、赋值等,还支持汇编语言嵌入。本编译器是利用编译器生成器Parse Generator和VC6.0在Windows平台上实现的,并开发了一个基于Windows平台的32位编译集成开发环境CompilerMan,提供了关键字彩色提示、出错同屏提示、出错代码跳转等较为完善方便的功能。
由于编译程序本身涉及到词法分析、语法分析、代码生成、错误恢复和优化等诸多模块,要在实验中做到面面俱到不太可能,所以本编译器不可避免的会存在各种问题,但作为一个具有基本功能的、可扩充的系统,完全达到了巩固编译原理的理论知识,并将其运用于实践的目的。
四.背景
编译程序,就是一种具有编撰和翻译功能的程序。人们要用计算机来解决问题,首先面临的一个问题,就是要告诉计算机解决什么问题,或者告诉计算机如何解决这个问题。这就涉及到用什么样的语言来描述的问题,人所习惯的自然语言和计算机认识的机器语言有很大的差别,用机器语言来描述人想解决的问题十分不便,因而,计算机科学家设计一些人们比较习惯的语言来描述要解决的问题,称之为高级语言。用语言来描述的问题,统称为程序。然而,用高级语言写的程序,不能被计算机所直接认识和理解,必须经过等价的转换,变成机器能理解并执行的机器语言的程序。进行这种等价转换工作的工具,就是编译程序。
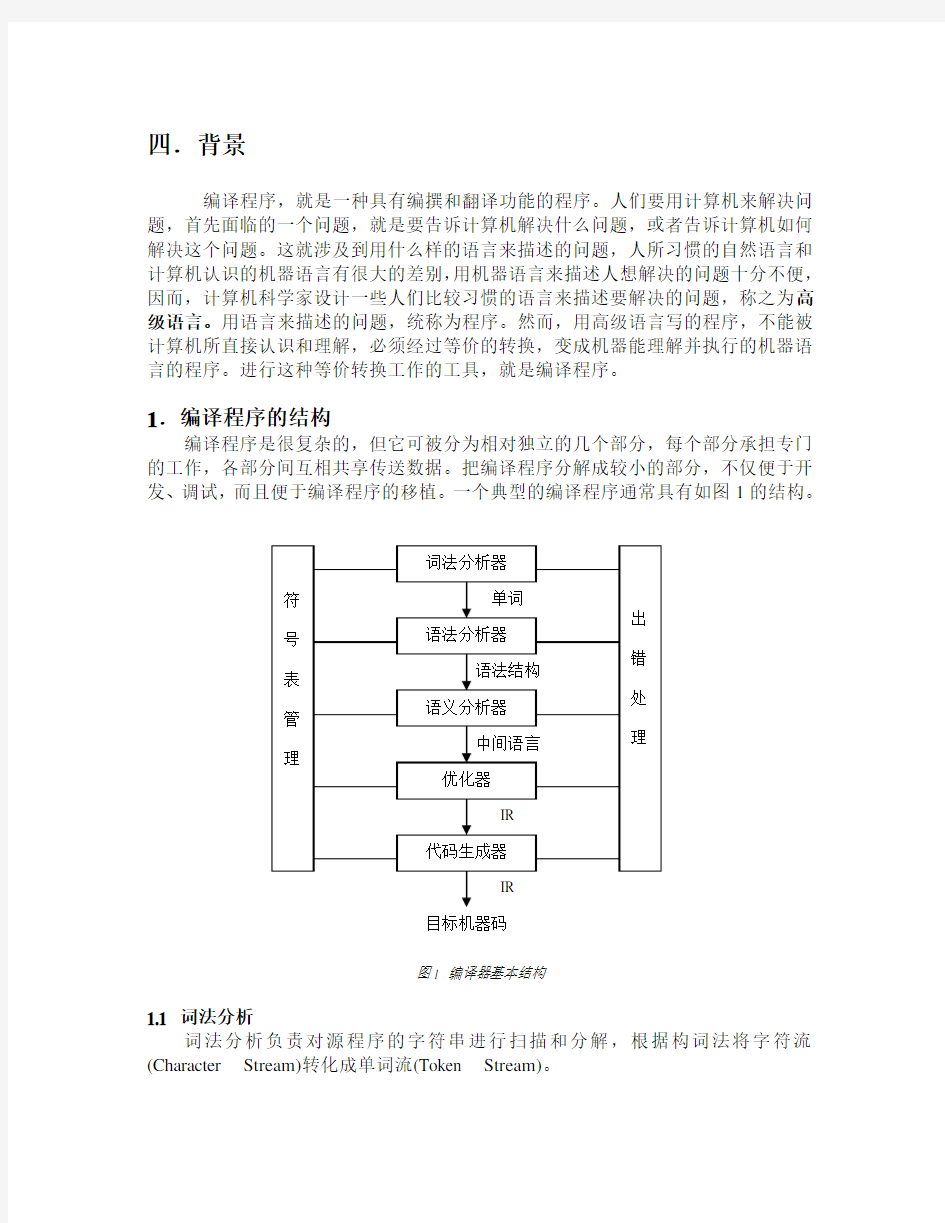
1.编译程序的结构
编译程序是很复杂的,但它可被分为相对独立的几个部分,每个部分承担专门的工作,各部分间互相共享传送数据。把编译程序分解成较小的部分,不仅便于开发、调试,而且便于编译程序的移植。一个典型的编译程序通常具有如图1的结构。
图1 编译器基本结构
1.1 词法分析
词法分析负责对源程序的字符串进行扫描和分解,根据构词法将字符流(Character Stream)转化成单词流(Token Stream)。
例如对于C--语句:
x = y + z – m * 10;
词法分析的结果是:
ID ASSIGN ID ADD ID SUB ID MUL NUM SEMI
构词的规则就是词法,例如标识符(ID)可定义为以字母开头,后面跟零个或任意个字母或数字的序列。词法分析程序就根据词法构造有限自动机来识别每一个单词,将产生的单词交给语法分析程序。
1.2 语法分析
语法分析模块的任务是根据文法规则把单词序列分解成各类语法单位,识别出一个一个句子,例如对前面的语句进行语法分析可得到如图2的分析树。
如果输入单词不能构成语法树,则说明有语法错误。常见的语法分析方法分为自顶向下分析和自底向上分析两大类。在C--编译器中采用了一种自底向上的方法,即LR方法。
1.3 语义分析
这一阶段部分是根据前一阶段产生的语法树,按语言的语义进行翻译,产生四元式或三元式等中间语言。中间语言可以很方便地转换成目标代码。前面的语法树可能产生的四元式序列为:
(*,_t0,10,m)
(-,_t1,z,_t0)
(+,_t0,y,_t1)
(=,x,_t0)
由于中间语言对后面的代码优化和目标代码生成有密切关系,又和目标机器的体系结构有关,所以中间语言的选择对于编译器的效率和质量有很大的影响。
1.4 代码优化
代码优化是把中间代码进行变换,以产生更加高效的目标代码。
1.5 目标代码生成
目标代码生成是编译最后一个阶段,它把中间代码转换成汇编指令或可重定位的目标代码。例如对于前面生成的中间代码,可以产生IBM PC汇编指令为:mov ax, m
mul ax, 10
mov bx, z
sub bx,ax
add bx,y
mov x, bx
汇编代码经过Masm汇编器(Assembler)和连接器(Linker)处理,就产生了可在IBM PC机器上运行的二进制代码。
2.形式语言简介
2.1 文法和语言
文法是产生语言的规则,它可定义为:
对于一个四元式G=(V N,V T,S,P),其中
(1) V N是非终结符号的有限集合
(2) V T是终结符号的有限集合,且V T∩V N=
(3) 开始符号S,S∈V N
(4) 一组产生式P,P中的每一个产生式都具有如下形式:
u→v,u∈(V N∪V T)+且至少要有一个非终结符号,v∈(V N∪V T)*
则G表示一个文法。
