中山大学 数据库期末考试试题(含答案)B-2011

中山大学软件学院2009级软件工程专业(2011 春季学期)
《数据库系统原理》期末试题试卷(B)
(考试形式:开卷考试时间:2小时)
考试作弊不授予学士学位
方向:姓名:______ 学号:
出卷:冯剑琳审核:
注意:答案一定要写在答卷中,写在本试题卷中不给分。本试卷要和答卷一起交回。
Question 1 Logical Databases (20 marks)
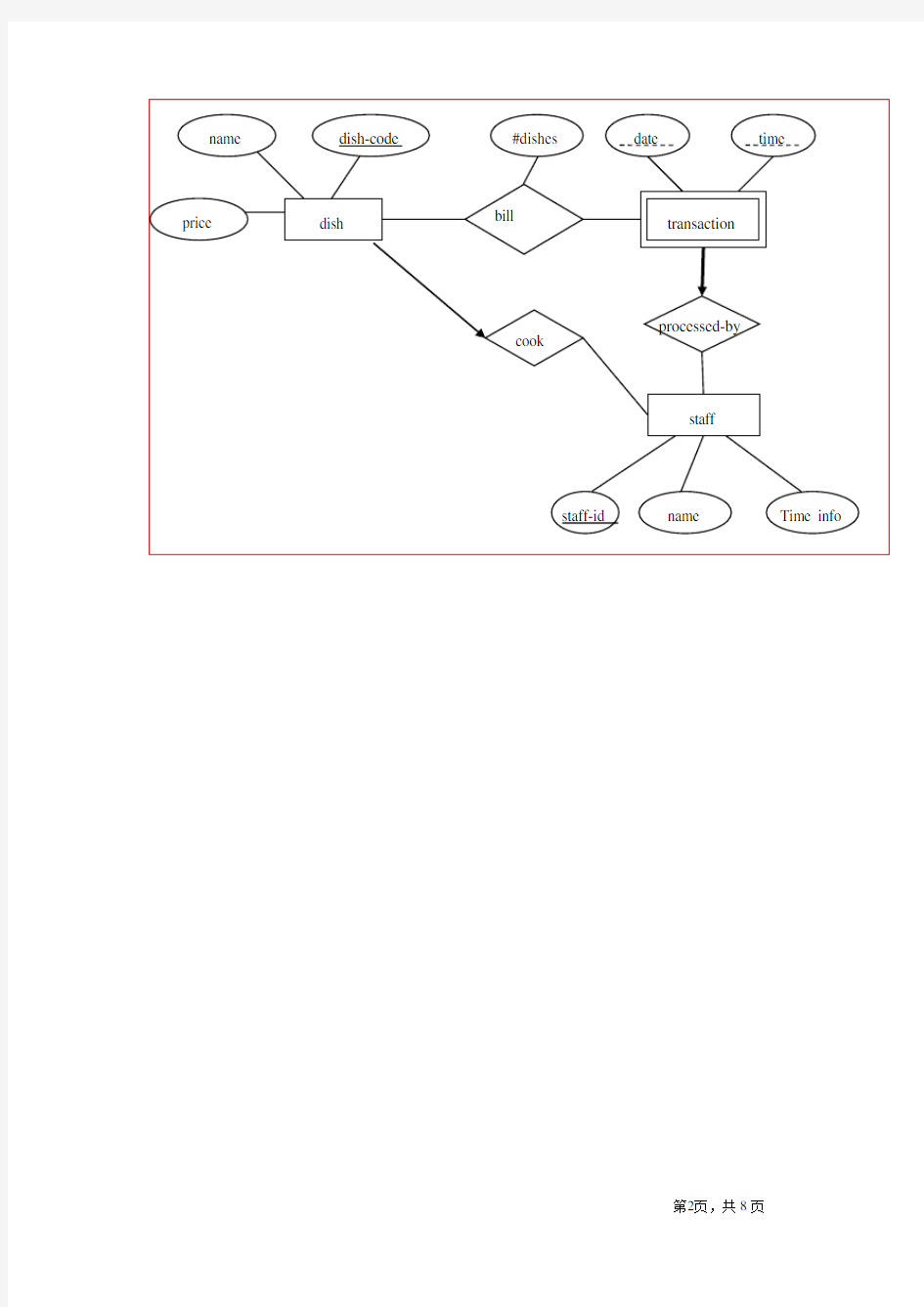
You are required to construct an ER Diagram for a restaurant which maintains data about the following three entities: dish, staff and transaction. The three relationships are bill, cook and processed-by and the details of the relationships are described as follows:
? A record in dish is uniquely identified by a five-digit dish-code, and contains the information for the name of the dish, the price of the dish;
? A staff member has staff-id, name, and working-time-info;
?Each dish is cooked by exactly one staff member, but a staff member can cook more than one dishes, assume that all the staff members can cook for simplicity;
? A transaction can be uniquely identified by the following information: date, time, and the responsible staff who has processed the transaction.
?More than one units of the same dish could be sold and should be recorded by
a distinct transaction, this relationship is called bill.
(a)(15 marks) Draw the ER diagram that consists of the three entities and the three
relationships. You should write down the assumptions clearly if you think that the above description of the three entities and three relationships is not adequate for drawing the ER Diagram. You should also indicate all important information of
the ER Diagram such as keys, weak entities and cardinalities.
(b)(5 marks) Convert the above ER Diagram into the corresponding relational
schemas. Underline all the attribute(s) of the primary key. Specify clearly
whether a schema is obtained from an entity, a weak entity or a relationship.
entities:
dish(dish-code, name, price)
staff(staff-id, name, working-time-info)
weak entity:
transaction(date, time, staff-id)
relationships:
cook(dish-id, staff-id)
bill(date, time, dish-code, num-of-dish-sold)
Note: there is no extra table for the relationship process-by between a weak entity and its “owner/strong” entity.
Question 2 Indexing Structure (18 marks)
Suppose that we are using extendable hashing index that contains the following search-key values K: 2, 10, 10, 12, 15, 15, 3, 13. Assuming the search-key values arrive in the given order (i.e. 2 being the first coming key and 13 being the last one). Show the extendable hash structure for each case of inserting a group of the above key values if the hash function is h(x) = x mod 16 and buckets can hold two keys.The initial configuration of the structure and the binary form of all keys are given in the diagram below.
Convention requirement: You should use the bits starting from the most-significant one or MSB (the left-hand side) as the hashing index.
Initial hash table Empty bucket
Binary values of all keys K
a)After inserting 2, 10, 10;
b)After inserting 12;
c)After inserting 15, 15, 3, 13.
a)After inserting 2, 10, 10;
b)After inserting 12;
c)After inserting 15, 15, 3, 13.
Question 3 (22 marks) Join Algorithms
Consider the following two relations R and S. The number of records in R and S is also given.
?R(A, B, C, D): 5,000 records
?S(A, E, F, G): 18,000 records
The sizes of all attribute values are given in the table.
