spss数据分析具体操作步骤
大家现在都要写论文的数据分析了……很多同学都一点不会……所以把我知道的跟大家分享一下……下面以PASW18.0为例,也就是SPSS18.0…………什么?不是18.0,好吧……差不多的,凑合着看吧……要不去装个……= =……下面图片看不清的请右键查看图片……
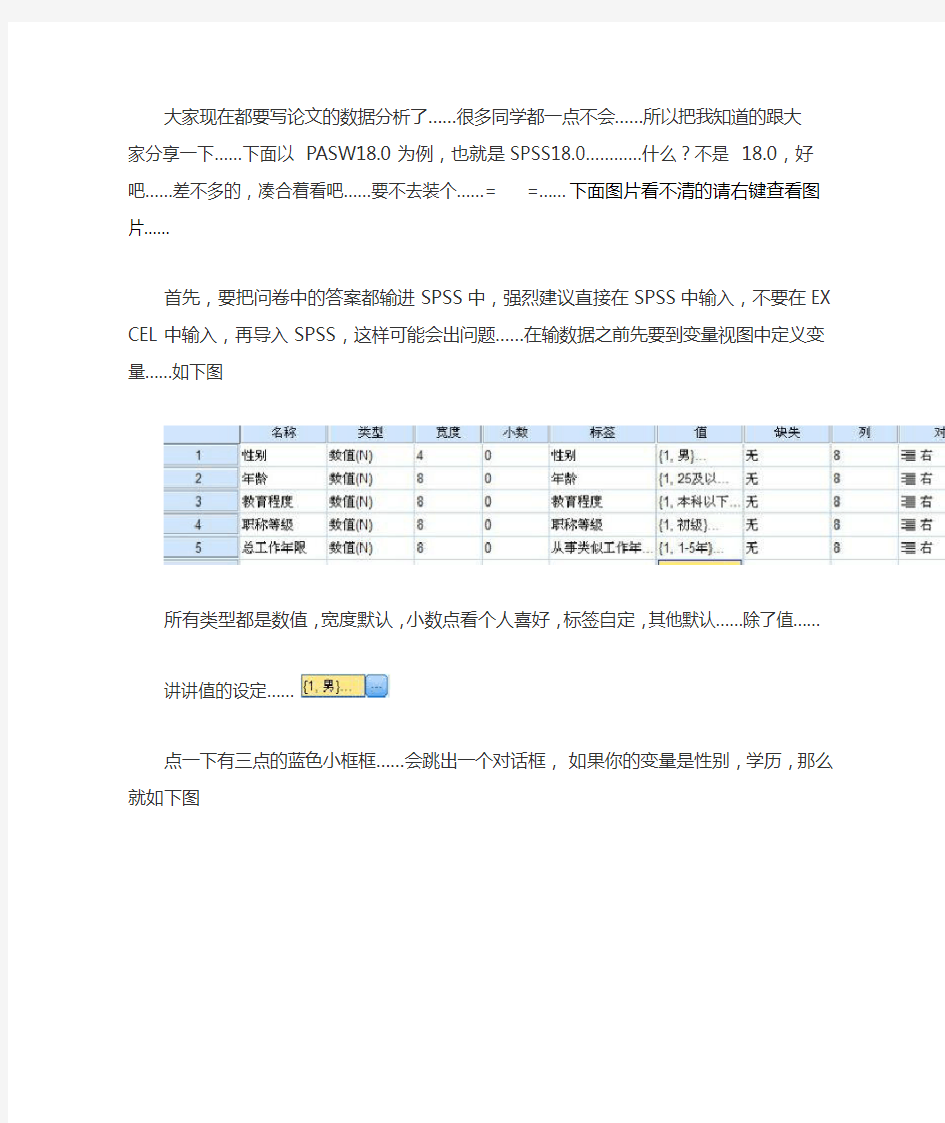
首先,要把问卷中的答案都输进SPSS中,强烈建议直接在SPSS中输入,不要在EXCEL中输入,再导入SPSS,这样可能会出问题……在输数据之前先要到变量视图中定义变量……如下图
所有类型都是数值,宽度默认,小数点看个人喜好,标签自定,其他默认……除了值……
讲讲值的设定……
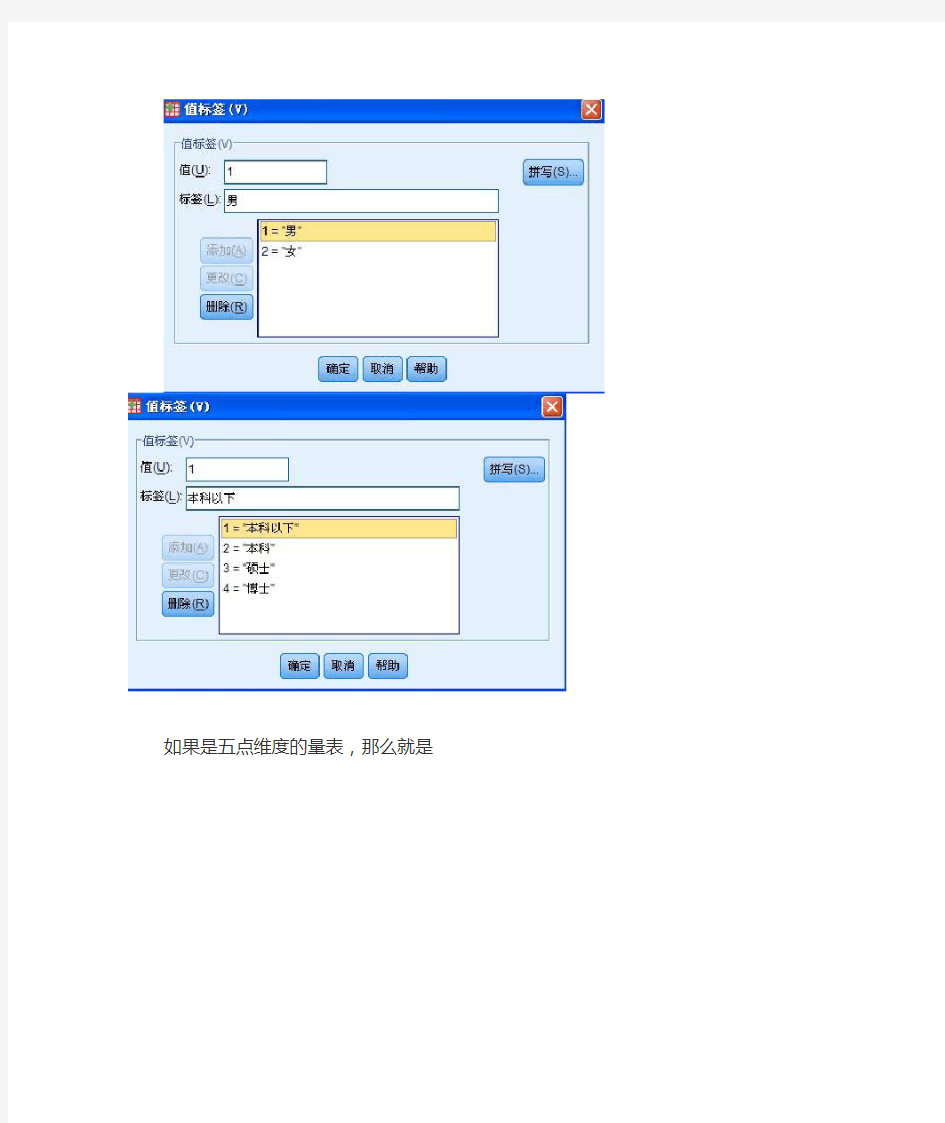
点一下有三点的蓝色小框框……会跳出一个对话框,如果你的变量是性别,学历,那么就如下图
如果是五点维度的量表,那么就是
记住,每一题都是一个变量,可以取名Q1,Q2……设定好所有问卷上有的变量之后,就可以到数据视图中输入数据啦……如下图
都输完后……还有要做的就是计算你的每个维度的平均得分……如果你的问卷Q1-Q8是一个维度,那么就把Q1-Q8的得分加起来除以题目数8……那么得到的维度1分数会显示在数据视图中的最后……具体操作如下……
转换——计算变量
点确定,就会在数据视图的最后一列出现计算后的变量……如果你的满意度有3个维度,那么就要计算3个维度,外加满意度这个总维度,满意度=3个维度的平均分=满意度量表的所有题目的平均分…………把你所有的维度变量都计算好之后就可以分析数据啦……
1.描述性统计
将你要统计的变量都放到变量栏中,直接点确定……
如果你要统计男女的人数比例,各个学历或者各个年级的比例,就要用描述统计中的频率……如果要统计男女中的年级分布,比如大一男的有几个,大二女的有几个,就用交叉表……不细说了……地球人都懂的…………
2.差异性分析
差异性分析主要做的就是人口学变量的差异影响,男女是否有差异,年级是否有差异,不做的就跳过……
对于性别来说,差异分析采用独立样本T检验,也可以采用单因素ANOVA分析,下面以T 检验为例……
将性别放进下面的分组变量中,
接着定义组……
按确定
看Sig(双侧)得分,小于0.05就表明有显著差异,上图可见男女在组织承诺上是有显著差异的,在变革型领导行为的认同上没有显著差异……
而对于学历,年级,年龄,工作年限等因素,我们可以采用单因素ANOVA分析,如下……
按确定……
由上图可知,在KY工作年限不同,在感情承诺、规范承诺、机会承诺上都有显著差异……显著性小于0.05……
如果做出来没有差异,可以在下图中选择两两比较……
选中LSD(最小显著方差法)……
继续……确定……就会出来多重比较的图……
再找有没上标为小星星的……有就可以说明二者有差异,没就没办法了……你改数据吧……= =……上图说明1年和3年、5年的在感情承诺上有明显差异……我去……4年的怎么没差异……= =0……
别的也就这么做……不重复说了……
3.相关分析
相关分析主要就是分析你两个大变量中各个维度是否存在相关性和两大变量是否存在相关性……下例为两大变量的相关分析……
分析——相关——双变量
确定后……
可见变革型领导行为和组织承诺在0.01水平上显著相关……上标两颗星……相关性比较好……
其他维度也是一样的做法…………
4.回归分析
相关分析只能说明二者的相关性,并不能表明是否是由于A的变化引起B的变化,要想证明因果关系就要用回归分析……
在做回归之前,首先要做一下自变量之间的相关性,如果相关系数超过0.75就不能做回归……会有比较大的偏差……这里不说了,不会的看3.相关分析
回归如下
如果你想用ABC变量预测D,就把D放因变量中,ABC放自变量中,方法选择进入……直接确定,如下图
上图的结果表明德行垂范和愿景激励被踢出回归方程,因为Sig大于0.05……所以只有个性化关怀和领导魅力可以显著预测组织承诺……
5.问卷信度和效度
信度=分析——度量——可靠性分析
把你同一份量表的题目全部放进去,比如变革型领导量表有26题……直接确定……
结果表明Cronbach's值为0.939,量表信度很好……超过0.7才行
效度分析一般采用结构效度分析,就是因子分析……
分析——降维——因子分析
把你同一量表的题目都放进去……
spss的数据分析案例精选文档
s p s s的数据分析案例 精选文档 TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-
