编译原理复习整理(重点含答案)培训资料

1、给出下面语言的相应文法。L1={a n b n c i|n≥1,i≥0}
从n,i的不同取值来把L1分成两部分:前半部分是anbn:A→aAb|ab后半部分是ci:B→Bc|ε所以整个文法G1[S]可以写为:G1(S):S→AB;A→aAb|ab;B→cB|ε
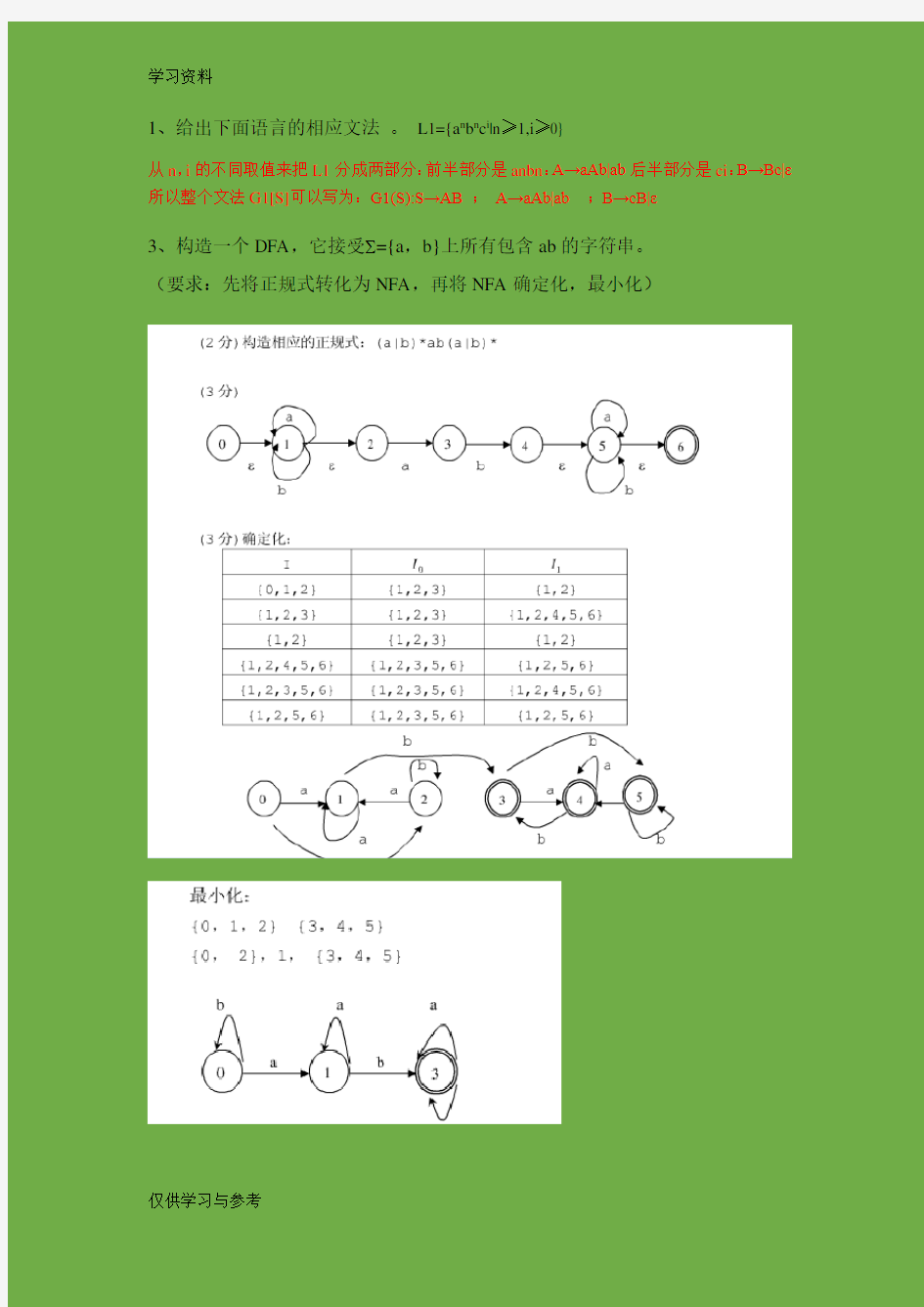
3、构造一个DFA,它接受 ={a,b}上所有包含ab的字符串。
(要求:先将正规式转化为NFA,再将NFA确定化,最小化)
4、对下面的文法G:
E →TE ’ E ’→+E|ε T →FT ’ T ’→T|ε
F →PF ’ F ’ →*F ’|ε P →(E)|a|b|∧
(1)证明这个文法是LL(1)的。 (2)构造它的预测分析表。
(1)FIRST(E)={(,a,b,^}FIRST(E')={+,ε}FIRST(T)={(,a,b,^}FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^}FIRST(F')={*,ε}FIRST(P)={(,a,b,^}FOLLOW(E)={#,)}
FOLLOW(E')={#,)}FOLLOW(T)={+,),#}FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#}FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:
'→+'→'→'→E E T T F F P E a b ||*|()|^||εεε
FIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φ
FIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φ FIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ 所以,该文法式LL(1)文法. (3)
+
*
(
)
a
b
^
#
E
E TE →'
E TE →' E TE →' E TE →'
E' '→+E E
'→E ε
'→E ε
T
T F T →'
T F T →' T F T →' T F T →'
T' '→T ε
'→T T '→T ε '→T T '→T T '→T T '→T ε
F
F P F →'
F P F →' F P F →' F P F →'
F' '→F ε '→'F F * '→F ε '→F ε '→F ε '→F ε '→F ε '→F ε
P
P E →()
P a → P b → P →^
5、考虑文法: S →AS|b A →SA|a (1)列出这个文法的所有LR(0) 项目。
0.'→?S S 1.'→?S S 2.S AS →? 3.S A S →? 4.S AS →? 5.S b →? 6.S b →?7.A SA →?8.A S A →? 9.A SA →? 10.A a →? 11.A a →?
(2)给出识别文法所有活前缀的DFA 。
S A ε
S 7 1
8 9
εεε
ε a
εε
ε
A S
ε
ε
b
确定化:
S A a b
{0,2,5,7,10} {1,2,5,7,8,10
}
{2,3,5,7,10} {11} {6}
{1,2,5,7,8,10
}
{2,5,7,8,10} {2,3,5,7,9,10} {11} {6}
{2,3,5,7,10} {2,4,5,7,8,10
}
{2,3,5,7,10} {11} {6} {2,5,7,8,10} {2,5,7,8,10} {2,3,5,7,9,10} {11} {6}
{2,3,5,7,9,10
} {2,4,5,7,8,10
}
{2,3,5,7,10} {11} {6}
{2,4,5,7,8,10
} {2,5,7,8,10} {2,3,5,7,9,10} {11} {6} 0 10
5
6
11
2 3 4
{11} φ φ φ φ {6} φ
φ
φ
φ
A S
S A a
b
S a A S b S A b a A
A S
0:'→?S S
S AS →? S b →? 4:S A S →?
