网页图片下载方法

https://www.360docs.net/doc/c48484070.html,
网页图片下载方法
有些朋友在逛微博网页的时候,会发现一些高质量的图片,想一张一张的保存下来,这其实是很浪费时间的。如果使用八爪鱼采集器的话,只需做好规则,即可全自动地将我们的想要的图片采集下来。下面以微博图片下载为例,介绍网页图片批量下载方法。
采集网站:
在开始之前,请大家注意,如果没有在八爪鱼中登录过,需先建立一个登录流程。微博登录教程请参考:
使用功能点:
分页列表及详细信息提取
AJAX滚动教程
八爪鱼7.0教程——AJAX点击和翻页教程
步骤1:创建微博图片采集任务
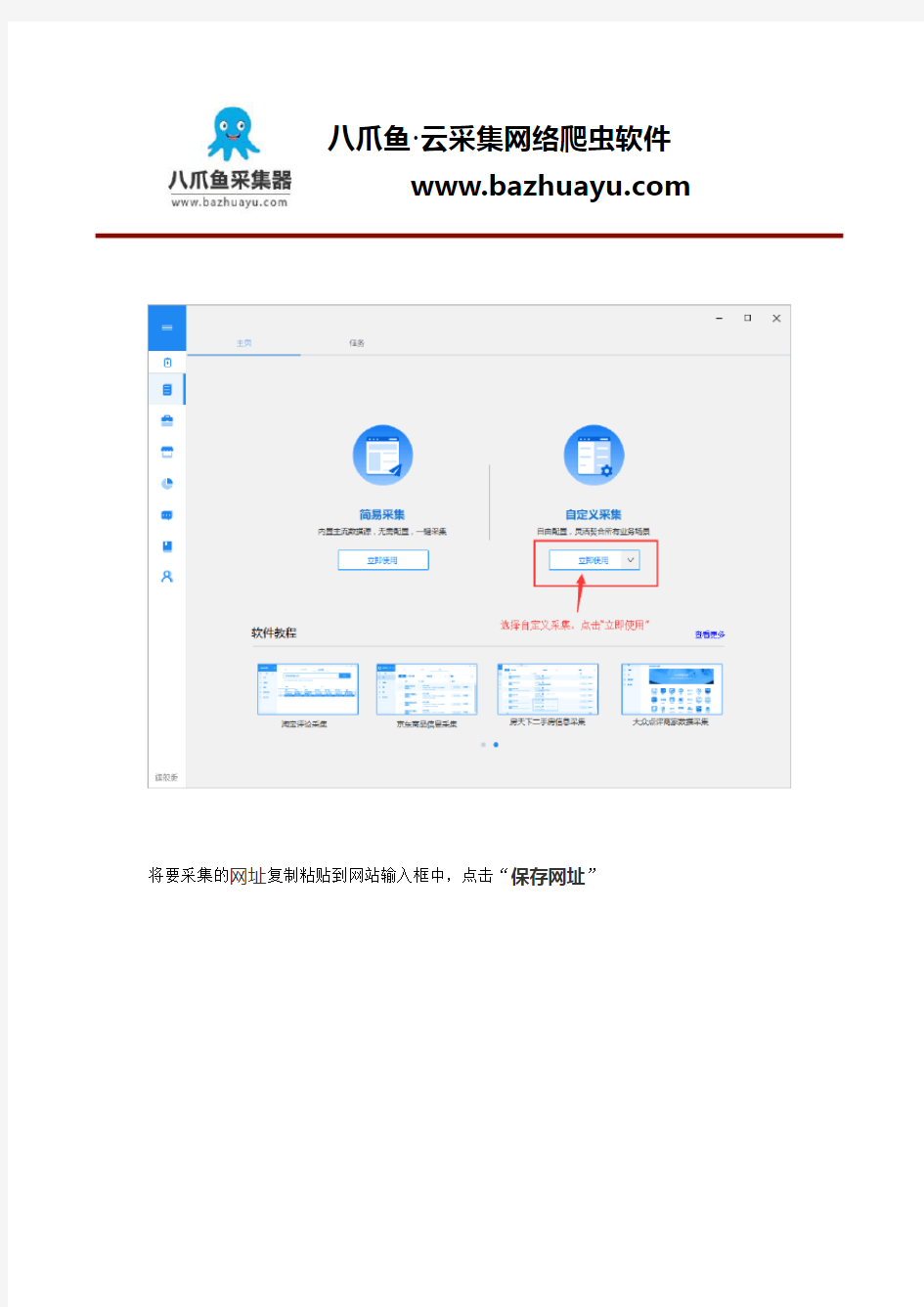
1)进入主界面,选择“自定义模式”,点击“立即使用”
https://www.360docs.net/doc/c48484070.html,
将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/c48484070.html,
步骤2:创建翻页循环
系统自动打开网页,进入微博。观察网页结构,当把页面下拉至底部的时候,会出现“正在加载中,请稍后”的字样,随着我们的下拉,页面会有新的数据加载出来。经过2次下拉加载,此页面达到最底部,出现“下一页”按钮
https://www.360docs.net/doc/c48484070.html,
此网页涉及Ajax下拉加载,需要对其进行一些高级选项的设置。打开“高级选项”,
勾选“页面加载完成后向下滚动”,设置滚动次数为“3次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
https://www.360docs.net/doc/c48484070.html,
注意:这里的滚动次数及间隔时间,需要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载很慢,还需根据具体情况进行调整。
具体请看:八爪鱼7.0教程——AJAX滚动教程
2)将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.360docs.net/doc/c48484070.html,
与“打开网页”类似,此步骤同样涉及Ajax下拉加载。打开“高级选项”,勾选“页面加载完成后向下滚动”,设置滚动次数为“次”,每次间隔“3秒”,滚动方式为“直接滚动到底部”,最后点击“确定”
https://www.360docs.net/doc/c48484070.html,
注意事项同上
步骤3:创建列表循环
1)移动鼠标,选中页面里的第一条微博链接。选中后,系统会自动识别页面里的其他相似链接。在右侧操作提示框中,选择“选中全部”
https://www.360docs.net/doc/c48484070.html,
2)选择“循环点击每个链接”,以创建一个列表循环
https://www.360docs.net/doc/c48484070.html,
步骤4:提取微博文本和图片
1)系统会自动点击进入第一条微博的详情页。微博详情页中,我们首先采集博主ID、发博时间、微博内容、微博URL、微博发送方式。点击要采集的字段,在右侧的操作提示框中,选择“采集该元素的文本”(采集微博URL,则选择“采集该链接地址”)
https://www.360docs.net/doc/c48484070.html,
字段信息选择完成后,选中相应的字段,可以进行字段的自定义命名。完成后,点击“确定”
https://www.360docs.net/doc/c48484070.html,
3)点击页面中第一张图片,在操作提示框中,选择“选中全部”
https://www.360docs.net/doc/c48484070.html,
4)选择“循环点击每个图片”
https://www.360docs.net/doc/c48484070.html,
由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
https://www.360docs.net/doc/c48484070.html,
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
验证方式:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或者转圈状态。
点击第一张图片,在弹出的操作提示框中,选择“采集该图片的地址”。图片的地址已经被采集下来,将此字段修改为“图片地址”
https://www.360docs.net/doc/c48484070.html,
6)接下来为将图片URL批量导出为图片做准备。点击“添加特殊字段”,选择“添加固定字段”,输入“D:\微博图片采集\”,其中“D:\\”为图片存储盘,“微博图片采集”为图片保存文件夹名
https://www.360docs.net/doc/c48484070.html,
步骤5:数据采集及导出
点击左上角的“开始采集”,选择启动“本地采集”
https://www.360docs.net/doc/c48484070.html,
注:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
采集完成后,会跳出提示,选择“导出数据”。选择“合适的导出方式”,将采集好微博发博数据导出,这里我们选择excel作为导出为格式
https://www.360docs.net/doc/c48484070.html, 3)数据导出后如下图所示
