数学实验第10次作业_回归分析资料报告

回归分析
一实验目的
1 了解回归分析的基本原理,掌握MATLAB实现的方法;
2 练习用回归分析解决实际问题。
二实验容
1电影院调查电视广告费用和报纸广告费用对每周收入的影响,得到下面的数据(见下表),建立回归模型并进行检验,诊断异常点的存在并进行处理。
每周收入
电视广告费用
报纸广告费用
初步解决:
首先对于题目作初步分析,题目中电视广告费用和报纸广告费用都会对与每周收入产生影响,但是两者对于每周收入的影响都是独立的。
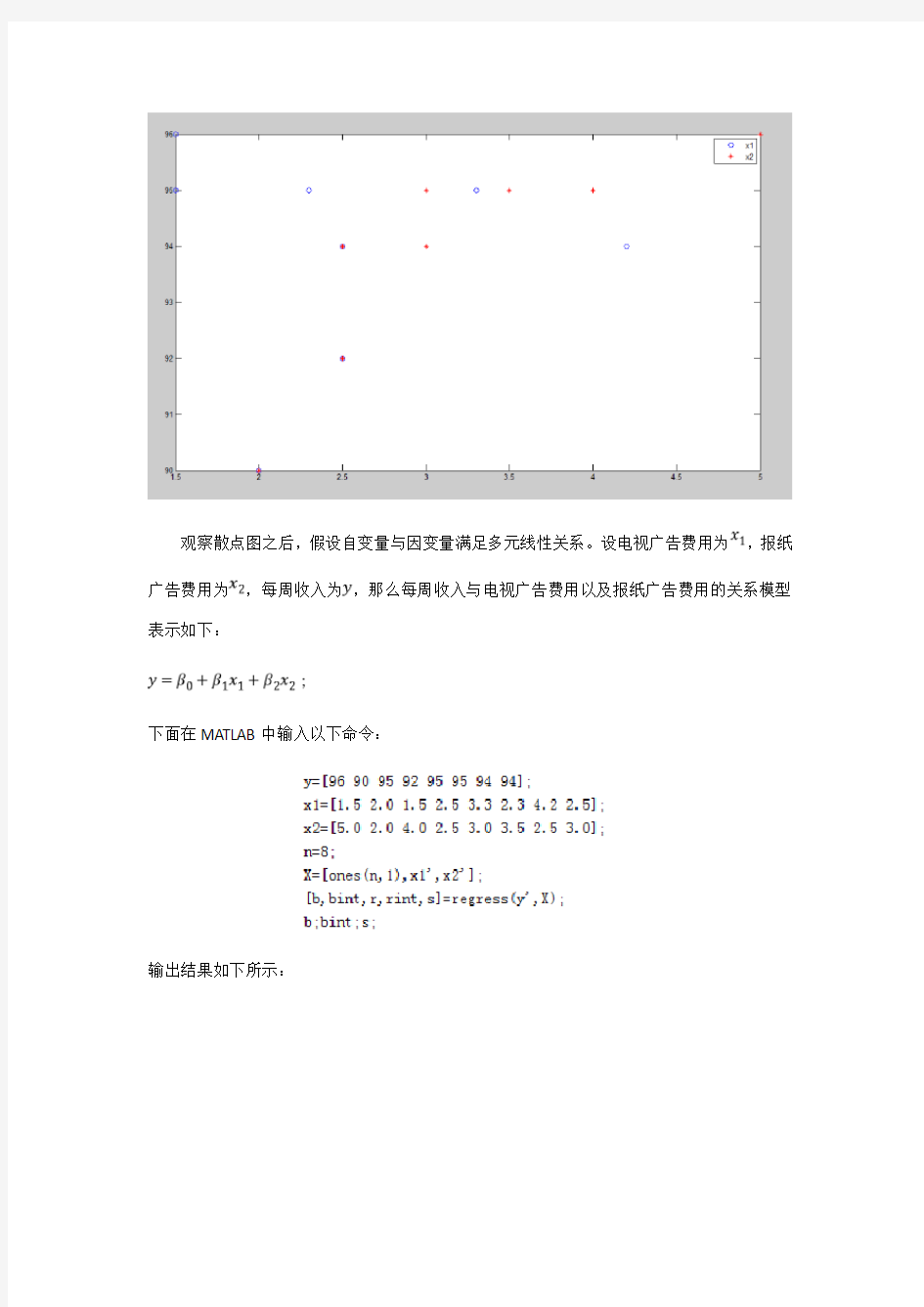
首先画出散点图如下:
观察散点图之后,假设自变量与因变量满足多元线性关系。设电视广告费用为,报纸广告费用为,每周收入为,那么每周收入与电视广告费用以及报纸广告费用的关系模型表示如下:
下面在MATLAB中输入以下命令:
输出结果如下所示:
结果列表如下:
回归系数回归系数估计值回归系数置信区间
于是由它得到的预测模型为。
做出残差和置信区间的图像如下:
由图像可以看出,只有第一组数据的置信区间不包括零,改组数据可能有误,去掉之后再进行计算。
在命令栏中输入以下命令:
输出结果如下所示:
将结果列表如下:
回归系数回归系数估计值回归系数置信区间
由它得到的回归模型为。
对于实验结果的分析:
回归模型:。对比剔除异常点后的分析结果可知,第一次分析的过程中,第一组数据的置信区间不包括零点,所以该点为异常点,需要剔除再进行一次计算。剔除之后,发现所有点的置信区间都包括了零点。
剔除数据之后计算结果与剔除之前的比较
原始数据
剔除后
纵向比较可以看出,剔除了异常数据之后,置信区间明显的有了缩小,所以说,剔除异常数据可以有利于更加精确地建立模型。
2汽车销售商认为汽车销售量与汽油价格、贷款利率有关,两种类型汽车(普通型和豪华型)个月的调查资料见下表,其中是普通型汽车售量(千辆),是豪华型汽车售辆(千辆),是汽油价格(元/),是贷款利率()。
序号
回归分析 实验报告
城镇居民家庭收入的逐步回归分析 07级数学1班盛平0707021012 摘要:用多元统计中逐步回归分析的方法和SAS软件解决了可支配收入与其他收入之间的关系,并用此模型预测在以后几年里居民平均每人全年家庭可支配收入。 关键词:逐步回归分析多元统计SAS软件 正文 1 模型分析 各地区城镇居民平均每人全年家庭可支配收入y与工薪收入x1、经营净收入x2、财产性收入x3和转移性收入x4有关,共观测了15组数据,试用逐步回归法求‘最优’回归方程。 各地区城镇居民平均每人全年家庭收入来源(2007年) 单位:元 2模型的理论 (1)基本思想:逐个引入自变量,每次引入对y影响最显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。 (2)逐步筛选的步骤:首先给出引入变量的显著性水平 和剔除变量的显著性 in
水平 ;然后按图4.1的框图筛选变量。 out 3模型的求解 (1)源程序: data ch; input x1 x2 x3 x4 x5 y @@; cards; 28.2 47.9 44.1 3.8 23.9 100.0 31.3 47.1 43.6 3.5 21.6 100.0 30.2 48.2 43.9 4.3 21.6 100.0 ?? 31.9 46.1 41.9 4.2 22.0 100.0 33.4 44.8 40.6 4.1 21.8 100.0 33.2 44.4 39.9 4.5 22.4 100.0 32.1 43.1 38.7 4.4 24.8 100.0 28.4 42.9 38.3 4.6 28.7 100.0 ?? 27.2 43.7 38.6 5.1 29.1 100.0
排序操作实验报告
数据结构与算法设计 实验报告 (2016 — 2017 学年第1 学期) 实验名称: 年级: 专业: 班级: 学号: 姓名: 指导教师: 成都信息工程大学通信工程学院
一、实验目的 验证各种简单的排序算法。在调试中体会排序过程。 二、实验要求 (1)从键盘读入一组无序数据,按输入顺序先创建一个线性表。 (2)用带菜单的主函数任意选择一种排序算法将该表进行递增排序,并显示出每一趟排序过程。 三、实验步骤 1、创建工程(附带截图说明) 2、根据算法编写程序(参见第六部分源代码) 3、编译 4、调试 四、实验结果图 图1-直接输入排序