S AS →? S b →?
3:'
→?S S
A S A →?
A SA →?
A a →?
5:A S A →?
S AS →? S b →?
A SA →? 6:A SA →?
S A S →?
S AS →? S b →?
7:S AS →?
A S A →?
S AS →?
b
a a
b b a
DFA
6、设有文法:P →P+Q|Q Q →Q*R|R R →(P)|i
(1)证明Q*R+Q+Q 是它的一个句型。(3分) P=>P+Q=>P+Q+Q=>Q+Q+Q=>Q*R+Q+Q
(2)给出Q*R+Q+Q 的所有短语,直接短语和句柄。(4分)
短语: Q*R,Q*R+Q,Q*R+Q+Q 直接短语: Q*R 句柄: Q*R
(3)给出句子i+i*i的最右推导。(4分) (4)给出句子i+i*i的最左推导。(4分)
7、设有文法:E →E+T|T T →T*F|F F →(E)|i
(1)证明E+T*F 是它的一个句型。(3分)E E T E T F ?+?+* (2)给出E+T*F 的所有短语,直接短语和句柄。(4分)
短语: E+T*F, T*F, 直接短语: T*F 句柄: T*F
(3)给出句子i+i*i的最右推导。(4分)
2:S b →?
1:A a →?
11、构造下面正规式相应的DFA
1(0|1)*101
14、对下面的文法G:
Expr→- Expr Expr→(Expr)|Var ExprTail ExprTail→- Expr|εVar→id VarTail VarTail→(Expr) |ε
(1)构造LL(1)分析表。(12分)
(2)给出对句子id—id((id))的分析过程。(8分)
16、已知文法G[S] 为: S->a|^|(T) T->T,S|S
①消除文法G[S]中的左递归,得文法G ′[S]。
ε
|,)
(||^)
(T S T T S T T a S S G '→''→→'
② 文法G ′[S]是否为LL(1)的?若是,给出它的预测分析表。
FIRST(S)={a,^,(} FIRST(T)={a,^,(} FIRST('T )={,,ε} FOLLOW(S)={),,,#} FOLLOW(T)={)} FOLLOW('T )={)} 预测分析表
a
^
(
) , # S S a → S →^
S T →()
T
T ST →' T ST →' T ST →'
'T
'→T ε '→'T ST ,
是LL(1)文法
17、对下面的文法G:
S → S ∨ a T | a T | ∨ a T T → ∧ a T | ∧ a
(1) 消除该文法的左递归和提取左公因子;构造各非终结符的FIRST 和FOLLOW 集合;
18、文法G(S)及其LR分析表如下,请给出串baba#的分析过程。(1) S → DbB (2) D → d (3) D →ε
(4) B → a (5) B → Bba (6) B →ε
LR分析表
2、写出表达式a=b*c+b*d对应的逆波兰式、四元式序列和三元式序列。答:逆波兰式: abc*bd*+:=
编译原理期末复习
编译原理期末复习 鉴于编译原理马上就要期末考试,我将手中集中的一些资料上的题目进行了整理归类,每种类型题目给出了所涉及到的基本知识,然后对每类题目中的第一道例题进行了做法进行了讲解,剩下的例题请给大家作为练习,答案也都给出,希望对大家复习有所帮助,最后由于时间很紧,整理的有些仓促,整理中难免有遗漏或错误,请大家见谅。 注:下面出现的字母中,若无特别说明,小写英文字母为终结符,大写英文字母为非终结符,希腊字母为终结符与非终结符的任意组合。 1、简答题(或者名词解释) 下面涉及到的概念中,加下划线的都是在以往一些试卷中出现的原题,务必掌握。 注:这类题目老师说答案不会超过一百个字,否则写的再多也不给分,有些点到即可,不要重复啰嗦。(1)简述编译程序的概念及其构成 答:1)编译程序:它特指把某种高级程序设计语言翻译成等价的低级程序设计语言的翻译程序。 2)构成: (2)简述词法分析阶段的主要任务(也有可能问语法分析阶段主要任务)答:词法分析的任务是输入源程序,对源程序进行扫描,识别其中的单词符号,把字符串形式的源程序转换成单词符号形式的源程序。 语法分析的主要任务是对输入的单词符号进行语法分析(根据语法规则进行推导或者归约),识别各类语法单位,判断输入是不是语法上正确的程序 (3) 简述编译程序的构造过程(这个大家看看,是对(1)和(2)的综合) 答:1)构造词法分析器:用于输入源程序进行词法分析,输出单词符号; 2)构造语法分析器:对输入的单词符号进行语法分析,识别各类语法单位,判断输入是不是语法上正确的程序 3)构造语义分析和中间代码产生器:按照语义规则对已归约出的语法单位进行语义分析并把它们翻译成中间代码。 4)构造优化器:对中间代码进行优化。 5) 构造目标代码生成器:把中间的代码翻译成目标程序。 6) 构造表格管理程序:登记源程序的各类信息和编译各阶段的进展情况。 7)构造错误处理程序:对出错进行处理。 (4) 说明编译和解释的区别: 1)编译要程序产生目标程序,解释程序是边解释边执行,不产生目标程序; 2)编译程序运行效率高而解释程序便于人机对话。 (5)文法:描述语言语法结构的形式规则,一般用一个四元式表示: G=(V T,V N,S,P),其中V T:终结符集合(非空) V N:非终结符集合(非空),且V T ?V N=? S:文法的开始符号,S?V N P:产生式集合(有限)。
编译原理习题及答案(整理后)
第一章 1、将编译程序分成若干个“遍”就是为了。 a.提高程序得执行效率 b.使程序得结构更加清晰 c.利用有限得机器内存并提高机器得执行效率 d.利用有限得机器内存但降低了机器得执行效率 2、构造编译程序应掌握。 a.源程序b.目标语言 c.编译方法d.以上三项都就是 3、变量应当。 a.持有左值b.持有右值 c.既持有左值又持有右值d.既不持有左值也不持有右值 4、编译程序绝大多数时间花在上。 a.出错处理b.词法分析 c.目标代码生成d.管理表格 5、不可能就是目标代码。 a.汇编指令代码b.可重定位指令代码 c.绝对指令代码d.中间代码 6、使用可以定义一个程序得意义。 a.语义规则b.语法规则 c.产生规则d.词法规则 7、词法分析器得输入就是。 a.单词符号串b.源程序 c.语法单位d.目标程序 8、中间代码生成时所遵循得就是- 。 a.语法规则b.词法规则 c.语义规则d.等价变换规则 9、编译程序就是对。 a.汇编程序得翻译b.高级语言程序得解释执行 c.机器语言得执行d.高级语言得翻译 10、语法分析应遵循。 a.语义规则b.语法规则 c.构词规则d.等价变换规则 二、多项选择题 1、编译程序各阶段得工作都涉及到。 a.语法分析b.表格管理c.出错处理 d.语义分析e.词法分析 2、编译程序工作时,通常有阶段。 a.词法分析b.语法分析c.中间代码生成 d.语义检查e.目标代码生成 三、填空题 1、解释程序与编译程序得区别在于。 2、编译过程通常可分为5个阶段,分别就是、语法分析、代码优化与目标代码生成。 3、编译程序工作过程中,第一段输入就是,最后阶段得输出为程序。