Assume the size of each memory page is 4K bytes and the memory buffer has 25 pages. All the computations should show the steps. Consider the following SQL query:
Query: SELECT C, E FROM R, S WHERE R.A=S.A
(a) (4 marks) What is the size of R and S in terms of pages?
For R: each R record contains 10+20+30+20=80 bytes. There are 4000/80=50 records per page. Thus, the size of R is 5,000/50=100 pages.
For S: each S record contains 100 bytes. There are 4000/100=40 R records per page. The size of S is thus 18,000/40=450 pages.
(b) (18 marks) Assume using sort-merge join to process the query as follows:
Step 1: Sort R on R.A and store the sorted relation in disk, assuming we discard irrelevant attributes as soon as possible. (Note: You may need to round up to whole page after removing the irrelevant attributes in the first pass.)
Step 2: Sort S on S.A but compare with R (sorted already in Step 1) once a sorted page of S is generated in the final pass, assuming again we discard irrelevant attributes as soon as possible. (Note: S pages generated in the final pass do not need to write back to disk.)
Sept 3: Transfer sorted R page by page from disk to memory buffer to compare the sorted pages of S once a sorted page is generated in Step 2.
Estimate the cost of each step and then compute the total cost of sort-merge join. Step 1: We have ?100/25? = 4 sorted runs. At each sorted run 25 R pages are read and 13 pages are written due to discarding attributes B and D. One more pass can merge all. Cost of sorting R = (100+13*4)(first pass)+(13*4+50)(second pass)=152+52+50=254.
Step 2: We have ?450/25? = 18 sorted runs. At each sorted run 25 S pages are read and 15 pages are written due to discarding attributes F and G. One more pass can merge all and the generated pages are used for direct comparison. Cost of sorting S = 450+18*15+18*15 (half of the final pass) =450+270+270=990
Step3: Cost of transfer sorted R = 50
Total cost = 254+990+50=1294
Question 4 (20 marks) Physical Database Design
Consider the following schemas with usual meaning: Students and professors belong to some departments. Students are enrolled in the courses offered by some professors. The size of all the attribute values is assumed to be the same in each schema.
General information: There are 500 different professor names, 1,000 different student names, and 100 different department names. On the average, each student is enrolled in 10 offerings and each offering has 10 students. Each department offers 10 courses. Assume that professor salaries are uniformly distributed in the range from 10,000 to 110,000.
Index information: All index pages are stored in disk. We assume B-trees with height 3 for clustered index stored and there are no overflow buckets for hash index. For indexes on a non-candidate key, you may have multiple entries with the same search key entry. We also ignore the cross-page factor for multiple records with same search key in a file if the number of records is within the page limit.
We optimize the queries in (a) and (b) as follows.
(a) Query 1: Display the names of all professors whose salary is in the range from 30,000 to 35,000.
Approach 1: Build a clustered index on professor.salary.
Approach 2: Build a multi-attribute index on
Which approach is better? Your answer should be based on the cost estimation with clear explanations.
Approach 1: Build a clustered index on professor.salary. The query is expected to retrieve 50 (5%) professors, i.e., 5 pages.
Total Cost = 3+5.
Approach 2: We can use a multi-attribute index on professor
Total cost= 3+2.(Better)
(b) Query 2: Given a professor’s name, find the name of the department that the professor belongs to.
Approach 1: Build one hash index on professor. p_name and another hash index on department.d_id.
Approach 2: Build one hash index on professor.p_name and a hash file organization on department.d_id where the department records are partitioned in 5 buckets.
Which approach is better? Your answer should be based on the cost estimation with clear explanations.
Approach 1: Build a hash index on professor.p_name. Use the index to find the two professors with the input name. Cost = 1 (for locating the p_name entry in the index) + 2 (for following the two pointers in the file).
For each d_id of these professors, use a hash index on department.d_id to retrieve the department record (and d_name), with cost 2.
Total cost 3+2x2=7. (Better)
Approach 2: Instead of a hash index on department.d_id, use a hash file organization on department, where the records are partitioned in 5 buckets (each bucket has 4 pages) based on their d_id. In this case, we can retrieve each project record with cost 4.
Total cost 3+2x4=11.
Question 5 Transaction Management (20 marks)
(a) (2 marks) Give two reasons why a serial schedule for database transactions is not practical for commercial DBMSs.
?No sharing of data. (No concurrency)
?Cannot fully utilize the system idle time
In the following questions, the notation is self-explanatory. For example, R1(X) means transaction T1 reads item X. Similarly, “W”means WRITE and “C”means “Commit”.
(b) (18 marks) For each of the following schedules, indicate whether it is conflict serializable and recoverable. If it is conflict serializable, then write out one equivalent serial schedule. The following is an example of the expected answer.
[Example]
R1(X), R2(X), W2(Y), C2, R1(Y), C1.
Answer:
It is serializable.
It is recoverable.
The equivalent serial schedule is T2, T1.
(i)R1(X), W1(X), R2(X), W2(X), R1(Y), W1(Y), R2(Y), W2(Y), C2, C1.
Answer:
It is serializable.
It is not recoverable.
The equivalent serial schedule is T1, T2.
(ii)R1(X), R1(Y), R2(X), W2(Y), W2(X), C2, W1(Z), C1.
Answer:
It is serializable.
It is recoverable.
The equivalent serial schedule is T1, T2
(iii)R1(X), R2(X), R3(X), W2(Y), W3(X), R3(Y), R1(Y), C3, C2, W1(X), C1
Answer:
It is not serializable.
It is not recoverable.
