计量经济 异方差性的检验与修正讲解

10.12异方差性的检验与修正
⒈图形分析检验
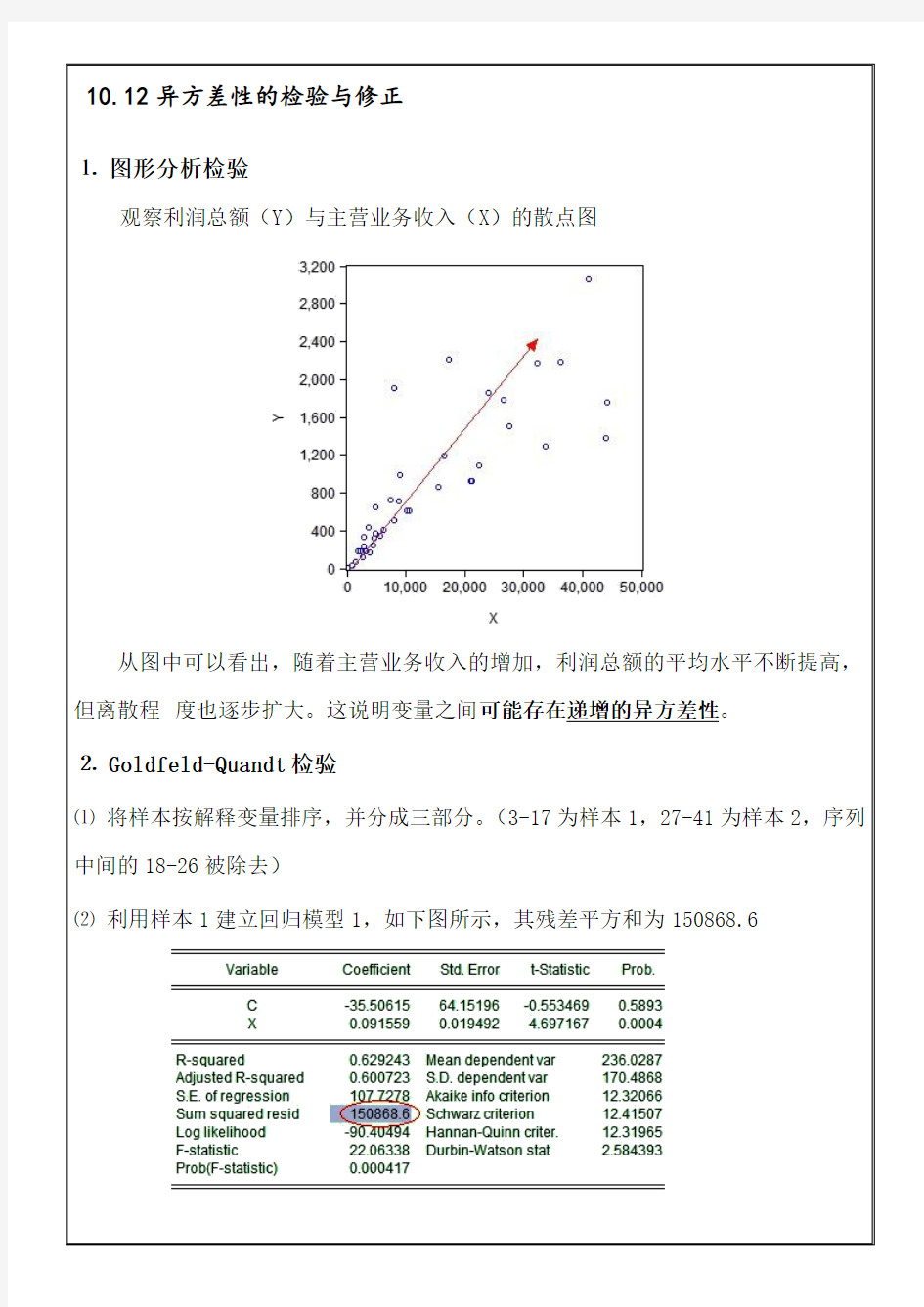
观察利润总额(Y)与主营业务收入(X)的散点图
从图中可以看出,随着主营业务收入的增加,利润总额的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。
⒉ Goldfeld-Quandt检验
⑴将样本按解释变量排序,并分成三部分。(3-17为样本1,27-41为样本2,序列中间的18-26被除去)
⑵利用样本1建立回归模型1,如下图所示,其残差平方和为150868.6
⑶ 利用样本2建立回归模型2,如图所示,其残差平方和为4030726
⑷ 在同方差性假定下,计算F 统计量:
12/RSS RSS F = = 4030726/150868.6 = 26.7168, (21RSS RSS 和分别是模型1和模型2的残差平方和)
取05.0=α时,查F 分布表得 F 0.05(15-1-1,15-1-1)=2.5769,
而 F = 26.7168 > F 0.05 = 2.5769,所以拒绝同方差性假设,表明存在异方差性。
⒊ White 检验
⑴利用序前数据建立回归模型: Y C X ,回归结果如图:
回归模型
⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图
white 检验结果
其中F 值为辅助回归模型的F 统计量值。在同方差性假定下,取显著水平05.0=α,
怀特统计量2nR =4.42908<2
0.05X (2)=5.59,不拒绝同方差性假设。 接下来就有两种可能:
1、 原模型具有同方差性
2、 由于怀特检验只能检验单调递增或单调递减型异方差,所以原模型可能是复杂型的异方差。
4.异方差的修正(WLS)
在运用 WLS 法修正过程中,我们选用了权数W=1/x。在工作文件窗口中点Quick\Estimate Equation输入 y c x,然后在图中点Options 选项,选中 Weighted LS/TLS 复选框,在 Weight 框中输入1/x,即可得到加权最小二乘法的结果。
运用加权小二乘法消除了异方差性后,可决系数大幅提高,F检验也有了显著改进(由原先的82变为137)。
演示完毕
------------------------------------------------------------------------------
计量经济学异方差的检验与修正
《计量经济学》实训报告 实训项目名称异方差模型的检验与处理 实训时间 2012-01-02 实训地点实验楼308 班级 学号 姓名
实 训 (实 践 ) 报 告 实 训 名 称 异方差模型的检验与处理 一、 实训目的 掌握异方差性的检验及处理方法。 二 、实训要求 1.求销售利润与销售收入的样本回归函数,并对模型进行经济意义检验和统计检验; 2.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 3.如果模型存在异方差,选用适当的方法对异方差进行修正,消除或减小异方差对模型的影响。 三、实训内容 建立并检验我国制造业利润函数模型,检验异方差性,并选用适当方法对其进行修正,消除或不同) 四、实训步骤 1.建立一元线性回归方程; 2.建立Workfile 和对象,录入数据; 3.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 4.对所估计的模型再进行White 检验,观察异方差的调整情况,从而消除或减小异方差对模型的影响。 五、实训分析、总结 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料。假设销售利润与销售收入之间满足线性约束,则理论模型设定为: 12i i i Y X u ββ=++ 其中i Y 表示销售利润,i X 表示销售收入。
