完整版目标检测综述

一、传统目标检测方法
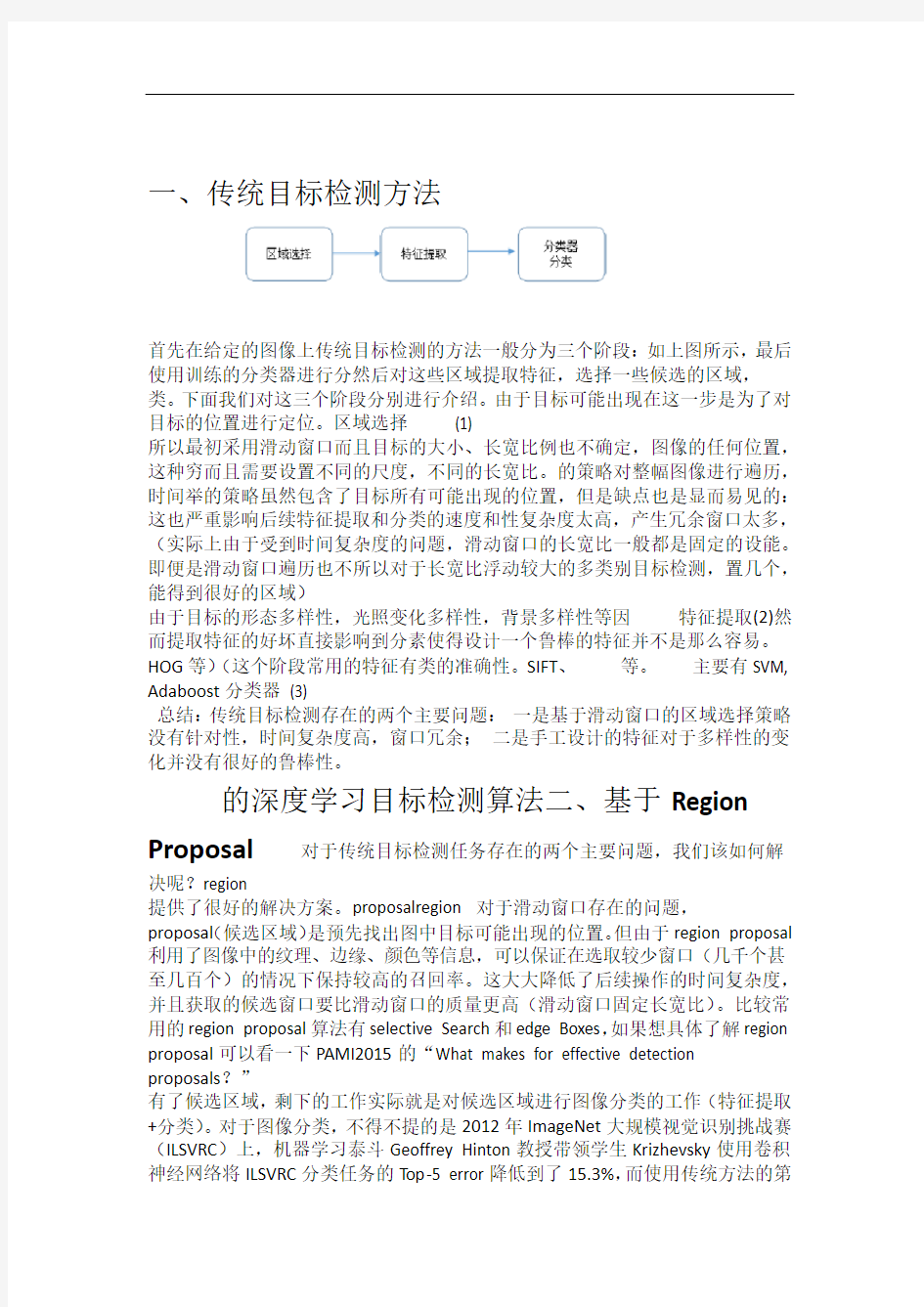
首先在给定的图像上传统目标检测的方法一般分为三个阶段:如上图所示,最后使用训练的分类器进行分然后对这些区域提取特征,选择一些候选的区域,类。下面我们对这三个阶段分别进行介绍。由于目标可能出现在这一步是为了对目标的位置进行定位。区域选择(1)
所以最初采用滑动窗口而且目标的大小、长宽比例也不确定,图像的任何位置,这种穷而且需要设置不同的尺度,不同的长宽比。的策略对整幅图像进行遍历,时间举的策略虽然包含了目标所有可能出现的位置,但是缺点也是显而易见的:这也严重影响后续特征提取和分类的速度和性复杂度太高,产生冗余窗口太多,(实际上由于受到时间复杂度的问题,滑动窗口的长宽比一般都是固定的设能。即便是滑动窗口遍历也不所以对于长宽比浮动较大的多类别目标检测,置几个,能得到很好的区域)
由于目标的形态多样性,光照变化多样性,背景多样性等因特征提取(2)然而提取特征的好坏直接影响到分素使得设计一个鲁棒的特征并不是那么容易。HOG等)(这个阶段常用的特征有类的准确性。SIFT、等。主要有SVM, Adaboost分类器(3)
总结:传统目标检测存在的两个主要问题:一是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;二是手工设计的特征对于多样性的变化并没有很好的鲁棒性。
的深度学习目标检测算法二、基于Region Proposal对于传统目标检测任务存在的两个主要问题,我们该如何解
决呢?region
提供了很好的解决方案。proposalregion 对于滑动窗口存在的问题,
proposal(候选区域)是预先找出图中目标可能出现的位置。但由于region proposal 利用了图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口(几千个甚至几百个)的情况下保持较高的召回率。这大大降低了后续操作的时间复杂度,并且获取的候选窗口要比滑动窗口的质量更高(滑动窗口固定长宽比)。比较常用的region proposal算法有selective Search和edge Boxes,如果想具体了解region proposal可以看一下PAMI2015的“What makes for effective detection proposals?”
