实验7 线性回归
实验编号: 07 四川师大SPSS实验报告2017 年 4 月 24 日
计算机科学学院2015级5班实验名称:线性回归
姓名:唐雪梅学号:2015110538 指导老师:__朱桂琼___ 实验成绩:___
实验七线性回归
一.实验目的及要求
1.了解SPSS 特点结构操作
2.利用SPSS进行简单数据统计
二.实验内容
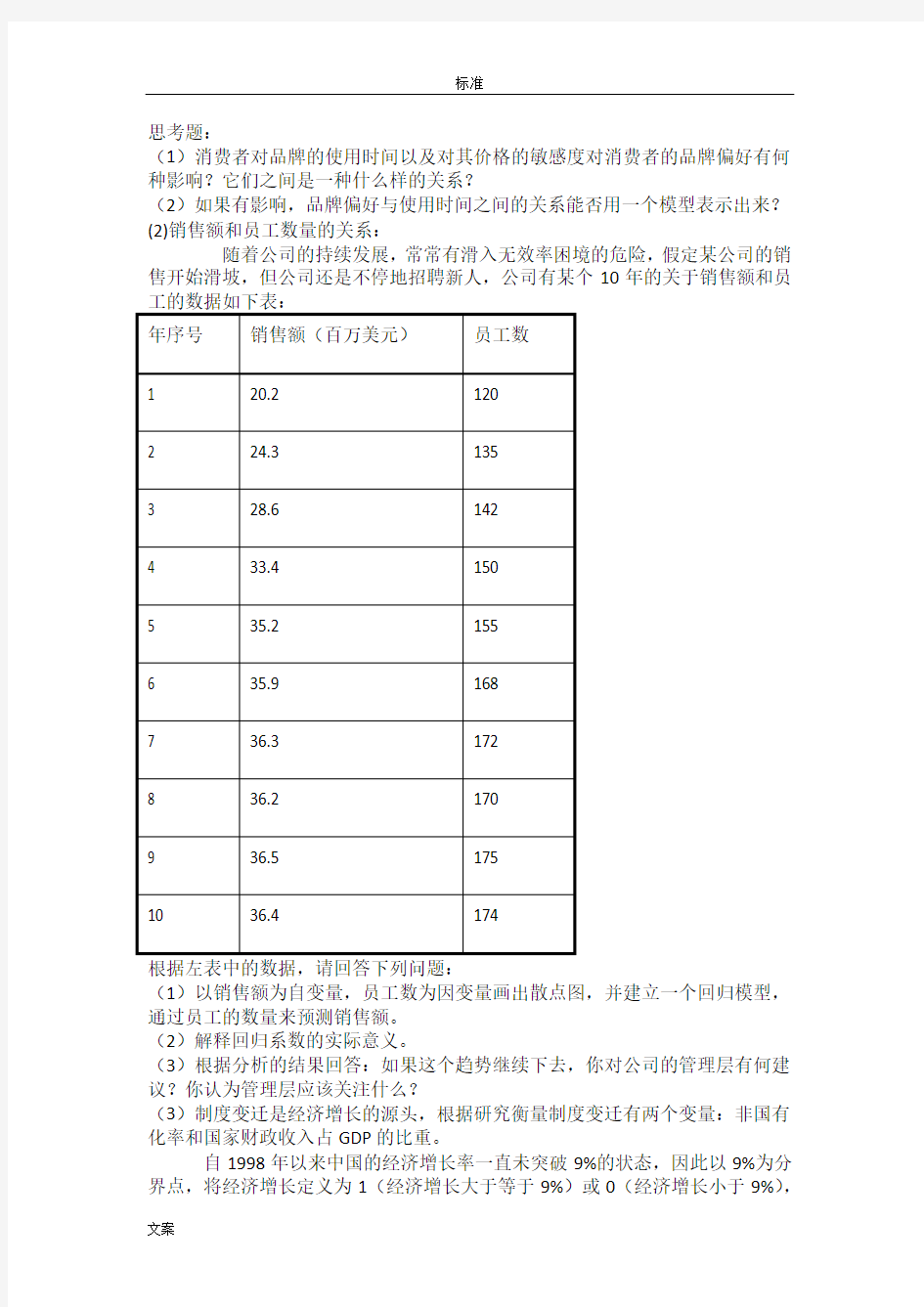
(1)消费者品牌偏好分析:通过品牌使用时间和价格敏感度了解消费者的品牌偏好。
某彩妆系列产品公司进行了一项关于消费者品牌偏好态度的分析,调研人员收集了有关的调研数据,用11点标尺度量态度(1=非常不喜欢该品牌,11=非常喜欢该品牌)对于价格敏感度的度量也用11点标尺(1=对价格完全不敏
思考题:
(1)消费者对品牌的使用时间以及对其价格的敏感度对消费者的品牌偏好有何种影响?它们之间是一种什么样的关系?
