spss考试试卷参考答案及评分标准格式-精选.pdf

spss统计分析期末考试题
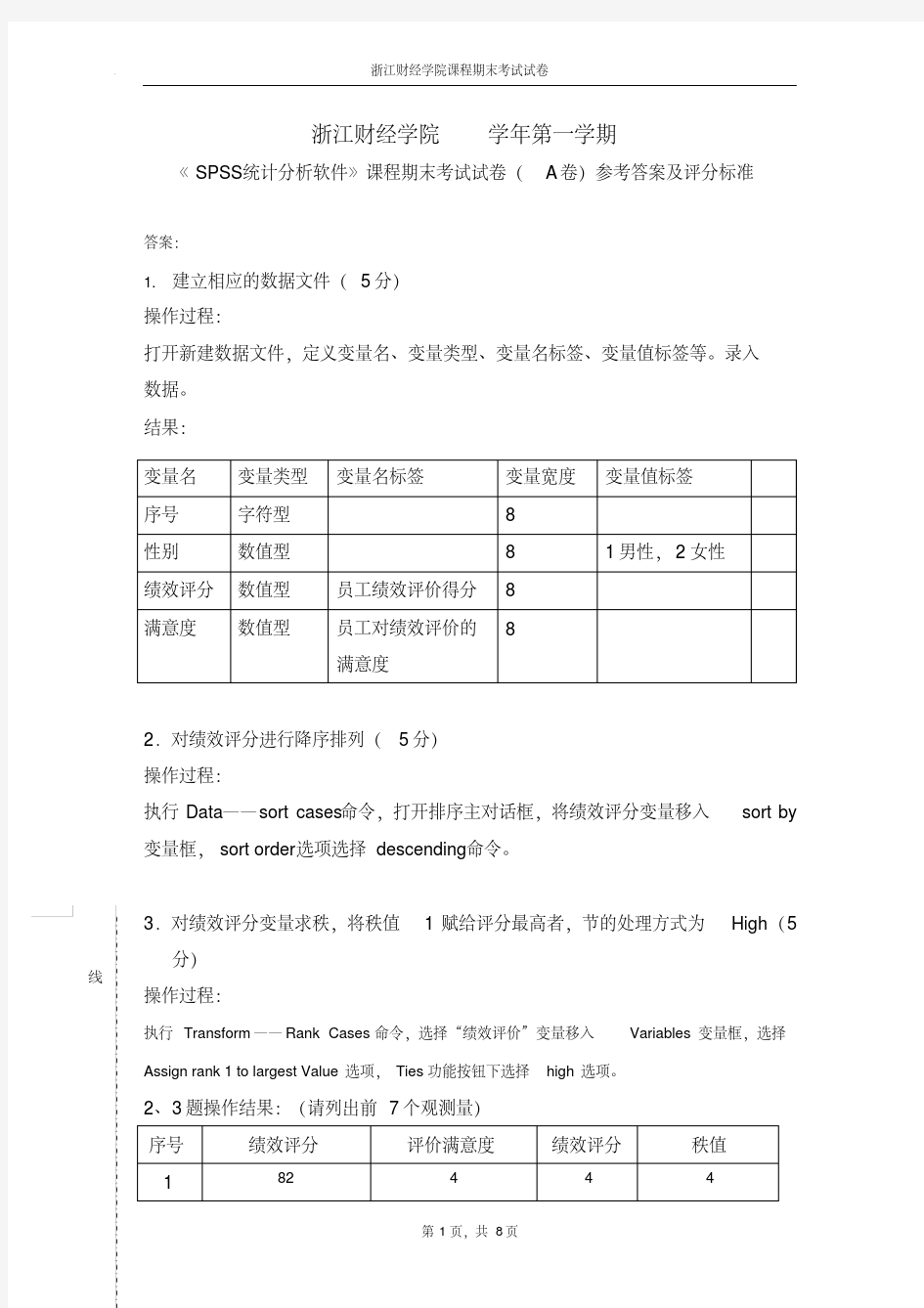
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
spss 期末题库
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
如何用spss做相关性分析
如何用spss做相关性分析 ? ?|DBQG4NOBE8KM2CR6GZWM83US94ILCFVVBJR9HEPF8WU7ONR4JD5KZ98GXIE5OPT7YGN BN6RT2X2NUI2MCI2E5JPUEYSB ?浏览:20013 ?| ?更新:2014-06-14 10:19 简介 相关性是指两个变量之间的变化趋势的一致性,如果两个变量变化趋势一致,那么就可以认为这两个变量之间存在着一定的关系(但必须是有实际经济意义的两个变量才能说有一定的关系)。相关性分析也是常用的统计方法,用SPSS统计软件操作起来也很简单,具体方法步骤如下。 方法步骤 1.选取在理论上有一定关系的两个变量,如用X,Y表示,数据输入到SPSS中。
2.从总体上来看,X和Y的趋势有一定的一致性。 3.为了解决相似性强弱用SPSS进行分析,从分析-相关-双变量。 4.打开双变量相关对话框,将X和Y选中导入到变量窗口。
5.然后相关系数选择Pearson相关系数,也可以选择其他两个,这个只是统计方法稍 有差异,一般不影响结论。
6.点击确定在结果输出窗口显示相关性分析结果,可以看到X和Y的相关性系数为 0.766,对应的显著性为0.076,如果设置的显著性水平位0.05,则未通过显著性检 验,即认为虽然两个变量总体趋势有一致性,但并不显著。
相关分析研究的是两个变量的相关性,但你研究的两个变量必须是有关联的,如果你把历年人口总量和你历年的身高做相关性分析,分析结果会呈现显著地相关,但它没有实际的意义,因为人口总量和你的身高都是逐步增加的,从数据上来说是有一致性,但他们没有现实意义。
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级XXX 班姓名XXX 学号XXX ____________ 1. 2. 考试时间为100分钟; 3. 每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav ;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav ”与“学生成绩二.sav ”合并,并保存为“成绩.sav. ” (2)对所建立的数据文件“成绩.sav ”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X > 85),良(75 < X < 84),中(X < 74),并对优良中的人数进行统计
分析: (2) 描述统计量
性别:rj sxcj 11391.0090.0061.00242.0D 1.00 r 214女91.0090.0061 Q0242,00 1.D0 31女95.0079.0065.00239.03200匸4Q女95.0079.0065 00239.00 2.D0 53立92.00B4.0062.00230.00200 S 4 女92.0084.0062 00238.00 2.00 79女眨00S2.0062.00236.00200 310女92.0002.0062 0023G.OO 2 DO 95男39.00S5.0D69 00233.03 1.00 10E男39.0085.0059 00233.00 1.00 1111立9U.OO SO.OO60.00230.0J200「1212女90.0080.0060 00230.00 2.00 1319立眨0075.0062.00229.03200 20女92.0076.00G2 00229.00 2 DO 1 1516男SB.00B2.0053.00220.03200 15男38.0077.0068 00223.00200 1 1717女91.0071.00 61 00223.00 3.00 女91.0071.0061 00223.03 3.00 