有了候选区域,剩下的工作实际就是对候选区域进行图像分类的工作(特征提取+分类)。对于图像分类,不得不提的是2012年ImageNet大规模视觉识别挑战赛(ILSVRC)上,机器学习泰斗Geoffrey Hinton教授带领学生Krizhevsky使用卷积神经网络将ILSVRC分类任务的Top-5 error降低到了15.3%,而使用传统方法的第
二名top-5 error高达26.2%。此后,卷积神经网络占据了图像分类任务的绝对统治地位,微软最新的ResNet和谷歌的Inception V4模型的top-5 error降到了4%以内多,这已经超越人在这个特定任务上的能力。所以目标检测得到候选区域后使用CNN对其进行图像分类是一个不错的选择。2014年,RBG(Ross B. Girshick)大神使用region proposal+CNN代替传统目标检测使用的滑动窗口+手工设计特征,设计了R-CNN框架,使得目标检测取得巨大突破,并开启了基于深度学习目标检测的热潮。
1. R-CNN (CVPR2014, TPAMI2015)(Region-based Convolution Networks for Accurate Object detection and Segmentation)
上面的框架图清晰的给出了R-CNN的目标检测流程:
(1)输入测试图像
(2)利用selective search算法在图像中提取2000个左右的region proposal。
(3)将每个region proposal缩放(warp)成227x227的大小并输入到CNN,将CNN 的fc7层的输出作为特征。
(4)将每个region proposal提取到的CNN特征输入到SVM进行分类。
上面的框架图是测试的流程图,要进行测试我们首先要训练好提取特征的CNN 模型,以及用于分类的SVM:使用在ImageNet上预训练的模型(AlexNet/VGG16)进行微调得到用于特征提取的CNN模型,然后利用CNN模型对训练集提特征训练SVM。
对每个region proposal缩放到同一尺度是因为CNN全连接层输入需要保证维度固定。
上图少画了一个过程——对于SVM分好类的region proposal做边框回归(bounding-box regression),边框回归是对region proposal进行纠正的线性回归算法,为了让region proposal提取到的窗口跟目标真实窗口更吻合。因为region proposal提取到的窗口不可能跟人手工标记那么准,如果region proposal跟目标位置偏移较大,即便是分类正确了,但是由于IoU(region proposal与Ground Truth 的窗口的交集比并集的比值)低于0.5,那么相当于目标还是没有检测到。
小结:R-CNN在PASCAL VOC2007上的检测结果从DPM HSC的34.3%直接提升到了66%(mAP)。如此大的提升使我们看到了region proposal+CNN的巨大优势。
但是R-CNN框架也存在着很多问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练边框回归器
(2) 训练耗时,占用磁盘空间大:5000张图像产生几百G的特征文件
(3) 速度慢: 使用GPU, VGG16模型处理一张图像需要47s。针对速度慢的这
个问题,SPP-NET给出了很好的解决方案。
2. SPP-NET (ECCV2014, TPAMI2015) (Spatial Pyramid Pooling
in Deep Convolutional Networks for Visual Recognition)
先看一下R-CNN为什么检测速度这么慢,一张图都需要47s!仔细看下R-CNN框架发现,对图像提完region proposal(2000个左右)之后将每个proposal当成一张图像进行后续处理(CNN提特征+SVM分类),实际上对一张图像进行了2000次提特征和分类的过程!有没有方法提速呢?好像是有的,这2000个region proposal不都是图像的一部分吗,那么我们完全可以对图像提一次卷积层特征,然后只需要将region proposal在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个region proposal的卷积层特征输入到全连接层做后续操作。(对于CNN来说,大部分运算都耗在卷积操作上,这样做可以节省大量时间)。现在的问题是每个region proposal的尺度不一样,直接这样输入全连接层肯定是不行的,因为全连接层输入必须是固定的长度。SPP-NET恰好可以解决这个问题:
经过CNN,-NET的网络结构图,任意给一张图像输入到上图对应的就是SPP共产生,VGG16最后的卷积层为conv5_3卷积操作我们可以得到卷积特征(比如对应到特征图的region proposalwindow张特征图)。图中的是就是原图一个512的特征映射到同样的维度,将其作为全连区域,只需要将这些不同大小window使用了空间金字塔NET-SPP接的输入,就能保证只对图像提取一次卷积层特征。.采样(spatial pyramid pooling):将每个window划分为4*4, 2*2, 1*1的块,然后每个块使用max-pooling下采样,这样对于每个window经过SPP层之后都得到了一个长度为(4*4+2*2+1)*512维度的特征向量,将这个作为全连接层的输入进行后续操作。小结:使用SPP-NET相比于R-CNN可以大大加快目标检测的速度,但是依然存在着很多问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练训练边框回归器
(2) SPP-NET在微调网络的时候固定了卷积层,只对全连接层进行微调,而对于一个新的任务,有必要对卷积层也进行微调。(分类的模型提取的特征更注重高层语义,而目标检测任务除了语义信息还需要目标的位置信息)针对这两个问题,RBG又提出Fast R-CNN, 一个精简而快速的目标检测框架。
3. Fast R-CNN(ICCV2015)
有了前边R-CNN和SPP-NET的介绍,我们直接看Fast R-CNN的框架图:
框架图对比,可以发现主要有两处不同:一是最后一个卷积层后CNNR-与,-task loss),加了一个ROI pooling layer二是损失函数使用了多任务损失函数(multi 网络中训练。将边框回归直接加入到CNN
对每个NET的一个精简版,SPP-NETSPPlayerROI (1) pooling 实际上是-只需要下采样到一layerpooling ROI 使用了不同大小的金字塔映射,而proposal
个7x7的特征图。对于VGG16网络conv5_3有512个特征图,这样所有region proposal对应了一个7*7*512维度的特征向量作为全连接层的输入。
(2) R-CNN训练过程分为了三个阶段,而Fast R-CNN直接使用softmax替代SVM 分类,同时利用多任务损失函数边框回归也加入到了网络中,这样整个的训练过程是端到端的(除去region proposal提取阶段)。
(3) Fast R-CNN在网络微调的过程中,将部分卷积层也进行了微调,取得了更好的检测效果。
小结:Fast R-CNN融合了R-CNN和SPP-NET的精髓,并且引入多任务损失函数,使整个网络的训练和测试变得十分方便。在Pascal VOC2007训练集上训练,在VOC2007测试的结果为66.9%(mAP),如果使用VOC2007+2012训练集训练,在VOC2007上测试结果为70%(数据集的扩充能大幅提高目标检测性能)。使用VGG16每张图像总共需要3s左右。
缺点:region proposal的提取使用selective search,目标检测时间大多消耗在这上面(提region proposal 2~3s,而提特征分类只需0.32s),无法满足实时应用,而且并没有实现真正意义上的端到端训练测试(region proposal使用selective search先提取处来)。那么有没有可能直接使用CNN直接产生region proposal并对其分类?Faster R-CNN框架就是符合这样需要的目标检测框架。
4. Faster R-CNN(NIPS2015)(Faster R-CNN: Towards
Real-Time
Object Detection with Region Proposal Networks)
在region proposal + CNN分类的这种目标检测框架中,region proposal质量好坏直接影响到目标检测任务的精度。如果找到一种方法只提取几百个或者更少的高质量的预选窗口,而且召回率很高,这不但能加快目标检测速度,还能提高目标
检测的性能(假阳例少)。RPN(Region Proposal Networks)网络应运而生。RPN 的核心思想是使用卷积神经网络直接产生region proposal,使用的方法本质上就是滑动窗口。RPN的设计比较巧妙,RPN只需在最后的卷积层上滑动一遍,因为。region proposal机制和边框回归可以得到多尺度多长宽比的anchor
,给定输入图像(假设分模型)网络结构图(使用了ZF我们直接看上边的RPN。)(大小约为40*60辨率为600*1000),经过卷积操作得到最后一层的卷积特征图最后一层卷与特征图进行卷积,的卷积核(滑动窗口)在这个特征图上使用3*3维2563*3的区域卷积后可以获得一个个feature map,那么这个积层共有
256CNNFast R-和reg layer分别用于分类和边框回归(跟后边接的特征向量,cls layer滑窗对应的每个特征。3*3类似,只不过这里的类别只有目标和背景两个类别)region )的种长宽比(1:1,1:2,2:1(区域同时预测输入图像3种尺度
128,256,512),3,总feature map的anchor。所以对于这个40*60proposal,这种映射的机制称为这样个region proposal。共有约20000(40*60*9)个anchor,也就是预测20000滑动窗口操作是但是:设计的好处是什么呢?虽然现在也是用的滑动窗口策略,次416*16倍(中间经过了在卷积层特征图上进行的,维度较原始图像降低了对应了三种尺度和三种长宽比,,种anchor操作);多尺度采用
了9pooling2*2的外的窗口也能得到一个跟目种anchor加上后边接了边框回归,所以即便是这9使用的检测框架-CNNNIPS2015版本的Faster R。标比较接近的region proposal
一样,CNN整体流程跟Fast R-RPN网络+Fast R-CNN网络分离进行的目标检测,是。search)RPNproposal现在是用网络提取的(代替原来的selective 只是region RPN训练-CNN网络实现卷积层的权值共享,的网络和同时作者为了让RPNFast
R :4-CNN的时候用了阶段的训练方法Fast R和网络;RPN上预训练的模型初始化网络参数,微调ImageNet使用在(1).
