学生成绩描述性统计
学生成绩的描述性统计
——以某校的高二年级为例
管理科学史培腾
201011231808 在得到学生的考试成绩后,我们往往需要对数据进行统计和分析,从而得到
此次考试情况的基本信息。本次以永川中学高二年级三个班的期中考试成绩为例,进行描述性统计,对三个班级进行比较分析,对三个班级学生知识掌握情况、此次考试的难易程度,区分程度等做出评价。
一、三个班成绩频数统计表及分布直方图
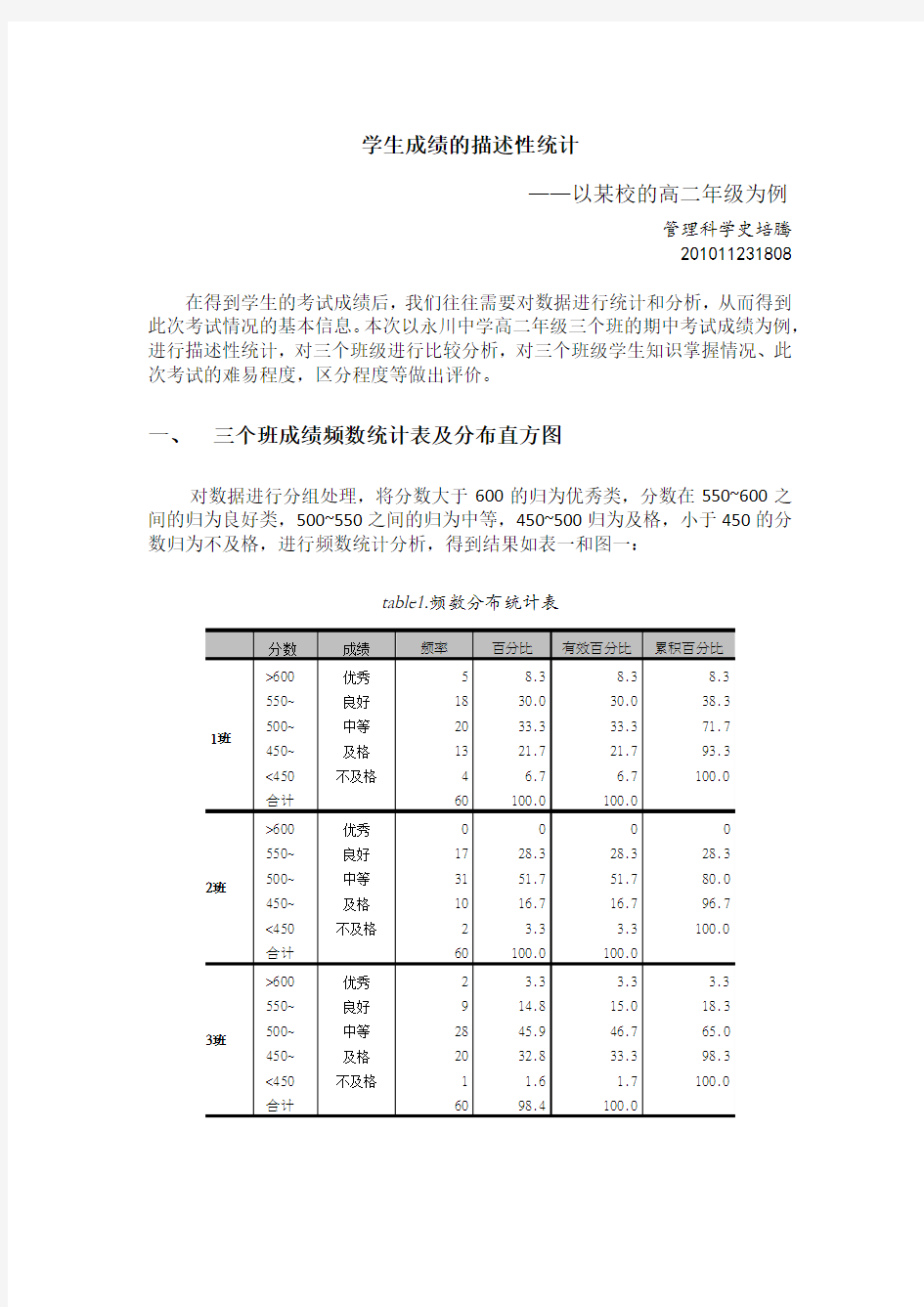
对数据进行分组处理,将分数大于600的归为优秀类,分数在550~600之间的归为良好类,500~550之间的归为中等,450~500归为及格,小于450的分数归为不及格,进行频数统计分析,得到结果如表一和图一:
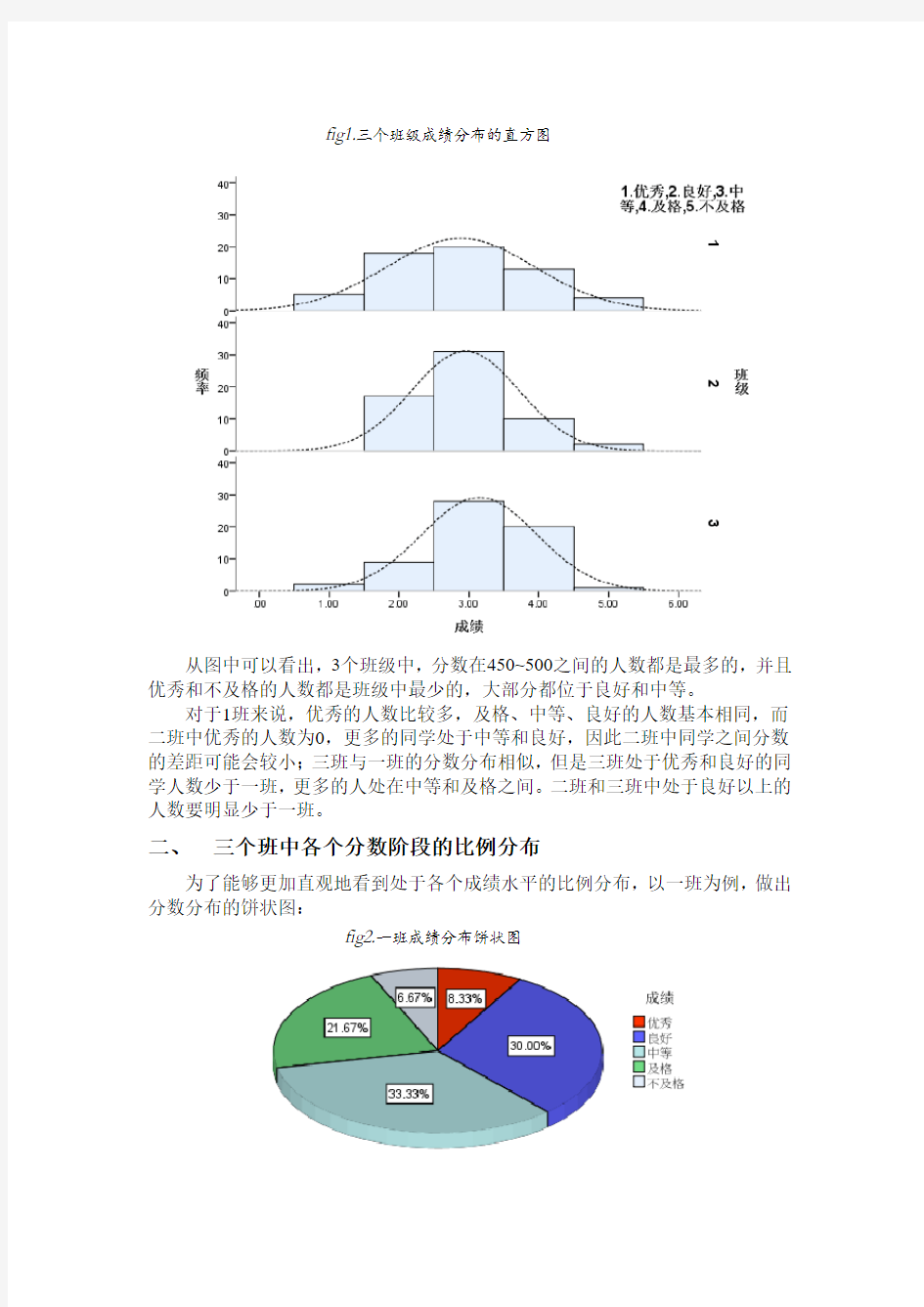
从图中可以看出,3个班级中,分数在450~500之间的人数都是最多的,并且优秀和不及格的人数都是班级中最少的,大部分都位于良好和中等。
对于1班来说,优秀的人数比较多,及格、中等、良好的人数基本相同,而二班中优秀的人数为0,更多的同学处于中等和良好,因此二班中同学之间分数的差距可能会较小;三班与一班的分数分布相似,但是三班处于优秀和良好的同学人数少于一班,更多的人处在中等和及格之间。二班和三班中处于良好以上的人数要明显少于一班。
二、三个班中各个分数阶段的比例分布
为了能够更加直观地看到处于各个成绩水平的比例分布,以一班为例,做出分数分布的饼状图:
fig1.三个班级成绩分布的直方图fig2.一班成绩分布饼状图
从图中可以看出,有8.33%的同学是优秀,有6.67%的同学是不及格,大部分的学生成绩都在良好和中等程度,并且成绩良好以上的同学占38.33%,因此,一班的整体水平较好,班中同学之间的分数差别可能会更大。
由于三个班级的人数相同,我们将三个班级中成绩的分布结构如下图表示:
fig3.三个班成绩分布比较
从图中可以比较清晰地看出三个班级中的成绩分布结构,三个班级中不及格的人数都很少,大部分的同学都在中等以上,但是每个班中只有很少的同学能够达到优秀,一班的情况相对好些,二班和三班比较明显。因此在以后的教学中,三个班都需要注重对学生的提高,在巩固好基础知识的同时,对学生进行一些提高性的练习,帮助处于中等水平的同学尽快达到良好和优秀。
三、3个班级总分的分布特征
1.集中趋势测度及箱线图
table2.集中趋势测度
fig4.三个班级成绩箱线图
通过上四分位数和下四分位数以及箱线图,可以得知,二班的分数更加集中。一班众数与均值和中位数的差别最大在20左右,而二班众数、平均值和中位数的差别在10左右,并且由箱线图可以直观的看到,二班的分数集中程度要好于一班。
2.离散程度
一班的极小值和极大值之间的差别最大,方差最大,二班的极大值和极小值之间的差别最小,方差也最小,并且由集中程度的分析可知,一班的集中程度最小,那么一班的,离散程度应该是最大的,二班的离散程度应该是最小的。与计算得到的离散系数相吻合。
3.偏态与峰度
由计算结果可知,一班和二班的偏度都小于0,故都为左偏分布,三班的偏度大于0,故为右偏分布,但是偏的幅度很小。三个班的峰度都小于3,故三者都为扁平分布。
四、对此次考试的评价
我们首先对三个班级分别检测其是否符合正态分布:
可见在三个班级中,成绩的分布不是特别严格地符合正态分布,符合我们对偏度和峰度的计算结果。
fig5.检验三个班级成绩是否符合正态分布
对于整个高二年级,使用QQ 概率图检验三个班中考试成绩是否符合正态分布,结果如下:
由图可看出,QQ 概率图基本上呈一条直线,散点与直线的误差分布大概在(-10,5)之间,只有极少数的极值点,故可认为此次学生的考试成绩符合正态分布,能够对学生进行很好的区分。
同时,此次三个年级中考试成绩的最大值为617,且仅有几位同学得到了600分以上,成绩的总分是750分,总分的85%是637.5,最高分的成绩还没有达到总成绩的85%,因此,此次试卷水平整体较难。