1016 1 19 1女89.0067.0059 00215.00 3.00 202女39.0067.0069 00215.0J 3. DO 注:成绩优良表示栏位sxcj 优为1良为2中为3 由表统计得,成绩为优的同学有4人,占总人数的20%良的同学有12人,占总人数的60%中的同学有4人,占总人数的40% 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进 行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调 查.exe ”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查.Sav ”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
SPSS期末重点整理
t检验:一般是用于检验两组观测值的均值之间差异是否显著的统计分析方法。 单样本t检验:用于检验样本均值与总体均值或某个已知值之间的差异的显著性。如果总体均值已知,那么样本均值与总体均值之间的差异显著性检验就属于单样本的t检验。 独立样本t检验:独立样本指的是样本之间彼此独立,没有任何关联。两个独立样本的t检验用于检验两个不相关样本在相同变量上的观测值均值之间差异的显著性。要求①正态性,各个样本均来自于正态分布的总体;②方差齐性,各个样本所在的总体的方差相等;③独立性,两组数据之间是相互独立的,不能够相互影响。 配对样本t检验:配对样本(或相关样本)指两个样本的数据之间彼此有关联。配对样本t 检验用于检验两个相关样本的均值或一个样本,两次测量结果的均值之间差异的显著性。 方差分析:是一种通过分析样本数据的各项变异来源,以检验三个或三个以上样本平均 数是否具有显著性差异的一种统计方法。 单因素方差分析:用于检验一个因素变量的不同水平是否给一个(或几个相互独立的)因变量造成了显著的差异或变化。 多重比较:进行了全方差分析之后,当自变量有3个或3个以上水平时,还有要对每两个组之间均值的差异进行比较,这称作事后组间均值的“多重比较”。 多因素方差分析:是检验两个或两个以上因素变量(自变量)的不同水平是否给一个(或几个相互独立的)因变量造成了显著的差异或变化的分析方法。 主效应和“交互作用”效应:主效应考察的是在忽略其他因素的情况下一个自变量对观察变量的影响,即这一个因素变量的不同水平分组下的观测值的均值之间的差异是否显著。当一个自变量的单独效应随另一个自变量的水平的不同而不同时,则这两个自变量对因变量的影响存在交互作用。 协变量方差分析:是在进行方差分析时将那些除了要考察的自变量之外的、很难控制的、且对因变量产生显著影响的无关变量作为“协变量”,在分析自变量对因变量的影响时,消除协变量对因变量的影响,从而使分析的结果更准确。。 多元方差分析:有两个或两个以上的因变量的方差分析(可以是单因素的,也可以是多因素的)称为多元方差分析。 重复测量的方差分析:用于某个测量指标对每个被试在不同的时间内进行多次(3次或3次以上)重复测量的情况。 组间因素:是被试分组的因素,组间因素有几个水平就把被试划分成几个组。 组内因素:又称重复测量因素,就是测试的不同水平或不同次数,是在每个被试内的因素。组内因素的不同水平决定了重复测量的次数。 方差成分分析:是对混合效应模型的分析,如对单变量重复测量和随机区组设计的分析,用于分析混合效应模型中各随机效应对因变量变异贡献的大小。通过对方差的成分进行分析,可以确定如何减小方差。 相关分析:是分析两个变量观测值变化的一致性程度或密切程度的统计方法。 简单相关分析:用于只对两个变量的数据做相关分析,其中包括两个连续变量之间的相关和两个等级变量之间的秩相关。 偏相关分析:是控制第三变量(或其他多个变量)的影响后,两变量间相关程度的统计方法。皮尔逊相关:是对两列变量为连续等间隔(等距、等比)数据,而且数据呈正态分布的相关
spss期末大数据分析报告
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
典型相关分析SPSS例析