乔姆斯基(Noam Chmosky)把文法分成四类:0型文法又称无约束文法,产生式的形式为a→b,a、b是任意字符串。1型文法又称上下有关文法,产生式形式为a→b,且|a|≥|b|。2型文法又称上下文无关文法(Context-Free Grammar),产生式形式为A→a,a∈(V N∪V T)*,A∈V N。3型文法又称正规文法,它的产生式左部是一个非终结符号,右部最多只有一个非终结符号且在右部的最左端或最右端。通常程序设计语言的文法属于2型文法,可被下推机(Pushdown Automaton)识别。
语言定义为L(G)={w|S=>*w,w∈V T*},可见,文法G中的V T相当于产生语言的字母表,G中的一组产生式是产生语言的一组规则;语言L(G)中的每一个句子w,是由G的开始符号S经推导得到的,完全由终结符号组成的字。非终结符号是引起推导继续进行的中间符号,在推导进行到某一步时,如果再没有非终结符号留在推导的结果中,则称推导成功。
在语言的设计和编译器的编写方面,文法都提供了极大的优点:
a) 文法给出了精确的,也易于理解的语言语法说明。
b) 对于某些文法类,可以自动产生高效的分析器。额外的好处是,分析器的构造过程可以揭露出语法的二义性和其它难于分析的结构,这些问题在语言和它的编译器的最初设计阶很可能没有发现。
c) 设计得漂亮的文法,把结构加于程序设计语言,这些结构对把源程序翻译成为正确的目标代码和错误诊断都是有用的。把以文法为基础的翻译的描述转变成程序的开发工具也是存在的。
d) 语言也是逐渐完善的,需要补充新的结构和完成附加的任务。如果存在以文法为基础的语言的实现,这些新结构的加入就更方便。
2.2巴科斯范式(BNF)
巴科斯范式(Backus Normal Form,BNF)是描述语法规则的一种形式方法,在该方法中,使用如下符号:
< > 非终结号
::= 定义符
| 或者
{ } 括号内的成份可以重复出现多次,也可以不出现
[ ] 括号内的成份为任选项,可以出现一次或不出现
例如C语言中IF-THEN语句可以表示成:
用巴科斯范式的形式表示文法的优点是简洁、清楚并容易被理解。
3.编译程序的实现环境Parse Generator简介及其使用
编译器生成工具----Parse Generator 基于Windows平台,它集成了词法生成器ALEX和语法生成器AYACC,并提供了较为强大的类库。其主要优点体现在以下几个方面:
●可以视一个编译程序为一个Project,集成Alex和Ayacc文件的环境有利于
整体调试和开发。且编辑界面友好,利于初学者使用。
●.l文件(lex文件)和.y文件(yacc文件)可生成为标准的C原代码,也可
生成Visual C++和Borland C++格式的原代码。这对习惯与BC或VC编程
的程序员,无疑是极大的方便。
●ALex和AYacc的表驱动代码隐藏在联接库中。库在程序LINK的时候连入
系统中。这在程序编译的效率和灵活性两个方面都有较大贡献。
●ALex和AYacc的原代码和和生成的目标代码(C或C++)可以建立语句的
对应,这对生成代码的调试提供很大方便。
实验中的编译程序采用将ALex和AYacc文件转化为Visual C++格式的代码。现将程序中使用的联接库中主要类和函数作一介绍。
●类yylexer ---- 所有词法分析器类的基类
yylexer类提供由Alex生成的C++词法分析器的一切基本功能。
yylexer是一个抽象类,要使用它,必须继承出自己的类,并实现抽象函数yylex 和yyaction。
C--编译器程序中的词法分析器类是其子类C_Lexer类。
●类yyparser ---- 所有语法分析器类的基类
yyparser类提供由AYacc生成的C++语法分析器的一切基本功能。
yyparser是一个抽象类,要使用它,必须继承出自己的类,并实现抽象函数yywork 和yyparseaction。
C--编译器程序中的语法分析器类是其子类C_Parser类。
五.详细设计
1.功能说明
输入:类C语言纯文本源程序。
输出:
·目标机为具有8086+处理器的MSDOS系统下的二进制可执行代
码。
·PC Assembly Language汇编语言源代码以供分析使用。
本编译程序实现的主要功能如下表所示:
2.词法分析器(lexer)
2.1 正规式和DFA