四、小结
通过分析我们可以看到,此次三个班的考试成绩比较而言,一班的成绩结构分布较为合理,二班和三班在以后的教学过程中均需注意在学生掌握好基础知识的同时加强对学生的提高性练习。二班的成绩分布较为集中,班级中同学之间的分数差距较小。对平均分来说,一班的平均分大于二班大于三班。
此次考试在三个年级中符合正态分布,因此能够对学生进行很好的区分,同时,学生的分数整体相对偏低,此次的试卷程度稍难。
fig6.检验高二年级成绩是否符合正态分布
matlab在统计数据的描述性分析的应用
统计数据的描述性分析 一、实验目的 熟悉在matlab中实现数据的统计描述方法,掌握基本统计命令:样本均值、样本中位数、样本标准差、样本方差、概率密度函数pdf、概率分布函数df、随机数生成rnd。 二、实验内容 1 、频数表和直方图 数据输入,将你班的任意科目考试成绩输入 >> data=[91 78 90 88 76 81 77 74]; >> [N,X]=hist(data,5) N = 3 1 1 0 3 X = 75.7000 79.1000 82.5000 85.9000 89.3000 >> hist(data,5)
2、基本统计量 1) 样本均值 语法: m=mean(x) 若x 为向量,返回结果m是x 中元素的均值; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的均值。 2) 样本中位数 语法: m=median(x) 若x 为向量,返回结果m是x 中元素的中位数; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的中位数3) 样本标准差 语法:y=std(x) 若x 为向量,返回结果y 是x 中元素的标准差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的标准差
std(x)运用n-1 进行标准化处理,n是样本的个数。 4) 样本方差 语法:y=var(x); y=var(x,1) 若x 为向量,返回结果y 是x 中元素的方差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的方差 var(x)运用n-1 进行标准化处理(满足无偏估计的要求),n 是样本的个数。var(x,1)运用n 进行标准化处理,生成关于样本均值的二阶矩。 5) 样本的极差(最大之和最小值之差) 语法:z= range(x) 返回结果z是数组x 的极差。 6) 样本的偏度 语法:s=skewness(x) 说明:偏度反映分布的对称性,s>0 称为右偏态,此时数据位于均值右边的比左边的多;s<0,情况相反;s 接近0 则可认为分布是对称的。 7) 样本的峰度 语法:k= kurtosis(x) 说明:正态分布峰度是3,若k 比3 大得多,表示分布有沉重的尾巴,即样本中含有较多远离均值的数据,峰度可以作衡量偏离正态分布的尺度之一。 >> mean(data) ,
SAS数据的描述性统计分析答案
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
描述性统计分析报告--Descriptive Statistics菜单详解
第六章:描述性统计分析-- Descriptive Statistics菜单详解 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并 不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明 Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】 确定是否在结果中输出频数表。 【Statistics钮】 单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。 现将各部分解释如下:
05.第五讲 描述性统计分析评价方法