关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为%和%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
16 59 17 11 18 9 19 27 20 2 .4 .4 21 1 .2 .2 Tot al 474 上 表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的%,其次为15年,共有116人,占中人数的%。且接受过高于20年的教育的人数只有1人,比例很低。 2、 描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的
spss的数据分析案例
关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够 了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
14 6 1.3 1.3 52.5 15 116 24.5 24.5 77.0 16 59 12.4 12.4 89.5 17 11 2.3 2.3 91.8 18 9 1.9 1.9 93.7 19 27 5.7 5.7 99.4 20 2 .4 .4 99.8 21 1 .2 .2 100.0 Tot 474 100.0 100.0 al 上表及其 直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教
spss数据处理结构分析
公司的行政人员认为自己与市场部的人员和研发部的人员差异太大;公司总经理则认 为行政人员的综合技能、教育背景与市场部人员和研发部人员也存在明显差异,行政 人员如何通过统计方法证实自己的结论?请构造相关数据,选择合适的统计方法进行 统计验证,并对统计结果进行分析和说明 (1)本例中职工按行政人员、市场人员、研发人员依次设为 合技能、教育背景和工资四个变量,采用单因素方差分析。 (2)SPSS 分析过程: 1、进入SPSS10.0,打开相关数据文件,选择“分析 均值检验 单因素方差分析”, 弹出单因素方差分析对话框,选择变量“职位”使其进入因子( F )框中,选择变量 “综合技能、教育背景、工资”使其进入因变量列表( D )框中。 I I L 対比紗… 两心做 凹?, Boatctrap(fl). ?定]岸陽曰]单? [取消J 、帮切J 2、单击两两比较按钮,选中假定方差齐性框中的 LSD (最小显著差法),同时选中 Equal 未假定方差齐性框中的 Tamhane 'T2。 趟羊吕秦AHOVA;两比较 | S | 佃疋性 1( L5D L) □ S-N-KO) Wall IF -Dune an
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 第一,将EXCEL中的原始数据导入到SPSS软件中; 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。 所的结论: 标准化后的所有指标数据。 注意: SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。 factor过程对数据进行因子分析(指标之间的相关性判定略)。 【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;
【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框; 【3】设置“抽取”,勾选“碎石图”复选框; 【4】设置“旋转”,勾选“最大方差法”复选框; 【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框; 【6】查看分析结果。 所做工作: a.查看KMO和Bartlett 的检验 KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析; Bartlett 球度度检验的Sig值越小于显著水平0.05,越说明变量之间存在相关关系。 所的结论: 符合因子分析的条件,可以进行因子分析,并进一步完成主成分分析。 注意: 1.KMO(Kaiser-Meyer-Olkin) KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。 Kaiser给出了常用的kmo度量标准: 0.9以上表示非常适合;0.8表示适合;0.7表示一般; 0.6表示不太适合;0.5以下表示极不适合。 2.Bartlett 球度检验: 巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析。 Bartlett 球度检验的原假设为相关系数矩阵为单位矩阵,Sig值为0.001小于显著水平0.05,因此拒绝原假设,说明变量之间存在相关关系,适合做因子分析。 所做工作: b. 全部解释方差或者解释的总方差(Total Variance Explained)