编译原理概念_名词解释
编译过程的六个阶段:词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成 解释程序:把某种语言的源程序转换成等价的另一种语言程序——目标语言程序,然后再执行目标程序。 解释方式是接受某高级语言的一个语句输入,进行解释并控制计算机执行,马上得到这句的执 行结果,然后再接受下一句。 编译程序:就是指这样一种程序,通过它能够将用高级语言编写的源程序转换成与之在逻辑上等价的低级语言形式的目标程序(机器语言程序或汇编语言程序)。 解释程序和编译程序的根本区别:是否生成目标代码 句子的二义性(这里的二义性是指语法结构上的。):文法G[S]的一个句子如果能找到两种不同的最左推导(或最右推导),或者存在两棵不同的语法树,则称这个句子是二义性的。 文法的二义性:一个文法如果包含二义性的句子,则这个文法是二义文法,否则是无二义文法。 LL(1)的含义:(LL(1)文法是无二义的; LL(1)文法不含左递归) 第1个L:从左到右扫描输入串第2个L:生成的是最左推导 1:向右看1个输入符号便可决定选择哪个产生式 某些非LL(1)文法到LL(1)文法的等价变换: 1. 提取公因子 2. 消除左递归 文法符号的属性:单词的含义,即与文法符号相关的一些信息。如,类型、值、存储地址等。 一个属性文法(attribute grammar)是一个三元组A=(G, V, F) G:上下文无关文法。 V:属性的有穷集。每个属性与文法的一个终结符或非终结符相连。属性与变量一样,可以进行计算和传递。 F:关于属性的断言或谓词(一组属性的计算规则)的有穷集。断言或语义规则与一个产生式相联,只引用该产生式左端或右端的终结符或非终结符相联的属性。 综合属性:若产生式左部的单非终结符A的属性值由右部各非终结符的属性值决定,则A的属性称为综合属继承属性:若产生式右部符号B的属性值是根据左部非终结符的属性值或者右部其它符号的属性值决定的,则B的属性为继承属性。 (1)非终结符既可有综合属性也可有继承属性,但文法开始符号没有继承属性。 (2) 终结符只有综合属性,没有继承属性,它们由词法程序提供。 在计算时:综合属性沿属性语法树向上传递;继承属性沿属性语法树向下传递。 语法制导翻译:是指在语法分析过程中,完成附加在所使用的产生式上的语义规则描述的动作。 语法制导翻译实现:对单词符号串进行语法分析,构造语法分析树,然后根据需要构造属性依赖图,遍历语法树并在语法树的各结点处按语义规则进行计算。 中间代码(中间语言) 1、是复杂性介于源程序语言和机器语言的一种表示形式。 2、一般,快速编译程序直接生成目标代码。 3、为了使编译程序结构在逻辑上更为简单明确,常采用中间代码,这样可以将与机器相关的某些实现细节置于代码生成阶段仔细处理,并且可以在中间代码一级进行优化工作,使得代码优化比较容易实现。 何谓中间代码:源程序的一种内部表示,不依赖目标机的结构,易于代码的机械生成。 为何要转换成中间代码:(1)逻辑结构清楚;利于不同目标机上实现同一种语言。 (2)便于移植,便于修改,便于进行与机器无关的优化。 中间代码的几种形式:逆波兰记号,三元式和树形表示,四元式 符号表的一般形式:一张符号表的的组成包括两项,即名字栏和信息栏。 信息栏包含许多子栏和标志位,用来记录相应名字和种种不同属性,名字栏也称主栏。主栏的内容称为关键字(key word)。 符号表的功能:(1)收集符号属性(2) 上下文语义的合法性检查的依据:检查标识符属性在上下文中的一致性和合法性。(3)作为目标代码生成阶段地址分配的依据
培训人员资料整理
行业篇: 一、高铁趋势 近年来,随着互联网的普及和网络的发达,一部分传统行业受到巨大冲击,2016年上半年,在单体百货、购物中心以及2000平方米以上的大型超市业态中,22家公司共关闭了41家店铺。其中,更是涉及到沃尔玛、家乐福等大型品牌。而传统零售行业在未来超过半数将会破产,如美特斯邦威已关店200多家,李宁更是关店1821家。 相比之下,中国高铁发展迅猛,2014年全国火车站已达到5500多个;2015年春运全国旅客发送量预计将超28亿人次!铁路商旅服务市场超千亿!互联网时代,造就了铁路商旅成财富新洼地! 二、站车商业 传统零售终端门可落雀之时,迅猛发展的高铁站、火车站却人流滚滚,候车室座位常常一座难求!高铁的迅速发展在直追航空的同时,也为铁路商旅服务提出了更高的要求,涉及到候车、购票、消费等诸多环节。在支付了更高票价的同时,旅客自然也希望能够获得更优质的服务。高铁服务硬件和软件的配套相对滞后,通过整合外部资源弥补不足成为新的趋势,高铁站招募商业服务商家提供服务,为高铁商旅服务企业创造了商机! 三、社会需求 社会需求也分物质需求和精神需求,从旅客出行的角度来考虑,华铁也从这两方面满足了社会群众的需求。华铁终端门店设置按摩椅,从物质上上解决了出行旅客对休息座位的需求,丰富了站车商业结构,改善车站整体的服务环境。同时华铁在终端门店给往来旅客带来优质、贴心的服务,从精神层面满足现代社会高品质商旅出行的需求。 商业篇 一、商业模式:
江苏华铁集商旅服务、线下实体店、线上电子商务为一体的互联网+商业机构,依托全国火车站候车室资源和互联网技术,打造集商旅休闲、商旅礼品为一体的,线上线下相结合的综合性商旅服务平台。 二、千店计划: 在未来3年内,江苏华铁将完成全国高铁站1000个终端店铺建设,招募粉丝(会员)1000万,形成覆盖全国的终端服务网络。 三、华铁愿景: 打造铁路商旅服务的领导品牌 价值篇 一、时代价值 现今社会追求和平与发展为时代价值,而只有社会的和平与发展,才能让人民获得幸福安定的生活。江苏华铁正是围绕着这一价值主题,在与人类出行最密切相关的铁路商旅上设置终端门店,将门店打造成未来铁路商旅服务发展和前进的坚定基石。 二、社会价值 现今社会以追求和谐、繁荣、发展为价值体现,在此之下也必然会形成一个忙碌、机械的社会环境,江苏华铁以高品质的服务在川流不息拥挤车站之中,营造一个供旅客安静舒适的休息港湾,以无微不至的关怀满足提升旅客的幸福感,为和谐社会贡献自己的力量。 三、铁路贡献 铁路是目前世界上最发达最便捷的交通方式,然而随着群众的权利意识越来越强,加上其他交通运输行业服务竞争的对比,铁路运输服务水平将受到挑战。江苏华铁在铁路客运处设立的终端门店,将更好的弥补铁路运输上的服务缺口,提升铁路运输的整体服务品质。 市场篇