第五讲描述性统计分析评价方法——综合指标 实际上,从这一讲开始的教学内容都是介绍教育评价技术中的重要方法——教育统计分析方法,也即是分析资料的方法。其中包括描述性统计分析方法和推断性统计分析方法两大部分。 一、描述性统计分析评价方法的主要特点。对数据资料计算综合指标,然后根据综合指标值对教育客观事物给予评价。所谓综合指标指的是从数量方面综合说明事物特征的指标。常用的综合指标有绝对数、相对数、平均数和标准差。重点介绍后面两种。 二、综合指标的计算及解释 (一)绝对数(规模) (二)相对数(程度) (三)平均数(水平) 通常可用符号表示平均数 1.算术平均数(未经分类汇总的测量数据资料)计算方法见p62的(4.1)公式。 2.加权平均数(已经分类汇总的资料)
①组距数列平均数(对测量数据分组统计人数)例如P63表4-1的资料。计算方法如P63的(4.2)公式及83名教师平均年龄的计算。 * 为了减少计算的麻烦,在此介绍计算器统计功能的使用: A、操作步骤 计算器的统计功能的计算只能得到如下六个统计结果:n(数据个数)、(数据和)、(数据平方和)、(平均数)、(总体标准差)和S(样本标准差)。操作步骤如下:1)显示统计状态:2ndF STAT(或SD) 2)输入数据:每输入一个数据按DATA 3)取出统计结果:这时六个统计结果均处于待取状态,可根据需要取出其中的结果。 B、注意事项 1)若需继续进行第二组数据的统计运算时,需取消统计状态,再按上述步骤操作。按2ndF STAT即可取消统计的状态。 2)若不需要计算、、、、和S时(即进行 其他一般运算时),也应取消统计状态)。
利用Excel进行数据整理和描述性统计分析
实训一利用Excel进行数据整理和描述性统计分析 一、实训目的 目的有三:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组;(3)学会使用Excel计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;理解描述性统计指标中的统计计算问题;已阅读本次实训指导书,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个描述性统计指标计算问题及相应数据(可用本实训所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 有顾客反映某家航空公司售票处售票的速度太慢。为此,航空公司收集了解100位顾客购票所花费时间的样本数据(单位:分钟),结果如下表。
航空公司认为,为一位顾客办理一次售票业务所需的时间在五分钟之内就是合理的。上面的数据是否支持航空公司的说法顾客提出的意见是否合理请你对上面的数据进行适当的分析,回答下列问题。 (1)对数据进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、饼图)。 (2)根据分组后的数据,计算中位数、众数、算术平均数和标准差。 (3)分析顾客提出的意见是否合理为什么 (4)使用哪一个平均指标来分析上述问题比较合理 答:(1): 2:
从表中我们可以得到中位数为众数为1平均数为标准差为 (3):合理,虽然他的平均数是<5属于正常范围,但是依旧有将近20%的购票时间>5分钟属于超过正常范围,那就是速度太慢了。平均数不能代表一切。 所以顾客提出的理由是正确的,购票太慢的现象确实存在。 (4):平均数比较合理,它能较好的反映购票的大概时间。比较有代表性! 实训二用Excel数据分析功能进行统计整理 和计算描述性统计指标 一、实训目的 学会使用Excel数据分析功能进行统计整理和计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解统计整理和描述性统计指标中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤
SAS中的描述性统计过程(终审稿)