数据库期末考试习题及答案
2004-2005学年第二学期期末考试 C 2002级计算机科学与技术专业《数据库原理与应用》课程试题一、选择题(15分,每空1分): 1.在数据库中,产生数据不一致的根本原因是____。 A.数据存储量太大 B.没有严格保护数据 C.未对数据进行完整性控制 D.数据冗余 2.相对于其他数据管理技术,数据库系统有①、减少数据冗余、保持数据的一致性、②和③的特点。 ①A.数据统一 B.数据模块化 C.数据结构化 D.数据共享 ②A数据结构化 B.数据无独立性 C.数据统一管理 D.数据有独立性 ③A.使用专用文件 B.不使用专用文件 C.数据没有安全与完整性保障 D.数据有安全与完整性保障 3.关系运算中花费时间可能最长的运算是____。 A.投影 B.选择 C.笛卡尔积 D.除 4.关系数据库用①来表示实体之间的联系,关系的数学定义是②。 ①A.层次模型 B.网状模型 C.指针链 D.二维表格数据 ②A.若干域(domain)的集合 B.若干域的笛卡尔乘积(Cartesian product) C.若干域的笛卡尔乘积的子集 D.若干元组(tuple)的集合 5.集合R与S的连接可以用关系代数的5种基本运算表示为________。 A.R-(R-S) B.σ F (R×S) C.空 D.空 6.在关系代数中,对一个关系做投影操作后,新关系的元组个数____原来关系的元组个数。 A.小于 B.小于或等于 C.等于 D.大于 7.下列SQL语句中,创建关系表的是____。 A.ALTER B.CREATE C.UPDATE D.INSERT 8.关系数据库设计中的陷阱(pitfalls)是指________。 A.信息重复和不能表示特定信息 B.不该插入的数据被插入 C.应该删除的数据未被删除 D.应该插入的数据未被插入 9.数据库的____是为了保证由授权用户对数据库所做的修改不会影响数据一致性的损失。 A.安全性 B.完整性 C.并发控制 D.恢复 10.事务是数据库进行的基本工作单位。如果一个事务执行成功,则全部更新提交;如果一个事务
外科学__中山大学(5)--五年制期末考试试题1
2010级临床五年制外科学期末考试试卷(B卷) 一、单项选择题:每题1分,共50分 1. 代谢性酸中毒的血钾浓度的变化趋势是 A.增高 B.降低 C.不变 D.无规律 E.增高后逐渐降低 2. 高钾血症的病人发生心律失常,应首先应用 A.输注葡萄糖溶液及胰岛素 B.阳离子交换树脂 C.11.2%乳酸钠50ml静脉滴注 D.10%葡萄糖酸钙20ml静脉注射 E.5%碳酸氢钠100ml静脉滴注 3. 迅速失血量一般超过机体总血量的多少即可引起失血性休克 A. 10% B. 20% C. 25% D. 30% E. 40% 4. 急性肾功能衰竭患者最严重的并发症是 A. 血钠下降 B. 肺水肿 C. 血钙下降 D. 血钾下降
E. 血钾升高 5.甲下脓肿应采取的最佳措施是 A. 理疗 B. 热敷 C. 抗生素 D. 拔除指甲 E. 在甲沟处切开引流 6. 下列损伤中,须优先处理的是 A. 张力性气胸 B. 单根多段肋骨骨折 C. 下肢开放性骨折 D. 包膜下脾破裂 E. 脑挫裂伤 7. 术后出现下列症状一般不属于麻醉并发症的是 A. 呕吐 B. 低热 C. 高热 D. 精神症状 E. 头痛 8. 临床各类器官移植中疗效最稳定最显著的是 A.肝移植 B.肾移植 C.心脏移植 D.骨髓移植 E.肺移植
9. 关于甲状腺结节的诊断,下列哪项是正确的 A.核素扫描为冷结节,多数是甲状腺癌 B.甲状腺球蛋白升高,有助于甲状腺癌的诊断 C.甲状腺的结节越多,患甲状腺癌的可能性越大 D.彩色B超是确诊甲状腺癌最好的方法 E.血清降钙素升高,有助于诊断甲状腺髓样癌 10. 确诊乳腺肿块最可靠的方法是 A.钼靶摄片 B. B超 C. 红外线 D. MRI E. 活检病理 11. 患儿,3岁,发现右侧阴囊可复性肿块,透光试验阴性,诊断考虑是 A.睾丸鞘膜积液 B.股疝 C.腹股沟直疝 D.腹股沟斜疝 E.隐睾 12. 腹部闭合性损伤诊断的关键在于首先确定有无 A.腹壁损伤 B.内脏损伤 C.腹痛 D.恶心、呕吐 E.腹膜后血肿 13. 对腹部闭合性损伤伴休克,腹穿抽出粪样液体者应 A.立即手术治疗
数据库期末考试试题及答案
数据库期末考试试题及答案 一、选择题(每题1分,共20分) 1(在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。 在这几个阶段中,数据独立性最高的是( A )阶段。 A. 数据库系统 B. 文件系统 C. 人工管理 D.数据项管理 2(数据库三级视图,反映了三种不同角度看待数据库的观点,用户眼中的数据库称为(D)。 A. 存储视图 B. 概念视图 C. 内部视图 D. 外部视图 3(数据库的概念模型独立于(A)。 A. 具体的机器和DBMS B. E-R图 C. 信息世界 D. 现实世界 4(数据库中,数据的物理独立性是指(C)。 A. 数据库与数据库管理系统的相互独立 B. 用户程序与DBMS的相互独立 C. 用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的 D. 应用程序与数据库中数据的逻辑结构相互独立 5(关系模式的任何属性(A)。 A. 不可再分 B. 可再分 C. 命名在该关系模式中可以不惟一 D.以上都不是 6(下面的两个关系中,职工号和设备号分别为职工关系和设备关系的关键字: 职工(职工号,职工名,部门号,职务,工资) 设备(设备号,职工号,设备名,数量) 两个关系的属性中,存在一个外关键字为( C )。
A. 职工关系的“职工号” B. 职工关系的“设备号” C. 设备关系的“职工号” D. 设备关系的“设备号” 7(以下四个叙述中,哪一个不是对关系模式进行规范化的主要目的( C )。 A. 减少数据冗余 B. 解决更新异常问题 C. 加快查询速度 D. 提高存储空间效率 8(关系模式中各级范式之间的关系为( A )。 A. B. C. D. 9(保护数据库,防止未经授权或不合法的使用造成的数据泄漏、非法更改或破坏。这是指 数据的( A )。 A. 安全性 B.完整性 C.并发控制 D.恢复 10(事务的原子性是指( B )。 A. 事务一旦提交,对数据库的改变是永久的 B. 事务中包括的所有操作要么都做,要么都不做 C. 一个事务内部的操作及使用的数据对并发的其他事务是隔离的 D. 事务必须使数据库从一个一致性状态变到另一个一致性状态 11(下列哪些运算是关系代数的基本运算( D )。 A. 交、并、差 B. 投影、选取、除、联结 C. 联结、自然联结、笛卡尔乘积 D. 投影、选取、笛卡尔乘积、差运算 12(现实世界“特征” 术语, 对应于数据世界的( D )。 A(属性 B. 联系 C. 记录 D. 数据项 13(关系模型中3NF是指( A )。 A.满足2NF且不存在传递依赖现象 B.满足2NF且不存在部分依赖现象
中山大学期末考试试题样题
中山大学期末考试试题样题
课程:C++程序设计语言 学号: 考试对象:网络教育计算机本科 姓名: 成绩:
一、
选择题 (每小题 2 分,共 30 分) 1 A 2 B 3 B 4 C 5 C 6 D 7 D 8 C 9 A 10 D 11 B 12 D 13 A 14 D 15 D