表1 我国制造工业1998年销售利润与销售收入情况 行业名称销售利润Y 销售收入X 行业名称销售利润销售收入 食品加工业187.25 3180.44 医药制造业238.71 1264.1 食品制造业111.42 1119.88 化学纤维制品81.57 779.46 饮料制造业205.42 1489.89 橡胶制品业77.84 692.08 烟草加工业183.87 1328.59 塑料制品业144.34 1345 纺织业316.79 3862.9 非金属矿制品339.26 2866.14 服装制品业157.7 1779.1 黑色金属冶炼367.47 3868.28 皮革羽绒制品81.7 1081.77 有色金属冶炼144.29 1535.16 木材加工业35.67 443.74 金属制品业201.42 1948.12 家具制造业31.06 226.78 普通机械制造354.69 2351.68 造纸及纸品业134.4 1124.94 专用设备制造238.16 1714.73 印刷业90.12 499.83 交通运输设备511.94 4011.53 文教体育用品54.4 504.44 电子机械制造409.83 3286.15 石油加工业194.45 2363.8 电子通讯设备508.15 4499.19 化学原料纸品502.61 4195.22 仪器仪表设备72.46 663.68 1.建立Workfile和对象,录入销售收入X和销售利润Y: 图1 销售收入X和销售利润Y的录入 2.图形法检验 ⑴观察销售利润Y与销售收入X的相关图:在群对象窗口工具栏中点击
计量经济学课后习题
计量经济学课后习题 1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。 计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 5.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 4.如何缩小置信区间?(P46) 由上式可以看出(1).增大样本容量。样本容量变大,可使样本参数估计量的标准差减小;同时,在同样置信水平下,n越大,t分布表中的临界值越小。(2)提高模型的拟合优度。因为样本参数估计量的标准差和残差平方和呈正比,模型的拟合优度越高,残差平方和应越小。 1.为什么计量经济学模型的理论方程中必须包含随机干扰项? (经典模型中产生随机误差的原因) 答:计量经济学模型考察的是具有因果关系的随机变量间的具体联系方式。由于是随机变量,意味着影响被解释变量的因素是复杂的,除了解释变量的影响外,还有其他无法在模型中独立列出的各种因素的影响。这样,理论模型中就必须使用一个称为随机干扰项的变量宋代表所有这些无法在模型中独立表示出来的影响因素,以保证模型在理论上的科学性。 3.一元线性回归模型的基本假设主要有哪些? 违背基本假设的模型是否不可以估计? 答:线性回归模型的基本假设有两大类:一类是关于随机干扰项的,包括零均值,同方差,不序列相关,满足正态分布等假设;另一类是关于解释变量的,主要有:解释变量是非随机的,若是
计量经济学-李子奈-计算题整理集合
计算分析题(共3小题,每题15分,共计45分) 1、下表给出了一含有3个实解释变量的模型的回归结果: 方差来源 平方和(SS ) 自由度(d.f.) 来自回归65965 — 来自残差— — 总离差(TSS) 66056 43 (1)求样本容量n 、RSS 、ESS 的自由度、RSS 的自由度 (2)求可决系数)37.0(-和调整的可决系数2 R (3)在5%的显著性水平下检验1X 、2X 和3X 总体上对Y 的影响的显著性 (已知0.05(3,40) 2.84F =) (4)根据以上信息能否确定1X 、2X 和3X 各自对Y 的贡献?为什么? 1、 (1)样本容量n=43+1=44 (1分) RSS=TSS-ESS=66056-65965=91 (1分) ESS 的自由度为: 3 (1分) RSS 的自由度为: d.f.=44-3-1=40 (1分) (2)R 2=ESS/TSS=65965/66056=0.9986 (1分) 2R =1-(1- R 2)(n-1)/(n-k-1)=1-0.0014?43/40=0.9985 (2分) (3)H 0:1230βββ=== (1分) F=/65965/39665.2/(1)91/40 ESS k RSS n k ==-- (2分) F >0.05(3,40) 2.84F = 拒绝原假设 (2分) 所以,1X 、2X 和3X 总体上对Y 的影响显著 (1分) (4)不能。 (1分) 因为仅通过上述信息,可初步判断X 1,X 2,X 3联合起来 对Y 有线性影响,三者的变化解释了Y 变化的约99.9%。但由于 无法知道回归X 1,X 2,X 3前参数的具体估计值,因此还无法 判断它们各自对Y 的影响有多大。 2、以某地区22年的年度数据估计了如下工业就业模型 i i i i i X X X Y μββββ++++=3322110ln ln ln 回归方程如下: i i i i X X X Y 321ln 62.0ln 25.0ln 51.089.3?+-+-= (-0.56)(2.3) (-1.7) (5.8) 2 0.996R = 147.3=DW 式中,Y 为总就业量;X 1为总收入;X 2为平均月工资率;X 3为地方政府的