步骤6:将图片URL批量转换为图片
https://www.360docs.net/doc/c48484070.html,
经过如上操作,我们已经得到了要采集的图片的URL。接下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
图片批量下载工具:https://https://www.360docs.net/doc/c48484070.html,/s/1c2n60NI
1)下载八爪鱼图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件2)打开File菜单,选择从EXCEL导入(目前只支持EXCEL格式文件)
3)进行相关设置,设置完成后,点击OK即可导入文件
选择EXCEL文件:导入你需要下载图片地址的EXCEL文件
https://www.360docs.net/doc/c48484070.html,
EXCEL表名:对应数据表的名称
文件URL列名:表内对应URL的列名称
保存文件夹名:EXCEL中需要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片存放至不同文件夹
如果要把文件保存到文件夹,则路径需要以“\”结尾,例如:“D:\同步\”,如果要下载后按照指定的文件名保存,则需要包含具体的文件名,例如“D:\同步\1.jpg”
如果下载的文件路径和文件名完全一样,则原先存在的文件会被删除
点击OK后,界面如图所示,再点击“开始下载”
教你如何提取网页中的视频、音乐歌曲、
教你如何提取网页中的视频、音乐歌曲、flash、图片等多媒体文件(很实用) 打开网页后,发现里面有好看的视频、好听的音乐、好看的图片、很炫的flash,是不是想把它们弄到自己电脑上或手机、mp4上?但很多时候视频无法下载,音乐只能试听,或者好听的背景音乐根本就不知道什么名字,更别说怎么下了;至于图片直接右键另存为即可,不过如果网页突然关掉了,但又想把看过的图片弄下来,而忘了图片网页地址或者不想再通过历史记录打开,这时又该怎么办? 其实这些问题都能很好的解决,并且很简单,只要用一个软件 来替你从电脑的缓存中搜索一下就OK了,因为网页中显示的内容基本 上全部都在缓存中,如果自己手动搜索,那将是很累人滴,又不好找,东西太多,又没分类。 无意中发现一个小软件很强(对此感兴趣,本人玩过无数小软件),我一直在用,也是用它帮了很多网友的忙,为了让更多的网友解决问题,于是拿来和亲们分享一下。不废话了,下面进入主题: 这款免费小软件就是YuanBox(元宝箱)v1.6,百度一搜就能下载。 下面是我自己整理的使用步骤,供亲们参考(其实不用看就行,软件简单,不用学就会),我只是用的时间长了,很熟练罢了: 软件下好后,解压,打开里面的YuanBox.exe即可,不用安装;打开此软件前,先打开你要提取东西的网页(之后再关掉也行),这是为了保证电脑缓存中有你要的东西。 运行软件,初始界面如下图:
之后直接是flv格式视频搜索结果的界面,原因就是此软件的全称是 元宝箱FLV视频下载专家,不想要视频的话,点击最上面的设置或者最下面的高级设置,即可进行搜索范围设定
下面是搜索条件设定界面 以swf格式flash为例,进行搜索,选择类型中的第二项 点击确定,开始搜索,结果如下:
淘宝图片抓取工具使用方法
https://www.360docs.net/doc/c48484070.html, 淘宝图片抓取工具使用方法 对于电商设计师来说,抓取竞品的宝贝的图片和店铺装修图片,来分析设计自己店铺的风格并做出差异化,是非常有用的方法哦。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝图片】为例,教大家如何使用八爪鱼采集软件采集淘宝图片的方法。 本文介绍使用八爪鱼7.0采集淘宝商品图片的方法:首先将淘宝商品搜索结果网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的淘宝商品图片URL,下载并保存到本地电脑中。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.360docs.net/doc/c48484070.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址
https://www.360docs.net/doc/c48484070.html, 使用功能点: ●翻页设置 ●图片链接采集 步骤1:创建淘宝商品图片采集任务1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1
https://www.360docs.net/doc/c48484070.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.360docs.net/doc/c48484070.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
网页图片提取方法
https://www.360docs.net/doc/c48484070.html, 网页图片提取方法 对于新媒体运营来说,平日一定要注意积累图片素材,这样到写文案用的时候,才不会临时来照图片,耗费大量的时间。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【图片采集】为例,教大家如何使用八爪鱼采集软件采集网络图片的方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/c48484070.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/c48484070.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置:
https://www.360docs.net/doc/c48484070.html, ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.360docs.net/doc/c48484070.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/c48484070.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/c48484070.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
网站图片抓取方法
https://www.360docs.net/doc/c48484070.html, 网站图片抓取方法 你是否有过想将网站上看到的图片抓取保存到本地电脑?图片少量时,还可以手动一张张下载,但是图片量巨大时,这个时候手动下载既耗费时间精力,效率又极其低下。遇到这种情况怎么办呢?让八爪鱼来帮你把~只需要在八爪鱼软件中配置相应的流程,图片下载到电脑就是so easy~下面就为大家介绍最全的网站图片抓取方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/c48484070.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/c48484070.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔;
https://www.360docs.net/doc/c48484070.html, ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.360docs.net/doc/c48484070.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/c48484070.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/c48484070.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
网页链接提取方法
https://www.360docs.net/doc/c48484070.html, 网页链接提取方法 网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.360docs.net/doc/c48484070.html, 网页链接提取方法1 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.360docs.net/doc/c48484070.html, 网页链接提取方法2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站: https://https://www.360docs.net/doc/c48484070.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
教你如何提取网页中的视频(主要flv),音乐,flash,图片等多媒体文件
教你如何提取网页中的视频(主要flv),音乐,flash,图片 等多媒体文件 打开网页后,发现里面有好看的视频、好听的音乐、好看的图片、很炫的flash,是不是想把它们弄到自己电脑上或手机、mp4上?但很多时候视频无法下载,音乐只能试听,或者好听的背景音乐根本就不知道什么名字,更别说怎么下了;至于图片直接右键另存为即可,不过如果网页突然关掉了,但又想把看过的图片弄下来,而忘了图片网页地址或者不想再通过历史记录打开,这时又该怎么办? 其实这些问题都能很好的解决,并且很简单,只要用一个软件来替你从电脑的缓存中搜索一下就OK了,因为网页中显示的内容基本上全部都在缓存中,如果自己手动搜索,那将是很累人滴,又不好找,东西太多,又没分类。 无意中发现一个小软件很强(对此感兴趣,本人玩过无数小软件),我一直在用,也是用它帮了很多网友的忙,为了让更多的网友解决问题,于是拿来和亲们分享一下。 工具/原料 这款免费小软件就是YuanBox(元宝箱)v1.6,全称:元宝箱FLV视频下载专家,百度一搜就能下载。 下面是我自己整理的使用步骤,供亲们参考(其实不用看就行,软件简单,不用学就会),我只是用的时间长了,很熟练罢了: 软件下好后,解压,打开里面的YuanBox.exe即可,不用安装;打开此软件前,先打开你要提取东西的网页(之后再关掉也行),这是为了保证电脑缓存中有你要的东西。 步骤/方法 ○11运行软件,初始界面如下图:
○22之后直接是flv格式视频搜索结果的界面,原因就是此软件的全称是 元宝箱FLV视频下载专家,不想要视频的话,点击最上面的设置或者最下面的高级设置,即可进行搜索范围设定 ○33下面是搜索条件设定界面
图片爬虫如何使用