(2)如果有影响,品牌偏好与使用时间之间的关系能否用一个模型表示出来?
(2)销售额和员工数量的关系:
随着公司的持续发展,常常有滑入无效率困境的危险,假定某公司的销售开始滑坡,但公司还是不停地招聘新人,公司有某个10年的关于销售额和员
(1)以销售额为自变量,员工数为因变量画出散点图,并建立一个回归模型,通过员工的数量来预测销售额。
(2)解释回归系数的实际意义。
(3)根据分析的结果回答:如果这个趋势继续下去,你对公司的管理层有何建议?你认为管理层应该关注什么?
(3)制度变迁是经济增长的源头,根据研究衡量制度变迁有两个变量:非国有化率和国家财政收入占GDP的比重。
自1998年以来中国的经济增长率一直未突破9%的状态,因此以9%为分界点,将经济增长定义为1(经济增长大于等于9%)或0(经济增长小于9%),
三、实验主要流程、基本操作或核心代码、算法片段(该部分如不够填写,请另加附页)实验一:多元线性回归分析
1.建立数据库
2.分析步骤:分析——回归——线性
3.结果
结论:在对编号为1的模型进行线性回归分析时所采用的方法是全部引入法:输入,此处无被剔出的变量
结论:R Square=0.966,接近于1,说明模型的拟合优度很高,方程拟合很好。
结论:sig=0<0.01,该模型具有显著性意义
系数a
模型
非标准化系数标准系数
t Sig.
B 标准误差试用版
1 (常量) .376 .629 .598 .565
使用时间.516 .060 .819 8.550 .000
价格敏感.235 .085 .266 2.772 .022
a. 因变量: 品牌偏好
拟合结果:y=0.516x1+0.235x2+0.376
Sig.取值大于0.05,没有理由拒绝原假设,即回归系数与零无显著性差异,模型中不存在共线性问题。
结论:特征根均不等于0,则不存在共线性问题,条件指数均小于30,本例中模型不存在共线性的问题。
(1)研究品牌偏好与使用时间之间的关系模型
B)原假设:回归系数与零无显著性差异
C)线性回归分析:
单击分析→回归→线性→打开线性回归主对话框;在弹出的线性回归对话框中,选择变量“品牌偏好(Y)”,添加到因变量框中;选择变量“使用时间(X1)”添加到自变量框中,单机统计量,选中估计、模型拟合度和DW 三个选项。
结果分析:R Square=0.936,接近于1,说明模型的拟合优度很高,方程拟合很好。
DW=2.783,说明残差是负自相关的,表明所假设的模型合理的。
拟合结果:y=0.59x+1.079
残差Mean=0,表明这些数据中无离群值,且数据的标准差也比较小,可以认为模型是合理的
实验二:回归分析
原假设:回归系数与零无显著性差异
1.建立数据库
2.散点图建立:图形——旧对话框——散点\点状——散点图
从图中看出销售额与员工数为非线性关系
(4)回归分析:
A)操作流程:
单击分析→回归→曲线估计→打开曲线估计主对话框;在弹出的曲线估计对话框中,选择变量“员工数”,添加到因变量框中;选择
变量“销售额”添加到自变量框中。
结论:从表中数据可以看出,三次方程的R Square=0.935最接近1,所以员工数和销售呈三次方的关系。
实验三:二维Logistic回归分析
(1)录入实验数据:
(2)二维Logistic回归分析:
1)原假设:回归系数与0无显著性差异
2)操作流程:选择菜单分析→回归→二维Logistic;然后选择Y变量使之添加到因变量框中,选择x1和x2变量,使它们分别进入协变量框中