图2-冒泡排序 图3-直接选择排序 五、心得体会 与哈希表的操作实验相比,本次实验遇到的问题较大。由于此次实验中设计了三种排序方法导致我在设计算法时混淆了一些概念,设计思路特别混乱。虽然在理清思路后成功解决了直接输入和直接选择两种算法,但冒泡
排序的算法仍未设计成功。虽然在老师和同学的帮助下完成了冒泡排序的算法,但还需要多练习这方面的习题,平时也应多思考这方面的问题。而且,在直接输入和直接选择的算法设计上也有较为复杂的地方,对照书本做了精简纠正。 本次实验让我发现自己在算法设计上存在一些思虑不周的地方,思考问题过于片面,逻辑思维能力太过单薄,还需要继续练习。 六、源代码 要求:粘贴个人代码,以便检查。 #include 《数据结构》实验报告排序实验题目: 输入十个数,从插入排序,快速排序,选择排序三类算法中各选一种编程实现。 实验所使用的数据结构内容及编程思路: 1. 插入排序:直接插入排序的基本操作是,将一个记录到已排好序的有序表中,从而得到一个新的,记录增一得有序表。 一般情况下,第i 趟直接插入排序的操作为:在含有i-1 个记录的有序子序列r[1..i-1 ]中插入一个记录r[i ]后,变成含有i 个记录的有序子序列r[1..i ];并且,和顺序查找类似,为了在查找插入位置的过程中避免数组下标出界,在r [0]处设置哨兵。在自i-1 起往前搜索的过程中,可以同时后移记录。整个排序过程为进行n-1 趟插入,即:先将序列中的第一个记录看成是一个有序的子序列,然后从第2 个记录起逐个进行插入,直至整个序列变成按关键字非递减有序序列为止。 2. 快速排序:基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 假设待排序的序列为{L.r[s] ,L.r[s+1],…L.r[t]}, 首先任意选取一个记录 (通常可选第一个记录L.r[s])作为枢轴(或支点)(PiVOt ),然后按下述原则重新排列其余记录:将所有关键字较它小的记录都安置在它的位置之前,将所有关键字较大的记录都安置在它的位置之后。由此可以该“枢轴”记录最后所罗的位置i 作为界线,将序列{L.r[s] ,… ,L.r[t]} 分割成两个子序列{L.r[i+1],L.[i+2], …,L.r[t]}。这个过程称为一趟快速排序,或一次划分。 一趟快速排序的具体做法是:附设两个指针lOw 和high ,他们的初值分别为lOw 和high ,设枢轴记录的关键字为PiVOtkey ,则首先从high 所指位置起向前搜索找到第一个关键字小于PiVOtkey 的记录和枢轴记录互相交换,然后从lOw 所指位置起向后搜索,找到第一个关键字大于PiVOtkey 的记录和枢轴记录互相 交换,重复这两不直至low=high 为止。 具体实现上述算法是,每交换一对记录需进行3 次记录移动(赋值)的操作。而实际上, 陕西科技大学实验报告 课 程: 数理金融 实验日期: 2014 年 5 月 22 日 班 级: 数学112 交报告日期: 2013 年 5 月 23 日 姓 名: 常海琴 报告退发: (订正、重做) 学 号: 201112010101 教 师: 刘利明 实验名称: 多元回归分析 一、实验预习: 1.多元回归模型。 2.多元回归模型参数的检验。 3.多元回归模型整体的检验。 二、实验的目的和要求: 通过案例分析掌握多元回归模型的建立方法和检验的标准;并掌握分析解决实际金融问题的能力。 三、实验过程:(实验步骤、原理和实验数据记录等) 软件:Eviews3.1 数据:给定美国机动车汽油消费量研究数据。 实验原理:最小二乘法拟合多元线性回归方程 数据记录: 实例中1950年到1987年机动汽车的消费量、汽车保有量、汽油价格、人口数、国民生产总值 图1各个量之间的关系 陕西科技大学理学院实验报告 - 2 - 1、录入数据 图2录入数据 2、回归分析 443322110X X X X Y βββββ++++= 图3运行结果 Y=24553723+1.418520x1-27995762x2-59.87480x3-30540.88x4 S (25079670) (0.266) (5027085) (198.5517) (9557.981) T (0.979) (5.314) (-5.568) (-0.301) (-3.195) 2R =0.966951 F=241.3764 - R =0.9629 dw=0.6265 四、实验总结:(实验数据处理和实验结果讨论等) 用残差和最小确定直线位置是一个途径。