S A S中的描述性统计过 程 公司内部档案编码:[OPPTR-OPPT28-OPPTL98-OPPNN08]
SAS中的描述性统计过程 (2012-08-01 18:07:01) 转载▼ 分类:数据分析挖掘 标签: 杂谈 SAS中的描述性统计过程 描述性统计指标的计算可以用四个不同的过程来实现,它们分别是means过程、summary过程、univariate过程以及tabulate过程。它们在功能范围和具体的操作方法上存在一定的差别,下面我们大概了解一下它们的异同点。 相同点:他们均可计算出均数、标准差、方差、标准误、总和、加权值的总和、最大值、最小值、全距、校正的和未校正的离差平方和、变异系数、样本分布位置的t检验统计量、遗漏数据和有效数据个数等,均可应用by语句将样本分割为若干个更小的样本,以便分别进行分析。 不同点: (1)means过程、summary过程、univariate过程可以计算样本的偏度(skewness)和峰度(kurtosis),而tabulate过程不计算这些统计量; (2)univariate过程可以计算出样本的众数(mode),其它三个过程不计算众数;
(3)summary过程执行后不会自动给出分析的结果,须引用output 语句和print过程来显示分析结果,而其它三个过程则会自动显示分析的结果; (4)univariate过程具有统计制图的功能,其它三个过程则没有; (5)tabulate过程不产生输出资料文件(存储各种输出数据的文件),其它三个均产生输出资料文件。 统计制图的过程均可以实现对样本分布特征的图形表示,一般情况下可以使用的有chart过程、plot过程、gchart过程和gplot过程。大家有没有发现前两个和后两个只有一个字母‘g’(代表graph)的差别,其实它们之间(只差一个字母g的过程之间)的统计描述功能是相同的,区别仅在于绘制出的图形的复杂和美观程度。 chart过程和plot过程绘制的图形类似于我们用文本字符堆积起来的图形,只能概括地反映出资料分布的大体形状,实际上这两个过程绘制的图形并不能称之为图形,因为他根本就没有涉及一般意义上图形的任何一种元素(如颜色、分辨率等)。而gchart过程和gplot过程给出的是真正意义上的图形,可以用很多的语句和选项来控制图形的各方面的性质和特征。 chart和gchart与plot和gplot的区别则体现在不同的作图功能,前两个过程可以绘制出的图形主要有条形图(包括横条和竖条)、圆图、环形图和星形图等,后两个过程通常用一个记录中的两个变量值表示点的坐标来绘制图形,如散点图和线图等。
描述性统计分析-Eviews
主讲人:刘莎莎 第三讲 描述性统计分析
一、 序列窗口下的描述性统计分析
知识点 1:如何以建立组对象的方式将数据导入到 Eviews 中去(第二种导入数 据的方式) 。 知识点 2:如何在序列窗口下实现简单描述性统计量和直方图,将直方图和正态 分布曲线叠加在一起,从而更直观地观察数据的分布特征。 (如何将 EViews 图形 复制粘贴到 word 中) 知识点 3:如何在序列窗口下实现描述性统计量的假设检验 知识点 4:如何实现将单序列按某一变量分类后再进行描述性统计分析(本案例 的分类变量是该天是星期几) 知识点 5:如何实现将单序列按某一变量分类后再进行假设检验 知识点 6:如何画上证综指日对数收益率的 QQ 图 知识点 7:如何估计数据的经验分布函数的参数 案例数据说明:2003 年 1 月 6 日-2009 年 6 月 26 日上证综指日对数收益率。
二、序列组窗口下的描述性统计分析
知识点 1:如何通过打开 excel 文件的方式将数据导入到 Eviews 中去。 (第三种 导入数据的方式) 。 知识点 2:如何实现多变量的描述性统计量 知识点 3:如何实现多变量描述性统计量的假设检验 案例数据说明:国家统计调查队分别在两个地区调查了 10 个家庭的收入 知识点 4:如何计算当前序列组的相关系数矩阵,协方差矩阵
主讲人:刘莎莎