3)结果分析:
其中常数项包括在模型中,初始-2LL为15.278,迭代结束于第三步,因为此时参数估计与其在上一步的变化已经小于0.001
分类结果表说明Step0的拟合效果。可以看出对于y=1,有100%的准确性,对于y=0,有0%准确性,总共有66.7%的准确性
似然比卡方检验的观测值等于0.039,概率p值等于0.981。显著性水平均大于0.05,所以可以拒绝原假设,即认为所有回归系数不同时为0,解释变量的全体与Logit P之间的线性关系显著,采用该模型合理。
模型拟合优度,给出了-2对数似然值较大,说明拟合优度并不理想,Cox和Shell 值以及Nagelkerke值较小,也说明拟合程度较低。
与前一步相比较,预测的准确率不变,模型的总体预测精度也不变。
Sig的值大于0.05,没有理由拒绝原假设,即认为该回归系数与0无显著性差异,它与Logit P的线性关系不是显著的,所以该模型是不可用的,应该重新建模。
四、实验结果的分析与评价(该部分如不够填写,请另加附页)
1.线性回归分析步骤
(1)确定回归方程中的解释变量(自变量)和被解释变量(因变量)。
(2)确定回归模型:通过观察散点图确定应通过哪种数学模型来概括回归线。
(3)建立回归方程:在一定的统计拟合准则下估计出模型中的各个参数,得到一个确定的回归方程
(4)对回归方程进行各种检验:检验回归方程是否真实地反映了事物总体间的统计关系以及回归方程能否用于预测等
(5)利用回归方程进行预测:根据回归方程对事物的未来发展趋势进行预测
2.一元线性回归操作
1.单击Analyze→Regression→Linear→打开Linear Regression主对话框
2.在弹出的LinearRegression对话框中,选择变量“气压”,添加到Dependent框中,表
示因变量;选择变量“沸点”,添加到Independent框中,表示自变量。
3.多元线性回归操作
Analyze→Regression→Linear命令,打开Linear Regression 对话框
选择解释变量Y进入Dependent框
将X1,X2和X5直接纳入模型
X3和X4通过逐步法。而X6直接不予考虑
选择被解释变量X1,X2和X5进入Independent(s)框
在Method框中选择Enter(默认)表示所选变量强行进入回归方程
单击Next
选择被解释变量X3、X4进入Independent(s)框
在Method框中选择Stepwise对所选变量进行逐步筛选策略
在Linear Regression对话框中单击Statistics按钮
选中Estimates 和Model fit 复选框
选中Collinearity diagnostics复选框
单击OK按钮
4. 二维Logistic回归的SPSS操作
选择菜单Analyze →Regression→Binary Logistic
选择y变量使之添加到Dependent框中,选择x1变量、x2、x3,使它们分别进入Covariates 框中,表示其为自变量
单击Logistic Regression对话框中的Options按钮,选择所有选项,但保留各选项中的缺省值单击Continue按钮,返回上一个对话框,单击OK按钮
注:实验成绩等级分为(90-100分)优,(80-89分)良,(70-79分)中,(60-69分)及格,(59分)不及格。