SPSS大数据案例分析实施报告
SPSS数据案例分析 目录 _Toc438655006 一.手机APP 广告点击意愿的模型构建 (2) 1.1构建研究模型 (2) 1.2研究变量及定义 (2) 1.3研究假设 (2) 1.4变量操作化定义 (2) 1.5问卷设计 (2) 二.实证研究 (2) 2.1基础数据分析 (2) 2.2频数分布及相关统计量 (2) 2.3相关分析 (2) 2.4回归分析 (2) 2.5假设检验 (2)
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。
1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机APP 广告点击意愿没有显著影响
SPSS概览--数据分析实例详解
第一章SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下:
1.将数据输入SPSS,并存盘以防断电。 2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采 用的检验方法。 3.按题目要求进行统计分析。 4.保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下: 请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、
Spss数据处理方法
Spss数据处理方法 1.打开软件,新建文件,双击变量一栏,出现一个表格,在名称一栏中依次填写指标名称 (只能是字母),输入后其他栏自动显示,小数点可调整到3,其他可不变;同时要输入组别名称 2.输完后在视图中点数据,就会出现数据栏,在相应的指标名称下输入数据,在组别名称 下输入样本标记,每组样本用同一个数字表示。 3.输完后点窗口上面的分析下拉菜单中的比较均衡,其中有单因素方差分析,出现对话框, 因变量中输入指标名称,因子中输入组的名称。 4.对话框中有选项,对比,两两比较,选项中描述性和两两比较中的LSD必选,其他的 项目也可以选,选完后确定就可以了。 LSD最小显著性差别S-N-K waller-duncan dunnett Tukey检验scheffe多重比较 Bonferroni邦弗伦尼统计量 Using repeated-measures single factor analysis of variance and Bonferroni statistical tests (P < 0. 05), intervertebral motion redistribution of each construct was compared with the intact. 使用重复测量变异的单因子分析和Bonferroni统计学测试,我们将每个结构的椎间盘运动再分布与完整运动进行了比较。 levene Tukey HSD Dunnett T3 bonferroni Using repeated-measures single factor analysis of variance and Bonferroni statistical tests (P < 0. 05), intervertebral motion redistribution of each construct was compared with the intact. 使用重复测量变异的单因子分析和Bonferroni统计学测试,我们将每个结构的椎间盘运动再分布与完整运动进行了比较。 LSD:最小显著性差异 ?Scheffe: (四)雪費法(Scheffe)事後檢定:經單因子變異數分析之後,如果F值達到顯著水準,再以雪費法(Scheffe)進行事後比較以瞭解真正存有差異組別之基于20个网页 - 搜索相关网页 ?雪费 本研究结果显示研究对象在籍贯的不同其牙医医疗服务利用有显著差异(P=0.046),且经雪费(Scheffe)的事后检定显示外省人在牙医医疗服务利用高于本省闽南,在其他的研究中未有此发现,研究者于是进一步的去了解,发现本研究对象中... 基于13个网页 - 搜索相关网页 ?以雪費 分析檢定;若P值小於0.05達到顯著水準,再以雪費(Scheffe)進行事後檢定,比較其差異,以下將一一進行分析。 基于12个网页 - 搜索相关网页 ?雪費法 (四)雪費法(Scheffe)事後檢定:經單因子變異數分析之後,如果F值達到顯著水準,再以雪費法(Scheffe)進行事後比較以瞭解真正存有差異組別之基于12个网页 - 搜索相关网页 -Scheffe Method:事后比较 ?事后比较