·ε和φ都是Σ上的正规式,它们所表示的正规集分别为{ε}和φ
·任何a∈Σ,a是Σ上的一个正规式,它所表示的正规集为
{a}
·假定U和V都是Σ上的正规式,它们所表示的正规集分别记为L(U)和L(V),那么,(U|V)、(U.V)和(U)*也都是正规式,它们所表示的正规集分别为L(U)
∪L(V)、L(U)L(V)和(L(U))*。
仅由有限次使用上述三步骤而定义的表达式才是Σ上的正规式,仅由这些正规所表示的字集才是Σ上的正规集。正规式可以有效地描述词法,而确定的有限自动机(DFA)能准确地识别正规集,执行词法分析的功能。
2.2 利用有限自动机进行词法分析
词法分析是整个编译过程的第一阶段,它将字符序列转化为单词序列。识别单词的基本方法是根据词法定义构造有限自动机即描述语言结构特征的状态转换图。例如对于十进制整数正规定义:
[1-9]+[0-9]*
可以构造如图3所示的有限自动机。
图 3 识别十进制整数的有限自动机
其中状态2为接收态,若对于一个字符序列有限自动机可以到达2状态,则说明一个整数已被识别出来。词法分析器构造程序LEX正是根据这一原理工作的。构造词法分析器的主要任务是设计词法的正规定义和相关的动作。上面例子的LEX程序段就是:
[1-9]+[0-9]* return ICON;
2.3 C--词法分析器的实现
·数据结构
1)关键字和系统标识符表Ktab []
保存关键字和系统标识符的信息,定义如下:
typedef struct {
char *name;
int val;
} KWORD;
其中
·name域保存关键字的名字,val域保存关键字的种类标识。
·val域就是词法分析器传递给语法分析器的终结符信息。
2)C--中的关键字
以下为Ktab[]数组的定义:
KWORD Ktab[] = {
{"break", BREAK },
{"char", TYPE },
{"continue",CONTINUE},
{"do", DO },
{"else", ELSE },
{"for", FOR },
{"goto", GOTO },
{"if", IF },
{"int", TYPE },
{"main", MAIN },
{"print", PRINT },
{"while", WHILE }
};
·具体实现(参见源文件C--_lex.l)
1)对注释的处理:
支持/*....*/和//两种注释风格,对于注释内容在匹配到/* 和// 后,直接通过动作input跳过。处理了注释符号遗漏的情况,并有出错信息显示。
2)常数的处理:
词法分析器可识别十进制、八进制和十六进制无符号整数以及字符常数(形为’a’),并通过函数int stoi(char *string, int radix)转化成数值形式。
3)标点符号的处理:
直接返回其相应的标识。
4)标识符的处理:
识别标识符后,调用函数id_or_keyword查找其属性值并返回。
·对于系统保留字和关键字,函数id_or_keyword返回相应的标识(token)。
返回值相同的,可以通过yytext区别。
·对于用户自定义的标识符,函数id_or_keyword返回NAME。
为了提高查找关键字和系统标识符表的效率,函数id_or_keyword采用二分查找法(bsearch函数)。
5)嵌入汇编(_asm{……})的处理:
在函数id_or_keyword()中当遇到yytext=“_asm”时,则进入嵌入汇编处理代码:先匹配字符‘{’,如果接下来的第一个字符不是‘{’,则打印出错信息。如果匹配则将后续代码原样写入汇编代码中,直至遇到字符‘}’结束;如果未遇到则打印出错信息。由于要防止嵌入汇编代码中出现字符立即操作数‘}’或注释语句中的‘{’,因此要考虑这些情况。
采用上述方法的好处是大大简化了语法分析器的工作,不必设计大量的产生式来处理汇编格式。但是这样就不能检查嵌入汇编的语法错误。可以采用这样的方法:用Masm编译嵌入的代码,重定向其输出而判断有无汇编语法错误。
6)生成的C_Lexer 的类定义(参见源文件C--_lex.h):
class C_Lexer : public yyflexer {
public: 嵌入
C_Lexer ();
protected:
void yytables();