https://www.360docs.net/doc/c48484070.html, 图片爬虫如何使用 目标网站上有许多我们喜欢的图片,想用到自己的工作或生活中去,但苦于工作量太大,图片一张张保存太过耗时耗力,因此总是力不从心。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【ebay】为例,教大家如何使用八爪鱼采集软件采集ebay网站的方法。 可以将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。 采集网站: https://https://www.360docs.net/doc/c48484070.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换
https://www.360docs.net/doc/c48484070.html, 步骤1:创建采集任务 1)进入主界面,选择“自定义采集” ebay爬虫采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/c48484070.html, ebay爬虫采集步骤2 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容
https://www.360docs.net/doc/c48484070.html, ebay爬虫采集步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接” ebay爬虫采集步骤4 由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。
最全的网页图片采集方法
https://www.360docs.net/doc/c48484070.html, 最全的网页图片采集方法 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.360docs.net/doc/c48484070.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.360docs.net/doc/c48484070.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔; ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集
https://www.360docs.net/doc/c48484070.html, 采集示例:百度网图片采集教程https://www.360docs.net/doc/c48484070.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.360docs.net/doc/c48484070.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.360docs.net/doc/c48484070.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
如何对整个网页页面进行截图
一、在键盘右上侧有一个键print screen sys rq键(打印屏幕),可以用它将显示屏显示的画面抓下来,复制到“剪贴板”中,然后再把图片粘贴到“画图”、“Photoshop”之类的图像处理软件中,进行编辑处理后保存成图片文件,或粘贴到“Word”、“Powerpoint”、“Wps”等支持图文编辑的应用软件里直接使用。 1、截获屏幕图像 ①将所要截取的画面窗口处于windows窗口的最前方(当前编辑窗口); ②按键盘上的“Print Screen”键,系统将会截取全屏幕画面并保存到“剪贴板”中; ③打开图片处理软件(如“画图”),点击该软件工具栏上的“粘贴”按钮或编辑菜单中的“粘贴”命令,图片被粘贴到该软件编辑窗口中(画布上),编辑图片,保存文件。 或打开(切换到)图文编辑软件(如“Word”、“Powerpoint”等),点击该软件工具栏上的“粘贴”按钮或编辑菜单中的“粘贴”命令,图片被粘贴到编辑窗口中,也可以使用该类软件的图片工具进行编辑。 注意,当粘贴到“画图”中时,可能会弹出一个“剪贴板中的图像比位图大,是否扩大位图?”对话框,此时点击“是”即可。 2、抓取当前活动窗口 我们经常不需要整个屏幕,而只要屏幕中的一个窗口,比如我们要“Word”窗口的图片。按下Alt键,同时按Print Screen即可。 ①将所要截取的窗口处于windows窗口的最前方(即当前编辑窗口); ②同时按下Alt键和“Print Screen”键,系统将会截取当前窗口画面并保存到“剪贴板”中; ③粘贴到图像处理软件中或图文编辑软件中。 二、直接点击Ctrl+Alt+A键,然后可见鼠标的箭头变成彩色的,按住左键移动鼠标选择截图范围,然后在截图内右键鼠标另存为即可,可方便了. 三、用第三方软件如QQ截图:点击聊天框截图---显示彩色鼠标---用其圈定所选目标(右键取消)----双击(单击左键为重新选择)---进入QQ聊天框--右键另存为---到达所到地址 如果想上传则:右键点击图片---编辑---另存为---把保存类型改为JPEG格式即可。 方法1.1 屏幕截图 登陆QQ—→按下“Ctrl+Alt+A”组合键—→按下鼠标左键不放选择截取范围—→用鼠标左键调整截取范围的大小和位置—→截取范围内双击鼠标左键。所截图像保存在系统剪贴板。
提取PPT中背景图片的三种方法
提取PPT中漂亮背景图片的三种方法 自己制作PPT课件过程中,经常需要用到一些比较好的背景图片,作为教师有必要随时储备一些精美的图片素材备用。网络中的图片虽然很多,但是要找到适合做课件背景的却不容易,一种可行的办法就是从现成课件里提取背景,那么如何提取呢?下面介绍三种可行的方法,与大家共享。 第一种: 最简单省事,就是直接提取人家PPT课件中的背景。 1.启动PowerPoint,打开相应的演示文稿文档。 2.在非文本框和组合内容外的空白处,单击右键选择“保存背景”,选择适当保存位置和对应背景图片名称,即完成背景图片的保存。 说明:此方法对有些PPT文件是不适用的,在非文本框和组合内容外的空白处,单击右键时不出现“保存背景”命令。 第二种: 制作者需要将某个PowerPoint演示文稿中的图片单独提取出来,只要将其另存为网页格式即可。