案例数据说明:1983-2000 年我国粮食生产与相关投入的数据,变量包括粮食产 量(单位:万吨)、农业化肥施用量(单位:万千克)、粮食播种面积(单位: 公顷)
附注:描述性统计量的计算公式
标准差(Std.Dev.)的计算公式是:
s=
2 ( y ? y ) ∑ t t =1
T
T ?1
其中,
yt 是观测值, y 是样本平均数。
偏度(Skewness)的计算公式是:
1 T yt ? y 3 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。对
称分布的偏度是零,比如正态分布。
峰度(Kurtosis)的计算公式是:
1 T yt ? y 4 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。
正态分布的峰度值是 3。
多组和分类数据的描述性统计分析
§3.2多组和分类数据的描述性统计分析17 ?盒子图 盒子图能够直观简洁地展现数据分布的主要特征.我们在R 中使用boxplot()函数作盒子图.在盒子图中,上下四分位数分别确定中间箱体的顶部和底部,箱体中间的粗线是中位数所在的位置.由箱体向上下伸出的垂直部分为“触须”(whiskers),表示数据的散布范围,其为1.5倍四分位间距内距四分位点最远的数据点.超出此范围的点可看作为异常点(outlier). §3.2多组和分类数据的描述性统计分析 在对于多组数据的描述性统计量的计算和图形表示方面,前面所介绍的部分方法不能够有效地使用,例如许多函数都不能直接对数据框进行操作.这时我们需要一些其他的函数配合使用. 1.图形表示: ?散点图:前面介绍的plot,可直接对数据框操作.此时将绘出数据框中所对应的所有变量两两之间的散点图.所做图框中第一行的散点图是以第一个变量为纵坐标,分别以第二、三...个变量为横坐标的散点图.这里数据举例说明. library(DAAG);plot(hills) ?盒子图:前面介绍的boxplot,亦可直接对数据框操作,其在同一个作图区域内画出各组数的盒子图.但是注意,此时由于不同组数据的尺度可能差别很大,这样的盒子图很多时候表达出来不是很有意义.boxplot(faithful).因此这样做比较适合多组数据具有同样意义或近似尺度的情形.例如,我们想做某一数值变量在某个因子变量的不同水平下的盒子图.我们可采用类似如下的命令: boxplot(skullw ~age,data=possum),亦可加上参数horizontal=T,将该盒子图横向放置. boxplot(possum$skullw ~possum$sex,horizontal=T) ?条件散点图:当数据集中含有一个或多个因子变量时,我们可使用条件散点图函数coplot()作出因子变量不同水平下的多个散点图,当然该方法也适用于各种给定条件或限制情形下的作图.其调用格式为 coplot(formula,data)比如coplot(possum[[9]]~possum[[7]] possum[[4]]),或 coplot(skullw ~taill age,data=possum); coplot(skullw ~taill age+sex,data=possum)
描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如 何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。 六、方差分析
数据的描述性统计分析