virtual int yyaction(int action);
public:
};
C_Lexer () 实现对词法分析器对象的初始化,它调用yytables()。
yyaction()则具体由定义的正则表达式实现归约。
3.语法分析器(parser)
3.1 上下文无关文法
上下文无关文法G可以用一个四元组表示
G=(V,T,P,S)
其中:
·V是文法的非终结符号集,每个非终结符号表示语言的一个语法变量;
·T是终结符号集,每个终结符号表示语言的一个基本符号,即词汇;
·P是产生式集,文法用产生式定义每个非终结符号;
·S是V中的一个非终结符号,称开始符号。
文法的每个产生式由左、右两部分组成,左部是一个非终结符号;右部是由零个或若干个终结符、非终结符组成的符号串。
3.2 LR分析方法
LR分析方法是自底向上进行语法分析,它的功能很强,适用于多种上下文
无关方法。L是指从左向右扫描输入串,R指的是按照最右推导的的逆过程进行归约。
LR分析法具有一些优点:
·能用上下文无关文法描述的程序设计语言结构,都可以构造其LR分析器
进行识别。
·LR分析法是具有一般性的无回溯移进归约分析法,并且能有效地被实现。
·能用LR分析器分析的文法类包含能用LL(1)分析器分析的全部文法类。
·LR分析器在自左向右扫描输入时,可以尽可能地发现语法错误。
图 4 LR分析器
图4是LR分析器的结构示意。其中分析栈存放状态和移进、归约的文法符号:S0X1S1...X m-1S m-1S0
其中,S i表示状态,X i表示文法符号;在实现中,文法符号不必进分析栈。动作表中的项目ACTION[S m,a i]表示当前输入符号为a i、栈顶状态为S m时,分析算法应执行的动作;若ACTION[S m,a i]=S i,表示移进,然后栈顶状态为i;r j表示用产生式j 归约;acc表示接收输入串,err表示语法错误。状态转换表中的项目GOTO[S i,X]表示归约出非终结符号X之后,当前栈顶状态为S i时,分析栈应转换到的下一上状态,即栈顶的新状态。
LR分析算法为:
根据输入符号a i、栈顶状态S m和动作表项action[S m,a i]的值,决定当前分析应执行的动作;移进、归约、接收或出错;移进或归约之后要根据动作表或状态转换表设置分析栈的状态。
可以把分析栈中的串和等待输入的终结答号串看成是两个分量,这两个分量构成如下形式的二元组:
(S0X1S1X2S2...X m S m, a i a i+1...a n#)
这个二元组结构表示右句型X1X2...X m a i a i+1...a n#
假定当前分析栈的栈顶为状态S m,下一个输入符号为a i,分析器的下一个动作由动作表项action[S m,a i]决定。
·如果action[S m,a i]=移进S,则分析器执行移进,二元组变成
(S0X1S1X2S2...X m S m a i S , a i+1...a n#)
即分析器将输入符号a i和状态S移进栈,于是,a i+1变成下一个输入符号。
·如果action[S m,a i]=归约A→β则分析器执行归约,二元组变成
(S0X1S1X2S2...X m-r S m-r AS , a i+1...a n#)
其中,S由goto表确定:S = goto[S m-r,a i],r=|β|,是句柄号串的长度。
归约时,分析器先从栈中弹出2r个元素:r个状态和r个文法符号;于是使状态S m-r 出现在栈顶;然后,再把归约产生式左部的非终结符A和由goto[S m-r,A]确定的状态S压入栈。在归约过程中不改变输入符号。对LR分析器来说,从栈中弹出的文法符号串X m-r+1...X m总是匹配归约产生式的右部β。
·如果action[S m,a i]=acc,则接收输入符号串,语法分析完成
·如果action[S m,a i]=err,则发现语法错误,调用错误处理子程序。
3.3 C--系统中使用的主要产生式(参见源文件C--_par.h)
program :MAIN LP RP c ompound_stmt
compound_stmt :LC local_defs stmt_list RC
local_defs :def_list
def_list :def_list def