(2) 使用(1)中RPN网络提取region proposal训练Fast R-CNN网络;
(3) 使用(2)的Fast R-CNN网络重新初始化RPN, 固定卷积层进行微调;
(4) 固定(2)中Fast R-CNN的卷积层,使用(3)中RPN提取的region proposal微调网络。
权值共享后的RPN和Fast R-CNN用于目标检测精度会提高一些。
使用训练好的RPN网络,给定测试图像,可以直接得到边缘回归后的region proposal,根据region proposal的类别得分对RPN网络进行排序,并选取前300
个窗口作为Fast R-CNN的输入进行目标检测,使用VOC07+12训练集训练,
VOC2007测试集测试mAP达到73.2%(selective search + Fast R-CNN是70%),目标检测的速度可以达到每秒5帧(selective search+Fast R-CNN是2~3s一张)。
需要注意的是,最新的版本已经将RPN网络和Fast R-CNN网络结合到了一起——将RPN获取到的proposal直接连到ROI pooling层,这才是一个真正意义上的
使用一个CNN网络实现端到端目标检测的框架。
小结:Faster R-CNN将一直以来分离的region proposal和CNN分类融合到了一起,使用端到端的网络进行目标检测,无论在速度上还是精度上都得到了不错的提高。然而Faster R-CNN还是达不到实时的目标检测,预先获取region proposal,然后
在对每个proposal分类计算量还是比较大。比较幸运的是YOLO这类目标检测方法的出现让实时性也变的成为可能。总的来说,从R-CNN, SPP-NET, Fast
R-CNN, Faster R-CNN一路走来,基于深度学习目标检测的流程变得越来越精简,
精度越来越高,速度也越来越快。可以说基于region proposal的R-CNN系列目标检测方法是当前目标最主要的一个分支。
三、基于回归方法的深度学习目标检测算法
Faster R-CNN的方法目前是主流的目标检测方法,但是速度上并不能满足实时的要求。YOLO一类的方法慢慢显现出其重要性,这类方法使用了回归的思想,既给定输入图像,直接在图像的多个位置上回归出这个位置的目标边框以及目标类别。
Unified,
Once: Look Only (You oral)(CVPR2016, YOLO 1.
Real-Time Object Detection)
YOLO的目标检测的流程图:我们直接看上面的网格7*7(1) 给个一个输入图像,首先将图像划分成个边框(包括每个边框是目标的置信度以2(2) 对于每个网格,我们都预测及每个边框区域在多个类别上的概率)个目标窗口,然后根据阈值去除可能性比7*7*2根据上一步可以预测出(3) NMS较低的目标窗口,最后去除冗余窗口即可。在找目标,直接region proposal可以看到整个过程非常简单,不需要中间的回归便完成了位置和类别的判
定。.
那么如何才能做到直接在不同位置的网格上回归出目标的位置和类别信息呢?的模型比较类似,主GoogLeNet上面是YOLO的网络结构图,前边的网络结构跟维的全连接层,然后后边又4096要的是最后两层的结构,卷积层之后接了一个就是划分的网格数,现在要在7*7全连接到一个7*7*30维的张量上。实际上这也就是每个网格上预测目标两个可能的位置以及这个位置的目标置信度和类别,1,长宽)4维坐标信息(中心点坐标+每个网格预测两个目标,每个目标的信息有(4+1)*2+20 = 30,总共就是2020(VOC上个类别)个是目标的置信度,还有类别数维的全图特征直接在每个网格上回归出目标维的向量。这样可以利用前边4096 检测需要的信息(边框信息加类别)。大大加快了检测的速度,YOLO将目标检测任务转换成一个回归问题,小结:张图像。而且由于每个网络预测目标窗口时使
用的45使得YOLO可以每秒处理YOLO。但是是全图信息,使得false positive比例大幅降低(充分的上下文信息)的网格回归会使得目标不只使用机制,7*7也存在问题:没有了region proposal YOLO的检测精度并不是很高。能非常精准的
定位,这也导致了(SSD: Single Shot MultiBox Detector) 2. SSD的粗糙网格内回归对目7*7上面分析了YOLO存在的问题,使用整图特征在
的思想实现精准一些那是不是可以结合region proposal标的定位并不是很精准。机制做到了这点。anchor的CNN-Faster R的回归思想以及YOLO结合SSD的定位?
一YOLOSSD获取目标位置和类别的方法跟上图是SSD的一个框架图,首先
预测某SSDYOLO预测某个位置使用的是全图的特征,样,都是使用回归,但是。那么如何建立某个位个位置使用的是这个位置周围的特征(感觉更合理一些)机的anchorFaster R-CNN置和其特征的对应关系呢?可能你已经想到了,使用
3*38*8,那么就使用(图b)大小是制。如SSD的框架图所示,假如某一层特征图然后这个特征回归得到目标的坐标信息和类别信息的滑窗提取每个位置的特征,c)。(图上,这样可以利用feature map,这个anchor是在多个CNN不同于Faster R-滑窗感受野不3*3多层的特征并且自然的达到多尺度(不同层的feature map 。同)机制,使anchorCNN中的结合了SSDYOLO中的回归思想和Faster R-小结:速度快的特性,也YOLO用全图各个位置的多尺度区域特征进行回归,既保持了可以上mAP一样比较精准。SSD在VOC2007CNN保证了窗口预测的跟Faster R-的提出给目标检测一YOLO总结:58帧每秒。达到72.1%,速度在GPU上达到的性能则让我们看到了目标检测在实际应用中真正的可能性。个新的思路,SSD目标检测框架给了我YOLOCNN系列目标检测框架和. 四提高目标检测方法R-们进行目标检测的两个基本框架。研究人员基于这些框架从其他方面入手提出了一系列提高目标检除此之外,测性能的方法。分类器时使在训练SVMCNN)hard negative mining R-难分样本挖掘((1)
由于使用端到端的训练CNNFaster RCNNFast R用了难分样本挖掘的思想,但-和-。策略并没有使用难分样本挖掘(只是设置了正负样本的比例并随机抽取).CVPR2016的Training Region-based Object Detectors with Online Hard Example Mining(oral)将难分样本挖掘(hard example mining)机制嵌入到SGD算法中,使得Fast R-CNN在训练的过程中根据region proposal的损失自动选取合适的region proposal作为正负例训练。实验结果表明使用OHEM(Online Hard Example Mining)机制可以使得Fast R-CNN算法在VOC2007和VOC2012上mAP提高4%左右。(2) 多层特征融合Fast R-CNN和Faster R-CNN都是利用了最后卷积层的特征进行目标检测,而由于高层的卷积层特征已经损失了很多细节信息(pooling操作),所以在定位时不是很精准。HyperNet等一些方法则利用了CNN的多层特征融合进行目标检测,这不仅利用了高层特征的语义信息,还考虑了低层特征的细节纹理信息,使得目标检测定位更精准。
(3) 使用上下文信息在提取region proposal特征进行目标检测时,结合region proposal上下文信息,检测效果往往会更好一些。(Object detection via a
multi-region & semantic segmentation-aware CNN model以及Inside-Outside Net等论文中都使用了上下文信息)
目标跟踪相关研究综述