计算残差和有相互抵消的问题。用残差绝对值和最小确定直线位置也是一个途径绝对值计算起来比较麻烦。最小二乘法用绝对值平方和最小确定直线位置。0β、1β、2β、3β、4β具有线性特性,无偏特性,有效性。-R =0.9629基本上接近于1,拟合效果较好。 电子科技大学实验报告 课程名称:数据结构与算法 学生姓名: 学号: 点名序号: 指导教师: 实验地点:基础实验大楼 实验时间: 5月20日 2014-2015-2学期 信息与软件工程学院 实验报告(二) 学生姓名学号:指导教师: 实验地点:基础实验大楼实验时间:5月20日 一、实验室名称:软件实验室 二、实验项目名称:数据结构与算法—排序与查找 三、实验学时:4 四、实验原理: 快速排序的基本思想是:通过一躺排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一不部分的所有数据都要小,然后再按次方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。 假设要排序的数组是A[1]……A[N],首先任意选取一个数据(通常选用第一个数据)作为关键数据,然后将所有比它的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一躺快速排序。一躺快速排序的算法是: 1)设置两个变量I、J,排序开始的时候I:=1,J:=N 2)以第一个数组元素作为关键数据,赋值给X,即X:=A[1]; 3)从J开始向前搜索,即(J:=J-1),找到第一个小于X的值,两者交换; 4)从I开始向后搜索,即(I:=I+1),找到第一个大于X的值,两者交换; 5)重复第3、4步,直到I=J。 二分法查找(折半查找)的基本思想: (1)确定该区间的中点位置:mid=(low+high)/2 min代表区间中间的结点的位置,low代表区间最左结点位置,high代表区间最右结点位置(2)将待查a值与结点mid的关键字(下面用R[mid].key)比较,若相等,则查找成功,否则确定新的查找区间: A)如果R[mid].key>a,则由表的有序性可知,R[mid].key右侧的值都大于a,所以等于a的关键字如果存在,必然在R[mid].key左边的表中,这时high=mid-1; B)如果R[mid].key 一元线性回归在公司加班 制度中的应用 院(系): 专业班级: 学号姓名: 指导老师: 成 绩: 完成时间 : 一元线性回归在公司加班制度中的应用 一、实验目的 掌握一元线性回归分析的基本思想与操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境 SPSS21、0 windows10、0 三、实验题目 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经10周时间,收集了每周加班数据与签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示 y 3、5 1、0 4、0 2、0 1、0 3、0 4、5 1、5 3、0 5、0 1. 画散点图。 2. x 与y 之间大致呈线性关系? 3. 用最小二乘法估计求出回归方程。 4. 求出回归标准误差σ∧ 。 5. 给出0 β∧ 与1 β∧ 的置信度95%的区间估计。 6. 计算x 与y 的决定系数。 7. 对回归方程作方差分析。 8. 作回归系数1 β∧ 的显著性检验。 9. 作回归系数的显著性检验。 10. 对回归方程做残差图并作相应的分析。 11. 该公司预测下一周签发新保单01000x =张,需要的加班时间就是多少? 12.给出0y的置信度为95%的精确预测区间。 13.给出 () E y的置信度为95%的区间估计。 四、实验过程及分析 1、画散点图 如图就是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以瞧出,数据均匀分布在对角线的两侧,说明x与y之间线性关系良好。 