题号 答案
1. 假定一个类的构造函数为 A ( int aa, int bb) { a = aa; b = bb; },则执行 A x(4,5);语法 后,x.a 和 x.b 的值分别为( ) 。 A.4 和 5 B.5 和 4 C.4 和 20 D.20 和 5 2. 假定 AB 为一个类,则执行 AB x;语句时将自动调用该类的( ) 。 A.有参构造函数 B.无参构造函数 C.拷贝构造函数 D.赋值重载函数 3. C++语言建立类族是通过( ) 。 A.类的嵌套 B.类的继承
C.虚函数
D.抽象类
4. 执行语句序列 ofstream outf("SALARY.DAT");if (…) cout<<"成功!"; else cout<<"失败!"; 后,如果文件打开成功,显示"成功!",否则显示"失败!"。由此可知,上面 if 语 句的处的表达式是( ) 。 A. !outf 或者 outf.fail() B. !outf 或者 outf.good() C.outf 或者 outf.good() D.outf 或者 ouf.fail() 5. 静态成员函数不能说明为( ) 。 A.整型函数 B.浮点函数
C.虚函数
D.字符型函数
6. 在 C++中,数据封装要解决的问题是( ) 。 A.数据规范化排列 B.数据高速转换 C.避免数据丢失 D.切断了不同模块之间的数据的非法使用 8. 如果 class 类中的所有成员在定义时都没有使用关键字 public、private 或 protected, 则所有成员缺省定义为( ) 。 A.public B.protected C.private D.static 9. 设置虚基类的目的是( ) 。 A.消除两义性 B.简化程序 C.提高运行效率 D.减少目标代码
1
数据库期末试卷
浙江工业大学 《数据库原理及应用》 一、填空题 1、SELECT Name,Tele FROM Person 的作用是。 2、数据独立性是指数据与应用程序之间不存在相互依赖关系,分为 和。 3、用树型结构表示实体类型及实体间联系的数据模型称为层次模 型。 4、提供数据库定义、数据装入、数据操纵、数据控制和DB维护功能的软件称为 _ 数据管理系统 _。 5、在关系代数中专门的关系运算包括、、、除等。 6、关系数据库的第一范式保证列的原子 性。 7、一个数据库由若干个表组成,关系的元组称为,属性称为。 8 久性。 9、数据字典通常包括数据项、数据结构、数据流、数据存储和处理过程5个部分。 10、并发操作带来的数据不一致性包括三类:丢失覆盖修改、 不可重复读、 读”脏数据。 11、管理信息系统的四种结构模式为:单机模式、、 和。 12、数据管理技术经历了:人工管理阶段、文件管理阶段以及数据库系统阶段 三个发展阶段。
14、实体之间的联系按照联系方式的不同可分为一对一或1:1 、 一对多或1:n 、___ 多对多或m:n 。 15、E-R图中包括__实体、____ 属性和联系三种基 本图素。 16、数据模型由三部分组成:模型结构、数据操作、数据约束条件 。 17、事务必须具有的四个性质是:原子性、一致性、隔离性和持久 性。 18、基本的封锁类型有排它锁和共享锁两种。 19、DB并发操作通常会带来三类问题,它们是丢失修改、不一致分析和读脏数据。 20、数据库系统可能发生的故障有:事务内部的故障系统故障、和介质故障等。计算机病毒 21、按转储时间来分,数据转储可分为静态转储和动态转储两种方式。 22、列举三种管理信息系统开发的方法:结构化开发方法、__原型方 法_ _____、 面向对象方法。 23、一个学生可以同时借阅多本图书,一本图书只能由一个学生借阅,学生和图书之间的联系为一对多联系。 二、判断题 1、关系中允许有重复的元组,但是不允许有重复的属性名。() 2、关系代数的运算对象是关系,但运算结果不是关系。() 3、连接操作可以多个表之间进行,也可以在一个表内进行。() 4、触发器是一种很有效的保证数据库完整性的手段。() 5、对于关系R、S,如果R-S的元组数是0,则说明R中包含了S的所有元组。 ()6、设关系R、S的元组数分别是20、30,则R和S连接的元组数不可能超过50。 () 7、数据库中的每一个基本表与外部存储器上一个物理文件对应。() 8、一个数据库可以有多个外模式和多个内模式。() 9、概念模型向关系模型转换时,实体间的n:m联系可以有两种转换方法,一
sql数据库期末考试题及答案
一、单选题(共 10 道试题,共 50 分。)V 1. SQL Server中,保存着每个数据库对象的信息的系统表是( C)。 A. sysdatabases B. Syscolumns C. Sysobjects D. Syslogs 2. 在存在下列关键字的SQL语句中,不可能出现Where子句的是(D )。 A. Update B. Delete C. Insert D. Alter 3. 在查询语句的Where子句中,如果出现了“age Between 30 and 40”,这个表达式等同于(A )。 A. age>=30 and age<=40 B. age>=30 or age<=40 C. age>30 and age<40 D. age>30 or age<40 4. 如果要在一张管理职工工资的表中限制工资的输入范围,应使用(D )约束。 A. PDRIMARY KEY B. FOREIGN KEY C. unique D. check 5. 记录数据库事务操作信息的文件是(D )。 A. 数据文件 B. 索引文件 C. 辅助数据文件 D. 日志文件 6. 要查询XSH数据库CP表中产品名含有“冰箱”的产品情况,可用( C)命令。 A. SELECT * FROM CP WHERE 产品名称 LIKE ‘冰箱’ B. SELECT * FROM XSH WHERE 产品名称 LIKE ‘冰箱’ C. SELECT * FROM CP WHERE 产品名称 LIKE ‘%冰箱%’ D. SELECT * FROM CP WHERE 产品名称=‘冰箱’ 7. 储蓄所有多个储户,储户能够在多个储蓄所存取款,储蓄所与储户之间是(D )。 A. 一对一的联系 B. 一对多的联系 C. 多对一的联系 D. 多对多的联系 8. SQL的聚集函数COUNT、SUM、AVG、MAX、MIN不允许出现在查询语句的( D)子句之中。 A. SELECT B. HAVING C. GROUP BY… HAVING D. WHERE 9. 列值为空值(NULL),则说明这一列( C)。 A. 数值为0
中山大学期末考试-计算机体系结构-A-期末考试答案
