oracle数据库结构
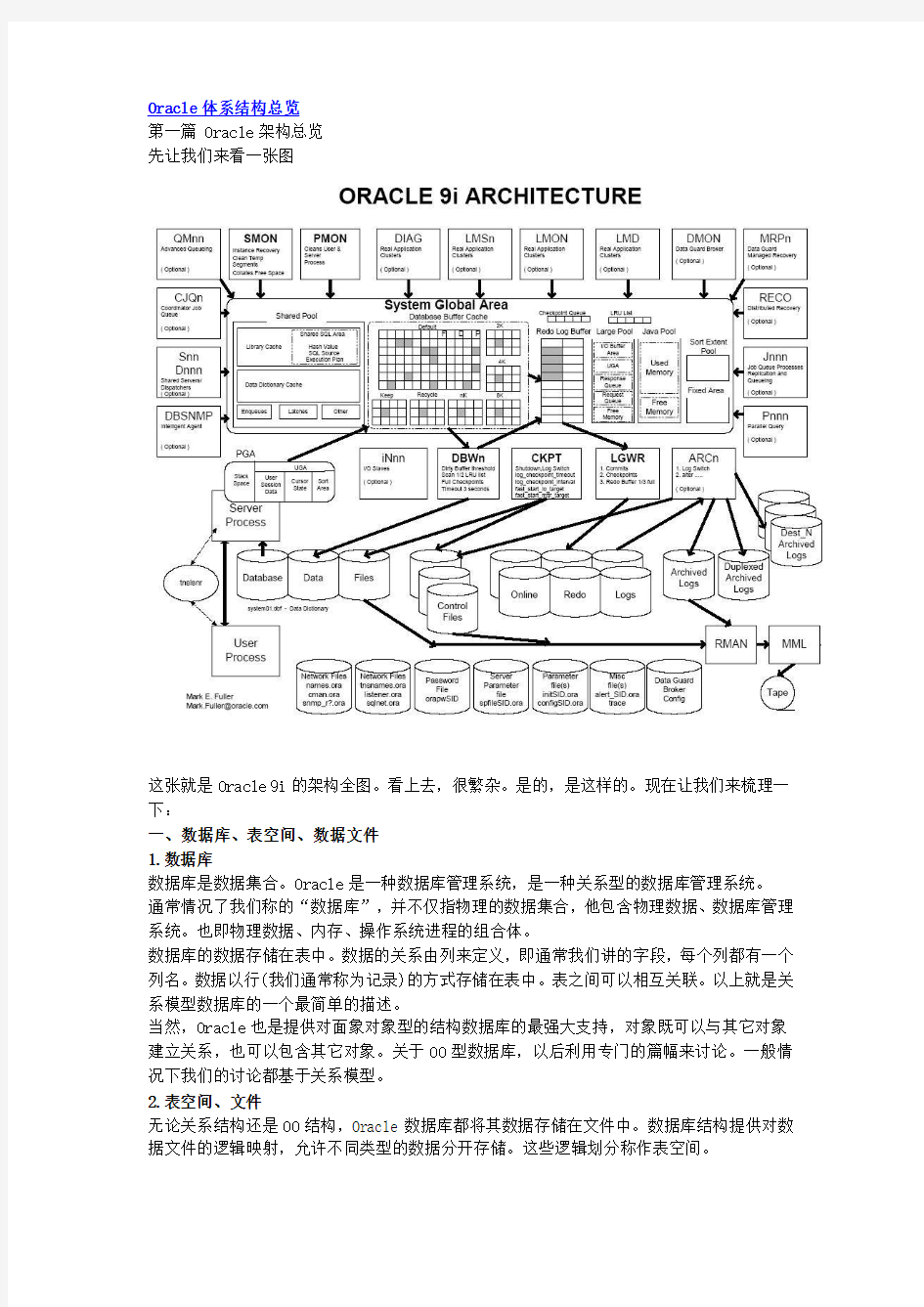

Oracle体系结构总览
第一篇 Oracle架构总览
先让我们来看一张图
这张就是Oracle 9i的架构全图。看上去,很繁杂。是的,是这样的。现在让我们来梳理一下:
一、数据库、表空间、数据文件
1.数据库
数据库是数据集合。Oracle是一种数据库管理系统,是一种关系型的数据库管理系统。
通常情况了我们称的“数据库”,并不仅指物理的数据集合,他包含物理数据、数据库管理系统。也即物理数据、内存、操作系统进程的组合体。
数据库的数据存储在表中。数据的关系由列来定义,即通常我们讲的字段,每个列都有一个列名。数据以行(我们通常称为记录)的方式存储在表中。表之间可以相互关联。以上就是关系模型数据库的一个最简单的描述。
当然,Oracle也是提供对面象对象型的结构数据库的最强大支持,对象既可以与其它对象建立关系,也可以包含其它对象。关于OO型数据库,以后利用专门的篇幅来讨论。一般情况下我们的讨论都基于关系模型。
2.表空间、文件
无论关系结构还是OO结构,Oracle数据库都将其数据存储在文件中。数据库结构提供对数据文件的逻辑映射,允许不同类型的数据分开存储。这些逻辑划分称作表空间。
表空间(tablespace)是数据库的逻辑划分,每个数据库至少有一个表空间(称作SYSTEM表空间)。为了便于管理和提高运行效率,可以使用一些附加表空间来划分用户和应用程序。例如:USER表空间供一般用户使用,RBS表空间供回滚段使用。一个表空间只能属于一个数据库。
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。在Oracle7.2以后,数据文件创建可以改变大小。创建新的表空间需要创建新的数据文件。
数据文件一旦加入到表空间中,就不能从这个表空间中移走,也不能与其它表空间发生联系。如果数据库存储在多个表空间中,可以将它们各自的数据文件存放在不同磁盘上来对其进行物理分割。在规划和协调数据库I/O请求的方法中,上述的数据分割是一种很重要的方法。数据库、表空间、文件之间的关系如下图所示:
二、数据库实例
为了访问数据库中的数据,Oracle使用一组所有用户共享的后台进程。此外,还有一些存储结构(统称为System Gloabl Area,即SGA),用来存储最近从数据库查询的数据。数据块缓存区和SQL共享池(Shared SQL Pool)是SGA的最大部分,一般占SGA内存的95%以上。通过减少对数据文件的I/O次数,这些存储区域可以改善数据库的性能。
数据库实例(instance)也称作服务器(server),是用来访问数据库文件集的存储结构及后台进程的集合。一个数据库可以被多个实例访问(这是Oracle并行服务器选项)。实例与数据库的关系如下图所示:
决定实例大小及组成的参数存储的init.ora文件中(在9i中是spfile)。实例启动时需要读这个文件,并且在运行时可以由数据库管理员修改。对该文件的任何修改都只有在下一次启动时才启作用。实例的init.ora文件件通常包含实例的名字:如果一个实例名为orcl,那么init.ora文件通常被命名为initorcl.ora。另一个配置文件config.ora用来存放在
数据库创建后就不再改变的变量值(如数据库的块大小)。实例的config.ora文件通常也包含该实例的名字:如果实例的名字为orcl,则config.ora一般将被命名为configorcl.ora。为了便于使用config.ora文件的设置值,在实例的init.ora文件中,该文件必须通过IFILE 参数作为包含文件列出。
-----------------------------------------
注:关于初始化参数文件,再另起篇幅详细介绍。
-----------------------------------------
通过以上对数据库及实例的介绍,Oracle数据库结构可分为三个范畴:
数据库内部结构(如表)
存储区内部的结构(包括共享存储区和进程)
数据库的外部结构
三、数据库的内部结构
即Oracle数据的逻辑表现层,也称oracle schema,包括以下这些内容:
表、列、约束条件、数据类型(包括抽象数据类型)
分区与子分区
用户与模式
索引、簇和散列簇
视图
序列
过程、函数、软件包和触发器
同义词
权限及角色
数据库链接
段、盘区和块
回滚段
快照与显形图
各部分的具体介绍以后将在Oralce schema栏目中讨论。
四、Oracle内部存储结构
包括内存缓冲池与后台进程:
1.系统全局区(SGA),主要包括:
a. 数据块缓存区
数据块缓存区(data block buffer cache)是S G A中的一个高速缓存区域,用来存储从数据库中读取数据段的数据块(如表、索引和簇)。数据块缓存区的大小由数据库服务器i n i t . o r a文件中的DB_LOCK_BUFFERS参数决定(用数据库块的个数表示)。在调整和管理数据库时,调整数据块缓存区的大小是一个重要的部分。
因为数据块缓存区的大小固定,并且其大小通常小于数据库段所使用的空间,所以它不能一次装载下内存中所有的数据库段。通常,数据块缓存区只是数据库大小的1 %~2 %,O r a c l e使用最近最少使用( L R U,least recently used)算法来管理可用空间。当存储区需要自由空间时,最近最少使用块将被移出,新数据块将在存储区代替它的位置。通过这种方法,将最频繁使用的数据保存在存储区中。
然而,如果S G A的大小不足以容纳所有最常使用的数据,那么,不同的对象将争用数据块缓存区中的空间。当多个应用程序共享同一个S G A时,很有可能发生这种情况。此时,每个应用的最近使用段都将与其他应用的最近使用段争夺S G A中的空间。其结果是,对数据块缓存区的数据请求将出现较低的命中率,导致系统性能下降。
b. 字典缓存区
数据库对象的信息存储在数据字典表中,这些信息包括用户帐号数据、数据文件名、段名、盘区位置、表说明和权限,当数据库需要这些信息(如检查用户查询一个表的授权)时,将读取数据字典表并且将返回的数据存储在字典缓存区的S G A中。
数据字典缓存区通过最近最少使用(LRU) 算法来管理。字典缓存区的大小由数据库内部管理。字典缓存区是S Q L共享池的一部分,共享池的大小由数据库文件i n i t . o r a
中的S H A R E D_PO O L_S I Z E参数来设置。
如果字典缓存区太小,数据库就不得不反复查询数据字典表以访问数据库所需的信息,这些查询称为循环调用(recuesive call),这时的查询速度相对字典缓存区独立完成查询时要低。
c. 重做日志缓冲区
重做项描述对数据库进行的修改。它们写到联机重做日志文件中,以便在数据库恢复过程中用于向前滚动操作。然而,在被写入联机重做日志文件之前,事务首先被记录在称作重做日志缓冲区(redo log buff e r )的S G A中。数据库可以周期地分批向联机重做日志文件中写重做项的内容,从而优化这个操作。
重做日志缓冲区的大小(以字节为单位)由i n i t . o r a文件中的L O G _ B U F F E R 参数决定。
d. SQL共享池
S Q L共享池存储数据字典缓存区及库缓存区(library cache),即对数据库进行操作的语句信息。当数据块缓冲区和字典缓存区能够共享数据库用户间的结构及数据信息时,库缓存区允许共享常用的S Q L语句。
S Q L共享池包括执行计划及运行数据库的S Q L语句的语法分析树。在第二次运行(由任何用户)相同的S Q L语句时,可以利用S Q L共享池中可用的语法分析信息来加快执行速度。
S Q L共享池通过L R U算法来管理。当S Q L共享池填满时,将从库缓存区中删掉最近最少使用的执行路径和语法分析树,以便为新的条目腾出空间。如果S Q L共享池太小,语句将被连续不断地再装入到库缓存区,从而影响操作性能。
S Q L共享池的大小(以字节为单位)由i n i t . o r a文件参数S H A R E D _ P O O L _ S I Z E决定。
e. 大池