1.启动PowerPoint,打开相应的演示文稿文档。 2.执行“文件→另存为网页”命令,打开“另存为网页”对话框。 3.将“保存类型”设置为“网页(*.htm*.html)” ,然后取名(如123)保存返回。 4.我们在上述网页文件保存的文件夹中,会找到一个名为“123.files”的文件夹,PPT文件所用的所有图片都是单独保存了文件夹中,包括背景图片。 第三种: 1.先打开课件,找到你喜欢那张背景的幻灯片,然后把它上面的所有文本框等删去,再按幻灯片放映,放到那张背景时,按CTRL+PRINT SCREEN(全屏截取)。 2.找开“画图”(开始---附件)或者其它图片处理程序,按CTRL+V(粘贴)调出截图,另存为JPEG或GIF文件(记住位置)。 3.打开新的幻灯片,右键单击空白处---背景---填充效果---图片---选择图片(找到刚刚保存的那张图片)---确定---应用。
Java抓取网页内容三种方式
java抓取网页内容三种方式 2011-12-05 11:23 一、GetURL.java import java.io.*; import https://www.360docs.net/doc/c48484070.html,.*; public class GetURL { public static void main(String[] args) { InputStream in = null; OutputStream out = null; try { // 检查命令行参数 if ((args.length != 1)&& (args.length != 2)) throw new IllegalArgumentException("Wrong number of args"); URL url = new URL(args[0]); //创建 URL in = url.openStream(); // 打开到这个URL的流 if (args.length == 2) // 创建一个适当的输出流 out = new FileOutputStream(args[1]); else out = System.out; // 复制字节到输出流 byte[] buffer = new byte[4096]; int bytes_read; while((bytes_read = in.read(buffer)) != -1) out.write(buffer, 0, bytes_read); } catch (Exception e) { System.err.println(e); System.err.println("Usage: java GetURL
阿里巴巴图片抓取教程
https://www.360docs.net/doc/c48484070.html, 阿里巴巴图片抓取教程 阿里巴巴网站上有大量质量非常高的商品图片,对我们做市场调研、竞品分析有很大的作用,那么如何才能批量的将他们采集保存下来? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【阿里巴巴】为例,教大家如何使用八爪鱼采集软件采集阿里巴巴商品图片的方法。 采集网站: 使用功能点: ●分页列表及详细信息提取 https://www.360docs.net/doc/c48484070.html,/tutorialdetail-1/fylbxq7.html ●AJAX滚动教程 https://www.360docs.net/doc/c48484070.html,/tutorialdetail-1/ajgd_7.html
https://www.360docs.net/doc/c48484070.html, 步骤1:创建阿里巴巴图片采集任务 1)进入主界面,选择“自定义模式”,点击“立即使用” 2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/c48484070.html, 步骤2:创建翻页循环 1)系统自动打开网页,进入阿里巴巴“衣服”商品列表页。观察网页结构,当把页面下拉至底部的时候,会加载出一批新的数据,随着我们的下拉,页面会有新的数据加载出来。经过2次下拉加载,此页面达到最底部,出现“下一页”按钮。 所以涉及 Ajax 下拉加载,需要对其进行一些高级选项的设置。点击右上角的“流程“按钮,选中左侧的“打开网页”,打开“高级选项”,勾选“页面加载完成
https://www.360docs.net/doc/c48484070.html, 后向下滚动”,设置滚动次数为“5次”,每次间隔“2秒”,滚动方式为“直接滚动到底部”,最后点击“确定” 注意:这里的滚动次数及间隔时间,需要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载很慢,还需根据具体情况进行调整。 具体请看:八爪鱼 7.0教程——AJAX 滚动教程 https://www.360docs.net/doc/c48484070.html,/tutorialdetail-1/ajgd_7.html
屏幕截取教你十种“屏幕图文”抓取方法图