中山大学软件学院2009级计算机应用软件(2011学年秋季学期) 《S E-315计算机体系结构》期末试题答案(A) I.Fill in the blank (1 pt per blank, 20 pts in total) 1. 存储容量I/O带宽;2.N N/2;3.SPEC2000 100;4.资源结构;5.向后向前;6.硬件软件; 7.平均修复时间平均无故障时间8.向量标量;、 9.超标量超流水线;10.集中式共享存储器多处理结构、分布式共享存储器结构 II. Single-choice questions (1 pt per question, 10 pts) 1.D; 2. A; 3. C; 4. B; 5. B; 6. D; 7. D; 8. D; 9. D; 10. C。 III. T or F questions (the right to play "√"; the wrong fight "×",1 pt per question, 10 pts in total) 1.√; 2.×; 3.√; 4.×; 5.×; 6.×; 7.√; 8.×; 9. √; 10.√。 IV. Calculation or to answer the following questions (12 points per question, 60 points in total) 1.⑴计算机体系结构的量化原则有:①大概率事件优先的原则;②Amdahl性能公式; ③CPU性能公式;(④局部性原理;⑤利用并行性。 ⑵加速比主要取决于两个因素:①在原有的计算机上,能被改进并增强的部分在总执行时间中所占的比例;②通过增强的执行方式所取得的改进,即如果整个程序使用了增强的执行方式,那么这个任务的执行速度会有多少提高。 ⑶一个计算机体系结构,从产生到消亡,大约需要15-20年时间,经历的阶段包括:硬件-系统软件-应用软件-消亡。 2.⑴指令 I1和 I2之间有 RW 相关,I2和 I3之间有 RW 相关,I1和 I3之间有 WW 相关,I1和 I2之间还有 WR 相关。 ⑵对 I1和 I2之间的 WR 相关,可用定向传送解决。根据寄存器重命名技术,对引起 RW 相关的 I2中的 R2,对引起 WW 相关的 I3 中的 R1,可分别换成备用寄存器 R2’、 R1’。经寄存器重命名后,程序代码段实际执行时变为: I1 ADD R1 ,R2,R4 I2 ADD R2’,R1,1 I3 SUB R1’,R4,R5 3.⑴根据平均访存时间公式:平均访存时间=命中时间+失效率×失效开销可知,可以从以下三个方面改进Cache性能: ⑵降低失效率;②减少失效开销;③减少Cache命中时间 ⑵在多处理机系统中的私有Cache 会引起Cache 中的内容相互之间以及共享存储器
数据库期末考试试卷A卷.docx
数据库期末考试试卷 A 卷 时间: 90 分钟总分: 100 分 题次一( 50 分)二( 40 分)三( 10 分)总( 100 分) 得分 注:请大家在试卷上注明自己的学号。 :一、选择题。(每题 2 分,共50 分) 名题号12345678910 姓答案 题号11121314151617181920 答案 题号2122232425 答案 1、 ACCESS 数据库是()。 A 、层状数据库 B、网状数据库 C、关系型数据库 D、树状数据库 2、在 ACCESS 数据库中,数据保存在()中。 A 、窗体 B、查询 :C、报表 号D、表 学3、数据库系统的核心是() A 、用户 B、数据 C、数据库管理系统 D、硬件 4、关系数据库中,一个关系代表一个() A 、表 B、查询 C、行 D、列 5、 ACCESS 数据库文件的扩展名是()。 A 、 DBF :B、 DBT C、 M DF 级 D、 MDB 班 6、关系类型中的“一对多”指的是()。 A 、一个字段可以有许多输入项 B、一条记录可以与不同表中的多条记录相关 C、一个表可以有多个记录 D、一个数据库可以有多个表 7、数据库文件中包含()对象。 A 、表 B、查询 C、窗体 D、以上都包含 8、在 ACCESS 的下列数据类型中,不能建立索引的数据类型是()。 A 、文本型 B、备注型 C、数字型 D、日期时间型 9、如果某一字段数据类型为文本型、字段大小为8,该字段中最多可输入()个汉字 A 、 8 B 、 4 C、 16 D 、32 10、在定义表字段时,输入掩码向导只能处理哪两种字段类型()。 A 、文本和数字B、文本和日期型 C、数据和日期型 D、货币和日期 11、下列哪一个不是设置“关系”时的选项()。 A 、实施参照完整性B、级联更新相关字段 C、级联追加相关记录 D、级联删除相关记录 12、如果字段内容为声音文件,可将此字段定义为()类型。 A 、文本B、查阅向导C、 OLE 对象D、备注 13、在表设计视图中,如果要限定数据的输入格式,应修改字段的()属性。 A 、格式B、有效性规则C、输入格式 D 、输入掩码 14、一般情况下,以下哪个字段可以作为主关键字() A 、基本工资 B 、补贴C、职工姓名D、身份证号码 15、级联删除相关记录的含义是() A、删除主表中的记录,将删除任何相关表中的相关记录 B、删除相关表中的记录,将删除主表中的记录 C、只能删除“一对一”表中的相关记录 D、不能删除“一对多”表中的相关记录 16、文本型字段最多可以存放()个字符。 A 、250B、 10C、 254D、 255 17、下面有关主键的叙述正确的是()。 A、不同的记录可以具有重复的主键值或空值 B、一个表中的主键何以是一个或多个 C、在一个表中的主键只可以是一个字段 D、表中的主键的数据类型必须定义为自动编号或文本 18、下面有关ACCESS 数据库的叙述正确的是() 1
数据库期末试题附答案
《数据库原理》课程考试模拟题四 一、单项选择题(在每小题的四个备选答案中选出一个正确答案。本题共16分,每小题1分) 1. 在数据库中,下列说法()是不正确的。 A.数据库中没有数据冗余 B.数据库具有较高的数据独立性 C.数据库能为各种用户共享 D.数据库加强了数据保护 2. 按照传统的数据模型分类,数据库系统可以分为( )三种类型。 A.大型、中型和小型 B.西文、中文和兼容 C.层次、网状和关系 D.数据、图形和多媒体 3. 在数据库的三级模式结构中,( )是用户与数据库系统的接口,是用户用到的那部分数据的描述。 A.外模式 B.内模式 C.存储模式 D.模式 4. 下面选项中不是关系的基本特征的是( )。 A. 不同的列应有不同的数据类型 B. 不同的列应有不同的列名 C. 没有行序和列序 D. 没有重复元组 5. SQL语言具有两种使用方式,分别称为交互式SQL和( )。 A.提示式SQL B.多用户SQL C.嵌入式SQL D.解释式SQL 6. 设关系模式R(ABCD),F是R上成立的FD集,F={A→B,B→C},则(BD)+为( )。 A.BCD B.BC C.ABC D.C 7. E-R图是数据库设计的工具之一,它适用于建立数据库的( )。 A.概念模型 B.逻辑模型 C.结构模型 D.物理模型8. 若关系模式R(ABCD)已属于3NF,下列说法中( )是正确的。 A.它一定消除了插入和删除异常 B.仍存在一定的插入和删除异常C.一定属于BCNF D.A和C都是 9. 解决并发操作带来的数据不一致性普遍采用( )。 A.封锁技术 B.恢复技术 C.存取控制技术 D.协商 10. 数据库管理系统通常提供授权功能来控制不同用户访问数据的权限,这主要是为了实现数据库的( )。 A.可靠性 B.一致性 C.完整性 D.安全性 11. 一个事务一旦完成全部操作后,它对数据库的所有更新应永久地反映在数据库中,不会丢失。这是指事务的( ) 。 A. 原子性 B. 一致性 C. 隔离性 D. 持久性 12. 在数据库中,软件错误属于( )。
数据库期末考试模拟试题及答案(一)