计量经济学练习题及参考全部解答
第三章练习题及参考解答 为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y ,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下: i i i X X Y 215452.11179.00263.151?++-= t= R 2= 92964.02=R F= n=31 1)从经济意义上考察估计模型的合理性。 2)在5%显着性水平上,分别检验参数21,ββ的显着性。 3)在5%显着性水平上,检验模型的整体显着性。 练习题参考解答: (1)由模型估计结果可看出:从经济意义上说明,旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。平均说来,旅行社职工人数增加1人,旅游外汇收入将增加百万美元;国际旅游人数增加1万人次,旅游外汇收入增加百万美元。这与经济理论及经验符合,是合理的。 (2)取05.0=α,查表得048.2)331(025.0=-t 因为3个参数t 统计量的绝对值均大于048.2)331(025.0=-t ,说明经t 检验3个参数均显着不为0,即旅行社职工人数和国际旅游人数分别对旅游外汇收入都有显着影响。 (3)取05.0=α,查表得34.3)28,2(05.0=F ,由于34.3)28,2(1894.19905.0=>=F F ,说明旅行社职工人数和国际旅游人数联合起来对旅游外汇收入有显着影响,线性回归方程显着成立。 表给出了有两个解释变量2X 和.3X 的回归模型方差分析的部分结果:
表 方差分析表 1)回归模型估计结果的样本容量n 、残差平方和RSS 、回归平方和ESS 与残差平方和RSS 的自由度各为多少 2)此模型的可决系数和调整的可决系数为多少 3)利用此结果能对模型的检验得出什么结论能否确定两个解释变量2X 和.3X 各自对Y 都有显着影响 练习题参考解答: (1) 因为总变差的自由度为14=n-1,所以样本容量:n=14+1=15 因为 TSS=RSS+ESS 残差平方和RSS=TSS-ESS=66042-65965=77 回归平方和的自由度为:k-1=3-1=2 残差平方和RSS 的自由度为:n-k=15-3=12 (2)可决系数为:265965 0.99883466042 ES R TSS S = == 修正的可决系数:2 2 2 115177 110.998615366042 i i e n R n k y --=-=-?=--∑∑ (3)这说明两个解释变量 2X 和.3X 联合起来对被解释变量有很显着的影响,但是还不 能确定两个解释变量2X 和.3X 各自对Y 都有显着影响。 经研究发现,家庭书刊消费受家庭收入及户主受教育年数的影响,表中为对某地区部分家庭抽样调查得到样本数据: 表 家庭书刊消费、家庭收入及户主受教育年数数据
试验一异方差的检验与修正-时间序列分析
案例三 ARIMA 模型的建立 一、实验目的 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容及要求 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2007年中国进出口贸易总额数据运用经典B-J 方法论建立合适的ARIMA (,,p d q )模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验指导 1、模型识别 (1)数据录入 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated –regular frequency ”,在“Date specification ”栏中分别选择“Annual ”(年数据) ,分别在起始年输入1950,终止年输入2007,点击ok ,见图3-1,这样就建立了一个工作文件。点击File/Import ,找到相应的Excel 数据集,导入即可。
所有计量经济学检验方法(全)