Artificial Intelligence and Robotics Research 人工智能与机器人研究, 2015, 4(3), 17-22 Published Online August 2015 in Hans. https://www.360docs.net/doc/bb5910213.html,/journal/airr https://www.360docs.net/doc/bb5910213.html,/10.12677/airr.2015.43003 A Survey on Object Tracking Jialong Xu Aviation Military Affairs Deputy Office of PLA Navy in Nanjing Zone, Nanjing Jiangsu Email: pugongying_0532@https://www.360docs.net/doc/bb5910213.html, Received: Aug. 1st, 2015; accepted: Aug. 17th, 2015; published: Aug. 20th, 2015 Copyright ? 2015 by author and Hans Publishers Inc. This work is licensed under the Creative Commons Attribution International License (CC BY). https://www.360docs.net/doc/bb5910213.html,/licenses/by/4.0/ Abstract Object tracking is a process to locate an interested object in a series of image, so as to reconstruct the moving object’s track. This paper presents a summary of related works and analyzes the cha-racteristics of the algorithm. At last, some future directions are suggested. Keywords Object Tracking, Track Alignment, Object Detection 目标跟踪相关研究综述 徐佳龙 海军驻南京地区航空军事代表室,江苏南京 Email: pugongying_0532@https://www.360docs.net/doc/bb5910213.html, 收稿日期:2015年8月1日;录用日期:2015年8月17日;发布日期:2015年8月20日 摘要 目标跟踪就是在视频序列的每幅图像中找到所感兴趣的运动目标的位置,建立起运动目标在各幅图像中的联系。本文分类总结了目标跟踪的相关工作,并进行了分析和展望。
运动目标检测方法总结报告
摘要 由于计算机技术的迅猛发展,使得基于内容的视频信息的存取、操作和检索不仅成为一种可能,更成为一种需要。同时,基于内容的视频编码标准MPEG-4和基于内容的视频描述标准MPEG-7正在发展和完善。因此提取和视频中具有语义的运动目标是一个急需解决的问题。运动目标提取和检测作为视频和图像处理领域的重要研究领域,有很强的研究和应用价值。运动检测就是将运动目标从含有背景的图像中分离出来,如果仅仅依靠一种检测算法,难以从复杂的自然图像序列中完整地检测出运动的目标。较高的检测精度和效率十分重要,因此融合多种检测方法的研究越来越受到重视。本文介绍了几种国内外文献中的经典的视频运动目标的检测和提取算法,并对各种方法进行了评价和总结。首先介绍了基本的运动目标检测的基本知识和理论,然后介绍了基本的几种目标检测方法及其各种改进方法。对今后的运动目标检测提取的相关研究提供一定的参考。 关键词:运动目标检测光流法帧差法背景建模方法
ABSTRACT Because of the rapid development of computer technology, it is possible to access, operate and retrieve the video information based on the content of the video. At the same time, based on the content of the video coding standard MPEG-4 and content-based video description standard MPEG-7 is developing and improving. Therefore, it is an urgent problem to be solved in the extraction and video. Moving object extraction and detection is a very important field of video and image processing, and has a strong research and application value. Motion detection is to separate moving objects from the image containing background, if only rely on a detection algorithm, it is difficult to from a complex natural image sequences to detect moving target. Higher detection accuracy and efficiency are very important, so the study of the fusion of multiple detection methods is becoming more and more important. In this paper, the detection and extraction algorithms of the classical video moving objects in the domestic and foreign literatures are introduced, and the methods are evaluated and summarized. Firstly, the basic knowledge and theory of basic moving target detection is introduced, and then the basic method of target detection is introduced. To provide a reference for the research on the extraction of moving target detection in the future. Keywords: Visual tracking Optical flow method Frame Difference Background modeling method
目标检测综述教学内容
一、传统目标检测方法 如上图所示,传统目标检测的方法一般分为三个阶段:首先在给定的图像上选择一些候选的区域,然后对这些区域提取特征,最后使用训练的分类器进行分类。下面我们对这三个阶段分别进行介绍。 (1) 区域选择这一步是为了对目标的位置进行定位。由于目标可能出现在图像的任何位置,而且目标的大小、长宽比例也不确定,所以最初采用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的尺度,不同的长宽比。这种穷举的策略虽然包含了目标所有可能出现的位置,但是缺点也是显而易见的:时间复杂度太高,产生冗余窗口太多,这也严重影响后续特征提取和分类的速度和性能。(实际上由于受到时间复杂度的问题,滑动窗口的长宽比一般都是固定的设置几个,所以对于长宽比浮动较大的多类别目标检测,即便是滑动窗口遍历也不能得到很好的区域) (2) 特征提取由于目标的形态多样性,光照变化多样性,背景多样性等因素使得设计一个鲁棒的特征并不是那么容易。然而提取特征的好坏直接影响到分类的准确性。(这个阶段常用的特征有SIFT、HOG等) (3) 分类器主要有SVM, Adaboost等。 总结:传统目标检测存在的两个主要问题: 一是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余; 二是手工设计的特征对于多样性的变化并没有很好的鲁棒性。 二、基于Region Proposal的深度学习目标检测算法 对于传统目标检测任务存在的两个主要问题,我们该如何解决呢? 对于滑动窗口存在的问题,region proposal提供了很好的解决方案。region