【精品管理学】spss因子分析案例 共(13页)
[例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。
图 ???对话框(图框。 图 钮返回 图11.3?描述性指标选择对话框 ???点击Extraction...钮,弹出FactorAnalysis:Extraction对话框(图11.4),系统提供如下因子提取方法: 图11.4?因子提取方法选择对话框 ???Principalcomponents:主成分分析法;
???Unweightedleastsquares:未加权最小平方法; ???Generalizedleastsquares:综合最小平方法; ???Maximumlikelihood:极大似然估计法; ???Principalaxisfactoring:主轴因子法; ???Alphafactoring:α因子法; ???对话框。 ???5种因图 ???旋转的目的是为了获得简单结构,以帮助我们解释因子。本例选正交旋转法,之后点击Continue钮返回FactorAnalysis对话框。 ???点击Scores...钮,弹出弹出FactorAnalysis:Scores对话框(图11.6),系统提供3种估计因子得分系数的方法,本例选Regression(回归因子得分),之后点击Continue钮返回FactorAnalysis对话框,再点击OK钮即完成分析。
图11.6?估计因子分方法对话框? ?11.2.3?结果解释 ??在输出结果窗口中将看到如下统计数据: ??系统首先输出各变量的均数(Mean)与标准差(StdDev),并显示共有25例观察单位进入分析;接着输出相关系数矩阵(CorrelationMatrix),经Bartlett检验表明:Bartlett值=326.28484,P<0.0001,即相关矩阵不是一个单位矩阵,故考虑进行因子分析。 好。今KMO值 NumberofCases?=?????25 CorrelationMatrix: X1???????X2???????X3???????X4???????X5???????X6???????X7 X1????????1.00000 X2?????????.58026??1.00000
SPSS相关分析案例讲解
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 spss数据录入时缺失值怎么处理 录入的时候可以直接省略不录入 分析的时候也一般剔除这样的样本。但也有替换的方法,一般有: 均值替换法(mean imputation),即用其他个案中该变量观测值的平均数对缺失的数据进行替换,但这种方法会产生有偏估计,所以并不被推崇。 个别替换法(single imputation)通常也被叫做回归替换法(regression imputation),在该个案的其他变量值都是通过回归估计得到的情况下,这种 方法用缺失数据的条件期望值对它进行替换。这虽然是一个无偏估计,但是却倾向于低估标准差和其他未知性质的测量值,而且这一问题会随着缺失信息的增多而变得更加严重。 多重替代法(multiple imputation)(Rubin, 1977) 。 ?它从相似情况中或根据后来在可观测的数据上得到的缺省数据的分布情况给每个缺省数据赋予一个模拟值。结合这种方法,研究者可以比较容易地,在不舍弃任何数据的情况下对缺失数据的未知性质进行推断(Little and Rubin,1987; ubin,1987, 1996)。 (一)个案剔除法(Listwise Deletion) 最常见、最简单的处理缺失数据的方法是用个案剔除法(listwise deletion),也是很多统计软件(如SPSS和SAS)默认的缺失值处理方法。在这种方法中如果任何一个变量含有缺失数据的话,就把相对应的个案从分析中剔除。如果缺失值所占比例比较小的话,这一方法十分有效。至于具体多大的缺失比例算是“小”比例,专家们意见也存在较大的差距。有学者认为应在5%以下,也有学者认为20%以下即可。然而,这种方法却有很大的局限性。它是以减少样本量来换取信息的完备,会造成资源的大量浪费,丢弃了大量隐藏在这些对象中的信息。在样本量较小的情况下,删除少量对象就足以严重影响到数据的客观性和结果的正确性。