统计分析往往是从了解数据的基本特征开始的。描述数据分布特征的统计量可分为两类:一类表示数量的中心位置,另一类表示数量的变异程度(或称离散程度)。两者相互补充,共同反映数据的全貌。 这些内容可以通过SPSS中的“Descriptive Statistics”菜单中的过程来完成。 1 频数分析 (Descriptive Statistics - Frequencies) 频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各 种统计量来描述数据的分布特征。 下面我们通过例子来学习单变量频数分析操作。 1) 输入分析数据 在数据编辑器窗口打开“data1-2.sav”数据文件。 2)调用分析过程 在主菜单栏单击“Analyze”,在出现的下拉菜单里移动鼠标至“Descriptive Statistics”项上,在出现的次菜单里单击“Frequencies”项,打开如图3-4所示的对话框。 图3-4 “Frequencies” 对话框 3)设置分析变量 从左则的源变量框里选择一个和多个变量进入“Variable(s):”框里。在这里我们选“三化 螟蚁螟[虫口数]”变量进入“Variable(s):”框。 4)输出频数分布表
Display frequency tables,选中显示。 5)设置输出的统计量 单击“Statistics”按钮,打开图3-5所示的对话框,该对话框用于选择统计量: 图3-5 “Statistics”对话框 ①选择百分位显示“Percentiles Values”栏: Quartiles:四分位数,显示25%、50%和75%的百分位数。 Cut points for 10 equal groups:将数据平分为输入的10个等份。 Percentile(s)::用户自定义百分位数,输入值0—100之间。选中此项后,可以利用“Add”、“Change”和 “Remove”按钮设置多个百分位数。 ②选择变异程度的统计量“Dispersion”:(离散趋势) Std.deviation标准差 Minimum 最小值 Variance 方差 Maximum 最大值 Range 极差 S.E.mean均值标准误 ③选择表示数据中心位置的统计量“Central Tendency”:(集中趋势) Mean 均值 Median 中位数 Mode 众数 Sum 算术和
描述性统计示例
一、实验概述: 【目的】了解SPSS软件的安装、启动、退出以及运行管理方式;掌握SPSS软件的Analyze 菜单中的Descriptive Statistics模块进行数据的描述性统计分析。 【实施环境】SPSS—17.0统计分析软件。 二、实验内容: 用SPSS软件对实验一数据中的“熟悉程度”进行描述统计分析:描述数据的频数分布、集中趋势、离散程度和形状、并给出直方图。 三、实验步骤 步骤1:用SPSS打开已知的数据文件 选择菜单“File—>Open—>Data”,在对话框中找到需要分析的数据文件(实验一&二描述统计和假设检验.sav),然后选择“打开” 步骤2:计算所要求的描述统计量值及频数分布 1.打开文件之后,选择菜单“Analyze—>Descriptive Statistics—>Frequencies”。 2.确定所要分析的变量 要在“Frequencies 对话框”中选中左侧列表框中的“Familiarity”,之后点击列表框中间的箭头按钮,将要分析的变量加入到右侧Variable(s)列表框中。然后,选择位于小窗口下端的“Display frequency tables 复选框”,以确定要输出频数分布表。
3. 选择所要计算的统计量 在变量选择确定之后,在同一窗口上,点击“Statistics”按钮,打开统计量对话框,选择统计输出选项。 步骤3:结果输出与分析 点击Frequencies:Statistics对话框中的“Continue”按钮,再点击Frequencies 对话框中的“OK”按钮,即得到频数分布结果。 步骤4:选择菜单“Graphs—>Legacy Dialogs—>Histogram”。
1数据的描述性统计练习题