proposal(候选区域)是预先找出图中目标可能出现的位置。但由于region proposal 利用了图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口(几千个甚至几百个)的情况下保持较高的召回率。这大大降低了后续操作的时间复杂度,并且获取的候选窗口要比滑动窗口的质量更高(滑动窗口固定长宽比)。比较常用的region proposal算法有selective Search和edge Boxes,如果想具体了解region proposal可以看一下PAMI2015的“What makes for effective detection proposals?” 有了候选区域,剩下的工作实际就是对候选区域进行图像分类的工作(特征提取+分类)。对于图像分类,不得不提的是2012年ImageNet大规模视觉识别挑战赛(ILSVRC)上,机器学习泰斗Geoffrey Hinton教授带领学生Krizhevsky使用卷积神经网络将ILSVRC分类任务的Top-5 error降低到了15.3%,而使用传统方法的第二名top-5 error高达26.2%。此后,卷积神经网络占据了图像分类任务的绝对统治地位,微软最新的ResNet和谷歌的Inception V4模型的top-5 error降到了4%以内多,这已经超越人在这个特定任务上的能力。所以目标检测得到候选区域后使用CNN对其进行图像分类是一个不错的选择。 2014年,RBG(Ross B. Girshick)大神使用region proposal+CNN代替传统目标检测使用的滑动窗口+手工设计特征,设计了R-CNN框架,使得目标检测取得巨大突破,并开启了基于深度学习目标检测的热潮。 1. R-CNN (CVPR2014, TPAMI2015) (Region-based Convolution Networks for Accurate Object d etection and Segmentation)
关于三维图像目标识别文献综述
关于三维目标识别的文献综述 前言: 随着计算机技术和现代信息处理技术的快速发展,目标识别已经迅速发展成为一种重要的工具与手段,目标识别是指一个特殊目标(或一种类型的目标)从其它目标(或其它类型的目标)中被区分出来的过程。它既包括两个非常相似目标的识别,也包括一种类型的目标同其他类型目标的识别。目标识别的基本原理是利用雷达回波中的幅度、相位、频谱和极化等目标特征信息,通过数学上的各种多维空间变换来估算目标的大小、形状、重量和表面层的物理特性参数,最后根据大量训练样本所确定的鉴别函数,在分类器中进行识别判决。它属于模式识别的范畴,也可以狭义的理解为图像识别。三维目标识别是以物体表面朝向的三维信息来识别完整的三维物体模型目标识别需要综合运用计算机科学、模式识别、机器视觉以及图像理解等学科知识。目标识别技术已广泛应用于国民经济、空间技术和国防等领域。 正文: 图像识别总的来说主要包括目标图像特征提取和分类两个方面。但是一般情况下,图像受各种因素影响,与真实物体有较大的差别,这样,就需要经过预处理、图像分割、特征提取、分析、匹配识别等一系列过程才能完成整个识别过程。 目前,最主流的三种三维物体识别研究思路是: 1)基于模型或几何的方法;
2)基于外观或视图的方法; 3)基于局部特征匹配的方法; 一、基于模型或几何的方法: 这种方法所识别的目标是已知的,原理就是利用传感器获得真实目标的三维信息并对信息进行分析处理,得到一种表面、边界及连接关系的描述,这里,三维物体识别中有两类最经常使用的传感器:灰度传感器和深度传感器,前者获取图像的每个像素点对应于一个亮度测量,而后者对应于从传感器到可视物体表面的距离;另一方面,利用CAD建立目标的几何模型,对模型的表面、边界及连接关系进行完整的描述。然后把这两种描述加以匹配就可以来识别三维物体。其流程如下图所示: 传感器数据获取过程,就是从现实生活中的真实物体中产生待识别的模型。分析/建模过程,是对传感器数据进行处理,从中提取与目标有关的独立应用特征。模型库的建立一般式在识别过程之前,即首先根据物体的某些特定特征建立一些关系以及将这些信息汇总成一个库。在模型匹配过程,系统通过从图像中抽取出的物体关系属性图,把物体描述与模型描述通过某种匹配算法进行比较、分析,最终得到与物体最相似的一种描述,从而确定物体的类型和空间位置。 基于模型的三维物体识别,需要着重解决以下4个问题:
目标检测方法简要综述
龙源期刊网 https://www.360docs.net/doc/bb5910213.html, 目标检测方法简要综述 作者:栗佩康袁芳芳李航涛 来源:《科技风》2020年第18期 摘要:目标检测是计算机视觉领域中的重要问题,是人脸识别、车辆检测、路网提取等领域的理论基础。随着深度学习的快速发展,与基于滑窗以手工提取特征做分类的传统目标检测算法相比,基于深度学习的目标检测算法无论在检测精度上还是在时间复杂度上都大大超过了传统算法,本文将简单介绍目标检测算法的发展历程。 关键词:目标检测;机器学习;深度神经网络 目标检测的目的可分为检测图像中感兴趣目标的位置和对感兴趣目标进行分类。目标检测比低阶的分类任务复杂,同时也是高阶图像分割任的重要基础;目标检测也是人脸识别、车辆检测、路网检测等应用领域的理论基础。 传统的目标检测算法是基于滑窗遍历进行区域选择,然后使用HOG、SIFT等特征对滑窗内的图像块进行特征提取,最后使用SVM、AdaBoost等分类器对已提取特征进行分类。手工构建特征较为复杂,检测精度提升有限,基于滑窗的算法计算复杂度较高,此类方法的发展停滞,本文不再展开。近年来,基于深度学习的目标检测算法成为主流,分为两阶段和单阶段两类:两阶段算法先在图像中选取候选区域,然后对候选区域进行目标分类与位置精修;单阶段算法是基于全局做回归分类,直接产生目标物体的位置及类别。单阶段算法更具实时性,但检测精度有损失,下面介绍这两类目标检测算法。 1 基于候选区域的两阶段目标检测方法 率先将深度学习引入目标检测的是Girshick[1]于2014年提出的区域卷积神经网络目标检测模型(R-CNN)。首先使用区域选择性搜索算法在图像上提取约2000个候选区域,然后使用卷积神经网络对各候选区域进行特征提取,接着使用SVM对候选区域进行分类并利用NMS 回归目标位置。与传统算法相比,R-CNN的检测精度有很大提升,但缺点是:由于全连接层的限制,输入CNN的图像为固定尺寸,且每个图像块输入CNN单独处理,无特征提取共享,重复计算;选择性搜索算法仍有冗余,耗费时间等。 基于R-CNN只能接受固定尺寸图像输入和无卷积特征共享,He[2]于2014年参考金字塔匹配理论在CNN中加入SPP-Net结构。该结构复用第五卷积层的特征响应图,将任意尺寸的候选区域转为固定长度的特征向量,最后一个卷积层后接入的为SPP层。该方法只对原图做一
(完整版)视频目标检测与跟踪算法综述
视频目标检测与跟踪算法综述 1、引言 运动目标的检测与跟踪是机器视觉领域的核心课题之一,目前被广泛应用在视频编码、智能交通、监控、图像检测等众多领域中。本文针对视频监控图像的运动目标检测与跟踪方法,分析了近些年来国内外的研究工作及最新进展。 2、视频监控图像的运动目标检测方法 运动目标检测的目的是把运动目标从背景图像中分割出来。运动目标的有效分割对于目标分类、跟踪和行为理解等后期处理非常重要。目前运动目标检测算法的难点主要体现在背景的复杂性和目标的复杂性两方面。背景的复杂性主要体现在背景中一些噪声对目标的干扰,目标的复杂性主要体现在目标的运动性、突变性以及所提取目标的非单一性等等。所有这些特点使得运动目标的检测成为一项相当困难的事情。目前常用的运动目标检测算法主要有光流法、帧差法、背景相减法,其中背景减除法是目前最常用的方法。 2.1帧差法 帧差法主要是利用视频序列中连续两帧间的变化来检测静态场景下的运动目标,假设f k(x, y)和f(k i)(x, y)分别为图像序列中的第k帧和第k+1帧中象素点(x,y)的象素值,则这两帧图像的差值图像就如公式2-1所示: Diff ki f k(x, y) f(k 1)(x, y)(2-1)2-1式中差值不为0的图像区域代表了由运动目标的运动所经过的区域(背景象素值不变),又因为相邻视频帧间时间间隔很小,目标位置变化也很小,所以运动目标的运动所经过的区域也就代表了当前帧中运动目标所在的区域。利用此原理便可以提取出目标。下图给出了帧差法的基本流程:1、首先利用2-1式得到第k帧和第k+1帧的差值图像Diff k 1;2、对所得到的差值图像Diff k 1二值化(如 式子2-2示)得到Qk+1 ;3、为消除微小噪声的干扰,使得到的运动目标更准 确,对Q k 1进行必要的滤波和去噪处理,后处理结果为M k 1。 1
视频目标跟踪算法综述_蔡荣太