因此,当缺失数据所占比例较大,特别是当缺数据非随机分布时,这种方法可能导致数据发生偏离,从而得出错误的结论。 (二)均值替换法(Mean Imputation) 在变量十分重要而所缺失的数据量又较为庞大的时候,个案剔除法就遇到了困难,因为许多有用的数据也同时被剔除。围绕着这一问题,研究者尝试了各种各样的办法。其中的一个方法是均值替换法(mean imputation)。我们将变量的属性分为数值型和非数值型来分别进行处理。如果缺失值是数值型的,就根据该变量在其他所有对象的取值的平均值来填充该缺失的变量值;如果缺失值是非数值型的,就根据统计学中的众数原理,用该变量在其他所有对象的取值次数最多的值来补齐该缺失的变量值。但这种方法会产生有偏估计,所以并不被推崇。均值替换法也是一种简便、快速的缺失数据处理方法。使用均值替换法插补缺失数据,对该变量的均值估计不会产生影响。但这种方法是建立在完全随机缺失(MCAR)的假设之上的,而且会造成变量的方差和标准差变小。 (三)热卡填充法(Hotdecking) SPSS数据初步整理须知 对于问卷收集到的调查数据或通过其它方法,如眼动仪、脑电仪以及生理记录仪等获得的数据,在进入SPSS分析前最好对数据进行预处理,其作用:防止错误数据导致不恰当的推论。本次主要谈谈问卷数据在分析前的一些预处理工作。 数据预处理的步骤: 1. 对所有数据源的质量进行初步审核。 1.1 剔除无效答卷。如是问卷数据,可以查看被调查者的回答是否呈现某种规律,或者回答者不符合我们调查的人群,或者存在大量题目漏答现象。 1.2 检查是否有明显错误回答。如是否按指导语进行回答,基本信息是否有误。是否有明显的回答矛盾等等。 2. 对数据进行编码。 编码主要有事前编码和事后编码,事前编码主要针对封闭式问卷,而事后编码则主要是针对开放式问题。 编码有三个工作:第一是定义数据的变量名,第二定义变量名标签,即这个变量代表什么意思。第三定义变量值及值标签。即变量的取值,以及这个取值的含义。如变量名为sex,其变量标签为“性别”,其变量的取值为“1”或“2”,分别表示“男”和“女”(变量值标签)。 2 2.1 单选题的编码。第一定义变量名,一般用题目序号,如第6题,则变量名为Q6,其变量名标签一般用问题。而变量的取值则为单选题的选项。有几个选项就有几个变量值,而值的标签则是选项的内容。 2.2 多选题的编码。每一个选项就得作为一个新变量。如第7题是多选题,有五个选项,可多选三项。则五道选项分别定义变量名为Q71,……Q75,每个变量名的标签即这五道选项的内容。而变量值及标签为“0”或“1”,0表示未选,1表示选中。 2.3 排序题的编码。有两种方法:其一跟多选题类似。如第7题要求对所选的三个选项进行排序。变量名及标签同上。而变量值除了“0”(表示未选)外,还有“1”“2”“3”分别表示排序第一,排序第二,排序第三。其二根据要求选择三项进行排序,则只需要定义三个变量,Q71,Q72,Q73,变量名标签则表示排序第一,排序第二,排序第三。变量值为五道选项的序号,而变量值标签则分别是五道选项的内容。 2.4 开放题的编码。首先应将开放题中受试所填写的选项进行分类汇总。初次归类尽量归细一点。再做统计分析时如果觉得分类太细可以再次进行归大类。 调查问卷的SPSS的基本处理方法(Z)SPSS是常用的数理统计软件之一,也可以用于调查问卷的统计分析,一下就调查问卷的一些基本分析处理方法做一些简单的描写。另外,虽然SPSS也有图表功能,但个人认为不是很好用,建议还是将统计分析的数据导到EXCEL中再作图表。 频度分析 频度就是某个选项出现的次数,一般用来描述单选项。 问卷设计实例: 企业经营规模为(年销售额:人民币): □>30亿□5~30亿□0.5~5亿□<0.5亿 数据记录要点: 单列记录,第几项选中记录数值几,例如选中“0.5~5亿”则记录3。 SPSS基本操作方法: 导入数据; Analyze……Descriptive statistics……Freq uencies 选入该列数据,“OK”。 多项频次分析 用来描述多选项目的频次。 问卷设计实例: 贵公司产品的主要竞争力表现在(多选): □外观□功能□质量□个性化□价格(成本)□交货期□其它 数据记录要点: 多列记录,有几个选项记几列,选中记为1,未选中记为0。例如如果选中了外观和质量,则多列的记录为1,0,1,0,0,0,0。 SPSS基本操作方法: 导入数据; Analyze……Multiple Response……Define Sets 选入该问题的多列数据,给新的集合变量取名(在Name那里填一个名字,例如“竞争力”),在Dichotomies Counted value中输入1,“Add”。 