编译原理知识点
1.解释程序:不生成目标代码 编译程序:生成目标代码 2.编译程序组成:8个 分析< 前端>:(词法分析程序、语法分析程序、语义分析程序、中间代码生成程序) 综合< 后端>:(代码优化程序、目标代码生成程序) 贯穿始末:表格管理程序、出错处理程序 3.文法四元组: 终结符号集合Vt 、非终结符号集合Vn、产生式集合P、识别符号(开始符号)S V T∩V N=Φ 文法-> 语言(推导、规约)唯一;语言-> 文法(凑规则)不唯一。 4.文法分类: 0型文法(短语结构文法):左侧至少含有一个非终结符 1型文法(上下文有关文法):左侧长度<= 右侧长度S->ε除外,S不能出现在右侧2型文法(上下文无关文法):左侧只能有一个非终结符( 语法分析) 3型文法(正规文法):A-> aB A->a 右线性;( 词法分析) A->Ba 或A->a 左线性(看非终结符位置) 5.A*=A0 ∪A+ A0 ={ε} !={ } =Φ空集 A+ =AA* =A*A 6.句型:符号串x是从识别符号S推导出来的,x称为一个句型 句子:x仅由终结符号组成,仅含终结符号的句型是一个句子 短语:子树的末端(叶子)从左至右连成的串(包括整棵语法树) 简单子树:只含有单层分枝的子树 直接短语( 简单短语):由简单子树的叶子组成 句柄:最左边的直接短语(不一定含终结符) 素短语:至少含有一个终结符的短语,并且除它自身之外不再含任何更小的素短语最左素短语:最左边的素短语 短语:P(相对于T、E)、P+T(相对于E)、i(相对于P、F)、P+T+i(相对于E)直接短语:P、i 句柄:P (最左边的直接短语) 素短语:P+T 、i (至少含有一个终结符的短语)最左素短语:P+T 7.二义性文法:有两个不同的最左推导或有两个不同的最右推导或能产生两棵语法树 8.文法产生式正规式 规则1 A→xB B→y A = xy
《编译原理》练习题
《编译原理》练习题一 一、填空题(每空1分) 1.设G [S ]是一个文法,我们把能由文法的 (1) 推导出来的符号串α称为G 的一个句型。当句型α仅由 (2) 组成时 (即α∈V T * ),则将它称为G 产生的句子。 2.从某一给定的状态q 出发,仅经过若干条 (3) 的矢线所能达到的状态所组成的集合称为ε-CLOSURE(q)。 3.设G=(V N ,V T ,P,S)是一文法,我们说G 中的一个符号X ∈V N ∪V T 是有用的,是指X 至少出现在 (4) 的推导过程中,否则,就说X 是无用的。我们将不含形如A→A 的产生式和不含无用符号及无用产生式的文法称为 (5) 。 4.我们常采用形如 (class, value)的二元式作为一个单词的 (6) 。其中,class 是一个整数,用来指示该单词的 (7) ,value 则是单词之值。 5.一个文法G[S]可表示成形如 (8) 的四元式。其中V N ,V T ,P 均为非空的有限集,分别称为非终结符号集、终结符号集和产生式集, S ∈V N 为文法的开始符号。此外,将出现在各产生式左部和右部的一切符号所组成的集合称为 (9) ,记作V 。显然,V=V N ∪V T ,V N ∩V T =?。 6.通常,可通过两种途径来构造词法分析程序。其一是根据对语言中各类单词的某种描述或定义,用 (10) 构造词法分析程序;另外一种途径是所谓词法分析程序的 (11) 。 7.设G 为一文法,A→α是G 的一个产生式,如果α具有υA δ的形式,其中υ,δ不同时为ε,则称产生式A→α是 (12) 。若存在推导δυαA A * ??,则 称产生式A→α是 (13) 。 8.设M=(K,Σ,f,S 0,Z)为一DFA ,并设s 和t 是M 的两个不同状态,我们说状态s,t 为某一输入串w (14) ,是指从s,t 中之一出发,当扫视完w 之后到达M 的终态,但从其中的另一个状态出发,当扫视完同一个w 后而进入 (15) 。 9.把最右推导称为 (16) ,而把右句型称为 (17) 。 10.如果从状态转换图的初态出发,分别沿着一切可能的路径到达 (18) ,并
编译原理复习整理(重点含答案)
1、给出下面语言的相应文法。L1={a n b n c i|n≥1,i≥0} 从n,i的不同取值来把L1分成两部分:前半部分是anbn:A→aAb|ab后半部分是ci:B→Bc|ε所以整个文法G1[S]可以写为:G1(S):S→AB;A→aAb|ab;B→cB|ε 3、构造一个DFA,它接受 ={a,b}上所有包含ab的字符串。 (要求:先将正规式转化为NFA,再将NFA确定化,最小化)
4、对下面的文法G: E →TE ’ E ’→+E|ε T →FT ’ T ’→T|ε F →PF ’ F ’ →*F ’|ε P →(E)|a|b|∧ (1)证明这个文法是LL(1)的。 (2)构造它的预测分析表。 (1)FIRST(E)={(,a,b,^}FIRST(E')={+, ε}FIRST(T)={(,a,b,^}FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^}FIRST(F')={*,ε}FIRST(P)={(,a,b,^}FOLLOW(E)={#,)} FOLLOW(E')={#,)}FOLLOW(T)={+,),#}FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#}FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式: '→+'→'→'→E E T T F F P E a b ||*|()|^||εεε FIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φ FIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φ
编译原理习题及答案(整理后)