屏幕截取招招看!教你十种“屏幕图文”抓取方法(图) 分类:电脑应用| 评论:0 | 引用:0 | 浏览:1750 说起屏幕截图,相信大家都不会陌生:随意翻翻每期的《电脑报》,哪篇不是图文并茂?但是对于刚刚接触电脑的朋友来说,对如何进行抓图还摸不着头脑,以为需要什么高深的技术或什么专业的软件,甚至还以为需要动用DC来帮忙呢。其实抓图的方法有很多种,但种种都很简单,看了下面的介绍,相信你也能抓出“美”图来! 一、PrintScreen按键+画图工具 不论你使用的是台式机还是笔记本电脑,在键盘上都有一个PrintScreen按键,但是很多用户不知道它是干什么用的,其实它就是屏幕抓图的“快门”!当按下它以后,系统会自动将当前全屏画面保存到剪贴板中,只要打开任意一个图形处理软件并粘贴后就可以看到了,当然还可以另存或编辑。 提示:PrintScreen键一般位于F12的右侧。 二、抓取全屏 抓取全屏幕的画面是最简单的操作:直接按一下PrintScreen键,然后打开系统自带的“画图”(也可以使用PS),再按下Ctrl+V即可。该处没有什么技术含量,只是要记住防止某些“不速之客”污染了画面,比如输入法的状态条、“豪杰超级解霸”的窗口控制按钮等等。 提示:提醒想投稿的朋友:这样的画面比较大,一般的报纸或杂志要求300像素×300像素,最大不超过500像素×500像素(当然特殊需要除外),这就需要到PS或ACDSee中进行调整。 三、抓取当前窗口 有时由于某种需要,只想抓取当前的活动窗口,使用全屏抓图的方法显然不合适了。此时可以按住Alt键再按下PrintScreen键就可只将当前的活动窗口抓下了。 四、抓取级联菜单 在写稿的过程中,免不了“以图代文”,特别是关于级联菜单的叙述,一张截图胜过千言万语。但是,若想使用抓取当前窗口的方法来抓级联菜单就不行了:当按下Alt键以后菜单就会消失。此时可以直接按下PrintScreen键抓取全屏,然后粘贴到图形处理软件中进行后期的处理。如果使用画图工具,就可以使用方形选定工具将所需要的部分“选定”并“剪切”,然后按下Ctrl+E打开“属性”界面将“宽度”和“高度”中的数值设的很小,最后再粘贴并另存即可(如图1)。 提示:如果“属性”中的数值大于剪切下来的图片,在“粘贴”以后会出现白色的多余背景,因此需要减小其值。
获取网页中全部图片
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Mvc; using https://www.360docs.net/doc/c48484070.html,; using System.IO; using System.Text; using System.Text.RegularExpressions; namespace Syccw.Controllers { public class Get_Url { ///
屏幕截取-教你十种“屏幕图文”抓取方法(图)
屏幕截取-教你十种“屏幕图文”抓取方法(图)
屏幕截取招招看!教你十种“屏幕图文”抓取方法(图) 分类:电脑应用| 评论:0 | 引用:0 | 浏览:1750 说起屏幕截图,相信大家都不会陌生:随意翻翻每期的《电脑报》,哪篇不是图文并茂?但是对于刚刚接触电脑的朋友来说,对如何进行抓图还摸不着头脑,以为需要什么高深的技术或什么专业的软件,甚至还以为需要动用DC来帮忙呢。其实抓图的方法有很多种,但种种都很简单,看了下面的介绍,相信你也能抓出“美”图来! 一、PrintScreen按键+画图工具 不论你使用的是台式机还是笔记本电脑,在键盘上都有一个PrintScreen按键,但是很多用户不知道它是干什么用的,其实它就是屏幕抓图的“快门”!当按下它以后,系统会自动将当前全屏画面保存到剪贴板中,只要打开任意一个图形处理软件并粘贴后就可以看到了,当然还可以另存或编辑。 提示:PrintScreen键一般位于F12的右侧。
二、抓取全屏 抓取全屏幕的画面是最简单的操作:直接按一下PrintScreen键,然后打开系统自带的“画图”(也可以使用PS),再按下Ctrl+V即可。该处没有什么技术含量,只是要记住防止某些“不速之客”污染了画面,比如输入法的状态条、“豪杰超级解霸”的窗口控制按钮等等。 提示:提醒想投稿的朋友:这样的画面比较大,一般的报纸或杂志要求300像素×300像素,最大不超过500像素×500像素(当然特殊需要除外),这就需要到PS或ACDSee中进行调整。 三、抓取当前窗口 有时由于某种需要,只想抓取当前的活动窗口,使用全屏抓图的方法显然不合适了。此时可以按住Alt键再按下PrintScreen键就可只将当前的活动窗口抓下了。
图片抓取工具使用方法
https://www.360docs.net/doc/c48484070.html, 图片抓取工具使用方法 我们日常工作中经常遇到需要大量提取图片的工作,但一张张的图片保存效率太低,有没有便捷的方法或工具能让我们事半功倍呢? 其实掌握这三大要素:明确图片网站类型、学会使用图片批量下载工具、明确能够/不能够实现的功能,图片采集不再是难事。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,教大家如何使用八爪鱼采集软件抓取图片的方法。 一、明确图片网站的几大类型 1、非瀑布流网站的图片采集 示例网站:豆瓣网 https://https://www.360docs.net/doc/c48484070.html,/photos/album/1620960735/?start=0