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R - ==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数)1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方 和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 )1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临 界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t 检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0 给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 统计量 )1(~1??? ----'--= k n t k n c S t ii i i i i i e e βββββ 在(1-α)的置信水平下βi 的置信区间是 ( , ) ββααββ i i t s t s i i -?+?2 2 ,其中,t α/2为显著性 水平为α、自由度为n-k-1的临界值。 五、异方差检验 1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程: i ji i X f e ε+=)(~2 或 i ji i X f e ε+=)(|~|
计量经济学
名词解释 1、 因果效应:在理想化随机对照实验中得到的,某一给定的行为或处理对结果的影响 2、 实验数据:来源于为评价某种处理(某项政策)抑或某种因果效应而设计的实验 3、 观测数据:通过观察实验之外的实际行为而获得的数据 4、 截面数据:对不同个体如工人、消费者、公司或政府机关等在某一特定时间段内收集到的数据 5、 时间序列数据:对同一个体(个人、公司、国家等)在多个时期内收集到的数据 6、 面板数据:即纵向数据,是多个个体分别在两个或多个时期内观测到的数据 7、 离散型随机变量:一些随机变量是离散的 连续型随机变量:一些随机变量是连续的 8、 期望值:随机变量经过多次重复实验出现的长期平均值,记作E (Y ) 9、 期望:Y 的长期平均值,记作μY 10、方差:是Y 距离其均值的偏差平方的期望值,记作var (Y ) 11、标准差:方差的平方根来表示偏差程度,记作σY 12、独立性:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息 13、标准正态分布:指那些均值102==σμ、方差的正态分布,记作N (0,1) 14、简单随机抽样:n 个对象从总体中抽取,且总体中的每一个个体都有相等的可能性被选入样本 15、独立分布:两个随机变量X 和Y 中的一个变量无法提供另一个变量的相关信息,那么这两个变量X 和Y 独立分布 16、偏差:设Y Y E Y Y μμμμ-??)(为的一个估计量,则偏差是; 一致性:当样本容量增大时,Y μ ?落入真实值Y μ的微小领域区间内的概率接近于1,即Y Y μμ与?是一致的 有效性:如果Y μ ?的方差比Y μ~更小,那么可以说Y Y μμ~?比更有效 17、最小二乘估计量:21)(m i n i -Y ∑ =最小化误差m -i Y 平方和的估计量m 18、P 值:即显著性概率,指原假设为真的情况下,抽取到的统计量与原假设之间的差异程度至少等于样本计算值与 原假设之间差异程度的概率 19、第一类错误:拒绝了实际上为真的原假设 20、一元线性回归模型:i i 10i μββ+X +=Y ;1β代表1X 变化一个单位所导致Y 的变化量 21、普通最小二乘(OLS )估:选择使得估计的回归线与观测数据尽可能接近的回归系数,其中近似程度用给定X 时预 测Y 的误差的平方和来度量 22、回归2R :可以由i X 解释(或预测)的i Y 样本方差的比例,即TSS SSR TSS ESS R -==12 23、最小二乘假设:①给定i X 时误差项i μ的条件均值为零:0)(i i =X μE ; ②从联合总体中抽取的, ,,,),,(n ...21i i i =Y X 满足独立同分布; ③大异常值不存在:即i i Y X 和具有非零有限的四阶距 24、1β置信区间:以95%的概率包含1β真值的区间,即在所有可能随机抽取的样本中有95%包含了1β的真值 25、同方差:若对于任意i=1,2,...,n ,给定) (条件分布的方差时χμμ=X X i i i i var 为常数且不依赖于χ,则 称误差项i μ是同方差
计量经济学分析计算题Word版
计量经济学分析计算题(每小题10分) 1.下表为日本的汇率与汽车出口数量数据, X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3= ,Y 554.2=,2 X X 4432.1∑ (-)=,2 Y Y 68113.6∑(-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义 是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。