| /* epsilon */
def:specifiers decl_list SEMI
decl_list :var_decl
| decl_list COMMA var_decl
var_decl :new_name
| var_decl LB ICON RB
| LP var_decl RP
new_name :NAME
specifiers :TYPE
stmt_list :stmt_list statement
| /* epsilon */
statement :SEMI
| compound_stmt
| PRINT LP expr COMMA DIVOP ICON RP SEMI
| expr SEMI
| GOTO target SEMI
| target COLON statement
| IF LP test RP statement
| IF LP test RP statement ELSE statement
| WHILE LP test RP statement
| DO statement WHILE LP test RP SEMI
| FOR LP opt_expr SEMI test SEMI
opt_expr RP statement
| BREAK SEMI
| CONTINUE SEMI
test :expr
| /* epsilon */
target :NAME
opt_expr :expr
expr :expr COMMA
non_comma_expr :non_comma_expr EQUAL non_comma_expr
| non_comma_expr ASSIGNOP non_comma_expr
| or_expr
or_expr :or_list
or_list :or_list OROR and_expr
| and_expr
and_expr :and_list
and_list :and_list ANDAND binary
| binary
binary : binary RELOP binary
|binary POWER binary
|……
|unary
unary : LP expr RP
|……
3.4 系统中符号表的实现
1)符号表的组织要求
编译程序用符号表跟踪关于名称的汇聚信息和作用域,当词法分析器识别出一个标识符后,编译程序就查找符号表,看它是否在符号表中,如果没有,则把这个新标识符填入符号表。在语义分析阶段和代码生成阶段也要通过查找符号表来获得标识符的属性信息。可见在编译过程中符号表的查、填动作非常频繁,因而提高符号表查填效率是提高编译程序运行效率的关键因素,也是对符号表设计的根本要求。
2)符号表的几种组织方式
·线性表
符表项按顺序排列,这种组织方式最简单并且实现也很容易。线性表的缺
点是插入和查找的效率较低,虽然可以采用反序查找、表项排序、动态调
整表项来提高效率,但其性能的改善是很有限的。
·哈希表
通过计算符号的哈希值来确定其在表格中的位置。哈希表结构简单、实现
较容易,而且其插入和查找效率很高。采用哈希表要解决“冲突”的问题,而解决冲突将会提高哈希表的复杂度。
·二叉树
二叉树的组织方式平均查填效率最高,但实现的复杂度较高。对于名称冲
突也要特别处理。在某些情况下,二叉树会退化成线性表,这个问题可以
通过采用A VL树的结构来解决,但这会进一步提高实现的代价。
3)C--系统中符号表的组织(参见源文件Symbol.h)
本编译程序中对符号表的管理和操作在C S ymbol类中实现,采用的是哈希杂凑表的方式。
该类的声明如下:
class CSymbol
{
public:
CSymbol();
symbol *NewSymbol(char *name, unsigned level);
symbol *FindSymbol(char *name);
bool DeleteNest(symbol *pHead);
unsigned Hash(char *name);
virtual ~CSymbol();
private:
Hash_Node *SymTable[TABLE_LEN];
};
类中所涉及到的结构声明如下:
struct symbol
{