1数据的描述性统计练习题 一、填空题 1. 一组数据向某以中心值靠拢的倾向反映了数据的(集中趋势)。 2. (众数)是一组数据中出现次数最多的变量值。 3. 一组数据排序后处于中间位置的变量值称为(中位数)。 4. 不受极端值影响的集中趋势度量指标有(四分位数)(众数)(中位数)。 5. 一组数据的最大值与最小值之差称为(极差)。 6. (离散系数)一组数据的标准差与其相应的均值之比。 7. 数据分布的不对称性是(偏度)。 8. 数据分布的尖峰程度称为(峰度)。 9. 计算比率的平均数一般用(几何平均法),它实际上是各变量值对数的(算术平均数)。 二、单项选择题 1. 对于对称分布的数据,众数、中位数和平均数的关系是(B) A. 众数>中位数>平均数 B. 众数=中位数=平均数 C. 平均数>中位数>众数 D. 中位数>众数>平均数 2. 可以计算平均数的数据类型是(C) A.分类数据 B.顺序型数据 C.数值型数据 D.所有数据 3. 顺序数据的集中趋势测度的指标(B) A.中位数 B.平均数 C.极差 D.标准差 4. 数值型数据的离散程度测度方法中,受极端变量值影响最大的是(A) A.极差 B.方差 C.均方差 D.平均差 5. 当偏态系数为正数是,说明数据的分布是(C) A.正态分布 B.左偏分布 C.右偏分布 D. U型分布 三、多项选择题 1. 数据的分布特征可以从以下哪几个方面测度和描述(ABCD) A.集中趋势 B.分布的偏态 C.分布的峰态 D.离散程度 E.长期趋势
2. 受极端变量值影响的集中趋势的度量指标是(CDE) A.众数 B.分位数 C.算数平均数 D.调和平均数 E.几何平均数 3. 加权算术平均数的大小的影响因素有(AC) A.变量值 B.样本容量 C.权数 D.分组的组数 E.数据的类型 4. 数值型数据离散程度的测度指标有(ABCDE) A.变异系数 B.极差 C.标准差 D.异众比率 E.四分位数 5. 离散系数的主要作用是(BD) A.说明数据的集中趋势 B.比较不同计量单位数据的离散程度 C.说明数据的偏态程度 D.比较不同变量值水平数据的离散程度 E.说明数据的峰态程度 四、简答题 1. 什么是数据的集中趋势?反映数据集中趋势的指标有哪些? 数据的集中趋势指一组数据向某一中心值靠拢的倾向。 反映数据集中趋势的指标主要有:众数、中位数、分位数、平均数等。 2. 什么是数据的离散程度?常用测度离散程度的指标有哪些? 离散程度反映的是各变量值远离其中心值的程度。 反映数据离散程度的指标主要有:四分位差、方差、标准差、极差、离散系数等。 3. 怎样理解平均数在统计学中的地位? 平均数在统计学中具有重要的地位,它是进行统计分析和统计推断的基础;平均数作为代表值,是误差相互抵消的结果,反映了事物必然性的数量特征。 4. 简述众数、中位数和平均数的特点和应用场合。 众数是一组数据分布的峰值,是一种位置代表值,不受极端值的影响,其缺点是不具有唯一性。虽然对数据型数据和分类数据也适用,但主要是用于分类数据的集中趋势测度值。 中位数是中间位置上的代表值,也是一种位置的代表值,其特点是不受极端值的影响。顺序数据可以计算众数,但以中位数宜。 平均数是根据数据型数据计算的,而且利用了所以信息,是实际中应用最广的集中趋势测度值。虽然数据型数据可以计算众数和中位数,但以平均数为宜。平均数的主要缺点是受极端值的影响,对于偏态分布,平均数的代表性差。特别是当偏态程度较大是,可用位置平均数代替。
描述性统计分析
第六章描述性统计分析-- Descriptive Statistics菜单详解 6.1 Frequencies过程 6.1.1 界面说明 6.1.2 分析实例 6.1.3 结果解释 6.2 Descriptives过程 6.2.1 界面说明 6.2.2 结果解释 6.3 Explore过程 6.3.1 界面说明 6.3.2 结果解释 6.4 Crosstabs过程 6.4.1 界面说明 6.4.2 分析实例 6.4.3 结果解释 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明
关于描述性统计分析
关于描述性统计分析 作者:记忆de&#…文章来源:csdn blog 点击数:156 更新时间:2007-2-12 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Anal ysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。 (3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