问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2 Y Y 68113.6∑ (-)=, 求判定系数和相关系数。 5.有如下表数据 日本物价上涨率与失业率的关系 (1)设横轴是U ,纵轴是P ,画出散点图。根据图形判断,物价上涨率与失业率之间是什么样的关系?拟合什么样的模型比较合适? (2)根据以上数据,分别拟合了以下两个模型: 模型一:1 6.3219.14 P U =-+ 模型二:8.64 2.87P U =- 分别求两个模型的样本决定系数。 7.根据容量n=30的样本观测值数据计算得到下列数据:XY 146.5= ,X 12.6=,Y 11.3=,2X 164.2=,2Y =134.6,试估计Y 对X 的回归直线。 8.下表中的数据是从某个行业5个不同的工厂收集的,请回答以下问题:
计量经济学检验汇总
最全计量经济学检验汇总 现代计量经济学的检验包括以下三个大类: §1.1 系数检验 一、Wald 检验——系数约束条件检验 Wald 检验没有把原假设定义的系数限制加入回归,通过估计这一无限制回归来计算检验统计量。Wald 统计量计算无约束估计量如何满足原假设下的约束。如果约束为真,无约束估计量应接近于满足约束条件。 考虑一个线性回归模型:εβ+=X y 和一个线性约束:0:0=-r R H β,R 是一个已知的k q ?阶矩阵,r 是q 维向量。Wald 统计量在0H 下服从渐近分布)(2q χ,可简写为: )())(()(112r Rb R X X R s r Rb W -'''-=-- 进一步假设误差ε独立同时服从正态分布,我们就有一确定的、有限的样本F-统计量 q W k T u u q u u u u F /) /(/)~~(=-''-'= u ~是约束回归的残差向量。F 统计量比较有约束和没有约束计算出的残差平方和。如果约束有效,这两个残差平方和差异很小,F 统计量值也应很小。EViews 显示2χ和F 统计量以及相应的p 值。 假设Cobb-Douglas 生产函数估计形式如下: εβα+++=K L A Q log log log (1) Q 为产出增加量,K 为资本投入,L 为劳动力投入。系数假设检验时,加入约束1=+βα。 为进行Wald 检验,选择View/Coefficient Tests/Wald-Coefficient Restrictions ,在编辑对话框中输入约束条件,多个系数约束条件用逗号隔开。约束条件应表示为含有估计参数和常数(不可以含有序列名)的方程,系数应表示为c(1),c(2)等等,除非在估计中已使用过一个不同的系数向量。 为检验规模报酬不变1=+βα的假设,在对话框中输入下列约束:c(2)+c(3)=1 二、遗漏变量检验 这一检验能给现有方程添加变量,而且询问添加的变量对解释因变量变动是否有显著作用。原假设 0H 是添加变量不显著。 选择View/Coefficient Tests/Omitted Variables —Likehood Ration ,在打开的对话框中,列出检验统计量名,用至少一个空格相互隔开。例如:原始回归为 LS log(q) c log(L) log(k) ,输入:K L ,EViews 将显示含有这两个附加解释变量的无约束回归结果,而且显示假定新变量系数为0的检验统计量。 三、冗余变量 冗余变量检验可以检验方程中一部分变量的统计显著性。更正式,可以确定方程中一部分变量系数是否为0,从而可以从方程中剔出去。只有以列出回归因子形式,而不是公式定义方程,检验才可以进行。 选择View/Coefficient Tests/Redundant Variable —likelihood Ratio ,在对话框中,输入每一检验的变量名,相互间至少用一空格隔开。例如:原始回归为: Ls log(Q) c log(L) log(K) K L ,如果输入K L ,EViews 显示去掉这两个回归因子的约束回归结果,以及检验原假设(这两个变量系数为0)的统计量。 §1.2 残差检验 一、相关图和Q —统计量 在方程对象菜单中,选择View/Residual Tests/Correlogram-Q-Statistics ,将显示直到定义滞后阶数的残差自相关性和偏自相关图和Q-统计量。在滞后定义对话框中,定义计算相关图时所使用的滞后数。如果残差不存在序列相关,在各阶滞后的自相关和偏自相关值都接近于零。所有的Q -统计量不显著,并且有大
异方差的检验与修正
财经学院 本科实验报告 学院(部)统计学院 实验室313 课程名称计量经济学 学生姓名 学号1204100213 专业统计学 教务处制 2014年12 月15 日