Analyze……Multiple Response……Frequencies 选人自定义的集合变量,“OK”。 交叉频次分析 用来描述变量之间的关联性,比如分析不同销售额企业的产品竞争力的关联关系(这两项之间不一定有关系,可以用logistic分析验证一下)。 问卷设计实例: 参见上面的两项。 数据记录要点: 参见上面两项。 SPSS基本操作方法(单选对单选,单选对多选,单选对多选在操作上略有不同): 导入数据;如果有多选项需要按2的方法定义集合变量。 如果是单选对单选 Analyze……Descriptive statistics……Crosstabs 否则: Analyze……Multiple Response……Crosstabs 将两变量分别选入行和列中(多选项是选人集合变量,如果是单选对多选还要设置单选项的最大最小值),“OK” 描述分析 一般用来描述单变量的描述统计量,这些述统计量有平均值、算术和、标准差,最大值、最小值、方差、范围和平均数标准误等。问卷中用得不是特别多。 问卷设计实例(一般是开放性问题): 贵企业三维CAD已经应用了年。 数据记录要点: 单列记录,直接记录所填数据。 SPSS基本操作方法: 导入数据; Analyze……Descriptive statistics……Descriptives 选入该列数据,“Options…”,在其中选择需要的统计项目,问卷常用的项目有Mean(平均值)、Minimum( 最小值)、Maximum(最大值)等,“Continue”, “OK”。 关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下: 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years) 上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别 和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。 Descriptive Ststistics SPSS多项选择问题处理方法 多项选择题是定量问卷调查中常见的封闭式选择题,这种选择题的出现可以在确定的范围内更多的考察被调研对象的看法。在针对消费者的调研中,这种选择题多是出现在针对品牌知名度,包括提示前知名度、第一提及率,提示后知名度的分析中。 ?常见的分析方法 一般的研究分析手段主要应用包括EXCEL与SPSS在内的频次分析,然后再将在不同数据字段同一类选项数据进行加总,然后再以被调研对象的总体数量为基数,二者相除来得到多项选择题中各选项在总体中的占有率,这种各选项占有率的加总大于1。 例如某类产品品牌知名度调查中,关于该类产品您能想起哪些品牌? 01 品牌A 02品牌B 03品牌C 04品牌D 05品牌E 06品牌F 07其它品牌_____ 该问题在数据字段设计时最少要设计10个字段以供数据录入与分析。按上面的数据分析方法,先在这10个字段中进行分别的频次计算,然后进行加总再除以总基数,得到该选项的总体占有比率。以A选项为例: (01字段中A的占有率+02字段中A的占有率+ …… +06字段中A的占有率)/被调对象总数=A的占有率以此类推分别计算出其它品牌的占有率,频次计算次数与分类加和计算次数比较繁杂,其工作量在被选项较少时还算省事,但当被选项数量在十几个、二十几个甚至三十几个时,该分析方法则极大降低了分析人员的工作效率。 ?高效率数据分析方法 运用SPSS重组再分析的数据方法将极大提高数据分析效率并降低人为计算失误。 在SPSS数据库中运用 “Multiple Response”对多组数据进行组合再定义,这样会针对每个单一选择题定义出一个新的字段组,在新字段组中对变量区间进行定义,再针对新字段组进行频次分析。当完成单一字段设置后,可运用程序段对其它多项选择题进行再利用分析,这样可以大大提高多项选择题数据分析效率。 分析程序例举: ************** MULT RESPONSE GROUPS=$tsh '新字段组名称' (var00018 var00019 var00020 var00021 var00022 var00013 var00014 var00015 var00016 var00017 (1,111)) SPSS数据案例分析 目录 一.手机APP 广告点击意愿的模型构建 构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显着影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显着影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。 