2、最小二乘估计求回归方程 系数a 模型非标准化系数标准系数t Sig、 B 的 95、0% 置信区间 B 标准误差试用版下限上限 实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日 一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1) 图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏 5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。 2010级数据结构实验报告 实验名称:排序 姓名:袁彬 班级: 2009211120 班内序号: 09 学号: 09210552 日期: 2010 年12 月19 日 1.实验要求 试验目的: 通过选择试验内容中的两个题目之一,学习、实现、对比各种排序的算法,掌握各种排序算法的优缺点,以及各种算法使用的情况。 试验内容: 题目一: 使用简单数组实现下面各种排序算法,并进行比较。 排序算法如下: ①插入排序; ②希尔排序 ③冒泡排序; ④快速排序; ⑤简单选择排序; ⑥堆排序 ⑦归并排序 ⑧基数排序 ⑨其他。 具体要求如下: ①测试数据分为三类:正序,逆序,随机数据。 ②对于这三类数据,比较上述排序算法中关键字的比较次数和移动次数(其中关键字交换记为三次移动)。 ③对于这三类数据,比较上述排序算法中不同算法的执行时间,精确到微妙。 ④对②和③的结果进行分析,验证上述各种算法的时间复杂度。 ⑤编写main()函数测试各种排序算法的正确性。 题目二: 使用链表实现下面各种排序算法,并进行比较。 排序算法如下: ①插入排序; ②冒泡排序; ③快速排序; ④简单选择排序; ⑤其他。 具体要求如下: ①测试数据分为三类:正序,逆序,随机数据。 ②对于这三类数据,比较上述排序算法中关键字的比较次数和移动次数(其中关键字交换记为三次移动)。 ③对于这三类数据,比较上述排序算法中不同算法的执行时间,精确到微妙(选作) ④对②和③的结果进行分析,验证上述各种算法的时间复杂度。 ⑤编写main()函数测试各种排序算法的正确性。 2. 程序分析 2.1 存储结构 程序中每一个算法均是用一个类来表示的,类中有自己的构造函数、排序函数。 程序的储存结构采用数组。数组的第一个位置不存储数据。数据从第二个位置开始。数组中的相对位置为数组的下标。 2.2 关键算法分析 ㈠、关键算法: 1、插入排序函数:Insert s ort(int n) ①、从2开始做循环,依次和前面的数进行比较:for(int i=2;i<=n;i++) ②、如果后面的比前面的小,则进行前移:if(number[i] 实验七查找、排序的应用 一、实验目的 1、本实验可以使学生更进一步巩固各种查找和排序的基本知识。 2、学会比较各种排序与查找算法的优劣。 3、学会针对所给问题选用最适合的算法。 4、掌握利用常用的排序与选择算法的思想来解决一般问题的方法和技巧。 二、实验内容 [问题描述] 对学生的基本信息进行管理。 [基本要求] 设计一个学生信息管理系统,学生对象至少要包含:学号、姓名、性别、成绩1、成绩2、总成绩等信息。要求实现以下功能:1.总成绩要求自动计算; 2.查询:分别给定学生学号、姓名、性别,能够查找到学生的基本信息(要求至少用两种查找算法实现); 3.排序:分别按学生的学号、成绩1、成绩2、总成绩进行排序(要求至少用两种排序算法实现)。 [测试数据] 由学生依据软件工程的测试技术自己确定。 三、实验前的准备工作 1、掌握哈希表的定义,哈希函数的构造方法。 2、掌握一些常用的查找方法。 1、掌握几种常用的排序方法。 2、掌握直接排序方法。 四、实验报告要求 1、实验报告要按照实验报告格式规范书写。 2、实验上要写出多批测试数据的运行结果。 3、结合运行结果,对程序进行分析。 五、算法设计 a、折半查找 设表长为n,low、high和mid分别指向待查元素所在区间的下界、上界和中点,key为给定值。初始时,令low=1,high=n,mid=(low+high)/2,让key与mid指向的记录比较, 若key==r[mid].key,查找成功 若key 【一】需求分析 课程题目是排序算法的实现,课程设计一共要设计八种排序算法。