《异方差》实验报告
五、实验过程原始记录(数据、图表、计算等) 一.选择数据 1.建立工作文件并录入数据File\New\workfile, 弹出Workfile create 对话框中选择数据类型。Object\new object\group,按向上的方向键,出现两个obs 后输入数据. 中国地2006年各地区农村居民家庭人均纯收入与消费支出 单位:元 城市 y x1 x2 城市 y x1 x2 5724.5 958.3 7317.2 2732.5 1934.6 1484.8 3341.1 1738.9 4489 3013.3 1342.6 2047 2495.3 1607.1 2194.7 3886 1313.9 3765.9 2253.3 1188.2 1992.7 广西 2413.9 1596.9 1173.6 2772 2560.8 781.1 2232.2 2213.2 1042.3 3066.9 2026.1 2064.3 2205.2 1234.1 1639.7 2700.7 2623.2 1017.9 2395 1405 1597.4 2618.2 2622.9 929.5 1627.1 961.4 1023.2 8006 532 8606.7 2195.6 1570.3 680.2 4135.2 1497.9 4315.3 2002.2 1399.1 1035.9 6057.2 1403.1 5931.7 2181 1070.4 1189.8 2420.9 1472.8 1496.3 1855.5 1167.9 966.2 3591.4 1691.4 3143.4 2179 1274.3 1084.1 2676.6 1609.2 1850.3 2247 1535.7 1224.4 3143.8 1948.2 2420.1 2032.4 2267.4 469.9 2229.3 1844.6 1416.4 二.对数据进行参数估计,得出多元线性回归模型 1.模型设定为εβββ+++=23121i i i X X Y Yi ----人均消费支出 X1--从事农业经营的纯收入 X2--其他来源的纯收入 2.点Quick\estimate equation,在弹出的对话框中输入”Y C X ”,结果如下:
计量经济学名词解释
1、计量经济学 计量经济学是一门从数量上研究物质资料的生产、交换、分配、消费等经济关系和经济活动规律及其应用的科学。 2、数据质量 数据满足明确或隐含需求程度的指标 3、相关分析 主要研究变量之间的相互关联程度,用相关系数表示。包括简单相关和多重相关(复相关)。 4、回归分析(Regression Analysis) 研究一个变量(因变量)对于一个或多个其他变量(解释变量)的数量依存关系。其目的在于根据已知的解释变量的数值来估计或预测因变量的总体平均值。 5.内生变量 指由模型系统内决定的变量,取值在系统内决定 6、面板数据 时间序列数据和截面数据的混合 7.异方差: 总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差。如果这一假定不满足,则称线性回归模型存在异方差性。 8.自相关 自相关是在时间序列资料中按时间顺序排列的观测值之间的相关或在横截面资料中按空间顺序排列的观测值之间的相关 9.多重共线性 解释变量之间存在完全的线性关系或近似的线性关系。解释变量存在完全的线性关系叫完全多重共线;解释变量之间存在近似的线性关系叫不完全多重共线。 10.虚拟变量 虚拟变量:在建立模型时,有一些影响经济变量的因素无法定量描述 构造只取“0”或“1”的人工变量,通常称为虚拟变量,记为D 11.平稳序列 是指时间序列的统计规律不会随着时间的推移而发生变化。
12.伪回归 所谓“伪回归”,是指变量间本来不存在相依关系,但回归结果却得出存在相依关系的错误结论。 13.协整 所谓协整,是指多个非平稳变量的某种线性组合是平稳的 14.前定变量 所有的外生变量和滞后的内生变量。前定变量=外生变量+滞后内生变量+滞后外生变量 15.恰好识别 恰好识别:能够唯一地估计出结构参数值。 16.结构式模型 体现经济理论中经济变量之间的关系结构的联立方程模型,称为结构式模型17.过度识别 过度识别:结构参数的估计值具有多个确定值 18.自回归模型 自回归模型:指模型中的解释变量仅是X 的当期值与被解释变量Y 的若干期滞后值,它由于被解释变量的滞后期值对被解释变量现期做了回归,故叫做自回归模型。 利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型。 19.拟合优度2R:拟合优度检验:指检验模型对样本观测值的拟合程度 20.修正的拟合优度2R 二、.