典型相关分析 典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,而不是两个变量组个别变量之间的相关。 典型相关与主成分相关有类似,不过主成分考虑的是一组变量,而典型相关考虑的是两组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的成分使之与另一组的成分具有最大的线性关系。 典型相关模型的基本假设:两组变量间是线性关系,每对典型变量之间是线性关系,每个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共线性。典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因变量。 典型相关会找出一组变量的线性组合**=i i j j X a x Y b y =∑∑与 ,称 为典型变量;以使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。i a 和j b 称为典型系数。如果对变量进 行标准化后再进行上述操作,得到的是标准化的典型系数。 典型变量的性质 每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关;原来所有变量的总方差通过典型变量而成为几个相互独立的维度。一个典型相关系数只是两个典型变量之间的相关,不能代
表两个变量组的相关;各对典型变量构成的多维典型相关,共同代表两组变量间的整体相关。 典型负荷系数和交叉负荷系数 典型负荷系数也称结构相关系数,指的是一个典型变量与本组所有变量的简单相关系数,交叉负荷系数指的是一个典型变量与另一组变量组各个变量的简单相关系数。典型系数隐含着偏相关的意思,而典型负荷系数代表的是典型变量与变量间的简单相关,两者有很大区别。 重叠指数 如果一组变量的部分方差可以又另一个变量的方差来解释和预测,就可以说这部分方差与另一个变量的方差之间相重叠,或可由另一变量所解释。将重叠应用到典型相关时,只要简单地将典型相关系数平方(2 CR),就得到这对典型变量方差的共同比例,代表一个典型变量的方差可有另一个典型变量解释的比例,如果将此比例再乘以典型变量所能解释的本组变量总方差的比例,得到的就是一组变量的方差所能够被另一组变量的典型变量所能解释的比例,即为重叠系数。 例1:CRM(Customer Relationship Management)即客户关系管理案例,有三组变量,分别是公司规模变量两个(资本额,销售额),六个CRM实施程度变量(WEB网站,电子邮件,客服中心,DM 快讯广告Direct mail缩写,无线上网,简讯服务),三个CRM绩效维度(行销绩效,销售绩效,服务绩效)。试对三组变量做典型相关分析。
SPSS期末考试整理
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级xxx班姓名xxx 学号xxx 题号一二三四五六总成绩成绩 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
SPSS典型相关分析
SPSS数据统计分析与实践 第二十二章:典型相关分析 (Canonical Correlation) 主讲:周涛副教授 北京师范大学资源学院 教学网站:https://www.360docs.net/doc/d115737272.html,/Courses/SPSS
典型相关分析(Canonical Correlation)本章内容: 一、典型相关分析的基本思想 二、典型相关分析的数学描述 三、SPSS实例 四、小节
典型相关分析的基本思想 z典型相关分析是研究两组变量之间相关关系的一种多元统计方法。 z简单相关系数;复相关系数;典型相关系数 z典型相关分析首先在每组变量中找出变量的线性组合,使其具有最大相关性; z然后再在每组变量中找出第二对线性组合,使其与第一对线性组合不相关,而第二对本身具有最大相关性; z如此继续下去,直到两组变量之间的相关性被提取完毕为止; z这些综合变量被称为典型变量(canonical variates);第I对典型变量间的相关系数则被称为第I 典型相关系数(一般来说,只需提取1~2对典型变量即可较为充分的概括样本信息)。