研究变量及定义 研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机APP 广告点击意愿没有显着影响 变量操作化定义 ?广告效用期望:广告对我了解某品牌来说很有用 ?APP 效用期望:使用APP 能够让我了解到多方面的信息 ?社会影响:身边的人都在使用手机APP 广告,所以我也要使用 ?感知风险:在点击手机APP 广告时,我担心我的个人隐私安全得不到保护?感知隐私安全重要性:确保点击手机APP 广告是安全的,对我来说是很重要的 ?使用意向:我愿意把手机APP 广告推荐给我周围的人 问卷设计 1.使用APP 能够让我了解到多方面的信息[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 2.广告对我了解某品牌来说很有用[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 3.身边的人都在使用手机APP 广告,所以我也要使用[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 4.在点击手机APP 广告时,我担心我的个人隐私安全得不到保护[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 5.确保点击手机APP 广告是安全的,对我来说是很重要的[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 6.我愿意把手机APP 广告推荐给我周围的人[单选题] [必答题] 常用SPSS数据处理方法,你都会吗? 数据编辑处理是在统计和分析数据时,第一步要做的。尤其是当面对大量数据时,数据处理是一个重要的过程,可以达到提高处理效率及精度的目的。 为配合进行更好的分析,研究过程过可能涉及到以下数据处理工作: 1、定义变量名 2、制定数据标签 3、数据编码 4、计算变量 5、无效样本处理 6、特殊值处理等 定义变量 定义变量,就是给每个指标起名字。每个变量都需要有对应的变量名,以便得到更规范的表格呈现和操作体验,spssau中通过“标题修改”定义变量名,一般用于以下情况: ●上传数据后,对不规范标题修改 ●完成数据编码后,进行标题修改 ●完成生成变量后,进行标题修改 ●有多余无意义的标题,进行删除标题(一次只能删除一个标题) 数据标签 除了标题名需要定义,数据标签也是一个重要的属性。数据标签用于标识数据中的数字代表的意义,对数据的含义进行解释说明,比如用1表示男,用2表示女。数据标签仅影响表格展示,完全不影响分析结果。 数据编码 量表问卷中经常会使用到反向计分,反项题得到数据在分析以前,要先进行重新编码。 数据编码通常除了用于处理反项题,还会用于数据组合。 比如1代表高中,2代表大专,3代表本科,4代表硕士,5代表博士。希望组合成三组分别是:本科以下,本科,硕士及以上.则可处理为:1->1,2->1,3->2,4->3,5->3,最终数字1代表本科以下,2代表本科,3代表硕士及以上 无效样本 在数据分析之前,首先需要进行数据查看,包括数据中是否有异常值,无效样本等。如果有无效样本则需要进行处理,然后再进行分析。另外如果数据中有异常值也需要进行处理后再进行分析。无效样本会干扰分析研究,扭曲数据结论等,因而在分析前先对无效样本进行标识显示尤其必要。 如果数据来源为问卷,则很可能出现无效样本,因为填写问卷的样本是否真实填写无从判定;如果数据库下载或者使用二手数据等,也可能出现大量缺失数据等无效样本。 SPSS分析调查问卷数据的方法 (2012-05-29 21:45:13) 分类:学习 标签: 杂谈 当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量﹑数据录入﹑统计分析和结果保存.下面将从这四个方面来对问卷的处理做详细的介绍. Spss处理: 第一步:定义变量 大多数情况下我们需要从头定义变量,在打开SPSS后,我们可以看到和excel相似的界面,在界面的左下方可以看到Data View, Variable View两个标签,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。在表格上方可以看到一个变量要设置如下几项:name(变量名)、type(变量类型)、width(变量值的宽度)、decimals(小数位) 、label(变量标签) 、Values(定义具体变量值的标签)、Missing(定义变量缺失值)、Colomns(定义显示列宽)、Align(定义显示对齐方式)、Measure(定义变量类型是连续、有序分类还是无序分类). 