第一章 1、将编译程序分成若干个“遍”是为了。 b.使程序的结构更加清晰 2、构造编译程序应掌握。 a.源程序b.目标语言 c.编译方法 3、变量应当。 c.既持有左值又持有右值 4、编译程序绝大多数时间花在上。 d.管理表格 5、不可能是目标代码。 d.中间代码 6、使用可以定义一个程序的意义。 a.语义规则 7、词法分析器的输入是。 b.源程序 8、中间代码生成时所遵循的是- 。 c.语义规则 9、编译程序是对。 d.高级语言的翻译 10、语法分析应遵循。 c.构词规则 二、多项选择题 1、编译程序各阶段的工作都涉及到。 b.表格管理c.出错处理 2、编译程序工作时,通常有阶段。 a.词法分析b.语法分析c.中间代码生成e.目标代码生成 三、填空题 1、解释程序和编译程序的区别在于是否生成目标程序。 2、编译过程通常可分为5个阶段,分别是词法分析、语法分析中间代码生成、代码优化和目标代码生成。 3、编译程序工作过程中,第一段输入是源程序,最后阶段的输出为标代码生成程序。 4、编译程序是指将源程序程序翻译成目标语言程序的程序。
一、单项选择题 1、文法G:S→xSx|y所识别的语言是。 a. xyx b. (xyx)* c. x n yx n(n≥0) d. x*yx* 2、文法G描述的语言L(G)是指。 a. L(G)={α|S+?α , α∈V T*} b. L(G)={α|S*?α, α∈V T*} c. L(G)={α|S*?α,α∈(V T∪V N*)} d. L(G)={α|S+?α, α∈(V T∪V N*)} 3、有限状态自动机能识别。 a. 上下文无关文法 b. 上下文有关文法 c.正规文法 d. 短语文法 4、设G为算符优先文法,G的任意终结符对a、b有以下关系成立。 a. 若f(a)>g(b),则a>b b.若f(a) 档案管理培训讲义 培训目的: 通过培训,提升各单位档案管理人员的专业知识水平和档案处理工作效率,规各级档案管理流程,为公司建立规化、科学化的档案管理体系夯实基础。 培训要点: 一、档案管理的基础知识 二、公司档案管理的容及要求 一、档案管理的基础知识 1、什么是档案? 国家机构、社会组织或个人在社会活动中直接形成的有价值的各种形式的历史记录。 2、什么是档案工作? 管理档案和档案事业的活动。 3、什么是档案统计? 对反映和说明档案及档案工作现象的数量特征进行搜集、整理和分析的活动。 4、什么是归档? 办理完毕且具有保存价值的文件经系统整理交档案室 或档案馆保存的过程。 5、什么是案卷? 由互有联系的若干文件组成的档案保管单位。 6、什么是档案整理? 按照一定原则对档案实体进行系统分类、组合、排列、编号和基本编目,使之有序化的过程。 7、什么是档案立卷? 将若干文件按形成规律和有机联系组成案卷的过程。 8、什么是档案实体分类? 根据档案的来源、形成时间、容、形式等特征对档案实体进行的分类。 9、什么是档号? 以字符形式赋予档案实体的用以固定和反映档案排列顺序的一组代码。 10、什么是文件? 国家机构、社会组织或个人履行其法定职责或处理事务中形成的各种形式的信息记录。 11、什么是文本? 同一文件由于作用不同而形成不同的版本,可分为正本、副本、试行本、修订本、各种文字文本等。 12、什么是归档文件? 在其职能活动中形成的、办理完毕、应作为档案保存的各种纸质文件材料。 13、什么是归档文件管理? 将归档文件以件为单位进行装订、分类、排列、编号、编目、装盒,使之有序化的过程。 14、什么是全宗号? 编译原理的复习提纲 1.编译原理=形式语言+编译技术 2.汇编程序: 把汇编语言程序翻译成等价的机器语言程序 3.编译程序: 把高级语言程序翻译成等价的低级语言程序 4.解释执行方式: 解释程序,逐个语句地模拟执行 翻译执行方式: 翻译程序,把程序设计语言程序翻译成等价的目标程序 5.计算机程序的编译过程类似,一般分为五个阶段: 词法分析、语法分析、语义分析及中间代码生成、代码优化、目标代码生成 词法分析的任务: 扫描源程序的字符串,识别出的最小的语法单位(标识符或无正负号数等) 语法分析是: 在词法分析的基础上的,语法分析不考虑语义。语法分析读入词法分析程序识别出的符号,根据给定的语法规则,识别出各个语法结构。 语义分析的任务是检查程序语义的正确性,解释程序结构的含义,语义分析包括检查变量是否有定义,变量在使用前是否具有值,数值是否溢出等。 语法分析完成之后,编译程序通常就依据语言的语义规则,利用语法制导技术把源程序翻译成某种中间代码。所谓中间代码是一种定义明确、便于处理、独立于计算机硬件的记号系统,可以认为是一种抽象机的程序 代码优化的主要任务是对前一阶段产生的中间代码进行等价变换,以便产生速度快、空间小的目标代码 编译的最后一个阶段是目标代码生成,其主要任务是把中间代码翻译成特定的机器指令或汇编程序 编译程序结构包括五个基本功能模块和两个辅助模块 6.编译划分成前端和后端。 编译前端的工作包括词法分析、语法分析、语义分析。编译前端只依赖于源程序,独立于目标计算机。前端进行分析 编译后端的工作主要是目标代码的生成和优化后端进行综合。独立于源程序,完全依赖于目标机器和中间代码。 把编译程序分为前端和后端的优点是: 可以优化配置不同的编译程序组合,实现编译重用,保持语言与机器的独立性。 7.汇编器把汇编语言代码翻译成一个特定的机器指令序列 第二章 1.符号,字母表,符号串,符号串的长度计算P18,子符号串的含义,符号串的简单运算XY,Xn, 2.符号串集合的概念,符号串集合的乘积运算,方幂运算,闭包与正闭包的概念P19,P20A0 ={ε} 3.重写规则,简称规则。非xx(V 第1 章 1、编译过程包括哪几个主要阶段及每个 阶段的功能。 答案:编译过程包括词法分析、语法分析、语义分析和中间代码生成、优化、目标代码生成5 个阶段。词法分析的功能是对输入的高级语言源程序进行词法分析,识别其中的单词符号,确定它们的种类,交给语法分析器,即把字符串形式的源程序分解为单词符号串形式。语法分析的功能是在词法分析结果的基础上,运用语言的语法规则,对程序进行语法分析,识别构成程序的各类语法范畴及它们之间的层次关系,并把这种层次关系表达成语法树的形式。词义分析和中间代码生成的功能是在语法分析的基础上,对程序进行语义分析,“理解”其含义,产生出表达程序语义的内部表达形式(中间代码)。优化的功能是按照等价变换的原则,对语义分析器产生的中间代码序列进行等价变换,删除其中多余的操作,对耗时耗空间的代码进行优化,以期最后得到高效的可执行代码。目标代码生成的功能是把优化后的中间代码变换成机器指令代码,得到可在目标机器上执行的机器语言程序。 第2 章 1、写一上下文无关文法G,它能产生配 对的圆括号串(如:(),(()),()(())等,甚至 包括0 对括号) 文法为:S→(L)|LS|L L→S| ε 2 、已知文法G :E→E+T|E-T|T T→T*F|T/F|F F→(E) |i (1)给出i+i*i,i*(i-i)的最左推导,最右推导以及语法树。 (2)i-i+i 哪个算符优先。 