典型相关分析的目的 T q T p Y Y Y Y X X X X ),,,() ,,,(2121K K ==设两组分别为p 与q 维 (p ≤q)的变量X ,Y :设p + q 维随机向量协方差阵,????????=Y X Z ??? ?????ΣΣΣΣ=Σ222112 11其中Σ11是X 的协方差阵,Σ22是Y 的协方差阵,Σ12=ΣT 21是X ,Y 的协方差阵 典型相关分析用X 和Y 的线性组合U =a T X , V =b T Y 之间的相关来研究X 和Y 之间的相关性。其目的就是希望找到向量a 和b ,使ρ(U ,V )最大,从而找到替代原始变量的典型变量U 和V 。
spss期末考试上机复习题(含答案)75709
江苏理工学院2017—2018学年第1学期 《spss软件应用》上机操作题库 1.随机抽取100人,按男女不同性别分类,将学生成绩分为中等以上及中等以下两类,结果 如下表。问男女生在学业成绩上有无显著差异? 中等以上中等以下 男 女 性别* 学业成绩交叉制表 计数 学业成绩 中等以上中等以下 合计 性别男23 17 40 女38 22 60 合计61 39 100 根据皮尔逊卡方检验,p=0.558〉0.05 所以男生女生在学业成绩上无显著性差异。 2.为了研究两种教学方法的效果。选择了6对智商、年龄、阅读能力、家庭条件都相同的儿童进行了实验。结果(测试分数)如下。问:能否认为新教学方法优于原教学方法(采用非参数检验)? 序号新教学方法原教学方法 1 83 78
2 3 4 5 6 69 87 93 78 59 65 88 91 72 59 答:由威尔逊非参数检验分析可知p=0.08〉0.05,所以不能认为新教学方法显著优于原教学方法。 3.下面的表格记录了某公司采用新、旧两种培训前后的工作能力评分增加情况,分析目的是比较这两种培训方法的效果有无差异。考虑到加盟公司时间可能也是影响因素,将加盟时间按月进行了记录。 方法加盟时间分数方法加盟时间分数 旧方法 1.5 9 新方法 2 12 旧方法 2.5 10.5 新方法 4.5 14 旧方法 5.5 13 新方法7 16 旧方法 1 8 新方法0.5 9 旧方法 4 11 新方法 4.5 12 旧方法 5 9.5 新方法 4.5 10 旧方法 3.5 10 新方法 2 10 旧方法 4 12 新方法 5 14 旧方法 4.5 12.5 新方法 6 16 (1)分不同的培训方法计算加盟时间、评分增加量的平均数。 (2)分析两种培训方式的效果是否有差异? 答:(1) 描述统计量 N 极小值极大值均值标准差 培训方法 = 1 (FILTER) 9 1 1 1.00 .000 加盟时间9 .50 7.00 4.0000 2.09165 分数增加量9 9.00 16.00 12.5556 2.60342 有效的 N (列表状态)9 所以新方法的加盟时间平均数为4 分数增加量的平均数为12.5556
SPSS相关分析案例讲解
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 第8章SPSS的相关分析 学习目标: 1.明确相关关系的含义以及相关分析的主要目标。 2.掌握散点图的含义,熟练掌握绘制散点图的具体操作。 3.理解简单相关系数、Spearman相关系数、Kendall相关系数的基本原理,熟练掌握计算 各种相关系数的具体操作,能够读懂分析结果。 4.理解偏相关系分析的主要目标以及与相关分析之间的关系,熟练掌握偏相关分析的具体 操作,能够读懂分析结果。 8.1 相关分析 相关分析是分析客观事物之间关系的数量分析方法,明确客观事物之间有怎样的关系对理解和运用相关分析是极为重要的。 客观事物之间的关系大致可归纳为两大类关系,它们是函数关系和统计关系。相关分析是用来分析事物之间统计关系的方法。 所谓函数关系指的是两事物之间的一种一一对应的关系,即荡一个变量x取一定值时,另一变量y可以依确定的函数取唯一确定的值。例如,商品的销售额与销售量之间的关系,在单价确定时,给出销售量可以唯一地确定出销售额,销售额与销售量之间是一一对应的关系,且这个关系可以被y=Ρx(y表示销售额,Ρ表示单价,x表示销售量)这个数学函数精确地描述出来。客观世界中这样的函数关系有很多,如圆面积和圆半径、出租车费和行程公里数之间的关系等。 另一类普遍存在的关系是统计关系。统计关系指的是两事物之间的一种非一一对应的关系,即当一个变量x取一定值时,另一变量y无法依确定的函数取唯一确定的值。例如,家庭收入和支出、子女身高和父母身高之间的关系等。