四、程序设计题(本大题共2小题,每小题15分,共30分) 1.对于教学数据库的三个基本表 学生student (sno,sname,sex,sage,sdept) 学习sc(sno,cno,grade) 课程course(cno,cname,cpno,ccredit) 试用SQL语句表示:下列语句。 (1)"查询全男同学信息情况" "select * from student where sex='男'" (2)"查询选修了1号课的学生的学号和成绩" "select sno,grade from sc where cno='1'" (3)"查询所有选修过课的学生的姓名,课程名及成绩" "select sname,cname,grade from student,sc,course where student.sno=sc.sno and https://www.360docs.net/doc/c43768738.html,o=https://www.360docs.net/doc/c43768738.html,o" (4)"查询选修了数据库原理课的最高成绩" "select max(grade) as '最高成绩' from student,sc,course where student.sno=sc.sno and https://www.360docs.net/doc/c43768738.html,o=https://www.360docs.net/doc/c43768738.html,o and cname='数据库原理'" (5)查询所有选修了1号课程的同学的姓名" " select sname from student where student.sno in (select sc.sno from sc where cno='1')" 2.设有一个SPJ数据库,包括S,P,J,SPJ四个关系模式(20分)供应商表S(SNO,SNAME,STATUS,CITY); 零件表P(PNO,PNAME,COLOR,WEIGHT); 工程项目表J(JNO,JNAME,CITY); 供应情况表SPJ(SNO,PNO,JNO,QTY);SPJ表 J表 S表 P表 请用关系代数完成如下查询: 1.求供应工程J1零件的供应商号 SNO 2.求供应工程J1零件P1的供应商号吗SNO 3.求供应工程J1零件为红色的供应商号码SNO 4.求没有使用天津供应商生产的红色零件的工程号JNO 5.求至少用了供应商S1所供应的全部零件的工程号JNO 1.∏sno(σJNO=‘J1’(SPJ)) 2.∏sno(σJNO=‘J1’ΛPNO=’P1’(SPJ)) 3.∏sno(σJNO=‘J1’(SPJ)∞σcolor=‘红’(P)) 4.∏jno(SPJ)-∏jno(∏sno(σcity=‘天津’(S))∞∏sno,jno (SPJ)∞∏jno σcolor=‘红’(P)) 5.∏jno, pno(SPJ)÷∏pno(σsno=‘s1’(SPJ)) 五、分析题(本大题共2小题,每小题15分本大题共30分) 1. 学生运动会模型: (1)有若干班级,每个班级包括: 班级号,班级名,专业,人数 (2)每个班级有若干运动员,运动员只能属于一个班,包括:运动员号,姓名,性别,年龄
中山大学《线性代数》期中考试卷答案
珠海校区2009年度第一学期《线性代数》期中考试卷 姓名:专业:学号:成绩: 一,填空题(每题3分,共24分) 1.在5 阶行列式中,含有a13a34a51且带有负号的项是________________ 2.设A是3阶方阵,| A |= 1/3 ,则|(3A)-1 + 2A*| = 1 1 0 0 1 1 1 1 3. 5 2 0 0 = : 4 . x c b a = ; 0 0 3 6 x2c2b2a2 0 0 1 4 x3c3b3a3 5 . 已知矩阵 A = 1 1 , B = 1 0 , 则AB – BA T = ; 0 -1 1 1 1 0 2 6. 已知矩阵 A = 1 k 0 的秩为 2 ,则k = ; 1 1 1 2 1 1 1 7. 1 2 1 1 = ; 8. 若A = diag( 1 ,2 ,3 ,4 ) , 则A-1= ; 1 1 2 1 1 1 1 2 二. 判断题(每题2分,共10分) 1. 任一n 阶对角阵必可与同阶的方阵交换。() 2. n 阶行列式中副对角线上元素的乘积a n1a n-1,2…a1n总是带负号的() 3. 若A为n 阶方阵,则(A*)T = ( A T )* () 4. 设A , B 为n 阶方阵,则有(AB)3= A3B3() 5. 设A与B 为同型矩阵,则 A ~ B的充要条件是R(A)=R ( B ) ( ) 三,计算下列行列式( 每题8 分,共16 分) -2 -1 1 -1 0 1 0 …0 0 D4 = -2 2 4 8 1 0 1 …0 0 -2 1 1 1 D n = 0 1 0 …0 0 -2 -2 4 8 . . . . . 0 0 0 …0 1 0 0 0 … 1 0 -1 -1 0 四. 已知 A = -1 0 1 且AB = A – 2B , 求 B . 2 2 1
数据库期末试卷和答案
数据库程序设计试题 1一、判断题(每题1分,共10分) 1、DB、DBMS、DBS三者之间的关系是DBS包括DB和DBMS。( ) 2、数据库的概念结构与支持其的DB的DBMS有关。( ) 3、下列式子R∩S=R—(R—S)成立。( ) 4、数据存储结构改变时逻辑结构不变,相应的程序也不变,这是数据库系统的逻辑独立 性。() 5、关系数据库基本结构是三维表。( ) 6、在嵌入式SQL语句中,主语句向SQL语句提供参数,主要用游标来实现。( ) 7、规范化的投影分解是唯一的。( ) 8、不包含在任何一个候选码中的属性叫做非主属性。( ) 9、在 Transact-SQL 语句的WHERE子句中,完全可以用IN子查询来代替OR逻辑表达式。 ( ) 10、封锁粒度越大,可以同时进行的并发操作越大,系统的并发程度越高。() 二、填空题(每空0.5分,共10分) 1、两个实体间的联系有联系,联系和联系。 2、select命令中,表达条件表达式用where子句,分组用子句,排序用 子句。 3、数据库运行过程中可能发生的故障有、和三类。 4、在“学生-选课-课程”数据库中的三个关系如下: S(S#,SNAME,SEX,AGE),SC(S#,C#,GRADE),C(C#,CNAME,TEACHER)。 现要查找选修“数据库技术”这门课程的学生姓名和成绩,可使用如下的SQL语句:SELECT SNAME,GRADE FROM S,SC,C WHERE CNAME= 数据库技术AND S.S#=SC.S# AND。 5、管理、开发和使用数据库系统的用户主要有、、 。 6、关系模型中可以有三类完整性约束:、 和。 7、并发操作带来数据不一致性包括三类:丢失修改、和。 8、事务应该具有四个属性:原子性、、隔离性和持续性。 9、数据库运行过程中可能发生的故障有事务故障、和三类。 10、在“学生-选课-课程”数据库中的三个关系如下:S(S#,SNAME,SEX,AGE),SC(S#,C#,GRADE),C(C#,CNAME,TEACHER)。 现要查找选修“数据库技术”这门课程的学生姓名和成绩,可使用如下的SQL语句:SELECT SNAME,GRADE FROM S,SC,C WHERE CNAME= ‘数据库技术’AND S.S#=SC.S# AND。 11、数据库设计包括、、逻辑结构设计、物理结构设计、数据库实施、数据库运行和维护。 12、MS SQL Server提供多个图形化工具,其中用来启动、停止和暂停SQL Server的图形 化工具称为_________。 13 、SELECT语句中进行查询 , 若希望查询的结果不出现重复元组 , 应在SELECT子 句中使用____________保留字。 14、如果一个关系不满足2NF,则该关系一定也不满足__________(在1NF、2NF、3NF 范围内)。 15、数据库的物理设计主要考虑三方面的问题:______、分配存储空间、实现存取路径。 三、单选题(每题1分,共20 分) 1、在SQL中,关系模式称为() A、视图 B、对象 C、关系表 D、存储文件 2、要保证数据库逻辑数据独立性,需要修改的是( )