这八种算法共包括:堆排序,归并排序,希尔排序,冒泡排序,快速排序,基数排序,折半插入排序,直接插入排序。 为了运行时的方便,将八种排序方法进行编号,其中1为堆排序,2为归并排序,3为希尔排序,4为冒泡排序,5为快速排序,6为基数排序,7为折半插入排序8为直接插入排序。 【二】概要设计 1.堆排序 ⑴算法思想:堆排序只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间。将序列所存储的元素A[N]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的元素均不大于(或不小于)其左右孩子(若存在)结点的元素。算法的平均时间复杂度为O(N log N)。 ⑵程序实现及核心代码的注释: for(j=2*i+1; j<=m; j=j*2+1) { if(j temp=su[i]; su[i]=su[0]; su[0]=temp; head(0,i-1); } cout<<"排序之后的数组为:"< 《数据结构》实验报告一 学院:班级: 学号:姓名: 日期:程序名 一、上机实验的问题和要求: 顺序表的查找、插入与删除。设计算法,实现线性结构上的顺序表的产生以及元素的查找、插入与删除。具体实现要求: 1.从键盘输入10个整数,产生顺序表,并输入结点值。 2.从键盘输入1个整数,在顺序表中查找该结点的位置。若找到,输出结点的位置;若找 不到,则显示“找不到”。 3.从键盘输入2个整数,一个表示欲插入的位置i,另一个表示欲插入的数值x,将x插 入在对应位置上,输出顺序表所有结点值,观察输出结果。 4.从键盘输入1个整数,表示欲删除结点的位置,输出顺序表所有结点值,观察输出结果。 二、源程序及注释: #include 回归分析实验报告 姓名:班级:学号(后3位): 一.实验名称:回归分析 二.实验性质:综合性实验 三.实验目的及要求: 1. 掌握统计工具【回归】的使用方法. 2.掌握线性回归分析的方法,并能对统计结果进行正确的分析. 3.学会非线性回归方程的构建方法,并能进行有关的分析. 四.实验内容、实验操作关键步骤及实验主要结果 x 1.为了研究某商品的需求量Y与价格之间的关系,收集到下列10对数据: x 1 1.5 2 2.5 3 3.5 4 4 4.5 5 价格 i y10 8 7.5 8 7 6 4.5 4 2 1 需求量 i x (1)求需求量Y与价格之间的线性回归方程. α0.05下,对线性回归关系显著性检验. (2)在显著性水平= 实验操作关键步骤及实验主要结果 在EXCEL中选用【 】工具模块,得到如下表的实验结果.因此: x. (1)求需求量Y与价格之间的线性回归方程为 α0.05(2)由于检验的P-value=,所以,在显著性水平= 下,线性回归关系 . 2.随机调查10个城市居民的家庭平均收入与电器用电支出Y 情况得数据(单位:千元)如下: x 收入i x 18 20 22 24 26 28 30 30 34 38 支出 i y 0.9 1.1 1.1 1.4 1.7 2.0 2.3 2.5 2.9 3.1 (1) 求电器用电支出Y 与家庭平均收入之间的线性回归方程. x (2) 计算样本相关系数. (3) 在显著性水平=α0.05下,作线性回归关系显著性检验. (4) 若线性回归关系显著,求=25时,电器用电支出的点估计值. x 实验操作关键步骤及实验主要结果 在EXCEL 中选用【 】工具模块,得到如下表的实验结果.因此: (1)求电器用电支出Y 与家庭平均收入之间的线性回归方程为 x . (2)样本相关系数 . (3)由于检验的P- value=,所以,在显著性水平 =α0.05下,线性回归关系 . (4)=25时,电器用电支出的点估计值 x . 一、实验目的 1、了解内排序都是在内存中进行的。 2、为了提高数据的查找速度,需要对数据进行排序。 3、掌握内排序的方法。 二、实验内容 1、设计一个程序e xp10—1.cpp实现直接插入排序算法,并输出{9,8,7,6,5,4,3,2,1,0}的排序 过程。 (1)源程序如下所示: //文件名:exp10-1.cpp #include 实验四:查找与排序 【实验目的】 1.掌握顺序查找算法的实现。 2.掌握折半查找算法的实现。 【实验内容】 1.编写顺序查找程序,对以下数据查找37所在的位置。 