【解答】 (1)最左推导:E?E+T?T+T? F+T ? i+T ? i+T*F ? i+F*F ?i+i*F ?i+i*i E?T?T*F? F*F ? i*F ? i*(E) ? i*(E-T) ? i*(T-T) ? i*(F-T) ? i*(i-T) ? i*(i-F) ?i*(i-i) 最右推导:E?E+T?E+T*F? E+T*i ? E+F*i ? E+i*i ? T+i*i ? F+i*i ? i+i*i E?T?T*F? T*(E) ? T*(E-T) ? T*(E-F) ? T*(E-i) ? T*(T-i) ? T*(F-i) ?T*(i-i) ? F*(i-i) ?i*(i-i) i+i*i 以及i*(i-i)的语法树如下所示: (2)i-i+i 的语法树如下图所示。 从上图的语法树可知:“-”的位置位 于“+”的下层,也就是前面两个i 先进 行“-”运算,再与后面的i 进行“+” 运算,所以“-”的优先级高于“+”的 优先级。 3 、文法G: E→ET+|T T→TF*|F F→FP↑|P P→E|i (1)试证明符号串TET+*i↑是G 的一 个句型(要求画出语法树). (2)写出该句型的所有短语,直接短语和句柄. 【解答】(1)采用最右推导: E?T?F? FP↑? Fi↑? Pi↑? Ei↑ ? Ti↑? TF*i↑? TP*i↑? TE*i↑? TET+*i↑ 语法树如下图所示。 从文法G 的起始符号出发,能够推导 出符号串TET+*i↑,所以给定符号串是文法G的句型。 (2) 该句型的短语有: ET+,TET+*,i ,TET+*i↑ 直接短语有:ET+, i 句柄是:ET+ 4、已知文法G:S→iSeS|iS|i ,该文法 是二义文法吗?为什么? 【解答】该文法是二义文法。 因为对于句子iiiei 存在两种不同的最 左推导: 第 1 种推导:S? iSeS? iiSeS? iiieS? iiiei 第2种推导:S?iS?iiSeS?iiieS?iiiei 第3 章 1、用正规式描述下列正规集: (1)C 语言的十六进制整数; (2)以ex 开始或以ex 结束的所有小写字母构成的符号串; (3)十进制的偶数。 【解答】 (1)C 语言十六进制整数以0x 或者0X 开头,所以一般形式应该为(+|-|ε) (0x|0X)AA*,其中前面括号表示符号, 可以有正号、负号,也可以省略(用ε表示)默认是正数,A 表示有资格出现在十六进制整数数位上的数字,AA*表示一位或者多位(一个或者多个数字的 翻译程序:把一种语言程序转换成另一种语言程序,且在功能上是相同的这样的程序。 编译程序:把高级语言转换成低级语言,且在功能上是相同的这样的程序。 解释程序:边解释边执行源程序的程序。区别:编译程序有中间代码,而解释程序没有。编译过程的五个阶段: 1、词法分析任务:对构成源程序的字符串进行扫描和分解,识别出一个个单词。 2、语法分析任务:在词法分析的基础上,根据语言规则,把单词符号串分解成各类语法 单位。 3、语义分析和中间代码产生任务:对语法分析所识别出的各类语法范畴,分析其含义, 并进行初步翻译。 4、优化任务:对前段产生的中间代码进行加工变换,以期在最后阶段能产生出更为高效 的目标代码。 5、目标代码生成任务:把中间代码变换成特定机器上的低级语言代码。 编译程序的七个部分词法分析器,语法分析器、语义分析与中间代码产生器、优化器、目标代码生成器、表格管理和出错处理。 编译程序生成的五个办法:机器语言、高级语言、移植、自编译方式和使用工具自动生成。词法规则:指单词符号的形成规则。(也就是正规式) 语法规则:规定了如何从单词符号形成更大的结构。就是语法单位的形成规则。 空字:不包含任何符号的序列。 闭包: 中所有的符号组成的集合。 上下文无关文法是指:所定义的语法范畴是完全独立于这种范畴可能出现的环境的文法。上下文无关文法的四个组成部分:一组终结符号、一组非终结符号、一个开始符号和一组产生式。 终结符号也就是不可再分的基本符号。 非终结符号是用来代表语法范畴,表示一定符号串的集合。 开始符号是语言中我们最感兴趣的语法范畴。 产生式是定义语法范畴的书写规则。 句子:文法中从开始符号推导的终结符号串。 句型:从开始符号推导的符号串。 语言:文法中所有句子的集合。 程序语言的单词符号分为五种:关键字、标识符、常数、运算符和界符。 二元式表示:(种类,属性) 正规式的运算符有三种:或,连接和闭包。优先顺序是:闭包,连接,或。 DFA怎么识别字:若存在一条从初态结点到某一终态结点的通路,且这条通路上所有弧的标记符连接成的字是a,则称a可为DFA所识别。 DFA怎么识别空字:若DFA的初态结点同时又是终态结点,则空字可为DFA所识别。NFA怎么识别字:若存在一条从某一初态结点到终态结点的通路,且这条通路上所有弧的标记字依序连接成的字等于a,则称a可为NFA识别。 NFA怎么识别空字:若M的某些结点即是初态又是终态结点,或者存在一条从某个初态结点到某个终态结点的空通路,那么,空字可为M所识别。 语言的语法结构是用上下文无关文法描述的。 语法分析分为两类:自上而下分析法,自下而上分析法。 自上而下分析法面临的问题:1.文法的左递归问题。2.回溯3.成功可能是暂时的,产生虚假匹配。4.难于知道输入串中出错的确切位置。5.效率低,代价高。 1.翻译程序:将某一种语言(源语言)程序转换为与其逻辑上等价的另一种语言(目标语言) 程序。 编译程序:源语言为高级语言,目标语言为汇编语言或机器语言的翻译程序。 汇编程序:源语言为汇编语言,目标语言为机器语言的翻译程序。 解释程序:源语言程序作为输入,但不产生目标程序,而是边解释边执行源程序本身。 2.解释器与编译器的主要区别在于:运行目标程序时的控制权在解释器而不在目标程序。 3.编译程序的工作过程可划分五个阶段: ①词法分析:从左到右一个字符一个字符的读入源程序,对构成源程序的字符串进行扫描 和分解,从而识别出一个个单词(也称单词符号或简称符号) ②语法分析:在词法分析的基础上将单词序列分解成各类语法短语,如“程序”,“语句”, “表达式”等等 ③语义分析和中间代码生成:语义分析是在语法分析程序确定出语法短语后,审查有无语义 错误,并为代码生成阶段收集类型信息。完成语法分析和语义 处理工作后,编译程序将源程序变成一种内部表示形式,这种 内部表示形式叫做中间语言或称中间代码,它是一种结构简单、 含义明确的记号系统。 ④代码优化:为了使生成的目标代码更为高效,可以对产生的中间代码进行变换或进行改造, 这就是代码的优化。 ⑤目标代码生成:目标代码生成阶段的任务就是是把中间代码变换成特定机器上的绝对指令 代码或可重定位的指令代码或汇编指令代码。 