https://www.360docs.net/doc/c48484070.html, 八爪鱼可以对网页中图片的URL进行采集,然后通过专用的图片批量下载工具将URL转化为图片,下载并保存到本地电脑。 2、瀑布流网站的图片采集:直接采集图片地址 示例网站:百度图片网 https://https://www.360docs.net/doc/c48484070.html,/search/index?tn=baiduimage&ipn=r&ct=201326592&cl =2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0 &width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word= %E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90 此类网站,需要按下面的步骤对采集规则进行Ajax滚动设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动;
如何导出WORD里面的图片(保持原有的分辨率) 提取图片
如何导出WORD里面的图片(保持原有的分辨率) 提取图片 如何将WORD里面的图片保存或者导出来,有许多方法。分析了各个方法的优缺点: 方法一:WORD导出。WORD——另存——网页(我的WORD是2007版),将会新产生一个.files文件,里面有原来的两倍图,即保留了原有分辨率及大小的始图及只有72分辨率(WORD固有分辨率)的在WORD里面显示的图。一般情况下,第二份图要小,相当于WORD经过分辨率转化快照出来的图,图片的大小正如在WORD里面放置的大小一样,一般情况与本身图片的大小及分辨率无关。此法能提取原始分辨率图,且可以一次性全部导出。 注若WORD——另存——筛选过的网页,提取的相当于为此法的WORD里面放置的图片大小与分辨率图片。 优点:快捷方便、分辨率高 推荐指数:★★★★★ 方法二:WORD复制。直接在WORD里面,选中后,复制,然后在画版工具或者PS中或者其它WORD或者PPT中。在PS中很明显的发现,默认的图片的分辨率为72(象素丢失明显),且大小与原图的大小一致。与在WORD里面显示大小无关。如果仅仅是为了实现WORD里面图片的再利用,从一个WORD中复制到另一个WORD里面,此方法不失为最快捷方便之法,运用的十分广泛。 优点:快捷方便 推荐指数:★★★★ 方法三、转化到PDF中复制。使用PdfWriter打印机生成PDF文件,然后再Acrobat中用快照或者复制工具都可。提取效果不错,是经常喜欢用PDF人的选择。 优点:图片清晰 推荐指数:★★★ 方法四、截图。用QQ截图或者PRINTSCREAM工具可以将图片截下来,当然想获得好的效果可以先将WORD里面的图片放大到容在整个屏幕上。用QQ聊天时,或者没有办法另存的方法时可以选择此法。 优点:图片清晰、快捷 推荐指数:★★★
完美解决35dir获取网站缩略图问题(两种方法)
两种修改方法针对商业版2.2 免费版本差不多 第一种方法也是我推荐的方法,把网页快照外链其他网站的缩略图,这样很省你的服务器空间和带宽资源 1.打开文件 source\module\prelink.php 查找代码: function get_webthumb($web_pic) { global $options; if (!empty($web_pic)) { $strurl = $options['site_root'].$options['upload_dir'].'/'.$web_pic; } else { $strurl = $options['site_root'].'public/images/nopic.gif'; } return $strurl; } 修改为: function get_webthumb($web_url) { return 'https://www.360docs.net/doc/c48484070.html,/webthumb.php?q='.$web_url; } 2.在将module\linkinfo.php文件内的 get_webthumb($link['web_pic']); 替换成 get_webthumb($link['web_url']); 3.在将module\siteinfo.php文件内的 get_webthumb($web['web_pic']); 替换成 get_webthumb($web['web_url']); 4.在将source\module\website.php文件内的(此处有两处修改) $row['web_pic'] = get_webthumb($row['web_pic']); 替换成
网页图片采集器使用详解
https://www.360docs.net/doc/c48484070.html, 我们有时候需要采集电商网站的商品图片,就需要用到网页图片采集器。这里详细介绍使用八爪鱼采集器采集网页图片。采集图片的步骤主要有两大步骤,第一,先将网页中图片的URL采集下来。第二,通过八爪鱼专用的图片批量下载工具,将采集到的图片URL,下载并保存到本地电脑中。 本文以采集淘宝商品搜索页面的商品图片为例,详细介绍网页图片采集器的使用方法。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.360docs.net/doc/c48484070.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址 使用功能点: ●翻页设置 ●图片链接采集
https://www.360docs.net/doc/c48484070.html, 步骤1:创建淘宝商品图片采集任务 1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/c48484070.html, 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.360docs.net/doc/c48484070.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