数据库期末考试试题及答案
一、选择题(每题1分,共20分) 1.在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。在这几个阶段中,数据独立性最高的是( A )阶段。 A. 数据库系统 B. 文件系统 C. 人工管理 D.数据项管理 2.数据库三级视图,反映了三种不同角度看待数据库的观点,用户眼中的数据库称为(D)。 A. 存储视图 B. 概念视图 C. 内部视图 D. 外部视图 3.数据库的概念模型独立于(A)。 A.具体的机器和DBMS B. E-R图 C. 信息世界 D. 现实世界 4.数据库中,数据的物理独立性是指(C)。 A. 数据库与数据库管理系统的相互独立 B. 用户程序与DBMS的相互独立 C. 用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的 D. 应用程序与数据库中数据的逻辑结构相互独立 5.关系模式的任何属性(A)。 A. 不可再分 B. 可再分 C. 命名在该关系模式中可以不惟一 D.以上都不是 6.下面的两个关系中,职工号和设备号分别为职工关系和设备关系的关键字: 职工(职工号,职工名,部门号,职务,工资) 设备(设备号,职工号,设备名,数量) 两个关系的属性中,存在一个外关键字为( C )。 A. 职工关系的“职工号” B. 职工关系的“设备号” C. 设备关系的“职工号” D. 设备关系的“设备号” 7.以下四个叙述中,哪一个不是对关系模式进行规X化的主要目的( C )。 A. 减少数据冗余 B. 解决更新异常问题 C. 加快查询速度 D. 提高存储空间效率 8.关系模式中各级X式之间的关系为( A )。 A. B. C. D. 9.保护数据库,防止未经授权或不合法的使用造成的数据泄漏、非法更改或破坏。这是指数据的( A )。 A. 安全性 B.完整性 C.并发控制 D.恢复 10.事务的原子性是指( B )。 A. 事务一旦提交,对数据库的改变是永久的 B. 事务中包括的所有操作要么都做,要么都不做 C. 一个事务内部的操作及使用的数据对并发的其他事务是隔离的 D. 事务必须使数据库从一个一致性状态变到另一个一致性状态 11.下列哪些运算是关系代数的基本运算( D )。 A. 交、并、差 B. 投影、选取、除、联结 C. 联结、自然联结、笛卡尔乘积 D. 投影、选取、笛卡尔乘积、差运算
数据库期末考试试题及答案
数据库期末考试试题 ━━━━━━━━━━━━━━━ 一、填空共30题(共计30分) ━━━━━━━━━━━━━━━ 第1题(分)题号:2385 ORDER BY 子句实现的是【1】. 答案: =======(答案1)======= 排序 第2题(分)题号:2374 如果列上有约束,要删除该列,应先删除【1】 答案: =======(答案1)======= 相应的约束 第3题(分)题号:2394 在每次访问视图时,视图都是从【1】中提取所包含的行和列. 答案: =======(答案1)======= 基表 第4题(分)题号:2372
1.在增加数据文件时,如果用户没有指明文件组,则系统将该数据文件增加到【1】文件组.答案: =======(答案1)======= 主 第5题(分)题号:2371 查看XSCJ数据库信息的存储过程命令是【1】 答案: =======(答案1)======= sp_helpdb 第6题(分)题号:2392 创建视图定义的T-SQL语句的系统存储过程是【1】. 答案: =======(答案1)======= sp_helptext 第7题(分)题号:2379 1.表的外键约束实现的是数据的【1】完整性. 答案: =======(答案1)======= 参照 第8题(分)题号:2390 要进行模糊匹配查询,需要使用【1】关键字来设置查询条件.
答案: =======(答案1)======= LIKE 第9题(分)题号:2380 定义标识列的关键字是【1】. 答案: =======(答案1)======= identity 第10题(分)题号:2383 在进行多表查询是,必须设置【1】条件. 答案: =======(答案1)======= 连接 第11题(分)题号:2363 联系两个表的关键字称为【1】 答案: =======(答案1)======= 外键 第12题(分)题号:2382 用【1】字句可以实现选择行的运算. 答案:
中山大学:生理学期末考试题
01级中山大学中山医学院本科生理学期末考试题(闭卷部分) (考试时间:2003年1月14日) 姓名__________________学号________________班别___________总分__________________ 一、A型题(选1个最佳答案,每题1分,共35分) 1.有关神经纤维传导兴奋的机制和特点,错误的是: A.通过局部电流完成传导B.具有绝缘性C.相对不容易疲劳 D.单向传导E.非衰减性传导 2.EPSP在突触后神经元首先触发动作电位的部位是: A.树突棘B.胞体C.突触后膜D.轴突始段E.轴突末梢3.关于HCO3-重吸收的叙述,错误的是: A.主要在近球小管重吸收B.与H+的分泌有关 C.HCO3-是以CO2的形式从小管液中转运至肾小管上皮细胞内的 D.HCO3-重吸收需碳酸酐酶的帮助E.Cl-的重吸收优先于HCO3-的重吸收4.α受体: A.位于交感神经节细胞B.可被普萘洛尔阻断C.与异丙肾上腺素亲和力强D.兴奋时引起血管舒张,小肠平滑肌收缩 E.仅对交感神经末梢释放的去甲肾上腺素起反应 5.在脊髓半横断患者,横断平面以下: A.对侧本体感觉障碍B.对侧精细触觉障碍C.同侧痛、温觉障碍 D.对侧随意运动丧失E.对侧痛、温觉障碍 6.尿崩症的发生与下列哪种激素不足有关? A.肾上腺素和去甲肾上腺素B.肾素C.抗利尿激素 D.醛固酮E.前列腺素 7.浦肯野细胞和心室肌细胞的动作电位的区别是: A.4期自动除极化B.3期复极速度不同C.平台期持续时间相差特别悬殊D.1期形成的机制不同E.0期除极速度不同 8.胸廓的弹性回位力何时向外? A.开放性气胸时B.胸廓处于自然位置时C.平静呼吸末 D.深呼气末E.深吸气末 9.关于胰液分泌的调节,哪项是错误的? A.迷走神经兴奋,促进胰液分泌B.体液因素主要是胰泌素与胆囊收缩素C.胰腺分泌受神经与体液调节的双重控制而以神经调节为主 D.食物是兴奋胰腺分泌的自然因素E.在非消化期,胰液基本上不分泌 10.近视物时,眼的主要调节活动是: A.眼球前后径增大B.房水折光指数增大C.角膜曲率半径变大 D.晶状体向前方和后方凸出E.晶状体悬韧带紧张度增加