大池( L a rge Pool)是一个可选内存区。如果使用线程服务器选项或频繁执行备份/恢复操作,只要创建一个大池,就可以更有效地管理这些操作。大池将致力于支持S Q L大型命令。利用大池,就可以防止这些S Q L大型命令把条目重写入S Q L共享池中,从而减少再装入到库缓存区中的语句数量。大池的大小(以字节为单位)通过init. ora文件的L A R G E _ P O O L _ S I Z E参数设置,用户可以使用i n i t . o r a文件的L A R G E _ P O O L _ M I N _ A L L O C参数设置大池中的最小位置。O r a c l e 8 i已不用这个参数。
作为使用L a rge Pool 的一种选择方案,可以用i n i t . o r a文件的S H A R E D _ P O O L _R E S E RV E D _ S I Z E参数为S Q L大型语句保留一部分S Q L共享池。
f. Java 池
由其名字可知, Java 池为J a v a命令提供语法分析。Java 池的大小(以字节为单位)通过在O r a c l e 8 i引入的i n i t . o r a文件的J AVA _ P O O L _ S I Z E参数设置。i n i t . o r a文件的J AVA _ P O O L _ S I Z E参数缺省设置为1 0 M B。
g. 多缓冲池
可以在S G A中创建多个缓冲池,能够用多个缓冲池把大数据集与其他的应用程序分开,以
减少它们争夺数据块缓存区内相同资源的可能性。对于创建的每一个缓冲池,都要规定其L R U锁存器的大小和数量。缓冲区的数量必须至少比L R U锁存器的数量多5 0倍。
创建缓冲池时,需要规定保存区(keep area)的大小和再循环区(recycle area)的大小。与S Q L共享池的保留区一样,保存区保持条目,而再循环区则被频繁地再循环使用。可以通过B U F F E R _ P O O L _ K E E P参数规定来保存区的大小。例如:
保存和再循环缓冲池的容量减少了数据块缓冲存储区中的可用空间(通过D B _ B L O C K _B U F F E R S参数设置)。对于使用一个新缓冲池的表,通过表的s t o r a g e子句中的b u ff e r _ p o o l参数来规定缓冲池的名字。例如,如果需要从内存中快速删除一个表,就把它赋予R E C Y C L E池。缺省池叫作D E FA U LT,这样就能在以后用alter table 命令把一个表转移到D E FA U LT池。
2.程序全局区( P G A )。
程序全局区( P G A,Program Global Area)是存储区中的一个区域,由一个O r a c l e 用户进程
所使用,P G A中的内存不能共享。
3.环境区
4.后台进程
数据库拥有多个后台进程,其数量取决于数据库的配置。这些进程由数据库管理,它们只需要进行很少的管理。
每个后台进程创建一个跟踪文件。在实例操作期间保存跟踪文件。后台进程跟踪文件的命名约定和位置随操作系统和数据库版本而不同。一般来说,跟踪文件含有后台进程名或后台进程的操作系统进程ID。可以设置初始化参数文件的BACKGROUND_DUMP_DEST参数来规
定后台进程跟踪文件的位置,但是有些版本的O r a c l e忽略这种设置。排除数据库故障时,跟踪文件就显得非常重要。影响后台进程的严重问题通常记录在数据库的警告日志上。警告日志通常位于BACKGROUND_DUMP_DEST目录下。一般来说,这个目录是
ORACLE_BASE目录下的/ADMIN/INSTANCE_NAME/BDUMP目录。
a. SMON
当启动一个数据库时, SMON(System Monitor,系统监控程序)进程执行所需的实例恢复
操作(使用联机重做日志文件),它也可以清除数据库,取消系统不再需要的事务对象。
S M O N的另一个用途是:将邻接的自由盘区组成一个较大的自由盘区。对于某些表空间,数据库管理员必须手工执行自由空间合并;S M O N只合并表空间中的自由空间,这些表空间的缺省
p c t i n c r e a s e存储值为非零。
b. PMON
P M O N (进程监控程序)后台进程清除失败用户的进程,释放用户当时正在使用的资源。当一个持有锁的进程被取消时,其效果是显而易见的, P M O N负责释放锁并使其可以被其他用户使用。同S M O N一样,P M O N周期性地唤醒检测它是否需要被使用。
c. DBWR
D B W R (数据库写入程序)后台进程负责管理数据块缓存区及字典缓存区的内容。它以批方式把修改块从S G A写到数据文件中。
尽管每一个数据库实例只有一个S M O N和一个P M O N进程在运行,但是根据平台和操作系统的不同,用户可以同时拥有多个D B W R进程。使用多个D B W R进程有助于在进行大的操作期间减少D B W R 中的冲突。所需D B W R 进程的数量由数据库的i n i t . o r a 文件中的D B _ W R I T E R _ P R O C E S S E S参数决定。如果系统支持异步I / O,
可以用多个DBWR I/O 从( s l a v e )进程创建一个D B W R进程。DBWR I/O 从进程的数量由i n i t . o r a文件的D B W R _ I / O _ S L AV E S参数设置。
如果创建多个D B W R进程,这些进程就不叫做D B W R,它们将有一个数字分量。例如,如果创建5个D B W R进程,进程的操作系统名就可能是D B W 0、D B W 1、D B W 2、D B W 3和D B W 4。
d. LGWR
L G W R (日志写入程序)后台进程负责把联机重做日志缓冲区的内容写入联机重做日志文件。L G W R分批将日志条目写入联机重做日志文件。重做日志缓冲区条目总是包含着数据库的最新状态,这是因为D B W R进程可以一直等待到把数据块缓冲区中的修改数据块写入到数据文件中。
L G W R是数据库正常操作时唯一向联机重做日志文件写入内容并从重做日志缓冲区直接读取内容的进程。与D B W R对数据文件执行的完全随机访问相反,联机重做日志文件以序列形式写入。如果联机重做日志文件是镜像文件, L G W R同时向镜像日志文件中写内容。对于O r a c l e 8,可以创建多个LGWR I/O从进程以改善向联机重做日志文件的写入性能,其个数由数据库的i n i t . o r a文件的L G W R _ I O _ S L AV E S参数决定。在O r a c l e 8 i中,这个参数已不能用, LGWR I/O从进程由D B W R _ I O _ S L AV E S设置值派生
而来。
e. CKPT
C K P T (检查点进程)用来减少执行实例恢复所需的时间。检查点使
D B W R把上一个检查点以后的全部已修改数据块写入数据文件,并更新数据文件头部和控制文件以记录该检查点。
当一个联机重做日志文件被填满时,检查点进程会自动出现。可以用数据库实例的i n i t . o r a文件中的L O G _ C H E C K P O I N T _ I N T E RVA L参数来设置一个频繁出现的检查点。
C K P T后台进程把早期数据库版本中L G W R的两个功能(向检查点发信号及复制日志内容)分成两个后台进程。当数据库实例的i n i t . o r a文件中的C H E C K P O I N T _ P R O C E S S参数被设置为T R U E时,就可以建立C K P T后台进程。
f. ARCH
L G W R后台进程以循环方式向联机重做日志文件写入;当填满第一个日志文件后,就开始向第二个日志文件写入;第二个日志文件填满后,再向第三个日志文件写入。一旦最后一个重做日志文件填满, L G W R就开始重写第一个重做日志文件的内容。
当O r a c l e以A R C H I V E L O G (归档日志)模式运行时,数据库在开始重写重做日志文件之前先对其进行备份。这些归档的重做日志文件通常写入一个磁盘设备中。也可以直接写入磁带设备中,但是这往往要增加操作员的劳动强度。