1引言 目标跟踪可分为主动跟踪和被动跟踪。视频目标跟踪属于被动跟踪。与无线电跟踪测量相比,视频目标跟踪测量具有精度高、隐蔽性好和直观性强的优点。这些优点使得视频目标跟踪测量在靶场光电测量、天文观测设备、武器控制系统、激光通信系统、交通监控、场景分析、人群分析、行人计数、步态识别、动作识别等领域得到了广泛的应用[1-2]。 根据被跟踪目标信息使用情况的不同,可将视觉跟踪算法分为基于对比度分析的目标跟踪、基于匹配的目标跟踪和基于运动检测的目标跟踪。基于对比度分析的跟踪算法主要利用目标和背景的对比度差异,实现目标的检测和跟踪。基于匹配的跟踪主要通过前后帧之间的特征匹配实现目标的定位。基于运动检测的跟踪主要根据目标运动和背景运动之间的差异实现目标的检测和跟踪。前两类方法都是对单帧图像进行处理,基于匹配的跟踪方法需要在帧与帧之间传递目标信息,对比度跟踪不需要在帧与帧之间传递目标信息。基于运动检测的跟踪需要对多帧图像进行处理。除此之外,还有一些算法不易归类到以上3类,如工程中的弹转机跟踪算法、多目标跟踪算法或其他一些综合算法。2基于对比度分析的目标跟踪算法基于对比度分析的目标跟踪算法利用目标与背景在对比度上的差异来提取、识别和跟踪目标。这类算法按照跟踪参考点的不同可以分为边缘跟踪、形心跟踪和质心跟踪等。这类算法不适合复杂背景中的目标跟踪,但在空中背景下的目标跟踪中非常有效。边缘跟踪的优点是脱靶量计算简单、响应快,在某些场合(如要求跟踪目标的左上角或右下角等)有其独到之处。缺点是跟踪点易受干扰,跟踪随机误差大。重心跟踪算法计算简便,精度较高,但容易受到目标的剧烈运动或目标被遮挡的影响。重心的计算不需要清楚的轮廓,在均匀背景下可以对整个跟踪窗口进行计算,不影响测量精度。重心跟踪特别适合背景均匀、对比度小的弱小目标跟踪等一些特殊场合。图像二值化之后,按重心公式计算出的是目标图像的形心。一般来说形心与重心略有差别[1-2]。 3基于匹配的目标跟踪算法 3.1特征匹配 特征是目标可区别与其他事物的属性,具有可区分性、可靠性、独立性和稀疏性。基于匹配的目标跟踪算法需要提取目标的特征,并在每一帧中寻找该特征。寻找的 文章编号:1002-8692(2010)12-0135-04 视频目标跟踪算法综述* 蔡荣太1,吴元昊2,王明佳2,吴庆祥1 (1.福建师范大学物理与光电信息科技学院,福建福州350108; 2.中国科学院长春光学精密机械与物理研究所,吉林长春130033) 【摘要】介绍了视频目标跟踪算法及其研究进展,包括基于对比度分析的目标跟踪算法、基于匹配的目标跟踪算法和基于运动检测的目标跟踪算法。重点分析了目标跟踪中特征匹配、贝叶斯滤波、概率图模型和核方法的主要内容及最新进展。此外,还介绍了多特征跟踪、利用上下文信息的目标跟踪和多目标跟踪算法及其进展。 【关键词】目标跟踪;特征匹配;贝叶斯滤波;概率图模型;均值漂移;粒子滤波 【中图分类号】TP391.41;TN911.73【文献标识码】A Survey of Visual Object Tracking Algorithms CAI Rong-tai1,WU Yuan-hao2,WANG Ming-jia2,WU Qing-xiang1 (1.School of Physics,Optics,Electronic Science and Technology,Fujian Normal University,Fuzhou350108,China; 2.Changchun Institute of Optics,Fine Mechanics and Physics,Chinese Academy of Science,Changchun130033,China)【Abstract】The field of visual object tracking algorithms are introduced,including visual tracking based on contrast analysis,visual tracking based on feature matching and visual tracking based on moving detection.Feature matching,Bayesian filtering,probabilistic graphical models,kernel tracking and their recent developments are analyzed.The development of multiple cues based tracking,contexts based tracking and multi-target tracking are also discussed. 【Key words】visual tracking;feature matching;Bayesian filtering;probabilistic graphical models;mean shift;particle filter ·论文·*国家“863”计划项目(2006AA703405F);福建省自然科学基金项目(2009J05141);福建省教育厅科技计划项目(JA09040)
(完整word版)基于图像处理的运动物体的跟踪与检测开题报告
1、课题来源 随着计算机技术的高速发展,运动物体的检测和跟踪在图像处理、计算机视觉、模式识别、人工智能、多媒体技术等领域越来越受到人们的关注。运动跟踪和检测的应用广泛,在智能监控和人机交互中,如:银行、交通、超市等场合常常使用运动跟踪分析技术,通过定位物体并对其行为进行分析,一旦发现物体有异常行为,监控系统就发出警报,提醒人们注意并即时的处理,改善了人工监督注意力分散、反应时间较慢、人力资源浪费等问题。运动目标的跟踪在虚拟现实、工业控制、军事设备、医学研究、视频监控、交通流量观测监控等很多领域也有重要的实用价值。特别在军事上,先进的武器导航、军事侦察和监控中都成功运用了自动跟踪技术。而跟踪的难点在于如何快速而准确的在每一帧图像中实现目标定位。正因如此,对运动目标的跟踪和检测的研究很有价值。 2、研究目的和意义 运动目标检测是图像处理与计算机视觉的一个分支,在理论和实践上都有重大意义,长久以来一直被国内外学者所关注。在实际中,视频监控利用摄像机对某一特定区域进行监视,是一个细致和连续的过程,它可以由人来完成,但是人执行这种长期枯燥的例行监测是不可靠,而且费用也很高,因此引入运动监测非常有必要。它可以减轻人的负担,并且提高了可靠性。概括起来运动监测主要包括三个内容:运动目标检测,方向判断和图像跟踪。运动目标检测是整个监测过程的基础,运动目标的提取准确与否,直接关系到后续高级过程的完成质量。3、国内外研究现状和发展趋势及综述 运动目标检测在国外已经取得了一些的研究成果,许多相关技术已经开始应用到实际系统中,但是国内研究相对落后,与国外还有较大差距。传统的视频目标提取大致可以分两类,一类以空间同性为准则,先用形态学滤波器或其他滤波器对图像作预处理;然后对该图像的亮度、色度或其他信息作空间上的分割以对区域作边缘检测;之后作运动估计,并合并相似的运动区域以得到最终的提取结果。如光流算法、主动轮廓模型算法。此类方法结果较为准确但是运算量相对较大。另一类算法主要以时间变化检测作为准则,这类算法主要通过帧差检测图像上的变化区域和不变区域,将运动物体与静止背景进行分割。此类方法运算量小,提取结果不如前类方法准确。此外,还有时空结合方法、时空亮度梯度信息结合的方法等等。 4、研究方法
交通场景中运动目标的检测文献综述
交通场景中运动目标的检测文献综述 摘要:运动目标检测是数字图像处理技术的一个主要部分,是一种基于视频监控系统的运动目标检测方法。这种算法主要包括:图像预处理、运动目标的检测、运动速度的求取。运动目标分割是实现交通场景下车辆检测的前提。常用的分割方法可以分为背景差分法、帧间差分法和基于光流的分割方法等。 关键词:数字图像处理;运动目标;检测方法 1 前言 运动目标检测是数字图像处理技术的一个主要部分,近些年来,随着多媒体技术的迅猛发展和计算机性能的不断提高,动态图像处理技术日益受到人们的青睐,并且取得了丰硕的成果,广泛英语与交通管理、军事目标跟踪、生物医学等领域。 目前,以数字图像处理技术为核心的视频监视系统越来越广泛地应用到交通监管中,它利用摄像机来获取图像,由计算机完成对运动目标的自动检测,如果车辆交通违规时,自动发出预警,记录全程违章视频,这在很大程度上减轻了监控人员的劳动强度,克服可能的人为失误,而且节省大量存储空间,使存储的数据更为有效,为交通违规的后续处理提供了客观依据。 交通场景中运动目标的检测是本文的研究对象。结合图书馆书籍、网上资料以及现有期刊杂志的相关信息,初步建立起交通场景中运动目标检测课题研究的整体思路和方法。 2 正文 2.1运动目标 运动目标是常生活中常见的.如活动的动物、行驶的运载工具等。在现实生活中,尽管人类的视觉既能看见运动又能看见静止的物体,但是在交通这样的复杂场景中大量有意义的视觉信息都包含在这些运动之中,人们往往只对运动的