实验异方差地检验与修正
实验异方差的检验与修正 实验目的 1、理解异方差的含义后果、 2、学会异方差的检验与加权最小二乘法 实验容 一、准备工作。建立工作文件,并输入数据,用普通最小二乘法估计方程(操作 步骤与方法同前),得到残差序列。 表2列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。 表2 我国制造工业1998年销售利润与销售收入情况 二、异方差的检验 1、图形分析检验 ⑴观察销售利润(Y)与销售收入(X)的相关图(图3-1):SCAT X Y
图3-1 我国制造工业销售利润与销售收入相关图 从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 ⑵残差分析 首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。 图3-2 我国制造业销售利润回归模型残差分布 图3-2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。 2、Goldfeld-Quant检验 ⑴将样本安解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本) ⑵利用样本1建立回归模型1(回归结果如图3-3),其残差平方和为2579.587。 SMPL 1 10 LS Y C X
图3-3 样本1回归结果 ⑶利用样本2建立回归模型2(回归结果如图3-4),其残差平方和为63769.67。 SMPL 19 28 LS Y C X 图3-4 样本2回归结果 ⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。 取05.0=α时,查F 分布表得44.3)1110,1110(05.0=----F ,而 44.372.2405.0=>=F F ,所以存在异方差性 3、White 检验 ⑴建立回归模型:LS Y C X ,回归结果如图3-5。
计量经济学计算题解法汇总
计量经济学:部分计算题解法汇总 1、求判别系数——R^2 已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2Y Y 68113.6∑(-)=, 2、置信区间 有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y Adjusted R-squared F-statistic Durbin-Watson (1(2)在95%的置信度下检验参数的显著性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在90%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其中29.3x =,2()992.1x x - =∑) 答:(1)回归模型的R 2 =,表明在消费Y 的总变差中,由回归直线解释的部分占到90%以上,回归直线的代表性及解释能力较好。(2分) 家庭收入对消费有显著影响。(2分)对于截距项,
检验。(2分) (3)Y f =+×45=(2分) 90%置信区间为(,+),即(,)。(2分) 注意:a 水平下的t 统计量的的重要性水平,由于是双边检验,应当减半 3、求SSE 、SST 、R^2等 已知相关系数r =,估计标准误差?8σ=,样本容量n=62。 求:(1)剩余变差;(2)决定系数;(3)总变差。 (2)2220.60.36R r ===(2分) 4、联系相关系数与方差(标准差),注意是n-1 在相关和回归分析中,已知下列资料: 222X Y i 1610n=20r=0.9(Y -Y)=2000σσ∑=,=,,,。 (1)计算Y 对X 的回归直线的斜率系数。(2)计算回归变差和剩余变差。(3) (2)R 2=r 2==, 总变差:TSS =RSS/(1-R 2)=2000/=(2分)
所有计量经济学检验方法(全)
所有计量经济学检验方法(全)
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R -== 12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数 ) 1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差 平方和的自由度,n-1为总体平方和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设: H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 ) 1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F
分布,给定显著性水平α,可得到临界值F α(k,n-k-1),由样本求出统计量F的数值,通过 F>F α(k,n-k-1)或F≤F α (k,n-k-1)来拒绝或接受 原假设H ,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:β i =0 (i=1,2…k); H1:β i ≠0 给定显著性水平α,可得到临界值t α/2 (n-k-1),由样本求出统计量t的数值,通过 |t|> t α/2(n-k-1) 或|t|≤t α /2 (n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。
异方差性的检验和补救
异方差性的检验和补救 一、研究目的和要求 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型,检验其是否存在异方差,并加以补救。 表1 我国制造工业1998年销售利润与销售收入情况 二、参数估计 EVIEWS 软件估计参数结果如下