char name[NAME_MAX+1]; // 输入变量名
char rname[NAME_MAX+1]; // 实际变量名
unsigned level; // 当前嵌套级
type *pType; // 变量类型
symbol *next; // 指向同层的下一个变量};
struct Hash_Node
{
Hash_Node *pre; // 上一个冲突节点
Hash_Node *next; // 下一个冲突节点
symbol *sym; // 指向此节点上的变量};
CSymbol采用哈希表来实现对变量的管理和查找。
变量表采用数组实现,对于每一个产生哈系冲突的变量节点,利用链表将其连接到已有的节点后。
在本编译程序中,采用了较复杂的计算哈系值的算法,其伪码如下:
unsigned CSymbol::Hash(char *name)
{
hash_val = 0;
for(对变量名中的每一个字符)
{
hash_val = (hash_val << 2) + 变量字符值;
if(i = hash_val & 0x3fff)
hash_val = (hash_val ^ (i >> 12)) & ~0x3fff;
}
返回hash_val;
}
CSymbol类中两个主要的成员函数是:
·symbol *FindSymbol(char *name),实现根据变量名,在变量表中查找该一项。
· symbol*New Symbol(char *name, unsigned level),实现在变量表中加入一
个symbol项。
4)其他主要结构定义(参见源文件Structs.h)
struct type
{
u nsigned noun; // CHAR INT
i nt num_ele; // number of elements if array
i nt v_int; // Value if constant
};
struct value
{
c har name[NAME_MAX * 2]; // Operan
d that accesses th
e value
t ype *pType; // Variable's type
s ymbol *sym; // Original symbol
b ool lvalue; // TRUE = lvalue, FALSE = rvalue
b ool is_tmp; // TRUE = temp, FALSE = non-temp
u nsigned offset; // Abolute value of offset from base of temp
// stack
};
3.5 系统中局部变量的处理
虽然本编译程序采用预分配栈来存放局部变量,这样的做法浪费空间且缺乏灵活性,但是它带来的一个好处是局部变量可以回收,而不像很多编译程序存在着局部变量无法回收的缺憾。
处理局部变量的主要函数有(参见源文件Functions.h及Functions.cpp):void figure_local_offsets(symbol *s);
void release_local(symbol *s);
函数figure_local_offsets为一个层中的局部变量分配空间,而函数release_local 则释放在某一层执行完时释放其中的所有变量。这可以通过遍历杂凑链表中的该层的变量链表(单向链表)得到所有变量的存储总长度,然后把局部变量堆栈指针减掉这个长度就可以了。这样该层的所有变量所占的空间都释放掉了。下一次又可以使用这些释放的空间。
3.6 系统中临时变量的处理
临时变量是编译系统中使用较多的部分,通过建立临时变量来记录每一次运算的结果,使后续的运算能方便地引用前次的值,是一个较通用的方法。所以,临时变量的管理成为编译程序中一个比较重要的部分。
·因为本编译程序的条件限制,系统中对临时变量的处理采取栈式结构存放的方法。
存放临时变量的堆栈是系统全局的,通过在编译程序初始化是建立,如下:fprintf(OutPut,"\t%s\tdb\t%d dup(?)\n\n", TMP_STACK, TMP_STACK_LEN);
此语句将在汇编源代码中生成如下的语句:
t_stack db 1024 dup(?)