描述性统计分析
描述性统计分析 作者:清华大学中国企业研究中心阅读次数:24704次发布日期:2005-07-04 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。
(3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
excel与描述性统计分析
用Excel进行数据分析:描述性统计分析 郑来轶发表于2013-04-14 22:03 来源:本站原创 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形,常用的指标有均值、中位数、众数、方差、标准差等等。 接下来我们讲讲在Excel2007中完成描述性统计分析。 一、案例场景 某网站的专题活动积累了一定访问数据后,需要统计流量的的均值、区间,以及给出该专题访问量差异的量化标准,借此来作为分析每天访问量的价值、参差不齐、此起彼伏一个衡量的依据。要求得到均值、区间、众数、方差、标准差等统计数据。 二、操作步骤 1、打开数据表格,这个案例中用的数据无特殊要求,只是一列数值就可以了。 2、选择“工具”——“数据分析”——“描述统计”后,出现属性设置框
注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,可以参考上一篇文章《用Excel进行数据分析:数据分析工具在哪里?》。 3、依次选择 选项有2方面,输入和输出选项 输入区域:原始数据区域,选中多个行或列,选择相应的分组方式逐行/逐列;
如果数据有标志,勾选“标志位于第一行”;如果输入区域没有标志项,该复选框将被清除,Excel 将在输出表中生成适宜的数据标志; 输出区域可以选择本表、新工作表或是新工作簿; 汇总统计:包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。第K大(小)值:输出表的某一行中包含每个数据区域中的第k 个最大(小)值。 平均数置信度:数值95% 可用来计算在显著性水平为5% 时的平均值置信度
用Excel进行数据分析:描述性统计分析
在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形,常用的指标有均值、中位数、众数、方差、标准差等等。 接下来我们讲讲在Excel2007中完成描述性统计分析。一、案例场景 某网站的专题活动积累了一定访问数据后,需要统计流量的的均值、区间,以及给出该专题访问量差异的量化标准,借此来作为分析每天访问量的价值、参差不齐、此起彼伏一个衡量的依据。要求得到均值、区间、众数、方差、标准差等统计数据。 二、操作步骤 1、打开数据表格,这个案例中用的数据无特殊要求,只是一列数值就可以了。 2、选择“工具”——“数据分析”——“描述统计”后,出现属性设置框
注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,可以参考上一篇文章《用Excel进行数据分析:数据分析工具在哪里?》。 3、依次选择 选项有2方面,输入和输出选项 输入区域:原始数据区域,选中多个行或列,选择相应的分组方式逐行/逐列;
如果数据有标志,勾选“标志位于第一行”;如果输入区域没有标志项,该复选框将被清除,Excel 将在输出表中生成适宜的数据标志; 输出区域可以选择本表、新工作表或是新工作簿; 汇总统计:包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。 第K大(小)值:输出表的某一行中包含每个数据区域中的第 k 个最大(小)值。 平均数置信度:数值 95% 可用来计算在显著性水平为 5% 时的平均值置信度。