Dependent Variable: Y Method: Least Squares Date: 06/01/16 Time: 20:16 Sample: 1 28 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 12.03349 19.51809 0.616530 0.5429 X 0.104394 0.008442 12.36658 0.0000 R-squared 0.854694 Mean dependent var 213.4639 Adjusted R-squared 0.849105 S.D. dependent var 146.4905 S.E. of regression 56.90455 Akaike info criterion 10.98938 Sum squared resid 84191.34 Schwarz criterion 11.08453 Log likelihood -151.8513 Hannan-Quinn criter. 11.01847 F-statistic 152.9322 Durbin-Watson stat 1.212781 Prob(F-statistic) 0.000000 用规范的形式将参数估计和检验结果写下 2?12.033490.104394(19.51809)(0.008442) =(0.616530) (12.36658)0.854694152.9322 i Y X t R F =+ = = 三、 检验模型的异方差 (一) 图形法 1. 相关关系图 X Y X Y 相关关系图
计量经济学计算题
1、某农产品试验产量Y (公斤/亩)和施肥量X (公斤/亩)7块地的数据资料汇总如下: ∑=255i X ∑=3050i Y ∑=71.12172i x ∑=429.83712i y ∑=857.3122i i y x 后来发现遗漏的第八块地的数据:208=X ,4008=Y 。 要求汇总全部8块地数据后进行以下各项计算,并对计算结果的经济意义和统计意义做简要的解释。 (1)该农产品试验产量对施肥量X (公斤/亩)回归模型Y a bX u =++进行估计; (2)对回归系数(斜率)进行统计假设检验,信度为; (3)估计可决系数并进行统计假设检验,信度为。 解:首先汇总全部8块地数据: 871 81 X X X i i i i +=∑∑== =255+20 =275 n X X i i ∑==8 1 )8(375.348 275 == 2) 7(7 127 127X x X i i i i +=∑∑== =+7?2 7255?? ? ??=10507 287 1 28 1 2X X X i i i i +=∑∑== =10507+202 = 10907 2) 8(8 1 28 1 28X X x i i i i +=∑∑== = 10907-8?2 8275?? ? ??= 87 1 81 Y Y Y i i i i +=∑∑===3050+400=3450 25.4318 3450 8 1 )8(== =∑=n Y Y i i 2) 7(7 1 2 712 7Y y Y i i i i +=∑∑== =+7?2 73050??? ??=1337300 287 1 2 81 2Y Y Y i i i i +=∑∑== =1337300+4002 = 1497300 2)8(8 1 28128Y Y y i i i i +=∑∑== =1497300 -8?( 8 3450)2 == ) 7()7(7 1 7 17Y X y x Y X i i i i i i +=∑∑== ==+7??? ??7255??? ? ??73050 =114230 887 1 81 Y X Y X Y X i i i i i i +=∑∑== =114230+20?400 =122230
计量经济学计算题
计量经济学计算题例题 0626 一元线性回归模型相关例题 1.假定在家计调查中得出一个关于 家庭年收入X 和每年生活必须品综合支出 Y 的横截面样 根据表中数据: (1) 用普通最小二乘法估计线性模型 Y t 0 1 X t u t (2) 用G — Q 检验法进行异方差性检验 (3) 用加权最小二乘法对模型加以改进 答案:(1)丫=+( 2)存在异方差(3)丫=+ 2 ?已知某公司的广告费用 X 与销售额(Y )的统计数据如下表所示: (1) 估计销售额关于广告费用的一元线性回归模型 (2) 说明参数的经济意义 (3) 在 0.05的显著水平下对参数的显著性进行 t 检验 答案: (1) 一元线性回归模型 Y t 319.086 4 185X i (2) 参数经济意义:当广告费用每增加 1万元,销售额平均增加万元
(3)t=> t o.025(10),广告费对销售额有显著影响
3. : 根据表中数据: (1) 求Y 对X 的线性回归方程; (2) 用t 检验法对回归系数进行显著性检验(a =) ; (3) 求样本相关系数r; 答案:Y =+ 用t 检验法对回归系数进行显著性检验(a =); 答案:显著 2 2 假设y 对x 的回归模型为% b o biX u ,,且Var (uJ x ,,试用适当的 方法估计此回归模型。 2 2 解:原模型: y b 0 b 1x 1 U i , Var (u ,) 为模型存在异方差性 为消除异方差性,模型两边同除以 X ,, 得: bo — a u._ (2分) X , X x , * y , * 1 u , 令: y ,x , ■,v , x x X , 得: * y , * b box ' (2分)
计量经济学计算题汇总
计量经济学计算题汇总
————————————————————————————————作者:————————————————————————————————日期:
计量经济学计算题总结1、表中所列数据是关于某种商品的市场供给量Y和价格水平X的观察值: ①用OLS法拟合回归直线; ②计算拟合优度R2; ③确定β1是否与零有区别。 2、求下列模型的参数估计量,
3、设某商品需求函数的估计结果为(n=18) : 解:(1)4
5、 模型式下括号中的数字为相应回归系数估计量的标准误。又由t分布表和F分布表得知:t0.025(5)=2.57,t0.025(6)=2.45;F0.05(3,6)=4.76,F0.05(4,5)=5.19, 试根据上述资料,对所给出的两个模型进行检验,并选择出一个合适的模型。
解: (1)总离差平方和的自由度为n-1,所以样本容量为 35。 (2) (3) 7.某商品的需求函数为 其中,Y 为需求量,X1为消费者收入,X2为该商品价格。 (1)解释参数的经济意义。 (2)若价格上涨10%将导致需求如何变化? (3)在价格上涨10%情况下,收入增加多少才能保持需求不变。 (4)解释模型中各个统计量的含义。 2 20.61143841 26783/(1) 10.587/(1) ESS R TSS RSS n k R TSS n ===--=-=-ESS/k 解:(1)由样本方程的形式可知,X1的参数为此商品的收 入弹性,表示X2的参数为此商品的价格弹性。 (2)由弹性的定义知,如果其它条件不变,价格上涨10%,那么对此商品的需求量将下降1.8%。 8、 现有X 和Y 的样本观察值如下表: X 2 5 10 4 10 Y 4 7 4 5 9 假设Y 对X 的回归模型为: 试用适当的方法估计此回归模型。