这种归档功能由A R C H (归档进程)后台进程完成,利用该性能的数据库在处理大数据事务时将遇到重做日志磁盘冲突问题,这是因为当L G W R准备写入一个重做日志文件时, A R C H正准备读取另一个。如果归档日志目标磁盘写满,数据库还将遇到数据库锁定问题。此时,A R C H冻结,禁止L G W R写入;从而禁止在数据库中出现进一步的事务处理;这种情况一起延续到归档重做日志文件的空间清空为止。
对于O r a c l e 8,可以创建多个ARCH I/O从进程以改善对归档重做日志文件的写入功能。在O r a c l e 8 . 0中,ARCH I/O从进程的个数由数据库的i n i t . o r a文件中的A R C H _ I O _ S L AV E S参数决定。在O r a c l e 8 i中,这个参数已不能用,A R C H _ I O _ S L AV E S设置值由D B W R _ I O _ S L AV E S设置值派生。
g. RECO
R E C O (恢复进程)后台进程用于解决分布式数据库中的故障问题。R E C O进程试图访问存在疑问的分布式事务的数据库并解析这些事务。只有在平台支持Distributed Option(分布式选项)且i n i t . o r a文件中的D I S T R I B U T E D _ T R A N S A C T I O N S参数大于零时才创建这个进程。
h. SNPn
O r a c l e的快照刷新及内部作业队列调度依赖于它们执行的后台进程(快照进程)。这些后台进程的名字以字母S N P开头,以数字或字母结束。为一实例所创建的S N P进程的个数由数据库的i n i t . o r a文件中的J O B _ Q U E U E _ P R O C E S S E S 参数决定(在O r a c l e 7 中,该参数名为S N A P S H O T _ R E F R E S H _ P R O C E S S E S )。
i. LCKn
当采用O r a c l e并行服务器选项时,多个L C K (锁定进程)后台进程(命名为L C K 0 ~ L C K 9 )用于解决内部实例的锁定问题。L C K进程的个数由G C _ L C K _ P R O C S 参数决定。
j . Dn n n
D n n n(调度程序进程)是M T S结构的一部分;这些进程有助于减少处理多重连接所需要的资源。对于数据库服务器支持的每一个协议必须至少创建一个调度程序进程,调度程序进程根据S Q L * N e t (或N e t 8 )的配置在数据库启动时创建,在数据库打开后可以创建或取消。
k. Sn n n
创建Sn n n(服务器进程)来管理需要专用服务器的数据库连接。服务器进程可以对数据文件进行I / O操作。
l. P n n n
如果启动数据库中的并行查询选项,一个查询的资源要求可以分布在多个处理器中。当实例启动由init. ora文件的PA R A L L E L _ M I N _ S E RV E R S参数确定时,指定数目的并行查询服务器进程就启动。每一个这样的进程都将出现在操作系统级。需要并行操作的进程越多,启动的并行查询服务器进程就越多。每个并行查询服务器进程在操作系统级将有一个P 0 0 0、P 0 0 1、P 0 0 2这样的名字。并行查询服务器进程的最大数量由init. ora 文件的PA R A L L E L _ M A X _S E RV E R S参数确定。
五、Oracle的外部结构
1. 重做日志
O r a c l e保存所有数据库事务的日志。这些事务被记录在联机重做日志文件(online redo logf i l e )中。当数据库被破坏时,这些日志文件能够以正确顺序恢复数据库事务。重做日志文件信息存储在数据库数据文件的外部。
重做日志文件也可以让O r a c l e优化向磁盘写入数据的方式。当数据库中出现一个事务时,就把该事务输入到重做日志缓冲区;同时受该事务影响的数据块不会立即写入磁盘。每个O r a c l e数据库都有两个或更多的联机重做日志文件。O r a c l e以循环方式向联机重做日志文件写入:第一个日志文件被填满后,就向第二个日志文件写入,然后依次类推。当所有联机重做日志文件都被填满时,就又回到第一个日志文件,用新事务的数据对其进行重写。如果数据库正以A R C H I V E L O G模式运行,在重写联机重做日志文件前,数据库将先对其进行备份。任何时候都可以用这些归档重做日志文件来恢复数据库的任何部分。
重做日志文件可以被数据库镜像(复制)。镜像联机重做日志文件不依赖操作系统或操作环境的硬件性能就可以对重做日志文件进行镜像。
2. 控制文件
数据库的全局物理结构由其控制文件(control file)维护。控制文件记录数据库中所有文件的控制信息。控制文件维护内部的一致性并引导恢复操作。
由于控制文件对数据库至关重要,所以联机存储着多个拷贝。这些文件一般存储在各个不同的磁盘上,以便将因磁盘失效引起的潜在危险降至最低限度。创建数据库时,同时就提供与之对应的控制文件。
数据库控制文件的名字通过init. ora文件的C O N T R O L _ F I L E S参数规定。尽管这是一个i n i t . o r a参数,但是C O N TO R L _ F I L E S参数通常用c o n f i g . o r a文件规定,因为它很少变化。如果需要给数据库添加一个新的控制文件,可关闭实例,把已存在的一个控制文件复制到新的地址,把新的地址添加到C O N T R O L _ F I L E S 参数设置值上,并重新启动这个实例。
3. 跟踪文件与警告日志
在实例中运行的每一个后台进程都有一个跟踪文件与之相连。跟踪文件记载后台进程遇到的重大事件的信息。除了跟踪文件外, O r a c l e还有一个称作警告日志(alert log)的文件,警告日志记录数据库文件运行中主要事件的命令及结果。例如,表空间的创建、重做日志的转换、操作系统的恢复、数据库的建立等信息都记录在警告日志中。警告日志是数据库每日管理的重要资源,当需要查找主要失败原因时,跟踪文件就非常有用。
应经常监控警告日志。警告日志的条目将通知你数据库操作期间遇到的任何问题,其中包括出现的任何O R A _ 0 6 0 0内部错误。为使警告日志便于使用,最好是每天能自动对其重新命名。例如,如果警告日志称作a l e r t _ o r c l . l o g,可以对它重新命名,以便其文件名包括当前日期。下次O r a c l e要写该警告日志时,将找不到具有a l e r t _ o r c l . l o g文件名的文件,因此数据库将创建一个新的文件名。这样,除了有以前的警告日志外,还有一个当前的警告日志( a l e r t _ o r c l . l o g )。用这种方式区分警告日志条目就可以使对警告日志条目的分析更有效。
oracle体系结构必须先了解的两个基本的概念
oracle体系结构必须先了解的两个基本的概念
要了解oracle体系结构必须先了解两个基本的概念: 数据库和实例.
一: 数据库
数据库(database)是一个数据集合.
无论数据库是采用关系结构还是面向对象结构, oracle数据库都将
其数据存放在数据文件中. 在其内部, 数据库结构数据对文件的逻辑
映射, 使不同的数据分开存储, 这些逻辑划分称为表空间.
表空间和文件介绍:
1: 表空间
表空间(tablespace)是数据库的逻辑划分, 每个数据库至少有一个表空间,叫做系统表空间(system 表空间). 一个表空间只能属于一个数据库.
每个表空间由同一个磁盘上的一个或多个文件组成, 这些文件称为数据文件.
表空间的特性:
1)控制数据库数据磁盘分配
2)限制用户在表空间中可以使用的磁盘空间大小
3)表空间具有 online, offline, readonly, readwrite属性
修改表空间的属性:
SQL> alter tablespace 表空间名称属性;
查询表空间状态:
SQL> select tablespace_name, status from
dba_tablespaces;
注意: system, undo, temp表空间不能设为offline属性.
4)完成部分数据库的备份与恢复
5)表空间通过数据文件来扩大, 表空间的大小等于构成该表空间的所以数据文件的大小只和.