这些事物之间存在一定的关系,但这些关系却不能像函数关系那样可用一个确定的数字函数描述,且当一个变量x取一定值时,另一变量y的值可能有若干个。统计关系可再进一步划分为线性相关和非线性相关关系。线性相关又可分为正线性相关和负线性相关。正线性相关关系指两个变量线性的相随变动方向相同,而负线性相关关系指两个变量线性的相随变动方向相反。 事物之间的函数关系比较容易分析和测度,而事物之间的统计关系却不像函数关系那样直接,但确实普遍存在,并且有的关系强,有的关系弱,程度各有差异。如何测度事物间统计关系的强弱是人们关注的问题。相关分析正是一种简单易行的测度事物之间统计关系的有效工具。绘制散点图和计算相关系数是相关分析最常用的工具,他们的互相结合能够达到较为理想的分析效果。 8.2绘制散点图 8.2.1散点图的特点 绘制散点图是相关分析过程中极为常用且非常直观的分析方式。它将数据以点的形式画在直角平面上。通过观察散点图能够直观地发现变量间的统计关系以及它们的强弱程度和数据对的可能走向。 在实际分析中,散点图经常表现出某些特定的形状。如绝大多数的数据点组成类似于“橄榄球”的形状,或集中形成一根“棒状”,而剩余的少数数据点零散地分布在四周。通常“橄榄球”和“棒状”代表了数据对的主要结构和特征,可以利用曲线将这种主要结构的轮廓描绘出来,使数据的主要特征更突显。图8—1是常见的几种散点图以及反映出的统计关系的强弱程度。 spss期末考试上机复习题(含答案) ————————————————————————————————作者:————————————————————————————————日期: 江苏理工学院2017—2018学年第1学期 《spss软件应用》上机操作题库 1.随机抽取100人,按男女不同性别分类,将学生成绩分为中等以上及中等以下两类,结果 如下表。问男女生在学业成绩上有无显著差异? 中等以上中等以下 男23 17 女38 22 性别* 学业成绩交叉制表 计数 学业成绩 合计 中等以上中等以下 性别男23 17 40 女38 22 60 合计61 39 100 卡方检验 值df 渐进 Sig. (双侧) 精确 Sig.(双侧) 精确 Sig.(单侧) Pearson 卡方.343a 1 .558 连续校正b.142 1 .706 似然比.342 1 .558 Fisher 的精确检验.676 .352 线性和线性组合.340 1 .560 有效案例中的 N 100 a. 0 单元格(.0%) 的期望计数少于 5。最小期望计数为 15.60。 b. 仅对 2x2 表计算 根据皮尔逊卡方检验,p=0.558〉0.05 所以男生女生在学业成绩上无显著性差异。 2.为了研究两种教学方法的效果。选择了6对智商、年龄、阅读能力、家庭条件都相同的儿童进行了实验。结果(测试分数)如下。问:能否认为新教学方法优于原教学方法(采用非参数检验)? 序号新教学方法原教学方法 1 2 3 83 69 87 78 65 88 4 5 6 93 78 59 91 72 59 检验统计量b 原教学方法 - 新 教学方法 Z -1.753a 渐近显著性(双侧) .080 a. 基于正秩。 b. Wilcoxon 带符号秩检验 答:由威尔逊非参数检验分析可知p=0.08〉0.05,所以不能认为新教学方法显著优于原教学方法。 3.下面的表格记录了某公司采用新、旧两种培训前后的工作能力评分增加情况,分析目的是比较这两种培训方法的效果有无差异。考虑到加盟公司时间可能也是影响因素,将加盟时间按月进行了记录。 方法加盟时间分数方法加盟时间分数 旧方法 1.5 9 新方法 2 12 旧方法 2.5 10.5 新方法 4.5 14 旧方法 5.5 13 新方法7 16 旧方法 1 8 新方法0.5 9 旧方法 4 11 新方法 4.5 12 旧方法 5 9.5 新方法 4.5 10 旧方法 3.5 10 新方法 2 10 旧方法 4 12 新方法 5 14 旧方法 4.5 12.5 新方法 6 16 (1)分不同的培训方法计算加盟时间、评分增加量的平均数。 (2)分析两种培训方式的效果是否有差异? 