数据库期末考试部分试题
题型:选择 第一章 题型:名词解释 题目: 1)DB 答:DB是长期存储在计算机内、有组织的、统一管理的相关数据的集合。2)DBMS 答:DBMS是位于用户与OS之间的一层数据管理软件,它为用户或应用程序提供访问DB的方法。 3)DBS 答:DBS是实现有组织地、动态地存储大量关联数据,方便多用户访问的计算机硬件、软件和数据资源组成的系统,即采用数据库技术的计算机系统。4)数据独立性 答:应用程序和DB的数据结构之间相互独立,不受影响。 5)物理独立性 答:在DB的物理结构改变时,尽量不影响应用程序。 6)逻辑独立性 答:在DB的逻辑结构改变时,尽量不影响应用程序。 题型:问答 题目: 1)人工管理阶段的数据管理有哪些特点? 答:人工管理阶段主要有4个特点:数据不保存在计算机内;没有专用的软件对数据进行管理;只有程序的概念,没有文件的概念;数据面向程序。2)文件系统阶段的数据管理有哪些特点? 答:文件系统阶段主要有5个特点:数据以“文件”形式长期保存;数据的逻辑结构与物理结构有了区别;文件组织已多样化;数据面向应用;对数据的操作以记录为单位。 3)文件系统阶段的数据管理有些什么缺陷?试取例说明。 答:主要有3个缺陷:数据冗余;数据不一致性;数据联系弱。 例如:学校里教务处、财务处、保健处建立的文件中都有学生详细资料,如联系电话、家庭住址等,这就是“数据冗余”,如果某个学生搬家,就要修改3个部门文件中的数据,否则会引起同一数据在3个部门中不一致,产生上述问题的原因是这3个部门文件中的数据没有联系。 题型:填空 题目: 1)数据管理技术的发展,与________、________和________有密切的联系。 答:硬件、软件、计算机应用 2)文件系统中的数据独立性是指________独立性。 答:设备 3)文件系统的缺陷是:________、________和________。 答:数据冗余、数据不一致、数据联系弱 4)就信息处理的方式而言,在文件系统阶段,________处于主导地位,________只起着服从程序设计需要的作用;而在数据库方式下,________占据了中心位置。
数据库期末考试复习题(附答案)
数据库期末考试复习题(附答案) 数据库系统概论 2011年期末考试复习题 一、选择题 ? 第(1)至(3)题基于以下的叙述:有关系模式A(C,T,H,R,S),基中各属性的含义是: ? C:课程T:教员H:上课时间R:教室S:学生 ? 根据语义有如下函数依赖集:? F={C→T,(H,R)→C,(H,T)→R,(H,S)→R} ? 1、关系模式A的码是(D) ? A. C B. (H,R)C.(H,T)D.H,S) ? 2、关系模式A的规范化程度最高达到(B) ? A. 1NF B. 2NF C. 3NFD. BCNF ? 3、现将关系模式A分解为两个关系模式A1(C,T),A2(H,R,S),则其中A1的规范化程度达到(D) ? A. 1NF B. 2NF C. 3NF D. BCNF ? 4.设有关系R(A,B,C)和S(C,D)。与SQL语句? select A,B,D from R,S where R.C=S.C ? 等价的关系代数表达式是(B) ? A. σR.C=S.C(πA,B,D(R×S)) ? B. πA,B,D(σR,C= S.C (R×S)) ? C. σR.C=S.C((πA,B R)×(πDS)) ? D. σR,C=S.C(πD((πA,BR)×S) ? 5、设关系R和关系S的元数分别是3和4,关系T是R与S的广义笛卡尔积,即:T=R×S,则关系T的元数是(C) ? A. 7 B. 9 C. 12 D. 16 ? 6、数据库设计阶段分为(B) ? A. 物理设计阶段、逻辑设计阶段、编程和调试阶段 ? B. 概念设计阶段、逻辑设计阶段、物理设计阶段、实施和调试阶段 ? C. 方案设计阶段、总体设计阶段、个别设计和编程阶段 ? D. 模型设计阶段、程序设计阶段和运行阶段 ? 7、设U是所有属性的集合,X、Y、Z都是U的子集,且Z=U-X-Y。下面关于多值依赖的叙述中,不正确的是(C) ? A. 若X→→Y,则X→→Z B. 若X→Y,则X→→Y ? C. 若X→→Y,且Y′?Y,则X→→Y′ D. 若Z=Φ,则X→→Y ? 8、查询优化策略中,正确的策略是(D) A.尽可能早地执行笛卡尔积操作B.尽可能早地执行并操作 C.尽可能早地执行差操作D.尽可能早地执行选择操作 ? 9、语句delete from sc 表明(A) A. 删除sc中的全部记录 B. 删除基本表sc? C. 删除基本表sc中的列数据 D. 删除基本表sc中的部分行 ? 10、在DB应用中,一般一条SQL 语句可产生或处理一组记录,而DB主语言语句一般一次只能处理一条记录,其协调可通过哪种技术实现(B) ? A. 指针 B. 游标 C. 数组 D. 栈 11、五种基本关系代数运算是( A ) ? A. ∪,-,×,π和σ B. ∪,-,?,π和σ
ORACLE数据库期末考试题目及答案
期末考试卷(卷) 课程名称:数据库考试方式:开卷()闭卷(√) 、本试卷共4 页,请查看试卷中是否有缺页。 2、考试结束后,考生不得将试卷、答题纸带出考场。 1、以下(a )内存区不属于SGA。 A.PGA B.日志缓冲区 C.数据缓冲区 D.共享池 2、d )模式存储数据库中数据字典的表和视图。 (A.DBA B.SCOTT C.SYSTEM D.SYS 3、Oracle 中创建用户时,在若未提及DEFAULT TABLESPACE 关键字,Oracle 就将 c )则(表空间分配给用户作为默认表空间。A.HR B.SCOTT C.SYSTEM D.SYS
4、a )服务监听并按受来自客户端应用程序的连接请求。(A.OracleHOME_NAMETNSListener B.OracleServiceSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer 5、b )函数通常用来计算累计排名、移动平均数和报表聚合等。(A.汇总B.分析C.分组D.单行 6、b)SQL 语句将为计算列SAL*12 生成别名Annual Salary (A.SELECT ename,sal*12 …Annual Salary? FROM emp; B.SELECT ename,sal*12 “Annual Salary” FROM emp; C.SELECT ename,sal*12 AS Annual Salary FROM emp; D.SELECT ename,sal*12 AS INITCAP(“Annual Salary”) FROM emp; 7、锁用于提供(b )。 A.改进的性能 B.数据的完整性和一致性 C.可用性和易于维护 D.用户安全 8、( c )锁用于锁定表,允许其他用户查询表中的行和锁定表,但不允许插入、更新和删除行。 A.行共享B.行排他C.共享D.排他 9、带有( b )子句的SELECT 语句可以在表的一行或多行上放置排他锁。 A.FOR INSERT B.FOR UPDATE C.FOR DELETE D.FOR REFRESH