查询表空间与数据文件对应关系:
SQL> select tablespace_name, bytes, file_name from
dba_data_files;
基于表空间的几个操作:
1)查询用户缺省表空间:
SQL> select username, default_tablespace from dba_users;
2)查询表与存储该表的表空间:
SQL> select table_name, tablespace_name from user_tables; 3)修改用户缺省表空间:
SQL> alter user username default tablespace tablespace_name;
4)将数据从一个表空间移动到另一个表空间:
SQL> alter table table_name move tablespace tablespace_name; 2: 数据文件
每个表空间由同一个磁盘上的一个或多个文件组成, 这些文件叫做数据文件(datafile),
数据文件只能属于一个表空间. 数据文件创建后可以改变大小. 创建新的表空间需要创建新的
数据文件. 数据文件一旦加入到表空间中, 就不能从表空间中移走, 也不能与其他表空间发生联系.
数据库必须的三类文件是 data file, control file, redolog file. 其他文件prameter file,
password file, archived log files并不是数据库必须的, 他们只是辅助数据库的.
查看数据库的物理文件组成:
1)查看数据文件: SQL> select * from v$datafile;
2)查看控制文件: SQL> select * from v$controlfile;
3)查看日志文件: SQL> select * from v$logfile;
二: 实例
通俗的讲实例就是操作oracle数据库的一种手段.
数据库实例也称作服务器, 是用来访问数据库文件集的存储结构及后台进程的集合.
一个数据库可以被多个实例访问(称为真正的应用群集选项).
决定实例的大小及组成的各种参数或者存储在名称init.ora的初始化文件中, 或者隐藏
在数据库内部的服务器参数文件中. 通过spfile引用该文件, spfile存储在spfile.ora文件中.
实例启动时读取初始化文件, 数据库系统管理员可以修改该文件, 对初始化文件的修改只有
在下次启动时才有效.
Instance分为两部分:
1: memory structure(内存结构)
memory structure分为两部分:SGA(System Global Area)区是用于存储数据库信息的内存区,
该信息为数据库进程所共享。它包含Oracle 服务器的数据和控制信息,
它是在Oracle 服务器所
驻留的计算机的实际内存中得以分配,如果实际内
存不够再往虚拟内存中写。
包括:
.share pool
.datafase
buffer cache
.redo log buffer .other structures
PGA(Program Global Area)区包含单个服务器进程或单个后台进程的
数据和控制信息,与几个进程共享的SGA 正相反PGA 是只被一个进程使
用的区域,PGA 在创建进程时分配在终止进程时回收
2: background process(后台进程)
包括: .PMON 负责在一个Oracle 进程失败时清理资源
.SMON 检查数据库的一致性如有必要还会在数据库打开时启动数据库的恢复
.DBWR 负责将更改的数据从数据库缓冲区高速缓存写入数据文件
.LGWR 将重做日志缓冲区中的更改写入在线重做日志文件
.CKPT 负责在每当缓冲区高速缓存中的更改永久地记录在数据库中时,更新控制文件和数据文件中的数据库状态信息。
.OTHER
Oracle体系结构:内存结构和进程结构
(一)内存结构和进程结构Oracle数据库的总体结构如下图:
1:Oracle实例(Instance)
在一个服务器中,每一个运行的Oracle数据库都与一个数据库实例相联系,实例是我们访问数据库的手段。
实例在操作系统中用ORACLE_SID来标识,在Oracle中用参数INSTANCE_NAME来标识,它们两个的值是相同的。数据库启动时,系统首先在服务器内存中分配系统全局区(SGA),构成了Oracle的内存结构,然后启动若干个常驻内存的操作系统进程,即组成了Oracle 的
进程结构,内存区域和后台进程合称为一个Oracle实例。
数据库与实例之间是1对1/n的关系,在非并行的数据库系统中每个Oracle数据库与一
个
实例相对应;在并行的数据库系统中,一个数据库会对应多个实例,同一时间用户只与一个
实例相联系,当某一个实例出现故障时,其他实例自动服务,保证数据库正常运行。在任何
情况下,每个实例都只可以对应一个数据库。
2:Oracle 10g动态内存管理
内存是影响数据库性能的重要因素,Oracle8i使用静态内存管理,Oracle 10g使用动态内存管理。所谓静态内存管理,就是在数据库系统中,无论是否有用户连接,也无论并发用
量大小,只要数据库服务在运行,就会分配固定大小的内存;动态内存管理允许在数据库服
务运行时对内存的大小进行修改,读取大数据块时使用大内存,小数据块时使用小内存,读
取标准内存块时使用标准内存设置。
按照系统对内存使用方法的不同,Oracle数据库的内存可以分为以下几个部分:
?系统全局区:SGA(System Global Area)
?程序全局区:PGA(Programe Global Area)
?排序池:(Sort Area)
?大池:(Large Pool)
?Java池:(Java Pool)
2-1:系统全局区SGA(System Global Area)
SGA是一组为系统分配的共享的内存结构,可以包含一个数据库实例的数据或控制信息。如果多个用户连接到同一个数据库实例,在实例的SGA中,数据可以被多个用户共享。当数据库实例启动时,SGA的内存被自动分配;当数据库实例关闭时,SGA内存被回收。 SGA是占用内存最大的一个区域,同时也是影响数据库性能的重要因素。
SGA的有关信息可以通过下面的语句查询,sga_max_size的大小是不可以动态调整的。 =====================================
SQL> show parameter sga
NAME TYPE VALUE
------------------------------------ ----------- --------
lock_sga boolean FALSE
pre_page_sga boolean FALSE
sga_max_size big integer 164M
sga_target big integer 0
SQL> alter system set sga_max_size=100m;
alter system set sga_max_size=100m
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
======================================
系统全局区按作用不同可以分为:
?数据缓冲区
?日志缓冲区
?共享池
2-1-1:数据缓冲区(Database Buffer Cache)
如果每次执行一个操作时,Oracle都必须从磁盘读取所有数据块并在改变它之后
又必须把每一块写入磁盘,显然效率会非常低。数据缓冲区存放需要经常访问的数据,供所有用户使用。修改数据时,首先从数据文件中取出数据,存储在数据缓冲区中,修改/插入数据也存储在缓冲区中,commit或DBWR(下面有详细介绍)进程的其他条件引发时,数据被写入数据文件。
数据缓冲区的大小是可以动态调整的,但是不能超过sga_max_size的限制。
======================================
SQL> show parameter db_cache_size
NAME TYPE VALUE
------------------------------------ ----------- -----------------
db_cache_size big integer 24M
SQL> alter system set db_cache_size=128m;
alter system set db_cache_size=128m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid ORA-00384: Insufficient memory to grow cache
SQL> alter system set db_cache_size=20m;
System altered.
SQL> show parameter db_cache_size;
NAME TYPE VALUE
------------------------------------ ----------- -----------------
db_cache_size big integer 20M
#此处我仅增加了1M都不行?
SQL> alter system set db_cache_size=25m;
alter system set db_cache_size=25m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid ORA-00384: Insufficient memory to grow cache
#修改显示格式,方便查看。
SQL> column name format a40 wrap
SQL> column value format a20 wrap
#下面语句可以用来查看内存空间分配情况,注意SGA各区大小总和。
SQL> select name,value from v$parameter where name like '%size' and value <> '0';
#先将java_pool_size调小,然后再修改db_cache_size
SQL> show parameter java_pool_size;
NAME TYPE VALUE
------------------------------------ ----------- -----
java_pool_size big integer 48M
SQL> alter system set java_pool_size=20m;
System altered.
SQL> alter system set java_pool_size=30m;
System altered.
#上面说明SGA中各区大小总和不能超过sga_max_size。
=====================================
数据缓冲区的大小对数据库的存区速度有直接影响,多用户时尤为明显。有些应用对速度要求很高,一般要求数据缓冲区的命中率在90%以上。
下面给出一种计算数据缓冲区命中率的方法:
?使用数据字典v$sysstat
=====================================
SQL> select name, value from v$sysstat
2 where name in('session logical reads',
3 'physical reads',
4 'physical reads direct',
5 'physical reads direct (lob)')
NAME VALUE
------------------------------- ----------
session logical reads 895243
physical reads 14992
physical reads direct 34
physical reads direct (lob) 0
======================================
命中率=1-(14992-34-0)/895243
可以让Oracle给出数据缓冲区大小的建议:
======================================
SQL> alter system set db_cache_advice=on;#打开该功能
System altered.
SQL> alter system set db_cache_advice=off;#关闭该功能
System altered.
======================================
2-1-2:日志缓冲区(Log Buffer Cache)
日志缓冲区用来存储数据库的修改信息。该区对数据库性能的影响很小,有关日志后面还会有详细的介绍。
查询日志缓冲区大小:
SQL> show parameter log_buffer
NAME TYPE VALUE
---------- ----------- -------
log_buffer integer 262144
2-1-3:共享池(Share Pool)
共享池是对SQL,PL/SQL程序进行语法分析,编译,执行的内存区域。
它包含三个部分:(都不可单独定义大小,必须通过share pool间接定义)。
?库缓冲区(Library Cache)包含SQL,PL/SQL语句的分析码,执行计划。
?数据字典缓冲区(Data Dictionary Cache)表,列定义,权限。
?用户全局区(Usr Global Area)用户MTS会话信息。
共享池的大小可以动态修改:
======================================
SQL> show parameter shared_pool_size
NAME TYPE VALUE
------------------------------------ ----------- ------
__shared_pool_size big integer 80M
shared_pool_size big integer 80M
SQL> alter system set shared_pool_size=78m
System altered.