·系统通过一个布尔型数组对临时变量栈进行管理。
bool Tmp_Reg[TMP_STACK_LEN];
Tmp_Reg[offset]的值表示临时变量栈中偏移量为offset的空间是否已被
分配为临时变量的存放。
·系统使用以下4个函数完成对临时变量的管理:
int tmp_alloc(int size);
value *tmp_create(type *t);
void tmp_free(int offset, int size);
void tmp_freeall(void);
3.7 系统中代码的生成
编译程序中的翻译的推导规则和每一个推导的相应动作,生成汇编源代码。(详见程序清单)
·主程序框架的生成
通过函数void Init(void) 和void End(void)完成。
Init主要任务:
·生成数据段、代码段;
·生成主程序的起始代码;
·返回地址入栈;
·创建全局和系统堆栈;
·初始化系统变量。
End主要任务:
·生成返回操作系统代码;
·结束代码段;
·结束程序。
·常量定义的翻译
本系统中常量的翻译,是通过函数:
value *make_icon(char *yytext, int numeric_val)
生成value结构并设置symbol结构,记录常量标识符的名称和值,把该symbol 加入处于栈顶的符号表。
·变量定义的翻译
本系统中变量的定义,是通过函数:
CSymbol类的NewSymbol(char *name, unsigned level) 成员函数实现。
该函数将判断是否有重复定义,如果有将提示出错信息;否则把新变量加
入符号表。
·赋值语句的翻译
赋值语句是构成程序体的基本语句。翻译赋值语句的任务是:计算在赋值
符号左边变量的地址,计算在赋值符号右边表达式的值,然后送入左值所
指的内存单元。
本系统只支持两种数据类型:int 和char。
所以可以方便的实现不同类型间的转化,具体由函数:
value* convert_type(value *v, type *t);
实现。
·当char 向 int转化时,高位补0;
·当int 向 char转化时,高位截断;
·控制流语句的生成
主要的控制语句有:if-then语句、do-while语句、while语句、for语句。
语句的生成较为简单,具体做法不详细描述。
值得一提的是:在通过实际的测试程序测试时,发现当生成的汇编跳转语
句“jz Label”与 Label 之间的代码长度超过128字节时,Masm编译将
报错。这是由汇编语言在16位地址下的局限性造成的。而实际上在while 和for语句中的循环体部分很容易超出128字节,所以通过对JZ 的模拟跳转来解决这个问题:
由gen("jz", L_NEXT, (void *)$$, -1);
变为
gen("jz", L_NEXT2, (void *)$$, -1);
gen("jmp", L_BUSTOP, (void *)$$, -1);
gen(":", L_NEXT2, (void *)$$, -1);
gen("jmp", L_NEXT, (void *)$$, -1);
gen(":", L_BUSTOP, (void *)$$, -1);
通过加入L_BUSTOP和L_NEXT2把JZ跳转限制在128字节内。但是此方法会使编译系统的输出代码变得冗长。
·print系统函数的处理
可以在Yacc文件中发现处理print系统函数的产生式。处理时调用了函数Print ()。该函数完成参数的入栈、过程调用以及堆栈恢复语句的生成,并且作一个标记表示程序中调用了print系统函数。
语法分析完毕时,函数End()会检查是否有print系统函数的调用,若有则在编译出的汇编代码之后插入print系统函数的汇编实现代码。
注:语法分析用到的所有函数都在Functions.h和Functions.cpp中定义声明。
六.总结
完成全部编程工作一共大约用了3个星期的时间,在整个编程过程中,我们小组成员通力合作,解决了不少无法想象的困难,最后经过大家的努力终于完成了这个程序。
文档编辑:朱嘉俊,王筱