5,13,19,21,37,56,64,75,80,88,92 2.编写折半查找程序,对以下数据查找37所在的位置。 5,13,19,21,37,56,64,75,80,88,92 【实验步骤】 1.打开VC++。 2.建立工程:点File->New,选Project标签,在列表中选Win32 Console Application,再在右边的框里为工程起好名字,选好路径,点OK->finish。 至此工程建立完毕。 3.创建源文件或头文件:点File->New,选File标签,在列表里选C++ Source File。给文件起好名字,选好路径,点OK。至此一个源文件就被添加到了你刚创建的工程之中。 4.写好代码 5.编译->链接->调试 #include "stdio.h" #include "malloc.h" #define OVERFLOW -1 #define OK 1 #define MAXNUM 100 typedef int Elemtype; typedef int Status; typedef struct { Elemtype *elem; int length; }SSTable; Status InitList(SSTable &ST ) { int i,n; ST.elem = (Elemtype*) malloc (MAXNUM*sizeof (Elemtype)); if (!ST.elem) return(OVERFLOW); printf("输入元素个数和各元素的值:"); scanf("%d\n",&n); for(i=1;i<=n;i++) { scanf("%d",&ST.elem[i]); } ST.length = n; return OK; } int Seq_Search(SSTable ST,Elemtype key) { int i; ST.elem[0]=key; for(i=ST.length;ST.elem[i]!=key;--i); return i; } int BinarySearch(SSTable ST,Elemtype key) { int low,high,mid; low=1; high=ST.length; 实验报告 实验目的: 1.构建一元及多元回归模型,并作出估计 2.熟练掌握假设检验 3.对构建的模型进行回归预测 实验内容: 对1970——1982年某国实际通货膨胀率、失业率和预期通货膨胀率进行分析,根据下表(表一)提供的数据进行模型设定,假设检验及回归预测。 表一 年份Y X2 X3 1970 5.92 4.90 4.78 1971 4.30 5.90 3.84 1972 3.30 5.60 3.31 1973 6.23 4.90 3.44 1974 10.97 5.60 6.84 1975 9.14 8.50 9.47 1976 5.77 7.70 6.51 1977 6.45 7.10 5.92 1978 7.60 6.10 6.08 1979 11.47 5.80 8.09 1980 13.46 7.10 10.01 1981 10.24 7.60 10.81 1982 5.99 9.70 8.00 实验步骤: 1.模型设定: 为分析实际通货膨胀率(Y)分别和失业率(X2)、预期通货膨胀率(X3)之间的关系,作出如下图所示的散点图。 图一 从上示散点图可以看出实际通货膨胀率(Y)分别和失业率(X2)不呈线性关系,与预期通货膨胀率(X3)大体呈现为线性关系,为分析实际通货膨胀率(Y)分别和失业率(X2)、预期通货膨胀率(X3)之间的数量关系,可以建立单线性回归模型和多元线性回归模型: 1231 Y X ββμ=++ 123322Y X X βββμ=+++ 2.估计参数 在Eviews 命令框中输入 “ls y c x2”,按回车,对所给数据做简单的一元线性回归分析。分析结果见表二。 