======================================
#上面的__shared_pool_size一行奇怪?
2-2:程序全局区PGA(Programe Global Area)
程序全局区是包含单个用户或服务器数据和控制信息的内存区域,它是在用户进程连
接到Oracle并创建一个会话时由Oracle自动分配的,不可共享,主要用于用户在编程存储变量和数组。
如上图:
?Stack Spac e是用来存储用户会话变量和数组的存储区域;
?User Session Data是为用户会话使用的附加存储区。
|--Session Information
|--Sort Area
|--Cursor Information
注意Session information(用户会话信息)在独占服务器中与在共享服务器中所处
的内存区域是不同的。
2-3:排序区,大池,Java池
排序区(Sort Area)为有排序要求的SQL语句提供内存空间。系统使用专用的内存区域进行数据排序,这部分空间就是排序区。在Oracle数据库中,用户数据的排序可使用两个区域,一个是内存排序区,一个是磁盘临时段,系统优先使用内存排序区进行排序。如果内存不够,Orcle自动使用磁盘临时表空间进行排序。为提高数据排序的速度,建议尽量使用内存排序区,而不要使用临时段。
参数sort_area_size用来设置排序区大小。(好象不能动态修改?)
大池(Large Pool)用于数据库备份工具--恢复管理器(RMAN:Recovery Manager)。 Large Pool的大小由large_pool_size确定,可用下面语句查询和修改:
=========================================
SQL> show parameter large_pool_size
NAME TYPE VALUE
----------------- ----------- -------
large_pool_size big integer 8M
SQL> alter system set large_pool_size=7m;
System altered.
=========================================
Java池主要用于Java语言开发,一般来说不低于20M。其大小由java_pool_size来
确定,可以动态调整。
2-4:Oracle自动共享内存管理(Automatic Shared Memory(SGA) Management)
在Oracle 8i/9i中数据库管理员必须手动调整SGA各区的各个参数取值,每个区要根据负荷轻重分别设置,如果设置不当,比如当某个区负荷增大时,没有调整该区内存大小,则
可能出现ORA-4031:unable to allocate ...bytes of shared memory错误。
在Oracle 10g中,将参数STATISTICS_LEVEL设置为TYPICAL/ALL,使用SGA_TARGET指定SGA区总大小,数据库会根据需要在各个组件之间自动分配内存大小。
下面是系统自动调整的区域:
?固定SGA区及其他?共享池?数据缓冲区? Java池?大池。
注意:如果不设置SGA_TARGET,则自动共享内存管理功能被禁止。
==========================================
SQL> show parameter statistics_level
NAME TYPE VALUE
--------------------- ----------- ------------
statistics_level string TYPICAL
SQL> alter system set statistics_level=all;
System altered.
#typical和all有什么区别?
SQL> alter system set statistics_level=typical;
System altered.
SQL> show parameter sga_target
NAME TYPE VALUE
------------- ----------- ----------
sga_target big integer 0
SQL> alter system set sga_target=170m;
alter system set sga_target=170m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid ORA-00823: Specified value of sga_target greater than sga_max_size
SQL> alter system set sga_target=20m;
System altered.
#不过后来又发现sga_target的值变成了140M? 下面是语句执行情况。
SQL> show parameter sga_target
NAME TYPE VALUE
------------- ----------- -------
sga_target big integer 140M
SQL> alter system set sga_target=0;
System altered.
SQL> show parameter sga_target
NAME TYPE VALUE
------------------------------------ ----------- ------
sga_target big integer 0
#改为20M
SQL> alter system set sga_target=20m;
System altered.
#显示的是140M
SQL> show parameter sga_target
NAME TYPE VALUE
------------------------------------ ----------- ------
sga_target big integer 140M
#不可缩减?
SQL> alter system set sga_target=130m;
alter system set sga_target=130m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid ORA-00827: could not shrink sga_target to specified value
#不可增加
SQL> alter system set sga_target=141m;
alter system set sga_target=141m
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid ORA-00823: Specified value of sga_target greater than sga_max_size
3:Oracle实例的进程结构(Process Structure)
Oracle包含三类进程:
?用户进程(User Process)
?服务器进程(Server Process)
?后台进程(Background Process)
3-1:用户进程和服务器进程
当数据库用户请求连接到Oracle的服务时启动用户进程(比如启动SQLPlus时)。?用户进程首先必须建立一个连接。
?用户不能直接与Oracle服务器,必须通过服务器进程交互。
?服务器进程是用户进程与服务器交互的桥梁,它可以与Oracle Server直接交互。?服务器进程可以有共享和独占两种形式。
3-2:后台进程(Backgroung Process)
数据库的物理结构与内存结构之间的交互要通过后台进程来完成。数据库的后台进程包含两类,一类是必须的,一类是可选的:
?Mandatory background processes
|--DBWn(Database Writer):数据写入
|--PMON(Process Moniter):进程监控
|--LGWR(Log Writer):日志写入
|--SMON(System Moniter):系统监控
|--RECO(Recovery):恢复
|--CKPT(Chekpoint):检查点
?Optional background processes
|--ARCn(Archiver):归档
|--LCKn(Lock):锁
|--Dnnn(Dispatcher):调度
|--......
可以用下面的语句查看正在运行的后台进程:
=========================================
SQL> select * from v$bgprocess where paddr<>'00';
PADDR PSERIAL# NAME DESCRIPTION
-------- ---------- ----- -------------------------------
6B0ED064 1 PMON process cleanup
6B0ED4E4 1 MMAN Memory Manager
6B0ED964 1 DBW0 db writer process 0
6B0EDDE4 1 LGWR Redo etc.
6B0EE264 1 CKPT checkpoint
6B0EE6E4 1 SMON System Monitor Process
6B0EEB64 1 RECO distributed recovery
6B0EEFE4 1 CJQ0 Job Queue Coordinator
6B0F01E4 1 QMNC AQ Coordinator
6B0F0664 1 MMON Manageability Monitor Process
6B0F0AE4 1 MMNL Manageability Monitor Process 2