4.前端(Front-End)——与目标机无关的部分 后端(Back-End )——与目标机有关的部分 5.编译系统:编译程序与运行系统合称编译系统 6.遍:对源程序或源程序的中间结果从头到尾扫描一次,并做有关的加工处理,生成新的中 间结果或目标程序。 7.文法是一个四元组:G[S]=(VN, VT, P, S) VN:非终结符集合; VT :终结符集合; P :产生式集合(α→β或α∷=β); S :开始符号(或称根符号,识别符号)。 若S ->α,α∈V*,则称α为文法G的句型 若S ->α,α,α∈VT*,则称α为文法G的句子 语言是所有句子构成的集合,它是所有终结符号串所组成的集合VT*的子集,即L(G) VT* 8.0型文法又叫短语文法,它所确定的语言称为0型语言。 1型文法,上下文敏感文法或上下文有关文法。 2型文法,上下文无关文法 3型文法线性文法、正则文法或正规文法 规范(最右)推导即任何一步α->β都是对α中的最右非终结符进行替换的,规范(最左)归约文法可唯一地确定一个语言 子树与短语:在句型所对应的语法树中,若某些符号按从左到右的顺序组成某棵子树的末端结点,那么由这些末端结点所组成的符号串是相对于子树根结点的短语。 原则上语法树有多少棵子树,就有多少个短语。 第2章形式语言基础 2.2 设有文法G[N]: N -> D | ND D -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 (1)G[N]定义的语言是什么? (2)给出句子0123和268的最左推导和最右推导。 解答: (1)L(G[N])={(0|1|2|3|4|5|6|7|8|9)+} 或L(G[N])={α| α为可带前导0的正整数} (2) 0123的最左推导:N ? ND ? NDD ? NDDD ? DDDD ? 0DDD ? 01DD ? 012D ? 0123 0123的最右推导:N ? ND ? N3 ? ND3 ? N23 ? ND23 ? N123 ? D123 ? 0123 268的最左推导:N ? ND ? NDD ? DDD ? 2DDD ? 26D ? 268 268的最右推导:N ? ND ? N8 ? ND8 ? N68 ? D68 ? 268 2.4 写一个文法,使其语言是奇数的集合,且每个奇数不以0开头。 解答: 首先分析题意,本题是希望构造一个文法,由它产生的句子是奇数,并且不以0开头,也就是说它的每个句子都是以1、3、5、7、9中的某个数结尾。如果数字只有一位,则1、3、5、7、9就满足要求,如果有多位,则要求第1位不能是0,而中间有多少位,每位是什么数字(必须是数字)则没什么要求,因此,我们可以把这个文法分3部分来完成。分别用3个非终结符来产生句子的第1位、中间部分和最后一位。引入几个非终结符,其中,一个用作产生句子的开头,可以是1-9之间的数,不包括0,一个用来产生句子的结尾,为奇数,另一个则用来产生以非0整数开头后面跟任意多个数字的数字串,进行分解之后,这个文法就很好写了。 N -> 1 | 3 | 5 | 7 | 9 | BN B -> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | B0 2.7 下面文法生成的语言是什么? G1: S->AB A->aA| εB->bc|bBc G2: S->aA|a A->aS 解答: B ? bc B ? bBc? bbcc B ? bBc? bbBcc ? bbbccc …… A ?ε A ? aA ? a A ? aA ? aaA ? aa …… ∴S ? AB ? a m b n c n , 其中m≥0,n≥1即L(G1)={ a m b n c n | m≥0,n≥1} S ? a S ? aA ? aaS ? aaa S ? aA ? aaS ? aaaA ?aaaaS ? aaaaa …… ∴S ? a2n+1 , 其中n≥0 即L(G2)={ a2n+1 | n≥0} 2.11 已知文法G[S]: S->(AS)|(b) A->(SaA)|(a) 请找出符号串(a)和(A((SaA)(b)))的短语、简单短语和句柄。 第八节习题一、单项选择题 1、将编译程序分成若干个“遍”是为了 b 。 a.提高程序的执行效率 b.使程序的结构更加清晰 c.利用有限的机器内存并提高机器的执行效率 d.利用有限的机器内存但降低了机器的执行效率 2、构造编译程序应掌握 d 。 a.源程序b.目标语言 c.编译方法d.以上三项都是 3、变量应当 c 。 a.持有左值b.持有右值 c.既持有左值又持有右值d.既不持有左值也不持有右值 4、编译程序绝大多数时间花在 b 上。 a.出错处理b.词法分析 c.目标代码生成d.管理表格 5、 d 不可能是目标代码。 a.汇编指令代码b.可重定位指令代码 c.绝对指令代码d.中间代码 6、使用 a 可以定义一个程序的意义。 a.语义规则b.词法规则 c.产生规则d.词法规则 7、词法分析器的输入是 a 。 a.单词符号串b.源程序 c.语法单位d.目标程序 8、中间代码生成时所遵循的是- d 。 a.语法规则b.词法规则 c.语义规则d.等价变换规则 9、编译程序是对 d 。 a.汇编程序的翻译b.高级语言程序的解释执行 c.机器语言的执行d.高级语言的翻译 10、语法分析应遵循 b 。 a.语义规则b.语法规则 c.构词规则d.等价变换规则 解答 1、将编译程序分成若干个“遍”是为了使编译程序的结构更加清晰,故选b。 2、构造编译程序应掌握源程序、目标语言及编译方法等三方面的知识,故选d。 3、对编译而言,变量既持有左值又持有右值,故选c。 4、编译程序打交道最多的就是各种表格,因此选d。 5、目标代码包括汇编指令代码、可重定位指令代码和绝对指令代码3种,因此不是目标代码的只能选d。 6、词法分析遵循的是构词规则,语法分析遵循的是语法规则,中间代码生成遵循的是语义规则,并且语义规则可以定义一个程序的意义。因此选a。 7、b 8、c 9、d 10、c 二、多项选择题 考试安排:7月13日(20周周三),15:00-17:00,20208 填空10X1分、选择10X2分、简答4X5分、大题5X10分 考试大题:循环优化 LL(1).定义之类的 算符优先算法 … 自下而上分析法(20分,选择、填空、大题) 第一章引论 一.编译程序(compiler): 把某一种高级语言程序等价地转换成另一种低级语言程序(如汇编语言或机器语言程序)的程序 二.编译程序的工作的五个阶段: 词法分析、语法分析、中间代码产生、优化、目标代码产生 1.