我们知道在spss中,我们可以把一份问卷上面的每一个问题设为一个变量,这样一份问卷有多少个问题就要有多少个变量与之对应,每一个问题的答案即为变量的取值.现在我们以问卷第一个问题为例来说明变量的设置.为了便于说明,可假设此题为: 1.请问你的年龄属于下面哪一个年龄段( )? A:20—29 B:30—39 C:40—49 D:50--59 那么我们的变量设置可如下: name即变量名为1,type即类型可根据答案的类型设置,答案我们可以用1、2、3、4来代替A、B、C、D,所以我们选择数字型的,即选择Numeric, width 宽度为4,decimals即小数位数位为0(因为答案没有小数点),label即变量标签为“年龄段查询”。Values用于定义具体变量值的标签,单击Value框右半部的省略号,会弹出变量值标签对话框,在第一个文本框里输入1,第二个输入20—29,然后单击添加即可.同样道理我们可做如下设置,即1=20—29、2=30—39、3=40—49、4=50--59;Missing,用于定义变量缺失值, 单击missing框右侧的省略号,会弹出缺失值对话框, 界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值”,最多可以定义3个值;最后一项为“缺失值范围加可选的一个缺失值”,在此我们不设置缺省值,所以选中第一项如图;Colomns,定义显示列宽,可自己根据实际情况设置;Align,定义显示对齐方式,有居左、居右、居中三种方式;Measure,定义变量类型是连续、有序分类还是无序分类。 以上为问卷中常见的单项选择题型的变量设置,下面将对一些特殊情况的变量设置也作一下说明. 1.开放式题型的设置:诸如你所在的省份是_____这样的填空题即为开放题,设置这些变量的时候只需要将Value 、Missing两项不设置即可. 2.多选题的变量设置:这类题型的设置有两种方法即多重二分法和多重分类法,在这里我们只对多重二分法进行介绍.这种方法的基本思想是把该题每一个选项设置成一个变量,然后将每一个选项拆分为两个选项项,即选中该项和不选中该项.现在举例来说明在spss中的具体操作.比如如下一例: 请问您通常获取新闻的方式有哪些( ) 1 报纸 2 杂志 3 电视 4 收音机 5 网络 1 重复测方差分析实例操作 分析过程 1.数据格式 2.软件实验步骤 3.结果解释与描述 原始数据 group t0 t1 t2 t3 group t0 t1 t2 t3 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1.1 数据格式 1.2 软件实验步骤 些处的描述过程输出无标准差, group=2时可用Analyze\ Explorer过程实现描述, group=3时可用Analyze→General Lineal Model→Multivariate去实现描述。 1.3 结果解释与描述 表1 有无合并症患者LC含量(s x ) 例数 重复测量时间 麻醉前麻醉后20分钟电切手术30分钟手术结束时 无合并症42 ±±±±有合并症18 ±±±± 统计描述可以通过Analyze\ Explorer过程实现,该过程较简单不赘述。 统计分析教程.(高级篇)张文彤P37 也就是说,在分析时,我们首先要判断,重复测量的不同时间点之间的结果是否存在相关性,也就是进行球形检验,即Mauchly's Test of Sphericity 。 如果P<,不符合 Huynh-Feldt 条件,说明重复测量数据之间存在相关性,不可按单因素方差分析方法处理,需要进行多变量方差分析。以多元检验结果为准。 统计分析教程.(高级篇)张文彤P41 如果P> ,符合Huynh-Feldt 条件,说明重复测量数据之间不存在相关性,可按单因素方差分析方法处理。 统计分析教程.(高级篇)张文彤P40 Table 2 Mauchly's Test of Sphericity Within Subjects Effect Mauchly's W Approx. Chi-Square df Sig. Epsilon a Greenhouse-G eisser Huynh-Feldt Lower-b ound Time 5 .000spss缺失值处理
SPSS数据初步整理须知
调查问卷的SPSS的基本处理方法
spss的数据分析案例
调查问卷数据SPSS分析中—多项选择问题处理方法
SPSS数据案例分析
常用SPSS数据处理方法
SPSS分析调查问卷数据的方法
SPSS操作实例-重复测量