========================================
3-2-1:DBWR(Database Writer,数据写入进程)
将数据缓冲区的数据写入数据文件,是负责数据缓冲区管理的一个后台进程。
当数据缓冲区中的一数据被修改后,就标记为dirty,DBWR进程将数据缓冲区中“脏”数据写入数据文件,保持数据缓冲区的”干净“。由于数据缓冲区的数据被用户修改并占用,空闲数据缓冲区会不断减少,当用户进程要从磁盘读取数据块到数据缓冲区却无法找到足够的空闲数据缓冲区时,DBWR将数据缓冲区内容写入磁盘,使用户进程总可以得到足够的空闲数据缓冲区。
DBWR的作用:
?管理数据缓冲区,以便用户进程总能够找到足够的空闲缓冲区。
?将所有修改后的缓冲区数据写入数据文件。
?使用LRU(最近最少使用)算法保持缓冲区数据是最近经常使用的。
?通过延迟写来优化磁盘I/0读写。
3-2-2:LGWR(Log Writer,日志写入进程)
将日志数据从日志缓冲区写入磁盘日志文件组。数据库在运行时,如果对数据库进行修改则产生日志信息,日志信息首先产生于日志缓冲区。当日志达到一定数量时,由LGWR 将
将日志数据写入到日志文件组,再经过日志切换,由归档进程(ARCH)将日志数据写入归档进程(前提是数据库运行在归档模式下)。数据库遵循写日志优先原则,即在写数据之前
先写日志。
数据库设计实例需求分析、概念结构、逻辑结构
数据库设计实例分析 一、需求分析实例 现要开发高校图书管理系统。经过可行性分析和初步的需求调查,确定了系统的功能边界,该系统应能完成下面的功能: (1)读者注册。 (2)读者借书。 (3)读者还书。 (4)图书查询。 1、数据流图 顶层数据流图反映了图书管理系统与外界的接口,但未表明数据的加工要求,需要进一步细化。根据前面图书管理系统功能边界的确定,再对图书管理系统顶层数据流图中的处理功能做进一步分解,可分解为读者注册、借书、还书和查询四个子功能,这样就得到了图书管理系统的第0层数据流图 从图书管理系统第0层数据流图中可以看出,在图书管理的不同业务中,借书、还书、查询这几个处理较为复杂,使用到不同的数据较多,因此有必要对其进行更深层次的分析,即构建这些处理的第1层数据流图。下面的图8-7分别给出了借书、还书、查询子功能的第1层数据流图 2、数据字典 数据项 数据项名称:借书证号 别名:卡号 含义说明:惟一标识一个借书证 类型:字符型 长度:20 …… 数据结构 (1)名称:读者类别 含义说明:定义了一个读者类别的有关信息 组成结构:类别代码+类别名称+可借阅数量+借阅天数+超期罚款额 (2)名称:读者 含义说明:定义了一个读者的有关信息 组成结构:姓名+性别+所在部门+读者类型 (3)名称:图书 含义说明:定义了一本图书的有关信息 组成结构:图书编号+图书名称+作者+出版社+价格 ……
数据流 (1)数据流名称:借书单 含义:读者借书时填写的单据 来源:读者 去向:审核借书 数据流量:250份/天 组成:借书证编号+借阅日期+图书编号 (2)数据流名称:还书单 含义:读者还书时填写的单据 来源:读者 去向:审核还书 数据流量:250份/天 组成:借书证编号+还书日期+图书编号 …… 数据存储 (1)数据存储名称:图书信息表 含义说明:存放图书有关信息 组成结构:图书+库存数量 说明:数量用来说明图书在仓库中的存放数 (2)数据存储名称:读者信息表 含义说明:存放读者的注册信息 组成结构:读者+卡号+卡状态+办卡日期 说明:卡状态是指借书证当前被锁定还是正常使用 (3)数据存储名称:借书记录 含义说明:存放读者的借书、还书信息 组成结构:卡号+书号+借书日期+还书日期 说明:要求能立即查询并修改 …… 处理过程 (1)处理过程名称:审核借书证 输入:借书证 输出:认定合格的借书证 加工逻辑:根据读者信息表和读者借书证,如果借书证在读者信息表中存在并且没有被锁定,那么借书证是有效的借书证,否则是无效的借书证。 …… 二、概念结构设计实例 1.标识图书管理系统中的实体和属性 参照数据字典中对数据存储的描述,可初步确定三个实体的属性为: 读者:{卡号,姓名,性别,部门,类别、办卡日期,卡状态} 读者类别:{类别代码,类别名称,可借阅天数、可借阅数量,超期罚款额}
数据库的逻辑结构
数据库逻辑存储结构 数据库的物理存储结构对应一系列的物理文件,这部分主要描述的是数据存储的实际位置,不过数据如果存储,是以什么结构存储到数据文件中,则取决于数据库的逻辑存储结构. Oracle数据库在执行操作时,并不是以数据文件为单位,而是从逻辑上定义出一组结构,操作的数据可以一步步细分不同的存储单元,oracle 操作数据的过程,实际上就是对这些不同级别的存储单元进行维护和管理的过程. 逻辑存储概述 --块(block)块是逻辑存储结构中最小存储单位,所有数据的存储都是以块为单位进行.初始化参数文件中BLOCK_SIZE来指定一个块的大小,也就是说oracle的块大小在数据库创建时指定,一经指定就无法修改,除非重建数据库. --区(extent) 区是oracle数据库的最小分配单位,由一组连续的块组成,这些块在物理上可能并不连续(也就是OS块),但是必需都存在于一个物理文件,单个区在分配时不能跨文件分配(这个文件应该是数据文件).在创建对象时,最少会为该对象分配一个区,这个区叫做初始区(initial extent) 在随着对象的不断扩展,超出初始区后,oracle就会再为其分配扩展区(incremental extent)扩展区不一定要与初始区连续存放,甚至大小也可以与初始区不同,不过扩展区也必需是由连续的块组成. 段(segment)从逻辑的角度看,段由一个或多个区组成,它是一个真正逻辑结构. 可以将段看作是对象的全部或某个部分 例如:一个普通的堆组织表(不含分区,LOB类型及索引等)那么该表就对应一个段,不管这个表中被存放多少记录,它都仍然只对应一个段,不过如果该表创建了索引,那么索引数据会存放专门的索引段,如果该表有LOB类型,LOB数据也会被存入单独的数据段. --表空间(tablespace)从逻辑上定义,是由一个或多个段组成,从物理上定义是由一个或多个数据文件组成.表空间是oracle数据库中空间分配的最大逻辑单位,在往上就是数据库级别. 平时进行的创建对象的操作,都是在表空间一级进行. **提示:如创建存储对象时只能指定存储到哪个表空间,而不能指定存储到更细粒度的逻辑结构,如段,区,块.也不能指定存储到某个数据文件中. *注意*:在创建存储对象时,只需要指定存储所在的表空间(如果未指定,则存储到用户当前的默认表空间中),其他一切由oracle自动处理图: 每层结构都是一对多的关系 逻辑结构对应关系图
数据库原理课后题答案
第1章 1.试述数据、数据库、数据库系统、数据库管理系统的概念。 答:(1)数据:描述事物的符号记录成为数据。数据的种类有数字、文字、图形、图像、声音、正文等。数据与其语义是不可分的。 (2)数据库:数据库是长期储存在计算机内的、有组织的、可共享的数据集合。数据库中的数据按照一定的数据模型组织。描述和储存,具有较小的冗余度、较高的数据独立性和易扩展性,并可为各种用户共享。 (3)数据库系统:数据库系统是指在计算机系统中引入数据库后的系统构成,一般由数据库、数据库管理系统(及其开发人具)、应用系统、数据库管理员构成。 (4)数据库管理系统:数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。DBMS的主要功能包括数据定义功能、数据操作功能、数据库的建立和维护功能。 6.试述数据库系统三级模式结构,这种结构的优点是什么? 答:数据库系统的三级模式机构由外模式、模式和内模式组成。 外模式,亦称子模式或用户模式,是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。 模式亦称逻辑模式,是数据库中全体数据呃逻辑结构和特征的描述,是所有用户的公共数据视图。模式描述的是数据的全局逻辑结构。外模式涉及的是数据的内部逻辑结构,通常是模式的子集。 内模式,亦称存储模式,是数据在数据库内部的表示,即对数据的物理结构和存储方式的描述。 数据库系统的三级模式是对数据的三个抽象级别,它对数据的具体组织留给DBMS管理,使用户能逻辑抽象地处理数据,而不必关心数据在计算机中的表示和存储。 为了能够在内部实现这三个抽象层次的联系和转换,数据库系统在这三级模式之间提供了两层映像:外模式∕模式映像和模式∕内模式映像。正是这两层映像保证了数据库系统中的数据能够具有较高的逻辑独立性和物理独立性。 7.定义并解释下列术语。 外模式:亦称子模式或用户模式,是数据库用户(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。 内模式:亦称存储模式,是数据在数据库内部的表示,即对数据的物理结构和存储方式的描述。 模式:亦称逻辑模式,是数据库中全体数据逻辑结构和特征的描述,是所有用户的公共数据视图。模式描述的是数据的全局逻辑结构。外模式涉及的是数据的内部逻辑结构,通常是模式的子集。 DDL:数据库定义语言,用来定义数据库模式、外模式、内模式的语言。DML:数据操纵语言,用来对数据库中数据进行查询、插入、删除和修改的语句。 8.什么叫数据与程序的物理独立性?什么叫数据与程序的逻辑独立性?为什么
数据库逻辑结构图
数据库逻辑结构图 一、实体的关系模型 1)、管理员(用户名,密码) 2)、个人(帐号,密码,姓名,年龄,出生日期,电话号码)3)、备忘录(时间,地点,事件) 4)、通讯录(姓名,城市,备注,工作地点,联系方式) 5)、日记(日期,地点,人物,事情) 6)、财务(标志,消费项目,消费时间,消费金额,剩余金额,总收入) 其中有下划线的是主键。 二、关系模型合并 1)、管理员(用户名,密码) 2)、个人(帐号,密码,姓名,年龄,出生日期,电话号码)3)、备忘录(时间,地点,事件) 4)、通讯录(姓名,城市,备注,工作地点,联系方式) 5)、日记(日期,地点,人物,事情) 6)、财务(标志,消费项目,消费时间,消费金额,剩余金额,总收入) 三、关系模型的函数依赖关系 1)、用户名——>密码 2)、(帐号,密码)——>姓名,(帐号,密码)——>年龄,(帐号,密码)——>出生日期,(帐号,密码)——>电话号码