表二 Dependent Variable: Y Method: Least Squares Date: 10/09/11 Time: 17:23 Sample: 1970 1982 Included observations: 13 Variable Coefficient Std. Error t-Statistic Prob. C 1.323831 1.626284 0.814022 0.4329 X3 0.960163 0.228633 4.199588 0.0015 R-squared 0.615875 Mean dependent var 7.756923 Adjusted R-squared 0.580955 S.D. dependent var 3.041892 S.E. of regression 1.969129 Akaike info criterion 4.333698 Sum squared resid 42.65216 Schwarz criterion 4.420613 Log likelihood -26.16904 F-statistic 17.63654 Durbin-Watson stat 1.282331 Prob(F-statistic) 0.001487 由回归分析结果可估计出参数1β、2β 即^ 31.3238310.960163Y X =+ (1.626284)(0.228633) ()()0.814022 4.199588 t = 2 0.615875R = F=17.63654 n=13 一元线性回归 一、实验题目1 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经过10周的时间,收集了每周加班时间的数据和签发的新保单数目,x为每周签发的新报数目,y为每周加班时间(小时),数据见下表: 二、实验内容 散点图如下所示: [数据集1] 描述性统计量 均值标准偏差N y 2.850 1.4347 10 x 762.00 379.746 10 残差图分析: 1.x 与y 之间大致呈线性关系。 2、设回归方程为01y x ββ∧ ∧ ∧ =+ 1β∧ = 12 2 1 (2637021717) 0.0036(71043005806440) ()n i i i n i i x y n x y x n x -- =- =--= =--∑∑ 01 2.850.00367620.1068y x ββ-∧- =-=-?= 0.10680.0036y x ∧ ∴=+可得回归方程为 3、 22 n i=1 1()n-2i i y y σ∧∧=-∑ 2 n 01i=1 1(())n-2i y x ββ∧∧=-+∑ =0.2305 σ∧ =0.4801 4、 由于2 1 1(, )xx N L σββ∧ t σ ∧= = 服从自由度为n-2的t 分布。因而 /2|(2)1P t n αασ????<-=- ?? ?? 也即:1/2 11/2 (p t t ααβββ∧ ∧ ∧ ∧ -<<+=1α- 可得195%β∧ 的置信度为的置信区间为 0.4801/0.4801/??(0.0036-1.8600.0036+1.860 即为:(0.0028,0.0044) 220 01()(,())xx x N n L ββσ- ∧ + 实验报告3 实验名称:数据结构与软件设计实习 题目:内部排序算法比较 专业:生物信息学班级:01 姓名:学号:实验日期:2010.07.24 一、实验目的: 比较冒泡排序、直接插入排序、简单选择排序、快速排序、希尔排序; 二、实验要求: 待排序长度不小于100,数据可有随机函数产生,用五组不同输入数据做比较,比较的指标为关键字参加比较的次数和关键字移动的次数; 对结果做简单的分析,包括各组数据得出结果的解释; 设计程序用顺序存储。 三、实验内容 对各种内部排序算法的时间复杂度有一个比较直观的感受,包括关键字比较次数和关键字移动次数。 将排序算法进行合编在一起,可考虑用顺序执行各种排序算法来执行,最后输出所有结果。 四、实验编程结果或过程: 1. 数据定义 typedef struct { KeyType key; }RedType; typedef struct { RedType r[MAXSIZE+1]; int length; }SqList; 2. 