物体或目标感兴趣。因此,研究运动目标的检测问题,有着很大的现实意义和应用价值。 2.2运动目标检测的基本概念 目前我们主要是通过对动态图像进行分析处理来获取运动目标信息,从而实现对运动目标的检测,它是图像处理与计算机视觉应用研究领域的一个重要课题。,所谓动态图像是由一序列图像组成的,即图像序列。图像序列是用一个传感器(如摄像机、数码相机)采集的一组随时间变化的图像,不同时刻采集的二帧图像或多帧图像中包含了存在于相机与景物之间的相对运动信息。还有景物本身发生变化的运动信息等等,这些信息表现为图像帧之间的灰度变化或诸如点、线、区域等记号的位置和运动方向速度等属性的变化。 运动目标检测的目的就是从序列图像中将变化区域从背景图像中提取出来。我们首先用摄像机获取运动目标的视频影像,经视频采集卡将视频信号传输到计算机,利用计算机对其进行相关处理,从视频图像中按一定时间间隔获取序列图像,然后通过对这些序列图像进行特定的处理,就可以检测出我们感兴趣的运动目标。 运动目标检测和分析是一种基于视频监控系统的运动目标检测方法。这种算法主要包括:图像预处理、运动目标的检测、运动速度的求取。这种算法在帧差法的基础之上,提取出运动目标,并对其求取运动速度。这种技术可以用于各类图像监控系统,用来检测运动目标,对于现实应用有重要意义。 2.3运动目标检测的基本方法 由运动目标所形成的图像序列可分为两种情况:一种是静止背景,一种是运动背景。前一种情况通常发生在摄像机相对静止状态(如监视某一路口车流量的固定摄像机),后一种情况通常发生在摄像机也在相对运动状态(如装在卫星或飞机上的监视系统)。从处理方法上看,对前一种情况可采用消除背景的方法检测运动目标,处理起来比较简单,如简单的帧间差分或自适应背景对消方法。对后一种情况.处理起来比较复杂,一般是采用突出目标或消除背景的思想检测运动目标。若采用消除背景的方法,则通常需要先进行帧间稳像及配准;若采用突出
视频中移动目标检测综述
基于视频的移动目标检测 论文研读报告 苏航00748178 智能科学系信息科学技术学院 北京大学 摘要 基于视频的移动目标检测是一个重要且有挑战性的任务,在许多应用中都起到相当关键的作用。本次论文研读围绕该主题展开,深入阅读了十余篇论文,在本文总结了视频中移动目标检测的一些主要方法及各自的优劣,并将几个重要的方法大致分为了两个不同的类别:基于像素的移动目标检测和基于区域的移动目标检测。在基于像素的方法中,图像特征完全由各个像素的坐标及灰度值(或颜色值)确定,而在基于区域的方法中,各个像素属性之间的关联成为主要特征来用以提取移动目标。另外本文还讨论了以上两类之外的一些方法。 关键词 视频移动目标检测背景差分高斯混合模型直方图 正文 1 引言 基于视频的移动目标检测在许多实际应用中都担当着核心的任务。譬如视频监视、人机交互、视频编码等广泛的领域都需要有效地进行该工作。帧差法(Frame Differencing)12是视频中检测移动目标最简单直观的方法,其在视频片段中固定间隔的两帧之间计算绝对差,该差值大于一定阈限的像素就认为是运动物体可能存在的区域: D t(x,y)=Abs.F t(x,y)?F t?k(x,y)/(1) 这种简单的方法有时十分有效,但在更多应用环境下并不能获得期望的效果。这主要是由于视频中各帧之间的差异并不仅仅来源于运动的物体,而同时可能来 1R. Jain and H. Nagel, “On the Analysis of Accumulative Difference Pictures from Image Sequences of Real World S cenes”, IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 1, no. 2, pp. 206–214, 1979. 2为了避免混淆,本文中将作为主要研读对象的文章列在报告最后的“参考文献”一栏中,而其他引用的 文献则作为脚注注明。
多目标跟踪方法研究综述
经过近40多年的深入研究和发展,多目标跟踪技术在许多方面都有着广泛应用和发展前景,如军事视觉制导、机器人视觉导航、交通管 制、 医疗诊断等[1-2]。目前,虽然基于视频的多运动目标跟踪技术已取得了很大的成就,但由于视频中图像的变化和物体运动的复杂性,使得对多运动目标的检测与跟踪变得异常困难,如多目标在运动过程中互遮挡、监控场景的复杂性等问题,解决上述难题一直是该领域所面临的一个巨大挑战,因此,对视频中多目标跟踪技术研究仍然是近年来一个热门的研究课题[3-5]。 1、多目标跟踪的一般步骤 基于视频的多目标跟踪技术融合了图像处理、模式识别、人工智能、 自动控制以及计算机视觉等众多领域中的先进技术和核心思想。不同的多目标跟踪方法其实现步骤有一定的差异,但多目标跟踪的主要 流程是相同的,如图1所示,其主要包括图像预处理、 运动目标检测、多目标标记与分离、多目标跟踪四个步骤。 图1多目标跟踪基本流程图 2、多目标跟踪方法 多目标跟踪方法可以根据处理图像或视频获取视点的多少分为两大类,一类是单视点的多目标跟踪,另一类就是多视点的多目标跟踪。 2.1单视点的方法 单视点方法是针对单一相机获取的图像进行多目标的检测和跟踪。该方法好处在于简单且易于开发,但由于有限的视觉信息的获取,很难处理几个目标被遮挡的情况。 块跟踪(Blob-tracking)是一种流行的低成本的跟踪方法[6-7]。这种方法需要首先在每一帧中提取块,然后逐帧寻找相关联的块,从而实现跟 踪。 例如BraMBLe系统[8]就是一个基于已知的背景模型和被跟踪的人的外表模型计算出块的似然性的多块跟踪器。这种方法最大的不足之处在于:当由于相似性或者遮挡,多个目标合并在一起时,跟踪将导致失败。因此,可以取而代之的方法是通过位置、外观和形状保留清晰目标的状态。文献[9]利用组合椭圆模拟人的形状,用颜色直方图模拟不同人的外观,用一个增强高斯分布模拟背景以便分割目标,一旦场景中发现对应于运动头部的像素,一个MCMC方法就被用于获取多个人的轮廓的最大后验概率,在单相机的多人跟踪应用中取得了非常有意义的结果。Okuma等人提出了一种将Adaboost算法和粒子滤波相结合的方法[10]。该方法由于充分利用了两种方法的优点,相比于单独使用这两种方法本身,大大降低了跟踪失败的情形,同时也解决了在同一框架下检测和一致跟踪的问题。Brostow等人提出了一个用于在人群中检测单个行人的特征点轨迹聚类的概率框架[11]。这个框架有一个基本假设是一起运动的点对可能是同一个个体的一部分,并且把它用于检测和最终的跟踪。对于完全和部分遮挡目标以及外观变化,这些方法和另外一些相似的方法都有很大的局限性。 为了解决遮挡问题,一系列单视点跟踪技术应运而生。典型的方法 是利用块合并来检测遮挡的发生[12]。当被跟踪的点消失, 跟踪特征点的方法就简单的将其作为一个被遮挡特征点。近年来,基于目标轮廓和外观的跟踪技术利用隐含的目标到相机的深度变化来表示和估计目标间的遮挡关系。但大多数方法都只能解决部分遮挡,不能解决完全被遮挡 的情况。 另外,小的一致运动被假设为是可以从遮挡视点中可以预测运动模式的,这些给没有预测运动的较长时间的遮挡的处理带来问题。尽管这些单视点的方法有较长的研究历史,但这些方法由于不能明锐的 观察目标的隐藏部分,因此不能很好地解决有2或3个目标的遮挡问题。 2.2多视点的方法 随着复杂环境中对检测和跟踪多个被遮挡的人和计算他们的精确 位置的需要,多视点的方法成为研究的热点。 多视点跟踪技术的目的就是利用不同视点的冗余信息,减少被遮挡的区域,并提供目标和场景的3D信息。尽管通过相机不能很好地解决目标跟踪问题,但却提出了一些很好的想法,如选择最佳视点,但这些方法都以实际环境模型和相机校正为特征。 90年代后半期,在很多文献中给出了多视点相关的多目标跟踪方法。 比如利用一个或多个相机与观察区域相连的状态变化映射,同时给出一系列的行为规则去整合不同相机间的信息。利用颜色在多个视点中进行多目标的跟踪的方法,该方法模拟了从基于颜色直方图技术的 背景提取中获得的连接块并应用其去匹配和跟踪目标。 除此之外,也有在原来的单视点跟踪系统进行扩展的多视点跟踪方法。该方法主要是通过一个预测,当预测当前的相机不在有一个好的视点时,跟踪就从原来凯斯的那个单相机视点的跟踪转换到另外一个相机,从而实现多视点的跟踪。基于点与它对应的极线的欧氏距离的空间匹配方法、贝叶斯网络和立体相对合并的方法都是多目标多视点跟踪的常见方法。尽管这些方法都试图去解决遮挡问题,但由于遮挡的存在,基于特征的方法都不能根本解决,其次,这些方法中的遮挡关系的推理一般都是根据运动模型,卡尔曼滤波或者更普遍的马尔科夫模型的时间一致性来进行的。因此,当这个过程开始发散,这些方法也不能恢复遮挡关系。 最近一种基于几何结构融合多个视点信息的Homegraphicoccupancyconsrraint(HOC)[12]方法,可以通过在多场景平台对人的定位来解决遮挡问题。仅采用随时间变化的外表信息用于从背景中检测前景,这使得在拥挤人流的场景中的外表遮挡的解决更健壮。利用多视点中的前景信息,主要是试图找到被人遮挡的场景点的图像位置,然后这些被遮挡的信息用于解决场景中多个人的的遮挡和跟踪问题。在这种思想指导下,Mittal,Leibe,Franco等的研究工作和机器人导航中基于遮挡网格的距离传感器的并行工作是相似的,这些方法在融合3D空间信息的时候需要进行校正相机。