3)、时间——>地点,时间——>事件 4)、姓名——>城市,姓名——>备注,姓名——>工作地点,姓名——>联系方式; 5)、日期——>地点,日期——>人物,日期——>事情 6)、标志——>消费时间,消费时间——>消费项目,消费时间——>消费金额,标志——>总收入,标志——>剩余金额。 其中6不是第一范式其他都是第一范式,且6为第二范式. 四、优化 1)、管理员(用户名,密码) 2)、个人(帐号,密码,姓名,年龄,出生日期,电话号码)3)、备忘录(时间,地点,事件) 4)、通讯录(姓名,城市,备注,工作地点,联系方式)5)、日记(日期,地点,人物,事情) 6)、财务(标志,消费时间,剩余金额,总收入) 消费(消费时间,消费项目,消费金额)
数据库-逻辑结构设计
1、关系模型与ER模型:(一个关系就是一张二维表) 关系模式:→二维表 ER模型:→ER图 2、关系模型的基本概念: 教师(教师编号,A, B, 姓名,性别,所在系)--主表 课程(课程号,课程名,上课教师,教师编号)--从表 关系名:实体与实体间的联系 元组----记录---行(非空) 字段----数据项---列(属性) 键----关键字----标识属性(主键,外键,候选键) 主从关系:以该属性为主键的表就是主表,以该属性为外键的表就是从表。 3、将ER模型转换成二维表,以下面为例: ER模型: 实体: 教师(教师编号,姓名,性别,所在系) 课程(课程号,课程名,教师编号,上课教室) 学生(学号,姓名,年龄,班级) 联系: 讲授(教师编号,课程号) 选修(学号,课程号,成绩)
二维表: ①将实体转为关系表 (实体名--关系名,实体属性--关系属性,即列,实体键--关系键) ②将实体的联系转为关系表(关系模式) 1:1的联系--可以转为一个独立的关系模式,也可以与任一实体合并 1:n的联系--可以转为一个独立的关系模式,也可以与n端实体合并 m:n的联系--可以转为一个关系模式 3个或3个以上实体之间的多元化的联系--可以转为一个关系模式 相同的键的关系模式可以合并 4、关系规范化:(5个等级----5个范式-----1NF→5NF)Form ①规范化原因:消除不合适的数据依赖,即关系模式中会存在以下弊端: 数据重复(冗余) 数据不一致性 数据插入异常 数据删除异常…. ②范式规范化的判定条件: 1NF:实体中的属性不能再分解 实例: 学生1(学号,姓名,性别,出生日期,系部代码,入学时间,家庭成员)不属于1NF 更改后: 学生1(学号,姓名,性别,出生日期,系部代码,入学时间,家庭) 家庭(学号,家庭成员姓名,亲属关系) 2NF:实体中的非键属性完全依赖键属性 实例: 属于1NF,不属于2NF 分析: 系部代码----由学号决定,出生日期---由学号决定,成绩---由学号+课程号决定 更改后: 3NF:没有一个非键属性传递依赖于键(关键字→非关键字1....→非关键字n) 实例: 属于2NF 分析: 姓名,性别,出生日期,入学时间---由学号唯一决定 系部代码,系名,系宿舍楼----不是由学号唯一决定,相互递推出来不属于3NF (例如:系部代码----由学号或者系名或者系宿舍楼推出) 更改后:
数据库逻辑结构
DATABASE-->TABLESPACES-->SEGMENTS-->EXENTS-->BLOCKS Oracle的逻辑存储结构单元从小到大依次分为数据块、区、段和表空间四种 数据块:由磁盘上特定数量的字节组成,是数据库中最小的逻辑存储单元,也是最小的I/O单元 区:有两个或更多个连续的数据块组成,是数据库中最小的存储分配单元。 段:是由若干个区形成的,是相同类型数据的存储分配区域 表空间:一个或多个数据文件的集合,通常由若干个相关联的段组成,是最大的逻辑存储单元,所有的表空间构成一个数据库。 表空间 一个表空间对应一个或多个数据文件,一个数据文件只能从属于一个表空间。 表空间是存储模式对象的容器,一个数据库对象只能存储在一个表空间中(分区表和分区索引除外),但可以存储在该表空间所对应的一个或多个数据文件中。 表空间管理的意义: 使用多个表空间,可以使得在执行数据库操作时非常方便灵活,比如: 可以控制整个数据库占用空间的大小、 可以控制用户所占用的存储空间的大小 用户数据与数据字典数据分开,减少I/O冲突 一个表空间脱机时,其他表空间保持联机 TABLESPACE(表空间)分类 PERMANENT 永久表空间 UNDO 撤销表空间 TEMPORARY 临时表空间 永久性表空间是指该表空间用于存放永久性数据库对象如SYSTEM系统表空间和USERS 用户表空间。
临时性表空间是指该表空间仅用于存放临时对象,任何永久性对象都不能驻留于临时表空间中。在建立用户时,如果不指定表空间,默认的临时表空间是TEMP。在数据库实例运行过程中,执行排序、管理索引和访问视图等操作时会产生大量的临时数据,这些临时数据将保存在临时表空间中。 撤销表空间存储撤销段(回退段),由例程自动处理撤销表空间中的撤销段。这样可以减轻DBA的工作负担。撤销段主要用于显式或隐式的回退一个事务;从逻辑错误中恢复等方面 创建表空间 创建表空间可以使用OEM或利用CREATE TABLESPACE命令方式 需要注意的是,一般情况下,建立表空间是特权用户或是dba来执行的,如果用其它用户来创建表空间,则用户必须要具有create tablespace的系统权限。 OEM例:创建永久性表空间“Stu_space”,区管理方式为“本地管理”,状态为“读写”。其对应数据文件“stu01.dbf”大小为10MB,数据文件允许自动增长,增长增量大小为10MB,最大限制为100MB,其他参数采用默认值。 在建立数据库后,为便于管理表,最好建立自己的表空间 createtablespace data01 datafile 'd:\test\dada01.dbf' size 20m uniform size 128k; 说明:执行完上述命令后,会建立名称为data01 的表空间,并为该表空间建立名称为data01.dbf 的数据文件,区的大小为128k 使用数据表空间 create table mypart(deptno number(4), dname varchar2(14), loc varchar2(13)) tablespace data01; 表空间的管理方式: 重点是段的管理方式和区的管理方式是在建立表空间时确定的。 段管理方式有AUTO和MANUAL两种,区管理方式有本地管理和字典管理(已淘汰)两种。 SQL> select tablespace_name,contents ,extent_management,segment_space_management from dba_tablespaces; 建一个使用缺省值的表空间 SQL> create tablespace a datafile '/u01/oradata/timran11g/a01.dbf' size 10m; 段、区和块 段是表空间中指定类型的逻辑结构,由一个或多个区间组成。一个单独的表可以是一个段。按照段中存储数据的特征,可以将段分为4种类型:数据段、索引段、回退段和临时段。 区间是由一系列物理上连续的数据块组成的存储结构。在创建表时,Oracle将为表创建一个数据段,并为数据段分配一个初始区间。当向表中添加数据时,初始区中的块将逐渐被写满,写满后,Oracle将为数据段再分配一个新的区间。
数据库设计实例需求分析概念结构逻辑结构完整版
数据库设计实例需求分 析概念结构逻辑结构 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
数据库设计实例分析 一、需求分析实例 现要开发高校图书管理系统。经过可行性分析和初步的需求调查,确定了系统的功能边界,该系统应能完成下面的功能: (1)读者注册。 (2)读者借书。 (3)读者还书。 (4)图书查询。 1、数据流图 顶层数据流图反映了图书管理系统与外界的接口,但未表明数据的加工要求,需要进一步细化。根据前面图书管理系统功能边界的确定,再对图书管理系统顶层数据流图中的处理功能做进一步分解,可分解为读者注册、借书、还书和查询四个子功能,这样就得到了图书管理系统的第0层数据流图 从图书管理系统第0层数据流图中可以看出,在图书管理的不同业务中,借书、还书、查询这几个处理较为复杂,使用到不同的数据较多,因此有必要对其进行更深层次的分析,即构建这些处理的第1层数据流图。下面的图8-7分别给出了借书、还书、查询子功能的第1层数据流图 2、数据字典 数据项 数据项名称:借书证号 别名:卡号 含义说明:惟一标识一个借书证 类型:字符型 长度:20 …… 数据结构 (1)名称:读者类别 含义说明:定义了一个读者类别的有关信息 组成结构:类别代码+类别名称+可借阅数量+借阅天数+超期罚款额 (2)名称:读者 含义说明:定义了一个读者的有关信息 组成结构:姓名+性别+所在部门+读者类型 (3)名称:图书 含义说明:定义了一本图书的有关信息
组成结构:图书编号+图书名称+作者+出版社+价格 …… 数据流 (1)数据流名称:借书单 含义:读者借书时填写的单据 来源:读者 去向:审核借书 数据流量:250份/天 组成:借书证编号+借阅日期+图书编号 (2)数据流名称:还书单 含义:读者还书时填写的单据 来源:读者 去向:审核还书 数据流量:250份/天 组成:借书证编号+还书日期+图书编号 …… 数据存储 (1)数据存储名称:图书信息表 含义说明:存放图书有关信息 组成结构:图书+库存数量 说明:数量用来说明图书在仓库中的存放数 (2)数据存储名称:读者信息表 含义说明:存放读者的注册信息 组成结构:读者+卡号+卡状态+办卡日期 说明:卡状态是指借书证当前被锁定还是正常使用 (3)数据存储名称:借书记录 含义说明:存放读者的借书、还书信息 组成结构:卡号+书号+借书日期+还书日期 说明:要求能立即查询并修改 …… 处理过程 (1)处理过程名称:审核借书证 输入:借书证 输出:认定合格的借书证 加工逻辑:根据读者信息表和读者借书证,如果借书证在读者信息表中存在并且没有被锁定,那么借书证是有效的借书证,否则是无效的借书证。 …… 二、概念结构设计实例