函数如下,代码详见文件“排序比较.cpp”int Create_Sq(SqList &L) void Bubble_sort(SqList &L)//冒泡排序void InsertSort(SqList &L)//插入排序 void SelectSort(SqList &L) //简单选择排序int Partition(SqList &L,int low,int high) void QSort(SqList &L,int low,int high)//递归形式的快速排序算法 void QuickSort(SqList &L) void ShellInsert(SqList &L,int dk)//希尔排序 void ShellSort(SqList &L,int dlta[ ]) 3. 运行测试结果,运行结果无误,如下图语速个数为20 实验四——查找 一、实验目的 1.掌握顺序表的查找方法,尤其是折半查找方法; 2.掌握二叉排序树的查找算法。 二、实验内容 1.建立一个顺序表,用顺序查找的方法对其实施查找; 2.建立一个有序表,用折半查找的方法对其实施查找; 3.建立一个二叉排序树,根据给定值对其实施查找; 4.对同一组数据,试用三种方法查找某一相同数据,并尝试进行性能分析。 三、实验预习内容 实验一包括的函数有:typedef struct ,创建函数void create(seqlist & L),输出函数void print(seqlist L),顺序查找int find(seqlist L,int number),折半查找int halffind(seqlist L,int number) 主函数main(). 实验二包括的函数有:结构体typedef struct,插入函数void insert(bnode * & T,bnode * S),void insert1(bnode * & T),创建函数void create(bnode * & T),查找函数bnode * search(bnode * T,int number),主函数main(). 四、上机实验 实验一: 1.实验源程序。 #include<> #define N 80 typedef struct { int number; umber; for(i=1;[i].number!=0;) { cin>>[i].name>>[i].sex>>[i].age; ++; cout< 实验报告三课程应用回归分析 学生姓名陆莹 学号20121315021 学院数学与统计学院 专业统计学 任课教师宋凤丽 二O一四年四月十七日 (1) shuju<-read.table("E:/4.14.txt") namesdata<-c("y",paste("x",1:2,sep="")) colnames(shuju)<-namesdata lm.shuju<-lm(y~.,data=shuju) summary(lm.shuju) Call: lm(formula = y ~ ., data = shuju) Residuals: Min 1Q Median 3Q Max -747.71 -229.80 -2.15 267.23 547.68 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -574.0624 349.2707 -1.644 0.1067 x1 191.0985 73.3092 2.607 0.0121 * x2 2.0451 0.9107 2.246 0.0293 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’ 1 Residual standard error: 329.7 on 49 degrees of freedom Multiple R-squared: 0.2928, Adjusted R-squared: 0.264 F-statistic: 10.15 on 2 and 49 DF, p-value: 0.0002057 >plot(lm.shuju,2) 由上图可知,残差通过正态性检验,原假设成立。《数据结构》实验报告——排序.docx
(实验2)多元回归分析实验报告
实验报告-排序与查找
一元线性回归分析实验报告
回归分析实验报告
排序问题实验报告
(完整word版)查找、排序的应用 实验报告
各种排序实验报告
顺序表的查找、插入与删除实验报告
5回归分析实验报告
数据结构内排序实验报告
查找与排序实验报告
一元回归分析实验报告
应用回归分析实验报告
内部排序比较 (实验报告+源程序)C++
《数据结构》实验报告查找
回归分析实验报告(含程序及答案)