词法分析 任务: 输入源程序, 符号。 依循的原则:构词规则 描述工具:有限自动机 保留字标识符等符整常数保留字整常数保留字 2.语法分析 任务:在词法分析的基础上,根据语言的语法规则把单词符号串分解成各类语法单位。 依循的原则:语法规则 述工具:上下文无关文法 3.语义分析与中间代码产生 任务:对各类不同语法范畴按语言的语义进行初步翻译。(变量是否定义、类型是否正确等) 依循的原则:语义规则 中间代码:三元式,四元式,逆波兰记号,树形结构等。是一种独立于具体硬件的记号系统。 例:将Z:=X + 0.618 * Y 翻译成四元式为 (1) * 0.618 Y T1 (2) + X T1 T2 (3) := T2 _ Z 4. 优化 任务:对于前阶段产生的中间代码进行加工变换,以期在最后阶段产生更高效 的目标代码。 依循的原则:程序的等价变换规则 FOR K:=1 TO 100 DO BEGIN M := I + 10 * K; N := J + 10 * K; END 4.目标代码产生 任务: 把中间代码变换成特定机器上的目标代码。 依赖于硬件系统结构和机器指令的含义 目标代码三种形式: a)绝对指令代码: 可直接运行 b)可重新定位指令代码: 需要连接装配 c)汇编指令代码: 需要进行汇编 三. 编译程序结构 编译程序总框 (简答题5分) 第二章高级语言及其语法描述 2.1.1语法 词法规则:单词符号的形成规则。 a)单词符号是语言中具有独立意义的最基本结构。一般包括:常数、标识符、基 本字、算符、界符等。 b)描述工具:正规式和有限自动机 语法规则:语法单位的形成规则。 a) 语法单位通常包括:表达式、语句、分程序、过程、函数、程序等; c)描述工具:上下文无关文法 2.1.2语义 语义:一组规则,用它可以定义一个程序的意义。 描述方法: a)自然语言描述:隐藏错误、二义性和不完整性 b)形式描述: ?无二义性 ?完整性 1学校领导干部培训资料整理 合,多方努力方能奏效。 首先,学校要转变教育思想,坚持“五育”并举的方针,努力创造和谐适度的教育环境和学习气氛。同时要抵制社会上不利于人才成长的舆论风气,转变上大学是唯一成才之路的片面认识,减轻社会对学校的压力。学校要给学生“松绑”,把学生从题海之中解放出来,寓教于乐,这是预防和减轻学生考试焦虑的根本途径。 (2)调整期待水平,正确对待考试。 期待水平是影响学生考试焦虑的重要因素,其中既有家长、教师的期待,也有学生自身的期待。过高的期待水平,会给学生造成较强的心理压力。为了减轻学生的考试焦虑,必须调整期待水平,使学生“放下包袱,轻装上阵”。(3)培养学生良好的个性品质。 正确的人生观、价值观,坚定的信念,崇高的理想,明确的学习动机,积极的学习兴趣,开朗的性格,顽强的意志,良好的情绪状态都对期待水平、认知评价及学习活动本身起重要作用,同时也是有利于克服考试焦虑的重要心理品质。因此,学校在教育过程中,要注重发展学生良好的个性,培养非智力因素,这是预防和减轻学生 考试焦虑、提高心理卫生水平的一项积极措施。(4)提高应试技能,做好应试准备。 学生应试技能的高低及应试准备程度与考试焦虑水平有一定的相关。应试技能差,准备不充分,考试焦虑水平就高。因此,加强对学生的考前指导,帮助他们提高应试技能,做好心理上、知识上、物品上的准备,对防治考试焦虑有十分重要的意义。 4、教师心理健康的标准 一是认同教师角色,悦纳教师职业,热爱教育工作; 二是具有积极乐观的人生态度和良好的心境; 三是具有健全的人格,良好的个性特点; 四是具备较强的适应能力和活动能力; 五是具有和谐的人际关系。 5、学生的本质特征 1.学生是以学习间接经验为主的人 2.学生具有主体性的人 3.具有明显的发展特征的人 6、教育对个体发展的负向功能表现: 1.过重的学业负担、惟“智”是举的做法,严重摧 第一章 1.典型的编译程序在逻辑功能上由哪几部分组成? 答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。 2. 实现编译程序的主要方法有哪些? 答:主要有:转换法、移植法、自展法、自动生成法。 3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式? 答:编译法、解释法。 4. 编译方式和解释方式的根本区别是什么? 答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快; 解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。 第二章 1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关 系如何? 答:1)0型文法、1型文法、2型文法、3型文法。 2) 2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。 答: Z→SME | B S→1|2|3|4|5|6|7|8|9 M→ε | D | MD D→0|S B→2|4|6|8 E→0|B 3. 设文法G为: N→ D|ND D→ 0|1|2|3|4|5|6|7|8|9 请给出句子123、301和75431的最右推导和最左推导。 答:N?ND?N3?ND3?N23?D23?123 N?ND?NDD?DDD?1DD?12D?123 N?ND?N1?ND1?N01?D01?301 N?ND?NDD?DDD?3DD?30D?301 N?ND?N1?ND1?N31?ND31?N431?ND431?N5431?D5431?75431 N?ND?NDD?NDDD?NDDDD?DDDDD?7DDDD?75DDD?754DD?7543D?75431 4. 证明文法S→iSeS|iS| i是二义性文法。 答:对于句型iiSeS存在两个不同的最左推导: S?iSeS?iiSes S?iS?iiSeS 所以该文法是二义性文法。 5. 给出描述下面语言的上下文无关文法。 (1)L1={a n b n c i |n>=1,i>=0 } (2)L2={a i b j|j>=i>=1} (3)L3={a n b m c m d n |m,n>=0} 答: (1)S→AB A→aAb | ab B→cB | ε (2)S→ASb |ab档案管理系统培训讲义
编译原理知识点汇总
编译原理课后习题答案
编译原理概念期末总结复习
编译原理中重点整理
编译原理一些习题答案
(2020年整理)编译原理期末总复习题(含答案).doc
编译原理复习要点
1学校领导干部培训资料整理
编译原理课后习题答案