数据库设计:逻辑结构设计
5.3逻辑结构设计 逻辑结构设计的任务就是把概念模型转换为某个具体的数据库管理系统所支持的数据模型。 具体来讲就是从E-R模型到关系模型的转换。 (1)根据E-R模型设计关系模式; (2)选择适当的范式对所得到的关系模式进行规范化; (3)将得到的关系模型转换为具体DBMS支持的数据模型,设计关系数据库模式。 (4)依据关系的完整性约束来设计用户视图。 1、关系模型 关系模型是指用二维表的形式表示实体和实体间联系的数据模型。关系模型中无论是实体还是实体间的联系均由单一的结构类型——关系来表示。在实际的关系数据库中的关系也称表。一个关系数据库就是由若干个表组成。 关系模型数据结构 (1)关系 一个关系也就是通常所说的一张表。 关系具有以下特征: 1.关系中不能有任意两条完全相同的记录。 2.关系中的记录是非排序的。 3.关系中记录的字段是非排序的。 4.字段名称不能相同。 5.字段不可再分。 (2)元组 每一横行称为一个元组。 (3)属性 属性:每一竖列称为一个属性,在DBMS中常被称作字段。在一个关系中,有
一个关系名,同时每个属性都有一个字段名 (4)码(键) 能唯一标识元组的属性或属性集称为码。码分为以下几种: 候选码:如果在关系的一个码中不能移去任何一个属性,否则它就不是这个关系的键,则称这个被指定的候选键为该关系的候选键或者候选码。 例如下列学生表中“学号”或“图书证号”都能唯一标识一个元组,则“学号”和“图书证号”都能唯一地标识一个元组,则“学号”和“图书证号”都可作为学生关系的候选键。 主键(主码):在一个关系的若干候选键中指定一个用来唯一标识该关系的元组,则称这个被指定的候选码称为主关键字,或简称为主键、关键字、主码。每一个关系都有并且只有一主键,通常用较小的属性组合作为主键。 外键(外码):关系中的某个属性虽然不是这个关系的主键,或者只是主键的一部分,但它却是另外一个关系的主键时,则称之为外键或者外码。 例如学生表,选定“学号”作为数据操作的依据,则“学号”为主键。而在选课表中,主键为(学号,课程号),外码为“学号”。 (5)关系模式 关系模式是对关系的描述,关系是关系模式的一个实例关系模式包括关系名、各属性名,通常简记为: R(A1,A2,…,An) 其中R为关系名,A1,A2,…,An为各属性名。 例如:学生(学号*,姓名,性别,出生日期,院系) 其中标“*”号的属性为主键 (6)关系完整性约束
数据库逻辑结构设计
数据库逻辑结构设计 该系列计划包括5部分:完整性约束理论及应用、范式理论及应用、需求分析、概念结构设计、逻辑结构设计。本文是第五部分,介绍逻辑结构设计的内容,包括E-R图向关系模型的转换、数据模型的优化、用户子模式的设计等问题。1.逻辑设计概述 概念结构是独立于任何一种数据模型的,在实际应用中,一般所用的数据库环境已经给定(如SQL Server或Oracel或MySql),本文讨论从概念结构向逻辑结构的转换问题。 由于目前使用的数据库基本上都是关系数据库,因此首先需要将E-R图转换为关系模型,然后根据具体DBMS的特点和限制转换为特定的DBMS支持下的数据模型,最后进行优化。 2.E-R图向关系模型的转换 2.1 一个例子 E-R图如何转换为关系模型呢?我们先看一个例子。 图2.1是学生和班级的E-R图,学生与班级构成多对一的联系。根据实际应用,我们可以做出这个简单例子的关系模式: 学生(学号,姓名,班级) 班级(编号,名称) “学生.班级”为外键,参照“班级.编号”取值。 这个例子我们是凭经验转换的,那么里面有什么规律呢?在2.2节,我们将这些经验总结成一些规则,以供转换使用。 2.2 转换规则 (1) 一个实体型转换为一个关系模式 一般E-R图中的一个实体转换为一个关系模式,实体的属性就是关系的属性,实体的码就是关系的码。
(2) 一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应 的关系模式合并。 图2.2是一个一对一联系的例子。根据规则(2),有三种转换方式。 联系单独作为一个关系模式 此时联系本身的属性,以及与该联系相连的实体的码均作为关系的属性,可以选择与该联系相连的任一实体的码属性作为该关系的码。结果如下: 职工(工号,姓名) 产品(产品号,产品名) 负责(工号,产品号) 其中“负责”这个关系的码可以是工号,也可以是产品号。 )与职工端合并 职工(工号,姓名,产品号) 产品(产品号,产品名) 其中“职工.产品号”为外码。 i)与产品端合并 职工(工号,姓名) 产品(产品号,产品名,负责人工号) 其中“产品.负责人工号”为外码。 (3) 一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关 系模式合并。
数据库逻辑结构设计
数据库逻辑结构设计 该系列计划包括5部分:完整性约束理论及应用、范式理论及应用、需求分析、概念结构设计、逻辑结构设计。本文就是第五部分,介绍逻辑结构设计的内容,包括E-R图向关系模型的转换、数据模型的优化、用户子模式的设计等问题。1.逻辑设计概述 概念结构就是独立于任何一种数据模型的,在实际应用中,一般所用的数据库环境已经给定(如SQL Server或Oracel或MySql),本文讨论从概念结构向逻辑结构的转换问题。 由于目前使用的数据库基本上都就是关系数据库,因此首先需要将E-R图转换为关系模型,然后根据具体DBMS的特点与限制转换为特定的DBMS支持下的数据模型,最后进行优化。 2.E-R图向关系模型的转换 2、1 一个例子 E-R图如何转换为关系模型呢?我们先瞧一个例子。 图2、1就是学生与班级的E-R图,学生与班级构成多对一的联系。根据实际应用,我们可以做出这个简单例子的关系模式: 学生(学号,姓名,班级) 班级(编号,名称) “学生、班级”为外键,参照“班级、编号”取值。 这个例子我们就是凭经验转换的,那么里面有什么规律呢?在2、2节,我们将这些经验总结成一些规则,以供转换使用。 2、2 转换规则 (1) 一个实体型转换为一个关系模式 一般E-R图中的一个实体转换为一个关系模式,实体的属性就就是关系的属性,实体的码就就是关系的码。
(2) 一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应 的关系模式合并。 图2、2就是一个一对一联系的例子。根据规则(2),有三种转换方式。 联系单独作为一个关系模式 此时联系本身的属性,以及与该联系相连的实体的码均作为关系的属性,可以选择与该联系相连的任一实体的码属性作为该关系的码。结果如下: 职工(工号,姓名) 产品(产品号,产品名) 负责(工号,产品号) 其中“负责”这个关系的码可以就是工号,也可以就是产品号。 )与职工端合并 职工(工号,姓名,产品号) 产品(产品号,产品名) 其中“职工、产品号”为外码。 i)与产品端合并 职工(工号,姓名) 产品(产品号,产品名,负责人工号) 其中“产品、负责人工号”为外码。 (3) 一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关 系模式合并。
数据库逻辑结构大全(精)
Oracle数据库逻辑结构 2.1.1Oracle系统体系结构 话说与其他数据库产品不同,Oracle有其自己独特的系统体系结构。Oracl e系统体系结构是整个Oracle服务器系统的框架,是管理和应用Oracle数据服务器的基础和核心。 Oracle系统体系结构由三部分组成:逻辑结构、物理结构和实例。其中,实例是维系物理结构和逻辑结构的核心,如图2-1和图2-2所示。图2-1表明了数据库三级模式及其物理文件之间的关系。 图2-1 数据库模式及其物理文件关系示意图 图2-2 Oracle系统体系结构与功能 不论是Oracle的应用开发还是数据库管理都是以实例作为切入点的。只不过Oracle的应用程序开发主要是以数据库的逻辑对象为主(如表、索引和视图等),而数据库管理则是针对数据库的全部内容。Oracle数据库由构成物理结构的各种文件组成,如数据文件、控制文件和重做日志文件等;实例是Oracle在内存中分配的一段区域SGA和服务器后台进程的集合。Oracle数据库服务器就是数据库和实例的组合。
2.1.2Oracle逻辑结构 Oracle的逻辑结构是一种层次结构。主要由:表空间、段、区和数据块等概念组成。逻辑结构是面向用户的,用户使用Oracle开发应用程序使用的就是逻辑结构。数据库存储层次结构及其构成关系,结构对象也从数据块到表空间形成了不同层次的粒度关系,如图2-3和图2-4所示。 图2-3 Oracle 10g数据库层次结构图图2-4 段、区和数据块之间的关系 1.数据块 Oracle数据块(Data Block)是一组连续的操作系统块。分配数据库块大小是在Oracle数据库创建时设置的,数据块是Oracle读写的基本单位。数据块的大小一般是操作系统块大小的整数倍,这样可以避免不必要的系统I/O操作。从Oracle9i开始,在同一数据库中不同表空间的数据块大小可以不同。数据块是O racle最基本的存储单位,而表空间、段、区间则是逻辑组织的构成成员。在数据库缓冲区中的每一个块都是一个数据块,一个数据块不能跨越多个文件。 数据块的结构主要包括: ·标题:包括一般的块信息,如块地址,段类型等。 ·表目录:包括有关表在该数据块中的行信息。 ·Oracle体系结构第2章 行目录:包括有关在该数据块中行地址等信息。 ·行数据:包括表或索引数据。一行可跨越多个数据块。