如何批量提取网页图片
https://www.360docs.net/doc/c48484070.html, 如何批量提取网页图片 很多人需要在网页上收集大量的图片,一个个下载费事费力。今天教给大家一个批量提取网页图片的方法,供大家提高工作效率。 采集网站: https://www.360docs.net/doc/c48484070.html,/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr= &sf=1&fmq=1511164186444_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&isty pe=2&ie=utf-8&hs=2&word=%E5%A4%8F%E7%9B%AE%E5%8F%8B%E4%BA%BA%E5%B8%90 使用功能点: ●?Ajax下拉滚动 /tutorialdetail-1/ajgd_7.html ●?分页列表信息采集 /tutorialdetail-1/fylb-70.html 步骤1:创建采集任务
https://www.360docs.net/doc/c48484070.html, 1)进入主界面,选择自定义模式 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/c48484070.html, 3)系统自动打开网页。我们发现,百度图片网是瀑布流的网页,经过每一次下拉加载,都会出现新的数据。当图片足够多的时候,可无数次下拉加载。因而,此网页涉及AJAX技术,需要设置AJAX 超时,以便确保数据采集的时候不会遗漏。
https://www.360docs.net/doc/c48484070.html, 选中“打开网页”步骤,打开“高级选项”,勾选“页面加载完成向下滚动”,设置滚动次数为“5次”(根据自身需求进行设置),时间为“2秒”,滚动方式为“向下滚动一屏”;最后点击“确定” 注意:示例网站,没有翻页按钮,滚动次数、滚动方式会影响数据采集数量,可按需设置 步骤2:采集图片URL
网页爬取工具使用方法
https://www.360docs.net/doc/c48484070.html, 网页爬取工具使用方法 市面上有很多的网页爬取工具,选择便捷又好用的才是最重要的。一般我们利用网页爬取工具来抓取那些可见的网页文本信息,甚至是一些内容被大面积的广告盖住看不到的以及一些页面上没直接显示出来但源码里有的信息,网页爬取工具都可以帮你把想要的网页文字内容给抓取下来。 示例爬取网站: https://https://www.360docs.net/doc/c48484070.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0 本文仅以nike关键词搜索结果页举例说明,大家在采集ebay图片的时候,如果有其他需求,可以更换关键词搜索结果页进行采集。 采集内容:ebay商品图片url,ebay商品标题。 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换
https://www.360docs.net/doc/c48484070.html, 步骤1:创建采集任务 1)进入主界面,选择“自定义采集” ebay 爬虫采集步骤 1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.360docs.net/doc/c48484070.html, ebay爬虫采集步骤2 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容
https://www.360docs.net/doc/c48484070.html, ebay爬虫采集步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接” ebay爬虫采集步骤4 由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。
如何实现在线批量网页链接提取
https://www.360docs.net/doc/c48484070.html, 如何实现在线批量网页链接提取 在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址” 八爪鱼提取页面内的超链接图1
https://www.360docs.net/doc/c48484070.html, 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来 八爪鱼提取页面内的超链接图2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站:
https://www.360docs.net/doc/c48484070.html, https://https://www.360docs.net/doc/c48484070.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=suggest 步骤1:创建采集任务 1)进入主界面,选择自定义模式 八爪鱼提取页面内的超链接图3 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”