但HOC方法是完全基于图像的,仅需要2D结构信息进行图像平面的融合。当然也有另外一些不需要进行相机校正的算法被提出,但需要学习一个与相机最小相关的信息。在目标跟踪过程中,由于这些方法依赖于单个相机的场景,对于拥挤场景中目标分布密度增加九无能为力了。在HOC的多视点的目标跟踪中,对于任何单一相机的场景,或者相机对的场景,都不需要进行定位和跟踪目标,而是从所有相机的场景中收集证据,形成一个统一的框架,由于该方法能够从多个时间帧的场景中进行场景被遮挡概率的全局轨迹优化,因此可以同时进行检测和跟踪。 3、总结 动态目标检测与跟踪是智能监控系统的重要组成部分,它融合了图像处理、模式识别、自动控制及计算机应用等相关领域的先进技术和研究成果,是计算机视觉和图像编码研究领域的一个重要课题,在军事武器、工业监控、交通管理等领域都有广泛的应用。尤其是对于多目标检测与跟踪中的遮挡与被遮挡的处理,对提高智能监控中目标的行为分析有着重要的意义。随着监控设备的发展和设施的铺设,多视点的场景图像是很容易得到的,因此借助信息融合的思想,充分利用不同角度对目标的描述信息,可以很大地改进目前基于单视点的多目标检测和跟踪的精度,能够很好地解决单视点方法中不能很好解决的遮挡问题。参考文献 [1]胡斌,何克忠.计算机视觉在室外移动机器人中的应用.自动化学报,2006,32(5):774-784. [2]A.Ottlik,H.-H.Nagel.InitializationofModel-BasedVehicleTrackinginVideoSequencesofInner-CityIntersections.InternationalJournalofComputerVision,2008,80(2):211-225.多目标跟踪方法研究综述 苏州联讯图创软件有限责任公司 陈宁强 [摘要]文章对目前现有的多目标跟踪方法从信息获取的不同角度进行了综述。主要分析比较了目前单视点和多视点目标跟踪方 法对于目标遮挡问题的处理性能,并指出多视点的基于多源信息融合的思想,可以较好地解决场景中目标的遮挡问题。[关键词]单视点多视点目标跟踪信息融合基金项目:本文系江苏省自然科学基金(BK2009593)。 作者简介:陈宁强(1973-),男,江苏苏州人,工程师,主要研究方向:GIS、模式识别和图像处理与分析。 目标跟踪多目标标记与分离 匹配 目标模型 运动检测当前帧图像 背景提取 去噪 ROI 预处理 视频序列 (下转第26页)
运动目标检测
运动目标检测 跟踪各过程算法综述图像预处理数字图像中的几种典型噪声有:高斯噪声来源于电子电路噪声和低照明度或高温带来的传感器噪声椒盐噪声类似于随机分布在图像上的胡椒和盐粉微粒主要由图像切割引起或变换域引起的误差加性噪声是图像在传输中引进的信道噪声。一般来说引入的都是加性随机噪声可以采用均值滤波、中值滤波、高斯滤波等方法去除噪声提高信噪比。均值滤波在噪声分布较平均且峰值不是很高的情况下能够得到较好的应用中值滤波对尖脉冲噪声的滤除有较好的效果并且能突出图像的边缘和细节高斯滤波对滤除高斯白噪声有较好的效果。运动目标检测背景差分法:能完整、快速地分割出运动对象。不足之处易受光线变化的影响背景的更新是关键。不适用摄像头运动的情况。光流法:能检测独立运动的对象可用于摄像头运动的情况但计算复杂耗时很难实时检测。帧差法:受光线变化影响较小简单快速但不能分割出完整的运动对象需进一步运用目标分割算法。还有一些改进的算法主要致力于减少光照影响和检测慢速物体变化。图像标识图像标识的作用是确定物体是否独立图像中有几个运动目标。 1领域:常取周围的4或8个像素作为领域。 2连通域:二值图像中互相连通的0像素集或1像素集称之为连通域。被1像素包围的0像素叫做孔。1像素连通域不含孔时叫做单连通成分含有一个或多个孔的连通成为叫做多重连通成分。 3标记:差值后的一帧图像可能存在多个连通域每个非连通域对应一个目标图像区给各目标区分配相应标号的工作成为标记。标识过程大致为:按一定顺序逐个扫描像素扫描到1的像素检测其领域的像素值若一样则为连通域并标记为第一个目标然后依次寻找下一个目标。在所有可能的目标都找到了之后可以为每个目标划出一个波门将目标框起来。并建立一个多目标位置链表找到的每一个目标区域的中心位置都作为一个结点加入该链表储存起来。波门的划分有可能将同一个目标分为两个部分或者一个波门里包括了两个目标使得目标数据错误增加或减少所以还要判断当前的目标是属于同一个目标还是不同的目标这将在后面的图像分割中完成。图像分割图像分割用于分离目标和背景的组合或者分离不同目标的组合。图像分割不仅可以大量压缩数据减少储存容量而且能大大简化其后的分析和处理步骤。 1直方图阈值分割法灰度直方图即为灰度级的像素数与灰度的二维关系反映了一副图像灰度分布的统计特性。如果前景物体内部灰度值分布比较均匀背景灰度值的分布也比较均匀这个图像的直方图将有明显的双峰这时可以选择两峰之间的谷底作为阈值。由于直方图不含目标的位置信息还要结合图像的内容来确定。 2最大类间方差阈值分割法利用图像目标与背景这两类的总体灰度之间存在的差距确定阈值从而进行分割。 3区域生长法指将周围特性相似的像素再次合并到目标区域中。 4边缘检测和轮廓提取分割法 5形态学分割法主要作用是使运动目标的区域更加完整。腐蚀的作用是消除物体边界点把小于结构元素的物体去除。如果两物体之间有细小的连通那么当结构元素足够大时通过腐蚀运算可以将两个物体分开。膨胀运算的作用是把图像周围的背景点合并到物体中。如果两个物体比较接近那么膨胀运算可能会使这两个物体连通在一起。膨胀对填补图像的空洞很有用膨胀最简单的应用之一就是将裂缝接起来。形态学也可用于图像滤波、增强等方面。运动轨迹预测在分割出运动目标后应提取出目标的特征然后在下一帧图像中匹配特征从而跟踪目标。但为了减少搜索特征匹配的区域提高实时性在此加入对目标运动轨迹预测这一步骤。运动轨迹预测也有利于增强遮挡情况下跟踪的鲁棒性。 1线性预测算法2Kalman滤波算法及其扩展算法 3粒子滤波算法目标跟踪 1特征选取灰度特
论文--基于深度学习的图像目标类别检测研究与实现--孔冬荣20160522
图书分类号: 密级: 毕业设计(论文) 基于深度学习的图像目标类别检测研究与实现RESEARCH AND IMPLEMENTATION OF IMAGE OBJECT CATEGORY DETECTION BASED ON DEEP LEARNING 学生姓名孔冬荣 学院名称信电工程学院 学号20120508106 班级12软嵌 1 专业名称计算机科学与技术 指导教师鞠训光吕宝旺 2016年6月3日
徐州工程学院学位论文原创性声明 本人郑重声明:所呈交的学位论文,是本人在导师的指导下,独立进行研究工作所取得的成果。除文中已经注明引用或参考的内容外,本论文不含任何其他个人或集体已经发表或撰写过的作品或成果。对本文的研究做出重要贡献的个人和集体,均已在文中以明确方式标注。 本人完全意识到本声明的法律结果由本人承担。 论文作者签名:日期:年月日 徐州工程学院学位论文版权协议书 本人完全了解徐州工程学院关于收集、保存、使用学位论文的规定,即:本校学生在学习期间所完成的学位论文的知识产权归徐州工程学院所拥有。徐州工程学院有权保留并向国家有关部门或机构送交学位论文的纸本复印件和电子文档拷贝,允许论文被查阅和借阅。徐州工程学院可以公布学位论文的全部或部分内容,可以将本学位论文的全部或部分内容提交至各类数据库进行发布和检索,可以采用影印、缩印或扫描等复制手段保存和汇编本学位论文。 论文作者签名:导师签名: 日期:年月日日期:年月日
摘要 大数据时代使得数字图像的数量和规模与日俱增,给图像处理带来挑战。提高图像识别的效率和速率,对图像物体检测与识别具有一定的现实意义。 深度学习DL(Deep Learning)是近几年热门的一种含有多层结构的深度神经网络。通过学习一种深层非线性网络结构,提高对复杂分类问题的泛化能力。 由此而言,在图像检测难度较大的情况下,为达到更高的处理效率和准确率,运用深度学习技术便顺理成章。本选题将研究应用机器学习方法的最新成果--深度学习来实现目标类别检测。 本文的主要工作包括: (1)查阅近年来的深度学习及目标检测的相关文献资料,了解深度学习和图像检测算法的国内外研究现状,概述深度学习的发展及其机理和训练方法,研究深度学习的Caffe 框架及卷积神经网络、Fast R-CNN等机理; (2)在Linux系统下搭建Caffe学习框架,应用CUDA并行架构,采用基于AlexNet 网络的图像目标检测Fast R-CNN模型,通过交替无监督和有监督学习训练网络,最终实现对图像目标人、猫、车、沙发等二十个类别的检测; (3)通过实验验证Fast R-CNN在数据集PASCAL VOC 2007的检测效果较为理想,证实使用深度学习进行图像目标检测具有可行性和有效性。 关键词目标类别检测;深度学习;卷积神经网络;Fast R-CNN