答:(1) 描述统计量 N 极小值极大值均值标准差 培训方法 = 1 (FILTER) 9 1 1 1.00 .000 加盟时间9 .50 7.00 4.0000 2.09165 分数增加量9 9.00 16.00 12.5556 2.60342 有效的 N (列表状态)9 所以新方法的加盟时间平均数为4 分数增加量的平均数为12.5556 描述统计量 S P S S皮尔逊相关分析实 例操作步骤 Prepared on 21 November 2021 SPSS皮尔逊相关分析实例操作步骤 选题: 对某地29名13岁男童的身高(cm)、体重(kg),运用相关分析法来分析其身高与体重是否相关。 实验目的: 任何事物的存在都不是孤立的,而是相互联系、相互制约的。相关分析可对变量进行相关关系的分析,计算29名13岁男童的身高(cm)、体重(kg),以判断两个变量之间相互关系的密切程度。 实验变量: 编号Number,身高height(cm),体重weight(kg) 原始数据: 实验方法: 软件: 操作过程与结果分析: 第一步:导入Excel数据文件? 1.open data document——open data——open; 2. Opening excel data source——OK. 第二步:分析身高(cm)与体重(kg)是否具有相关性 1.在最上面菜单里面选中Analyze——correlate——bivariate?,首先 使用Pearson,two-tailed,勾选flag significant correlations 进入如下界面: 2.点击右侧options,勾选Statistics,默认Missing Values,点击 Continue 输出结果: 图为基本的描述性统计量的Array输出表格,其中身高的均值 (mean)为、标准差(standard deviation)为、样本容量 (number of cases)为29;体重的均值为、标准差为、样本容量为29。两者的平均值和标准差值得差距不 显着。 Correlations 身高(cm)体重(kg) 身高(cm)Pearson Correlation1.719** Sig. (2-tailed).000 Sum of Squares and Cross- products Covariance N2929 体重(kg)Pearson Correlation.719**1 Sig. (2-tailed).000 Sum of Squares and Cross- products Covariance N2929 本科教学实验报告 (实验)课程名称:数据分析技术系列实验 实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。 1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1.分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze\DescriptiveStatistics\Crosstabs Step2.将性别(Gender)和收入(CurrentSalary)分别移入Rows列表框和Columns 列表框。 Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。 2.分析教育程度与工资之间是否存在相关关系。 分析:教育程度为定序变量,工资为连续变量,可使用Spearman和Kendall秩相关系数检验。 Step1.用散点图初步判断二变量的相关性,操作为Graphs/LegacyDialogs/Scatter,选择SimpleScatter,教育程度为自变量,工资为因变量,做散点图。 散点图结果如图示,二者存在线性相关关系。只有线性相关的关系确定后才能继续进行下一步分析。因此,在进行相关分析之前的预分析过程也是十分重要的。 Step2.两变量相关分析,操作为Analyze/Correlate/Bivariate,选择Kendall和Spearman 相关系数。 六、实验器材(设备、元器件): 计算机、打印机、硒鼓、碳粉、纸张 七、实验数据及结果分析 1.分析性别与工资之间是否存在相关关系。 卡方检验结果为 显着性水平为,即至少有%的把握认为性别和工资之间存在显着的相关系。SPSS的相关分析
spss期末考试上机复习题(含标准答案)
SPSS皮尔逊相关分析实例操作步骤
SPSS相关分析实验报告精选